第6节. mysql的主从复制高可用性解决方案MHA
我为什么要用这个东西呢,一个perl 语言写的东西,最新版本2012年,难道是因为免费实用够用?好吧
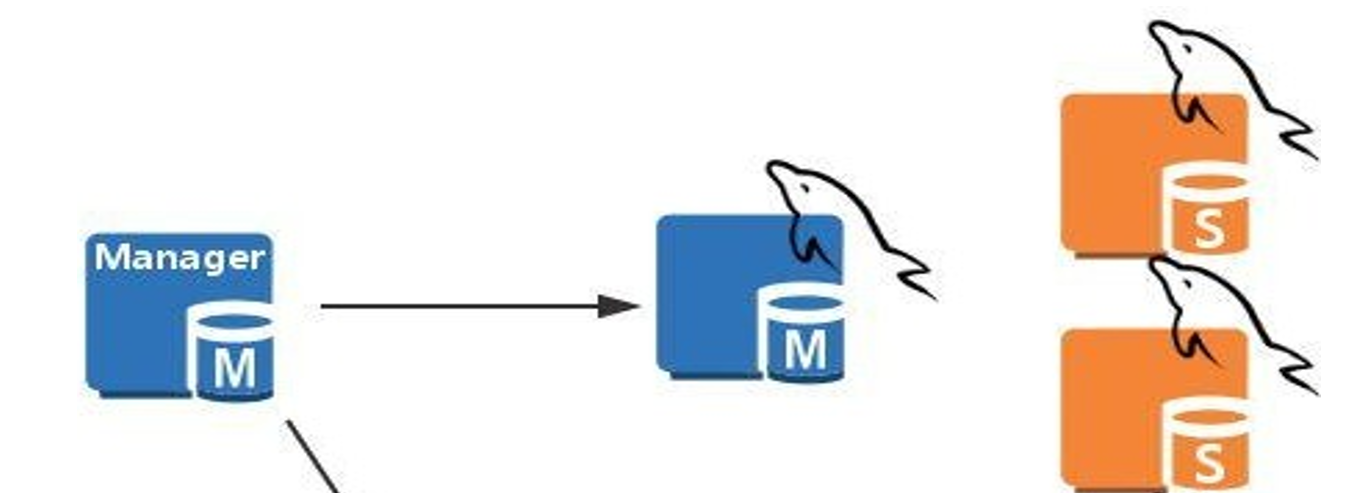
MHA架构
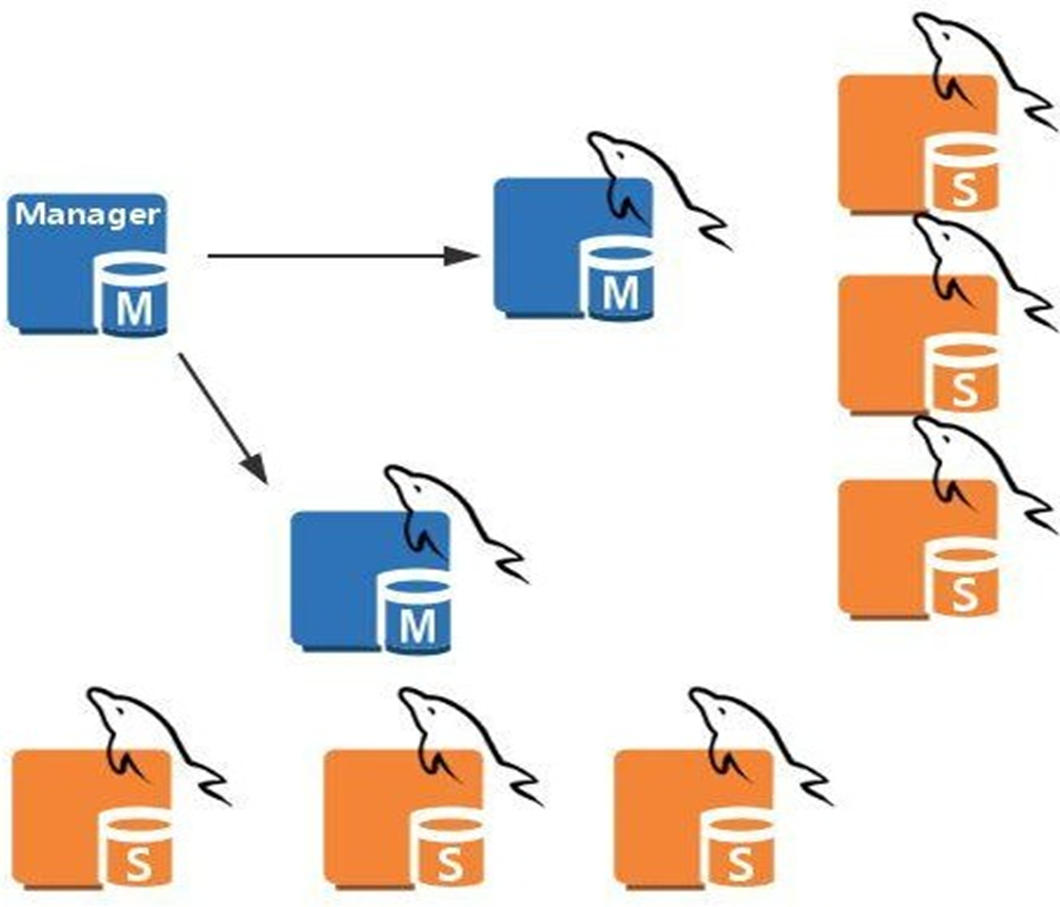
manager节点,管理着多个主从,某一堆主从的master挂了,就会把在那堆主从里的找一个slave提升为master。
manager管理节点,是单点,但是问题不大,因为用户访问的业务不走它走,它挂了,不影响业务;除非运气好,manager挂了的时间段里,某个主从的主也挂了,此时由于没有管理节点,所以就无法自动提升slave,所以也就导致业务出问题了,按传统的思路写是要分流到master上的,此时master都没了,所以业务收到了影响。
MHA的工作原理介绍
先复习一下主从的底层
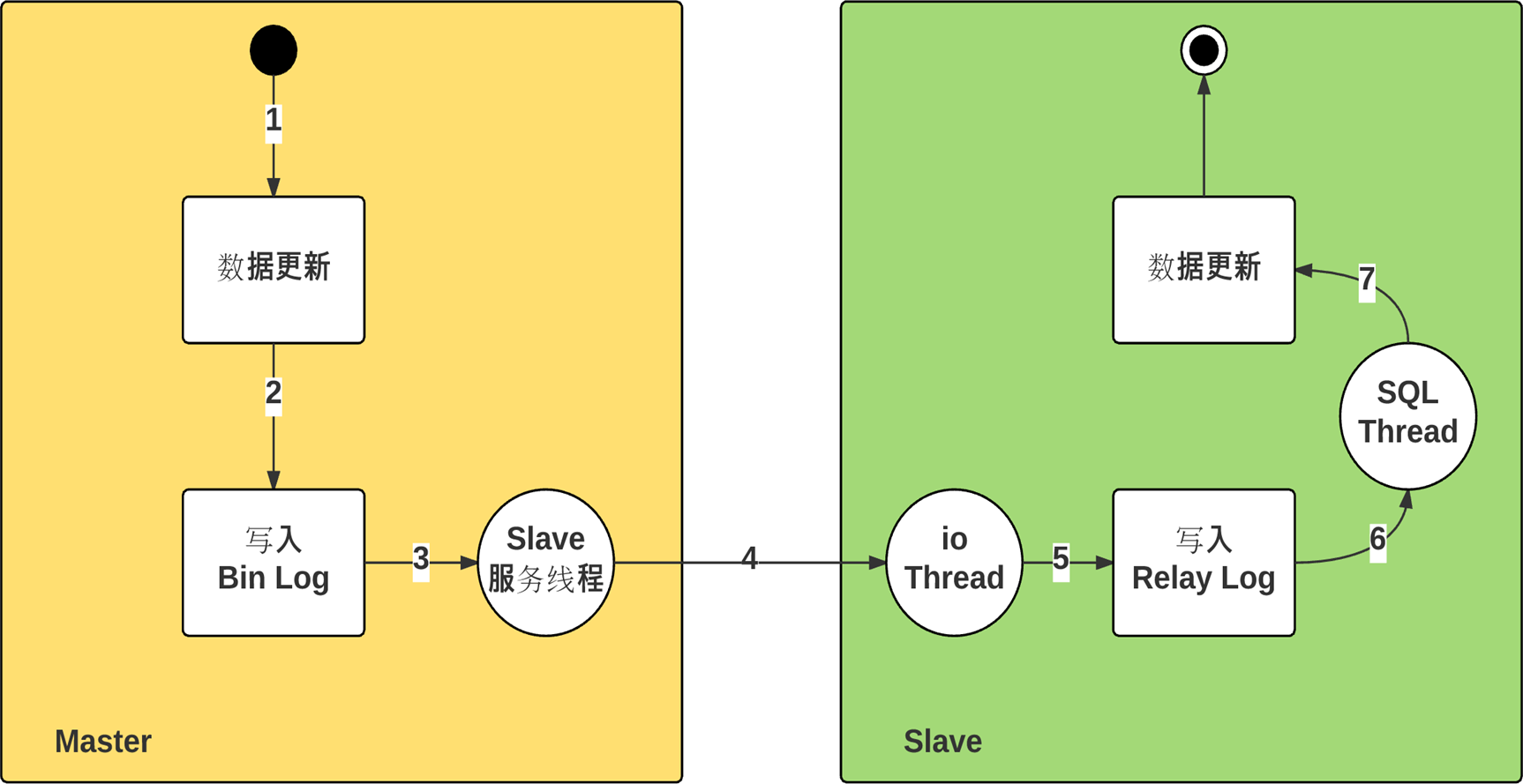

再来理解下图MHA的思路
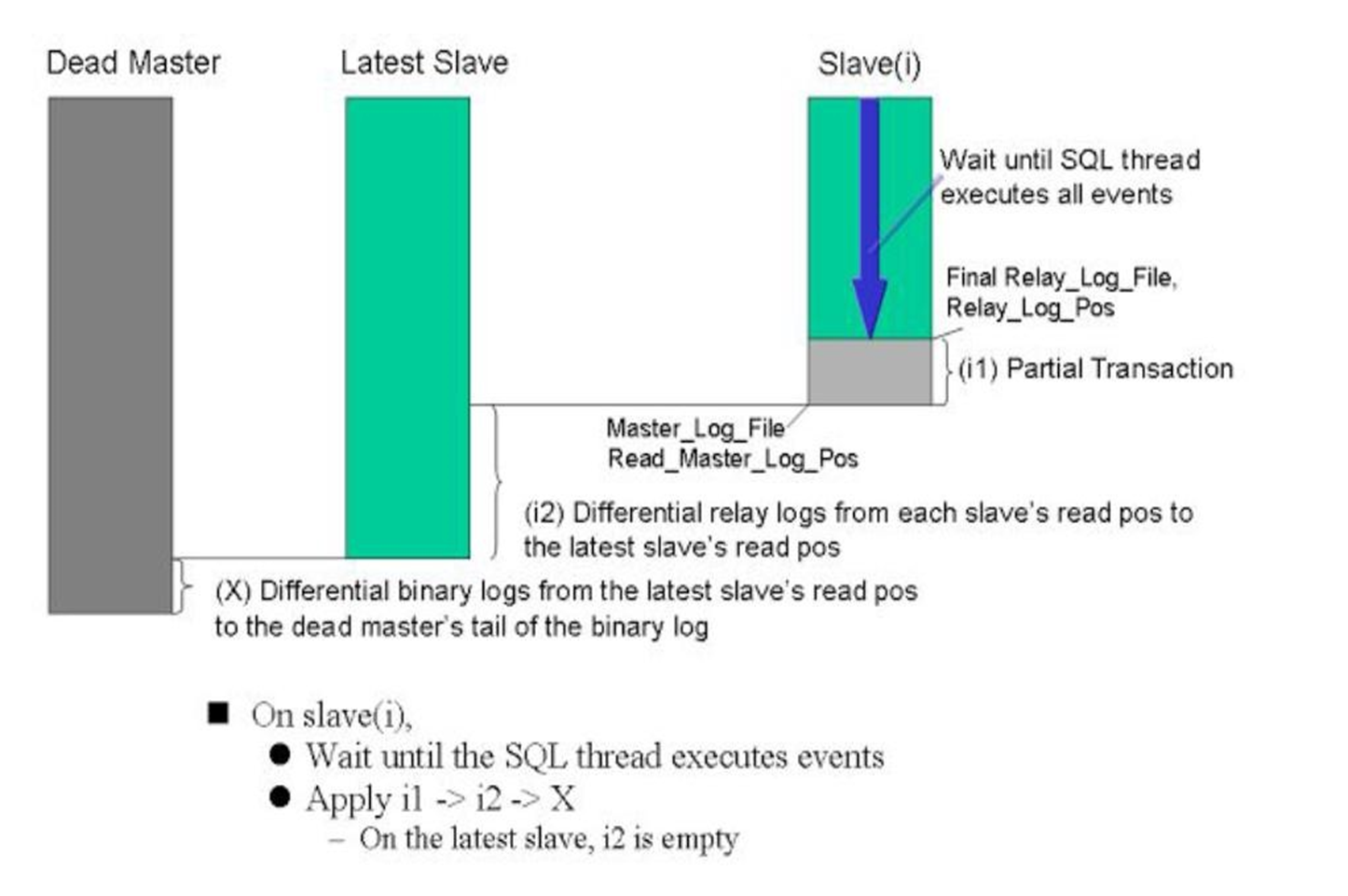
1、三根柱子代表什么
2、柱子之间的落差,就是binlog落差
3、slave(i)这个i是变量,就是很多个slave的意思,u known~,这些不太优秀的slave(i)们,不仅仅从master那拿到的binglog比最优秀的lastest slave要少一截 ,而且写到本地还写的慢
,而且写到本地还写的慢 。
。
4、所以矮子当中选将军咯,新的master选出来后,
5、想办法补齐DeadMaster和LatestSlave之间的binlog差,怎么想办法:①dead不是机器dead只是服务dead就去找binlog文件;②binlog是否有异地备份;③没有异地,本地重启看看也行啊对不对,总之找到dead master上的binlog,补齐到LatestSlave上,不过这些理论上都是MHA实现的,所以MHA不太可能说给你异地取备份,也不太可能给你重启deadmaster机器,所以MHA能自动处理的应该就是机器没死mysql服务死的的情况去去binlog文件。
6、slave(i)同步之前可能也要做两个事情:①SQL Thread进程走完,把已经拿到的binlog写到本地文件里;②把和Lastest Slave之间的差距通过I/O Thread补齐;然后就继续同步。

