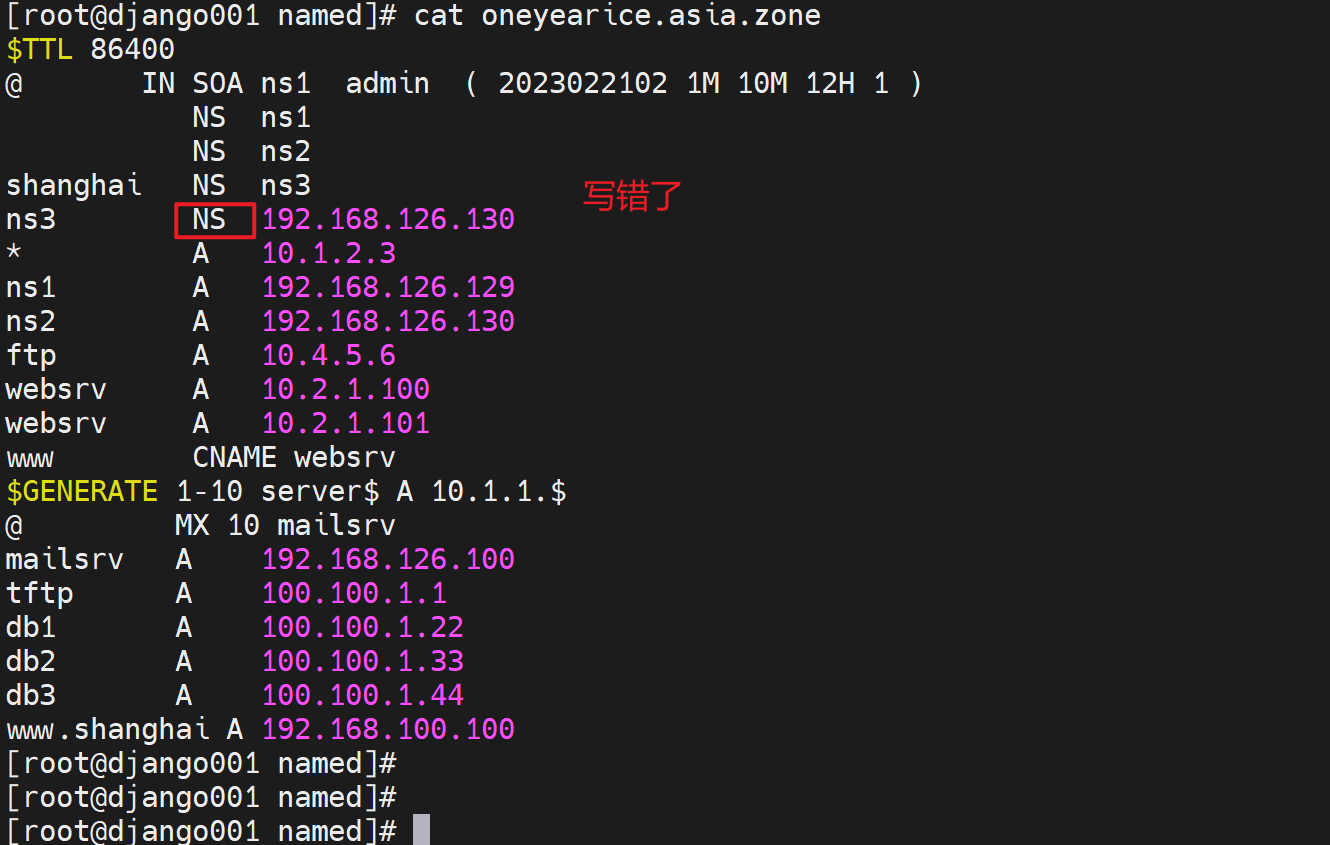
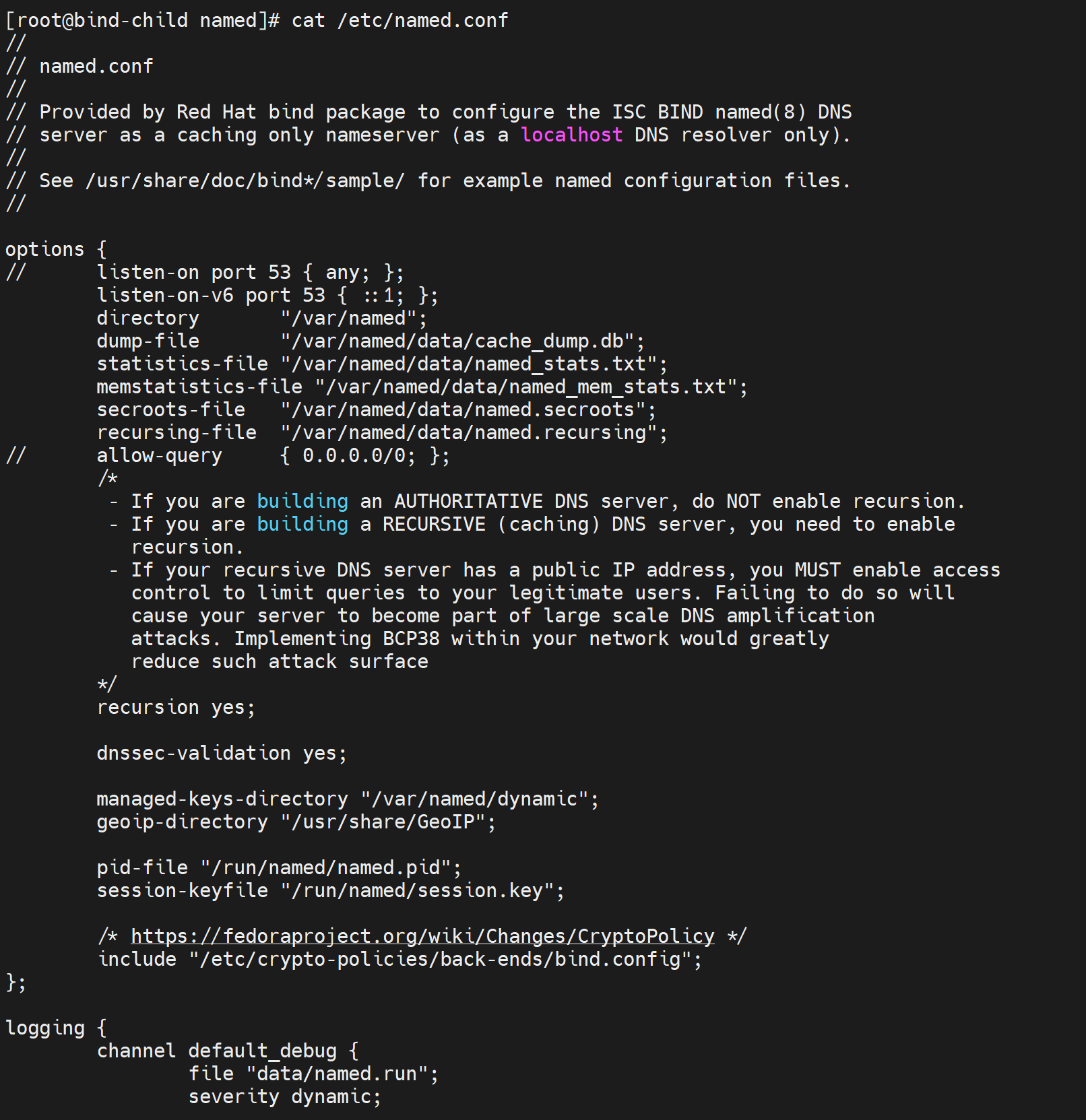
第5节. 实现DNS子域委派和转发
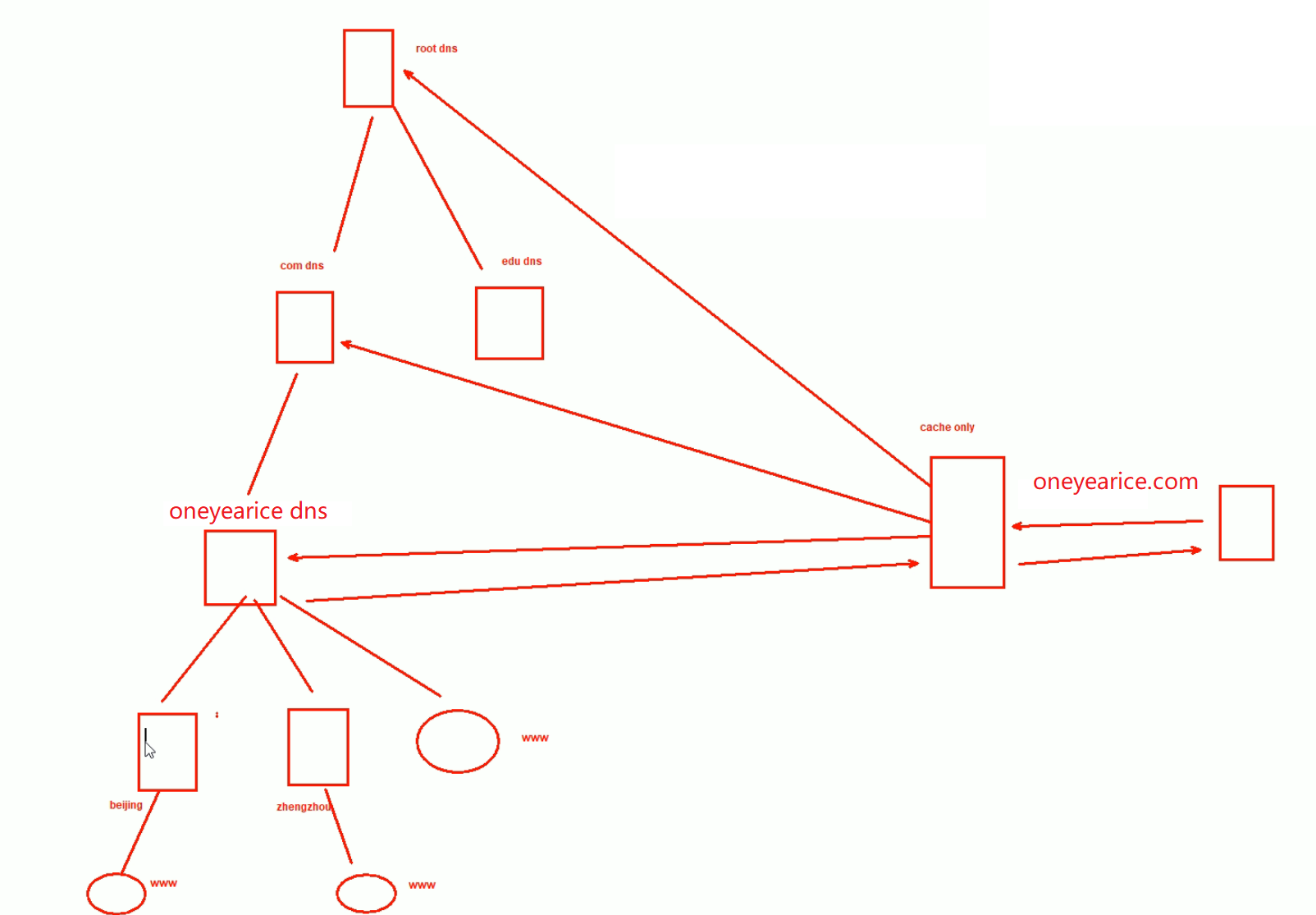
oneyearice算作父域,bejing、shanghai是子域,
1、如果父域和子域在一个机器上
shanghai.oneyearice.asia和oneyearice.asia放在同一台电脑上
根据前面章节学的内容,也就是一条A记录的事
