第2节. http协议各种版本详解
网站要防盗链的,否则,比如人家的图片都引用的你的网站的图片,
1、网站1盗链网站2的图片
2、用户打开网站1,看到的图片,其实都是网站1链接的2的图片
3、网站2的带宽白白被网站1的访问给占用了。
这里视频讲了一些HTML\CSS\JS的知识,只是简单的说了说,还不如走一遍《python编程从入门到实践第二版》P371的django案例。这块东西接触过了就知道确实不错有时间可以继续折腾下,做好了可以收纳自己的脚本工具到页面方便管理和用户入口。
MIME是邮件的一个功能,HTTP集成了👇

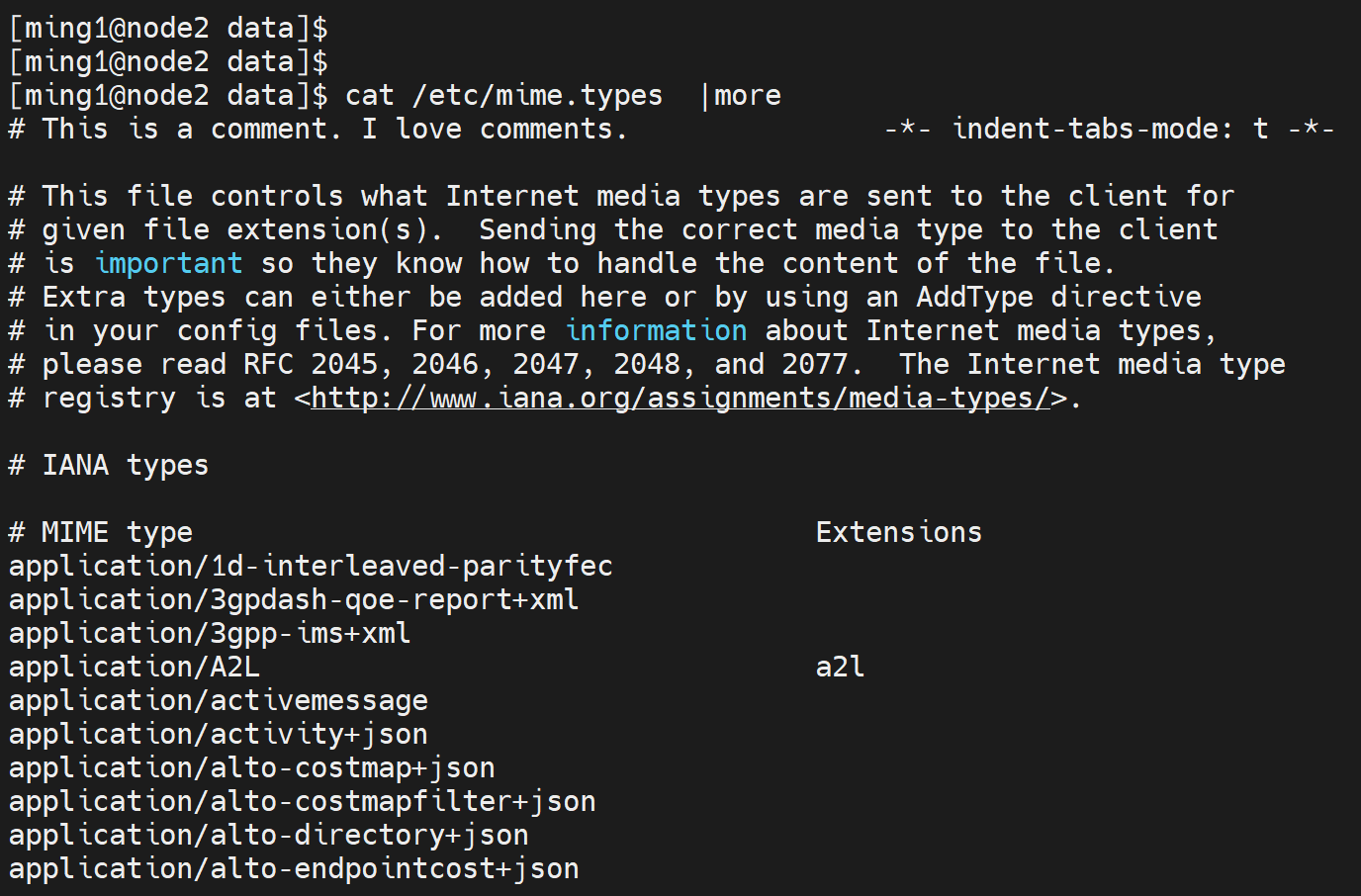
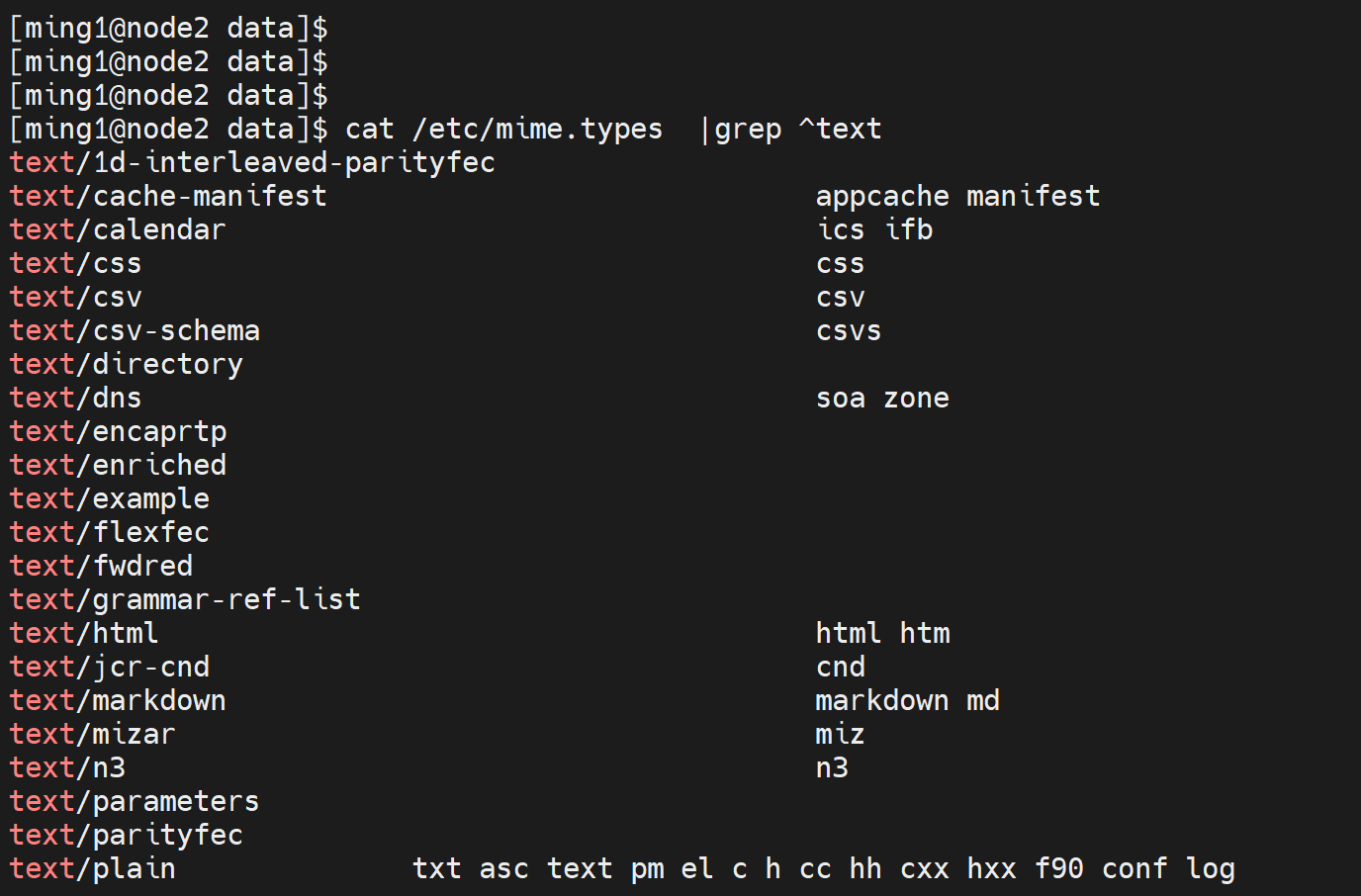
text是大类,/css这些是小类型。
然后浏览器里对应txt文件或者conf文件,都是不能直接打开看的,都是判断为下载,原因就是MIME里没有这个后缀的支持👇