看它意思,
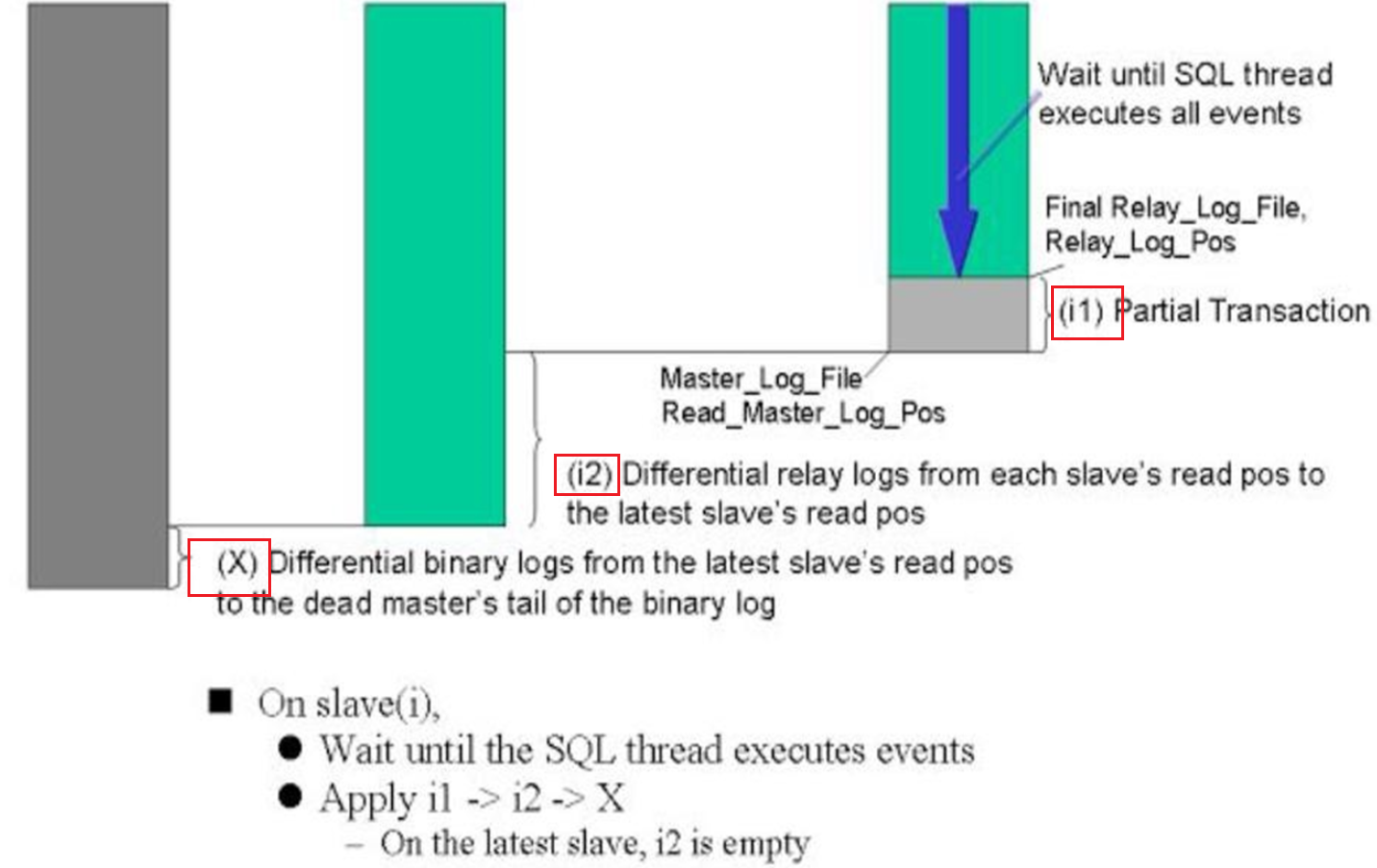
这么麻烦的吗,难道不是slave 所有的save包括最优的那个slave,统统从deadmaster同步X,唉不对,同步各自的差异binlog嘛。
估计是怕deadmaster连机器都挂了,ssh上不去,MHA的manage拿不到binlog,就做不了X,所以才有了i1-->i2-->X这么一个先后同步的过程,就是每次同步的动作不大,能成功的同步先做了。
i1就是本地的sql线程将relylog写到库里,i2就是slave们从最优的slave去取差异binlog;X就是deadMaster上取binlog这个可能就不一定成功。
所以MHA要利用到ssh,scp这些协议

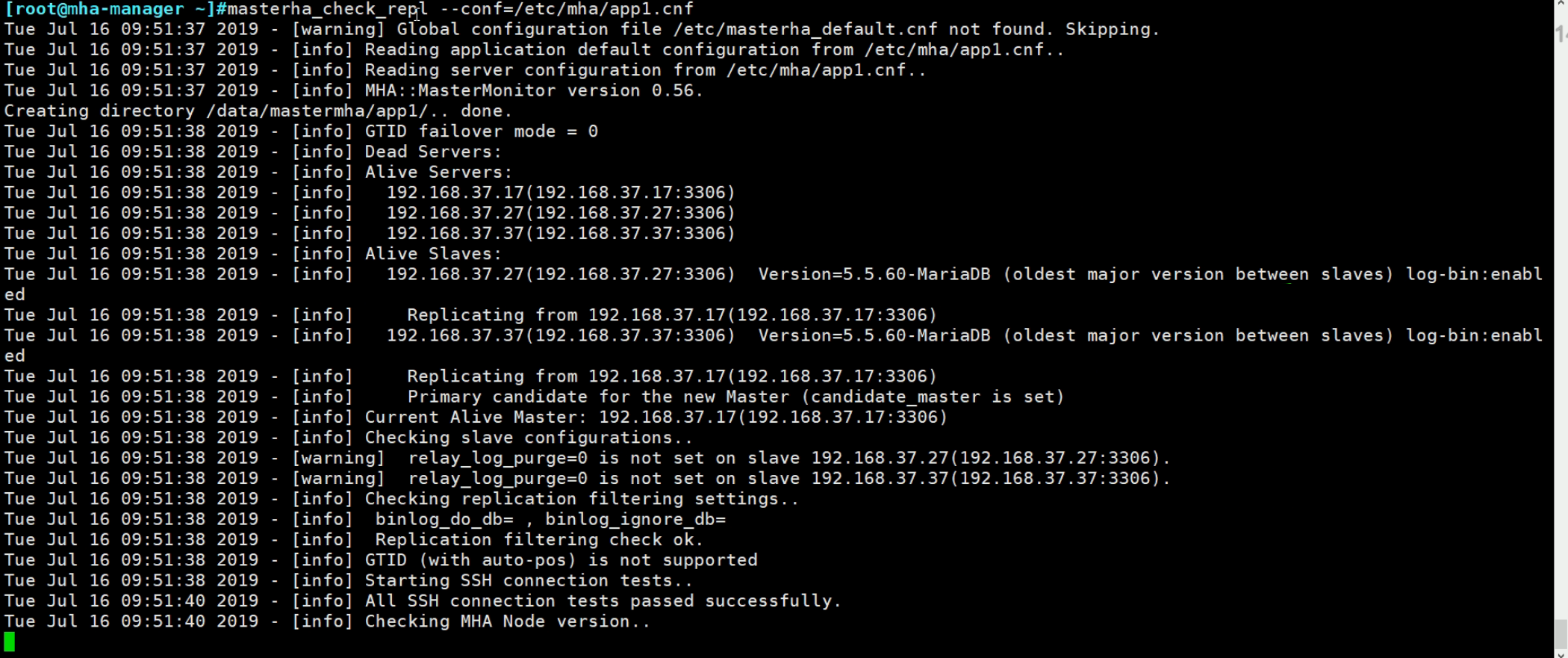
manager工具包需要epel源,node工具包不需要epel源。
manager工具包安装在manager节点上,node工具包安装在监控的主从节点上和manager节点上。

半同步复制,默认是异步会存在slave和master差异越来越大的可能,而半同步,就能保证只要有一台slave回应我master了,master就回答client了。参见 第二十七章 MYSQL数据05-第2节
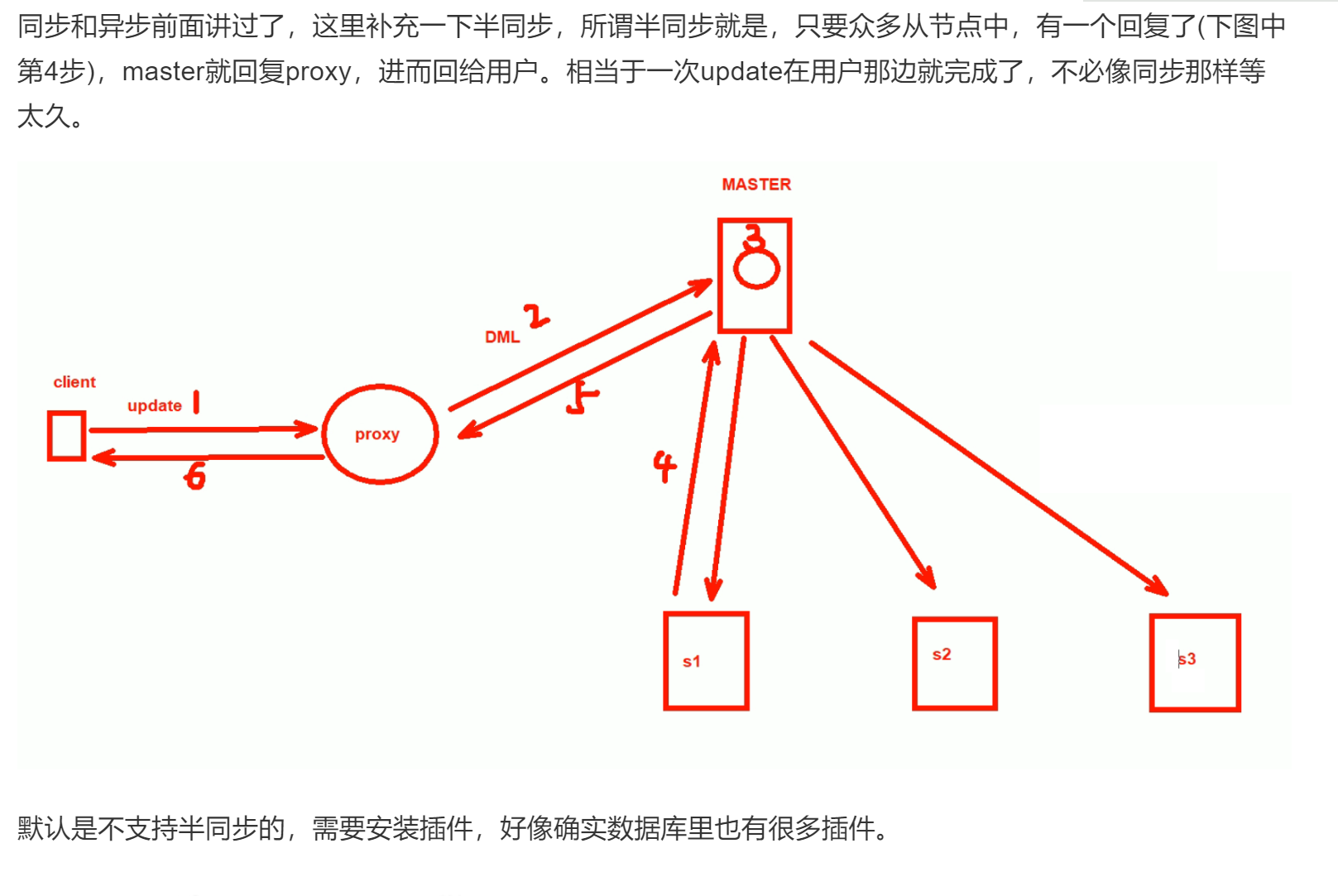
master作为半同步的一个关键点,它的行为就是只要收到一台slave的响应就会回应client。那么问题来了,这种行为下,slave(i)们是否是保证一定有一台是最优的,会不会出现不同的数据分散到不同的slave上,不会!同步的机制就是binlog的posti位置,按序复制的,所以某台slave回应了master,那么这台slave一定已经取到了最新的数据了! 呼~~~
简单了解👇

