第9节. http协议详解和相关工具
HTTP协议
HTTP请求报文
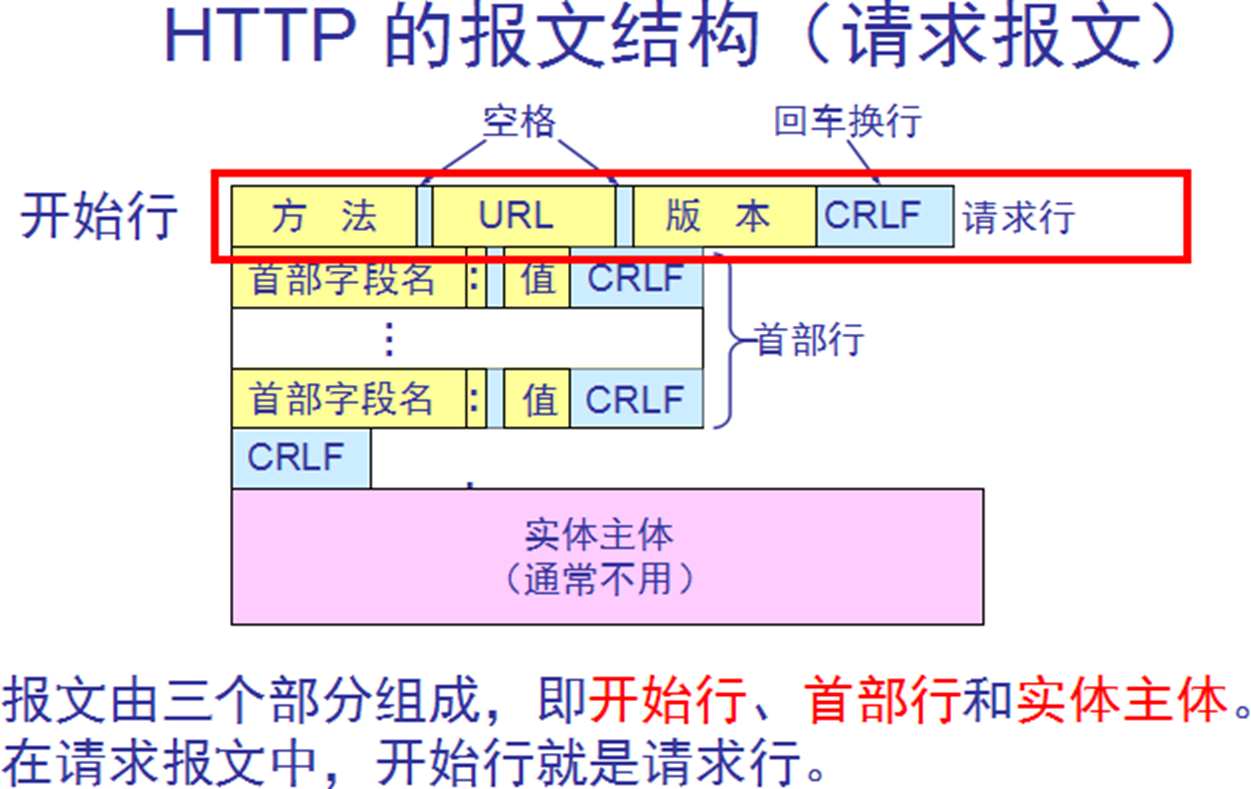
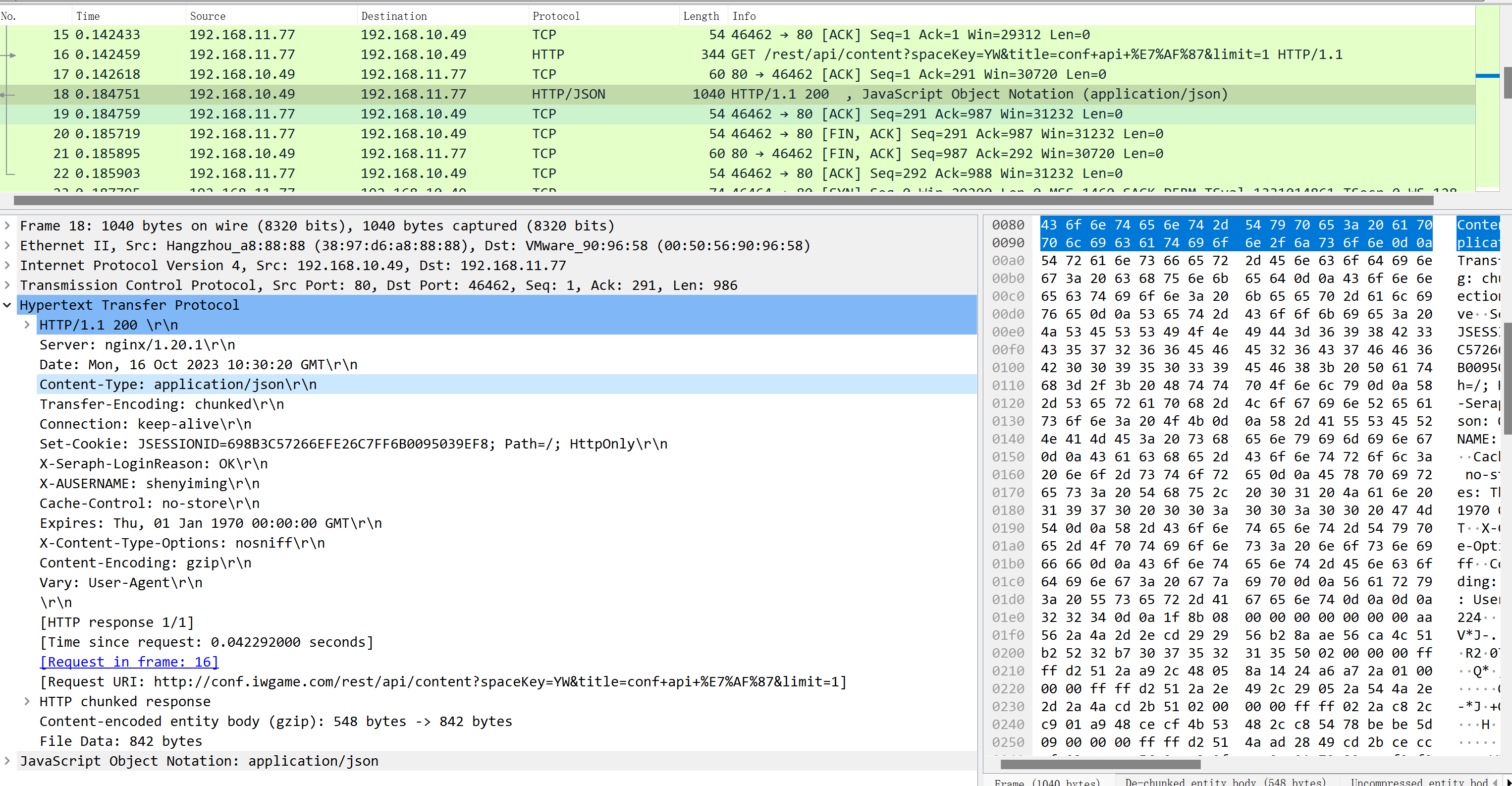
"实体主体",比如POST上传的数据内容,比如上传文章。正好我用confluence的api上传文章看看
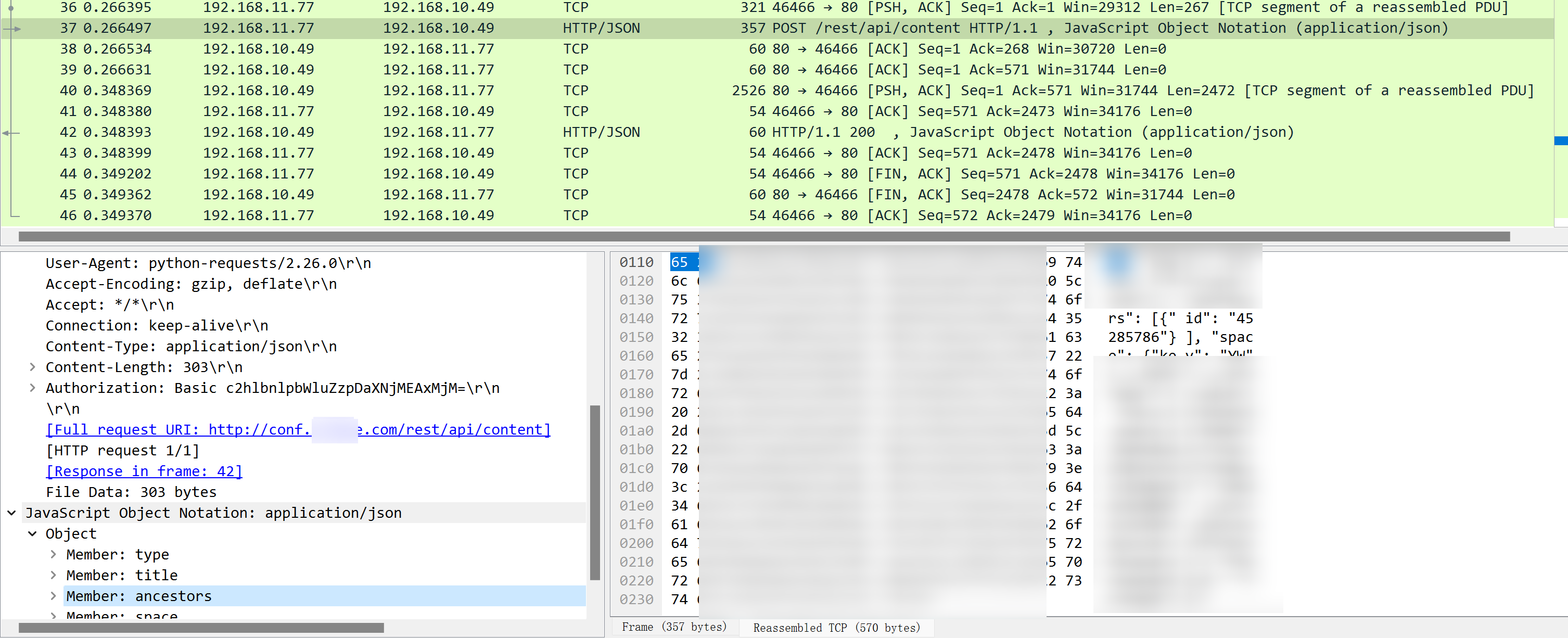
难道所谓的"实体主体"就是上图的JavaScript Object Notation,不过这部分内容确实是我上传conf的文章。
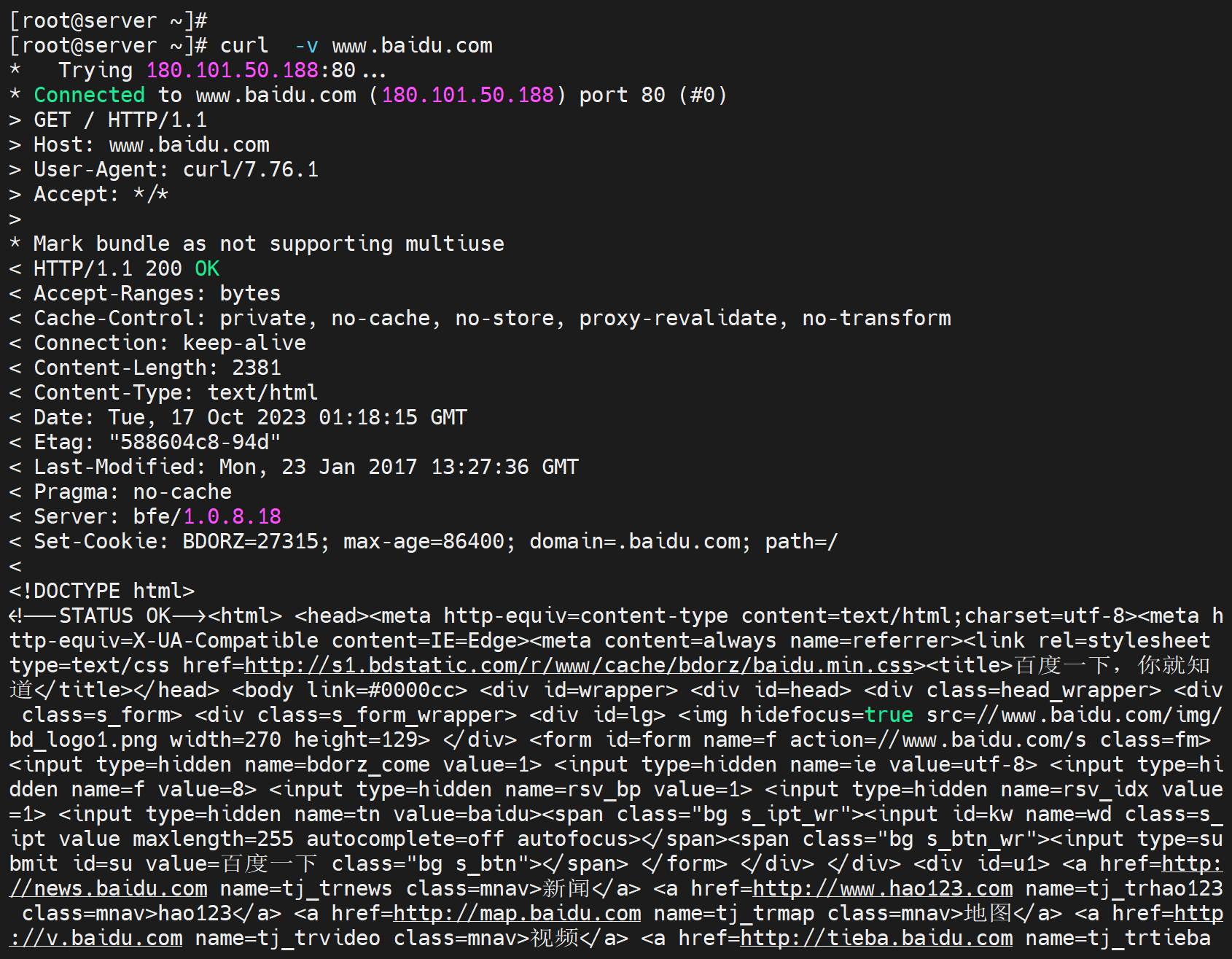
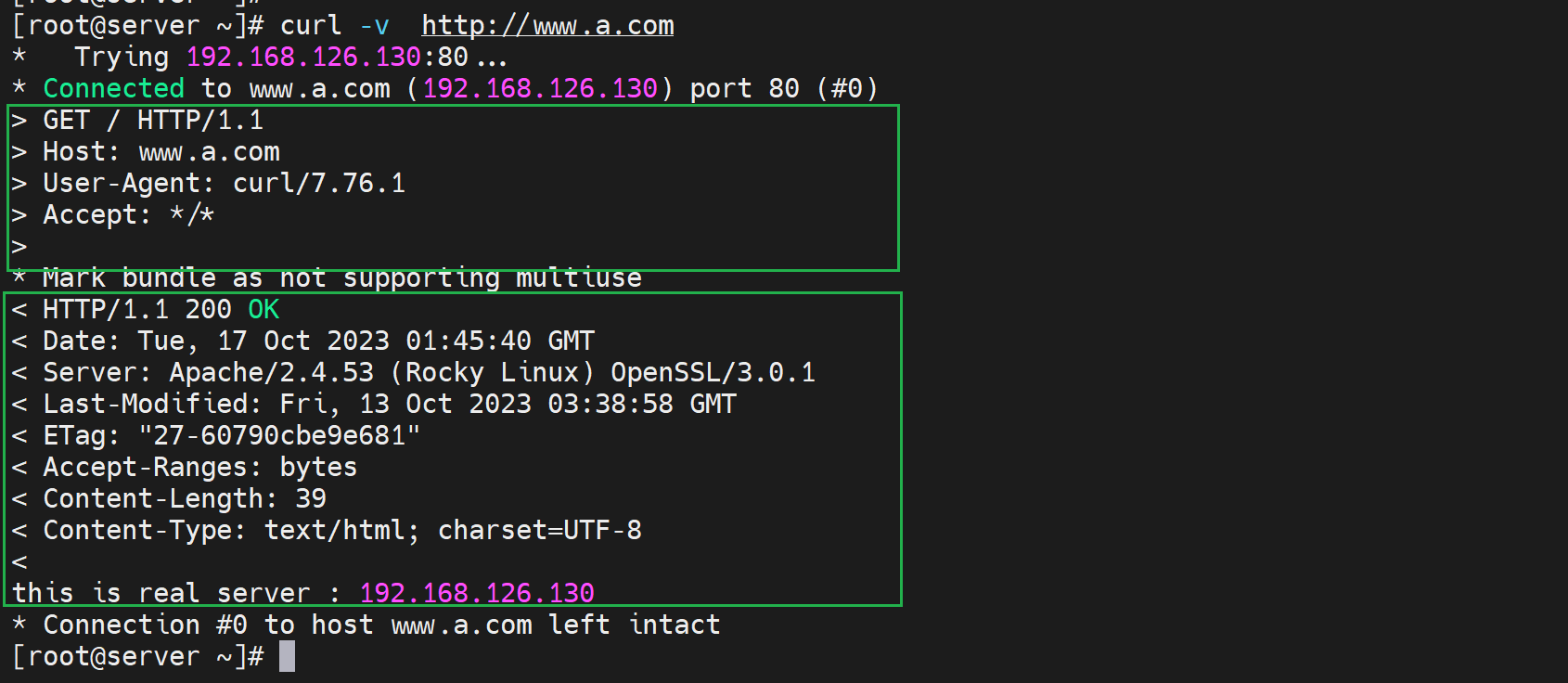
上图既有请求报文,也有响应报文,>就是请求,<就是响应
HTTP响应报文
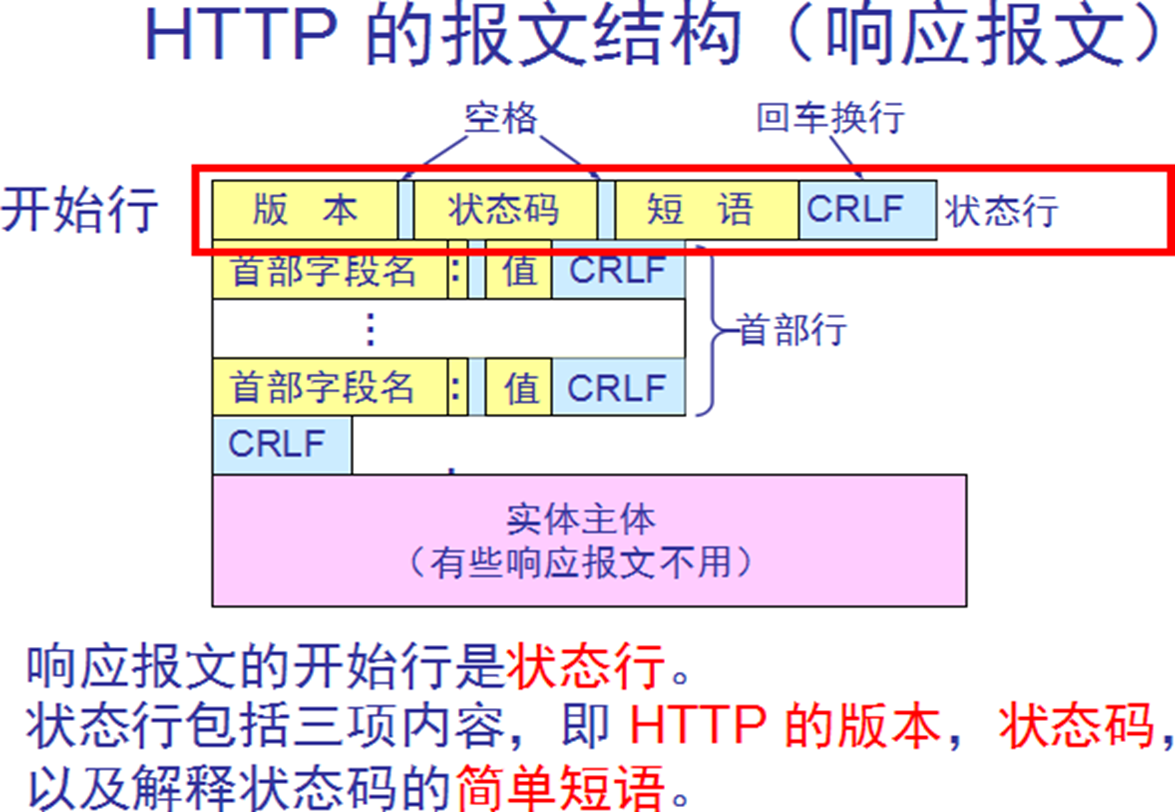
HTTP报文语法

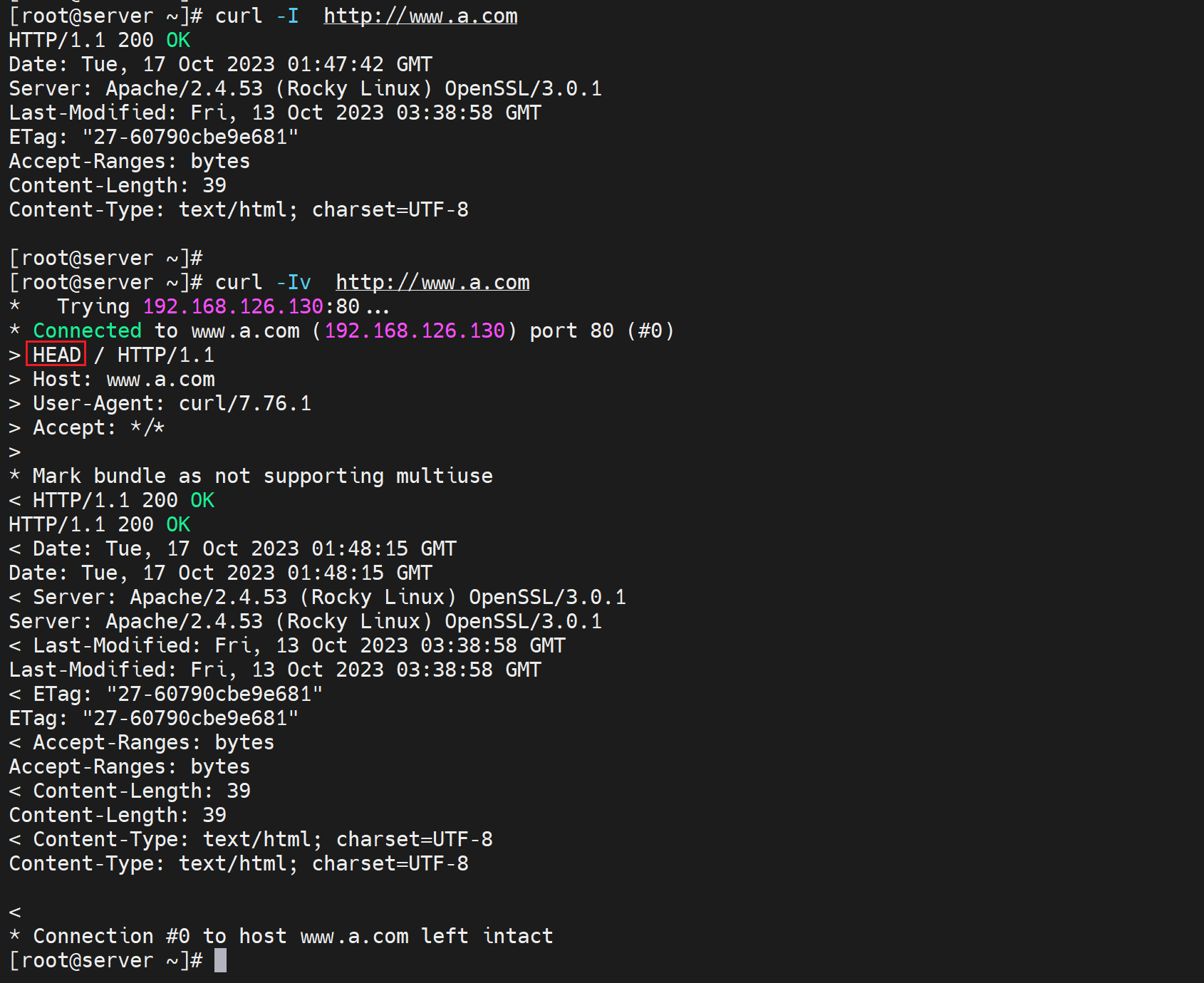
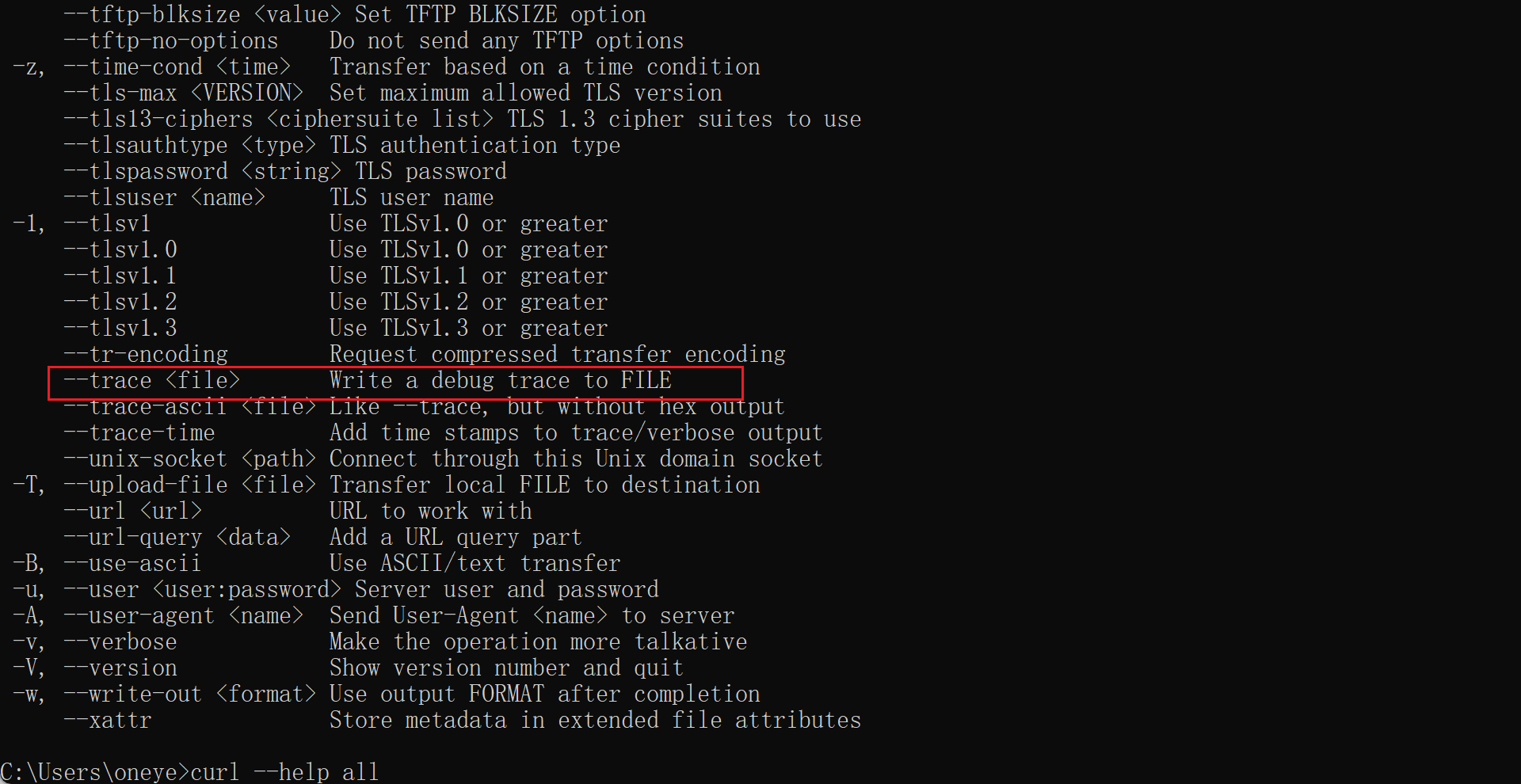
GET POST用的较多,HEAD就是只看头的请求,通过curl -Iv可见👇

