第8节 Docker的默认网络和容器间通信
网络简述
容器启动都会获取docker0一个网段的IP,默认都是172.17.0.0/16

同主机下不同容器互访,因为IP是动态获取的,存在变动的可能
不同主机下容器之间互访,首当其冲的就是IP段默认一样,出都出不来。听不懂啊,什么叫出不来,就是路由啊,同网段不会找GW,不走GW怎么出本地局域网呢。
启动一个容器,就会生成一个虚拟网卡,该网卡在宿主机表现为vethxxxx,在容器里表现为eth0#ifxxx; 一体两面 就这么理解就行了,官方称之为veth pair。
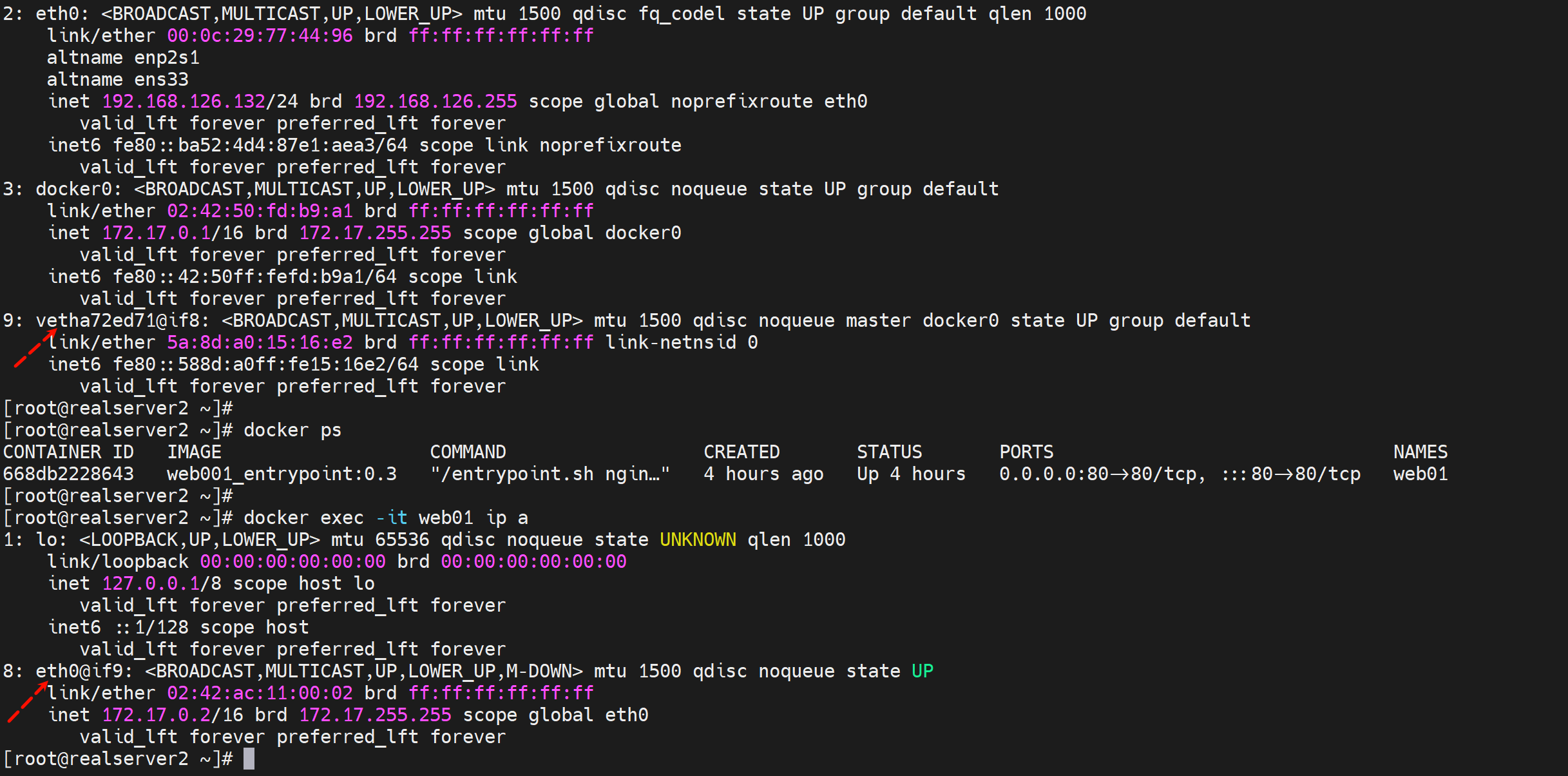
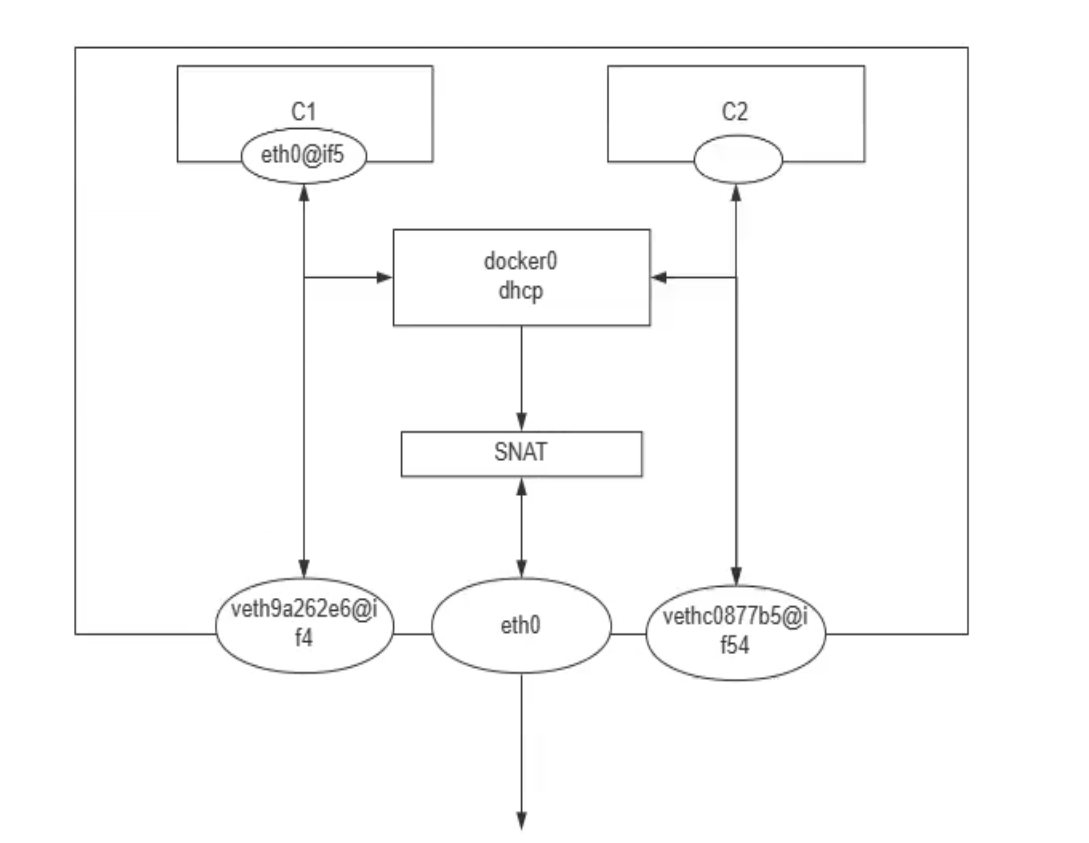
docker0相当于一个交换机,eth0--veth 都桥接上去。这样容器之间沟通,走docker0,容器出宿主的流量也走docker0不过还得过一层SNAT出去。
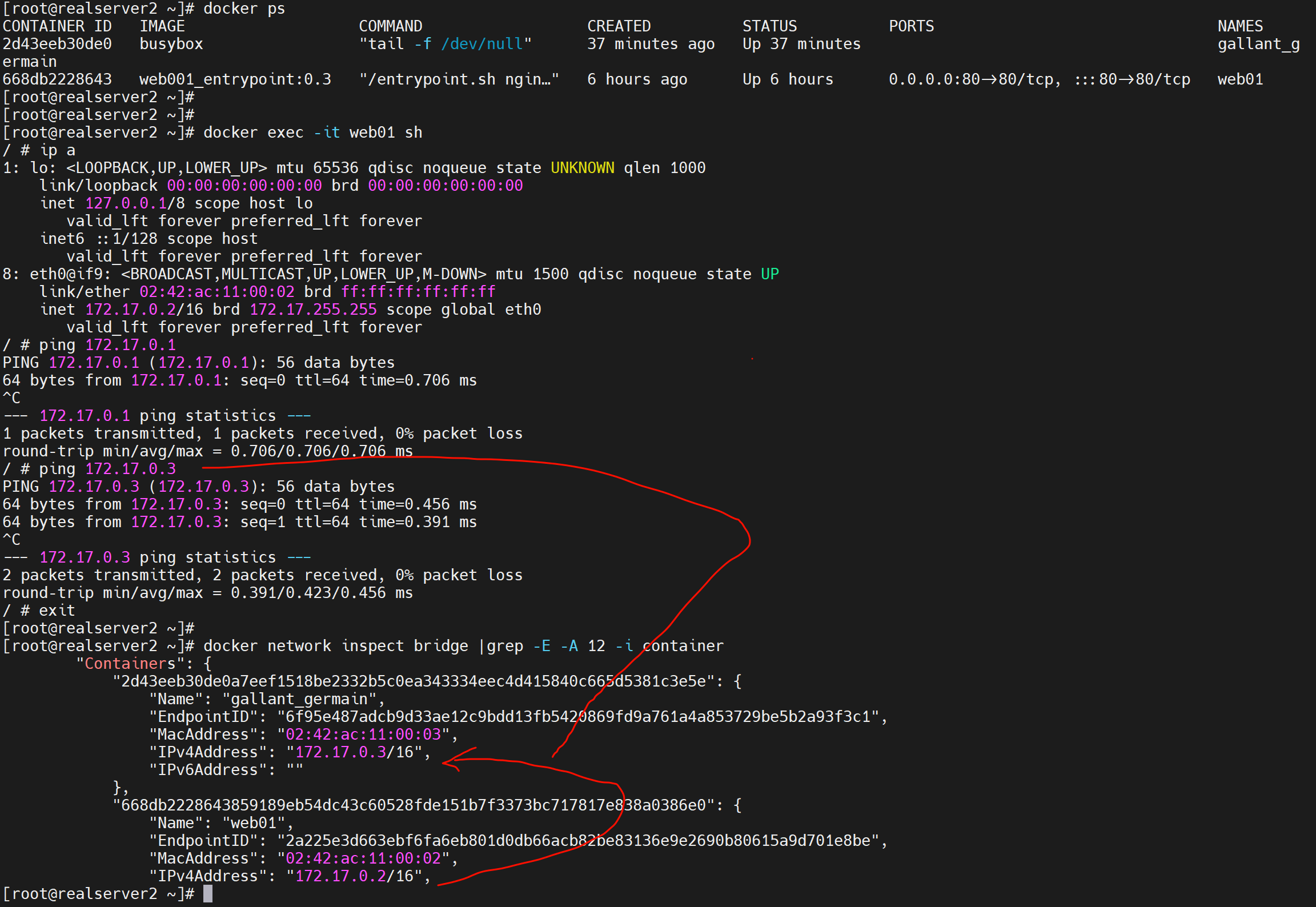
确认某个veth虚拟网卡所属容器
1、进入容器
看编号对应关系就行了,宿主上看9对应到容器的8,就是编号对应的。
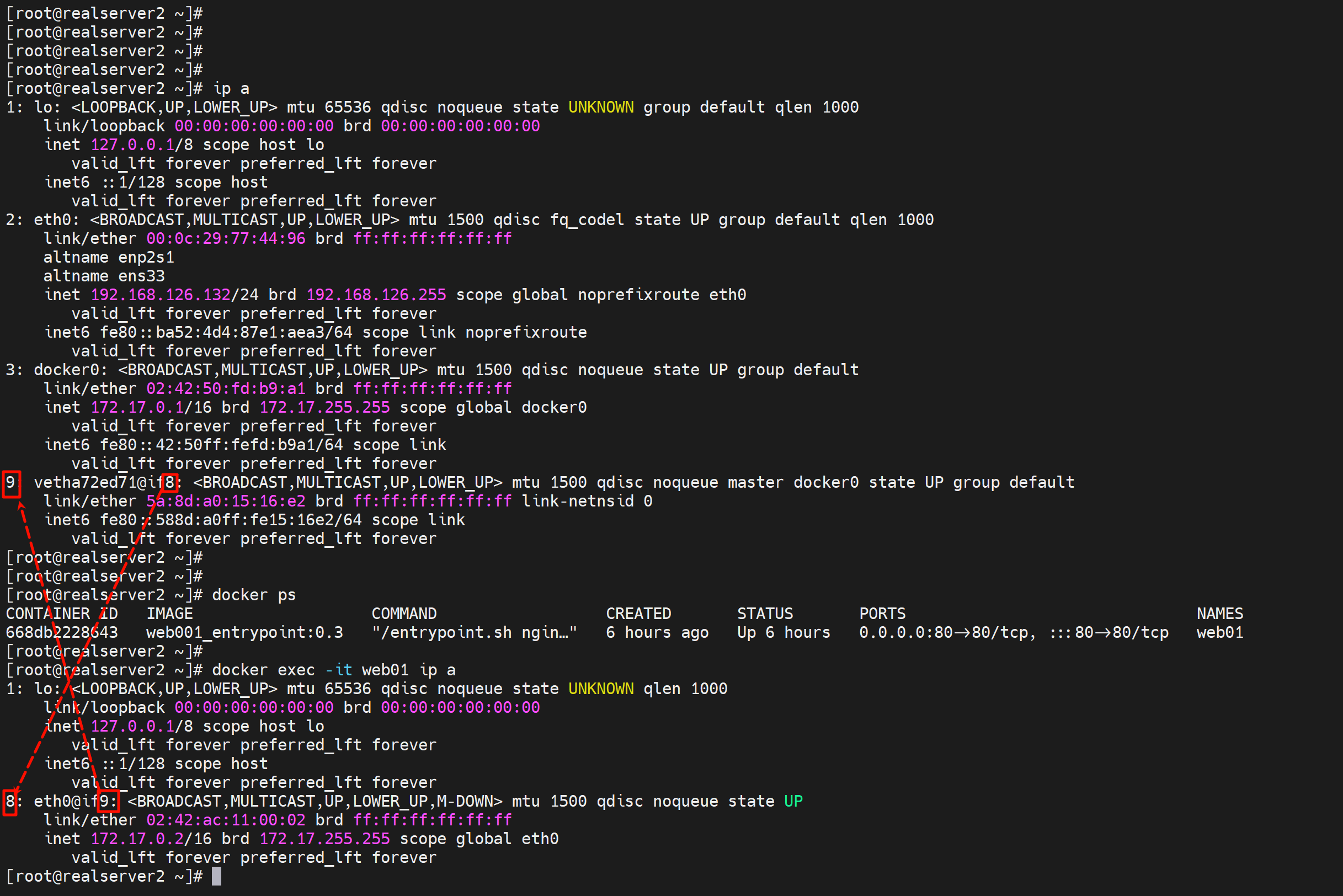
也要注意这个veth-pair,一体两面的 MAC 是不一样的;
然后docker0和veth是桥接关系。
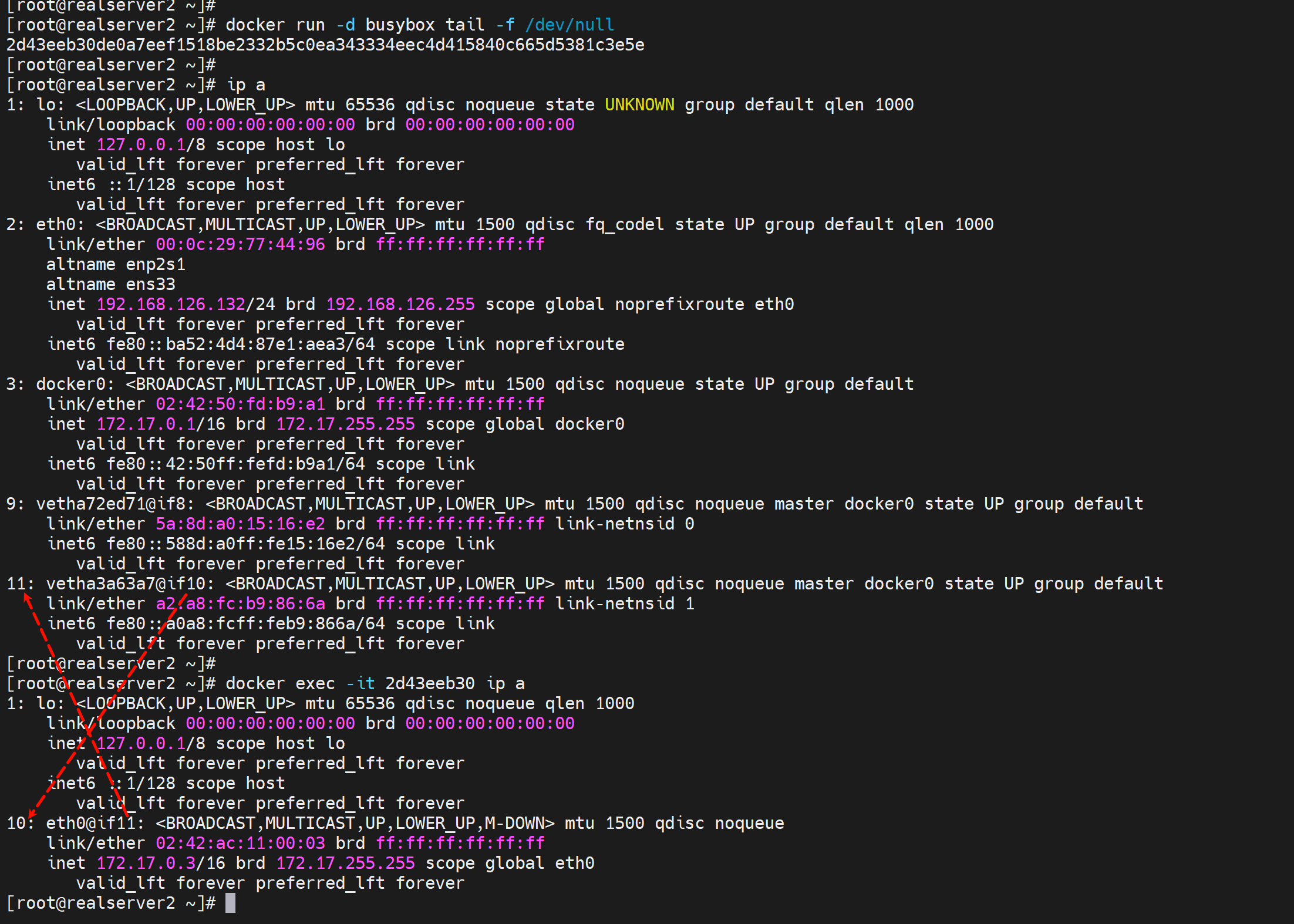
2、不进容器
但要注意:会导致 进入多层 bash,如果操作不当

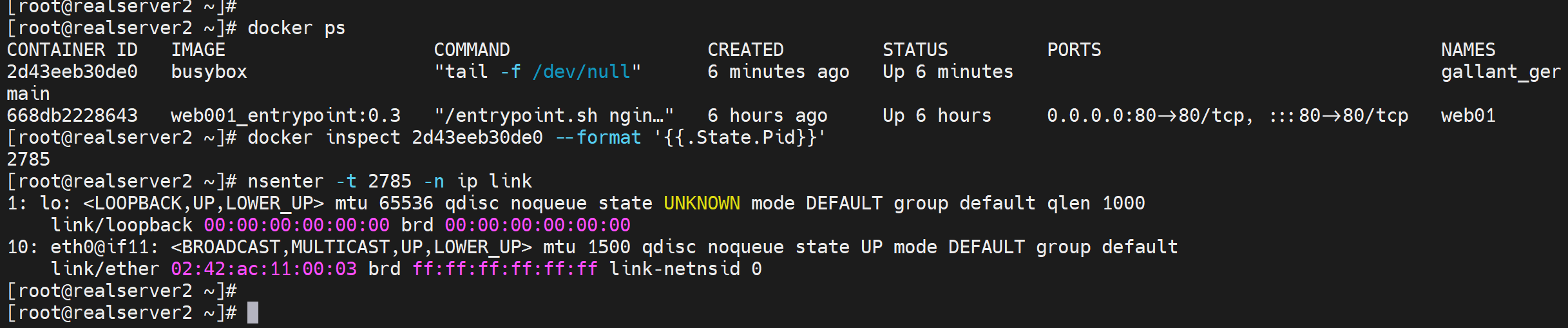
所以这个方法
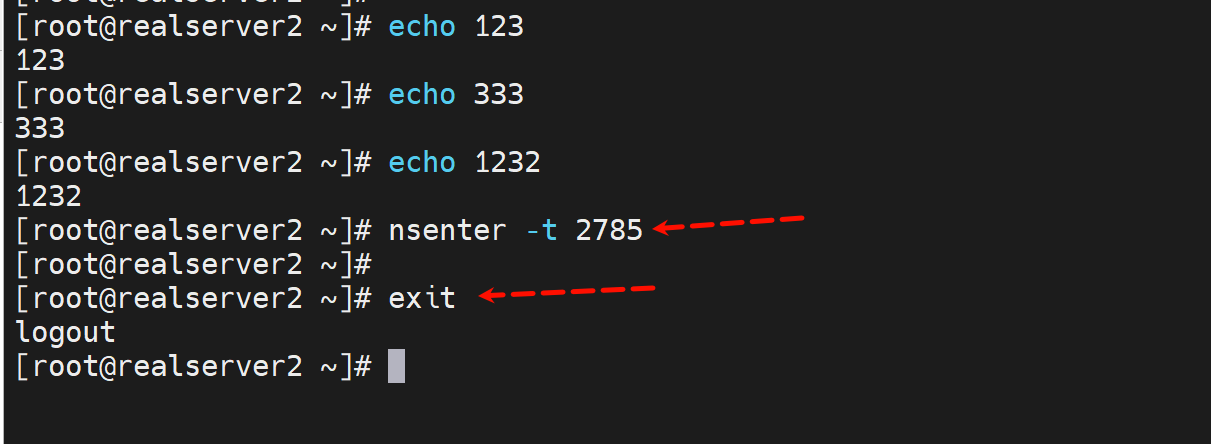
其实就是进入了命名空间了
其他工具看看docker0挂了几个容器或者几个veth
这个可以直观看到docker里挂的容器的NAME和容器里的IP和MAC,还不错👇
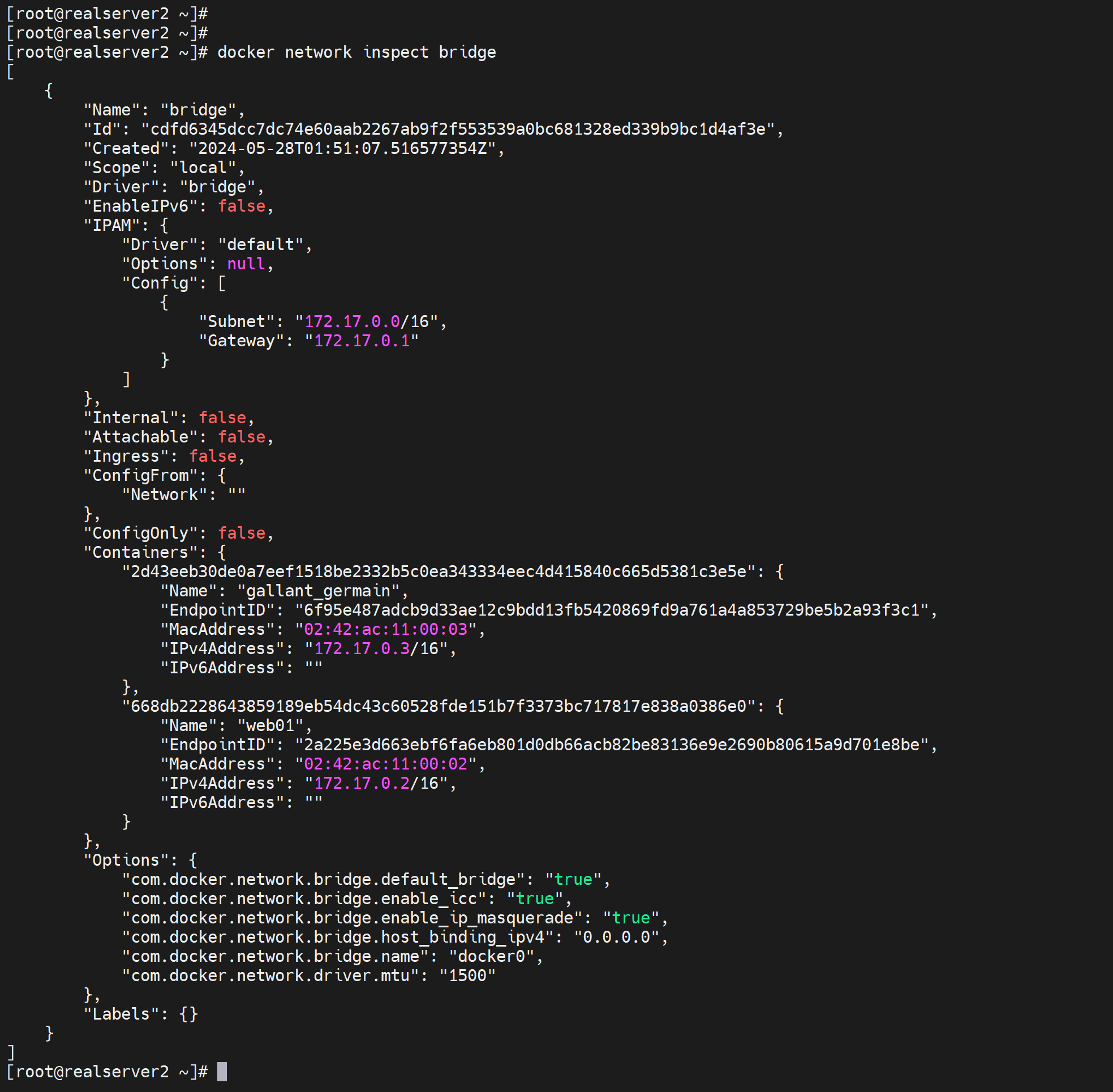
这个就是个排版看的舒服而已,ip a 看到的docker0自然是桥接到所有的vethxxx的。
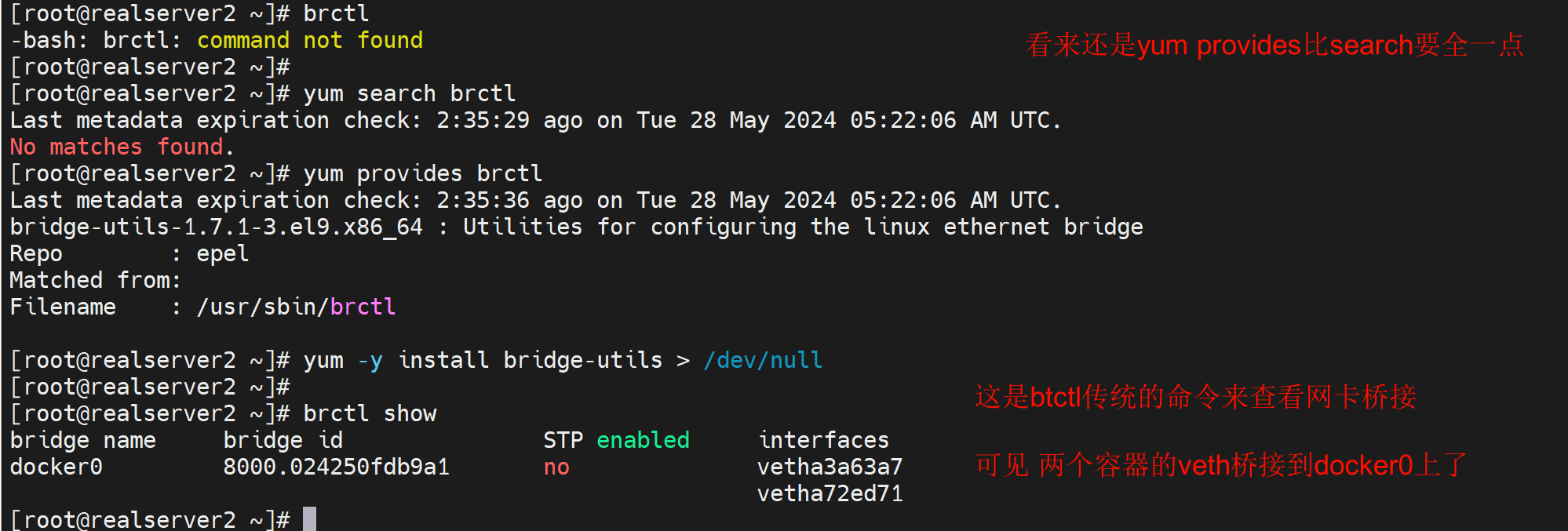
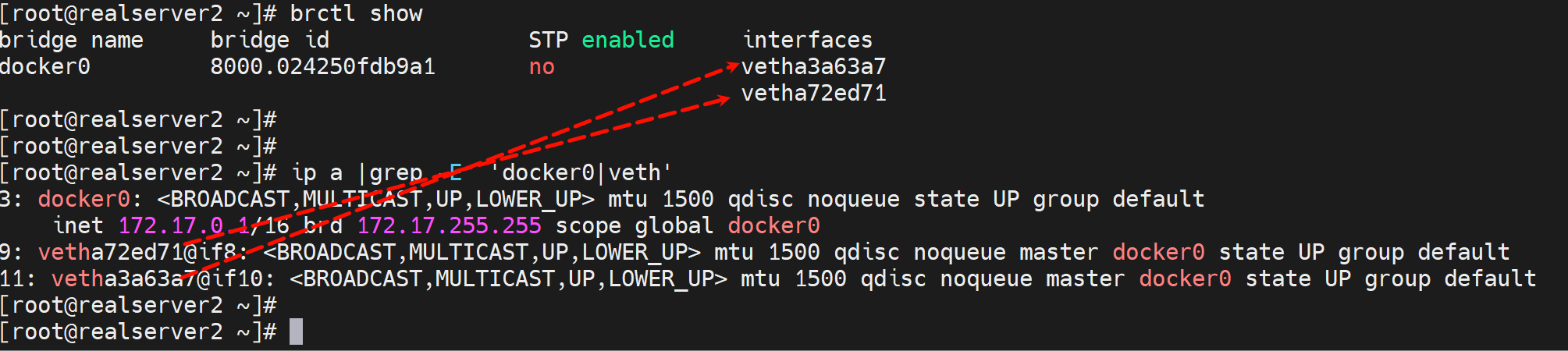
同宿主容器之间的ping就是默认通的👇
解决容器IP不固定的问题
背景:
1、容器run起来了,IP不确定,run起来了IP是不是也会受dhcp的释放周期影响的咯。
2、如果你公司内网有172.17段,那么容器如果要和这个段互通,就不行了。
