第7节. 实现galaracluster和性能测试


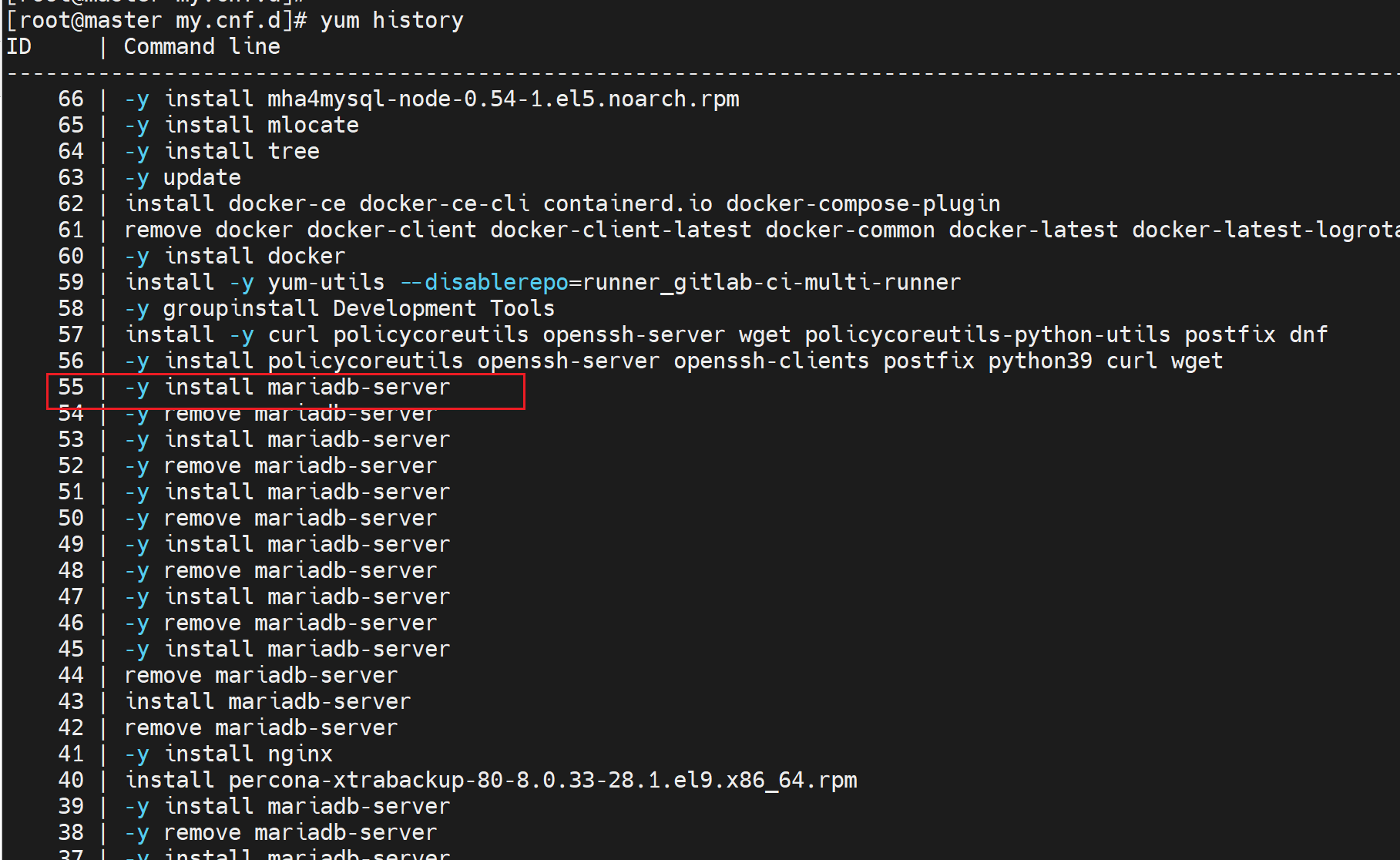
老版本的安装就是uyum install MariaDB-Galera-server,老版本的方法这里不管了,直接集成到新版里的。
然后就是看配置文件,在/etc/my.cnf里明确说了include
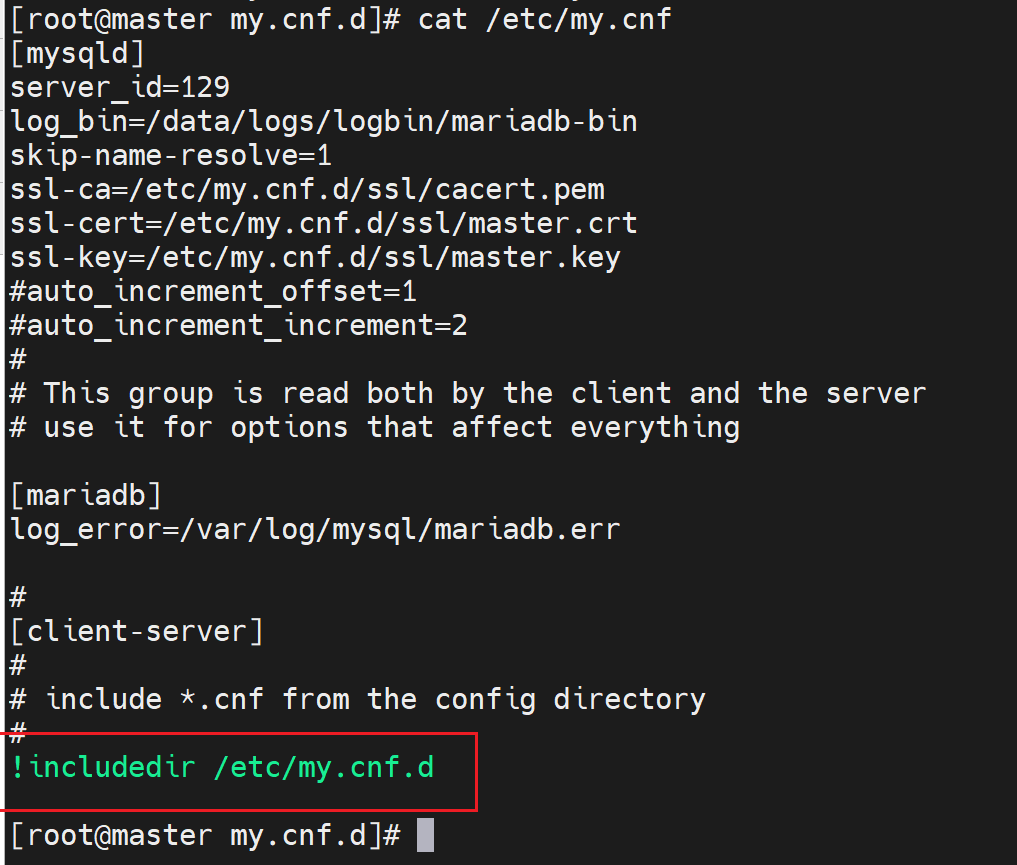
galeracluster的配置就在这里
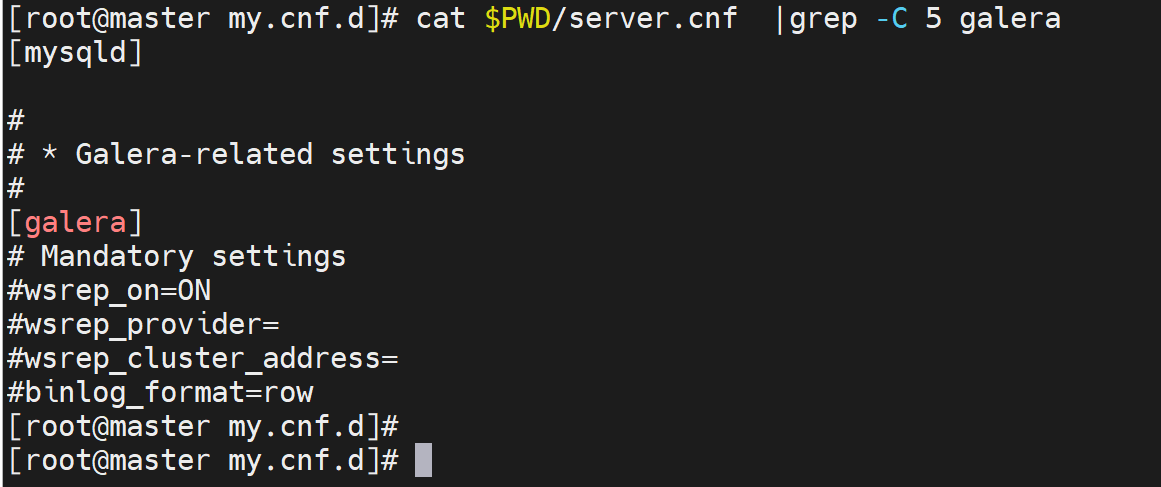
wsrep_provider=
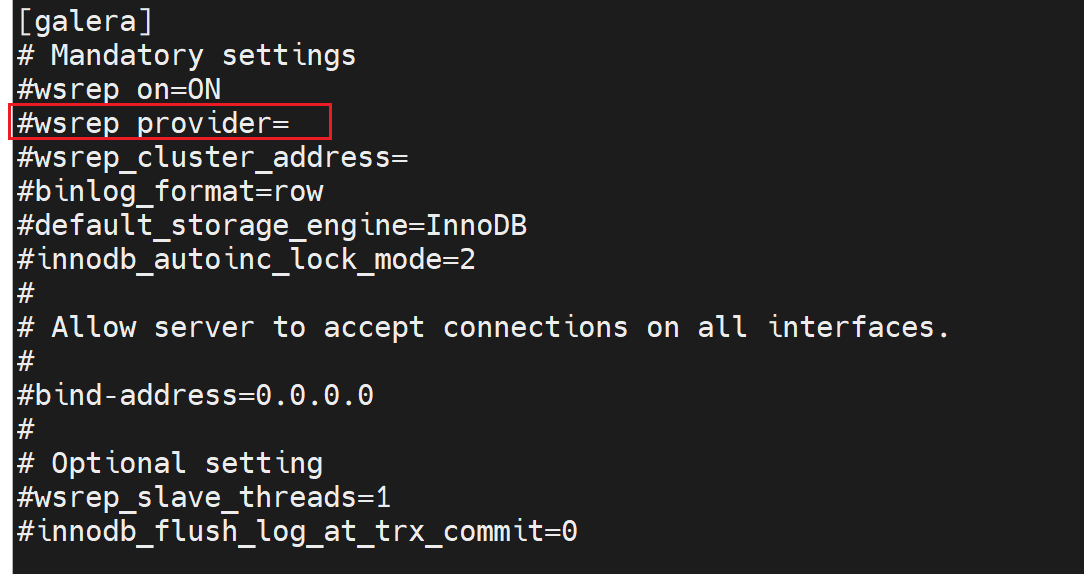
其中wsrep_provider=要填写一个叫做libgalera_smm.so的库文件,而这个文件是安装mariadb自带安装的,
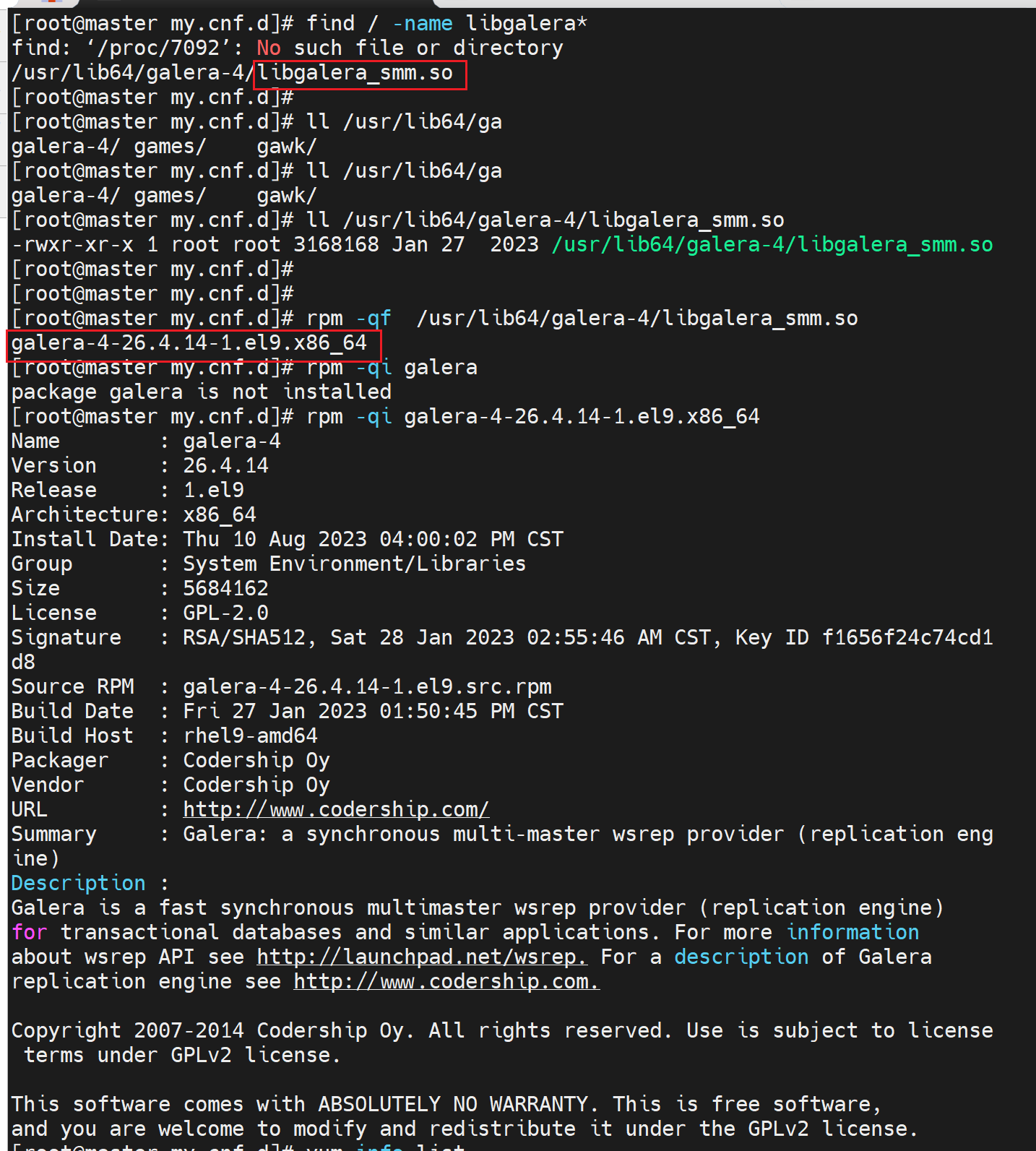
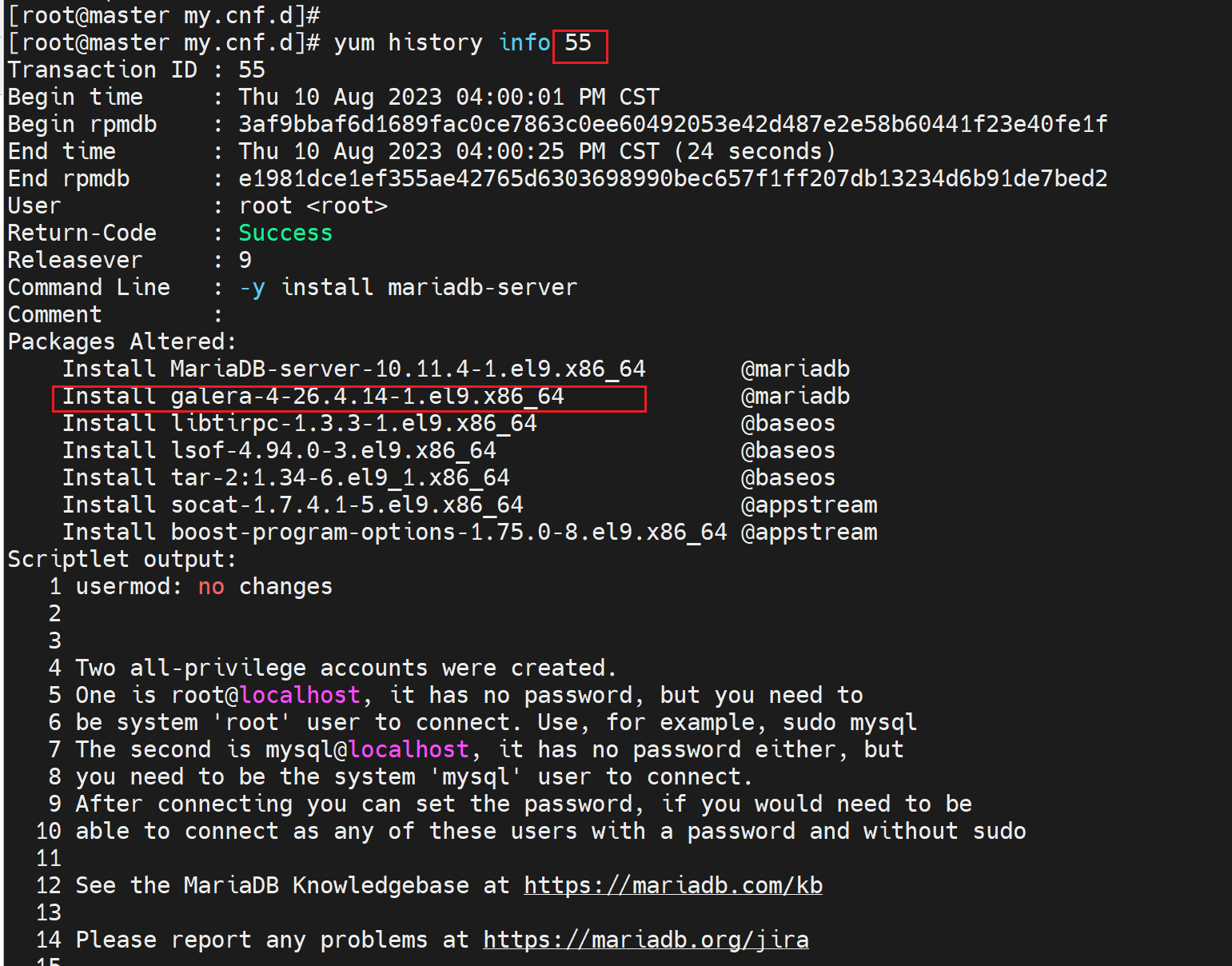
而且就是mariadb的yum源安装的@mariadb可见。
👇这个源就是按官网的yum源复制过来就行啦,详情将前文mysql安装吧。
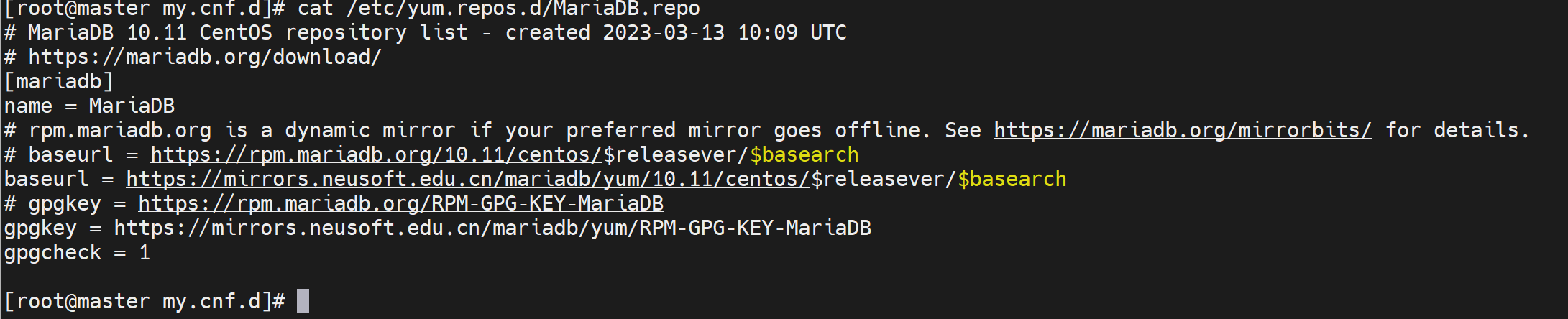
好了,基本零件都不缺了。
wsrep_cluster_address=
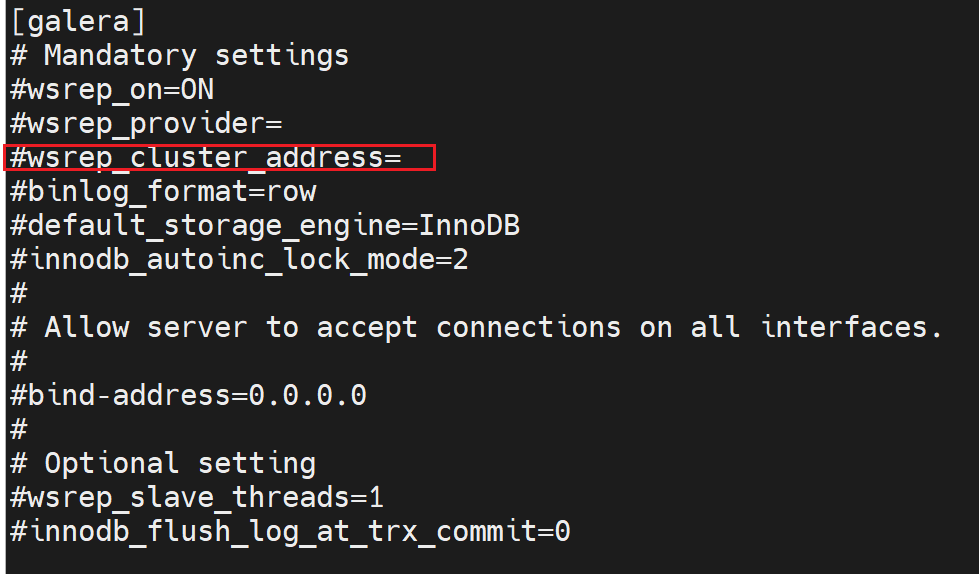
三个节点的各自地址
binlog_format=row,就是二进制格式,一般默认新版都是MIXED,这里取消注释用ROW吧,忘记了,看前文👇
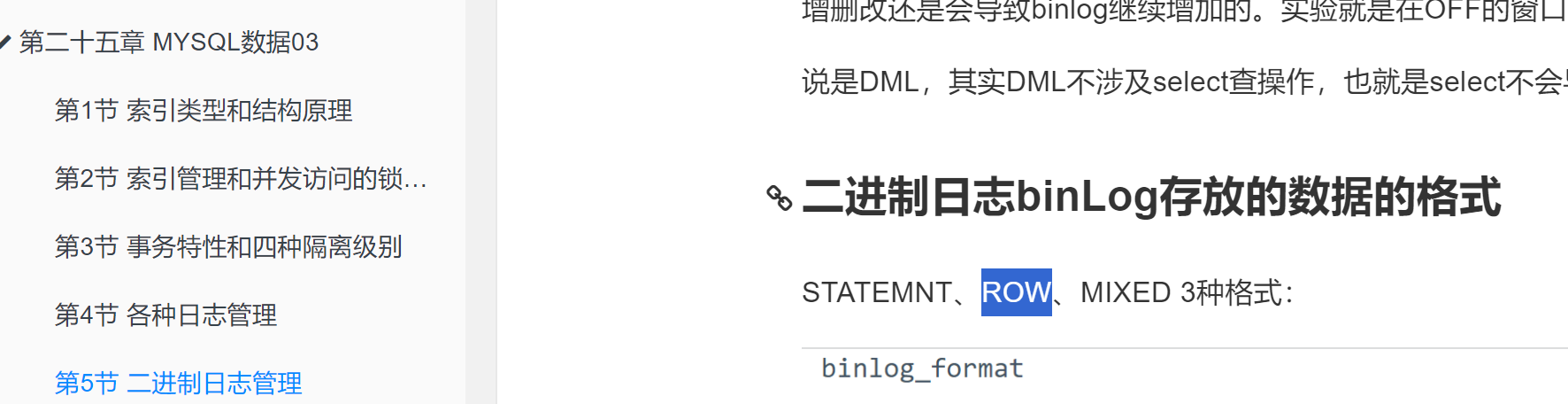
default_storage_engine=InooDB肯定是InnoDB了,MyISAM都不支持,官方就是说仅仅实验环境吧我看到好像。
innodb_autoinc_lock_mode=2这个不管默认就好
其实就是改wsrep_provider和wsrep_cluster_address以及binlog_format=row。
具体配置选项👇
https://mariadb.com/kb/en/configuring-mariadb-galera-cluster/