www.shanghai A 192.168.100.100
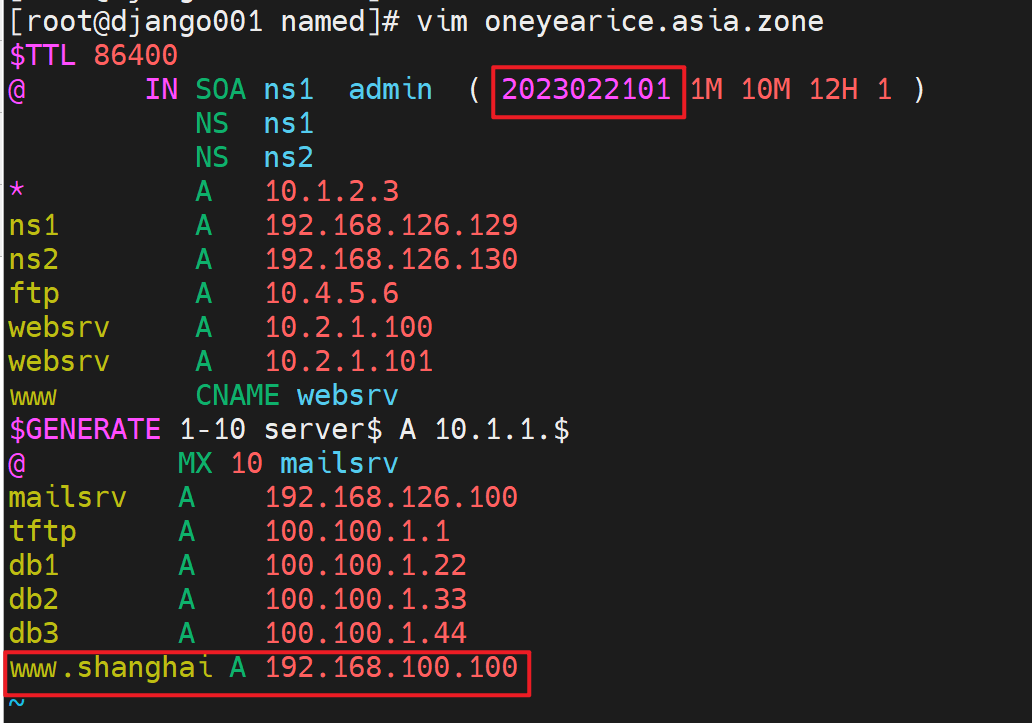
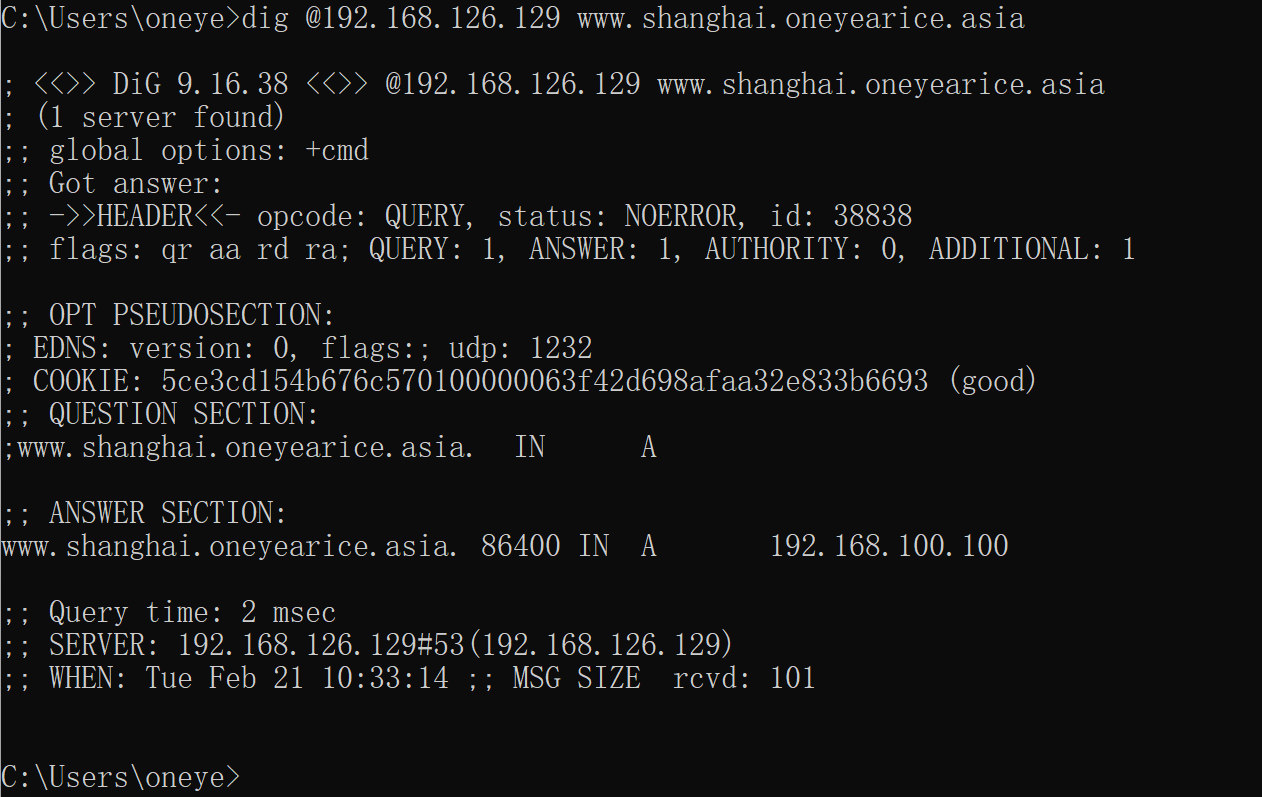
这样虽然有www.shanghai.oneyearice.aisa的解析看着有一个shanghai的子域,但是其实只是条A记录。
如果shanghai这个子域里的记录比较多,是可以独立出来成为单独的配置文件的。
比如
ftp.shanghai.
db.shanghai.
mysql.shanghai.
mail.shanghai.