需求:
解决这个不固定的问题咯,然后就可以更好的自动化咯。以及更换容器的网段。
落实:
修改docker0的dhcp的地址段
方法1:
vim /etc/docker/daemon.json
{
"bip": "172.19.0.0/16" # 这里写错啦,这写host和掩码而不是子网,改成0.1就行
}
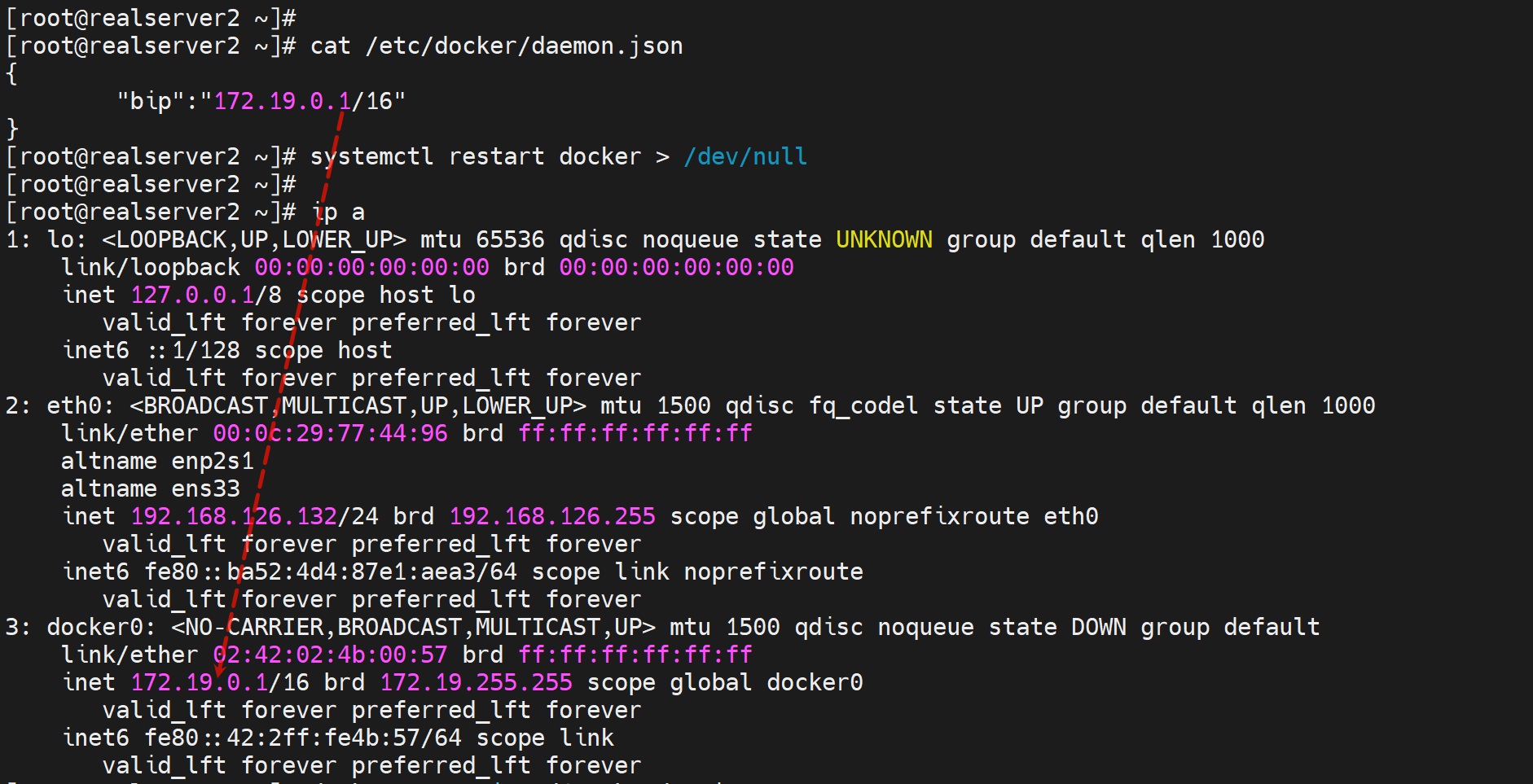
改完以后,哪怕删掉重启电脑,这个ip就是你改后的样子了,不会恢复到出厂默认值的。
可能猜测是,考虑到以前已经有容器在了,不管是up还是exited的,哪怕你删除了,也给你留存上一次修改的记录。
如果你想恢复出厂IP,那么就手动写成172.17.0.1/16,重启docker,顶多在删掉配置...不过无所谓了。
方法2:
vim /lib/systemd/system/docker.service
ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock --bip=172.19.100.0/24
方法2没有成功
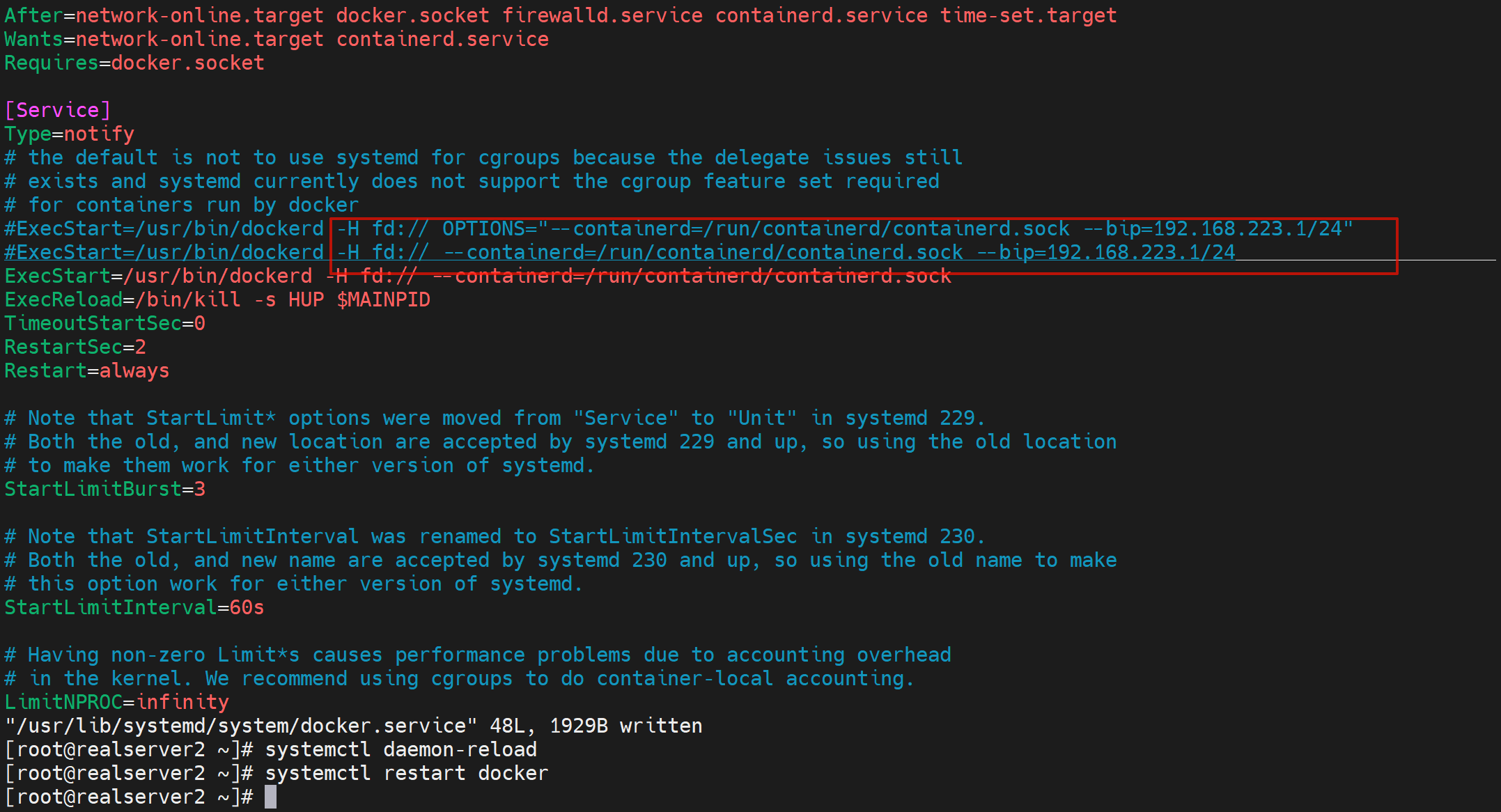
桥接到自定义的网桥
默认是docker的内外网卡都是桥接到docker0这个虚拟网桥的,现在改掉。
1、首先创建网桥
yum -y install bridge-utils
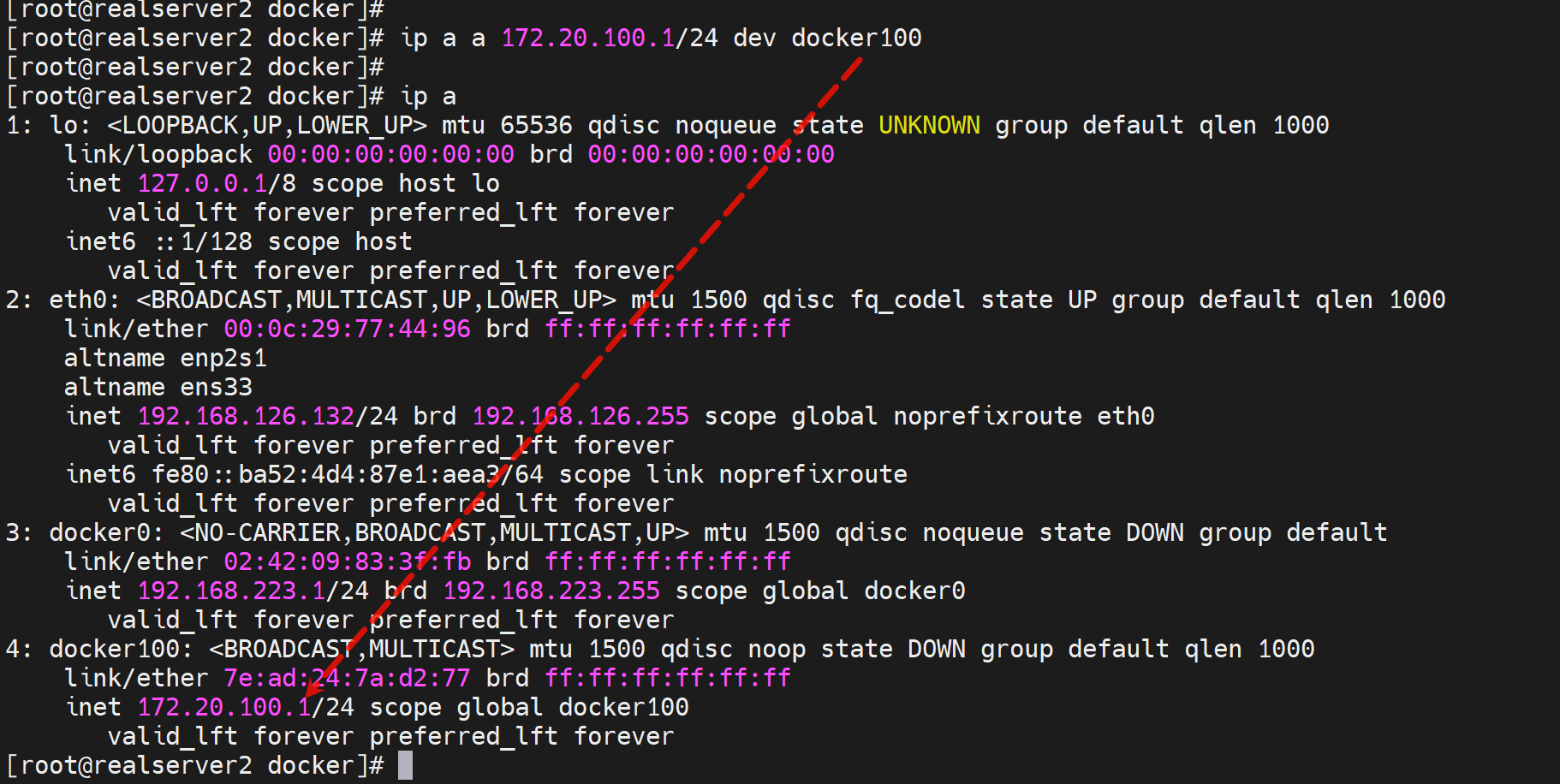
brctl addbr br0
ip a a 172.20.100.1/24 dev br0
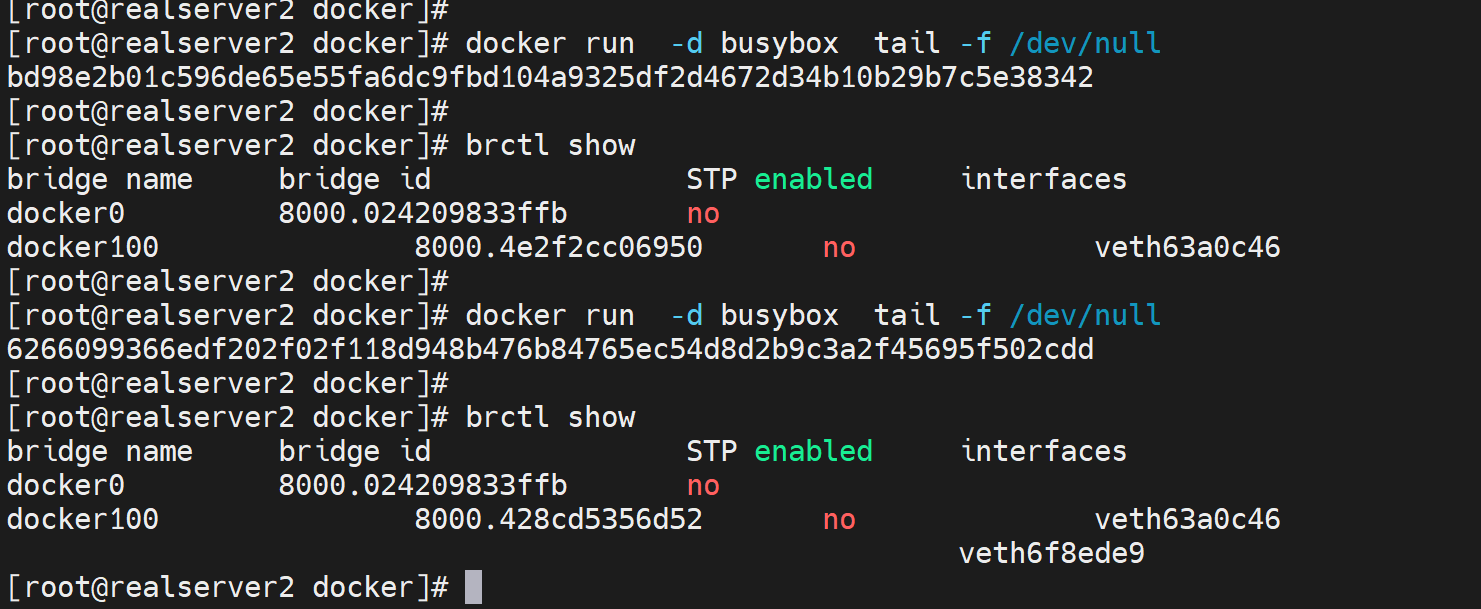
brctl show
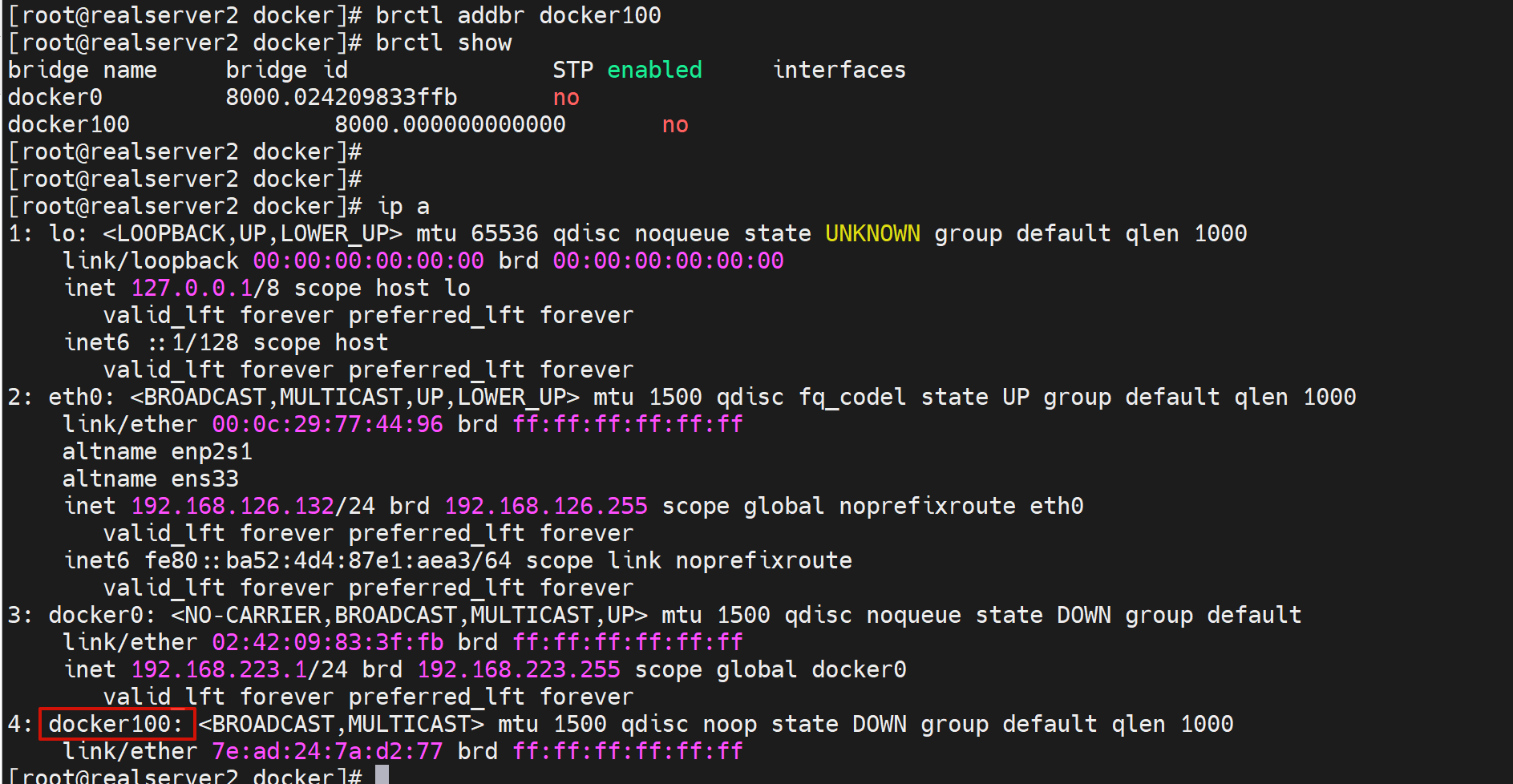
发现docker100还没有IP地址,然后docker0和docker100都是UP的。
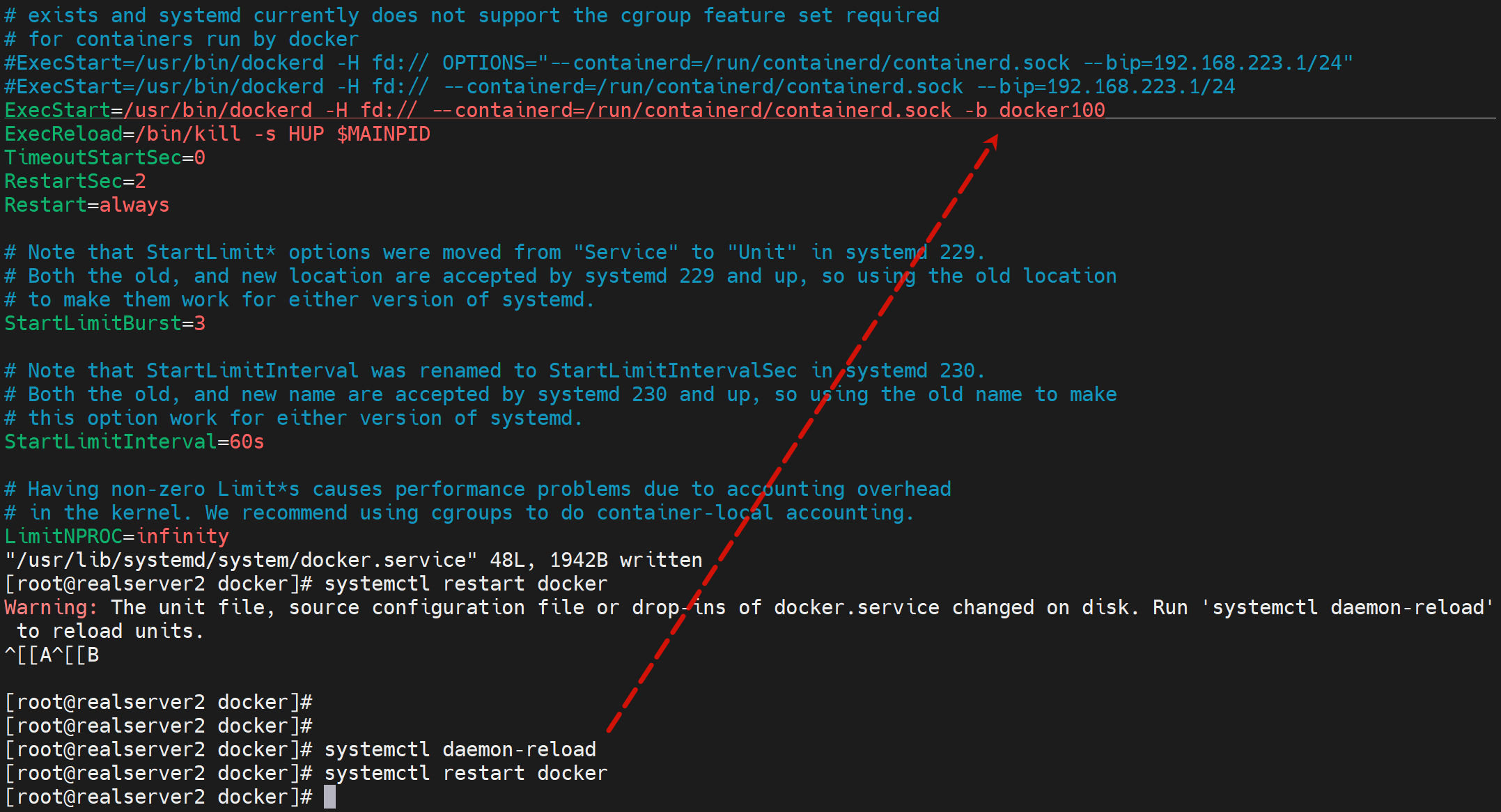
2、修改服务启动文件
vim /lib/systemd/system/docker.service
ExecStart=/usr/bin/dockerd -H fd:// --containerd=/run/containerd/containerd.sock -b docker 100
3、重载和重启
systemctl daemon-reload
systemctl restart docker
4、查看确认
ps -ef |grep dockerd
docker run --rm busybox hostname -i