实际需要的操作
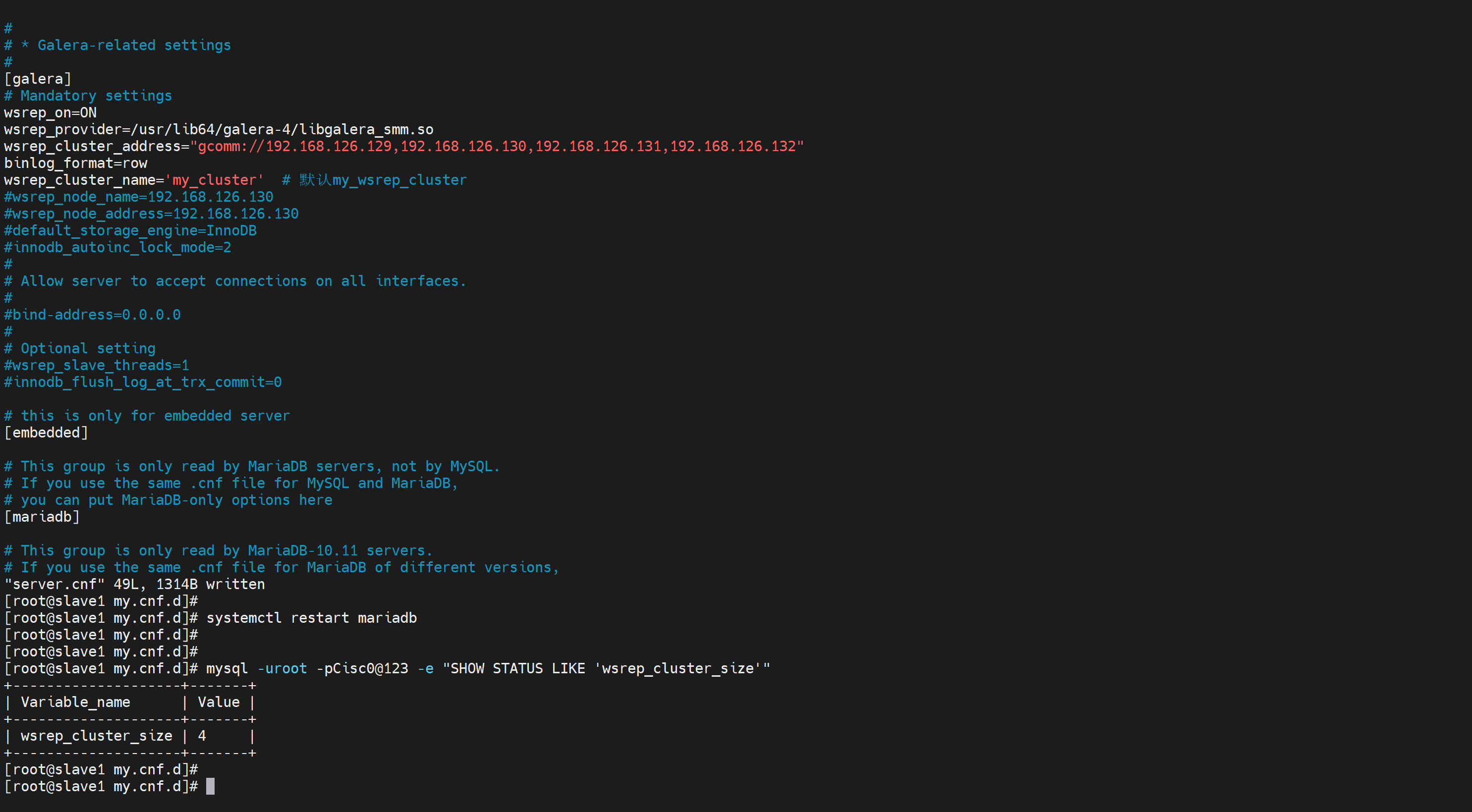
vim /etc/my.cnf.d/server.cnf
[galera]
wsrep_on=ON # 10.1.1多了个开关
wsrep_provider=/usr/lib64/galera/libgalera_smm.so wsrep_cluster_address="gcomm://192.168.126.129,192.168.126.130,192.168.126.131"
binlog_format=row
这个gcomm是协议,就好比ftp://还比https://一样,gcomm是glaeraCluster内部通讯的协议。
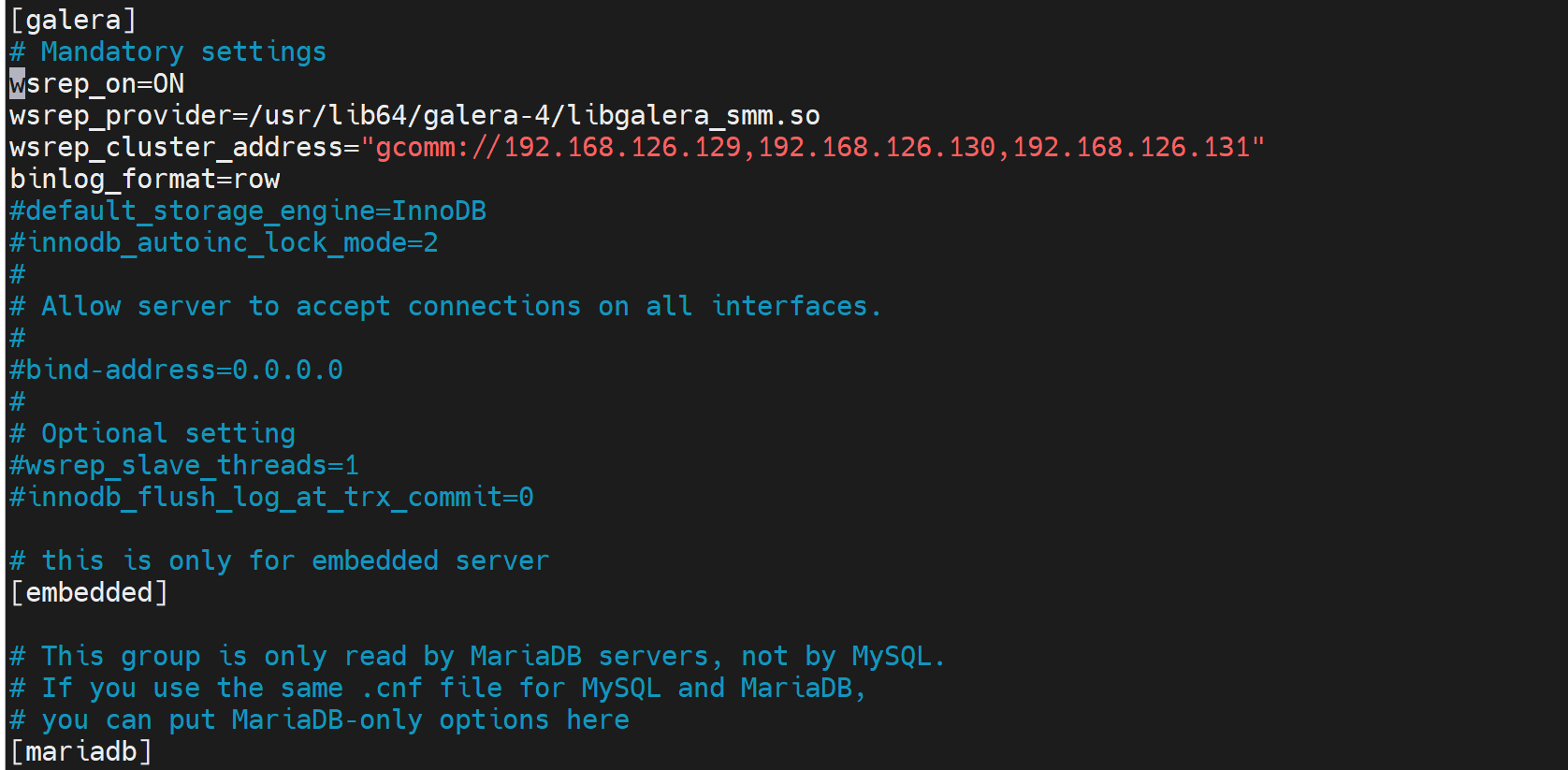
👆就改这么多,其他不动
优化设置
wsrep_cluster_name = 'mycluster' # 默认my_wsrep_cluster
wsrep_node_name = 'node1' # 本机器的名称,这里暂时不加
wsrep_node_address = '192.168.126.x’ # 当前机器的IP,不用写,这里只是强调写出,实际不写
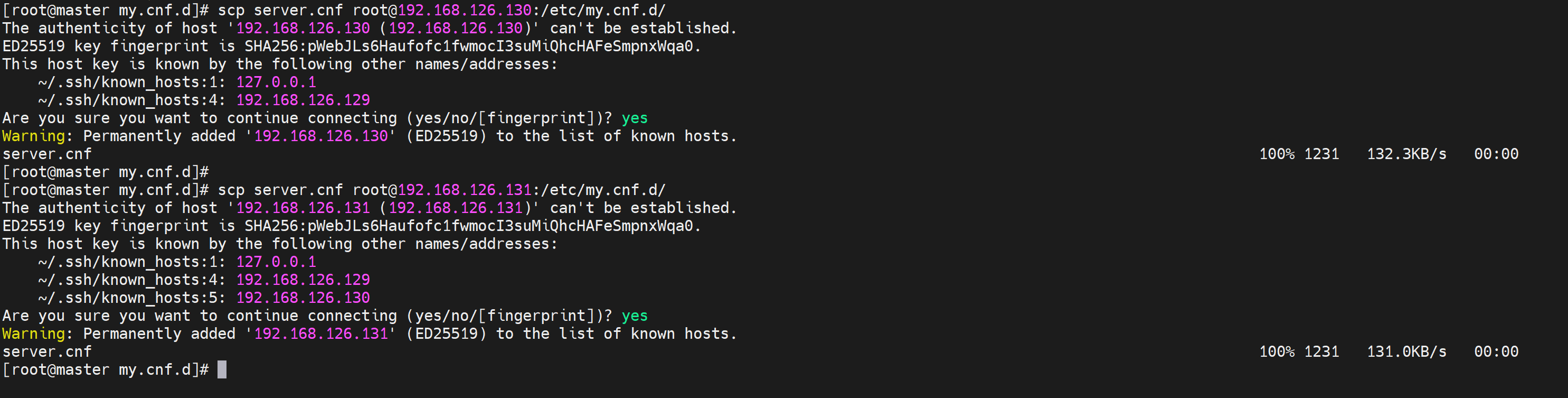
通过scp复制到其他2个节点
启动注意点
三台不是一样的方法启动;
集群存在/不存在,启动方式也是不同的。
1、原来没有cluster的启动方法和原来有cluster集群的启动方法是不同!
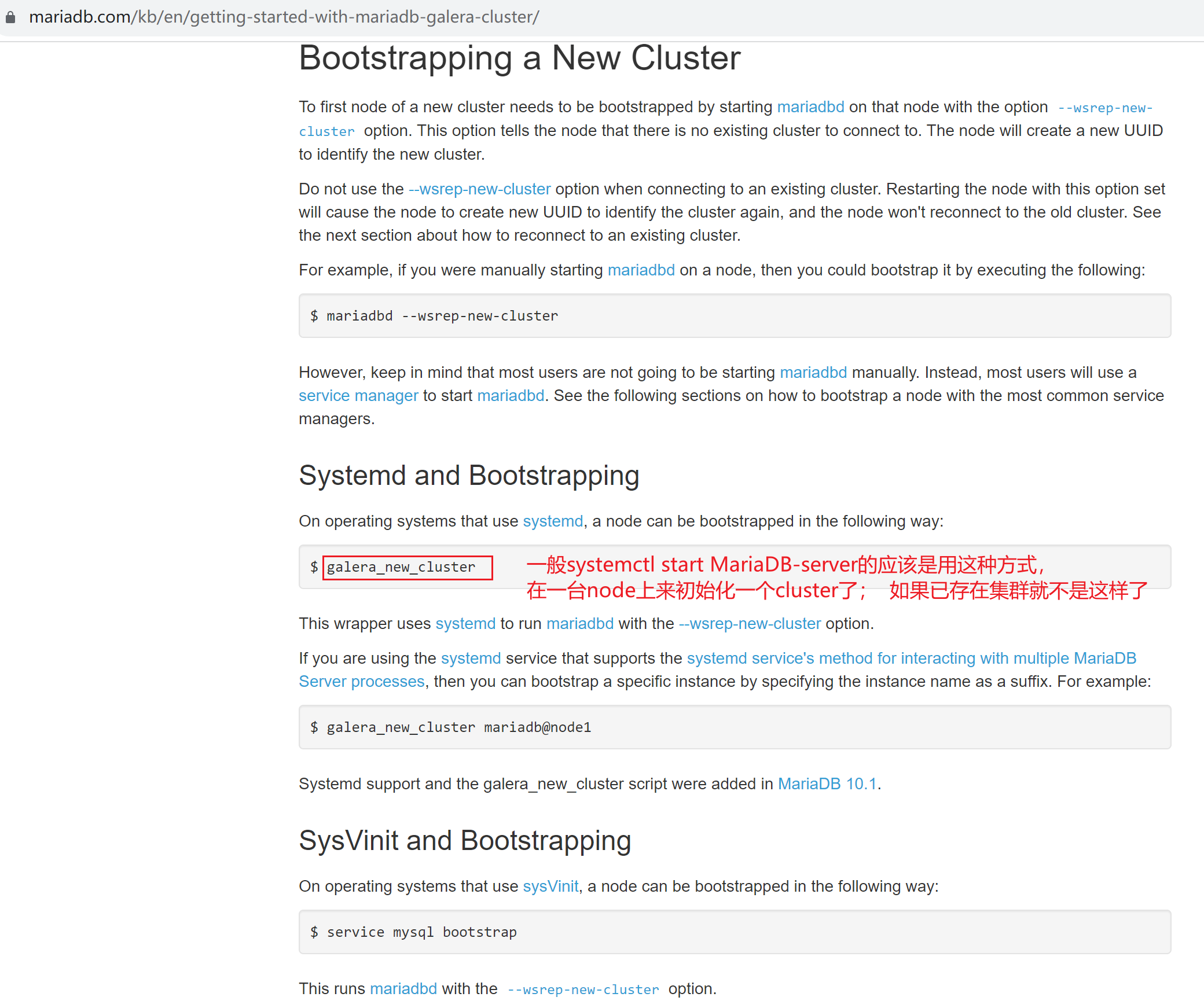
2、首次启动,其他节点,systemctl restart mariadb就行
本实验是初始化集群,开始启动
任意一个节点,来初始化集群
galera_new_cluster
其他节点就
systemctl restart mariadb

这里我就用192.168.126.129,这里的master主机名,不要在意,不用纠结,这是以前实验 主从起的名字,这里多主,每个节点既是master也是slave。
其他节点重启报错

而且初始化集群的node,直接重启也会报错
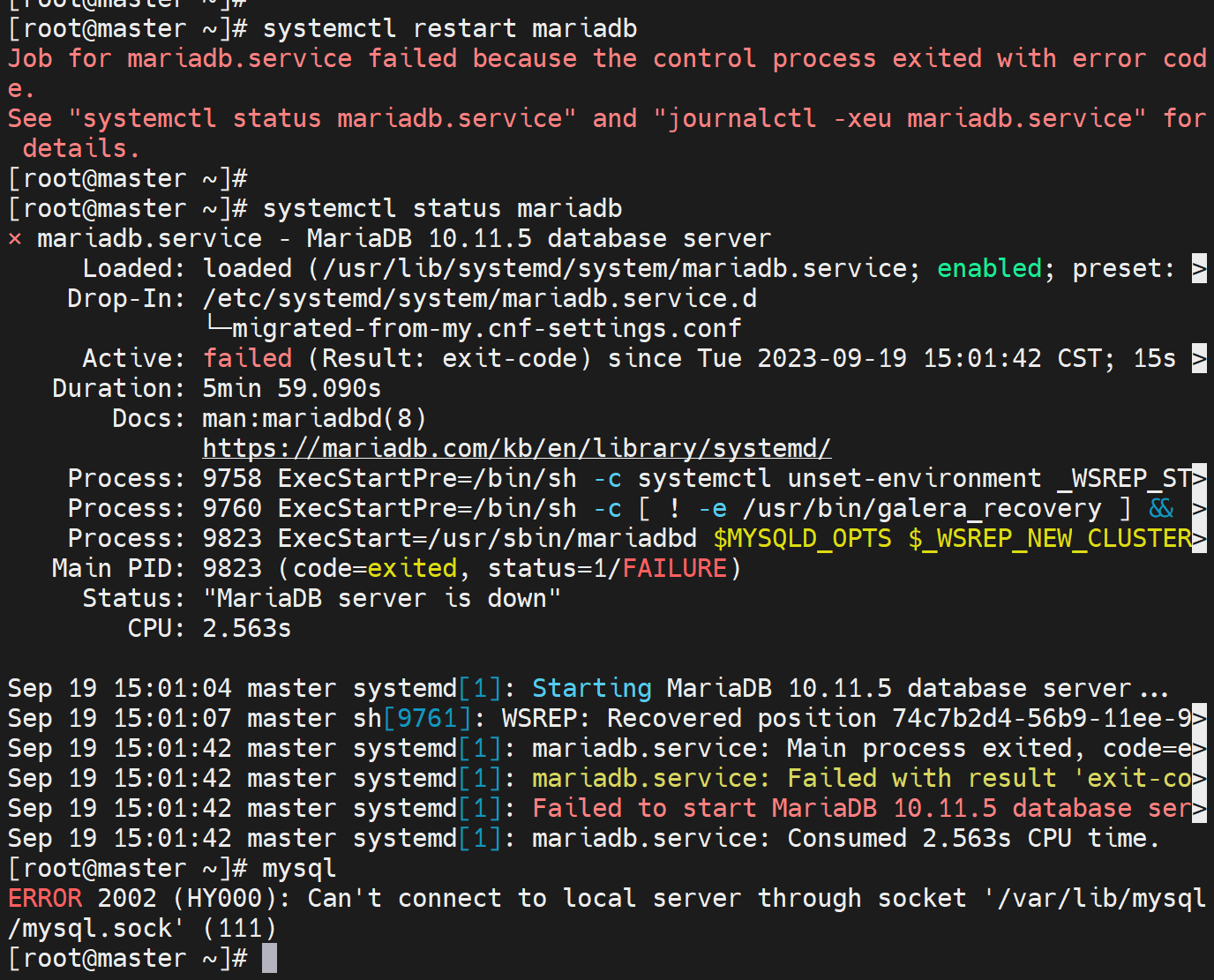
此时处理方法,在没有头绪的情况下,俺是第一次接触这个集群,所以注释掉/etc/my.cnf.d/server里的galer模块配置,重启mariadb。
然后再重新走一遍就行了。注意重新启动就用galera_recovery来启动集群
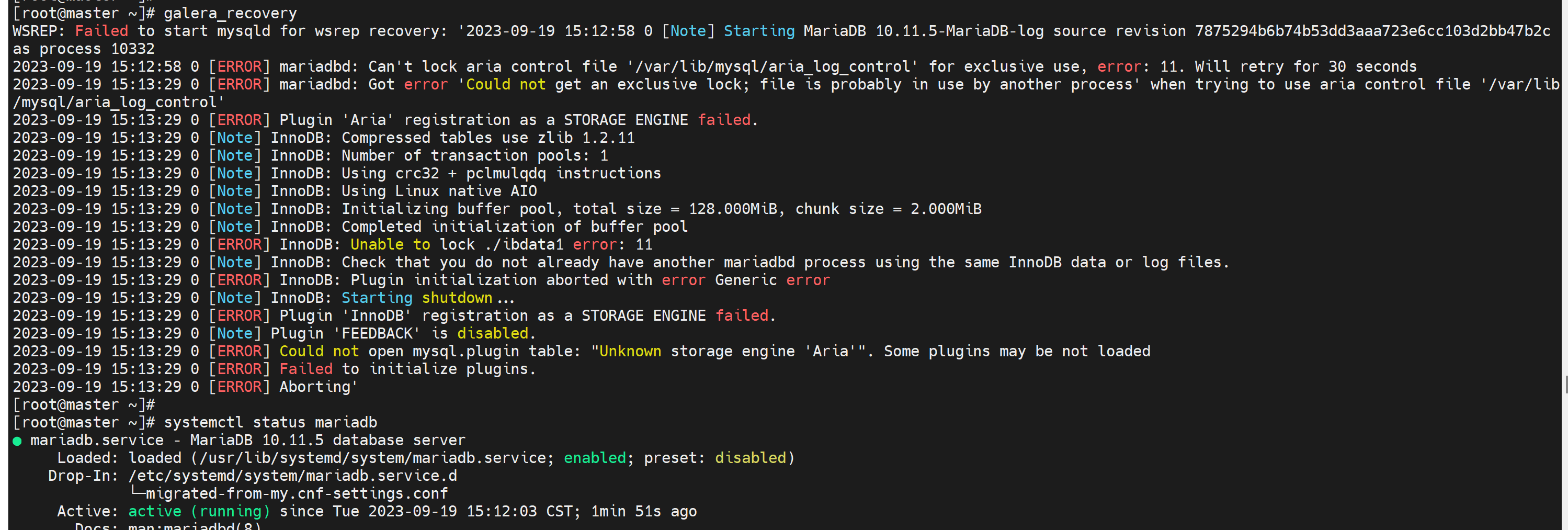

然后莫名其妙再敲一遍就OK了?

然后去重启其他节点的服务,看看能不能成功,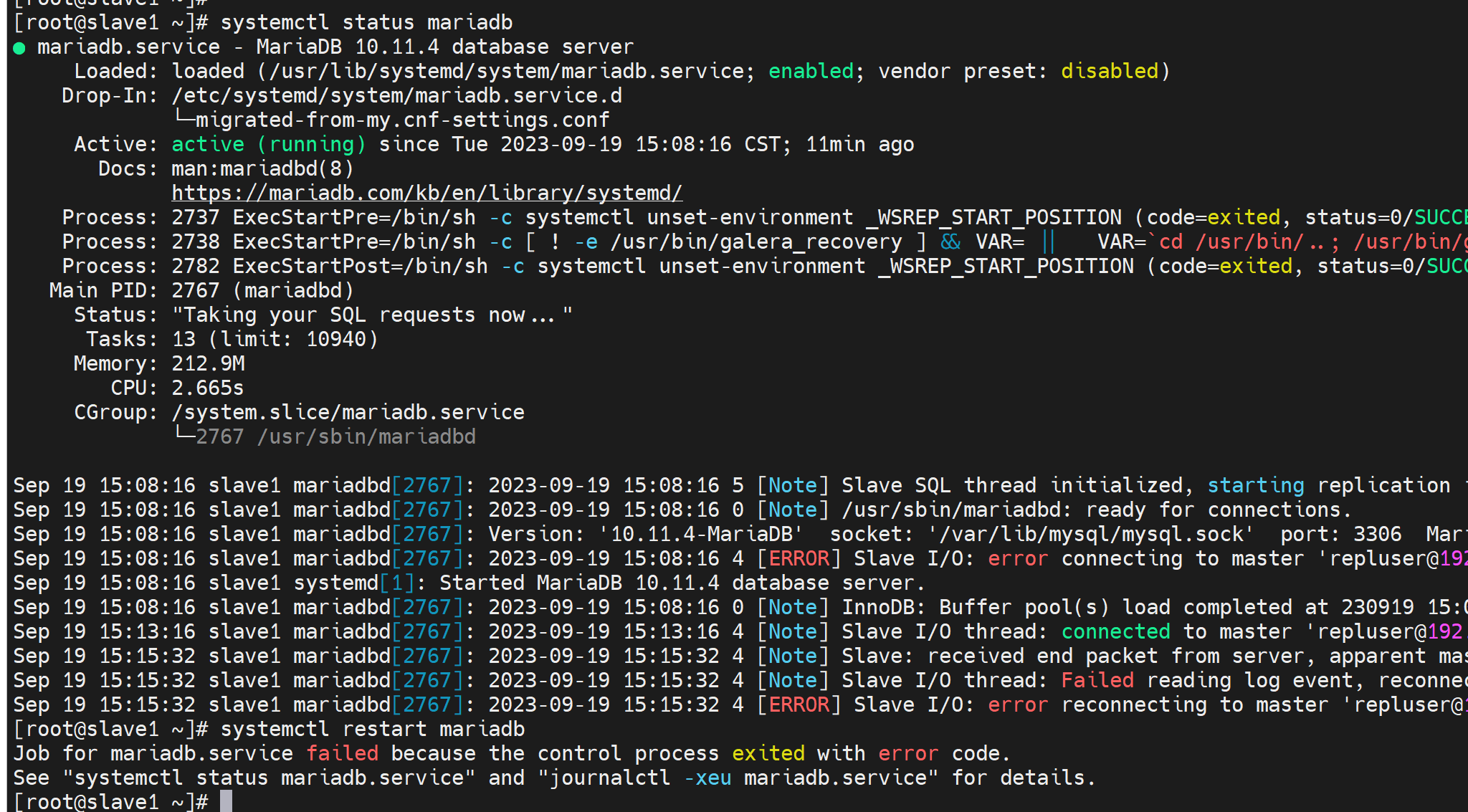
不行
排错
之前的配置注释掉
没用,重新做吧,把mariadb remove掉重弄?
重新rm -rf /var/lib/mysql/* 反复3次后倒是成功了
mb的怎么弄都OK了现在!!
应该就是/var/lib/mysql/下要干净,
然后有个明确的故障点处理方式就是
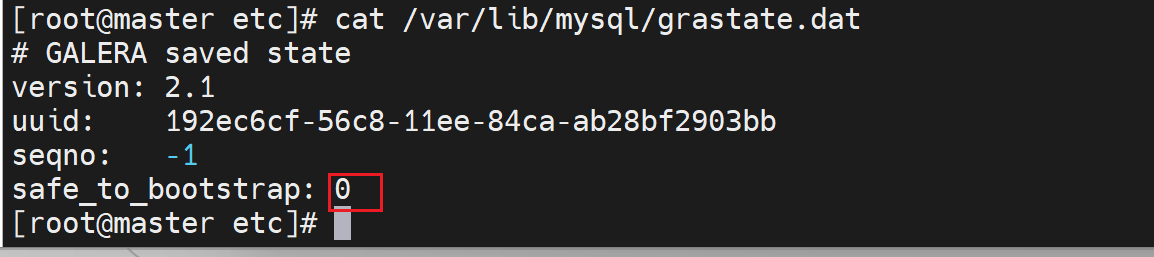
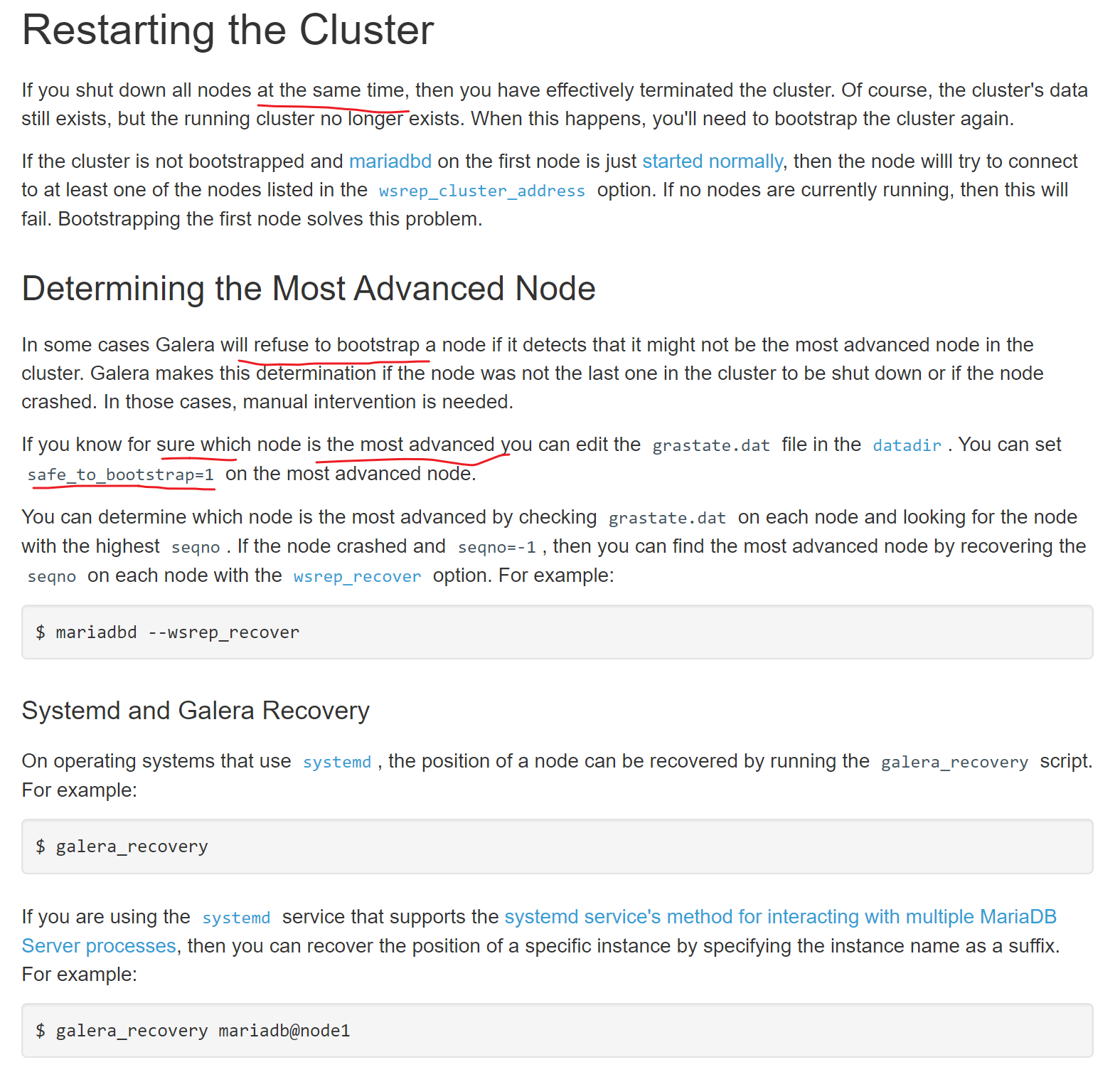
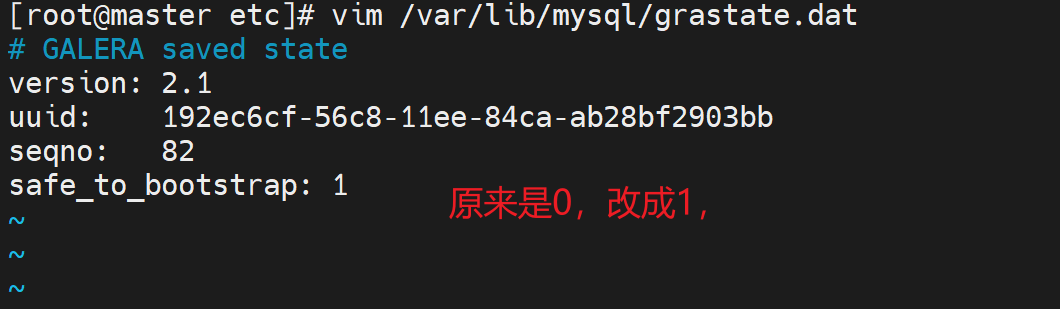
👆这个文件要么删掉,要么修改safe_to_bootstra:1就可以启动服务成功。
错误-2
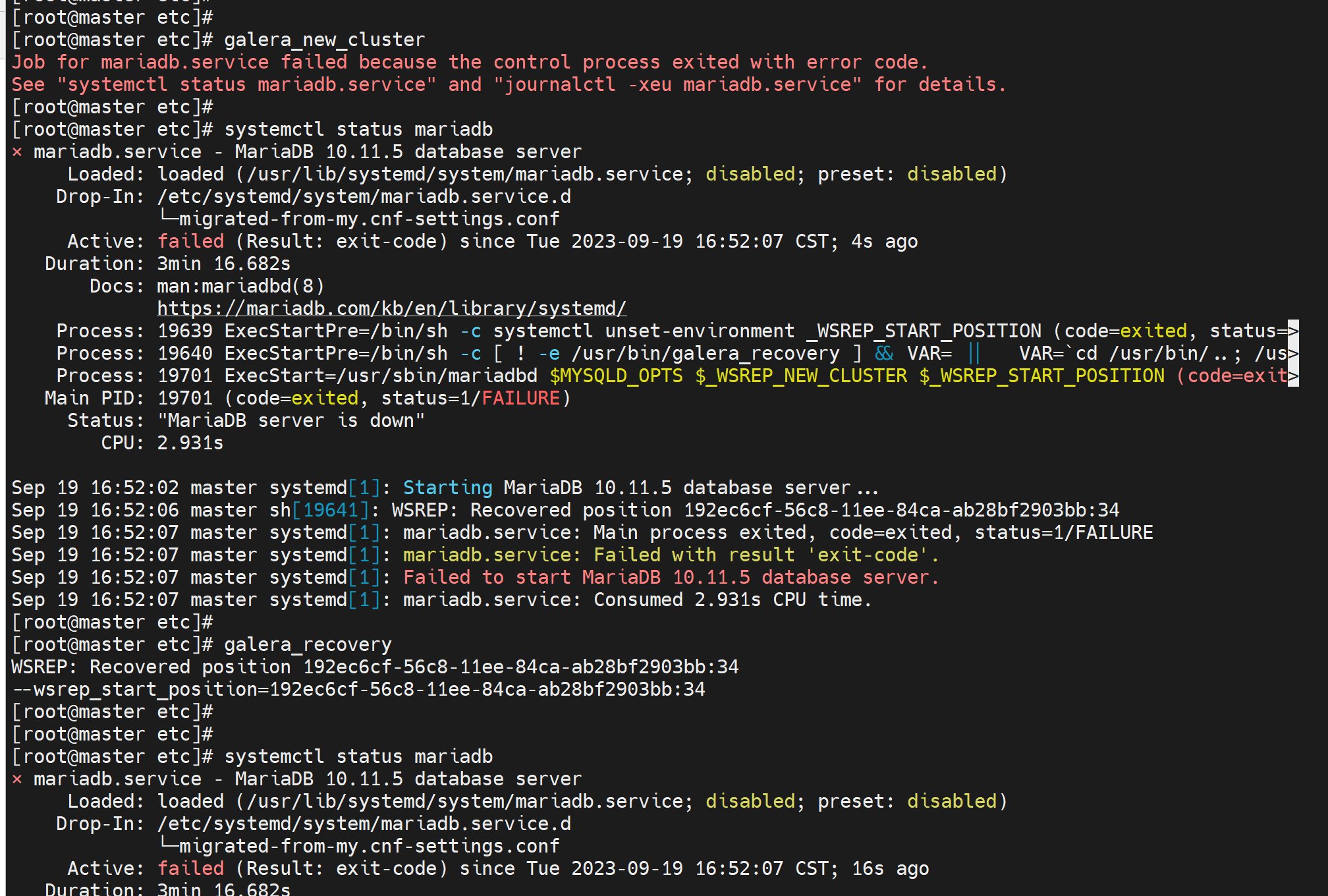
这是cli用错了,重启不能这么干,
好像所有的node 都stop mariadb就起不来了,因为可能没有gcomm的通信方了

