第5节. httpd2
继续上一篇的配置
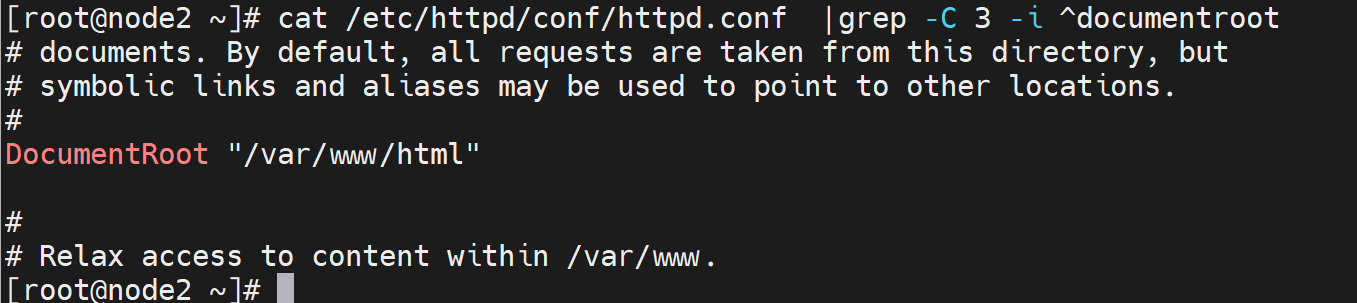
主站点页面-DocumentRoot
定义'Main' server的文档页面路径 DocumentRoot “/path”
文档路径映射:
DocumentRoot指向的路径为URL路径的起始位置 示例:
DocumentRoot "/app/data“
http://HOST:PORT/test/index.html --> /app/data/test/index.html 注意:SELinux和iptables的状态
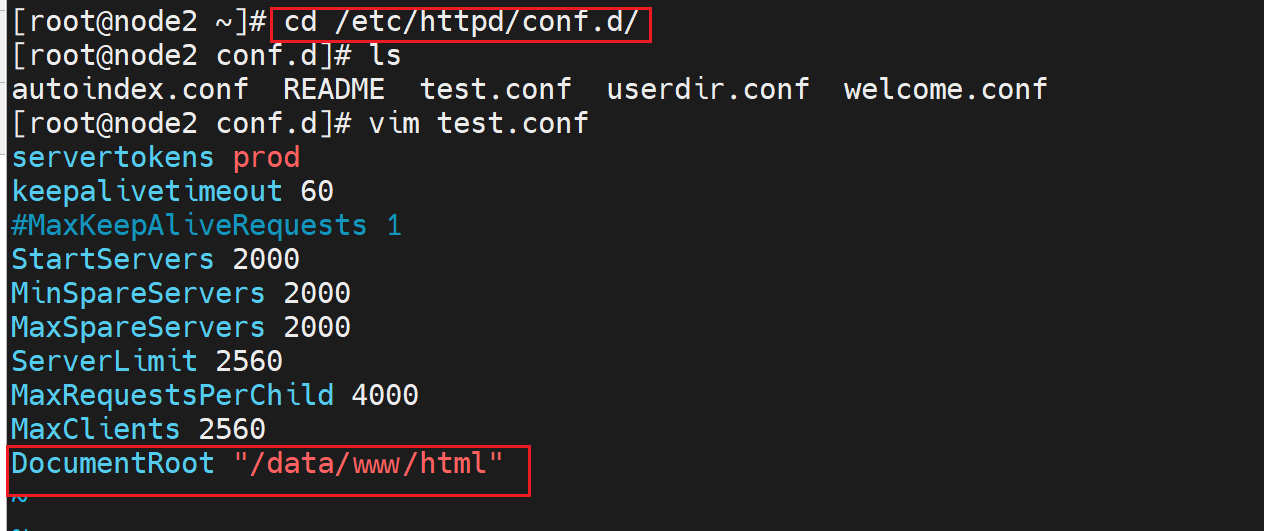
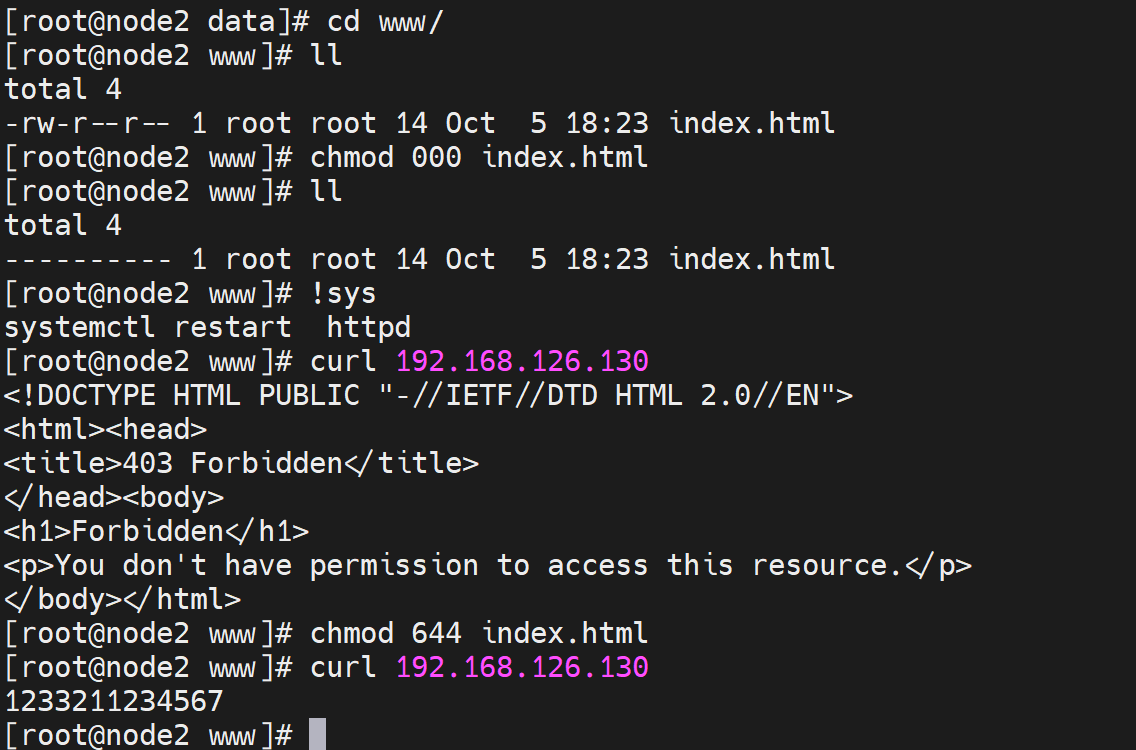
这里修改站点的页面存放路径,还需要保证该路径的文件的访问权限。注释掉👆上图的主站点配置。

下面对其进行修改👇,还是使用单独的配置文件,不对httpd.conf这个主文件进行修改
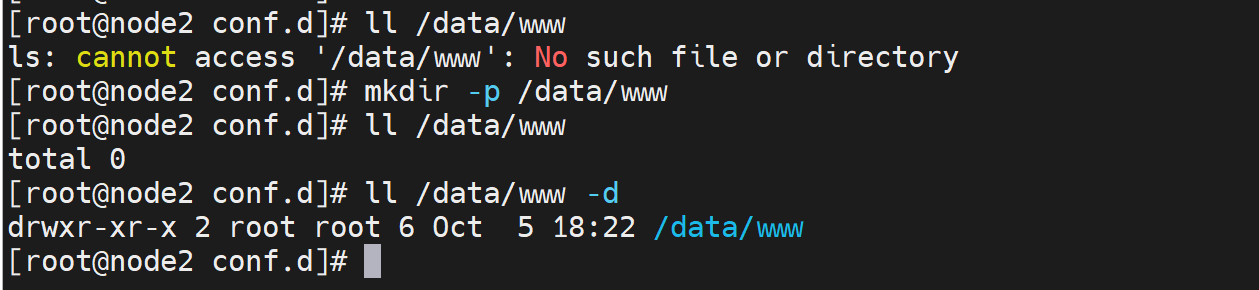
权限👆没问题
selinux没问题👇

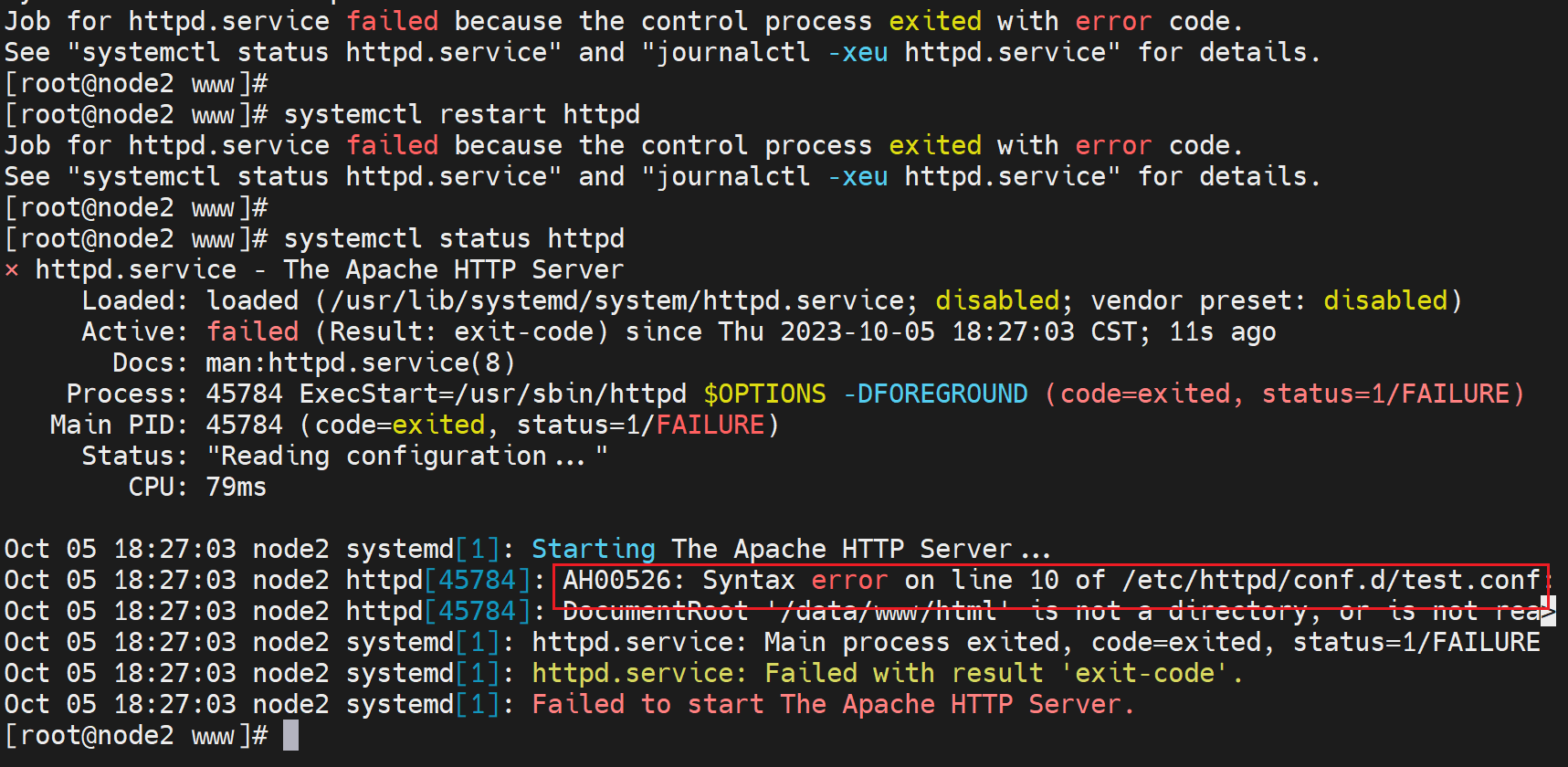
修改配置文件,
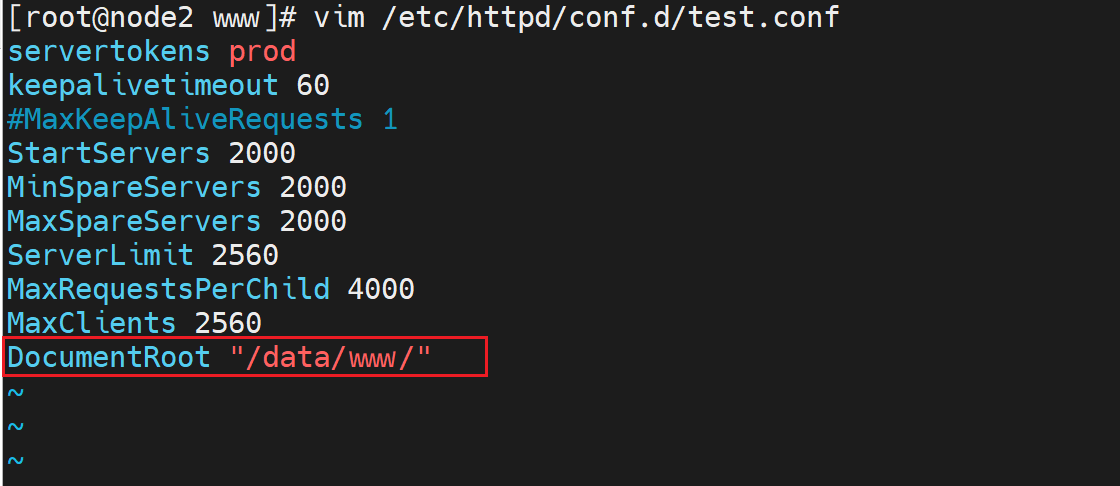
必须是文件夹,且其下放index.html
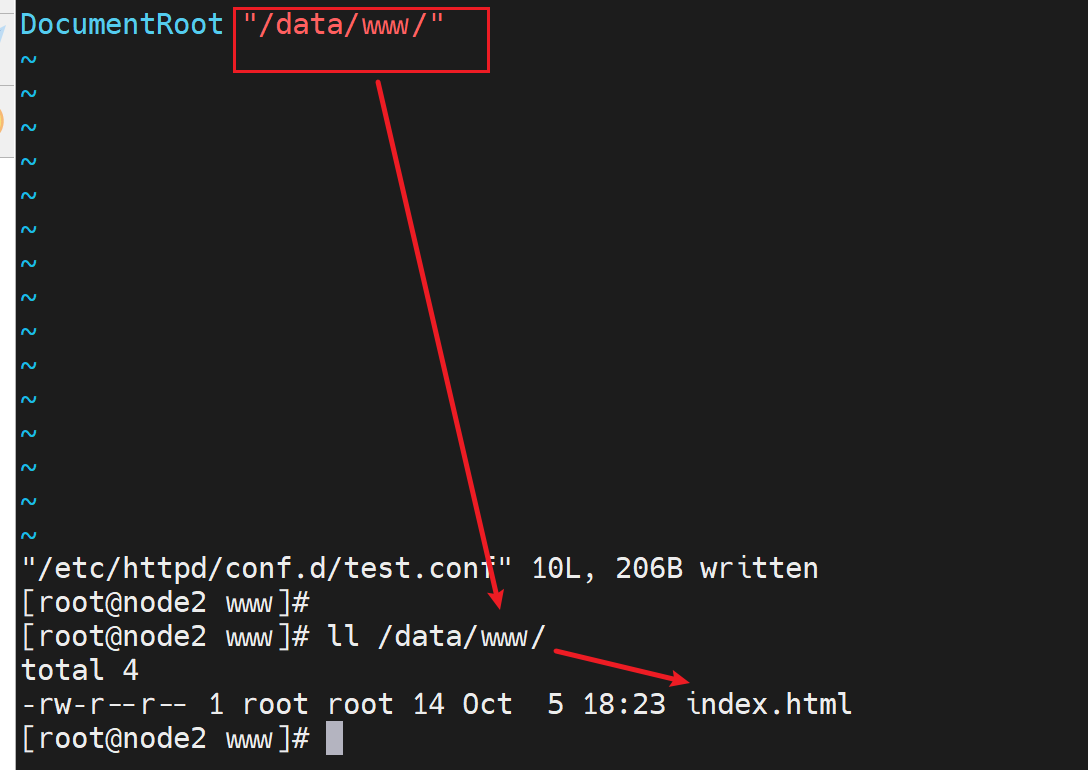
重启OK
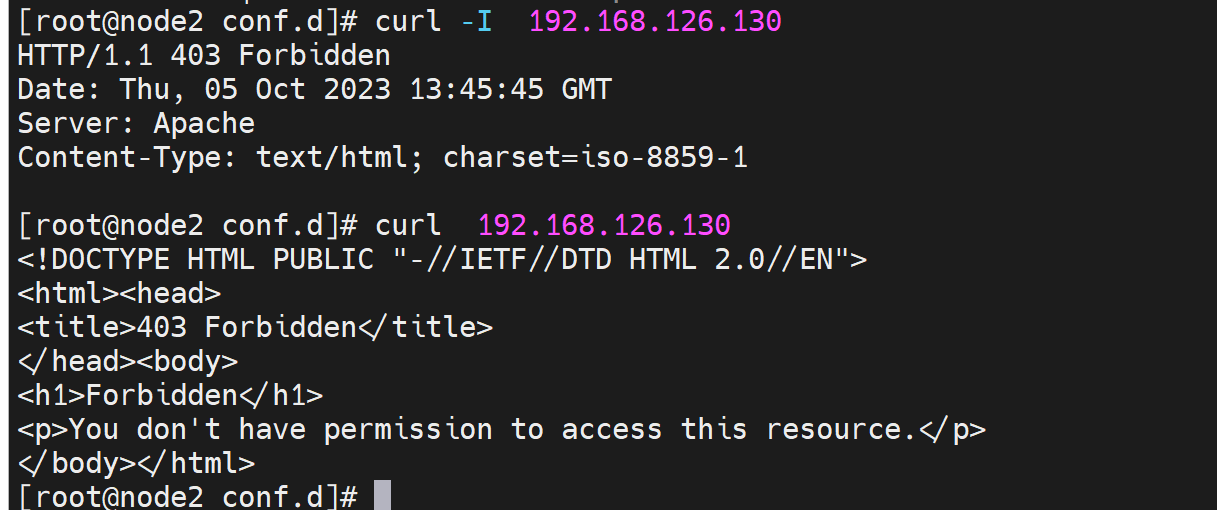
但是curl 发现不行
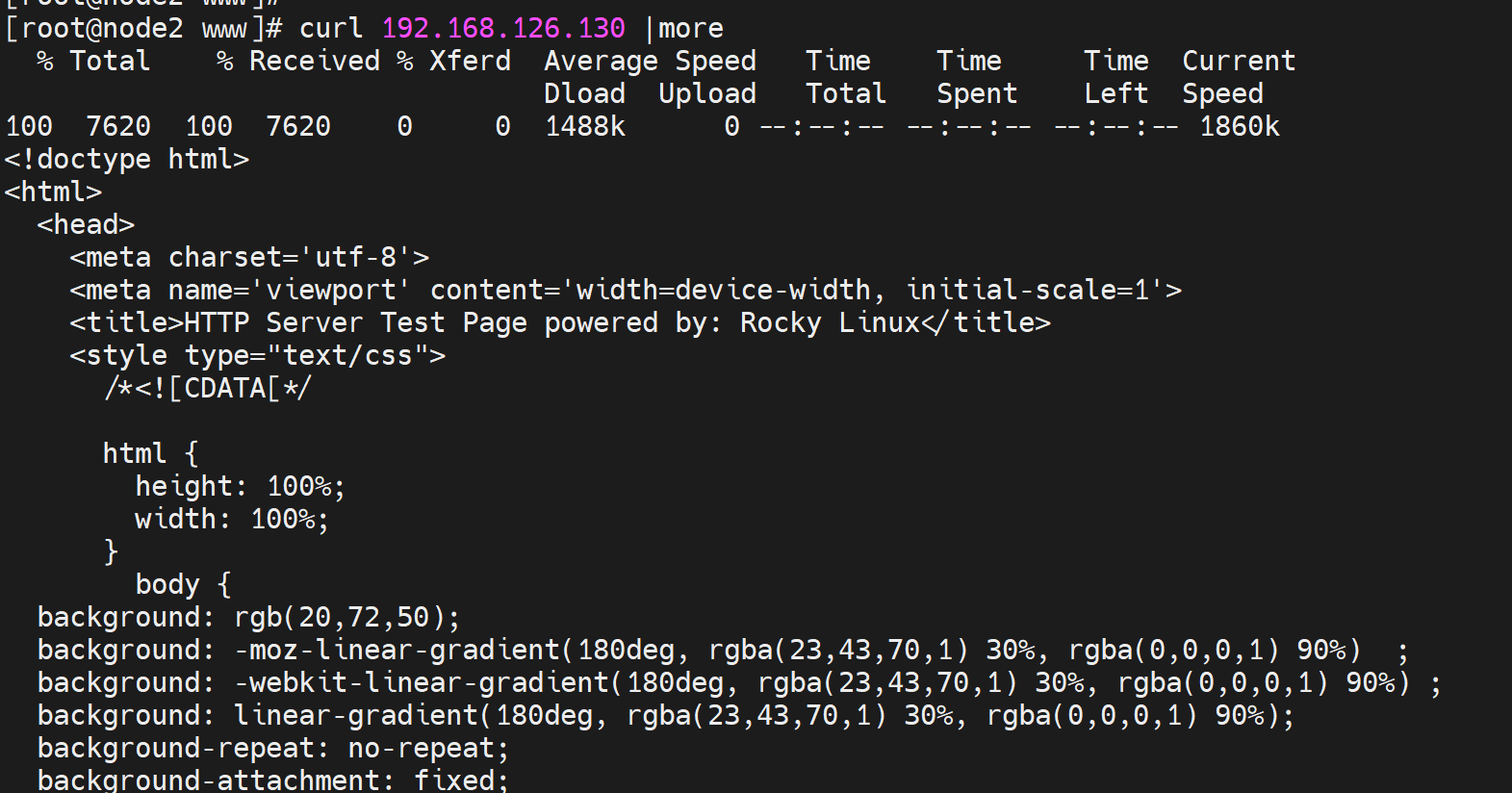
这就意味着页面一样是apache的默认页面了,因为index.html打不开
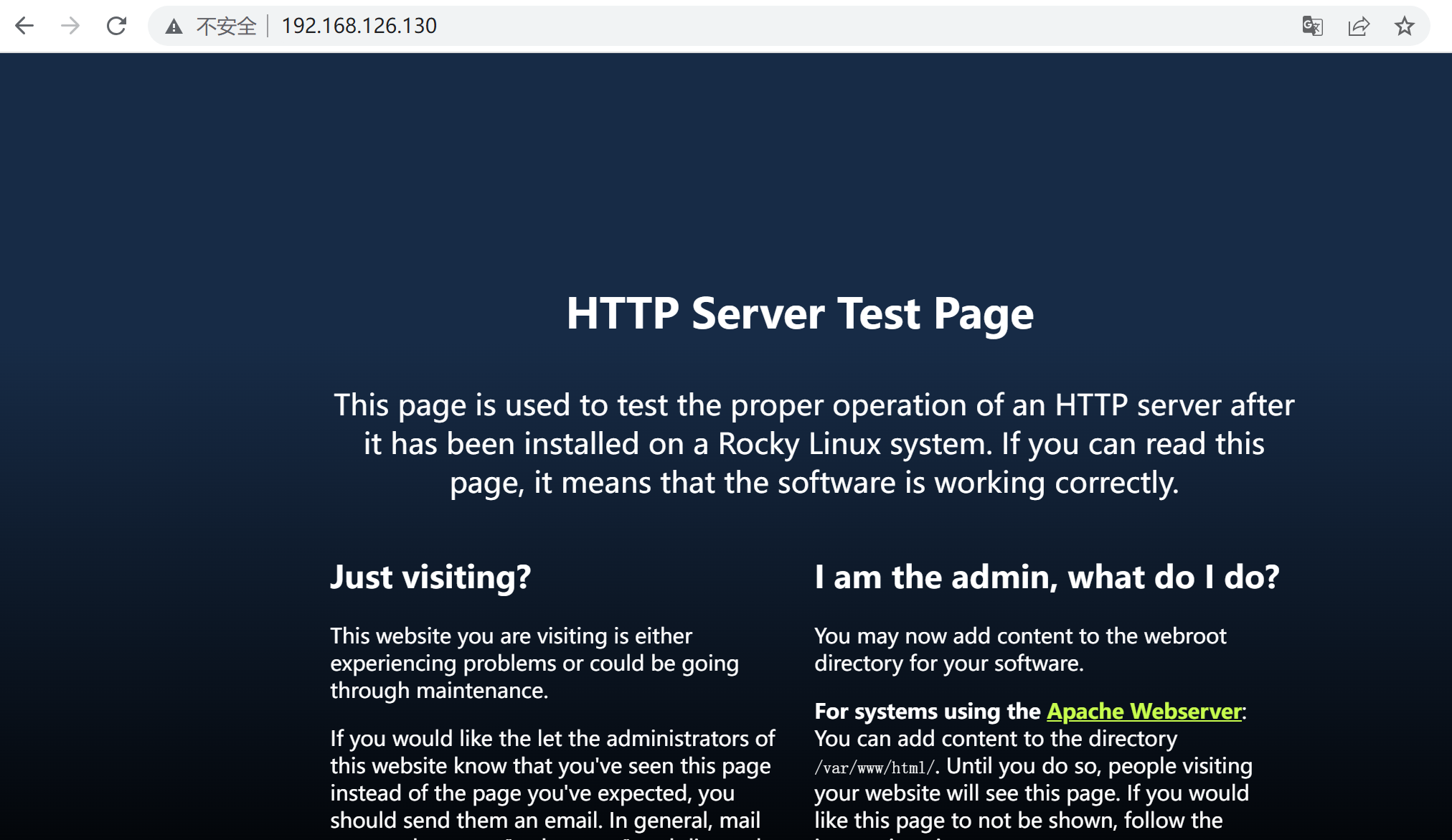
可是对应的文件夹的进入,和文件的可读权限都有的啊,奇怪了
但是就是403 Forbidden了
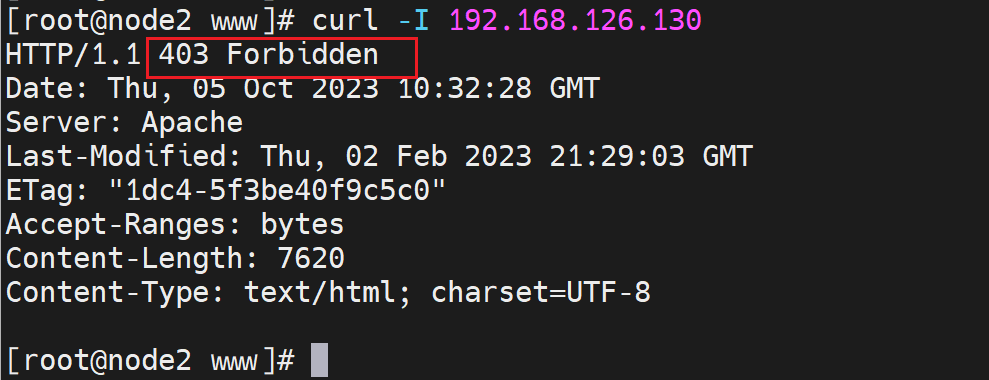
所谓授权不是linux系统文件的授权,而是httpd服务本身配置文件里要明确授权,所以还是配置文件里的配置不全。
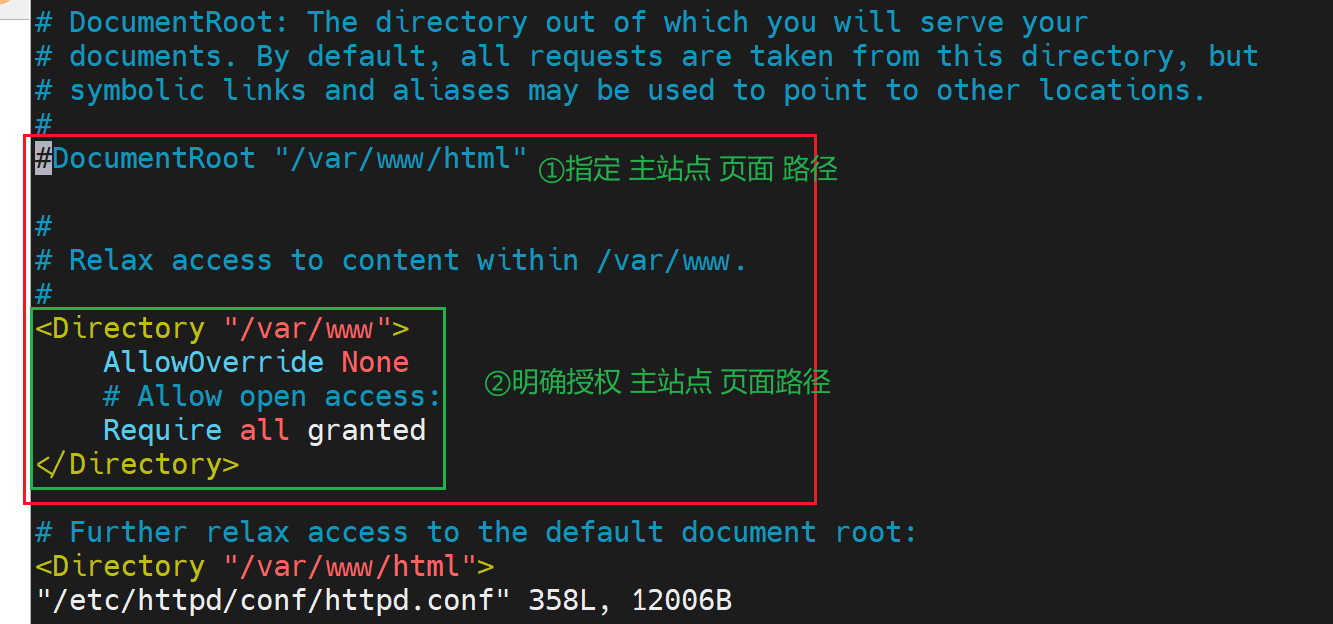
同样写道单独的配置文件里去
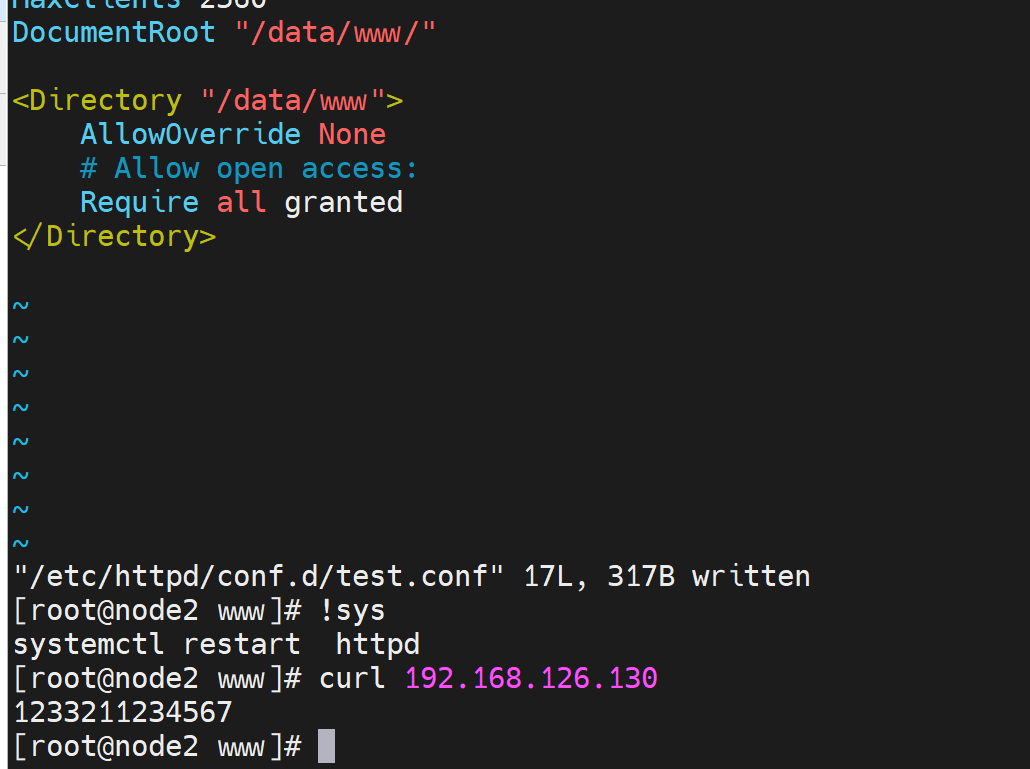
---------------这样就OK👆了------------------
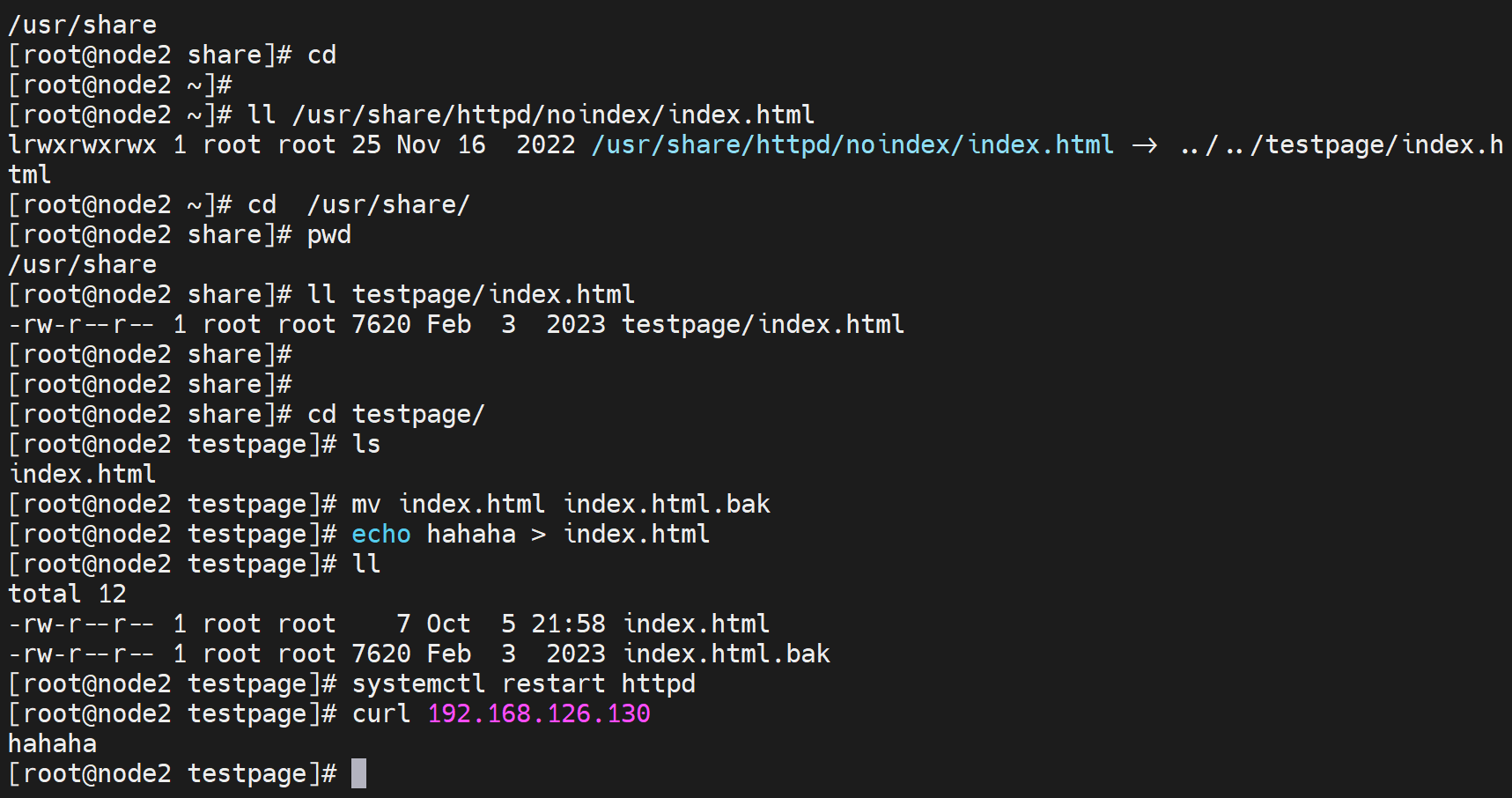
然后取消/data文件夹的所有权限,哈哈
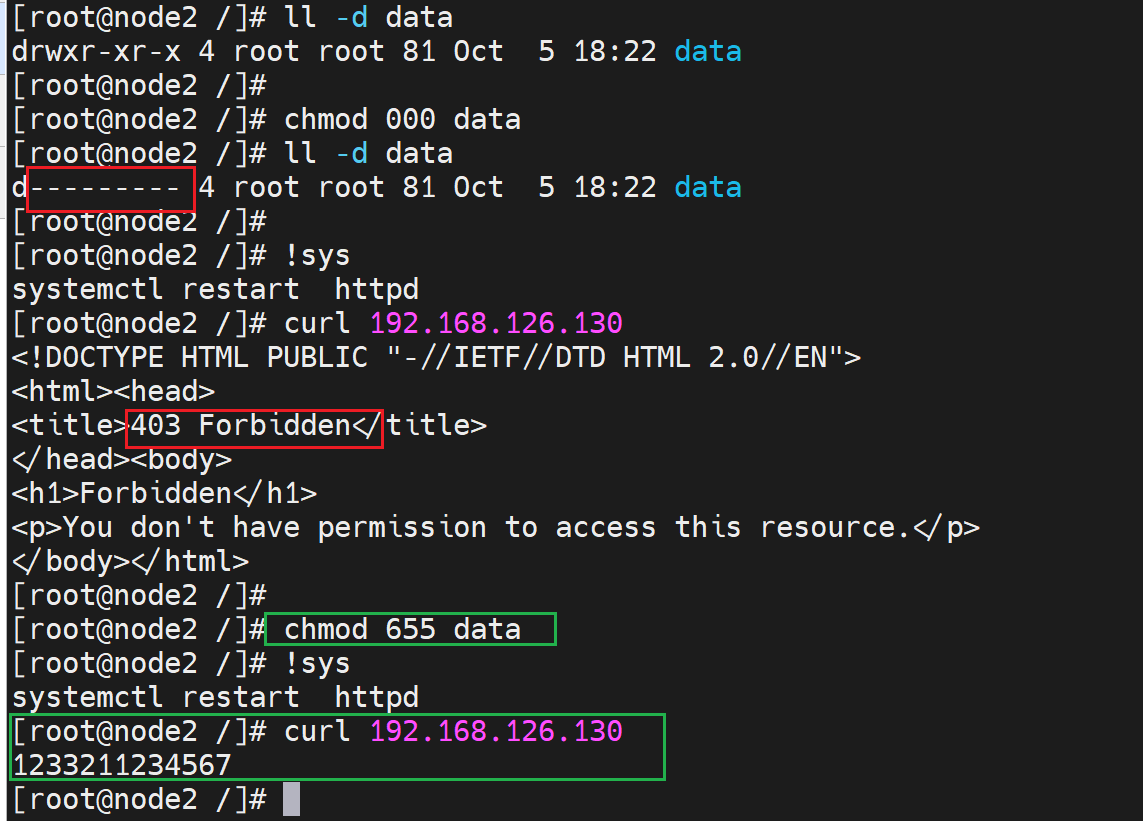
其上图不用重启服务,因为修改的os操作系统的权限,而不是httpd服务的配置文件,👇证明下:
如果是DocumentRoot下的子目录的index就是补一个路径就好了👇。
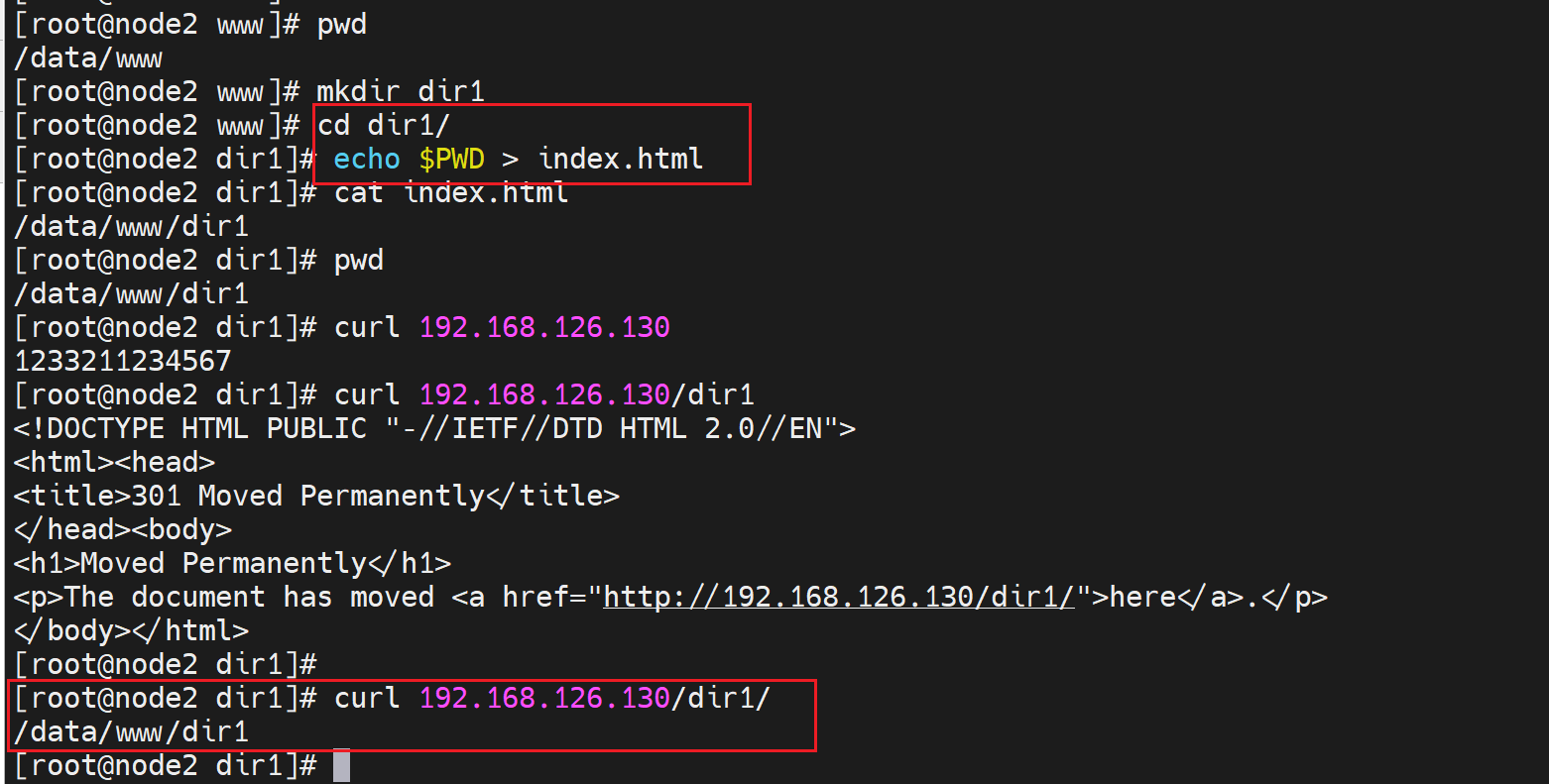
如果子目录不在DocumentRoot下呢
1、用软连接行不行:👇可以的,没得问题
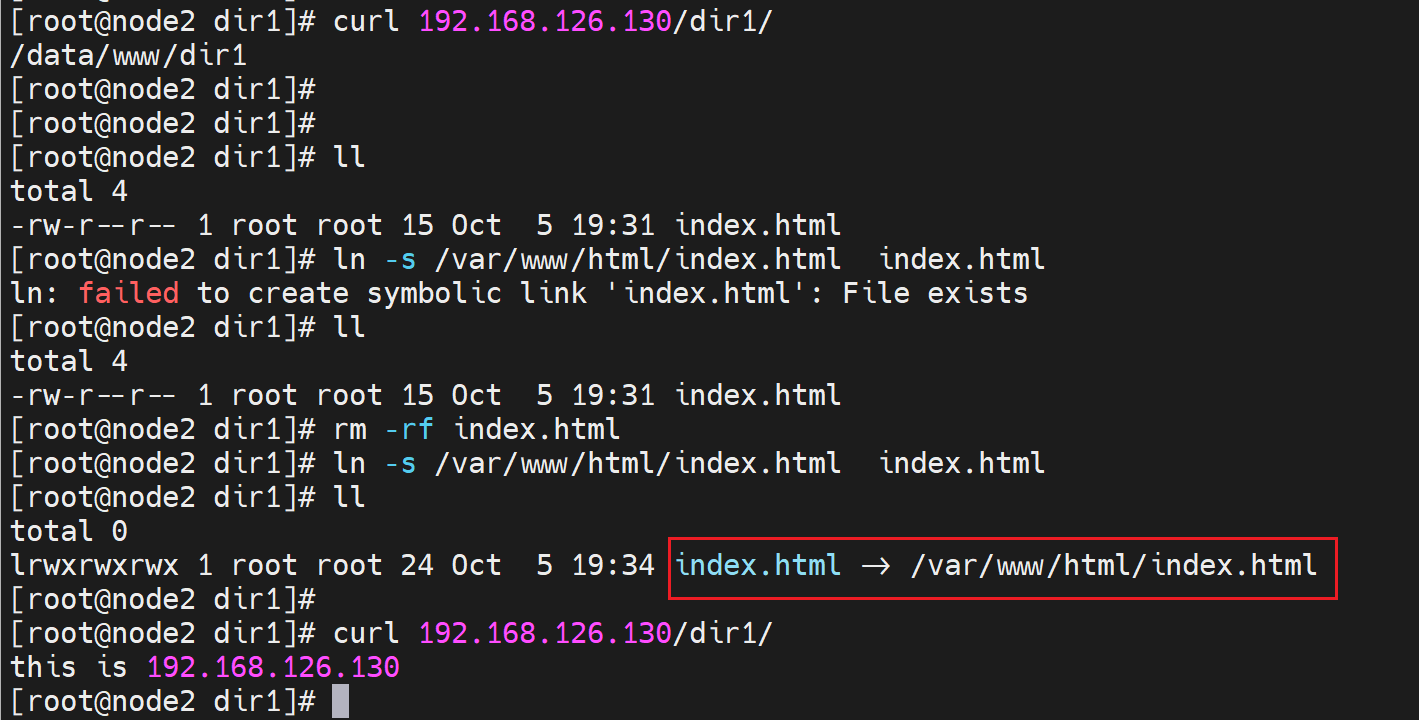
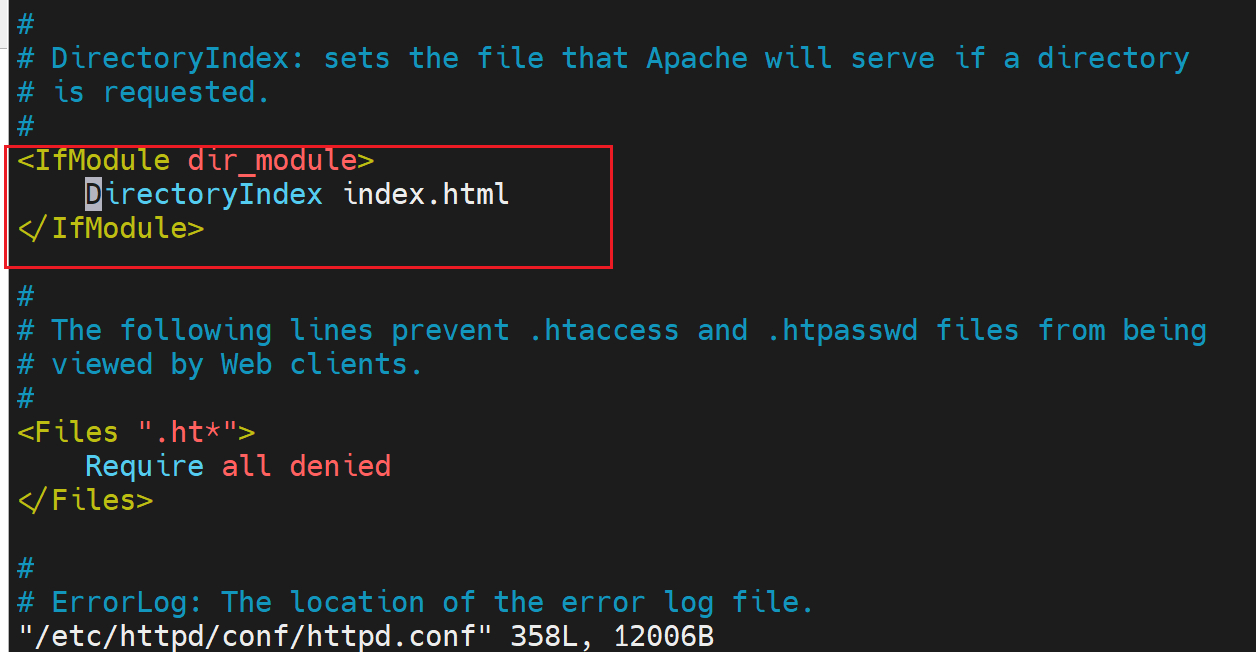
那为什么文件默认就是index.html,是否可以修改呢?可以,在配置里面找到关键词DirectoryIndex👇
定义站点主页面
DirectoryIndex index.html
增加一个
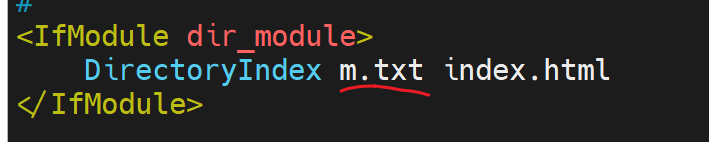
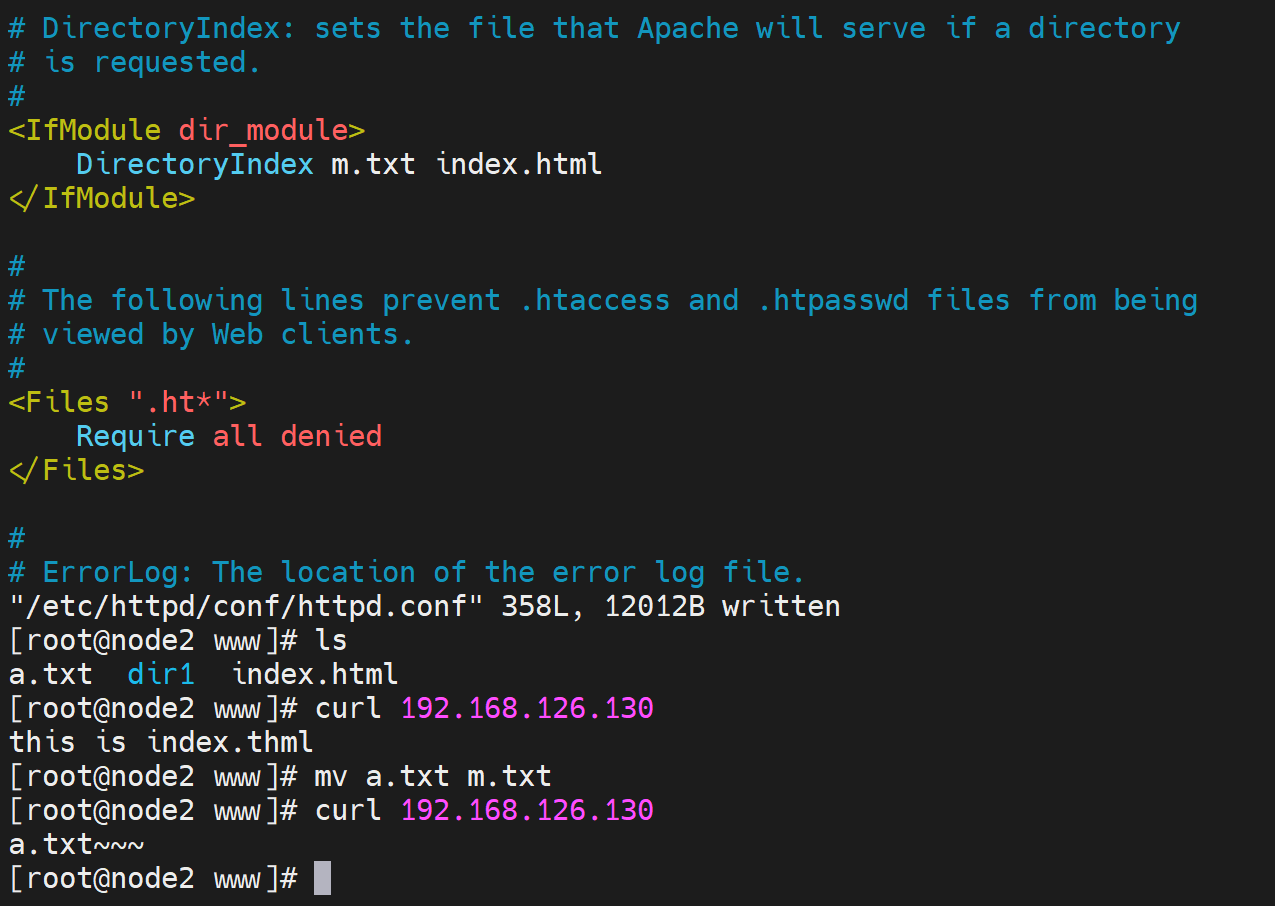
上图👆就说明了,配置文件的写法:DirectoryIndex m.txt index.html是优先级从左到右的。
如果m.txt和index.html文件都不存在,那么这个报错的页面403 Forbidden又是哪来的呢?
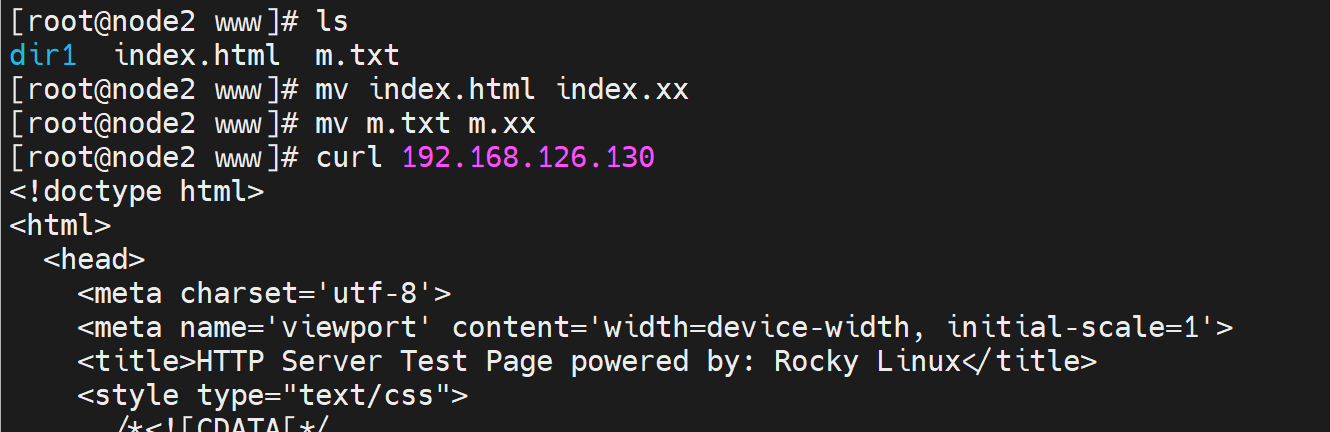
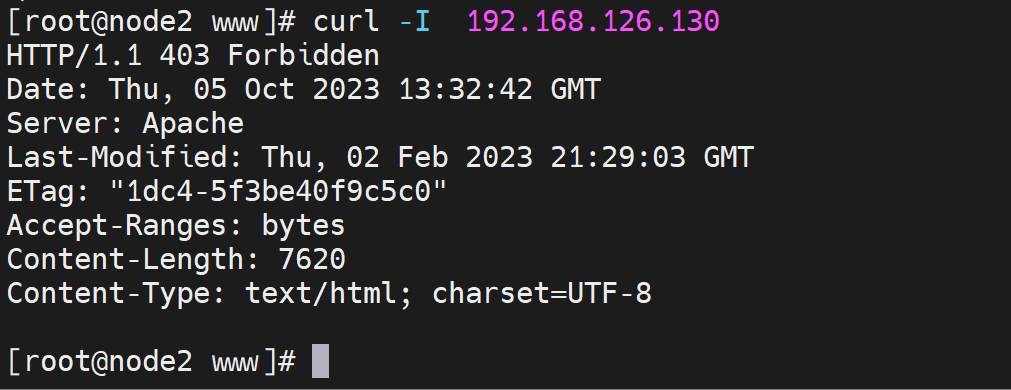
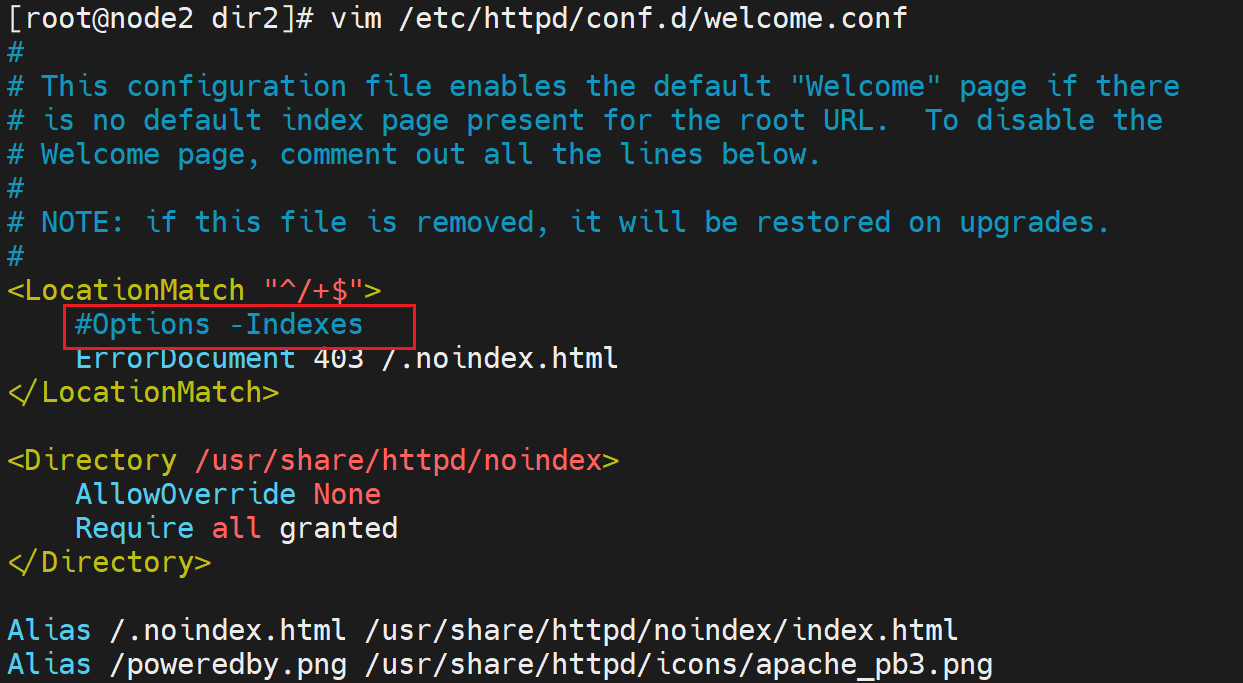
在/etc/httpd/conf.d/下有一个叫welcome.conf的配置文件,其中就有403对应的页面👇
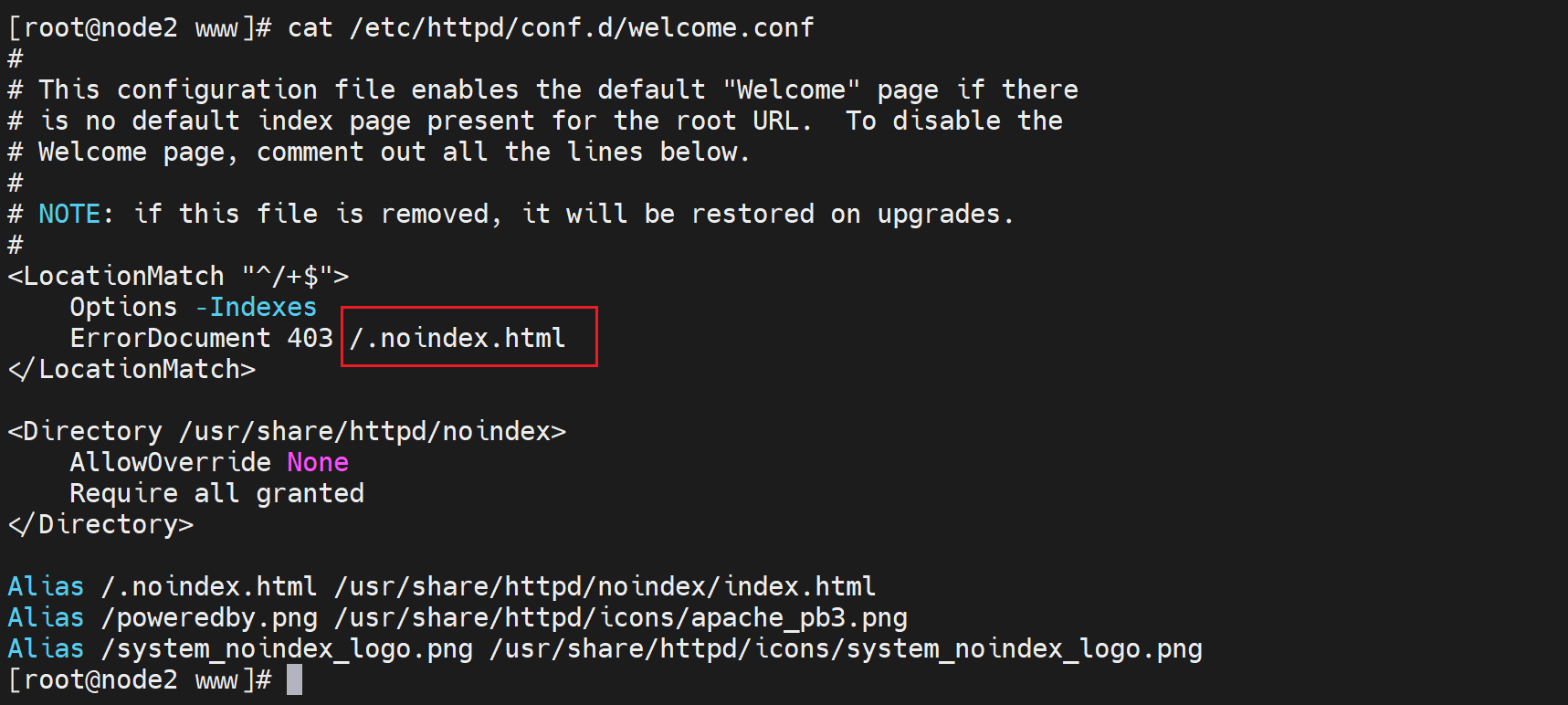
这里的/.noindex.html就是相对于DocumentRoot主页根路径来讲的。
但是没找到这个文件,增大俺的狗眼仔细看看上图 找找看,Alias啊,/.noindex.html全文里出现了2次,还不清楚嘛~(/≧▽≦)/
删掉这个welcome.conf文件,观察页面