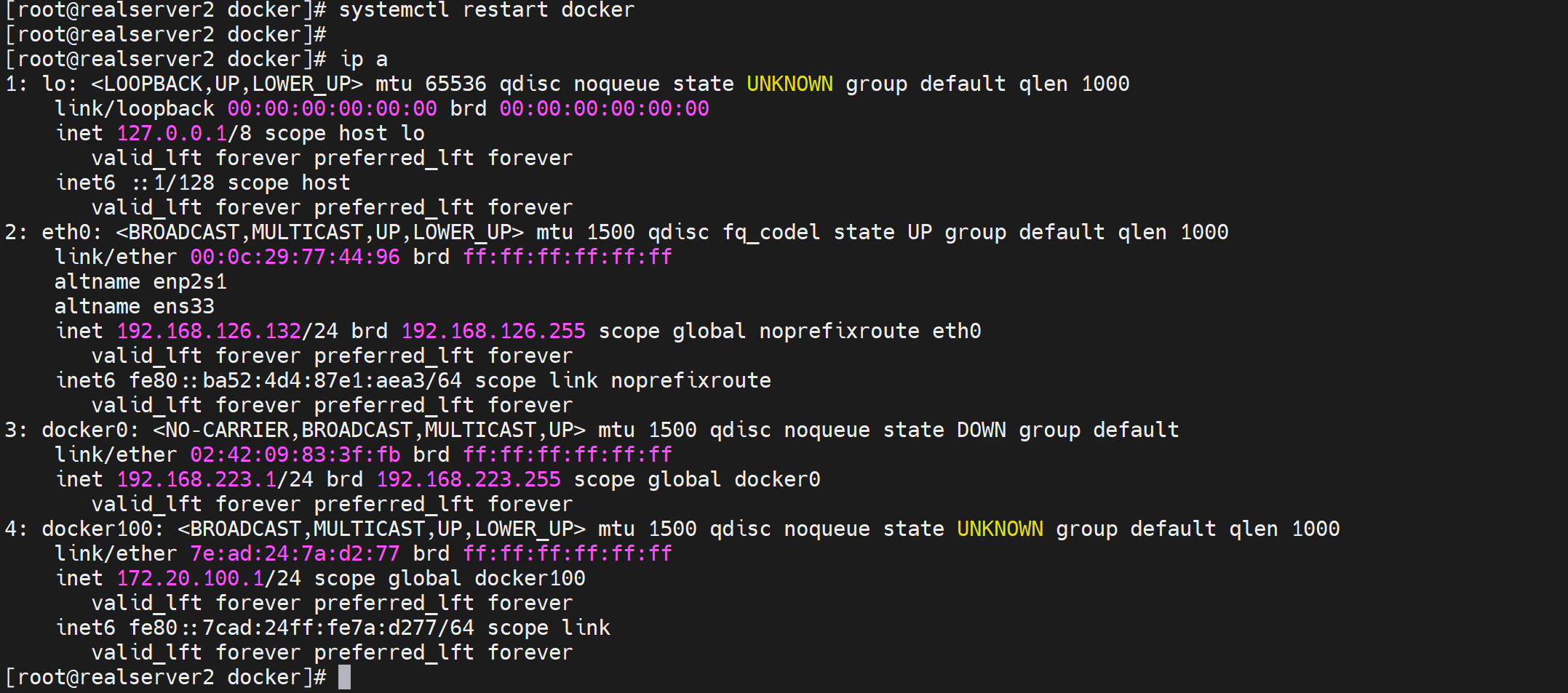
再创建容器,就会桥接到docker100上了
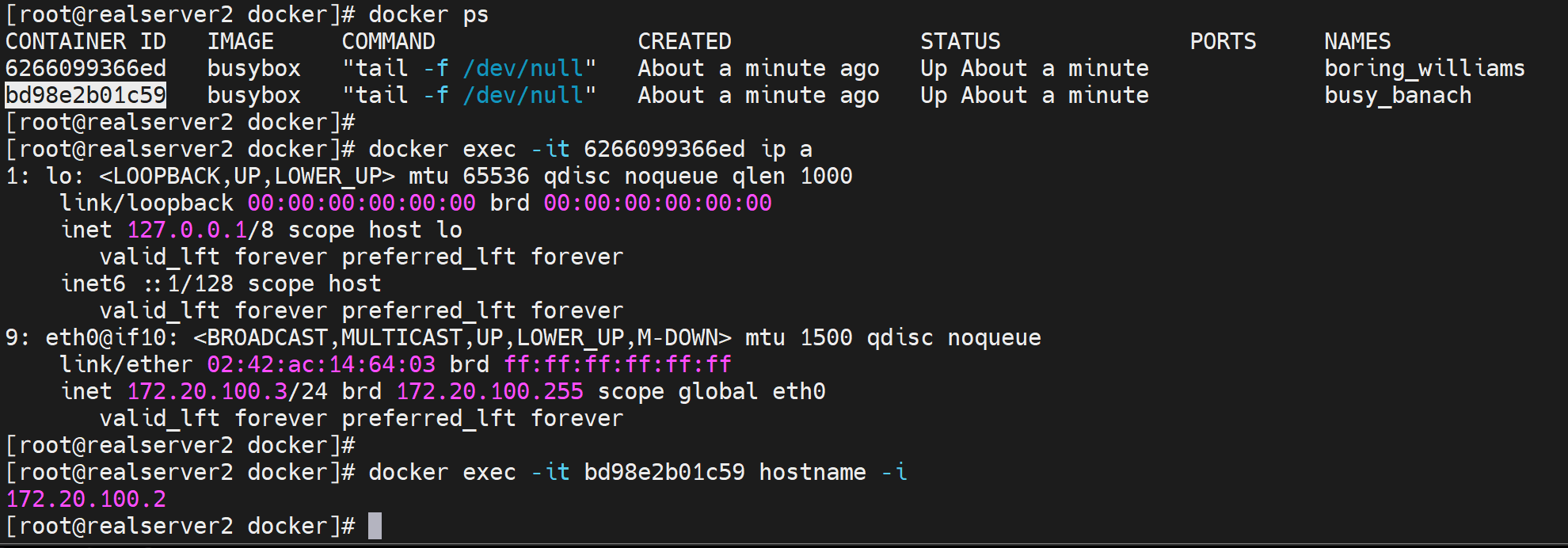
在检查下容器里面是否可以ping通外面
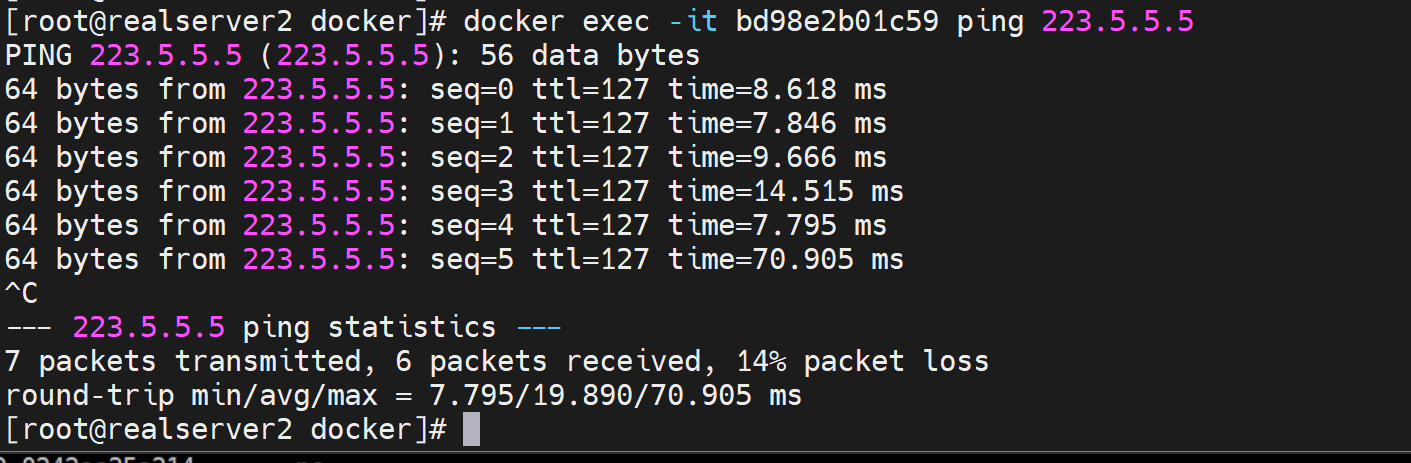
可以的,通过抓docker100的包也可以看到
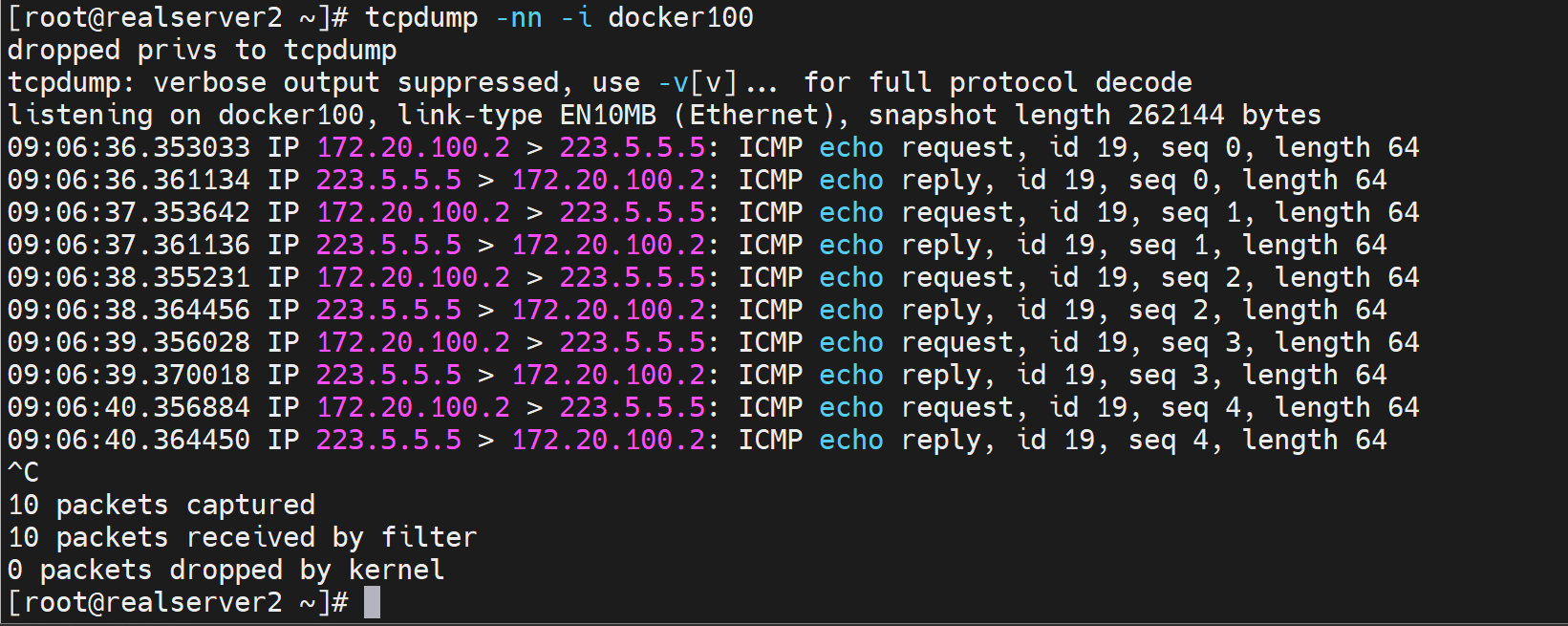
尝试抓容器的宿主虚拟接口的包
先定位这个容器id的内外IP是多少,当然我们通过上面抓包已经知道是172.20.100.2了。
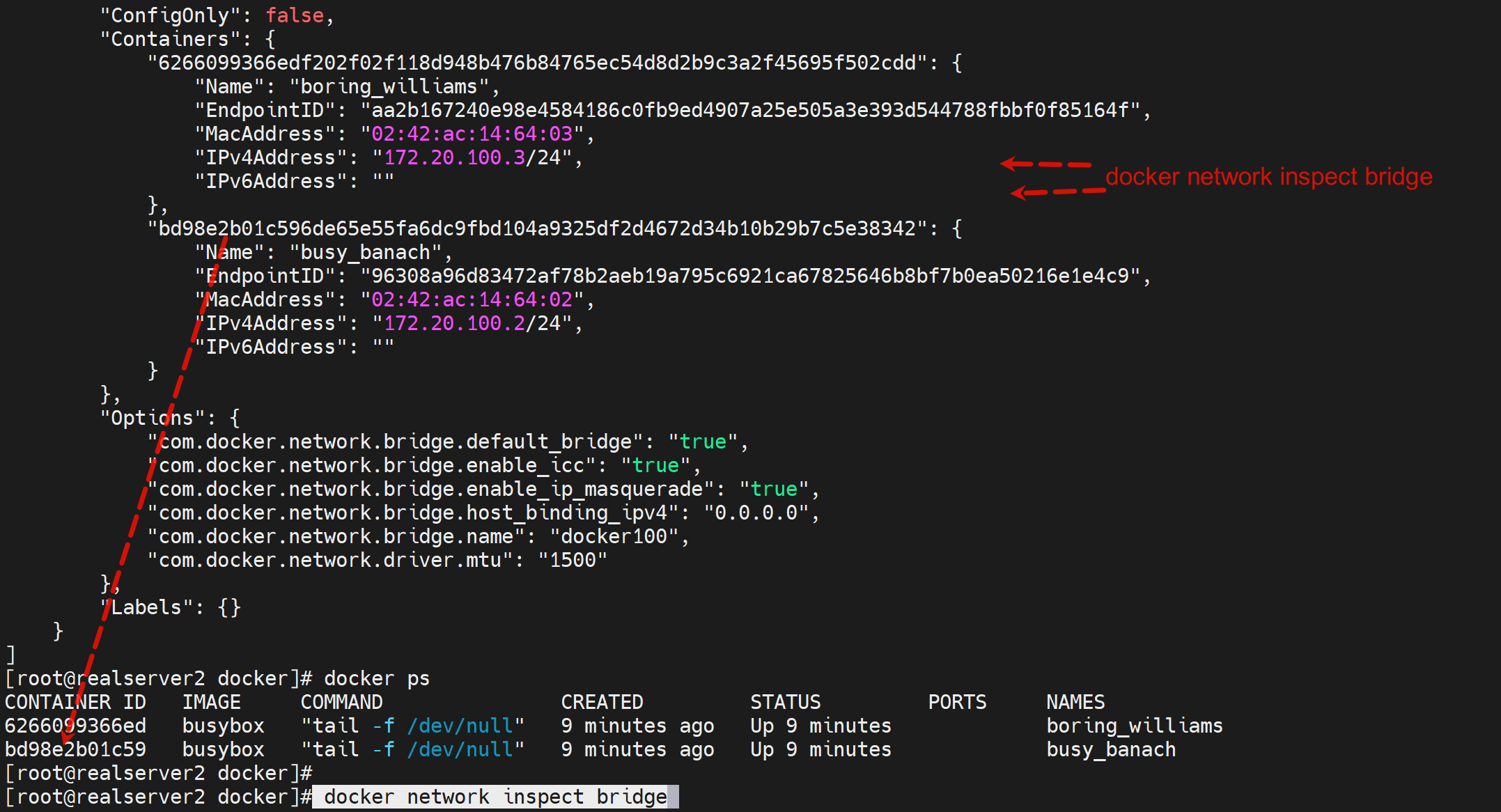
所以这一次通过这个命令docker network inspect得知什么容器的里面的ip是什么后
再检查这个容器里的接口名称
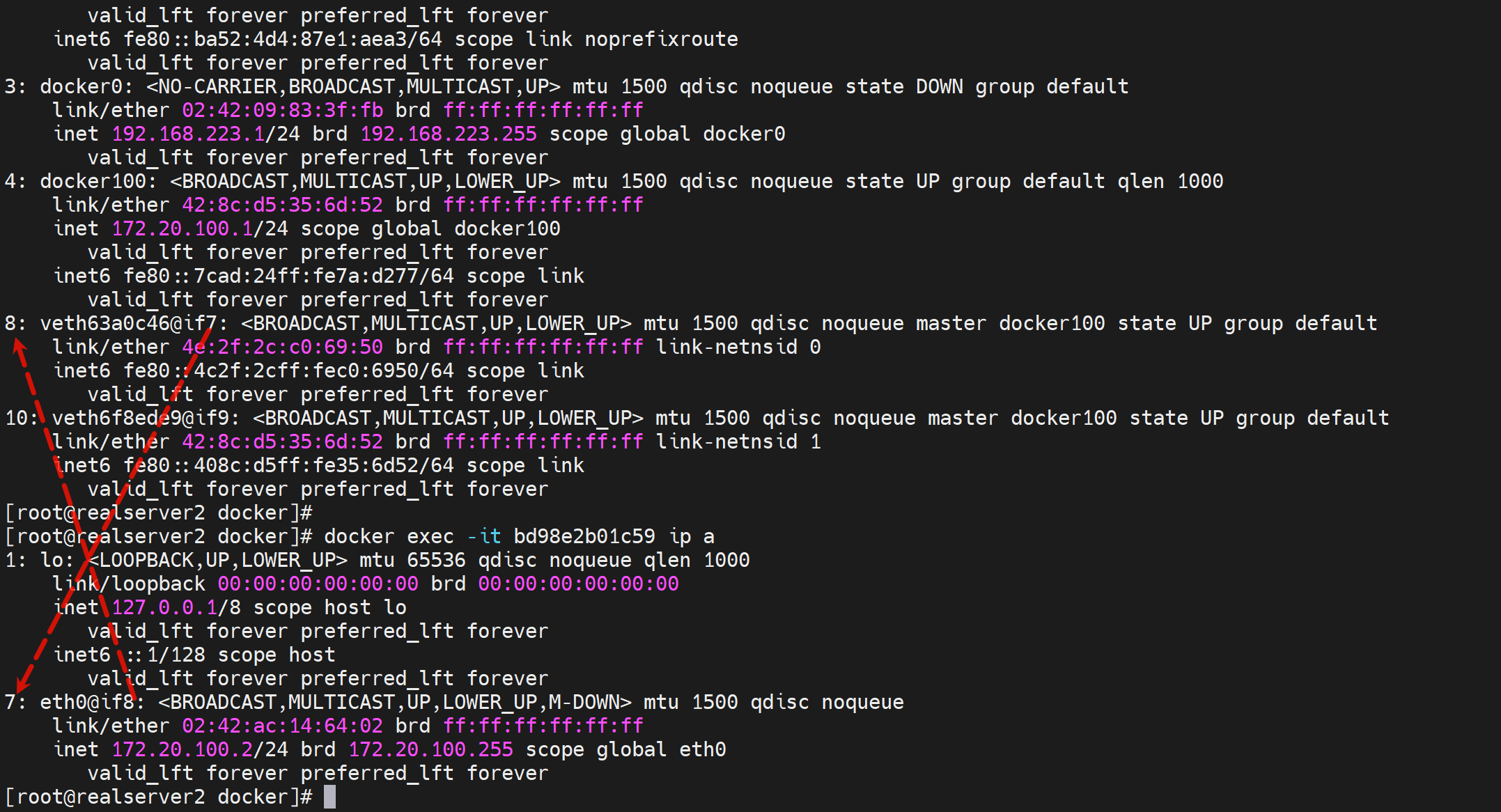
如何知道exec 容器的接口名称
1、比如我要使用这个bd98e2b01c59容器来做抓包
就可以通过exec -it xxxx ip a 知道接口对,就知道抓外面的哪个接口的包了
2、然后还可以通过,
docker network inspect 你要操作容器的id去确认待会抓包看到的内网IP是啥
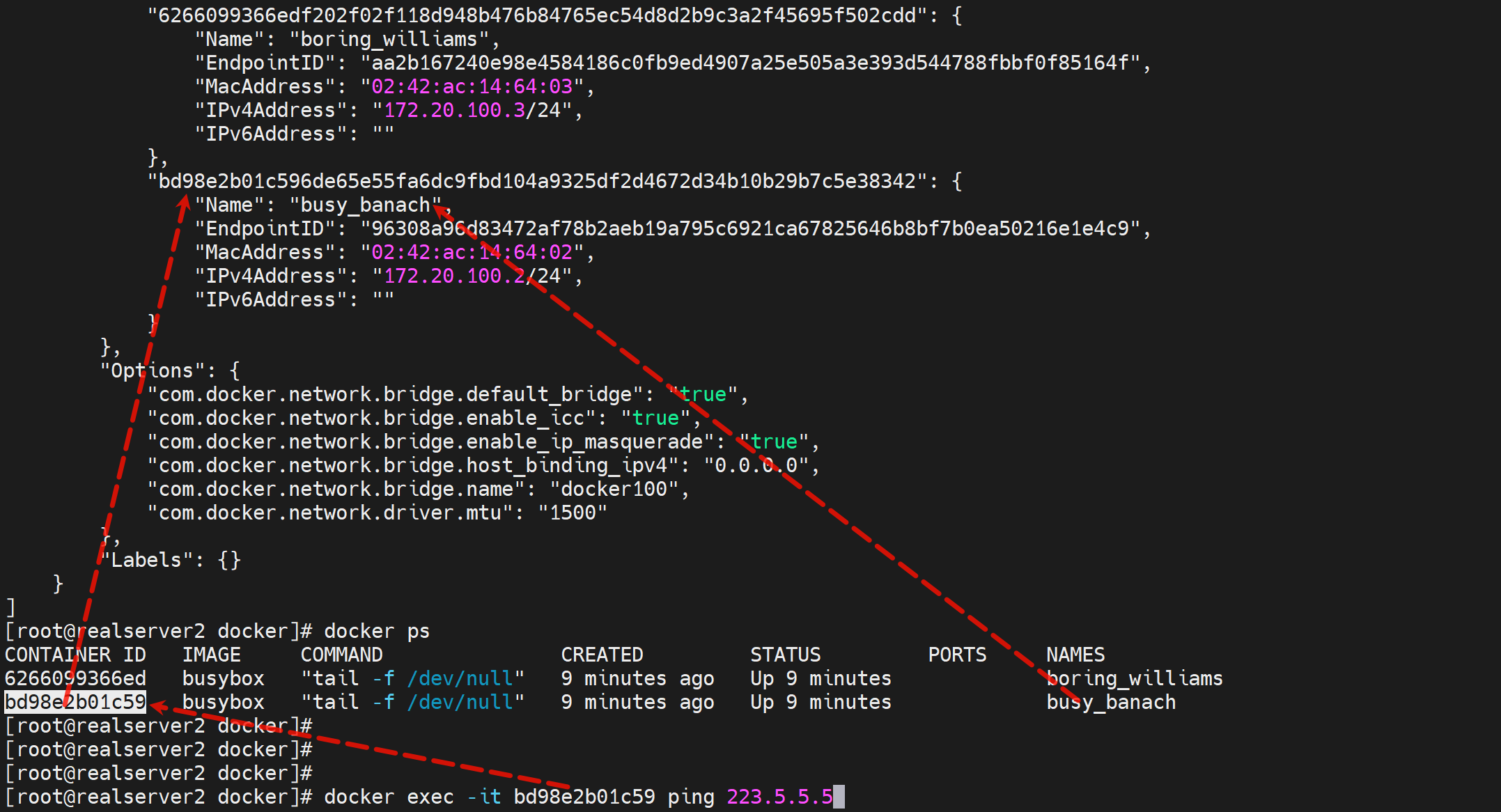
3、然后开始tcpdump 那个接口

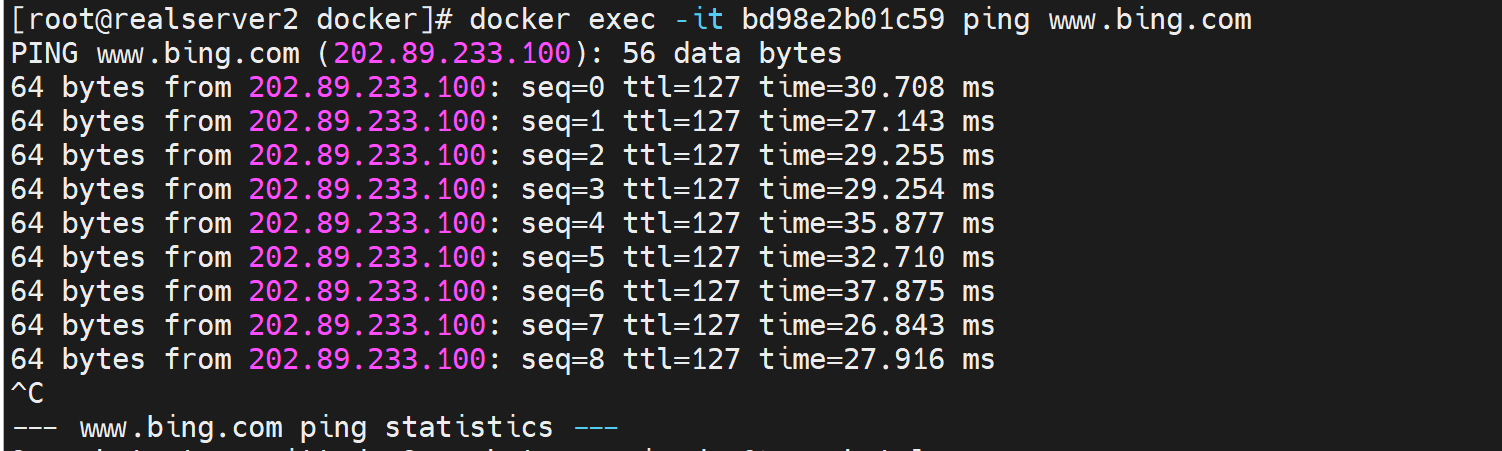
然后就看到包了
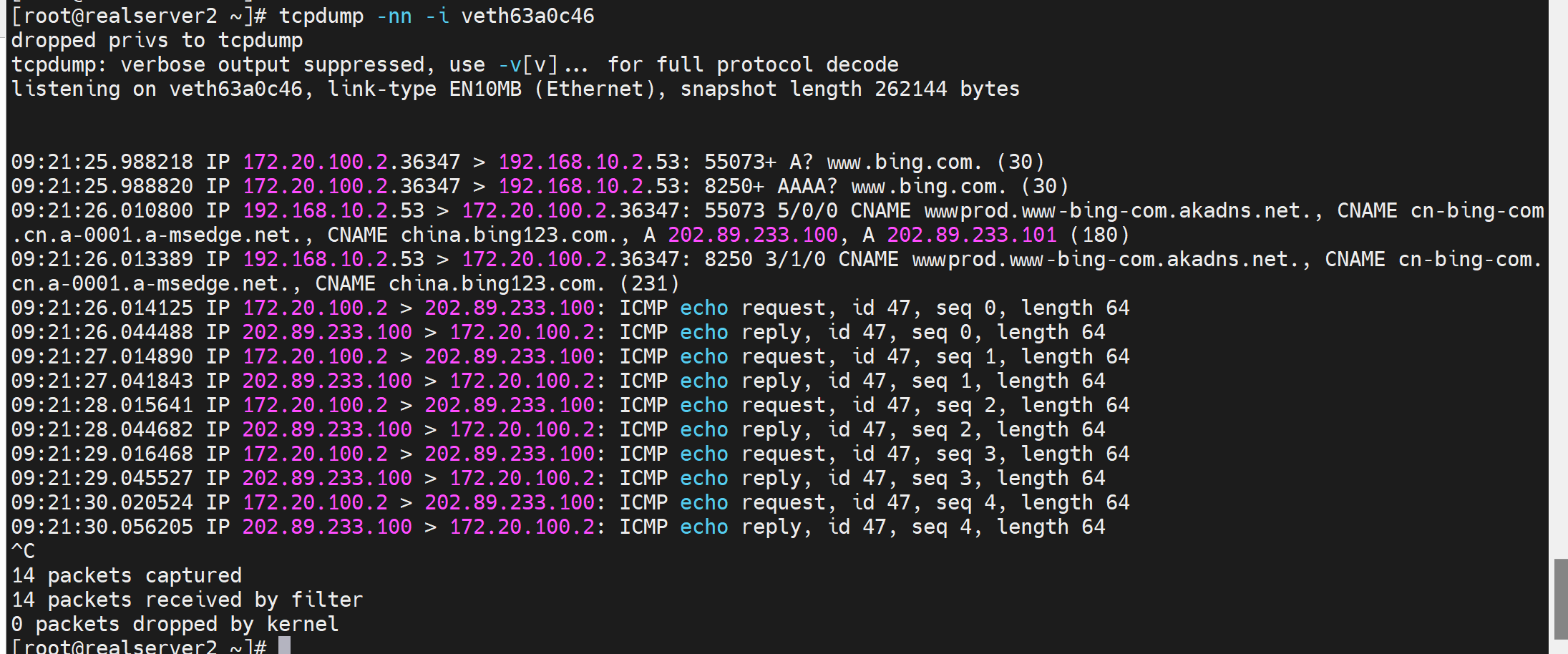
此时修了容器里的ip,也能够给通外面来,说明你修改了docker100为所有容器桥接的虚拟网桥,那么SNAT是自动给你做了的,无需配置的
可以通过iptables -vnL -t nat确认的
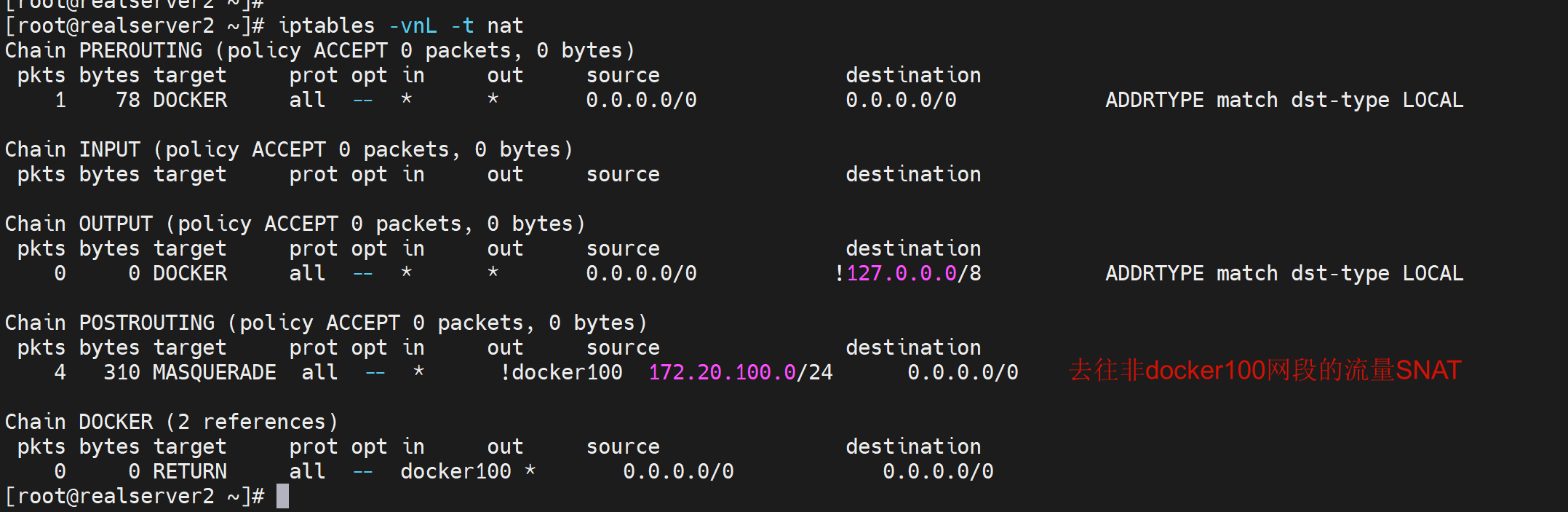
删除自定义的网桥
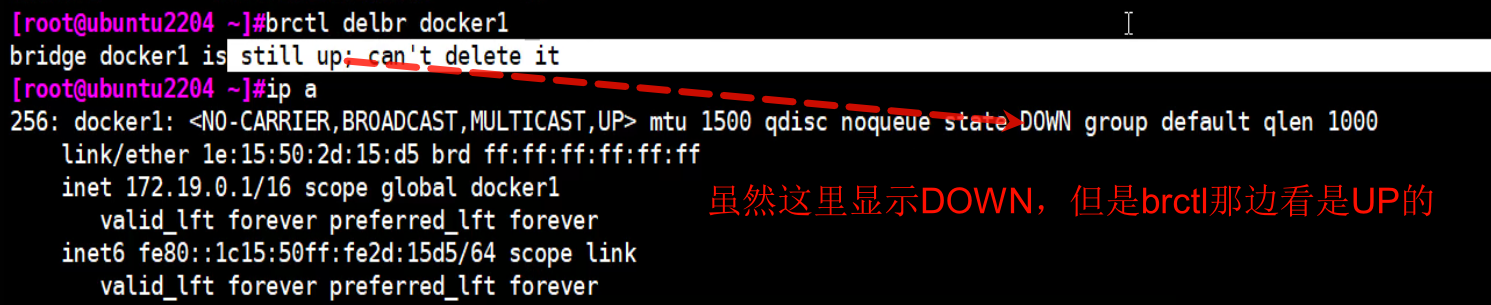
ip link down掉后,网卡信息还是少了很多东西的,上下两图docker1的信息都是全的。

此时再brctl delbr docker1就可以了
ip link set docker1 down
brctl delbr docker1
使用nmcli创建网桥才能存得住
上面的btctl创建的网桥,重启就没了,这里改写为nmcli来实现