我的理解,就是集群里必须有一个活着才能重启成功,测试下
现在3个node都挂了,如何起来了,简单,

这样处理就行了
随便找一台node,一般是最优的吧
果然就好了,所以前面的配置OK就是这里的处理手法要注意,这里你可以理解为是技术细节,也可以理解为产品不傻瓜化。
此时理论上另外2个node直接restart就行了
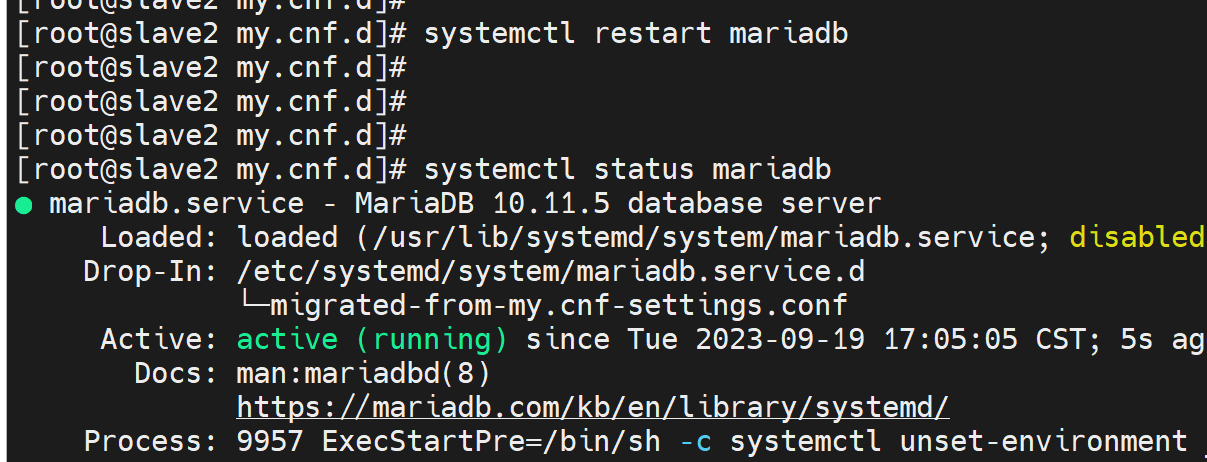
本来创建集群的那一台tm的竟然起不来
判断失误,没事,老方法,狗屁啊,safe_to_bootstrap=1这个参数是针对the most advanced node最优节点也就是数据最新的节点的操作,就是确定后要敲galera_recovery的,前面已经有一台node初始化了cluster,此时其他只能是加入了,所以操作就是systemctl restart mariadb,通过报错日志可见
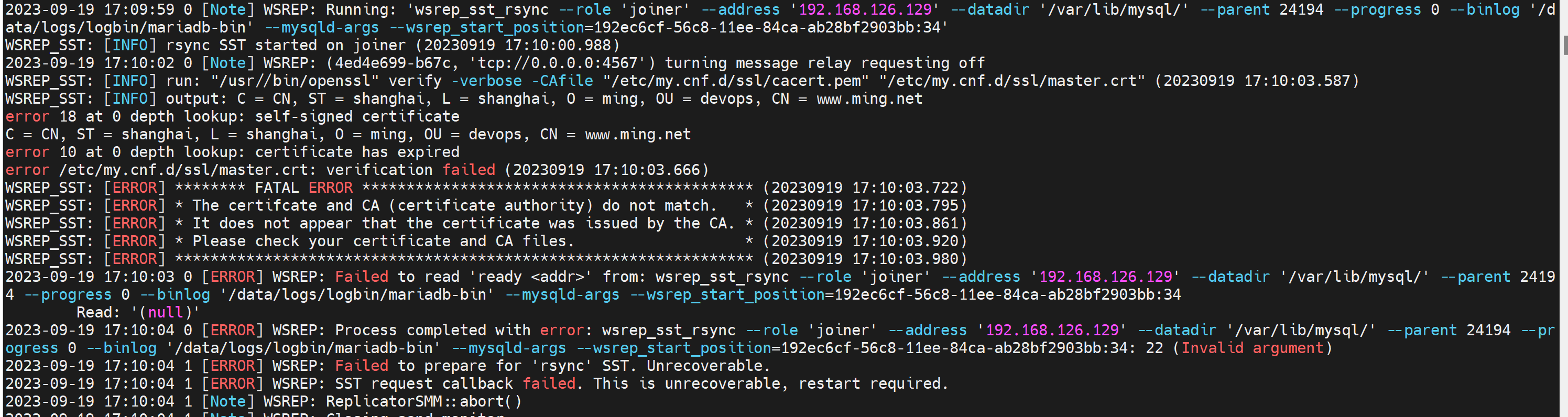
说明是SSL证书问题,关掉ssl
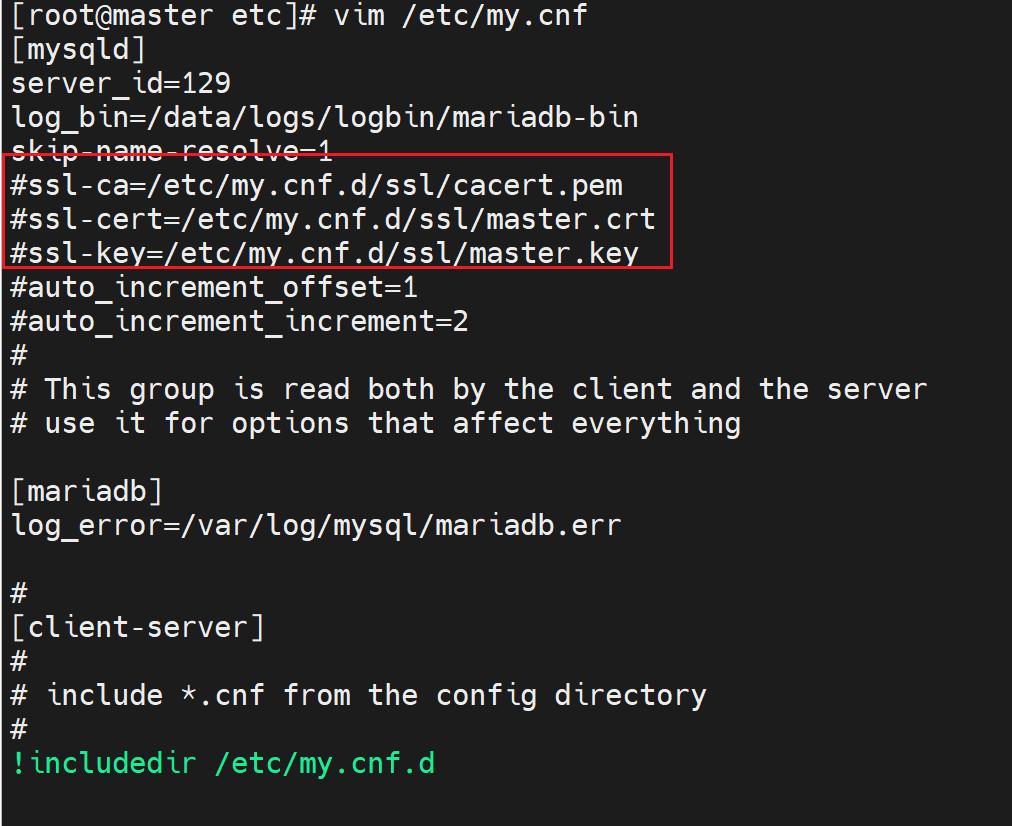
重启就好了

总结
1、初始化cluster
2、重启cluster
操作要小心
galera_recover重启cluster,报错没关系,集群不受影响👇
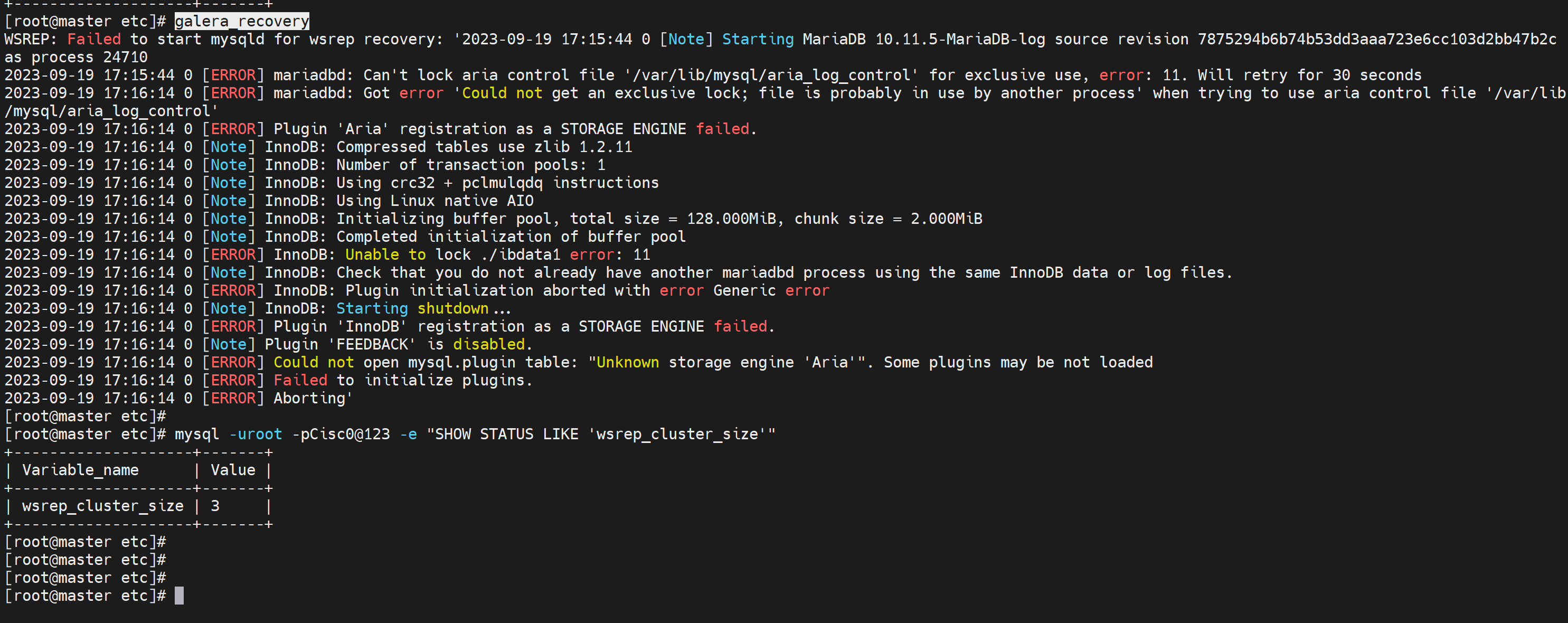
总结2:重启集群
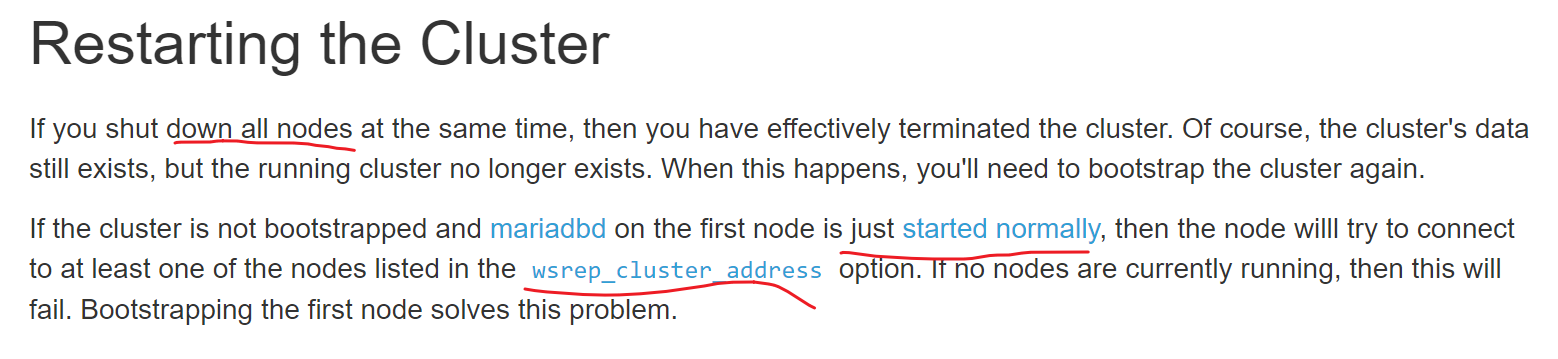
上图👆就告诉你了,如果nodes及群里的节点全部都stop了,此时就需要有一个node去做bootstrapped创建集群,如果只是简单的started normally就是systemctl start mariadb就会找wsrep_cluster_address里的IP地址去做gcomm协议连接,如果没有一个nodes是起来的,那么就会启动服务失败,这很关键。
测试下:
当前集群OK

停掉3台中的2台node,尝试将两台stop的start

没问题,处理方式OK
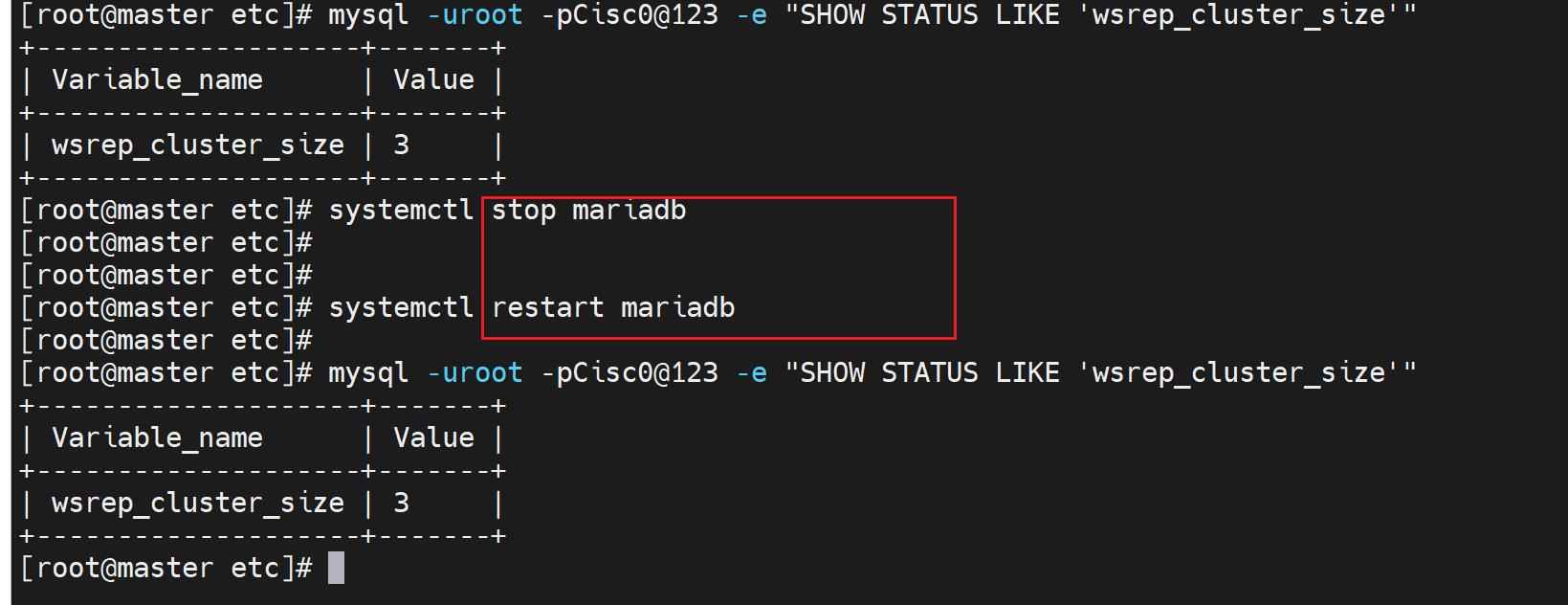
集群里的所有nodes全部停掉,这里就是3台咯
此时就需要恢复集群,
1、galera_recovery
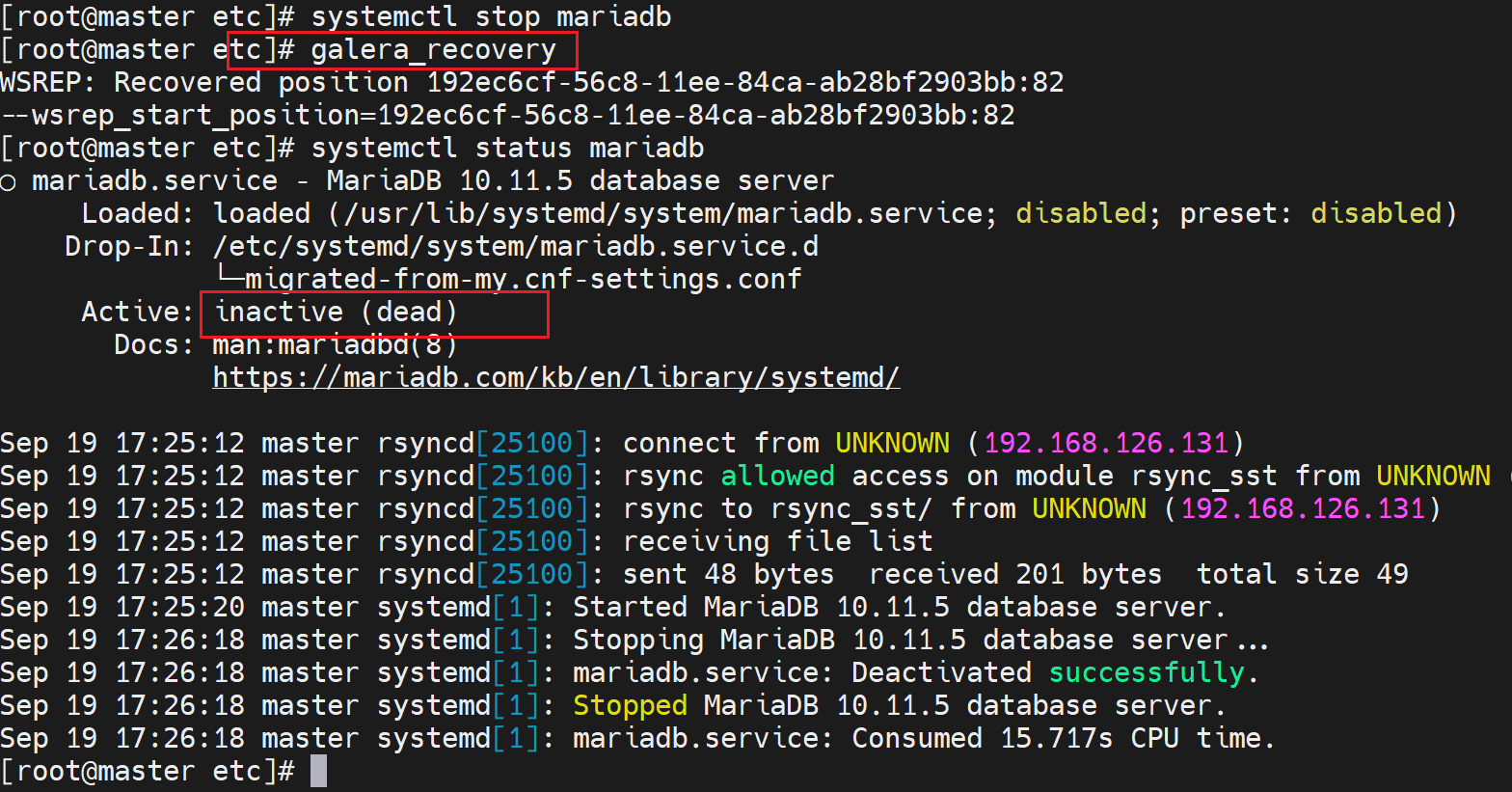
按上文的说明,就是要修改
还是起不来
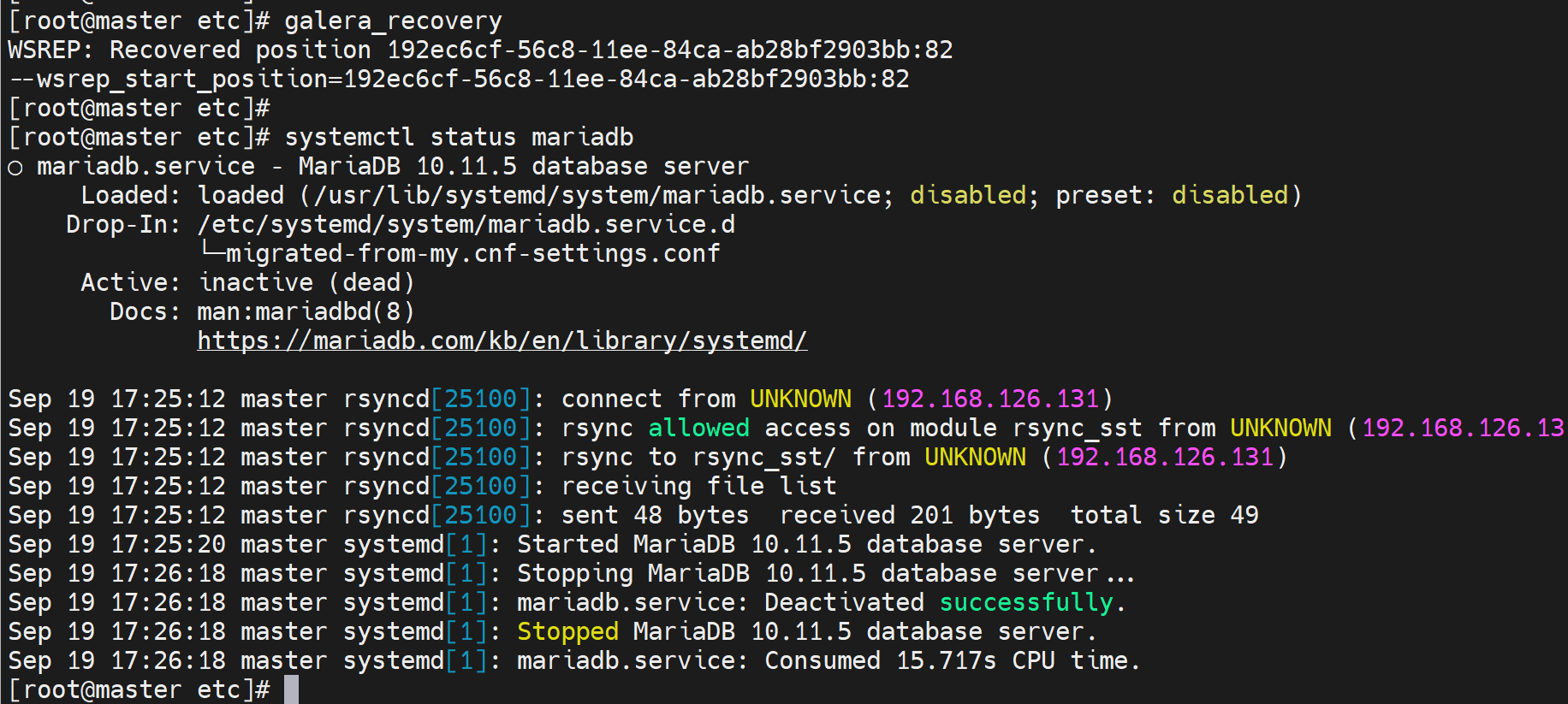
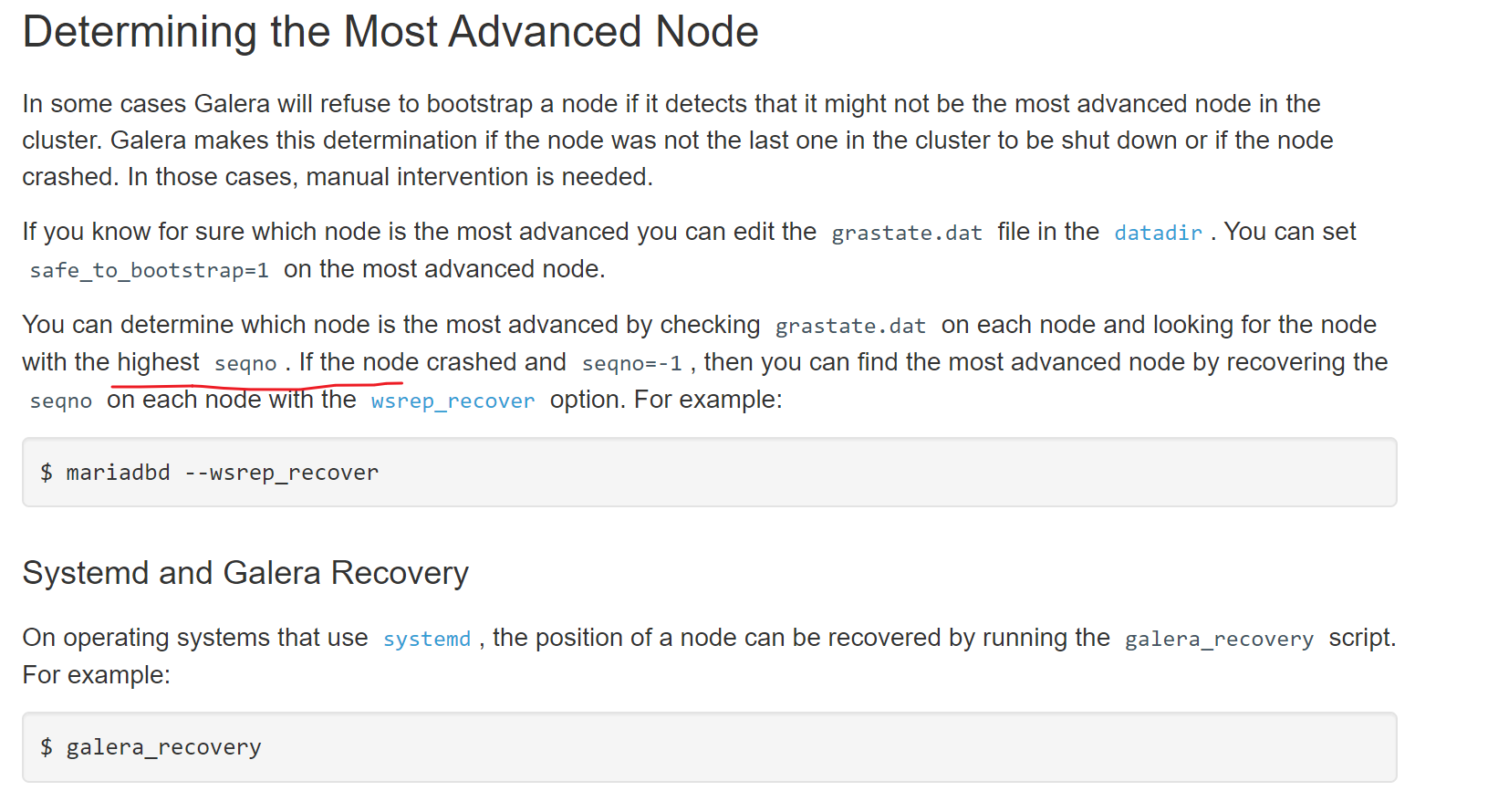
再次查看,发现人家让你找最优的node,何为最优,就是seqno
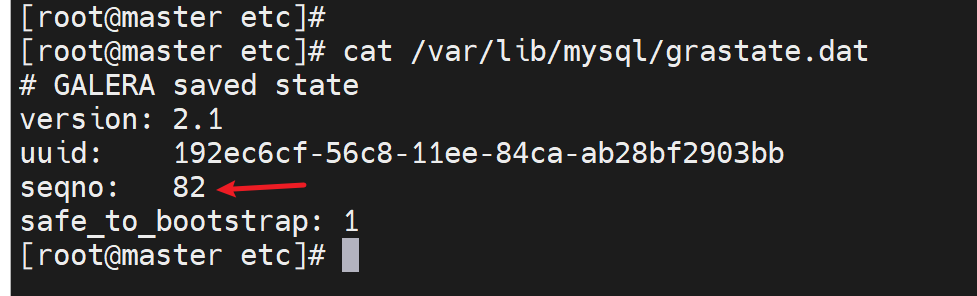
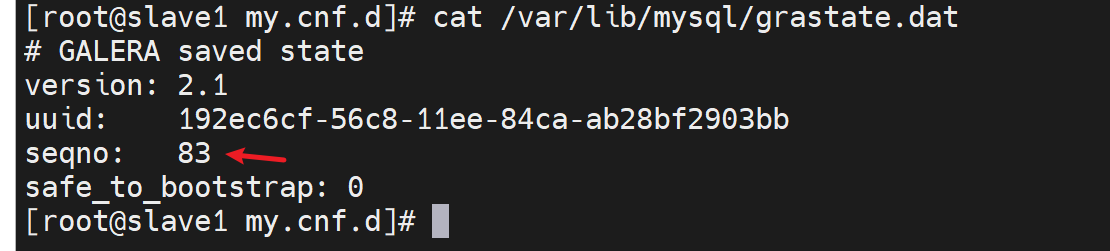
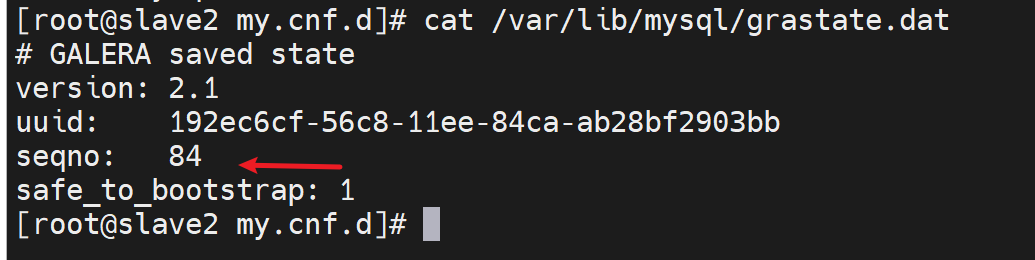
找到了,去84这台敲
galera_recovery
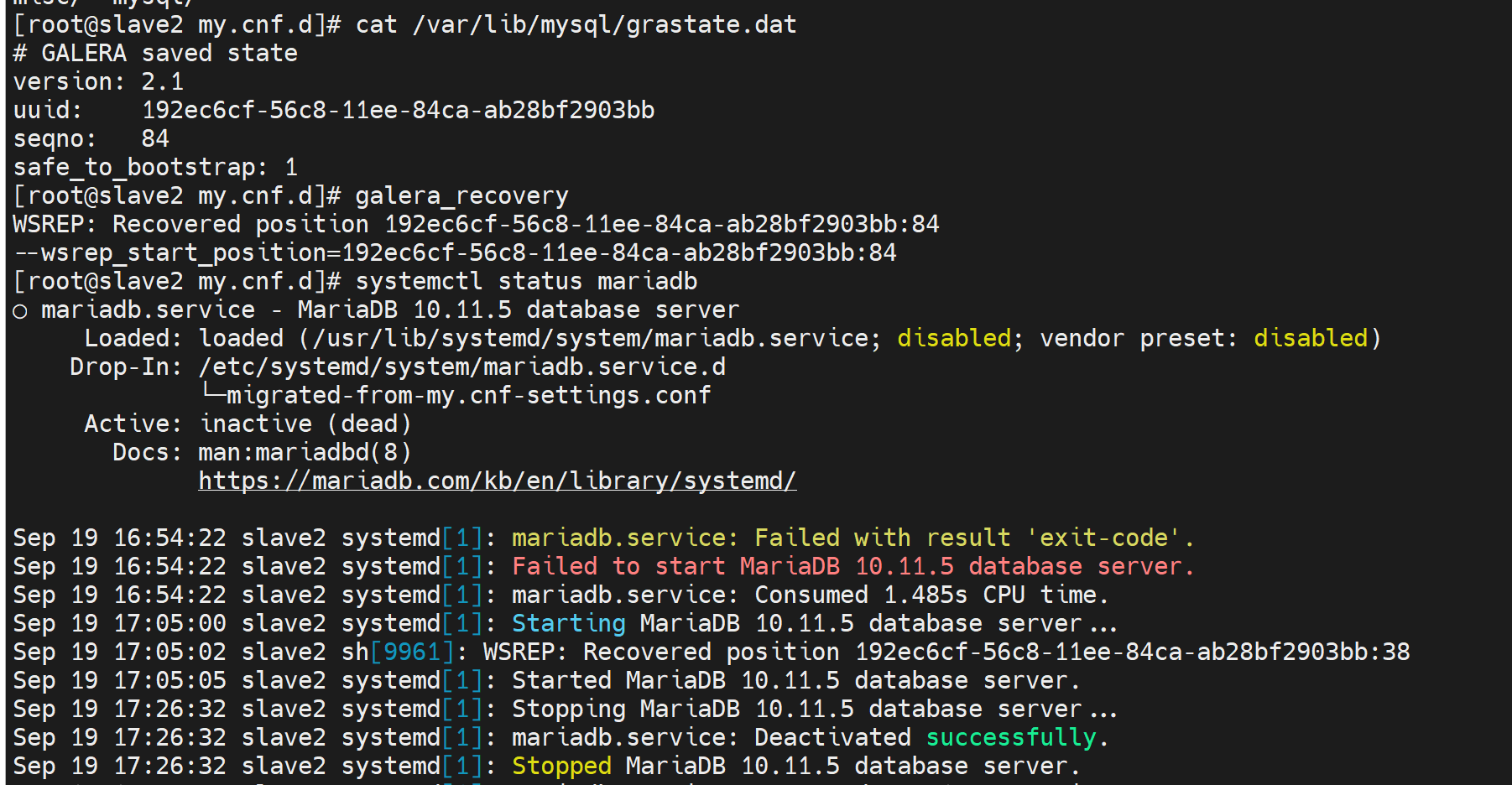
不行啊,操!
不过通过上面的操作已经知道了 不是恢复而是创建,用galera_new_cluster就可以了
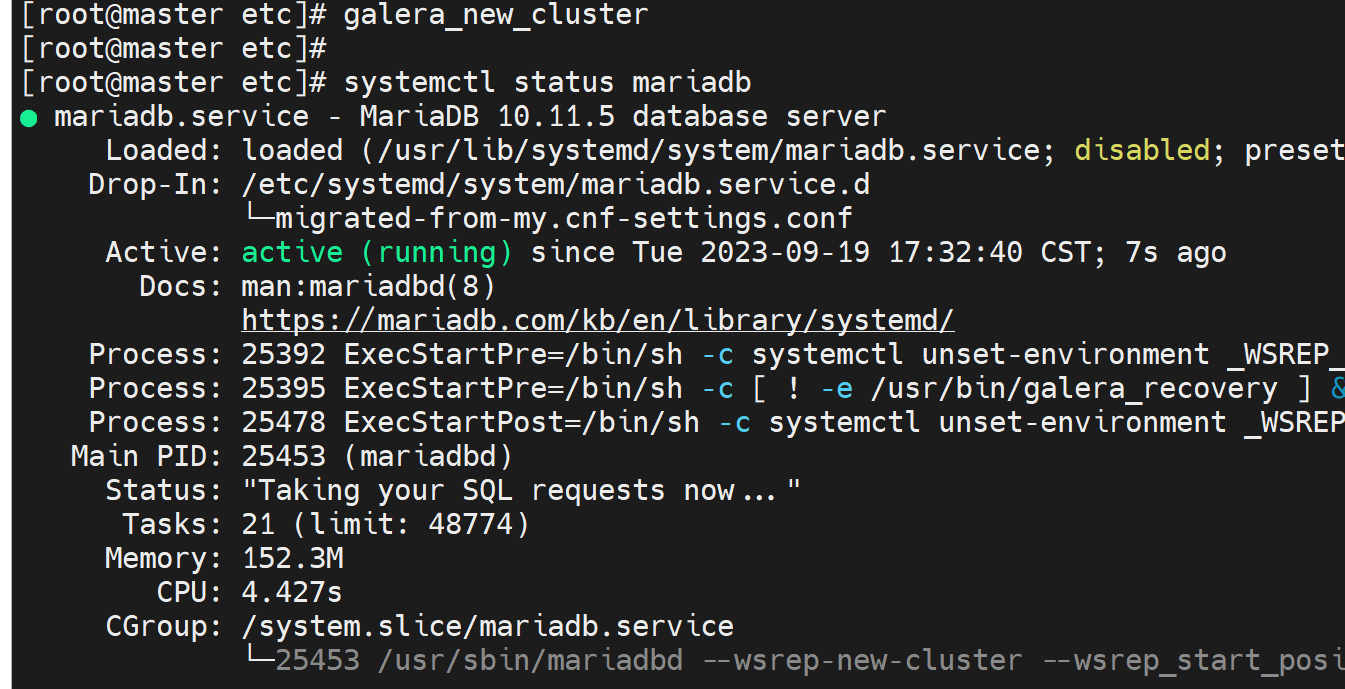
而且集群ID也不会变
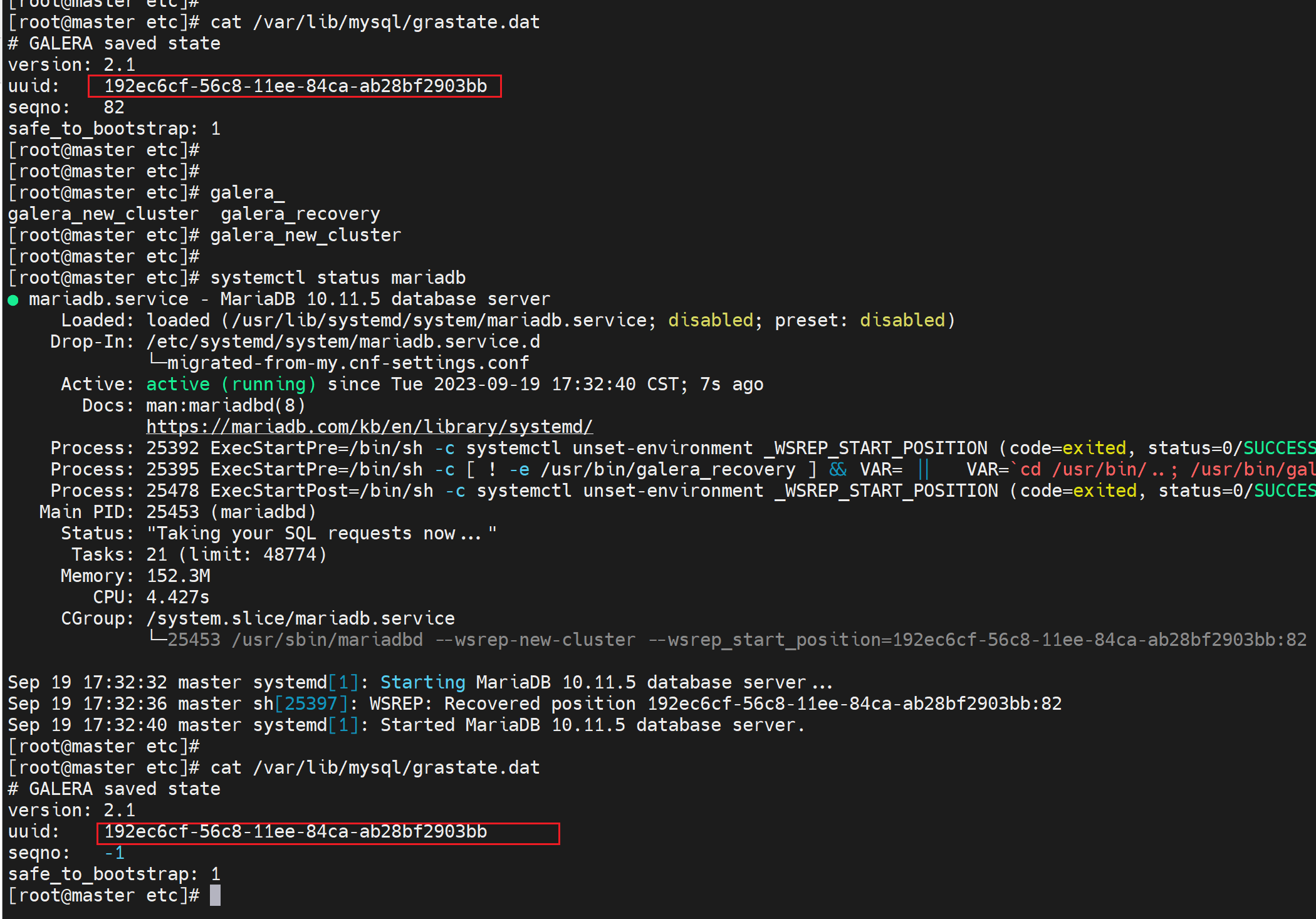
剩下两台node就简单了,重启服务就行了