MHA有个配置文件:
其中global配置:就是为各个主从(它叫做application)提供默认的统一配置模板
如果想为单个某个主从,配置,就针对他们配置application关键字的配置。
在管理节点上安装两个包 mha4mysql-manager mha4mysql-node
在被管理节点安装 mha4mysql-node
在管理节点建立配置文件
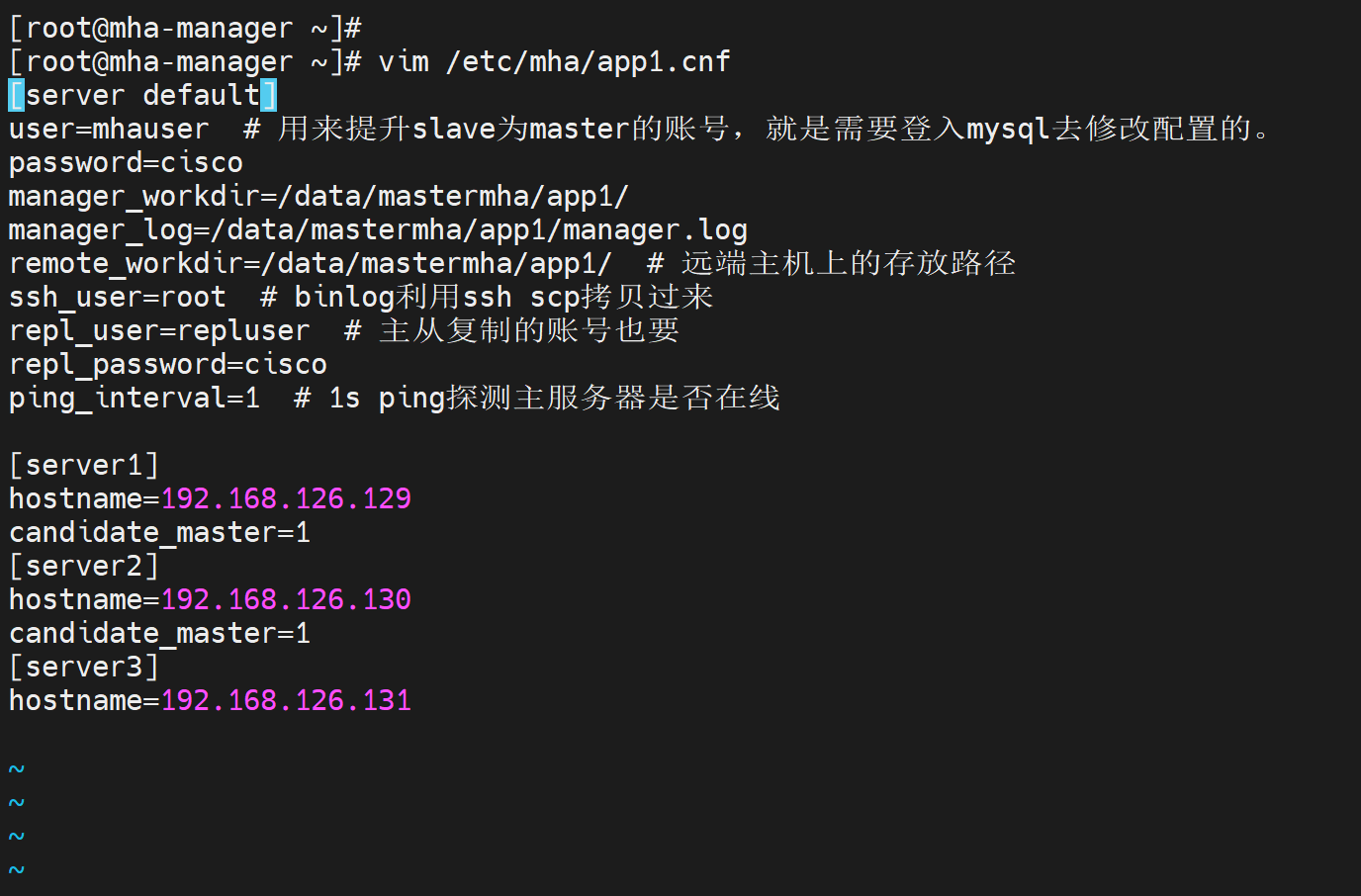
vim /etc/mastermha/app1.cnf # app1就是应用1,就是对应一组主从,另建一个app2.cnf就是对应第二组主从
[server default]
user=mhauser # 用来提升slave为master的账号,就是需要登入mysql去修改配置的。
password=cisco
manager_workdir=/data/mastermha/app1/
manager_log=/data/mastermha/app1/manager.log
remote_workdir=/data/mastermha/app1/ # 远端主机上的存放路径
ssh_user=root # binlog利用ssh scp拷贝过来
repl_user=repluser # 主从复制的账号也要
repl_password=cisco
ping_interval=1 # 1s ping探测主服务器是否在线
[server1]
hostname=192.168.126.129
candidate_master=1
[server2]
hostname=192.168.126.130
candidate_master=1
[server3]
hostname=192.168.126.131
在Master上配置
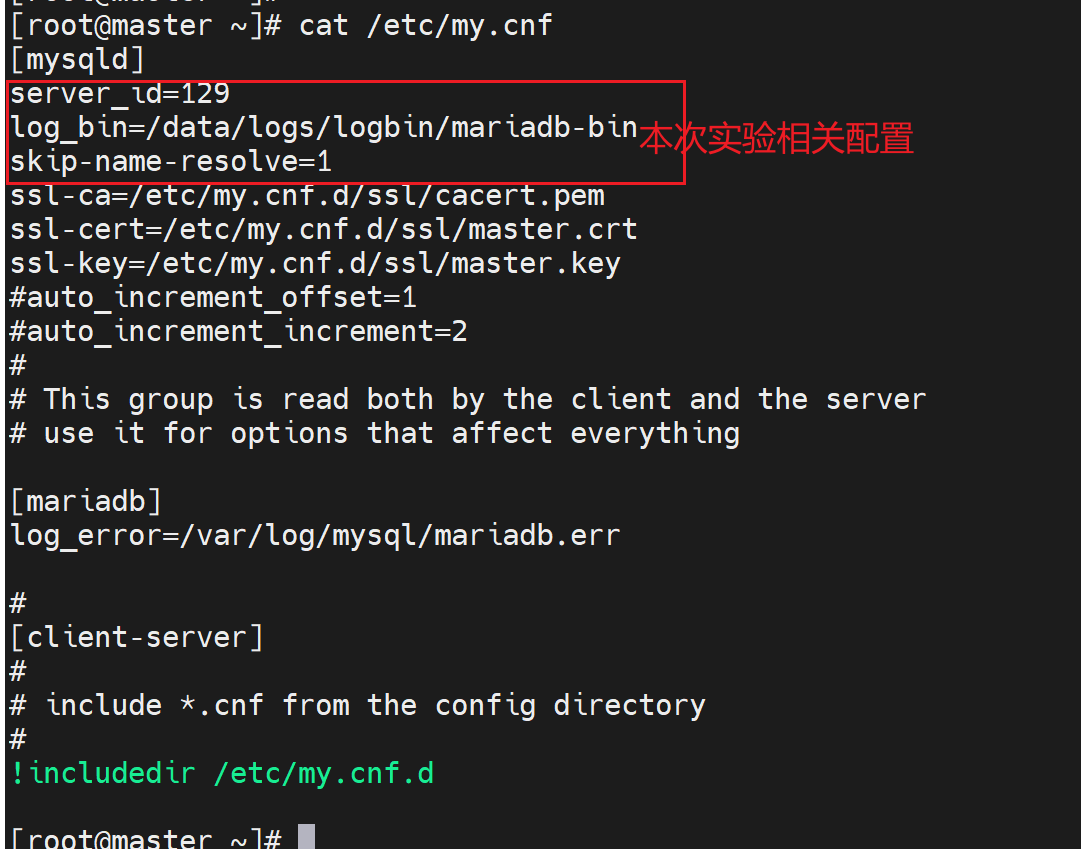
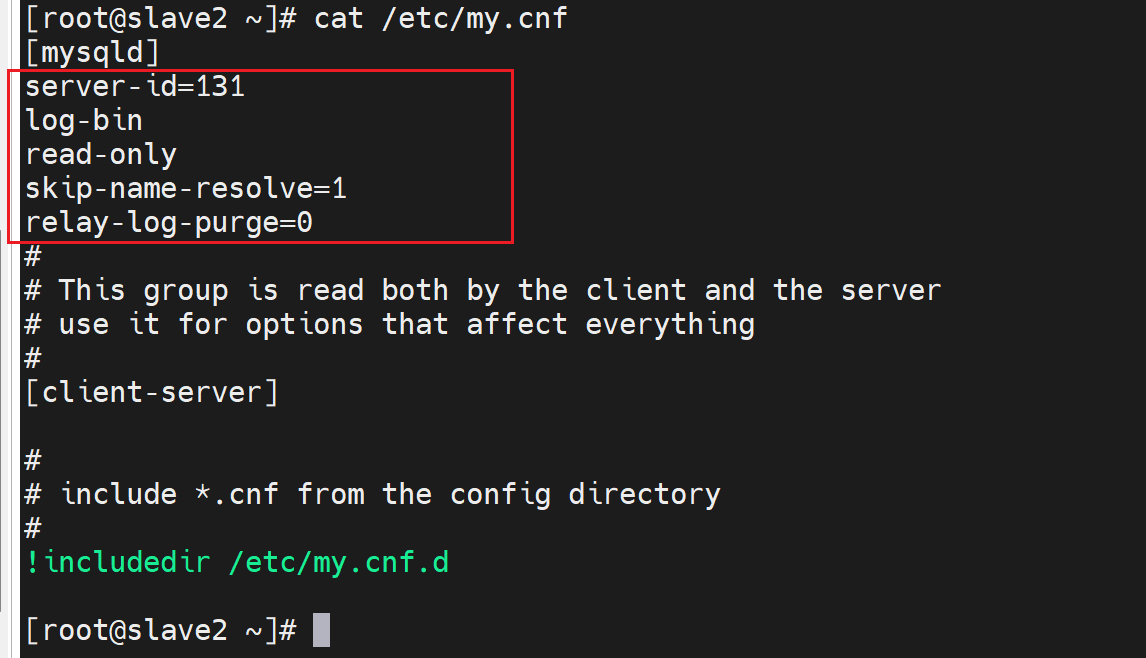
vim /etc/my.cnf
[mysqld] log-bin
server_id=1
skip_name_resolve=1 # 在MHA里必须要配置,否则默认MHA行为是做ip地址反向解析,导致用户ID识别出问题。
mysql>show master logs
mysql>grant replication slave on *.* to repluser@'192.168.8.%' identified by ‘cisco'; # 主从复制账号和授权
mysql>grant all on *.* to mhauser@'192.168.8.%’identified by‘cisco'; # mha的管理账号,用来提升slave为master,需要修改配置的。
在slave上
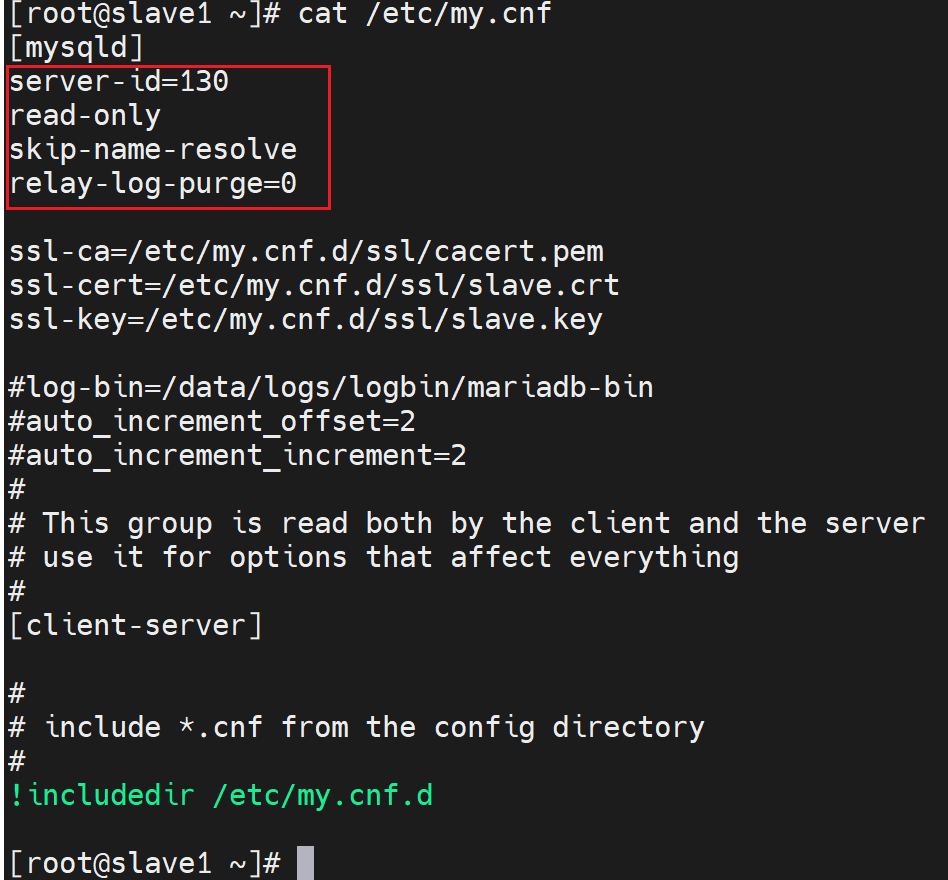
vim /etc/my.cnf
[mysqld]
server_id=2 #不同节点此值各不相同
log-bin # 从节点本来无需binlog,但是将来要提升为master,所以需要事先开启binlog
read_only
relay_log_purge=0 # 默认会清除中继日志,这里不清楚,将来可能恢复使用。
skip_name_resolve=1
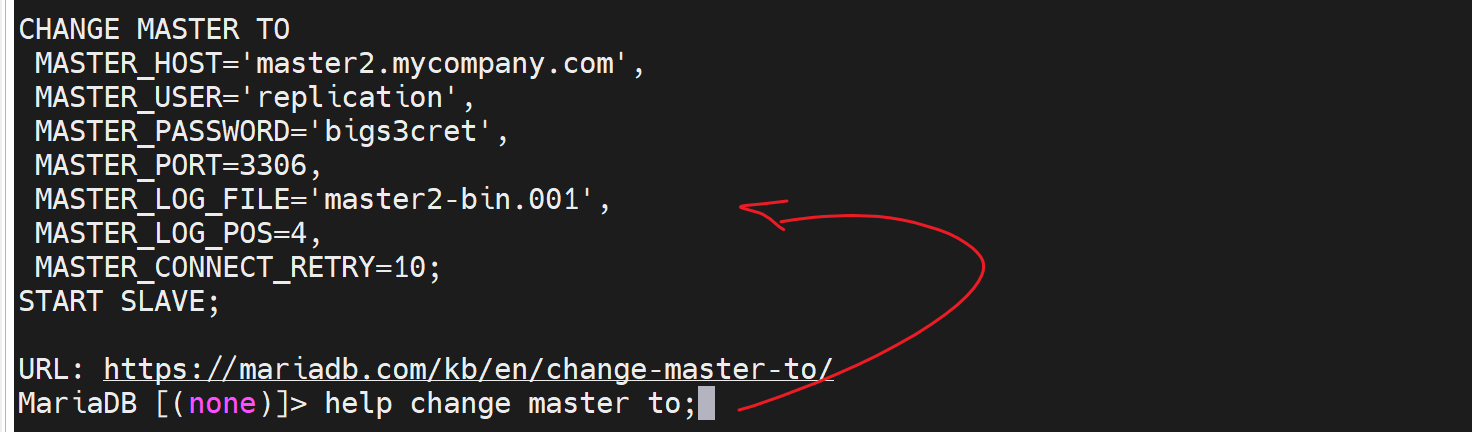
mysql>CHANGE MASTER TO MASTER_HOST=‘MASTER_IP’,
MASTER_USER='repluser', MASTER_PASSWORD=‘cisco’,
MASTER_LOG_FILE='mariadb-bin.000001', MASTER_LOG_POS=245;
在所有节点实现相互之间ssh key验证
MHA验证和启动
masterha_check_ssh --conf=/etc/mastermha/app1.cnf # 检查ssh key验证是否OK
masterha_check_repl --conf=/etc/mastermha/app1.cnf # 检查主从复制是否OK
masterha_manager --conf=/etc/mastermha/app1.cnf # 启动MHA集群,此时就可以正常使用了。
排错日志
/data/mastermha/app1/manager.log # 比如服务起不来,可以看看日志。
实验
4台就够了
命名
hostnamectl hostname mha-manager
hostnamectl hostname master
hostnamectl hostname slave1
hostnamectl hostname slave2