管理上父域和子域属于集团不同部门或者子公司的权限下发,就需要独立开来。
独立出来就很简单,cp -a 一份出来 改改就行
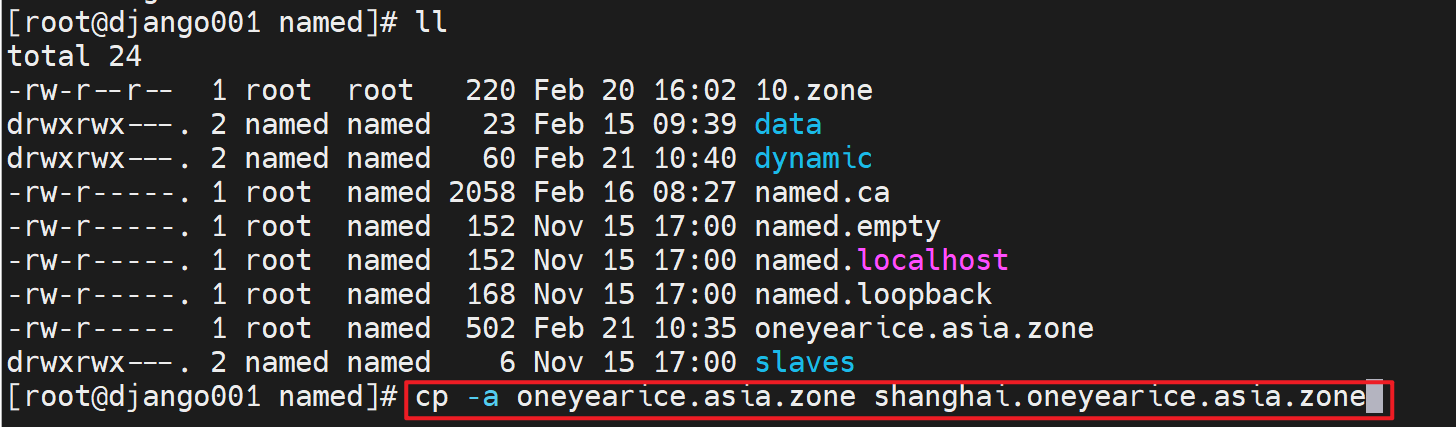
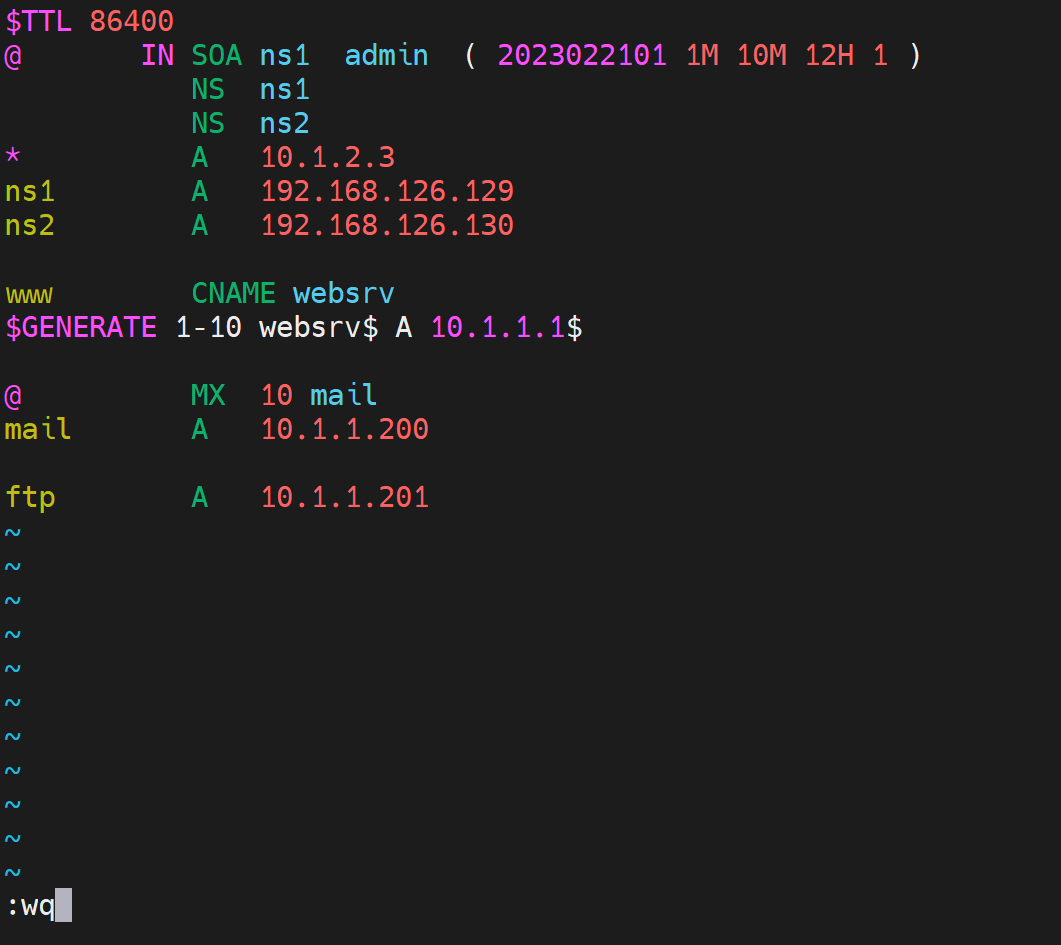
修改一下zone域配置文件。然后这里有个快捷键挺好玩的,👇记一下可以。

虽然说是父子域,但是从配置角度上来讲,就是两个独立的zone。
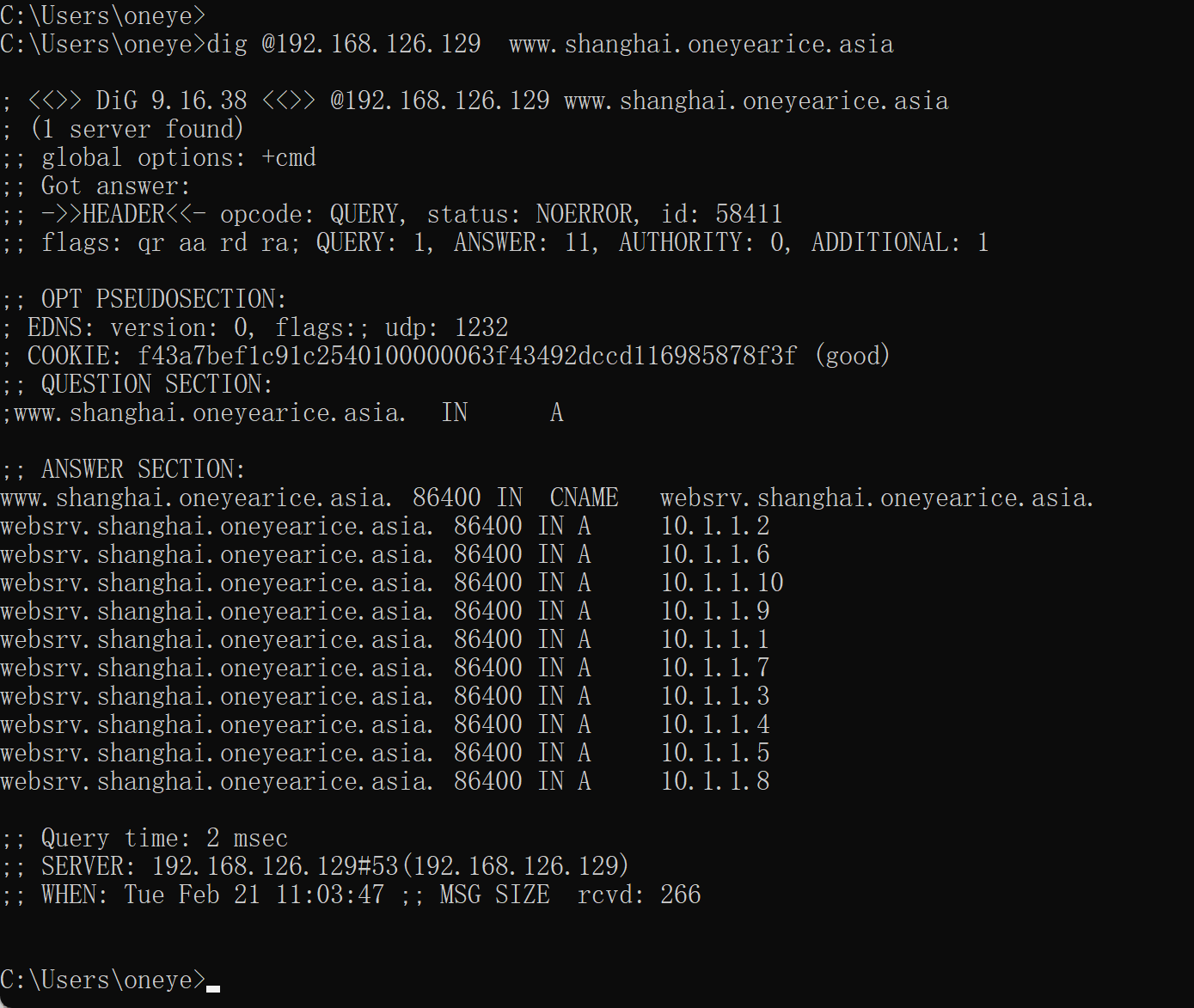
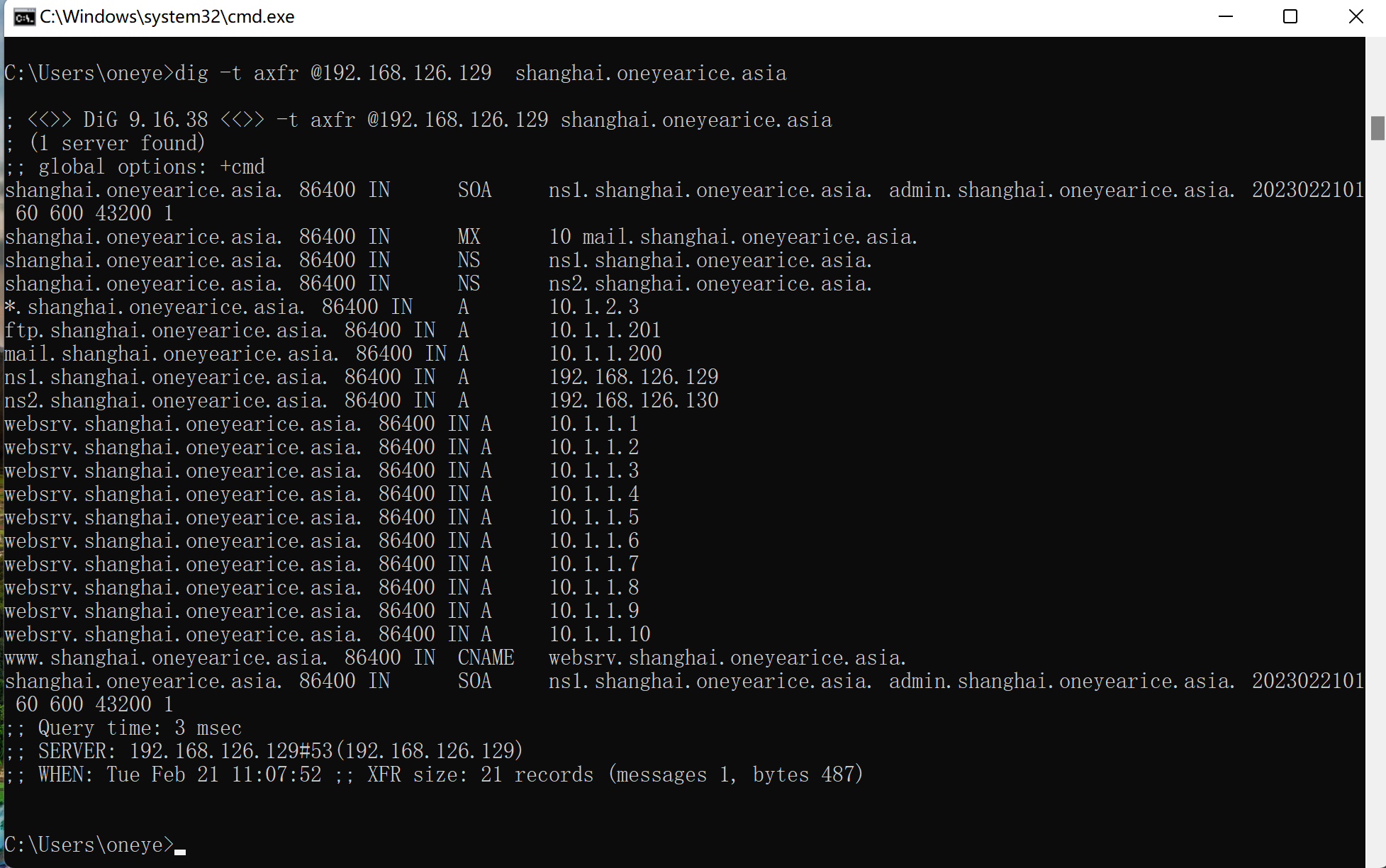
这样父子域 还在同一个设备,从管理角度上还没有完全分开。除非你用facl去管理权限?