到此不为此,基本的处理方法就有了。重点看总结就行,然后之前不行的原因就是①ssl没有弄好,之前实验遗留的,只配置了2个node的ssl,这里涉及3个呢,不过有一次ssl没关也OK,不过通过上文的报错可见确实有问题的;②就是集群的启动和重启有讲究的,重启有问题还是用的初始化创建的命令来解决问题的。
继续看集群的数据读写处理
说明:hostname无所谓master slave,这仅仅是之前实验的遗留,这里是多主,都是master。
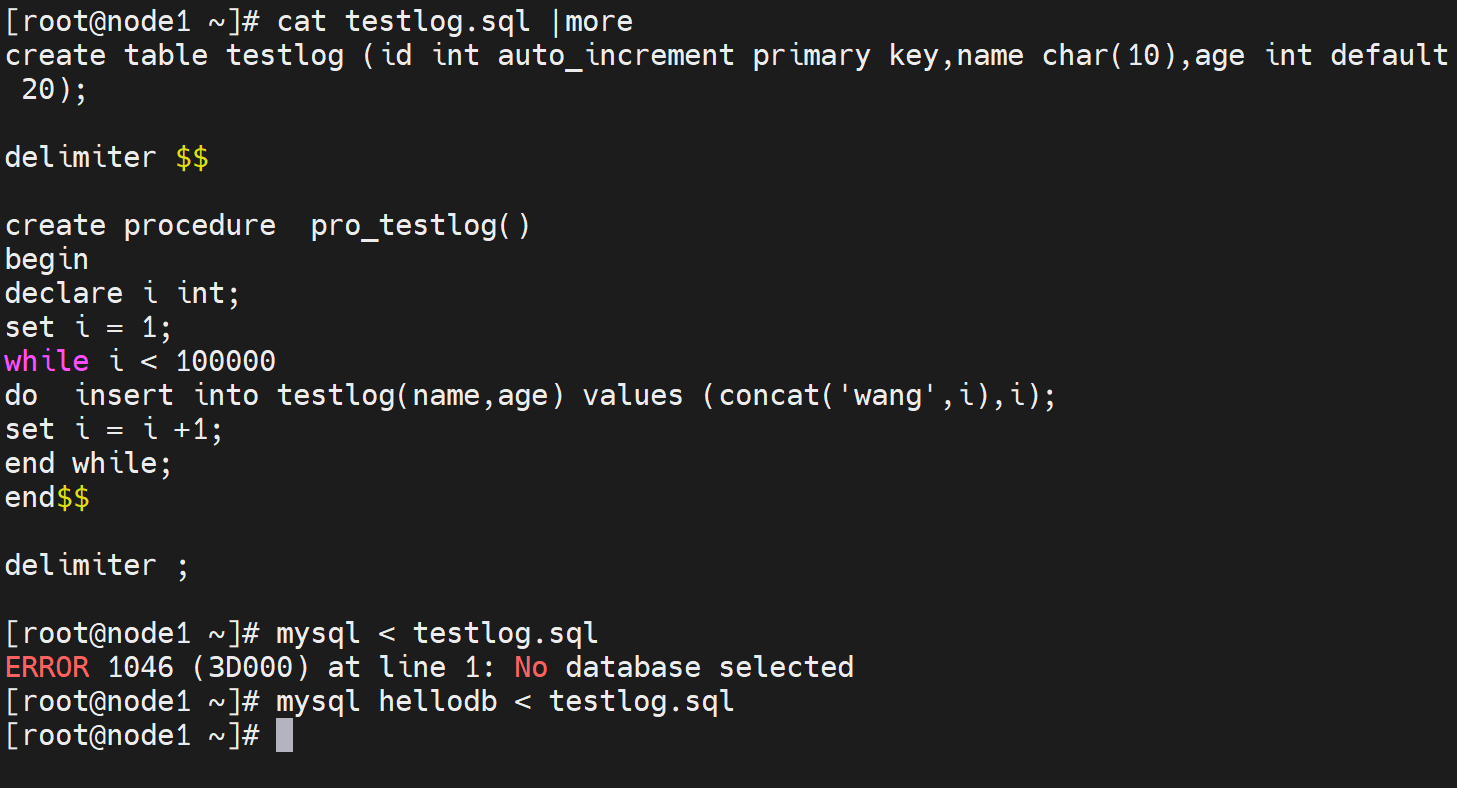
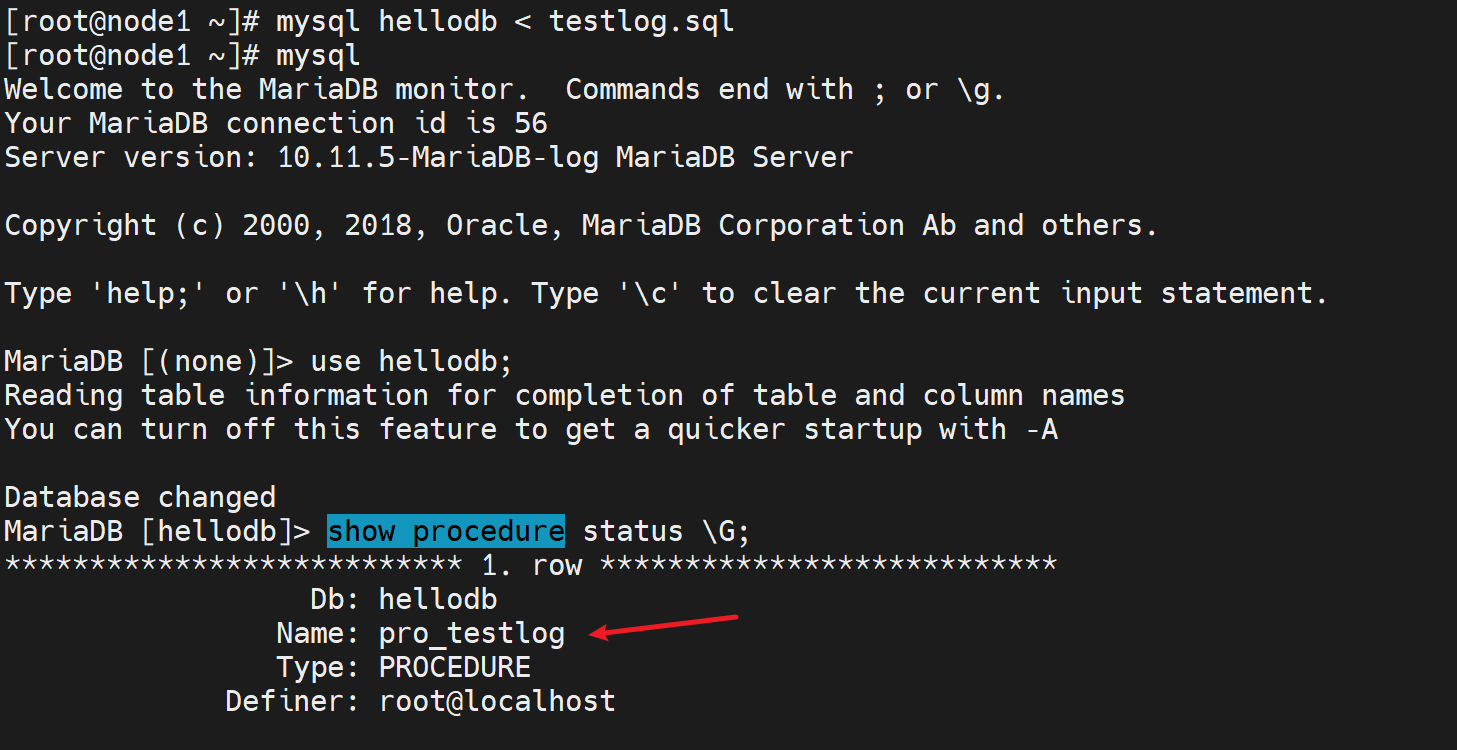
导入一个sql脚本,会创建新库和表,这是在第一个节点上做的。

然后其他所有nodes也就自动同步了👇
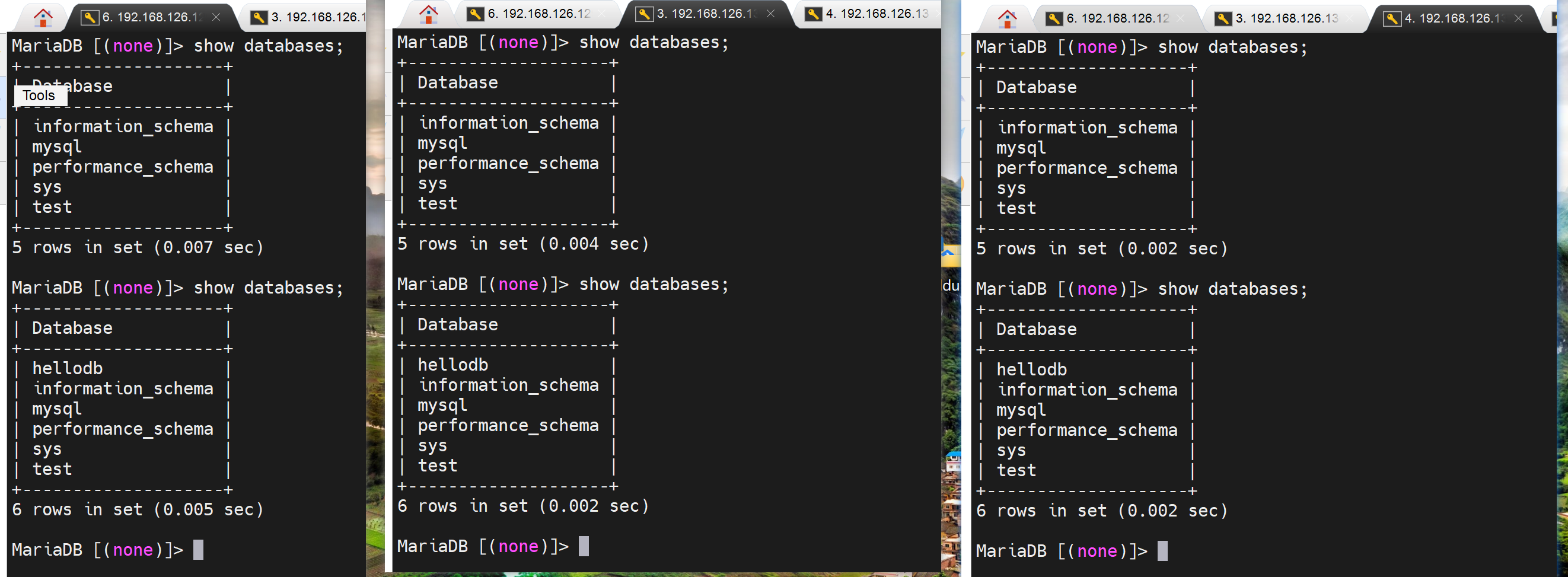
表同步自然也OK
变量查看
SHOW VARIABLES LIKE 'wsrep_%\G';
有当前自己的IP信息👇
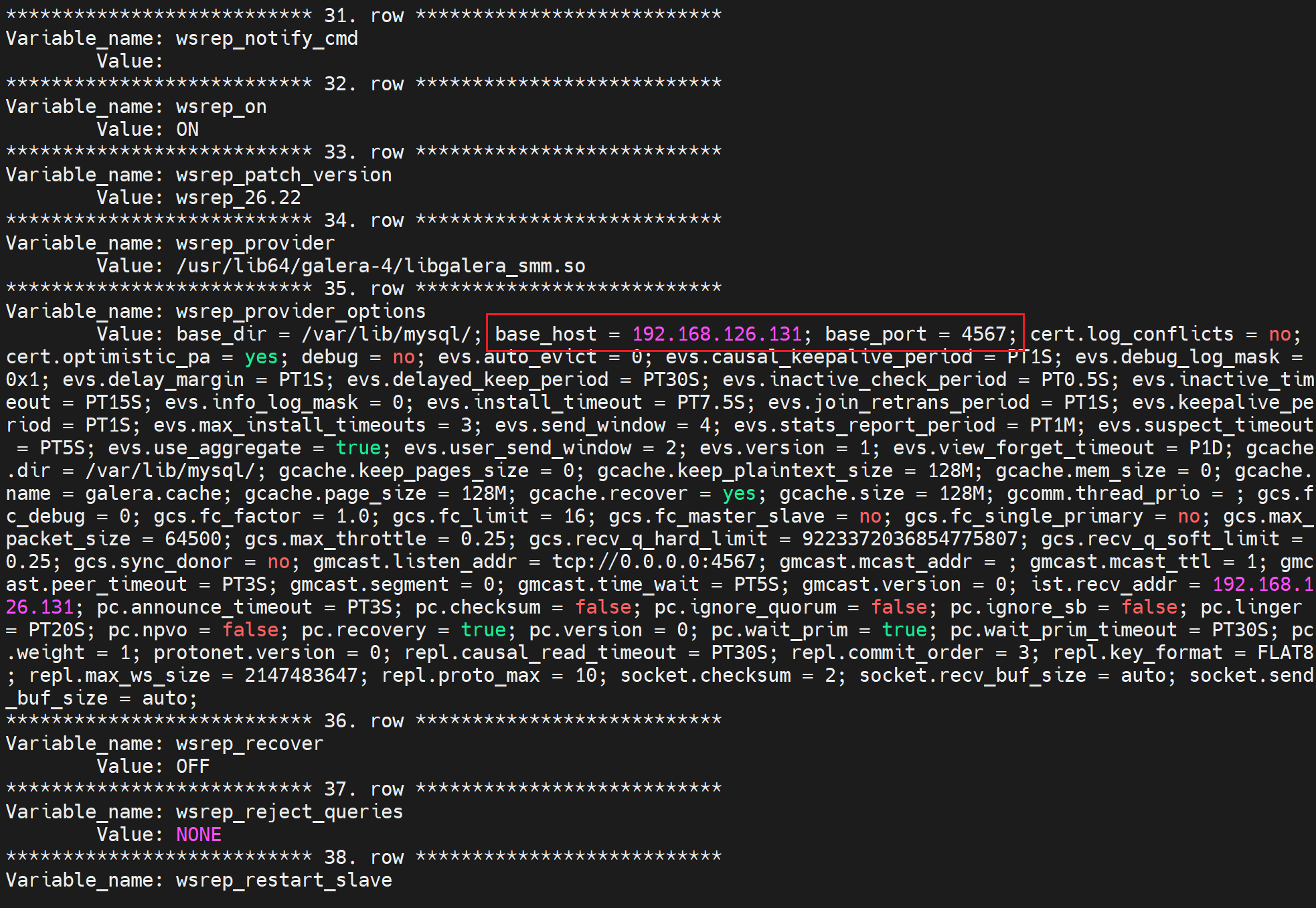
有/etc/my.cnf.d/server.conf里配置的信息👇