浏览器的源代码点不比操作系统简单;
都是浏览器给你下载好资源,比如图片。
动态文件和静态文件

动态:3P:php、jsp、asp都是执行程序,用户看到的是这些3p程序执行后的结果--实在server端执行后的结果,而不是程序本身。
静态资源下发到CDN,动态资源需要回源。
访问https://oneyearice.github.io/其实就是打开这个根目录下的index.html文件。
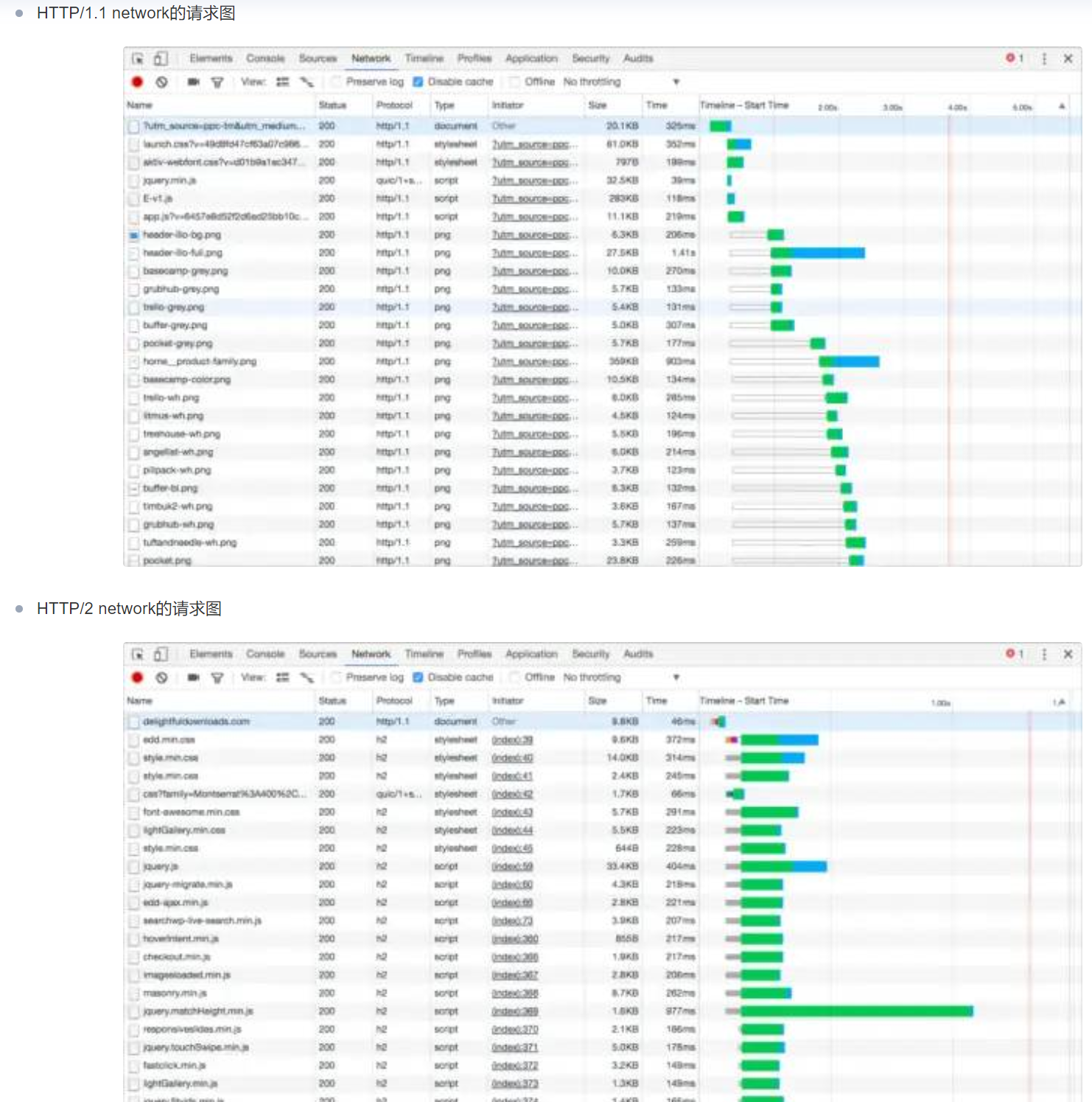
HTTP的串行和并行连接
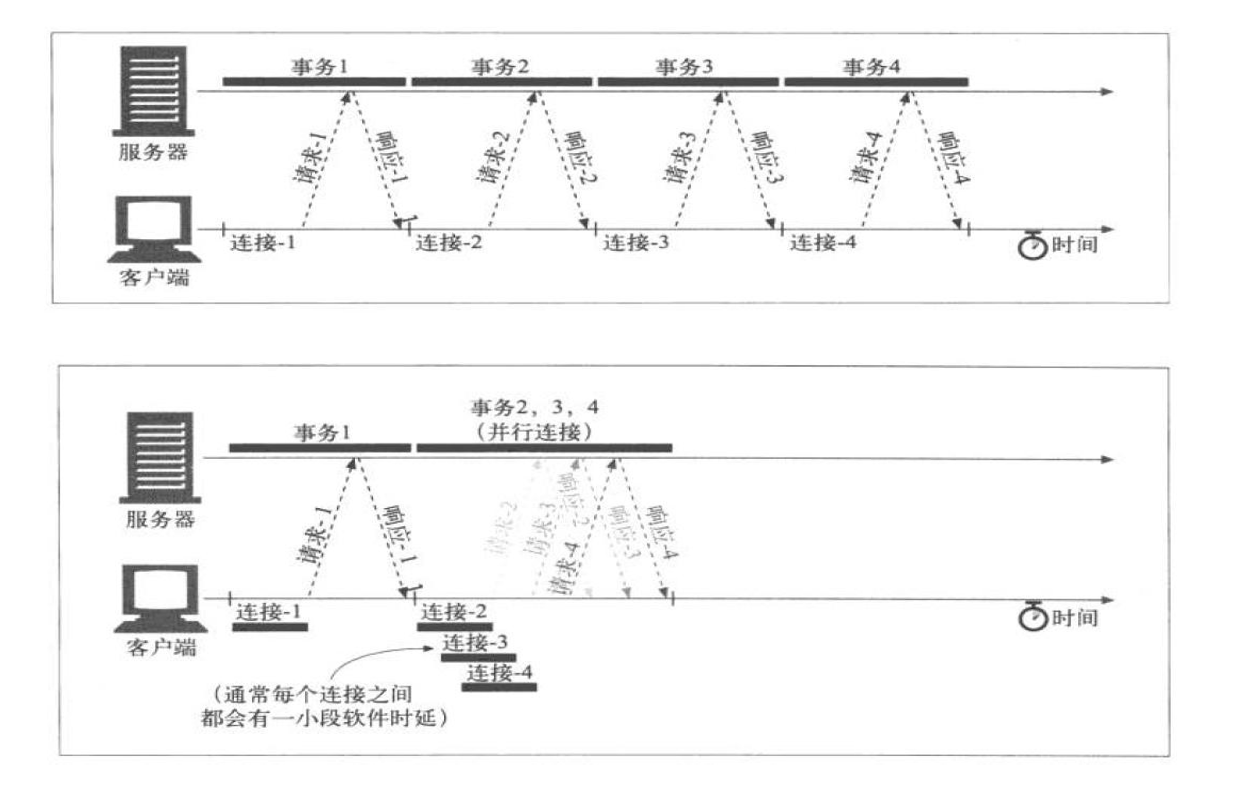
上图👆并行连接时,近乎同时发送多个tcp连接。
👇这篇的两个图,应该和串行和并行的案例还不同,👇这里提到的是一个tcp连接里传多个http的请求。