关于HTTP的响应码的说明查看方法

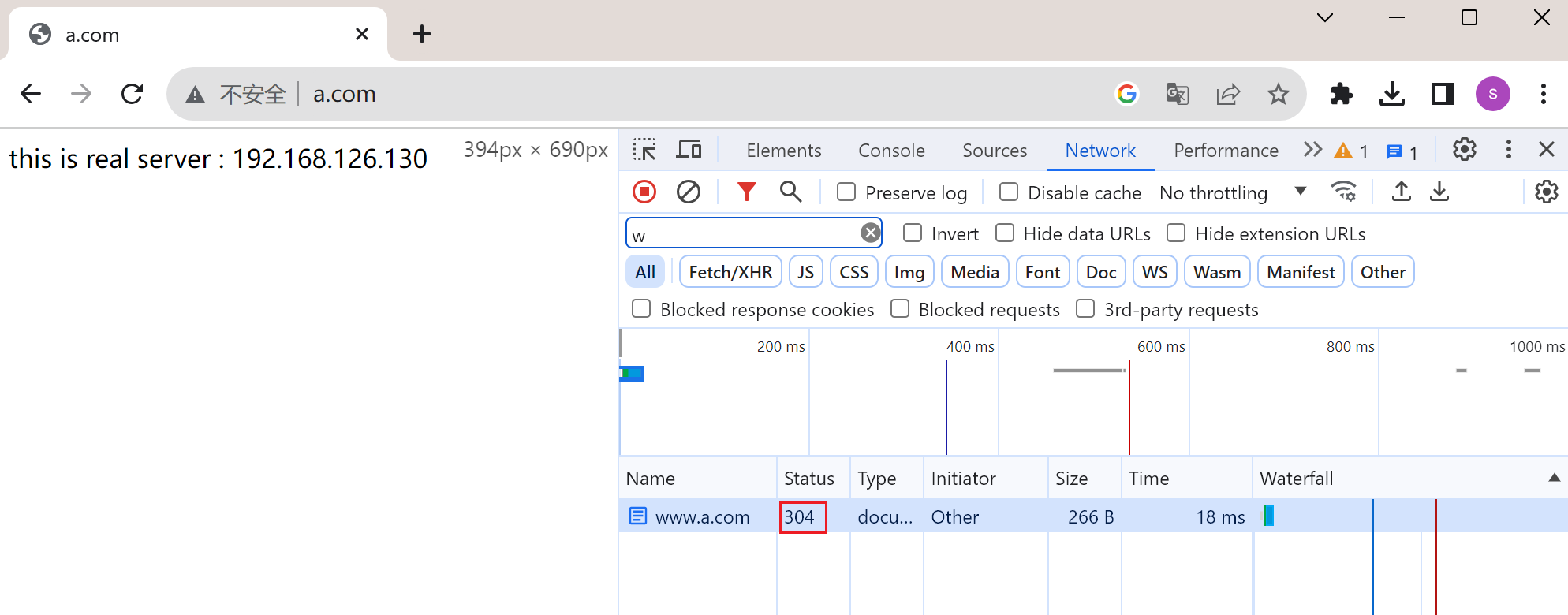
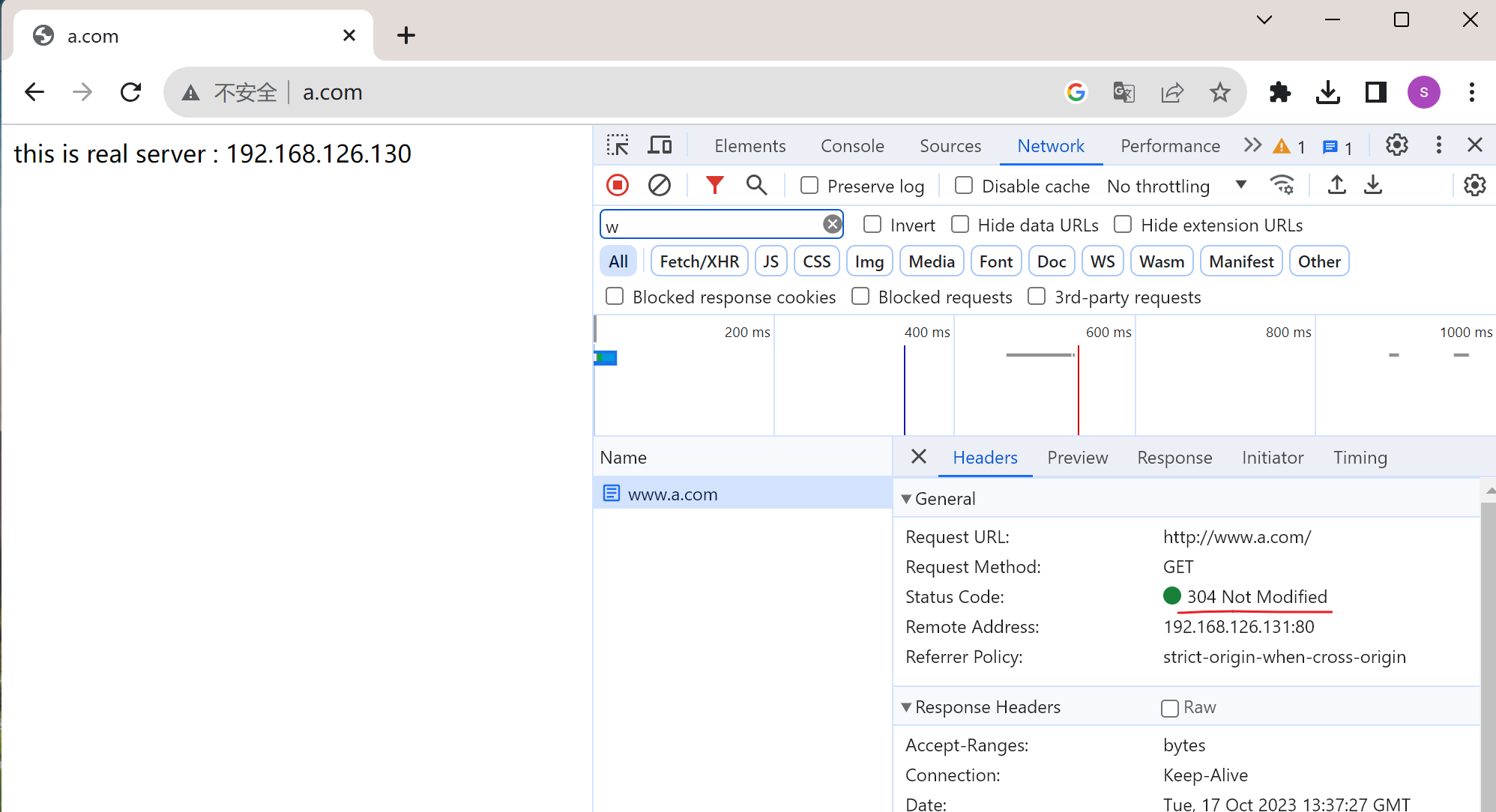
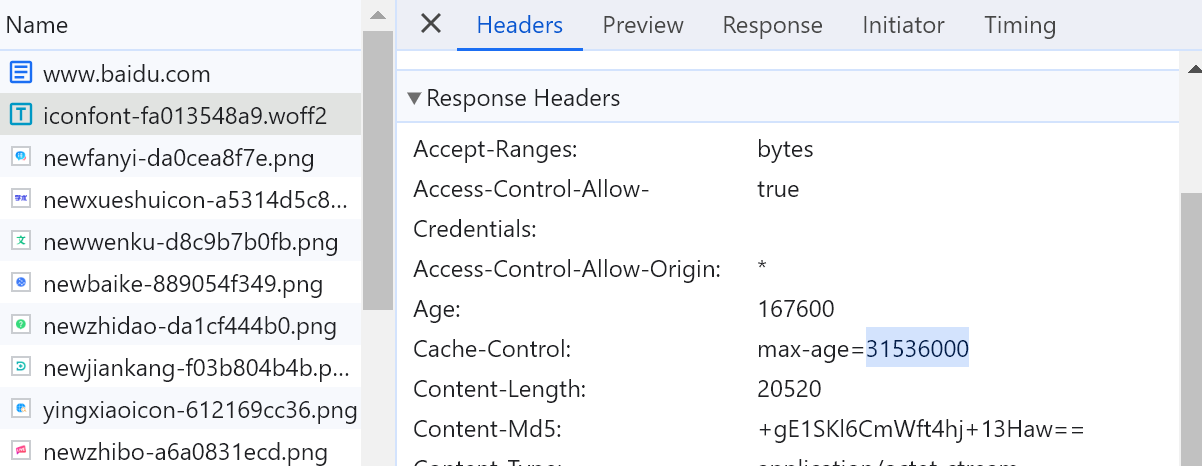
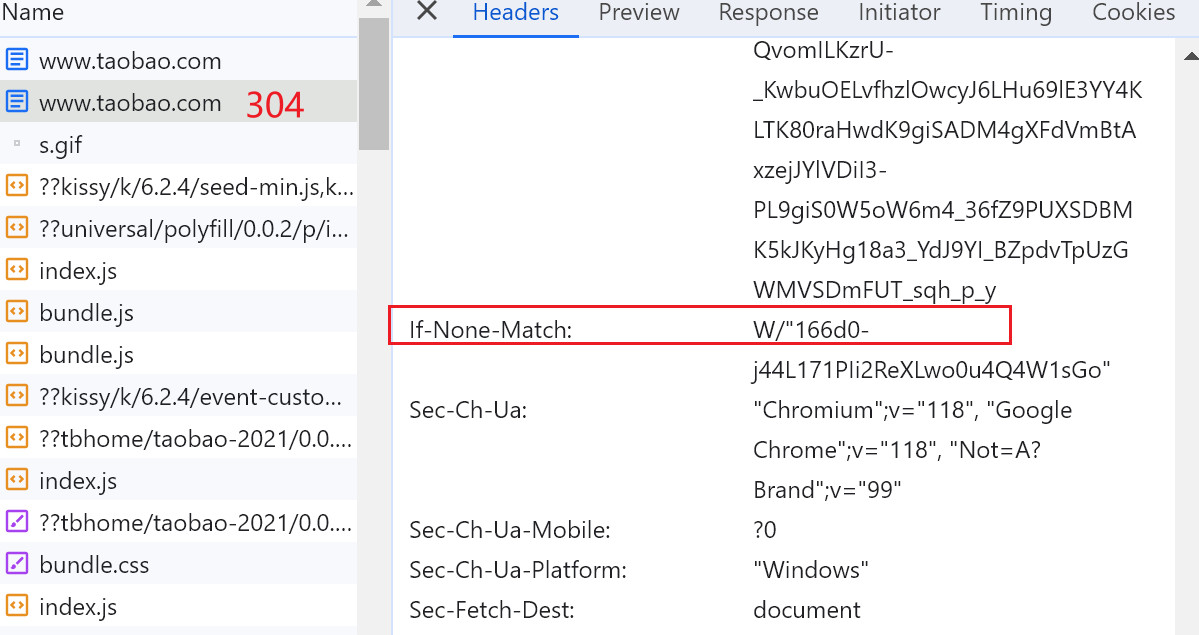
304缓存,F12里有Disable cache开关。我一般都是勾选的,防止缓存带来的误判。