nmcli conn add type bridge ifname docker100 con-name docker100
nmcli conn modify docker100 ipv4.address 172.16.100.254/24 ipv4.method manual ipv4.gateway xxx ipv4.dns 192.168.10.2

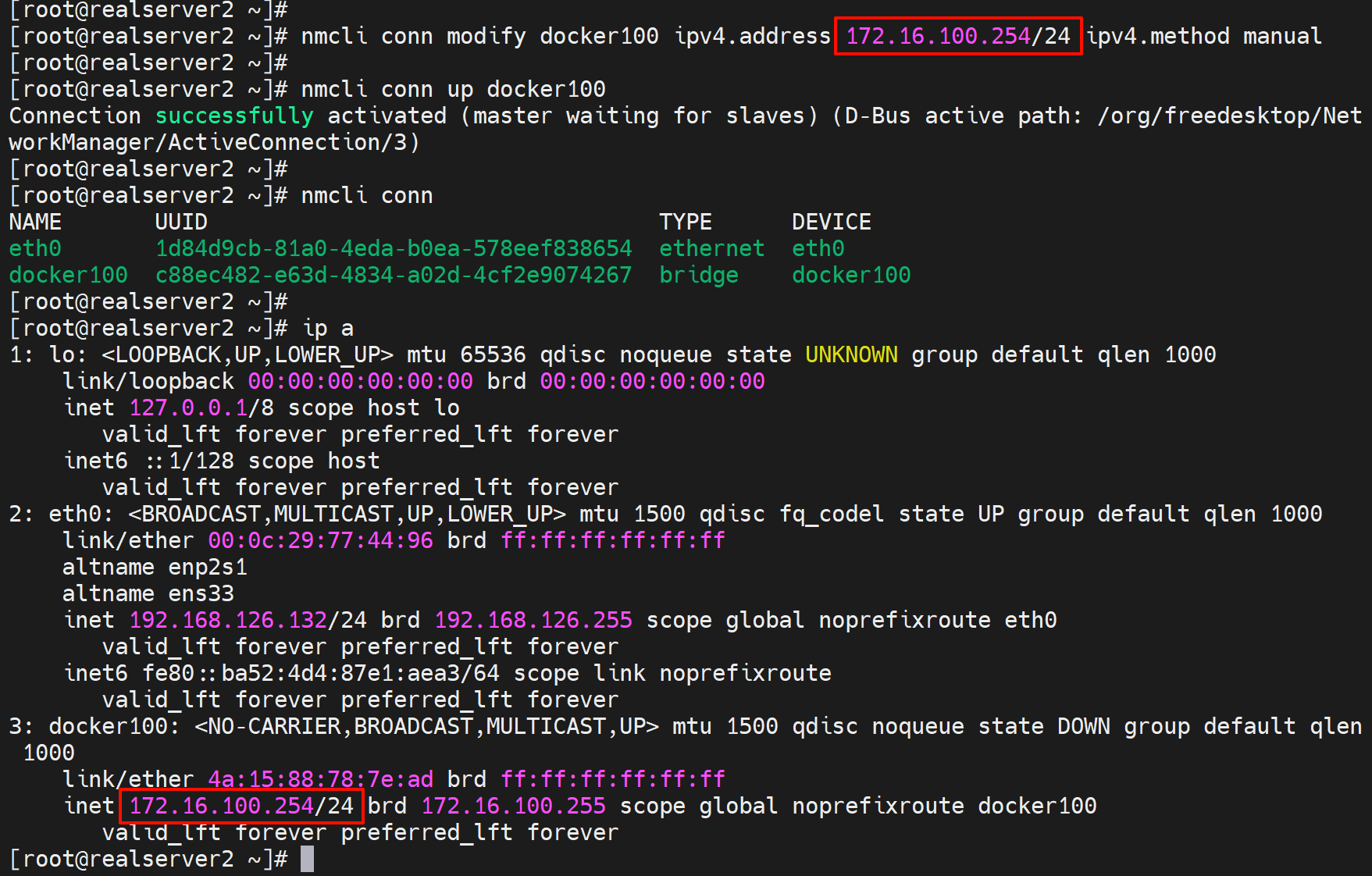
由于之前创建过导致冲突
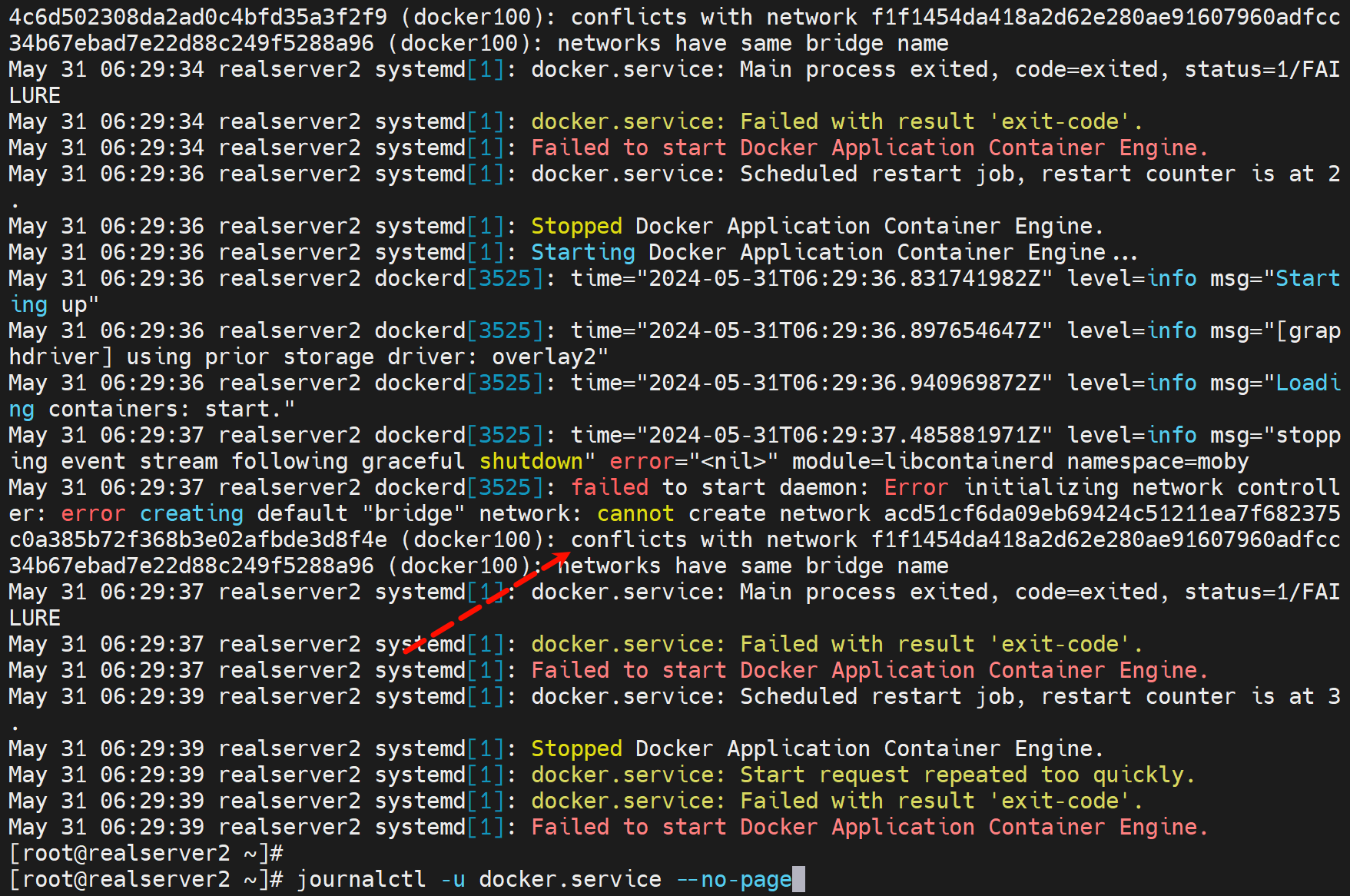
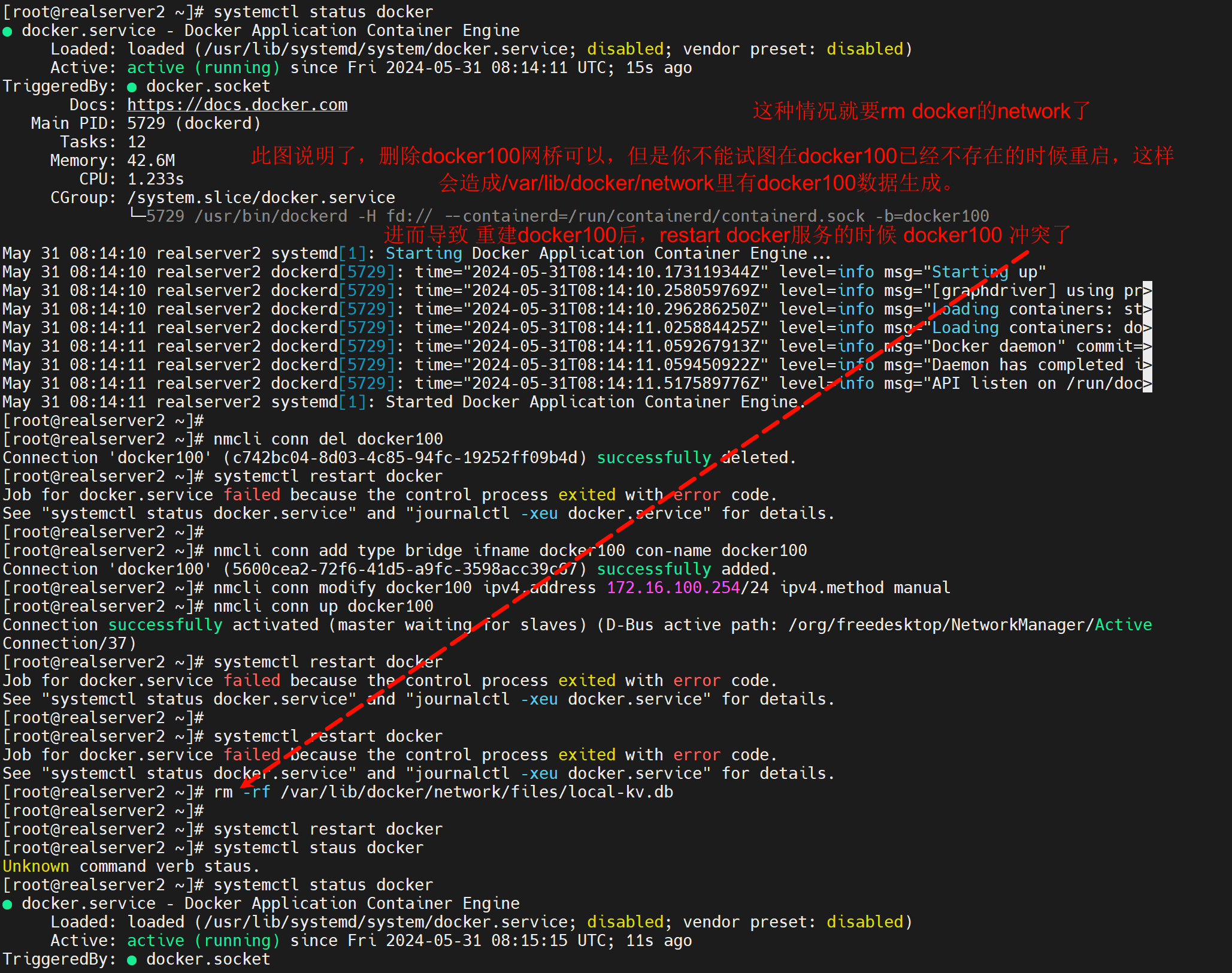
这个在/var/log/message里也看得到,需要删除/var/lib/docker/network里的db
上图这个故障是:之前brctl创建了docker100,重启后docker100没了,由于docker100没了docker服务也就起不来了;此时我又用nmcli 创建了新的brige同样也叫docker100,我试图重启docker服务,结果就报了上图的错误,说明docker自己里面有一个docker100的名字的网桥了,一定是从之前的brctl的docker100对等过的,解决方法就是,rm -rf /var/lib/docker/netwokr/删掉这个网络的配置,其实里面有一个db文件的。
此时再重启docker就OK了。自此就完成了bridge的nmlcli的配置,以便重启不丢失。
同样改回去,删除
改回去,

再删掉bridge网卡
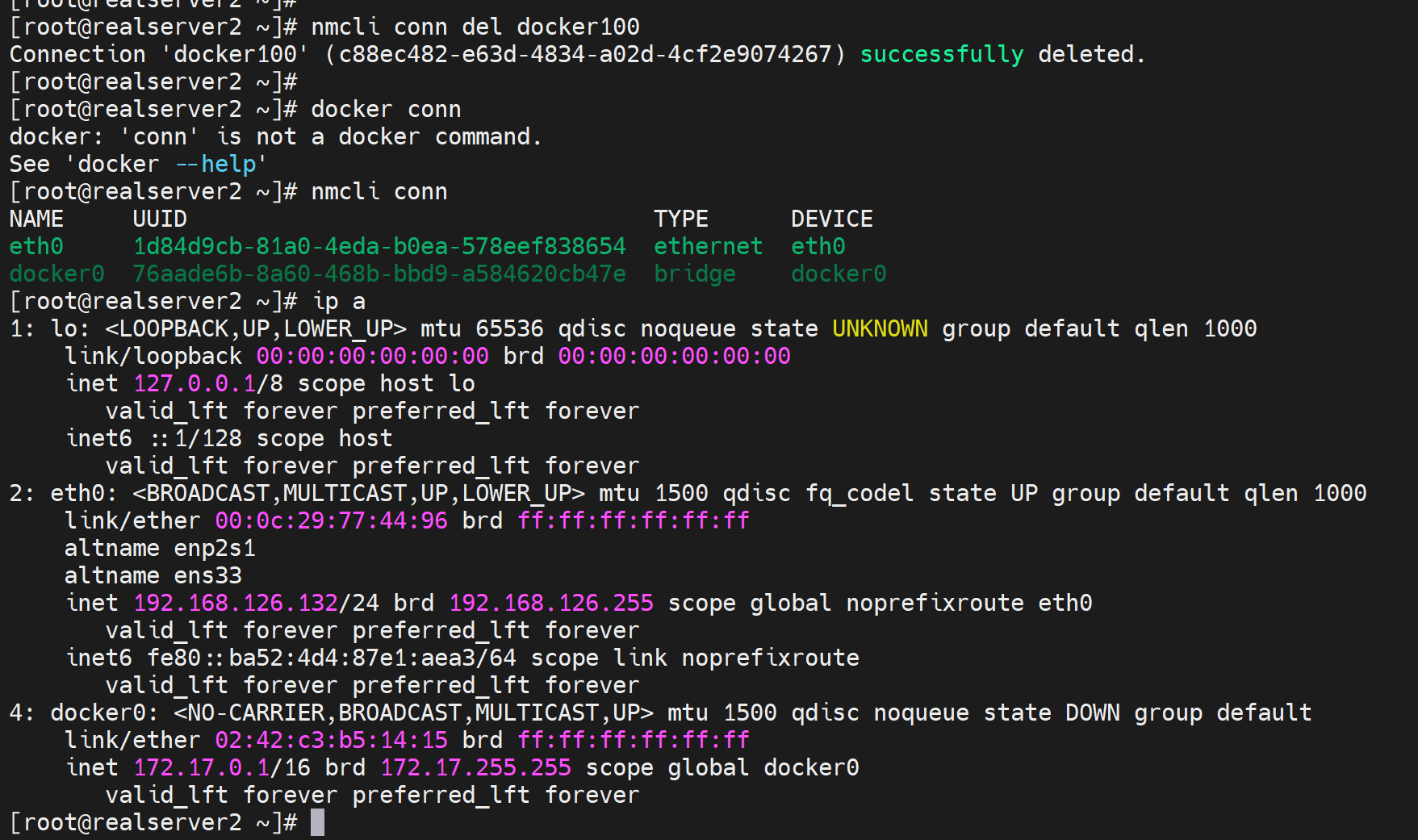
问题来了,此时再新建一个docker100,docker再改成-b docker100能否起来。预判起不来,理由如上,就是要删掉docker的network里的db。
其实理由就是,del可以删,但是此时docker服务不能重启,可以stop也可以不动它就让他active着,就是不能restart!,否则network数据在/var/lib/docker/network/files/local-kv.db里面产生;导致再次创建的docker100和里面的生成的docker100数据同名,但其实不是一个东西了。
解决这种冲突的方法就是:
rm -rf /var/lib/docker/network/files/local-kv.db
systemctl restart docker
但是有风险,就是docker的所有的网络信息就没了应该
删除虚拟网桥docker100的正确操作就是
systemctl stop docker
nmcli conn del docker100