重启服务后👇
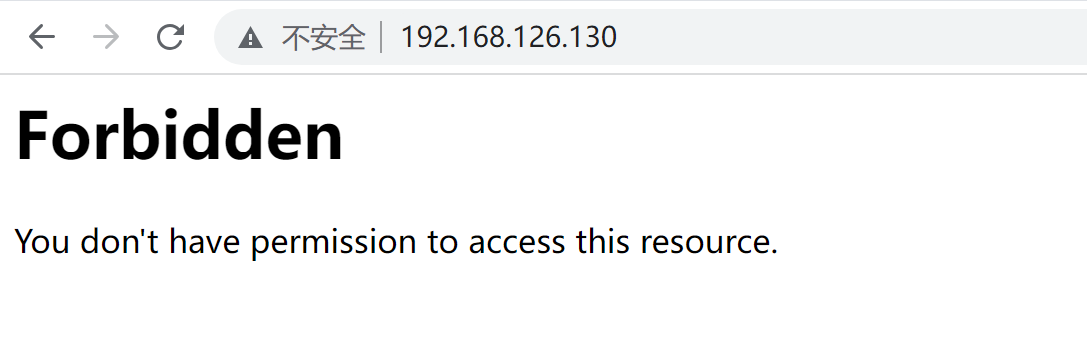
所以修改一下

页面一样效果👇
站点访问控制常见机制
可基于两种机制指明对哪些资源进行何种访问控制
两种机制:客户端来源地址,用户账号
哪些资源:文件系统路径、URL路径
文件系统路径:
①针对文件夹②针对文件③写正则匹配
<Directory “/path">
...
</Directory>
<File “/path/file”>
...
</File>
<FileMatch "PATTERN">
...
</FileMatch>
URL路径:
<Location "">
...
</Location>
<LocationMatch "">
...
</LocationMatch>
示例:
<FilesMatch "\.(gif|jpe?g|png)$"> # FilesMatch就是REGEX正则
<Files “?at.*”> 通配符 # 应该是Files 开头就是通配符
<Location /status> # Location就是URL
<LocationMatch "/(extra|special)/data"> # LocationMatch就是url里的regex正则
具体的写法-带上源
概述
<Directory>中“基于源地址”实现访问控制
(1) Options:后跟1个或多个以空白字符分隔的选项列表
在选项前的+,- 表示增加或删除指定选项
常见选项:
Indexes:指明的URL路径下不存在与定义的主页面资源相符的资源文件时,返回索引列表给用户
FollowSymLinks:允许访问符号链接文件所指向的源文件
None:全部禁用
All: 全部允许
示例:
<Directory /web/docs>
Options Indexes FollowSymLinks
</Directory>
<Directory /web/docs/spec>
Options FollowSymLinks
</Directory>
(2) AllowOverride
与访问控制相关的哪些指令可以放在指定目录下的.htaccess(由AccessFileName指定)文件中,覆盖之前的配置指令
只对<directory>语句有效
AllowOverride All: .htaccess中所有指令都有效
AllowOverride None: .htaccess 文件无效
AllowOverride AuthConfig .htaccess 文件中,除了AuthConfig 其它指 令都无法生效
Indexes:指明的URL路径下不存在与定义的主页面资源相符的资 源文件时,返回索引列表给用户
就是访问页面不存在,返回当前路径下的列表,页面显示出来的文件夹和文件都可以点击,类似yum源网站的点击浏览一样
然后页面访问是默认的报错页面
删掉该文件也没用!
找找官网说明
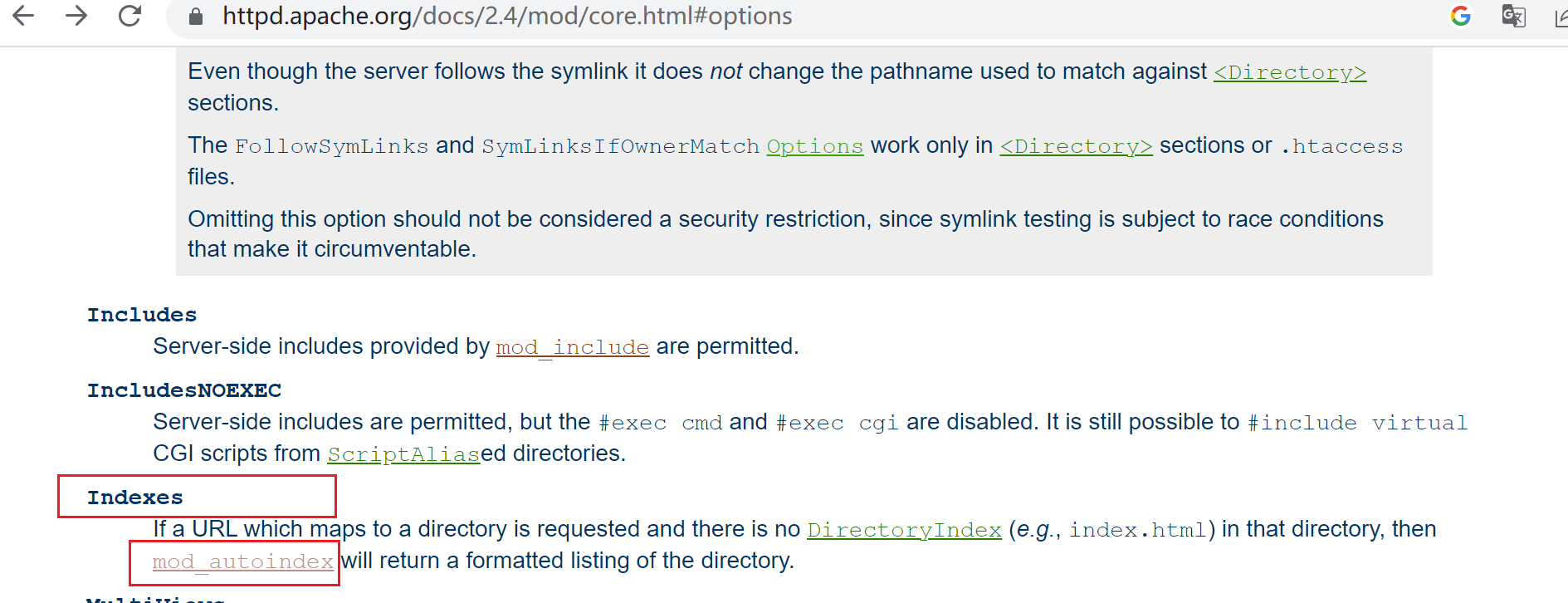
这个模块也加载了啊