有人缓存就清2个礼拜的,但实际缓存可以存在长达1年之久👇

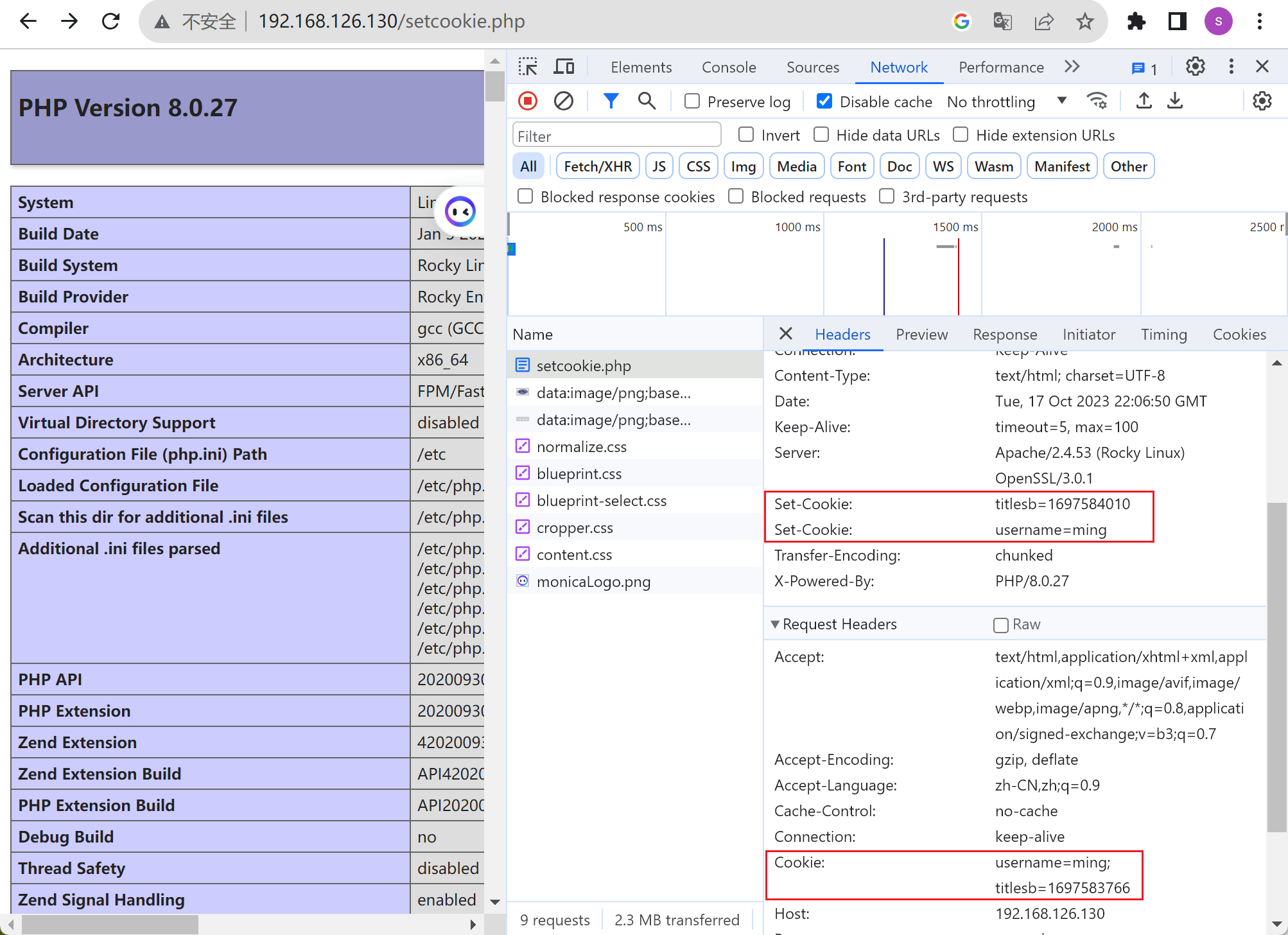
Cookie

cookie是键值对,里面存放了用户信息
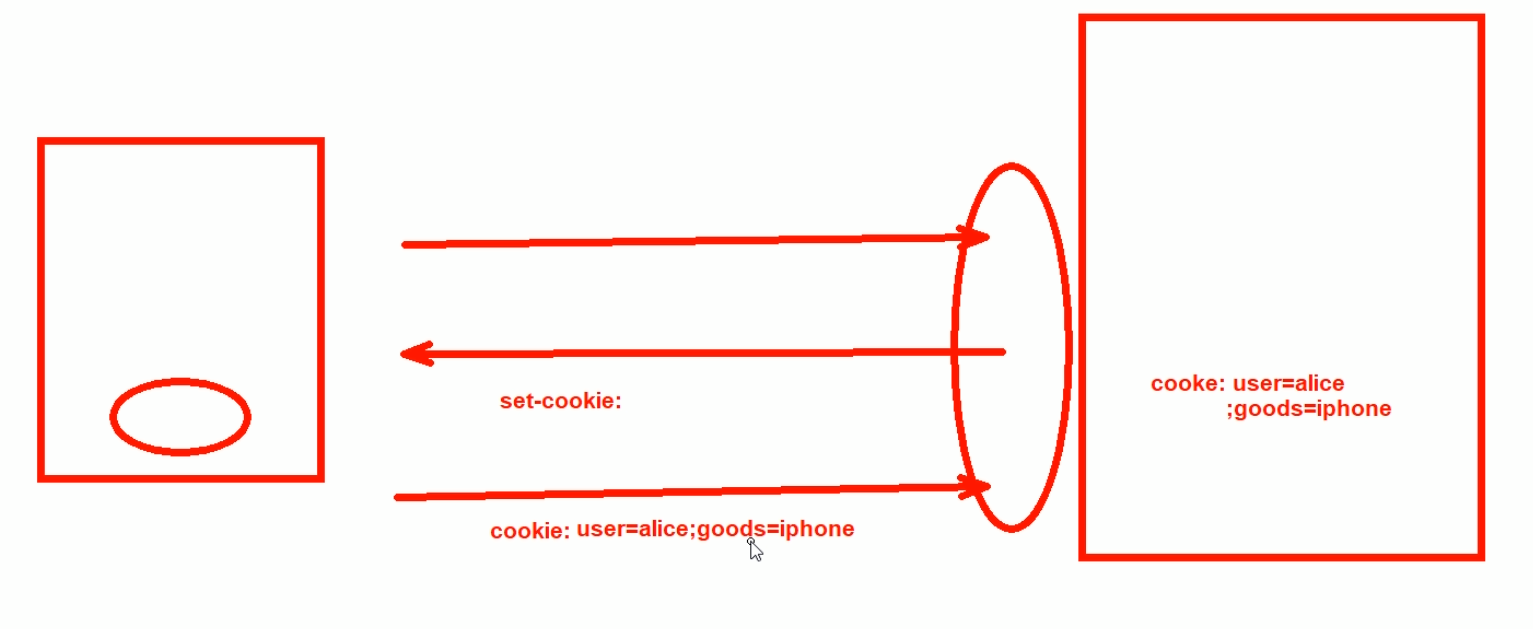
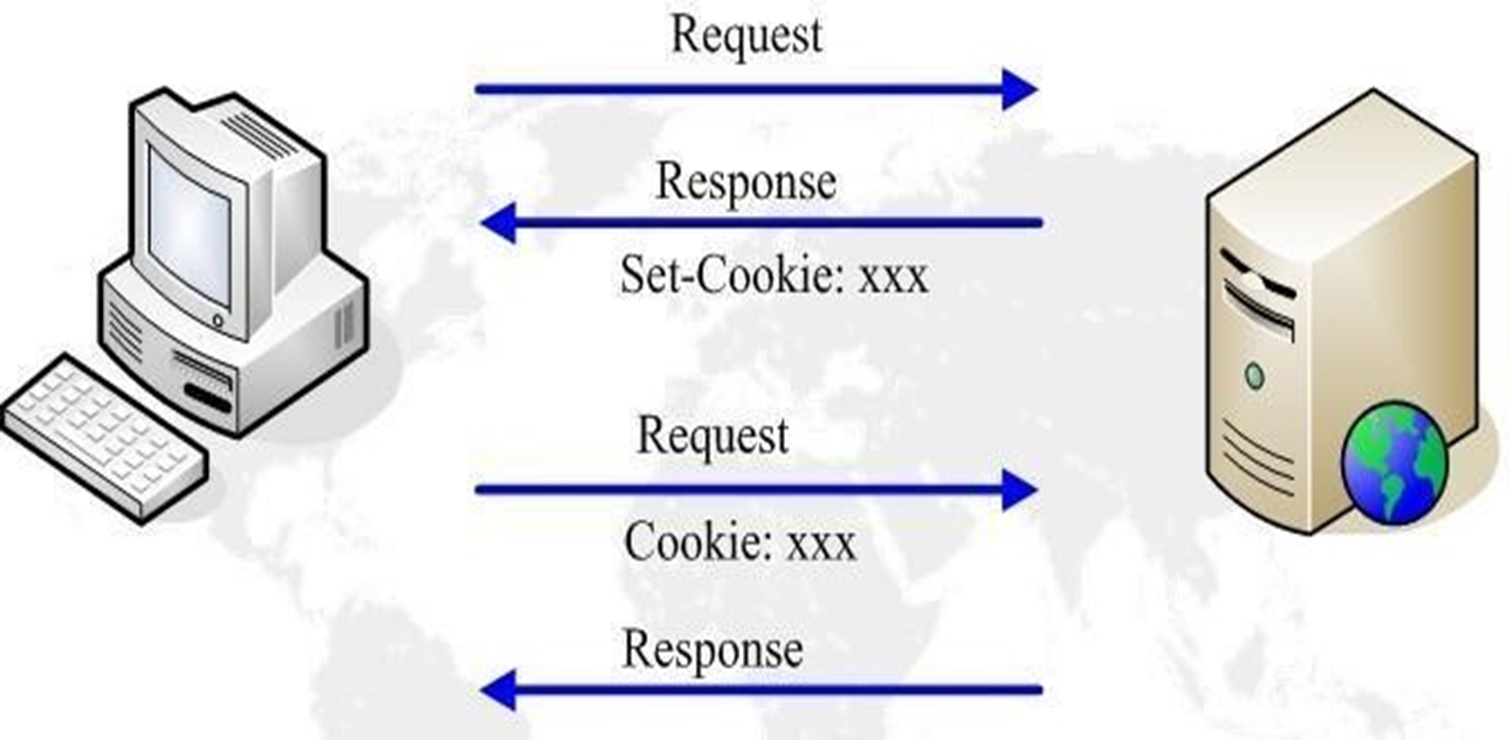
①用户访问服务器的时候,服务器生成cookie值,是key,value键值对,比如user=bob,goods=tesla
②server通过set-cookie这个首部字段信息,发给用户
③用户的浏览器就收到了, 然后存着,下次访问就会自动在请求报文中携带cookie,user=bob,goods=tesla
④网站服务器一看,这个人又来了,这就实现了HTTP无状态的用户信息连贯性。
胖cookie:早期什么信息都网cookie里放,造成cookie东西太多,带宽占用大。
cookie的有效期:应该也是set-cookie服务让用户浏览器缓存的时间。
会话级的cookie:就是类似mysql的会话级的变量一样,只针对当前会话生效;这里的会话级的cookie就是浏览器一关,cookie就没了。 好像有的登入ID就是用的session级别的cookie。
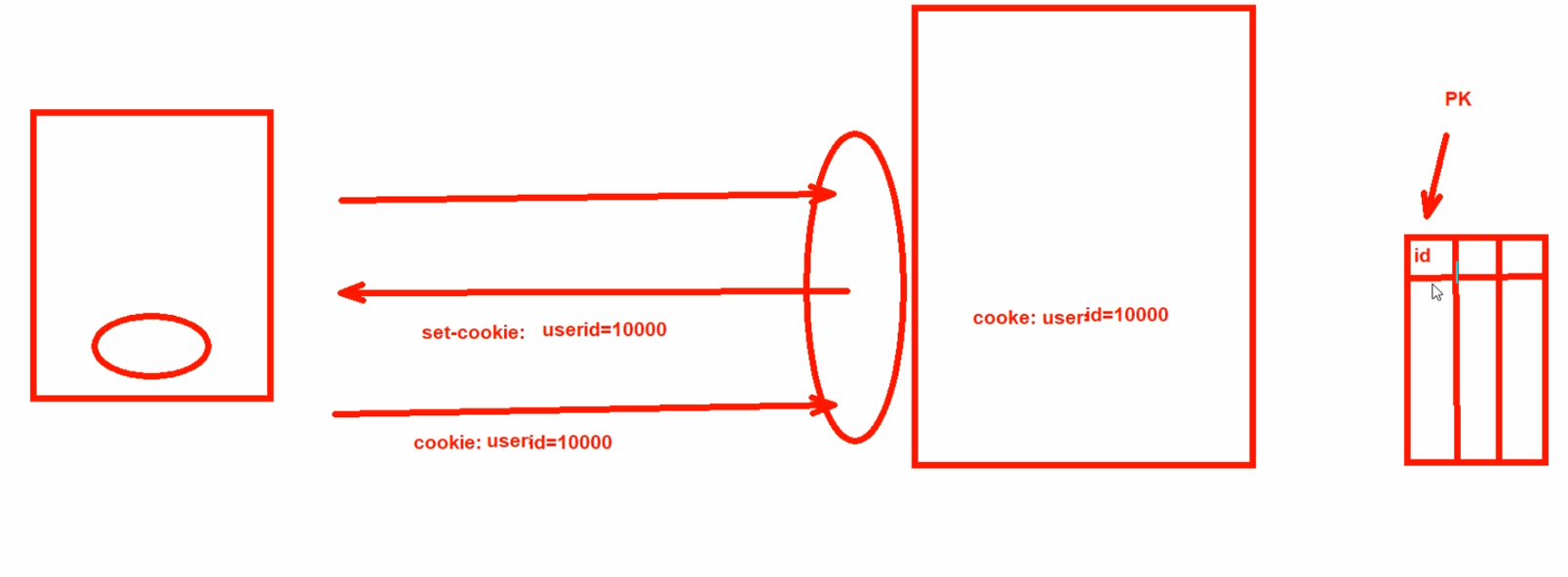
通过userid来简化cookie携带的内容,id对应的内容放到server端的DB里,这样信息在网络中的传递就少了很多。
说到信息的传递和验证,这块玩的花的玩的6的我接触到的还是cisco的ASA课程里其实不仅仅是ASA就是security方向里用的比较多,印象中有一个ISN、还有DOS防护的一些技巧,当然抗D肯定不是这么玩咯。
再一个session id,这个比如jd都没有登入,但是两次页面刷新,购物车里的东西还在,说明不是基于用户ID来保持购物车里的信息的,这里应该就是基于sessionID来的。
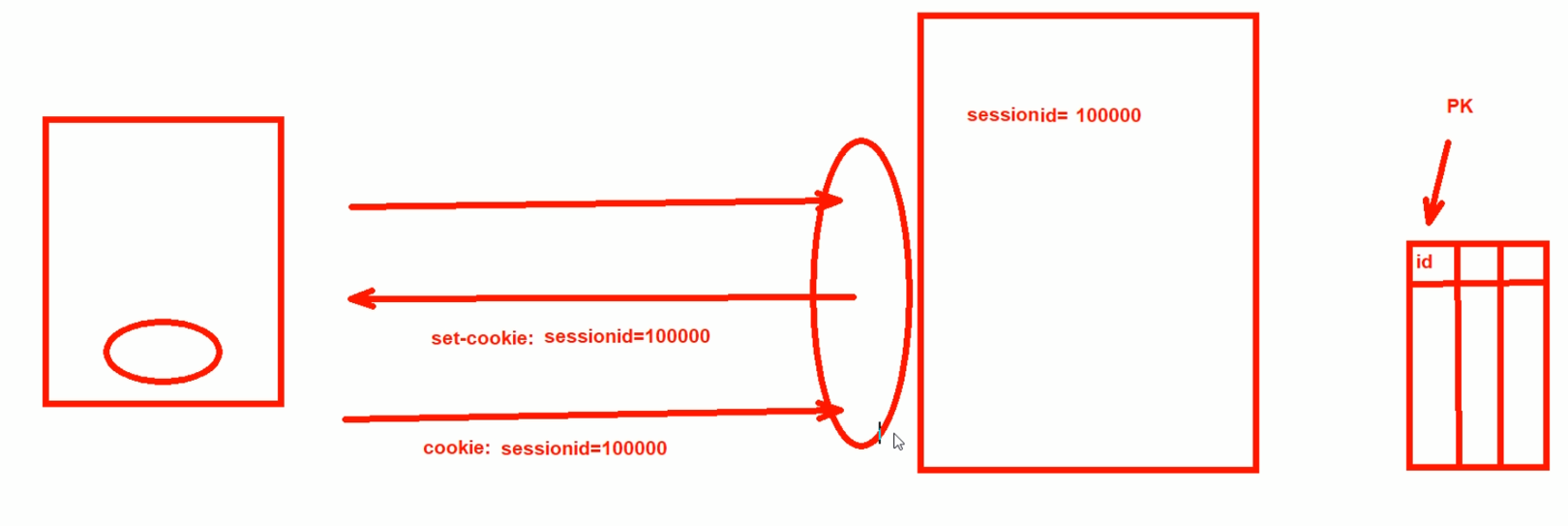
session ID 10000在DB里存在购物车里的商品信息。
sessionID也是放到set-cookie发给用户浏览器的,其实说白了就是因为http长连接也长不了多久,http会话不会保持,http本身设计就是短链接,所以需要有一个东西来做多个tcp连接的承上启下context的作用。不管session ID也好,userid也罢,都是打标 用标,然后标的信息完整信息放到server的DB里作为节省带宽的玩法。
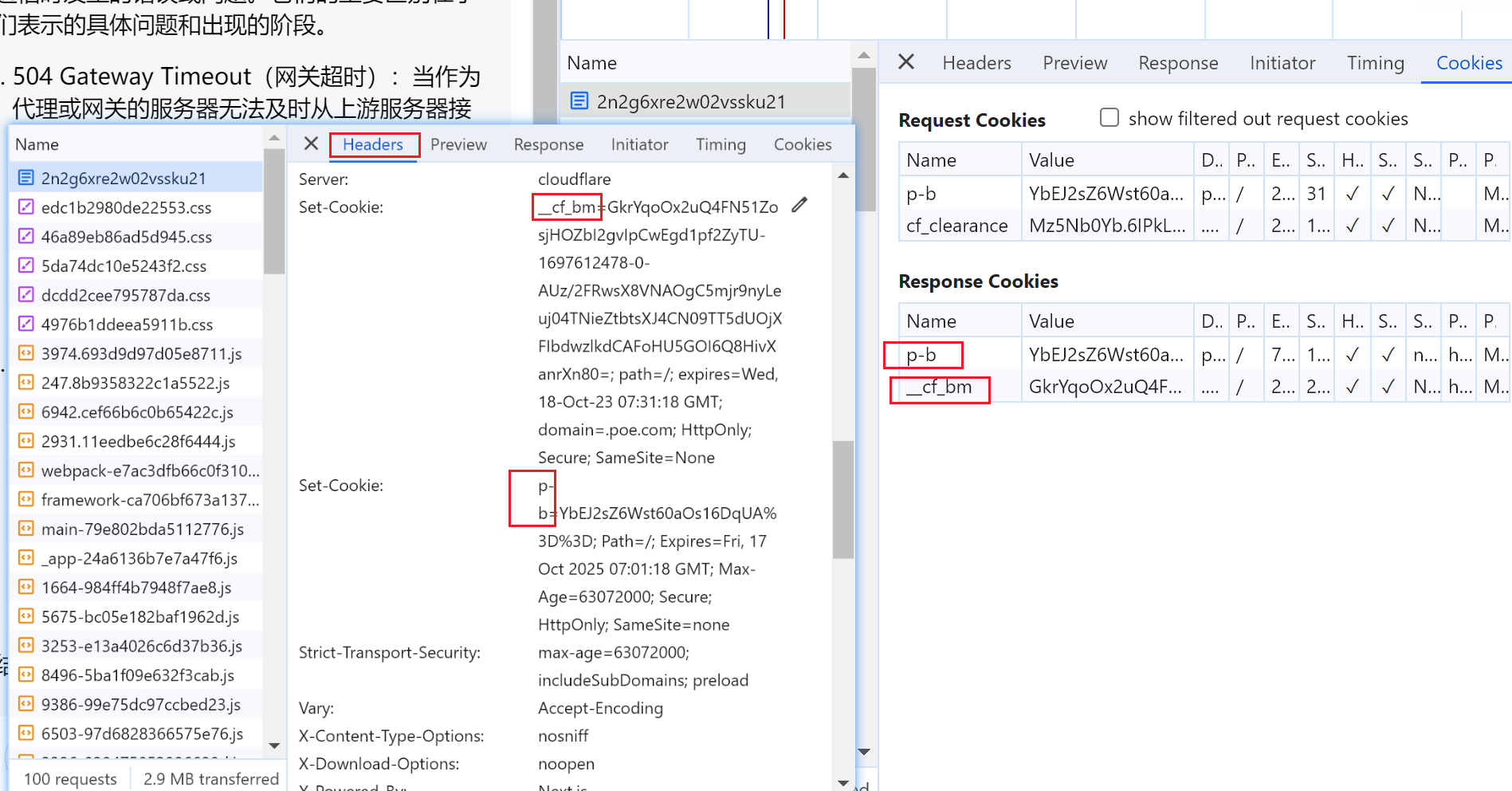
cookie也不会随浏览器关闭而关闭
cookie也可以进一步查看的
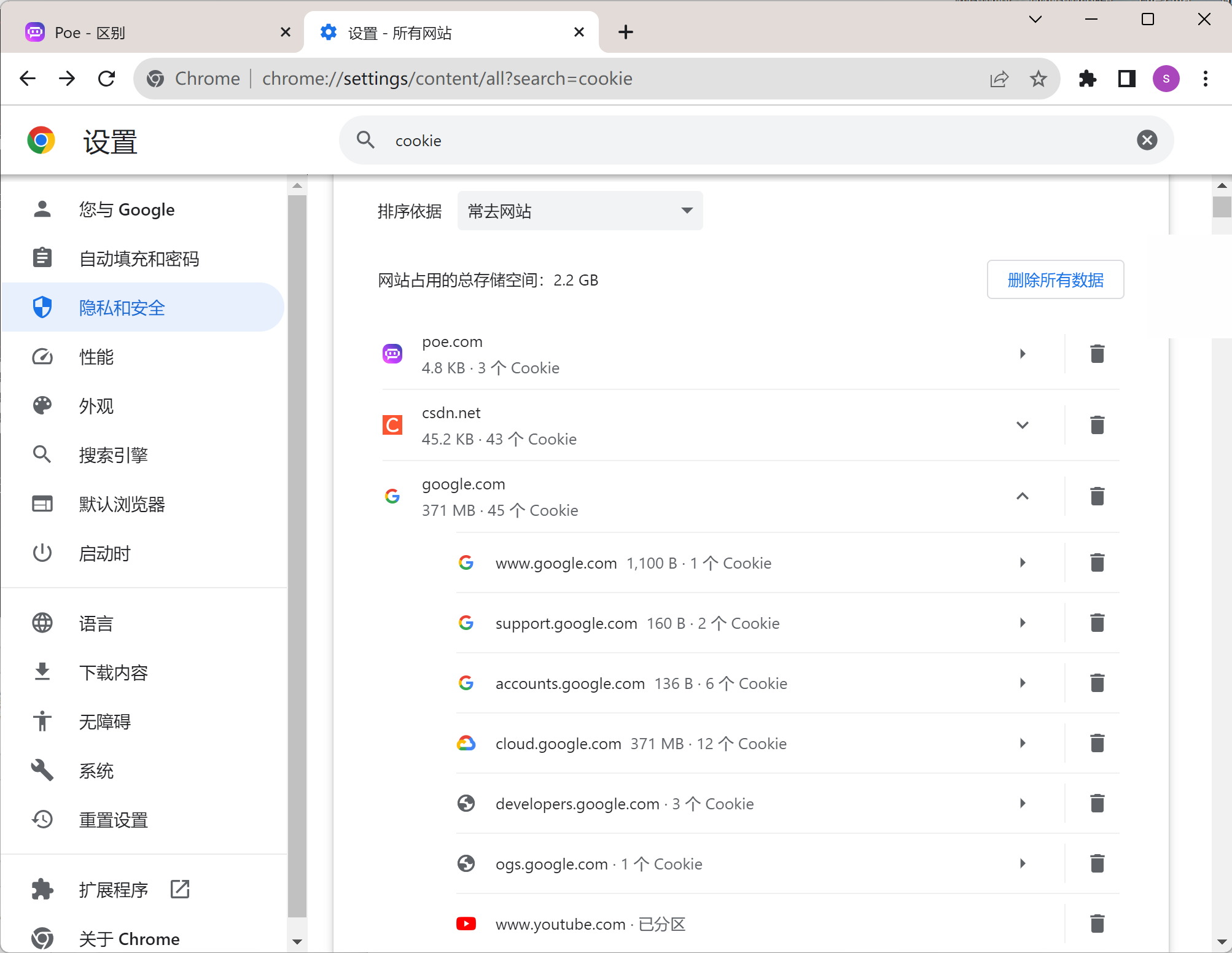
不过再详细好像现在版本直接看不到了,之前点进去可以看到类似浏览器F12里的cookie值得。
https://blog.csdn.net/u011781521/article/details/87791125
找到一个chrome浏览器得缓存
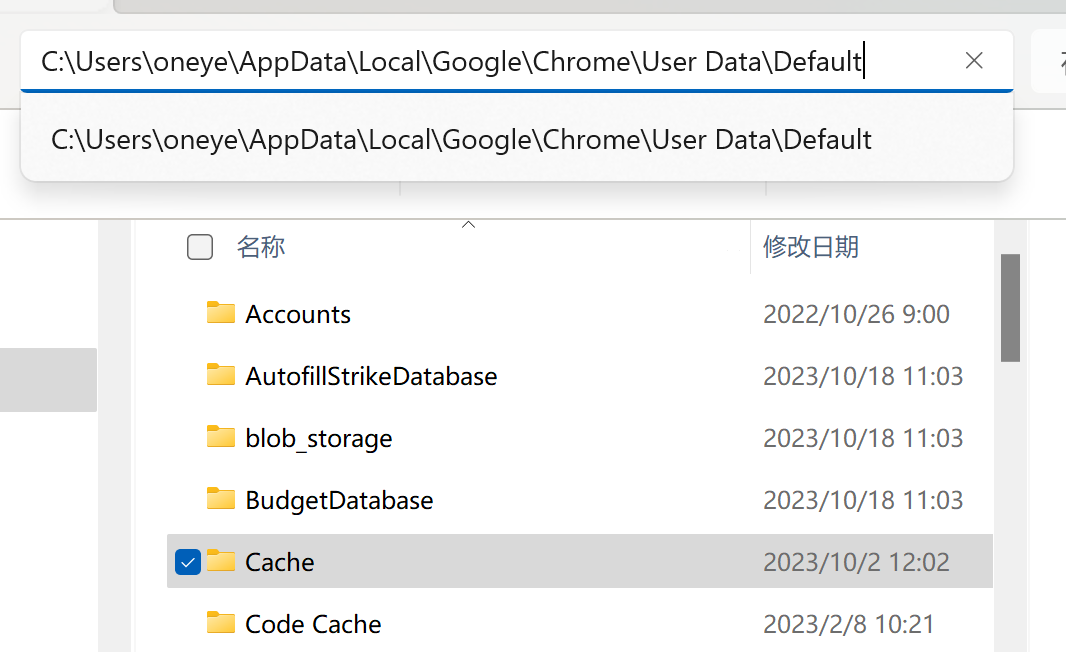
cookie找到了,这是chrome浏览器cookie的存放路径
发现是SQLite格式
传到linux里看算了,windows 和linux 一样要安装sqlite https://zhuanlan.zhihu.com/p/99643229
https://juejin.cn/post/7111861277751771173

