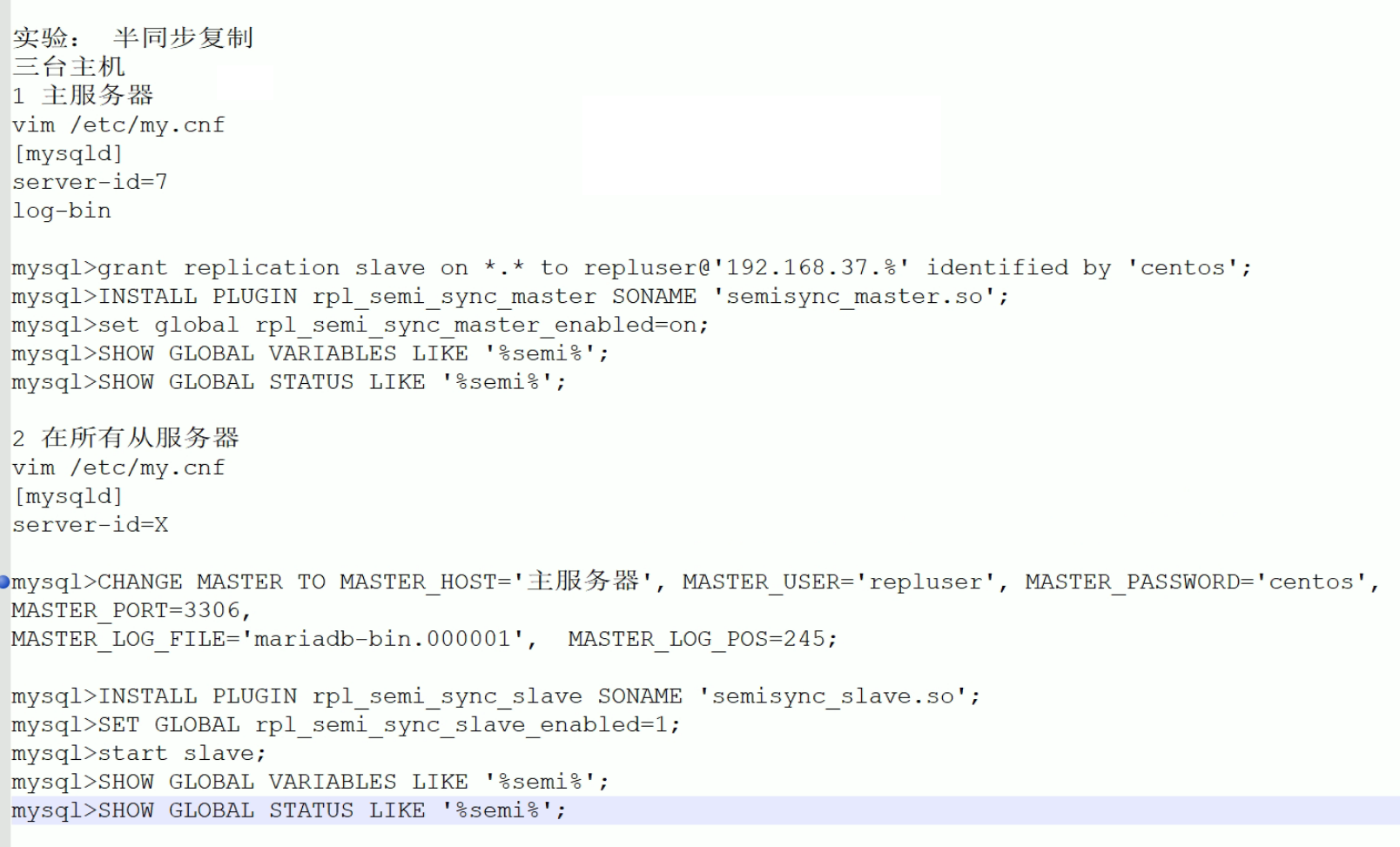
第2节. mysql主主和半同步复制
补充几个选项

5个写磁盘的及时性:
sync_binlog=1 binlog的及时写磁盘,
innodb_flush_log_at_trx_commit=1 事务的及时写磁盘,当然不是说及时就一定是好的,也要考虑IO的负担。
sync_master_info是 多少次 事件后 master.info的信息 写磁盘
sync_relay_log 多少次 后同步到relaylog磁盘文件,应该也是指relay-log.info文件吧。
sync_relay_log_info 多少次事务后 后同步到relay-log.info磁盘文件。
skip-slave-start=ON # 要知道一个事实--重启mariadb服务后,slave的两个线程IO和SQL都是OK的,也就是第一次手动start slave;后面都不用管的,都是随服务启动就启动的。这个特性就是依赖于skip-slave-start这个选项,如果置为ON,就不会随服务启动了,到时候就只能手动每次start slave了。
主-主 复制,需要调度固定分配成主-从
主-主前面一篇就讲过了,这种的好处,是多活吗,无需从节点提升 这么一个动作。
所谓主主,其实是互为主从,A-B 两个机器,A是B的主,又是B的从,B一样。
不过有人就是要真正意义上的主主,多活,A/A,类似ASA的A/A,人家就是要并发写,我那个去,怎么搞,这么搞。

所谓的并发写,A/A,其实就是通过
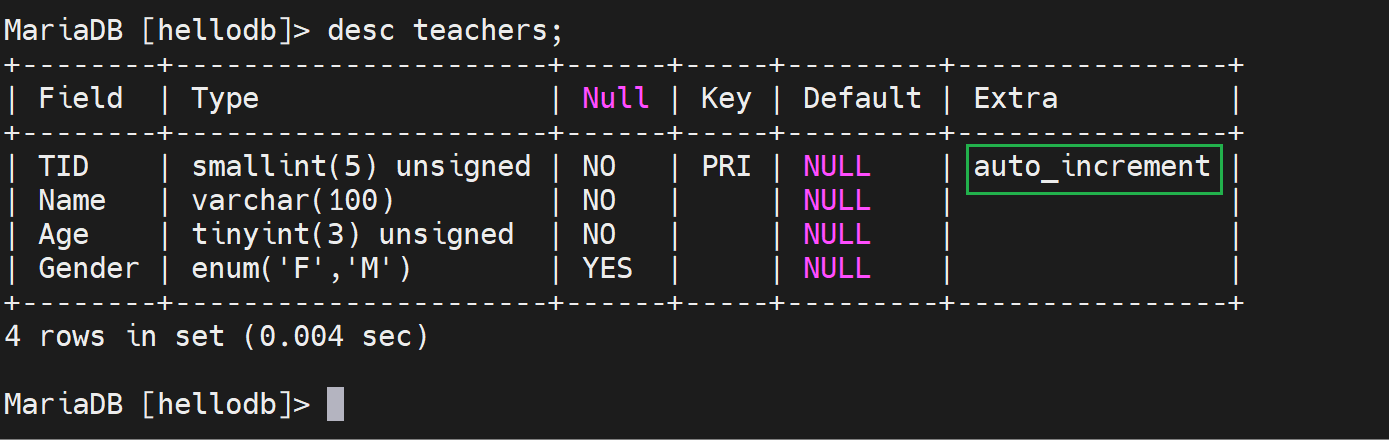
auto_increment:也就是奇偶区分,不同的主起始不通,间隔一样,错开序号了就。
然后再配合前置调度器,比如,来了2条写操作,调度器就直接并发的扔给2个主,而2个主处理的时候又是错开PRI主键ID的,于是就实现了多主。
节点A上
------
yum -y remove mariadb-server
rm -rf /var/lib/mysql/*
cp -a /etc/my.cnf /etc/my.cnf.bak
yum -y install mariadb-server
vim /etc/my.cnf
[mysqld]
server-id=1
log-bin
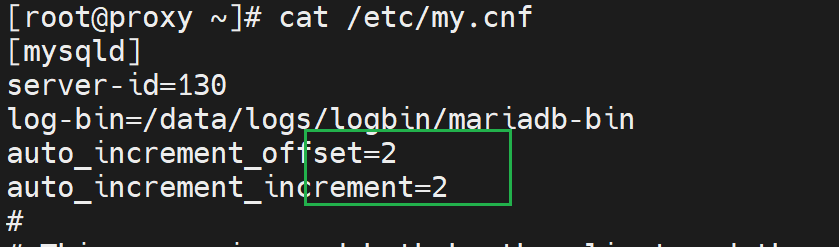
auto_increment_offset=1
auto_increment_increment=2
wr
systemctl start mariadb
mysql > grant replication slave on *.* to repluser@'192.168.126.%' identified by 'cisco';
节点B上
------
yum -y remove mariadb-server
rm -rf /var/lib/mysql/*
cp -a /etc/my.cnf /etc/my.cnf.bak
yum -y install mariadb-server
vim /etc/my.cnf
[mysqld]
server-id=2
log-bin
auto_increment_offset=2
auto_increment_increment=2
wr
systemctl start mariadb
// mysql > grant replication slave on *.* to repluser@'192.168.126.%' identified by 'cisco'; # 这句就不用敲了,直接复制过来从A。
mysql >
CHANGE MASTER TO
MASTER_HOST='192.168.126.129',
MASTER_USER='repluser',
MASTER_PASSWORD='cisco',
MASTER_PORT=3306,
MASTER_CONNECT_RETRY=10,
MASTER_LOG_FILE='mariadb-bin.000001', MASTER_LOG_POS=330; # 去A看下show master logs;将binglog文件和pos位置复制过来。不过这个要配合mysqldump 从A备份还原到B,如果不想这么麻烦,直接将这里的binglog设置成第一个文件的第一个位置一般是330左右。可以刷新一个binlog,看看初始值多少。放屁!这样从头复制直接报错!哈哈因为复制的时候可不会想mysqldump出来的有IF判断存在就DROP的语句,主从复制如果存在就直接报错卡住了。
所以这里的binlog和pos需要先去master上show master logs;复制过来的,然后master前面的数据需要dump过来的。
报错啦
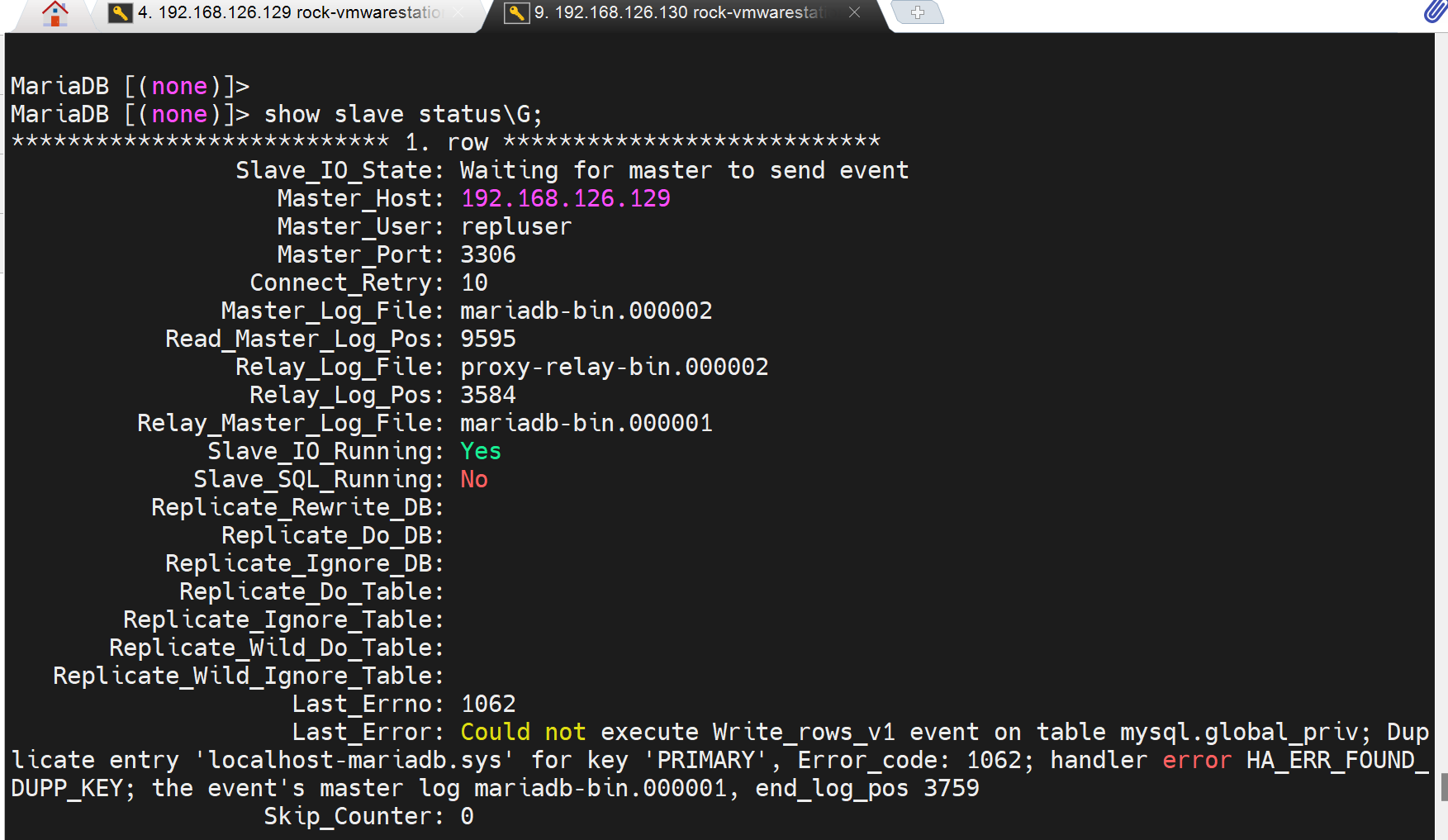
还是去A上dump吧
mysqldump -A --single-transaction --master-data=1 > /data/all.sql
scp /data/all.sql root@192.168.126.130:/data/

去B上还原下
msyql > stop slave;
mysql < /data/all.sql
msql > show databaes; 可见hellodb同步过来了
mysql > start slave;
mysql > show slave status\G; 这回就OK了。
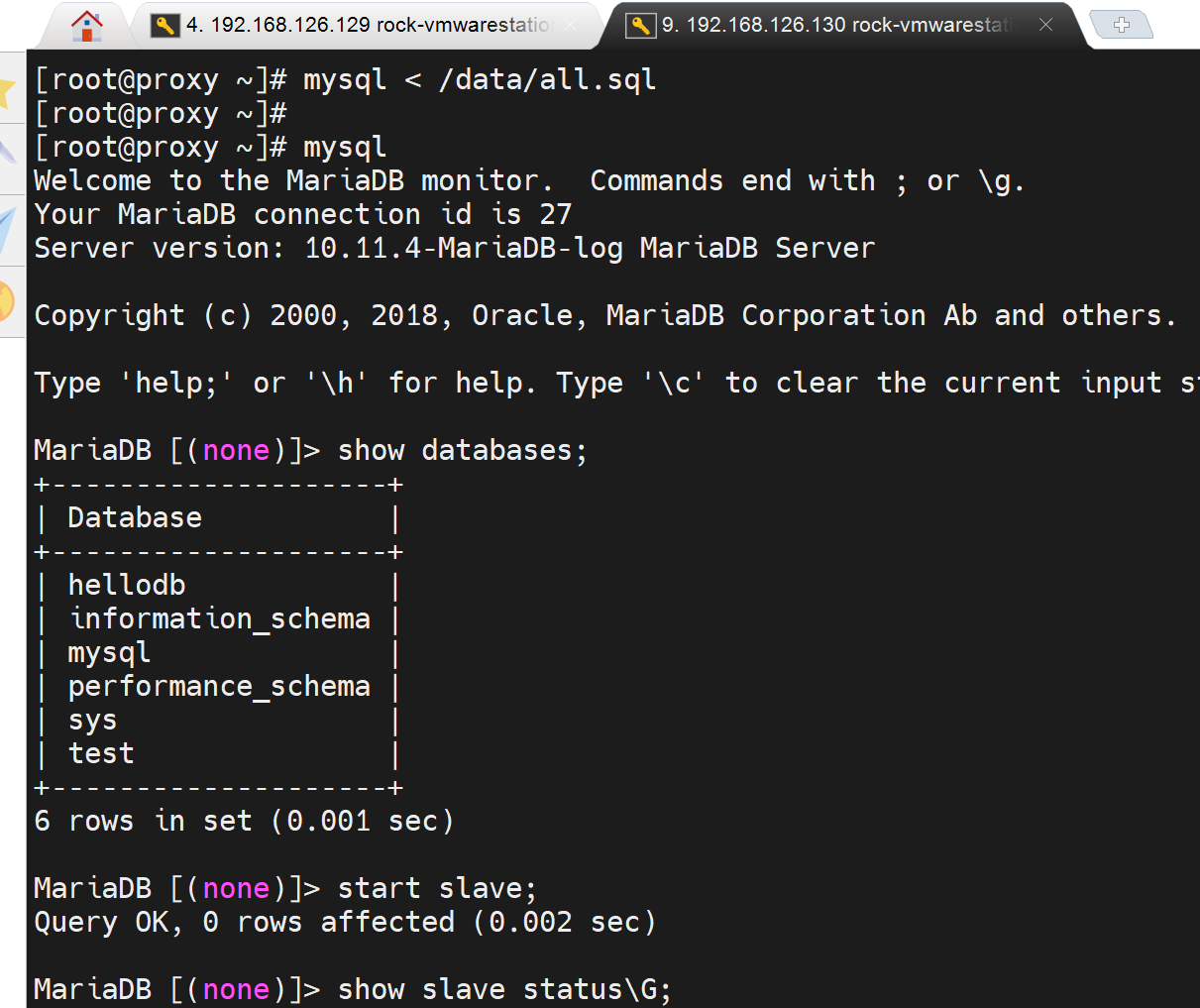
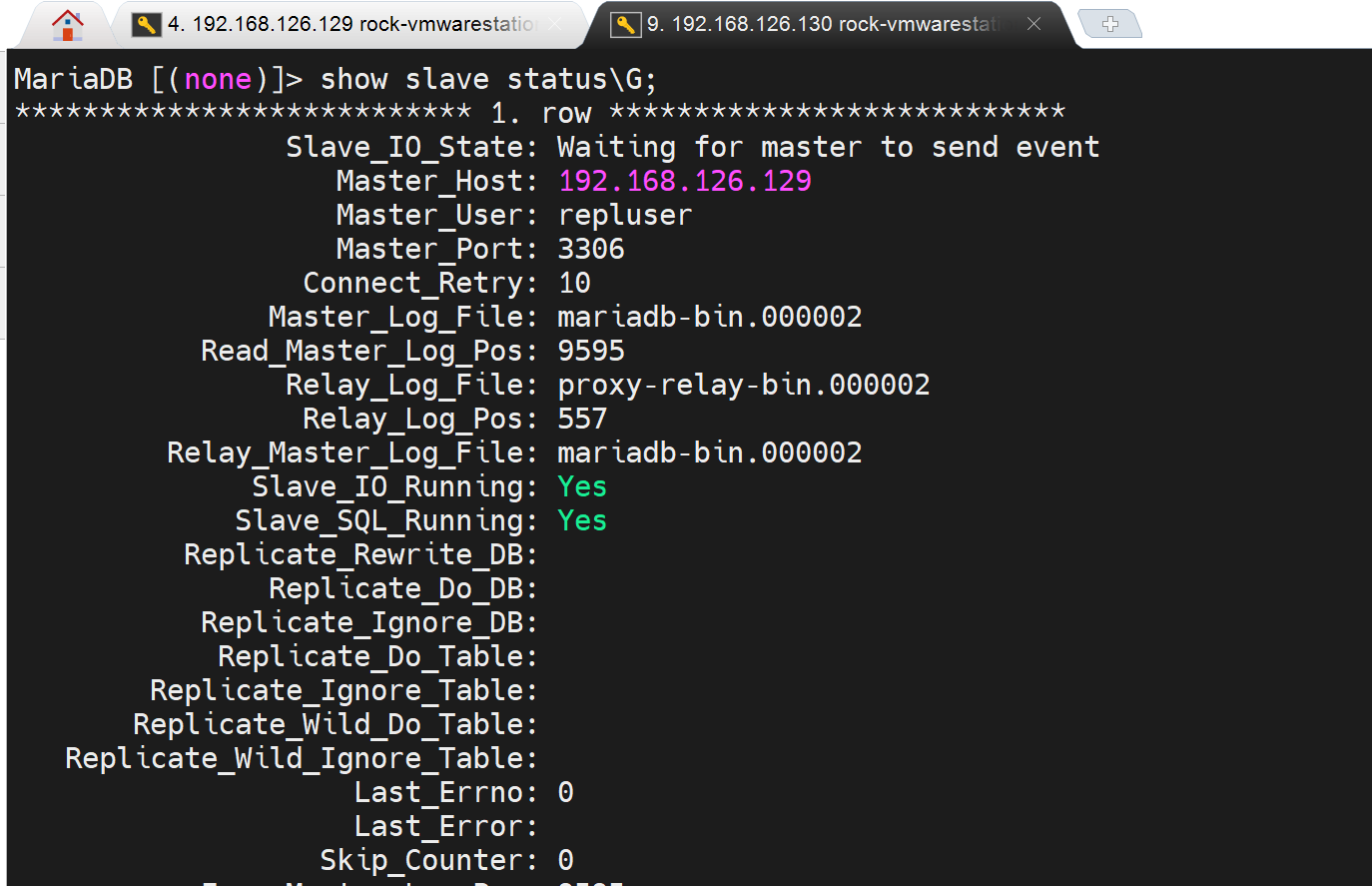
这就好了,果然是primary主键可能不让写奇数吧,因为/etc/my.cnf里是做了偶数限制
果然个屁,再仔细看看报错,是dupicate