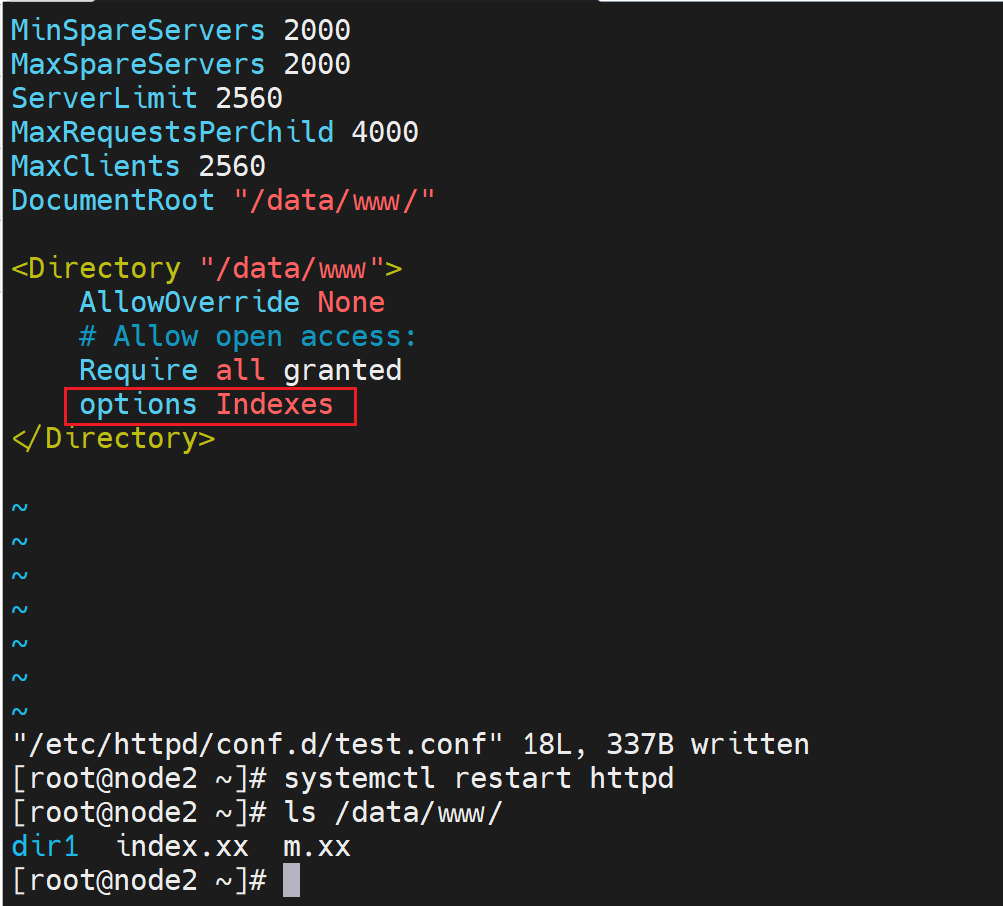
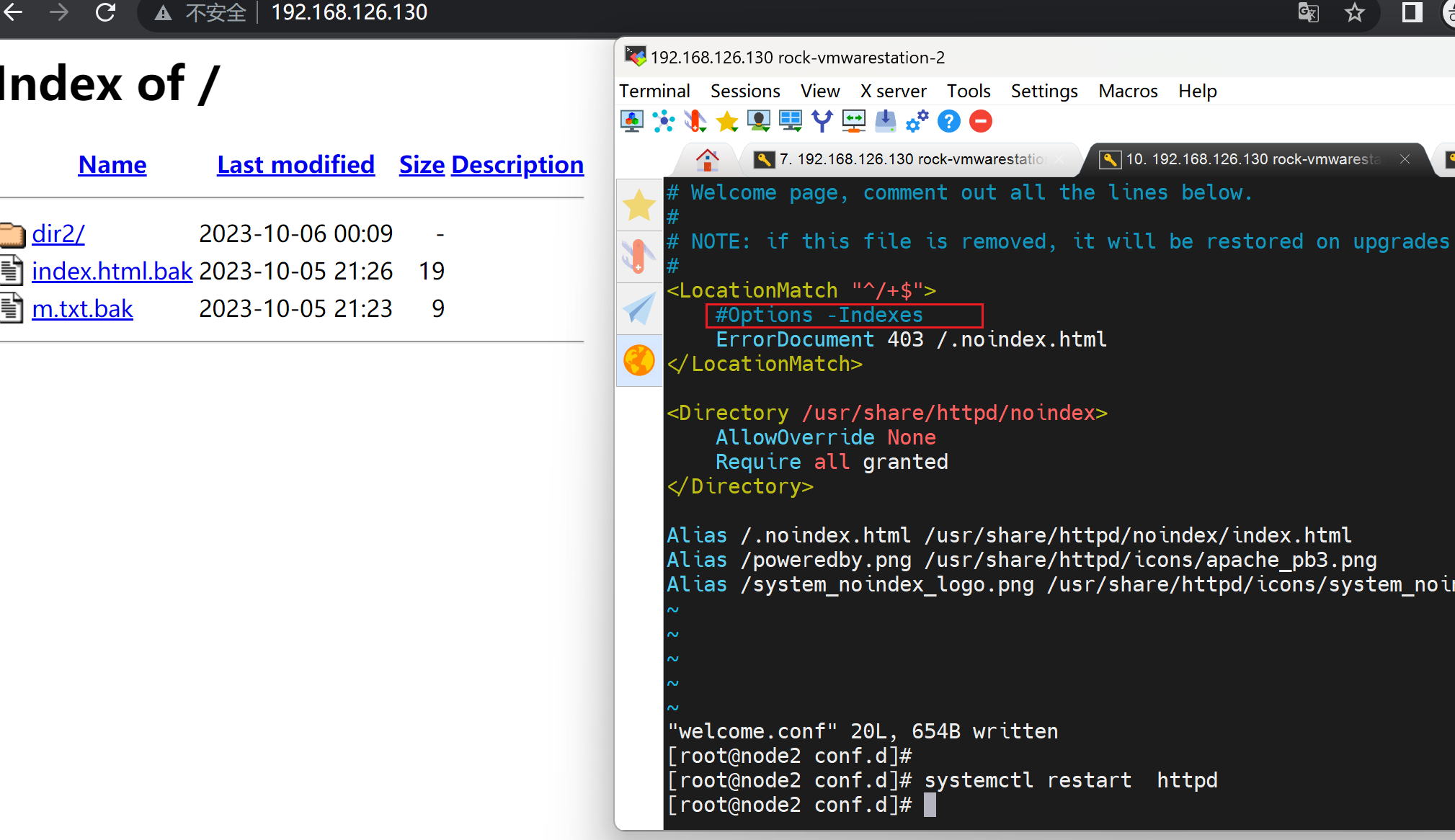
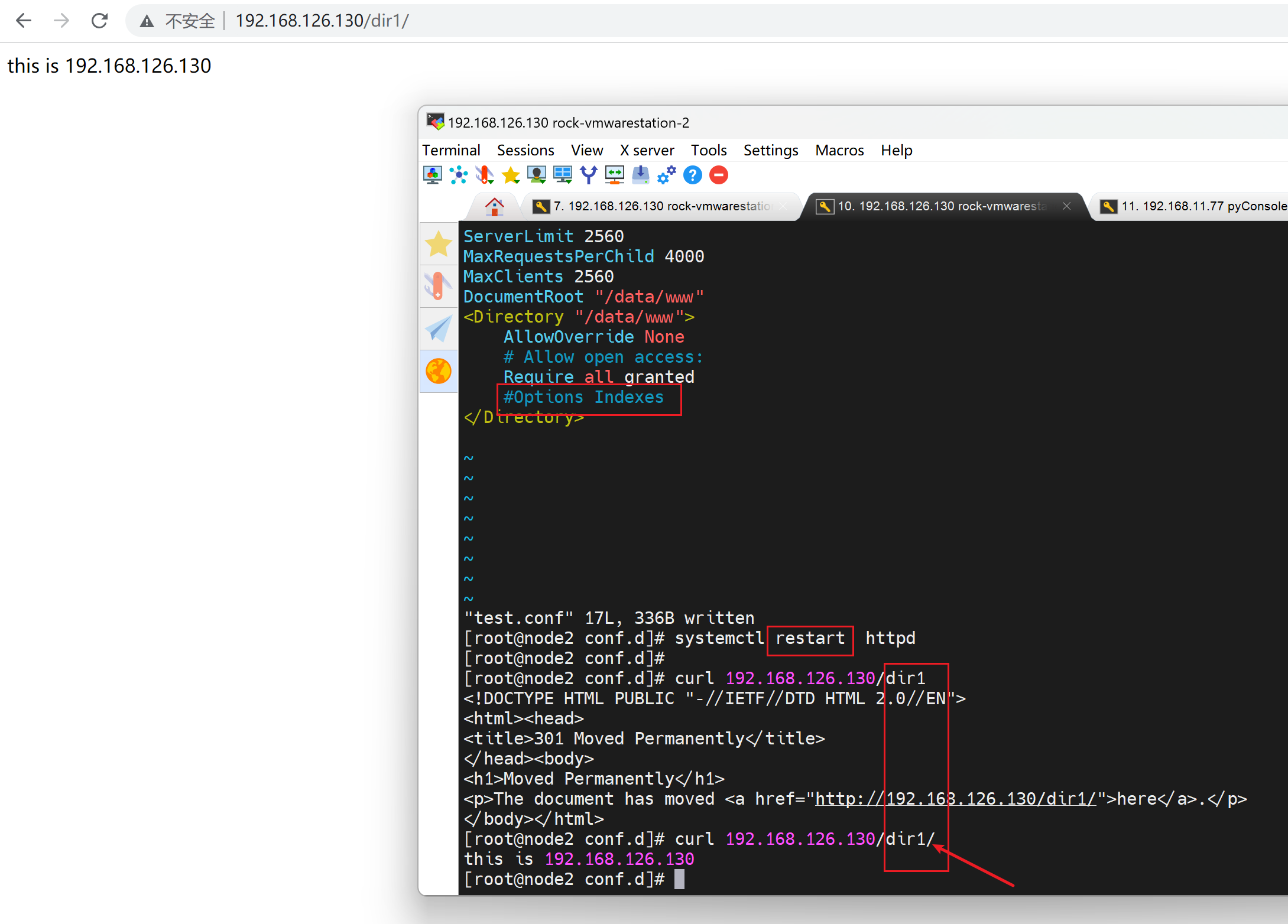
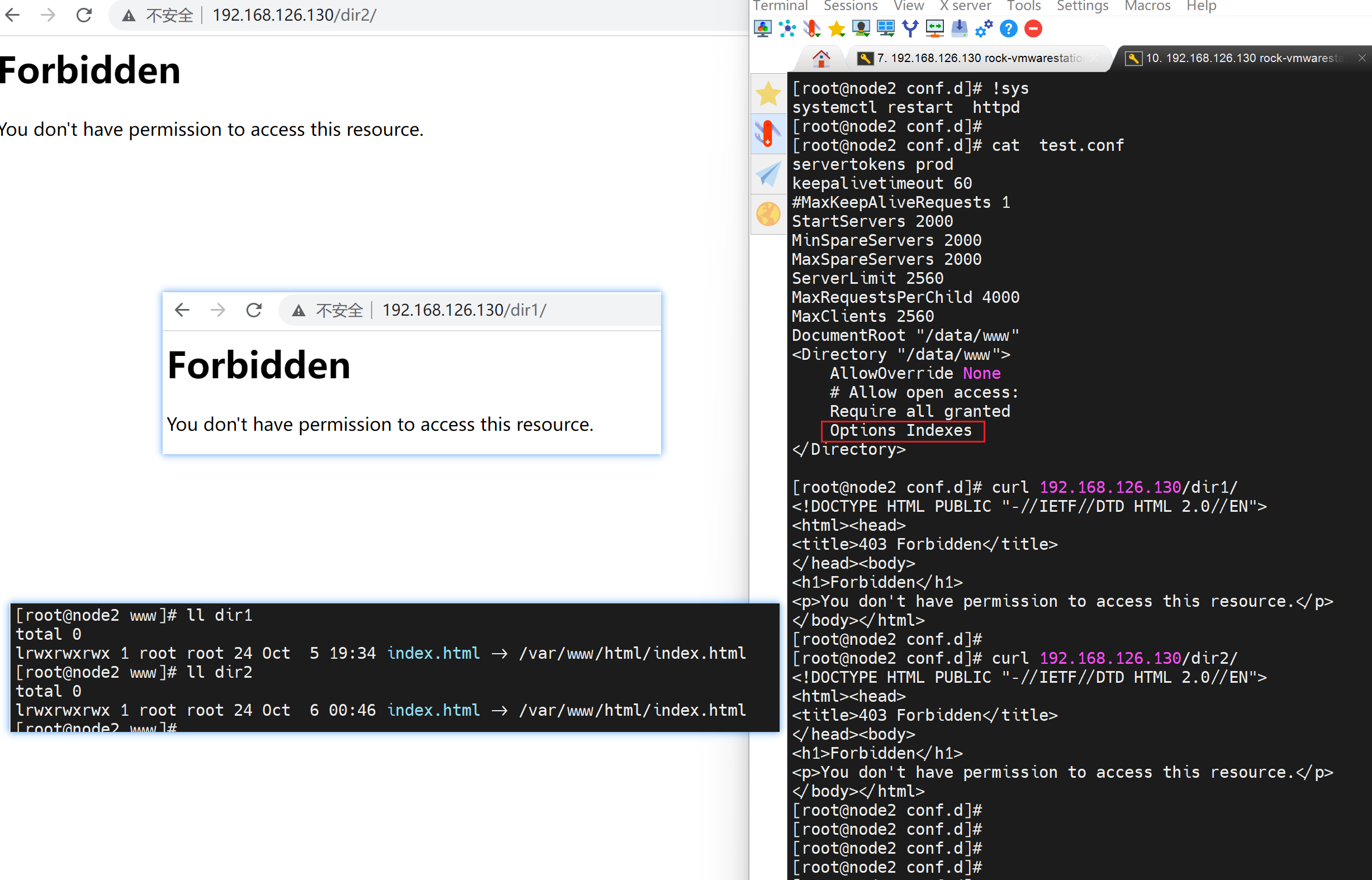
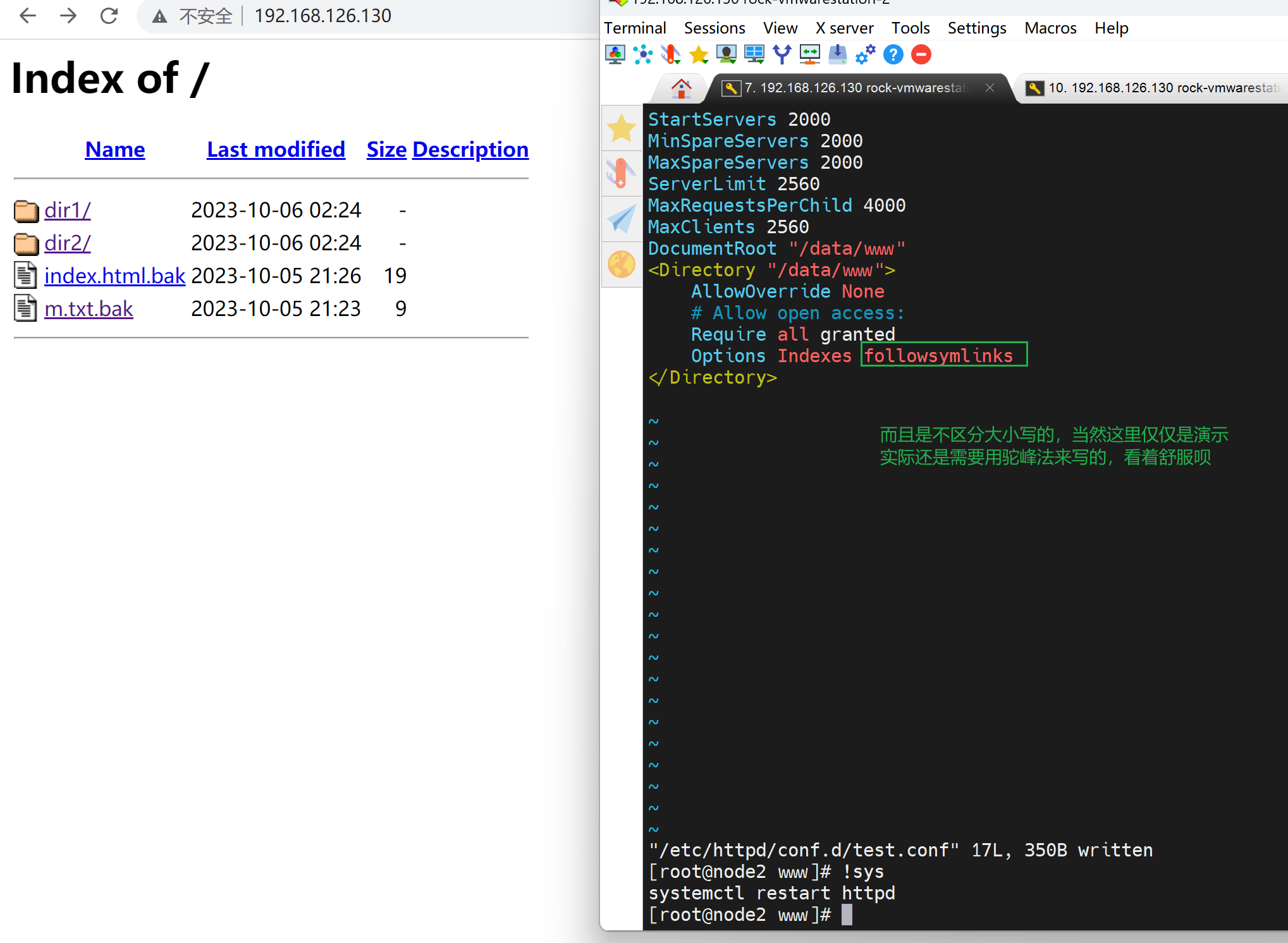
搞不懂,继续折腾,发现还是welcome.conf搞的鬼,这样就可以看到了,其实就是👇这里得options -Indexes。 - 减号就是禁止啊,禁用了目录索引功能。
然后dir1不现实,dir2可以的,研究下dir1为啥不显示
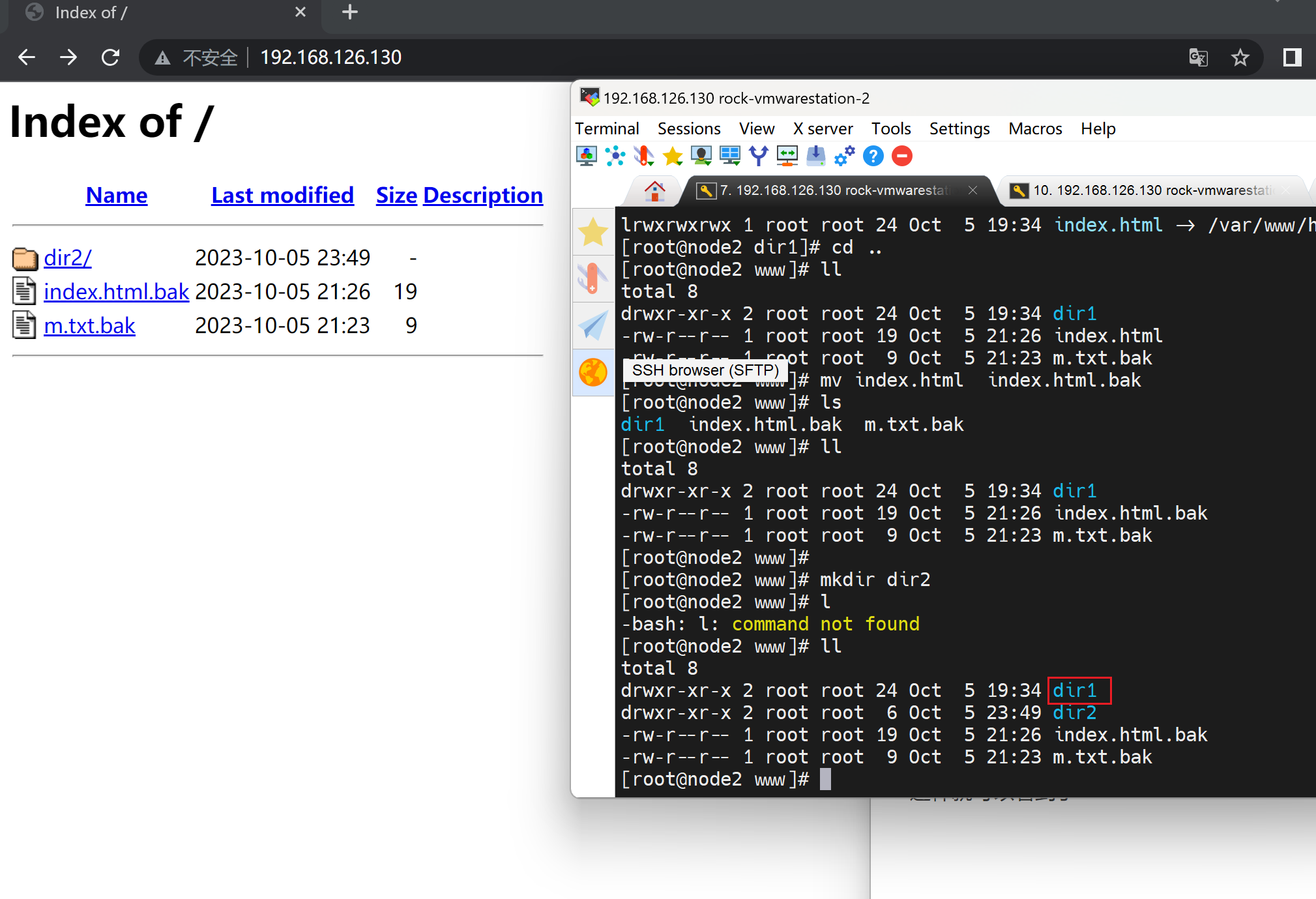
搞不懂dir1为啥不显示了,之前可以的啊
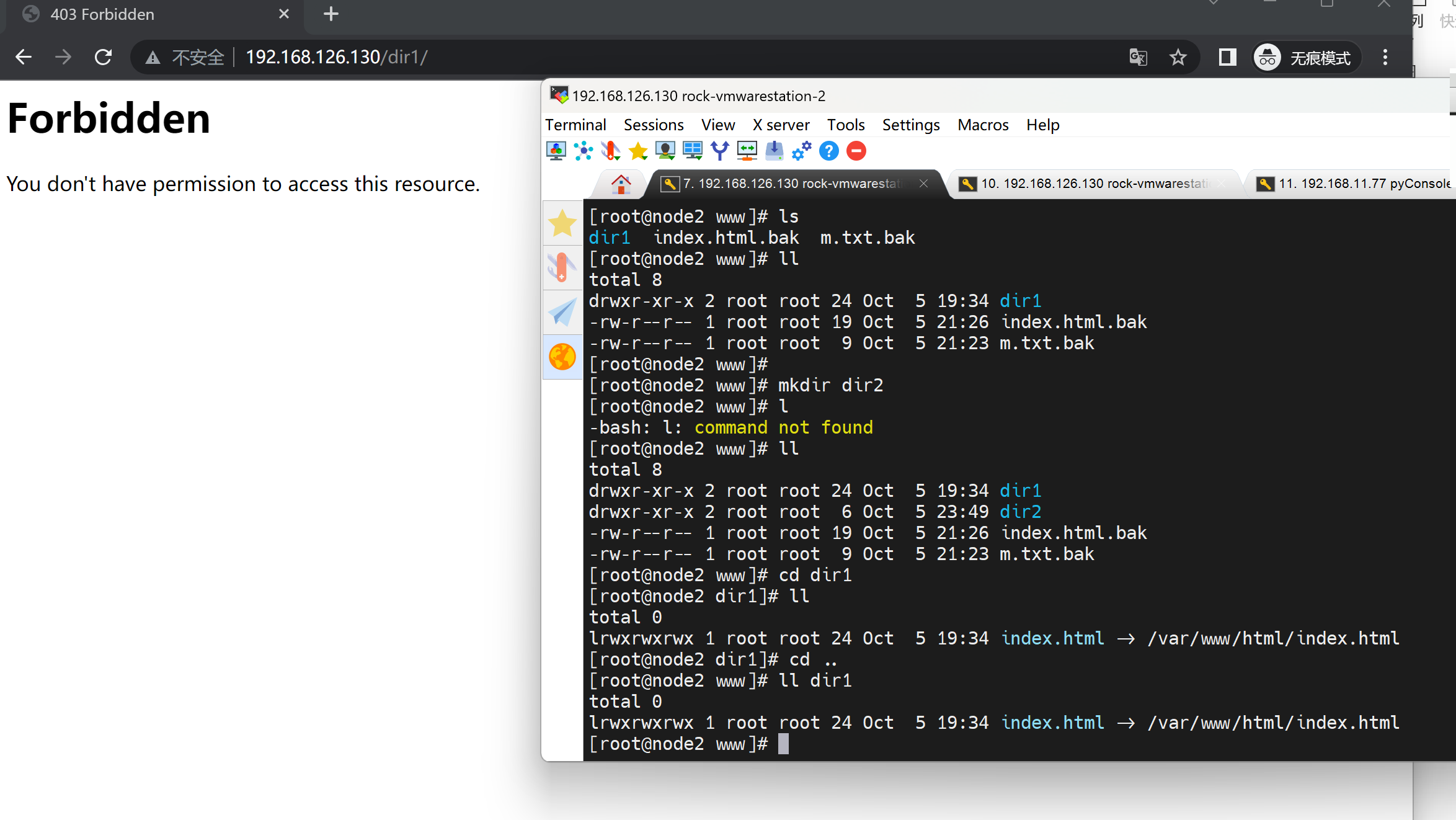

就是dir1好好的不行了,哈哈


👇结果发现是软连接得问题,但是之前可以得啊!
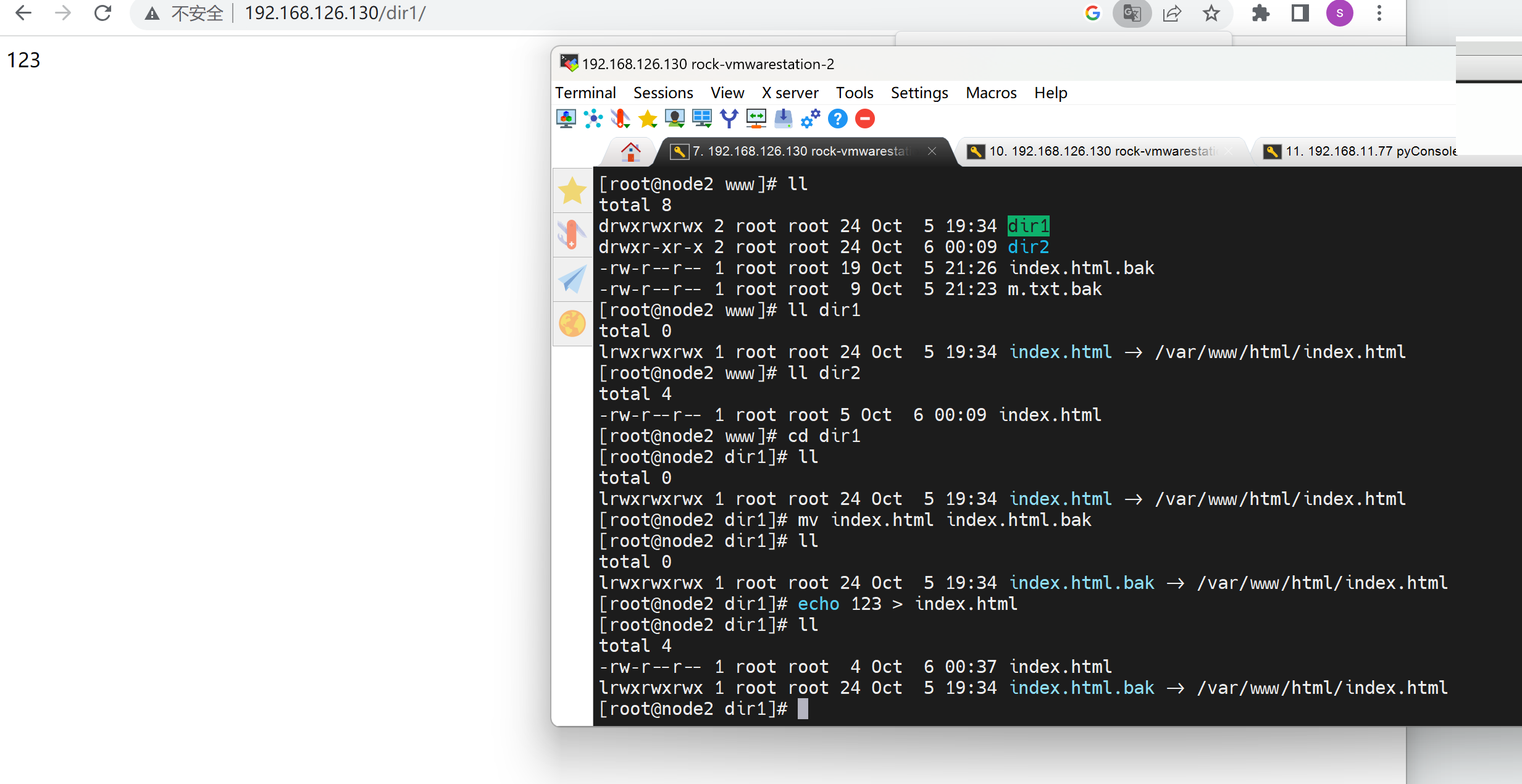
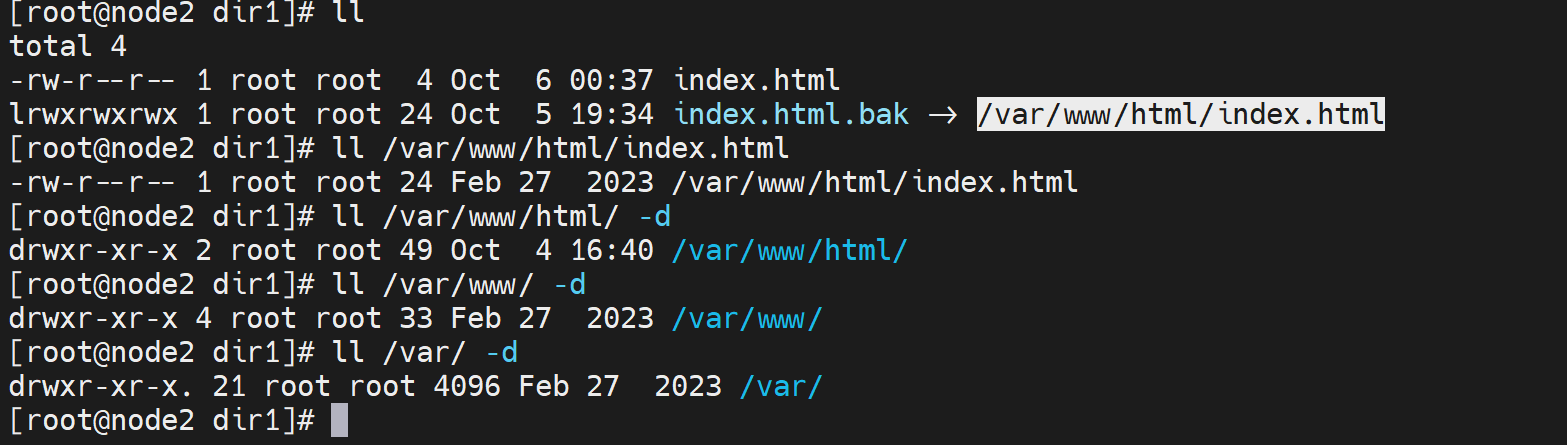
权限OK👆,找到元婴了,👇就是开启indexes就不支持软连接了,奇怪了,先记着这个点
👆同时注意:curl 不同于浏览器http://192.168.126.130/dir2 , 浏览器这样回车自动就是dir2/ 补一个斜杠的/; curl 没斜杆/有问题的。
来一张总结图👇,结论就是 options indexes会导致ln -s 的403 Forbidden。
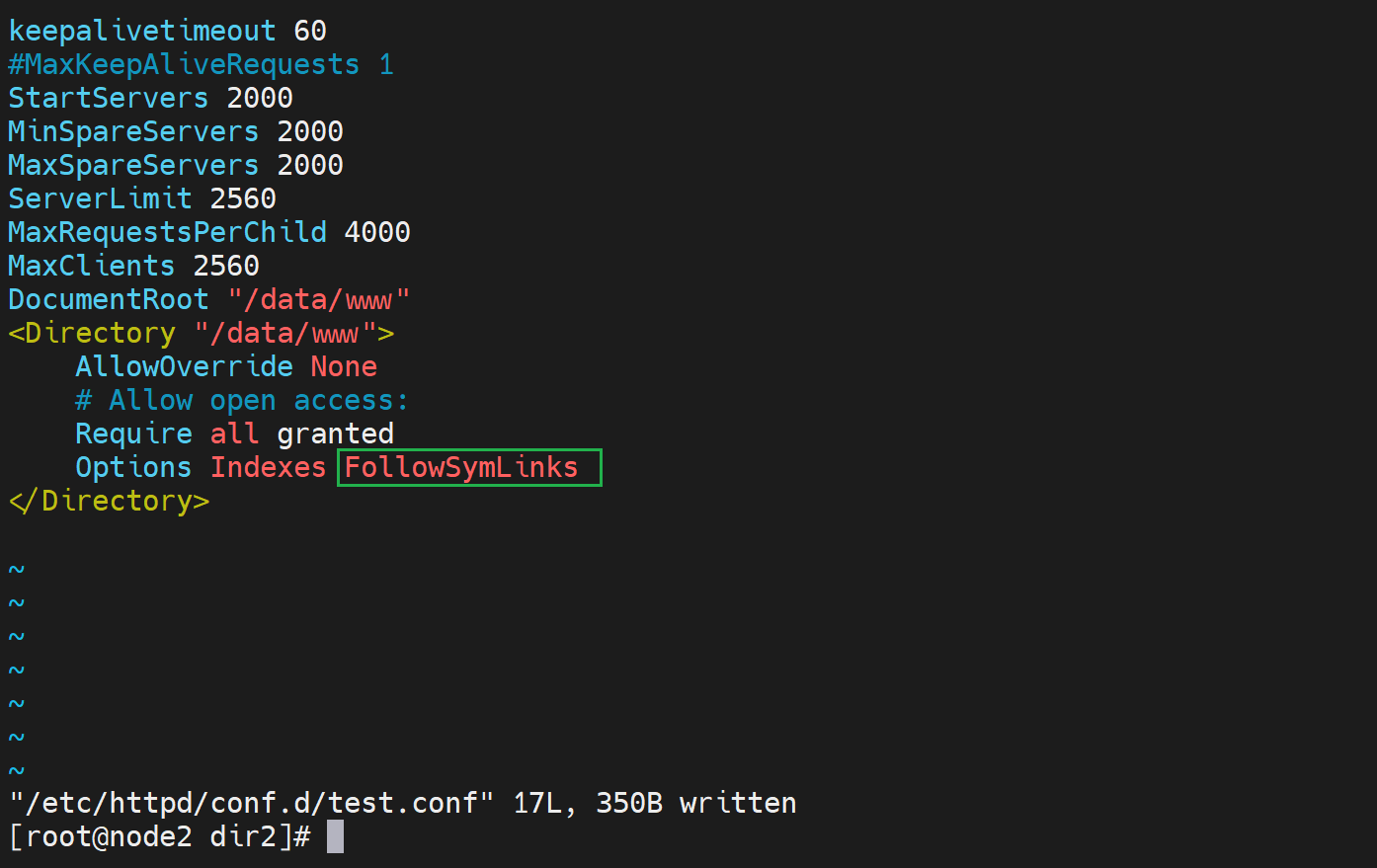
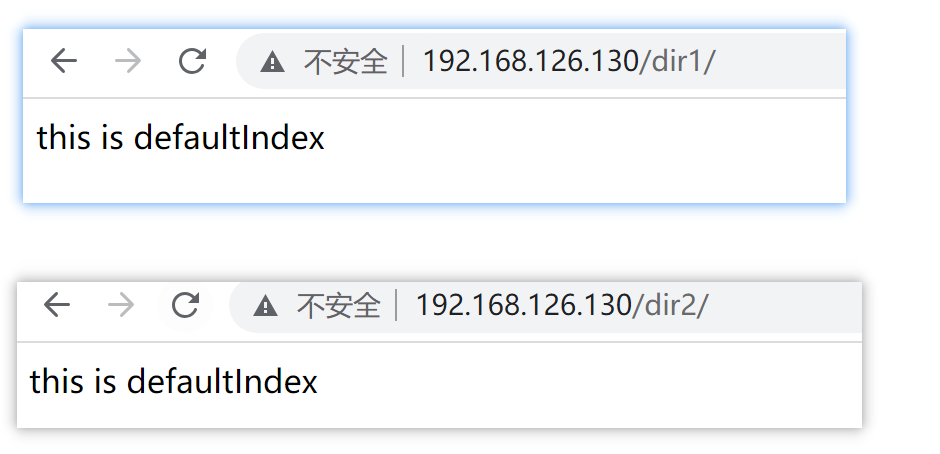
如果要把软连接也显示出来,需要再配置一下
FollowSymLinks:允许访问符号链接文件所指向的源文件
当然,welcome.conf里的-Indexes要去掉的
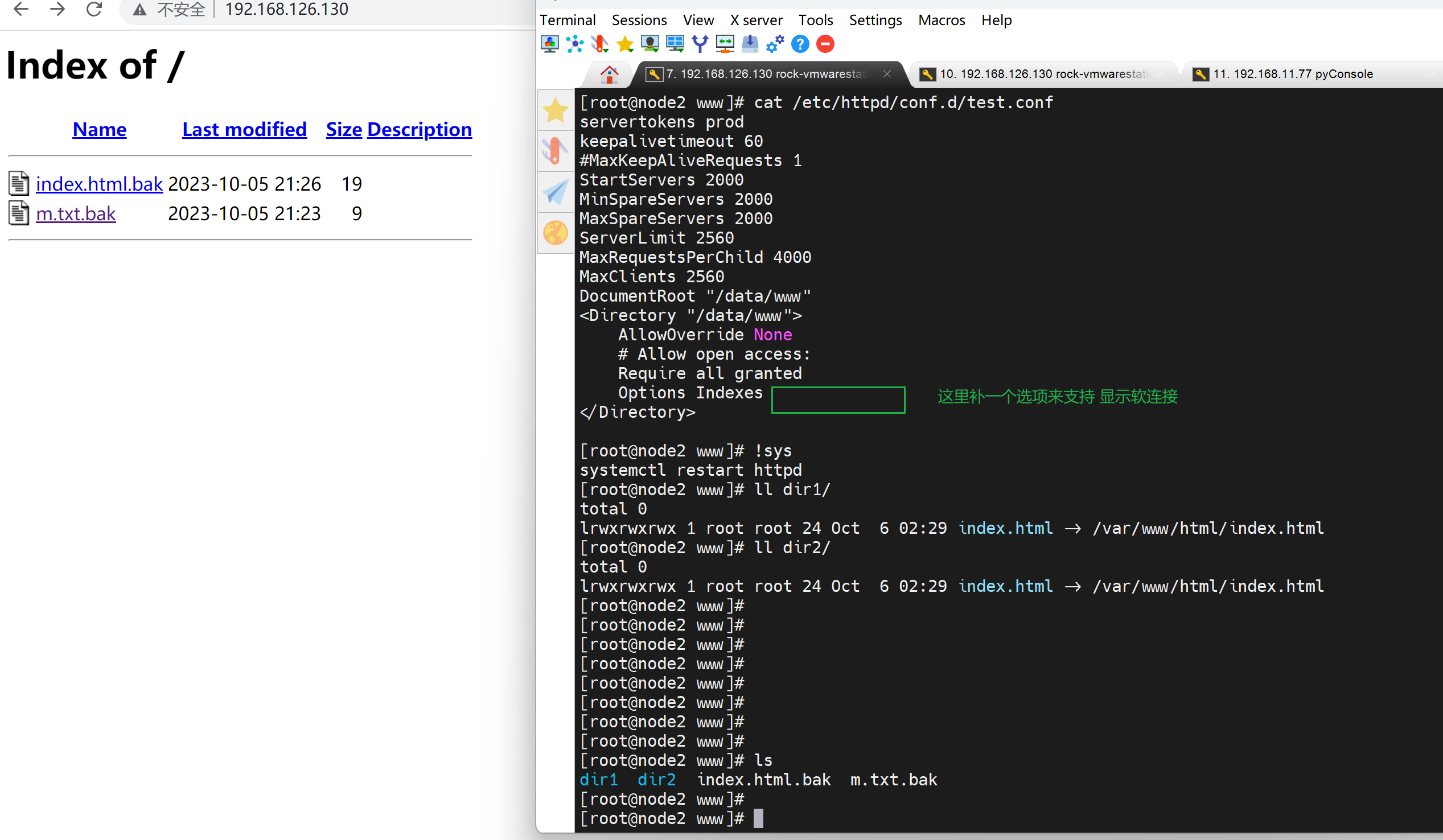
补上对应参数后就可以显示软连接了👇
.htaccess