https://cloud.tencent.com/developer/article/1893815
3.1 Fully multiplexed
解决了队首阻塞的问题。对于同一个TCP连接,现在可以发送多个请求,接收多个回应了!在HTTP/1.1里面,如果在一个连接里上一个请求发生了丢包,那么后面的所有请求都必须等第一个请求补上包,收到回应以后才能继续执行。而在HTTP/2里面,可以直接并行处理。



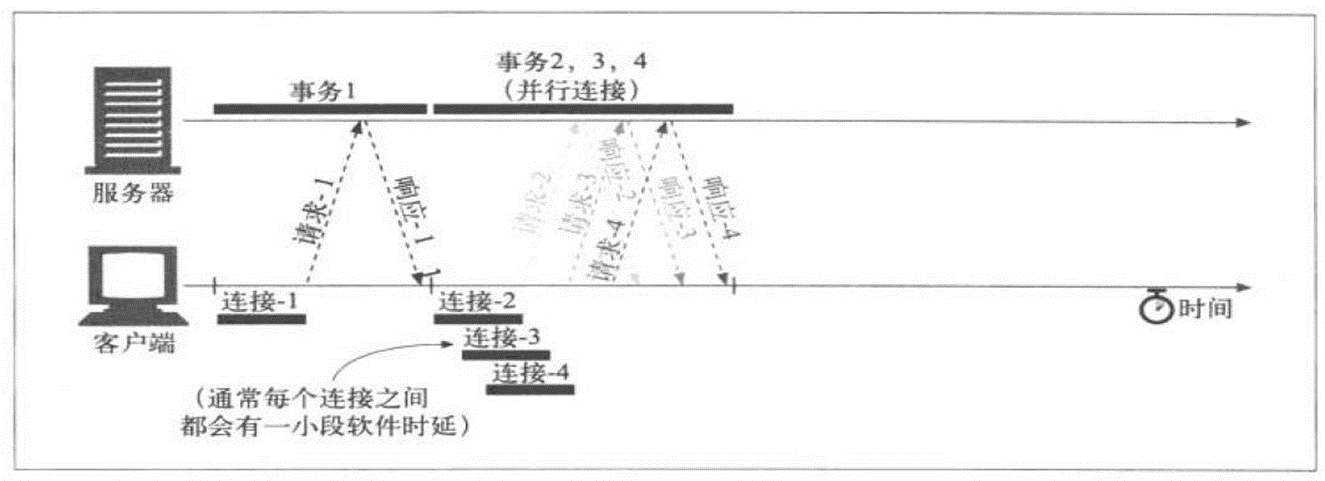
回到并发,服务器本身并发支持是OK的,浏览器的并发,发起是有限制的。
对于大的网站资源,表面上打开的是首页,其实背后的很多资源(首页的index.html里会涉及很多url),比如图片、JS 都是放在不同服务器上的,相当于client同时从不同的服务器上下载资源。其实是大大消耗的是客户端的带宽。
持久连接,这个好像就是上文提到的Fully multiplexed