这就是已经说主从复制的时候,已经有的数据库,里面的表,再次写的时候就报错了,
但是mysqldump 出来的all.sql里其实也是大量的sql语言,但是人家是写了IF 条件判断的,如果存在这个表格就DROP的啊,哈哈,对吧mydqldump是先铲除后还原啊,所以不会报错啊👇
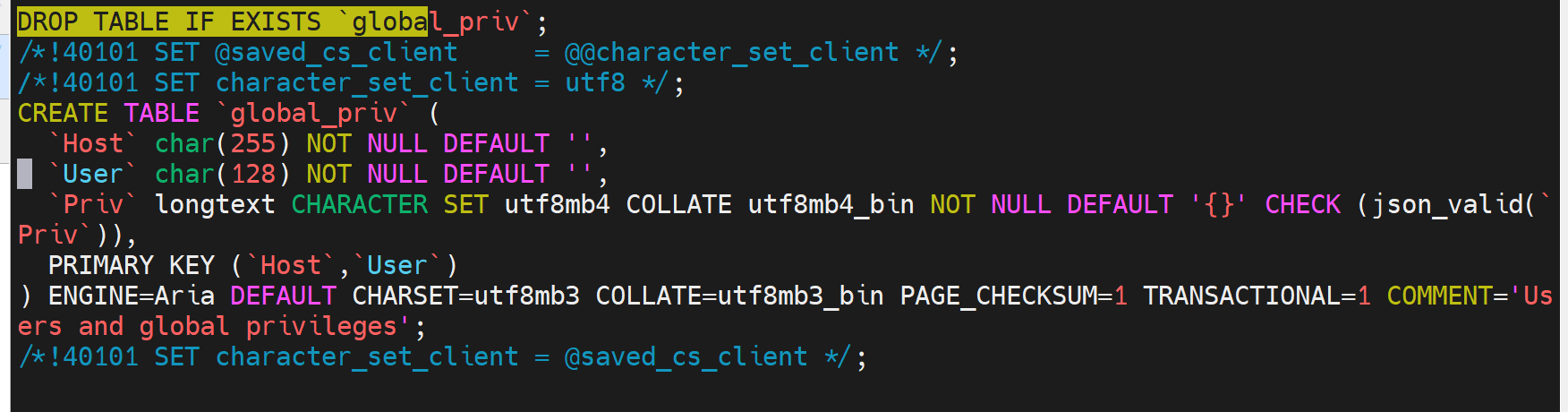
而复制就不是啦,存在的就冲突了。现在知道为什么每次都dump而不是从头做复制了吧。
现在传统的主-从就OK,测试一下
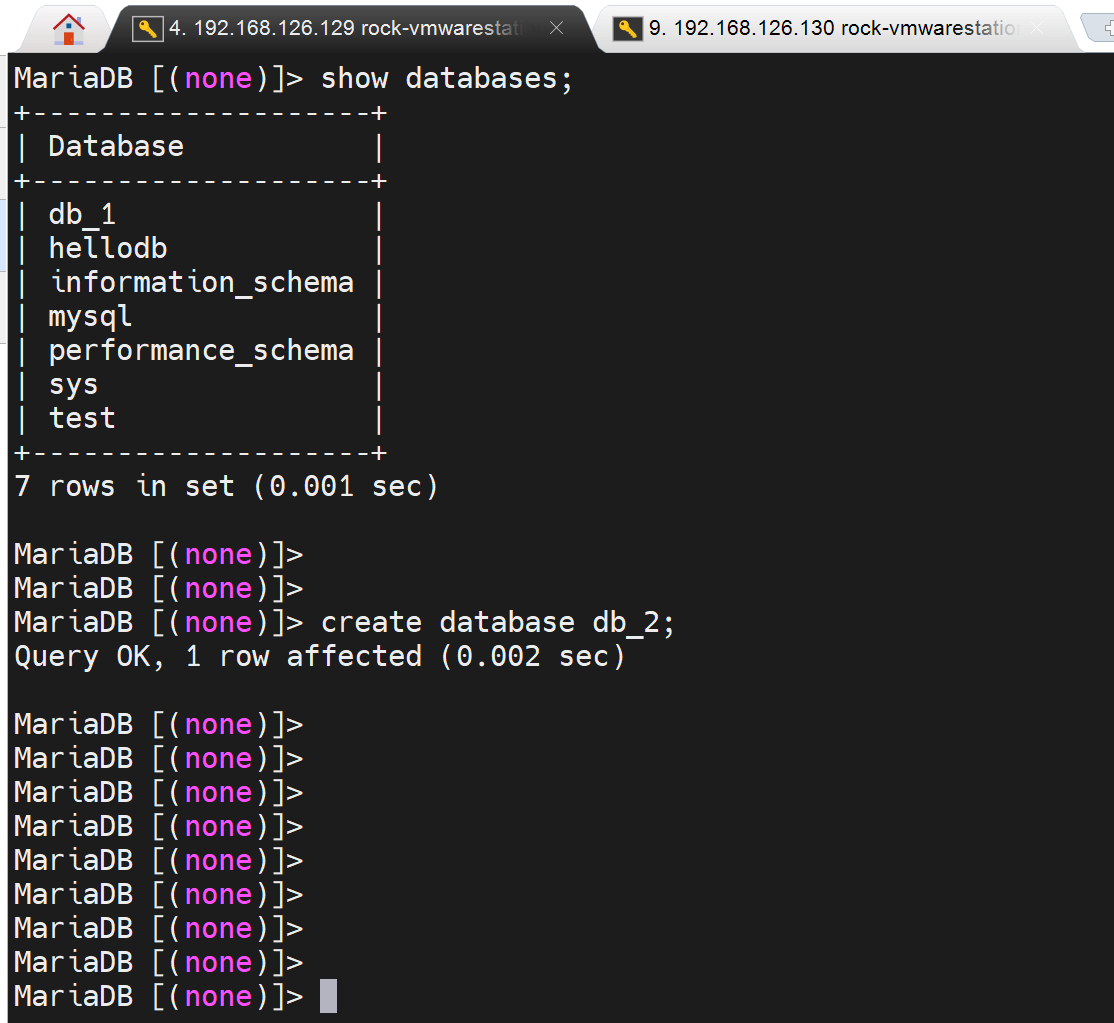
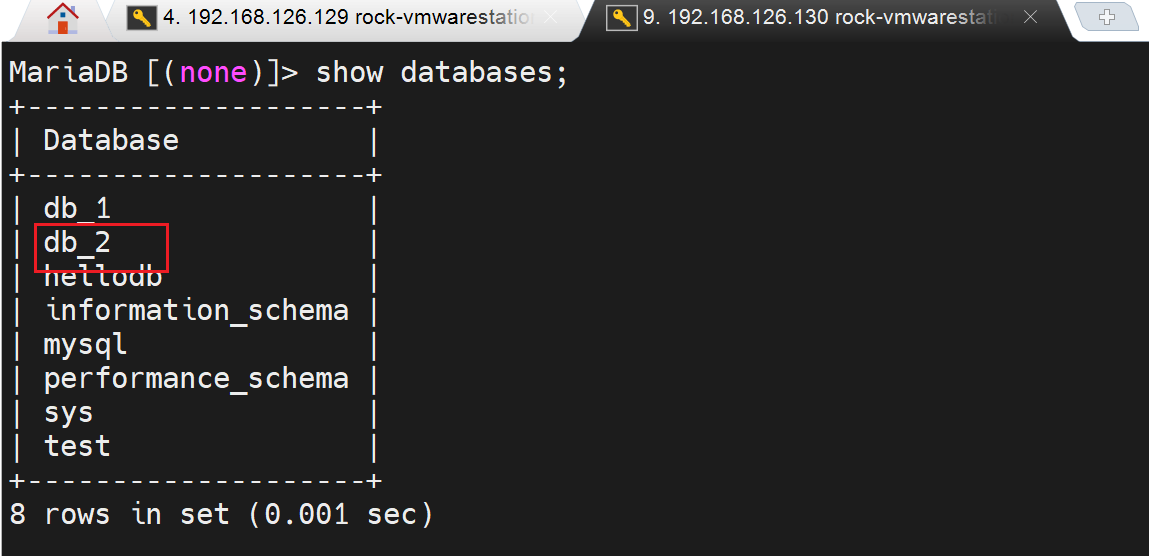
然后把节点B也就是slave也变成master
B上也就是slave:
------
mysql > show master logs;
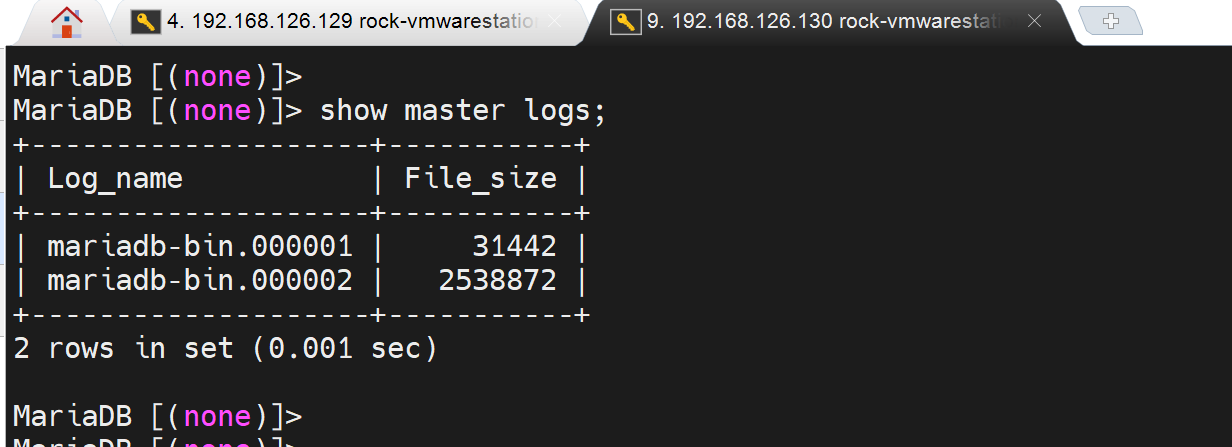
A上也就是master:
---------
mysql >
CHANGE MASTER TO
MASTER_HOST='192.168.126.130',
MASTER_USER='repluserB',
MASTER_PASSWORD='cisco',
MASTER_PORT=3306,
MASTER_CONNECT_RETRY=10,
MASTER_LOG_FILE='mariadb-bin.000002', MASTER_LOG_POS=2539205;
上面的binglog文件和pos位置就是B上看到的复制过来的,敲完A就是从了,当然还得start slave一下;
mysql > start slave;
mysql > show slave status\G;
然后就报错了
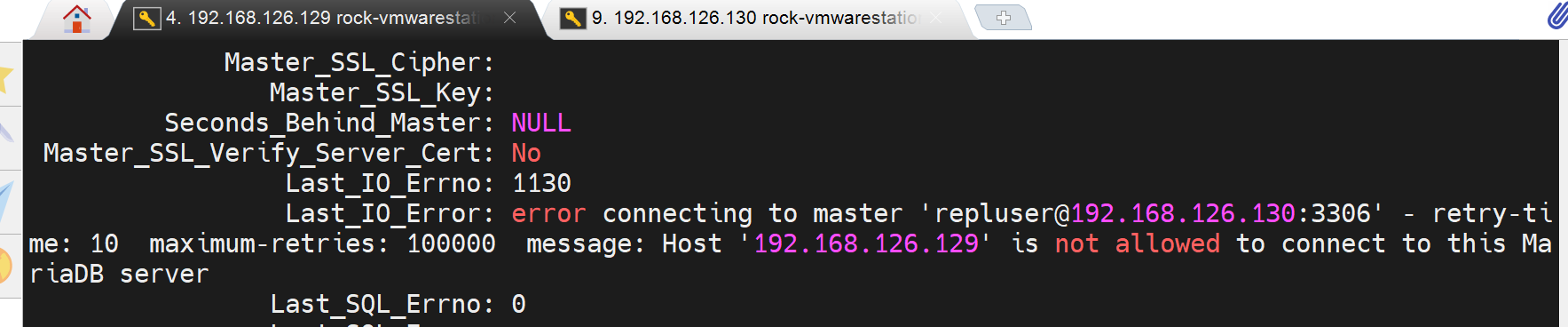
奇了怪了,用户确认同步过去了啊,密码通过哈希值都能判断是一致的👇
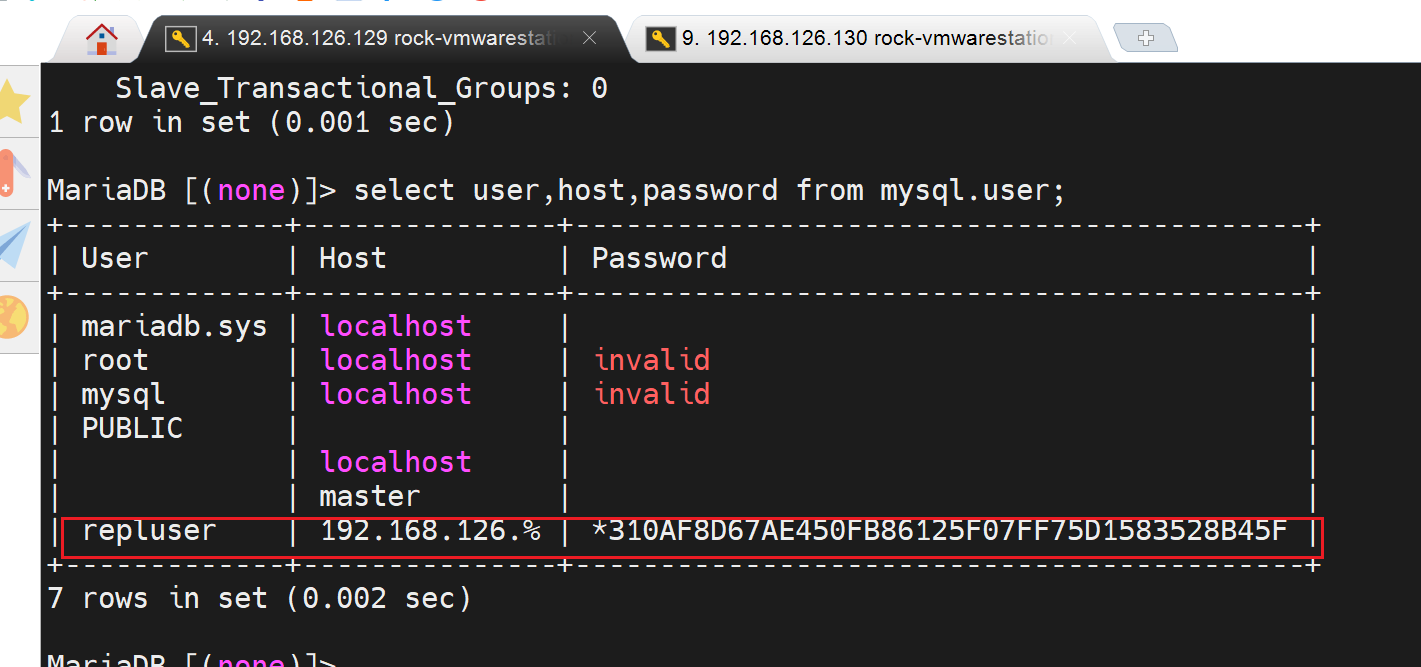
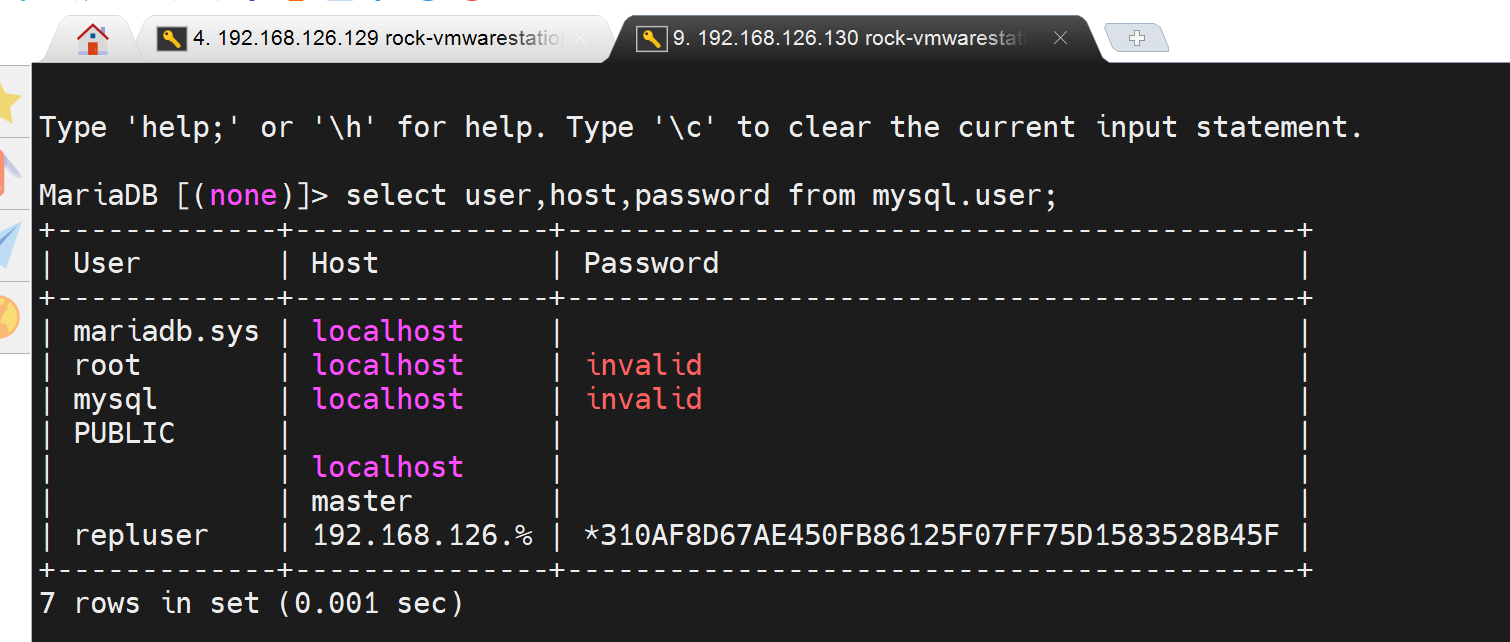
不管先在B上新建一个用户试试
在B上
-----
grant replication slave on *.* to repluserB@'192.168.126.%' identified by 'cisco';
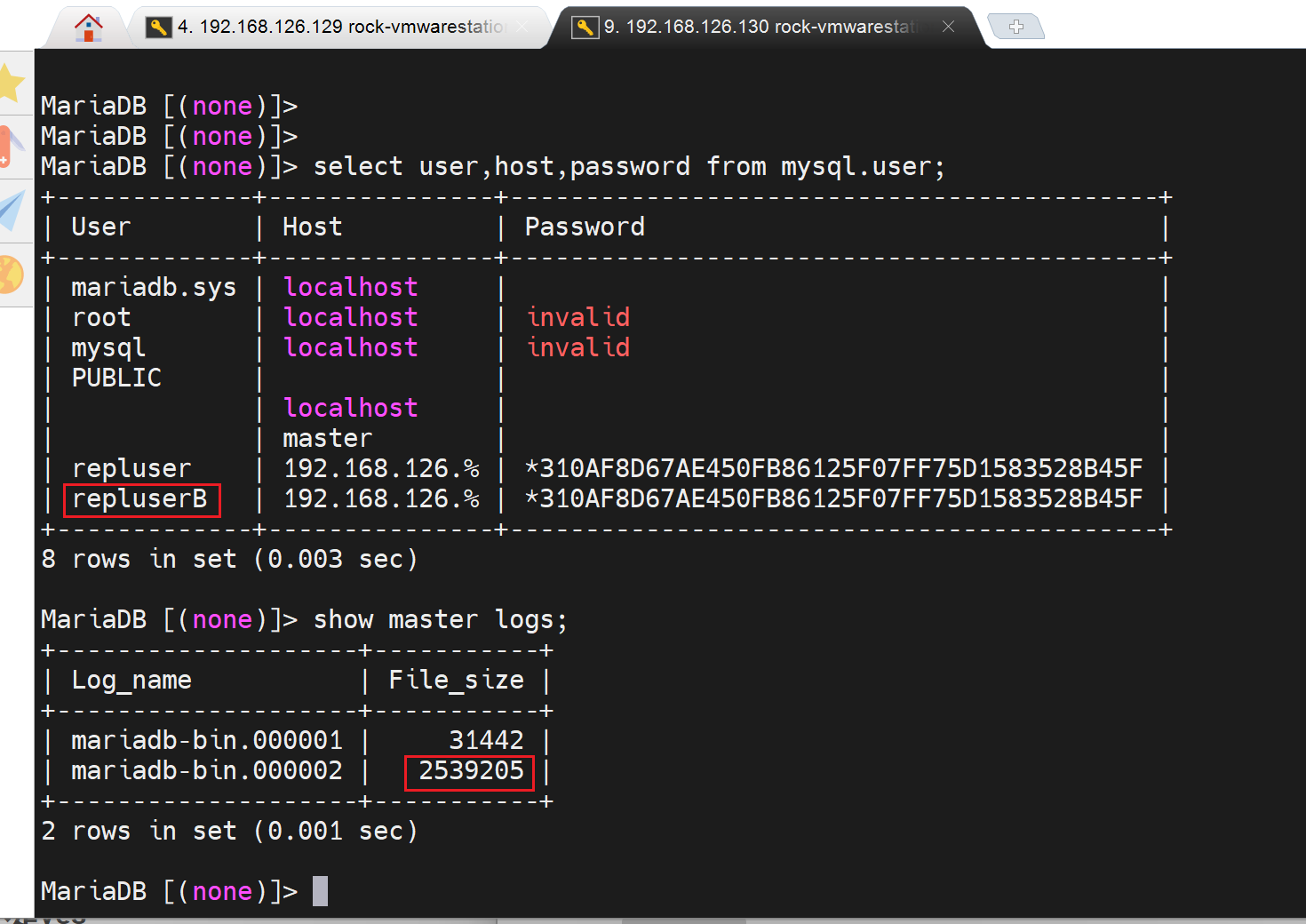
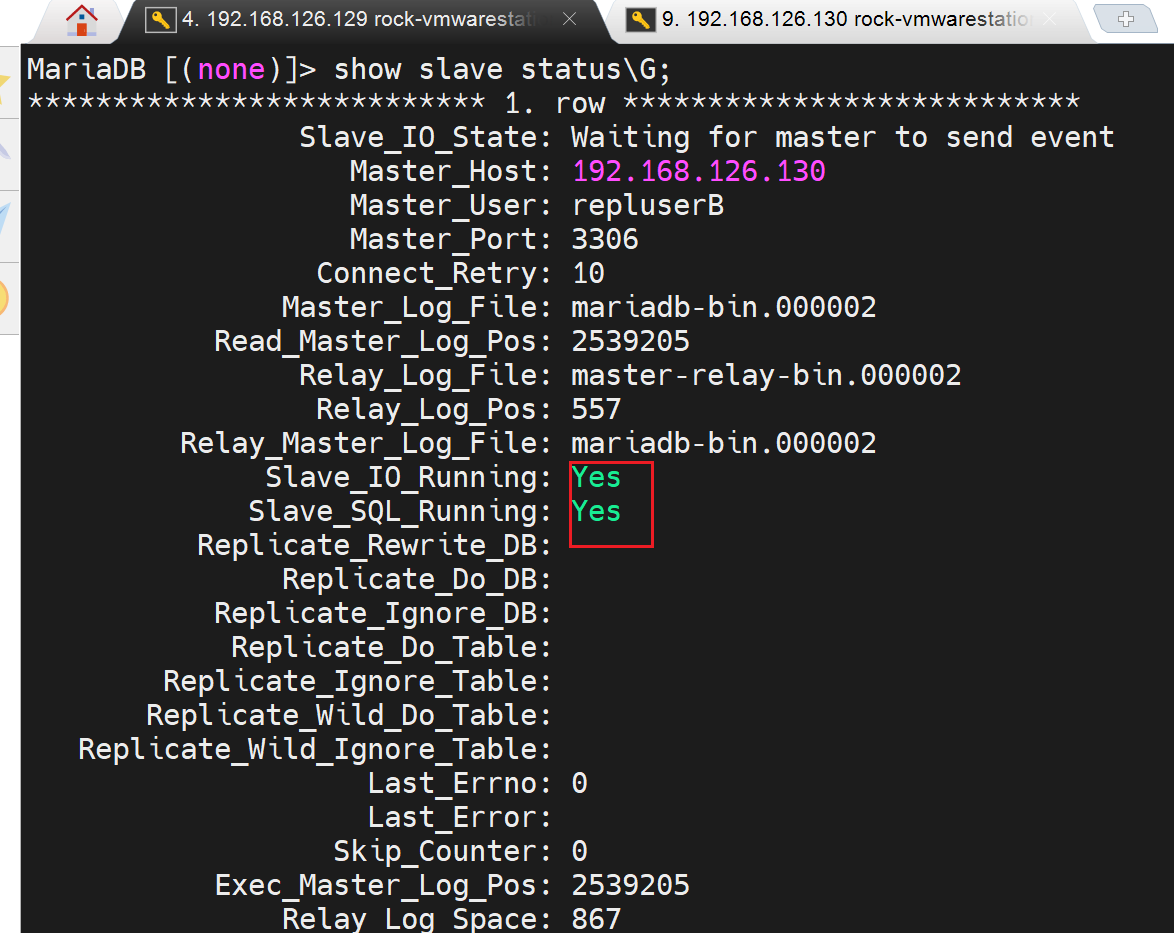
靠!好了,难道用户要单独创建咯,好吧。难道主主,复制用户必须各自单独创建。不是,后面我又把A的复制用户换回去又可以了。感觉是这个用户没有在B上生效。
好像flush privileges;就好了,不过我记得我刷过啊,估计就是没生效当时,然后过一会生效了,或者是创建repluserB的时候相当于又刷了一次,我当时应该多刷几次的,( ̄▽ ̄)"。
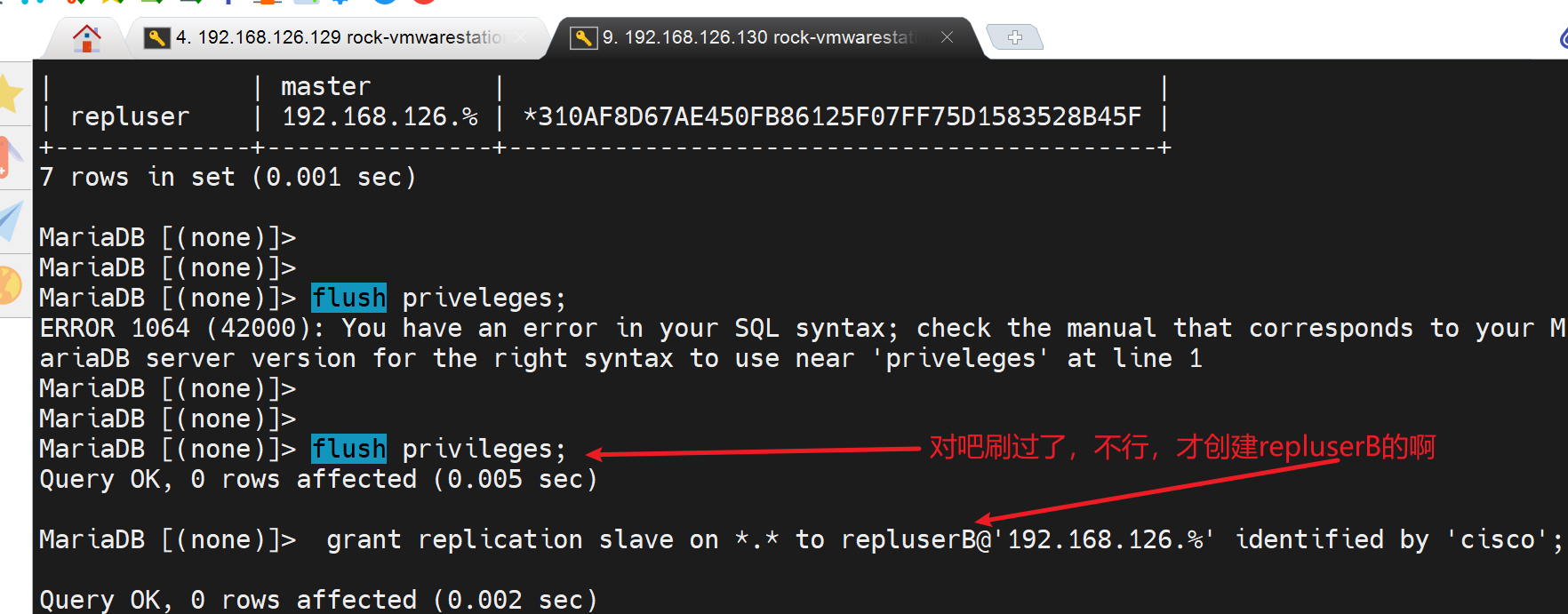
A->B 和A<-B 双向同步就都测试到了👇
模拟写表看看是否冲突-主主的时候
A上
-----
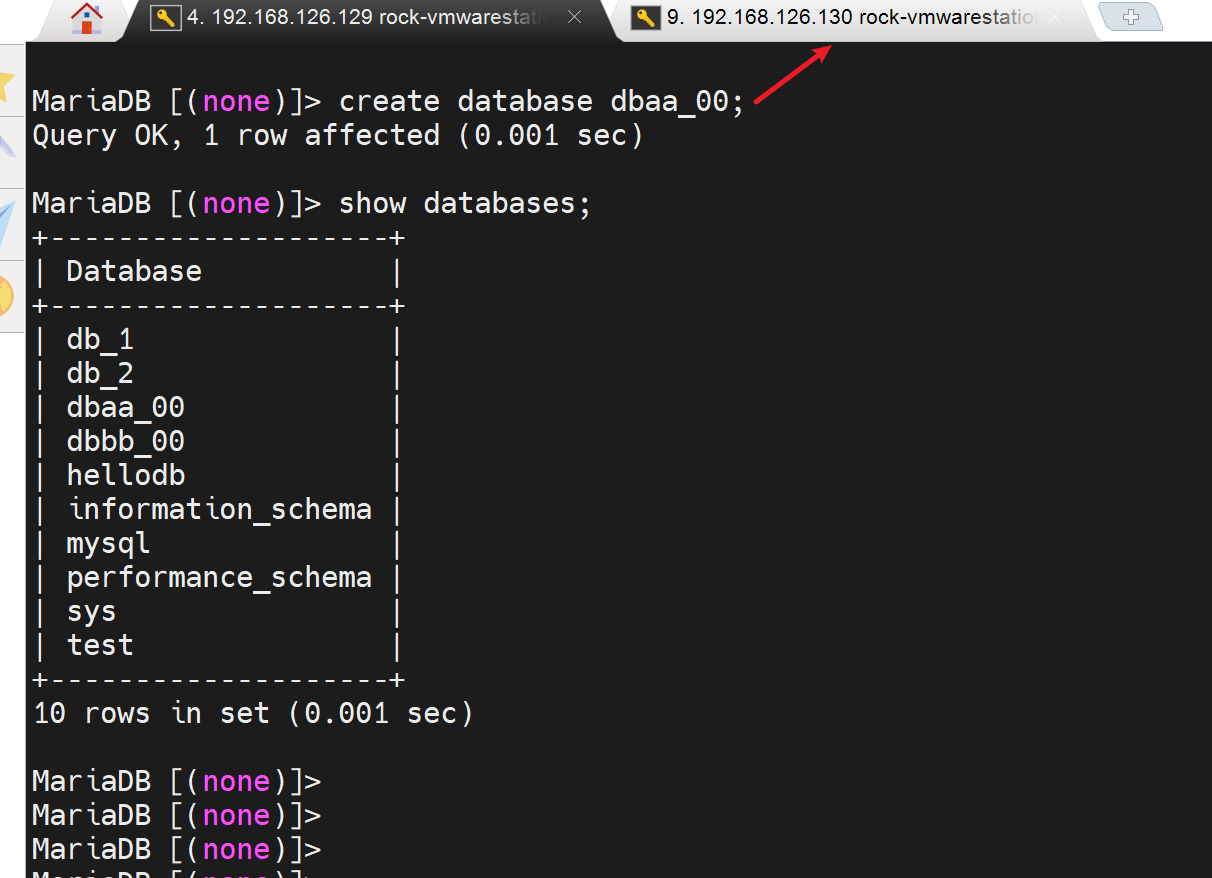
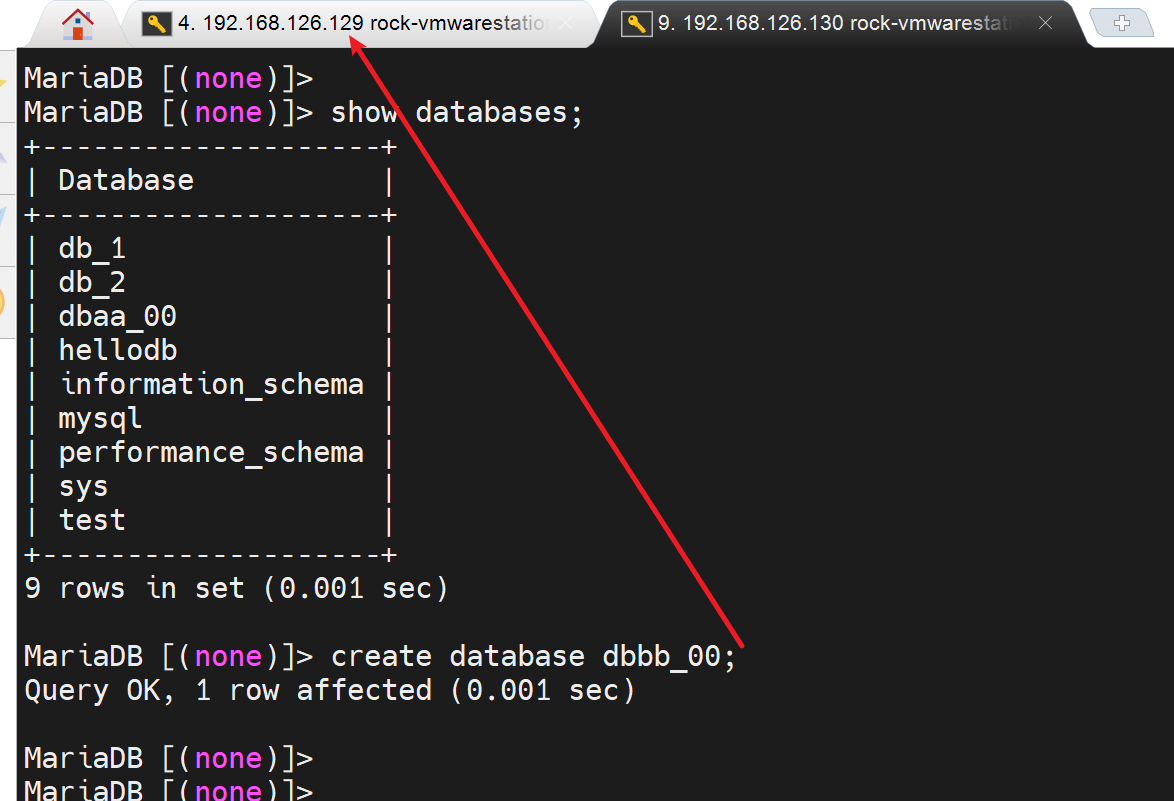
mysql > use hellodb
mysql > create table test (id int auto_increment primary key, name char(10));
mysql > desc test;