yum -y install sqlite

select * from cookies;结果一堆乱码,操

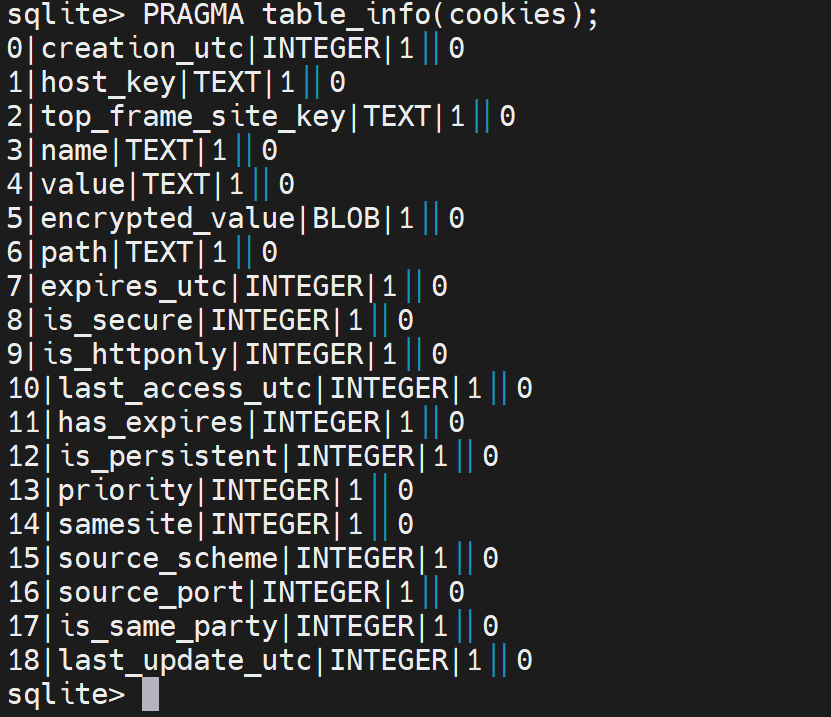
一堆乱码,唉
算了,不看了,可能是字符集要修改一下👆

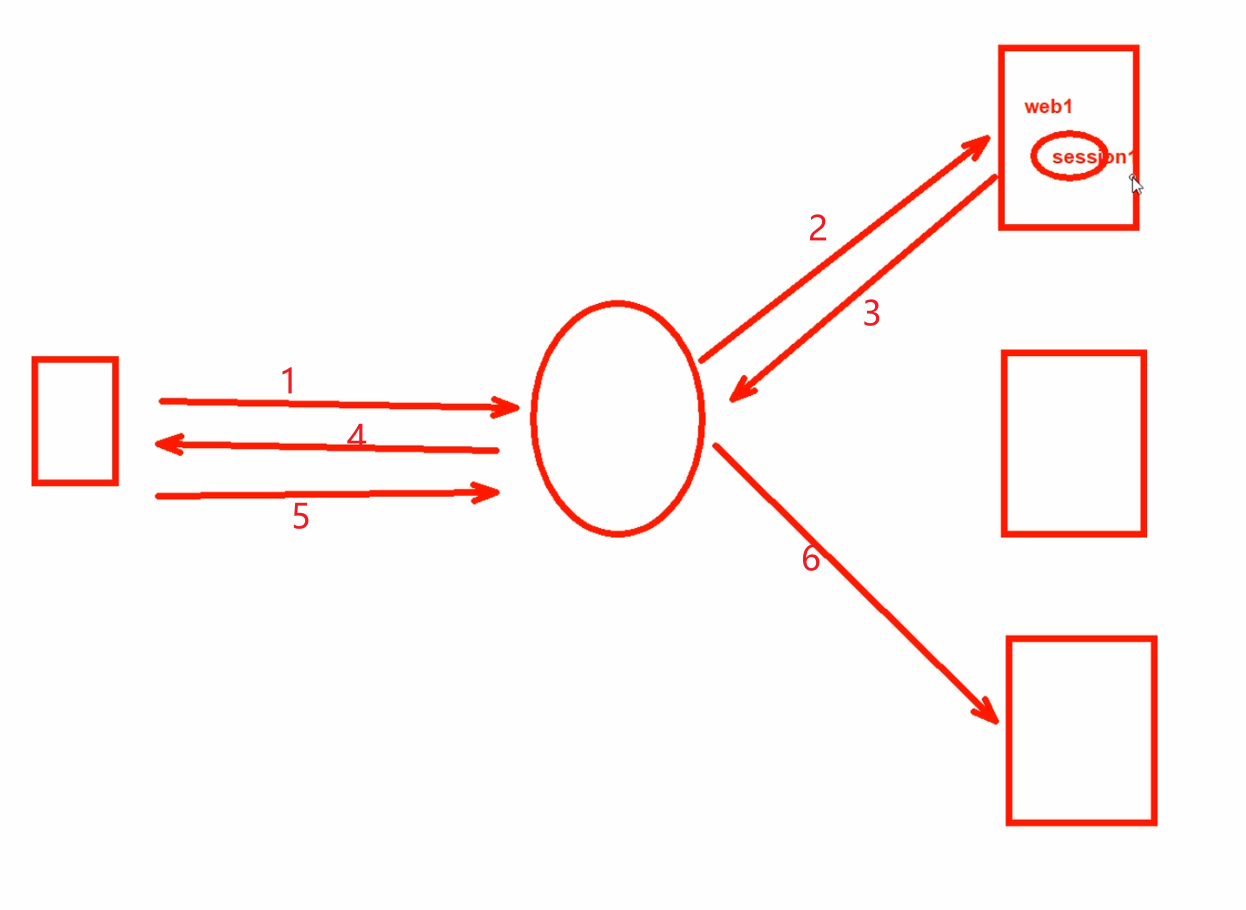
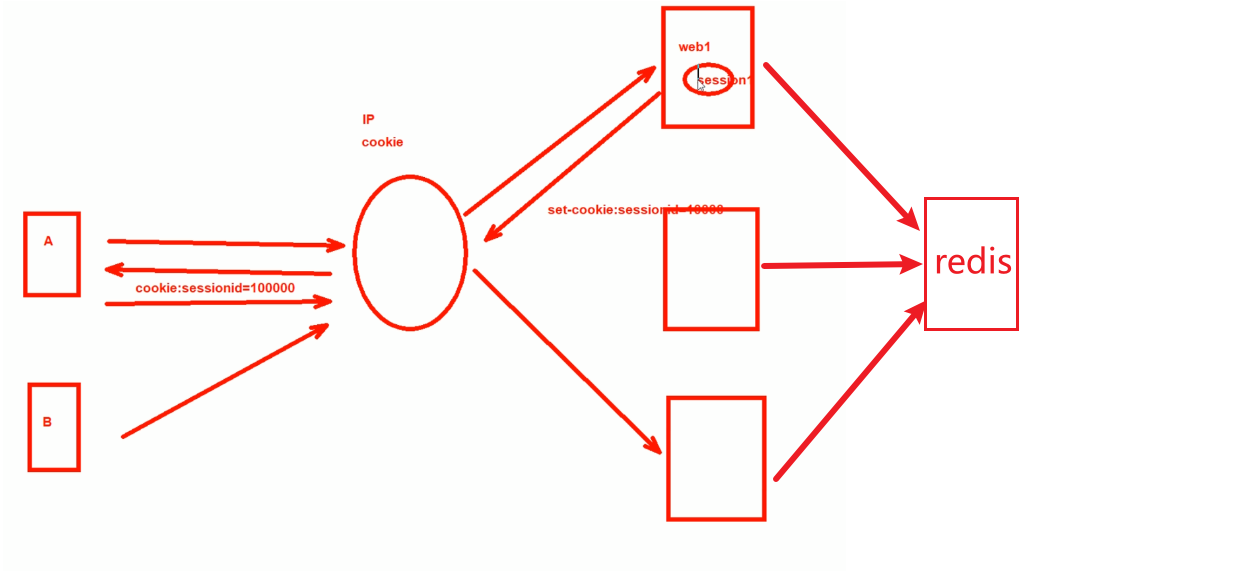
1、2、3、4就是一个session1存入到浏览器上了,这里涉及负载均衡和身后的服务器nodes。session1是对应在特定的node节点的。
如果5请求过来,假设负载均衡没有做session保持,那么就有可能将请求路由到其他的node,而新的node上没有之前的信息,比如登入信息,购物车里的商品,这样原来的页面就没了。
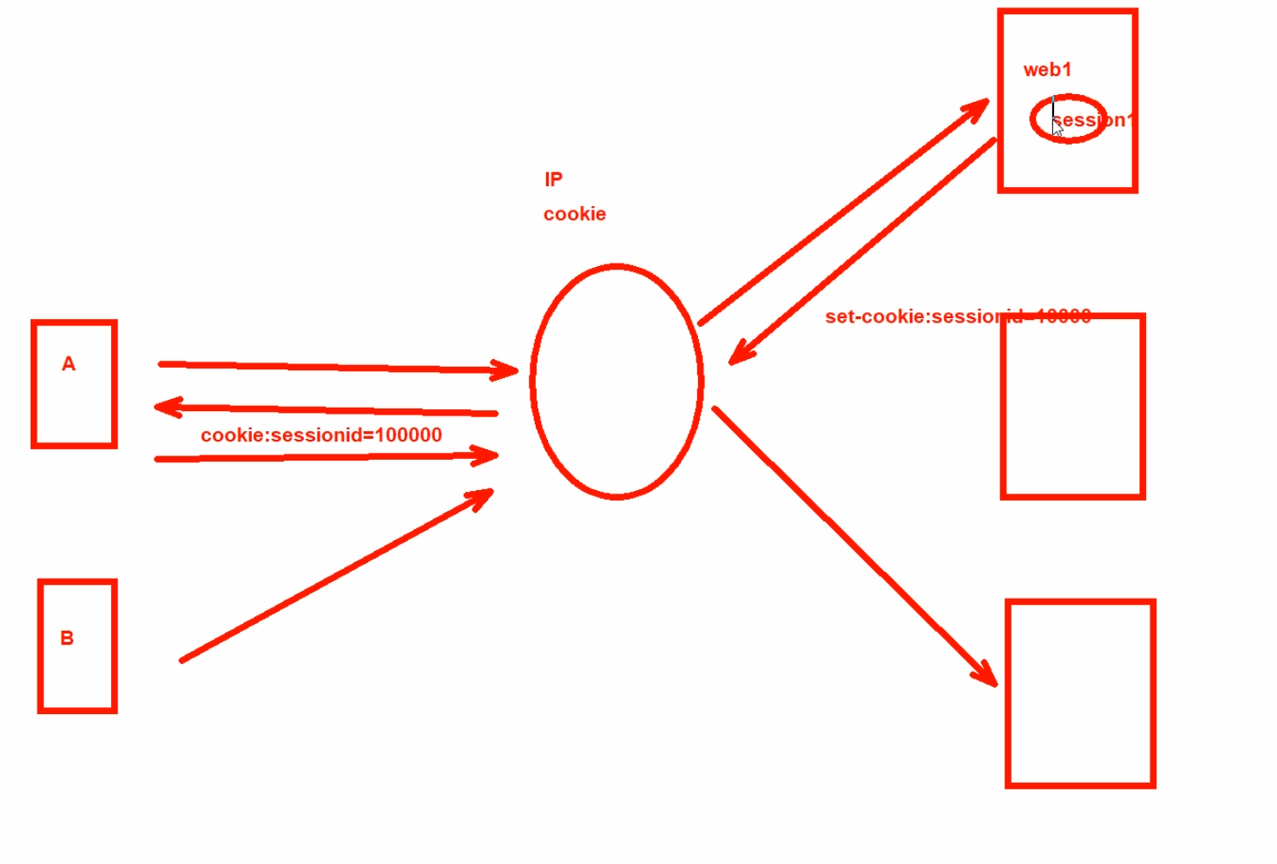
解决误区-不做会话保持,为了保持会话,基于某个源IP-1就路由到特定node上,理论上OK的,因为该源IP都是和一个特定node进行通信的,所以会话一致都在--就是用cookies里存放session ID标记就行了;但是如果IP是PAT身后一堆PC呢。这样针对这一堆IP就全部负载分担到某一台node了吧,可能造成一台node负担重。
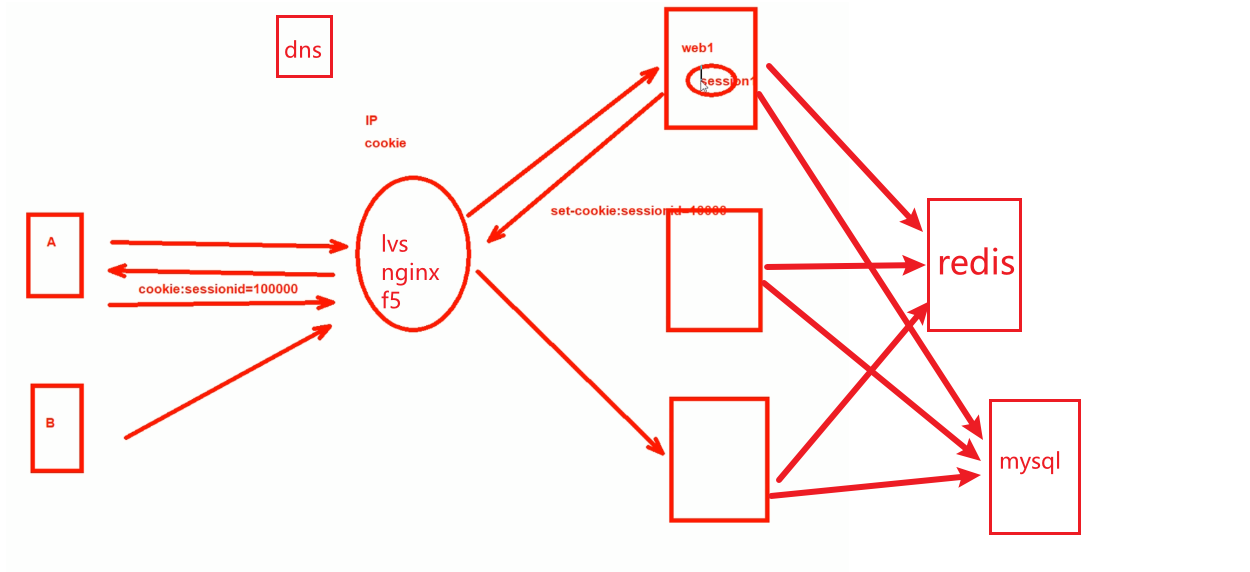
解决方法-基于sessionID,nodes1通过set-cookies打上sessionid1000给A,A就存入缓存。然后负载均衡就基于该session1000进行转发。 这种方式也存在某一个node承担太多的情况,也不能实现均衡。
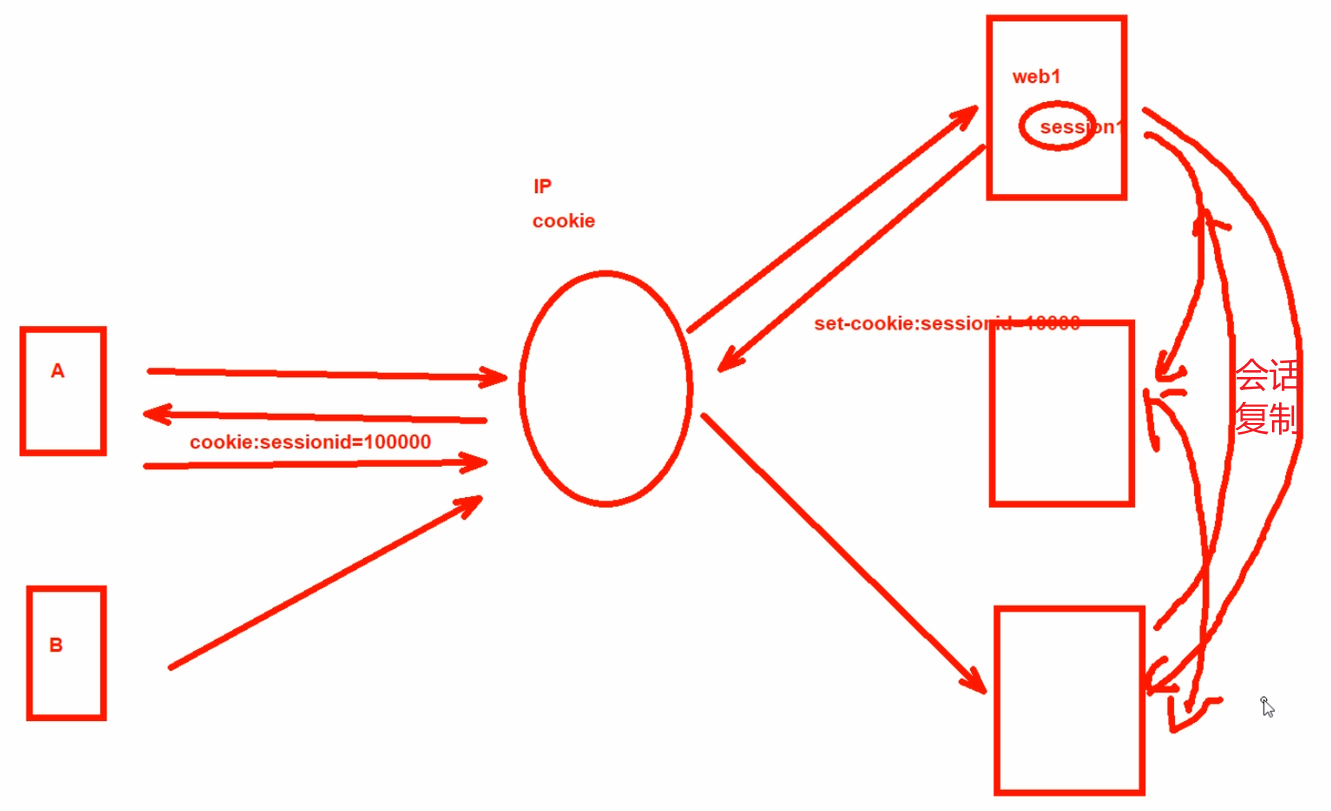
解决方法-session复制,随便调度到哪个node都有会话同步,消耗内存大-因为整体上来看,session是每台机器都要保持。
最佳方案-session服务器,主流软件redis。用户访问网站了产生session了,session信息不放在web服务器上,统一放到redis服务上。因为session大家共用的,所以也无需上图复制。
redis特点:基于内存的,速度快;但是不适用于数据持久化,重启就没了,持久化还得靠数据库比如mysql。
比如用户登入密码,放到mysql里。
cookie是开发,java、PHP开发人员大概去具体实施的,动态页面才需要cookie吧,因为静态页面通常页面数据不大,在http的超时时间内拿掉就行了,不过太大最好也要cookie了吧。 动态页面需要更多的交互也就是会话。
JAVA里的sessionID:JSESSIONID
PHP里的sessionID:PHPSESSID
浏览器如果禁用了cookies,就无法记录sessionID,就无法保持会话了,一些应用就失效了。
php配置cookie👇
vim /var/www/html/setcookie.php
<?php
setcookie('username','ming'); # 没写超时时间,就是session会话级的超时时间。
setcookie('title'.'sb',time()+3600); # time()当前时间+1小时的有效时长,所以tilte.sb就是超时的那个时刻。 # 其实这里是写错了应该是 'tile','sb'是逗号不是点,然后3600秒超时时间的设定。错误的写法也会生效,就是tile.sb是一个key,然后当前时间可能被linux针对1970-1-1翻译成数字然后加上3600了,就只是一个数值了,不是key:value的超时时间了。不写就是session会话级别的cookie,会话没了cookie就没了
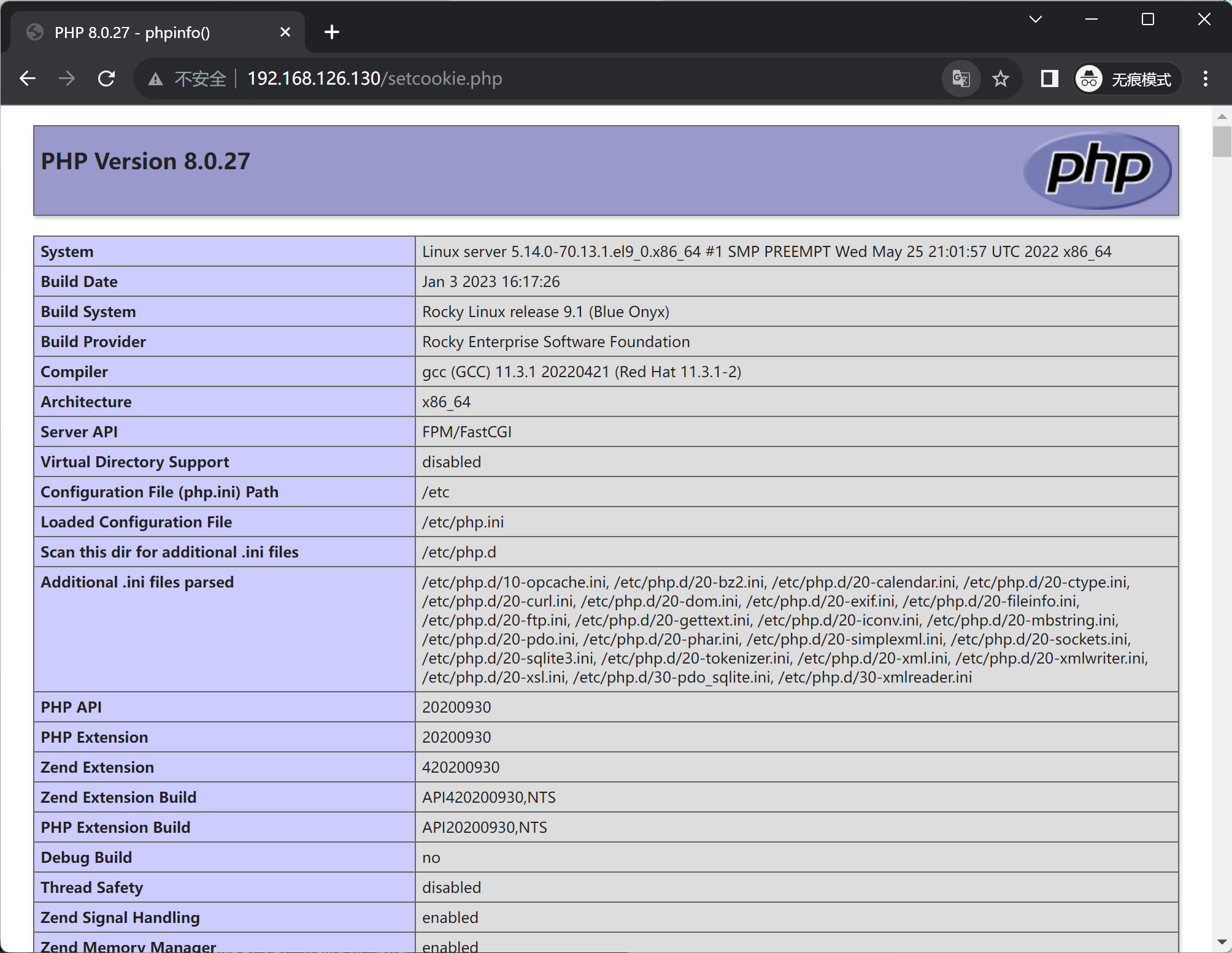
phpinfo(); # 页面显示一下php版本信息
?>
安装php
yum -y install php
systemctl restart httpd # 安装完php后要重启httpd
差不多👆上图的时间确实就是从unix元年1970-1-1 00:00:00开始的,通过man date可见
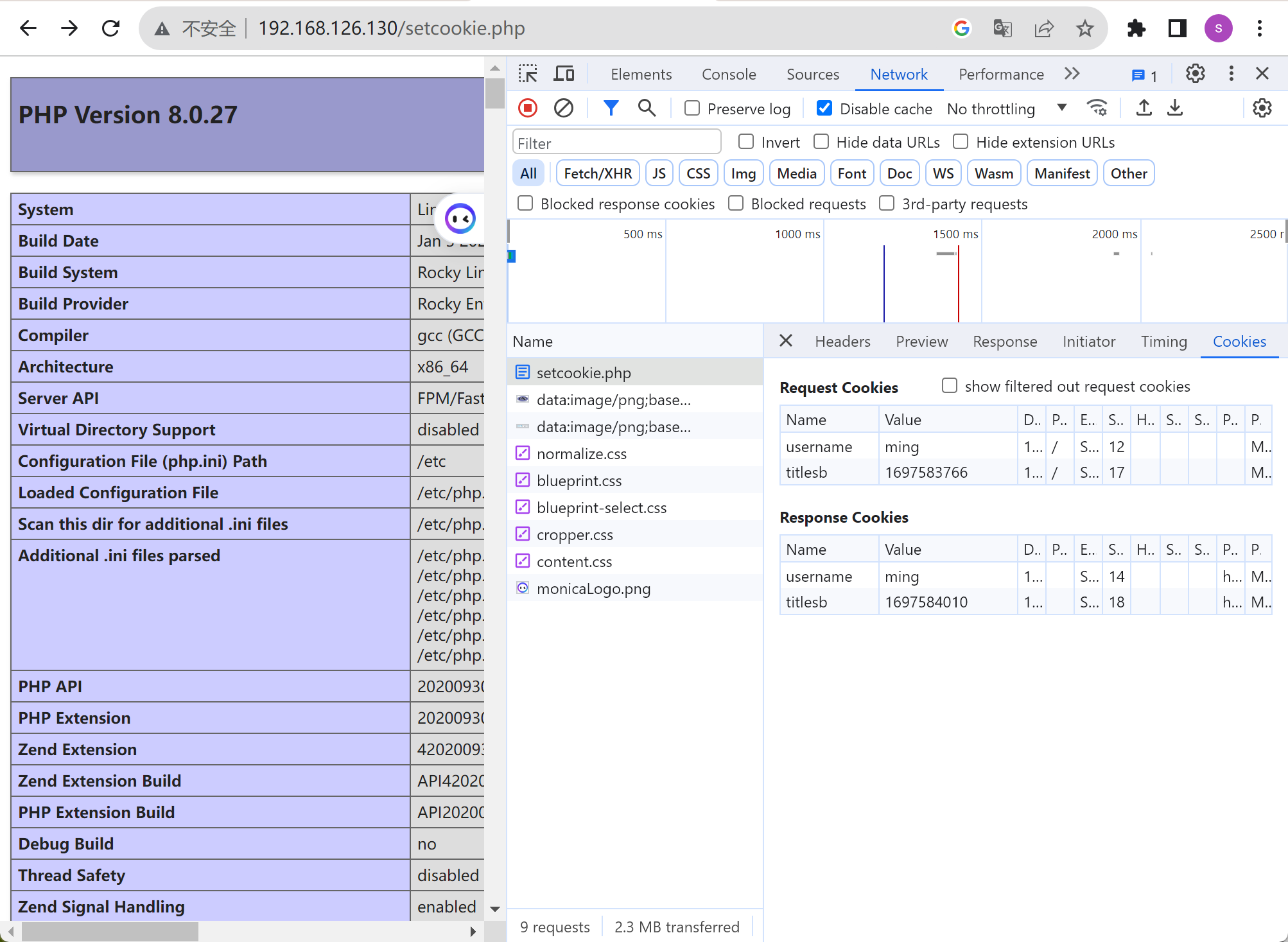
下图是第二天上午敲得命令,
时间相差4个小时,差不多

在这纠结时间不如找到head头里有date字段的看看,验证下图
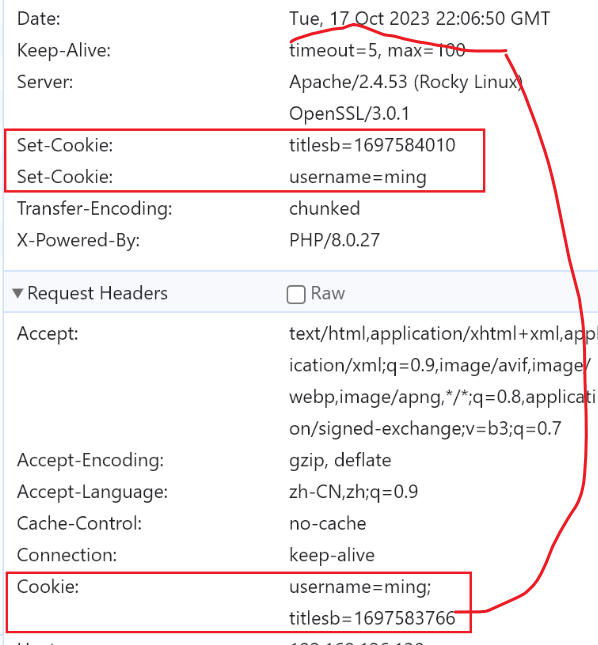

诺,真要掌握了so easy的时间OK的。
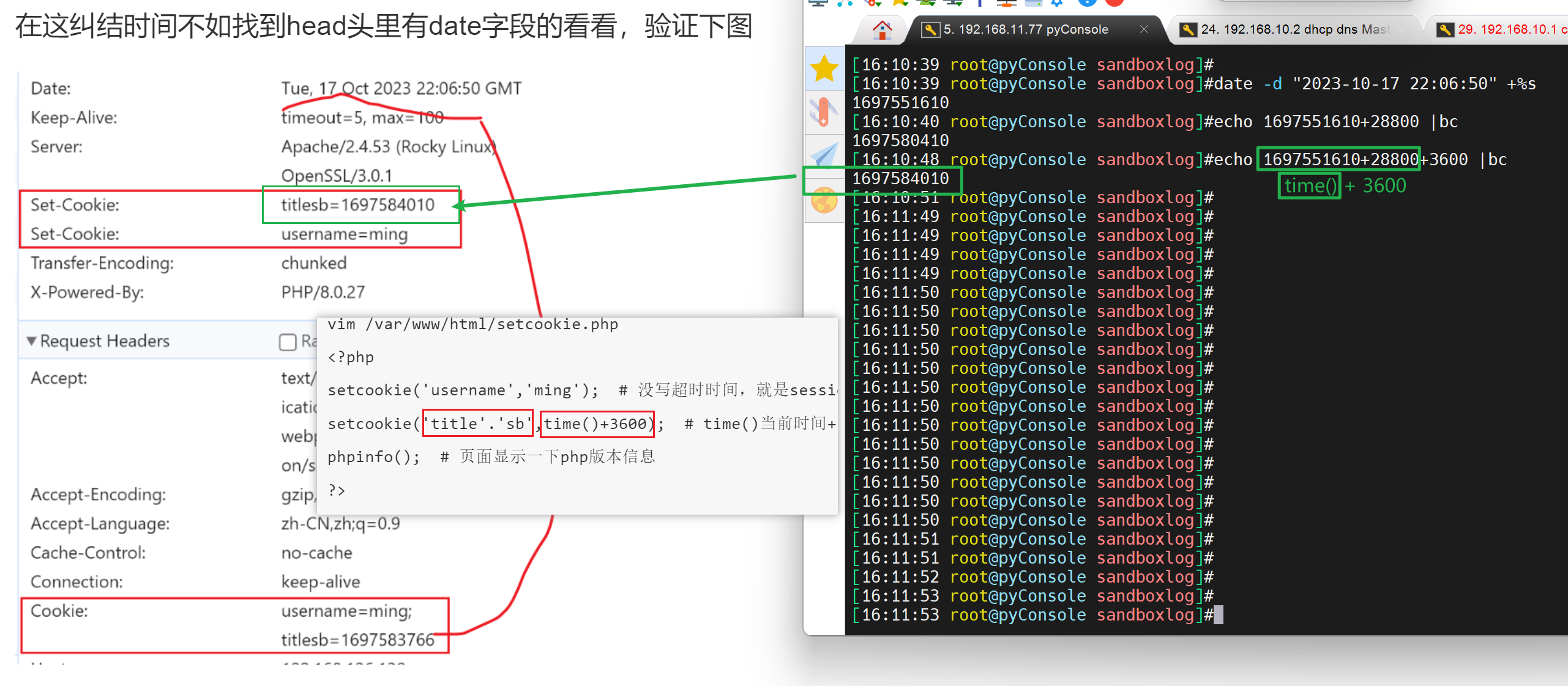
这样上图的1697584010就终于搞明白了,