①同样用来针对
②不过,需要在配置文件里开启功能AllowOverride ALL
③.htaccess是优先于配置文件的,不然也不会叫AllowOverride允许覆盖了。
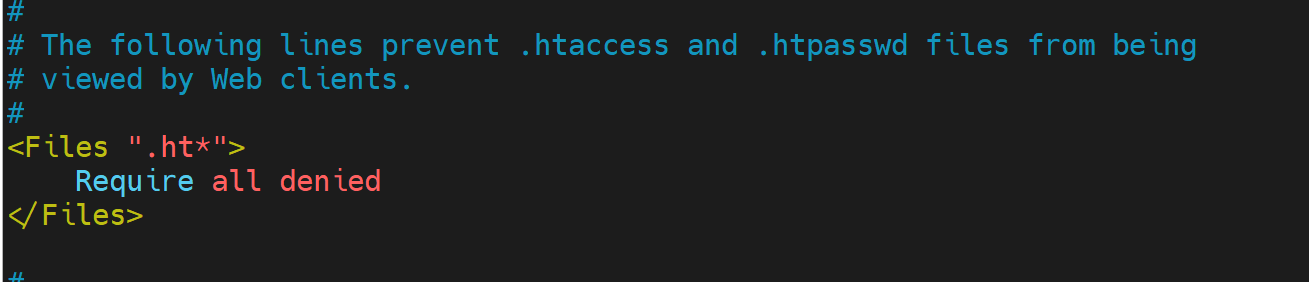
④.htaccess本身是不会被看到的,因为在主配置文件里有如下配置👇:
当前状态👇
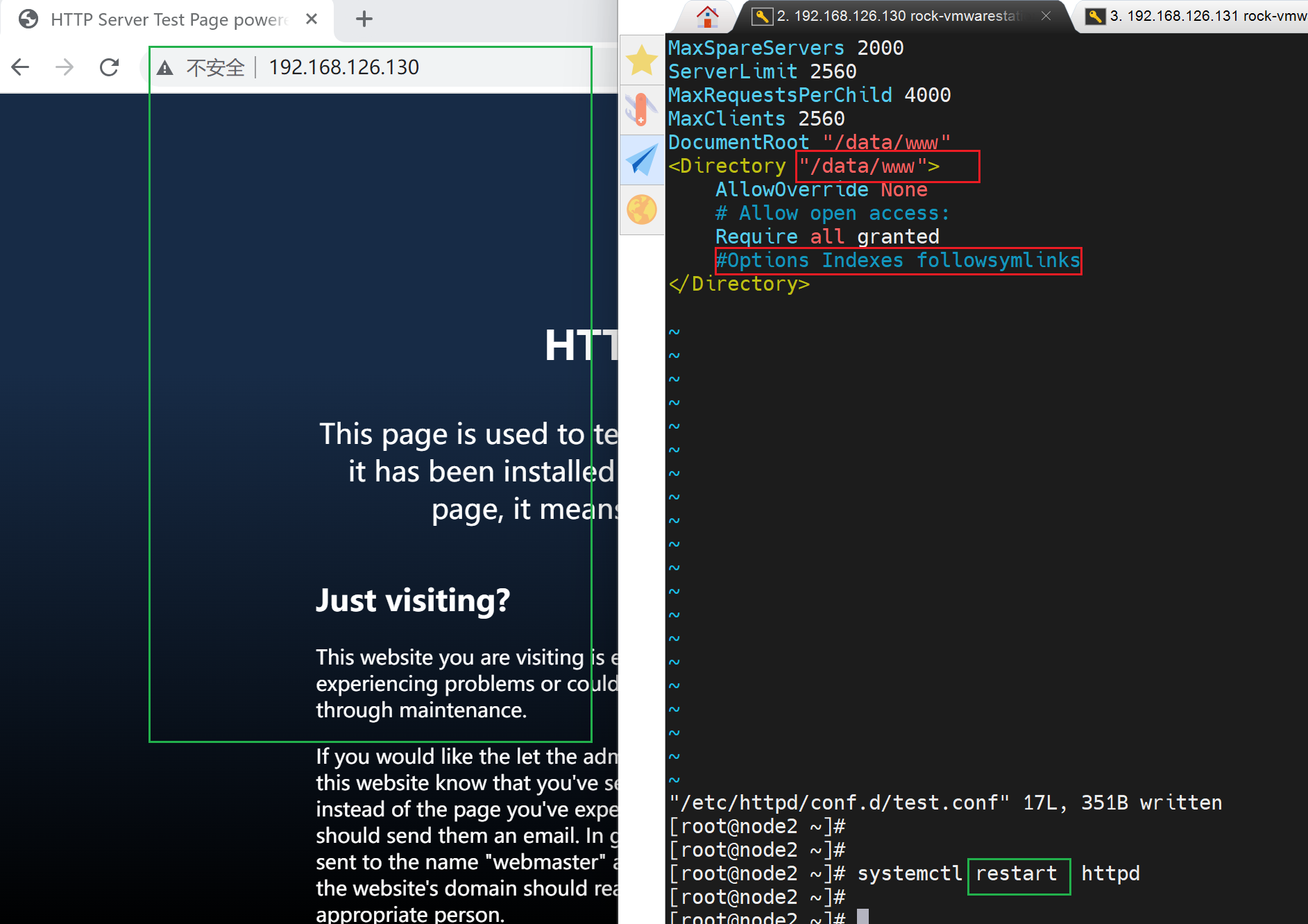
去哪里创建.htaccess整个文件呢,去accessFileName,整个文件其实不是单一的路径,而是一个递归检索的路径。
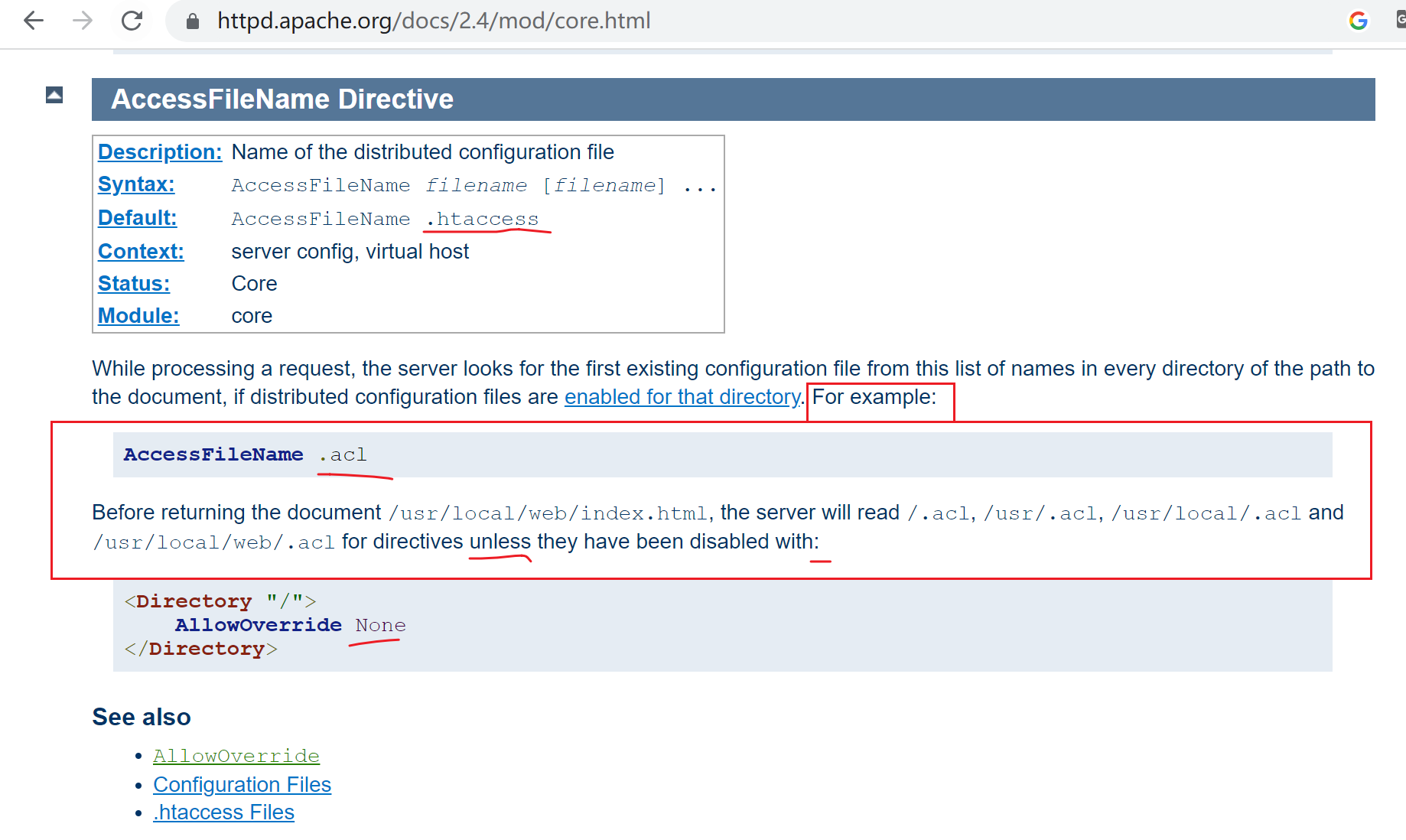
所以就在documentRoot里创建就行了
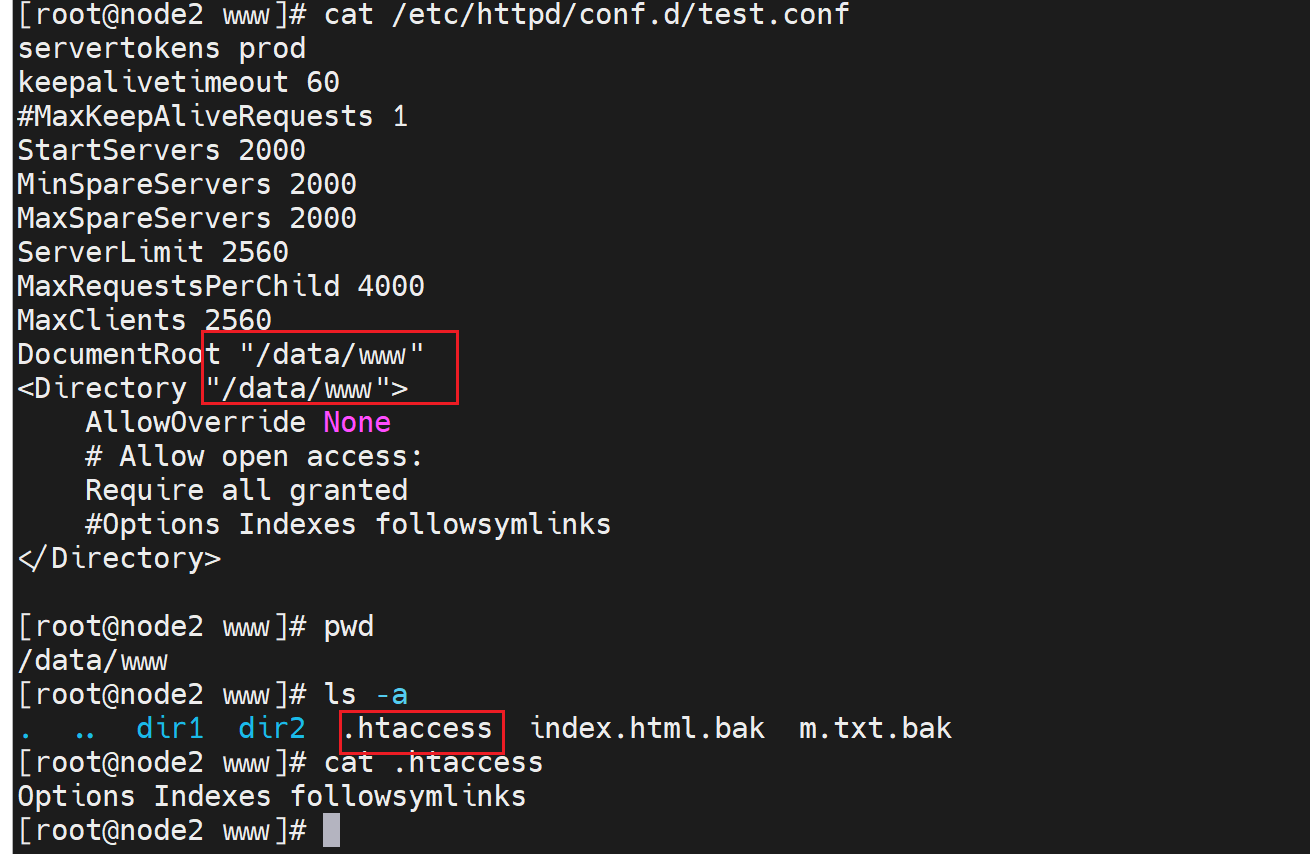
上图👆漏了一个AllowOverride All,这就是针对.htaccess的生效开关。
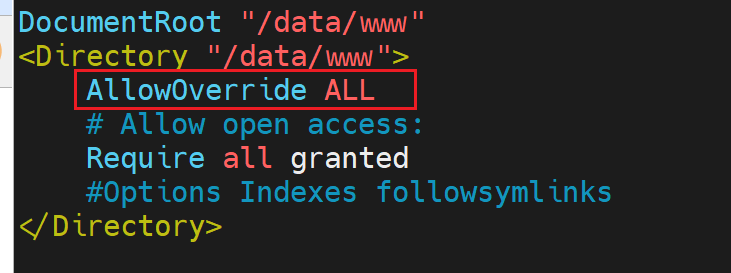
然后就可以了
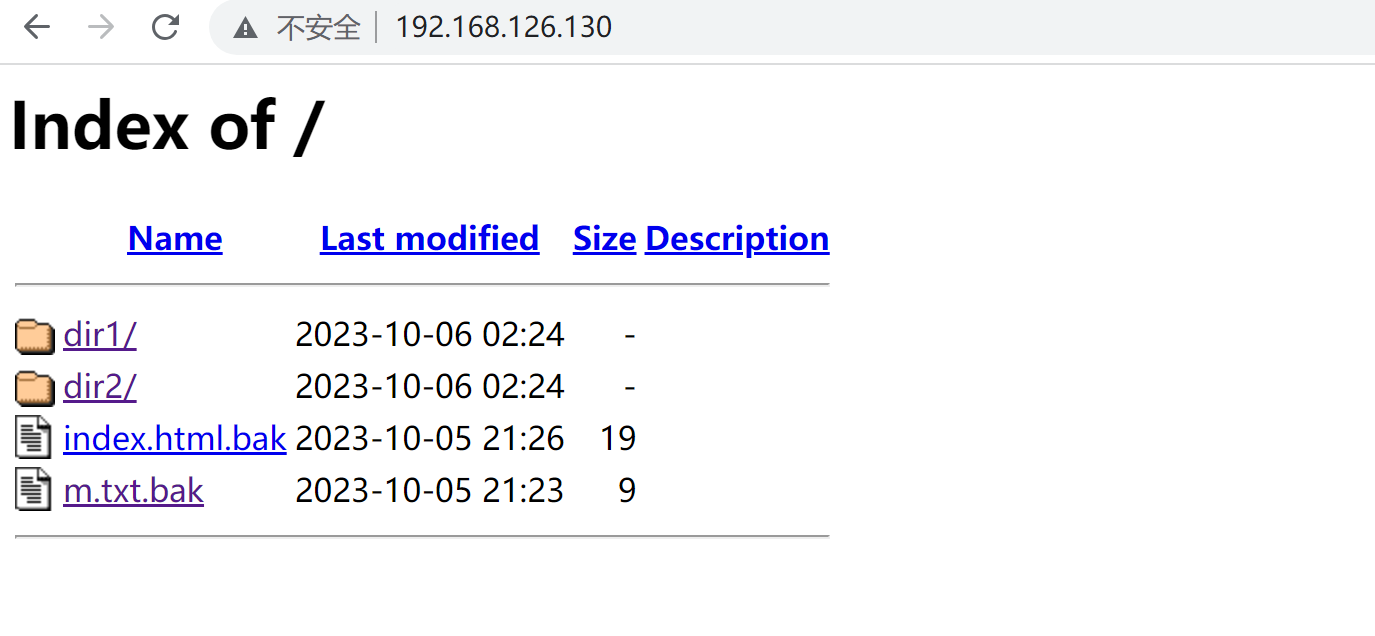
阶段总结一下



下面开始学习(3)基于IP的访问控制
基于IP的访问控制:
先做一个拒绝所有的conf文件的访问
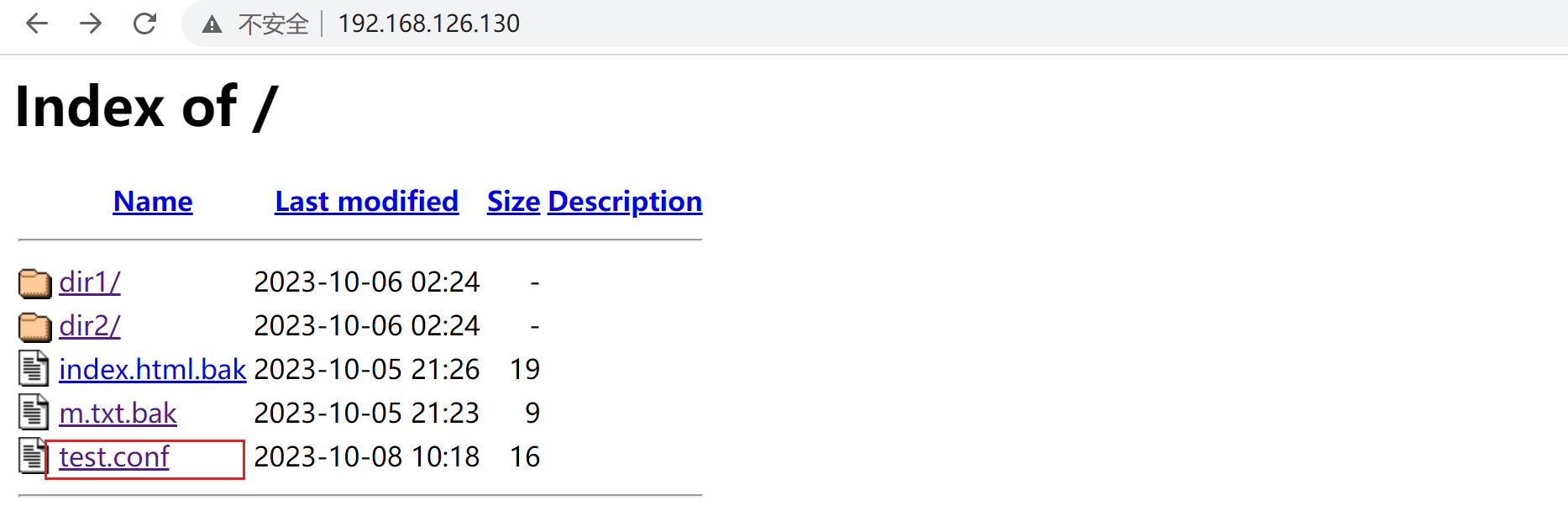

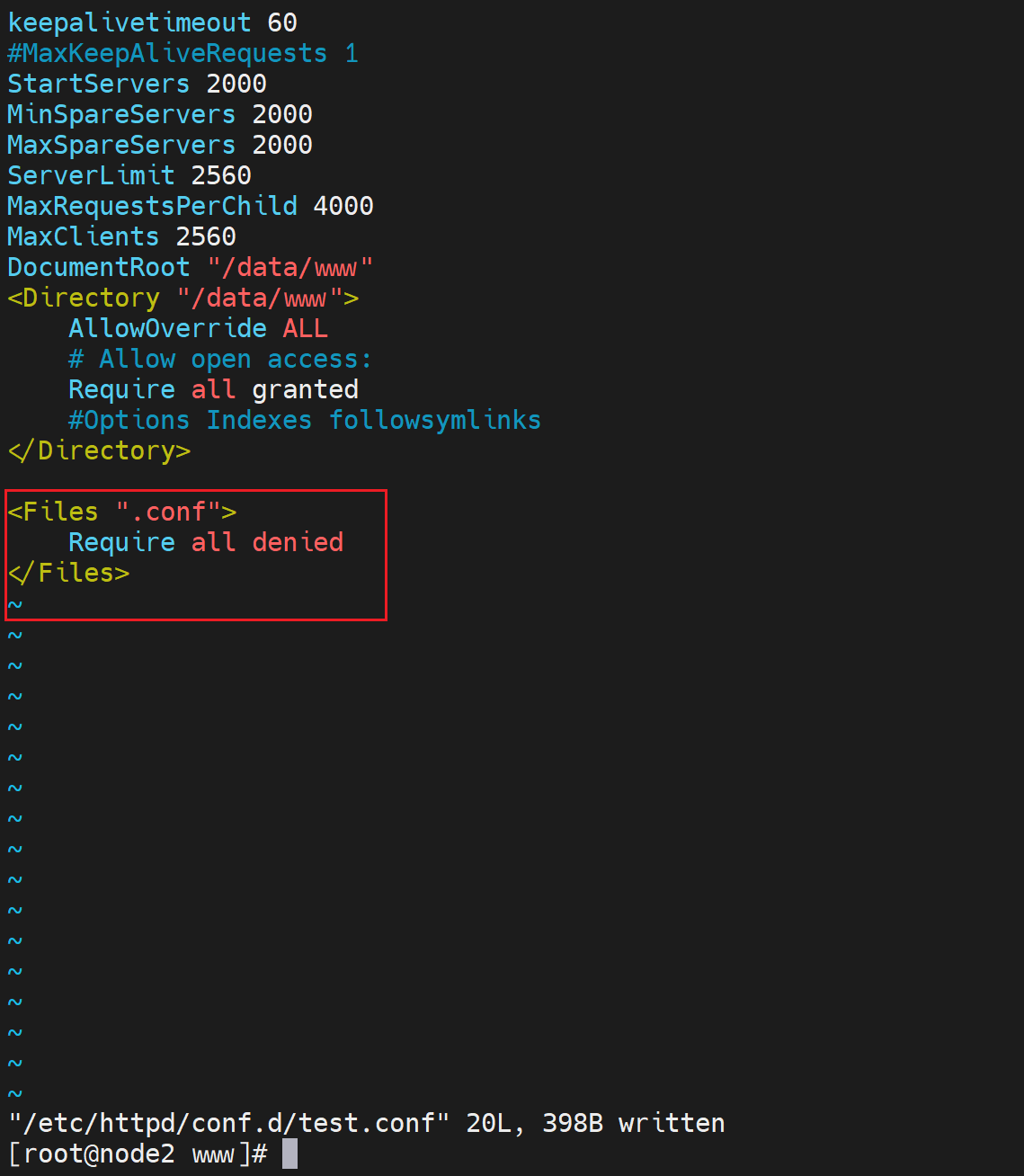
这里files 就是通配符,filesMatch才是正则表达式了,嗯~ o( ̄▽ ̄)o上面的通配符写错了哦,改下👇:
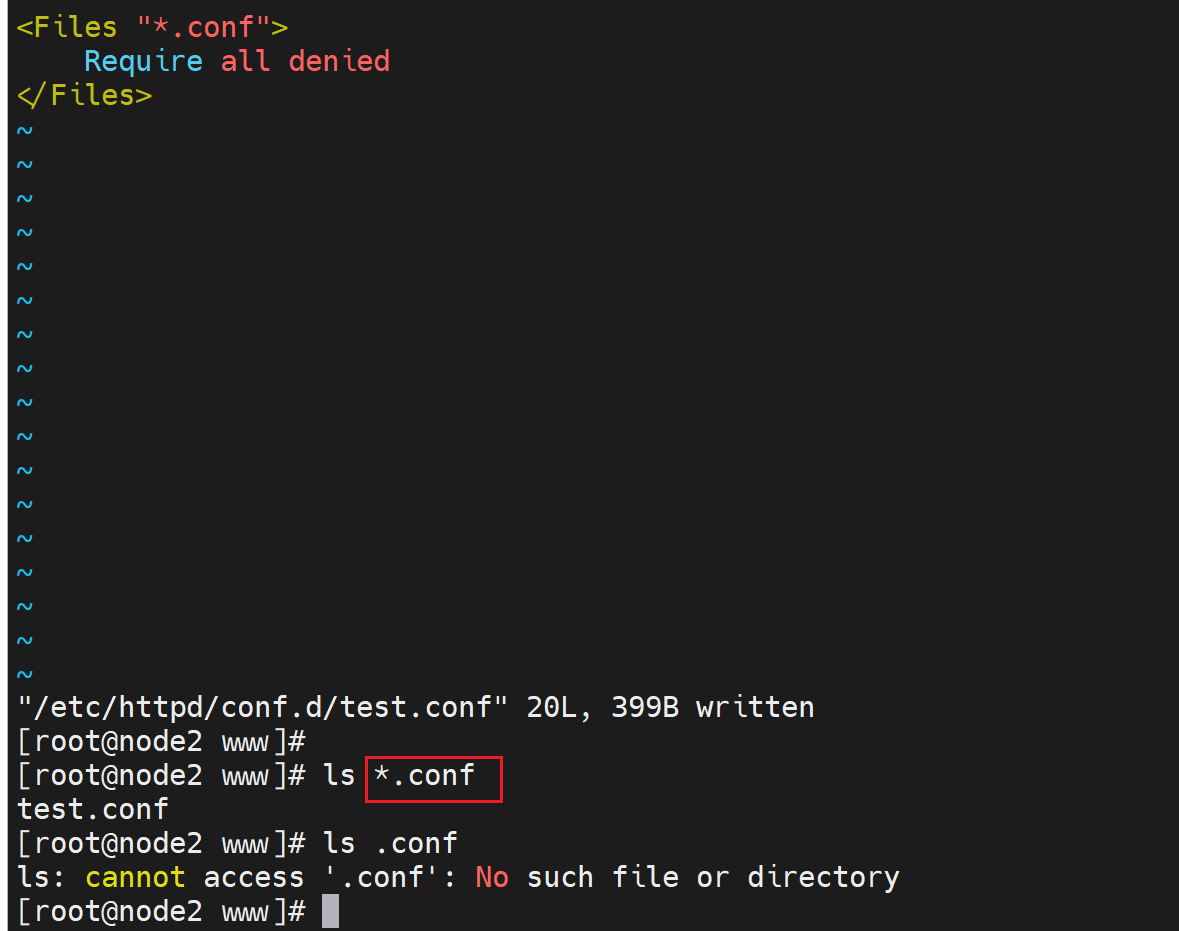
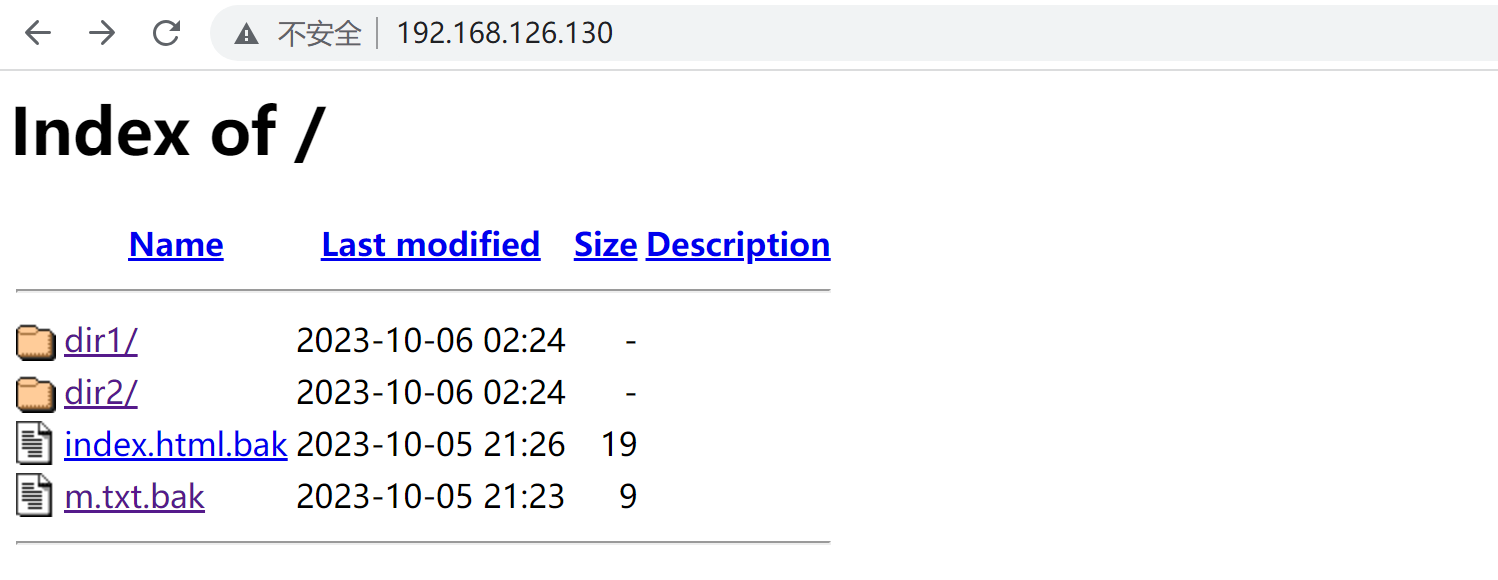
重启服务后,xxx.conf文件就看不到了,
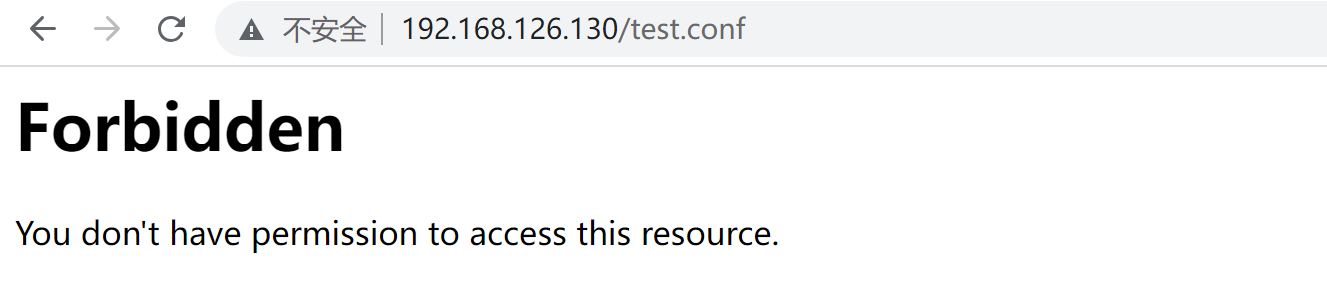
将通配符改成正则
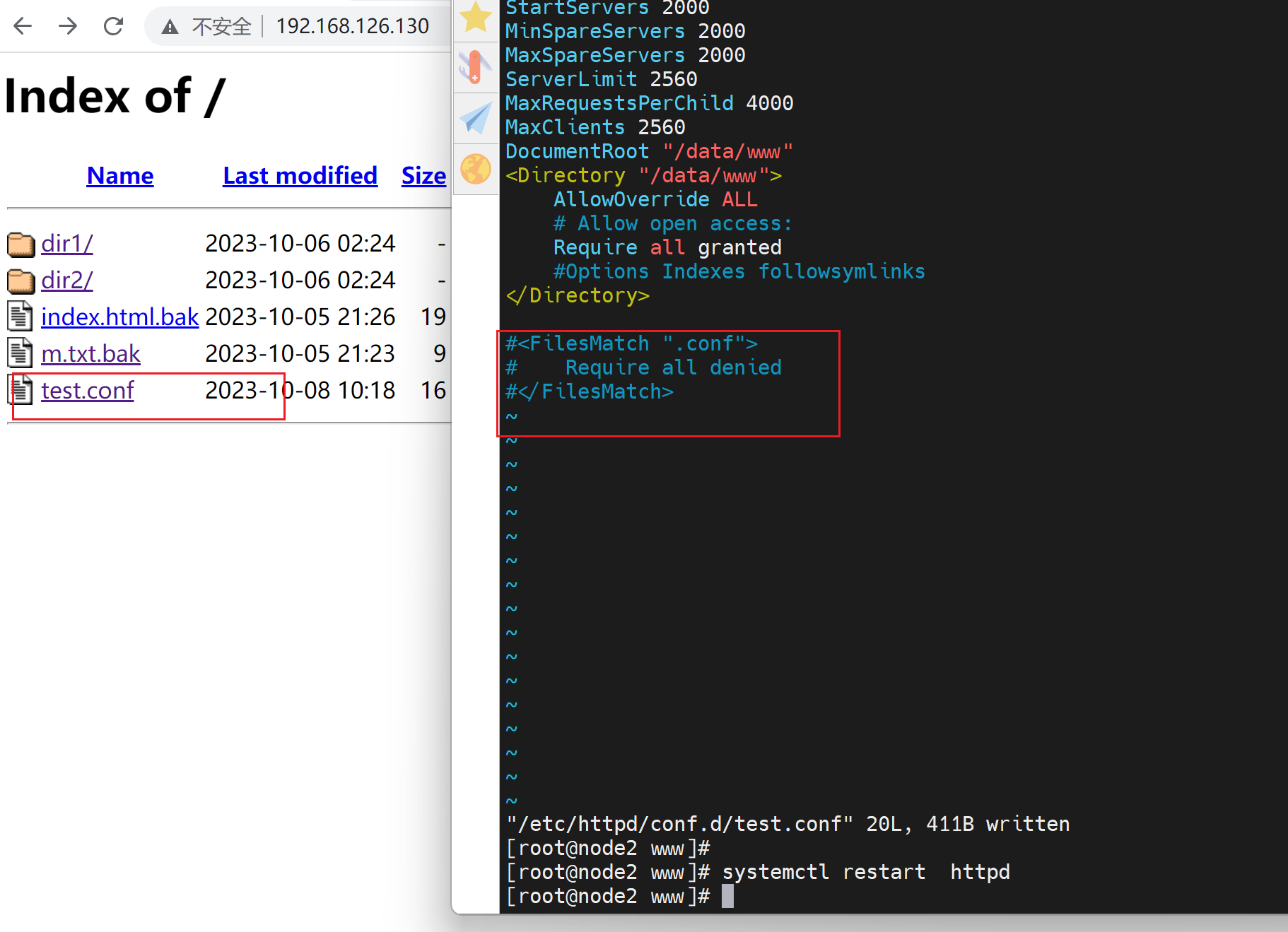
打开上图注释,就会实现拒绝访问 包含.conf的文件,当然regex要写好一点,优化下
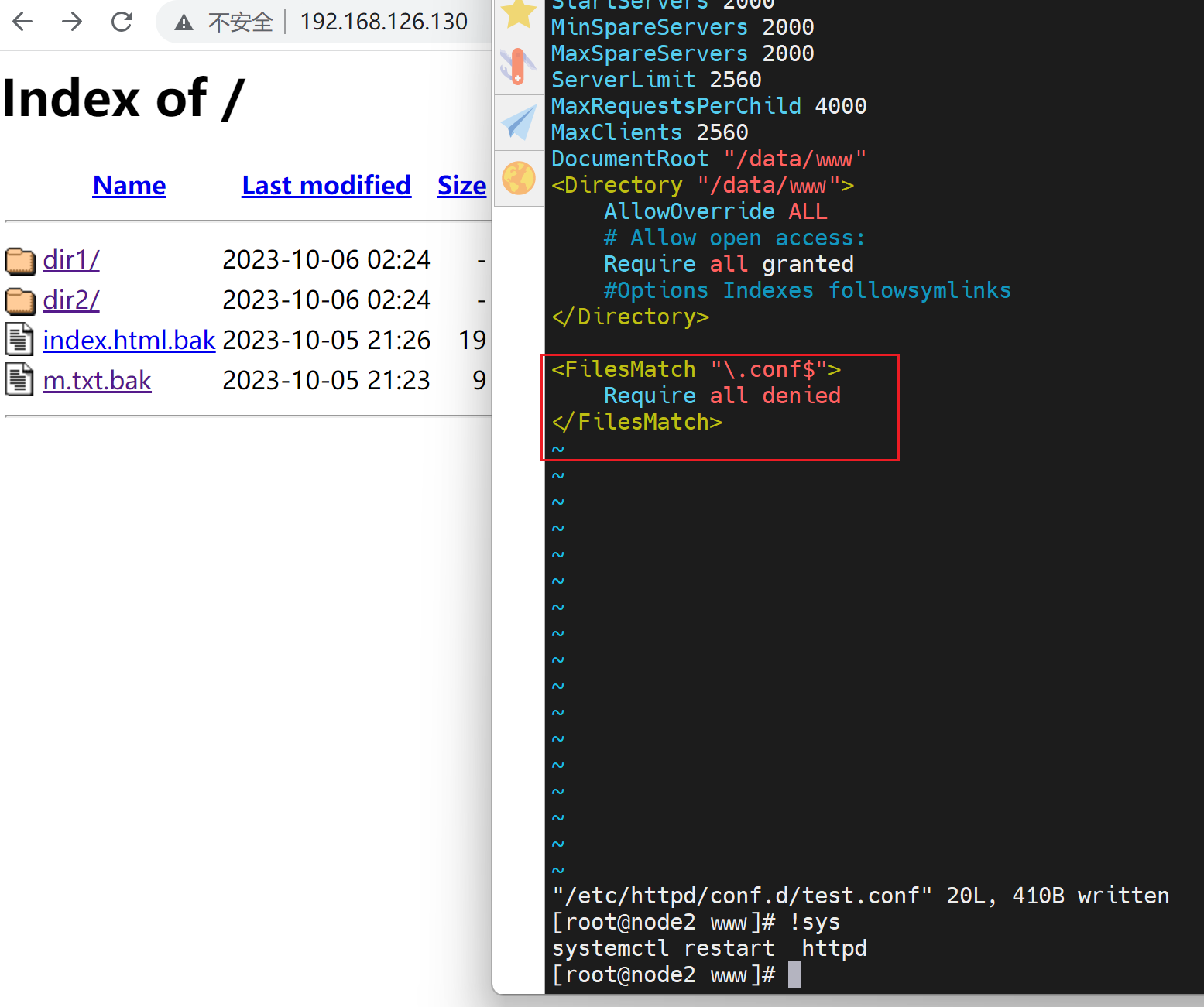
这样就实现了regex的写法,参见上文
进一步实现针对192.168.126.1这个IP,不能访问beijing/index.html,其他都可以
mkdir beijing
echo this is beijingbeijing > beijing/index.html
ls beijing/