此时B上也有了
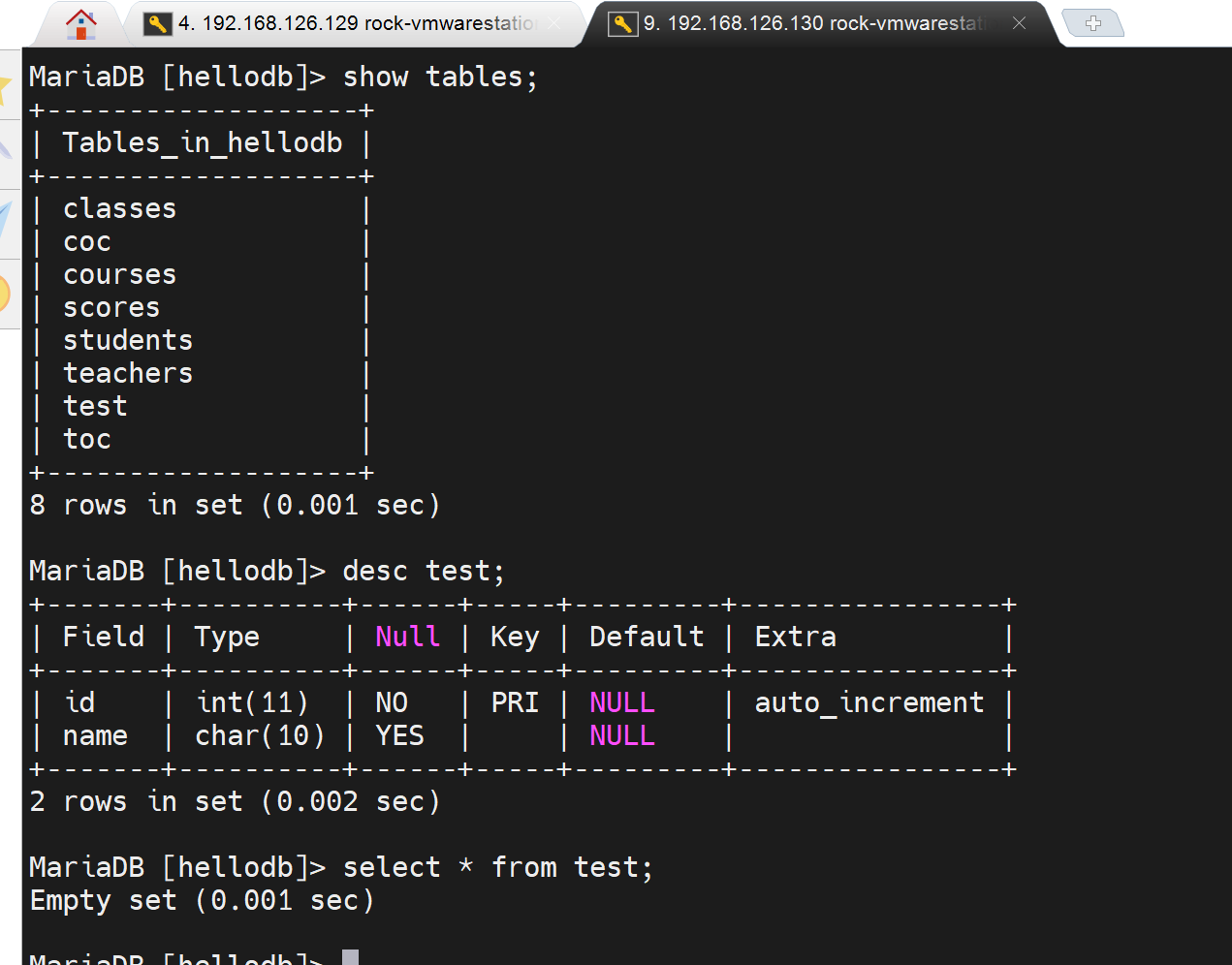
通过xshel的批量下发cli,给A和B同事敲入insert
insert test (name) values ('wang');
这样就同时键入了sql insert
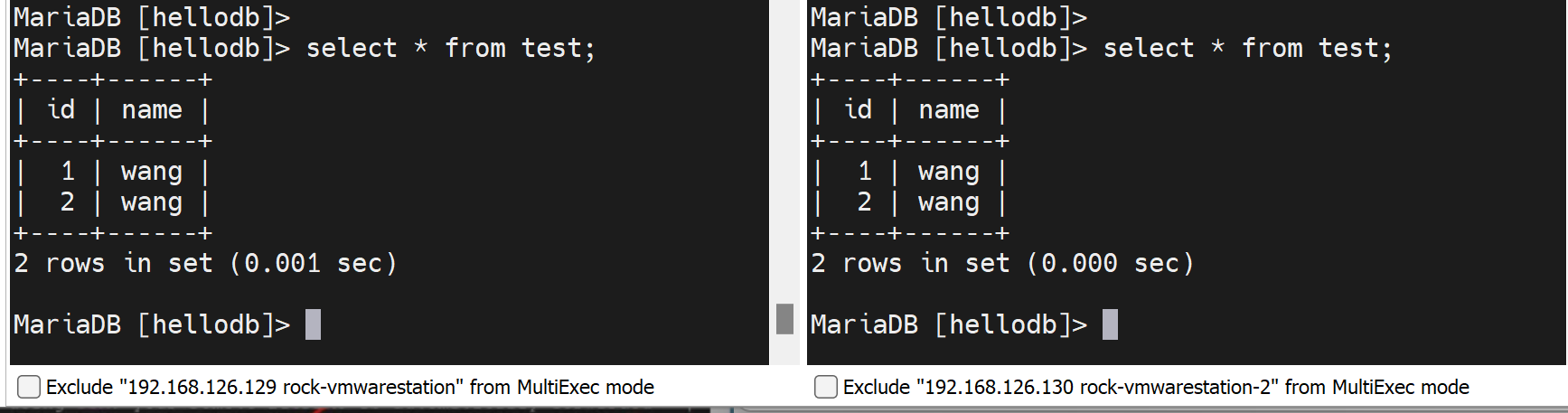
不冲突,左边A是1,右边B插入的是2偶数,奇偶错开来的。
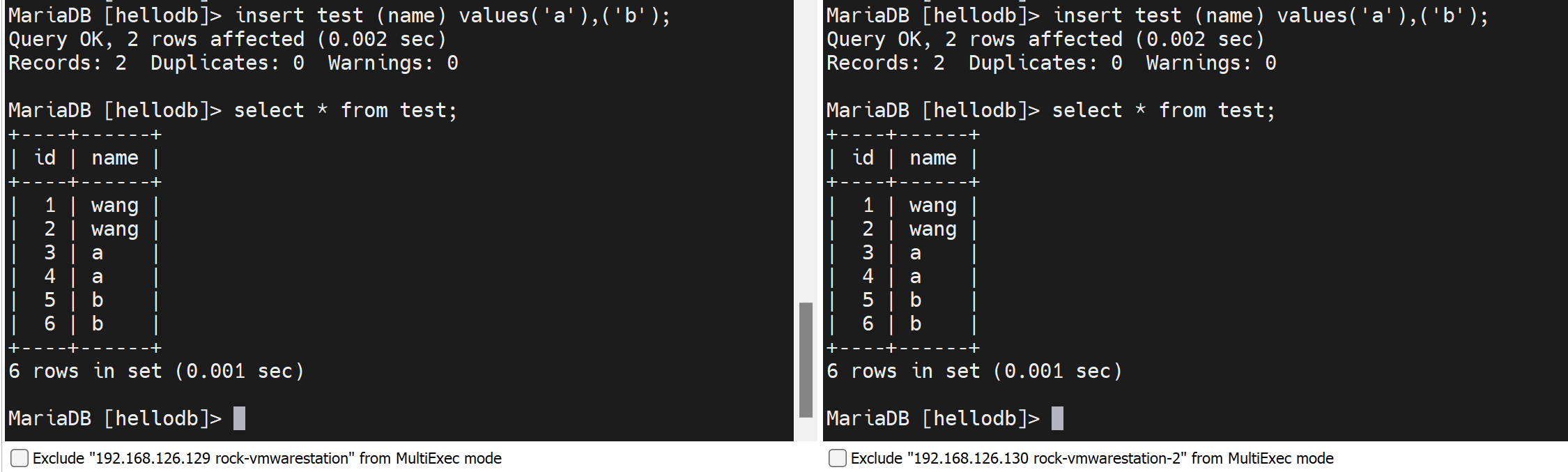
还是一样左边1 3 5 ,右边2 4 6
创建表,理应冲突
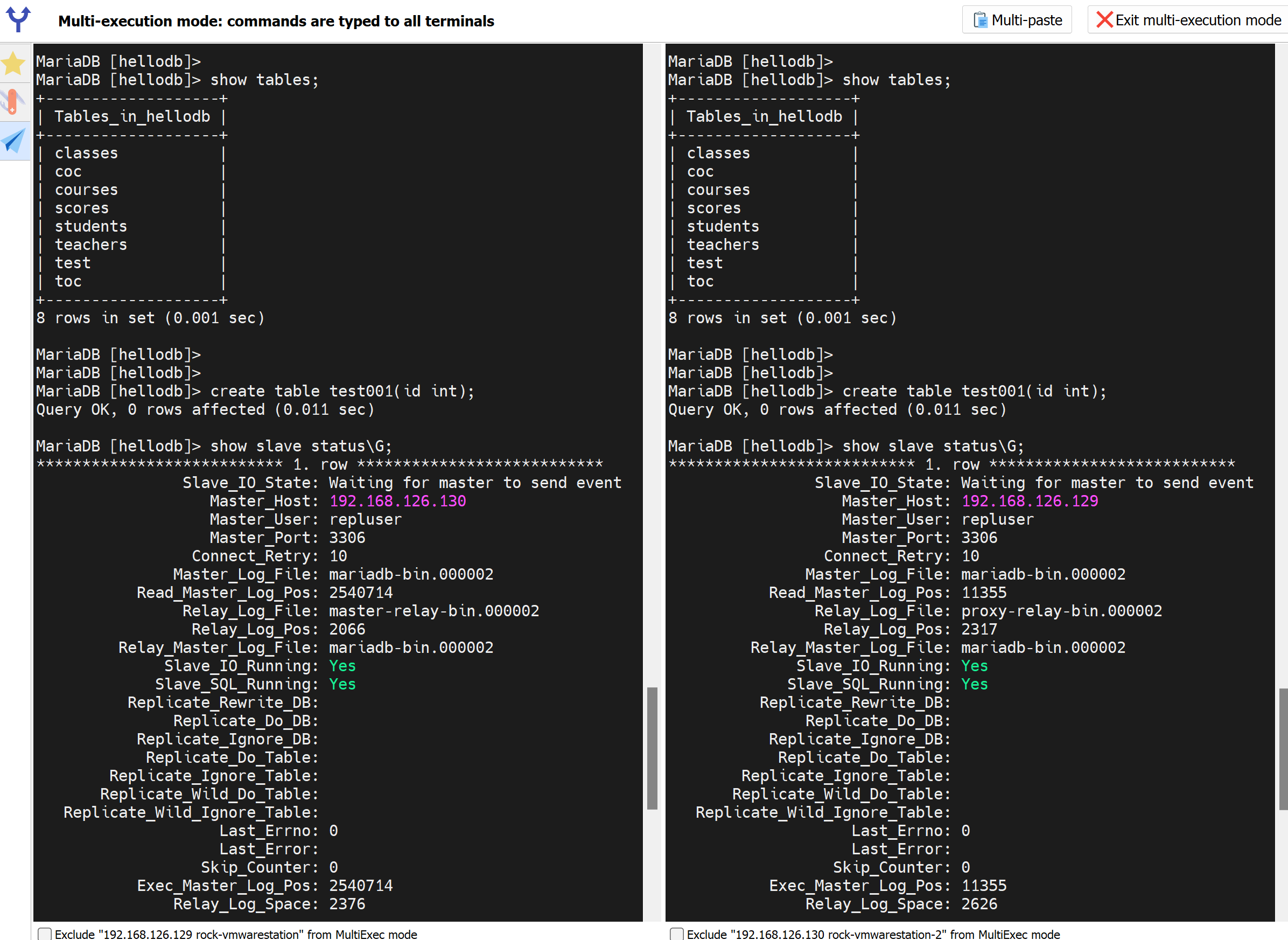
但是高版本确实不会了,不知道怎么实现的。
我理解一定是有一个被回退了,内部忽略了,去找找相关资料。

中文会翻译掉了一写 重要的 专业词汇,就是人家起的名字吧,通过英文去问得到英文的回答
通过GPT找到了关键信息,然后通过关键信息去官网再找
https://mariadb.com/kb/en/about-galera-replication/

然后看看默认的值就是1👇

确认了👆
还有这一篇也写的不错
https://galeracluster.com/library/documentation/certification-based-replication.html
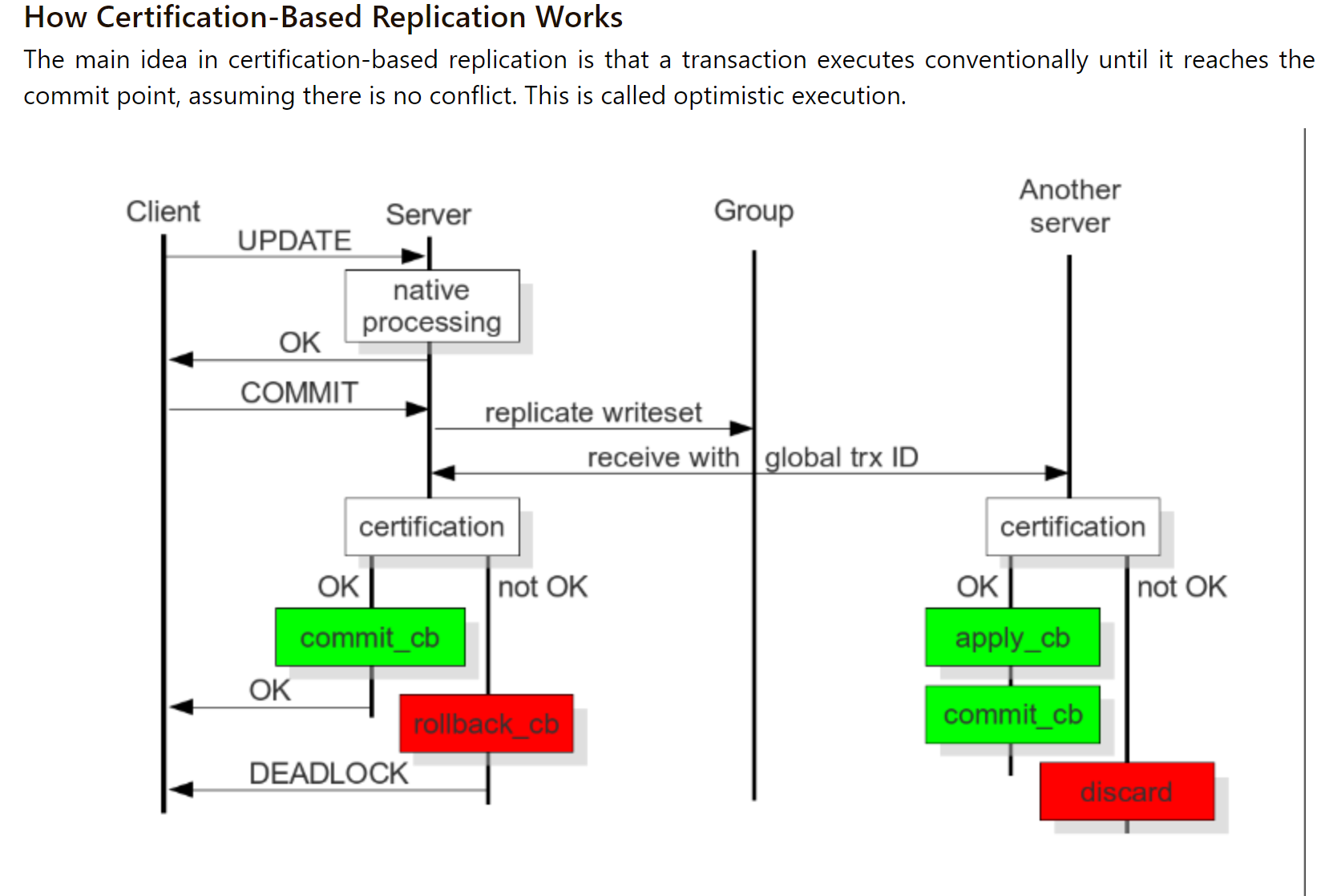
虽然主主现在高版本有write set replication API辅助,但是生产中是不可能直接用的,会在主主前面加上调度器的,只往一个主节点上写数据,另一个虽然是主,本质上是做查询操作的,这样的主主好处就是当主节点挂了,另一台可以快速替代,不用像以前从那样还要费劲地操作一下才能提升为主。
如果是三个环形指主,如果是4个环形指主
都是串起来,头尾相连,本质上和主主一样地,无非是从2个串,变成了3个,4个环型罢了。

上图👆是主主地间隔,如果是3个串起来,
将auto_increment_increment=3就行了;就是1 4 7 ,2 5 8,3 6 9。
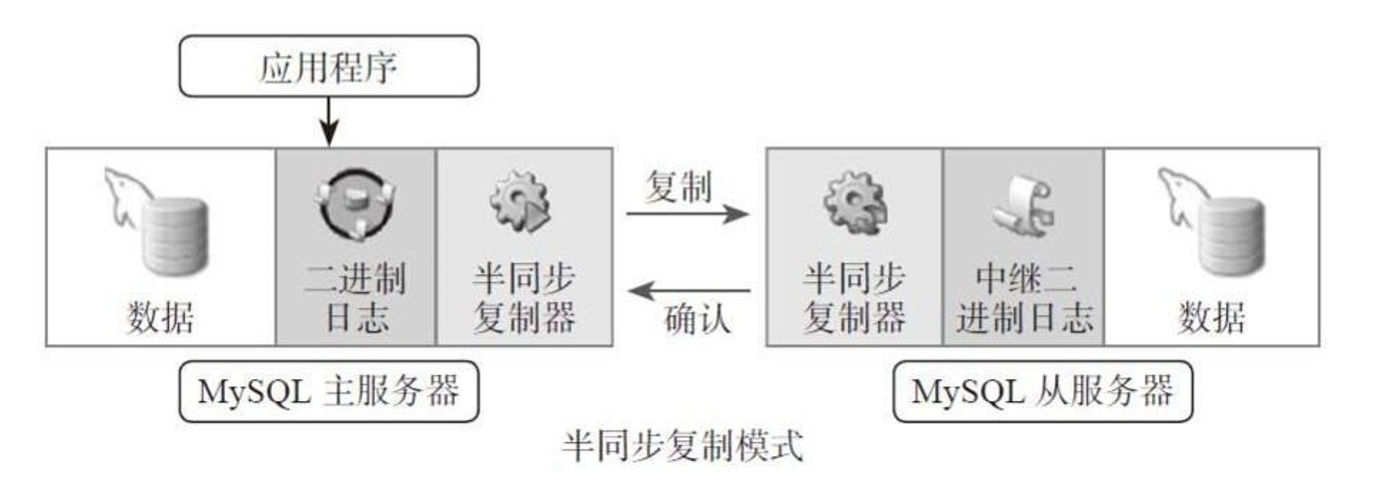
同步虽好,异步落地,半同步为优