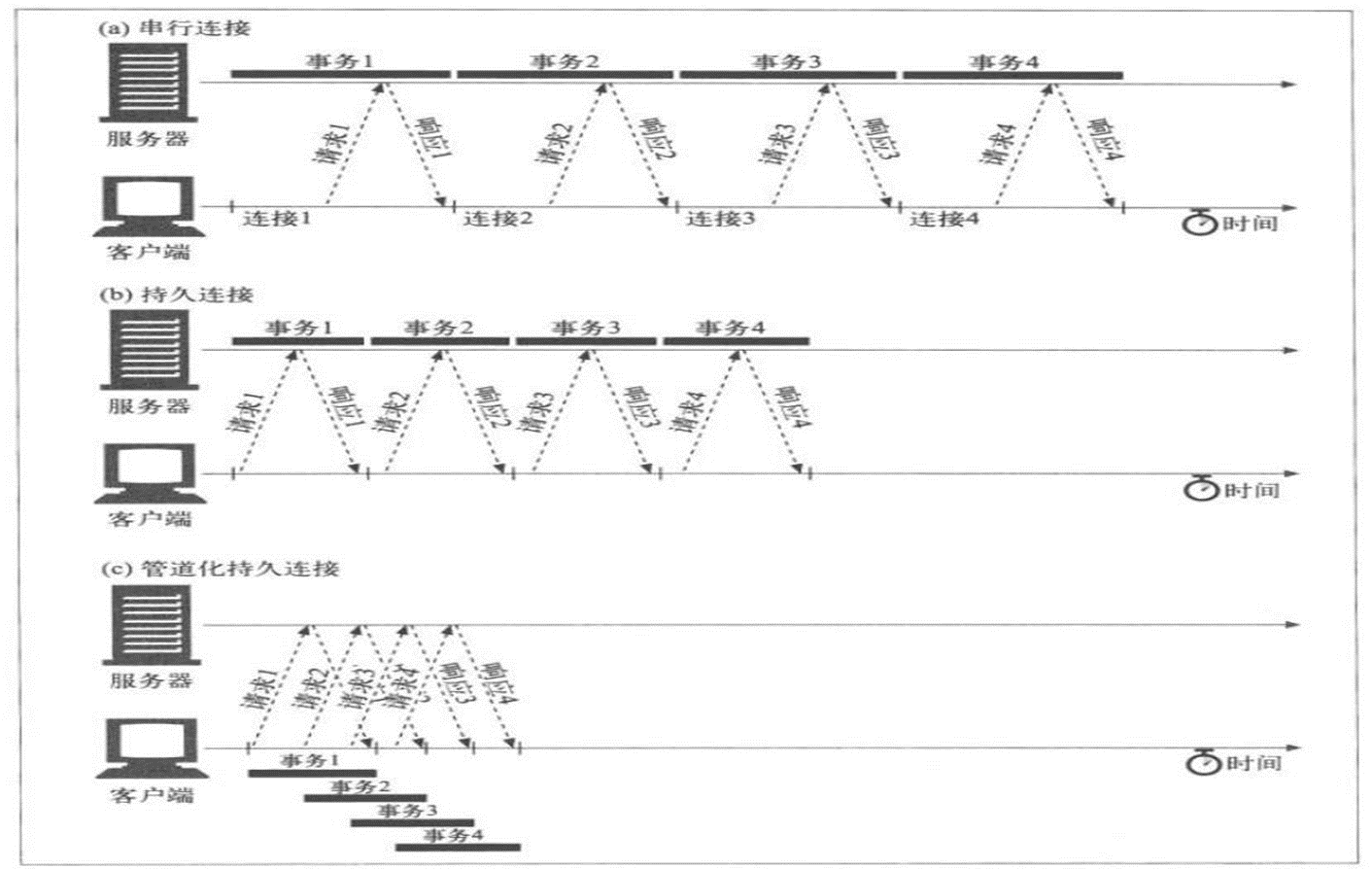
👆图(a)就是串行,针对多个资源的下载,tcp连接一个个建立,http请求一个个发送;
(b)是优化了tcp就一个,在一个tcp连接里,串行的发送http请求;
(c)是进一步优化,tcp一个,然后在这个tcp连接里,并行的发送http请求。
不过,这理论感觉看看就就好,正向gpt所说,也不是并行就好的,早在硬盘的IO上就知道串行才是王道,并行干扰解决不好,同样http传输就涉及两个并行①tcp连接②http请求;干扰我不知道有没有,也许这里不同于硬盘不存在干扰,但是并行一定涉及排序重组,本身就消耗CPU了,所以也不一定就很好,考虑到浏览器的复杂性,这没必要深入,大概浏览器本身也会择优应用机制。
不过,串行的最大问题就是 one by one 一个过不去,后面都阻塞。
HTTP工作机制总结

HTTP协议