systemctl stop docker
nmcli conn del docker100
nmcli conn add type bridge ifname docker100 con-name docker100
nmcli conn modify docker100 ipv4.address 172.16.100.254/24 ipv4.method manual
nmcli conn up docker100
systemctl restart docker
这种操作网桥删掉再创建,docker的/var/lib/docker/network/下无残留,还会起得来的。
以下是一个完整的全过程演示截图
1、此时docker服务ok
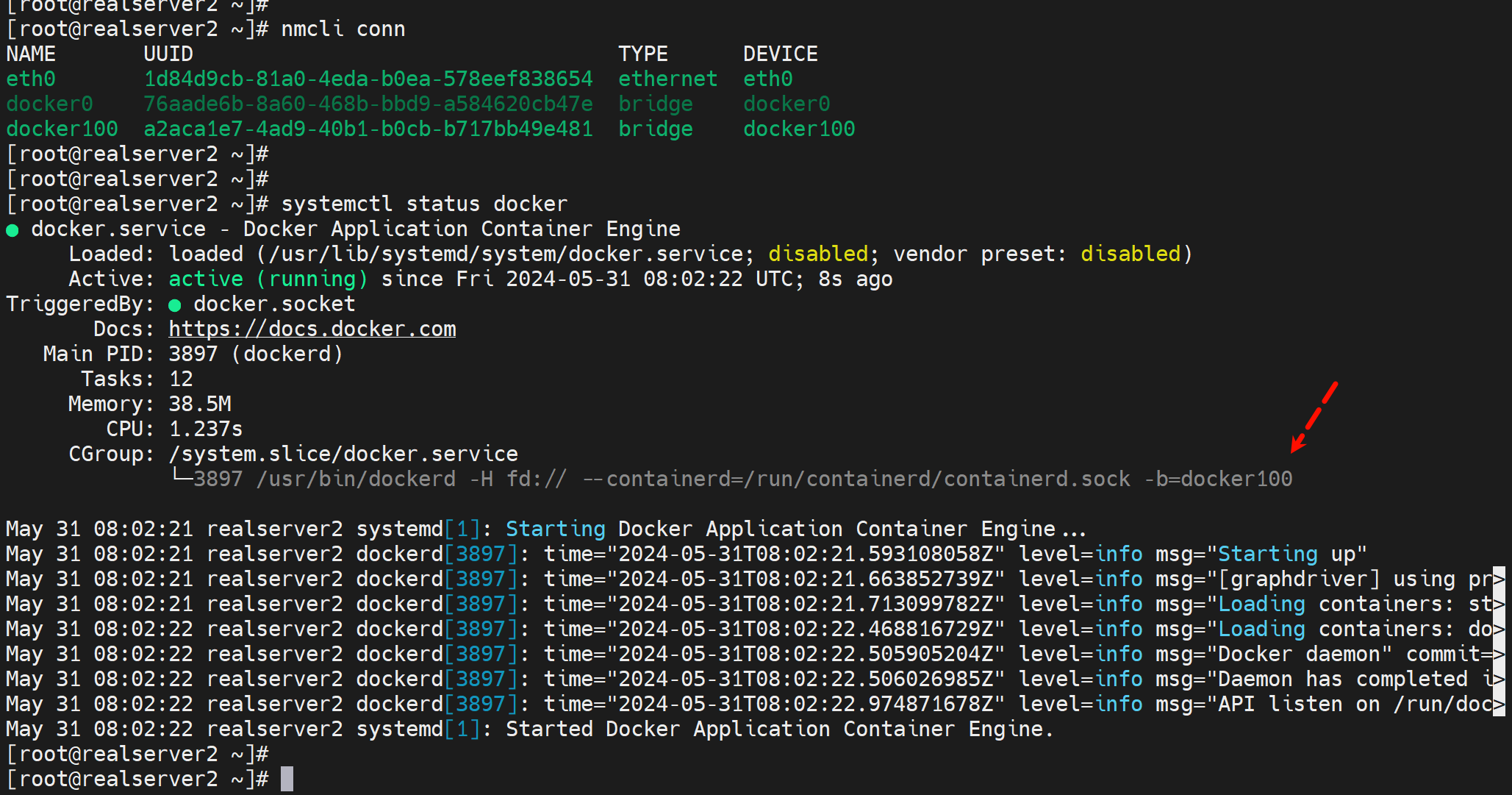
2、直接del docker100
3、再补一个docker100回去
4、重启docker,是起的来的
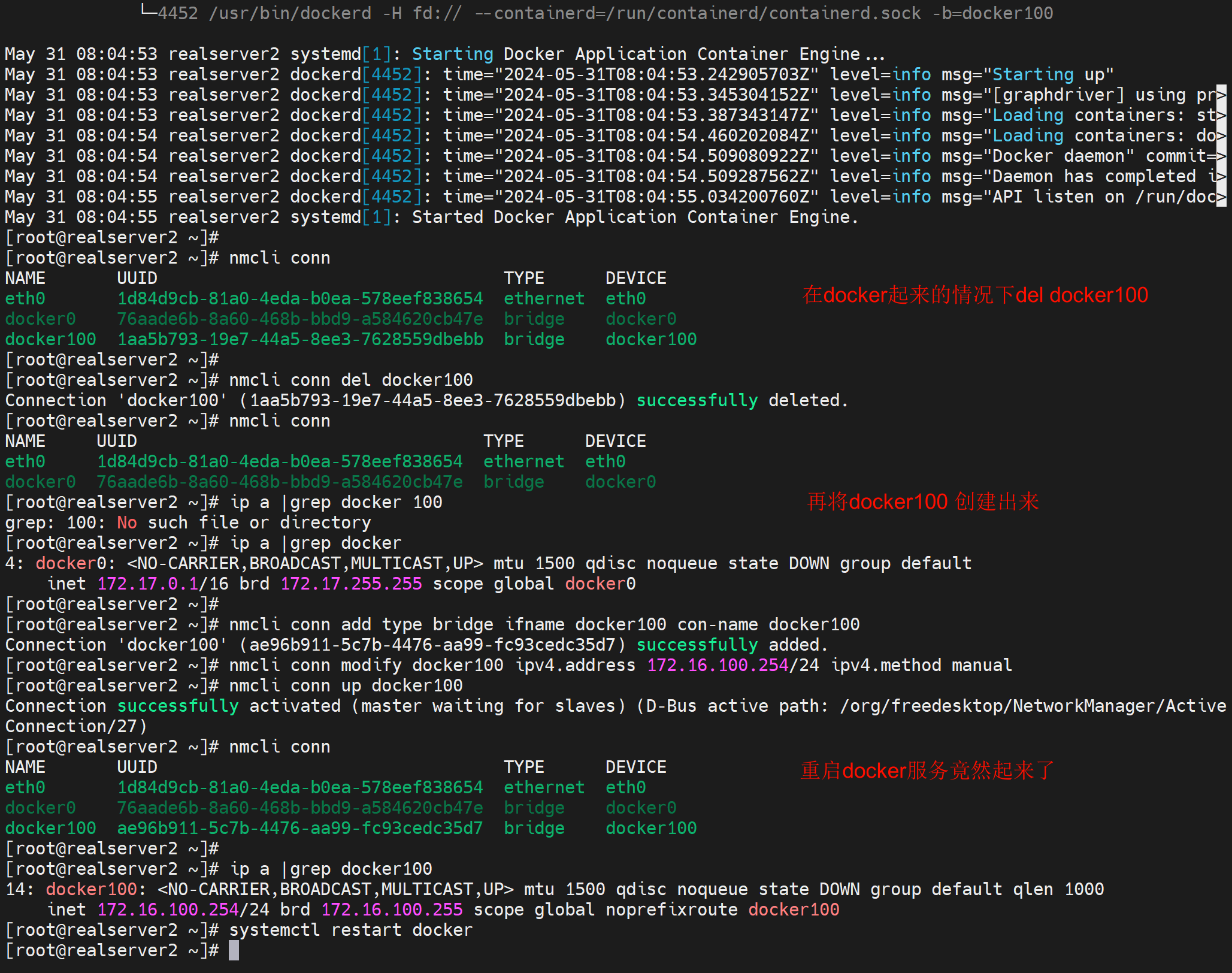
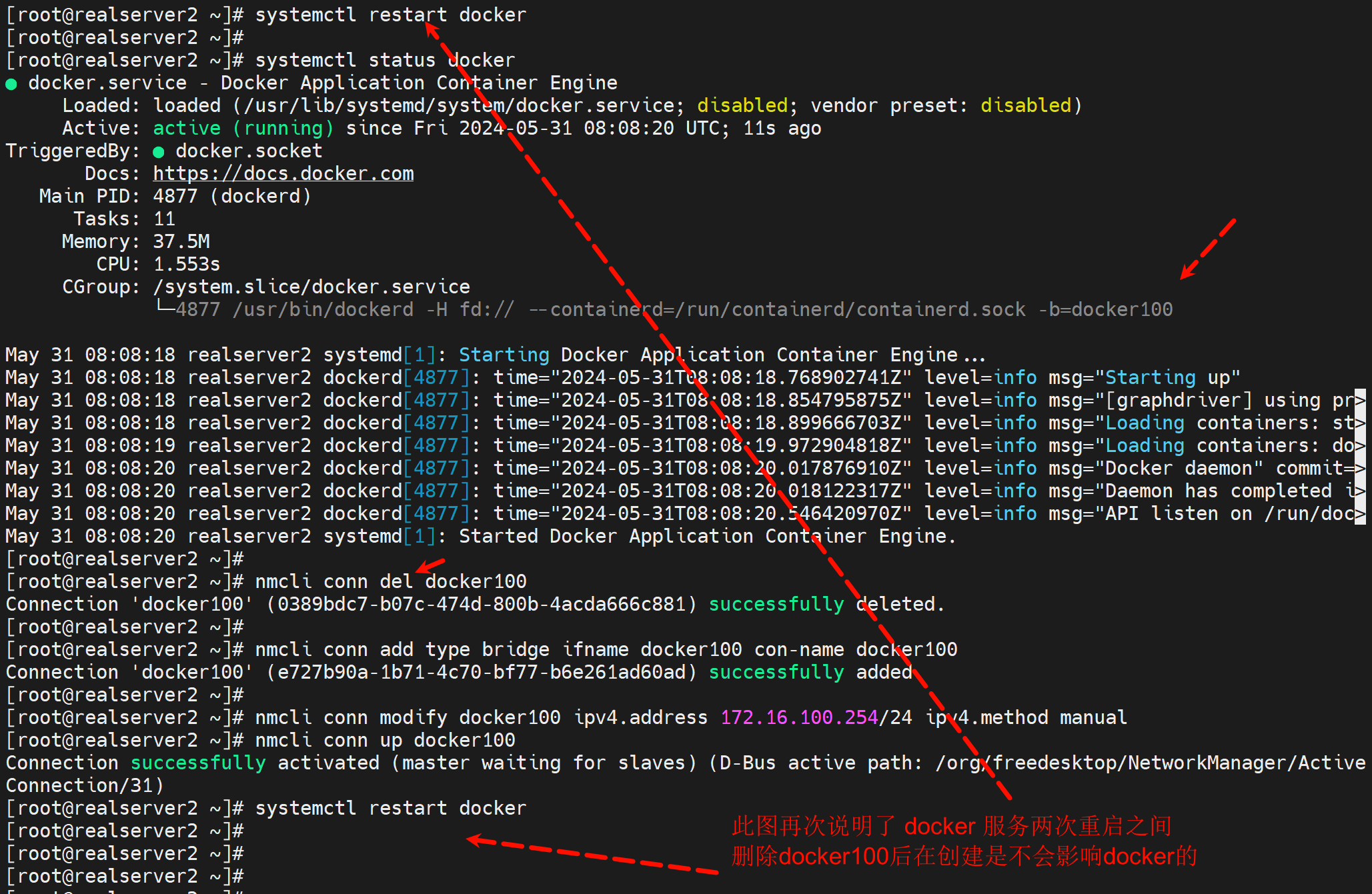
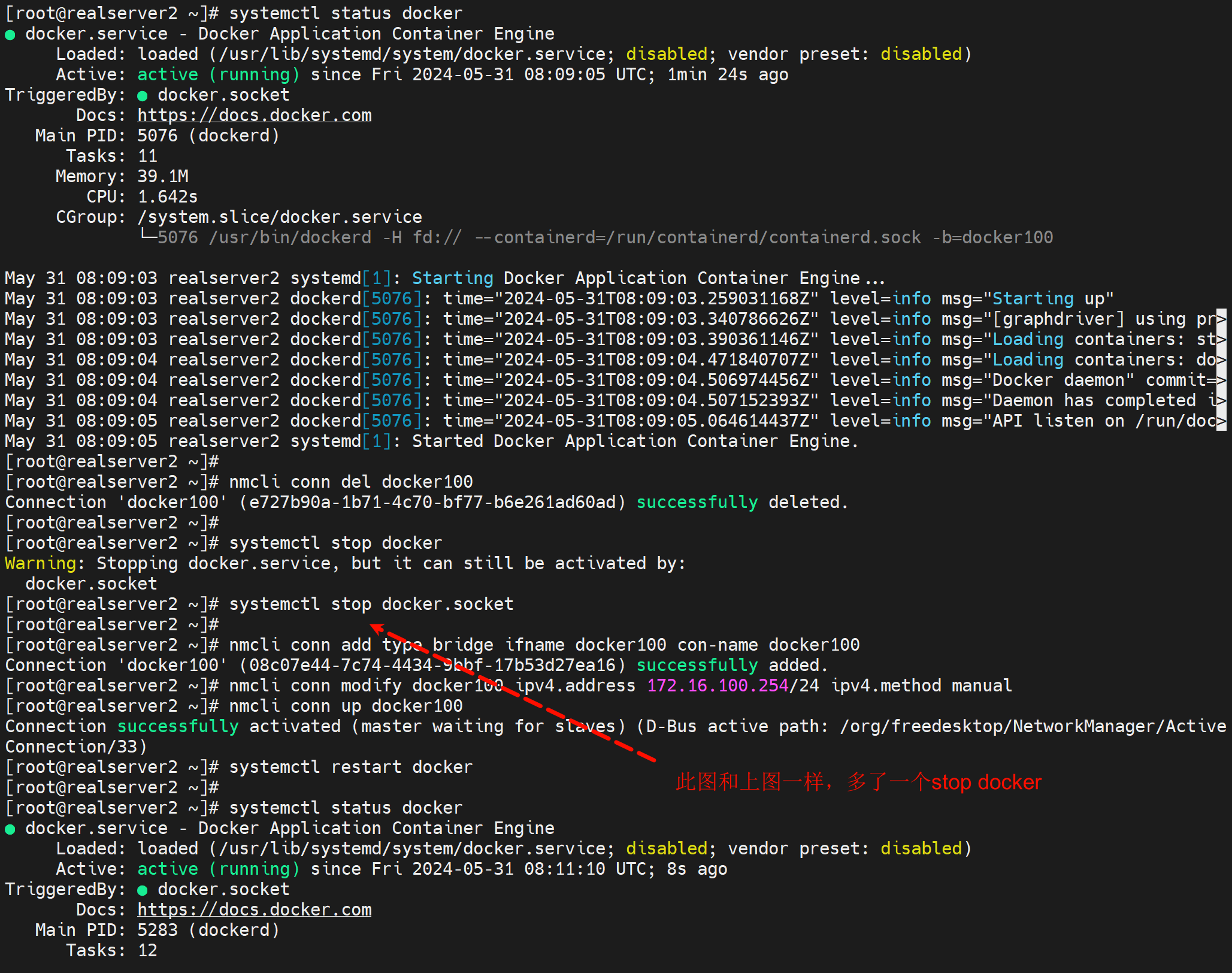
故障点:docker100不在的情况下不能启动dockerf,否则docker会自动生成docker100的数据,导致你nmlic再次创建docker100的时候产生冲突。倒是起不来。
使用busybox来测试
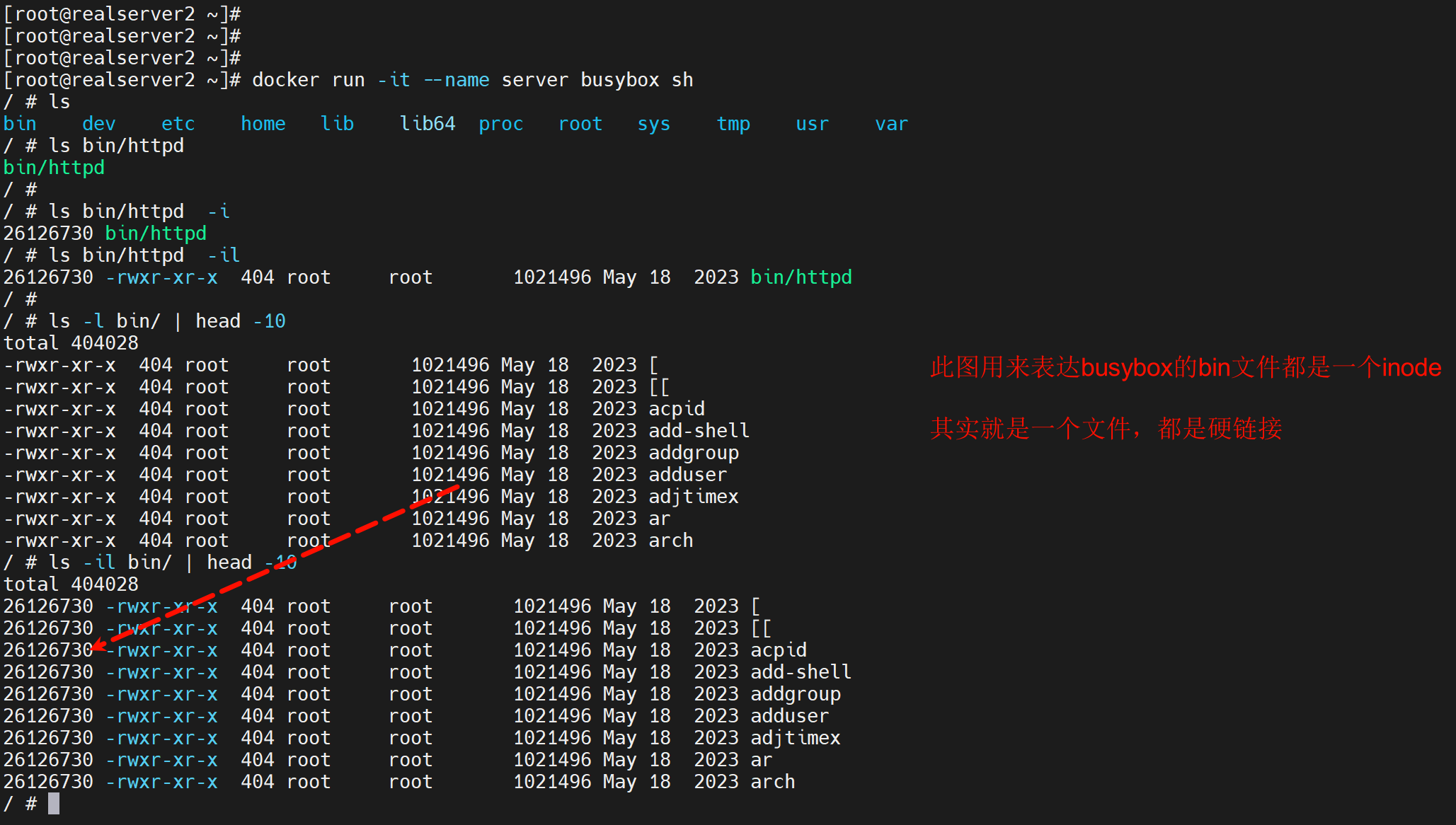
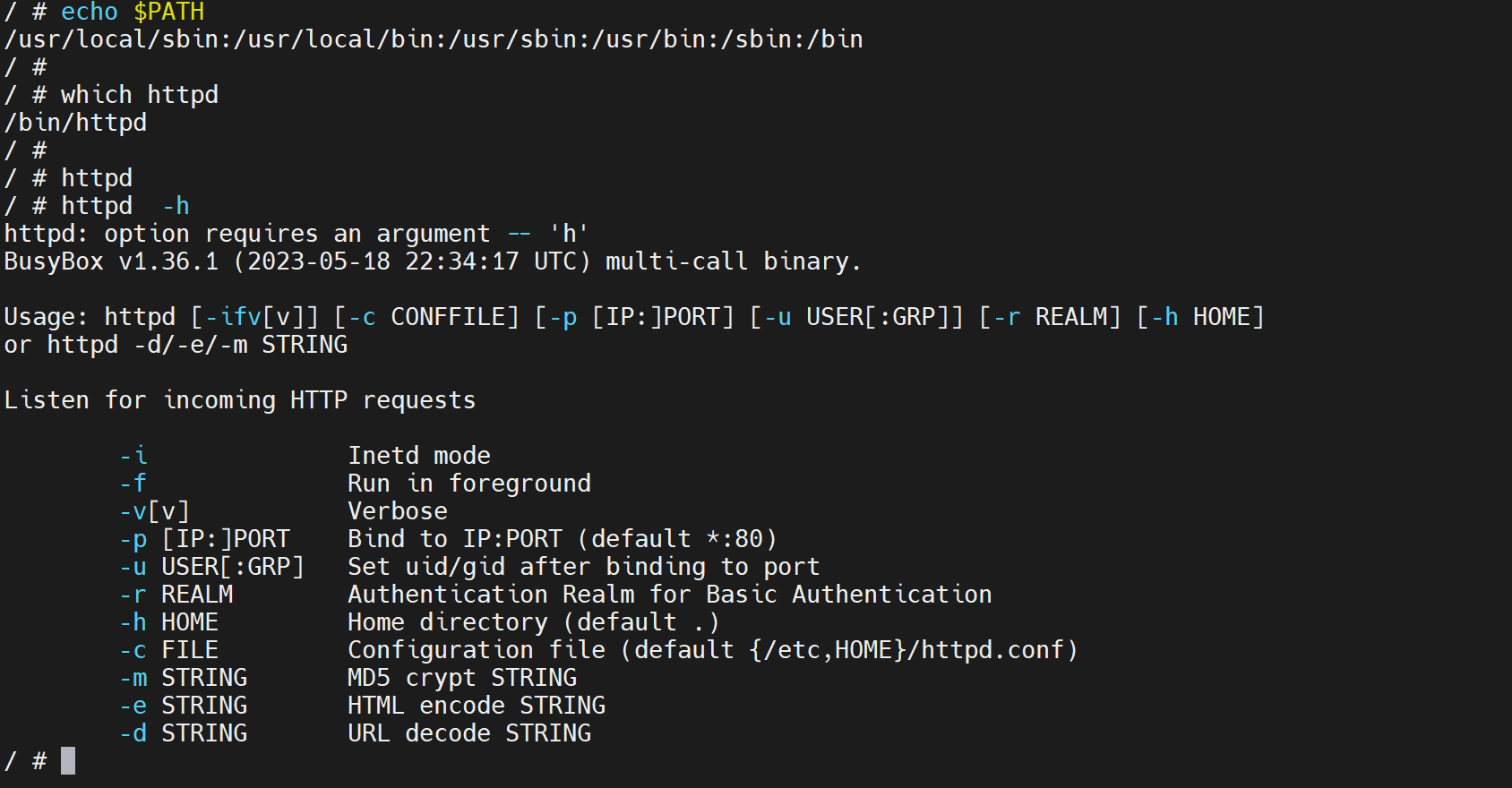
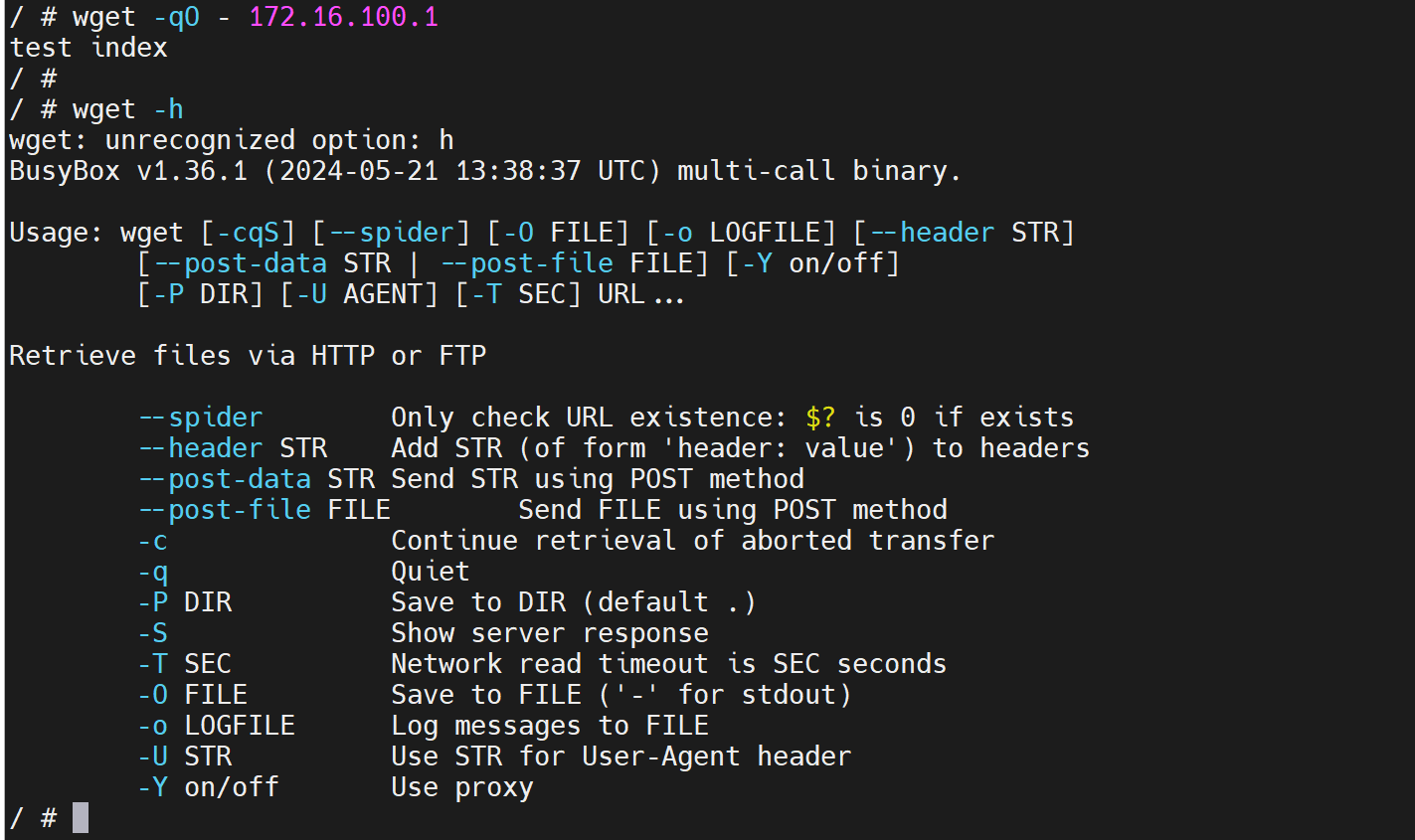
通过help可见:
1、-f是要用的,用来保证容器里是前台,从而宿主上run -d 不会Exited
2、Home directory default . 表示 index.html要创建在运行httpd程序的工作目录就是当前文件夹
然后宿主curl看看,可见内容就是test index。
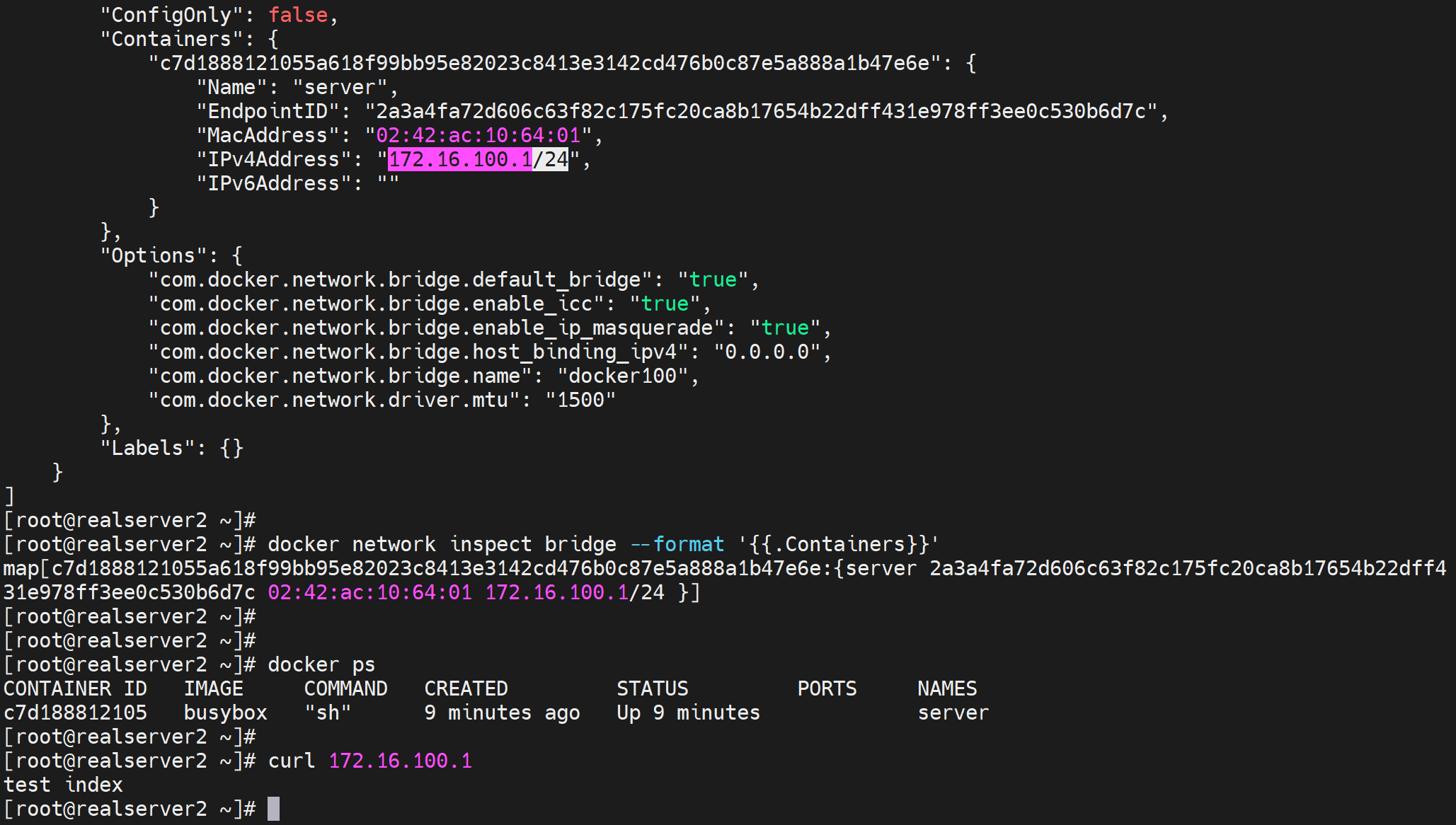
再用别的容器测试 OK
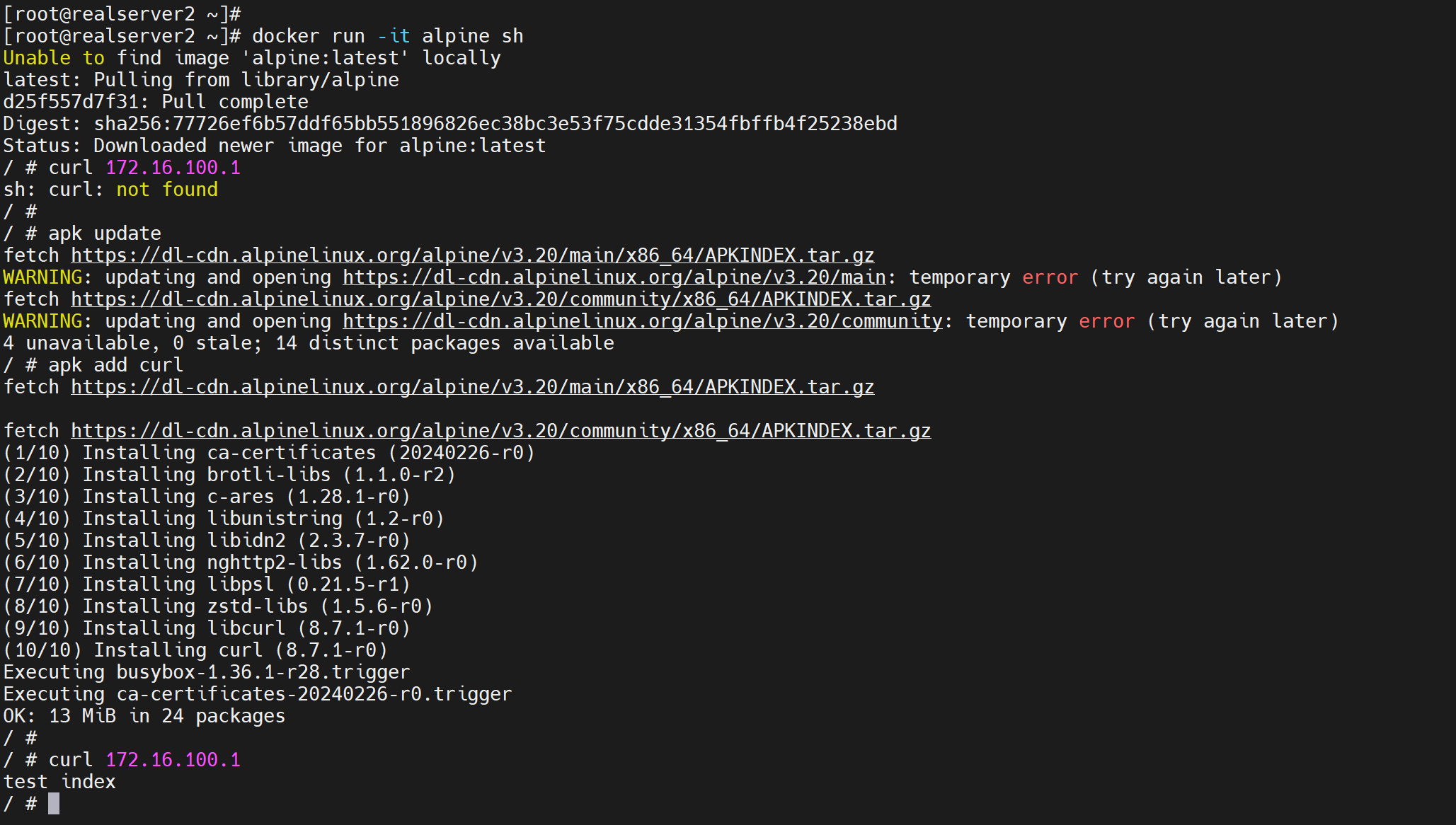
其实没有curl,用wget也行:wget模拟curl
busybox的httpd -v就是带访问日志

但是问题是这个web的容器里的IP不是固定的,哇靠终于回到正题了,我哭哦~~~~
解决容器IP不固定的问题
就是不用IP,用名字...