同步和异步前面讲过了,这里补充一下半同步,所谓半同步就是,只要众多从节点中,有一个回复了(下图中第4步),master就回复proxy,进而回给用户。相当于一次update在用户那边就完成了,不必像同步那样等太久。
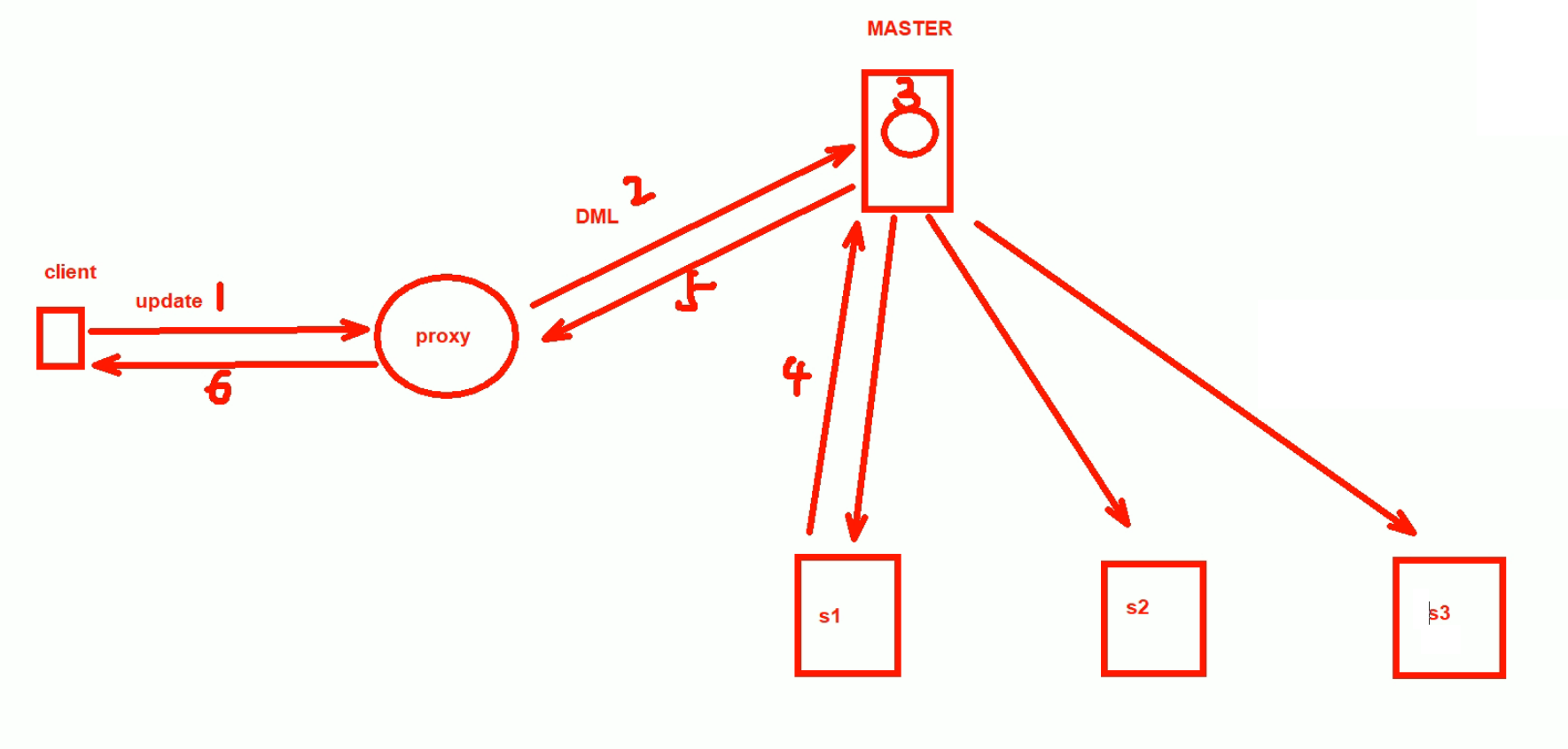
默认是不支持半同步的,需要安装插件,好像确实数据库里也有很多插件。
下面开始实验
1、拓扑:master--带 两个 slave,一个slave断开网络模拟未同步,然后master也能完成记一次updata交互。
2、开始
master上
--------
vim /etc/my.cnf
serer-id=1
log-bin
wr
systemctl restart mariadb
mysql > show master logs; # 记一下binlog的编号和pos复制到下面CHANGE MASTER cli里
mysql > grant replication slave on *.* to repluser@'192.168.126.%' identified by 'cisco';
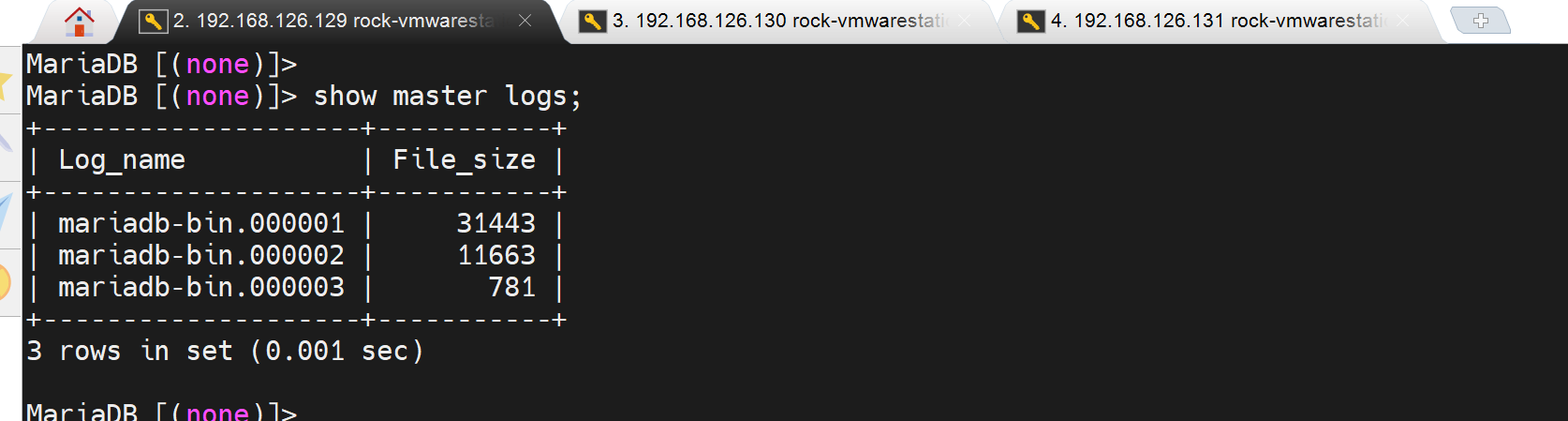
左一 master; 中间 slave1; 右一 slave2;
slave1上
---------
vim /etc/my.cnf
server-id=2
wr
systemctl restrat mariadb
msyqll > CHANGE MASTER TO
MASTER_HOST='192.168.126.129',
MASTER_USER='repluser',
MASTER_PASSWORD='cisco',
MASTER_PORT=3306,
MASTER_CONNECT_RETRY=10,
MASTER_LOG_FILE='mariadb-bin.000003', MASTER_LOG_POS=781;
遇到一个报错
重启服务后,就可以了,我日,肯定有什么残留导致直接 授权的方式无法创建用户了。
好像有时候flush一下可以,有时候flush 也不行,下图是OK的截图
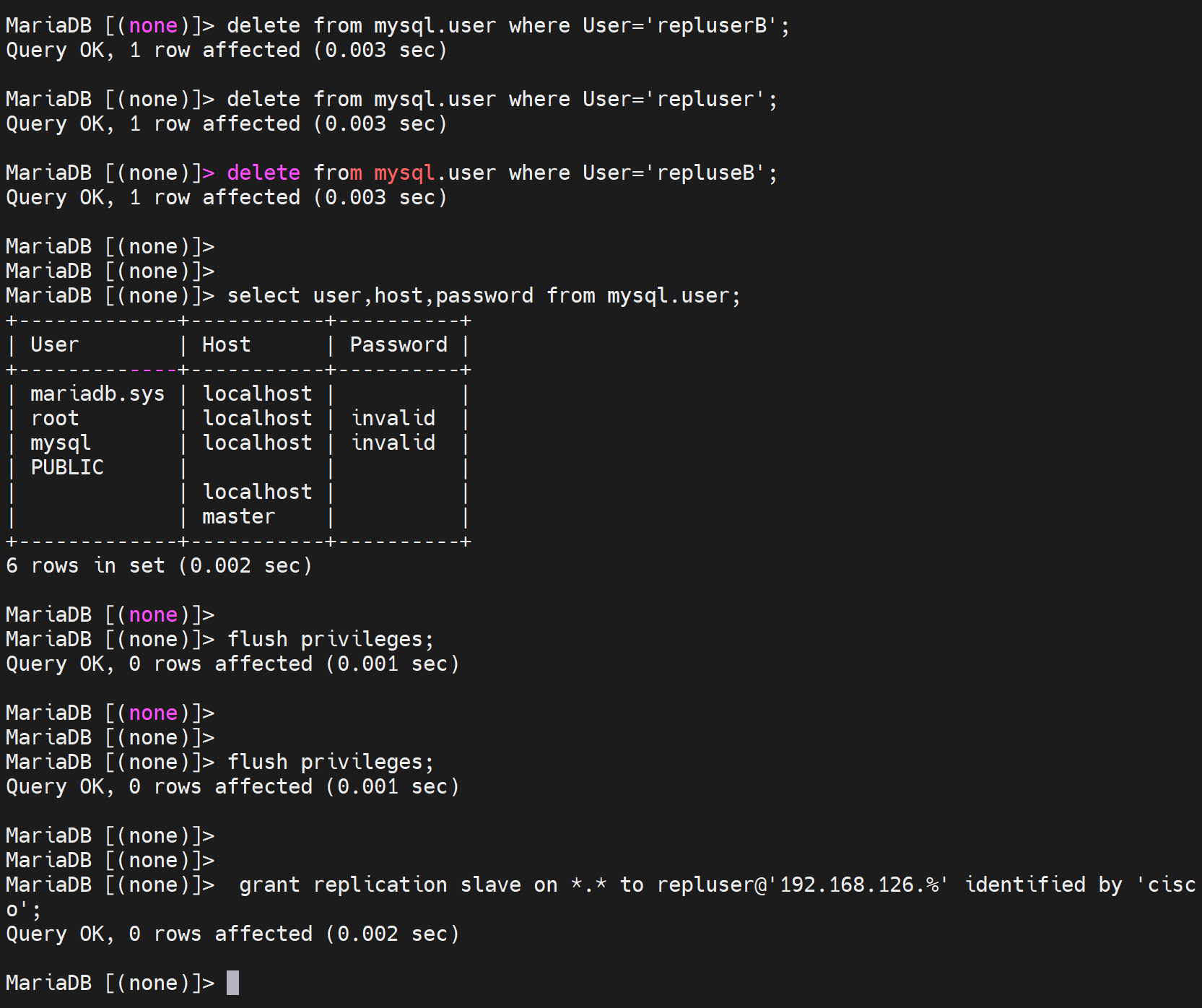
遇到报错,stop slave还不行,还必须reset!
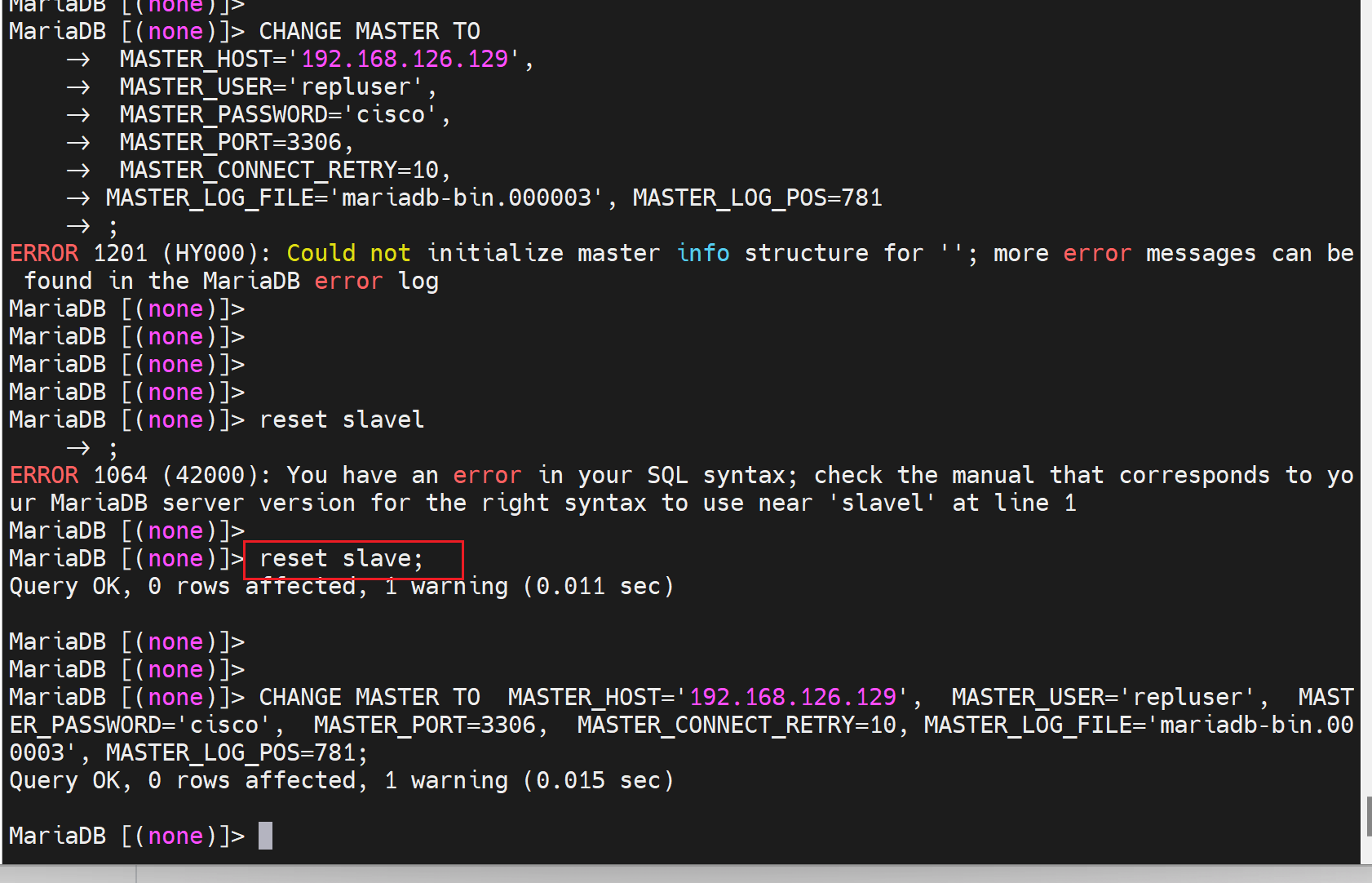
slave2一样要reset一下,因为之前有做了其他实验
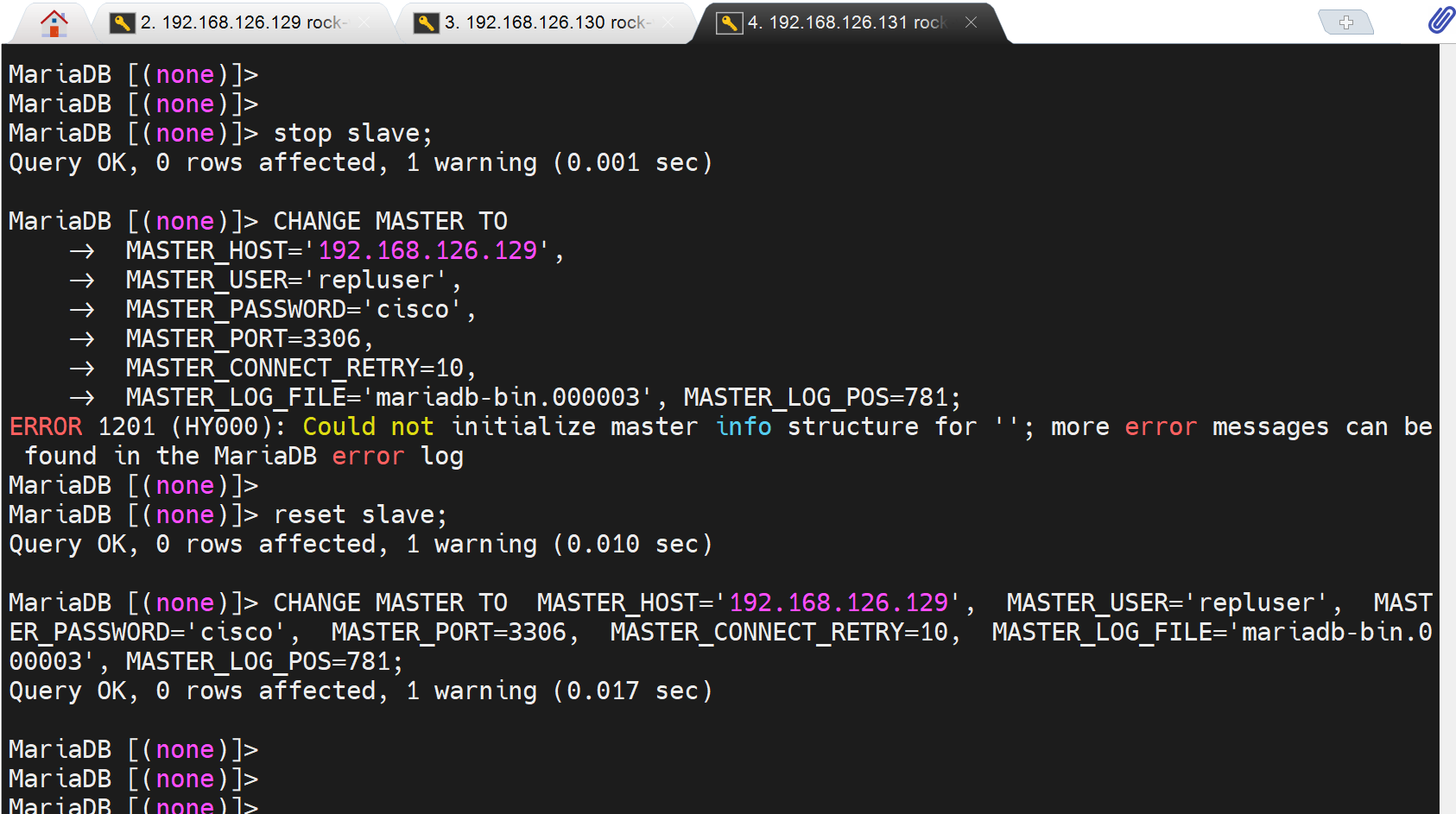
然后两台slave就都好啦👇
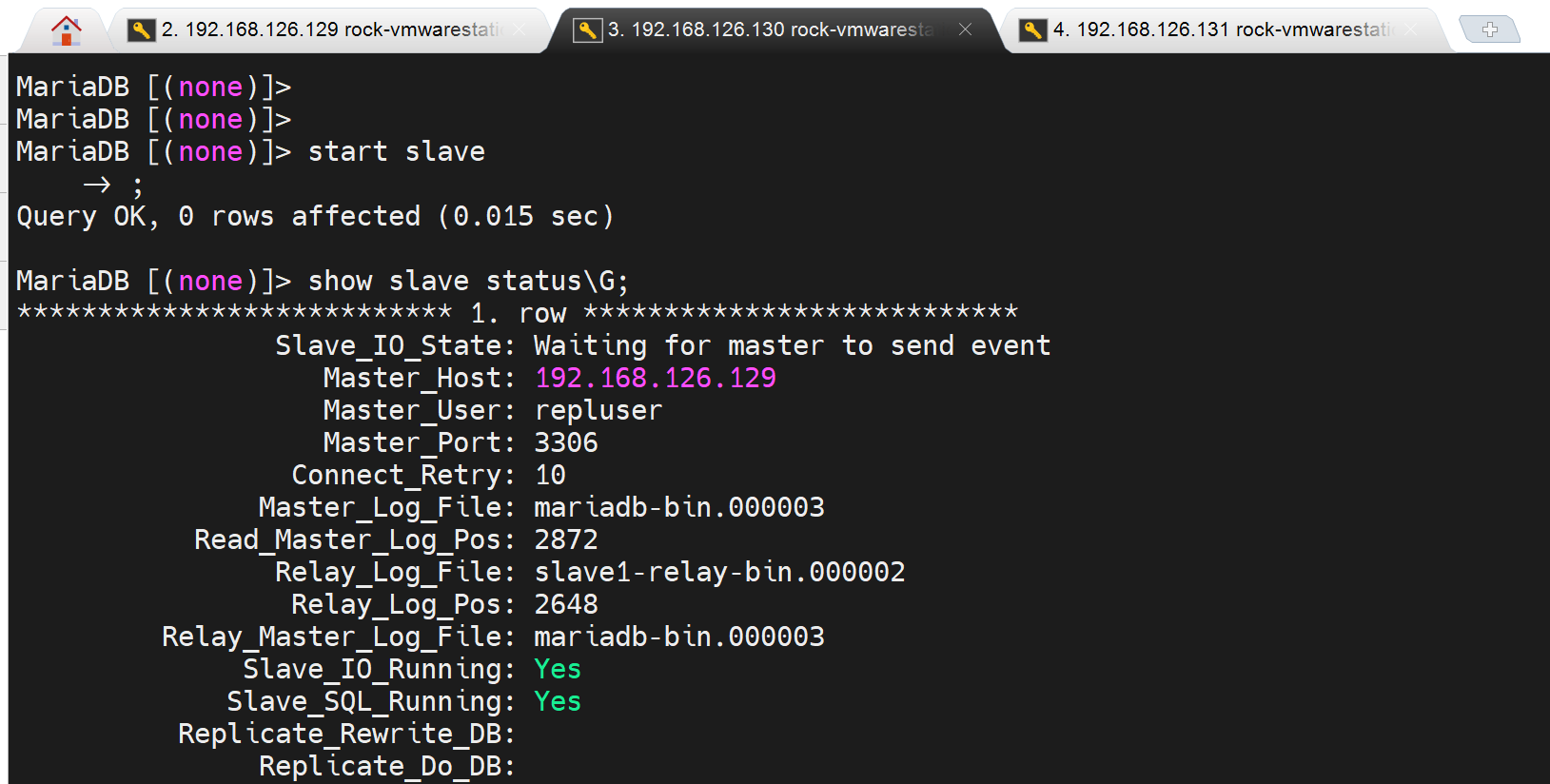
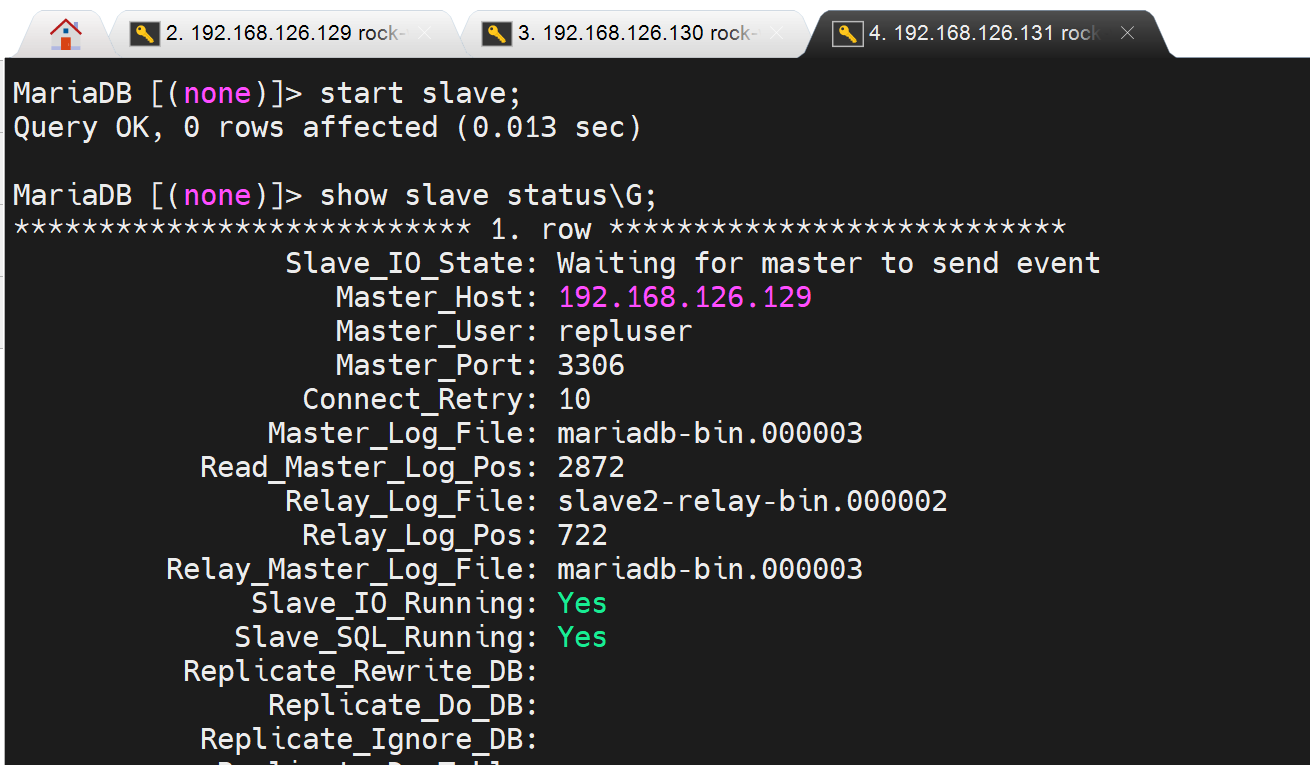
下面做半同步啦,安装插件:rpl_semi_sync_master
高版本都是wsrep-write set replication这种API了。

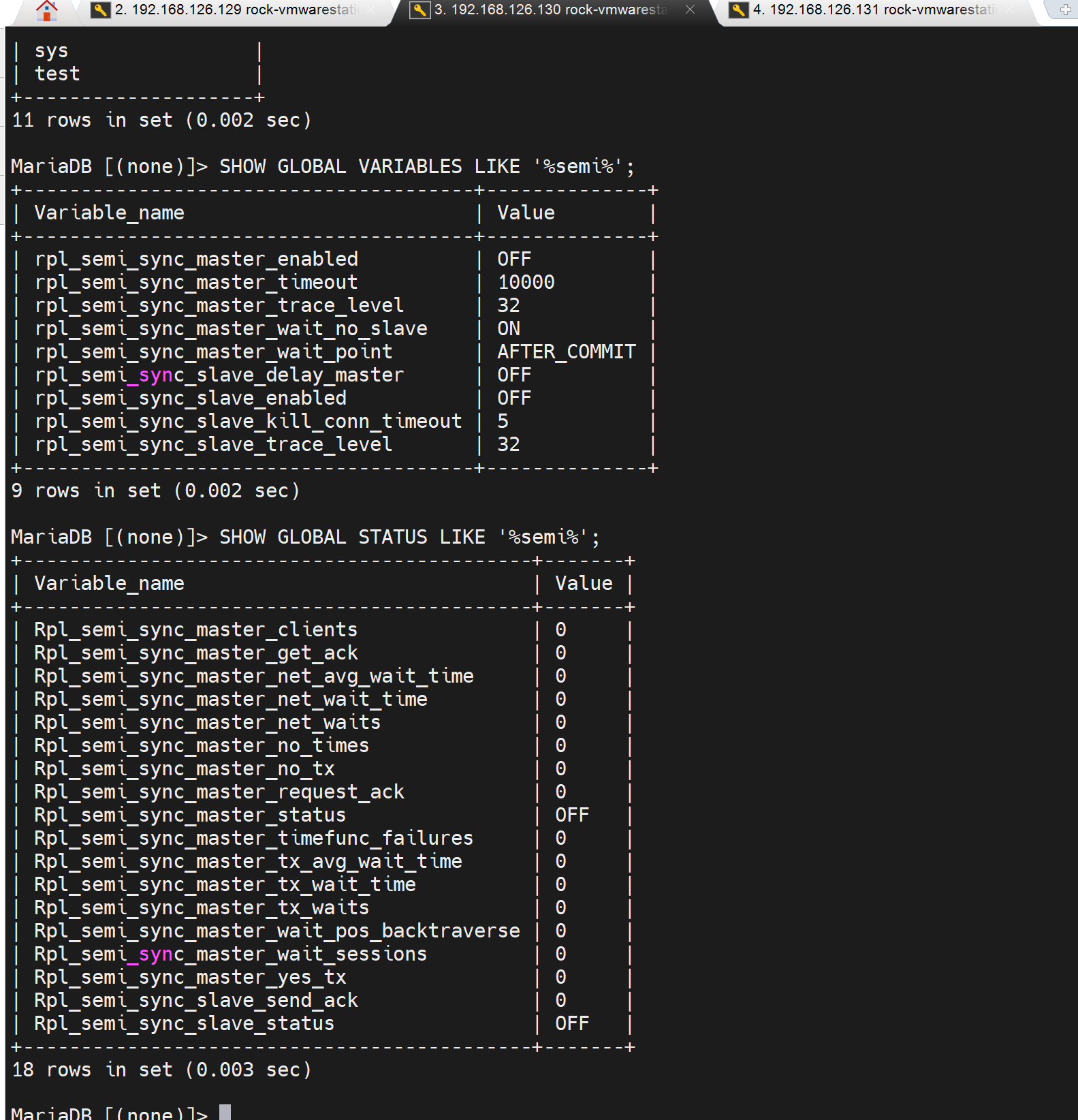
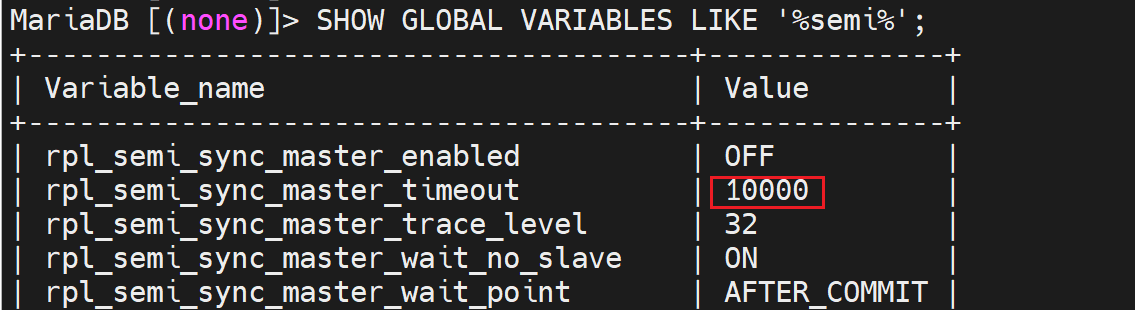
不管,硬上,直接看变量SHOW GLOBAL VARIABLES LIKE '%semi%';有唉~我日
估计这个插件名称变了,被集成到别的插件里了,可能就是wsrep这个
然后看插件的方法
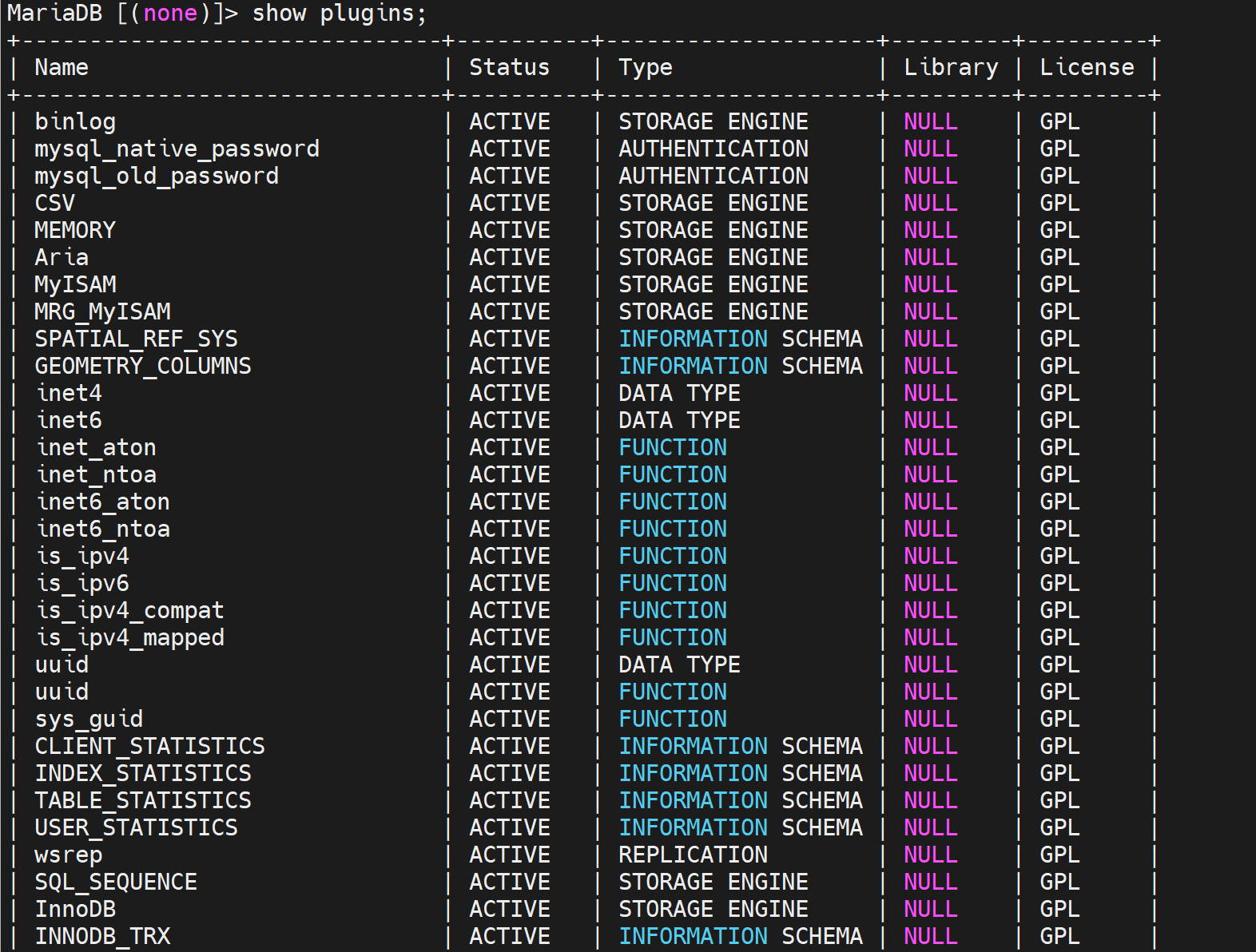
老版本视频截图
master上安装master字眼的插件
👆安装后,👇看看
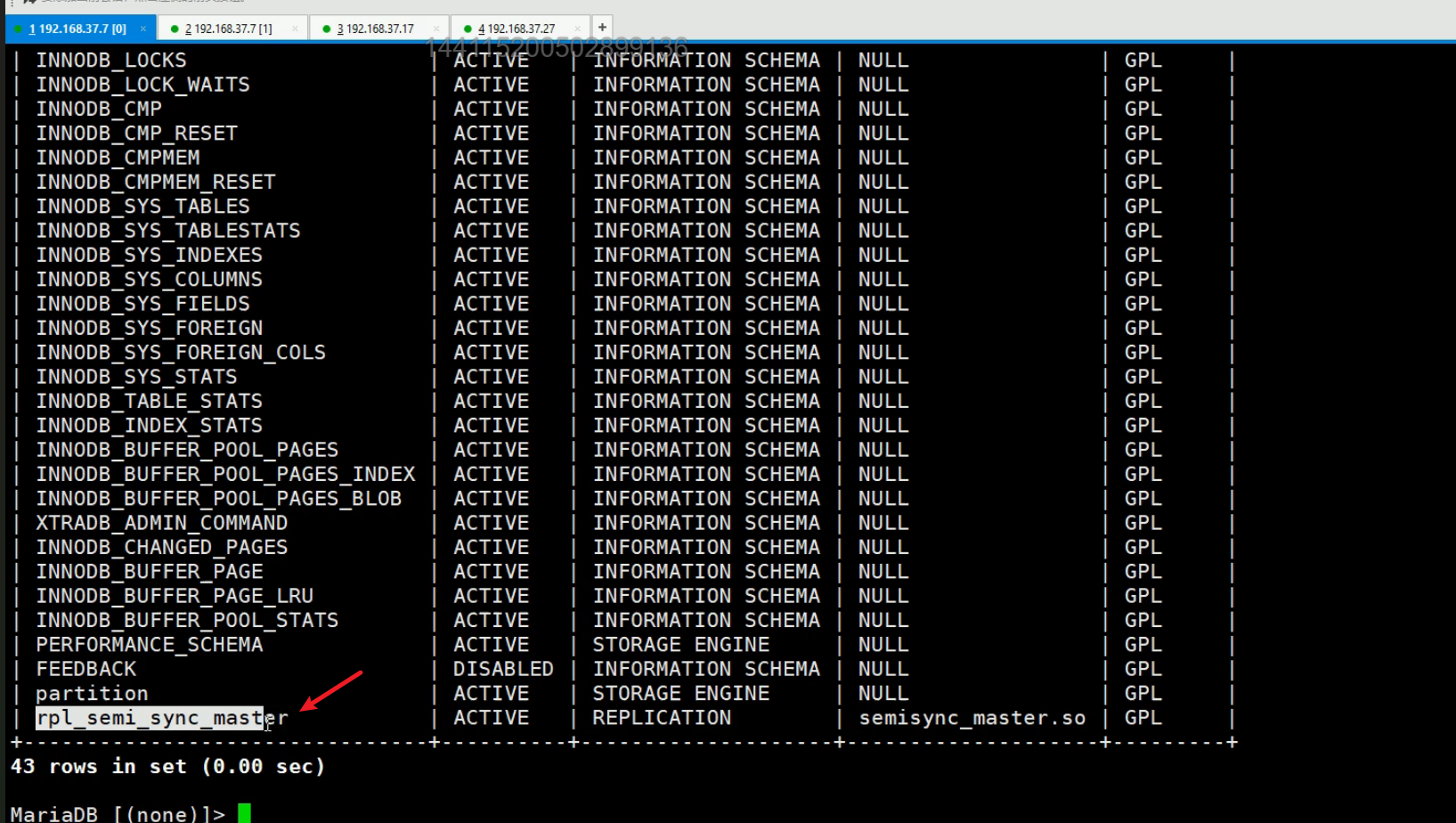
看到这我猜这个rpl_semi_sync_master就是被高版本里的👇这个取代了