至于下面的1697583766是request,client请求的时候的时间是client打上去的time()就是这个时候

而上面的1697584010就是server回应的response的time()打上去的时间是满了4分钟的样子,这个可以猜测很可能就是一个client的时间和linux服务器的时间的误差,哦否则c-s之间的请求/响应也就是1s钟了不得了,实验环境啊;所以此项细节研究到此为止,呵呵;不要在细节,要在意细节。话都是你们说的,但是事情原本是什么样的就该什么样的对不对~
针对上图titlesb,修改一下配置文件
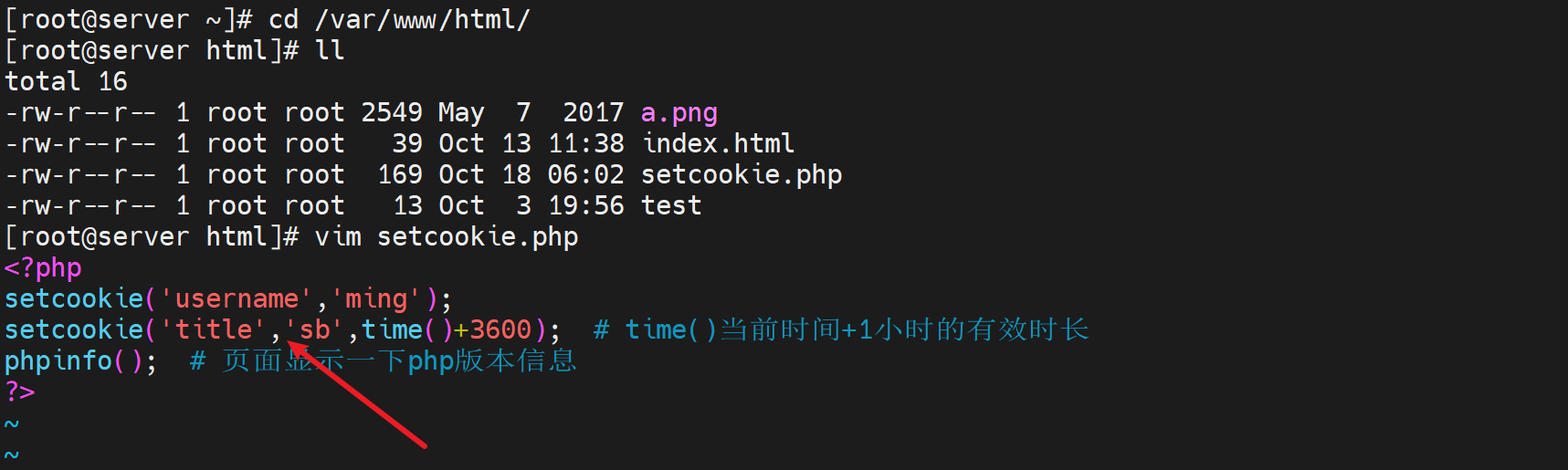
这下超时时间1小时就对了👇
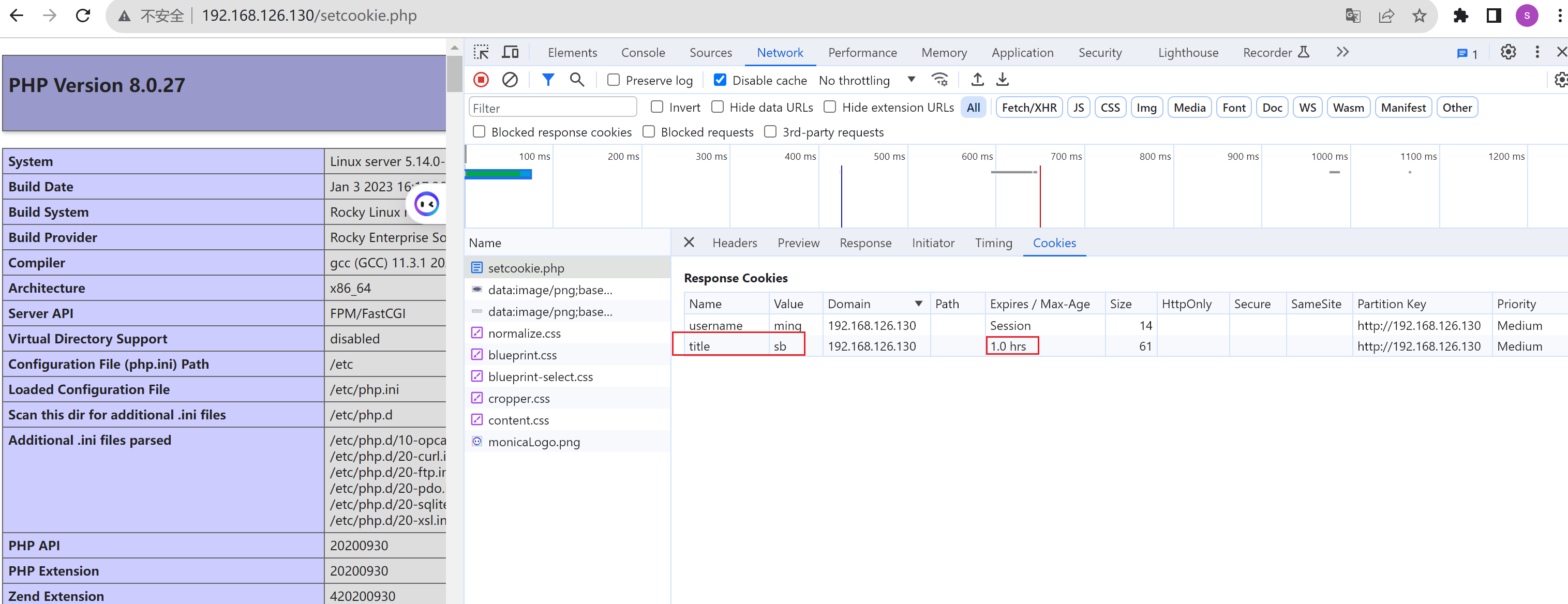
注意上图Expires/Max-Age,一个是session也就是会话级的cookie,一个是1小时超时。
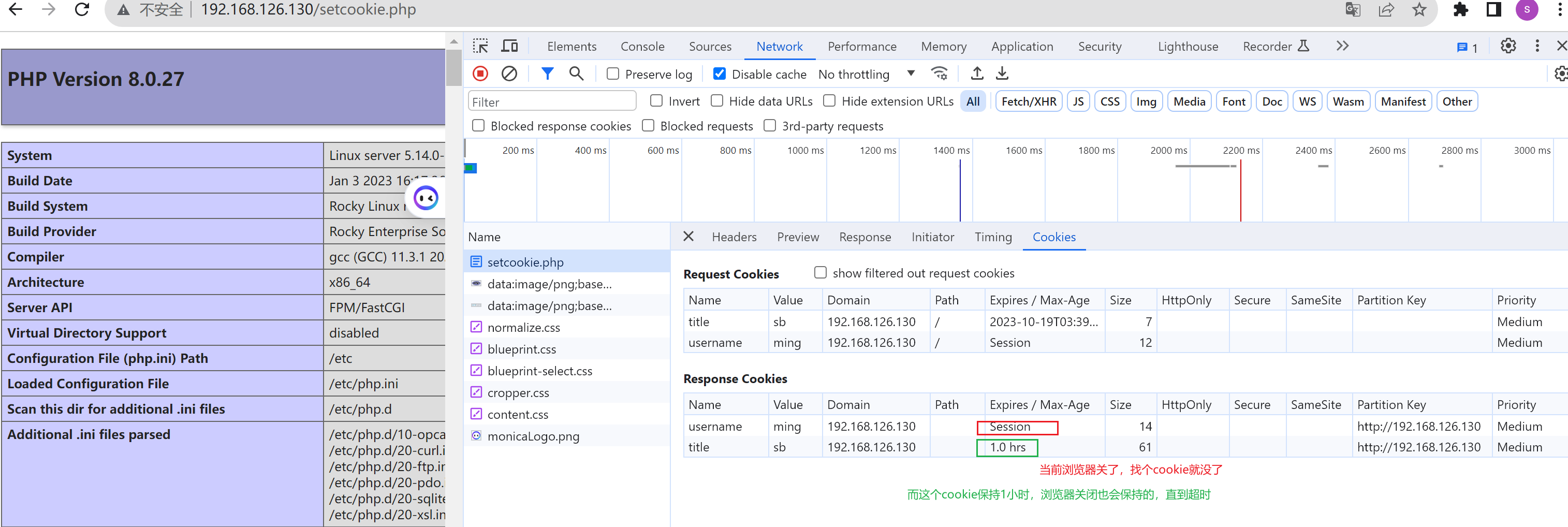
然后重新打开浏览器,但是不要再访问这个192.168.126.130页面
可见就也给cookie了不过这个cookie是啥,现在看不到了,以前浏览器版本点击去就有的,不过可以换浏览器看,或者这样看
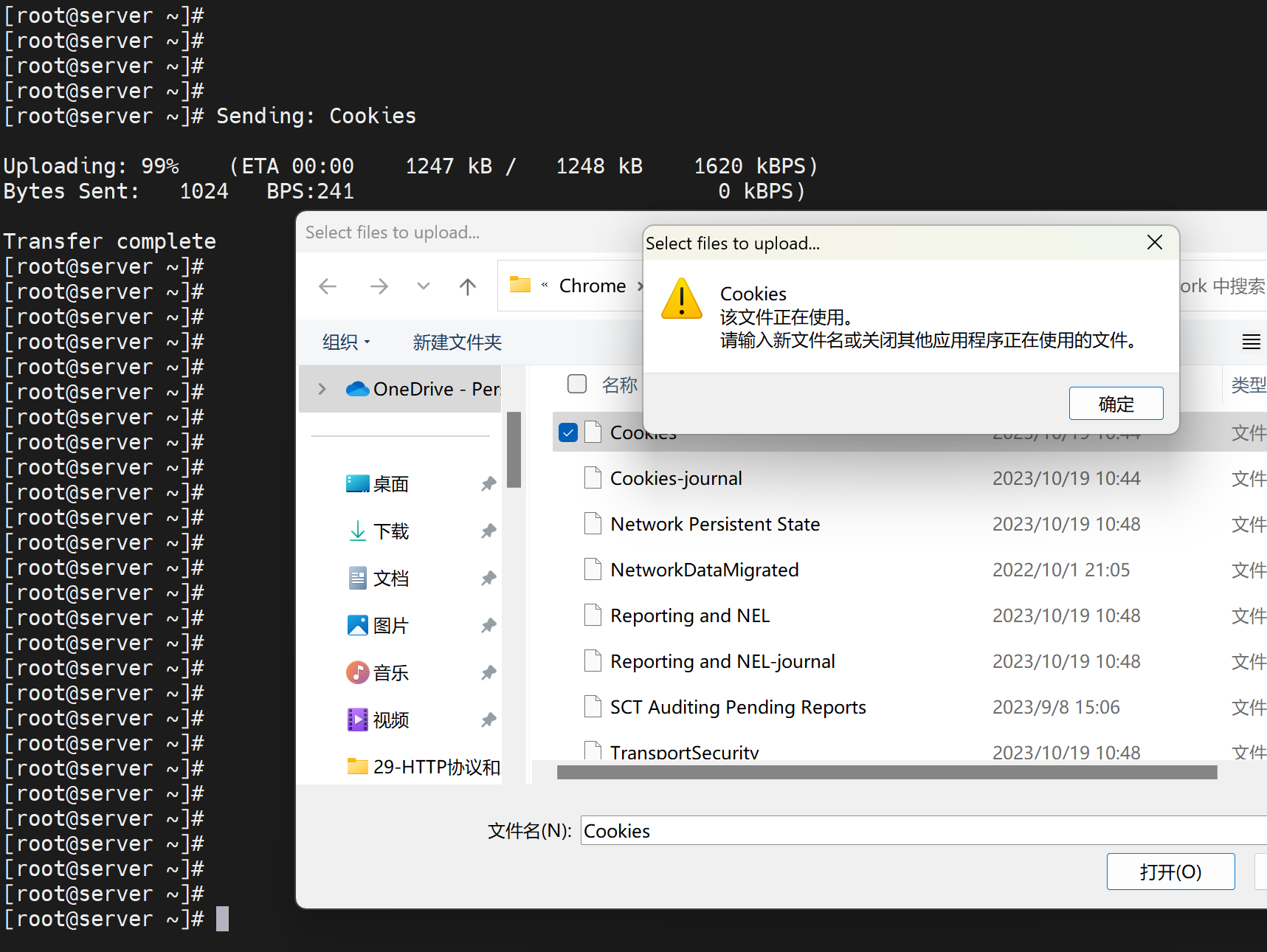
cookies文件正在被使用,C:\Users\oneye\AppData\Local\Google\Chrome\User Data\Default\Network
在这个路径下的Cookies文件咯,说被使用,其实就是chrome浏览在使用中,关闭浏览器就好了。
然后就看到浏览器里(仅显示1个Cookie-看不到内容)里面的内容了
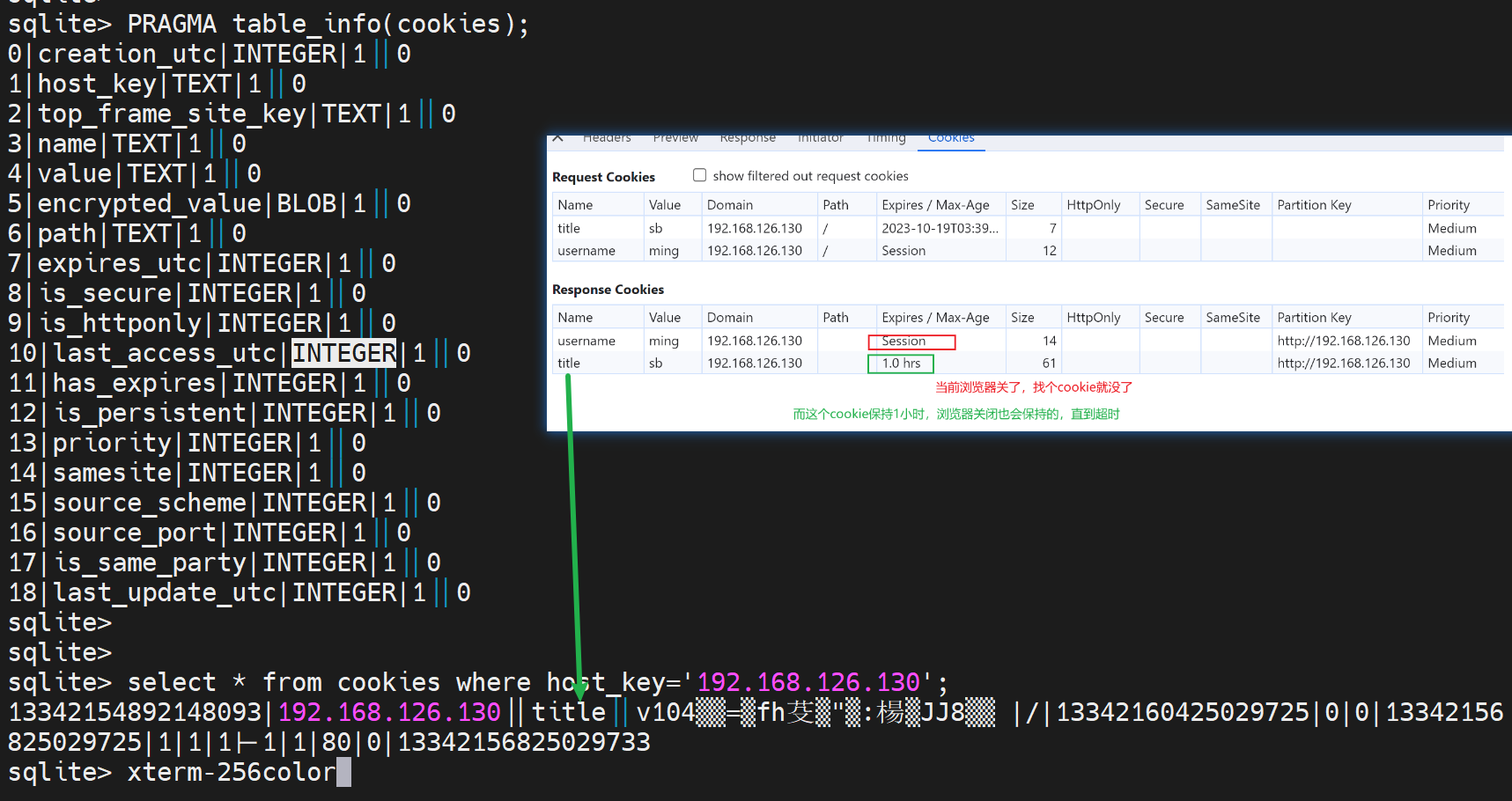
7列13342160425029725 是expres_utc,通过date可得出,得出个鬼啊,你算算多大,呵呵

搞不懂,value TEXT竟然连sb字符都不显示的嘛,加上现在浏览器设置里都看不到cookie的具体值,只能在F12里看,是不是从安全出发做了限制了。
links和curl简单用法
有些网站不让看源码,其实下都下来了怎么会看不到呢
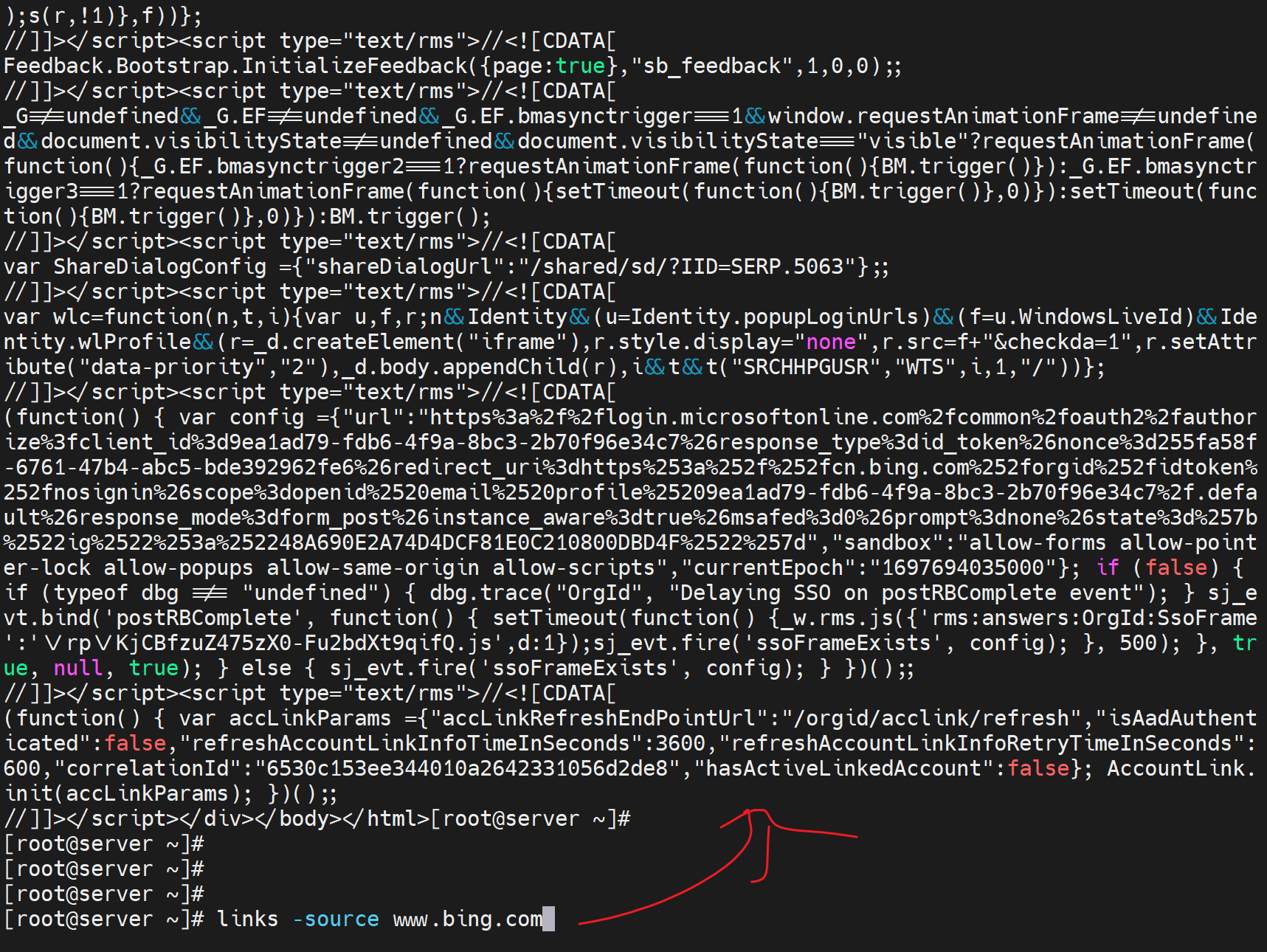
网站的文章不错,但是不让你复制粘贴可以这样

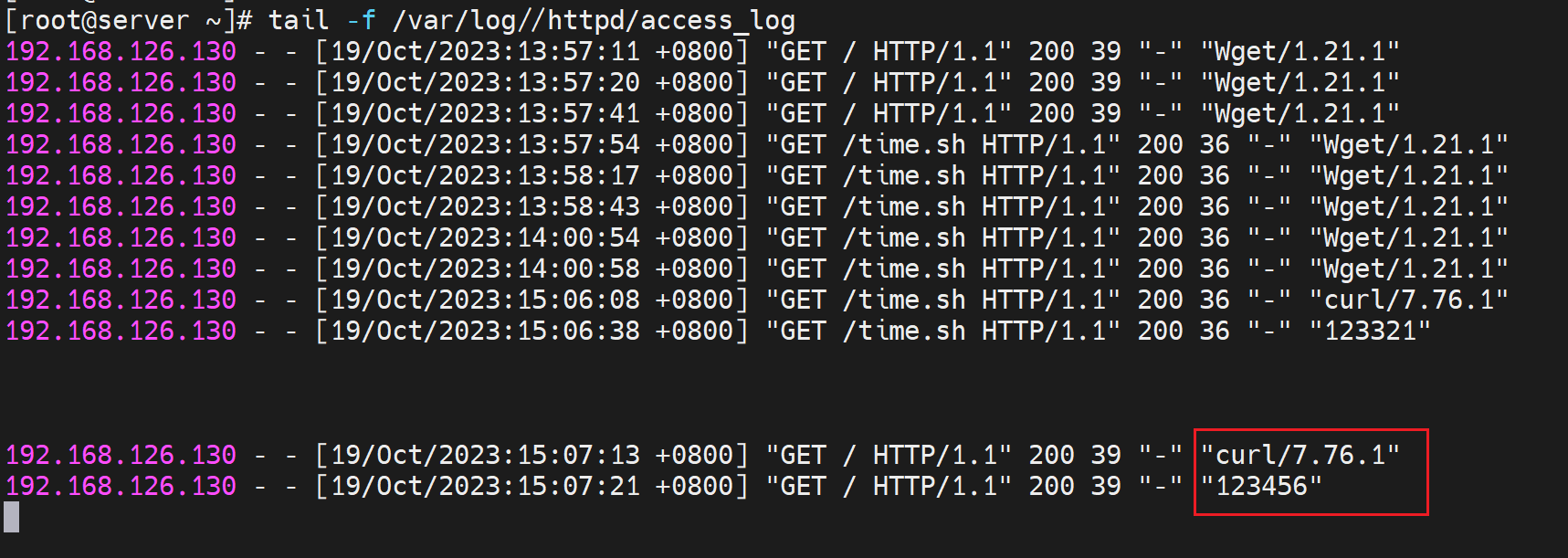
wget简单使用
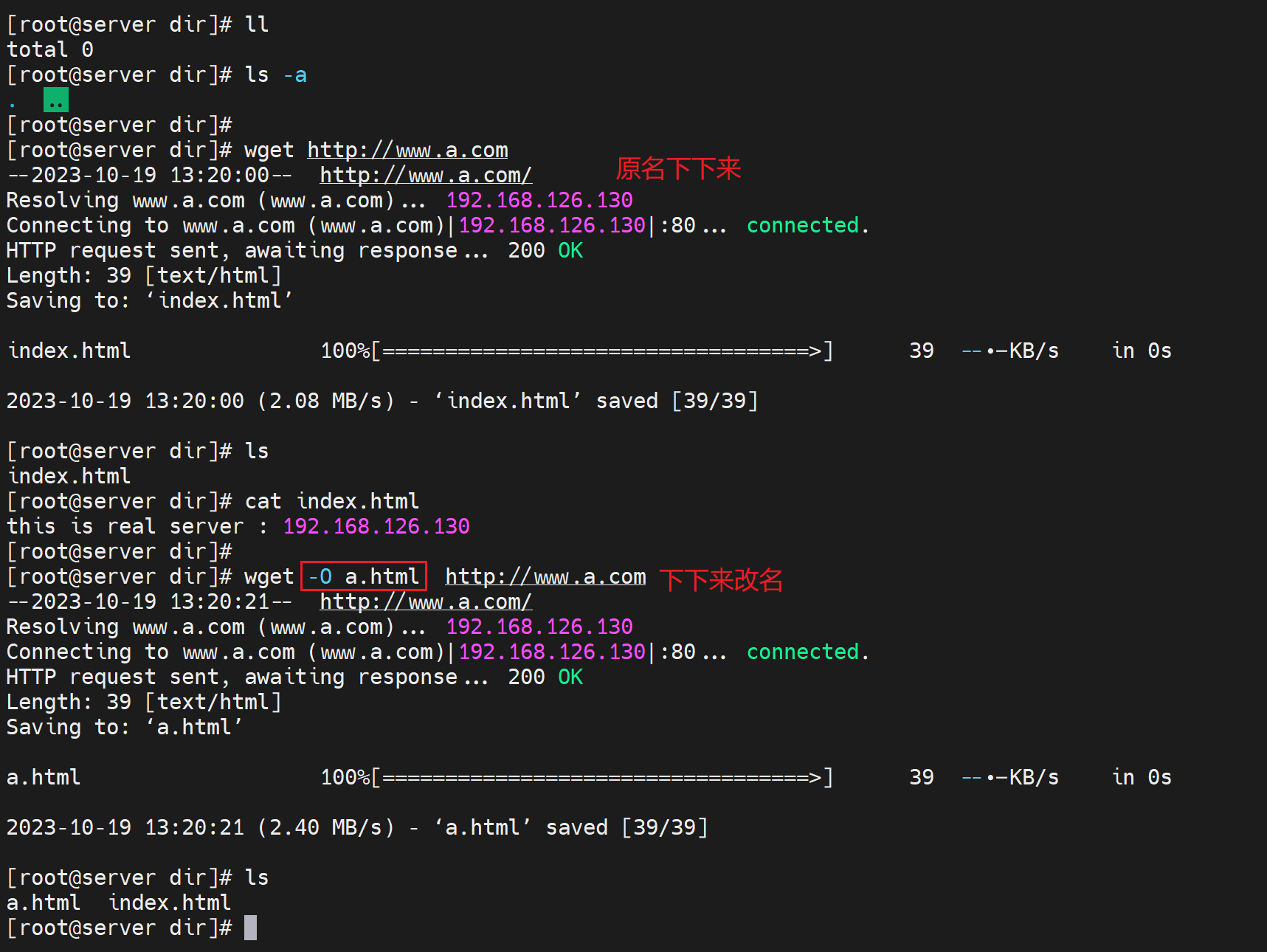
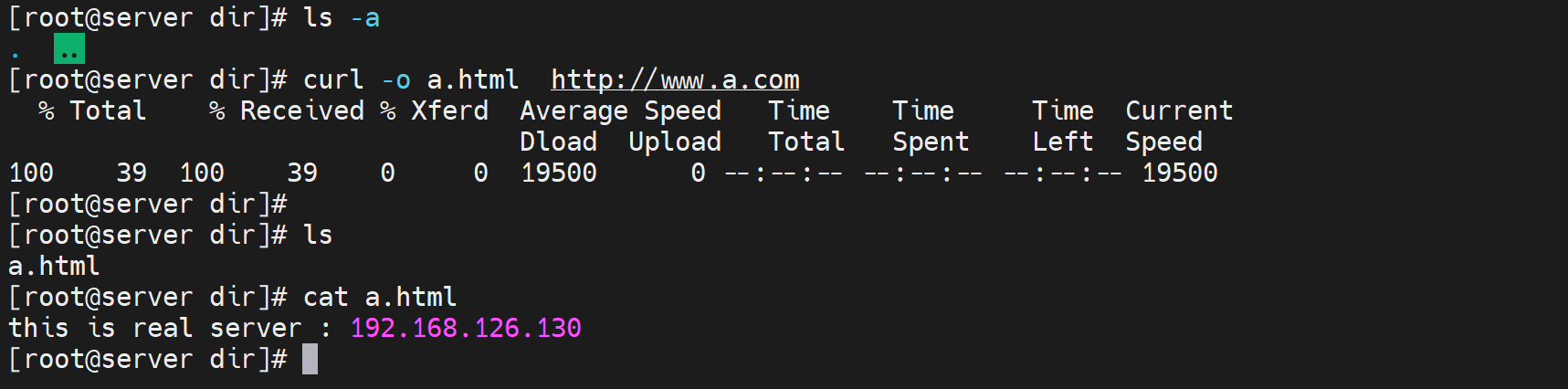
wget 是-O 大的,可不带 ;curl 是-o 小的下载必带
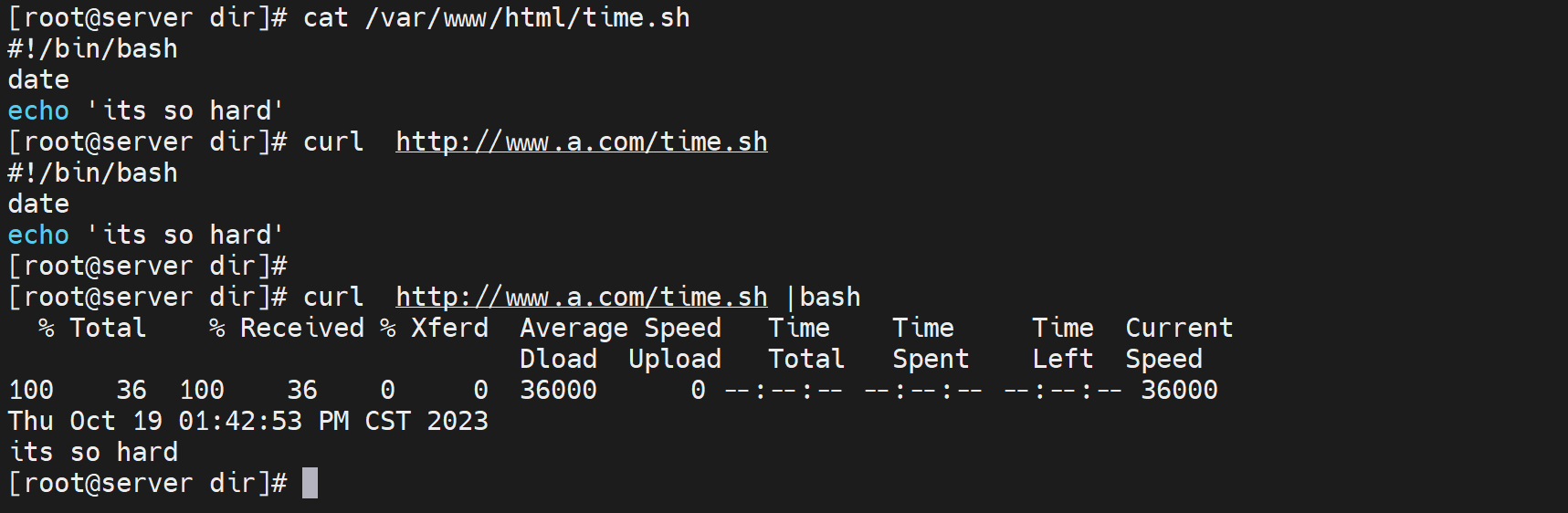
如果页面是一个bash脚本,就可以这样写
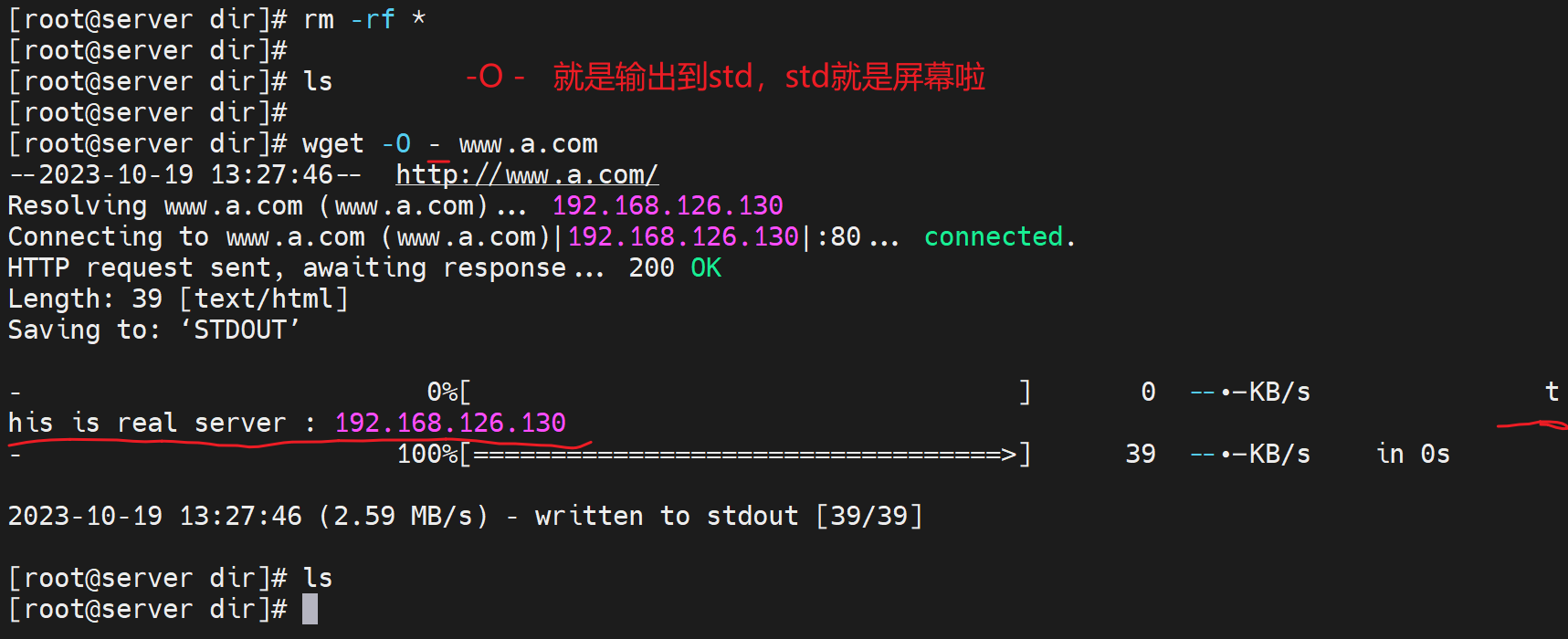
优化输出