配置主从
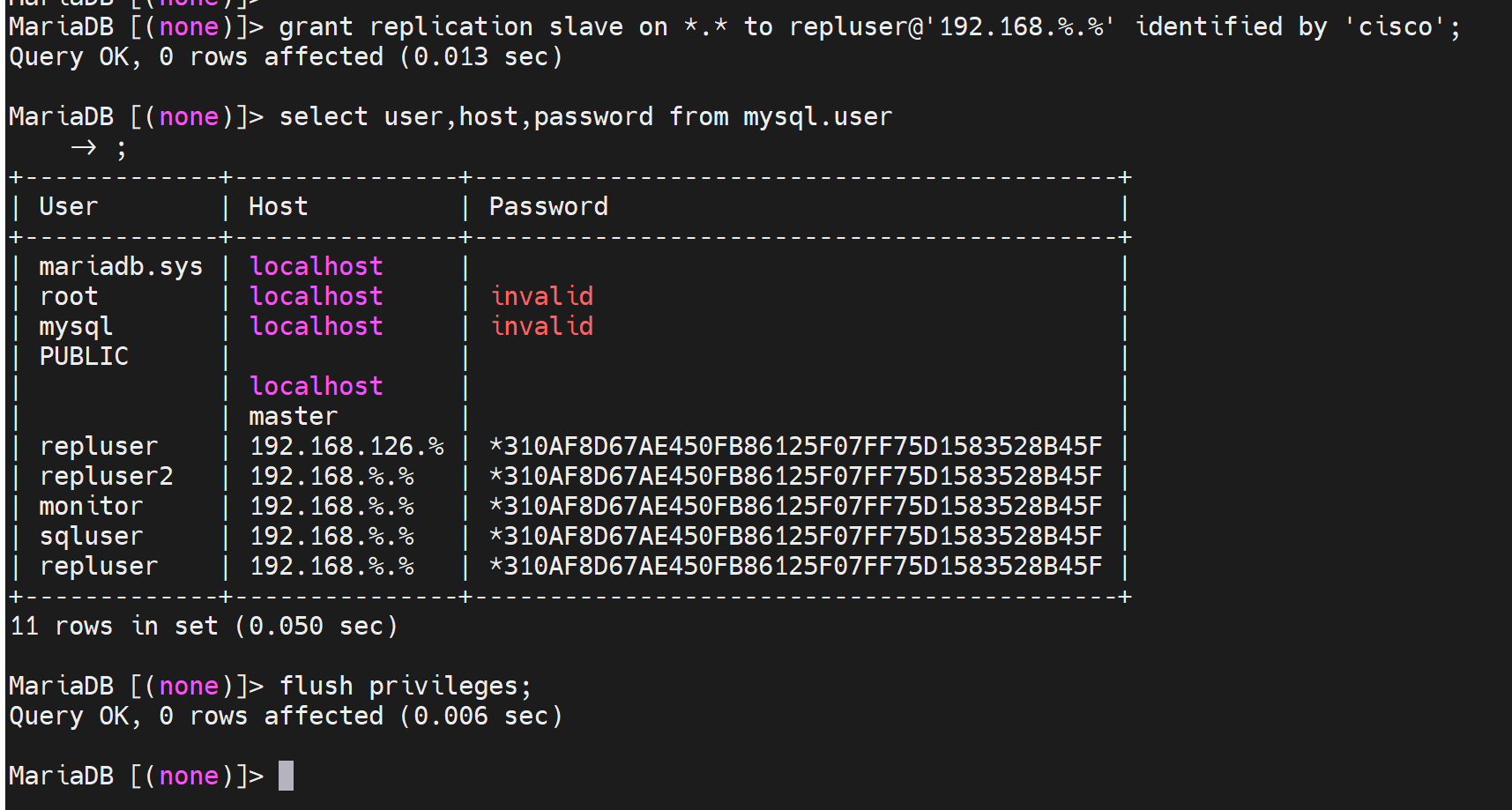
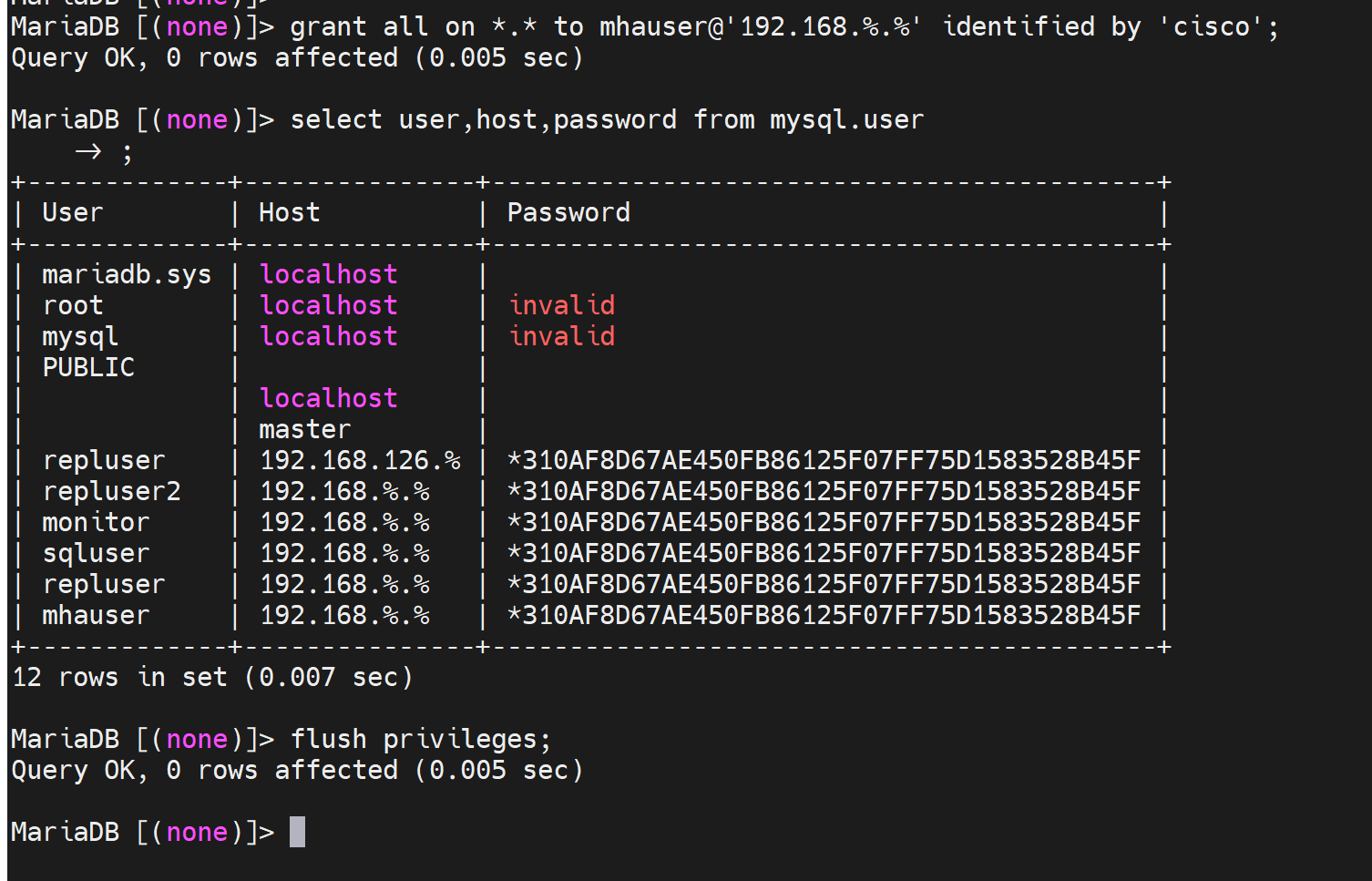
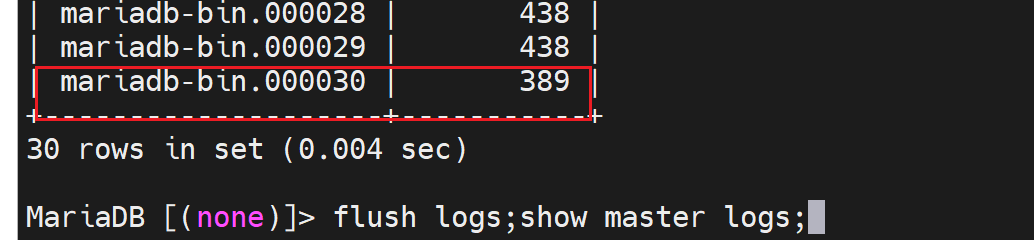
master上创建了两个账号,slave 配置的时候就从binlog的初始pos开始(通过flush logs刷新binlog可知初始位置在哪我的是389);就可以把这两个账号带过去,不过最好手动配置吧。
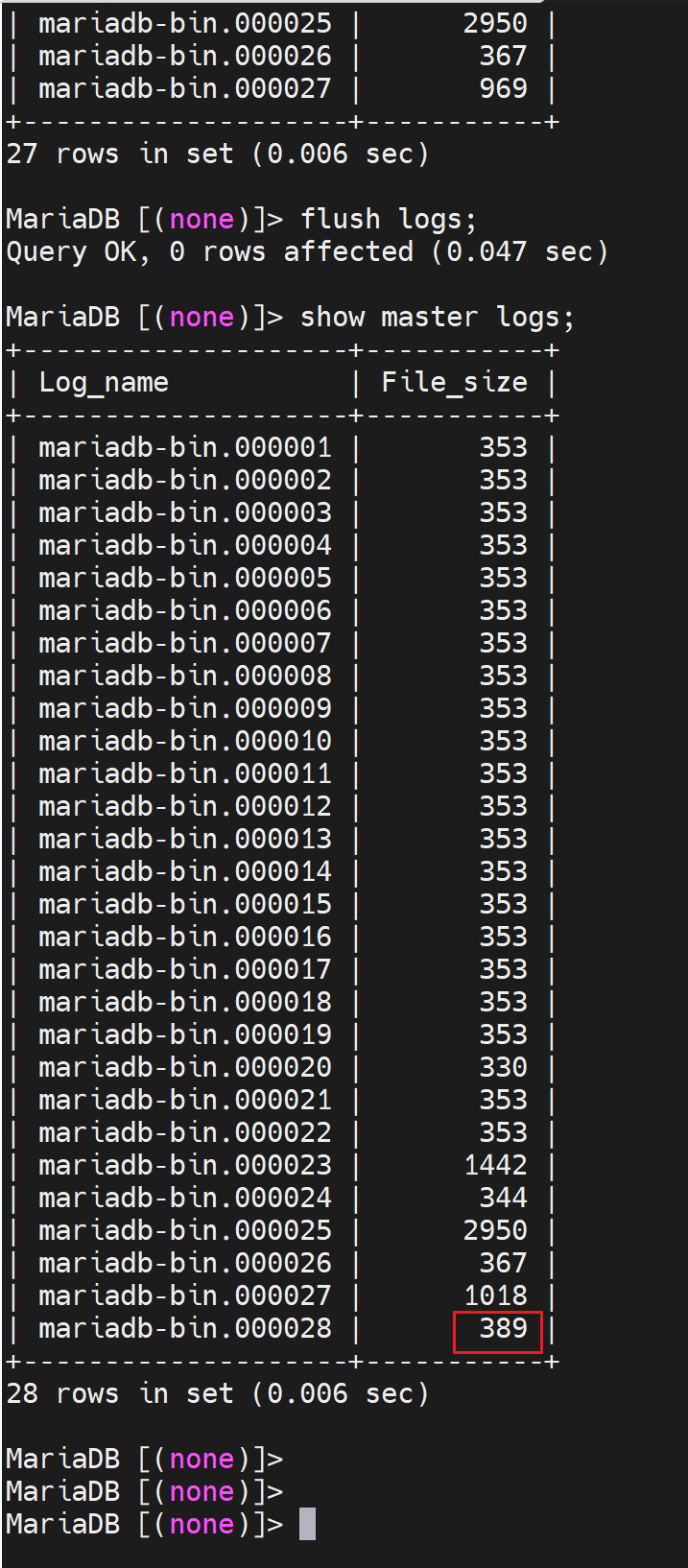
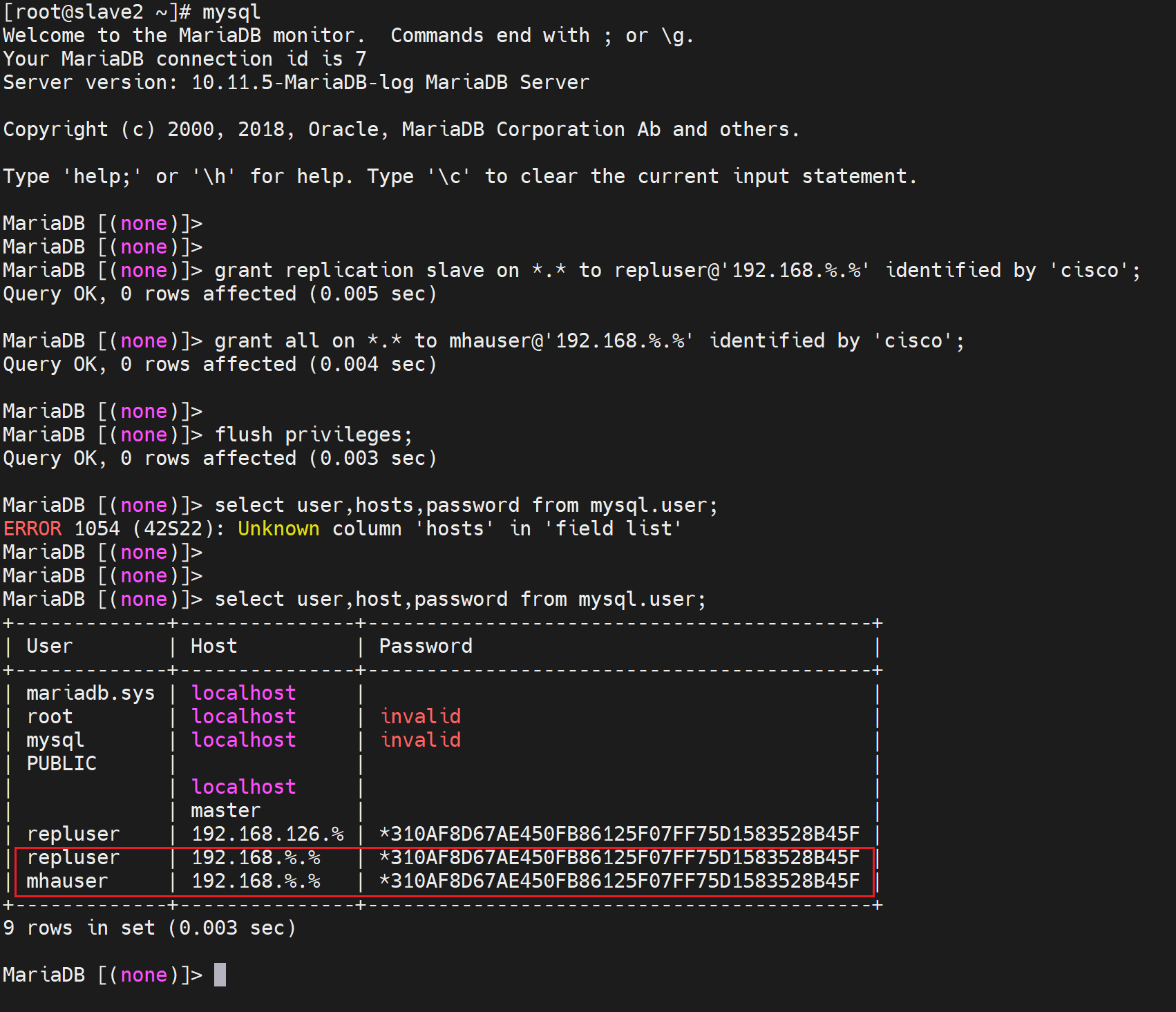