最好分开来合乎管理,下面就是学习 父子不在一起的场景。
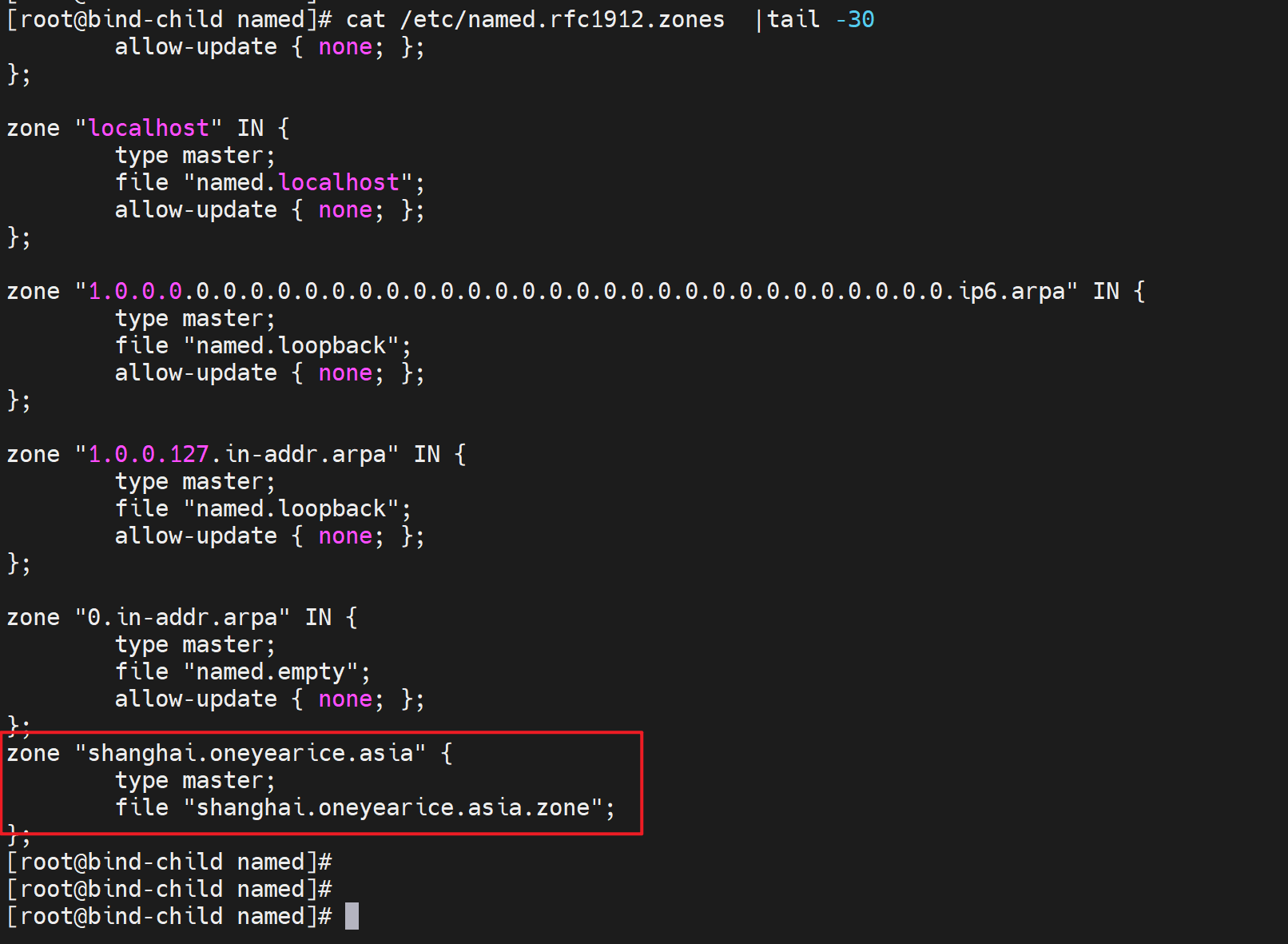
2、如果父域和子域在不同机器上
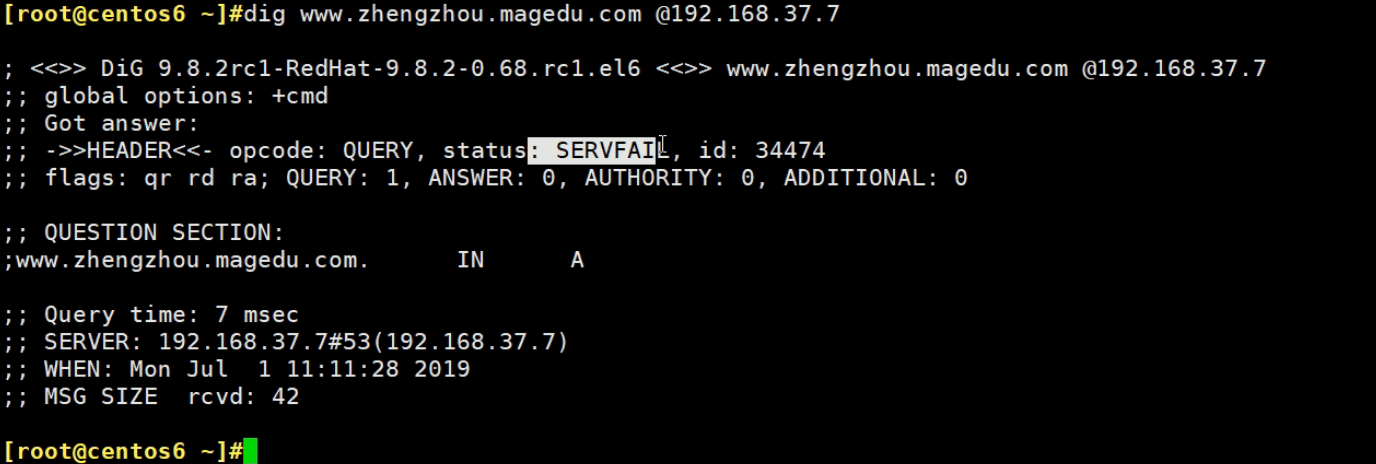
其实就是子域委派,感觉就是NS写一下就好了,之前freenom里就这么写的。
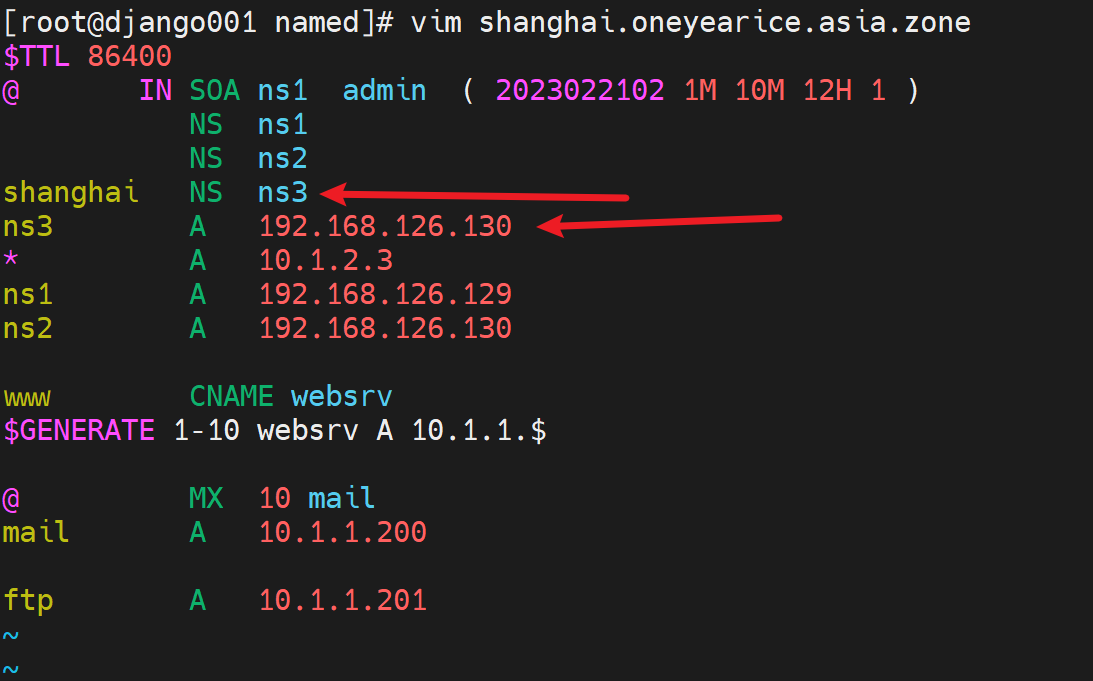
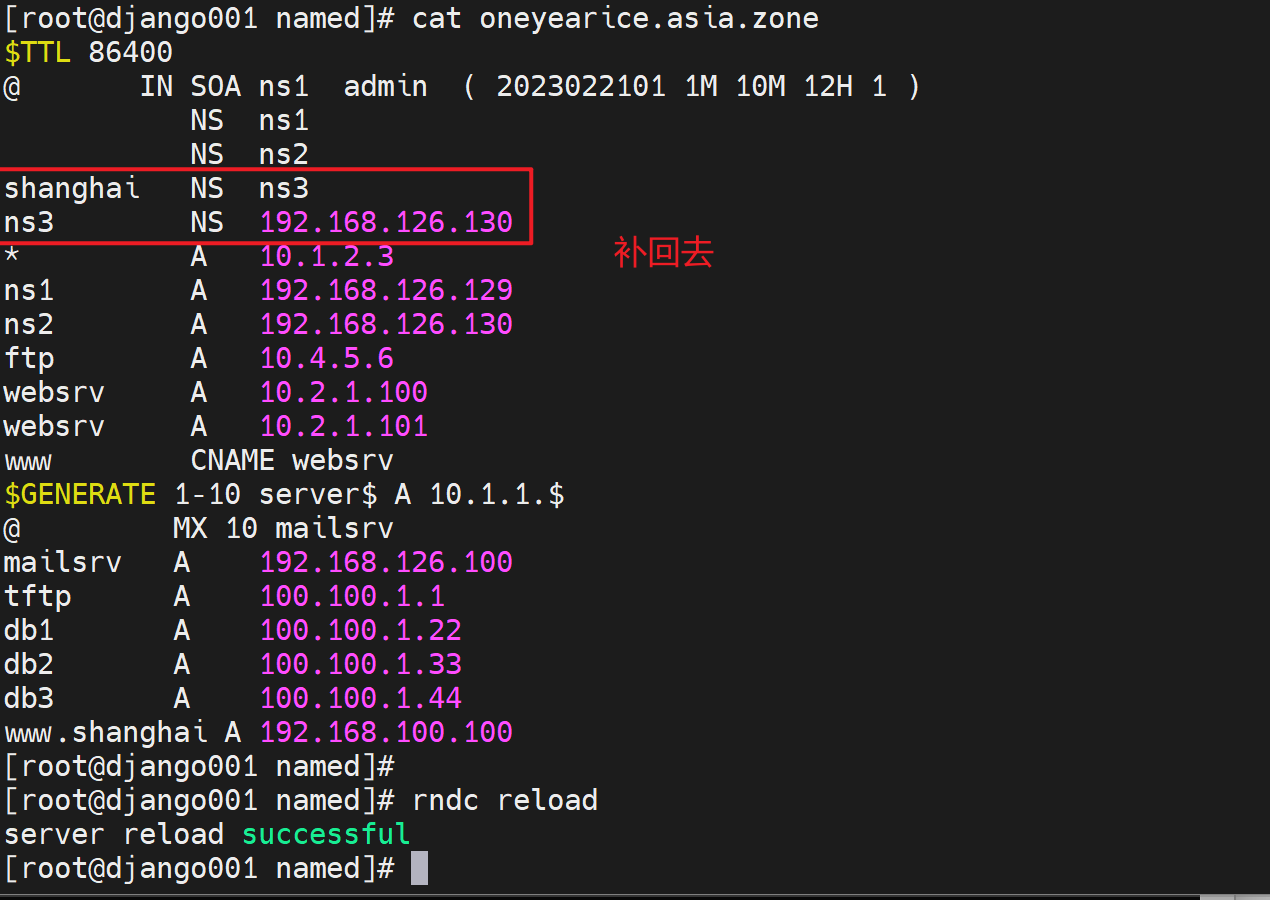