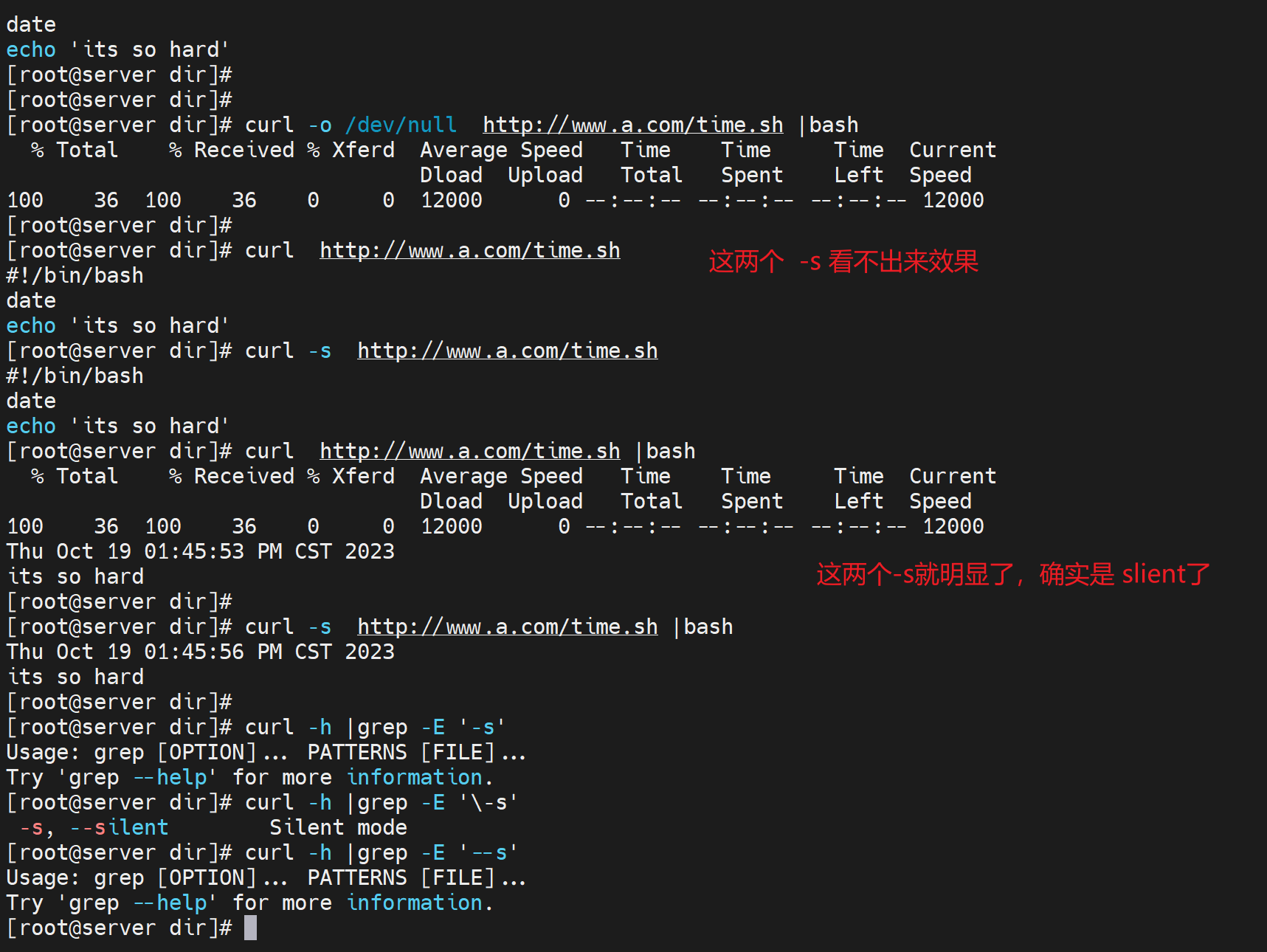
curl -s xxx |bash -s其实也是有std的,所以可以|管道符到bash 去运行。
还可以用wget的std打印和管道符的用法👇
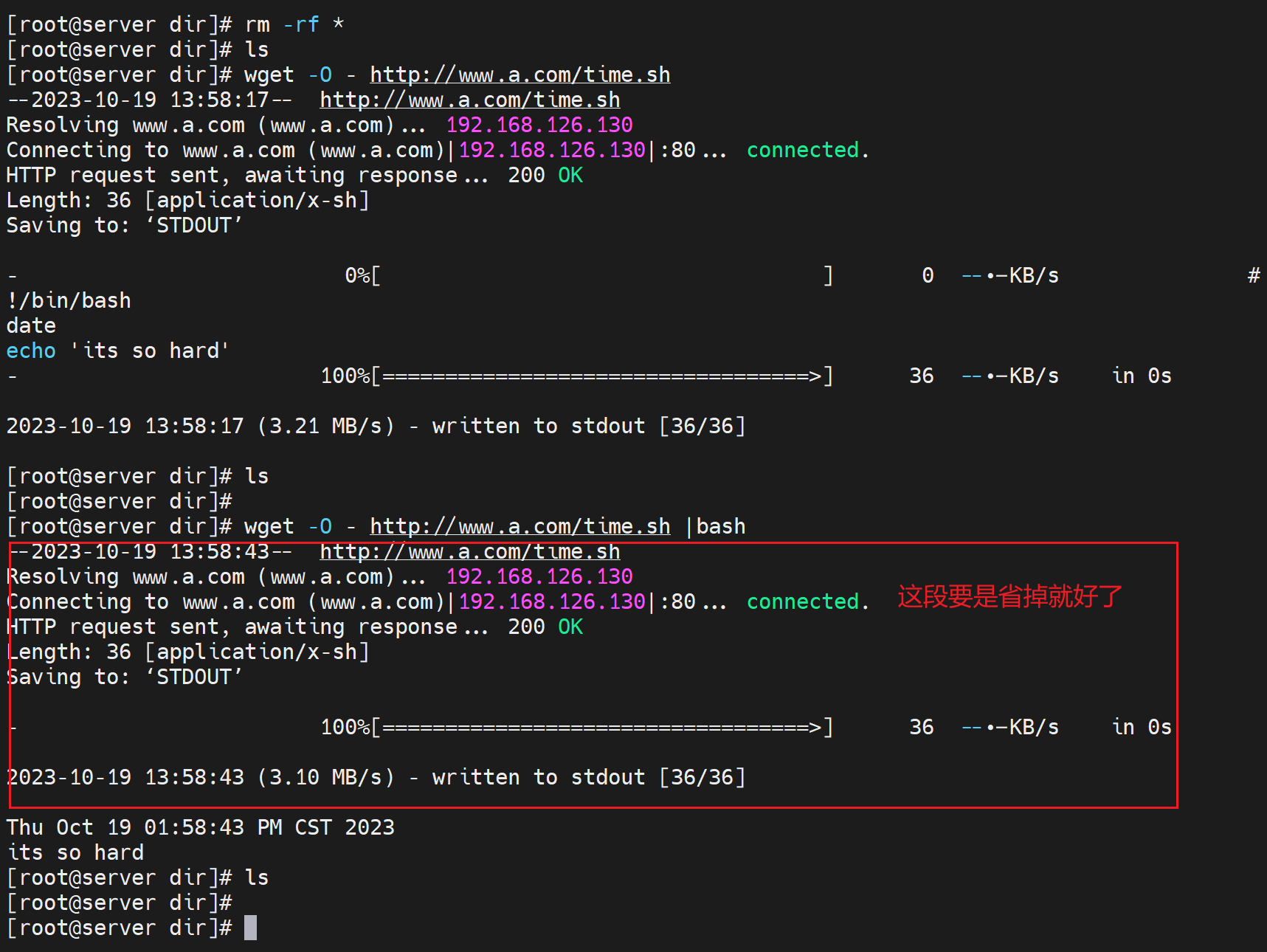
不过还需要进一步优化-q静默一下
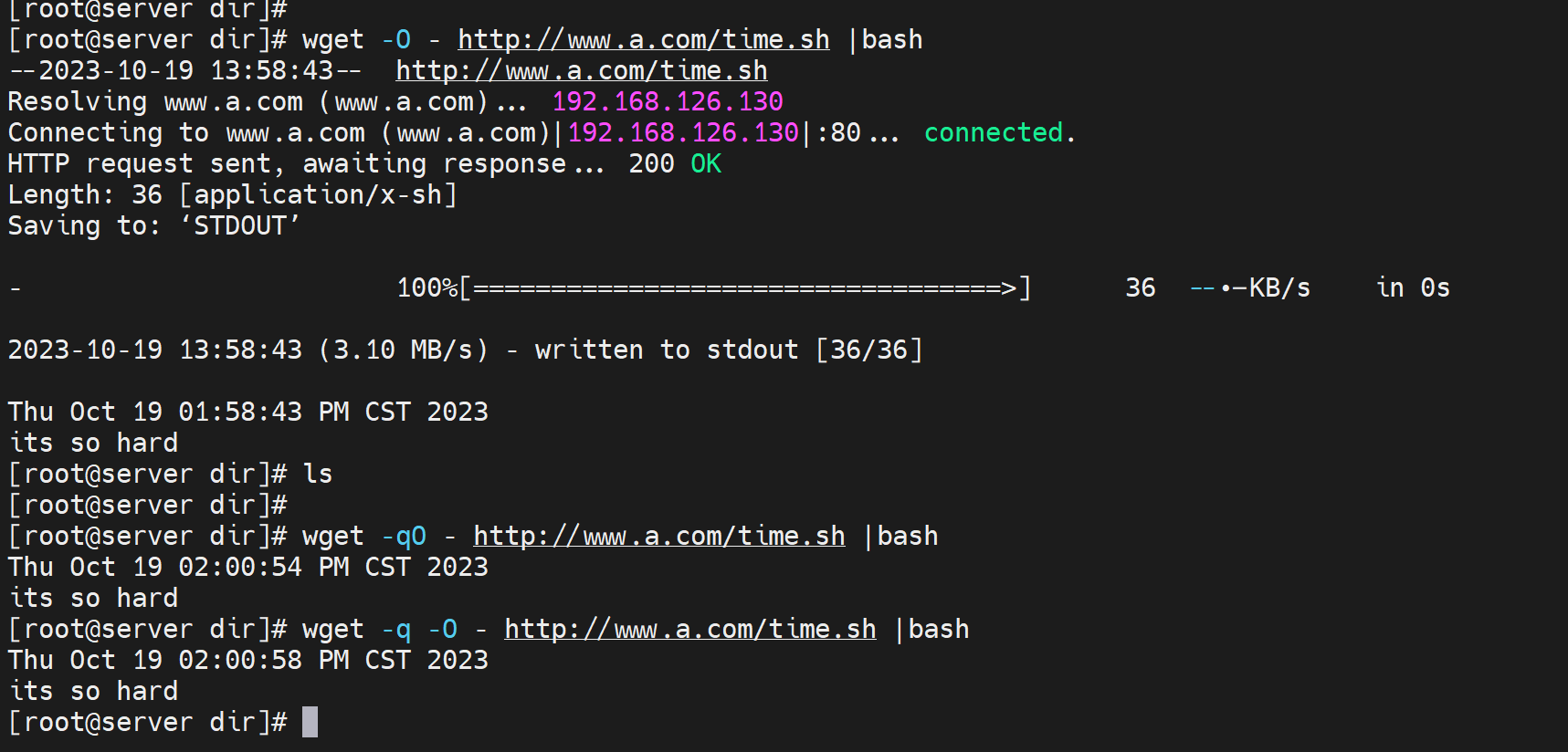
就干净了👆。
所以上面就是一个很好的,将脚本share出去的方法,比如shell/python就可以用这种方式,不过得有web服务咯。这种适合简单场景无需传递参数的情况。 很多这个安装脚本都是这样玩的,比如 玄学上网一键安装脚本(科学的尽头是玄学嘛,你懂的)。
不过我更多脚本share出去一般推荐这样,才可以传递参数👇,然后使用curl去和该api交互
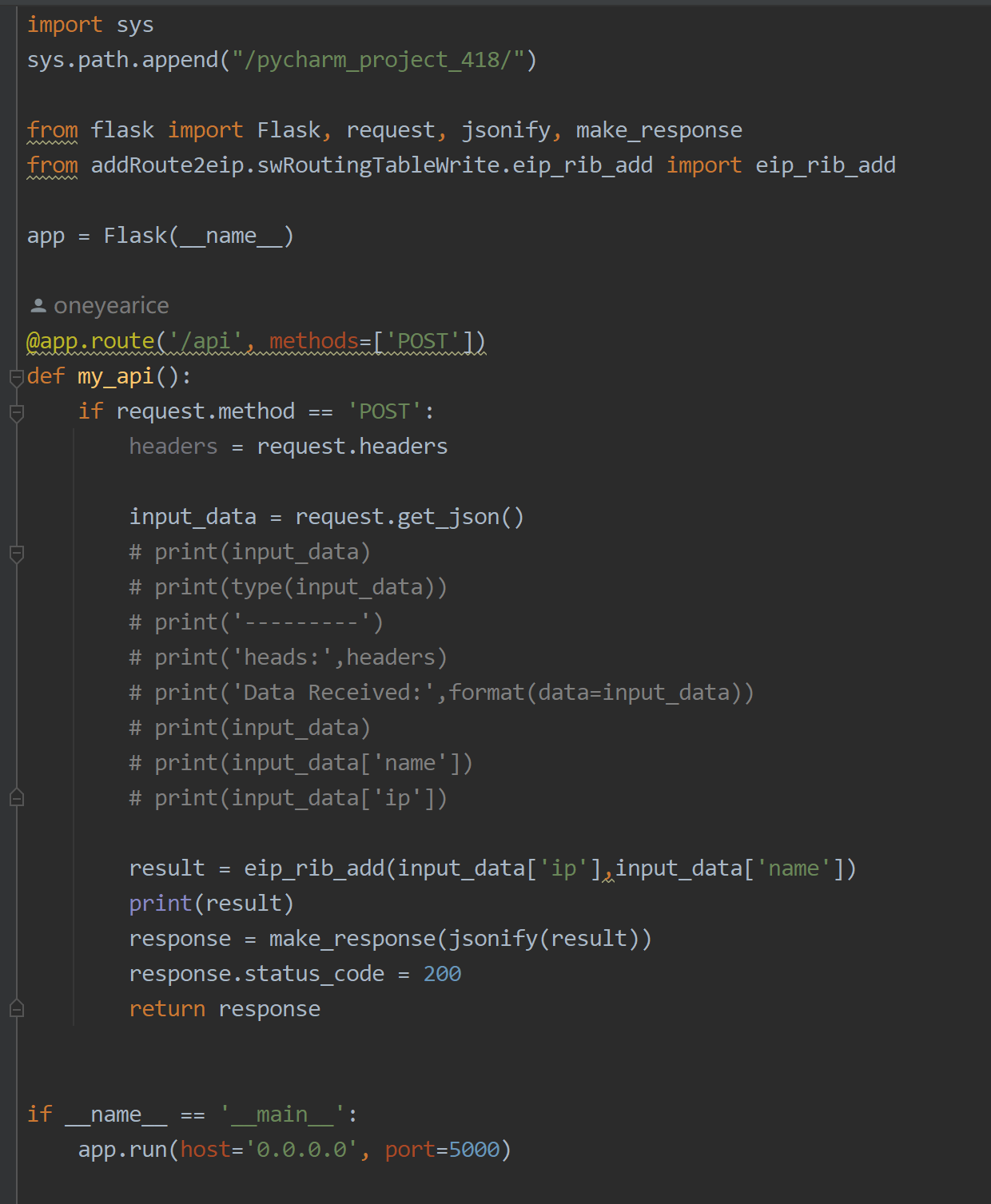
curl -X POST -H "Content-Type: application/json" -H "Data_Type:msg" -d "{\"name\": \"Alice\", \"ip\": \"130.1.1.11\"}" -s http://192.168.11.77:5000/api | python -c "import sys; print(sys.stdin.read().encode('utf-8').decode('unicode_escape'))"
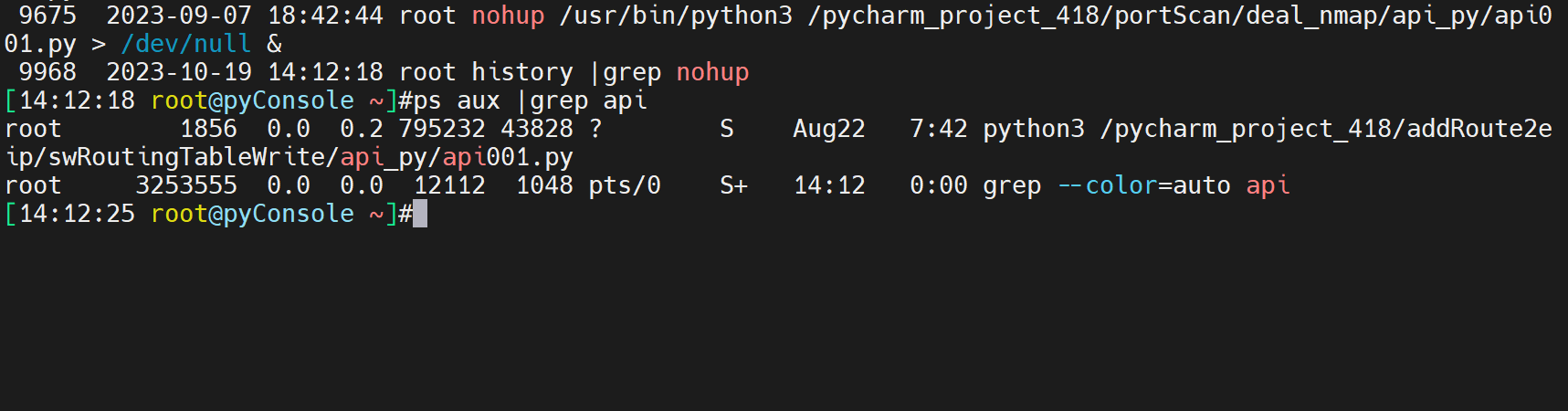
当然eip_rib_add是一个python脚本函数。再一个上图脚本后台运行就行了,nohup clixxx > /dev/null & 敲完后exit退出保证后台运行,或者screen -S xxx开启后台运行clixxx然后直接关闭该窗口就行了--具体用法参见本blog的screen章节。
wget也支持限速
--limit-rate=
curl也支持很多协议不仅仅是HTTP
https://curl.se/docs/tutorial.html