都是REPLICATION
先不管wsrep这个事,先看老版本的操作流程
插件rpl_semi_sync_master有了,但是还需要启用,通过变量看看状态👇。
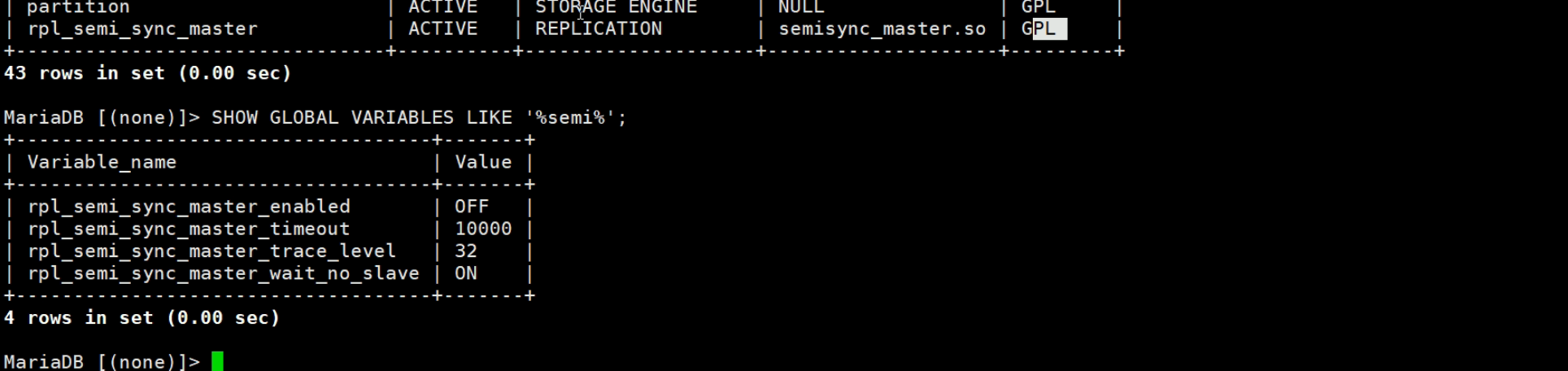
这个_enabled是启用与否;_timeout 10000是万一主--从同步从迟迟没有回应,主也就等这么久10000是10s,就会往client/proxy那边回应了。
启用一下-在maser上的半同步
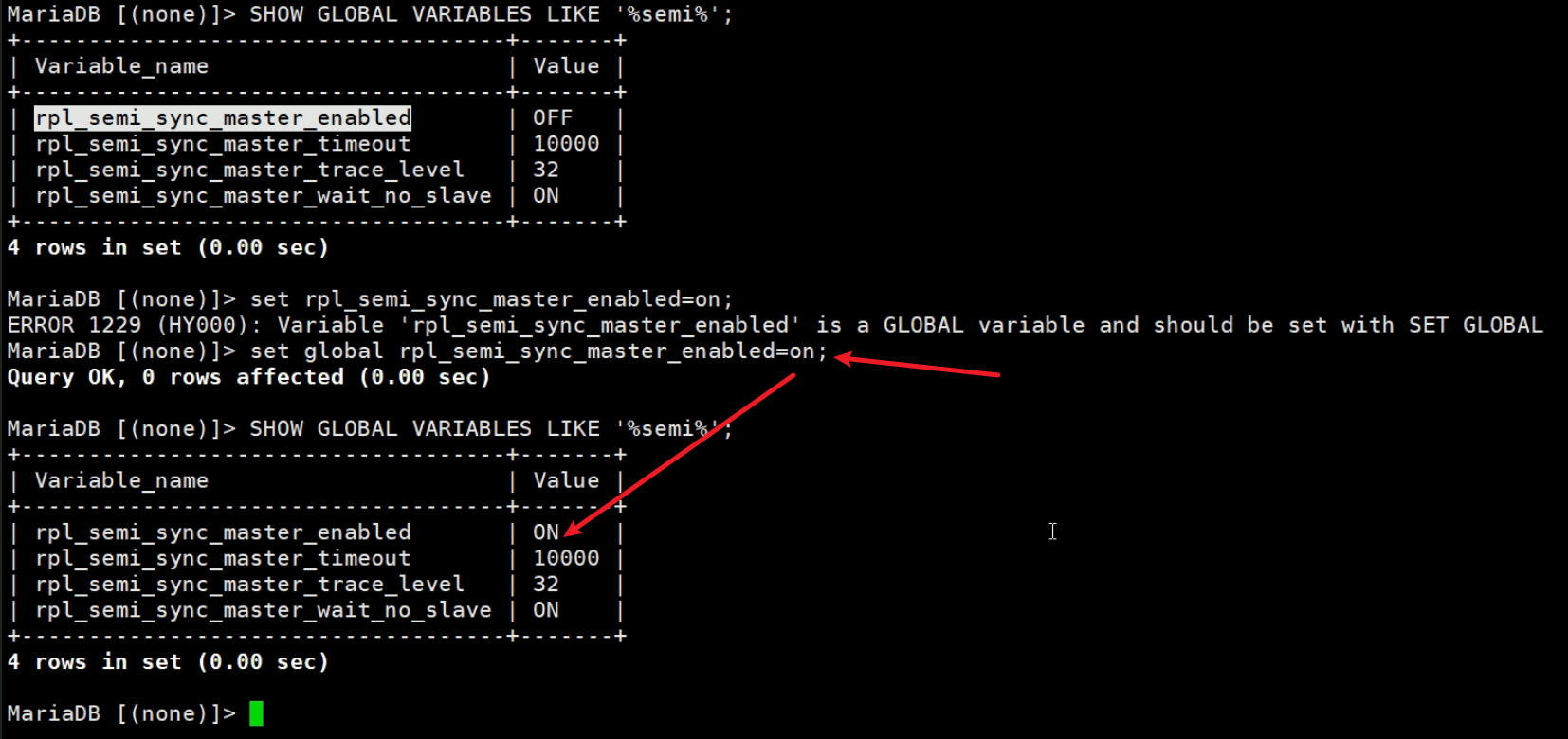
然后看看状态变量
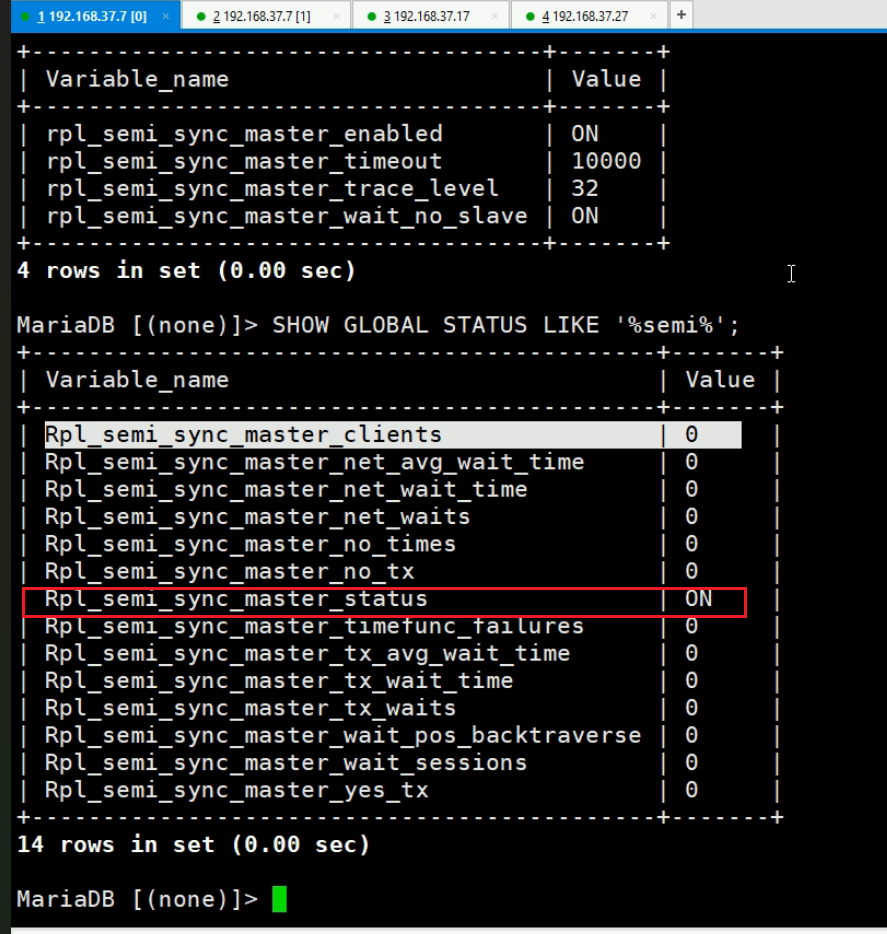
可见👆ON了,然后client那边还没有使用半同步的插件,也没有开启,所以client是0。
回到我的实验,我用的高版本的mariadb,我试试蒙一下,我估计插件不用安装
直接set一下长得像的变量on试试👇
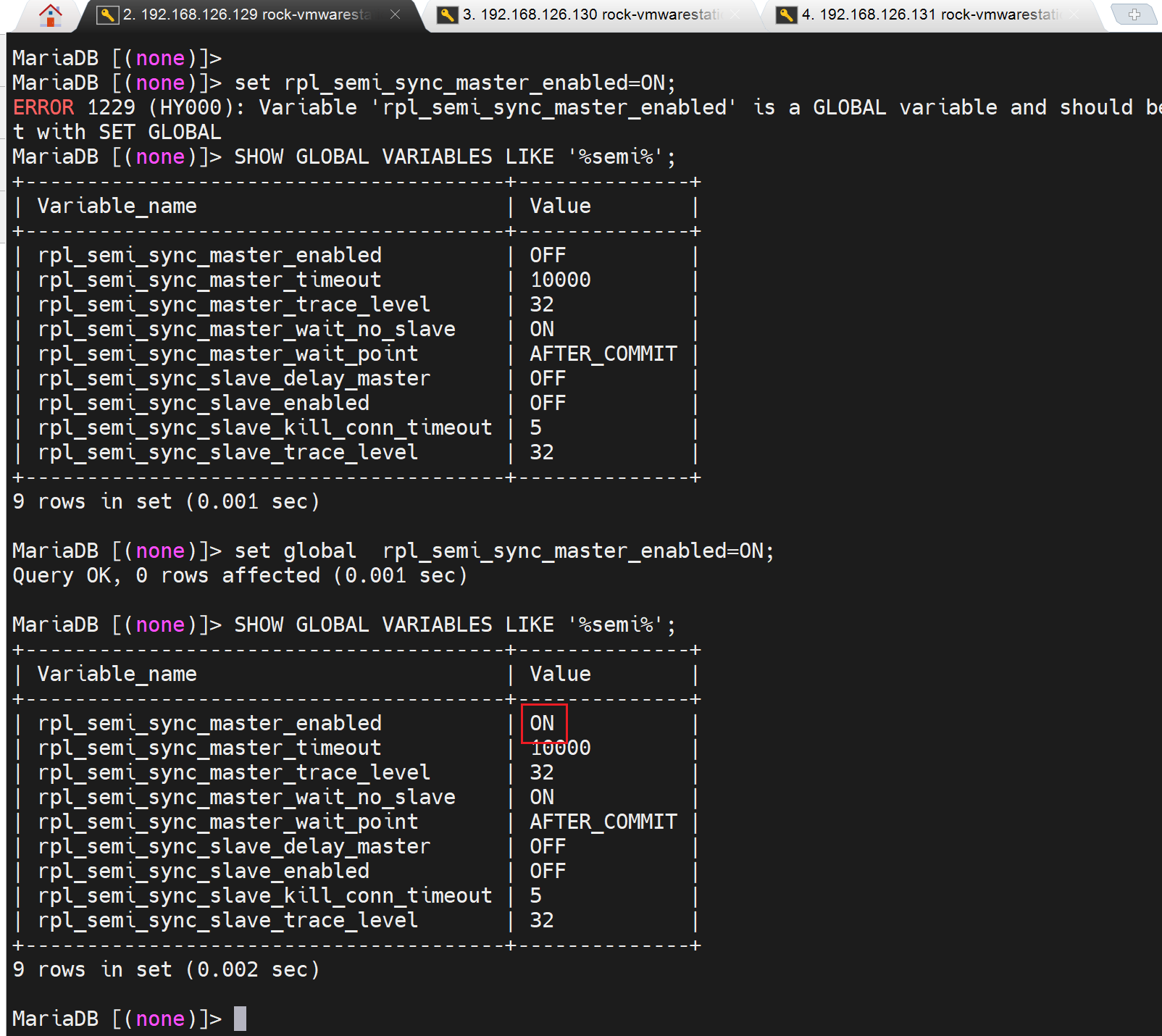
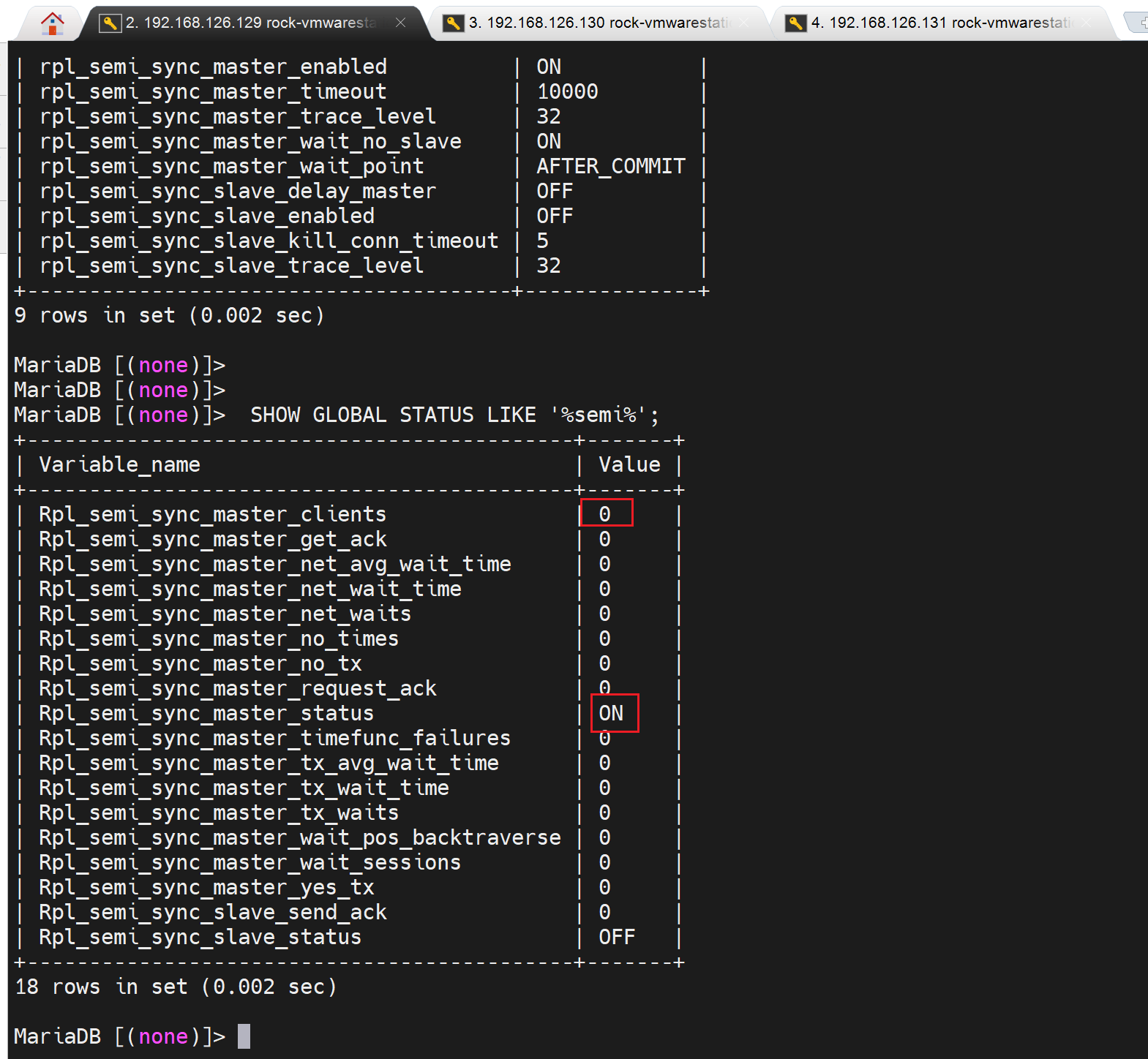
果然,新版本无需安装什么半同步插件了,至于这些个变量的功能来源于哪个插件,或者是不是 被取代了,再说回头我去翻一翻一资料
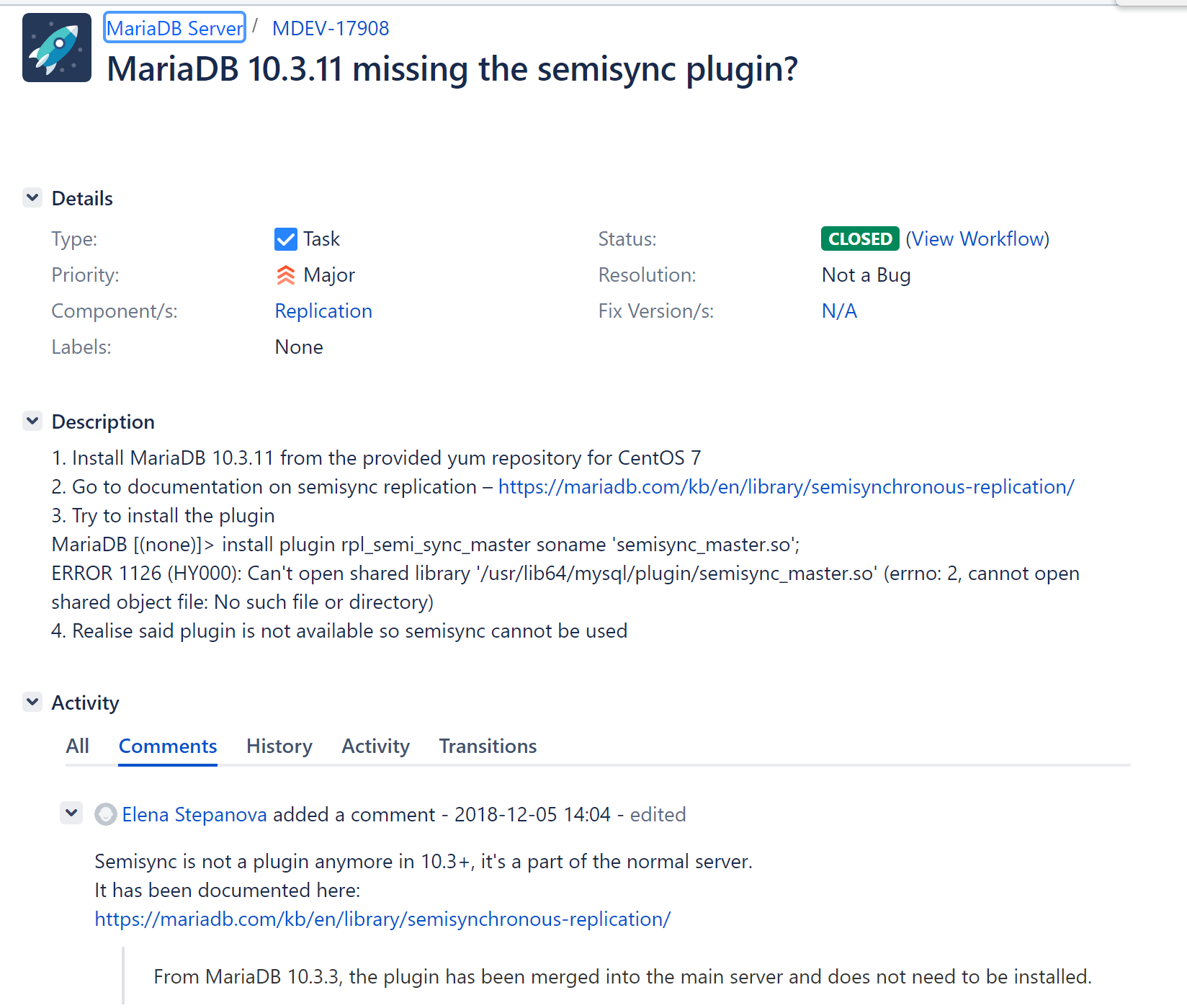
https://jira.mariadb.org/browse/MDEV-17908👆
官网上也说了
https://mariadb.com/kb/en/semisynchronous-replication/
好像也没将是集成到wsrep里,呵呵,不管了。
启用一下-在slave上半同步
老版本具体就是10.3.3之前

然后show plugins;看下👇

高版本就不用安装了,默认就有半同步功能
不管是老还是新版本,启用都是要启用的,启用的变量和查看状态的变量都是一样的。
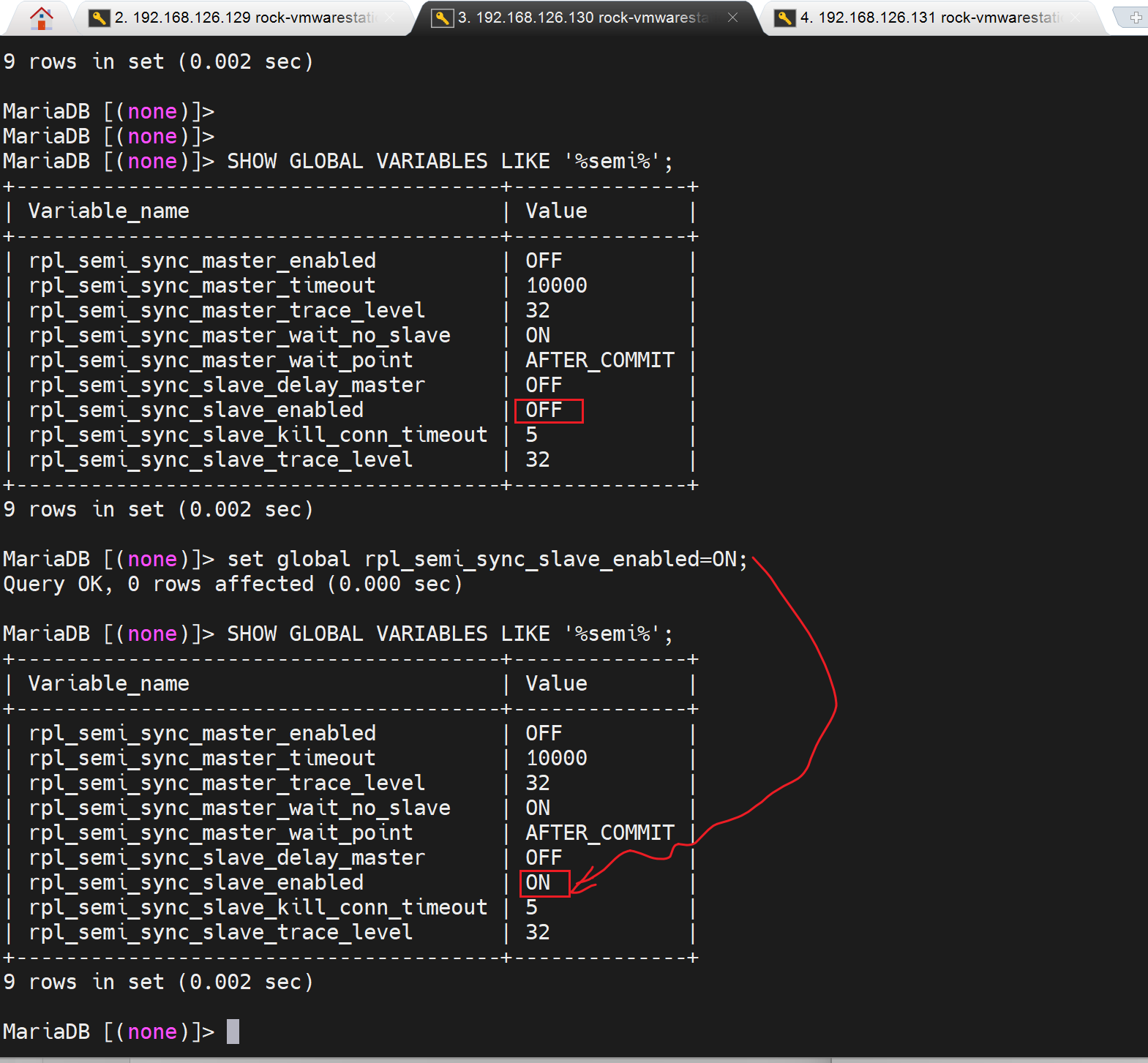
slave2一样启用一下
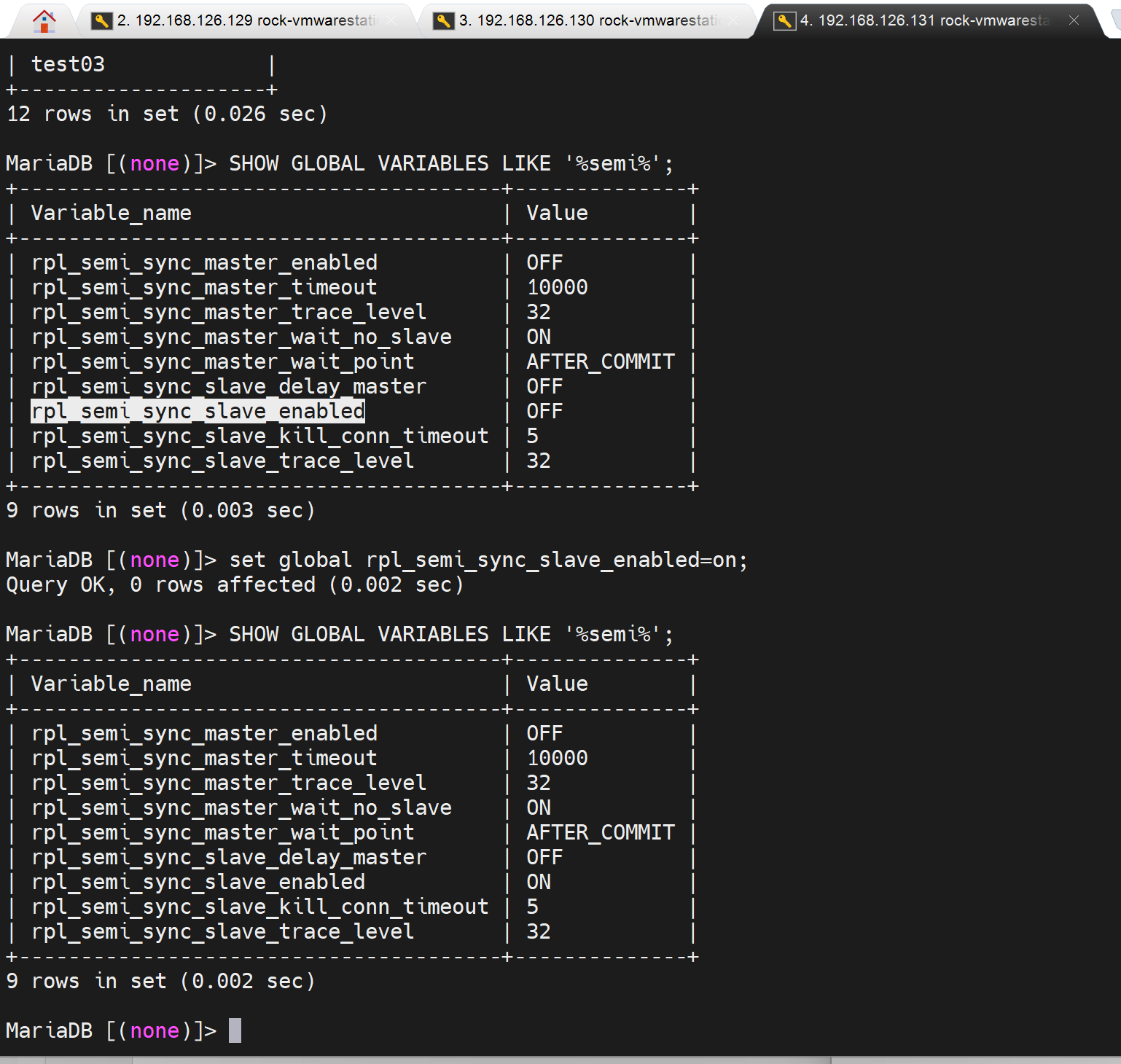
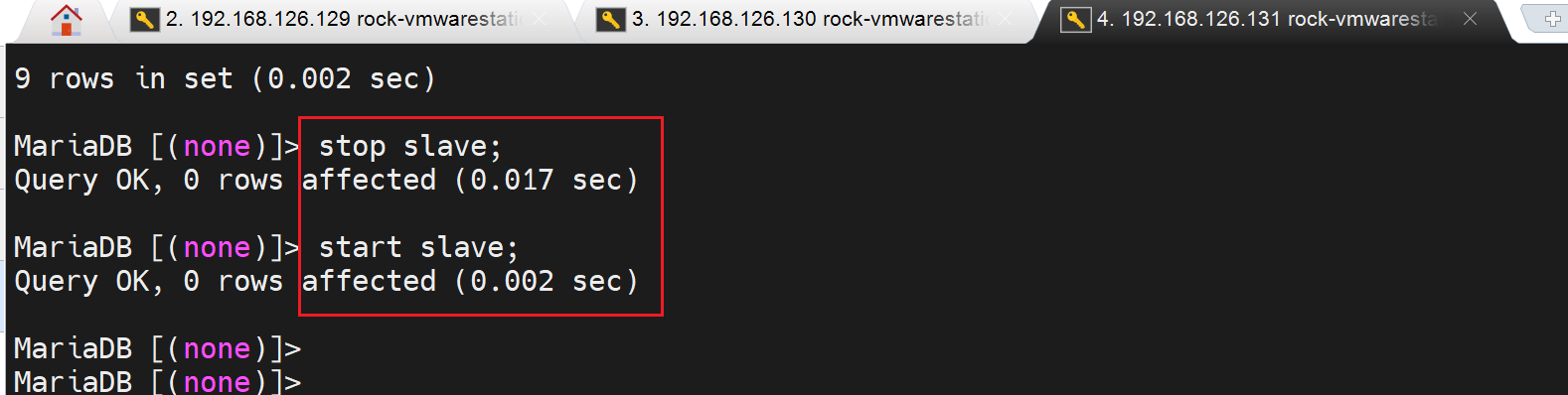
最后还需要重启slave的线程,stop slave,start slave
记住!不是reset salve。我日你奶,想要reset 还得先stop,不过reset也不会真的清空就是了,只是重新设置的时候有时候需要reset一下。
开始测试同步机制
1、当前状态是同步OK