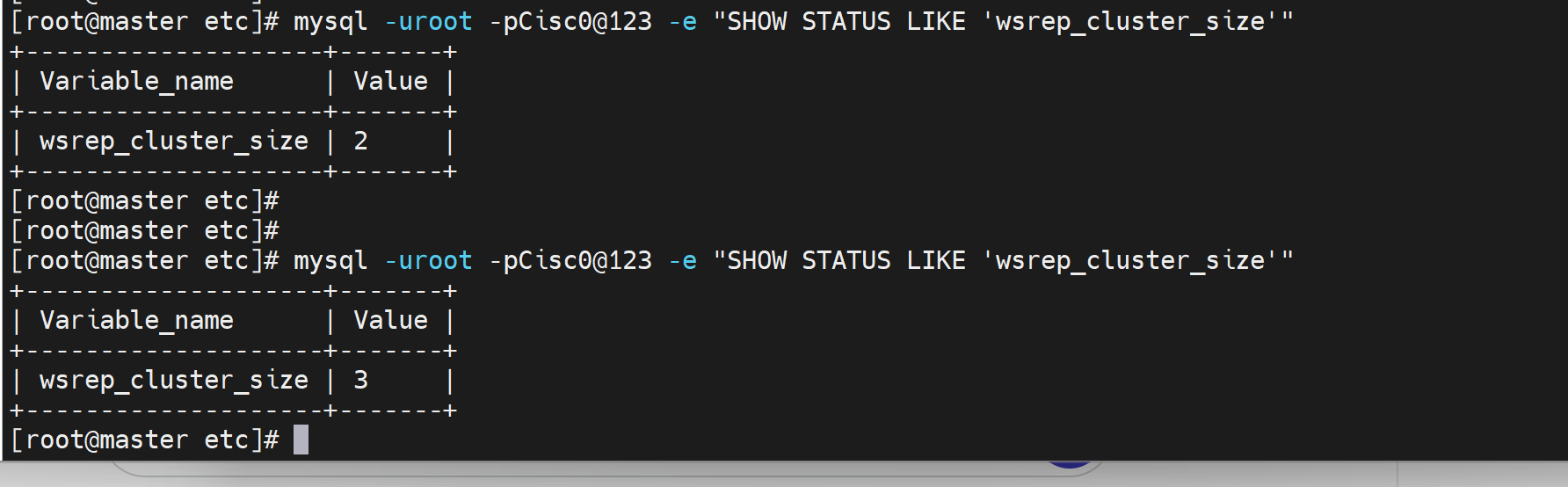
SHOW STATUS LIKE 'wsrep_%'; # 状态变量
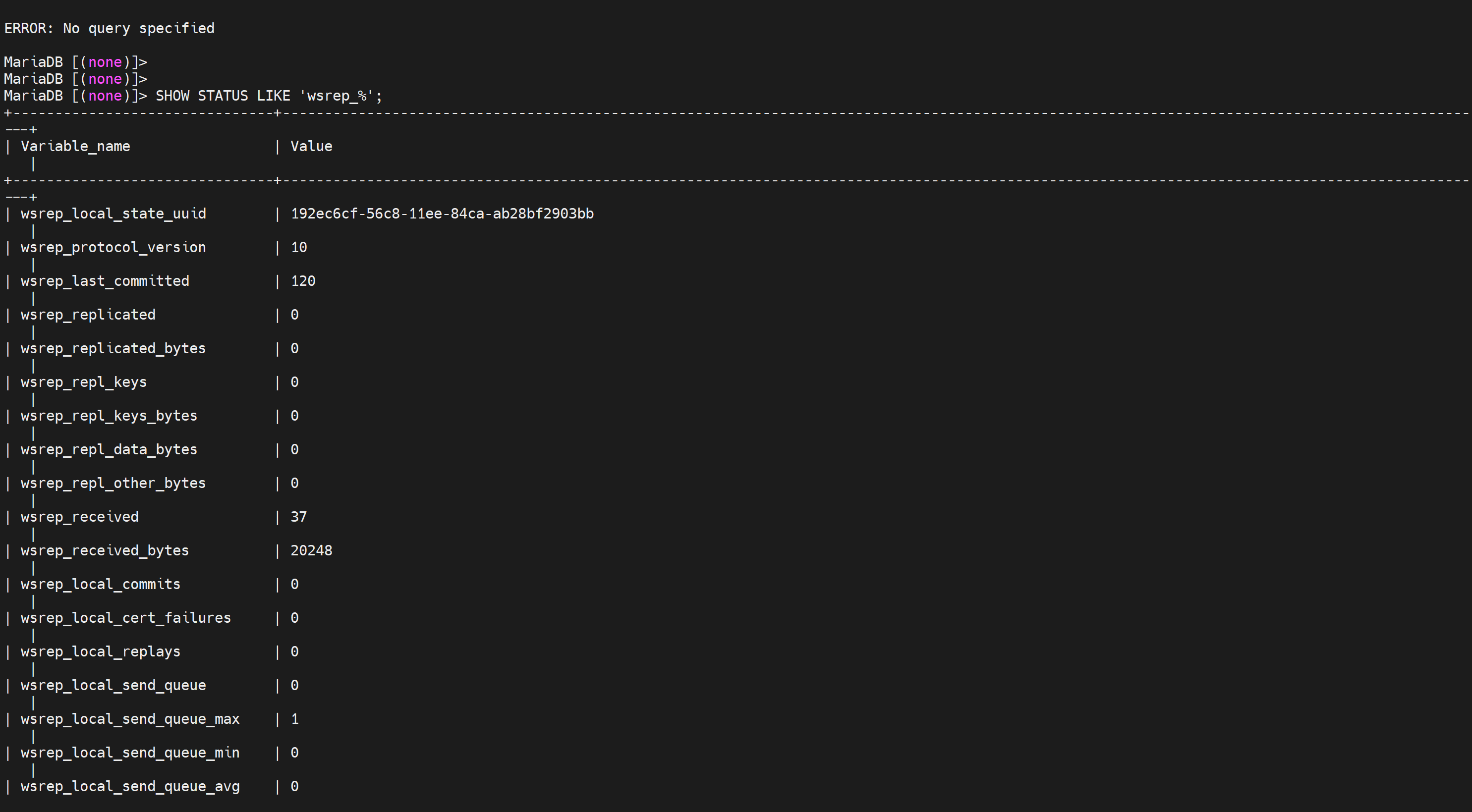
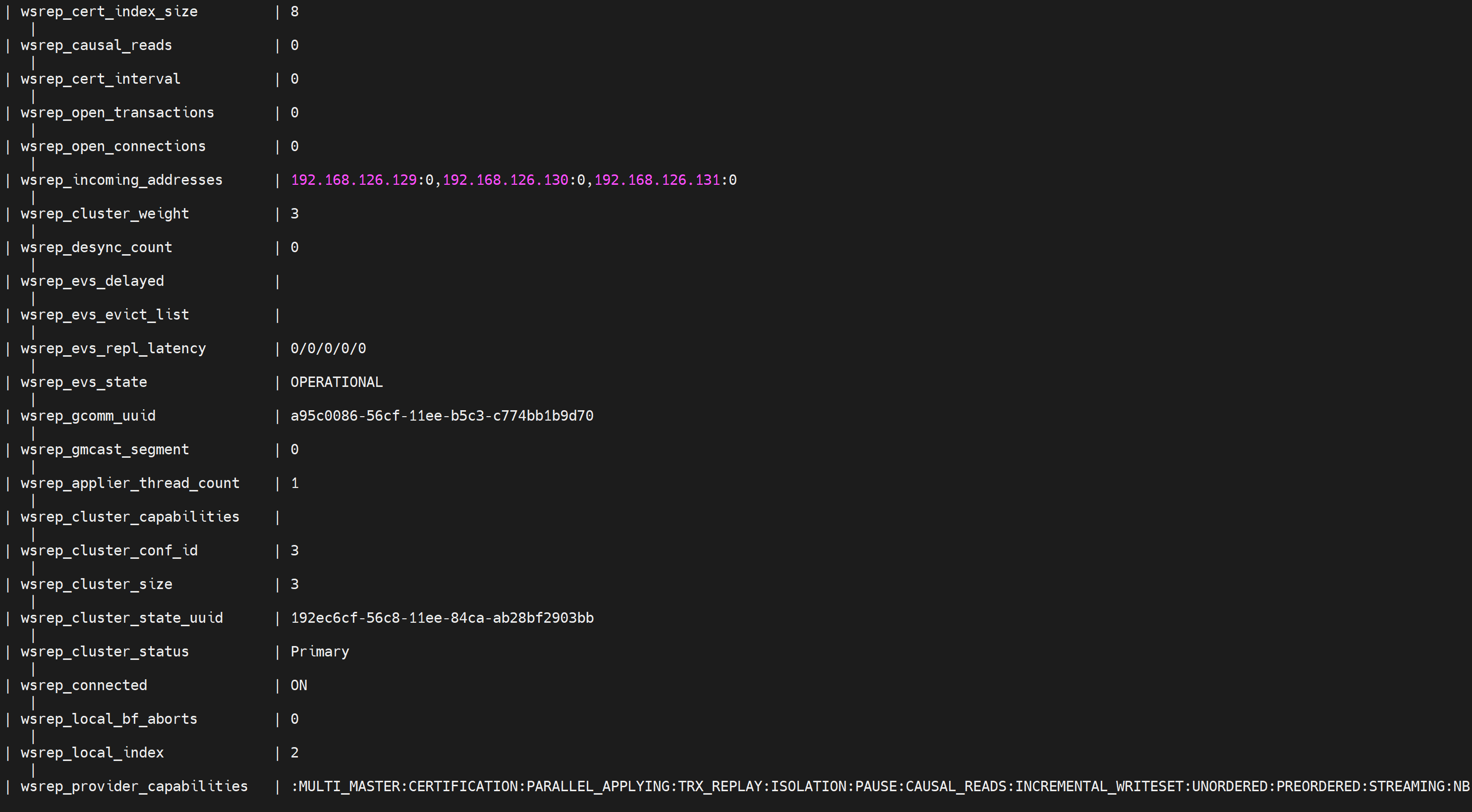
SHOW STATUS LIKE 'wsrep_cluster_size';
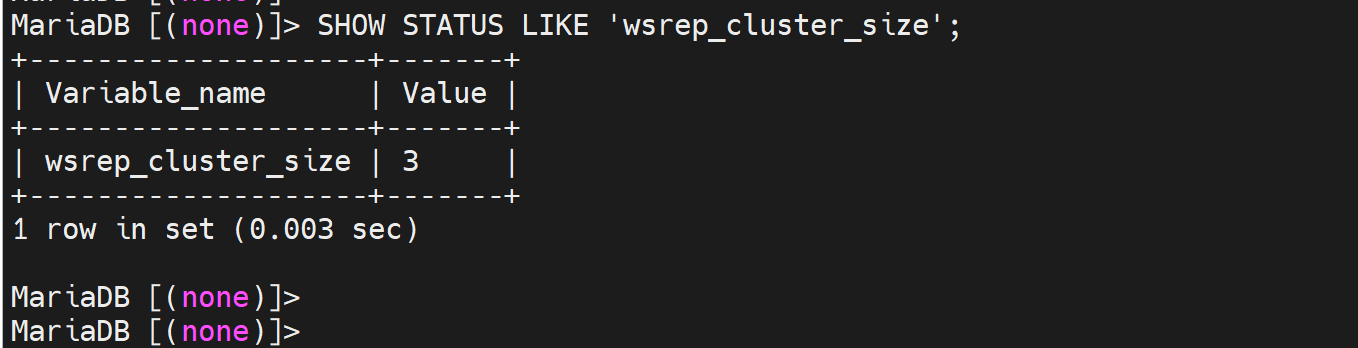
查看集群nodes数👆