user-agent伪装
修改user-agent这个翻译叫用户代理,其实就是使用的什么方式访问server的,包括浏览器,本质上就是个注释👇



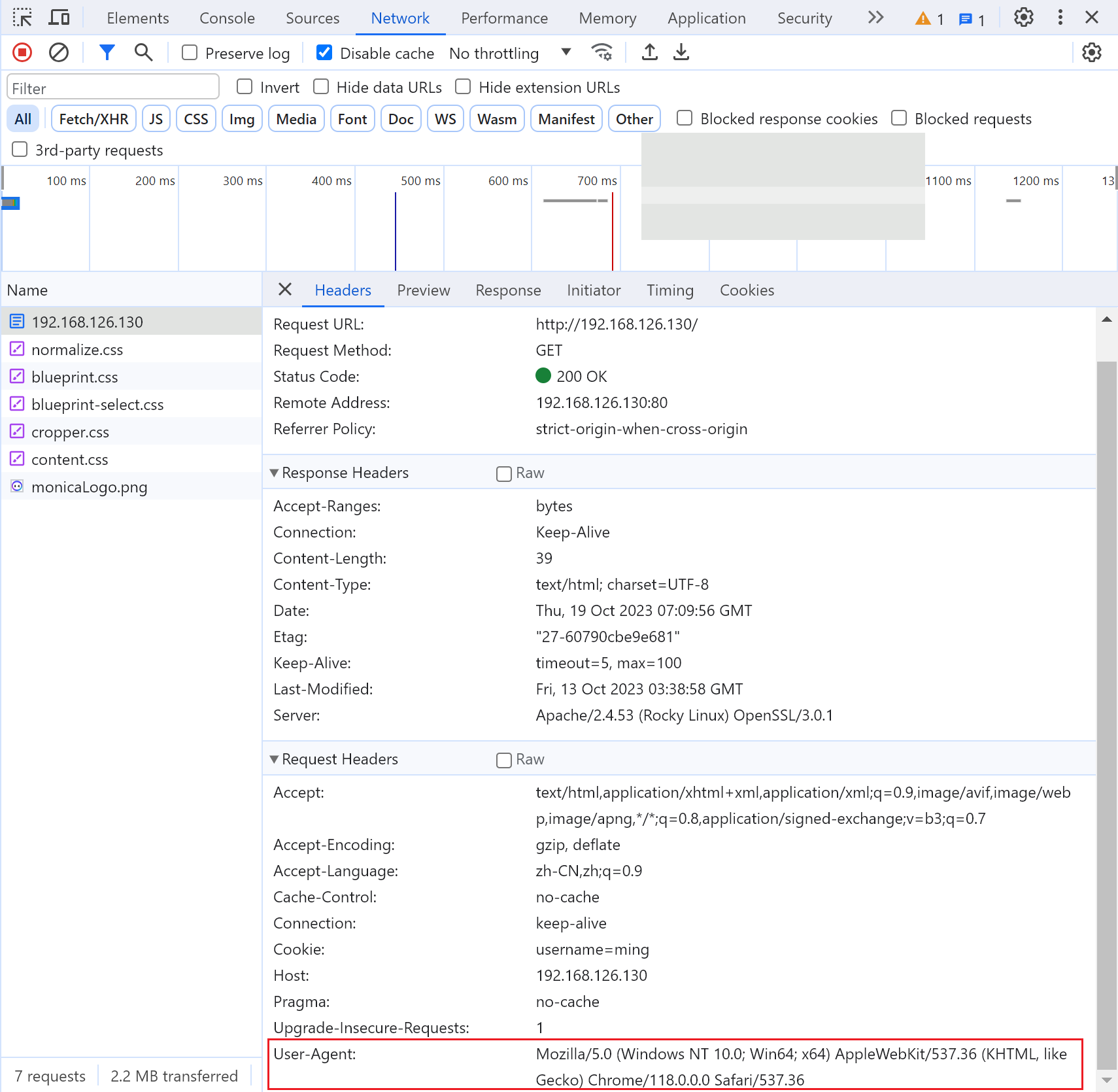
这就比较多了👆,一般都是浏览器访问,user-agent里携带的都是浏览器的表示,不过Mozilla需要了解下
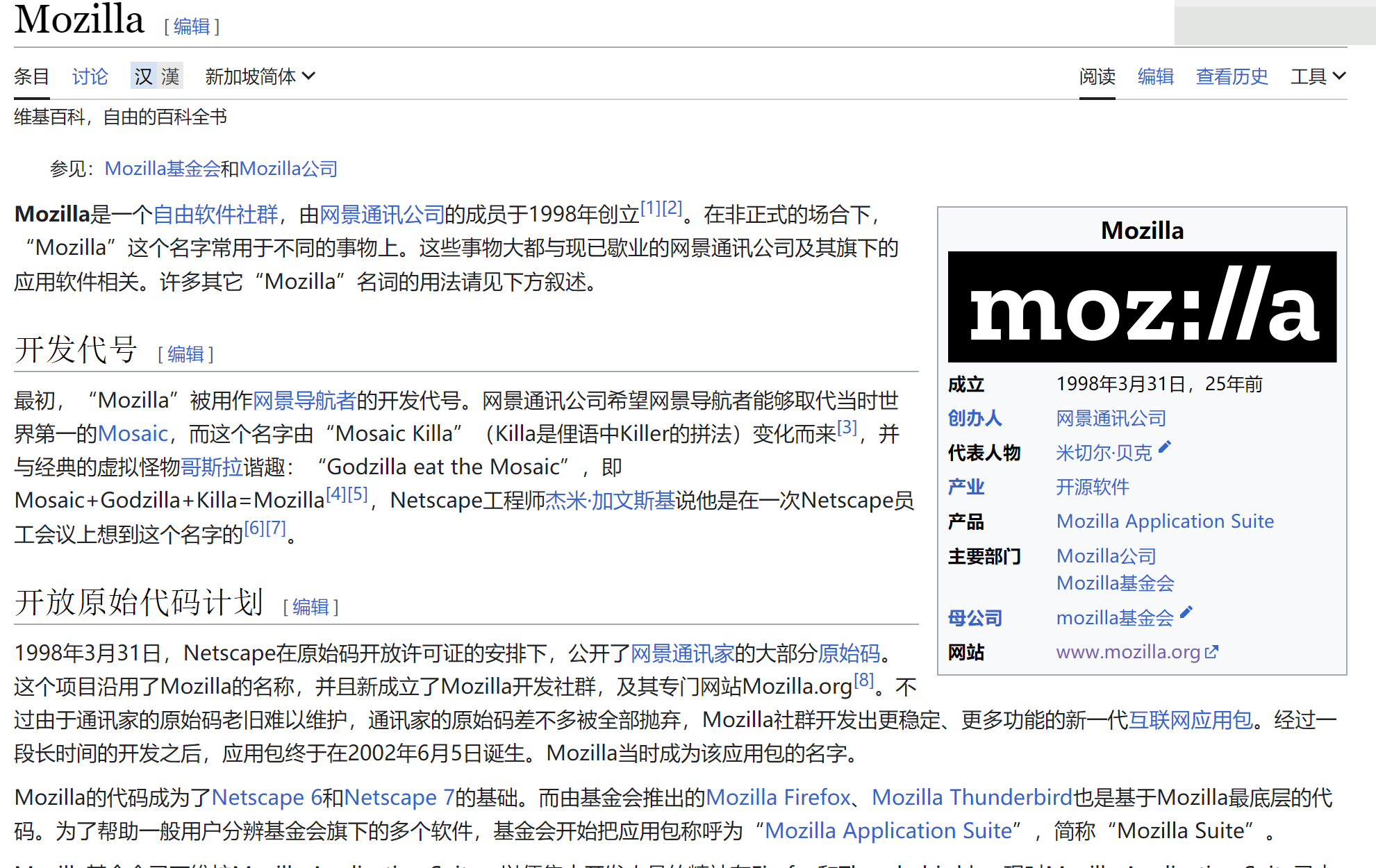
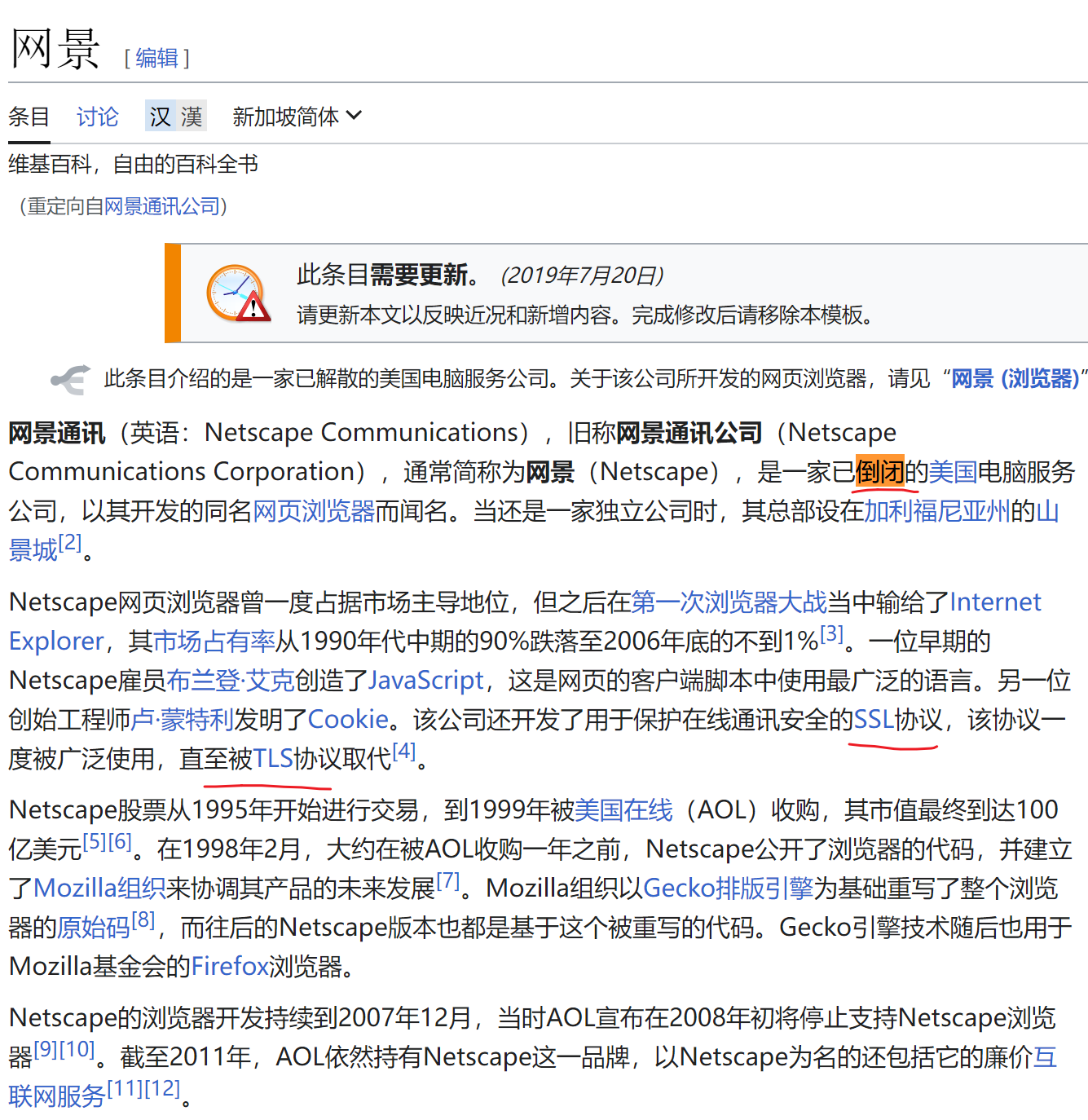
网景 Netscape 值得了解
伪装从哪个网站跳转过来的


这里就涉及字段解释,这个没记错就是在配置文件里有

上文又讲,这里略
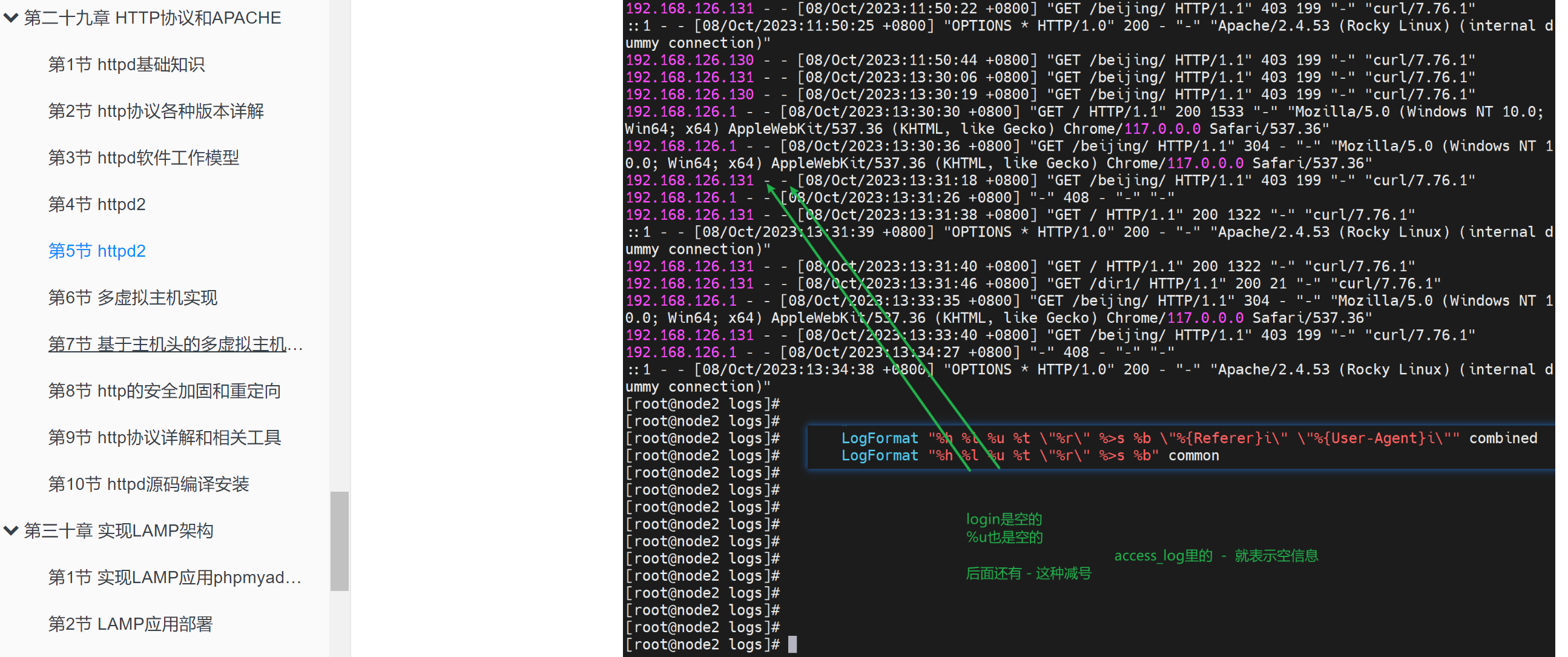
然后basic好像加不加一样啊,
帮助信息里也讲了this option is usually pointless。
curl --basic其实是修改认证方式的👇


除了systemctl还有一个启动关闭服务的工具

http对访问日志的处理
日志越来越大,达到一定大小就切分,然后按序命名,然后再生成一个新的access.log文件。

而且默认就是有切分的
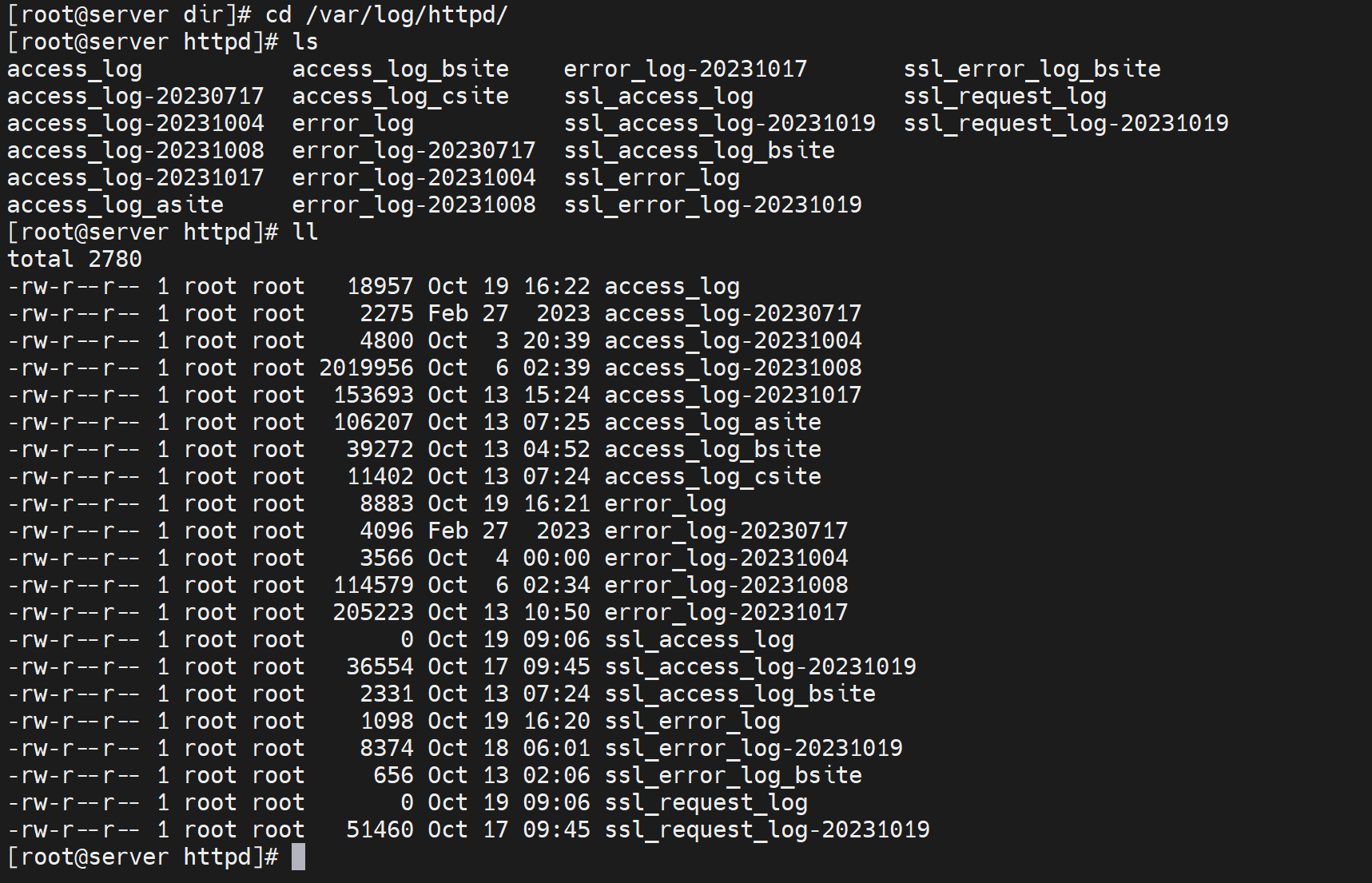
具体用法
https://www.apachehttpd.com/programs/rotatelogs.html # 破网站,换成下面的👇
https://httpd.apache.org/docs/2.4/programs/rotatelogs.html