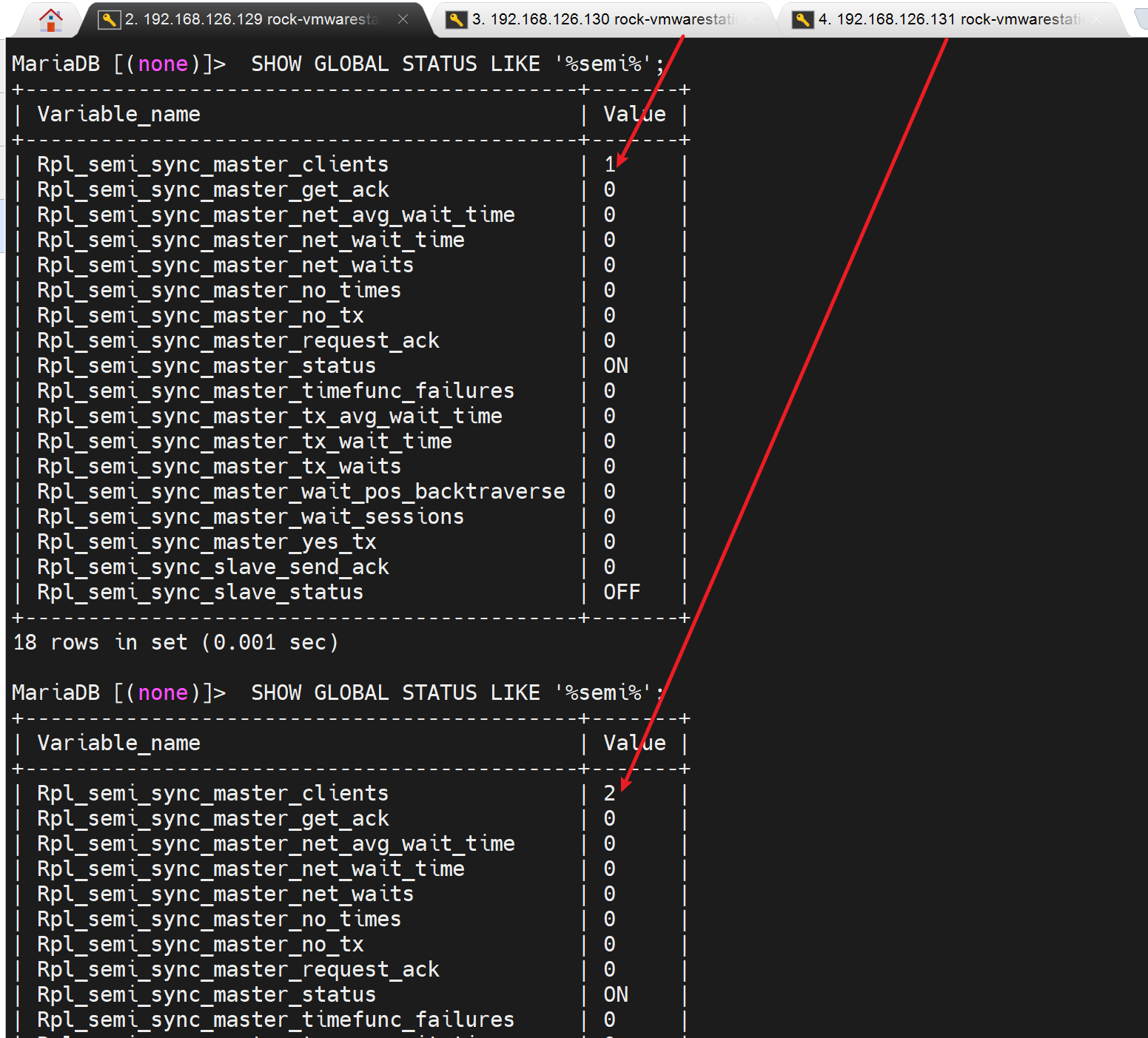
2、然后半同步不是已经配置且master上认到2个client了吗,所以将两个slave都停服,这样就一个同步都不会发生,理论上master就遇到sql写入,就会卡住,就不会回应cliet/proxy了。但是也不会永久卡在那,因为有超时时间10s
测试
slave2 停服
slave1 正常
master创库之类的写入正常

再继续将slave1停服
此时master 创库卡住,时间卡了10s

OK!
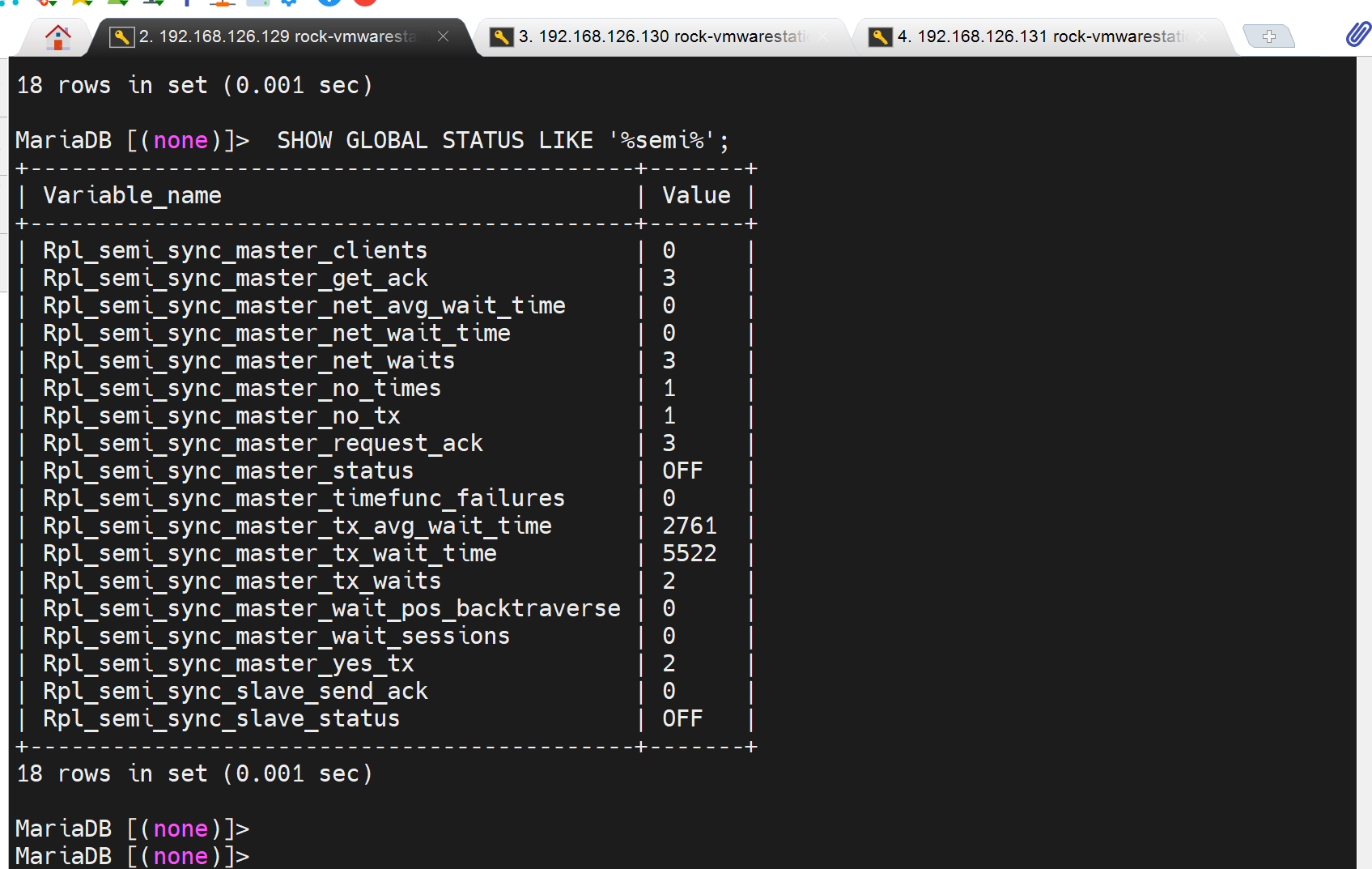
然后看看状态,就有变化了
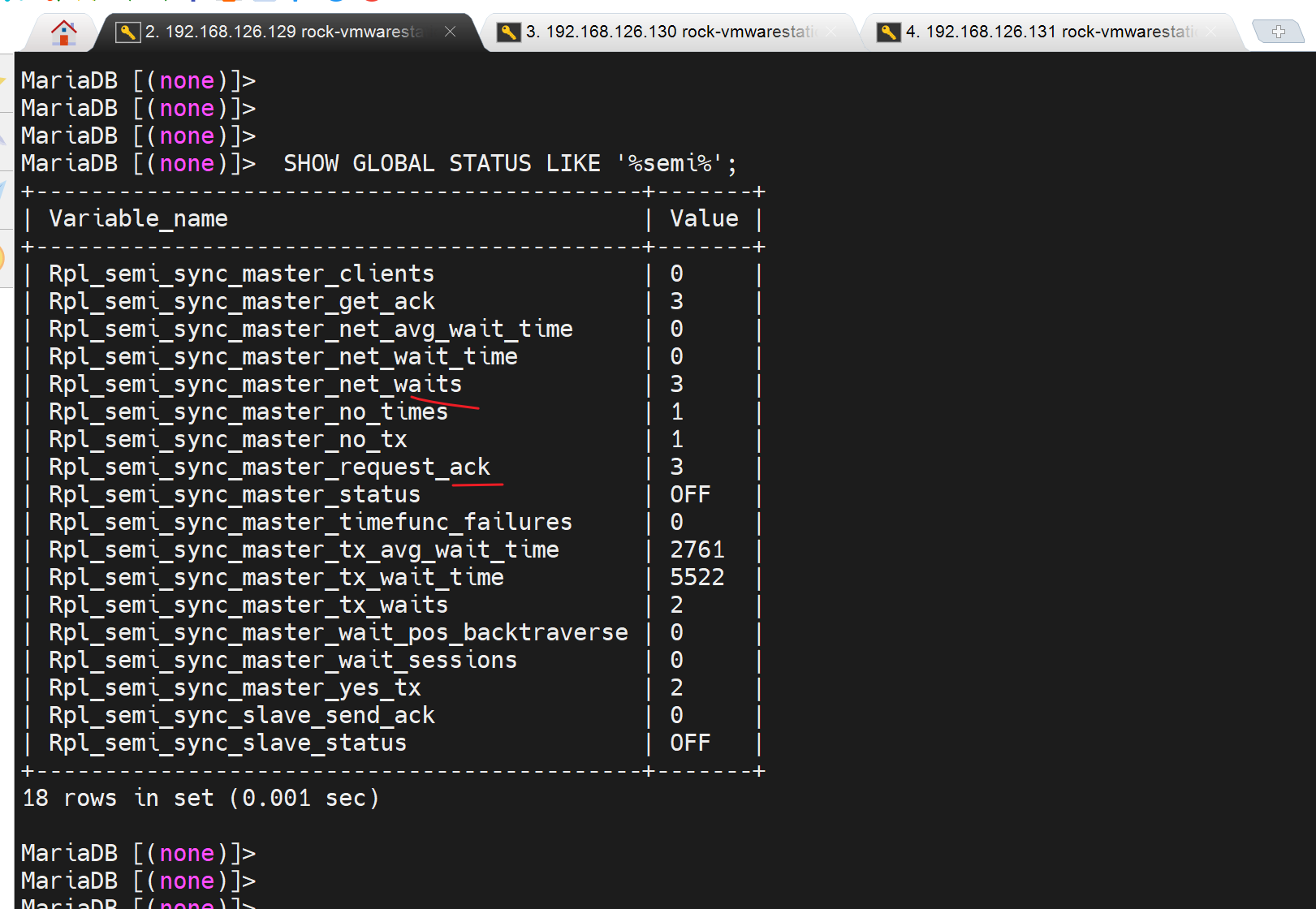
要知道原来是0都是基本上
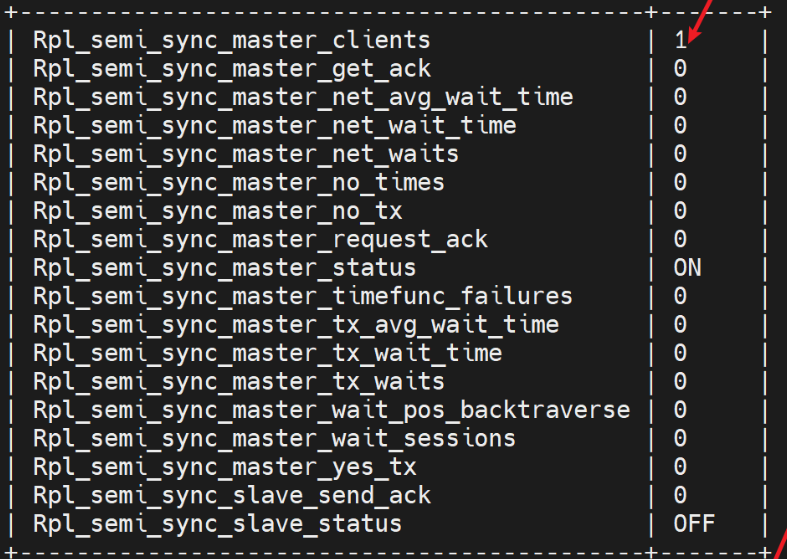
再一个slave只要启动mysql,也会自动同步过来,因为slave是默认 第一次手动,后面都是随服务启动而启动的。
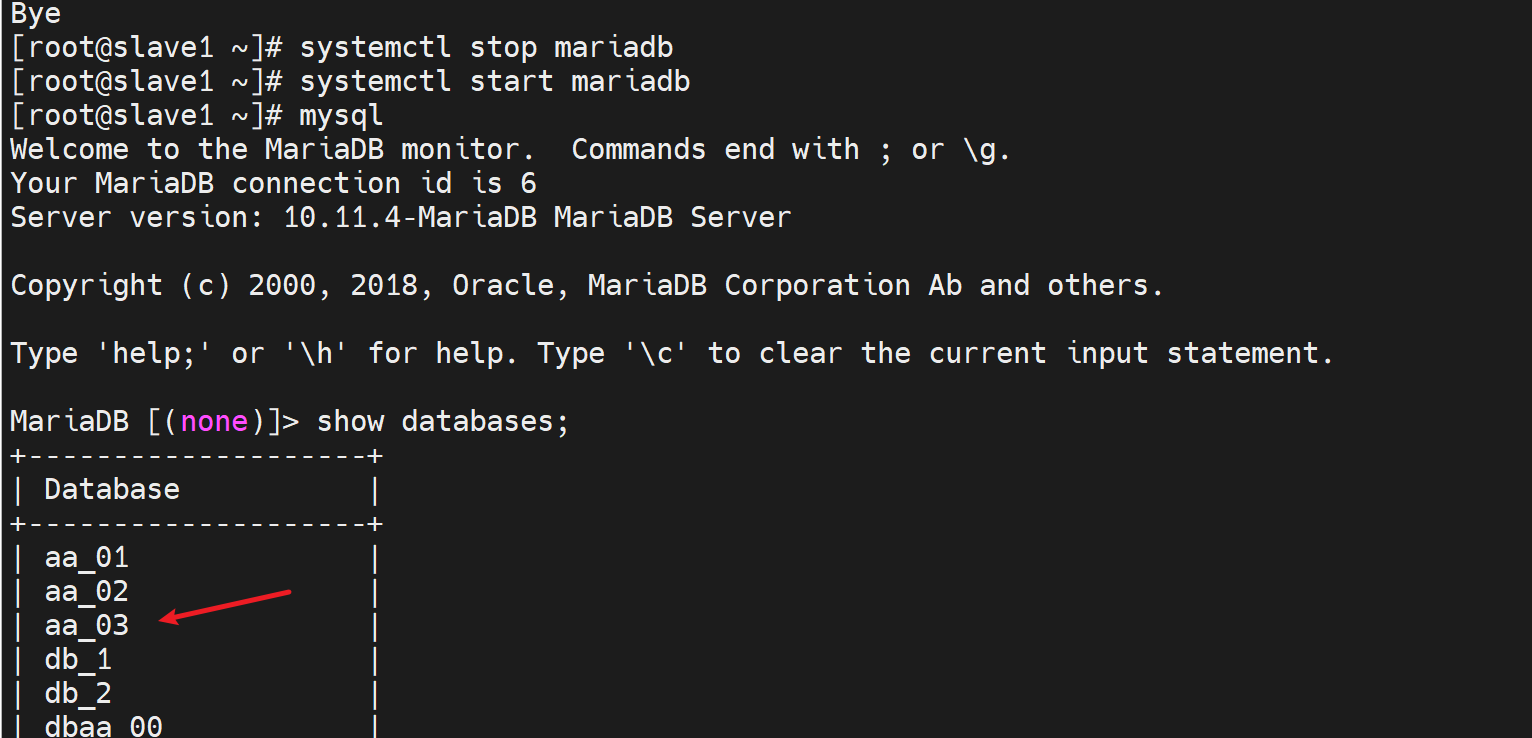
但是我发现半同步没有启动,client还是0
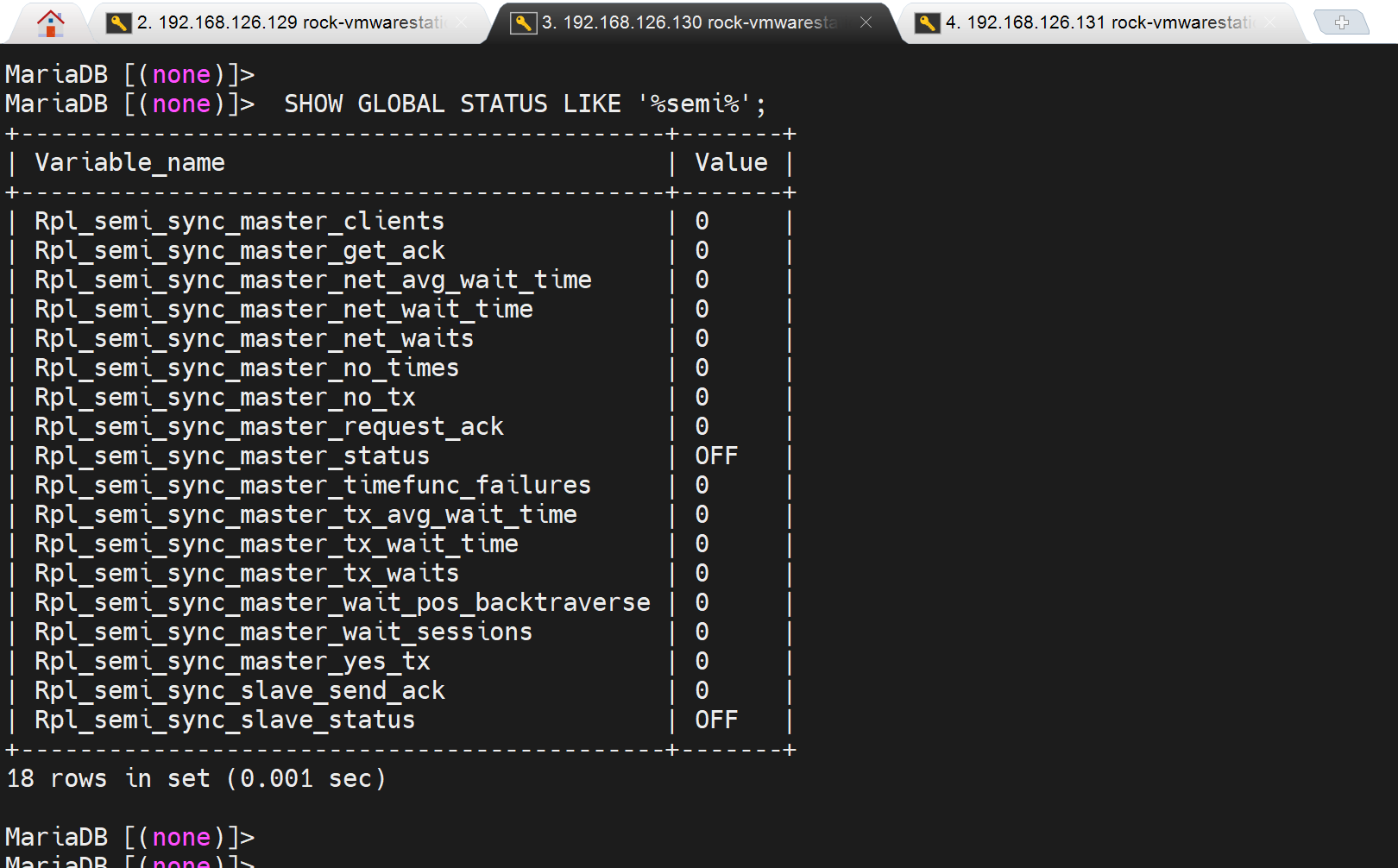
哦,不是的,是之前set设置的global变量,所以重启服务后失效了,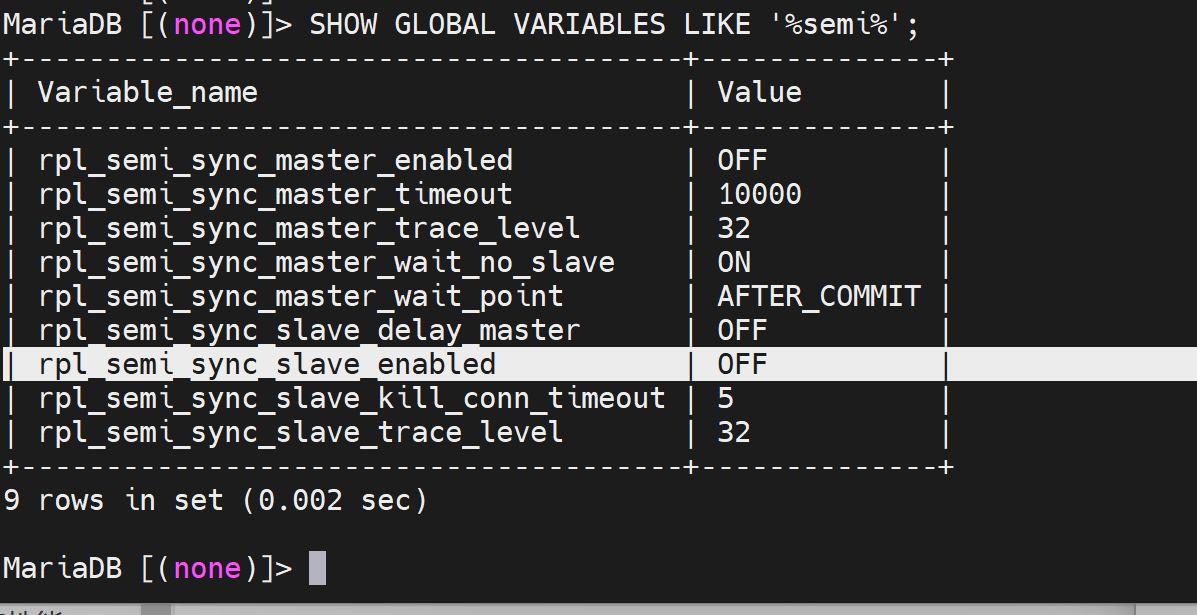
去配置文件配置下。
slave上
-------
vim /etc/my.cnf
rpl_semi_sync_slave_enabled
wr
systemctl restart mariadb
jiu ok la~ 此时master上show得到client了
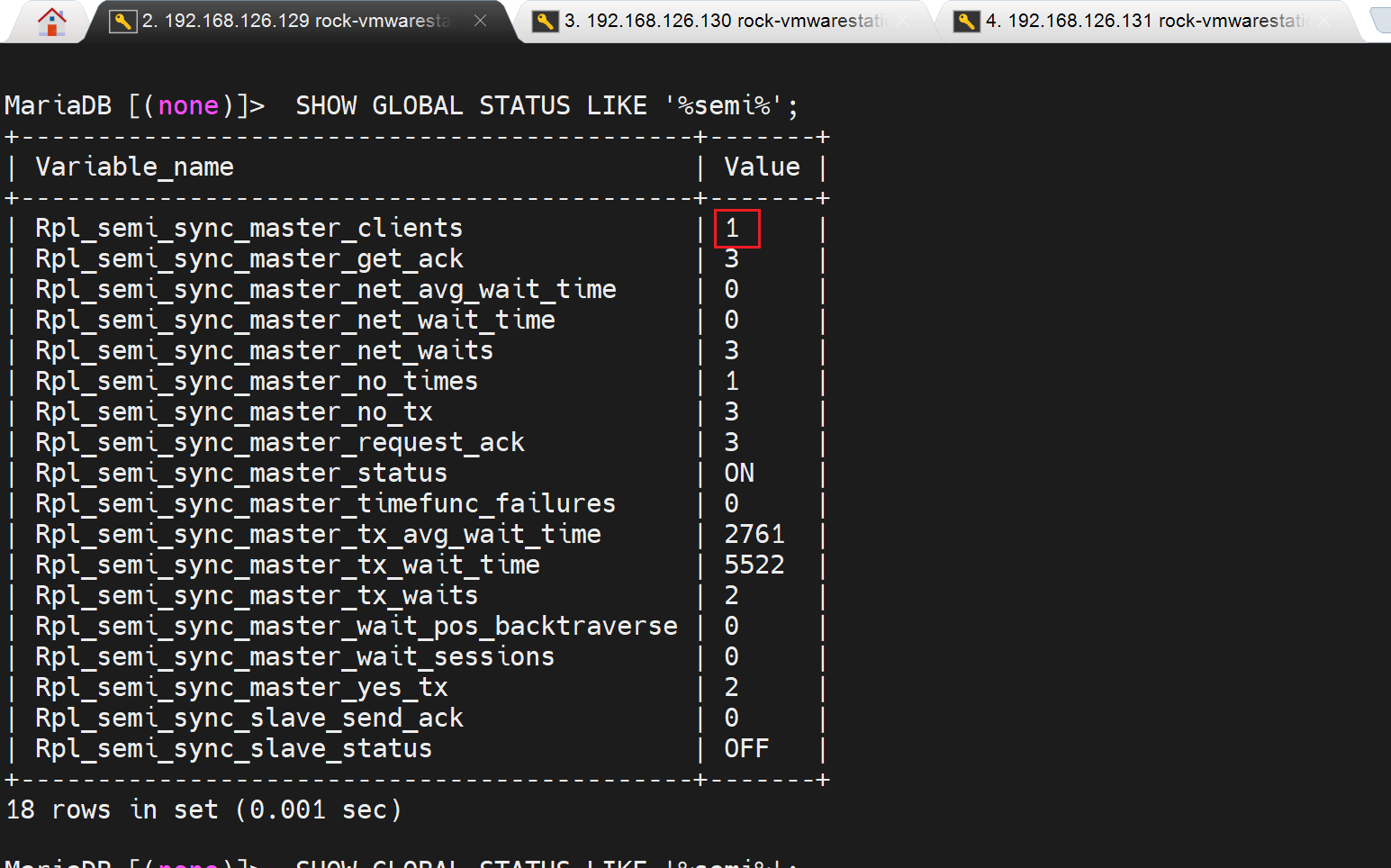
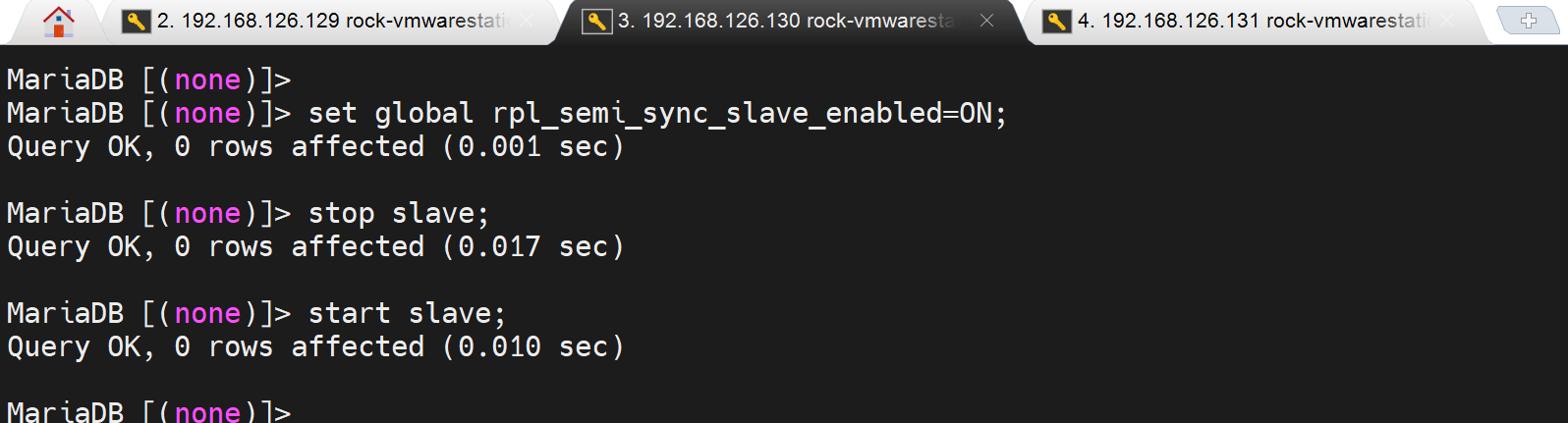
相反,set global rpl_semi_sync_slave_enabled=ON;是需要stop 和start slave的👇
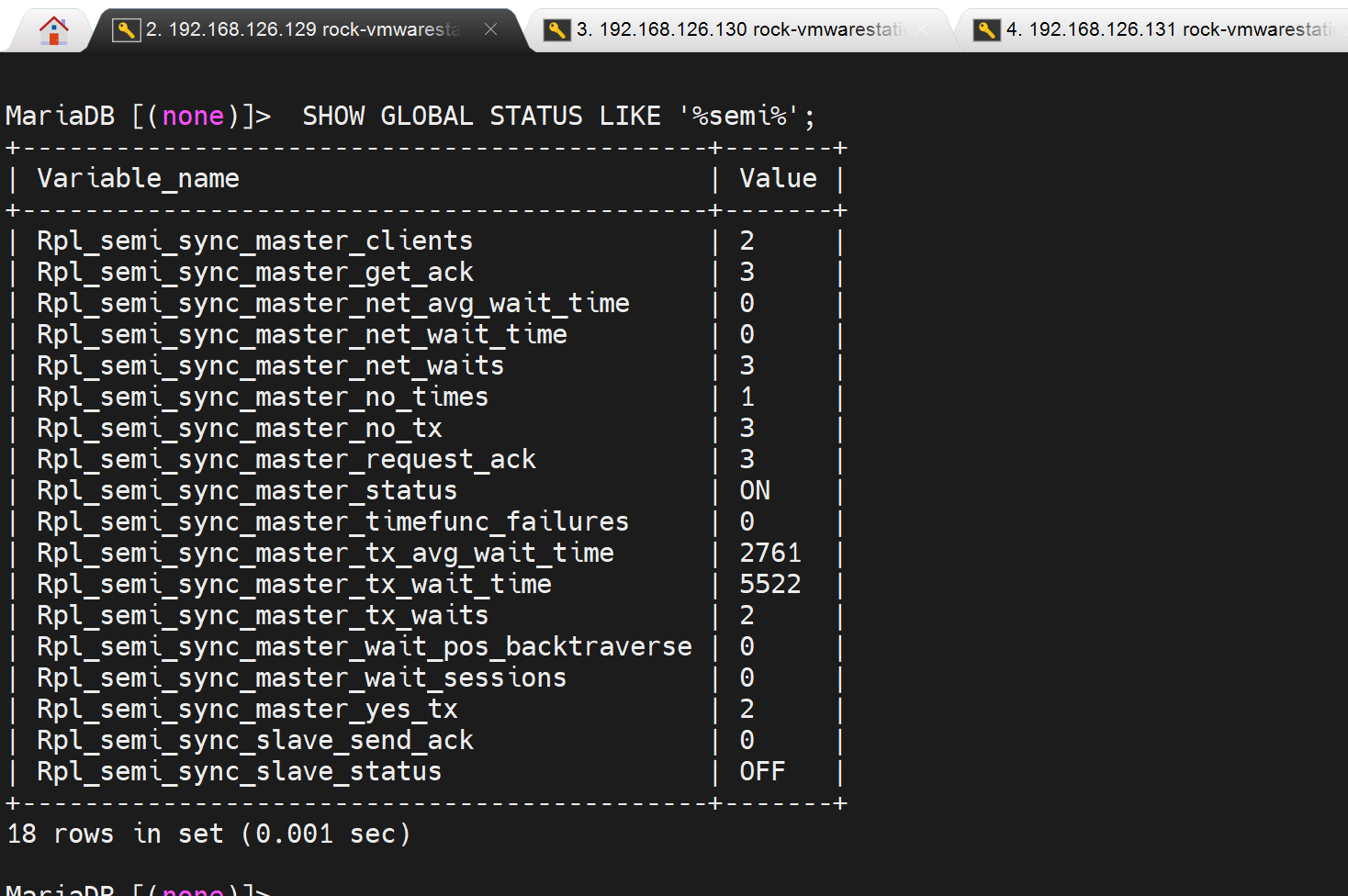
这是最终的效果
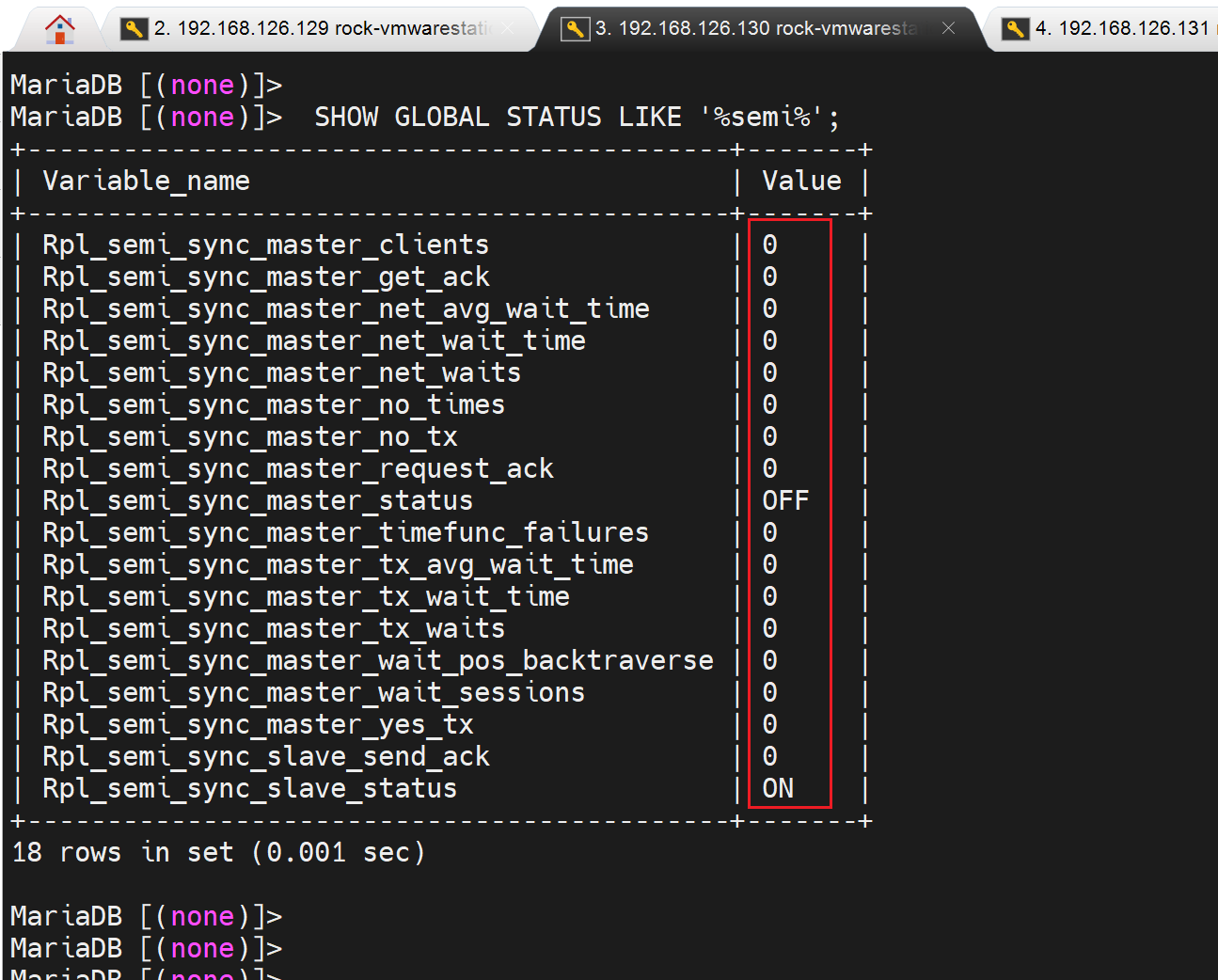
slave上倒是都是0哦,呵呵
这些变量的意思,去官网看咯
https://mariadb.com/kb/en/full-list-of-mariadb-options-system-and-status-variables/