上图有问题写错文件了,应该写道oneyearice.asia.zone这个父域文件里的NS记录,然后这个shanghai.oneyearice.aisa.zone的子域文件就可以删除了。
修改一下:
1、删除zone 配置文件
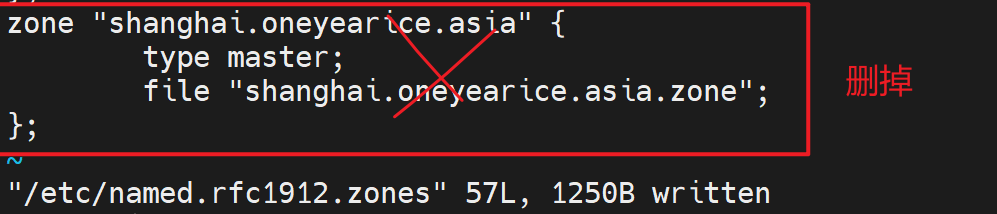
2、删掉对应的zone file记录文件
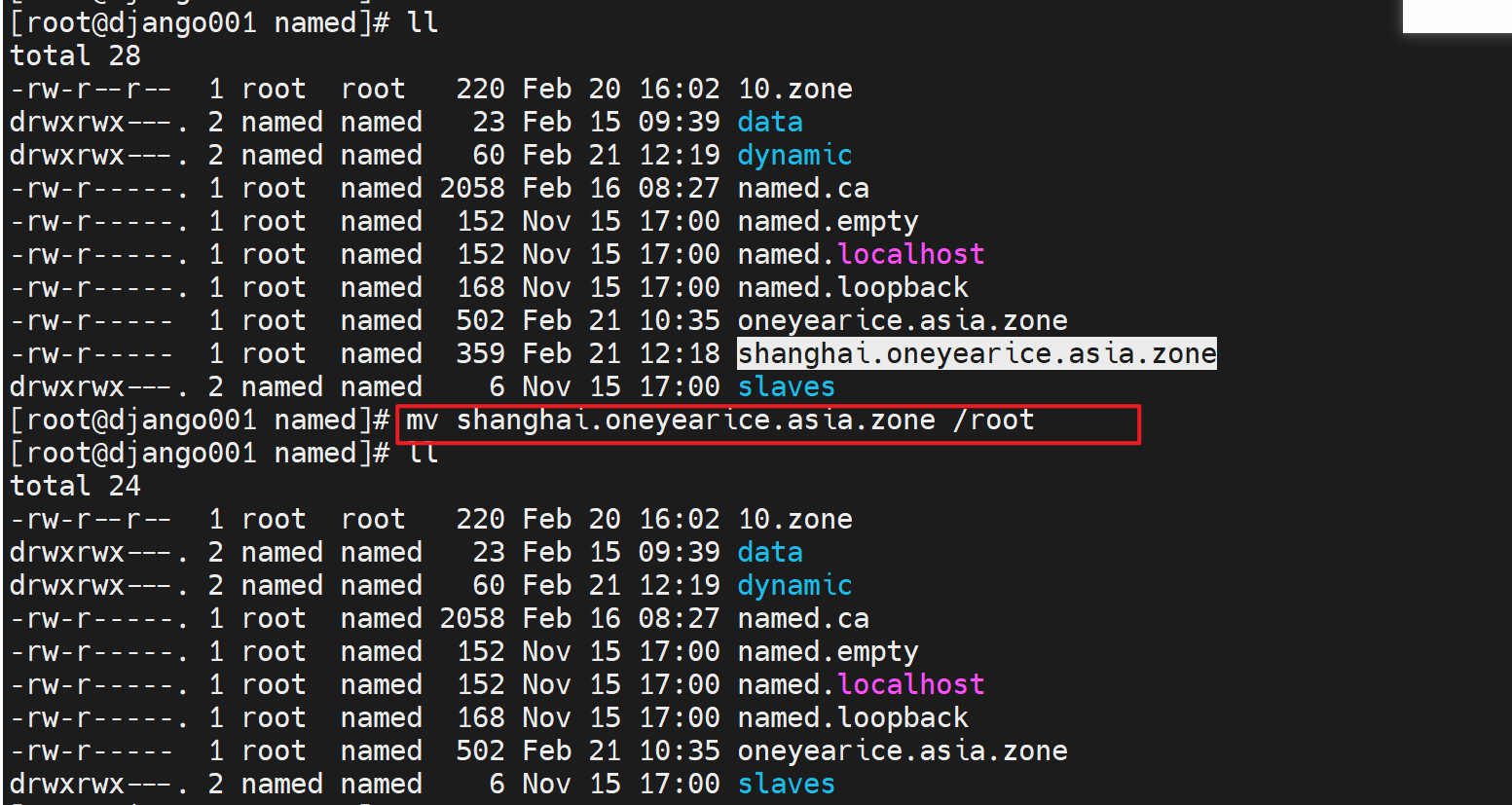