head是什么,头,就是数据包的头,类似于IP头,TCP头一个意思。
IP|TCP|HTTP|DATA
这个HTTP的头就是涉及http数据包格式了。
head里会涉及的内容,头部本身就是个文本。
1、content-type:告诉上层应用,拆包的机器一开,就是里面是啥,比如是data是也给音频、文本、图片啥的。就是MIME的大类/小类值咯。 比如用户收到这个response的头,看到这个image/png,浏览器就会用对应的图片解释模块来渲染DATA,来显示图片来。
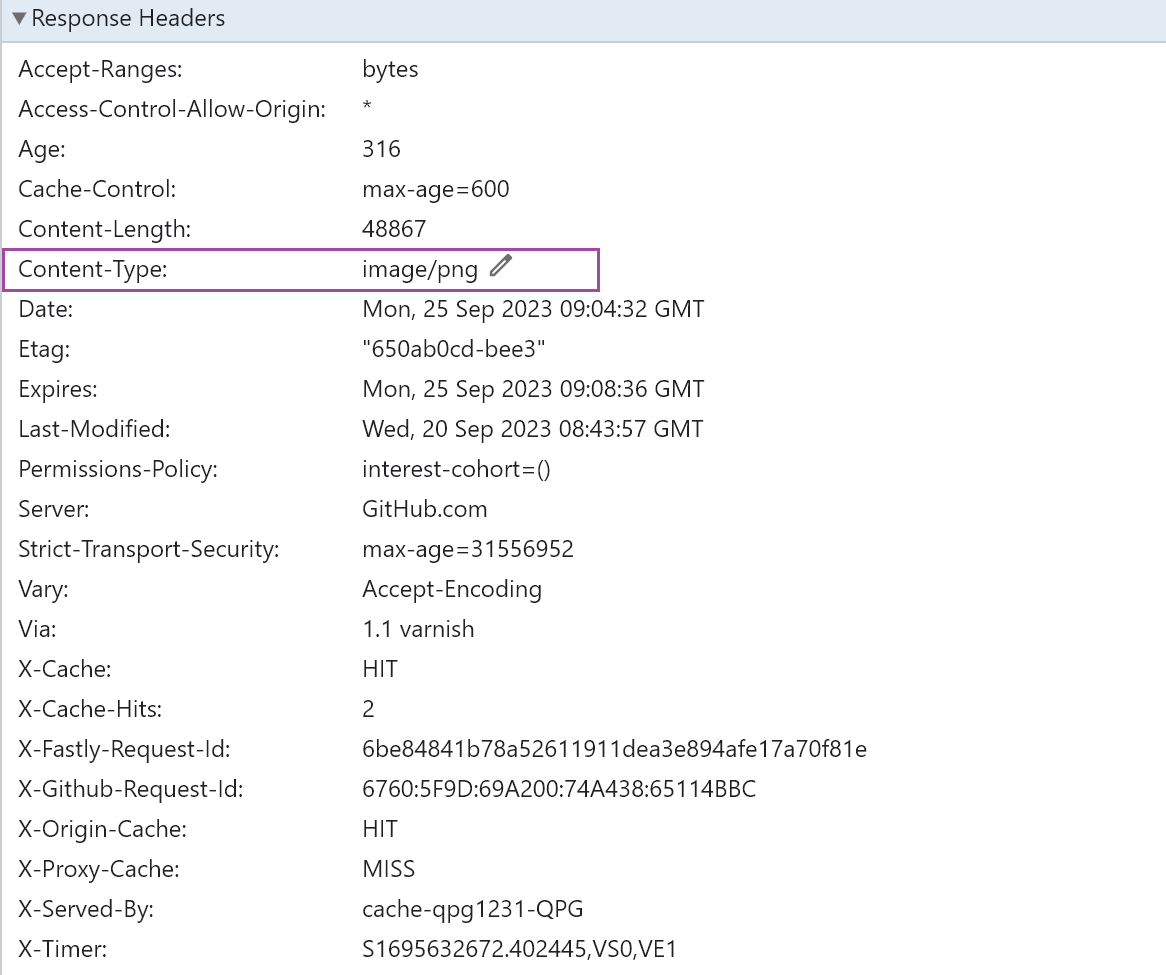
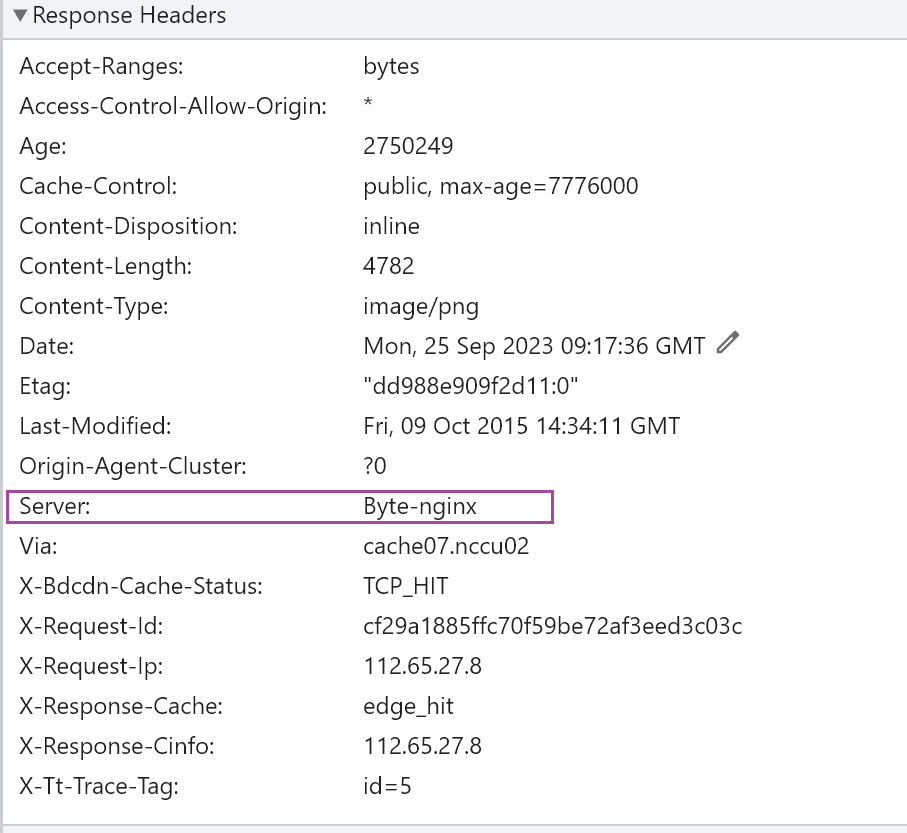
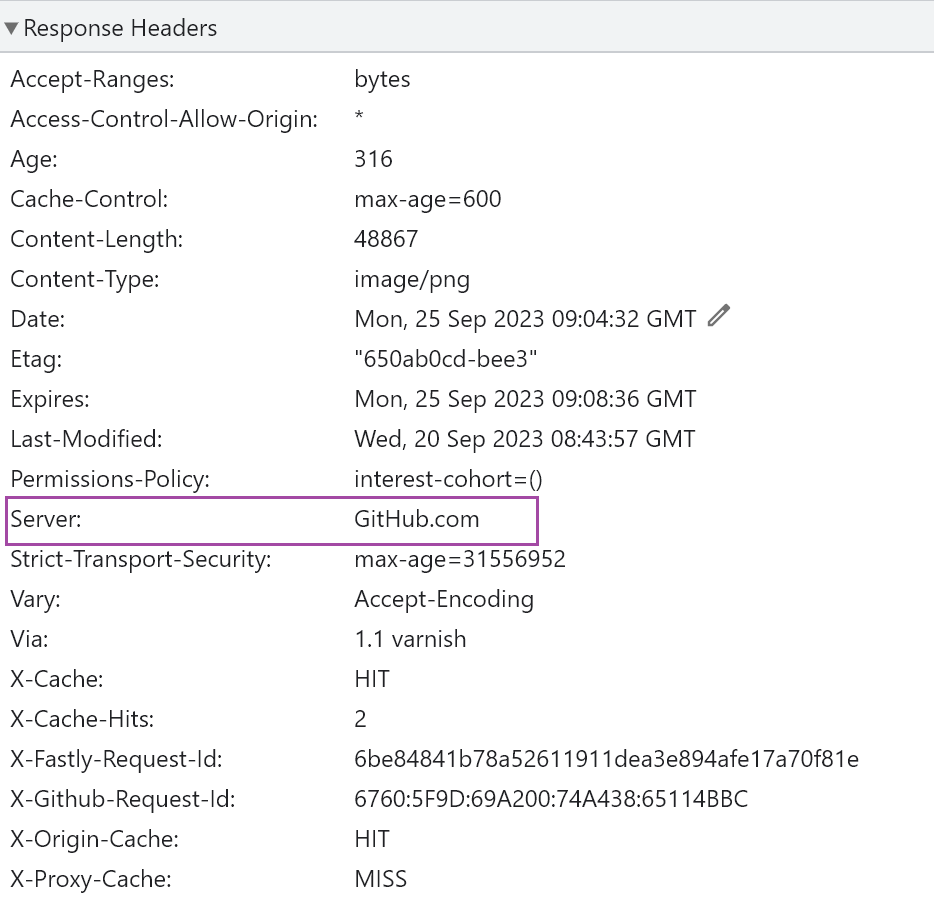
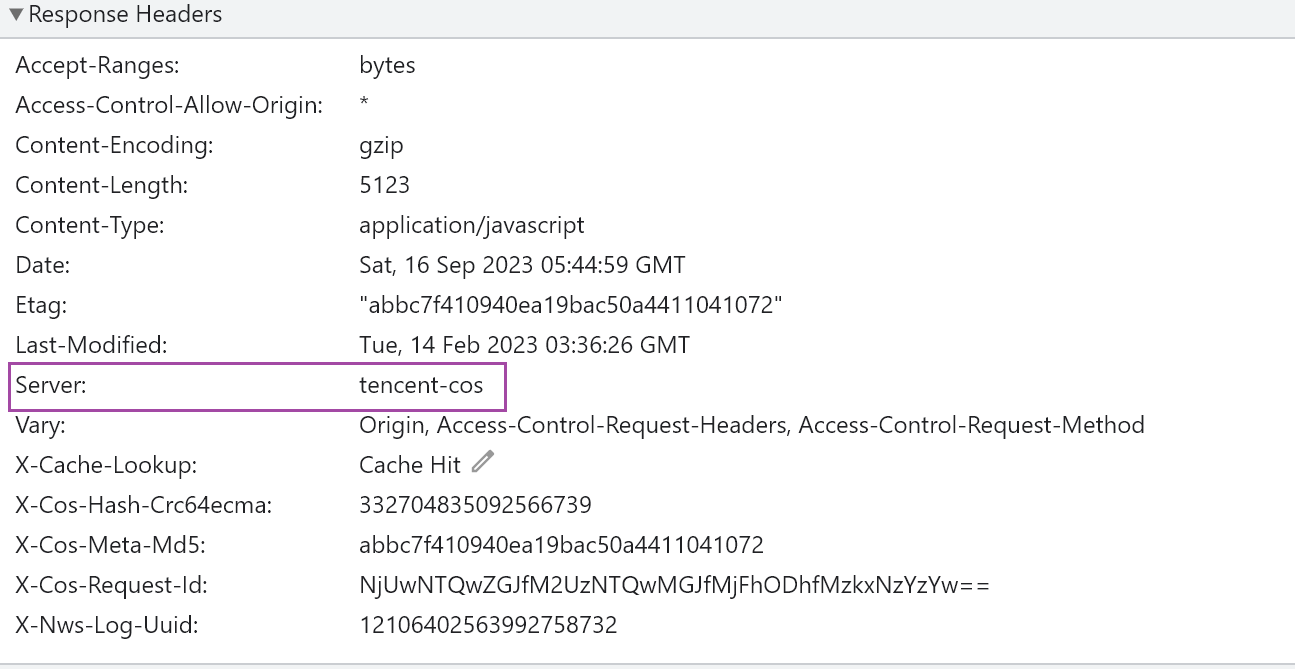