一堆,所以dba说白了就是要去学习这个几千个变量~
复制延迟演示下
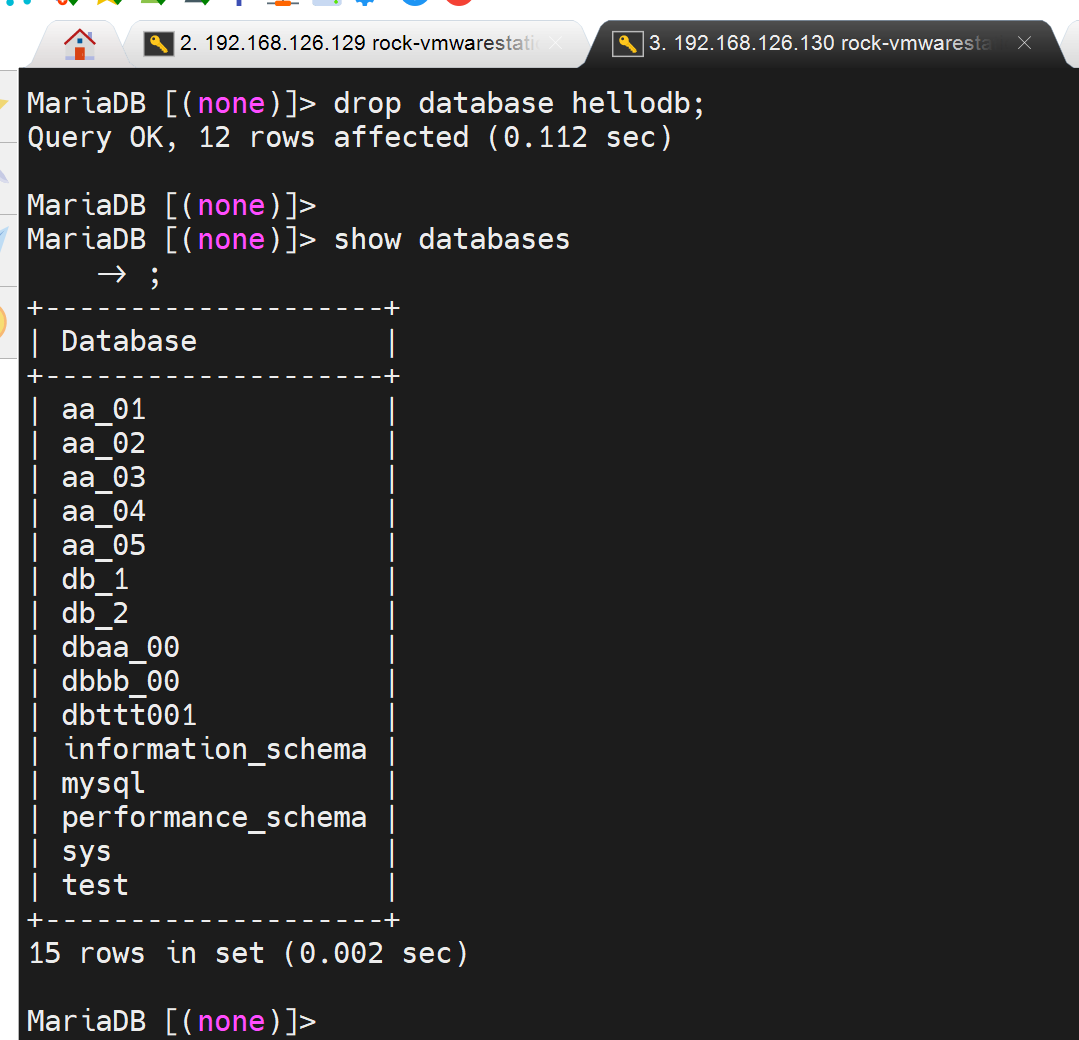
1、slave上删掉hellodb库
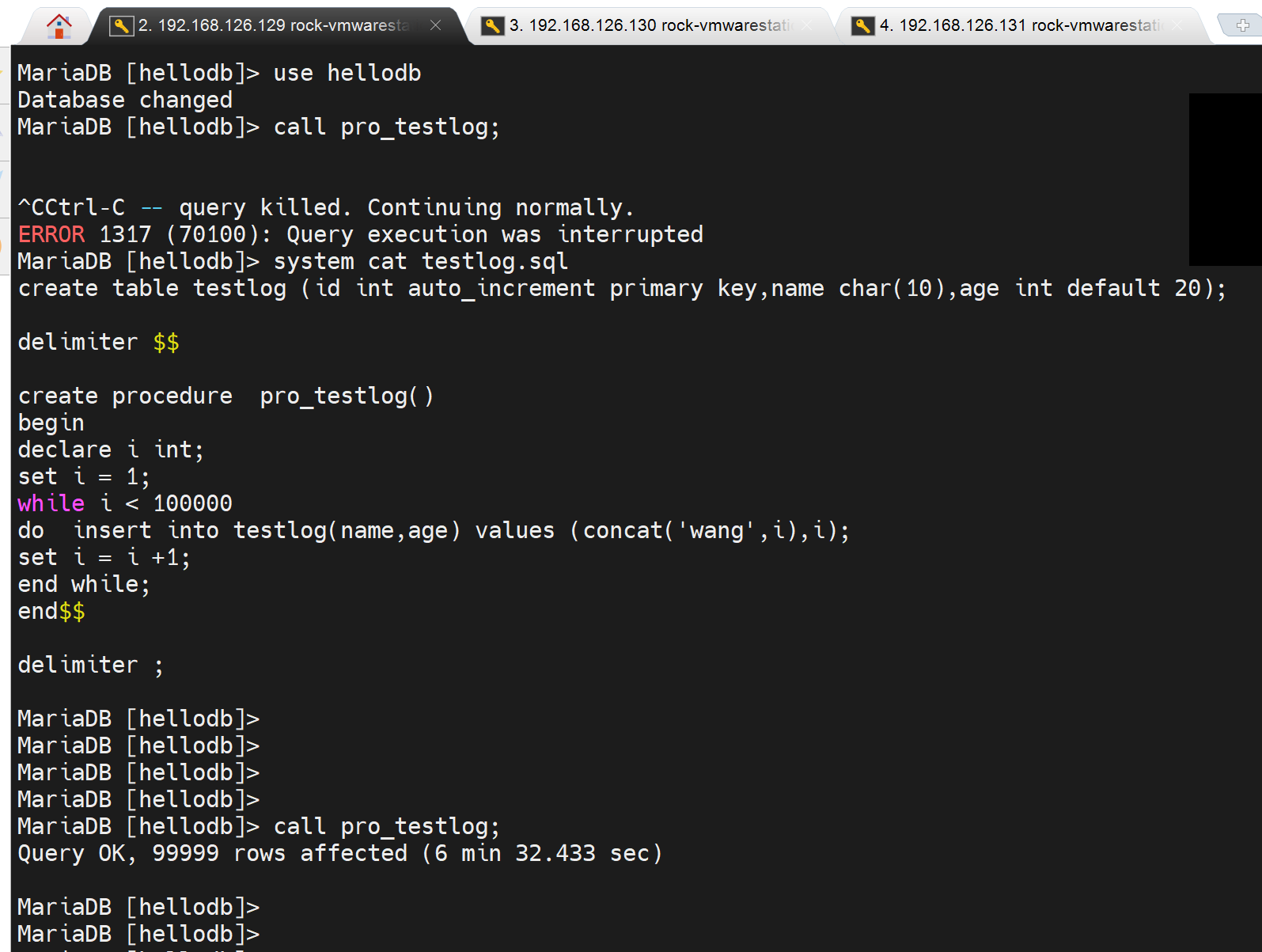
2、master上在hellodb里执行存储过程,创建大量数据
3、此时slave上就会因为没有hellodb库,而出现同步失败,
4、在slave上补齐hellodb库,然后stop start一下slave。及时show slave status\G;看看延迟。
开始👇
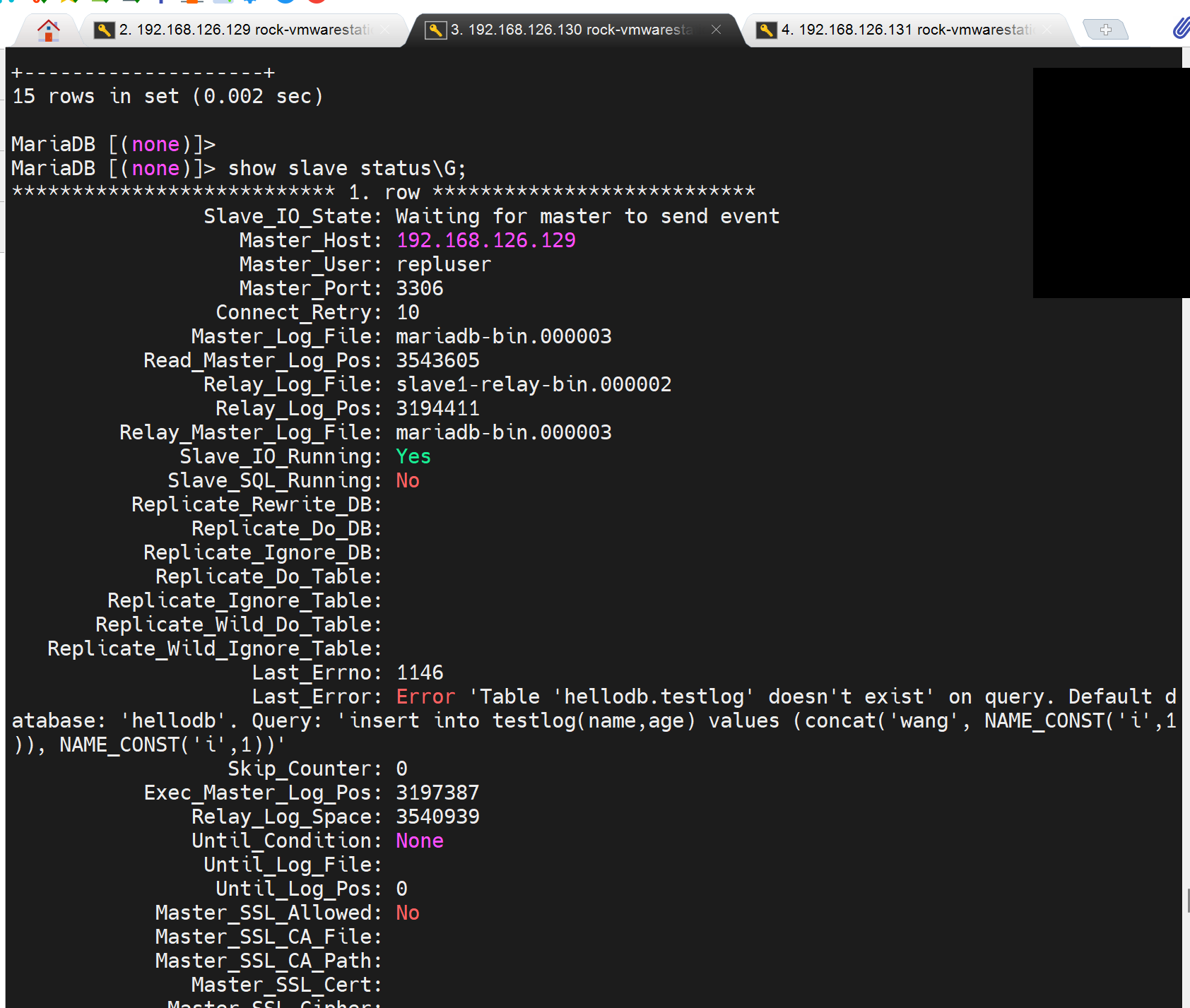
reset 用了就真的清掉额了👇连master的binlog文件编号都没了。
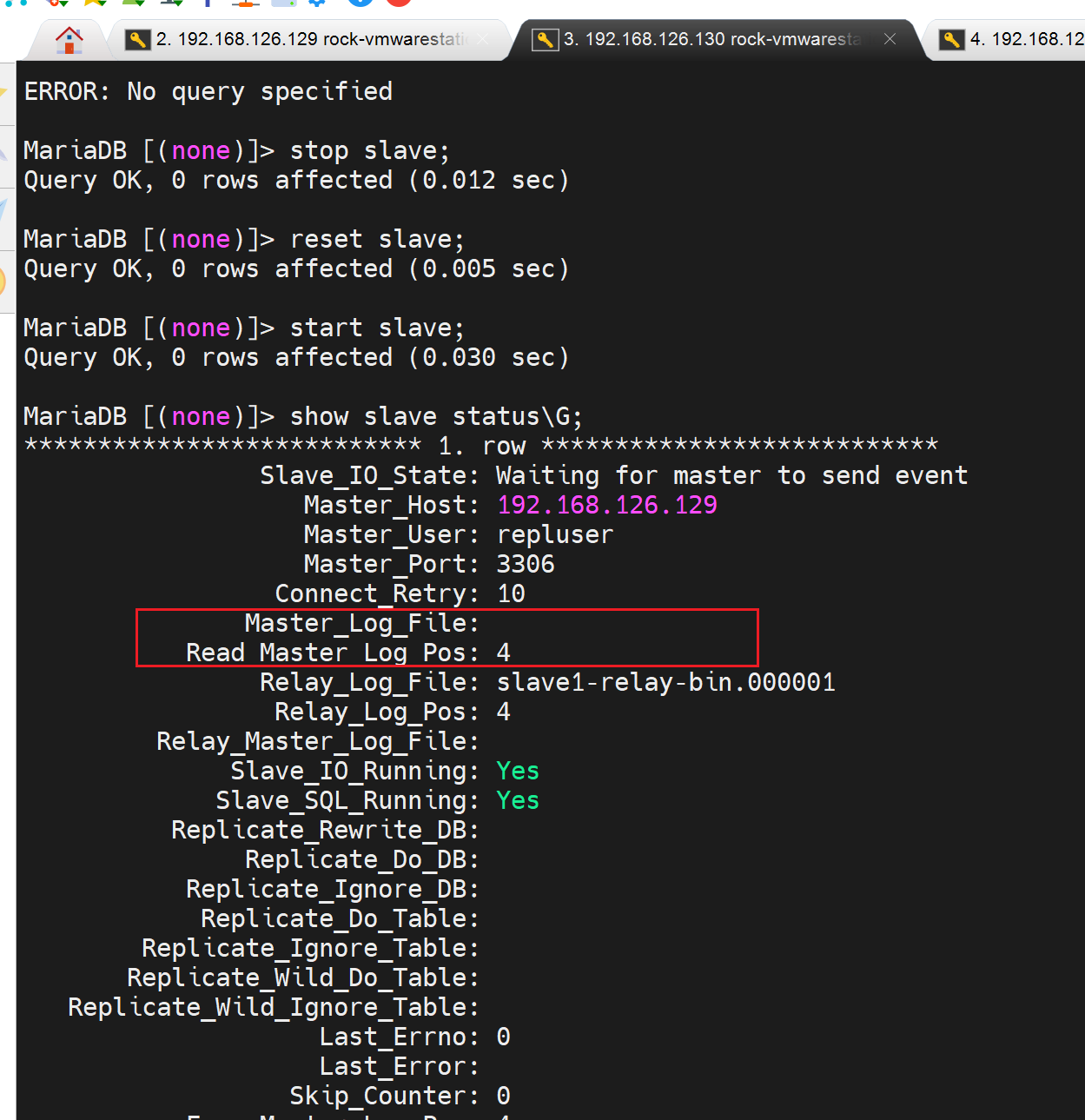
对比slave2的正常情况
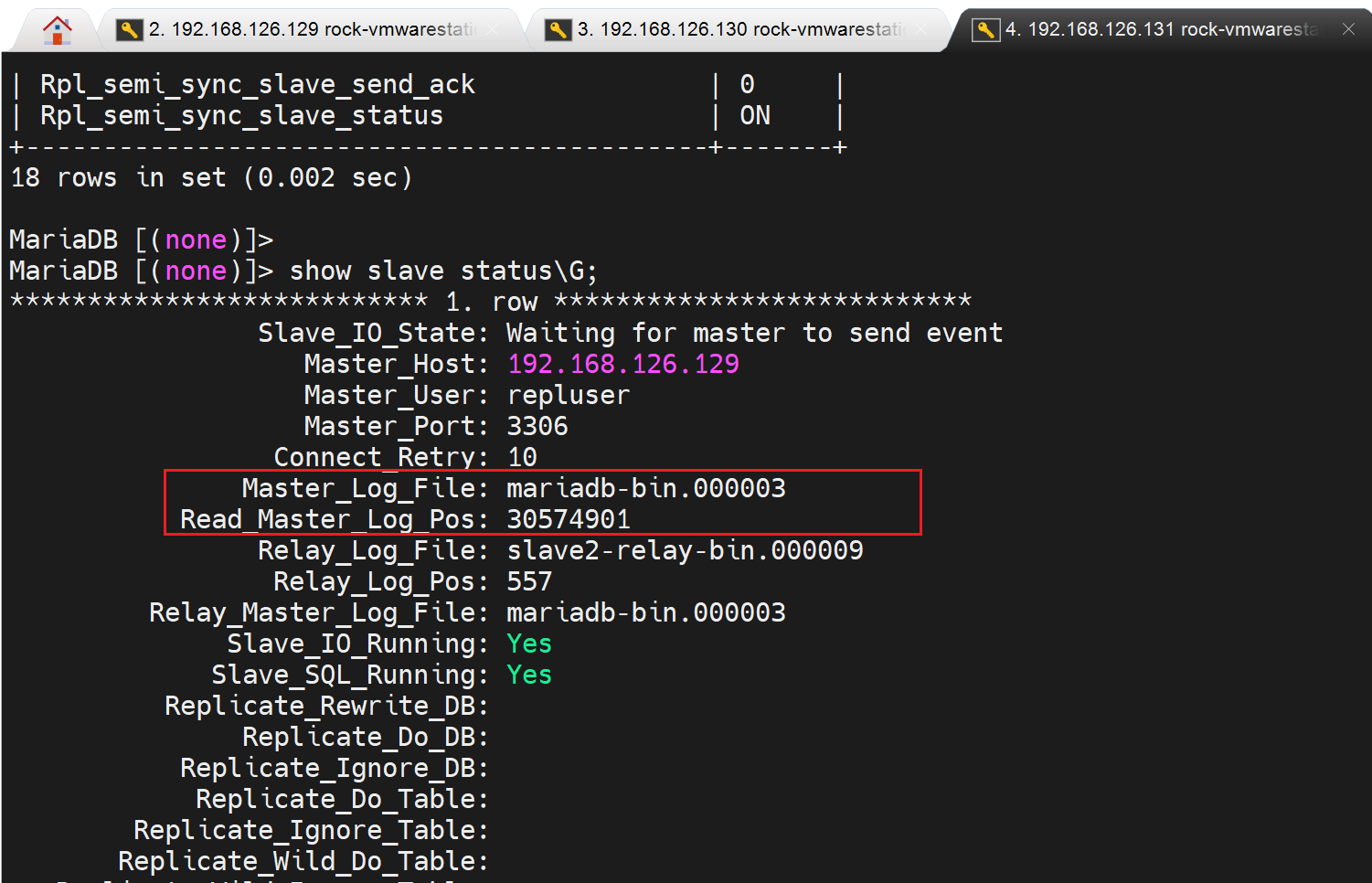
确实reset造成的,翻看了上图的历史截图,重新截了上下文
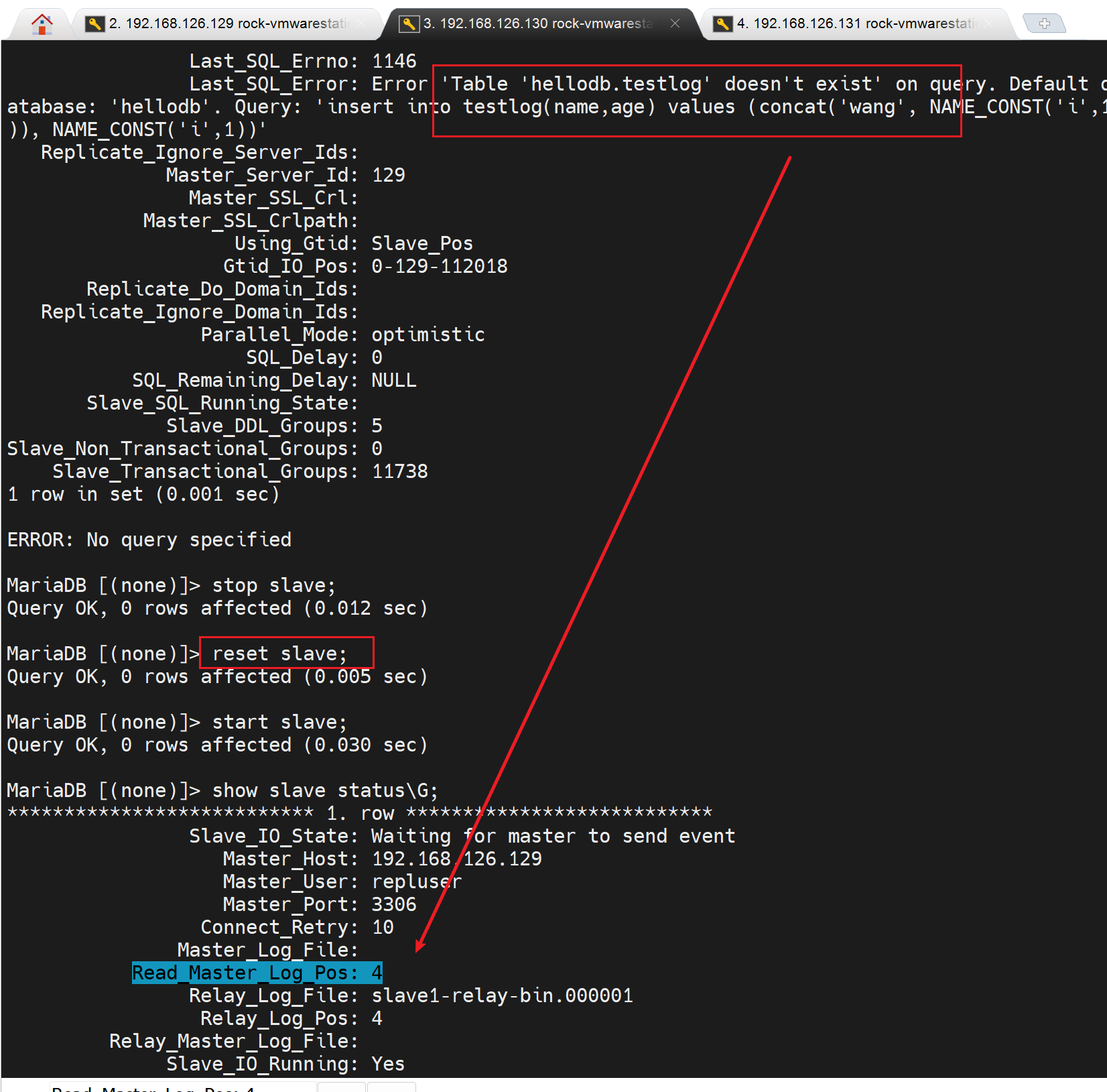
但是我在slave2上反复测试,都没有看到reset的这种效果了,需要手动
stop slave;
reset slave;
CHANGE MASTER TO MASTER_HOST='192.168.126.129', MASTER_USER='repluser', MASTER_PASSWORD='cisco', MASTER_PORT=3306, MASTER_CONNECT_RETRY=10, MASTER_LOG_FILE='mariadb-bin.000003', MASTER_LOG_POS=781;
start slave;
反正能搞好也是了,呵呵。感觉slave 复制还有点坑。
其实很好理解吧,就是同步的binlog是