添加新成员node
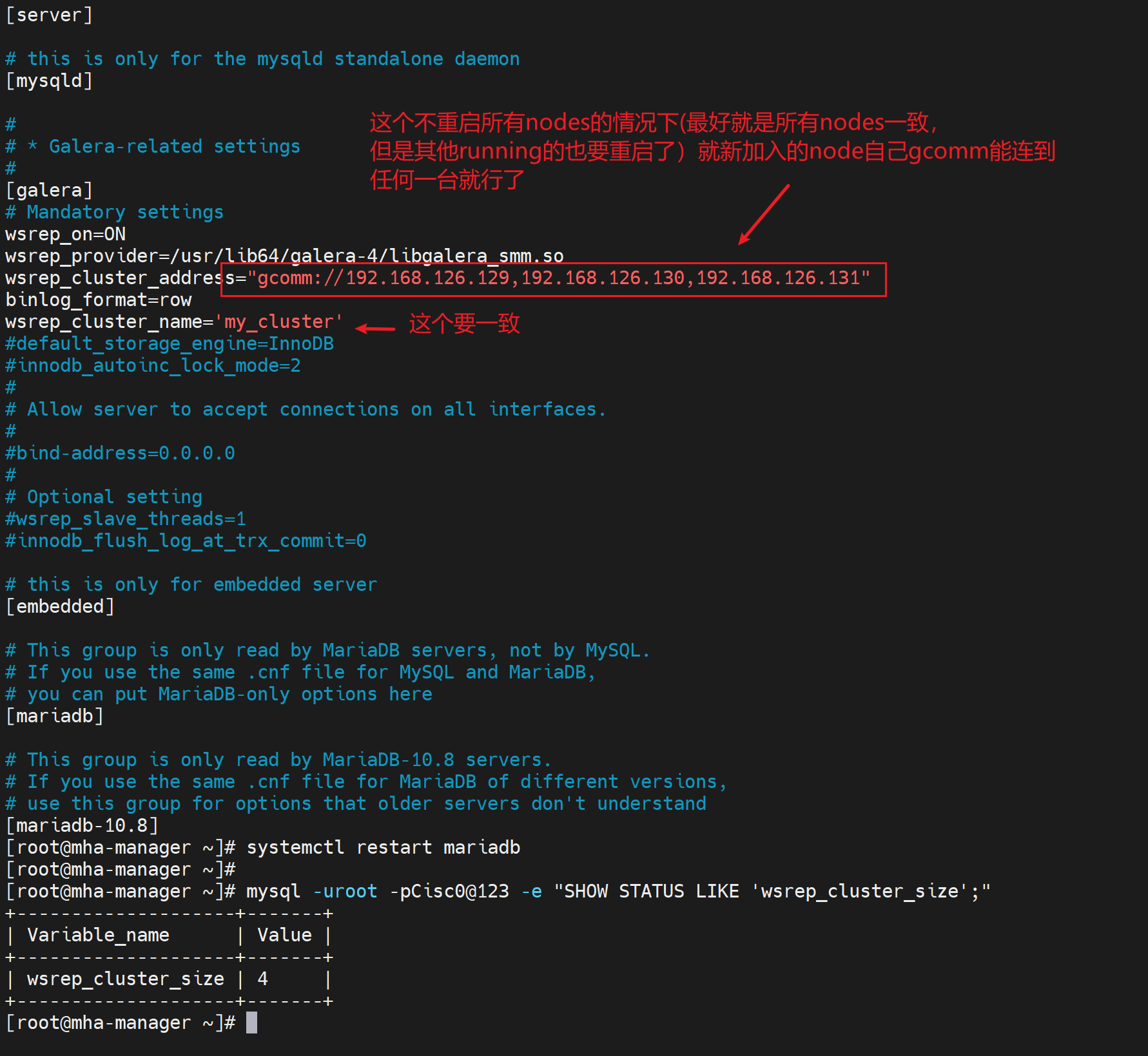
不过人家官方说了,the first node has x.x.x.x,才能加入x.x.x.x,呵呵~。👇
其实就是每台node都补一个IP,然后一个个重启就行了
只要cluster里有一个活着,就能重启服务OK,除非同时down了
人家说的就是这个意思,所有nodes都down了,才需要重新初始化(这个我走成功了),或者没有走成功的galera_recovery;
然后新加入的node,也会很快同步db的
建表也不会冲突,因为有wsrep机制啊
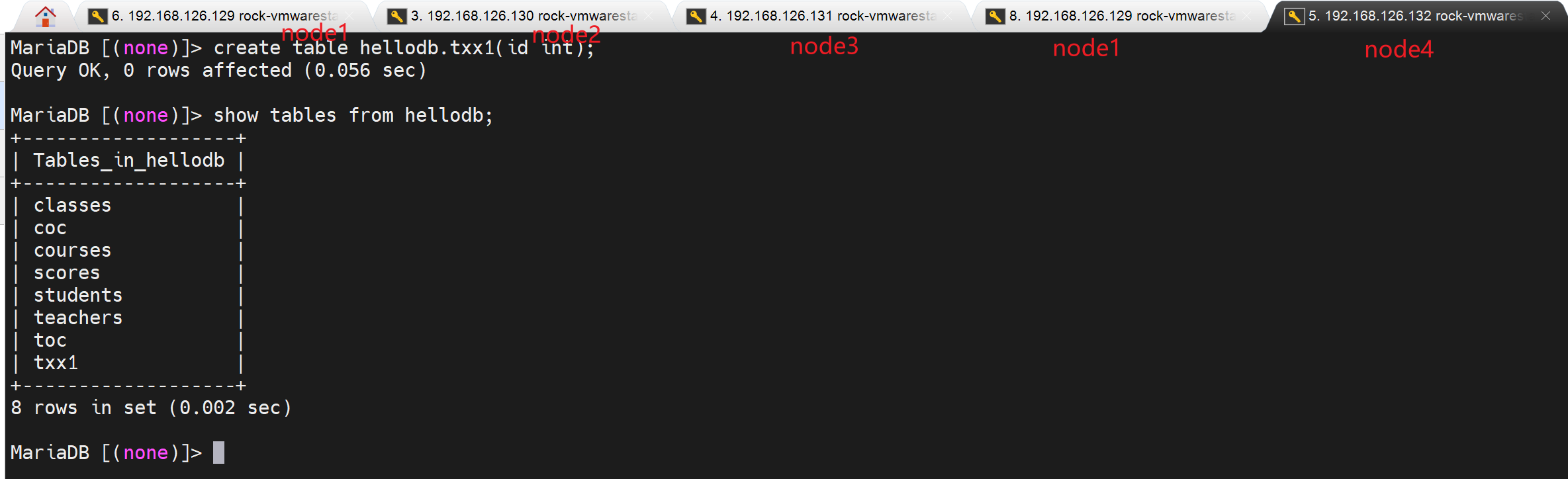
只会有一个成功👇
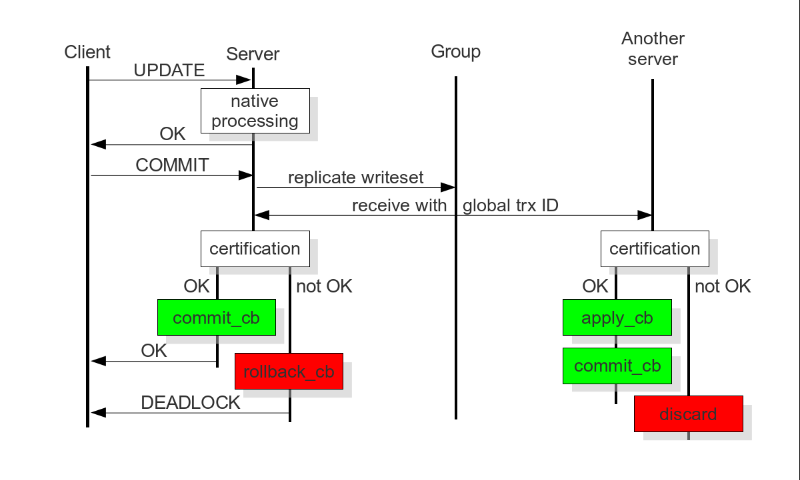
然后看看大量数据写入的一个速度,是明显比主从慢很多的,因为👆
下班关机
算了明天继续弄吧,由于机器关机了,之前就是临时做实验,所以mysql服务都停了,这里正好重演一次cluster的启动
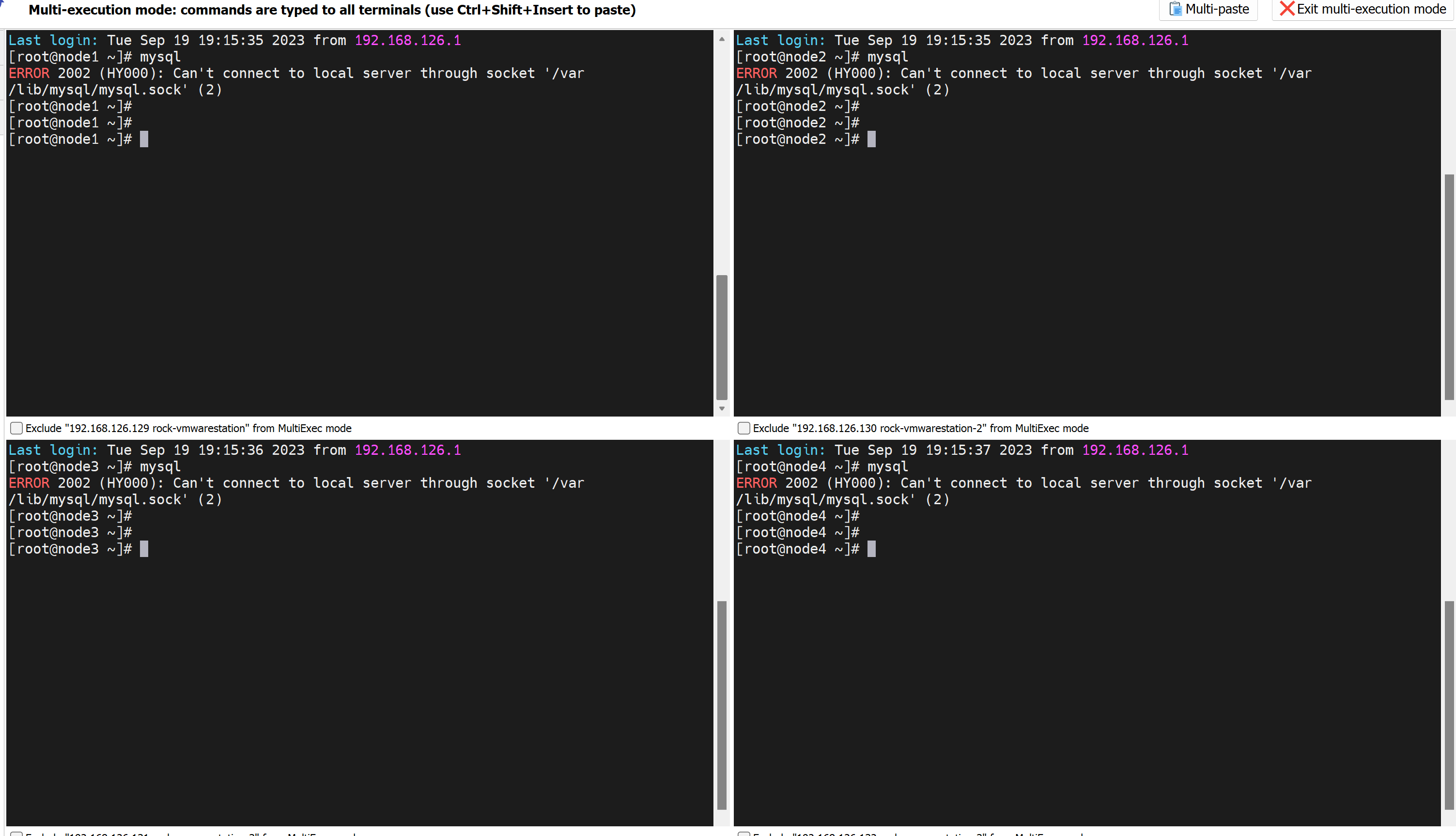
可见👆所有服务都没起来
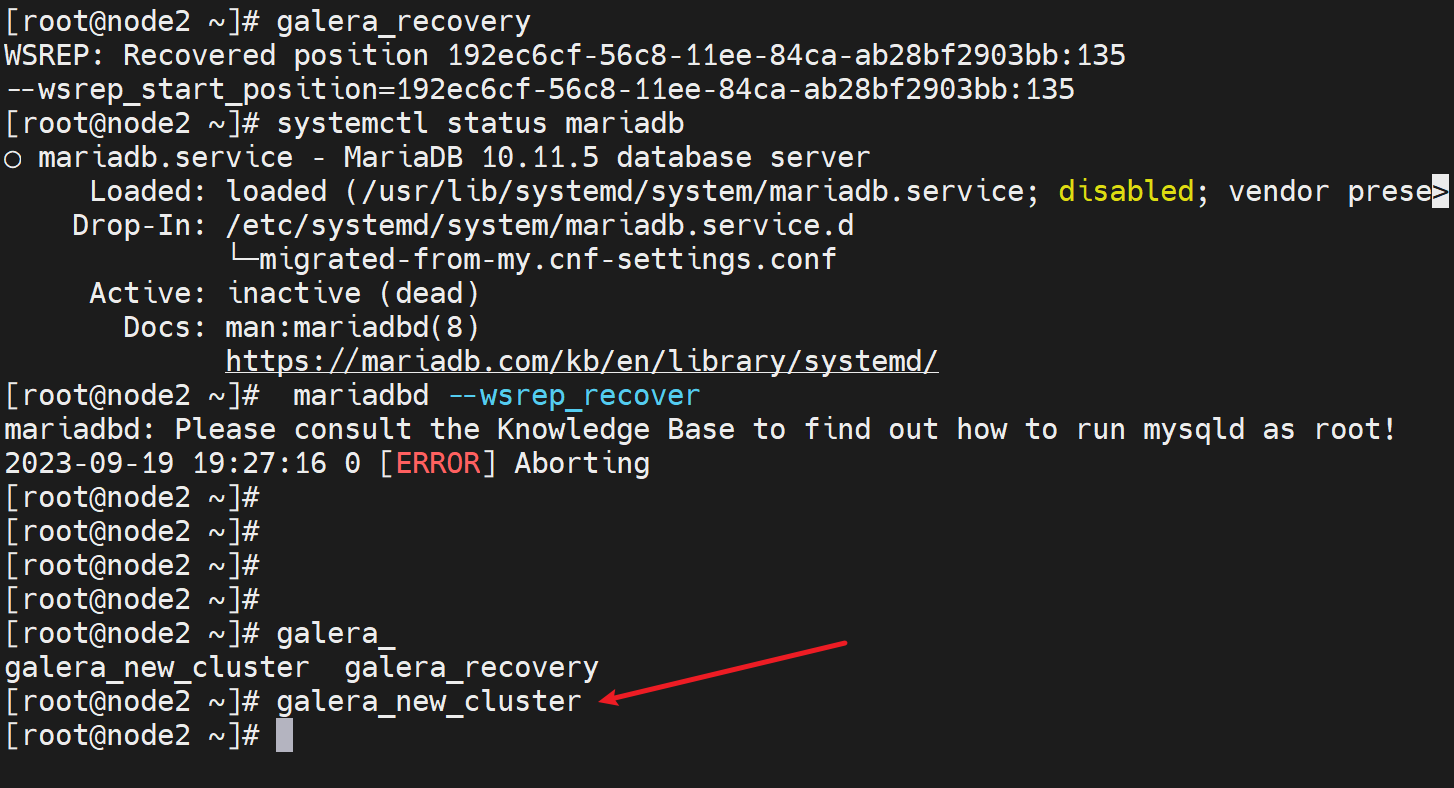
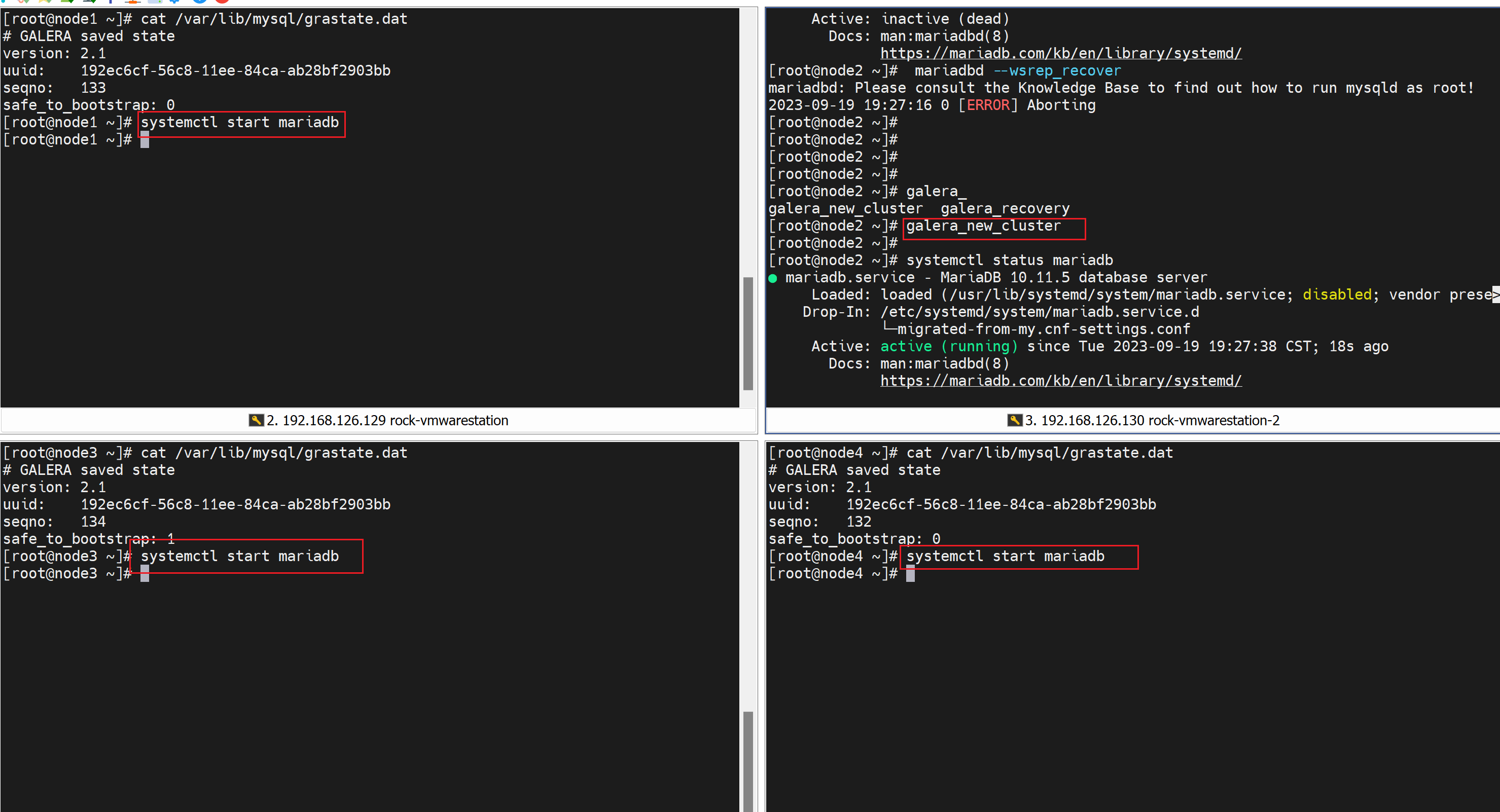
随便选一台初始化集群
查看seqno虚拟号,👇下图注意哦,135的seqno最优秀,所以safe_to_bootstrap:1就是1,其他都是0,这是系统给默认设置好的,然后有个node3的1是我改的!我之前准备用node3初始化新建的,所以看到的是1。
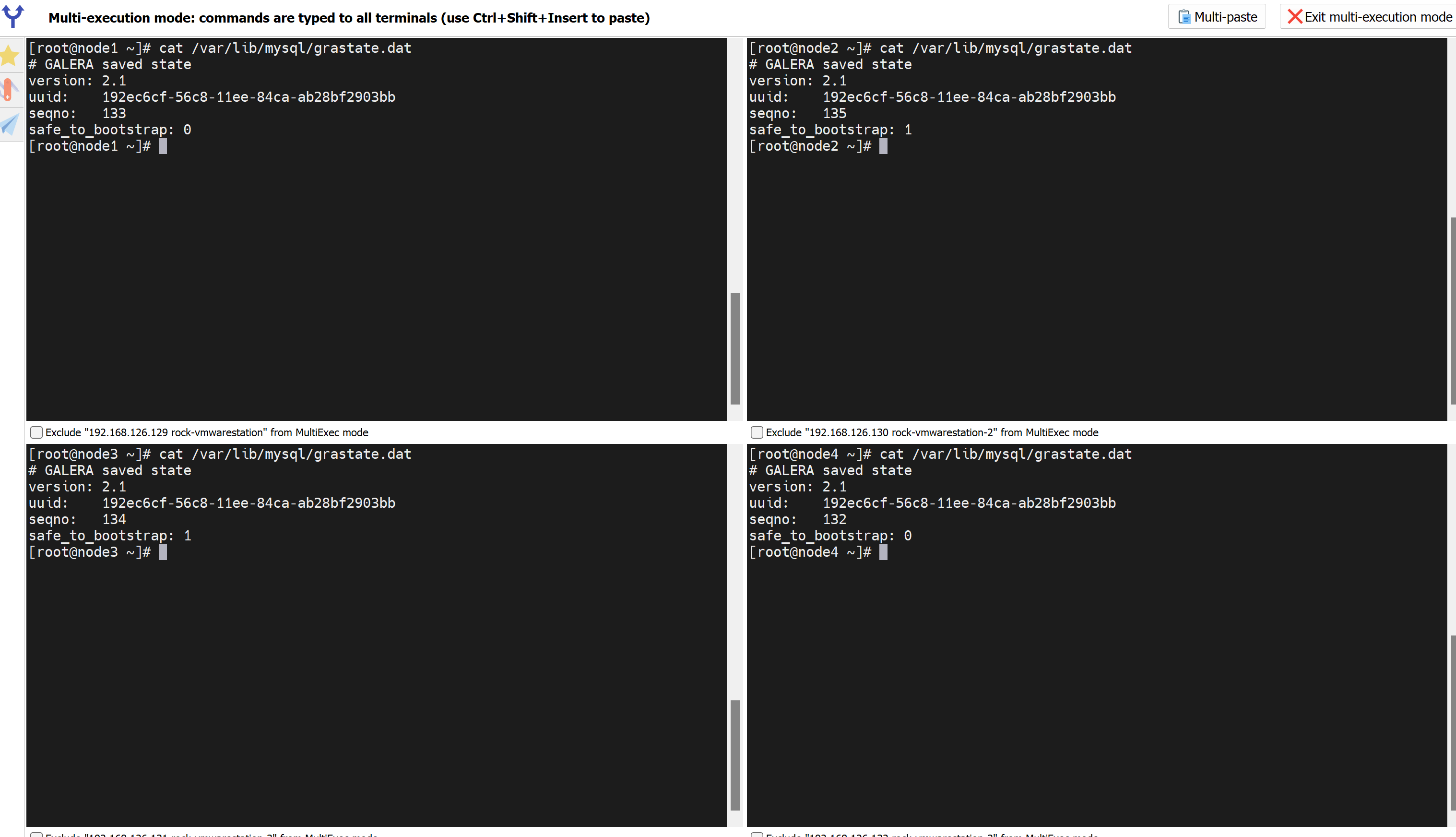
node2最优秀,尝试不初始化,重启的专用cli试试
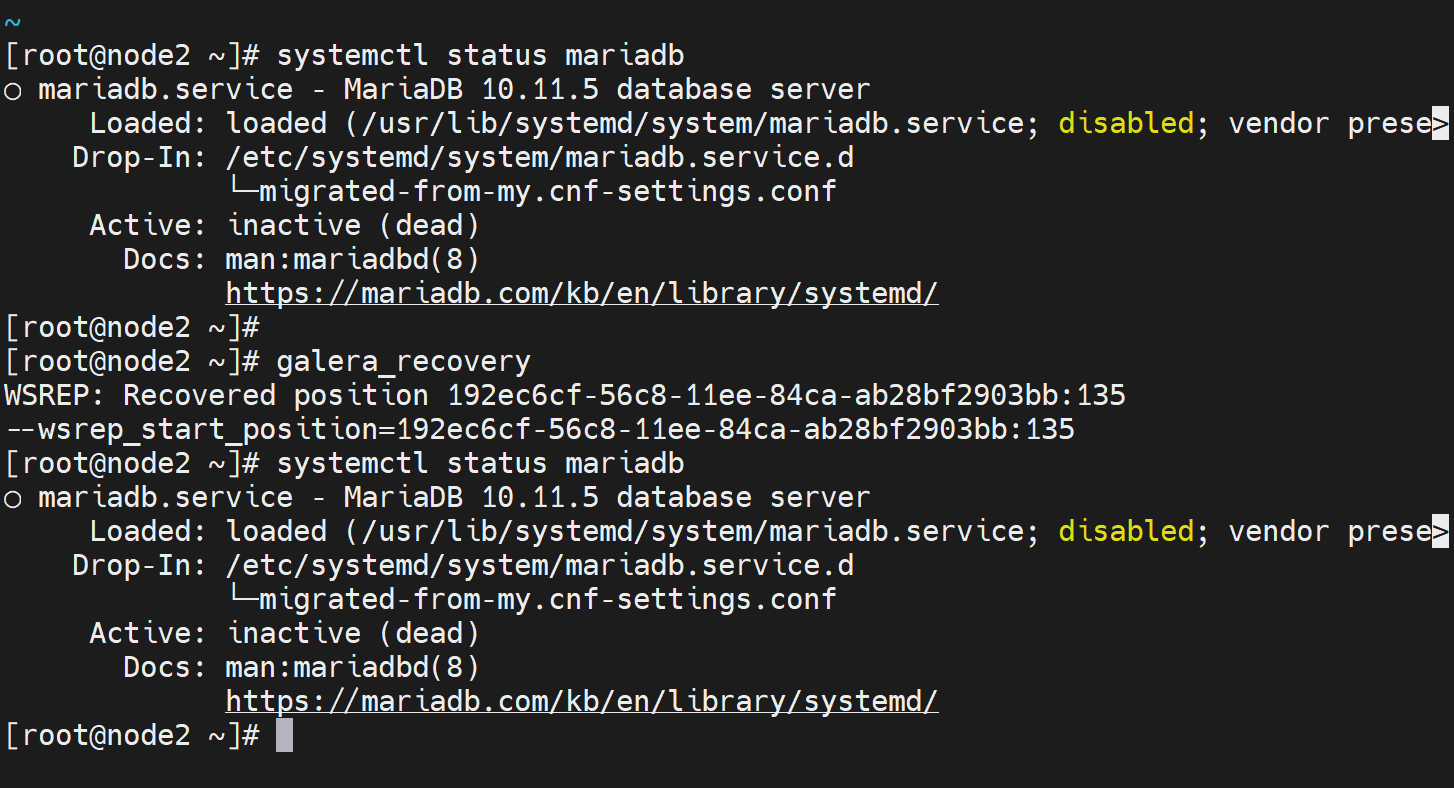
起不来啊~
直接new吧哈哈
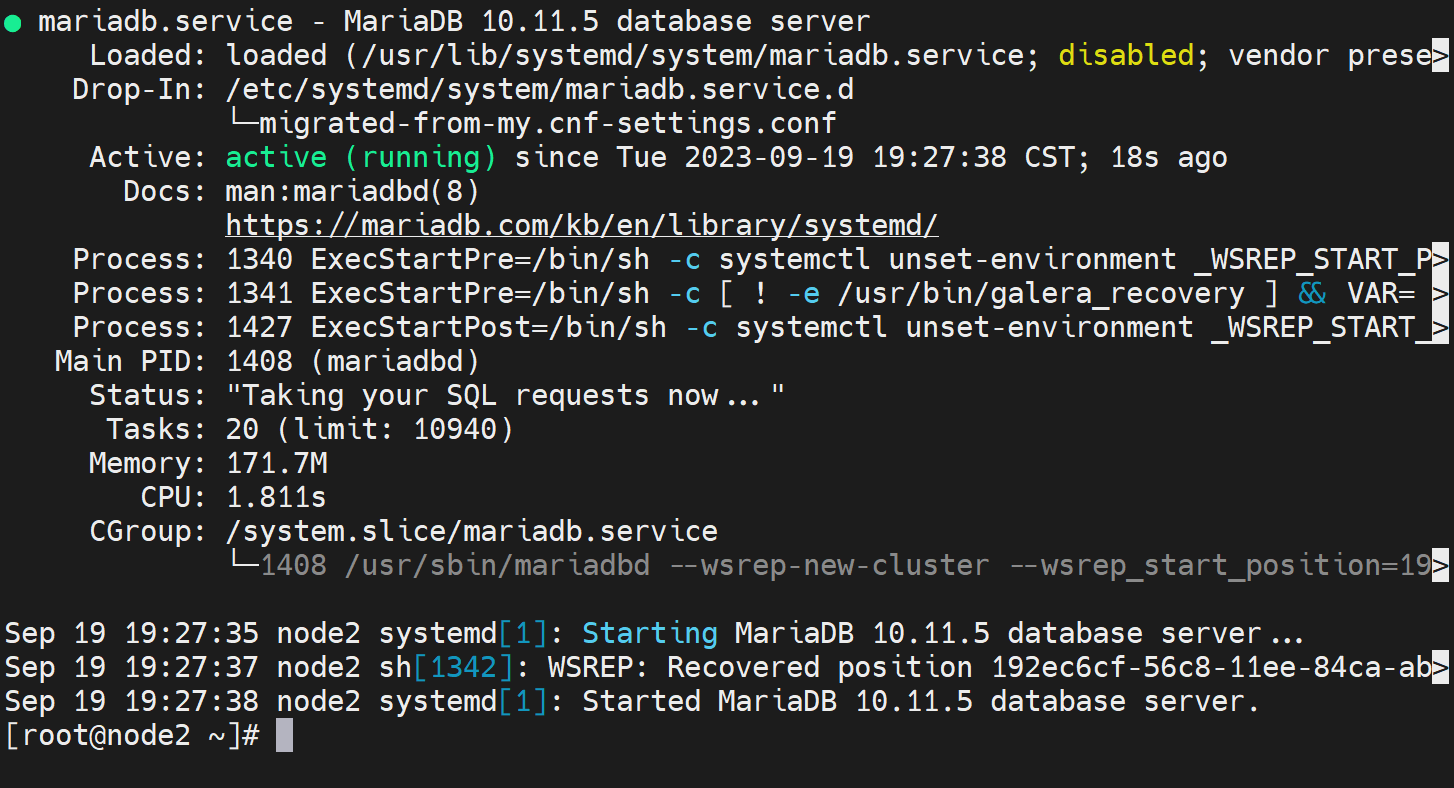
然后其他node 都systemctl start mariadb就行了
同时创建的cli的没问题👇
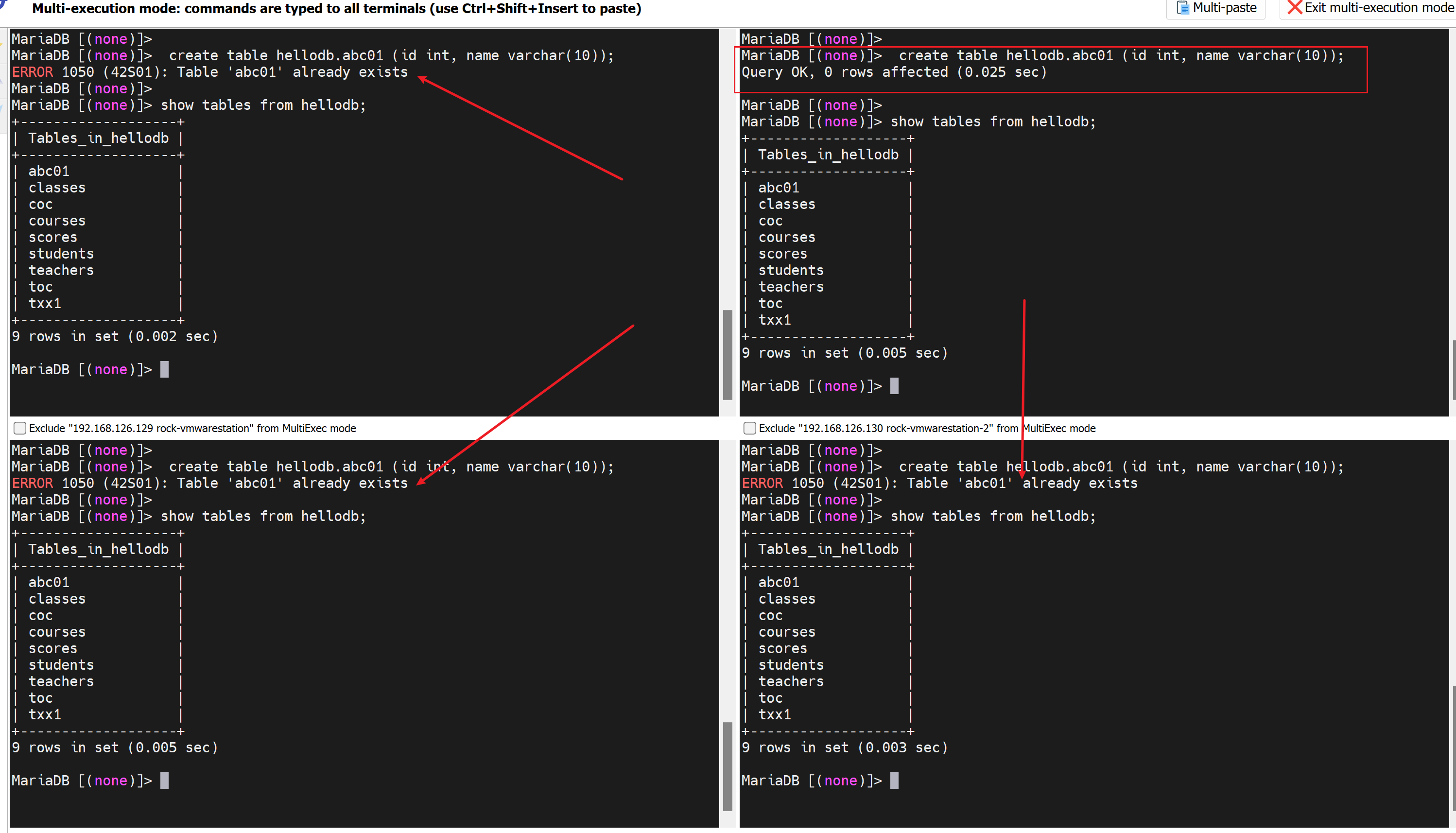
测试开始
然后就看看数据的增长
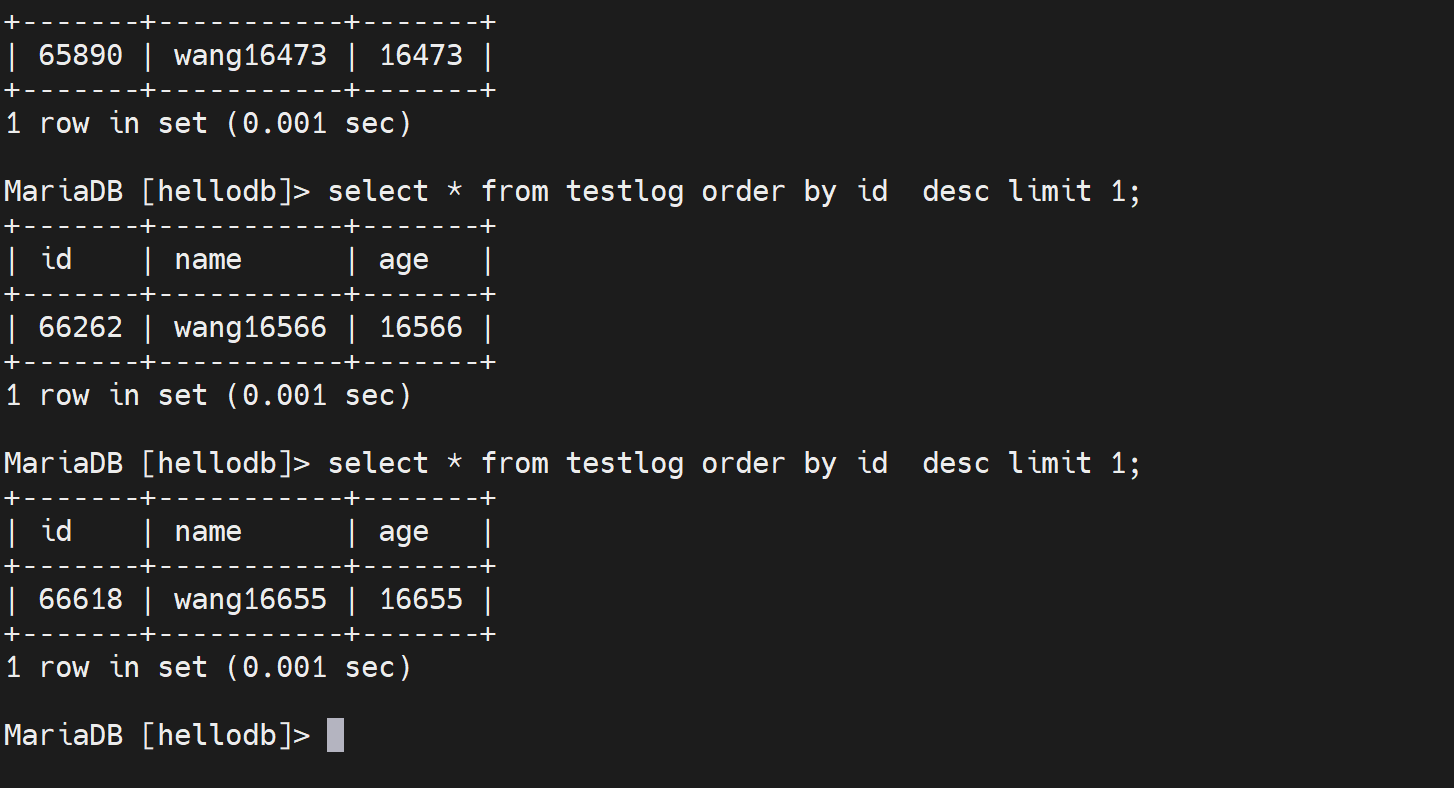
发现这个速度比简单的主从还要慢很多,然后其实可以做成事务,事务就是一起提交,会快一点。
像这种就好比大量用户的写咯,所以具体用的时候还存在问题,需要优化吧应该!好像他们业务实际也不这么玩。
还发现一个现象👇
就是galera cluster默认就给你做了table的插入的自动间隔,以前是 这么配置的。
这么配置的。
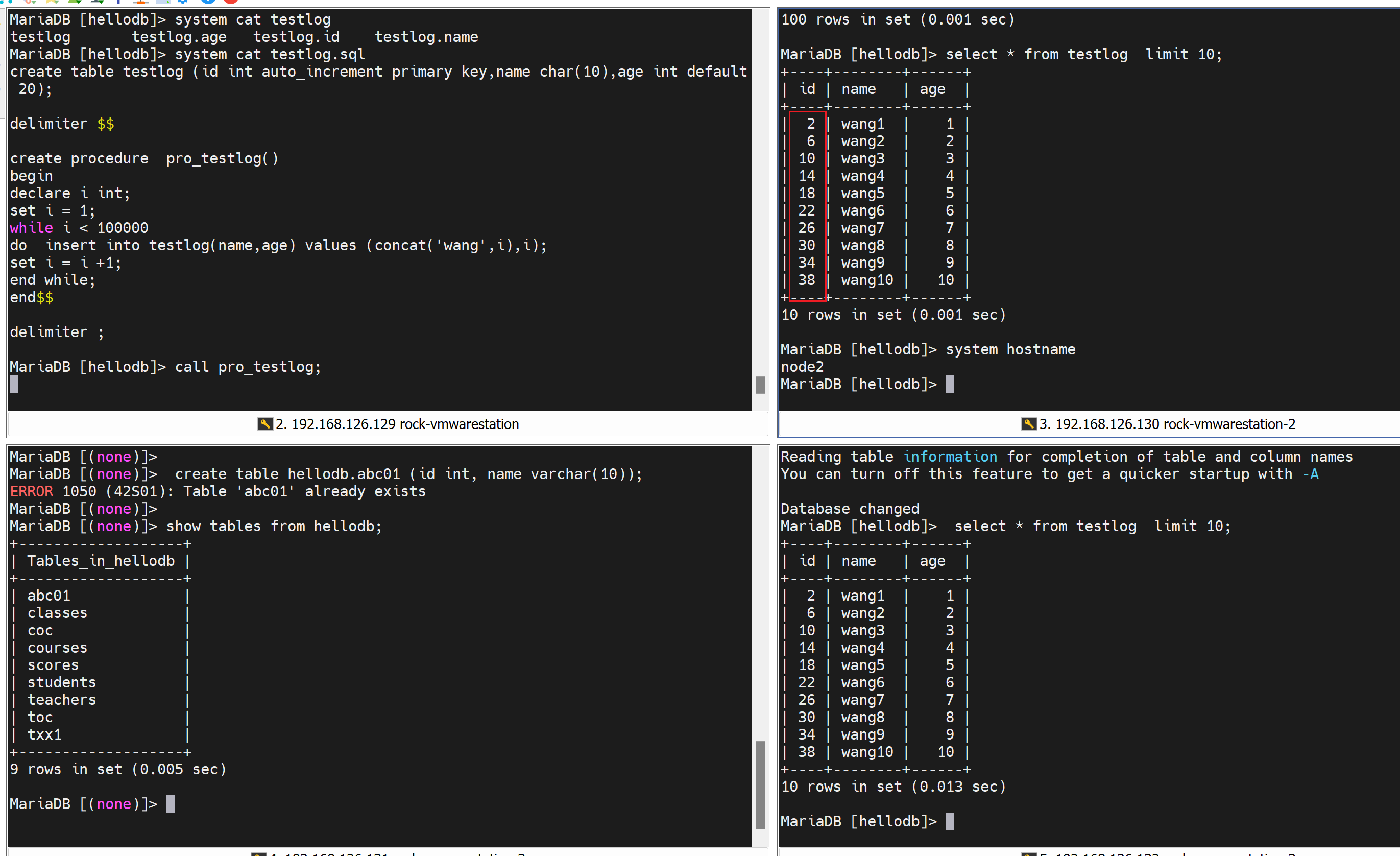
👇12分钟终于结束了:
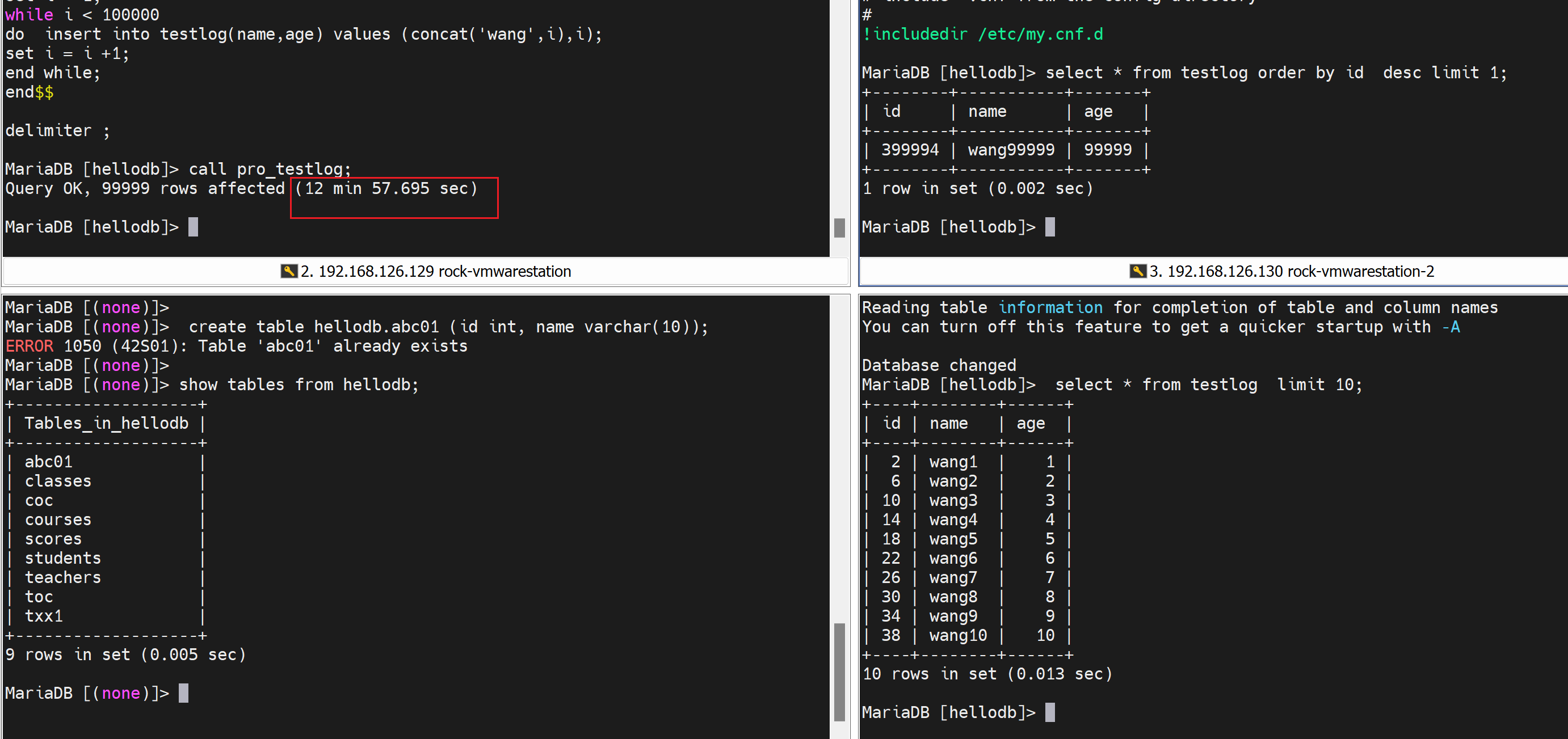
试试 事务的方式,理论上会快一些

这TM也太夸张了,不对吧
第二十运行事务,一样是6秒种,一共插入了3次,每次99999行,300000-3=299997行,对的👇
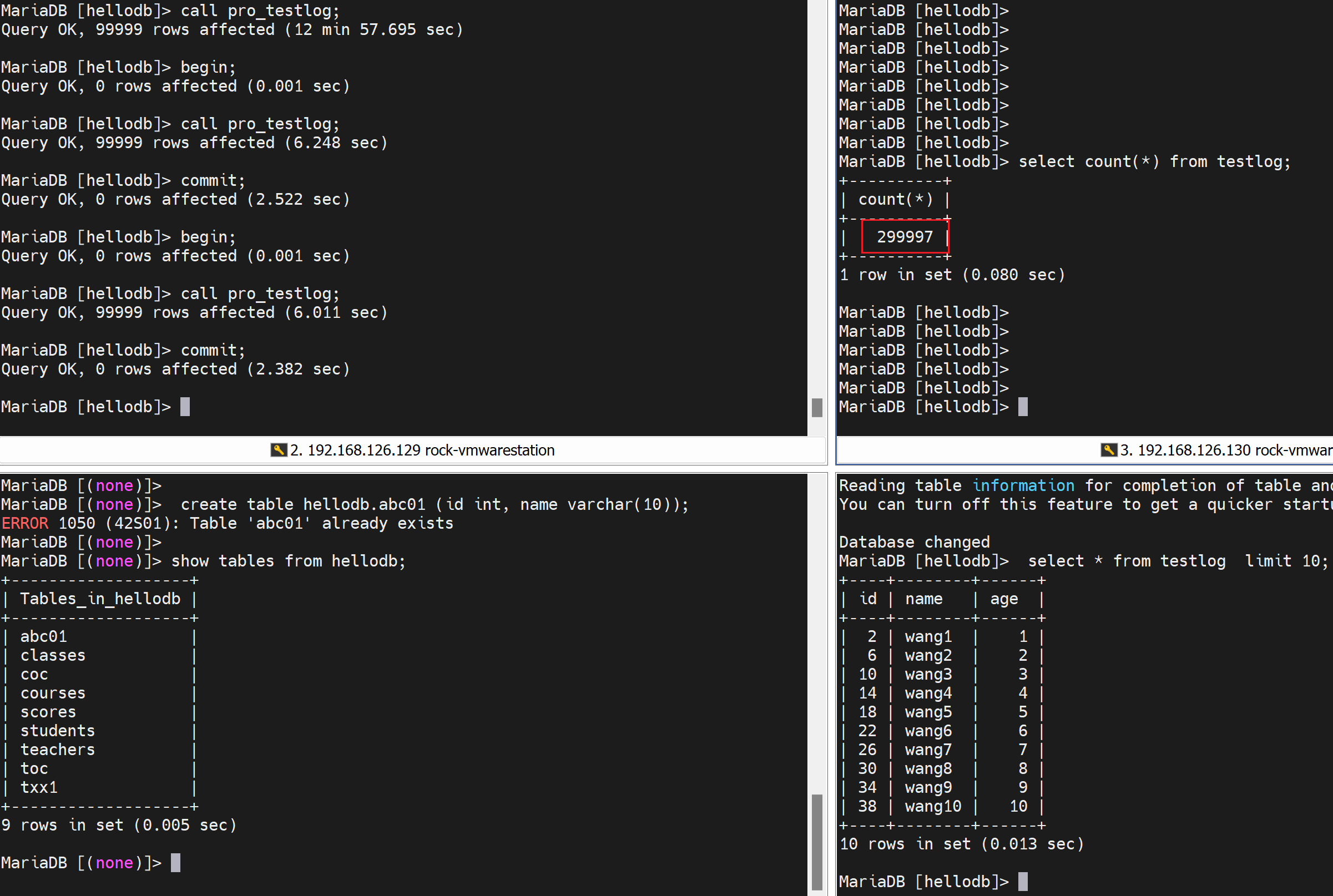
再次不跑事务看看
结论,galeraCluster集群,大数据并发写入,使用事务就很快!不使用事务就灰常慢!
复制的问题和解决方案
其实以下这段文字算不得什么问题和方案,聊胜于无,看看吧👇
(1)数据损坏或丢失
Master: MHA + semi repl
Slave:重新复制
(2)混合使用存储引擎
MyISAM:不支持事务
InnoDB: 支持事务
(3)不惟一的server id
重新复制
(2)复制延迟:
需要额外的监控工具的辅助
一从多主:mariadb10版后支持
多线程复制:对多个数据库复制,好像是高版本的特性。
TiDb概述
主从、多主,对于写操作,本质上都是在一台上操作的,所以mysql这种HA,本质上就是有瓶颈的。这话欠妥,没有讲到点子上,我们将LB的行为,在很多地方体现:①portchannel②f5这些其实都是针对多个session多个会话或多个用户去负载分担的,mysql的瓶颈本质的一个点就是如果是一个session里的一个事务,而这个事务里面有大量的操作,那么这个事务肯定是往一台机器持续读写的,而针对这个单个事务的负载分担解决方案就是TiDB它可以做到分布式事务。

牛逼👆
而更优的解决方案就是TiDb分布式数据库。

RDBMS关系型数据的 数据一致性ACID特性;NoSQL性能好但是没有保证数据的一致性;TiDb结合了两者的优点,又叫做NewSQL
所以DB分为了:RDBMS、NoSQL、NewSQL