配置acl后的效果:
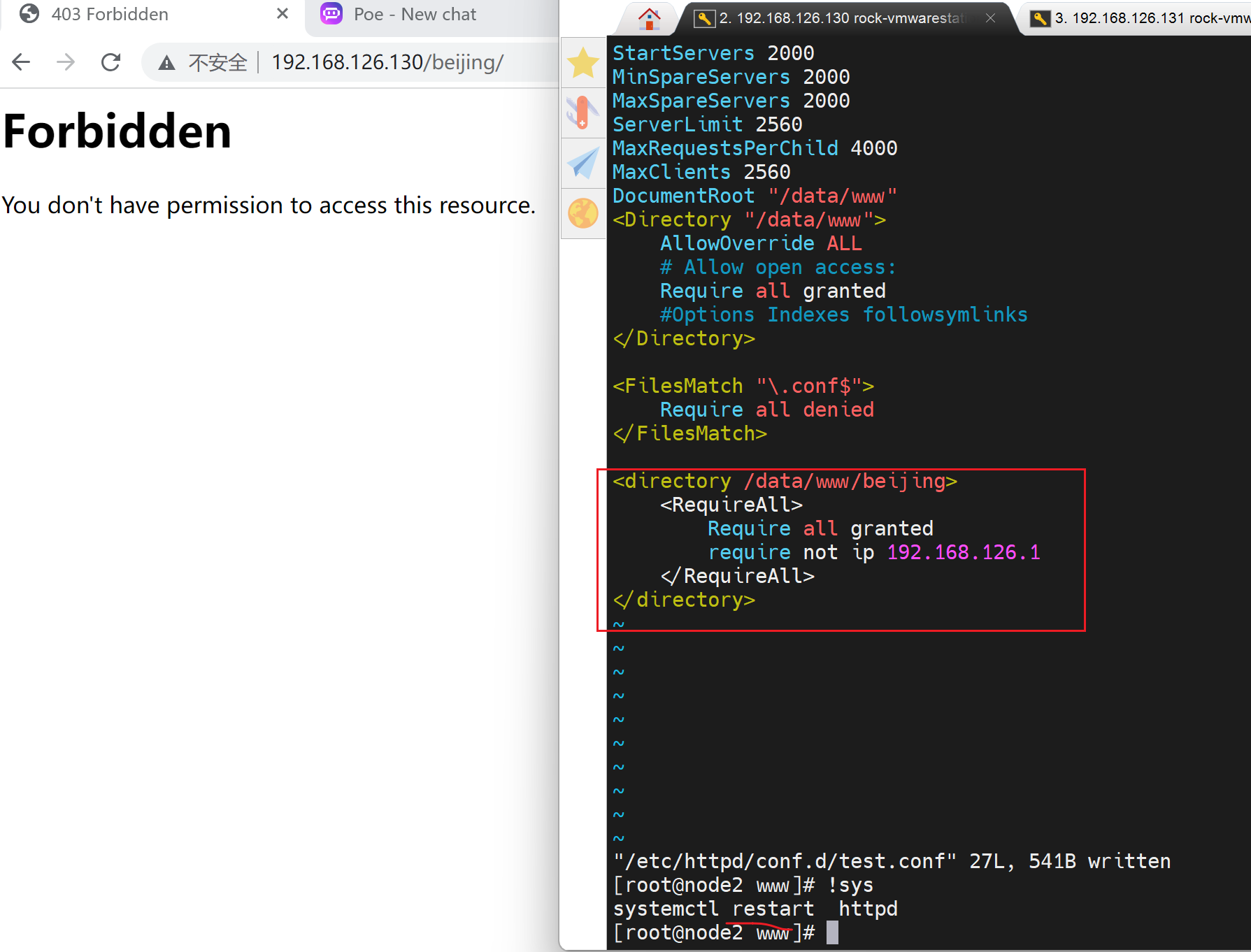
其他都OK
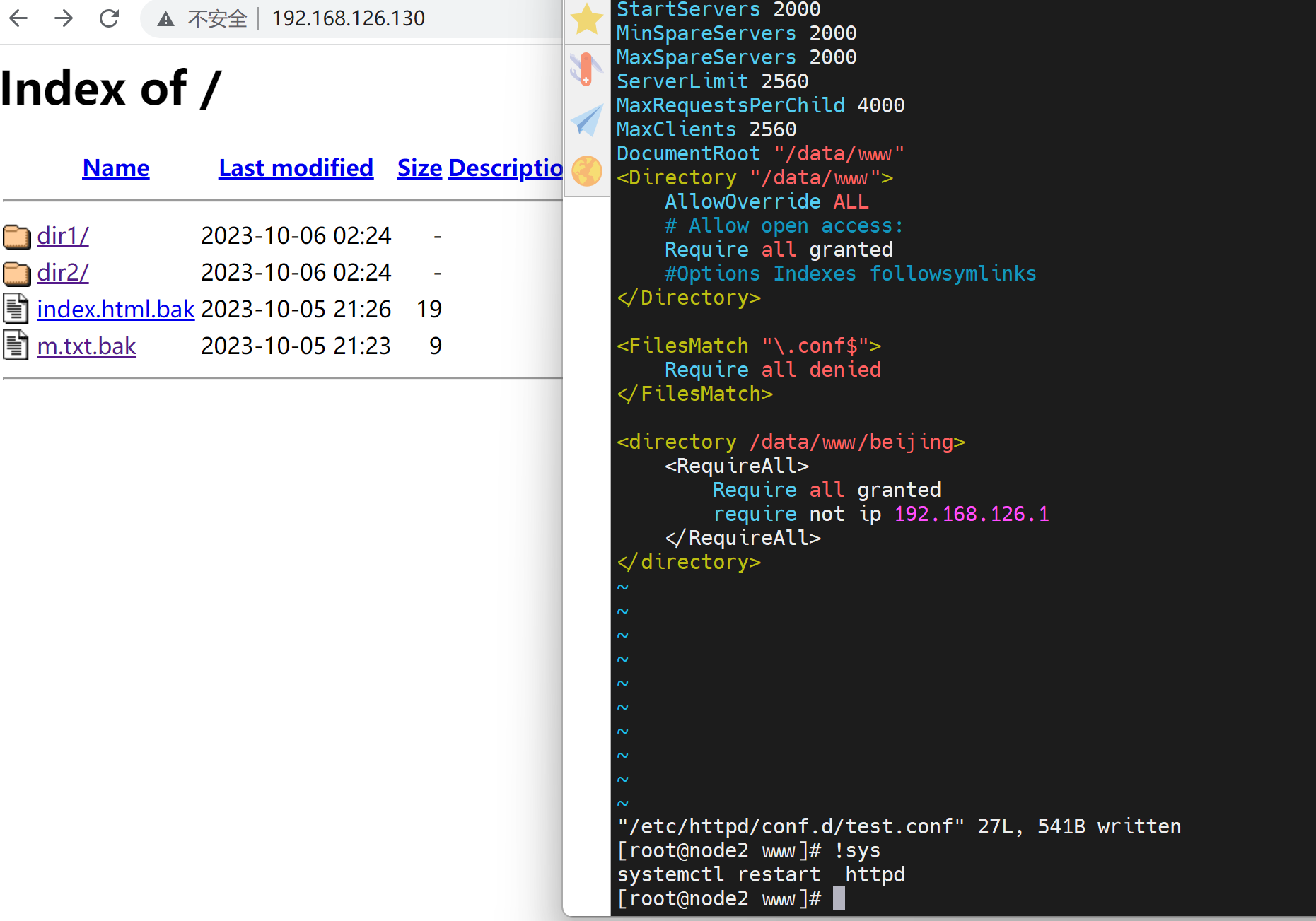
由于只是针对192.168.126.1的禁止访问/beijing/index.html,所以其他IP可以访问
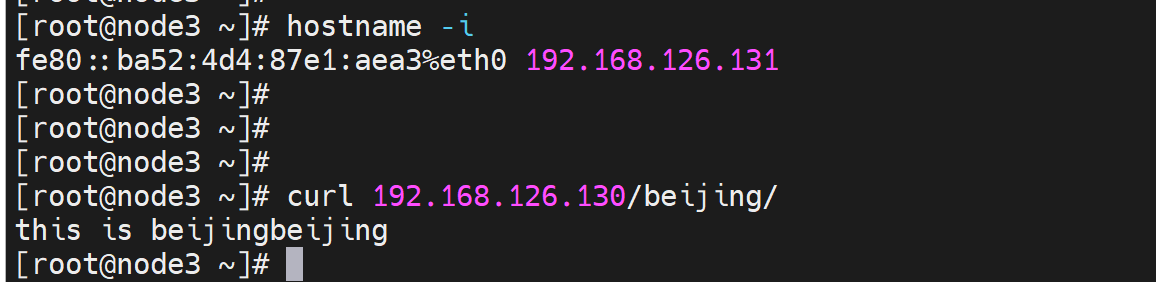
改为拒绝整个子网
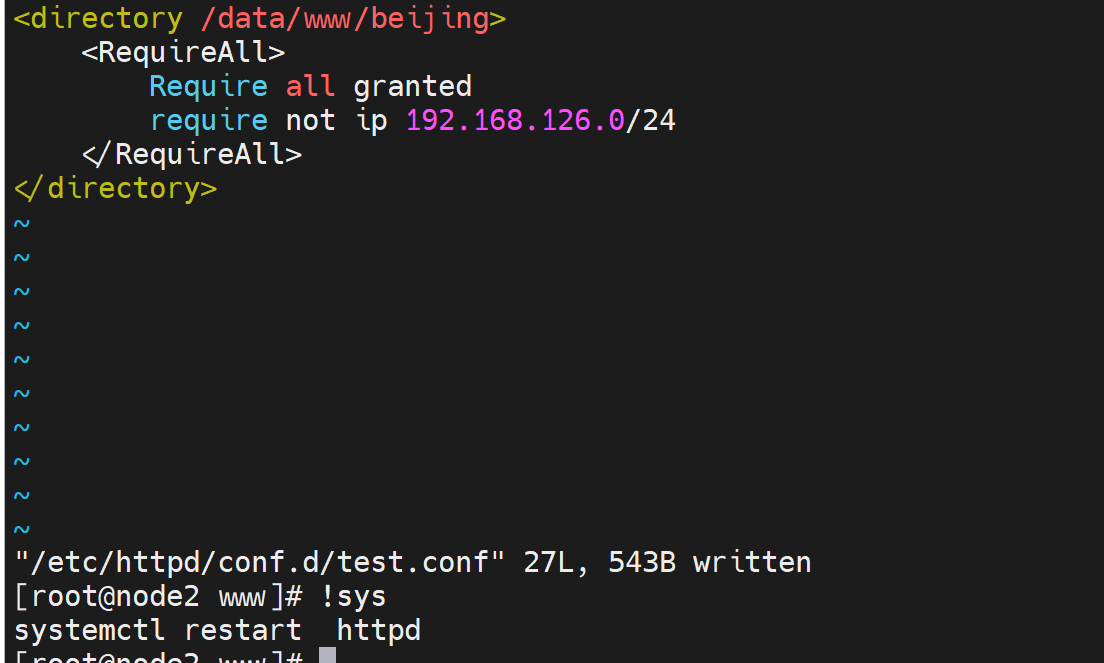
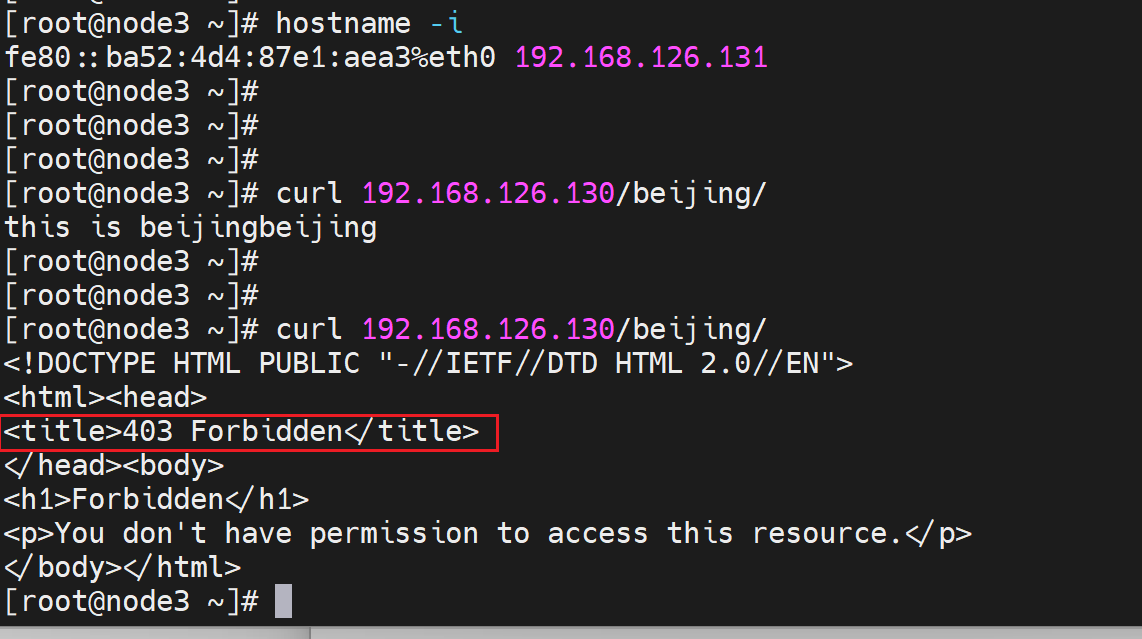
然后研究下优先级和默认行为
先上结论:
①RequireAll 搭配 all granted 然后拒绝谁,这是黑名单写法
②RequireAny搭配all denied然后放行谁,这是白名单写法。
③宇宙法则之--从上到下匹配,被打破了,这里明明all granted还可以下面deny,明明all deny了还可以下面permit所以这里打破了从上往下的宇宙法则。

👆上图的划红线出 文字表达是摸棱两可的,不要按他的思路理解。
就理解成RequireAll是黑名单机制,RequireAny是白名单机制,就好了啊,还折腾啥呢,浅测一下👇
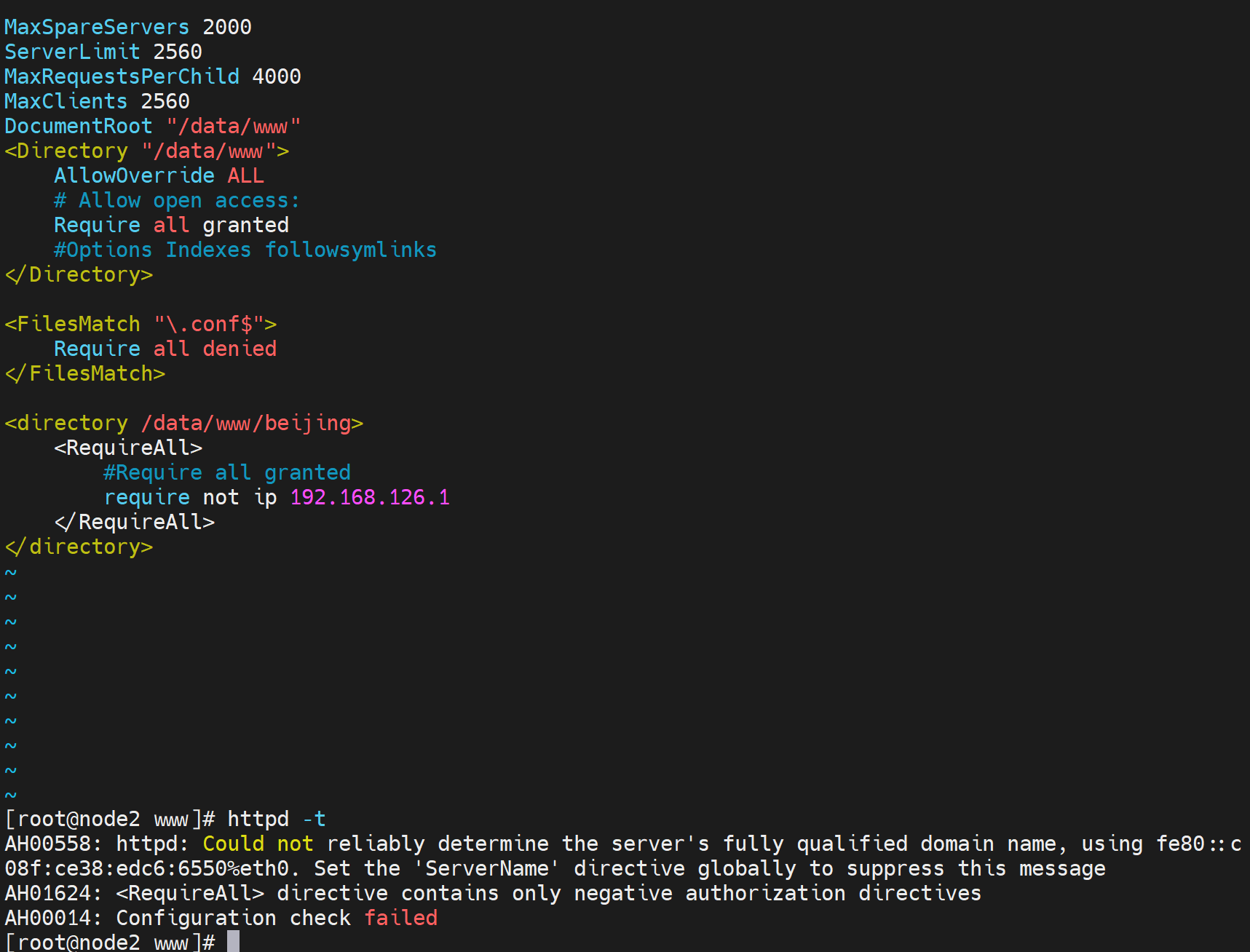
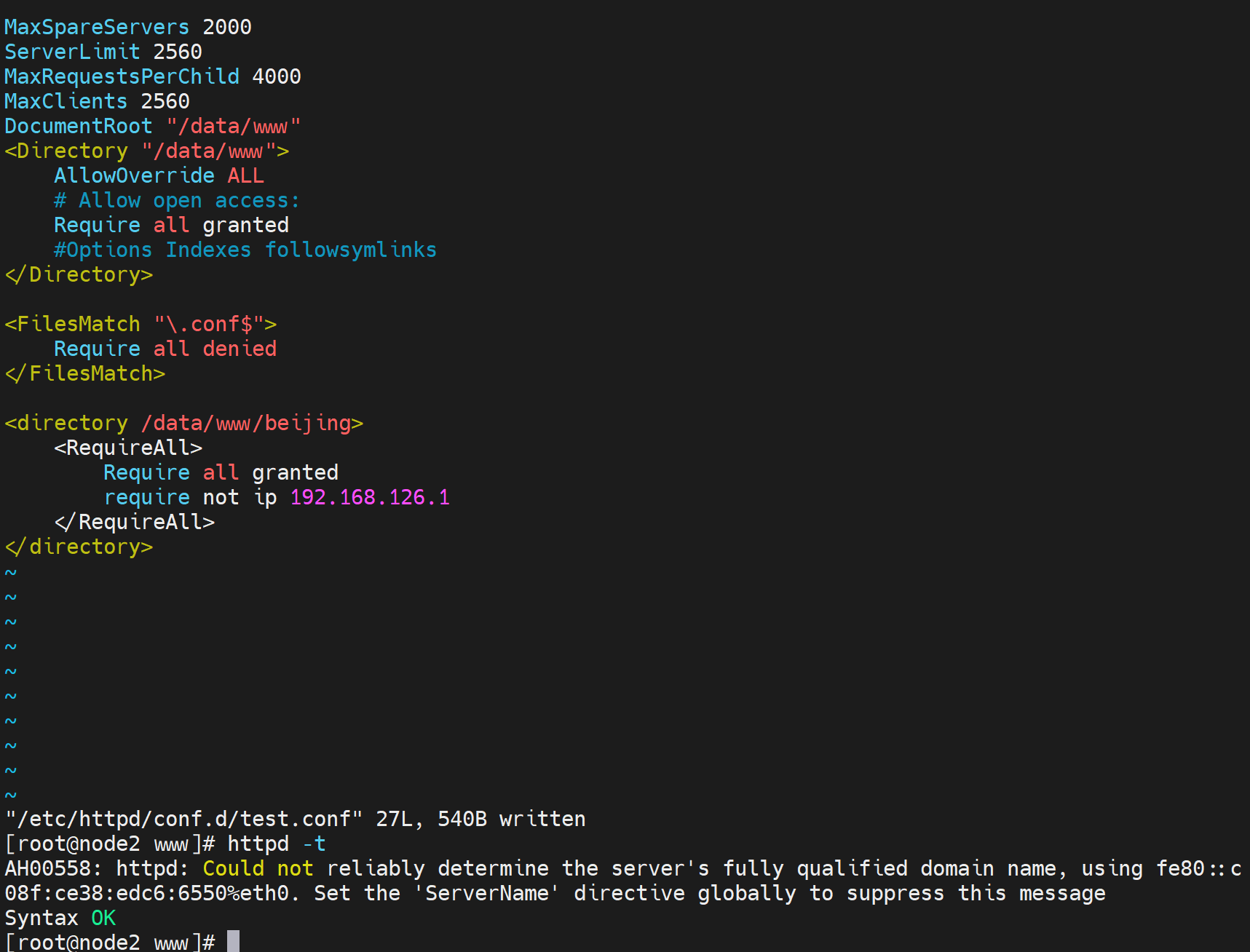
看来不能注释掉,哈哈
改成RequreAny就不行了
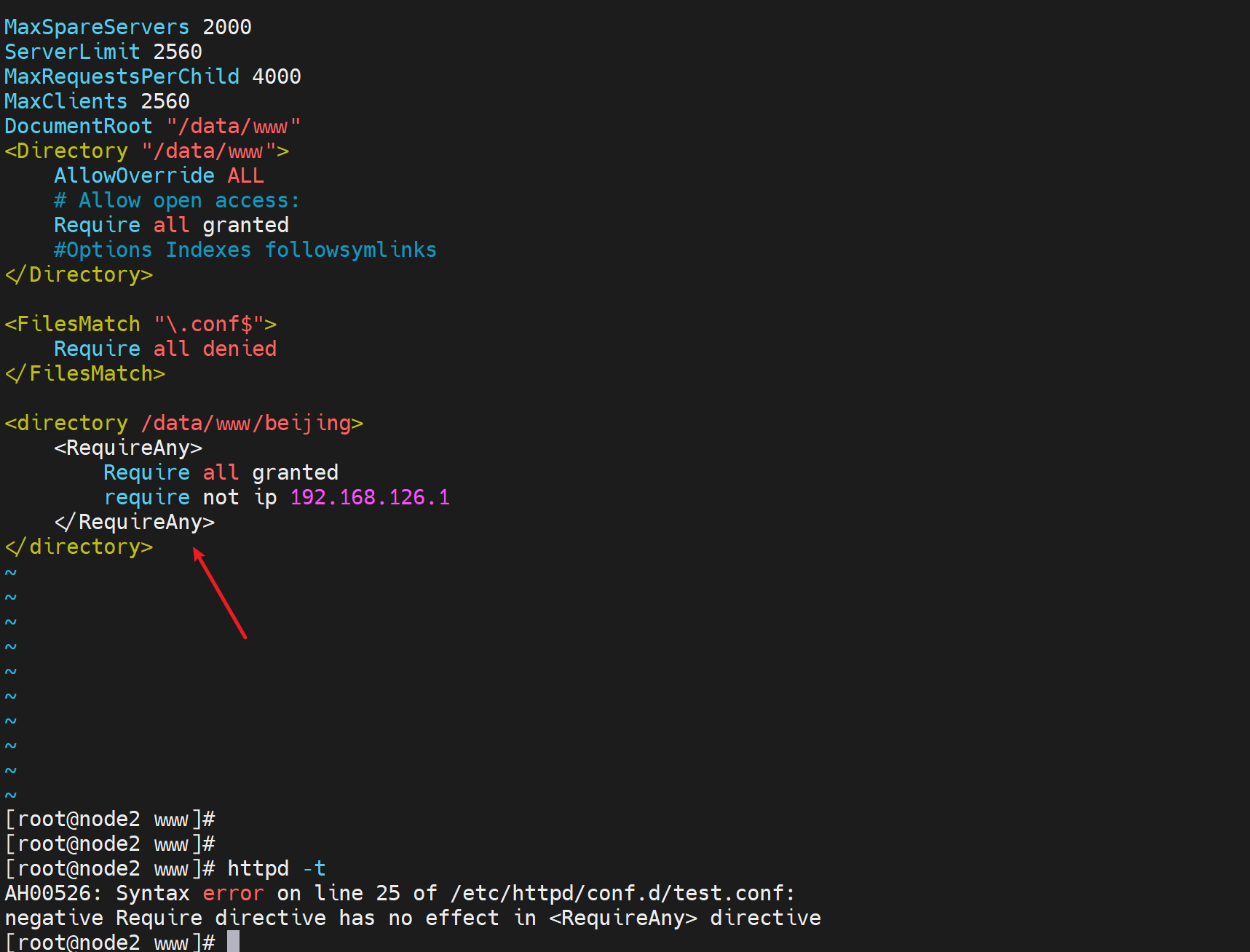
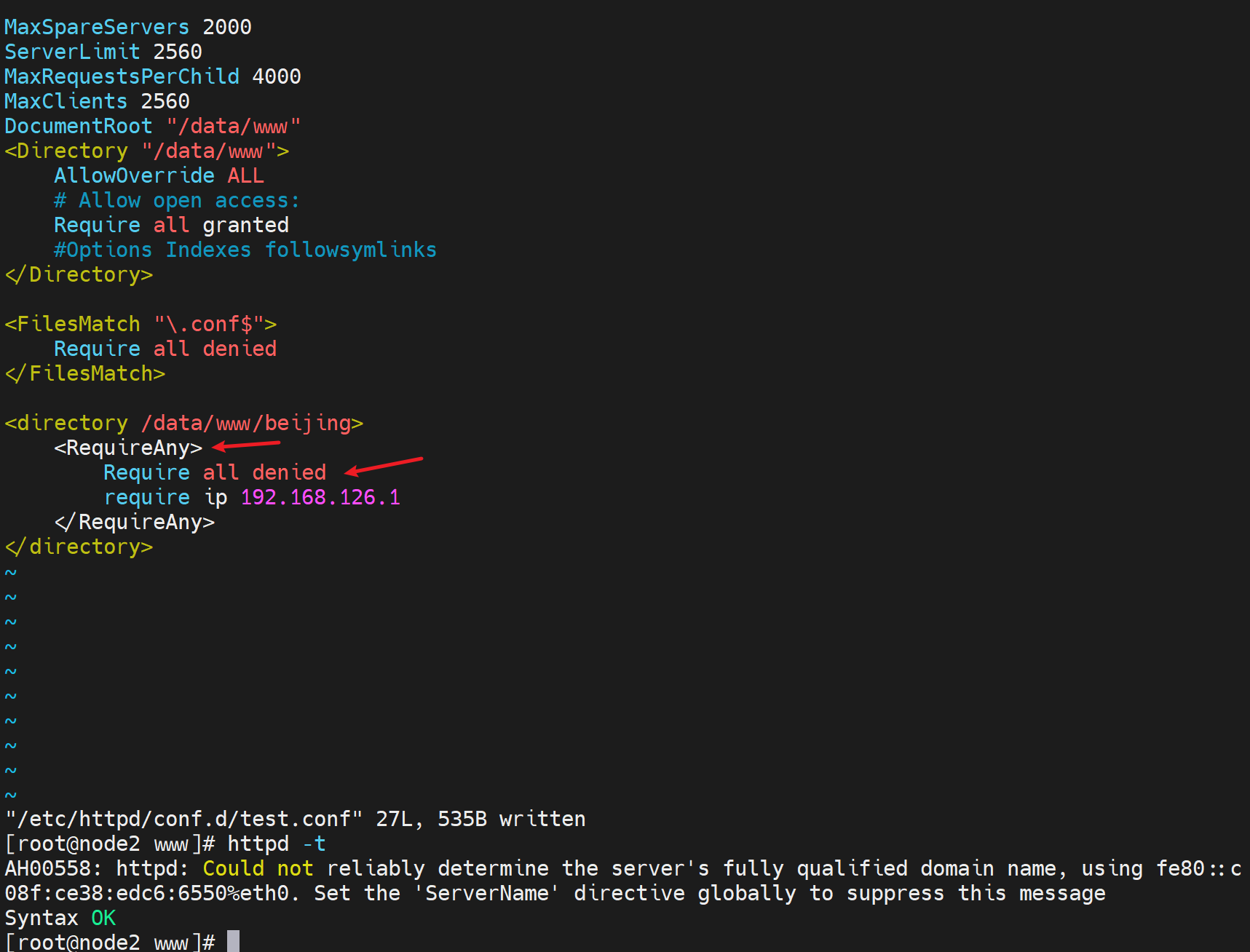
可以大概判断出来,就是固定写法当作就行了,
any就是任意,任意就是任意一个OK就OK,所以是白名单;
all就是所有OK,针对某个拒绝,所以就是黑名单了。
白名单写法👇
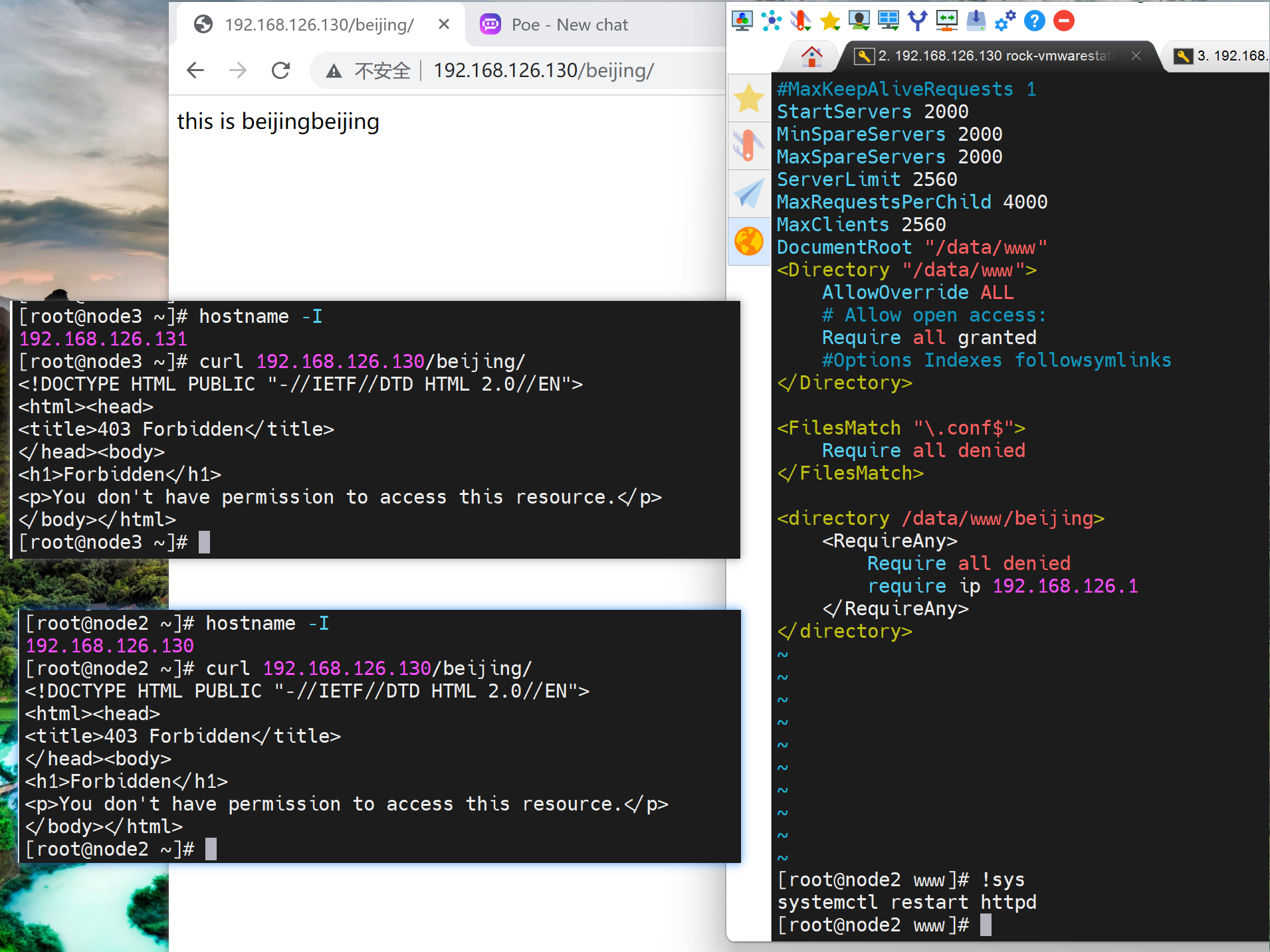
两个日志
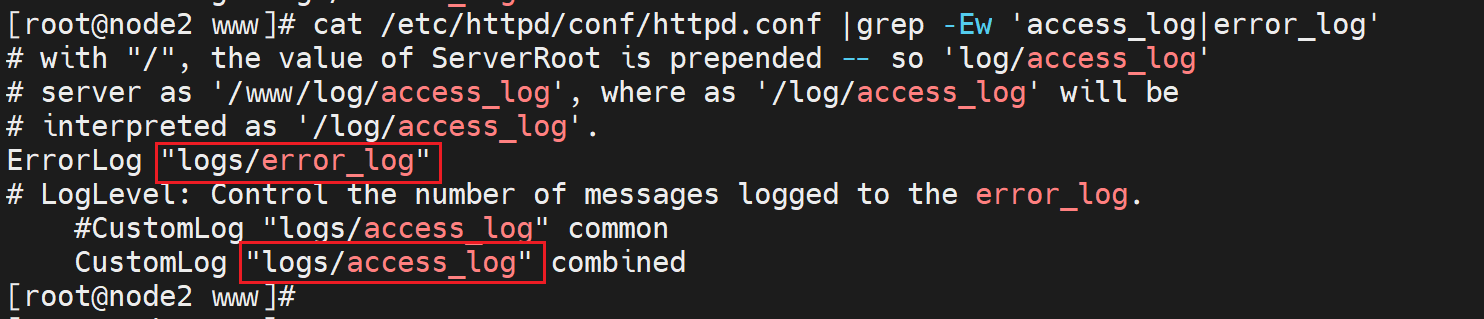
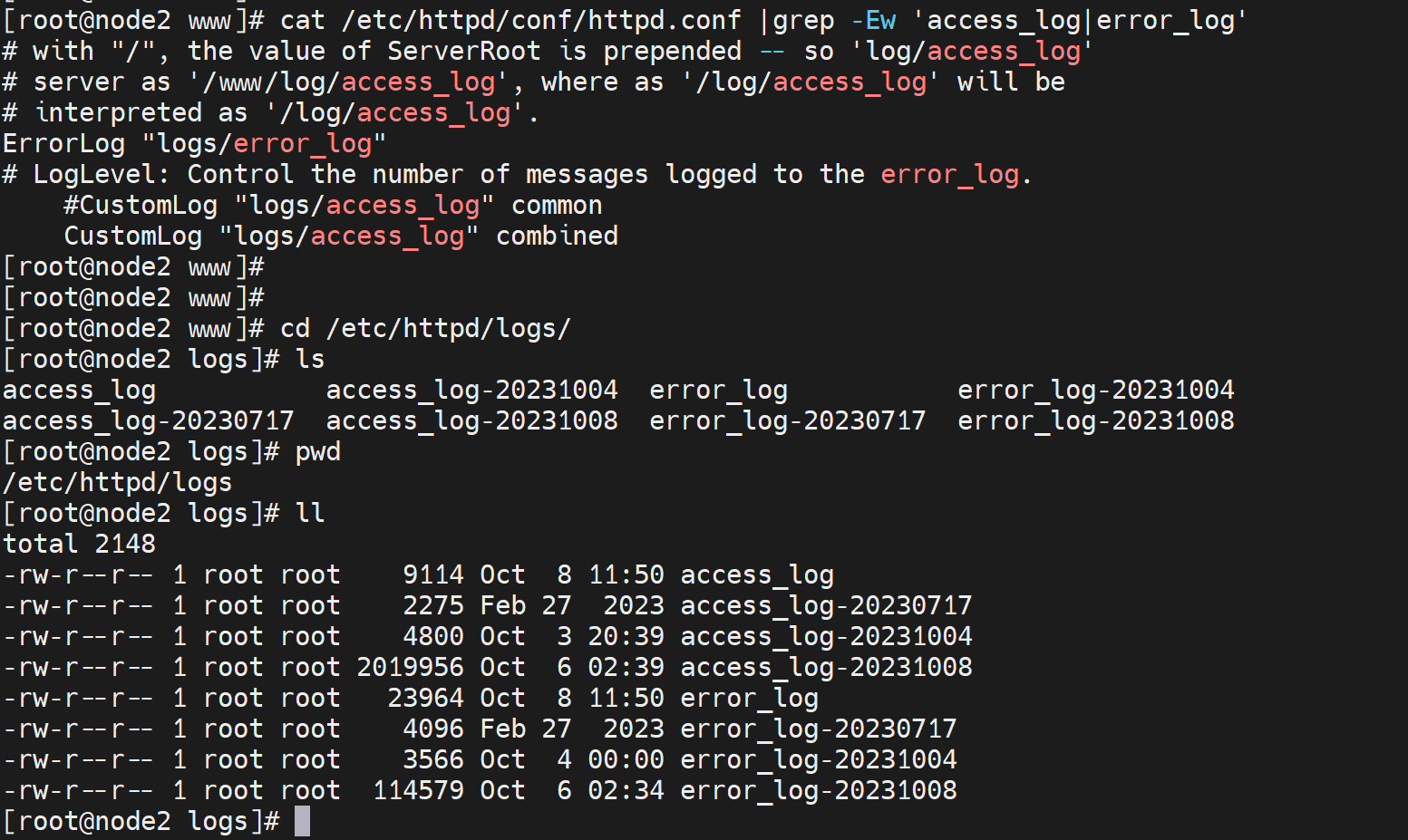
可能会奇怪log不是应该通常放到/var/log/下吗,怎么在/etc/httpd/下呢,其实都是对的,这里人家用的软连接