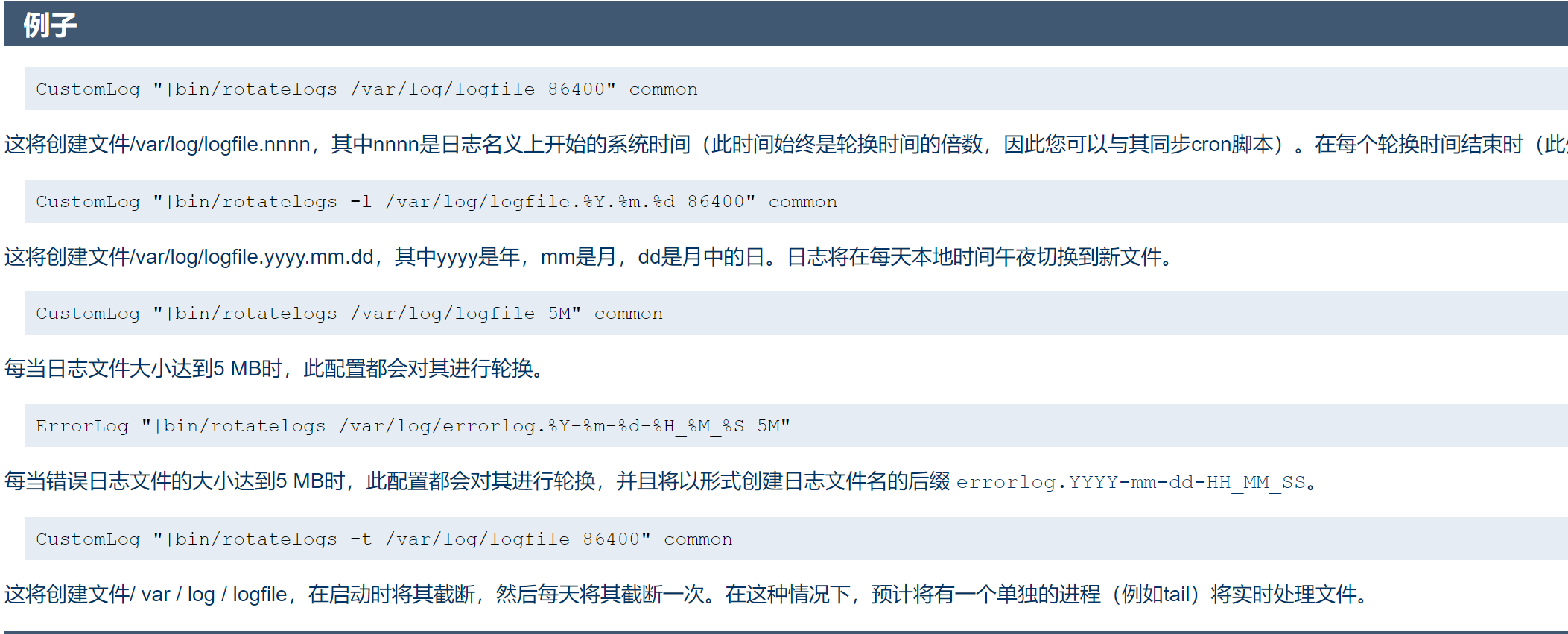
配置到这里👇去:
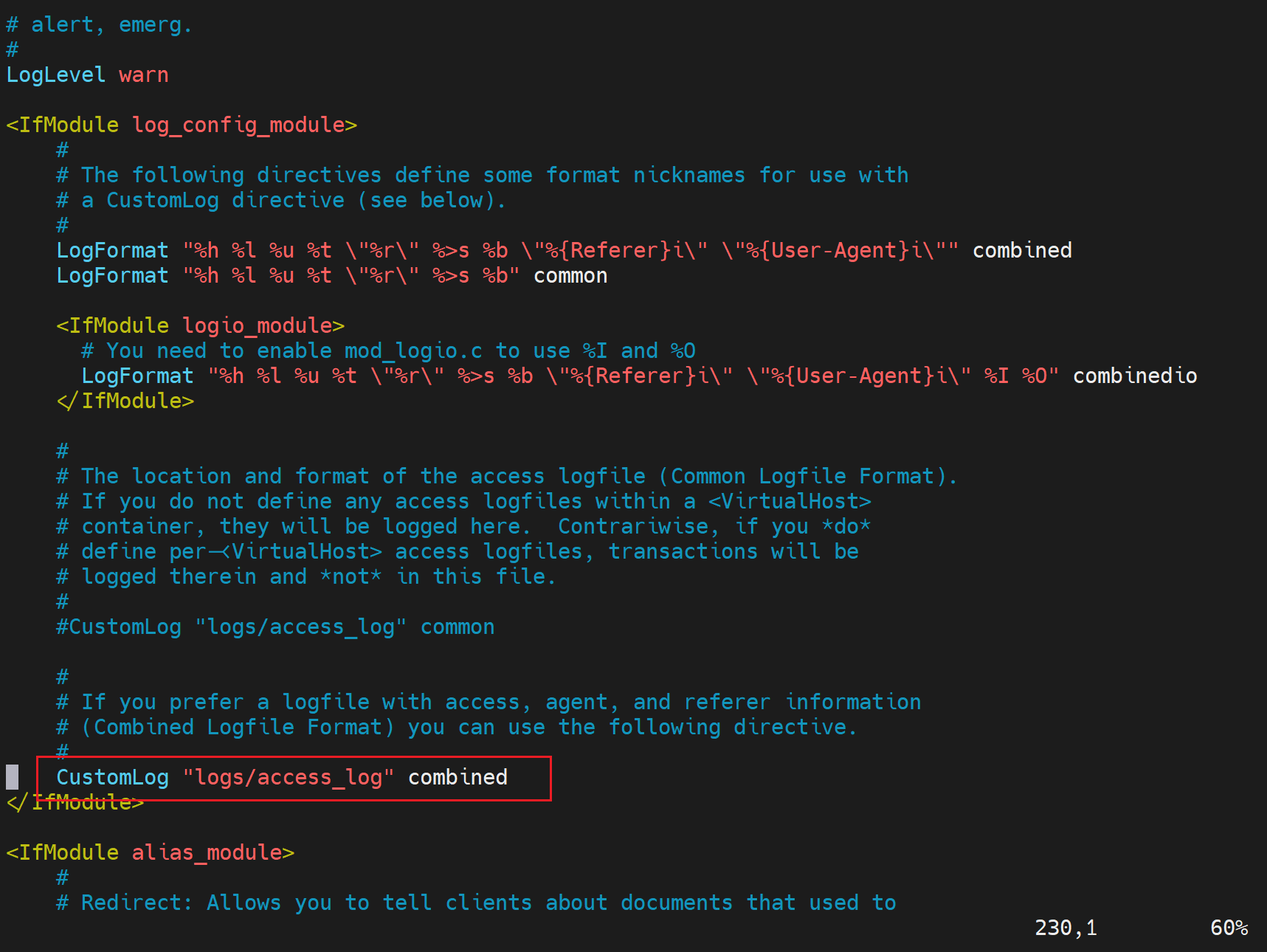
修改报错记录
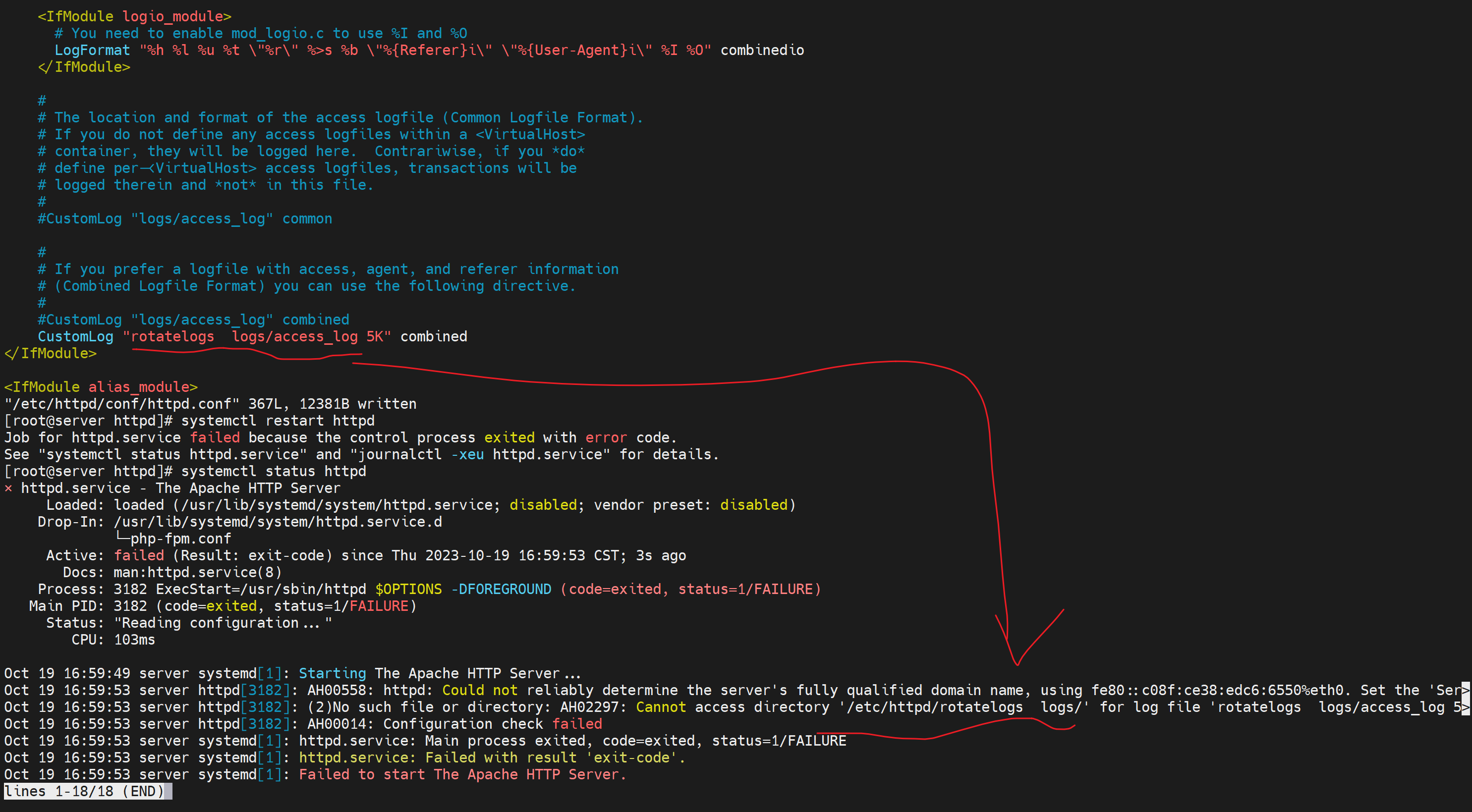
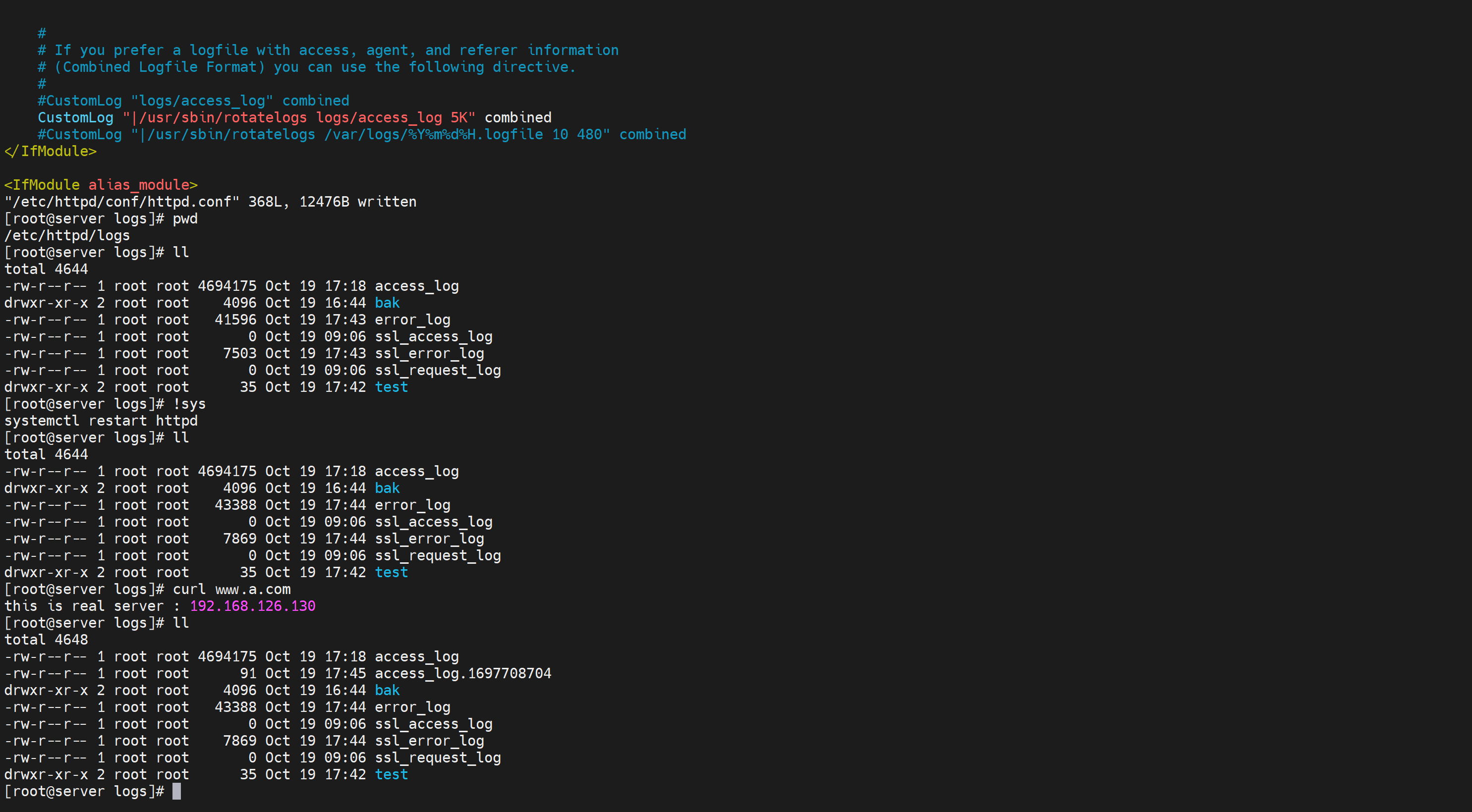
修改,"|/usr/sbin/rotatelogs" 最前面的|是将原来的log通过管道符传递过来,需要注释掉原来的CustomLog行
这配置是ok的啦,不过你别想看到效果,
不信你看下
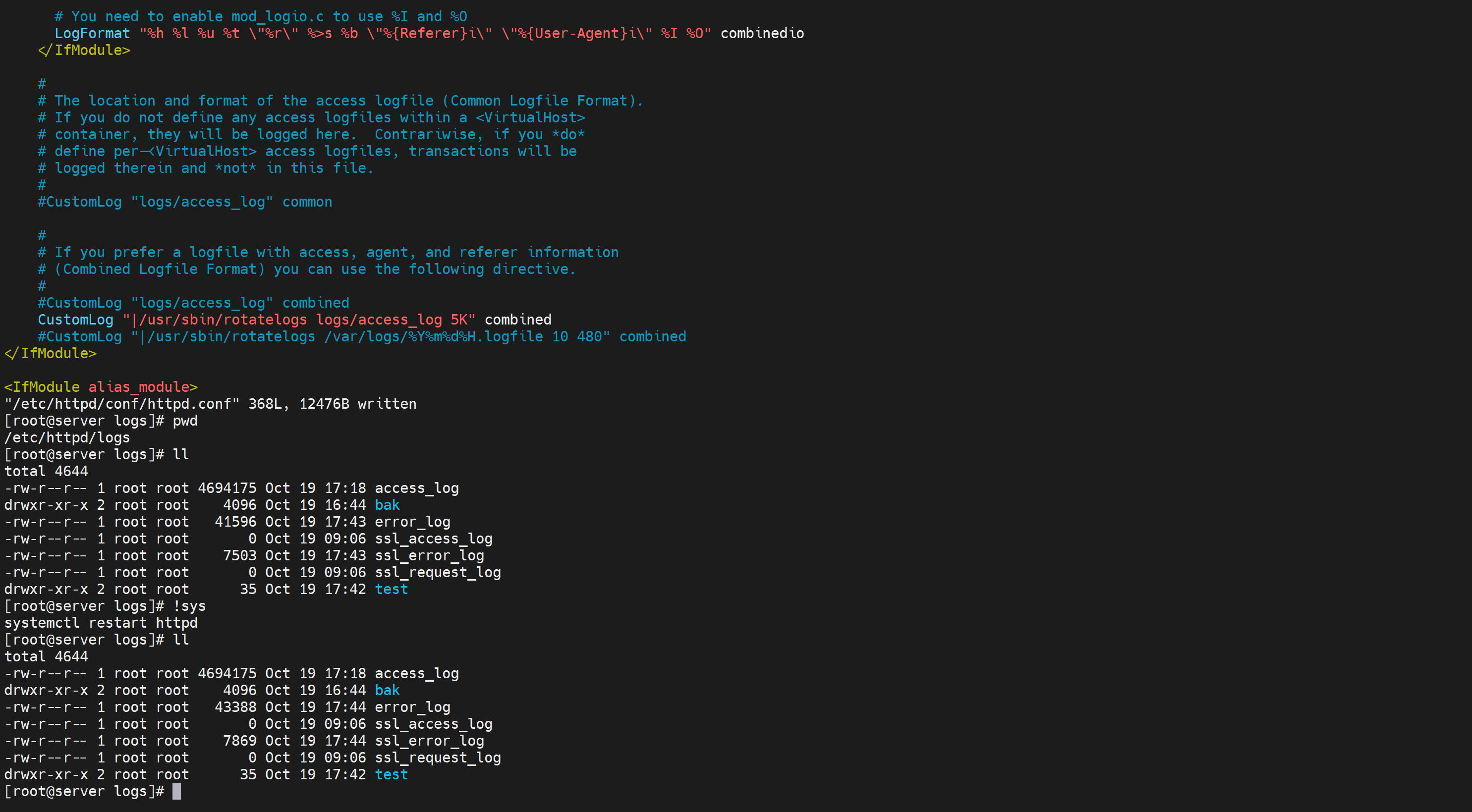
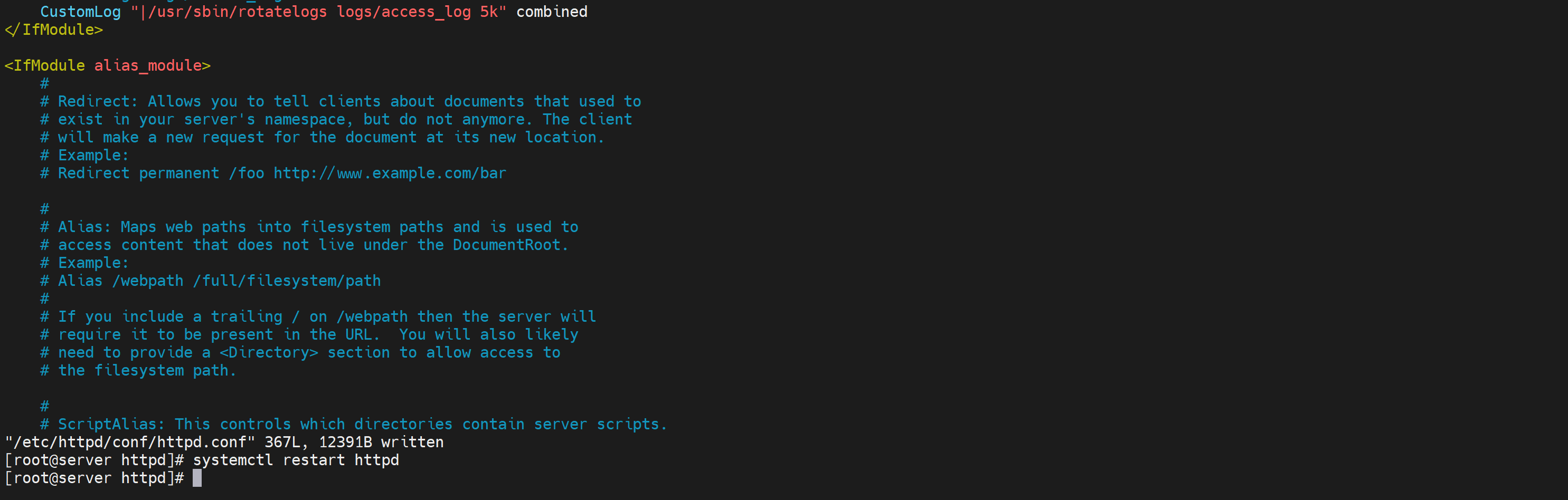
如何才能看到呢,往下看咯,curl一下有新的日志生成才会有触发
然后要注意httpd里的默认时间是UTC的
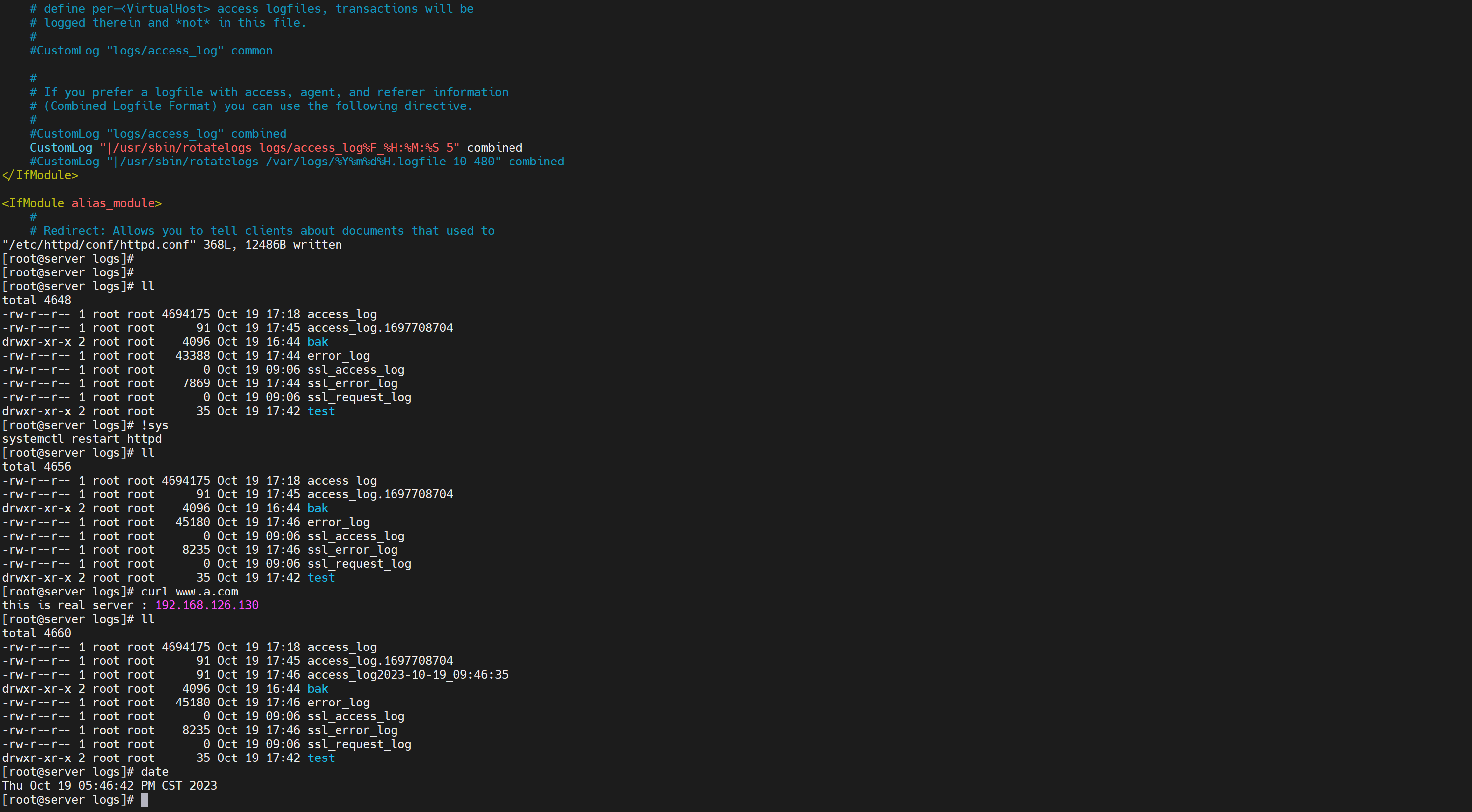
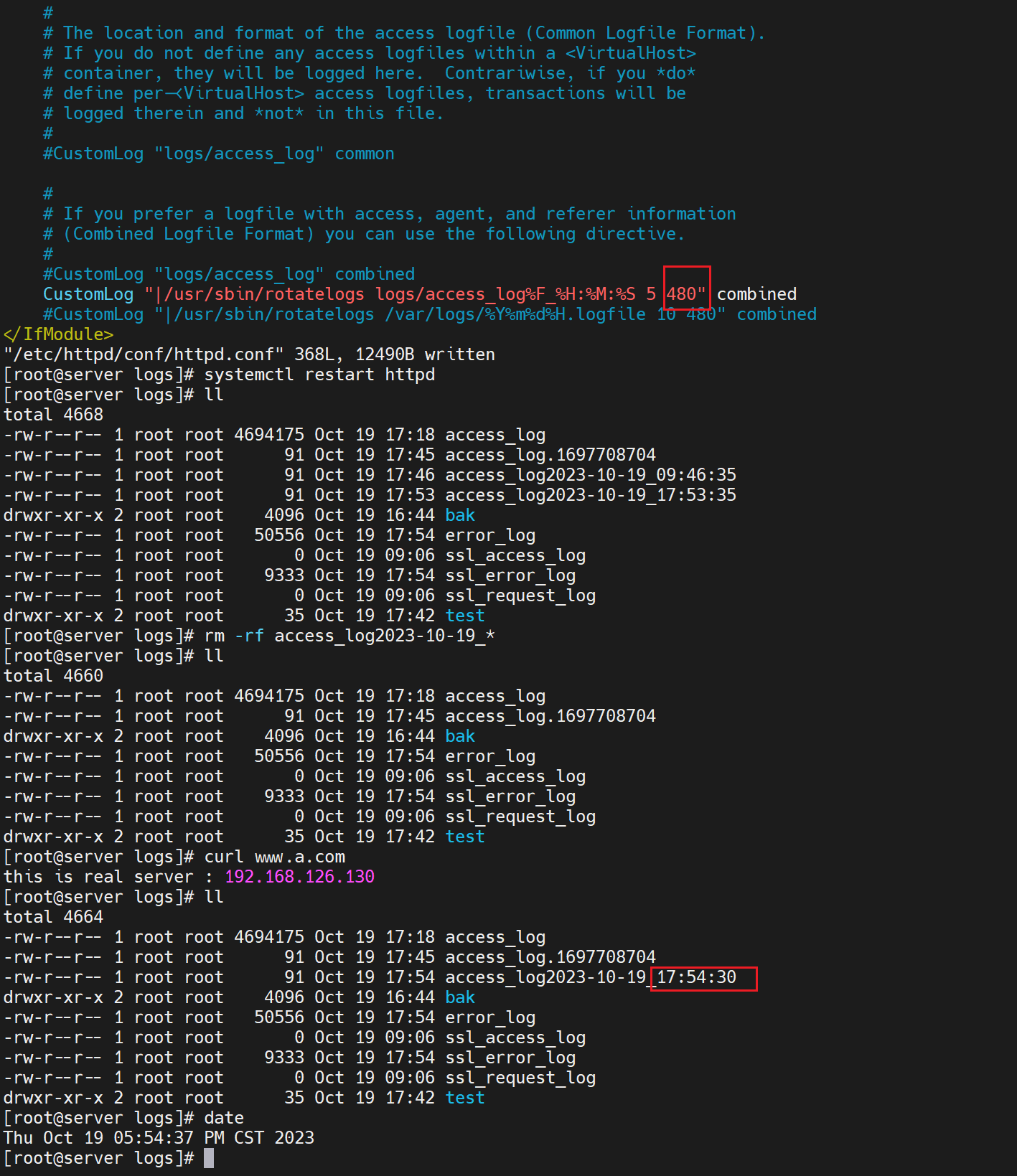
需要修改offset

480就是480分钟,也就是GMT+8啦,然后5就是5秒中一次 生成日志--但是你真要是等5秒钟结果是没有新的文件的,必须是满足5s后且+有新的access日志产生。
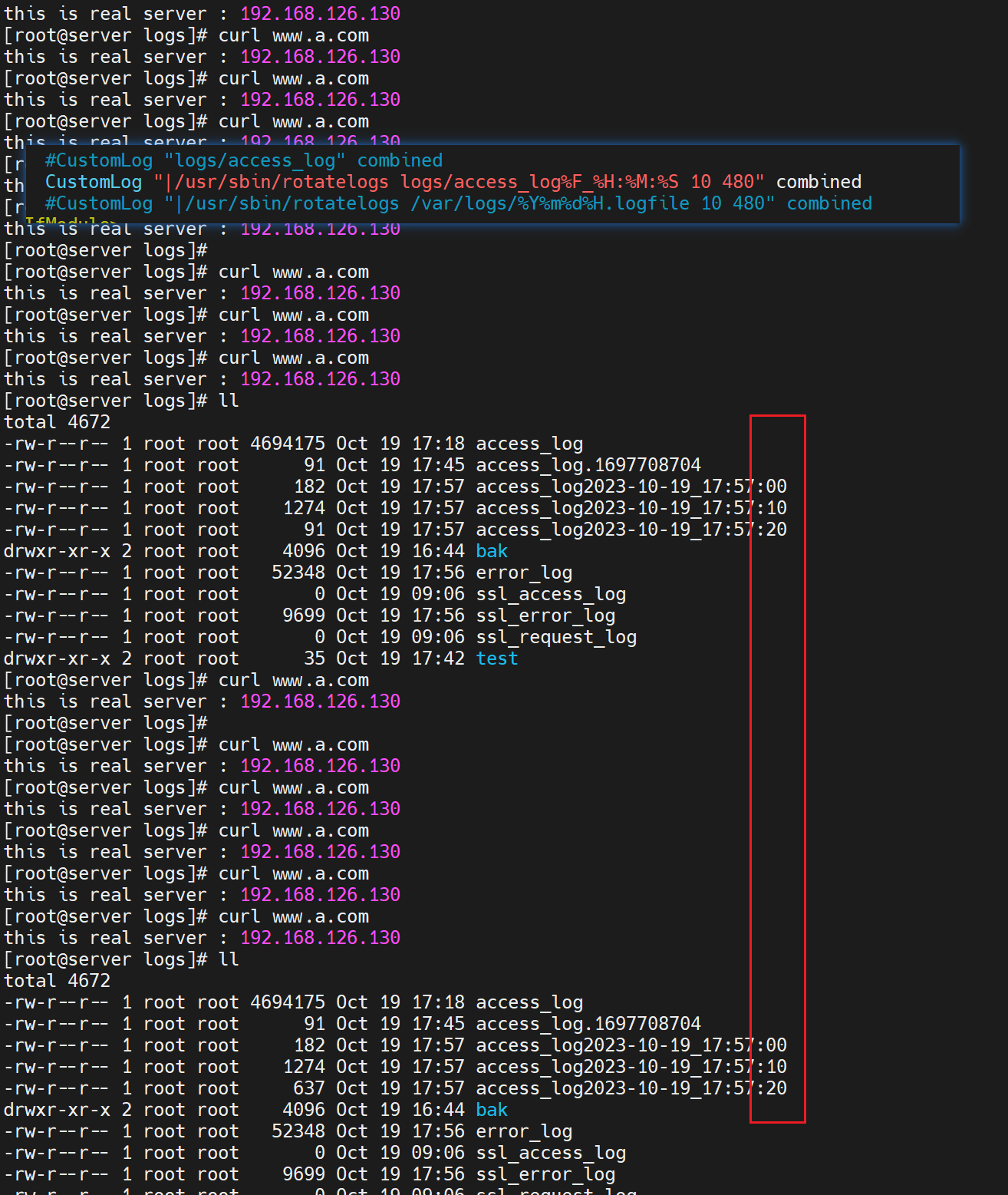
http压力测试

弄一下Jmeter
https://jmeter.apache.org/download_jmeter.cgi
https://www.jianshu.com/p/6bc152ca6126
问题记录
1、JAVA安装后就可以打开jmeter.bat了