据说:mysql的业务迁到TiDb,基本上不用改动,直接搬过去就能用,不用改代码。
TiDB的核心特点
1 高度兼容 MySQL 大多数情况下,无需修改代码即可从 MySQL 轻松迁移至 TiDB,分库分 表后的 MySQL 集群亦可通过 TiDB 工具进行实时迁移 2 水平弹性扩展 通过简单地增加新节点即可实现 TiDB 的水平扩展,按需扩展吞吐或存储,轻 松应对高并发、海量数据场景。 3 分布式事务 TiDB 100% 支持标准的 ACID 事务 4 真正金融级高可用 相比于传统主从 (M-S) 复制方案,基于 Raft 的多数派选举协议可以提 供金融级的 100% 数据强一致性保证,且在不丢失大多数副本的前提下,可以实现故障的自动 恢复 (auto-failover),无需人工介入。 5 一站式 HTAP 解决方案 TiDB 作为典型的 OLTP 行存数据库,同时兼具强大的 OLAP 性能, 配合 TiSpark,可提供一站式 HTAP解决方案,一份存储同时处理OLTP & OLAP(OLAP、OLTP 的介绍和比较 )无需传统繁琐的 ETL 过程。 6 云原生 SQL 数据库 TiDB 是为云而设计的数据库,同 Kubernetes (十分钟带你理解 Kubernetes核心概念 )深度耦合,支持公有云、私有云和混合云,使部署、配置和维护变得十 分简单。 TiDB 的设计目标是 100% 的 OLTP 场景和 80% 的 OLAP 场景,更复杂的 OLAP 分析可以通过 TiSpark 项目来完成。 TiDB 对业务没有任何侵入性,能优雅的替换传统的数据 库中间件、数据库分库分表等 Sharding 方案。同时它也让开发运维人员不用关注数据库 Scale 的细节问题,专注于业务开发,极大的提升研发的生产力.
数据库的整理差不多了就 下面介绍以下压力测试
性能衡量指标
数据库服务衡量指标
QPS: query per second # 查询性能: 每秒处理的查询次数,简单的单表select和多表join对系统资源的消耗是截然不同!所以压力测试的时候是要事先定义select查询规则--涉及哪些查询方法。
TPS: transaction per second # 事务的处理,主要指的就是数据的修改性能了,涉及增删改。
压力测试工具 mysqlslap # 系统自带,无需安装 Sysbench:功能强大 https://github.com/akopytov/sysbench tpcc-mysql MySQL Benchmark Suite MySQL super-smack MyBench
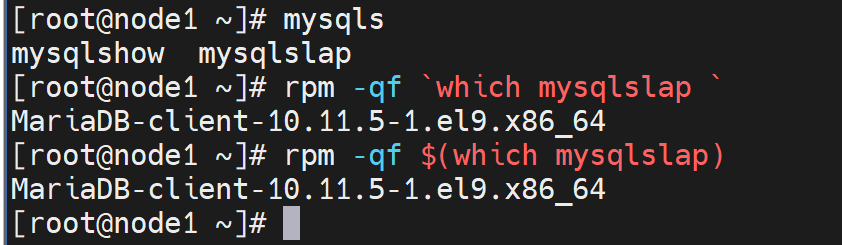
mysqlslap使用
该工具来源于MariaDB-client软件👇



注意:虽然这个工具测试完成后不会在DB中留痕,但是binlog肯定会大量被它修改的,所以测试的时候binlog要么关闭,要么单独存放。
binlog除了在/etc/my.cnd里定义,也可以放到/etc/my.cnf.d/server.conf里一样的,👇涉及集群galera里定义了binglog的格式row,所以也可以log-bin开启也放在这个配置文件里。
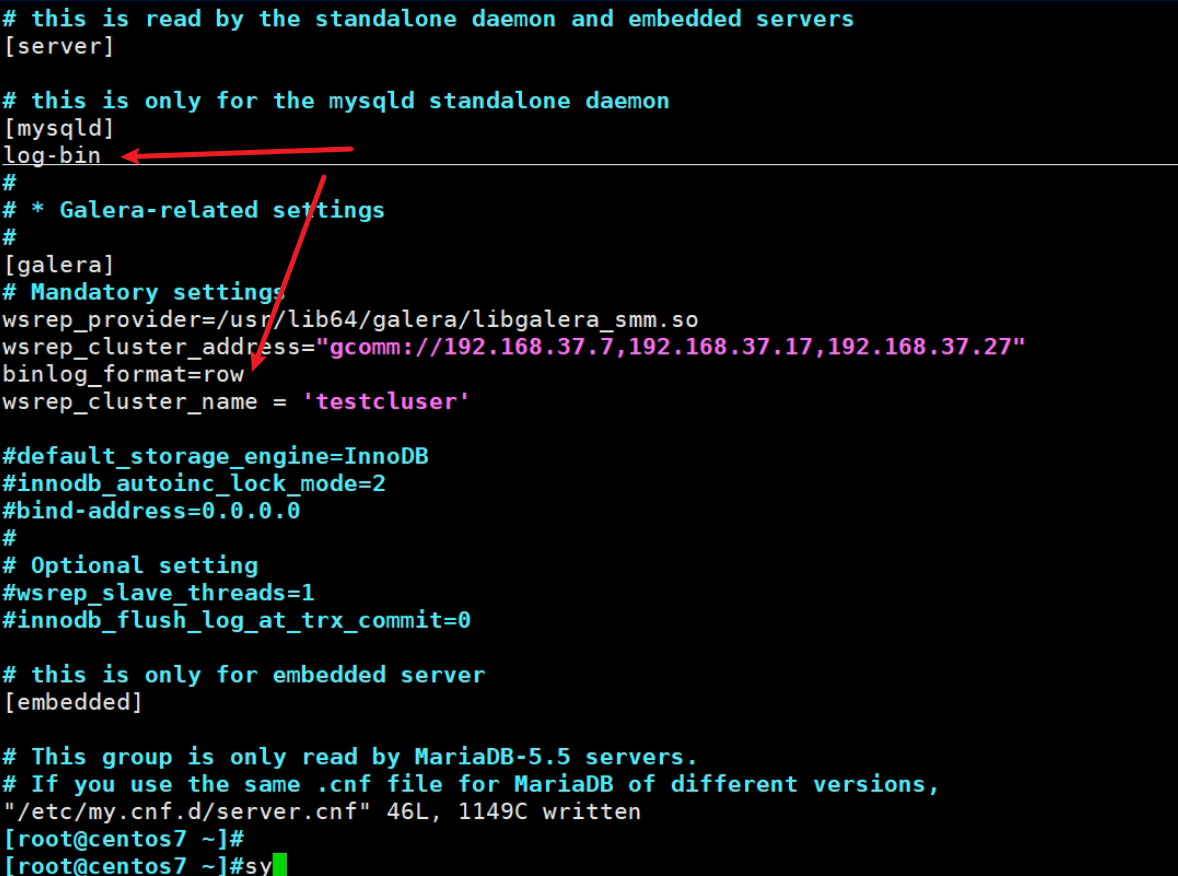
binlog是否启用,最好还是看变量,而不是ll /var/lib/mysql/去看相关文件有没有对吧,你这样还得去先看看cnf人家配置在哪里了。
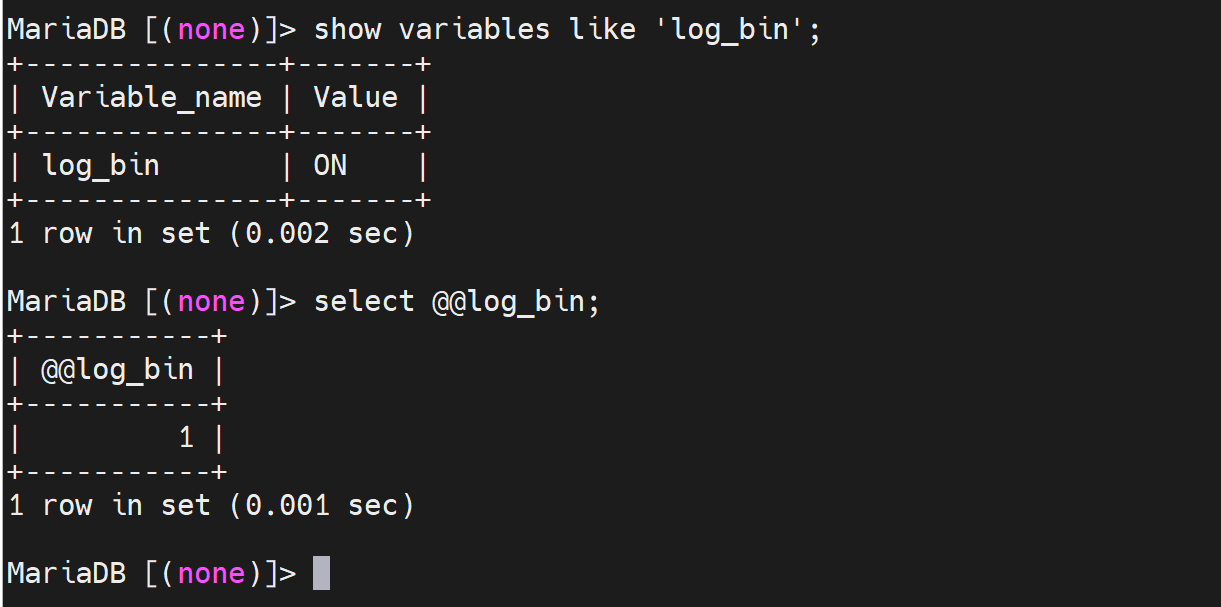


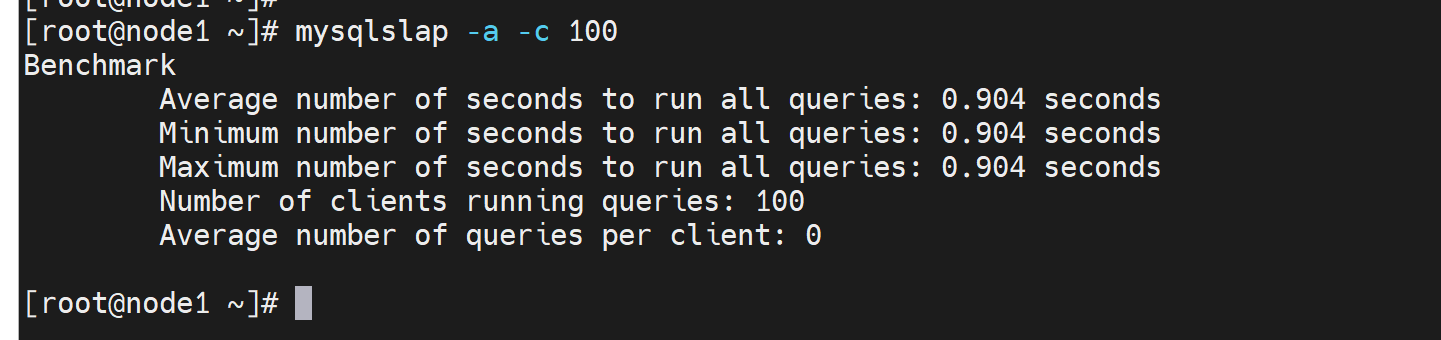
生产了大量的binlog
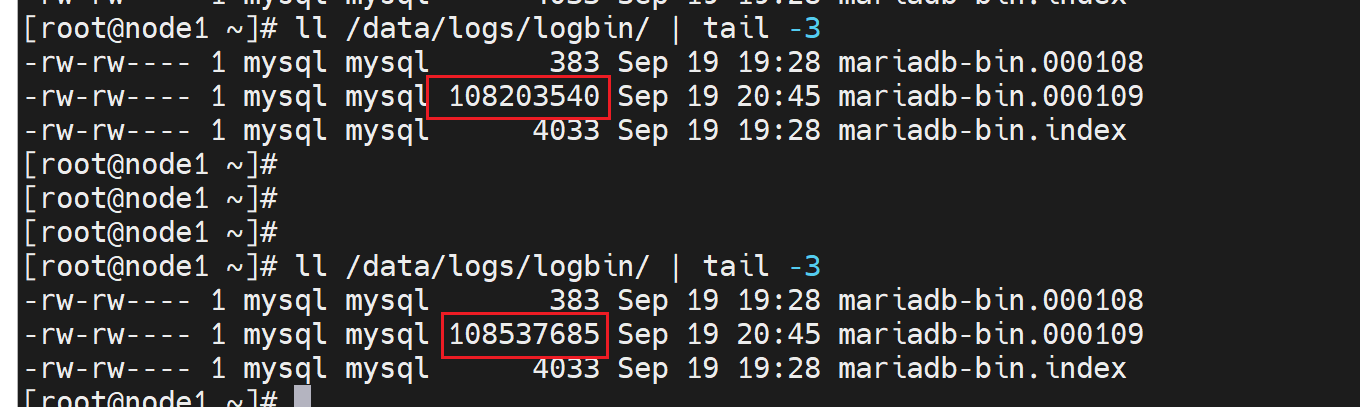
如果要停binlog,set 变量这种挺不掉,因为是基于你当前cli交互进去的session的,而压力测试是多session并发的,完全没有一点效果,因为session完全撞不到一起去,哈哈。而且sql_log_bin是session级别的变量,没有全局的。真的是session的,看看官方
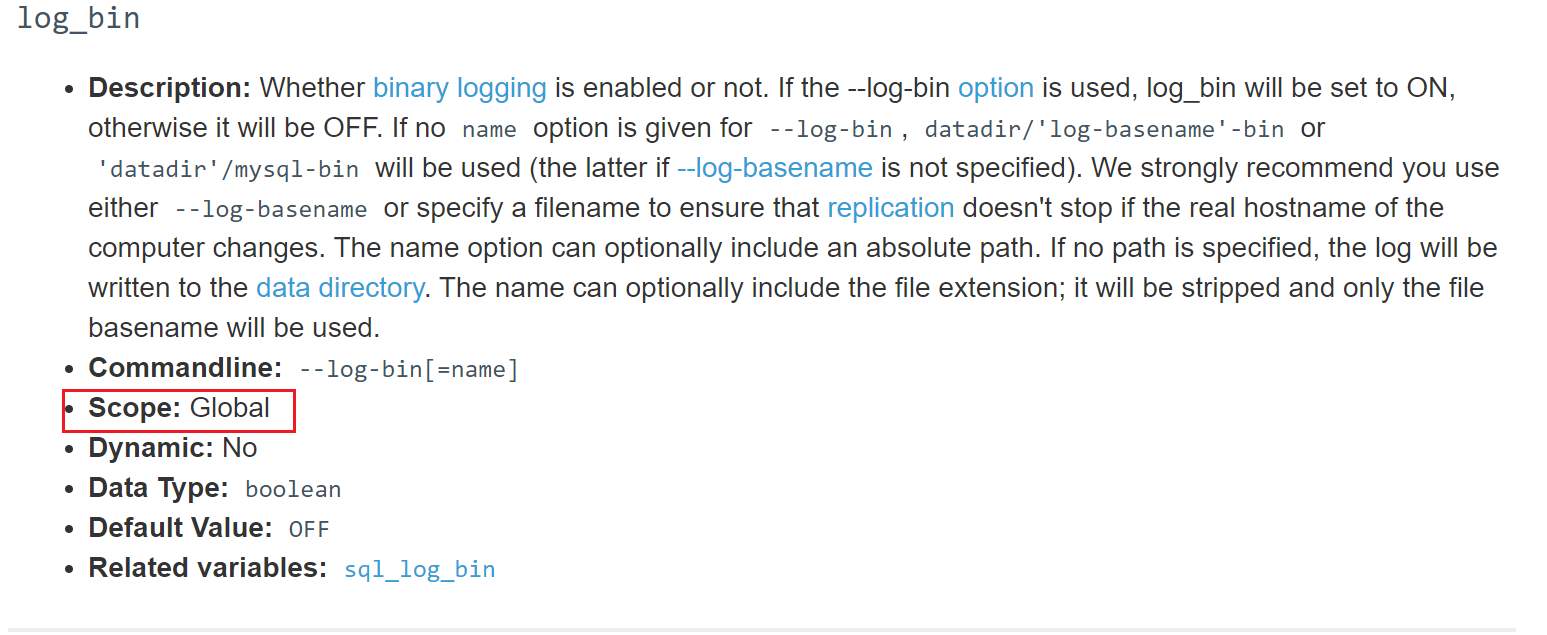
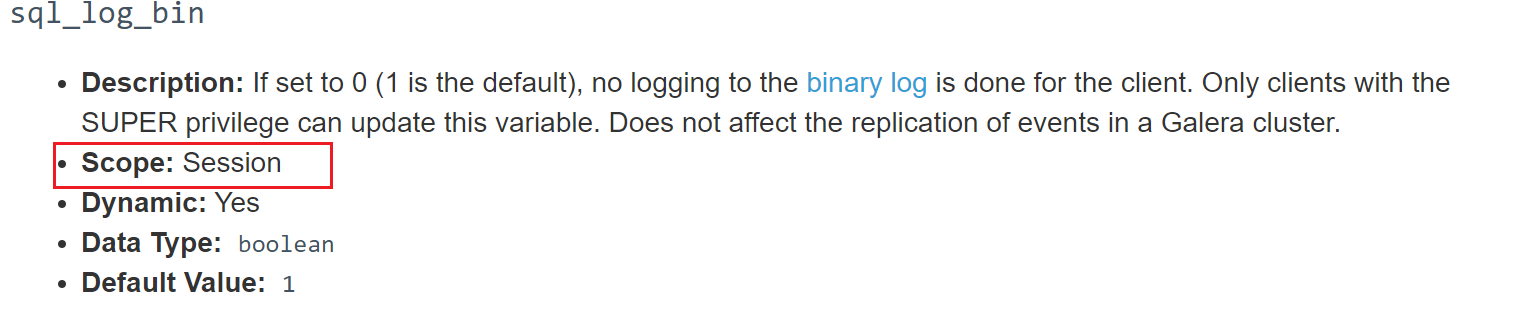
再试试
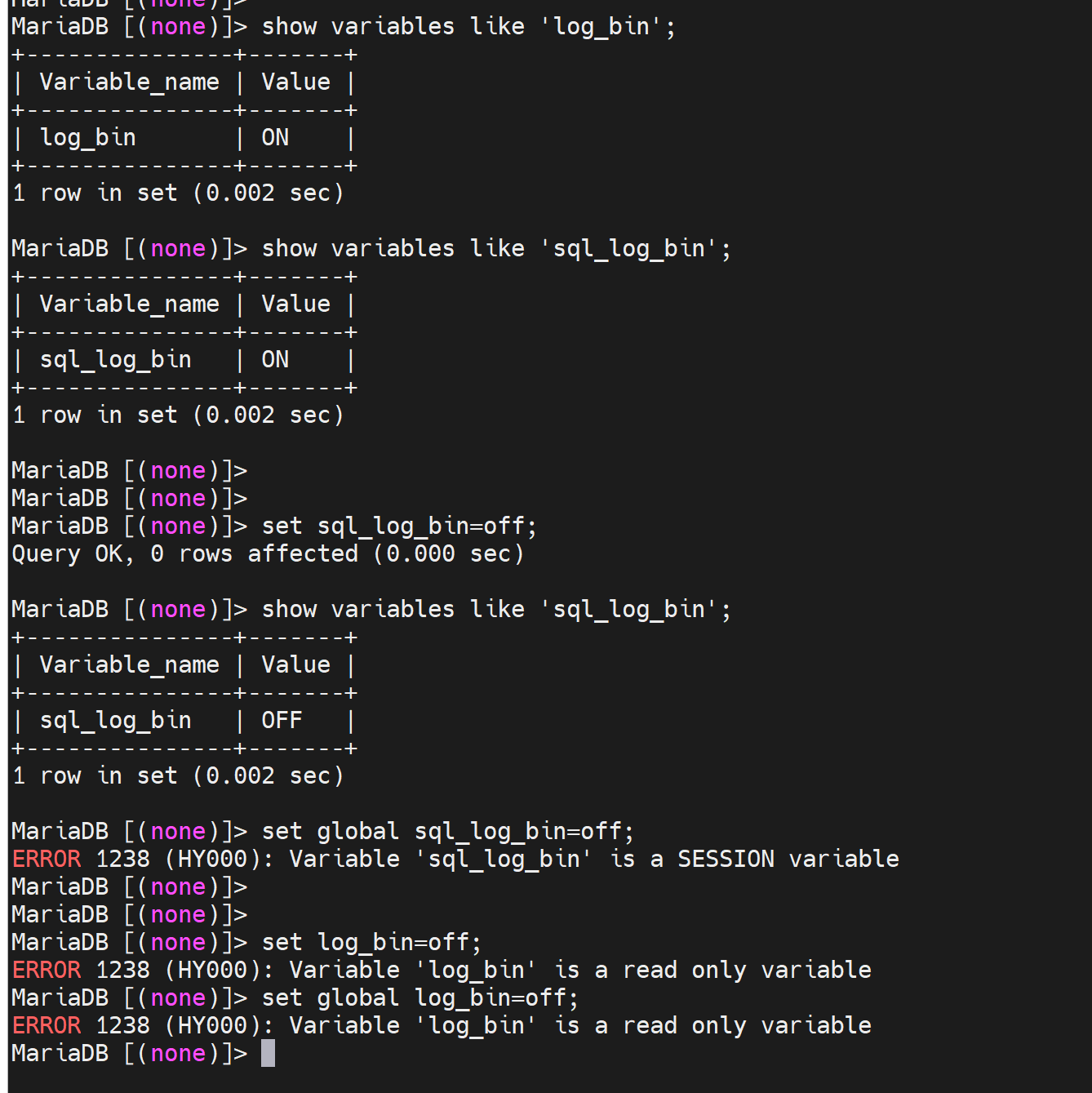
果然👆,无法实现:关闭全局binlog的效果,只能去cnf文件了。
等等👇这TM什么回事:
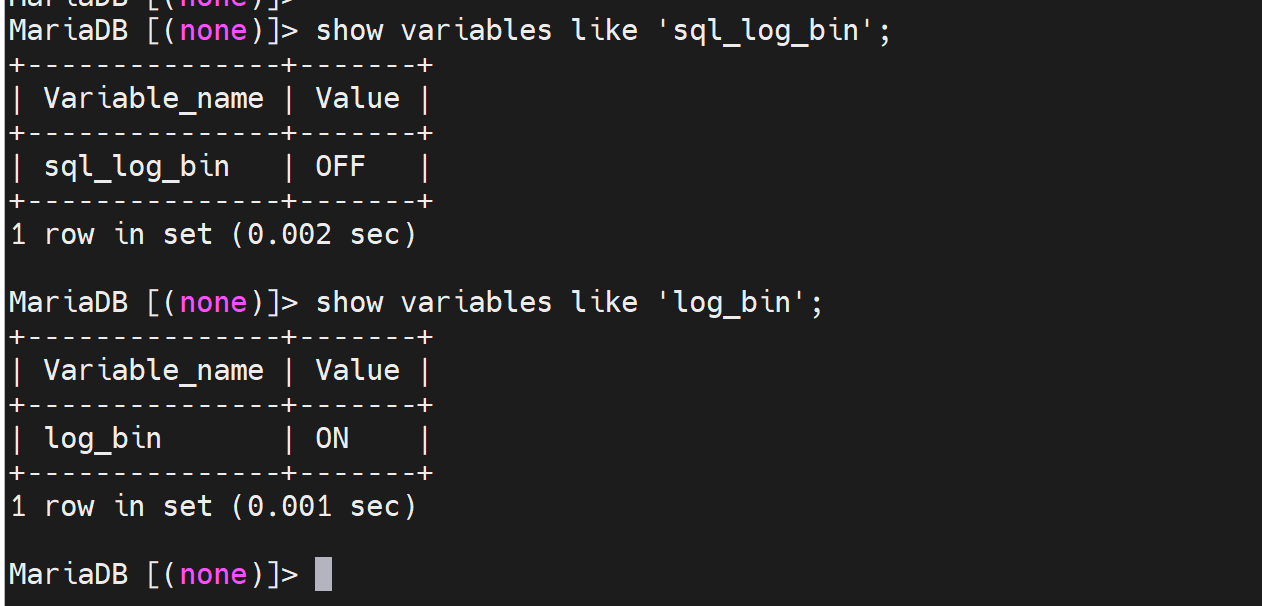
问👆binlog基于本会话到底是关了还是没关?
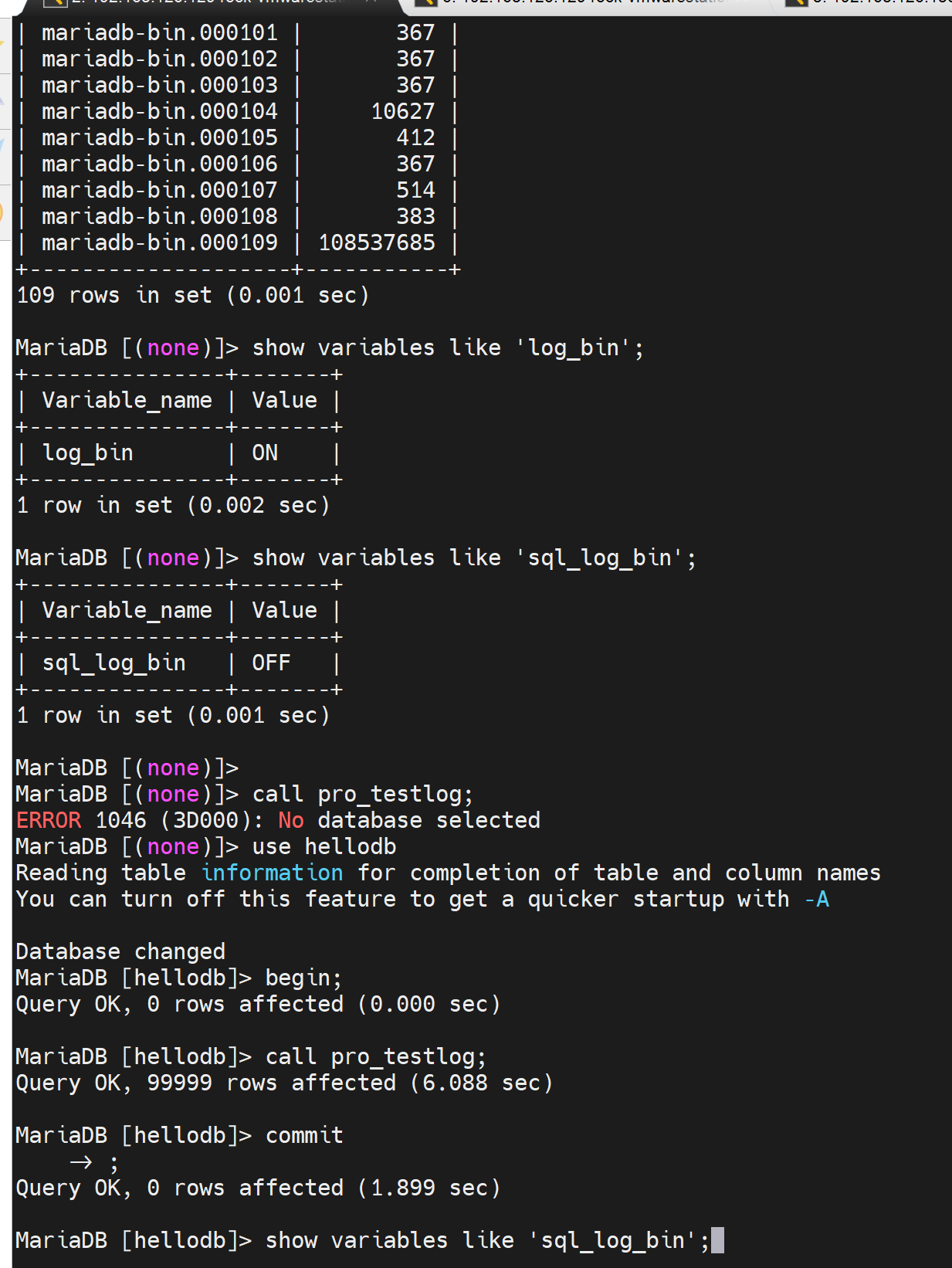
确实关了
测试引擎之间的差异👇
[root@node1 ~]# mysqlslap -a --concurrency=50,100 --number-of-queries 1000 --iterations=5 --engine=myisam,innodb --debug-info -uroot -pmagedu
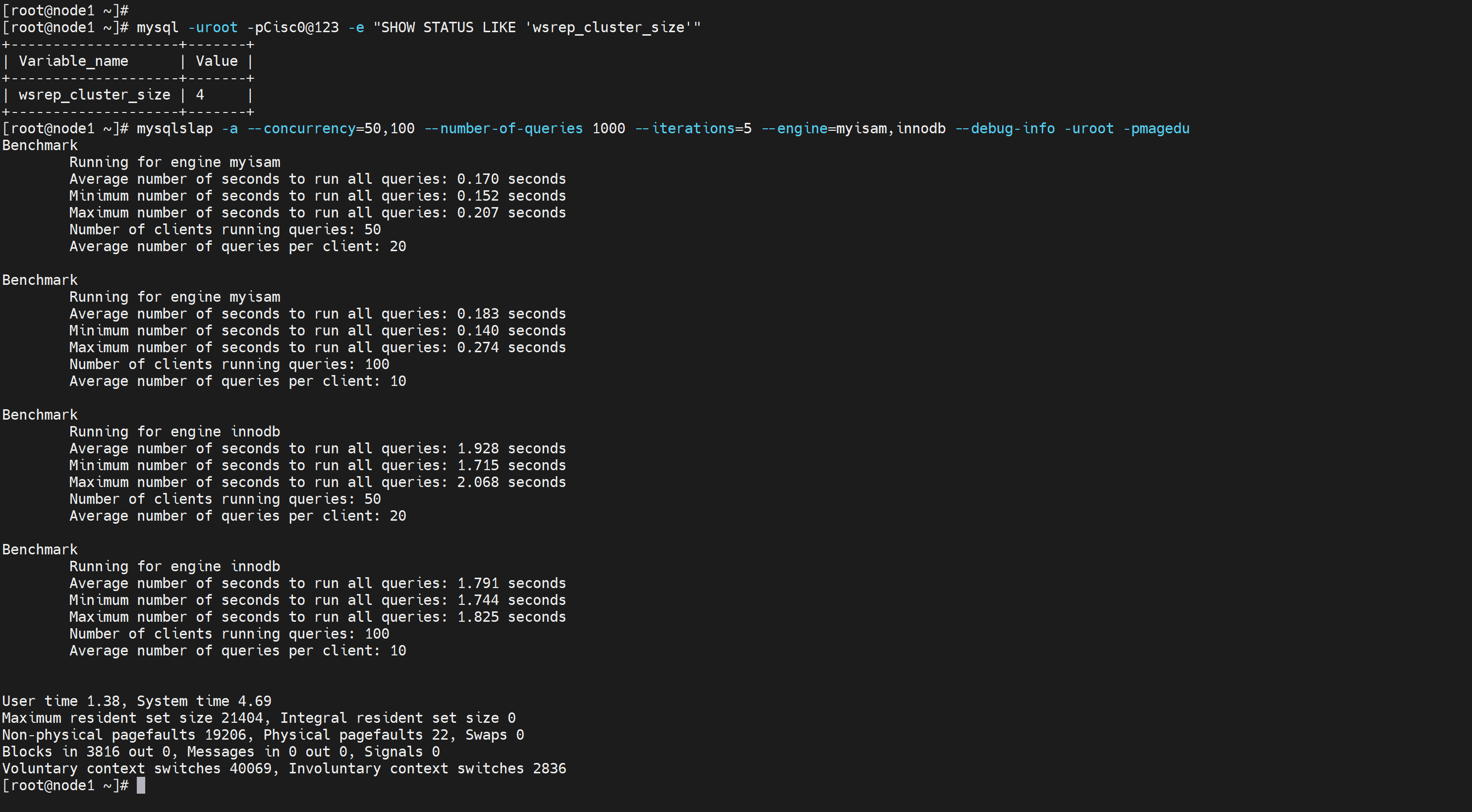
--concurrency=50,100 # 50到100个并发数,是个范围区间。
案例
也不是绝对的👇,网速随便搜搜都有推荐配置优化方案,也可以参考他们的。