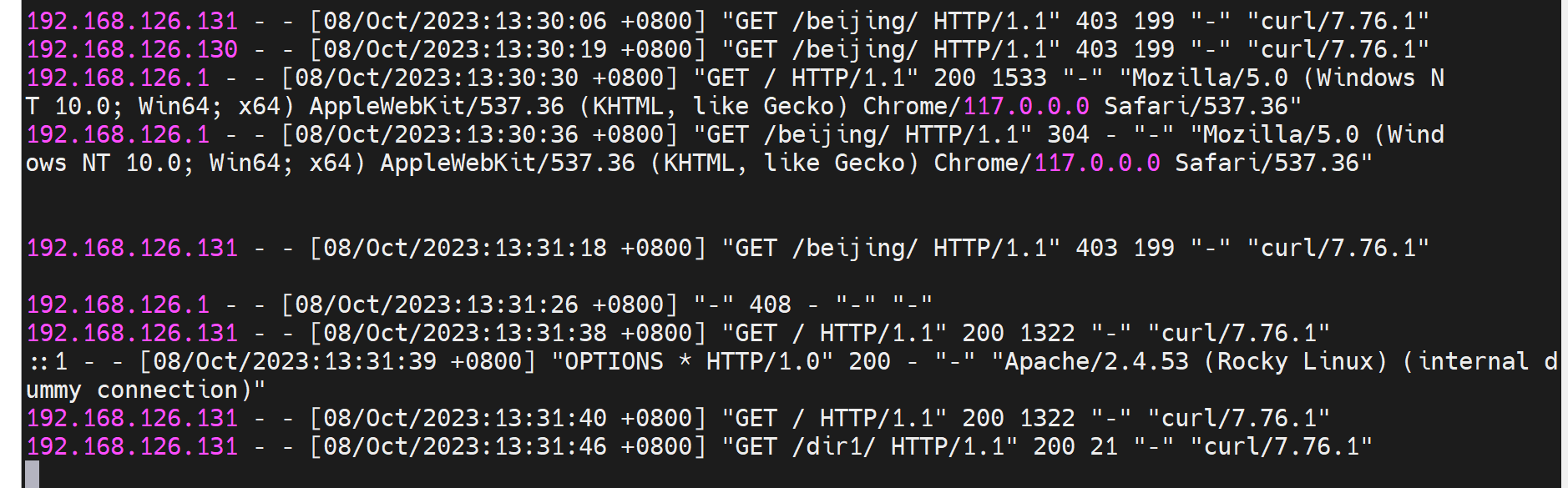
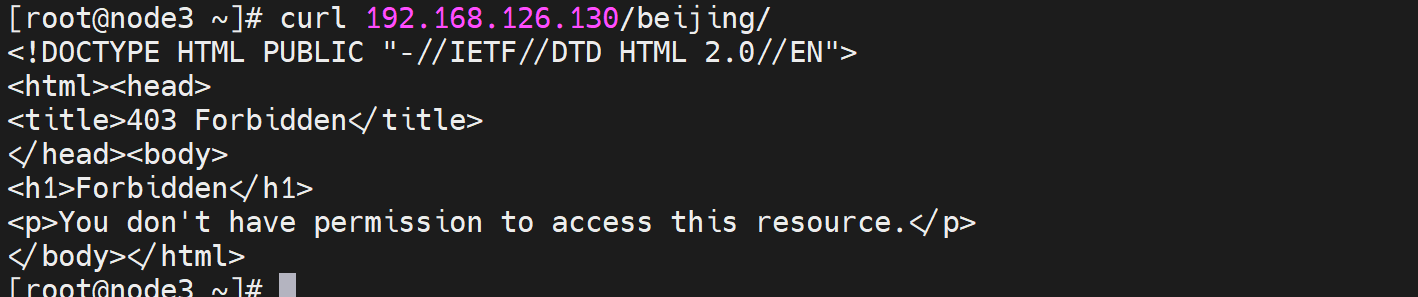
这种拒绝访问也是记录到错误日志里的👇
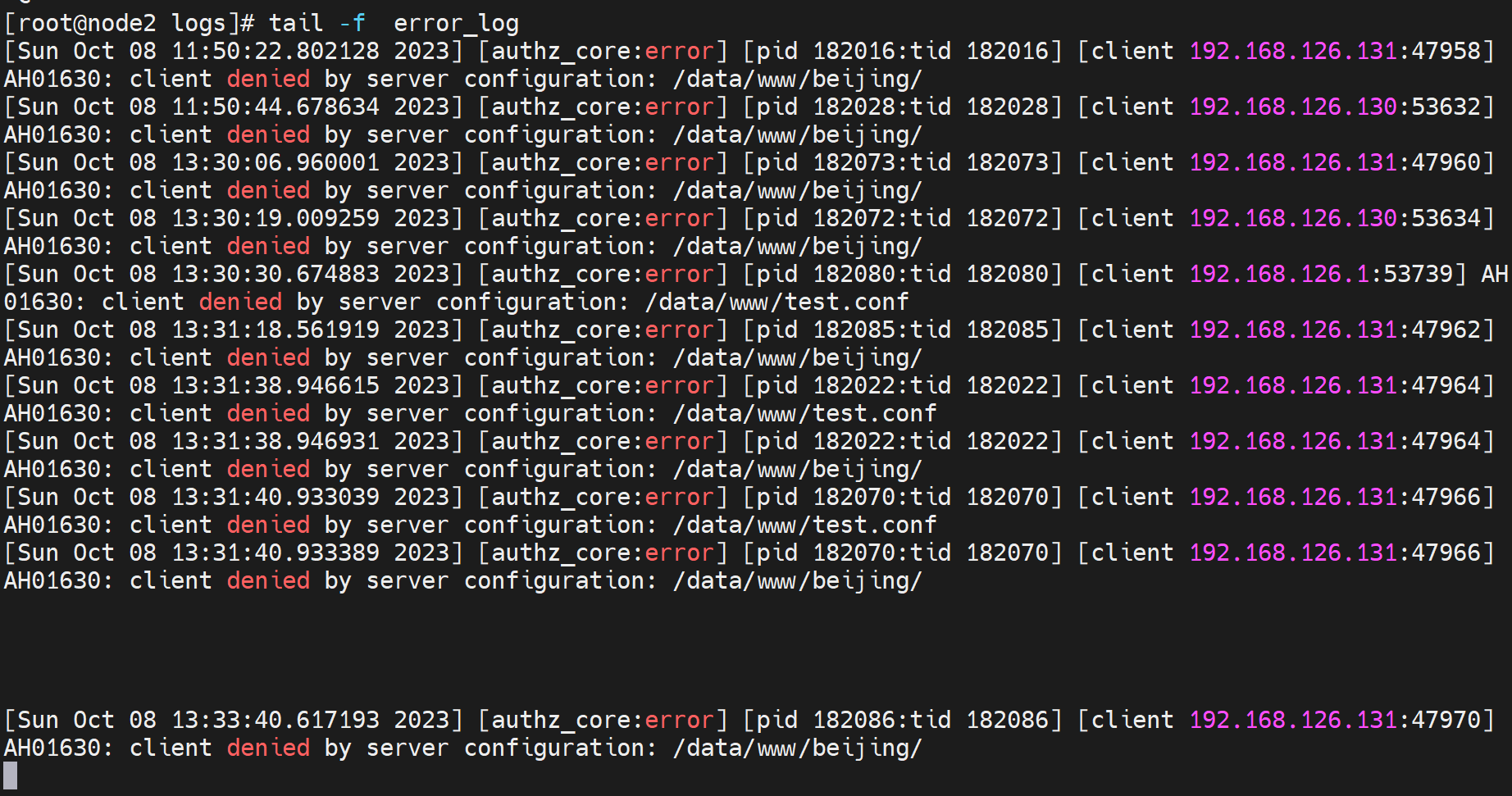
关于FQDN的提示处理
首先,这不是个报错

同样也会在错误日志里存放,当然error_log叫错误日志不一定就单单存放错误信息。
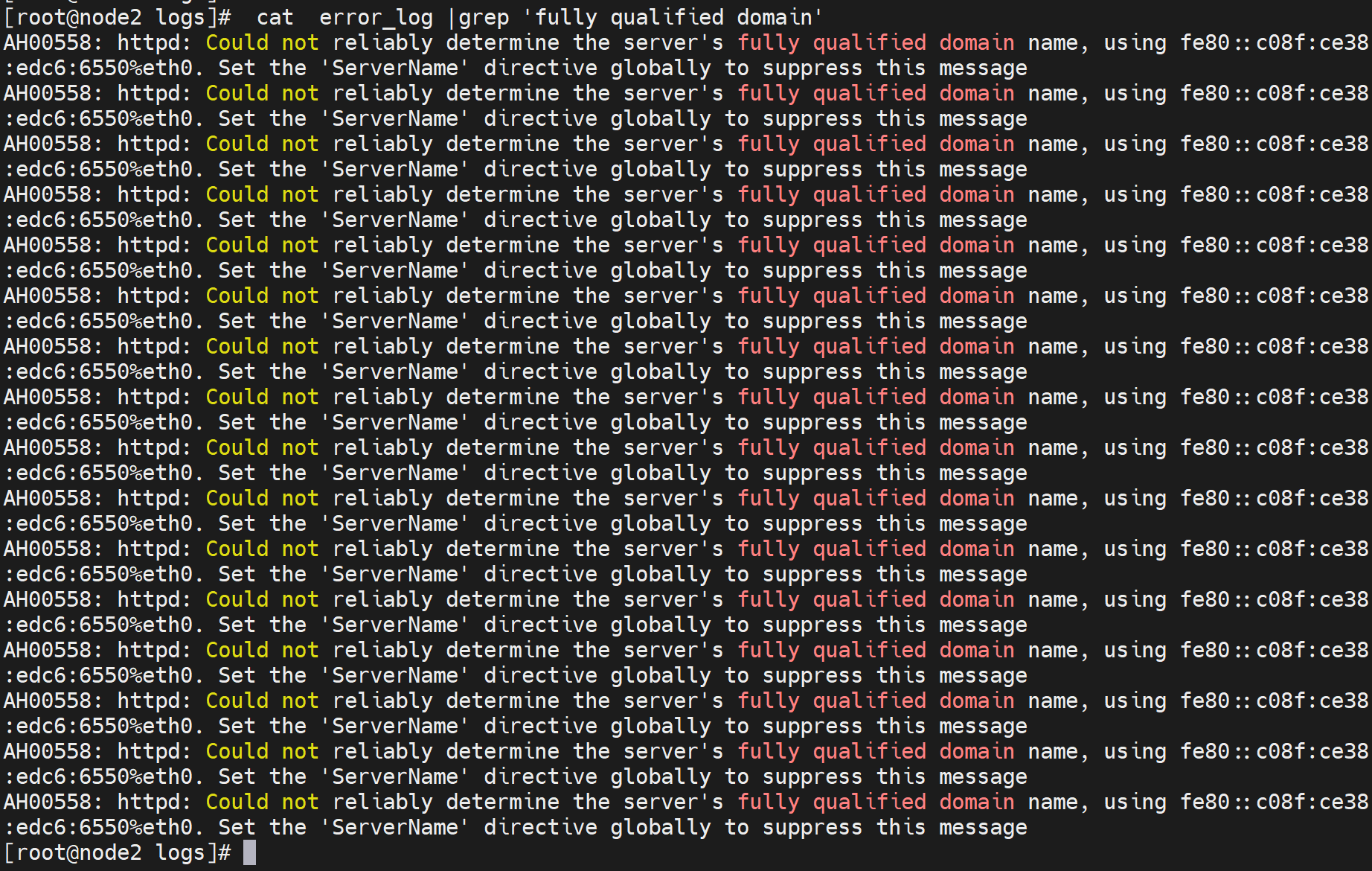
优化处理下,很简单
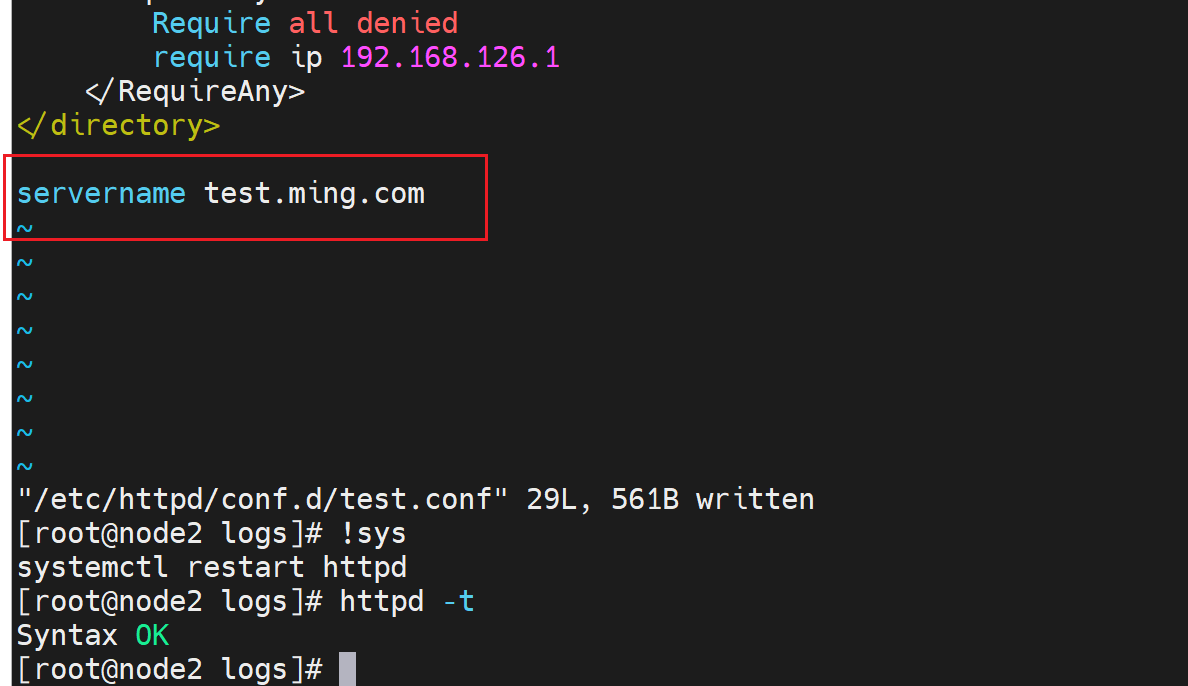
没啥实际作用吧应该。
再看看访问日志access_log的格式
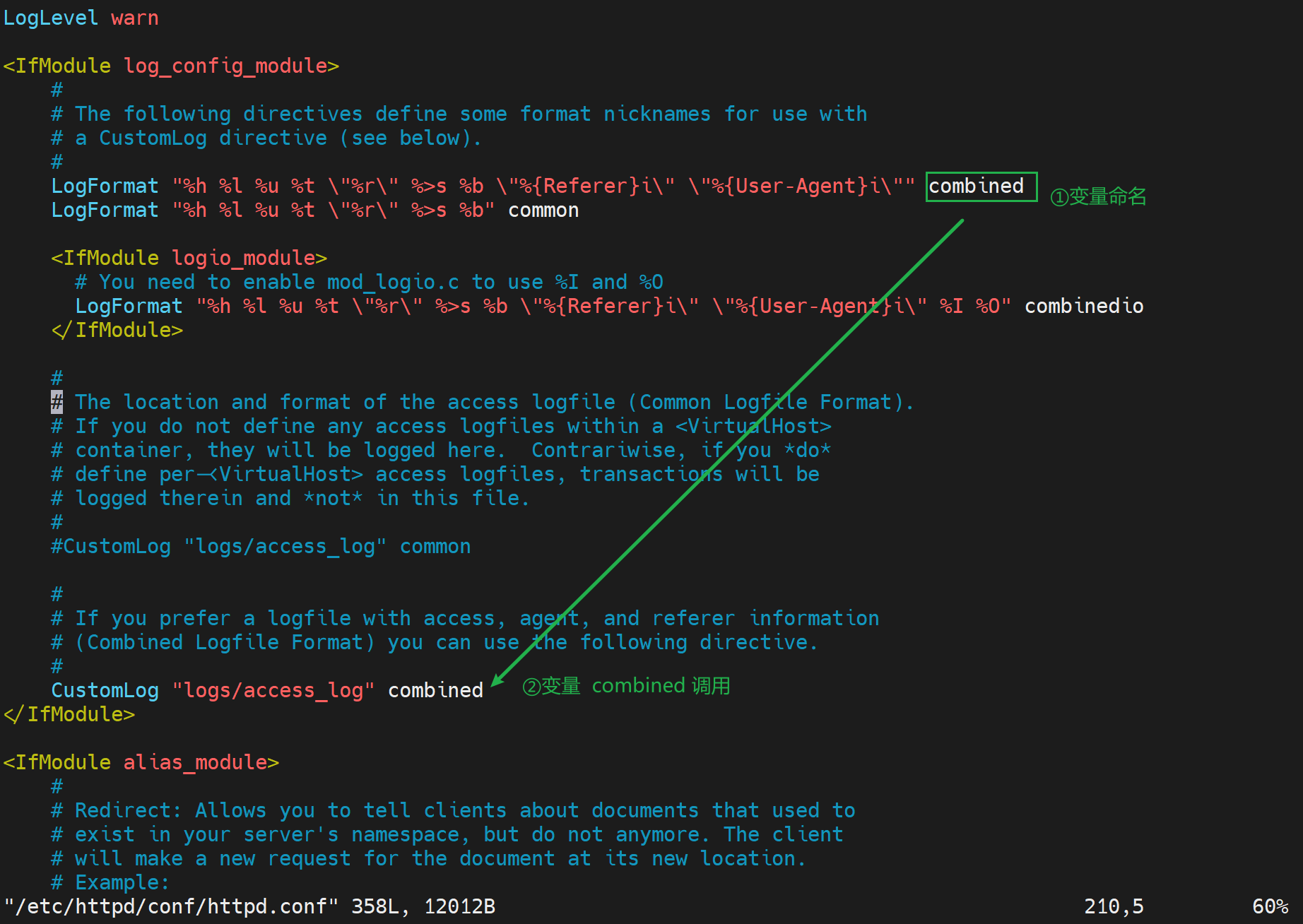
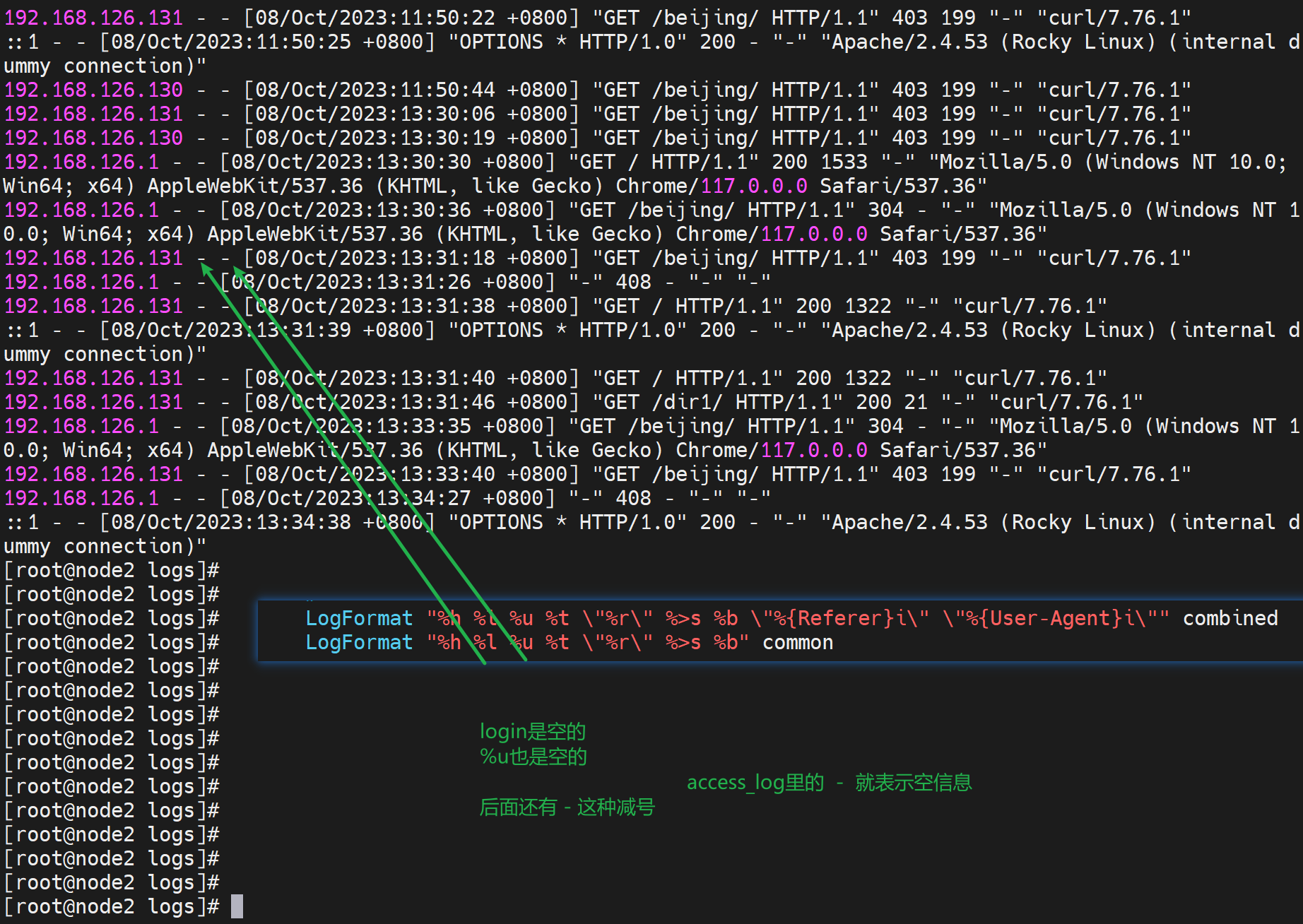
👆上图定义了LogFormat两种格式,分别命名为combined和common,然后access_log(CustomLog就是用户日志) 调用的格式是combined。
看看是不是这么个格式
官方解释👇https://httpd.apache.org/docs/2.4/mod/mod_log_config.html#logformat
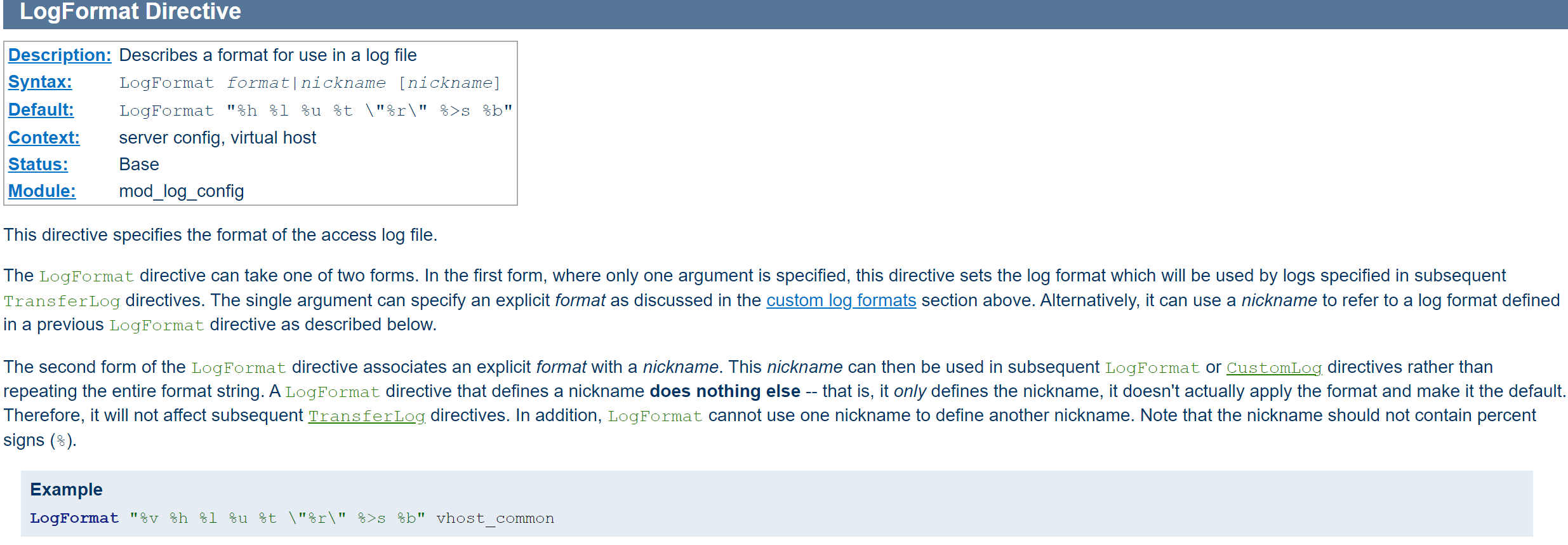
https://httpd.apache.org/docs/2.4/mod/mod_log_config.html#formats
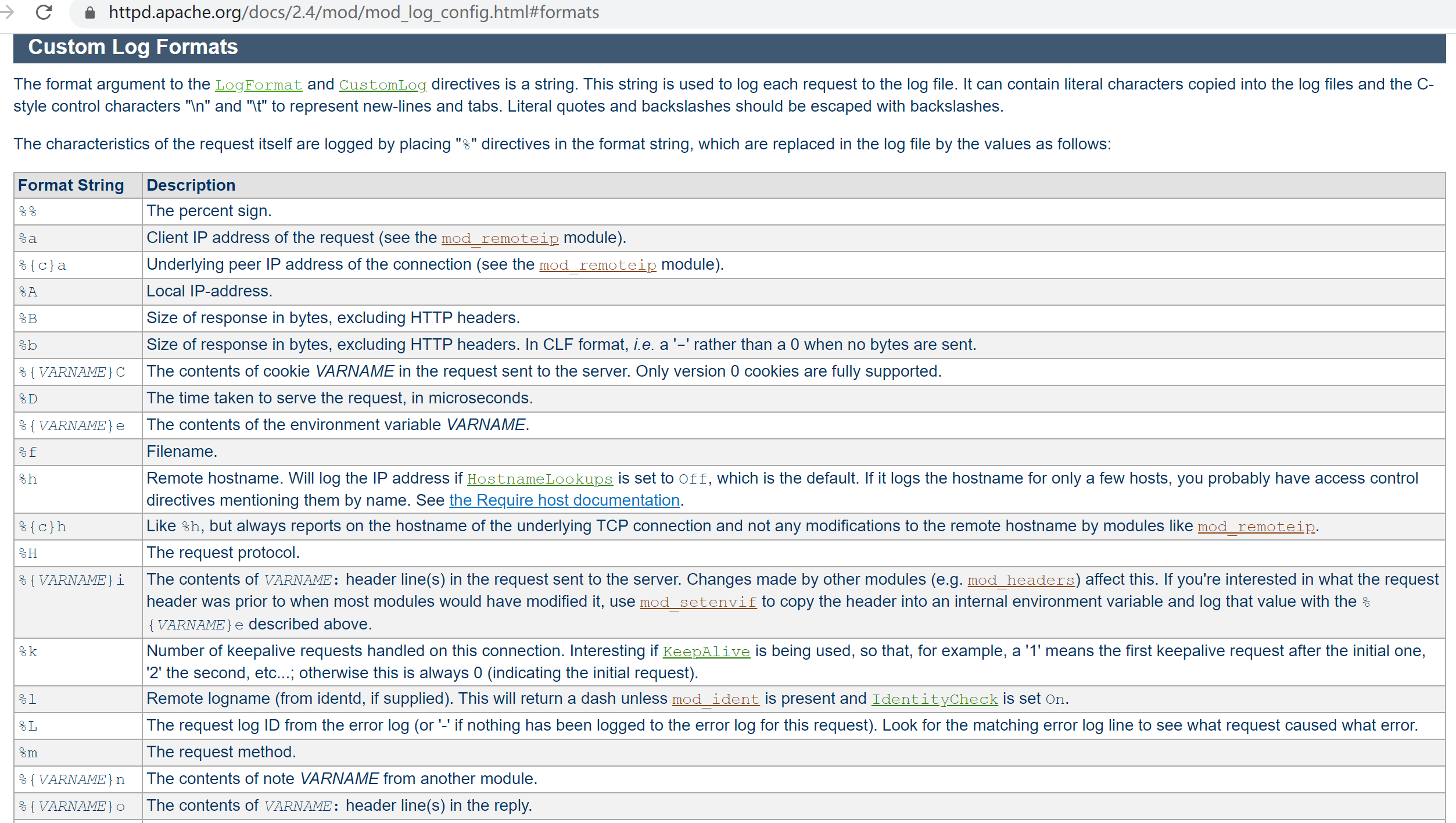
%h Remote hostname. Will log the IP address if HostnameLookups is set to Off, which is the default. If it logs the hostname for only a few hosts, you probably have access control directives mentioning them by name. See the Require host documentation.
%l Remote logname (from identd, if supplied). This will return a dash unless mod_ident is present and IdentityCheck is set On.
%u Remote user if the request was authenticated. May be bogus if return status (%s) is 401 (unauthorized). # 这是基于basic的验证,上一章节提到的mod_auth_basic.so干的活吧应该是。
%t Time the request was received, in the format [18/Sep/2011:19:18:28 -0400]. The last number indicates the timezone offset from GMT
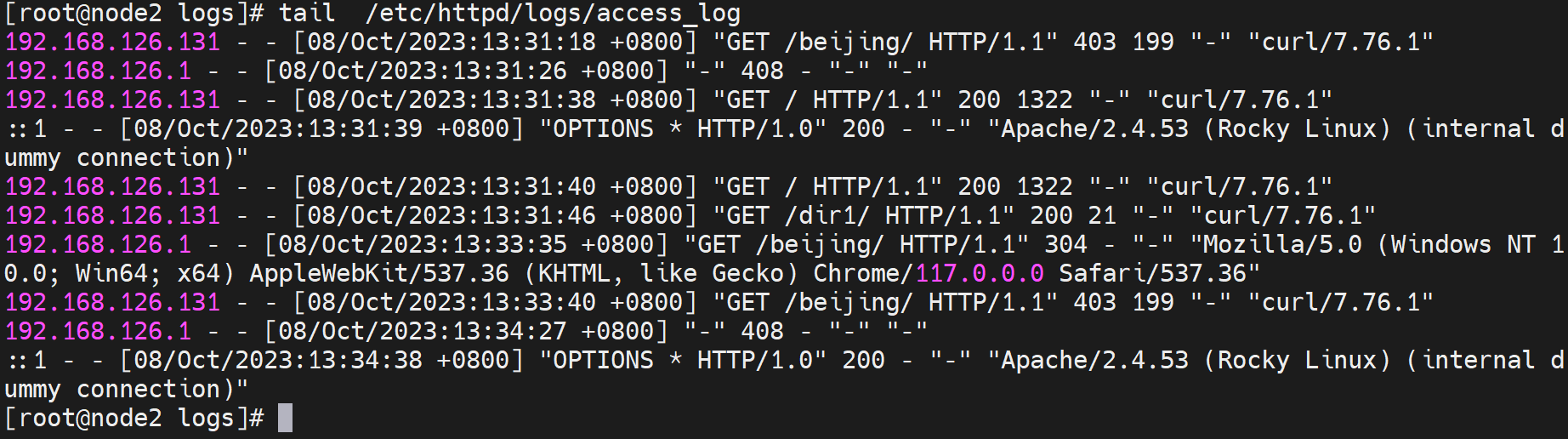
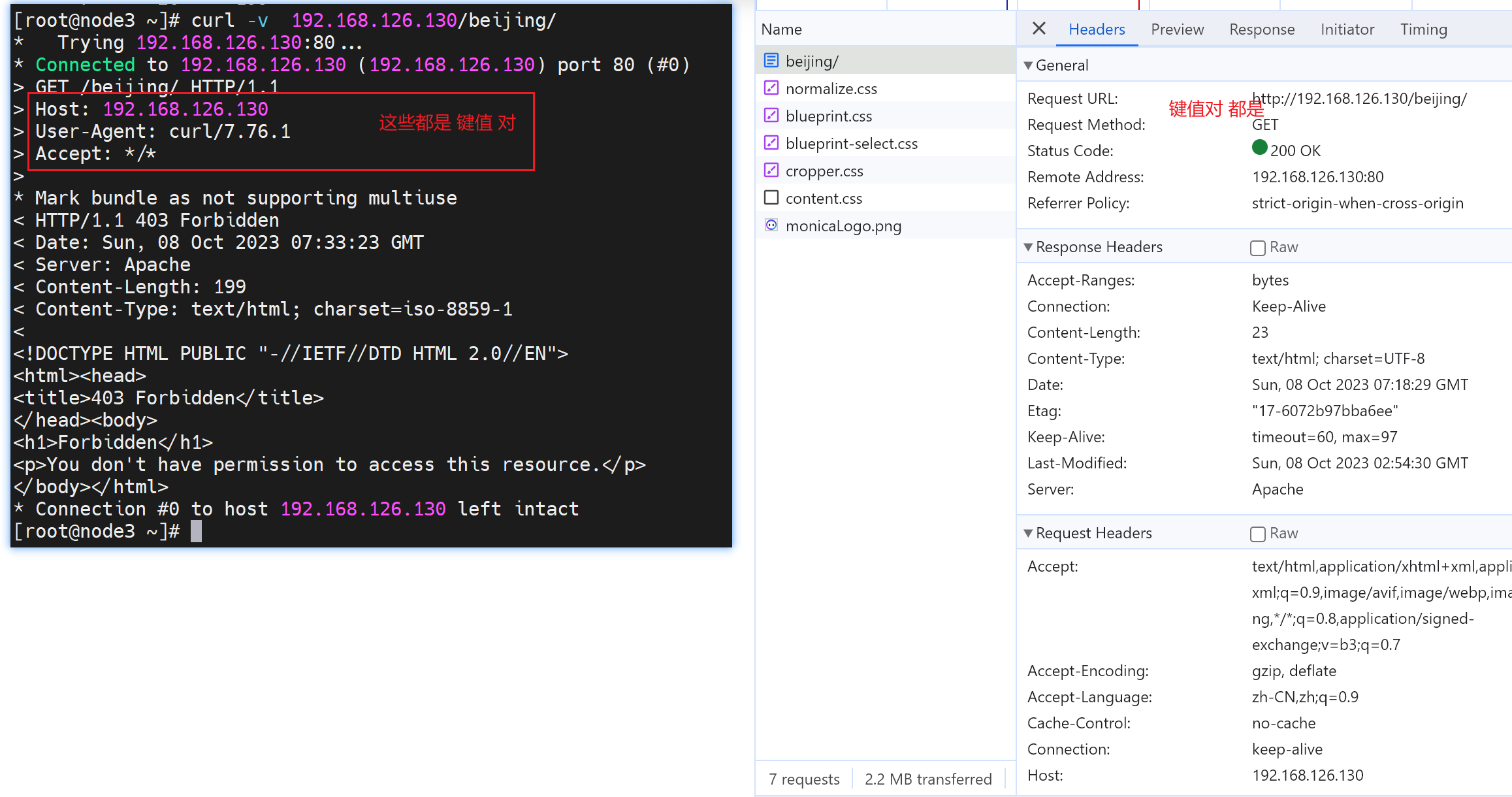
%r First line of request. # 👇对应下图的\"%r\"也就是log里的"GET /beijing/ HTTP/1.1"
%s Status. For requests that have been internally redirected, this is the status of the original request. Use %>s for the final status. # 说的是%s,但是其实用的是%>s。 这里涉及重定向,比如先从page1,301到page2,然后再200;估计%s就是301了,%>s就是200啦,这个后面可以尝试一下。
这个200 403 301 这些数字本身就很大程度上反映除了 页面请求的结果,比如200是页面拿到了,403是禁止访问了,301是重定向。这个和shell里的exit 1000 退出时候的返回1000这个数字一个道理啊;也和echo $?看到的0是cli执行成功和非0执行失败一个道理啊。