1、首先server运行的时候要带--name的,有名字就是固定的信息了
2、然后其他容器就--link 参数run就会自动写hosts吧,不过宿主怎么弄呢?
实验开始
所谓server其实就是被访问的那一方了。
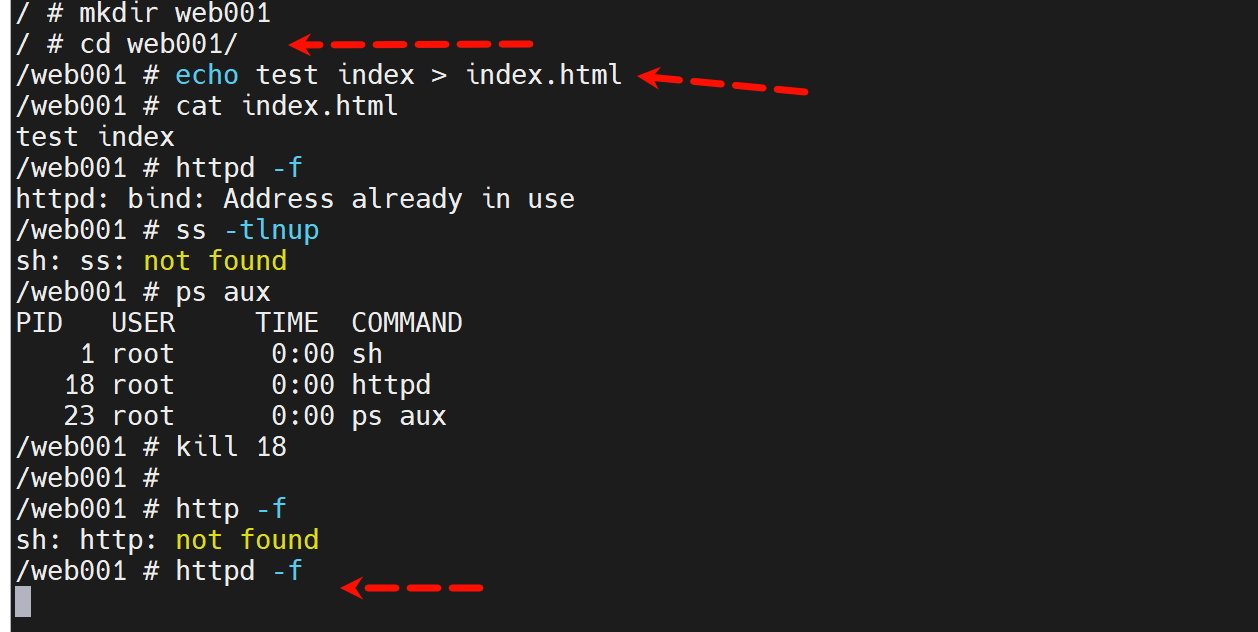
docker run -d --name web001 busybox httpd -v -f

显然还需要补一个端口暴露
再补一个index.html文件
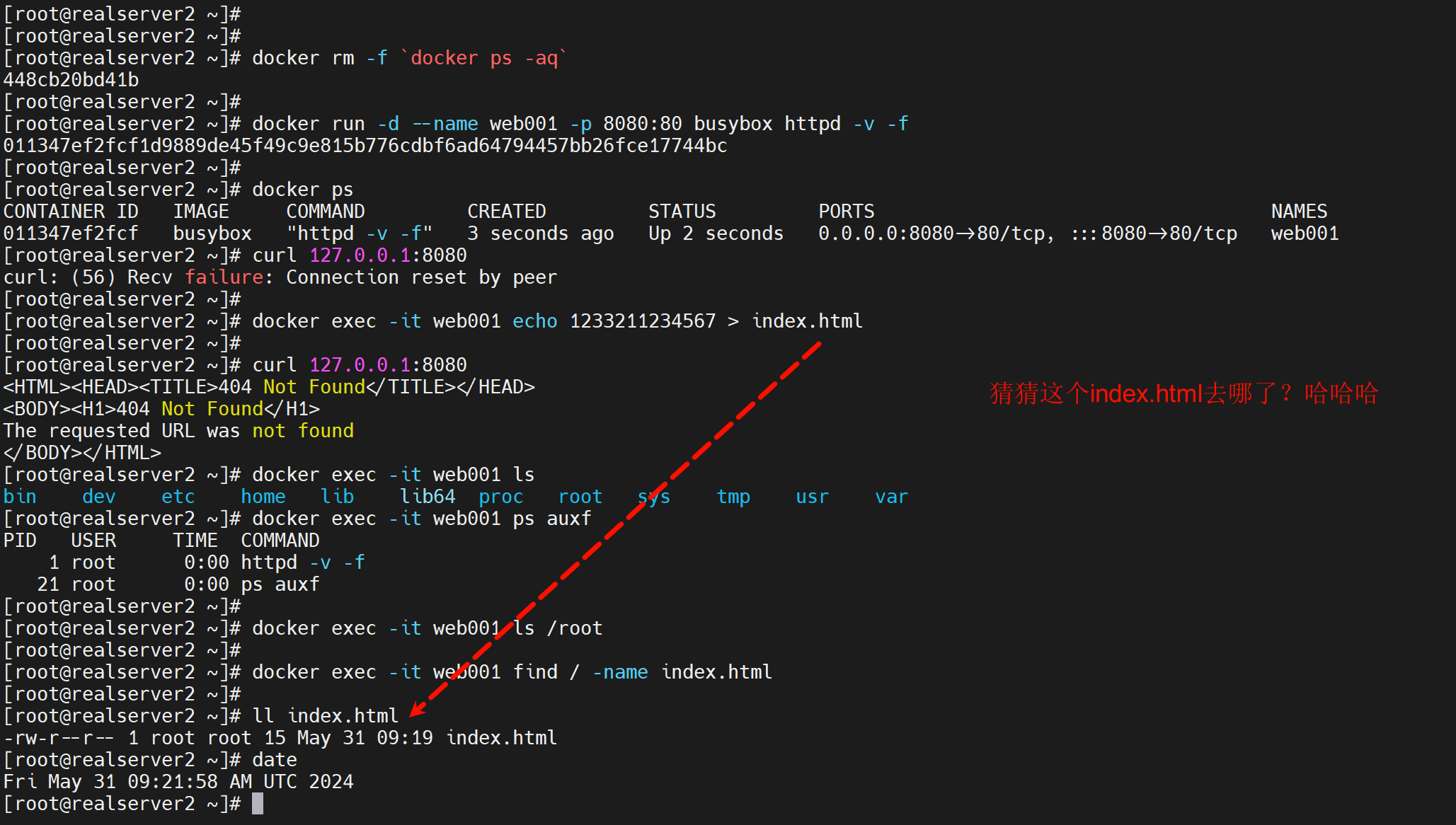
这样就可以了

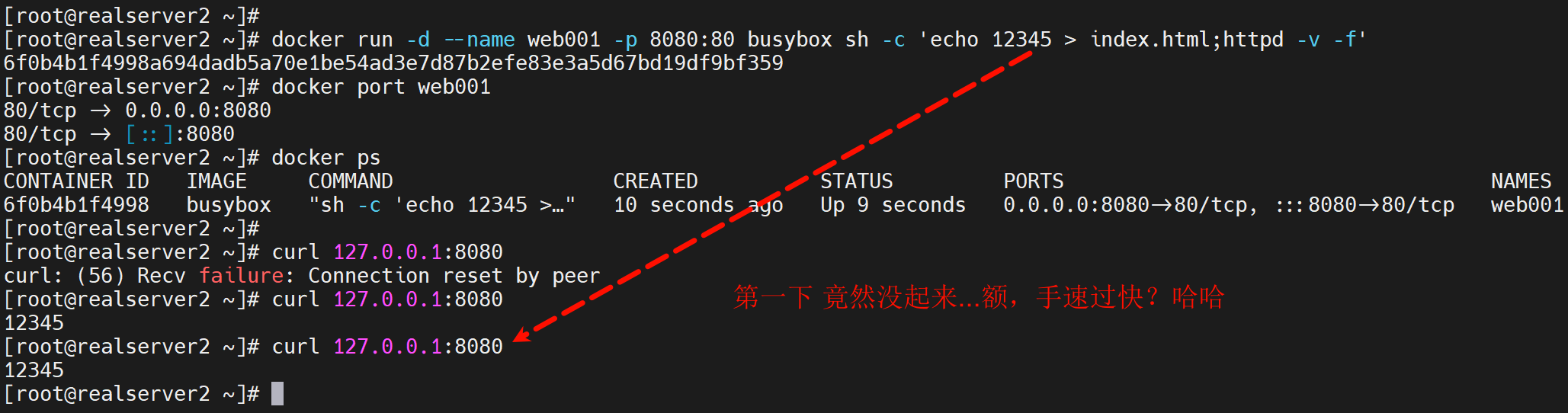
合成一个docker run试试,慢慢来嘛,就是玩,不要捉急实验本身,因为实验本身不代表你工作干活做事情的那个场景,你遇到的问题解决得越多,你就越发得蜜汁自省,哦是自省哦,就会更加能hold猪,加油~
docker run -d --name web001 -p 8080:80 busybox sh -c 'echo 12345 > index.html;httpd -v -f'
link选项就是自动添加host了👇 添加了web001这个容器名 和 ip的解析。
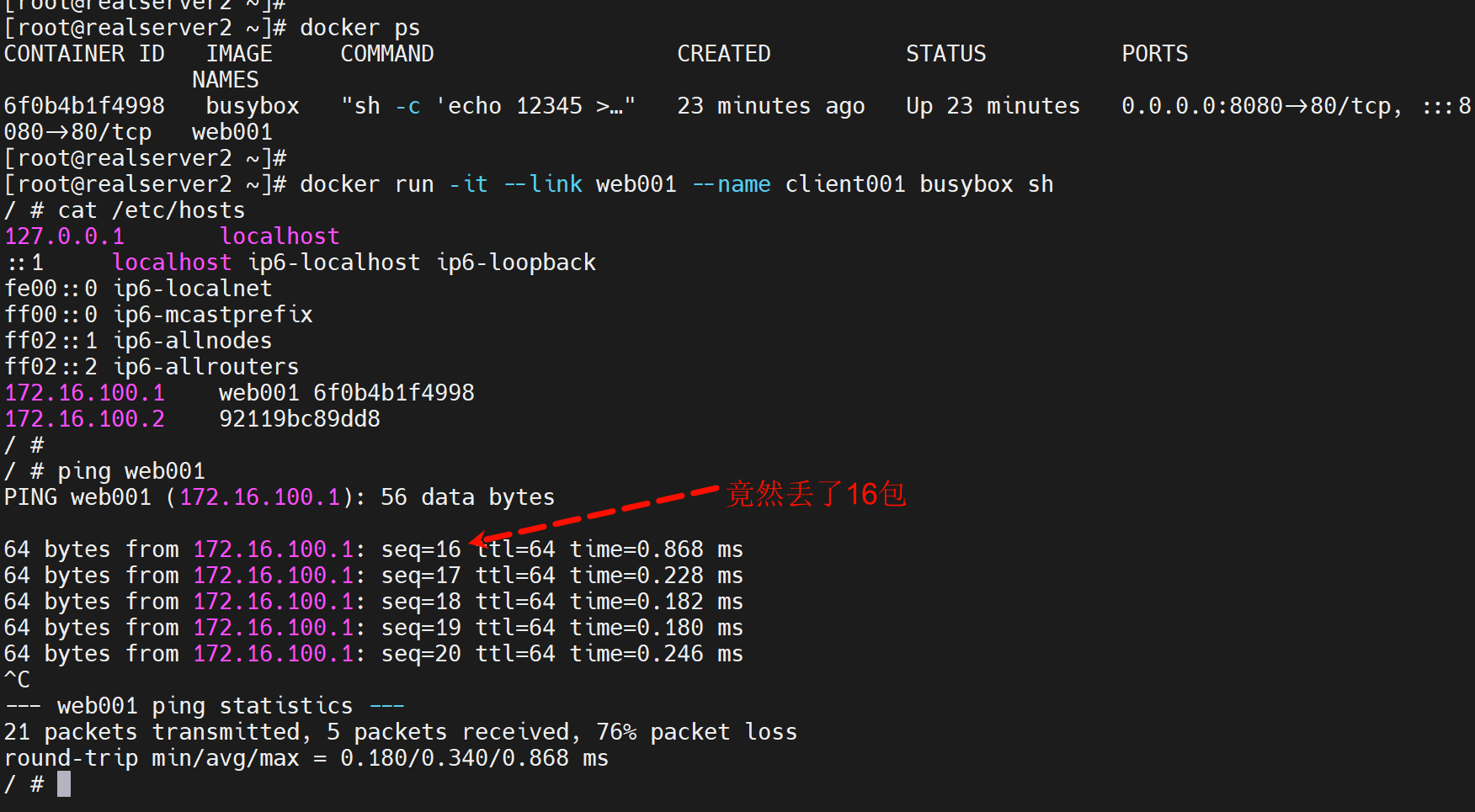
从0开始计数的👆,所有就是丢了16个。
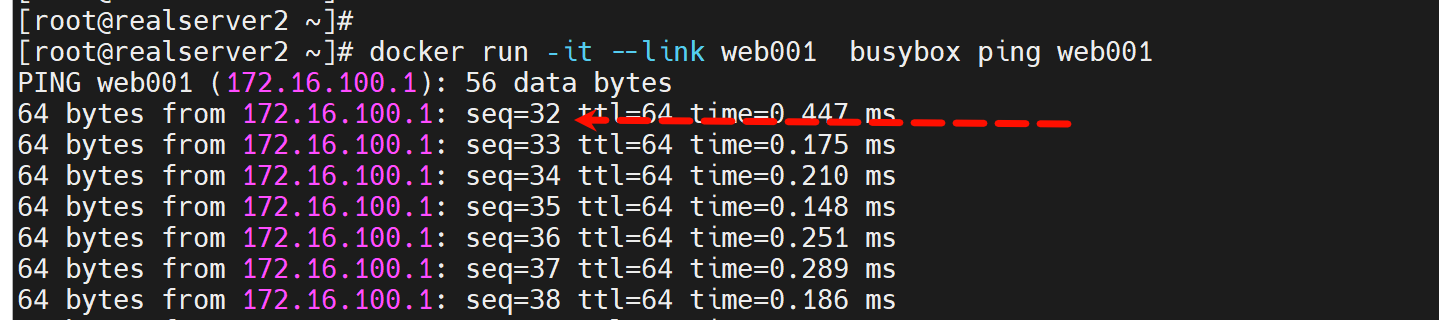
不知道为啥,我感觉这是坑。
初步定位了:就是使用默认的docker0不会卡这么久,而使用自建的docker100,我是用nmcli创建的这个网桥,就不行,ping就会卡30多个包才通这么久。。。
举例,wordpress的运行就可以采用link的方式了
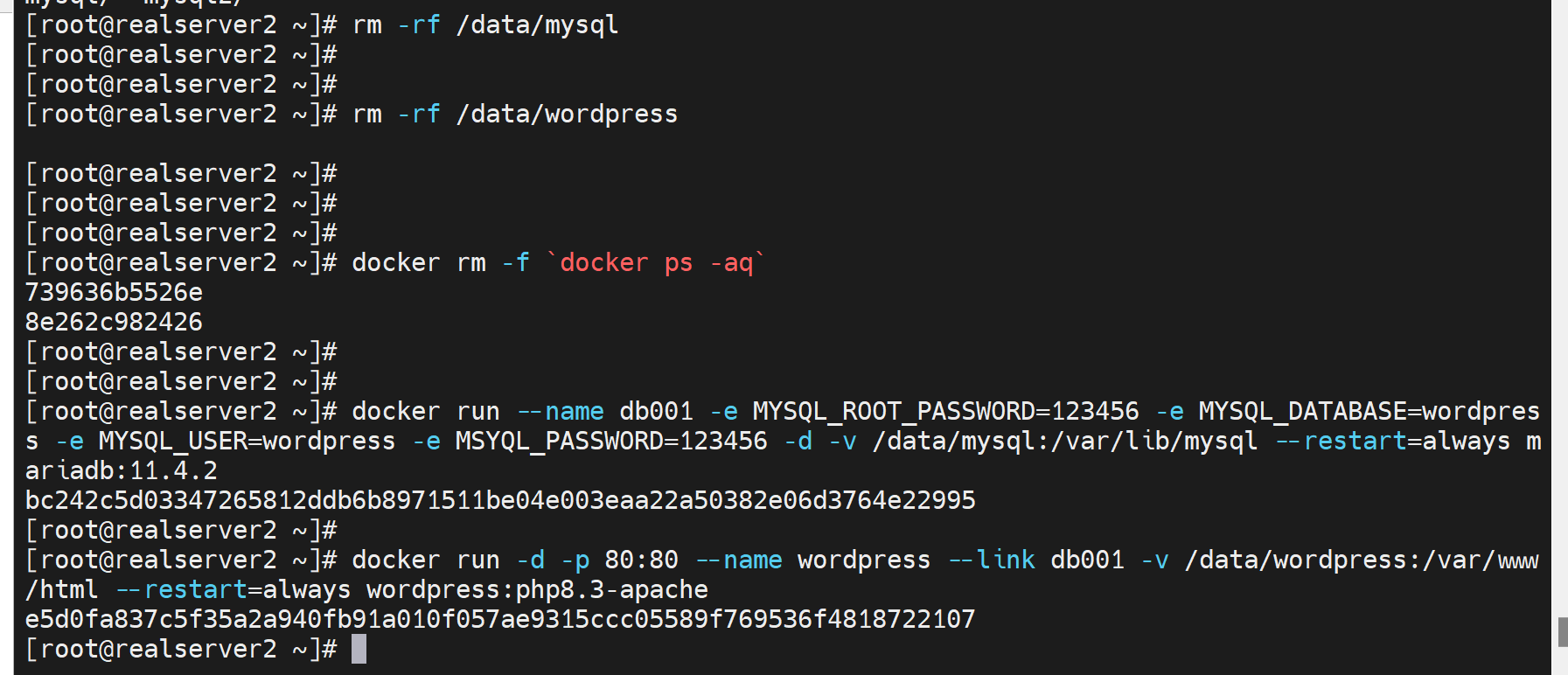
docker run --name db001 -e MYSQL_ROOT_PASSWORD=123456 -e MYSQL_DATABASE=wordpress -e MYSQL_USER=wordpress -e MYSQL_PASSWORD=123456 -d -v /data/mysql:/var/lib/mysql --restart=always mariadb:11.4.2
docker run -d -p 80:80 --name wordpress --link db001 -v /data/wordpress:/var/www/html --restart=always wordpress:php8.3-apache
版本匹配注意下
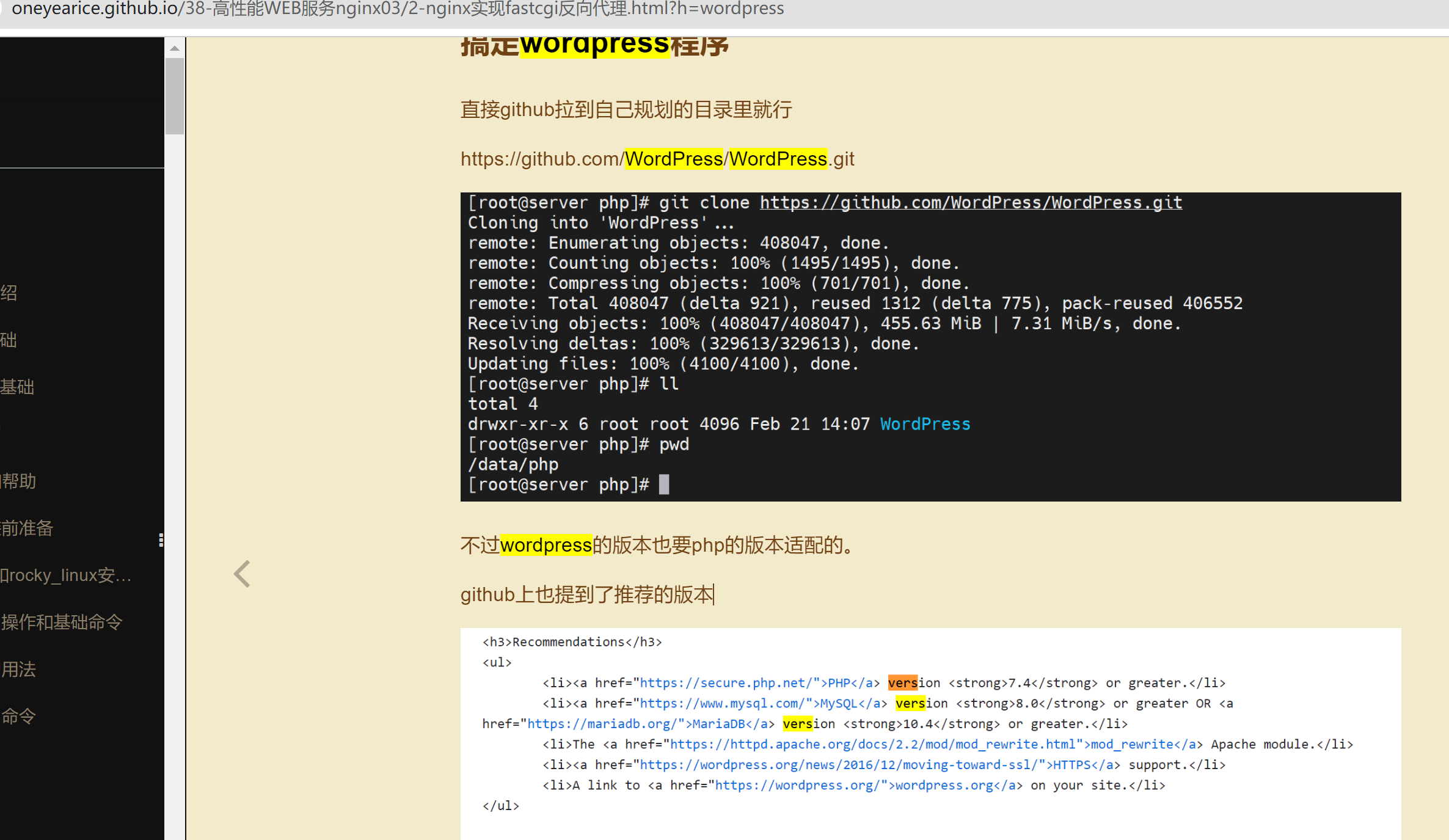
👇图中MYSQL_PASSWORD写成了MSYQL_XXX,导致排查了半天。。。
换了个公司内部源,终于pull下来了
DB没有暴露端口,因为就是让wordpress访问的,
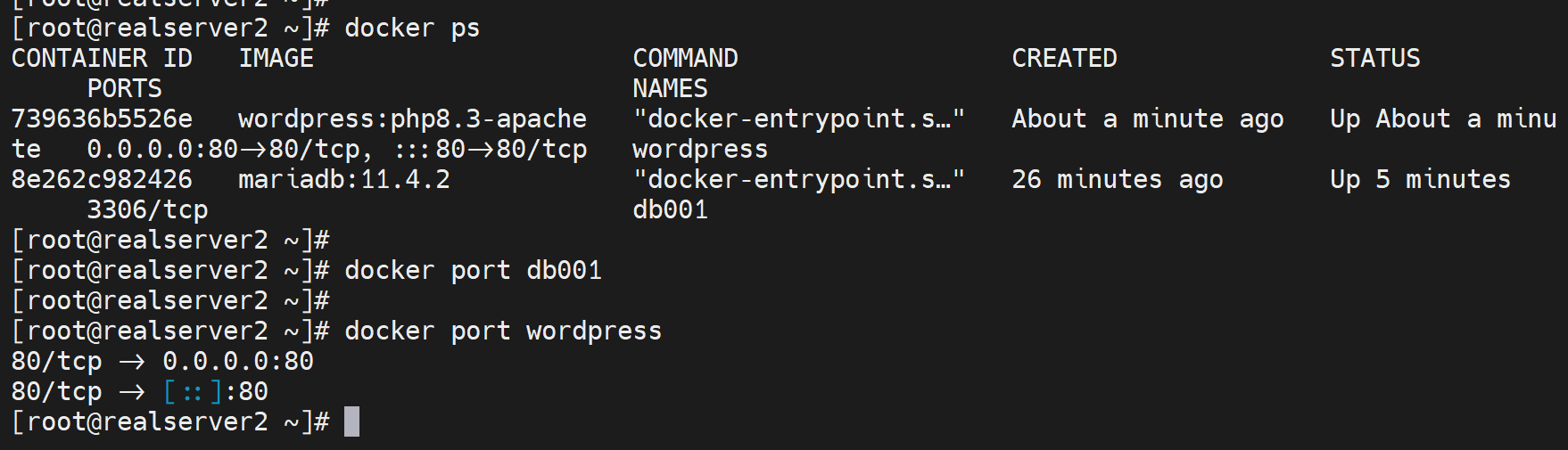
然后打开网页报错
因为之前实验有残留信息,删除之前的持久化路径,删除所有容器,重新run就好了
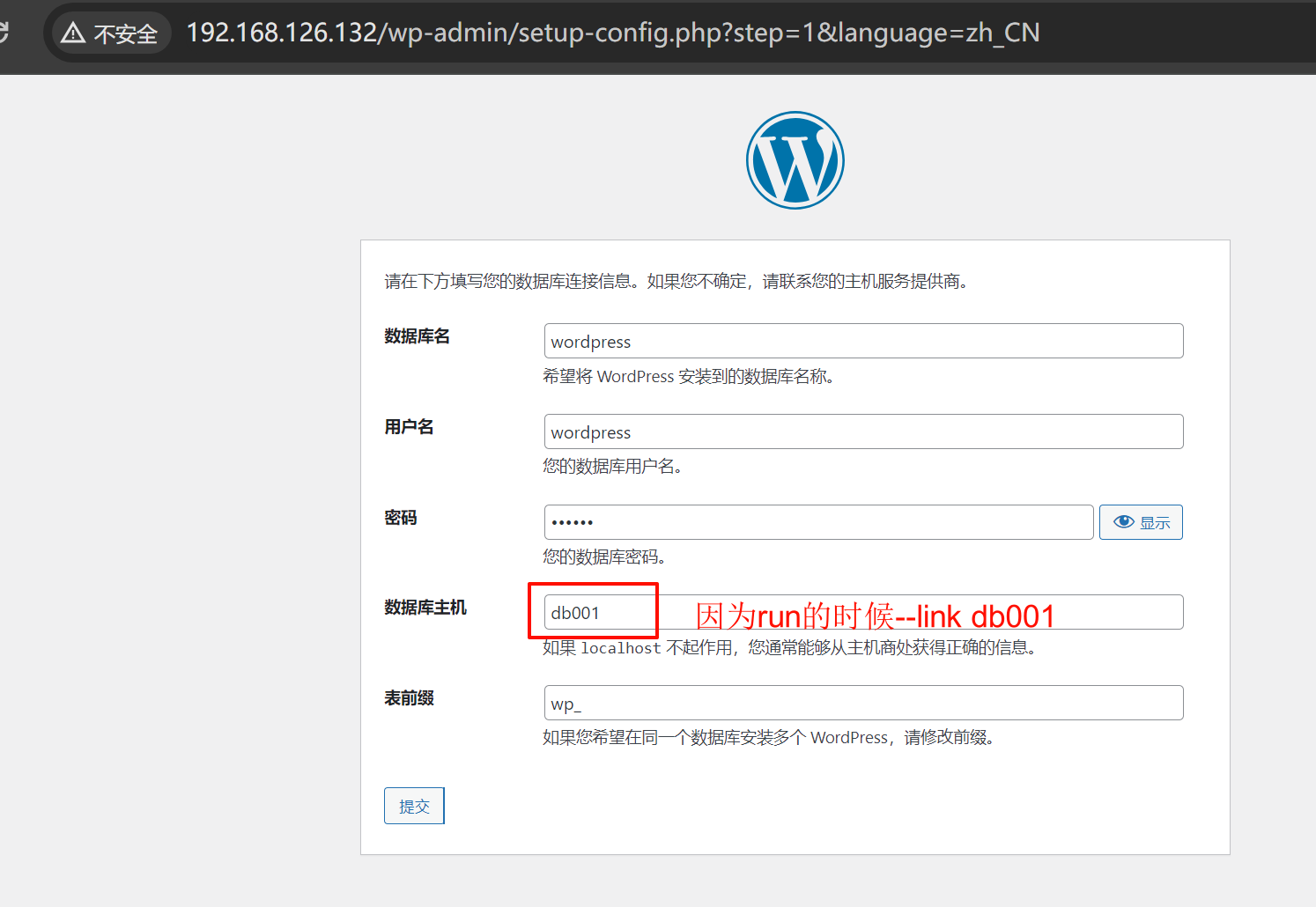
--link db001就是run 的时候就自动给你添加了 hosts解析,是db001这个主机名解析到db001这个容器name的IP。
这样就是实现了db容器里的IP如果变了,也不会影响业务了。而且mysql不对外暴露端口,你想攻击都攻击不了。
但是此时如果db001的容器里的IP地址手动改变,wordpress将无法访问。