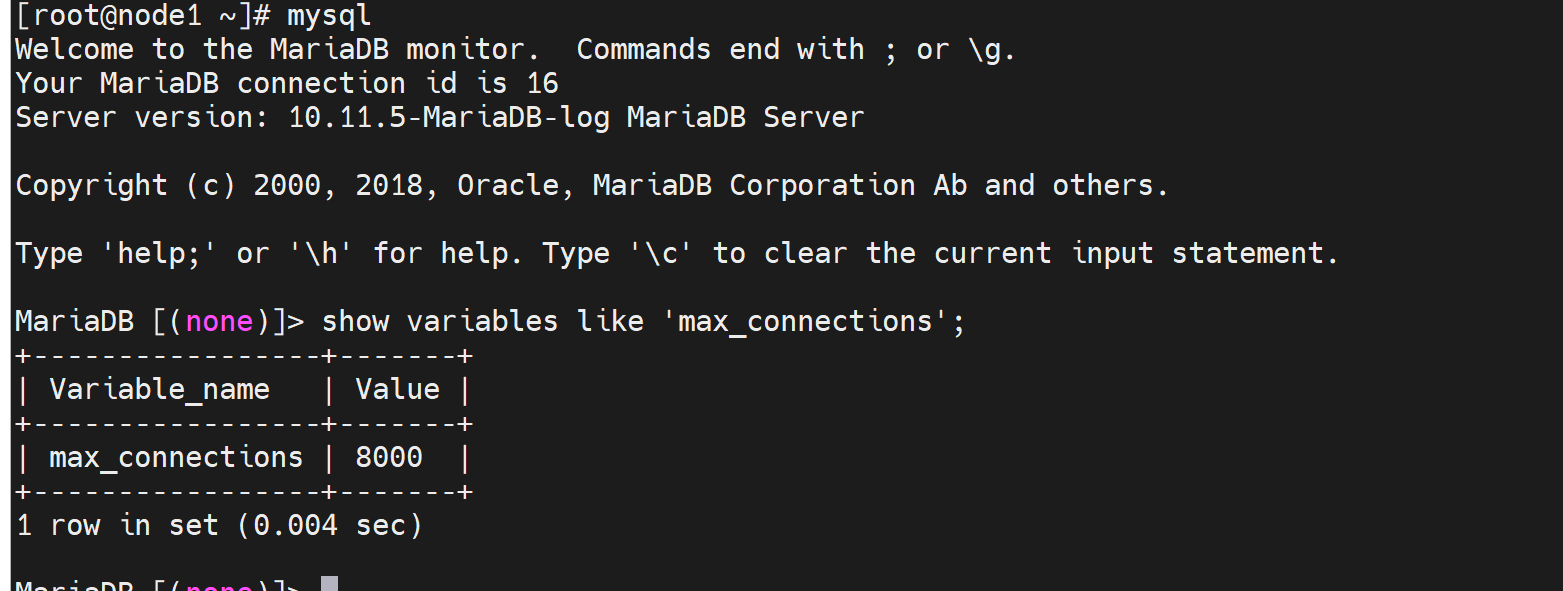
max_connections的默认值看看
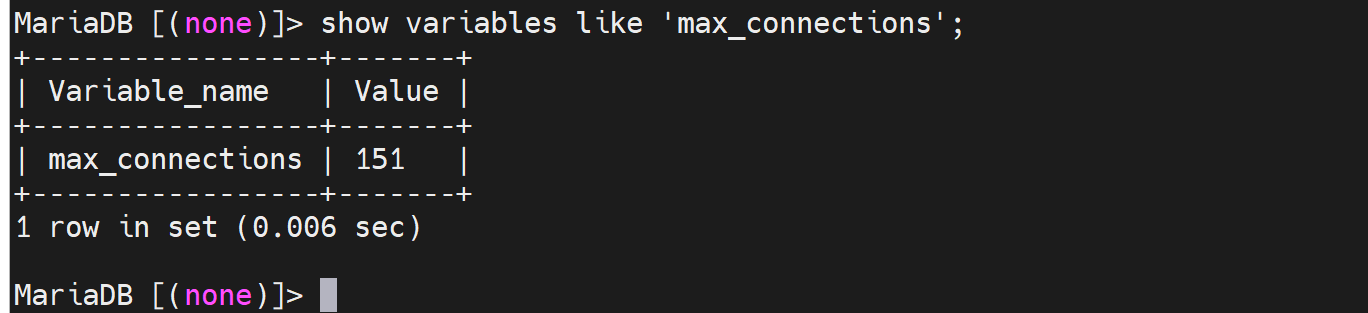
因为这个默认限制,所以并发测试看下效果👇,并发就是多个sessions同时测试的。
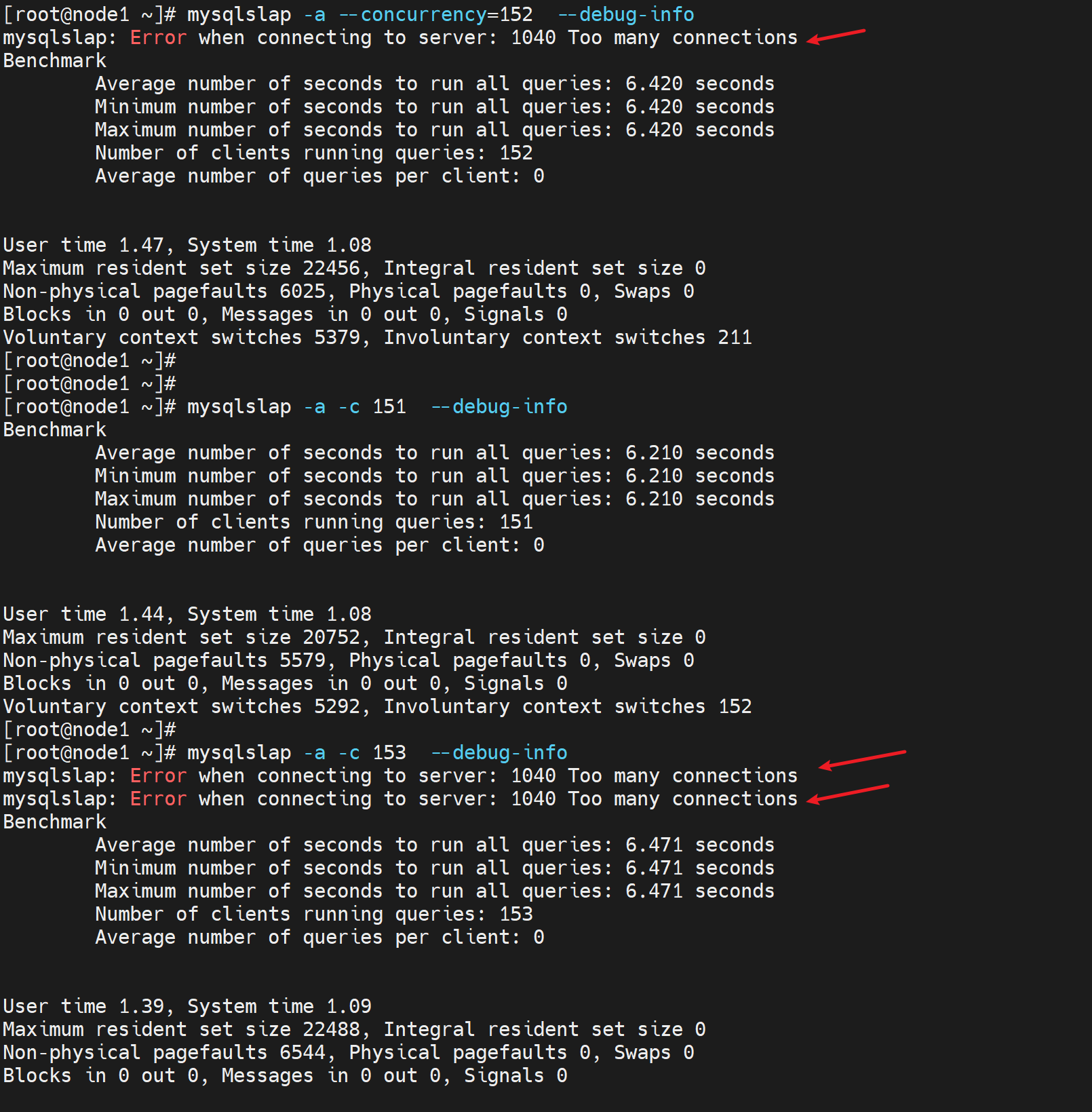
修改并发数👇
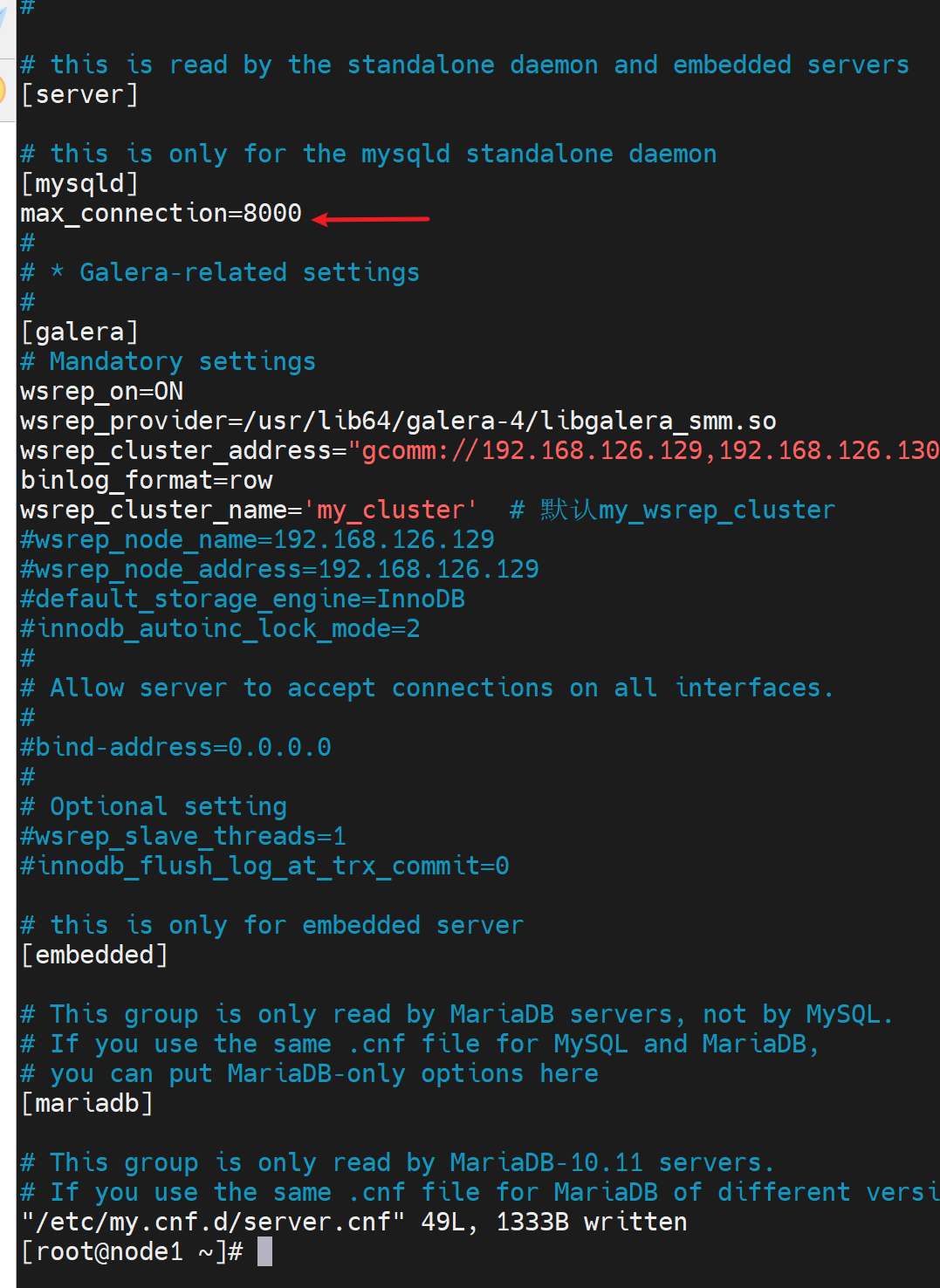
重启服务后
那个遇到低版本的并发改不上去(mariadb5.5.60就是上不去151只能通过my.cnf改成214的上限)的处理方法,这里也做一下记录,因为涉及底层逻辑:151的默认,明明mysql的配置文件里改的是2000,但是实际只能到214,是因为并发底层走的是文件socket,这个socket要调上去的,是系统层面的东西,底层的东西。打开一个socket就会开启一个文件描述符fd。
1、mysql的配置文件里
/etc/my.cnf里或者/etc/my.cnf.d/server.cnf的max-connectsions=2000
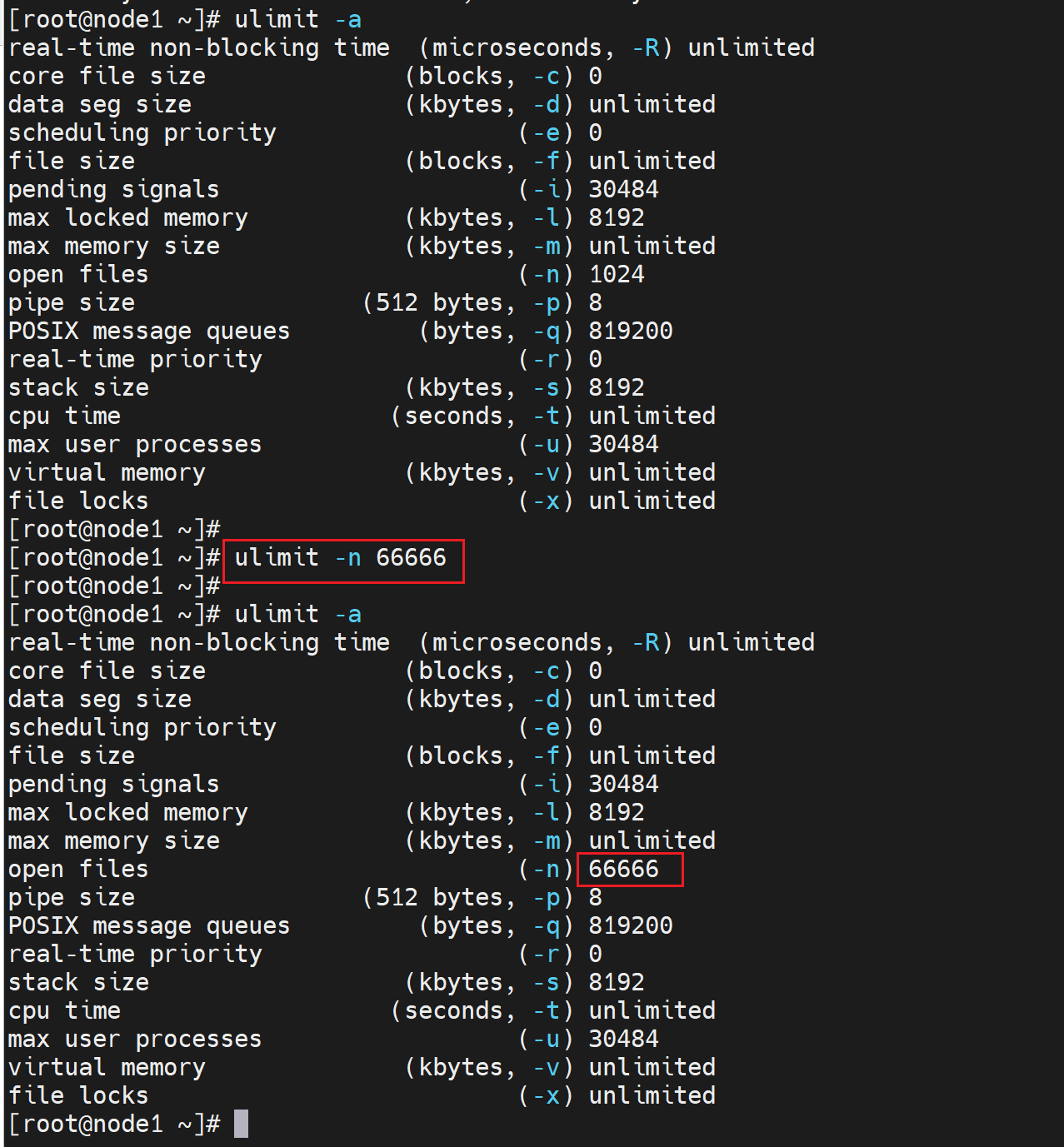
2、系统级别的socket,文件socket的限制扩容
ulimit -n 66666 # 设置
ulimit -a # 查看 就可以看到open files这项改了,不过这个命令是基于session修改的,也就是当前shell窗口有效。
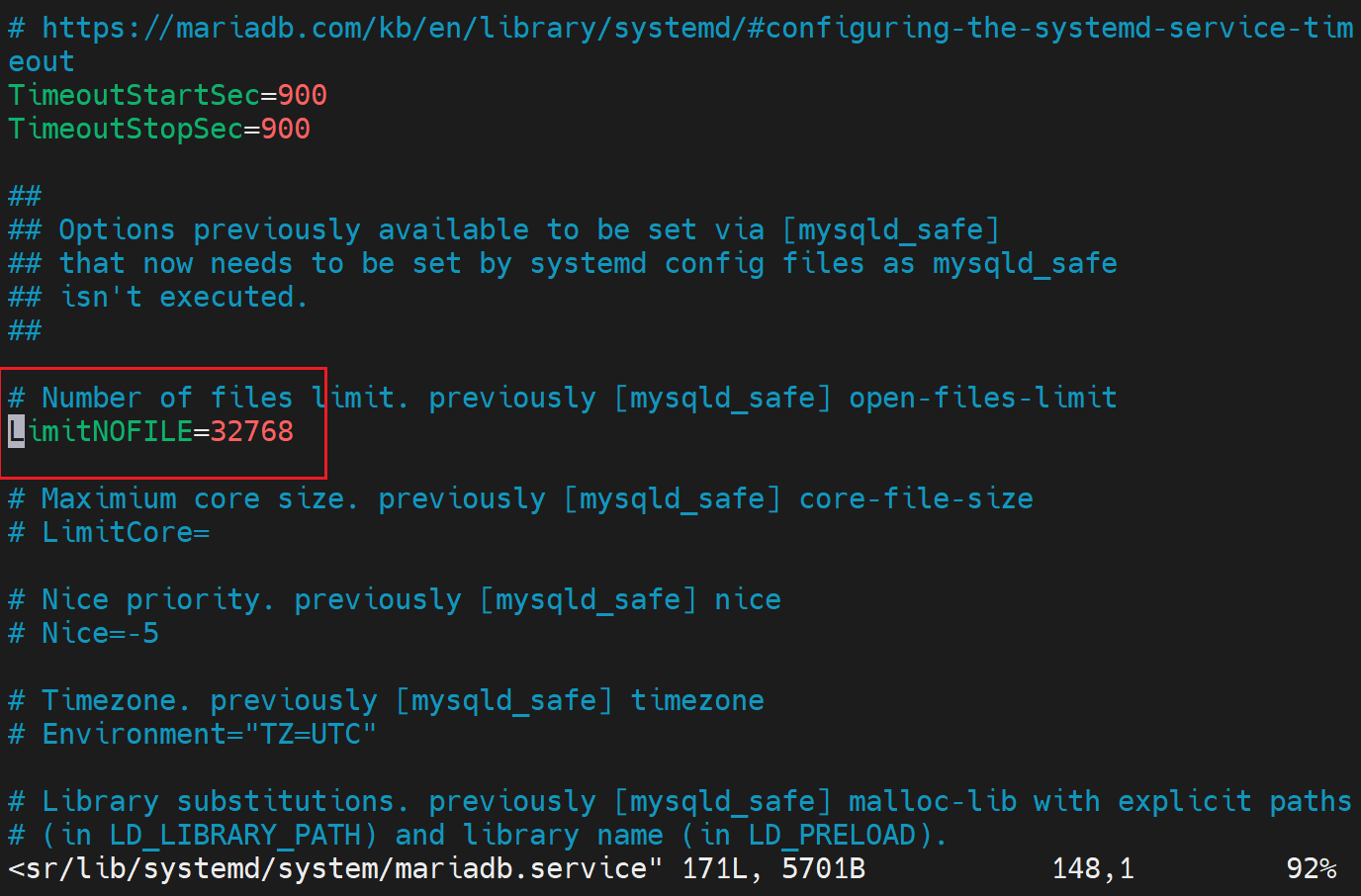
3、LimitNOFILE
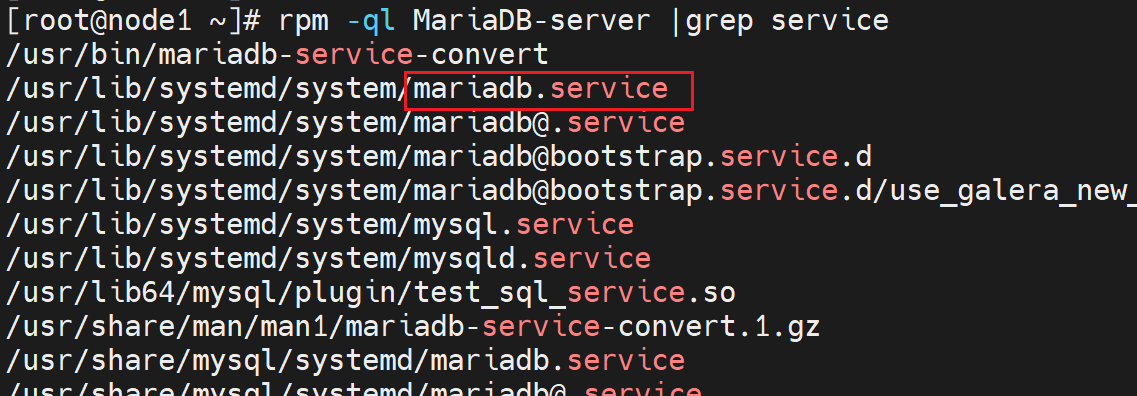
高版本就是改了的,至于第二点ulimit应该不用改!确保下面👇的数据足够以及mysql配置文件里max_connections改了就行了。
一般数据库1000-2000并发就差不多了,不想apache或nginx上万都行。
所数据库的并发数,不是越大越好,设置一个你的服务器资源能够承受的值就好,如果设置过大比如8000,结果真的来了这么多并发,就会导致db处理不过来,结果就是一个用户都访问不了了。
back_log
并发加入是2000,那么如果超出2000,又来了10个人,那么10个就是进入backlog进行排队。这个排队好像和QoS里的队列不是一回事,是保持的tcp连接数,本来2000个tcp连接上线,超出了也不是说就拒绝掉,而是用back_log机制暂存以下这些tcp连接。
max_connect_errors
针对单个用户,如果连接报错的次数达到一定的值,就会禁止该client连接过来。直到mysql服务重启,或者flush hosts命令清空此client主机的相关信息。所以这个参数的计数周期也就是两次服务重启或者flush hosts之间的时间。
比如黑客不断尝试连接,密码出错了10次,此时应该就可以触发此机制。
open_files_limit
这个其实就是 /usr/lib/systemd/system/mariadb.service 文件里的LimitNOFILE参数
两个都是干一件事的,不过使用场景不同
open_files_limit是适用于二进制安装或者编译安装的,这两类的服务启动都是二进制文件启动的,此时调整socket文件的打开数就这么调,这就是一个配置选项直接配置在my.cnf配置文件里。
LimitNOFILEs是用于 systemctl 启动的服务
本身就是一个配置选项,也是变量,所以直接配置到/etc/my.cnf里就行啦,他👇这里的三个配置方式,最后一个是/etc/security/limits.onf估计也是一个意思。
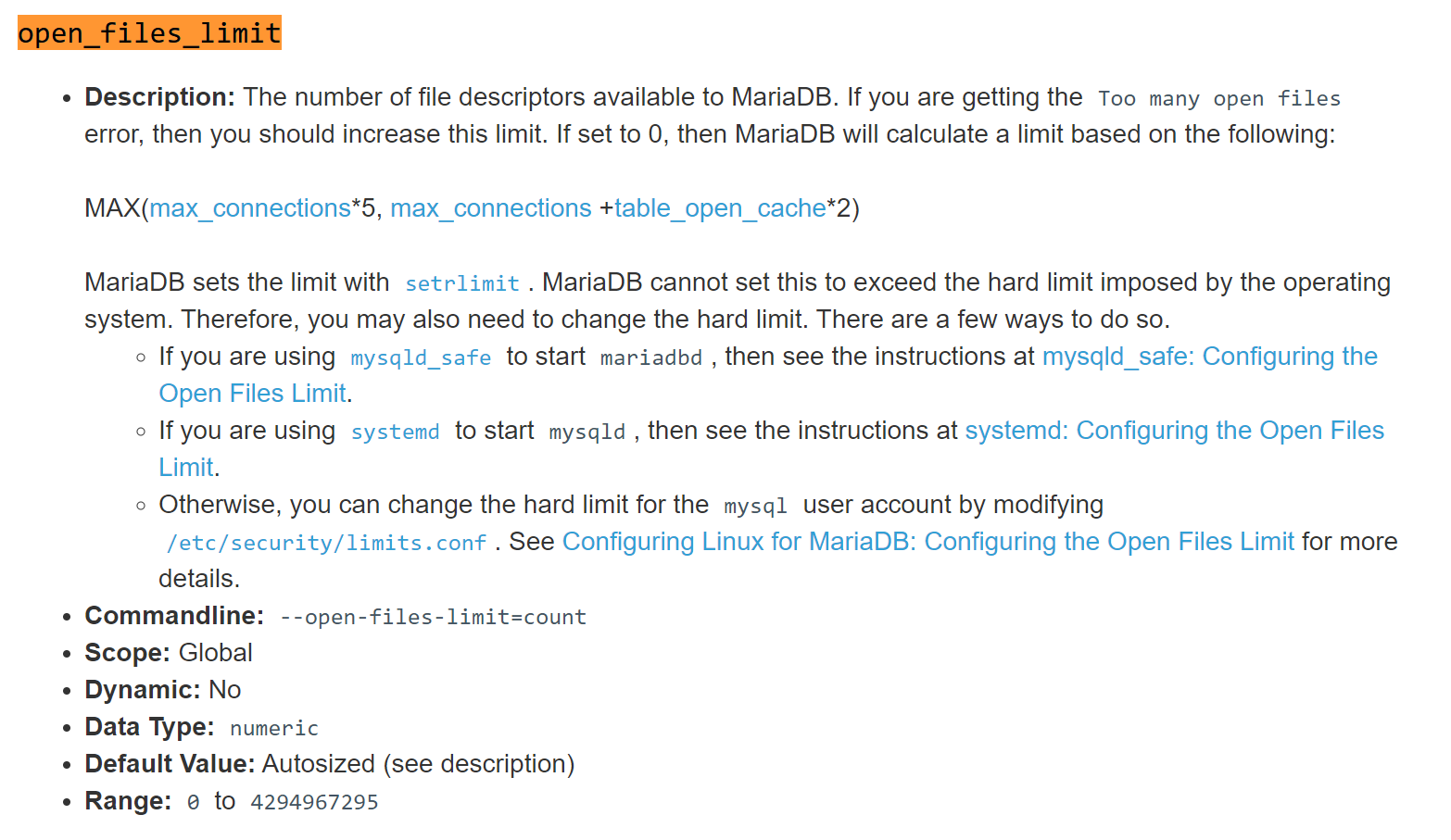

就是知道有这么个东西,具体最合适的还需要自己修订,和找最新的实践分享。