%b Size of response in bytes, excluding HTTP headers. In CLF format, i.e. a '-' rather than a 0 when no bytes are sent.
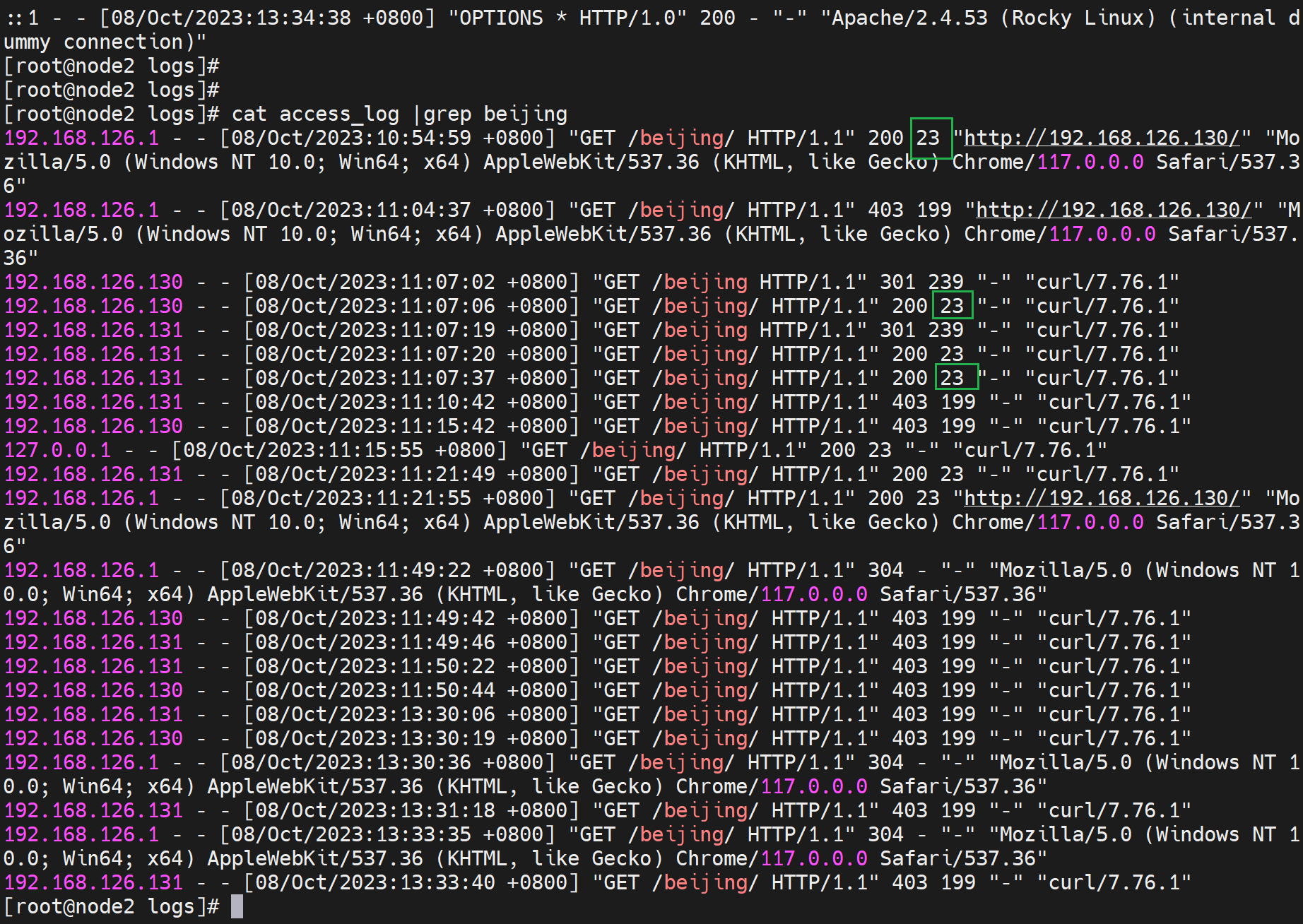
23是对,200请求OK后23字节就是对的,然后403是禁止了199就是那个报错的页面啦-人家是199个字节
200 23 怎么理解👇

不过23Bytes其实是去掉了head头的吧
403 199 怎么理解👇

继续-----

在httpd日志里看到花括号{}就表示头信息,这里LOG里记录了head信息里的 Referer--从哪个站点跳转过来的信息,以及User-Agent用户浏览器信息。这些都是%{xxxx}i 代表的head里的键值对信息,具体用哪个你就写哪个就行了。
关于referer浅测一下
<html>
<head>
<title>html语言</title>
</head>
<body>
<img src="http:/xxx/xxx/logo.ping" >
<h1>你好</h1>
<p><a href=https://www.bing.com>这是跳转测试</a>你好啊</p>
</body>
</html>
借鉴上面的跳转写法,做两个页面来实验
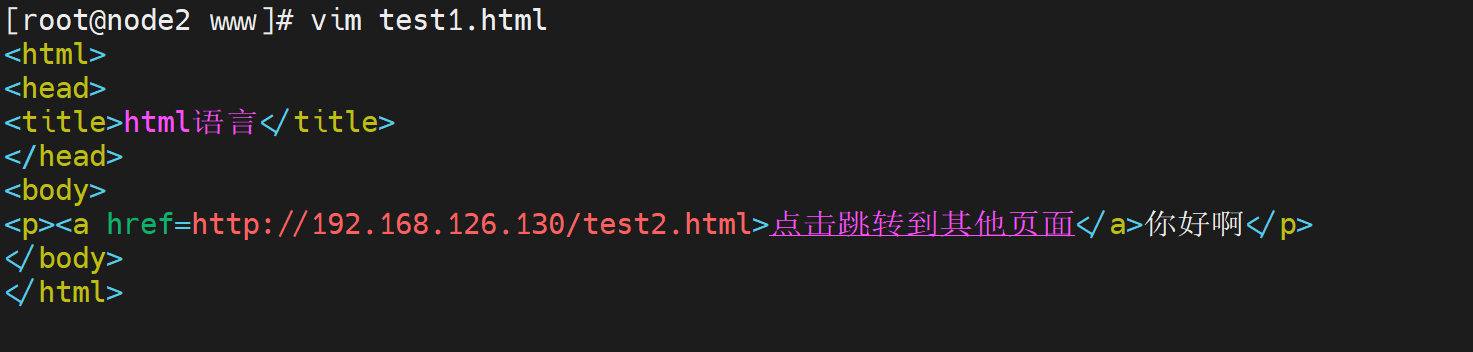
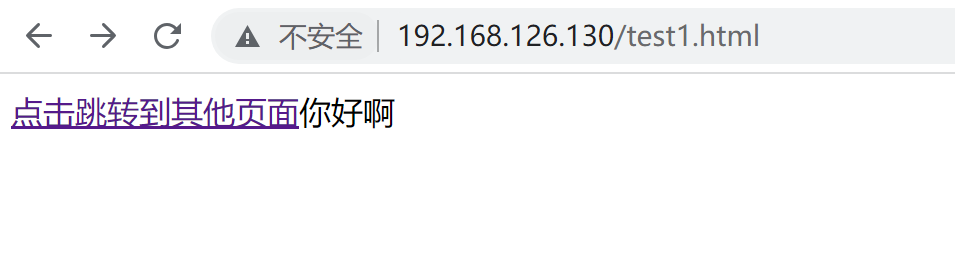
此时到test2.html第二个页面就可以看到referer的上一个跳转过来的链接了👇
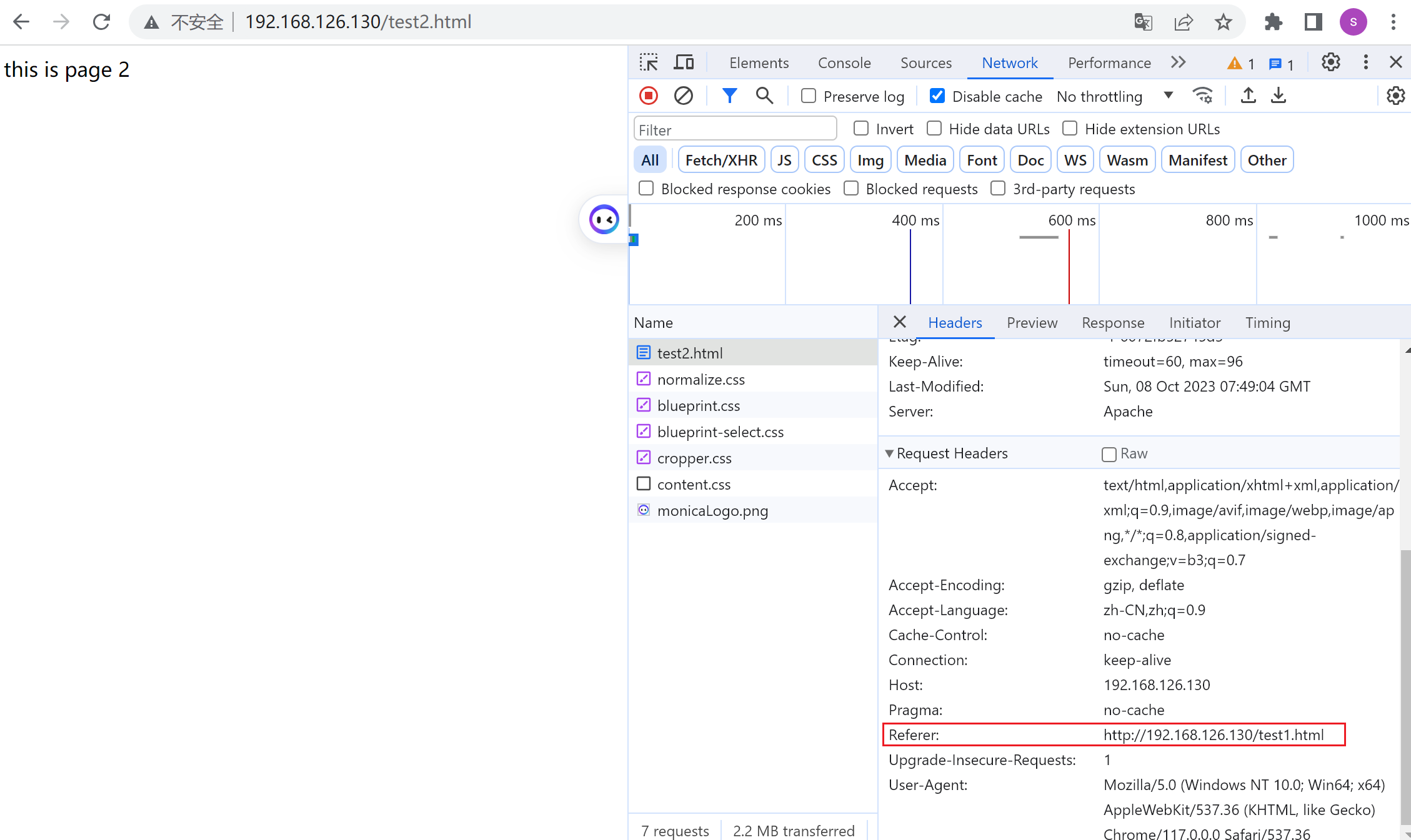
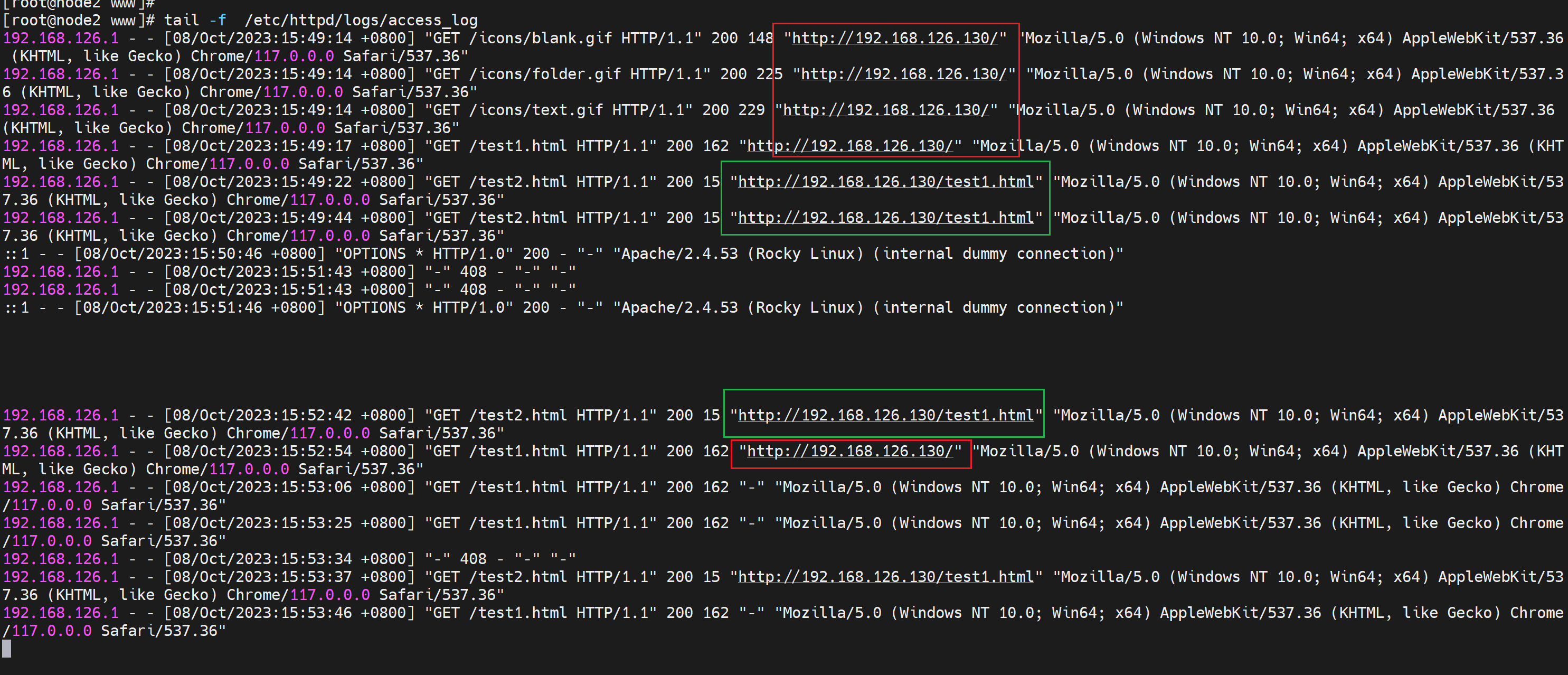
产生test1.html会有referer的原因有点奇怪,好像是偶尔从test2.html页面返回后退回来F5一下弄出来的。不过有时候出不来,搞不清楚,
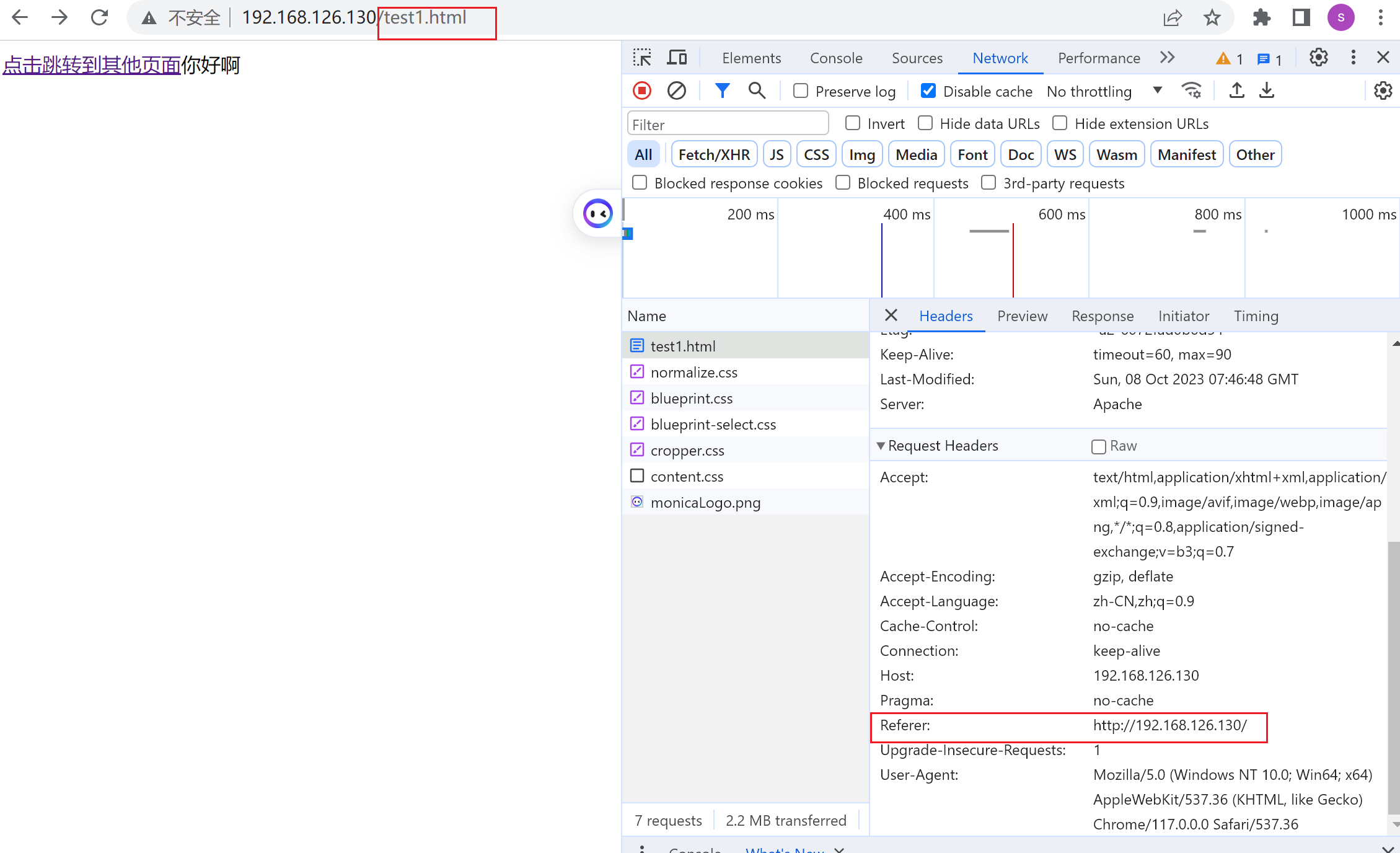
噢噢噢,我知道,是这样的,人家写了是从http://192.168.126.130/ 上一个页面来的,所以答案就清楚了
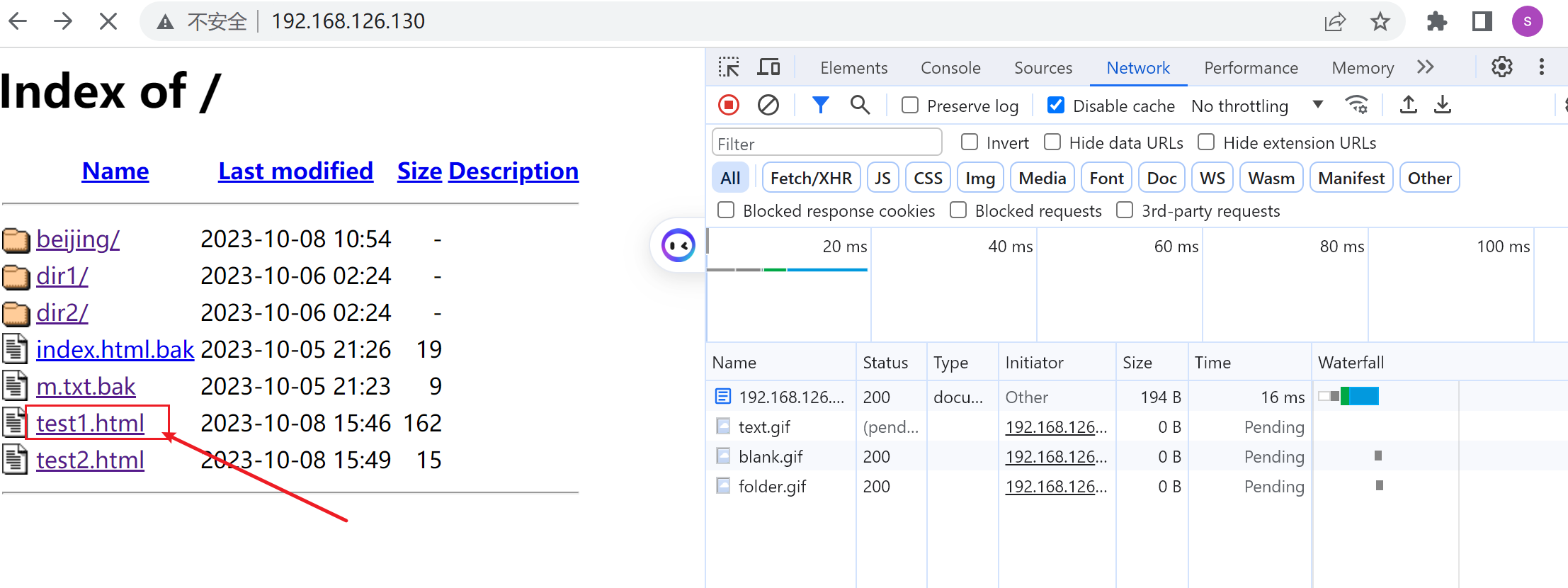
从👆这里点进去不就是httpd默认给你弄出来的跳转嘛,
再开一个机器192.168.126.131做一个图片页面,
然后在192.168.126.130上做跳转referer过去

写错了哦👆上图http://192写错了,导致👇
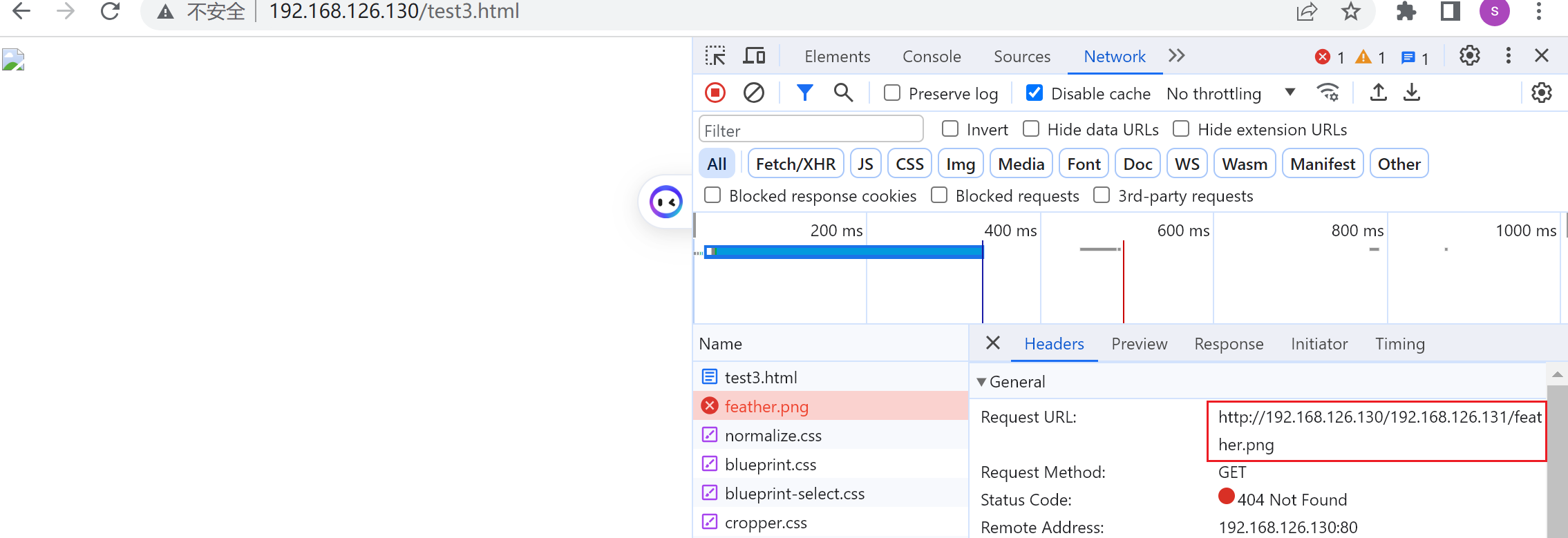
修改之
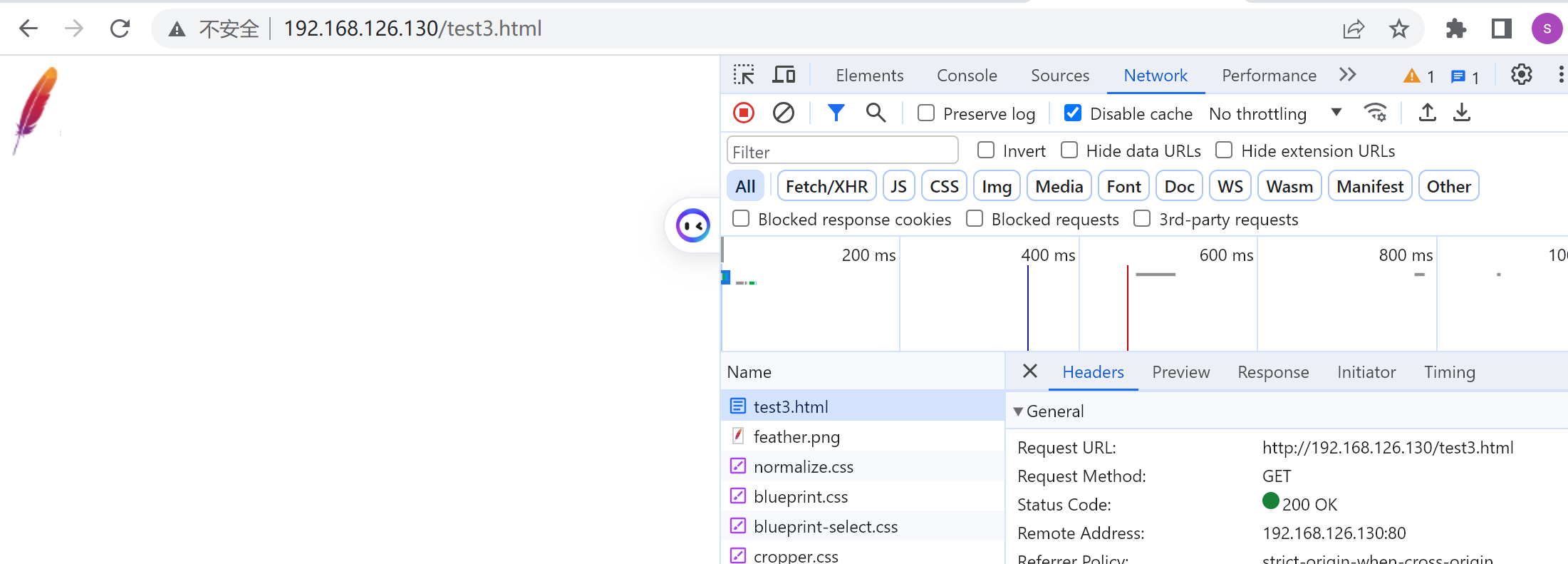
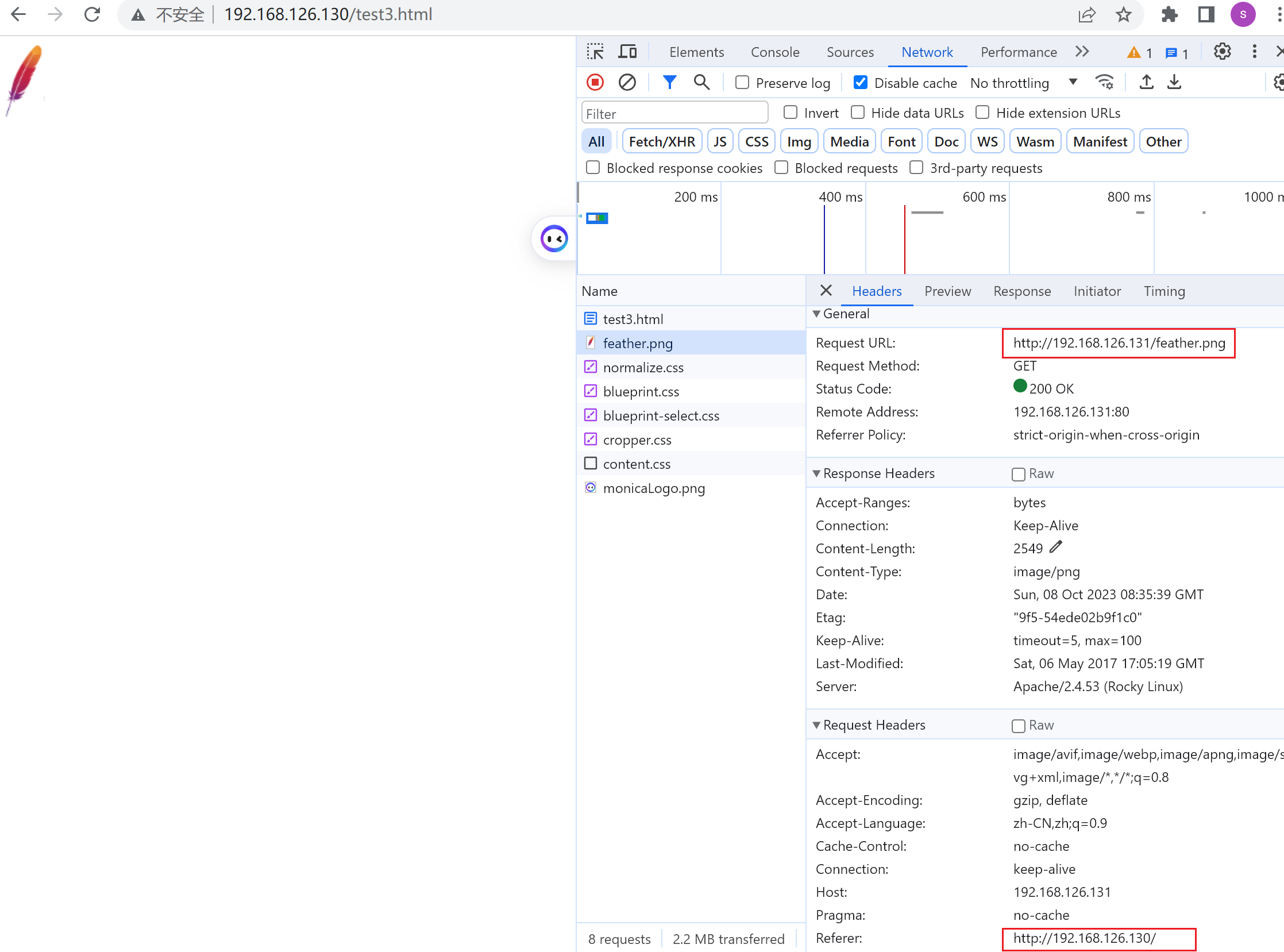
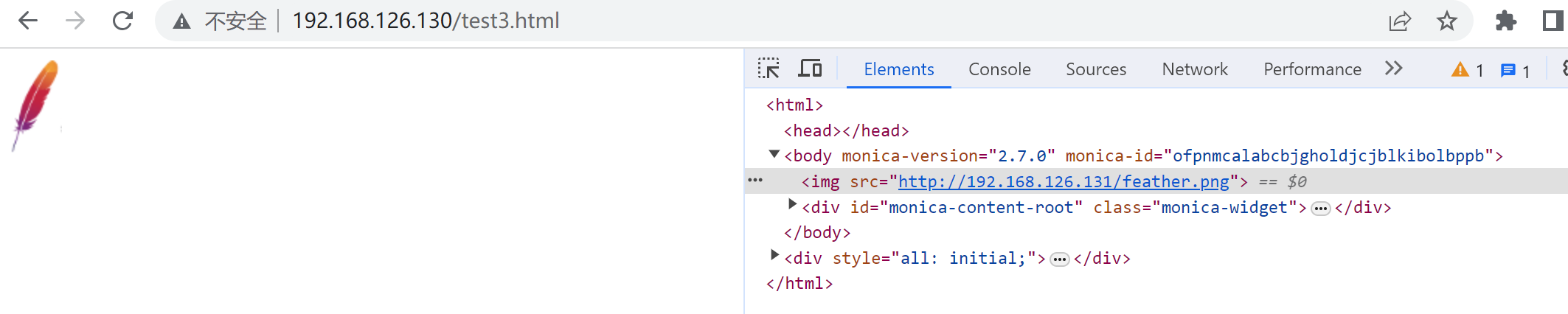
这就是盗链,如何发现盗链呢,就是去server上看referer
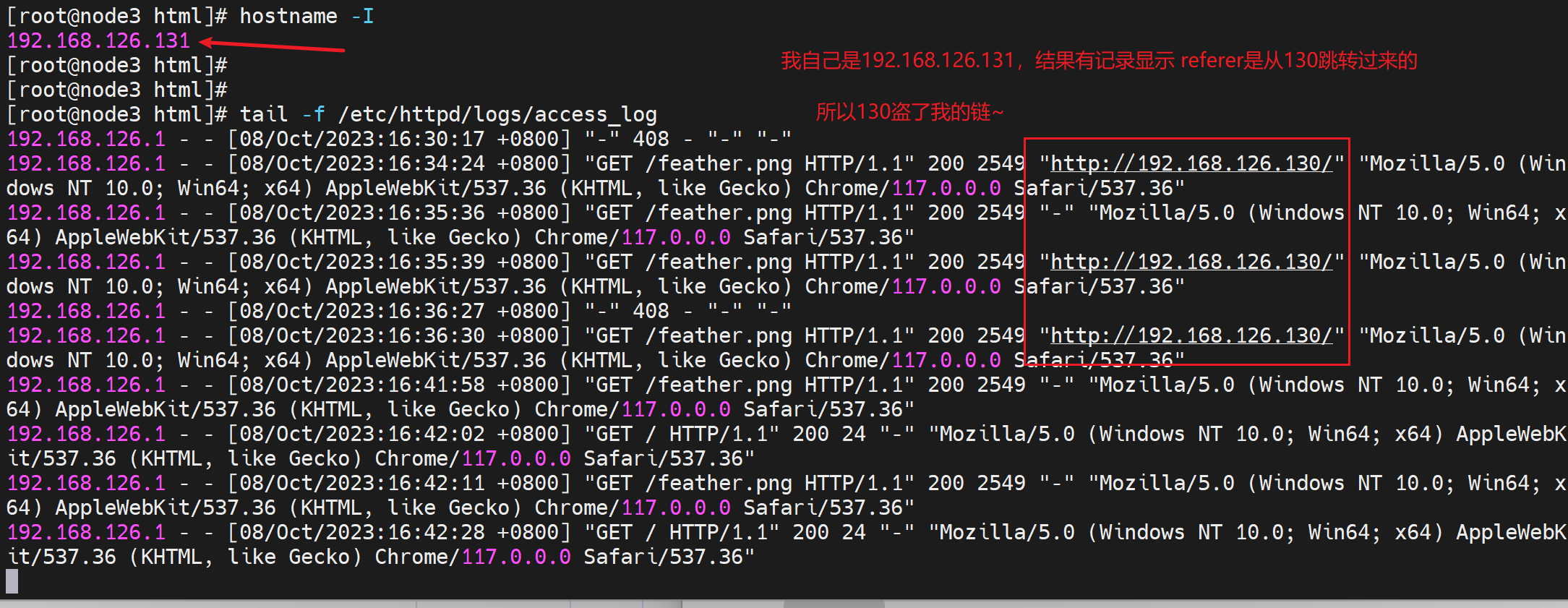
问:是否可以通过在server上写iptables -A INPUT -s 192.168.126.130 -j REJECT来防止盗链呢?
答:该方法实现不了,因为跳转的实际效果是让用户重新下载一个新的内容,是用户去访问而不是130这个referer的上一个链接地址去访问。 所以要防止盗链就要继续学习咯... ...
再一个,如果是referer里显示的是百度的IP,说明什么,也是盗链么?应该就不是了,这是广告费没白给,哈哈,或者人家一搜,就你家的网站,总之十有八九算是好事了,这种情况。
关于日志的阶段性总结PPT放着了,随便看看,不看也行,图个完整性