但是如果db001的容器IP是DHCP重新获取而改变,则wordpress可以自动更新/etc/hosts文件,也就可以继续访问。所以一般不会有人手动👇修改,所以--link也就是可以解决容器里ip变动的问题的。
docker exec -it --privileged db001 sh
ip a add 172.17.0.100/16 dev eth0
ip a del 172.17.0.2/16 dev eth0
此时wordpress无法连接db
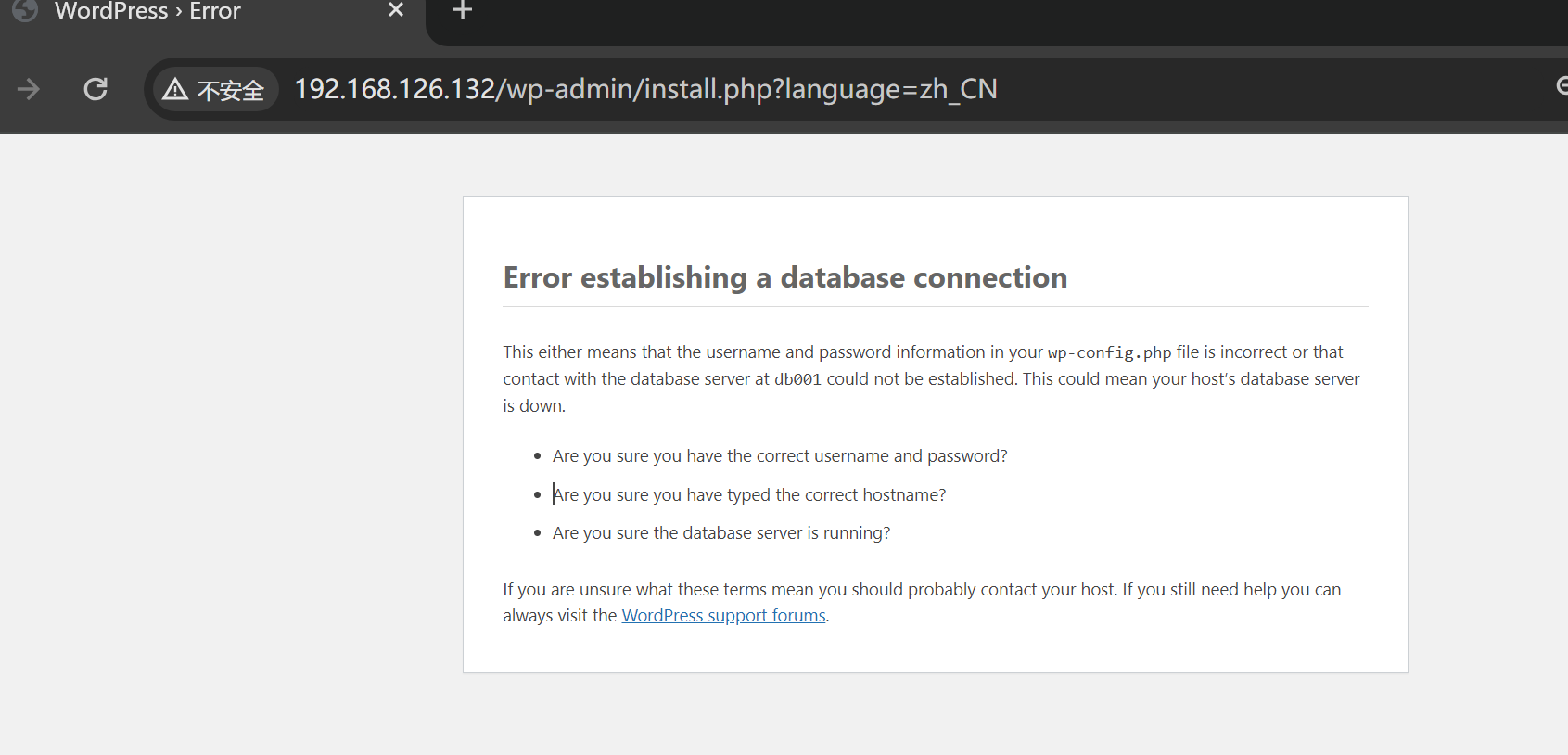
而且只要容器1stop了,然后新开一个容器2就会抢了容器1的IP了
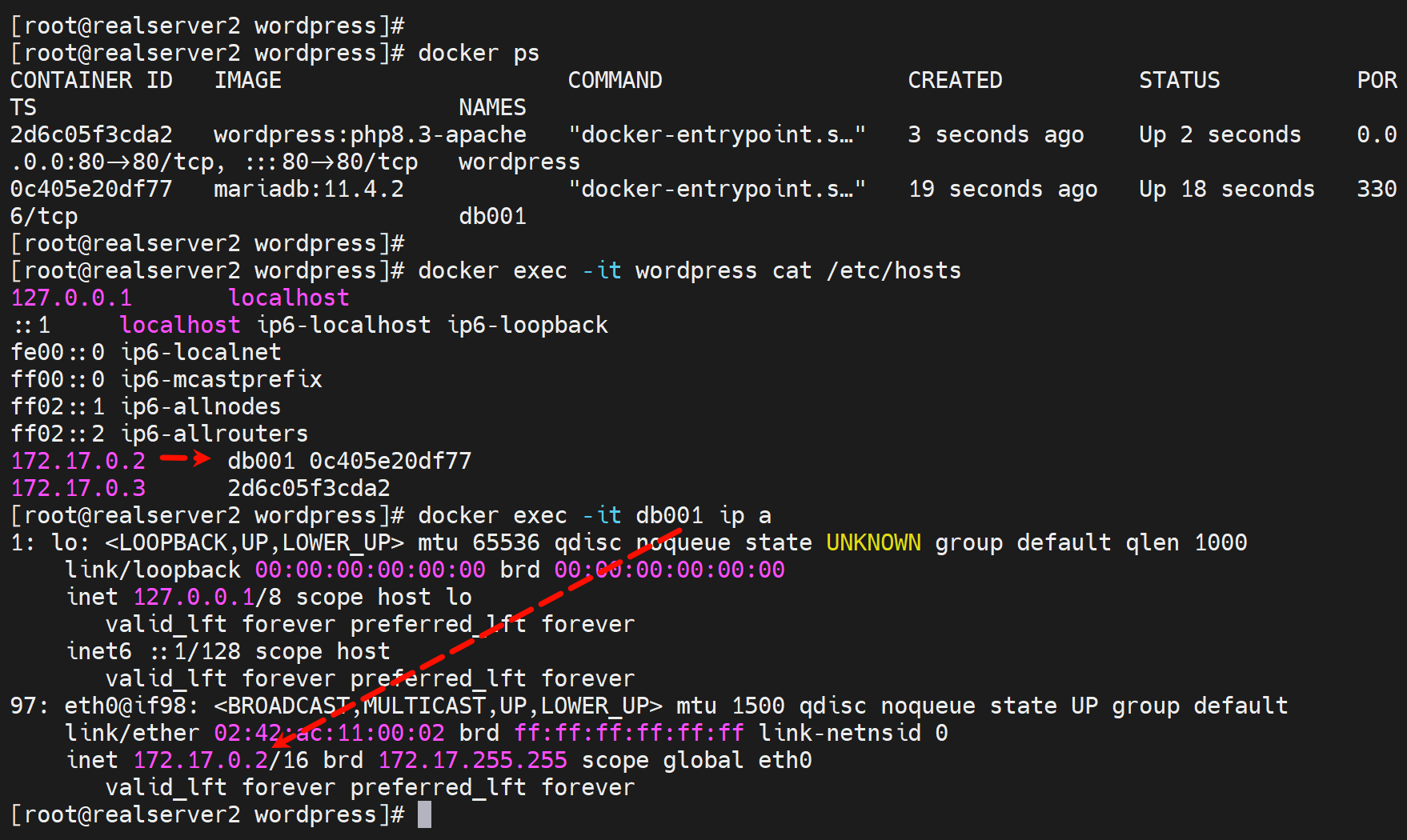
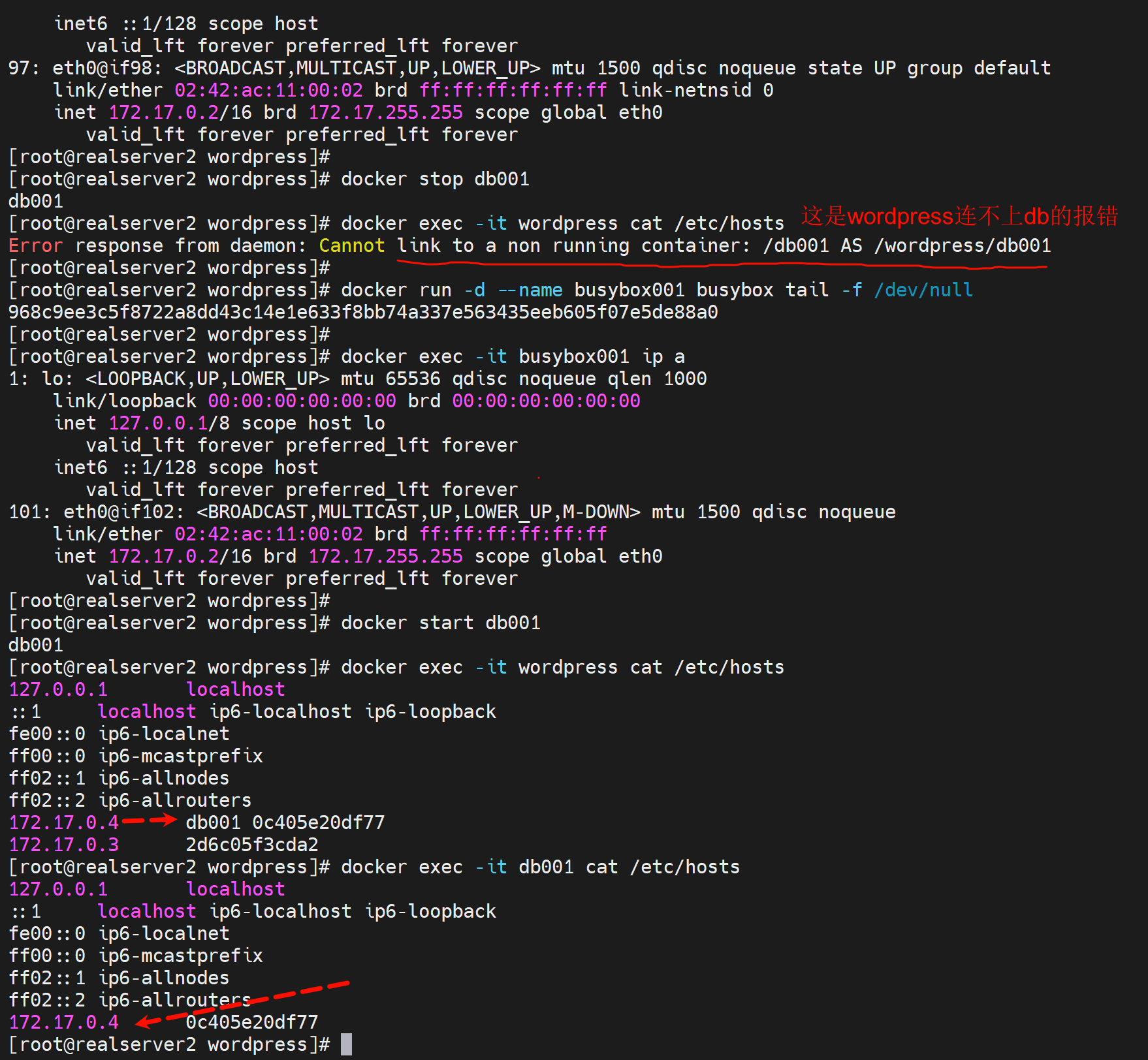
此时都不用重启wordpress,hosts文件就会自动更新,所以业务也一定是OK的(已测过了)。
容器别名
本质就是run的时候hosts里一个ip对应多个容器名称
实验过程,和别名使用场景不怎么相干了感觉,但是可以看到hosts的效果。
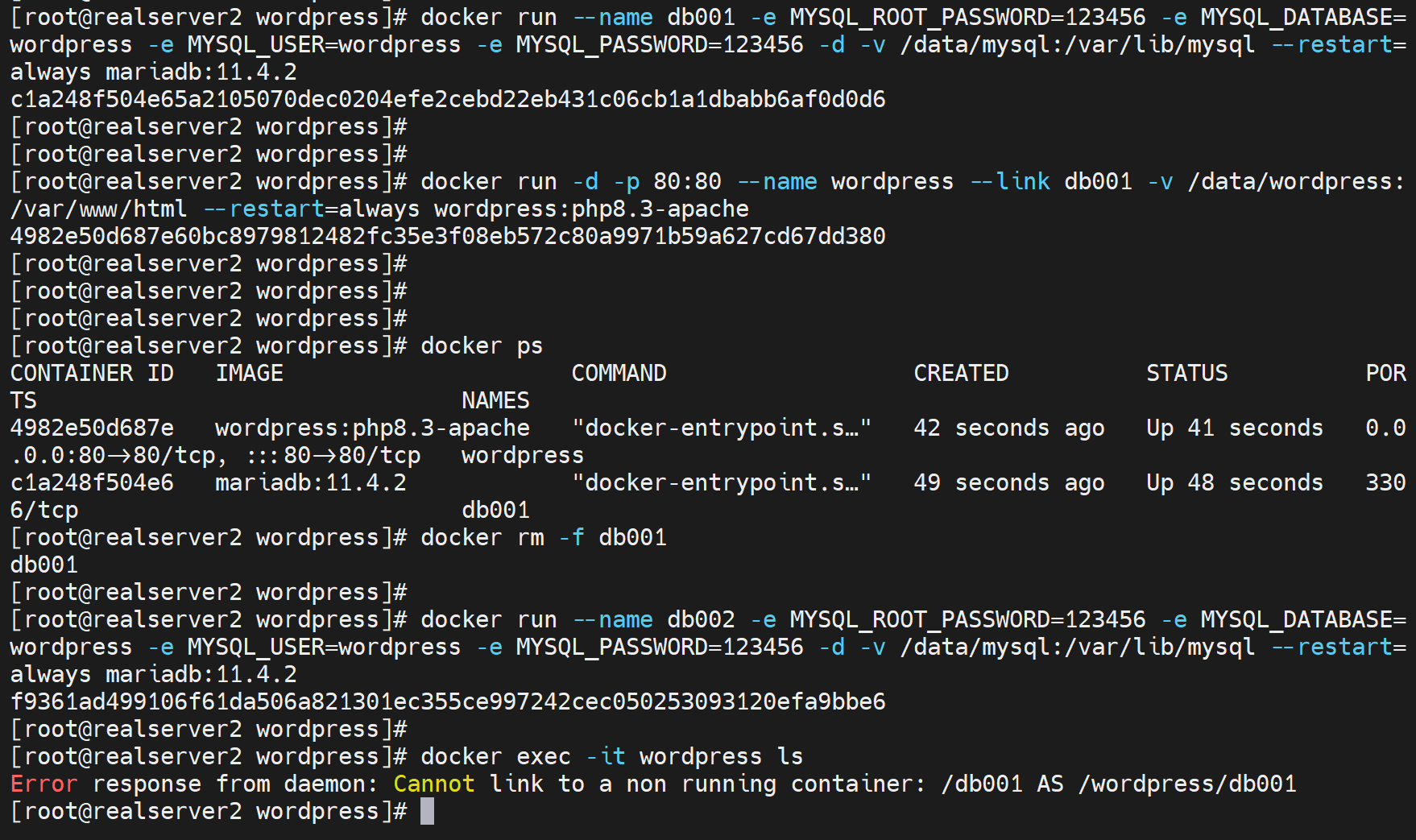
由于db001重新run,改名字,wordpress里的hosts文件还是写的db001,所以找不到了。
但是此时业务倒是正常的👇前提是db002要up的,虽然docker exec -it wordpress ls报错,但是业务出奇的正常
但是问题依然要处理,别名来解决
docker run --name db001 -e MYSQL_ROOT_PASSWORD=123456 -e MYSQL_DATABASE=wordpress -e MYSQL_USER=wordpress -e MYSQL_PASSWORD=123456 -d -v /data/mysql:/var/lib/mysql --restart=always mariadb:11.4.2
docker run -d -p 80:80 --name wordpress --link db001:"db002 db003 db004" -v /data/wordpress:/var/www/html --restart=always wordpress:php8.3-apache
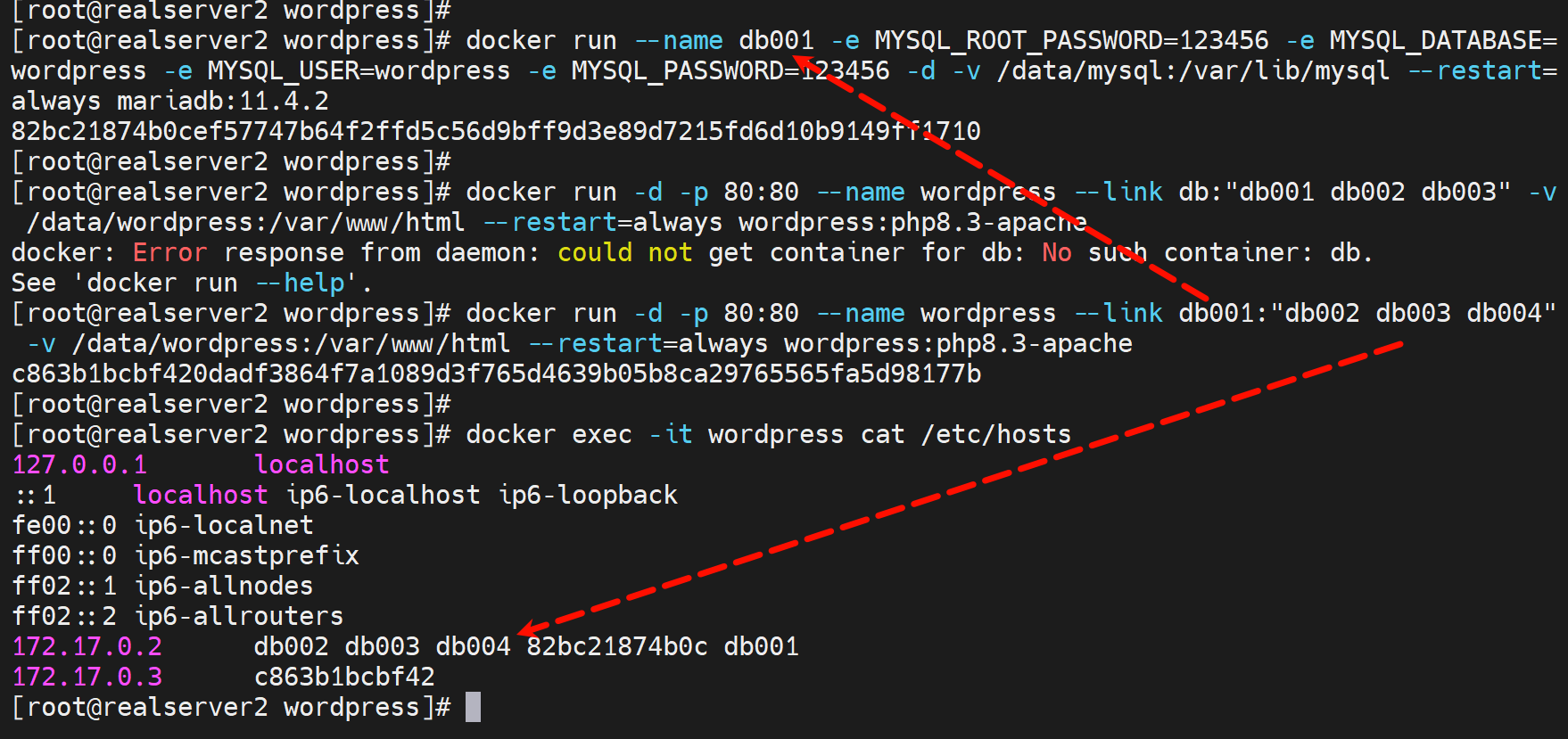
使用场景:
1、程序里写死了是访问db004
2、容器run的时候就不一定非得要叫db004,可以叫db001,
3、然后run这个程序容器的时候可以使用 --lnk db001:db004,就可以将db004解析为db001的IP了。
大概可以这么用。
总结:
工作案例-linux的ping测
linux常ping脚本,
方法1:
ping 10.100.8.29 | awk '{ print $0 " " strftime("%F %H:%M:%S",systime()) }' >> test.ping
注意这种直接 >> 重定向到 文件,大概是60个ping包一起写入文件的。不是每个包写一个的,相当于默认的有一个I/O优化吧
方法2:
ping 223.5.5.5 |& while read -r line;do echo "$(date) $line";done >> ping.log
ping 223.5.5.5 |& while read -r line;do echo "$(date) $line" >> /tmp/123.ping;done
这种方式写入文件很及时,一个ping包就是一个。
时间格式优化下
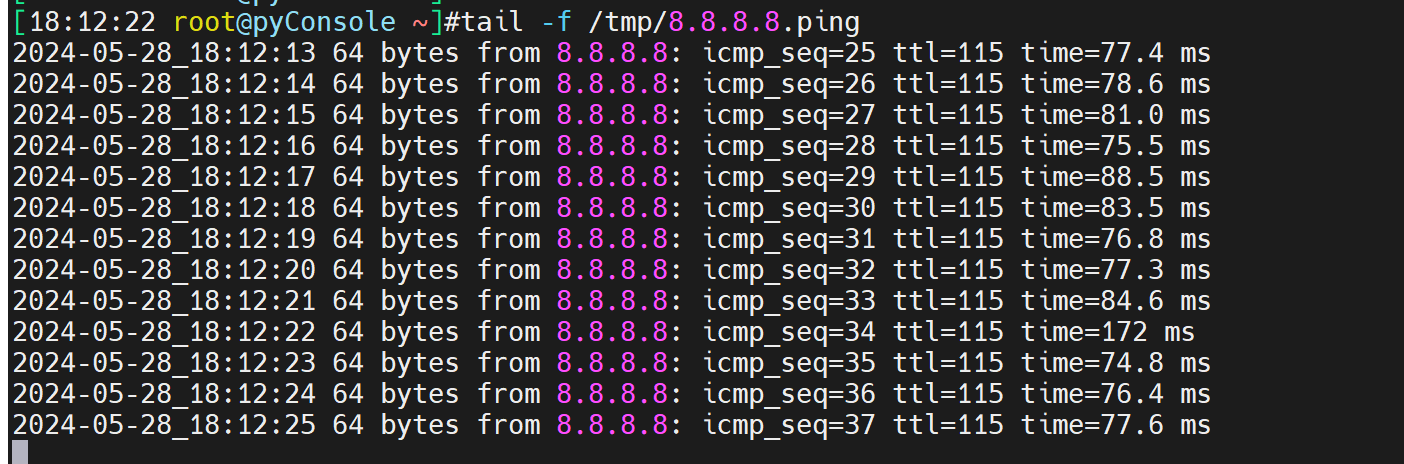