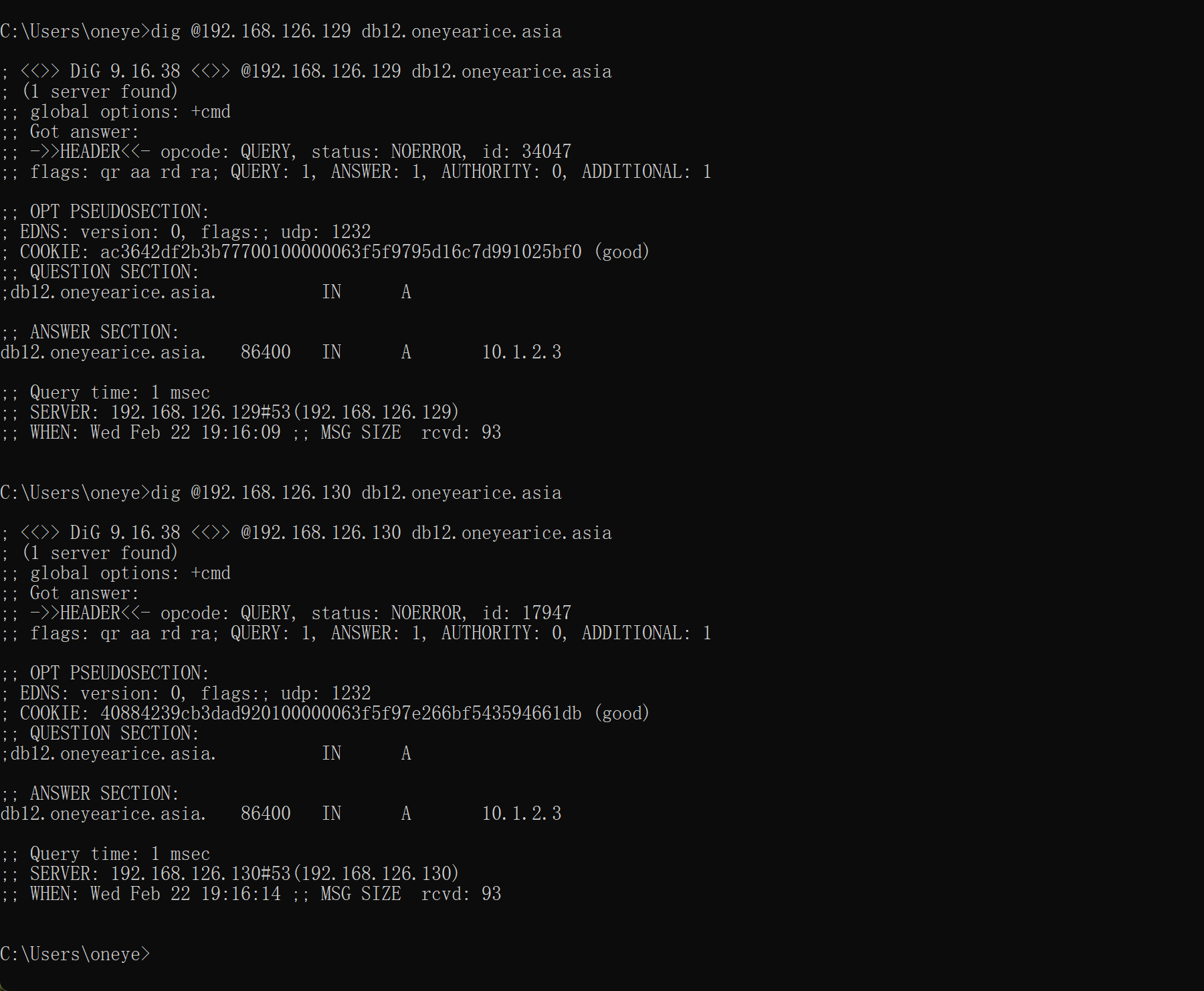
3、修改添加一条父域里,关于子域shanghai的NS记录,指向对应的服务器,这里就简单点,直接利用从了。之前从服务器,已经同步了主之前还有的shanghai.oneyearice.asia.zone子域记录文件了(文中未体现,其实就是在从那边配置了一个zone type slave并指明master,然后重启从的服务就拿到了。),所以此时就可以解析了
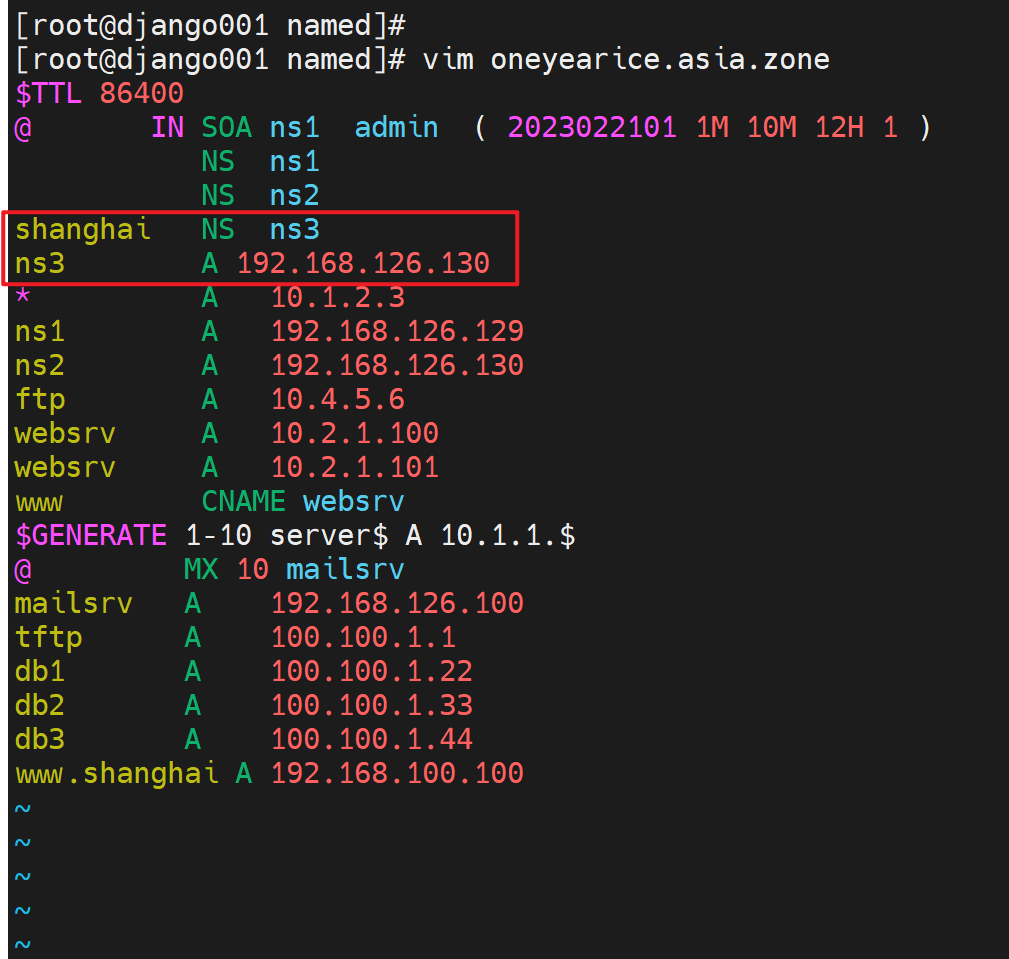