修改一下,我的操作是在master下flush logs; show master log;然后手动在slave那边创建账号,master我们本次实验就当作是干净,或者不用同步之前的数据。
CHANGE MASTER TO
MASTER_HOST='192.168.126.129',
MASTER_USER='repluser',
MASTER_PASSWORD='cisco',
MASTER_PORT=3306,
MASTER_LOG_FILE='mariadb-bin.000030',
MASTER_LOG_POS=389,
MASTER_CONNECT_RETRY=10; # 这个就是默认值
START SLAVE;
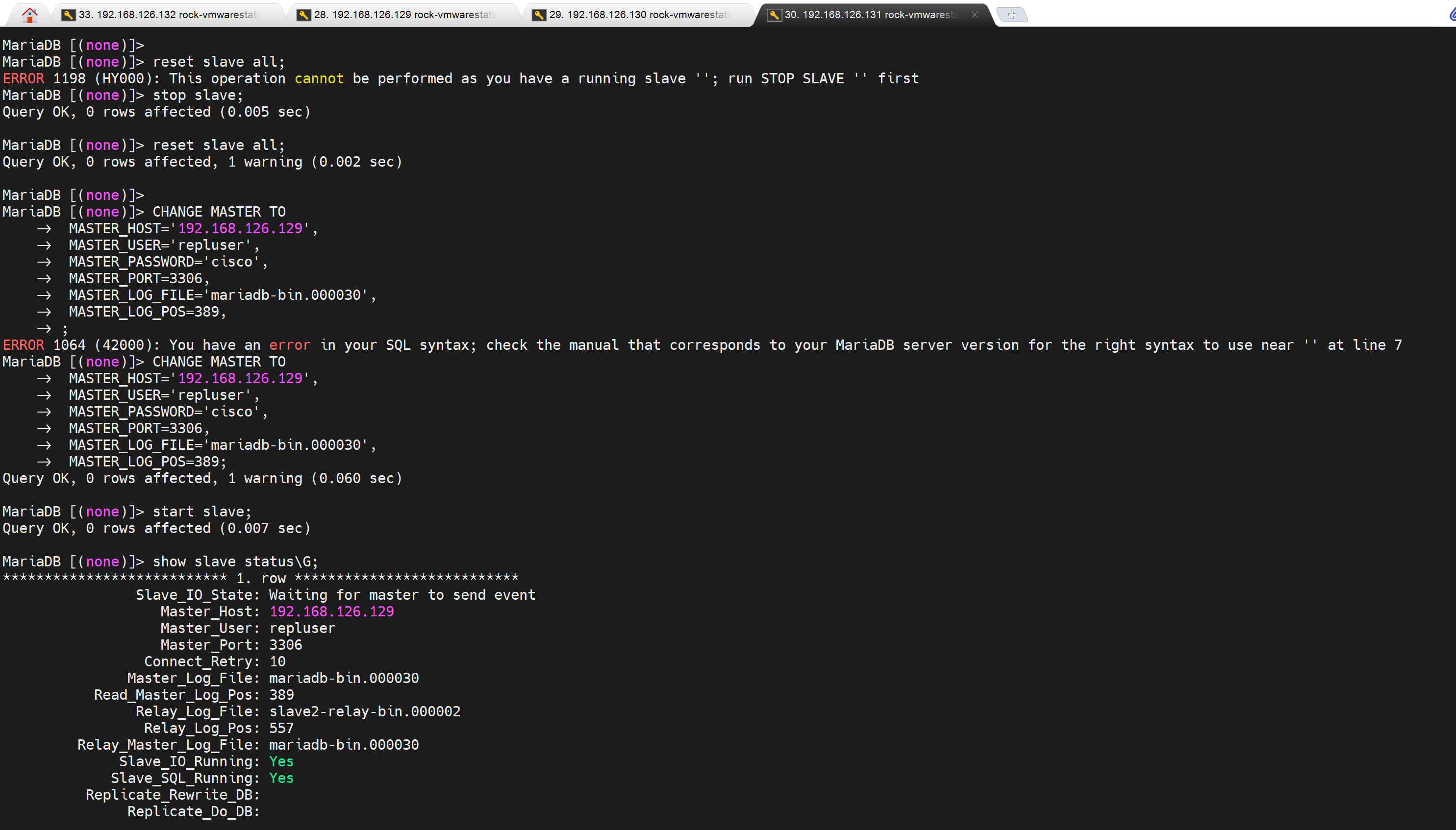
这样slave2也就同步了,slave1一样的,略
两个slave确认下 read_only变量
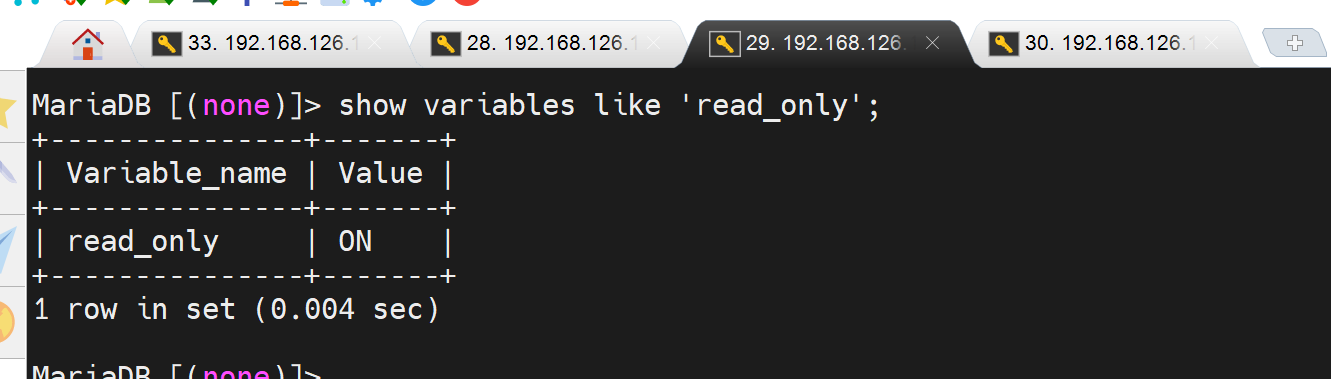
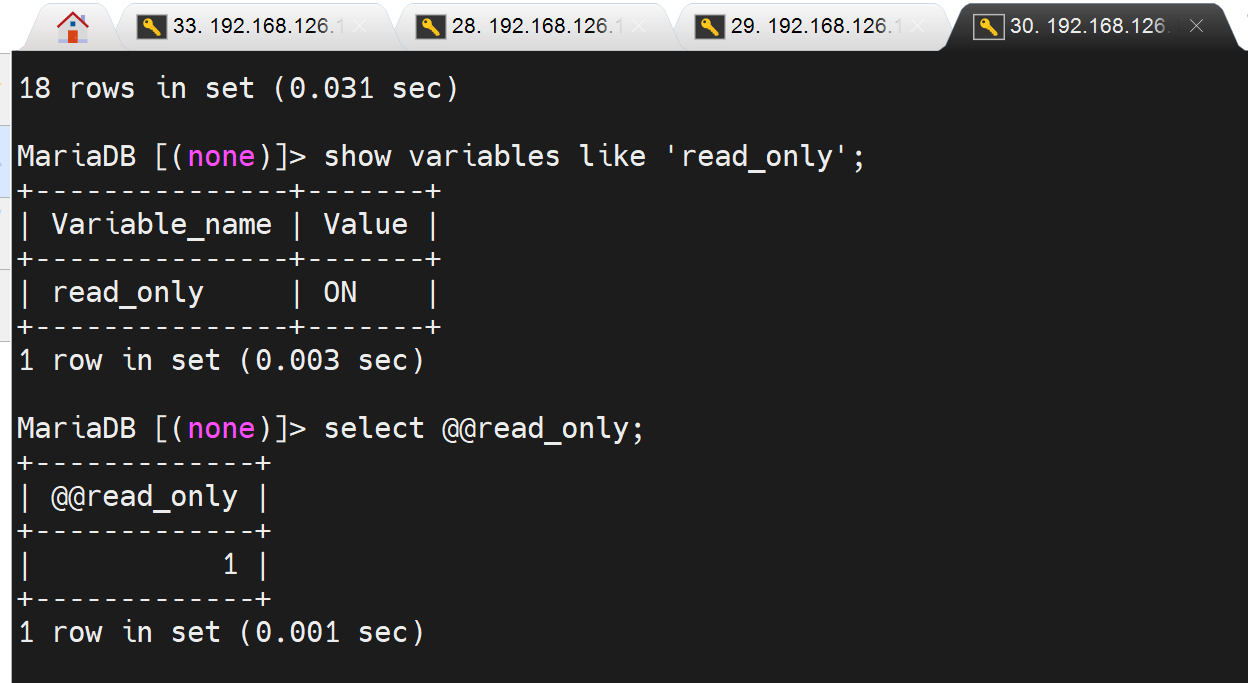
这个只读,mha后面就而已直接改了,好像是通过set 设置变量,而read_only本身就是变量,所以mha可以直接修改为OFF的。 我就想问了,不能修改/etc/my.cnf吗,ssh都有了,估计底层不是用走的修改配置文件的逻辑。
安装mha包
直接yum可没有的,都是老软件了,不过可以用的。
https://code.google.com/archive/p/mysql-master-ha/downloads
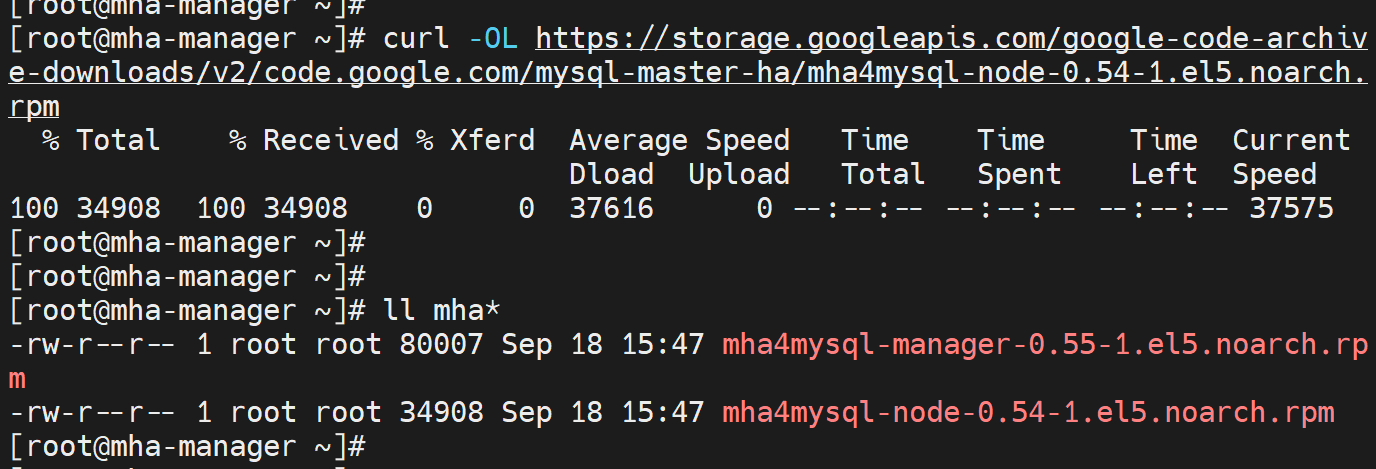