ping 223.5.5.5 |& while read -r line;do echo "$(date +%F_%H:%M:%S) $line" >> /tmp/ping.test ;done
然后改成脚本,做成服务,可以实现异常停止后的服务自动起来,也包括重启机器自动起来。
做成服务
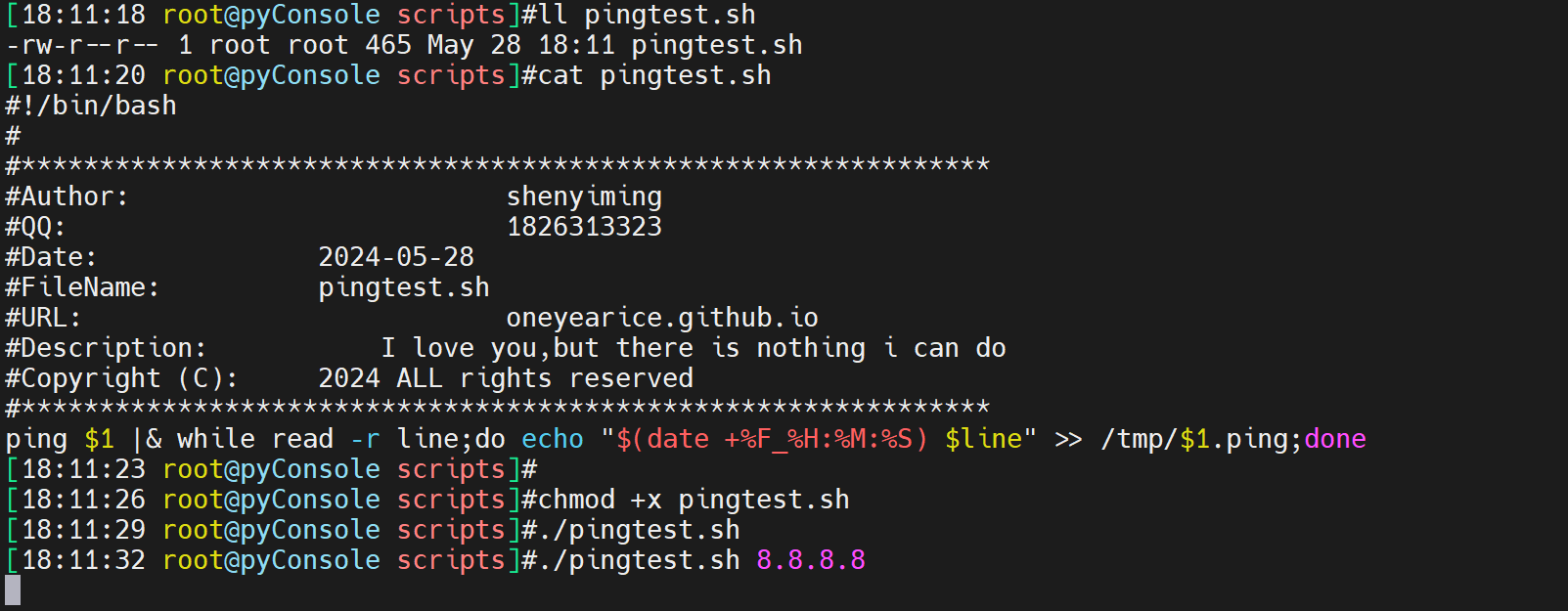
vim /etc/systemd/system/pingtest.service
[Unit]
Description=Ping Test Service
After=network.target
[Service]
User=root
Type=simple
ExecStart=/path/to/pingtest.sh 8.8.8.8
Restart=always
RestartSec=10
[Install]
WantedBy=multi-user.target
systemctl daemon-reload
systemctl start pingtest.service
systemctl enable pingtest.service
systemctl status pingtest.service
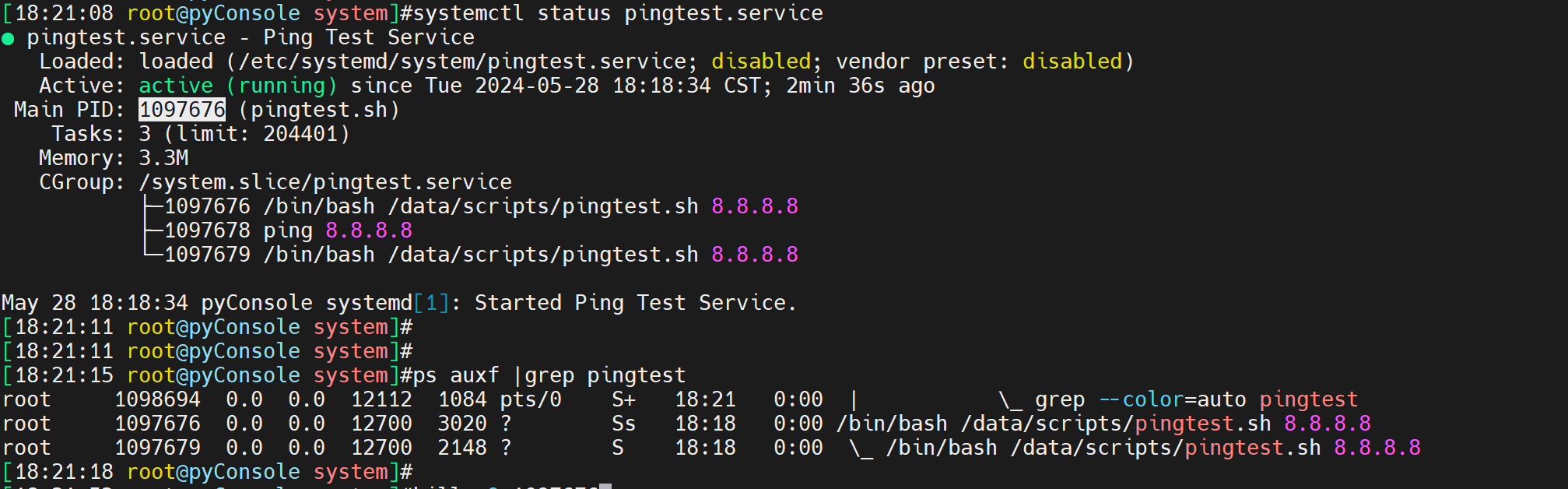
测试kill 后自动起来
找到main pid
kill -9会自动起来
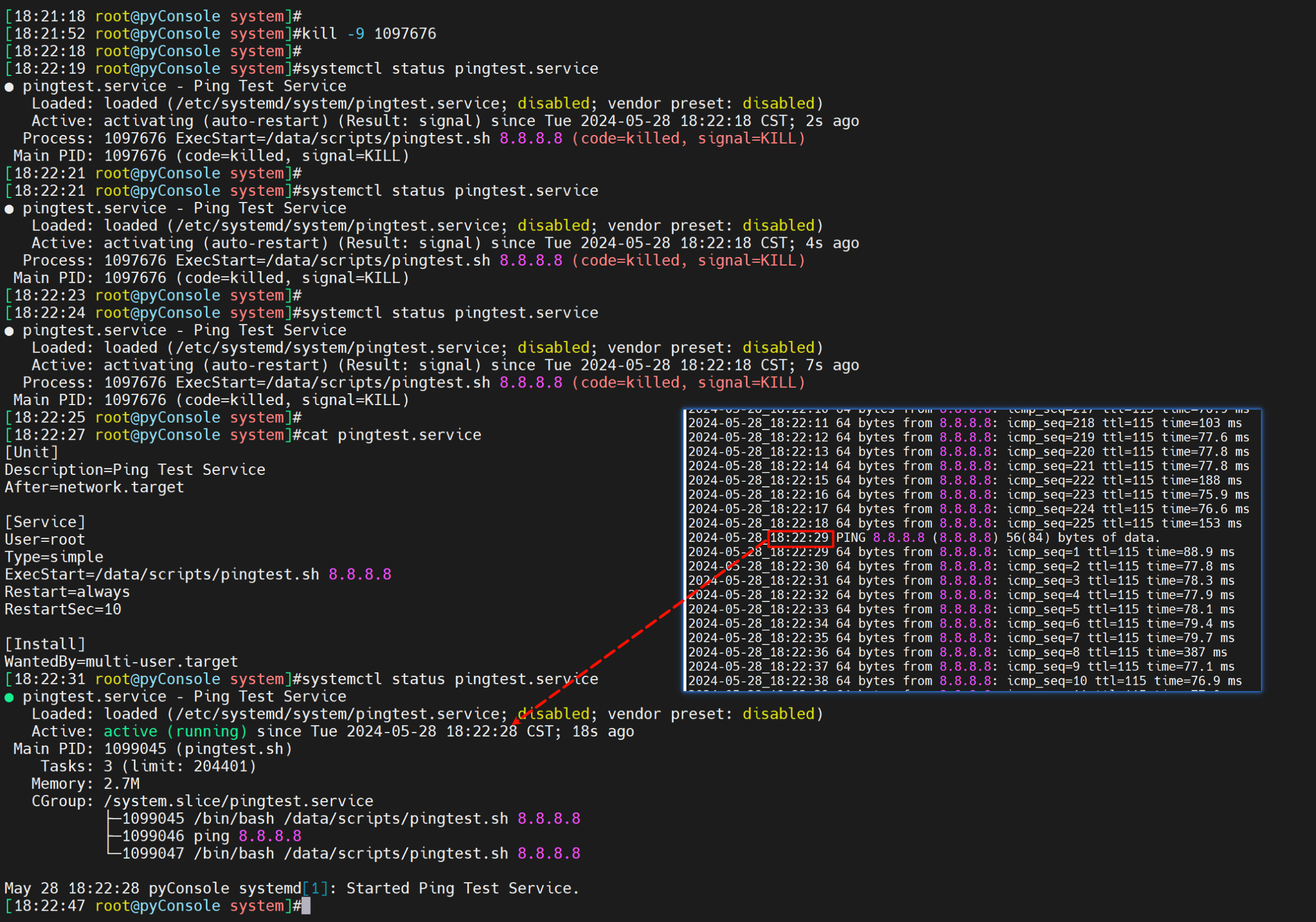
kill 也会起来
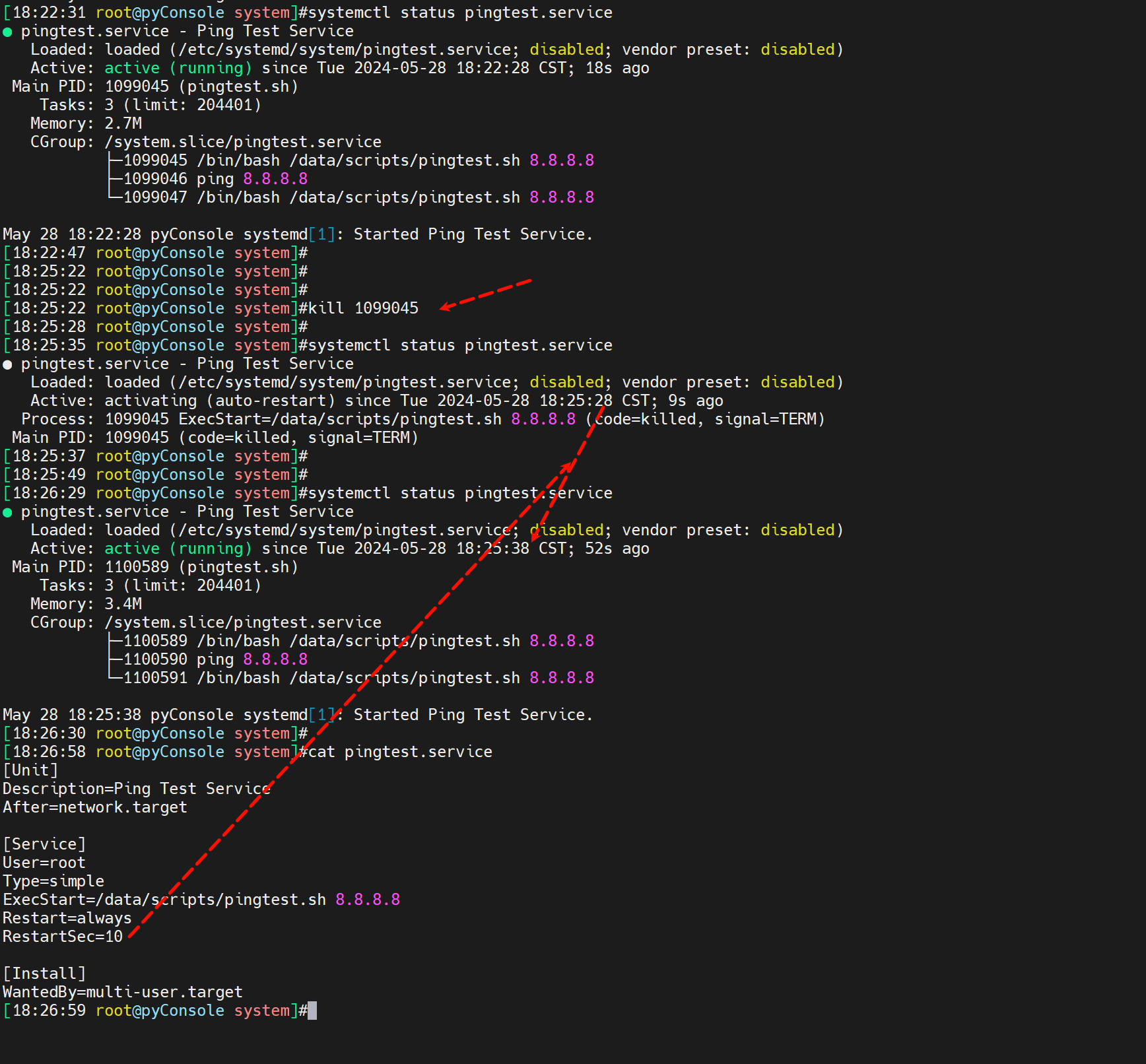
stop纯人工停止自然不会起来咯,否则你怎么停服务~
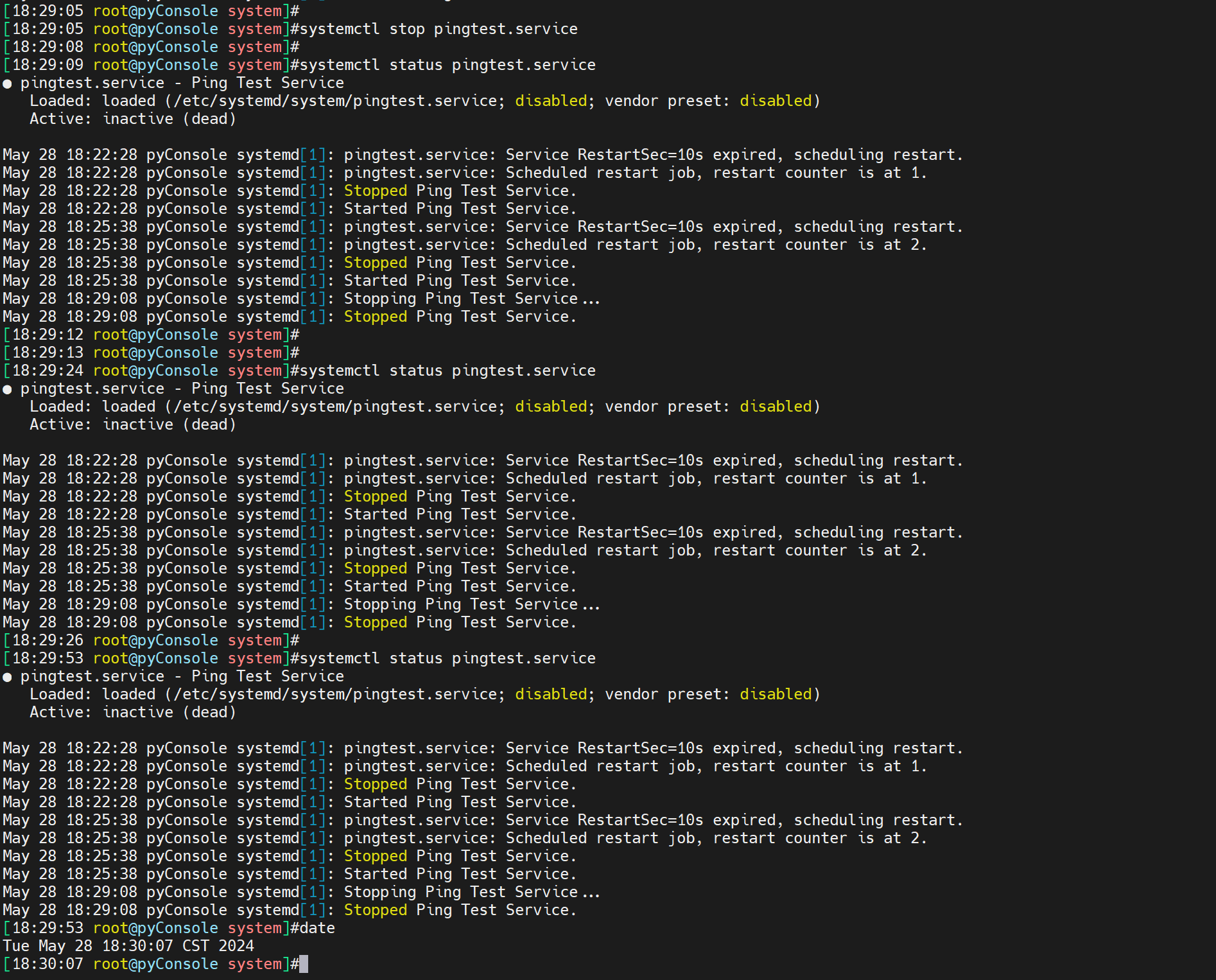
注意status里可以看到一些服务器启动日志的含时间。
系统message也可以看
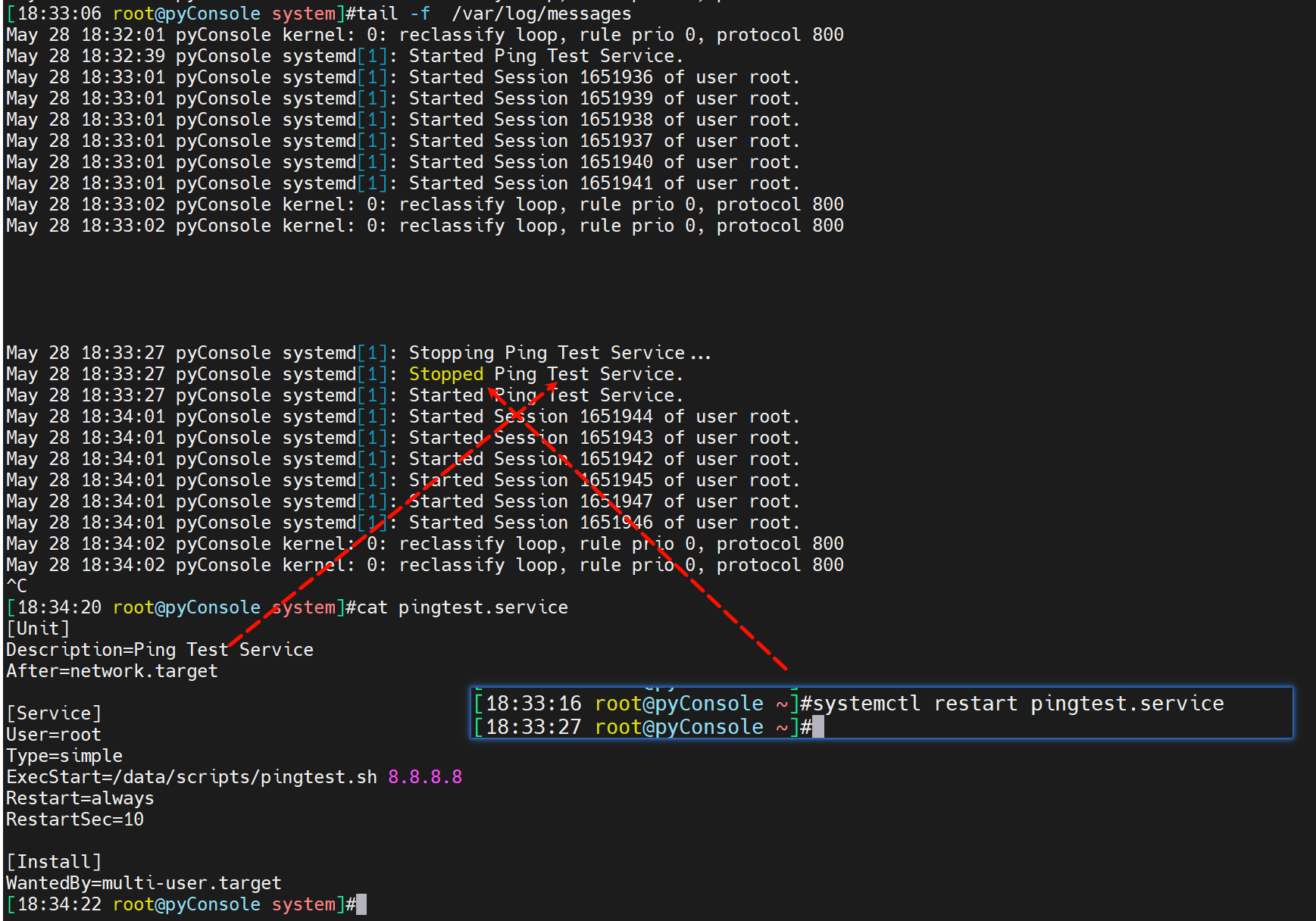
以上就是简单的一个做法,或者不写服务用screen去做也不错,
不过正规还是要上监控的,比如用zabbix-agent去实现,这个前文也有。
案例2,如何做个远端节点的PING测监控
其实和斗数一样,也是看三方四正
举例,你要监控从上海到洛杉矶的云主机的ping测。就需要出5张图,也是一个三方四正
①公司zabbix-----洛杉矶节点
②proxy1代理----到洛杉矶节点
③proxy2代理----到洛杉矶节点
④公司zabbix----到proxy1节点
⑤公司zabbix----到proxy2节点
看图
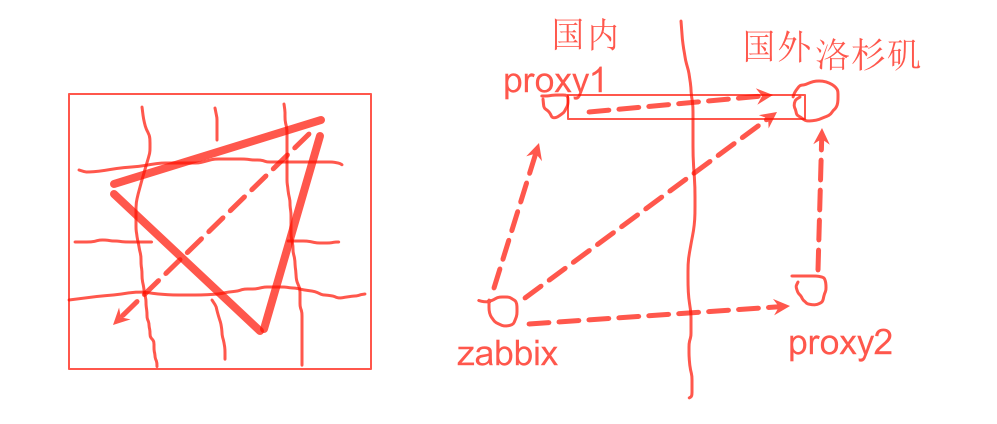
有了这个总结,以后做监控,基本上如果重要的节点,就可以一步到位全面监控住。
案例-ipsecvpn
云上的VPN的网关其实是PAT出来的,要IDC的SSG开启NAT-T来解封的。
文章中的这个传输模式同样不能转换端口的
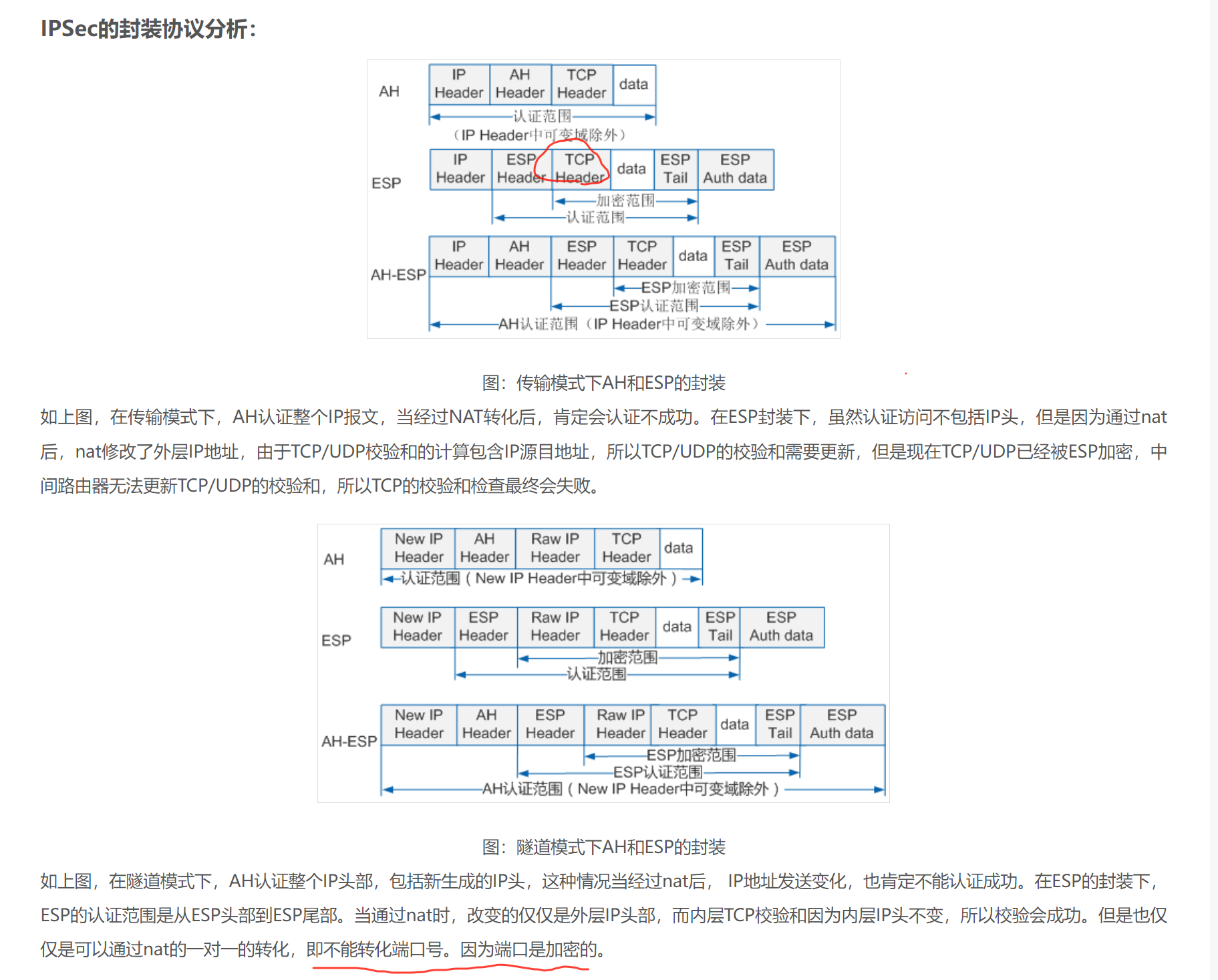
还有一个问题就是rekey的问题,
理由:云上86400协商,云下28800协商,这是IKE阶段,也就是第一个阶段的周期,于是就会协商成28800也就是8小时,结果发现8小时就会断一次业务,排查发现必须是云下往云上ping一下或者发包来触发,否则要等15分钟左右才能重新拉起隧道。
因为,云上发起的rekey,云下ssg没有开启rekey功能,所以无法重协商SPA,所以就断了,解决方法有2:
1、云下做一个常ping放到screen后台运行就行了
2、最好是SSG上在ipsec阶段开启rekey,注意要和monitor一起,否则开不了。