然后日志的一个访问IP排序
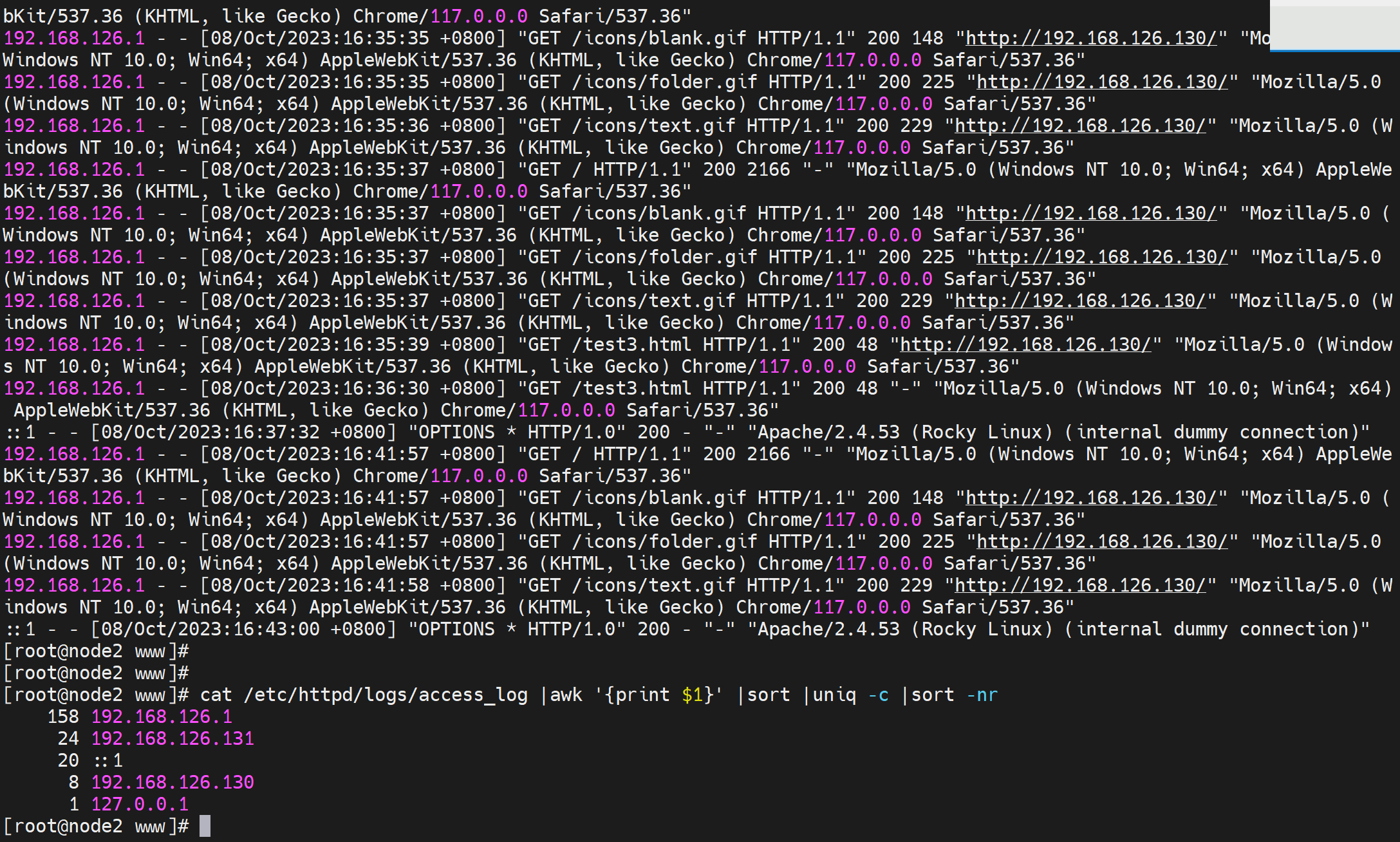
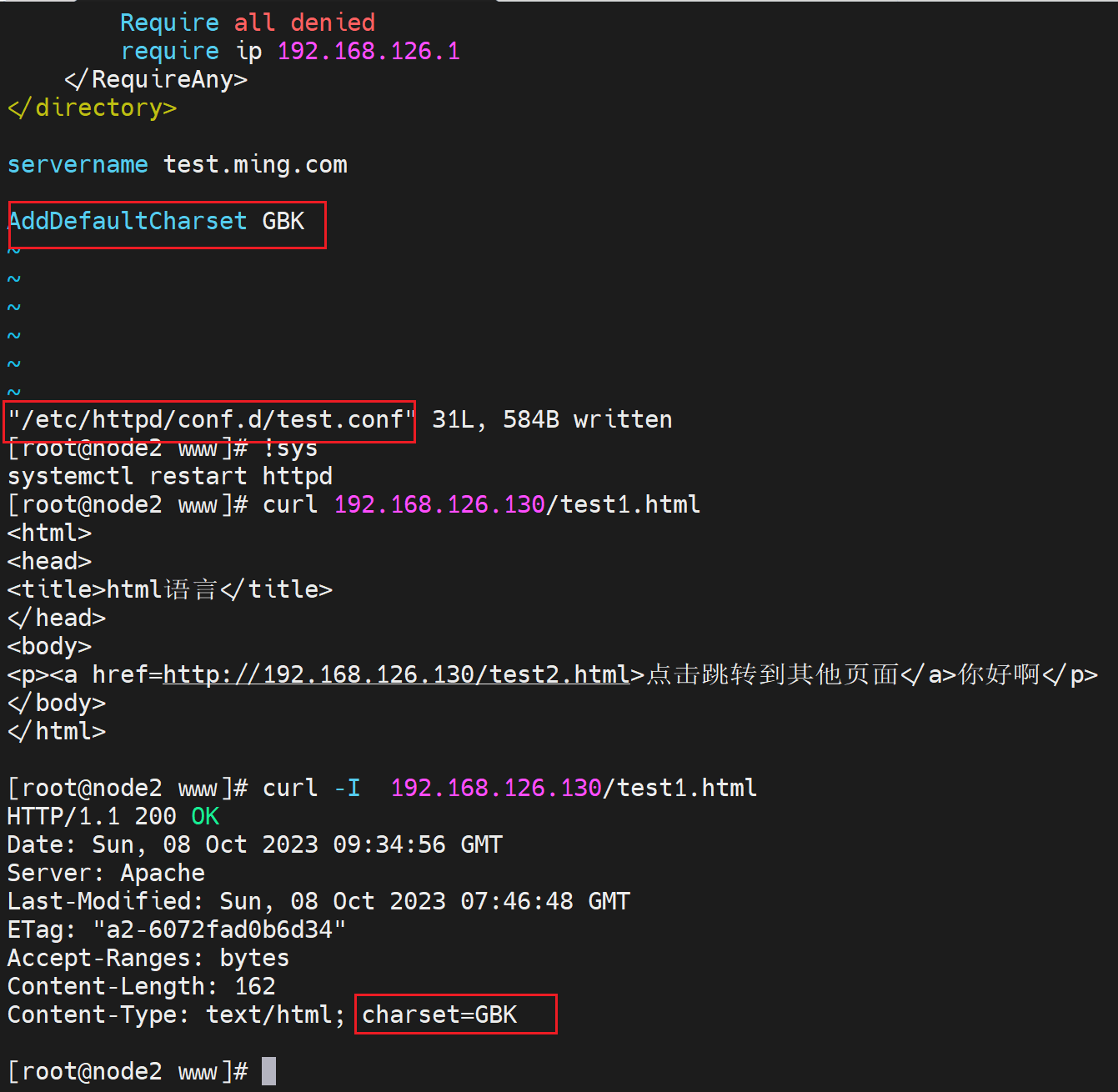
字符集

iconv -l # 查看所有字符集
通常可以看得到网页的字符集的
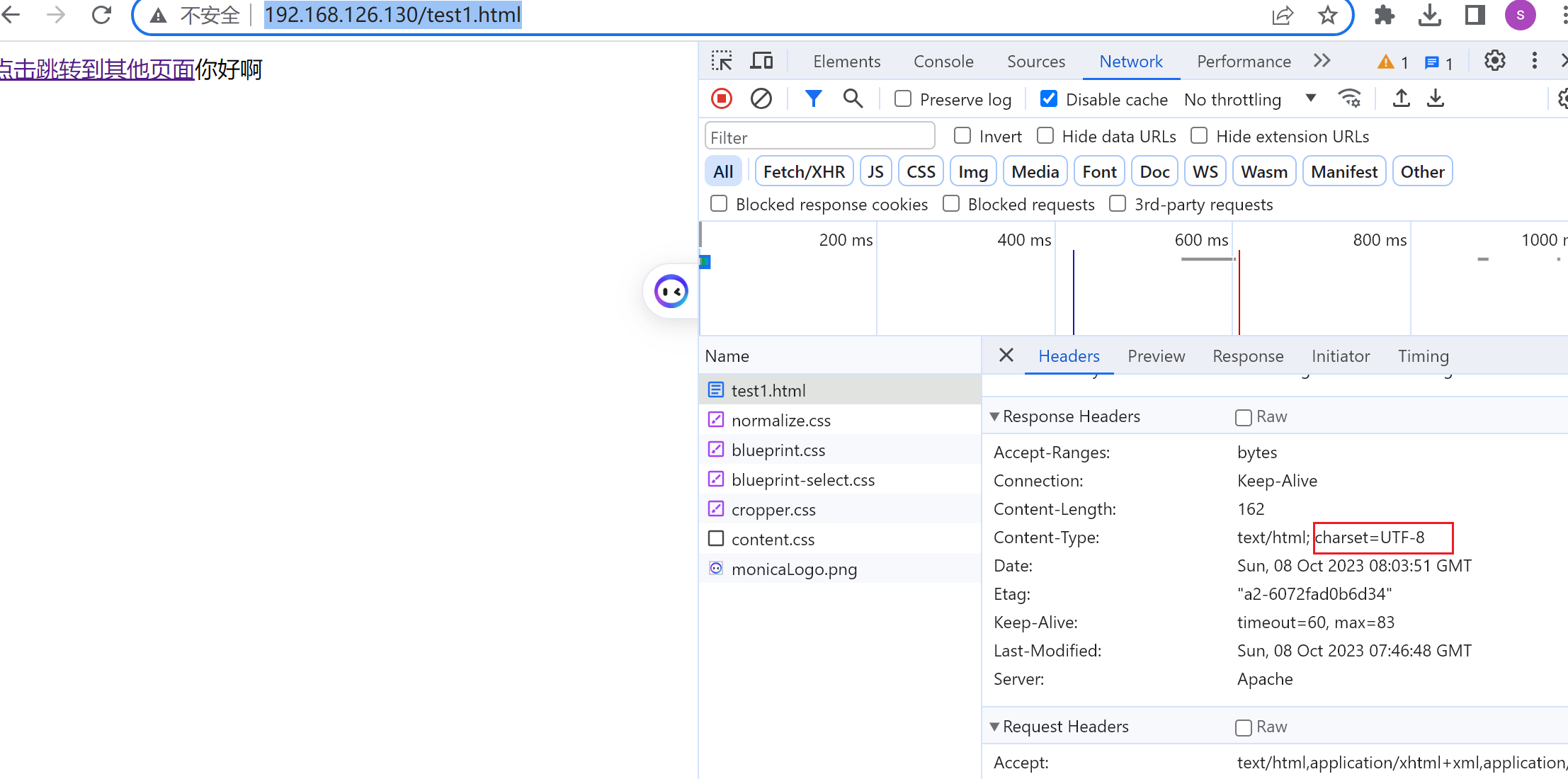
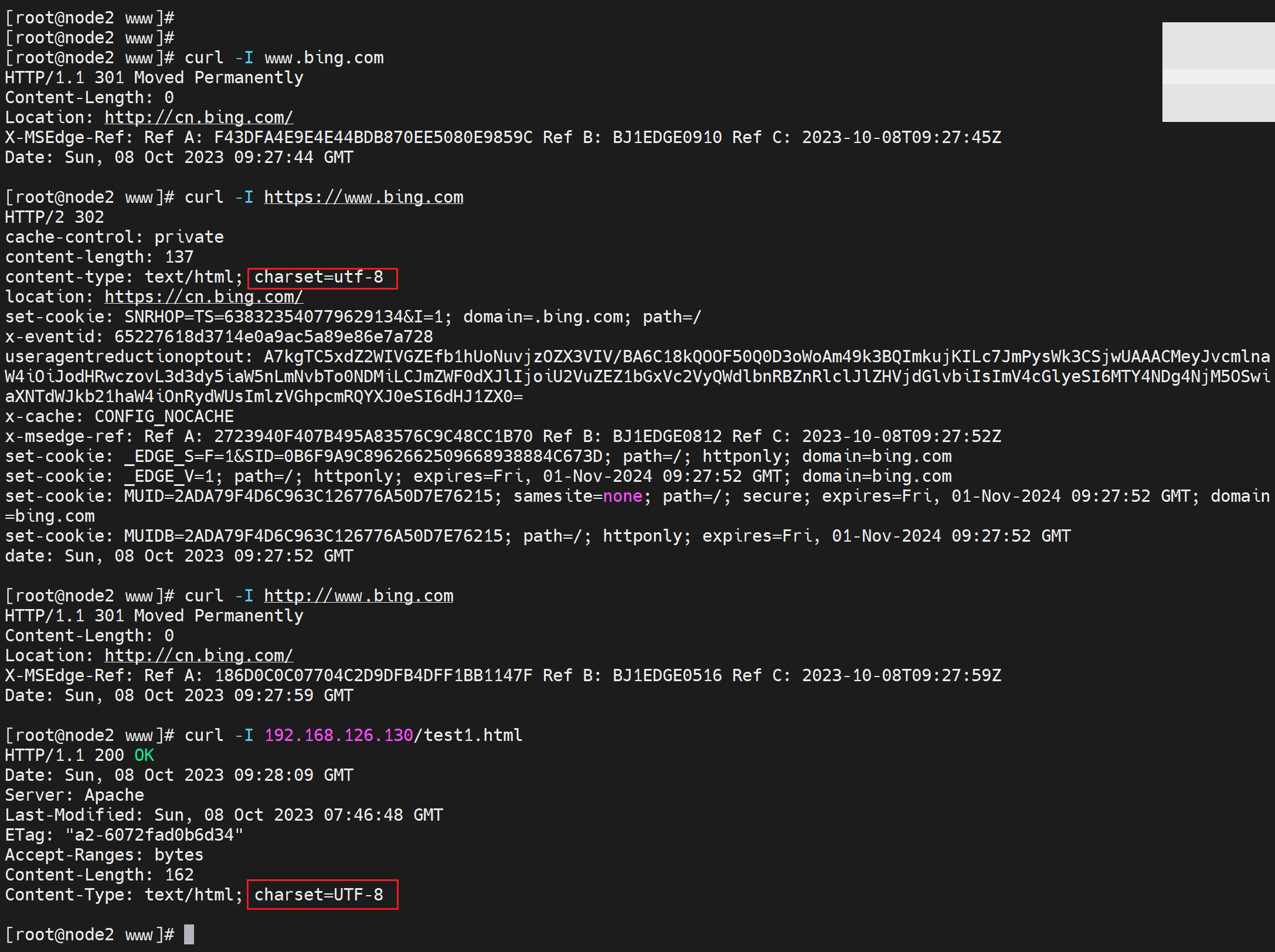
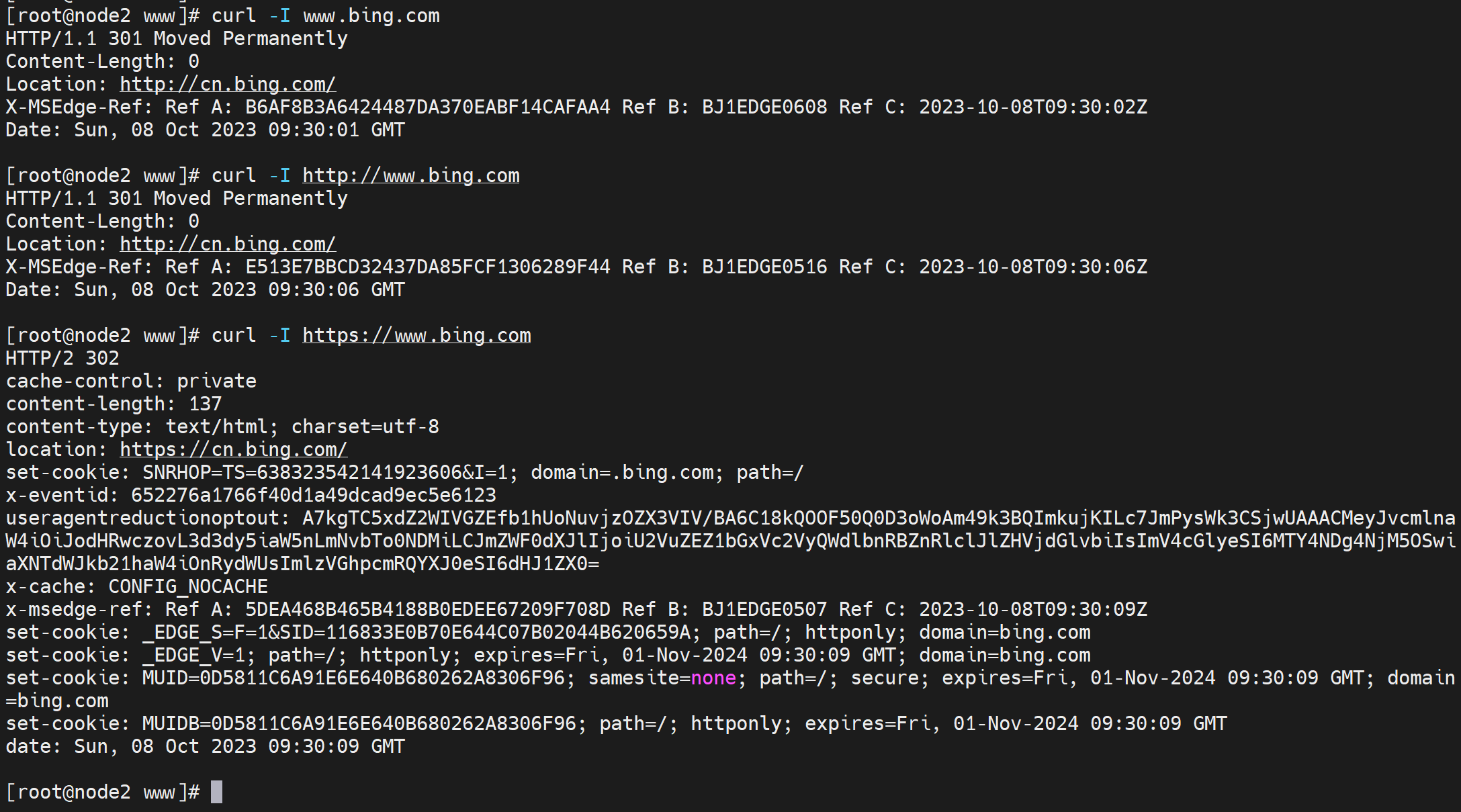
带不带s https的s 也不一样
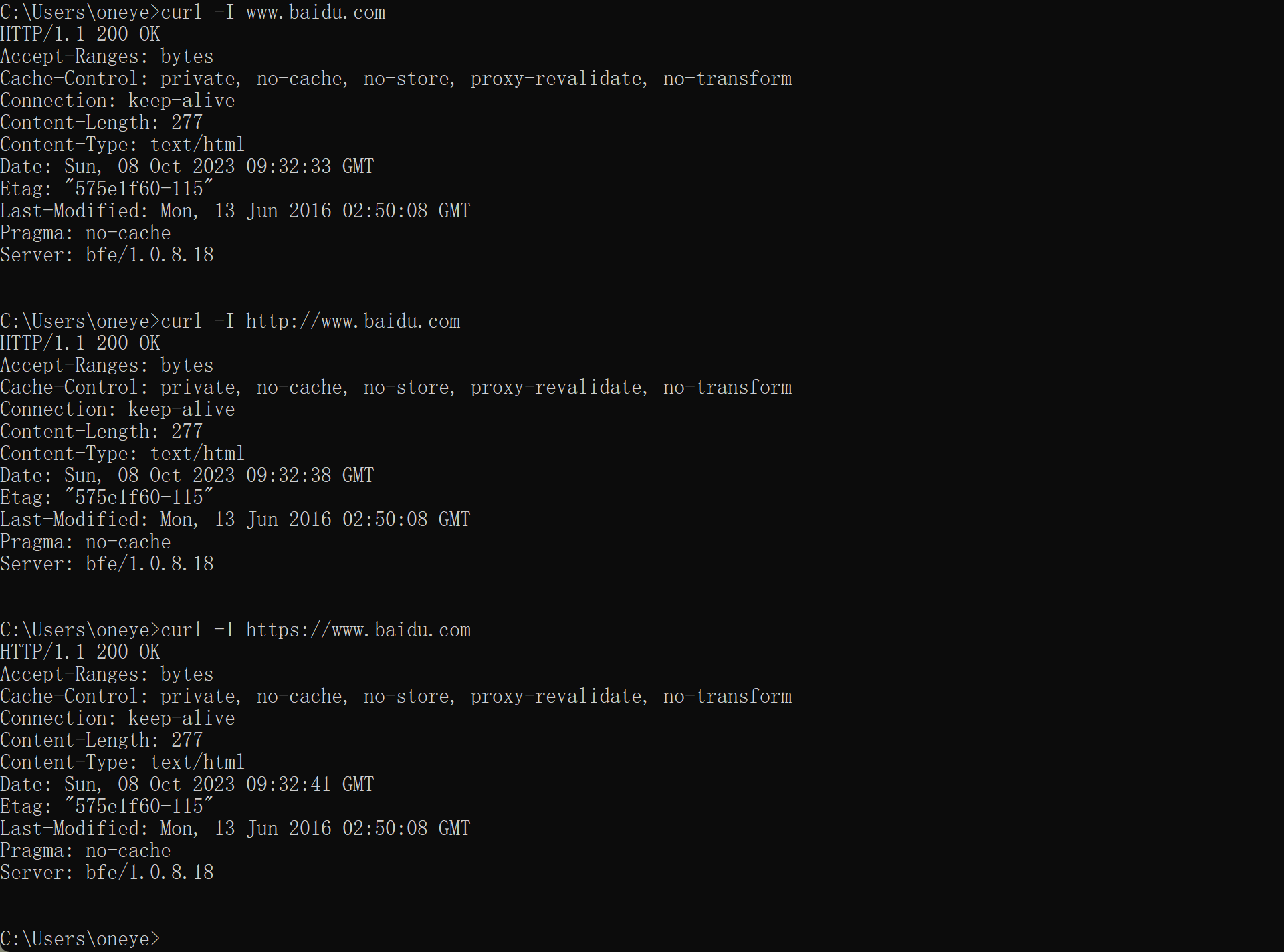
不过针对使用curl百度,不显示字符集👇
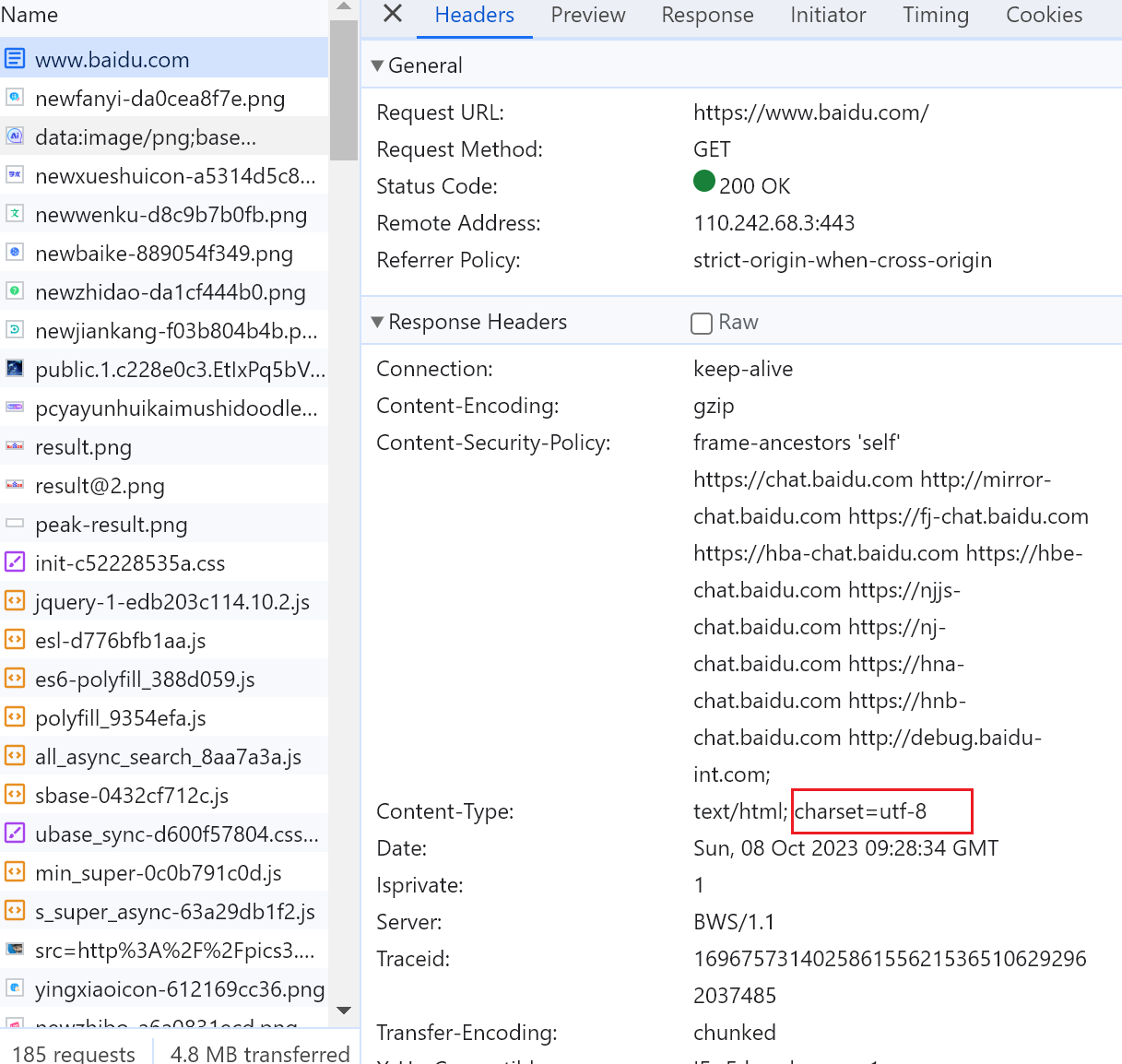
浏览器是有的
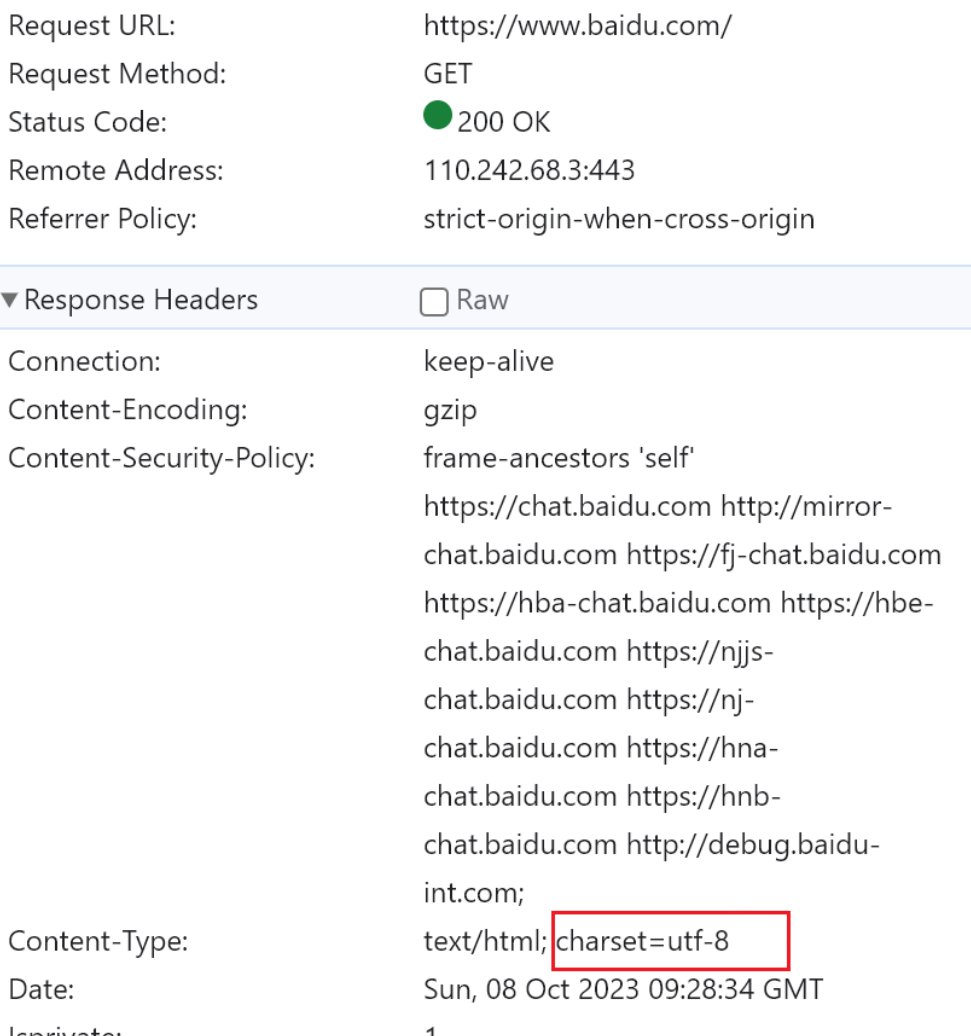
改一下字符集看看效果