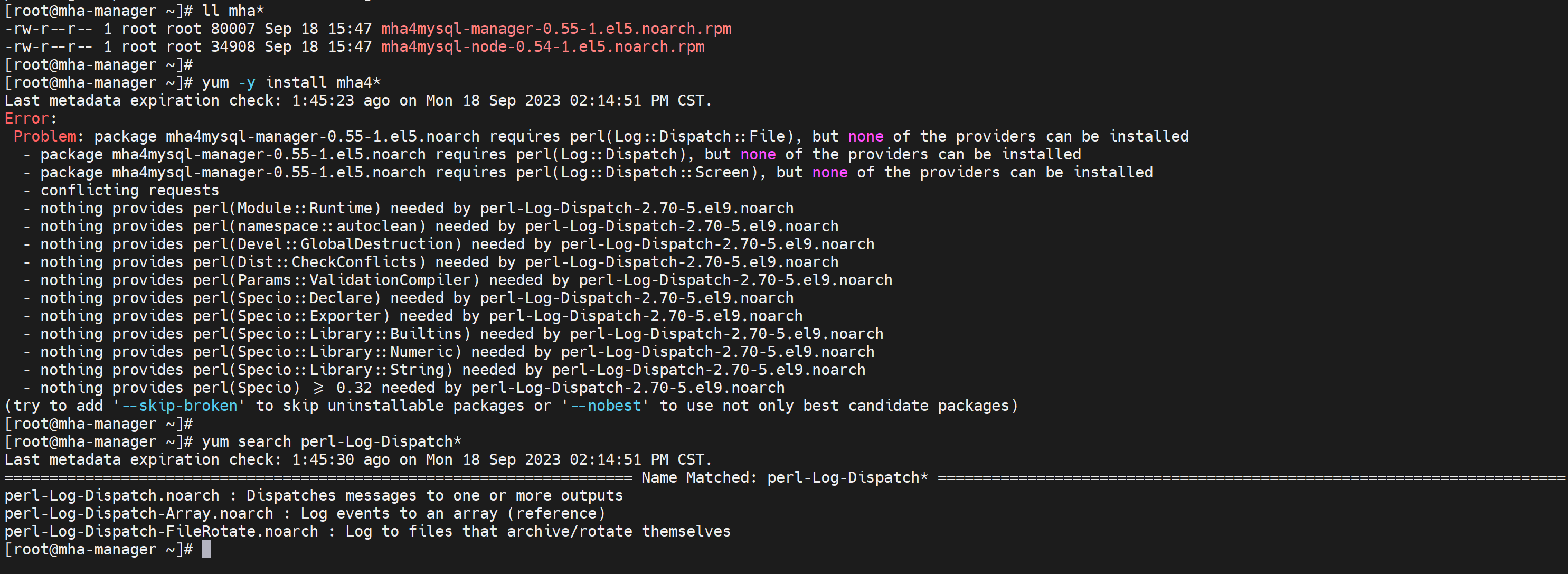
跳过报错试试
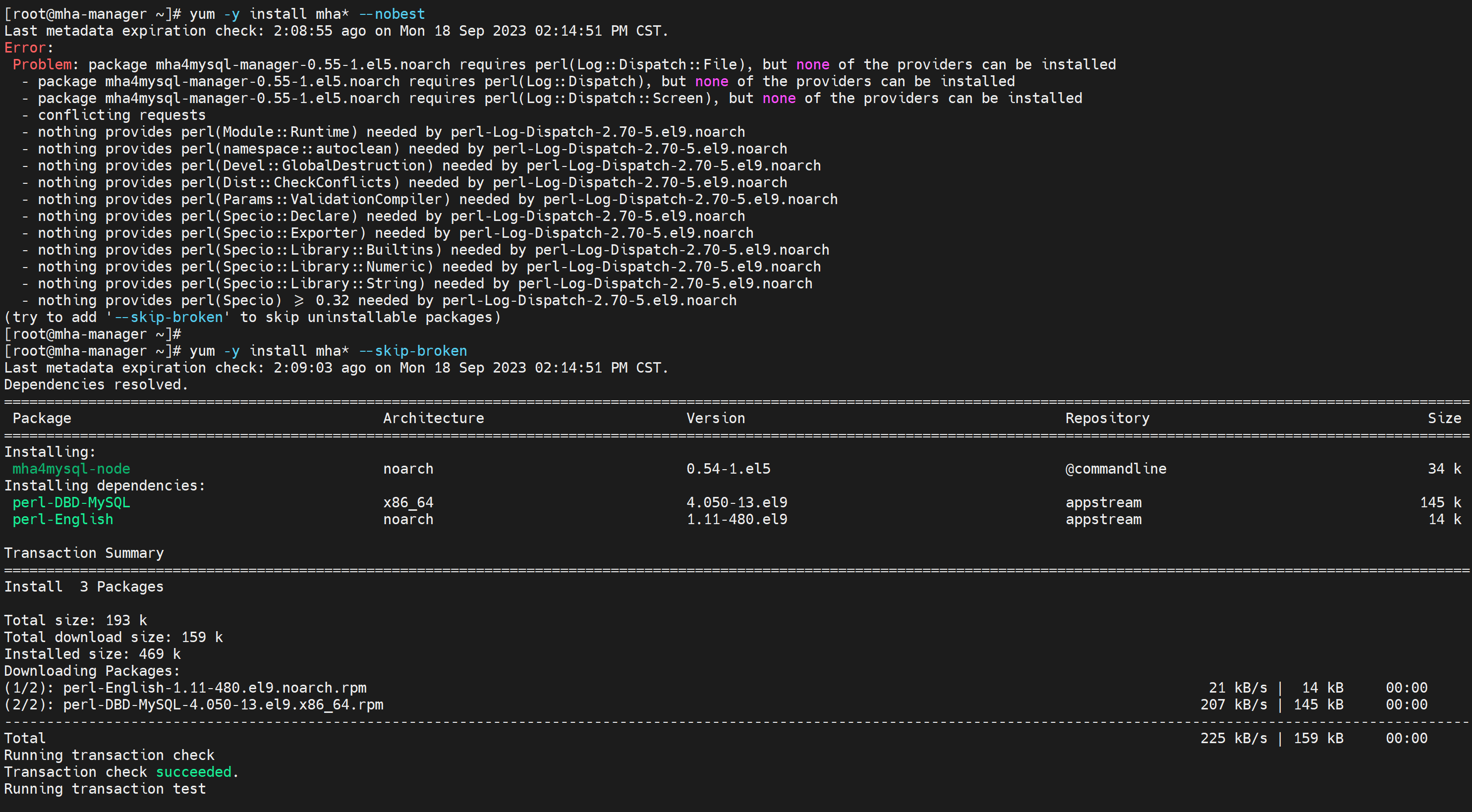
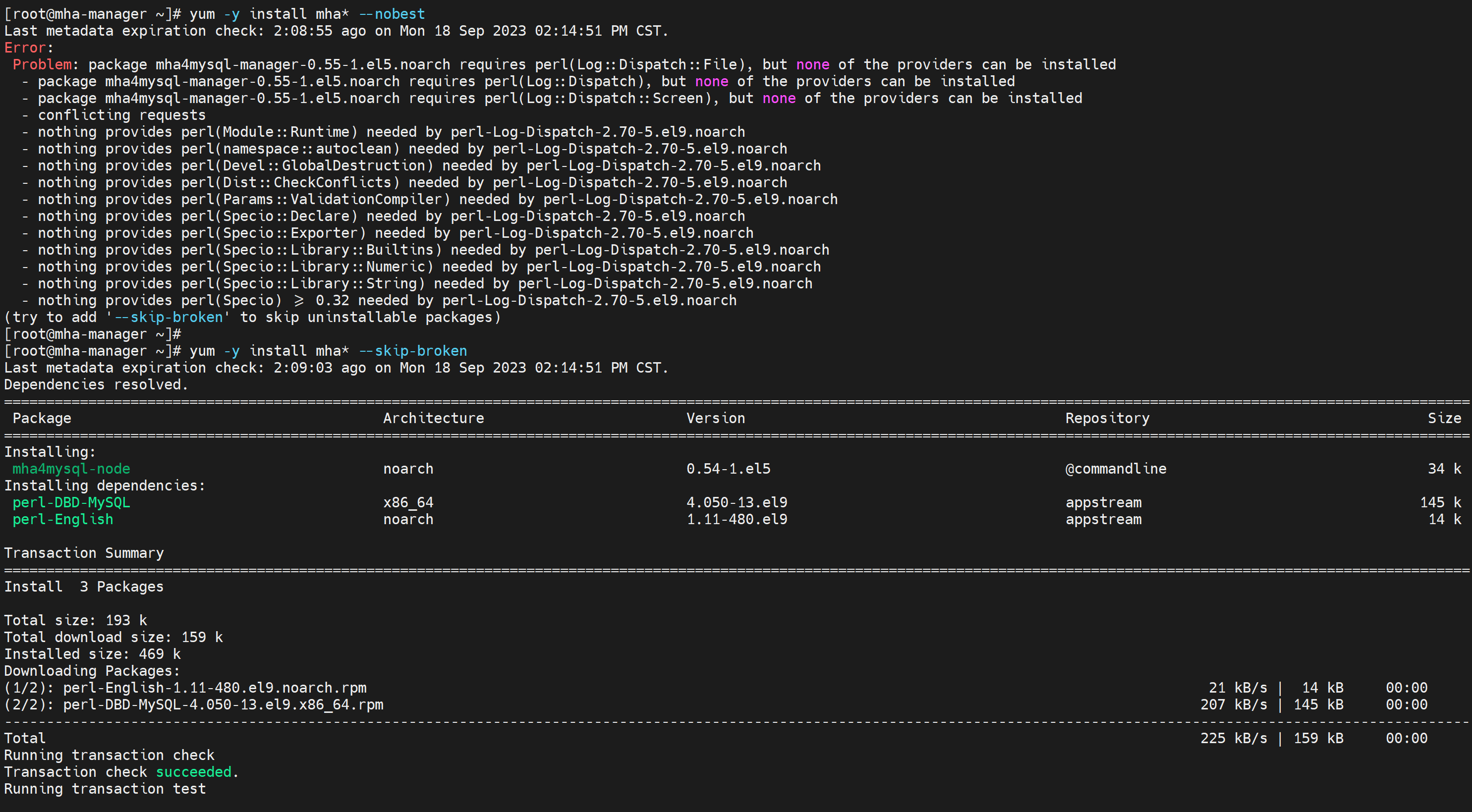
可能少一个perl-Log-Dispatch包
slave节点安装没问题
基于key的ssh配置