如果没有hellodb库,没有testlog表,就不行,所以同步的哪个,你将上图往上翻一翻看看从master那边复制的binlog起点,如果这个pos始终在hellodb.testlog创建之后,那么报错必然始终都在。
你只有将复制的位置POS点提前去覆盖到库表的创建才能消除报错。我不管你reset是怎么清空了master的binglo位置--其实就提前了吗,也不管你有时候reset slave又不清空,我只管复制的post位置是否符合逻辑对吧。
你看哦,这个现象就对了
下面是一个整图哦,受限屏幕才分开来的
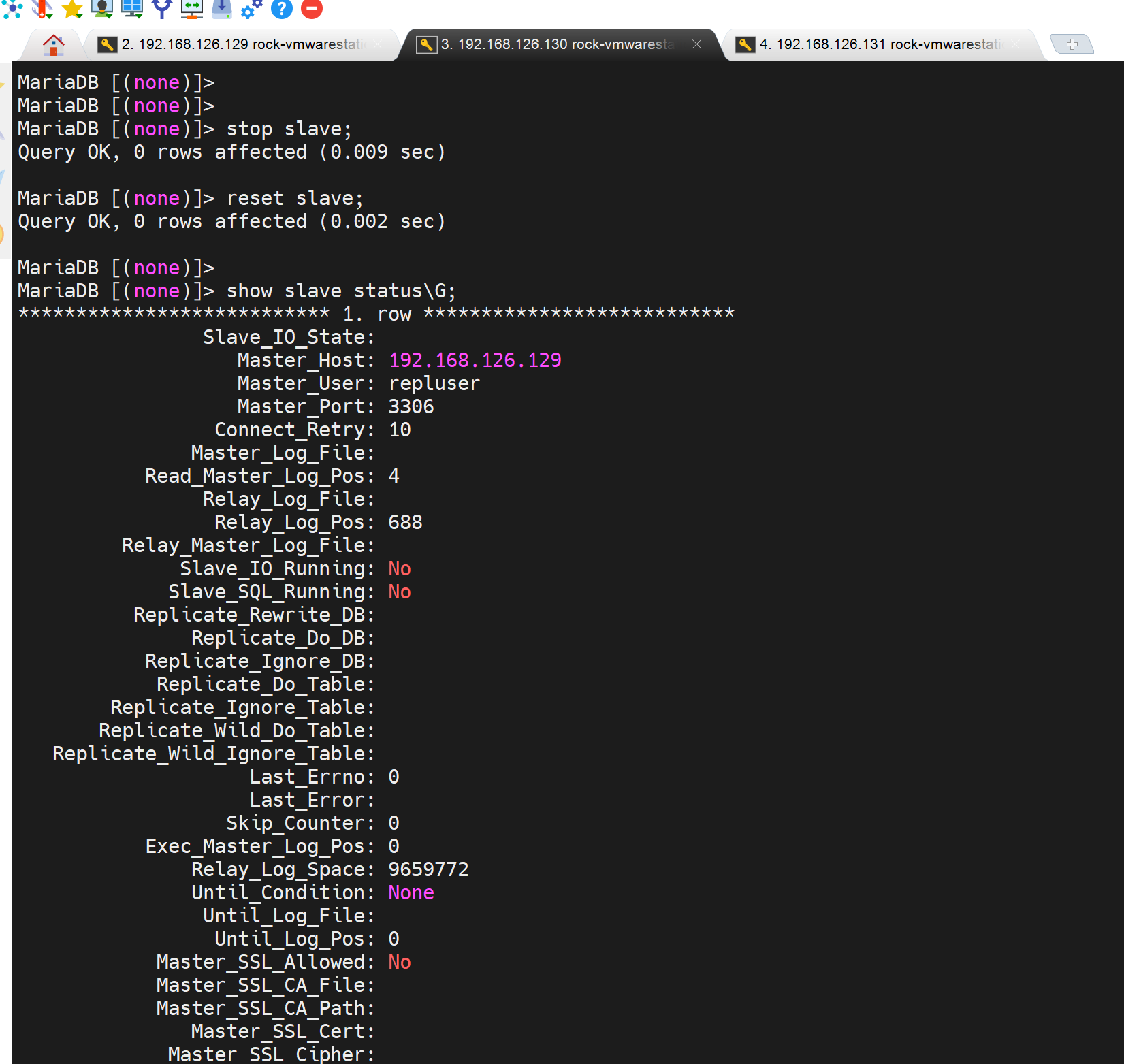
reset后,start 的瞬间是两个YES就是OK的
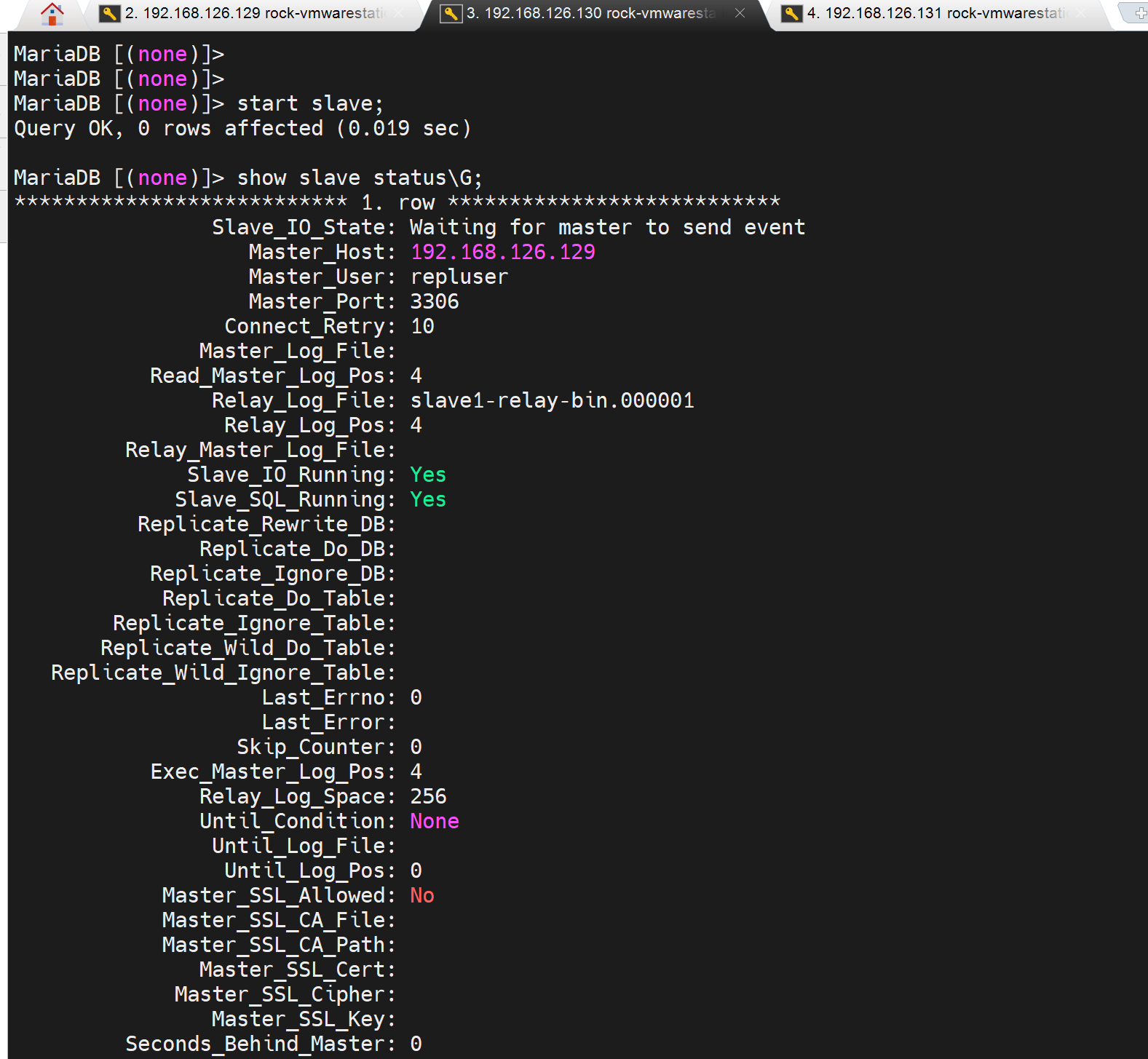
但是又瞬间报错了
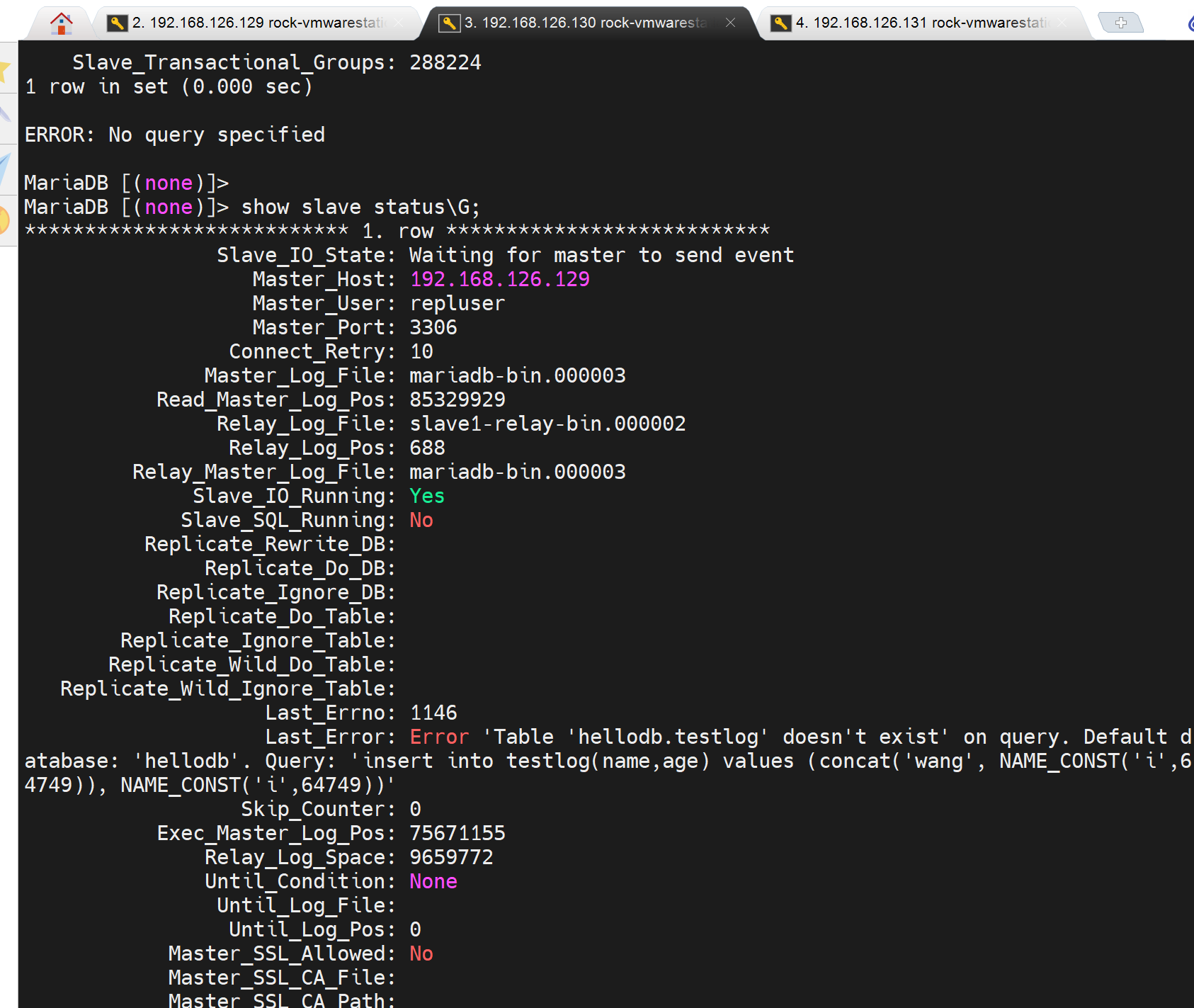
很简单啊,就是,我说的复制的主上的post点又读取了缓存记录--类似的吧,没有从头开始读取。
说了这么屁话,其实就一句话,操作上讲★就是要
stop slave;
reset slave;
CHANGE MASTER TO MASTER_HOST='192.168.126.129', MASTER_USER='repluser', MASTER_PASSWORD='cisco', MASTER_PORT=3306, MASTER_CONNECT_RETRY=10, MASTER_LOG_FILE='mariadb-bin.000003', MASTER_LOG_POS=781;
start slave;
MASTER_LOG_FILE='mariadb-bin.000003', MASTER_LOG_POS=781一定要确实是否合适!
★其实规范操作就是先mysqldump出来master的数据,还原到slave后,再做slave的复制。
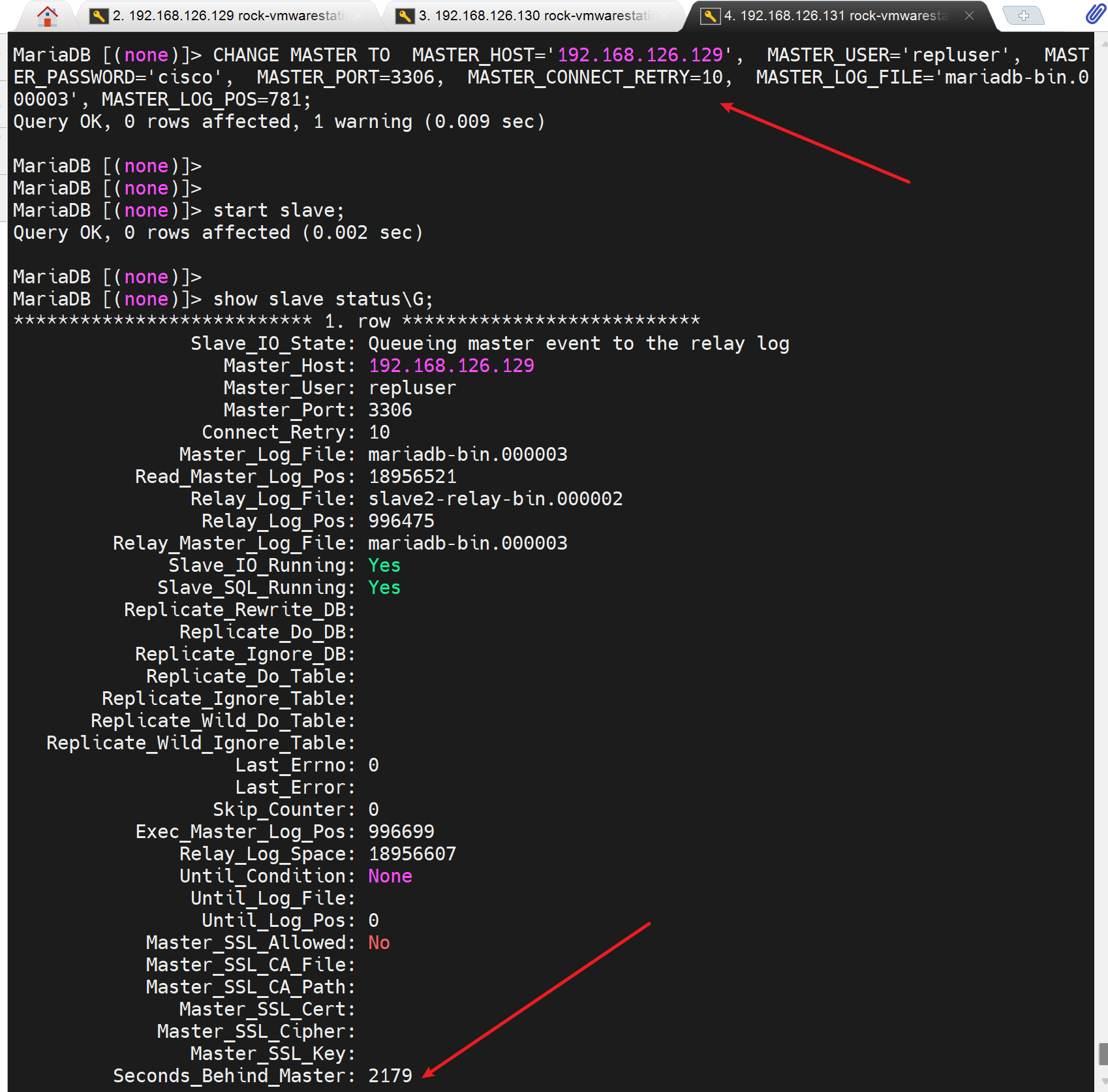
再说回来,你要看复制延迟,简单啊,直接POS指到前面去就行啦👇
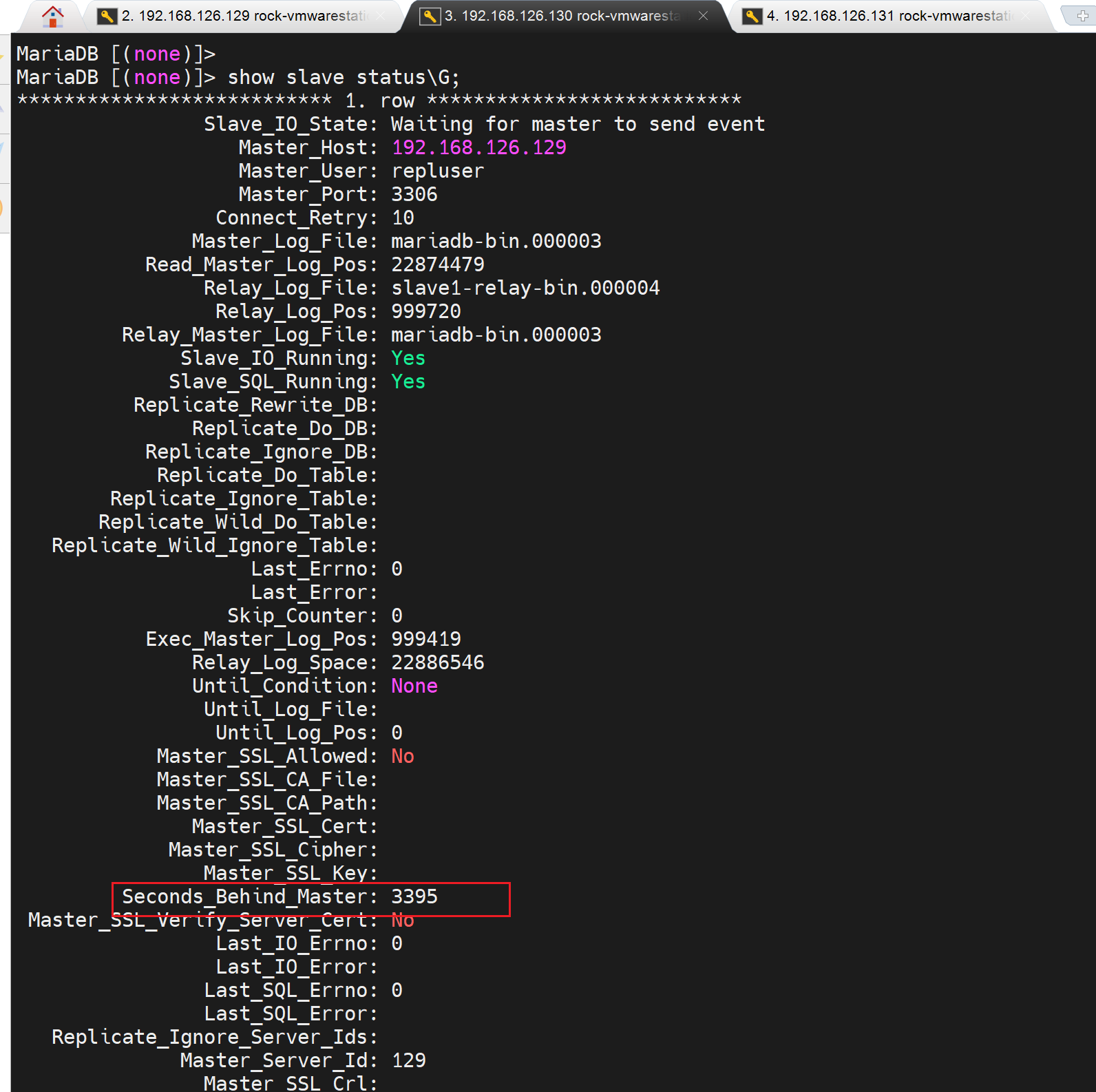
那么问题来了3395是秒,还是记录还是,啥,简单 官网变量走一波,你麻痹,别学了,secondes_behind,你跟我讲去查资料。(●ˇ∀ˇ●),而且明确告诉你没有这个变量的。