2、表示http服务是什么软件提供的,nginx、github、tencent-cos桶。还真是五花八门,自定义的啊?估计是。
单个TCP的利用效率从Http1.1开始的
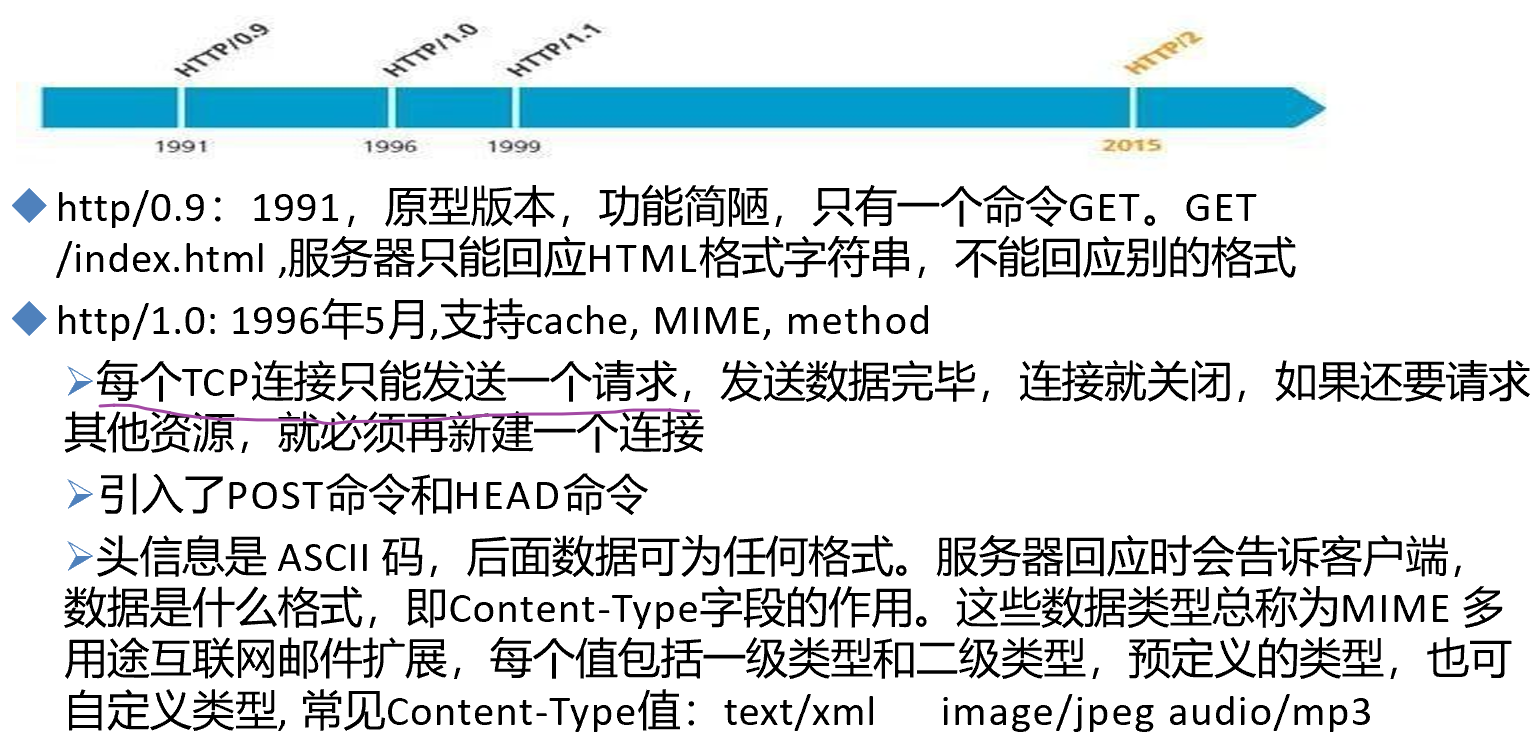

注意上图,除了tcp 持久化之外,还有一个浏览器同时6个持久连接,这个我在做URL访问LOG的时候,其实iptables的审计LOG啊,
# 👇这是iptables的log配置
-A FORWARD -s 192.168.30.181,10.100.2.93,10.100.2.182,172.16.31.31 -m set --matc
h-set xxx.com dst -j LOG --log-prefix "[ user_name xxx.com ]" --log-level 4