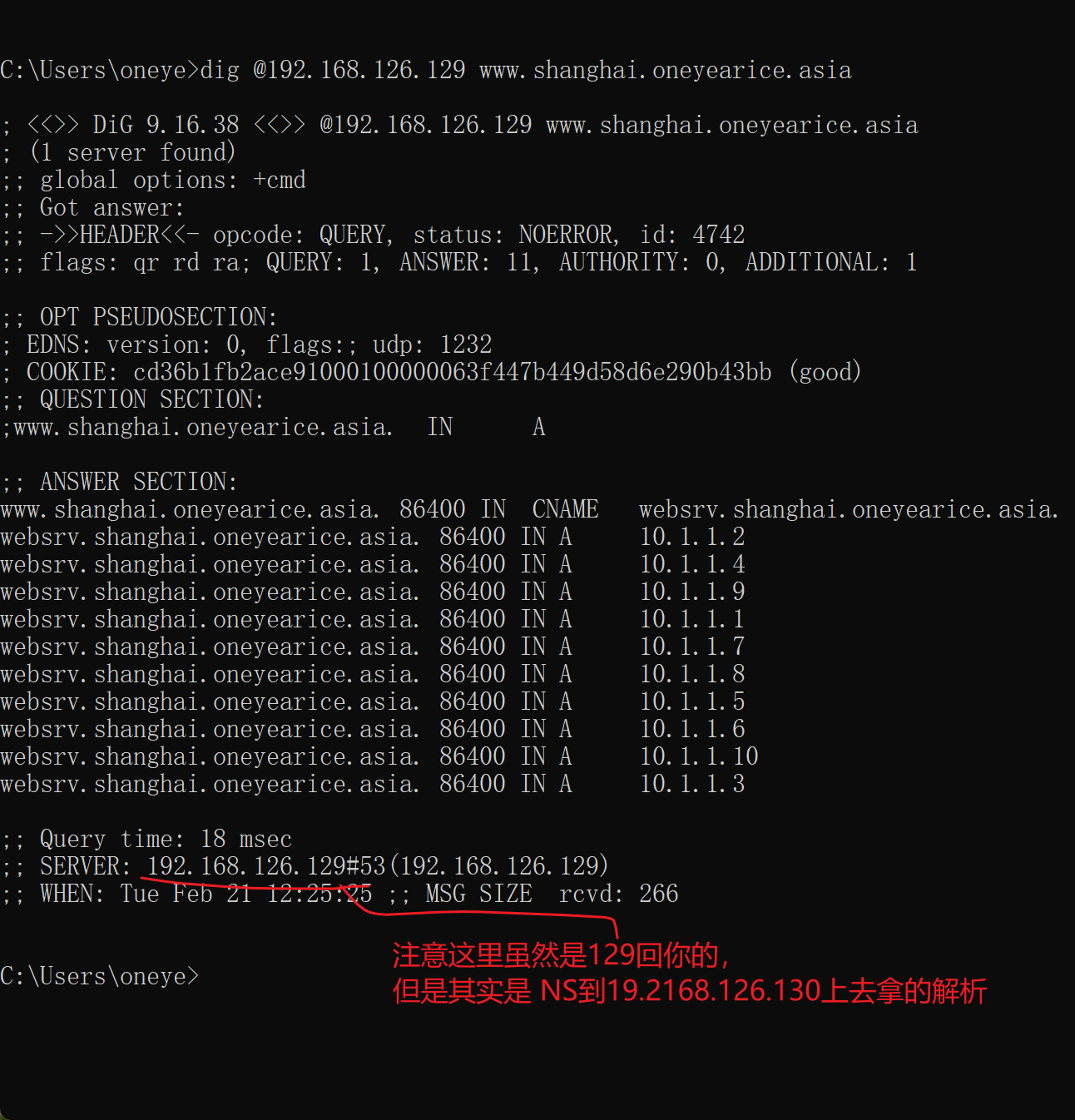
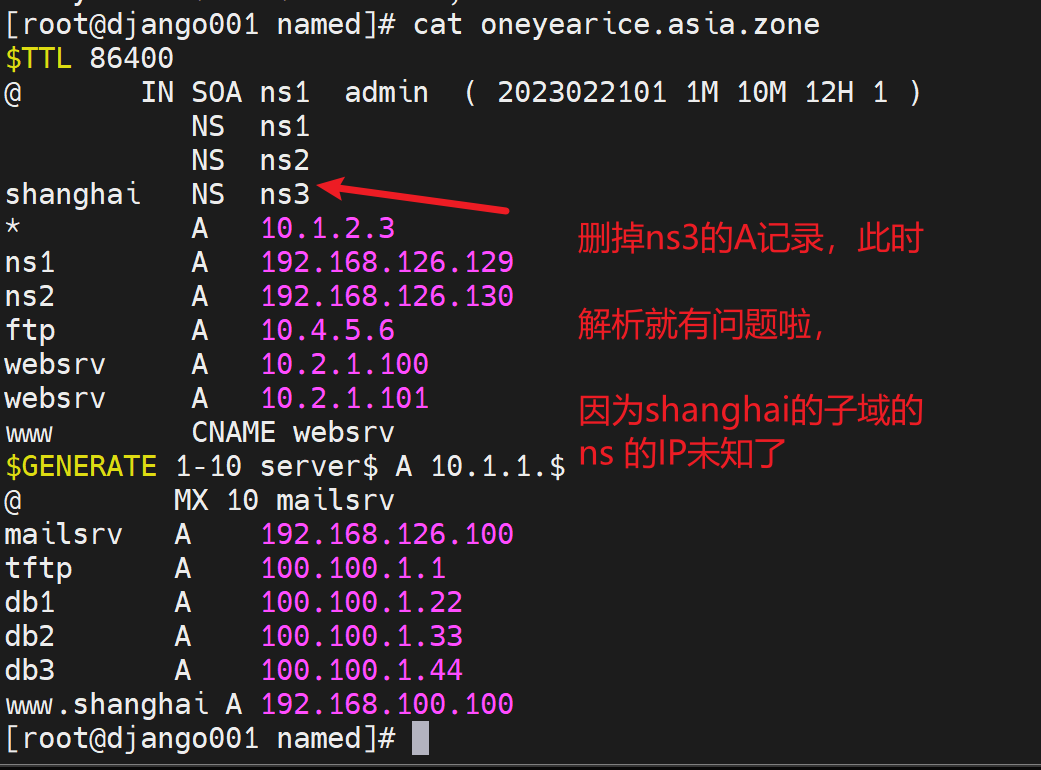
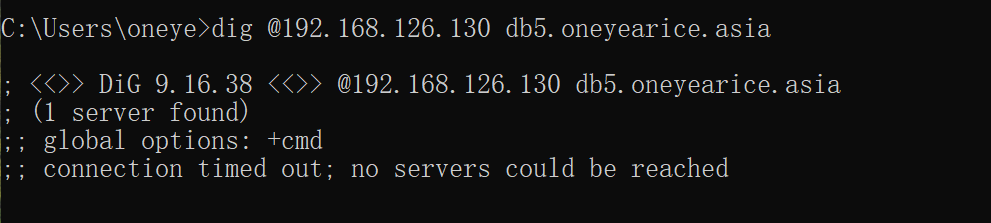
必须重启192.168.126.129这个主域上的named才能看到现象,因为有缓存的。
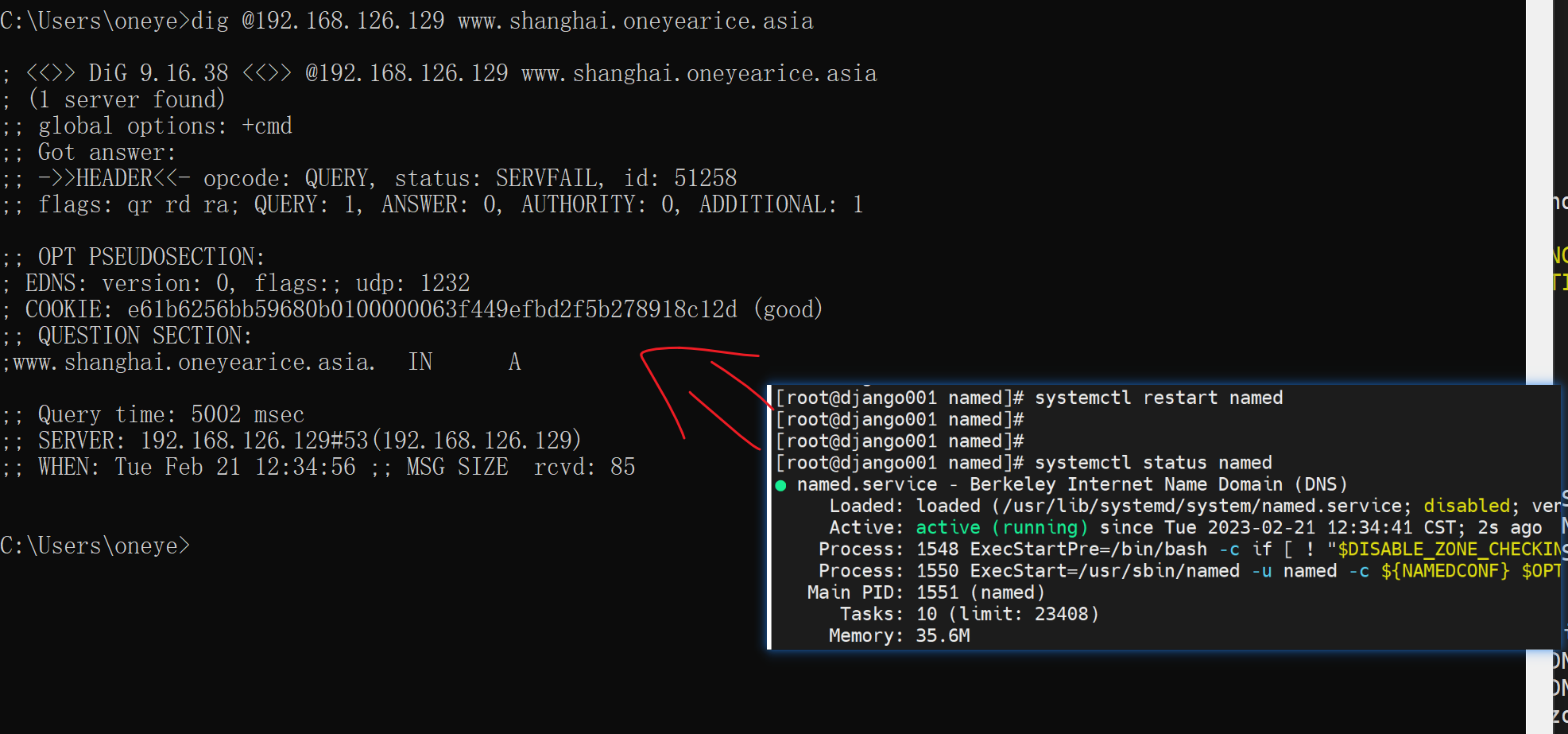
还原
不行还是,