这里偷懒,直接做成4个机器 两两 ssh key 互通,所以操作如下
这样就实现了ssh-key

一个主从对应一个app1.cnf配置文件👇

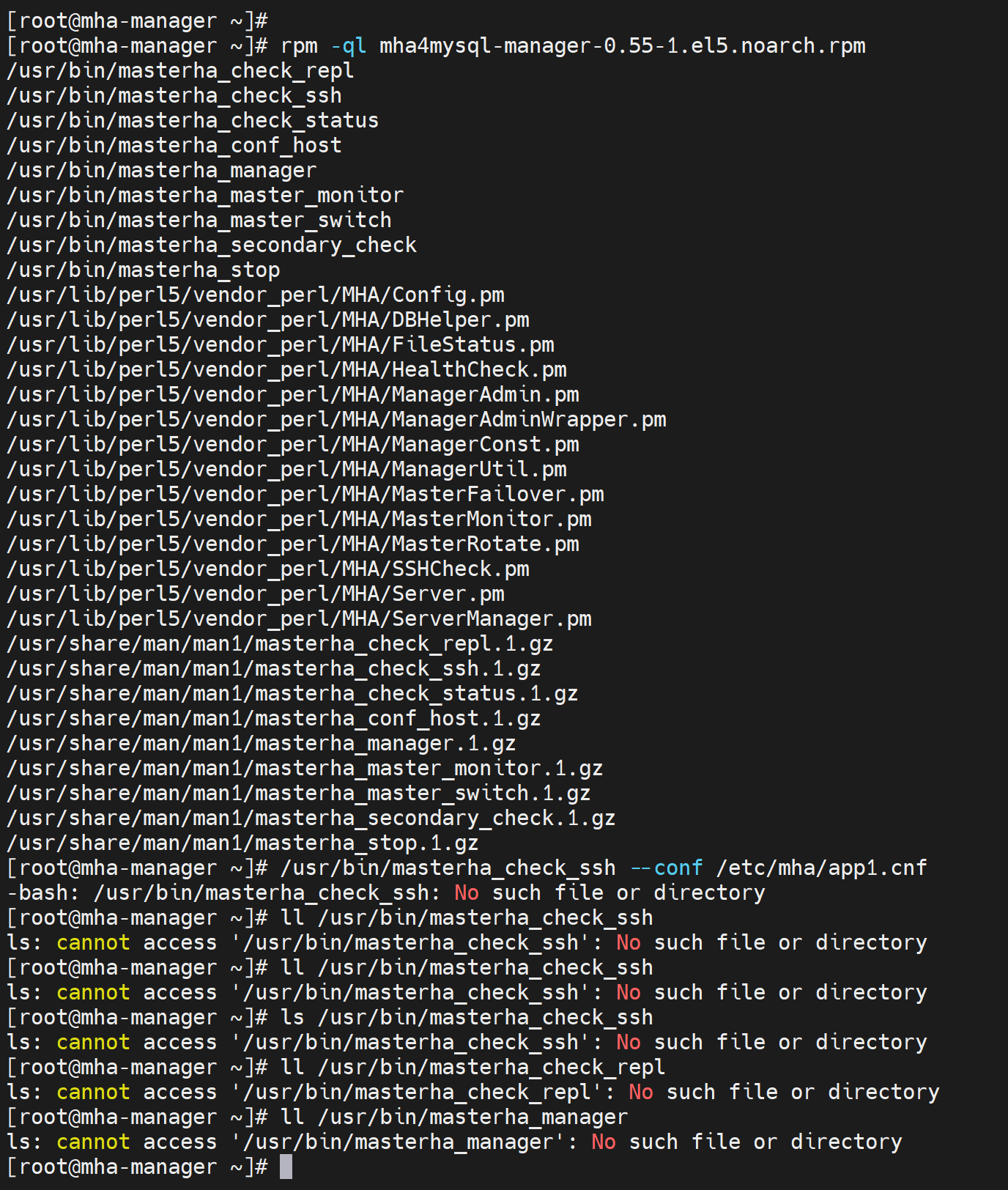
上图👆就表示,这个包安装有问题了,还是之前的报错,不能跳过了就。
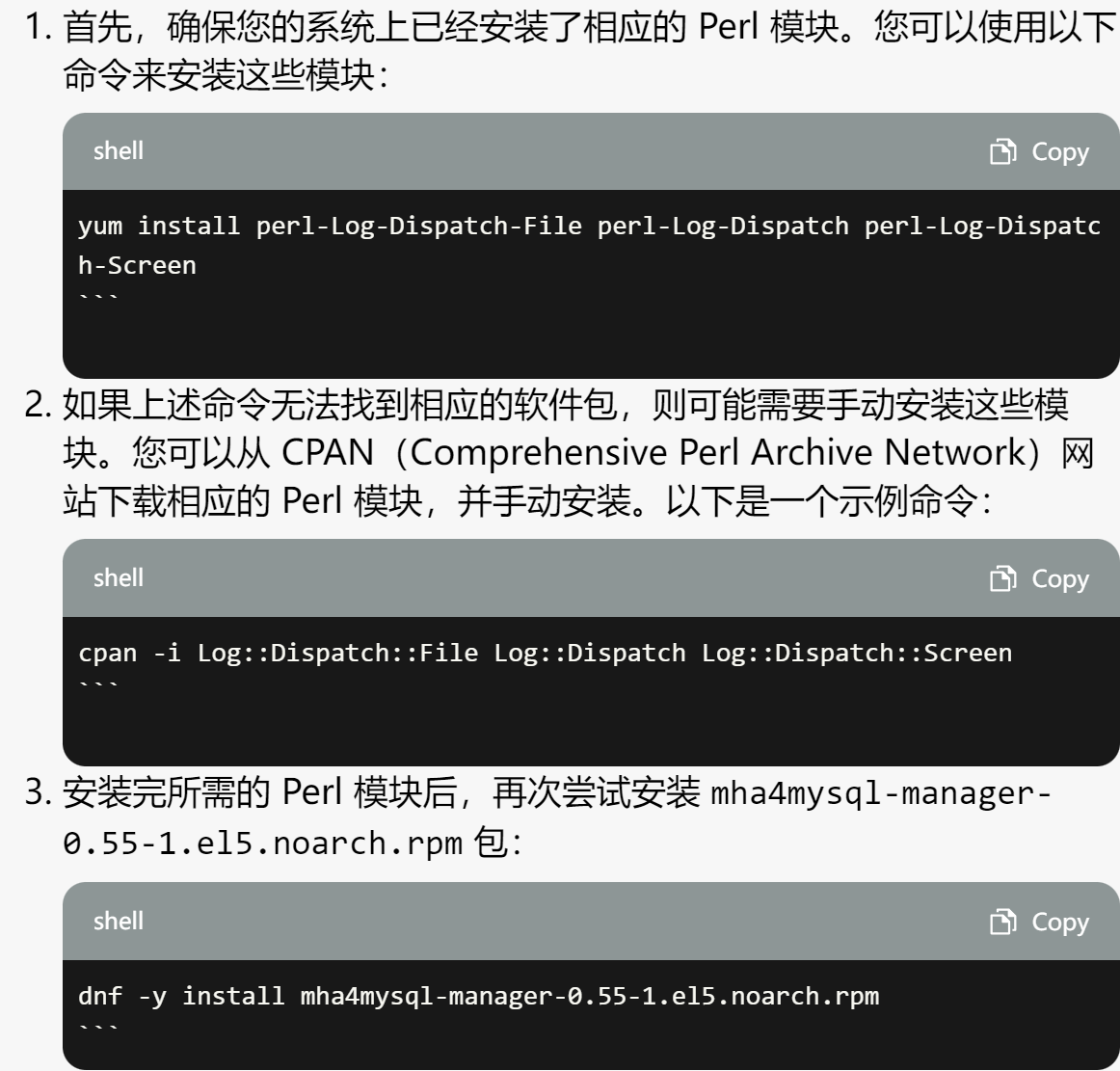
算了算了,👆按这个跑一边还是报错
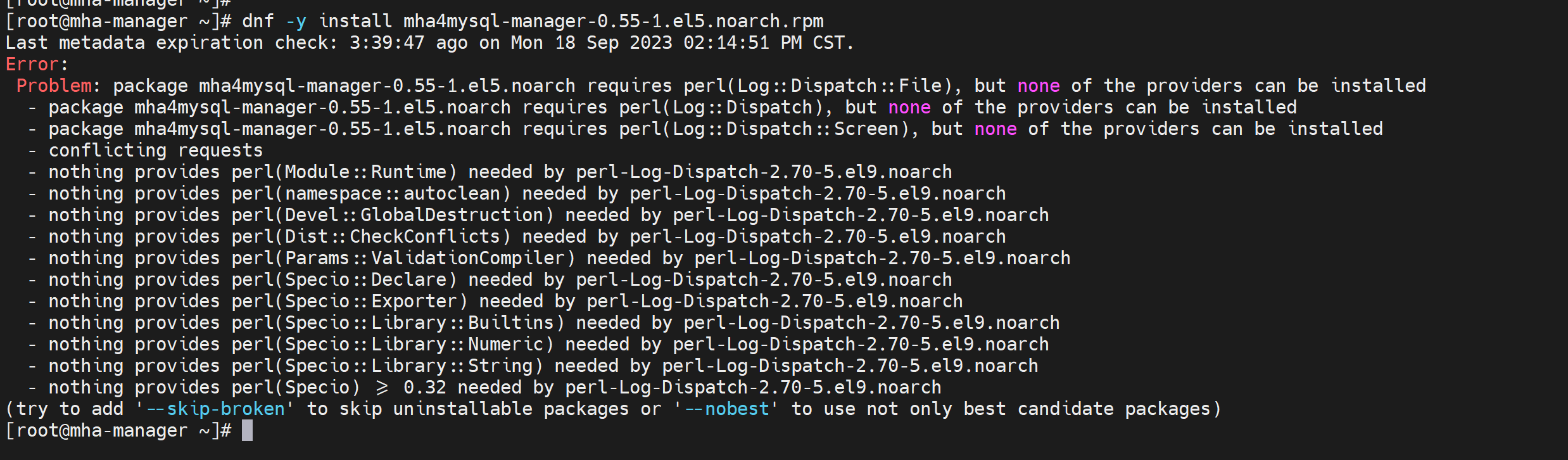
估计就是el5的版本,太老了,算了,放弃这个工具了,也就只能在centos5\6上跑跑了。
以下是视频里的老板不能继续演示,不过视频,应该是centos7,所以centos7也能用咯,还不错
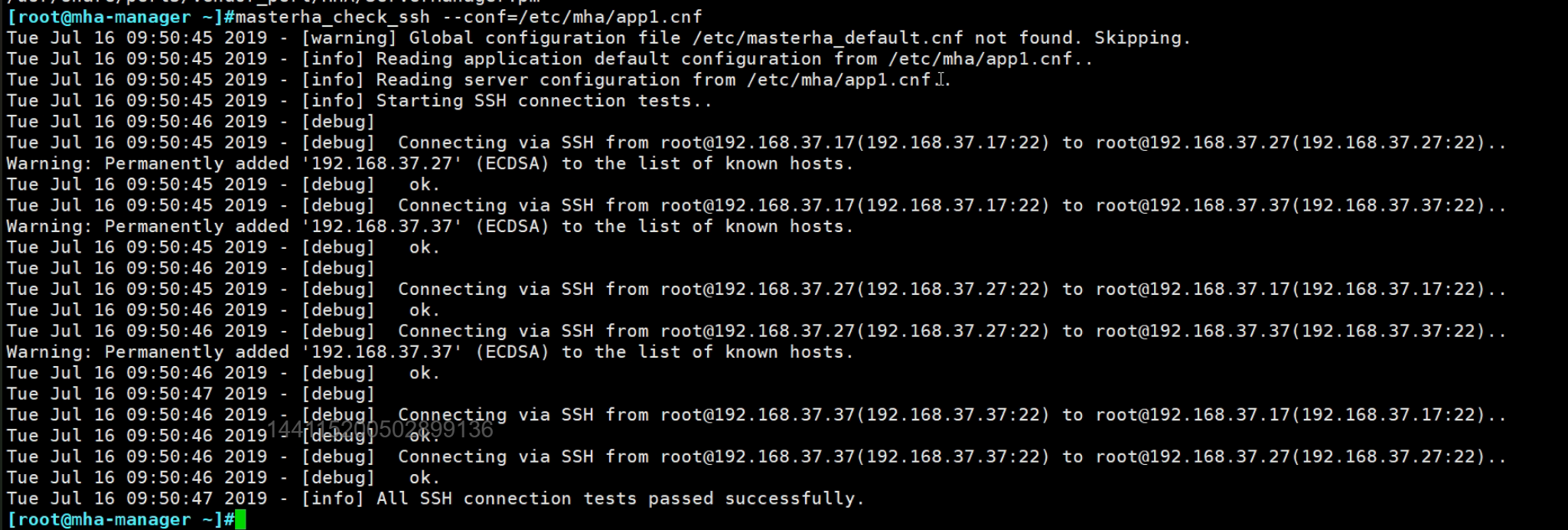
...中间省略...
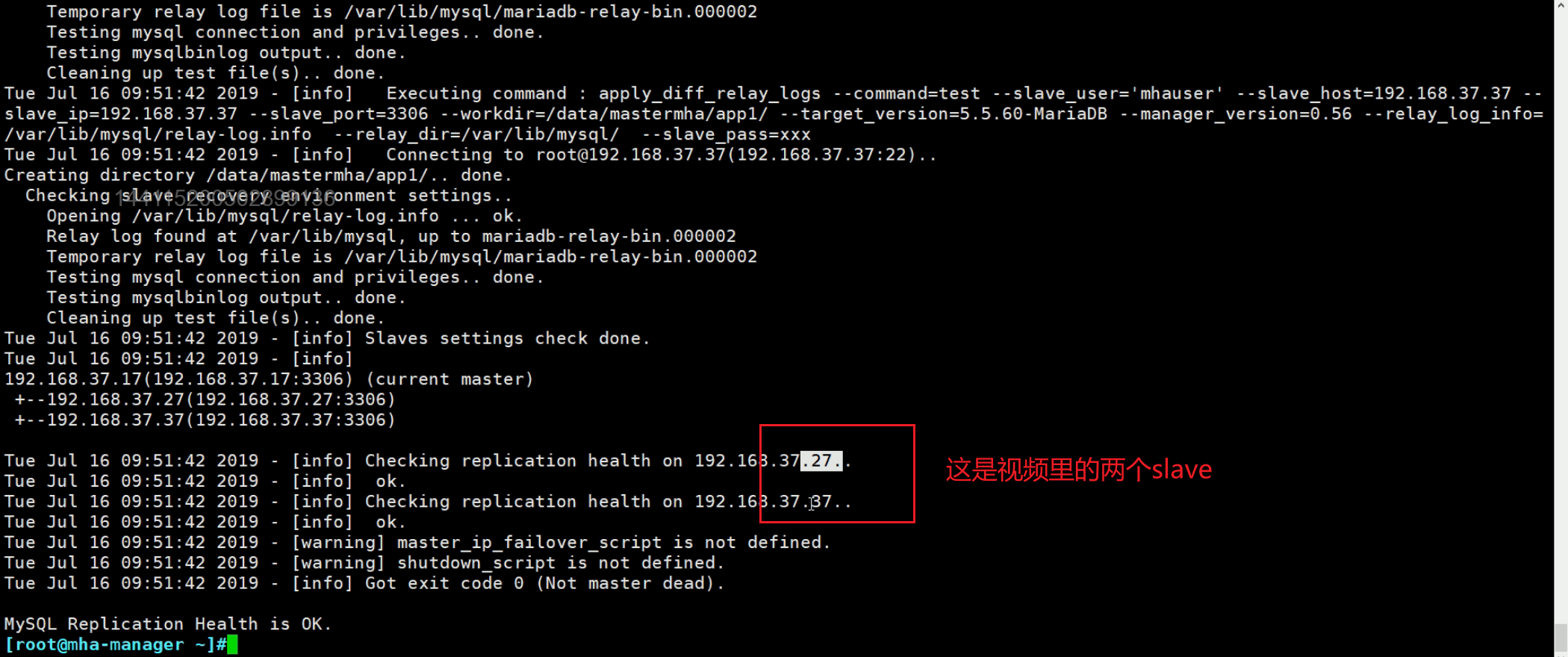
最后就执行mha运行👇,从warning消息可见,是有一个默认的cnf存放路径的,我们这里手工指定的。

这个程序是一个前台执行的程序,就是一直盯着集群,只要master挂了,就提升一个slave。只要master正常,这个mha程序就卡在这里。

做mysql集群的时间也要同步
最好用ntp一级chronyd
模拟测试集群的HA
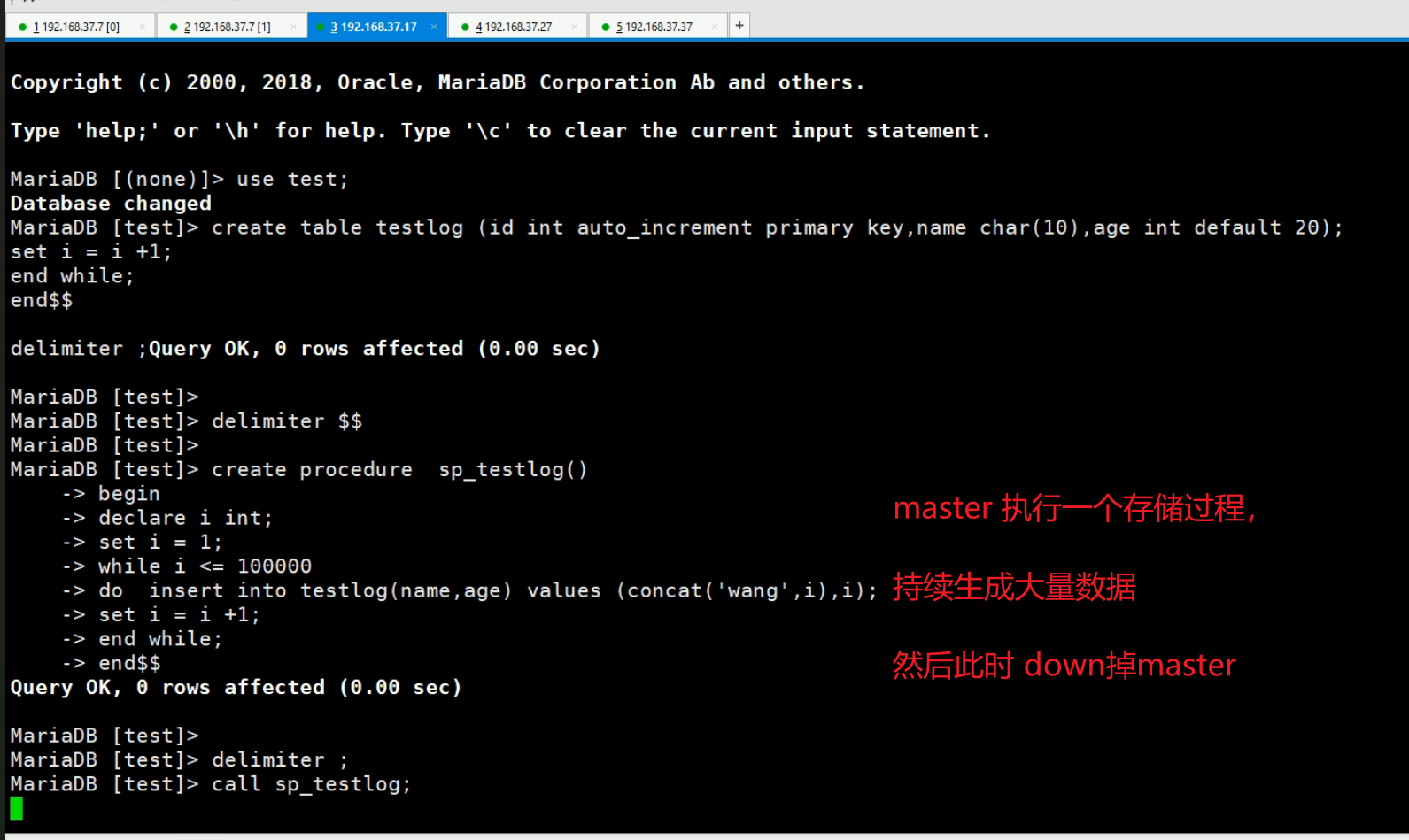
此时直接down掉master,然后看manager上