# 👇这是修改iptables的log默认存放目录,默认是放在/var/log/message下的,当然你这样做,默认里还是有的,无所谓了,这里多一份也OK,通过这里的日志分析,就会知道其实一个web页打开,就会涉及很多个sessions了,就可以和这里所学的浏览器的默认6个持久连接联系起来,不过呢6个也是他说的,不要当真,就算是真的也不要较真。
kern.warning /log/iptables/iptables.log
👇以下截图是流量LOG的说明截图,哈哈,当时就发现了一个网页会有多个tcp连接。

这里面还涉及专业术语,前面没有提炼出来:
1、单个tcp连接的持久化,里面支持多个http应答,不管http是否并发还是串行,这个叫持久连接 persistent connection;
2、一个TCP里,同时发送http请求,也许是有细微的间隔不过近似于并发(我看图猜的),这个叫管道机制,TNN的真TM不会起名字。但是没办法,可能有的教程里还真这么些的。英文叫pipelining,真TM不会起名字,pipline是gitlab runnerr做CI/CD的流水线啊,操,老外起名字的水平肯定是不行的。

不过老早就http2.0了,这些参数也发生变化了,总之了解一下。

缓存工作原理,前面章节讲过LRU算法,涉及过期时间。
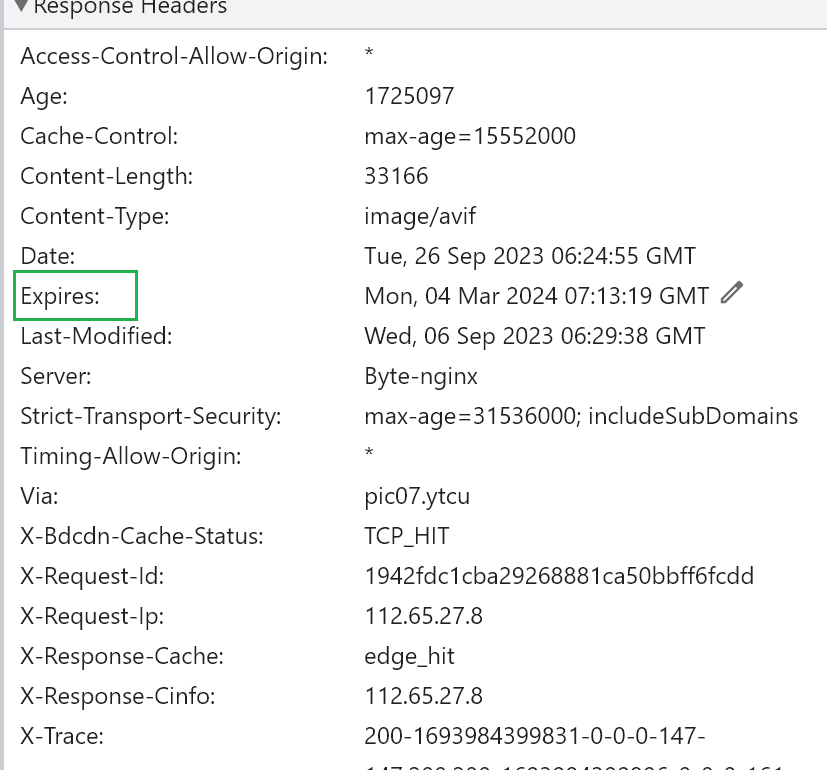


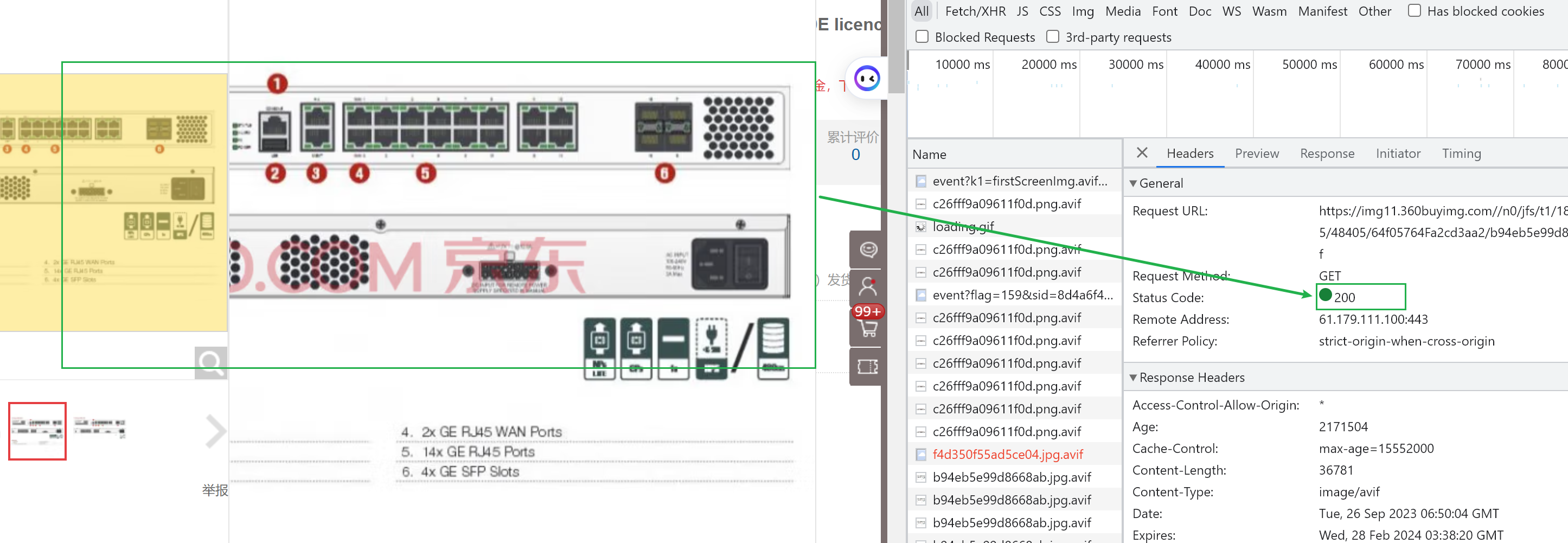
视频举例提到是jd的图片预览,但是实测并不是206而依旧是200的返回码。
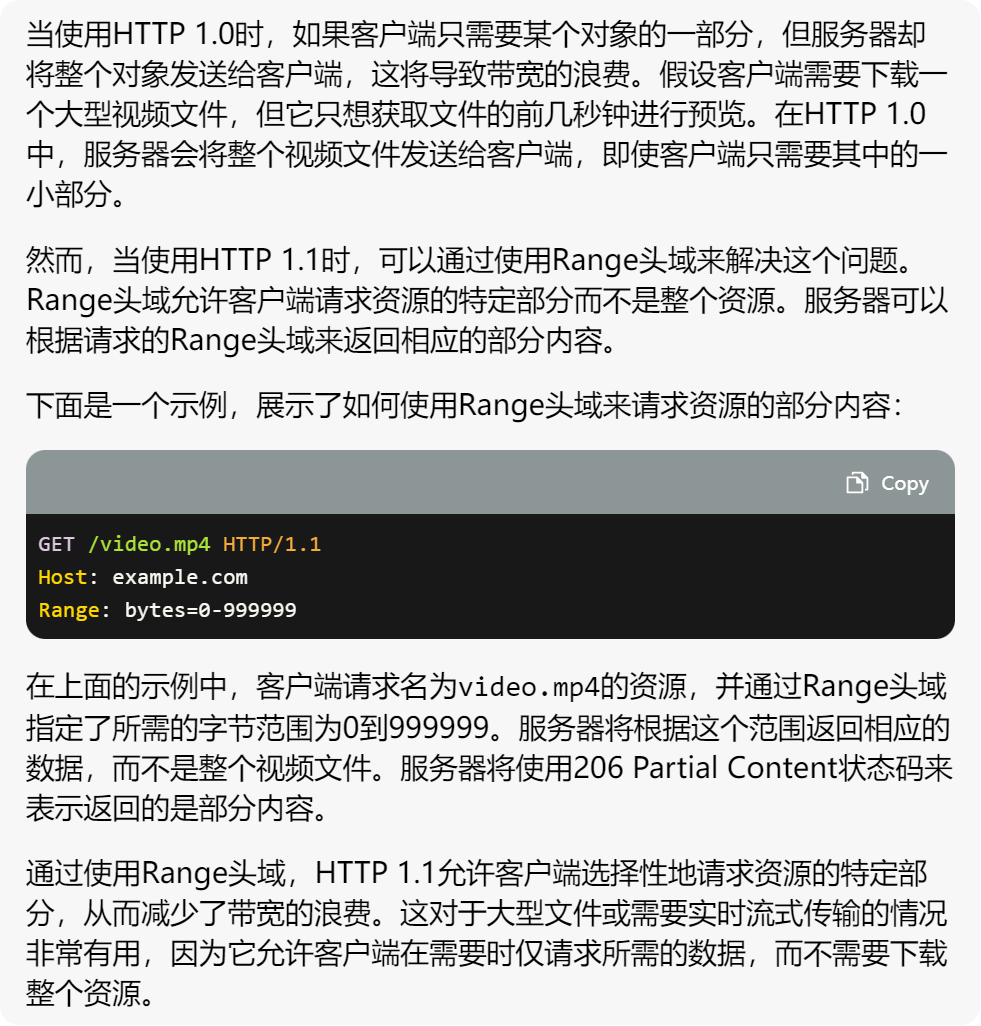
问问gpt

虚拟主机,主机名,不过现在都是基于head头转发啊,niginx就可以啊,这也是个老技术了。

可见👆keep-alive也不一定是件好事,关键点就是长连接不释放,占用资源。


SPDY就是私有变公有HTTP2

推消息啊,所有个性化广告就是这么推过来的哦。