发现此时manager已经推出了
然后看看日志
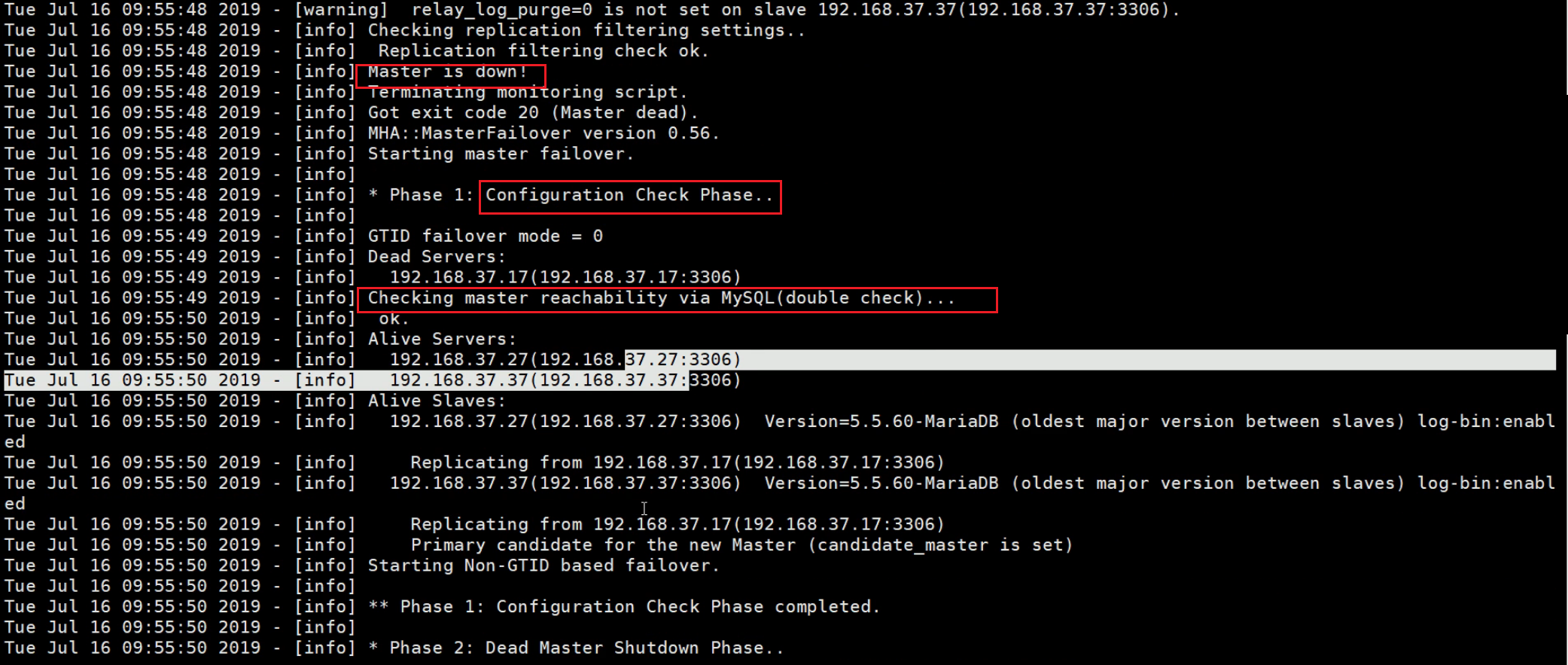
最后可见从192.168.37.17切换到了192.168.37.17这台新的master。
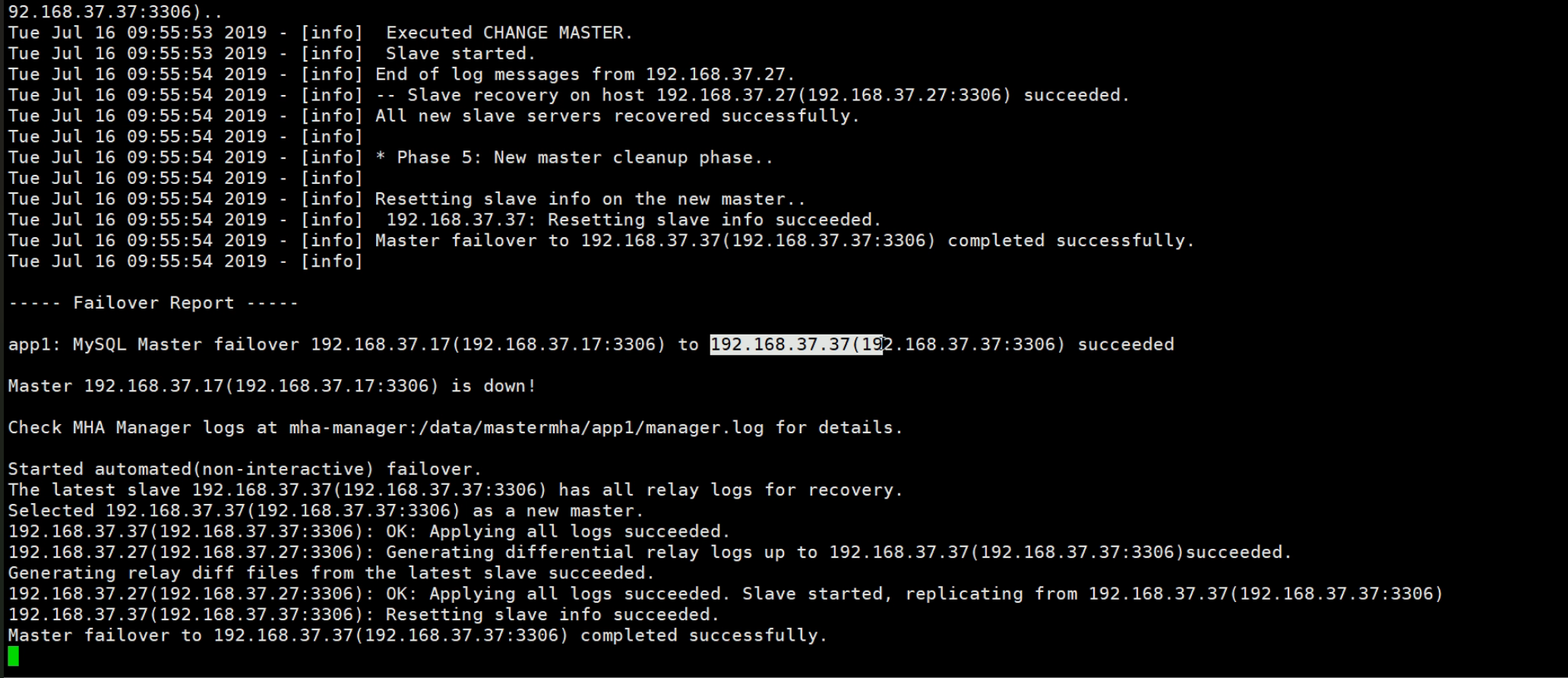
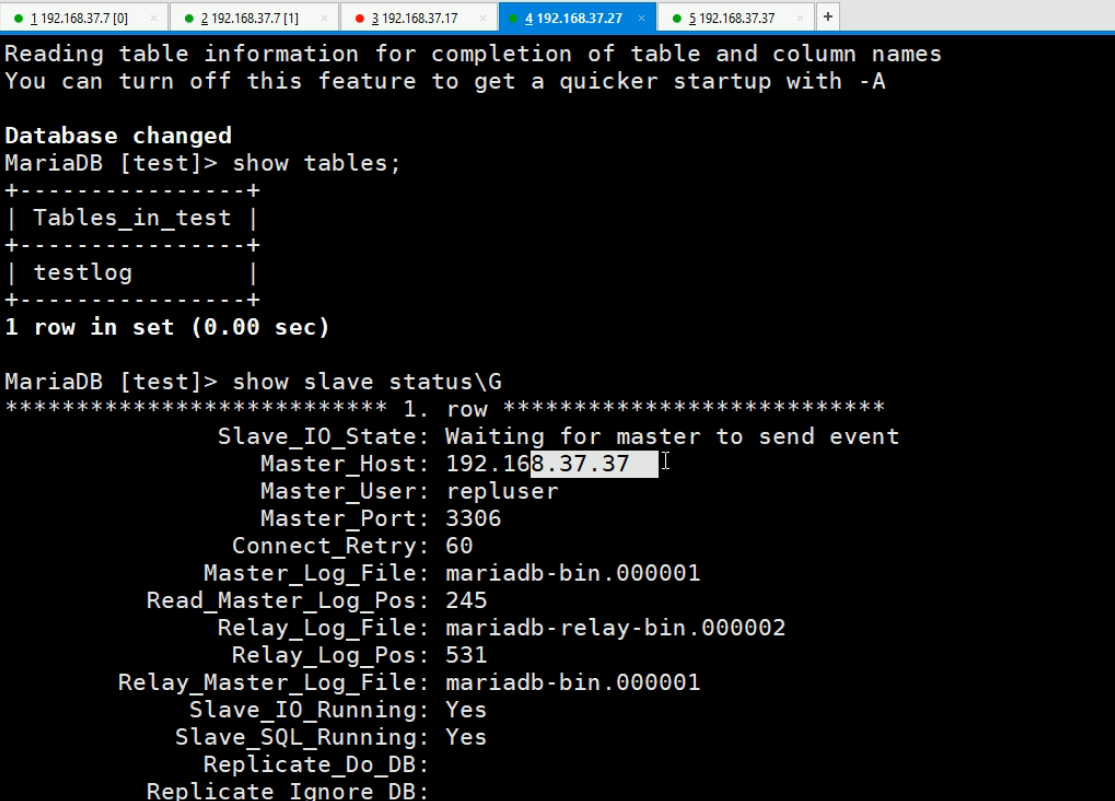
此时192.168.37.37由于是master,show slave status\G;就是空信息了。然后read_only就通过set的方式修改了变量为OFF了,但是配置文件是不会改的-->这就带来了只要重启服务就会变成read_only=on了,需要手动去改一改的。
此时192.168.37.27就指向了新的master37
挺好的一个软件mha,怎么不更新了,rocky9,直接无法安装manager了。。。回头再搞搞
接上面主从切换,原来的master挂了,然后slave升为master,然后业务OK了,去修复老的master,然后将其配置为slave即可。然后重新在manager上运行管理命令masterha_manager --conf=/etc/mha/app1.cnf
然后这里的mha不能解决proxySQL读写分离的场景,因为主从自动切,但是proxySQL的分组我记得是写死的hostgroup就固定了,比如10组里就是写操作层,10组里加入得就是master了,这个地方就存在自动切得需求,而mha方案里没有提到,所以mha也不是很好得一个方案。
重点学习Galera Cluster这个工具

mha还是单主多从,总归有数据没有同步丢失的可能;多主可能才是更极致的方案,percana、mariadb、mysql都有各自的多主方案。
多主存在的冲突如何解决的?下一篇说明
calera cluster 至少3个master,每个机器都可以读和写

多主架构,对于client来讲,到底访问谁呢?
这里是不是就涉及负载均衡啦,不过还可以轻量化的用keepalived的VIP虚拟IP来做--只不过就是单节点读写了-应该。而LB就是针对不同session可以做到负载分担的。
https://galeracluster.com/library/documentation/certification-based-replication.html
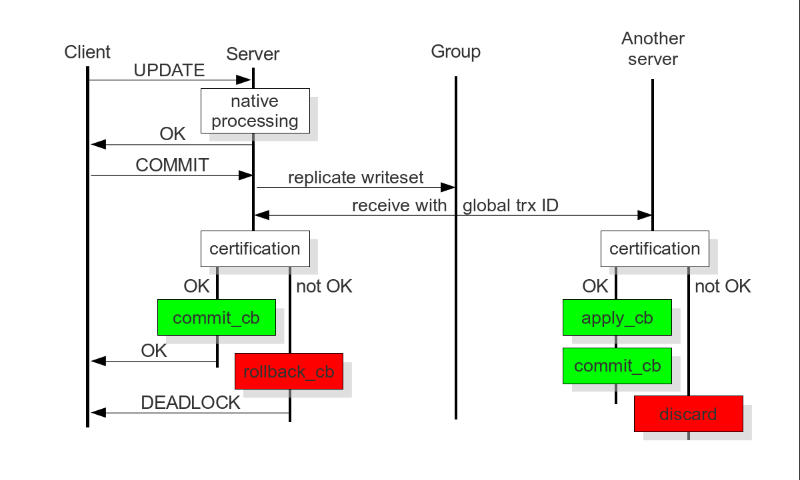
图中关键字:global trx id就是 全局事务ID,关于GTID前文也讲过👇

上图说明了如何保证多主集群下的数据一致性:
1、client往多主--Galera Cluster集群里写数据,多主至少是三主了,图中简单画成了2个server示意;
2、client update 数据,不管是LB还是keepalive都是发送到一个master上的;
3、这个master,也就是图中server,就开始处理啦,OK,后就提交,因为涉及事务,还需要提交;
4、提交能否真正提交成功,还不一定的,往下看,此时就会触发replicate writeset应该也叫write set replication (wsrep)写集复制这个功能,
然后所有的server就都收到一个GTID全局事务ID,然后就开始处理
5、接收到update的server就检查,检查不通过就rollback_cb回滚,通过就是commit_cb提交到db里去。
同时;别的server也会检查,不通过就discard--由于数据不是本地提交的是别的server的,所以直接discard,如果通过,就应用数据apply_cb就是update一下,然后commit_cb提交事务。
有时间可以看看这个
https://mariadb.com/kb/en/getting-started-with-mariadb-galera-cluster/
其中提到了

所以我的实验环境是默认就有的应该,无需安装,同时也可以安装吧。
Galera Cluster官方文档
http://galeracluster.com/documentation-webpages/galera-documentation.pdf http://galeracluster.com/documentation-webpages/index.html https://mariadb.com/kb/en/mariadb/getting-started-with-mariadb-galera-cluster/
Galera Cluster包括两个组件
Galera replication library (galera-3)
WSREP:MySQL extended with the Write Set Replication
WSREP复制实现
PXC:Percona XtraDB Cluster,是Percona对Galera的实现
MariaDB Galera Cluster
参考仓库国外的慢:https://mirrors.tuna.tsinghua.edu.cn/mariadb/mariadb-5.5.X/yum/centos7-amd64/
注意:都至少需要三个节点,不能安装mariadb-server