重启服务试试
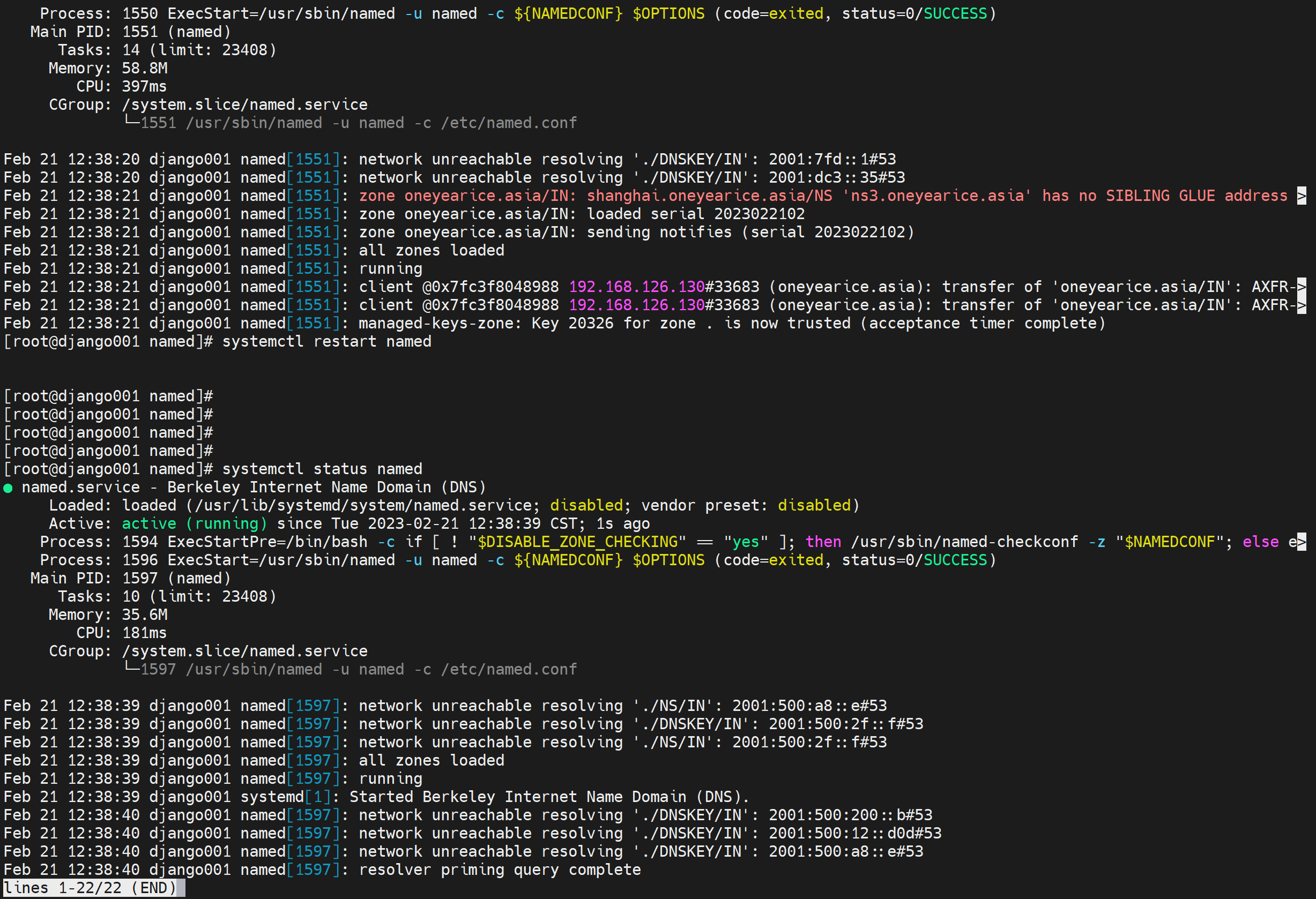
还是不行,会卡在这里
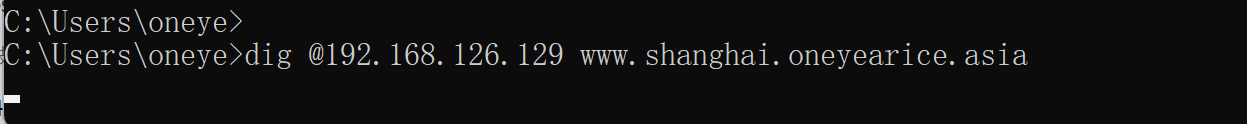
过一会就
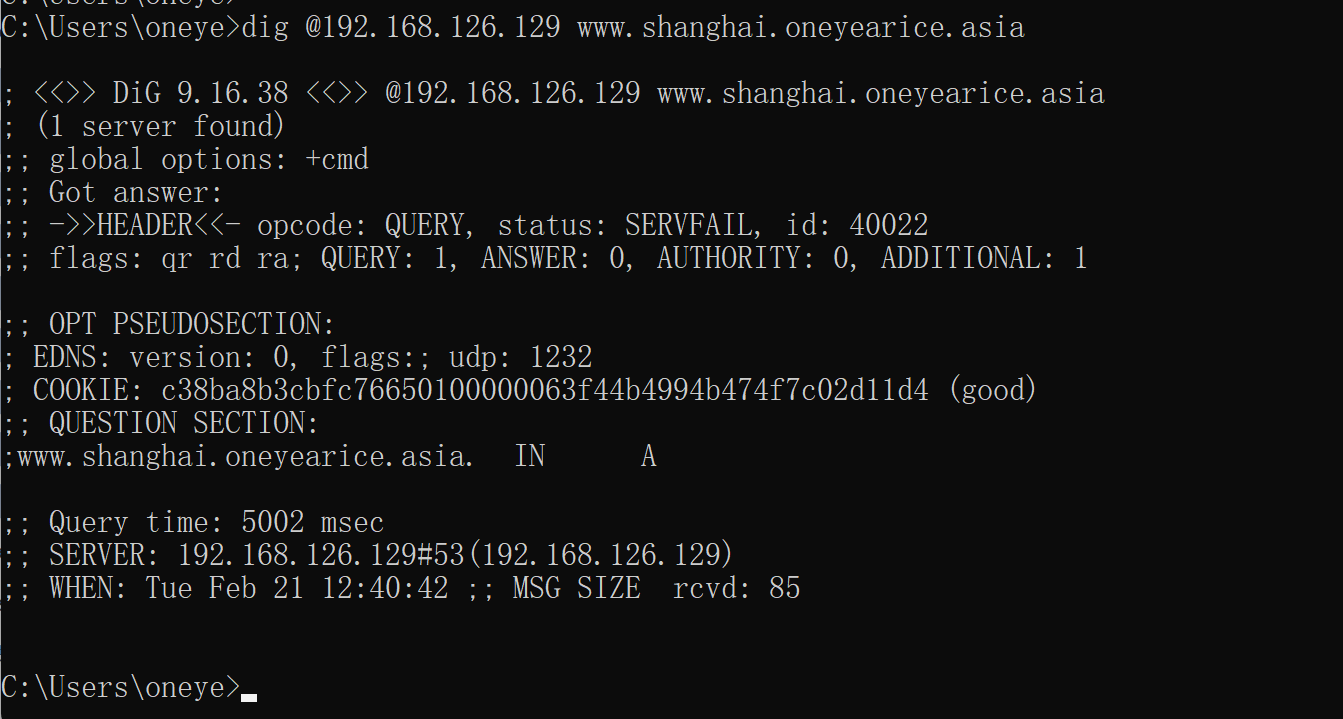
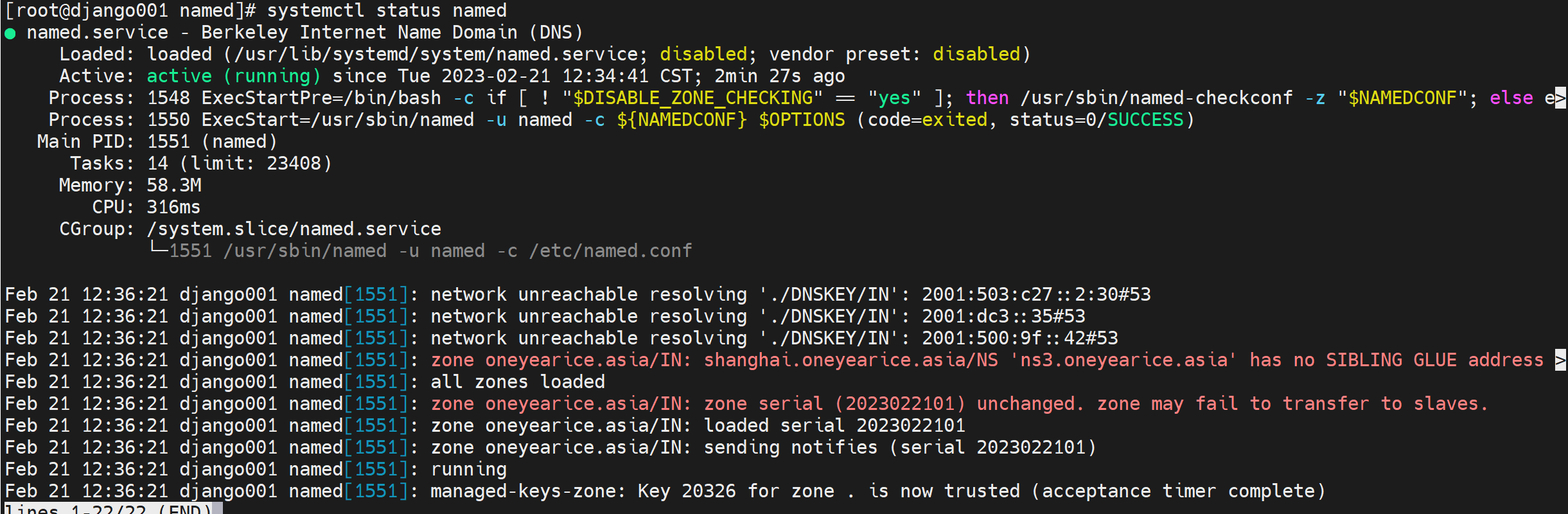
找到原因了
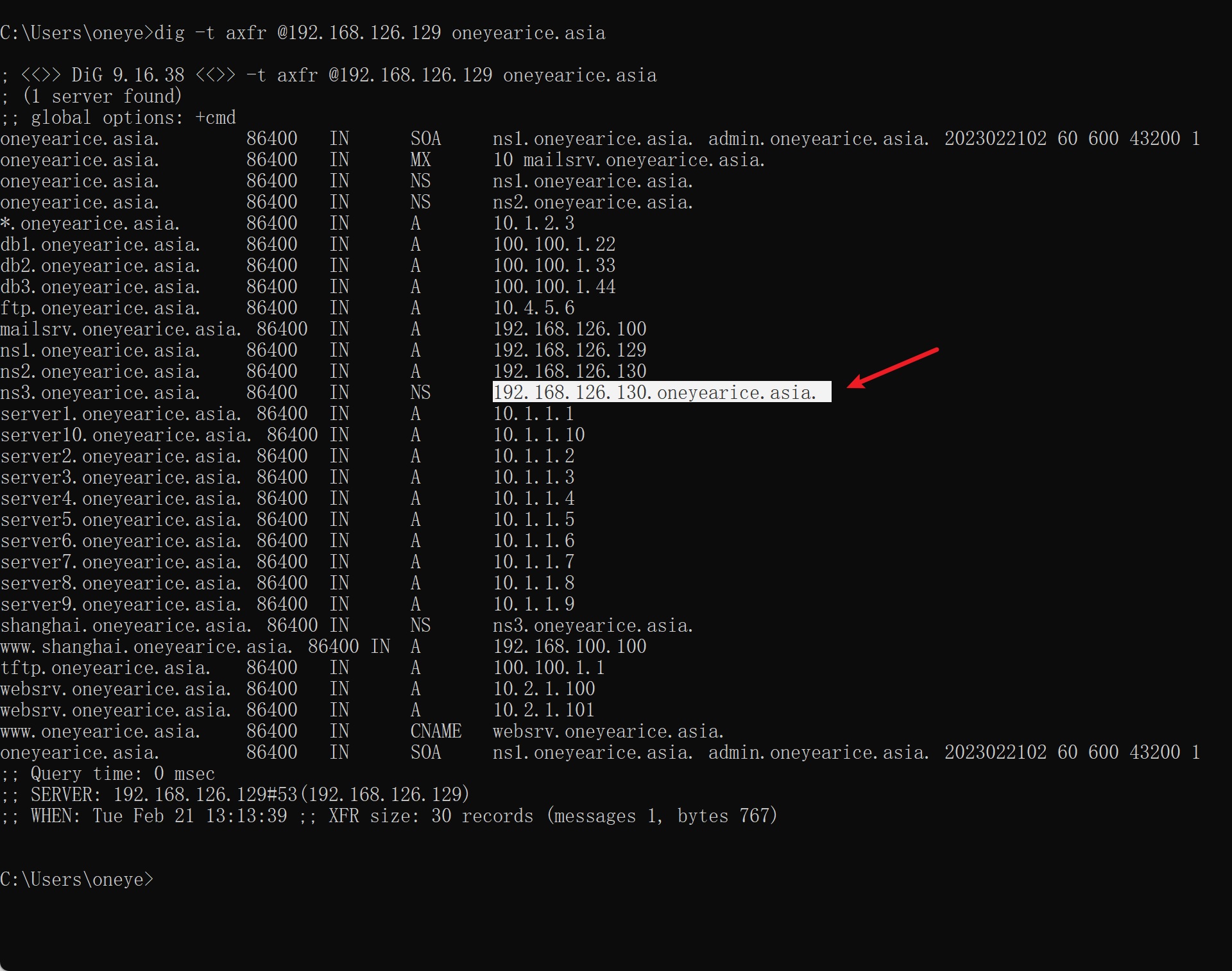
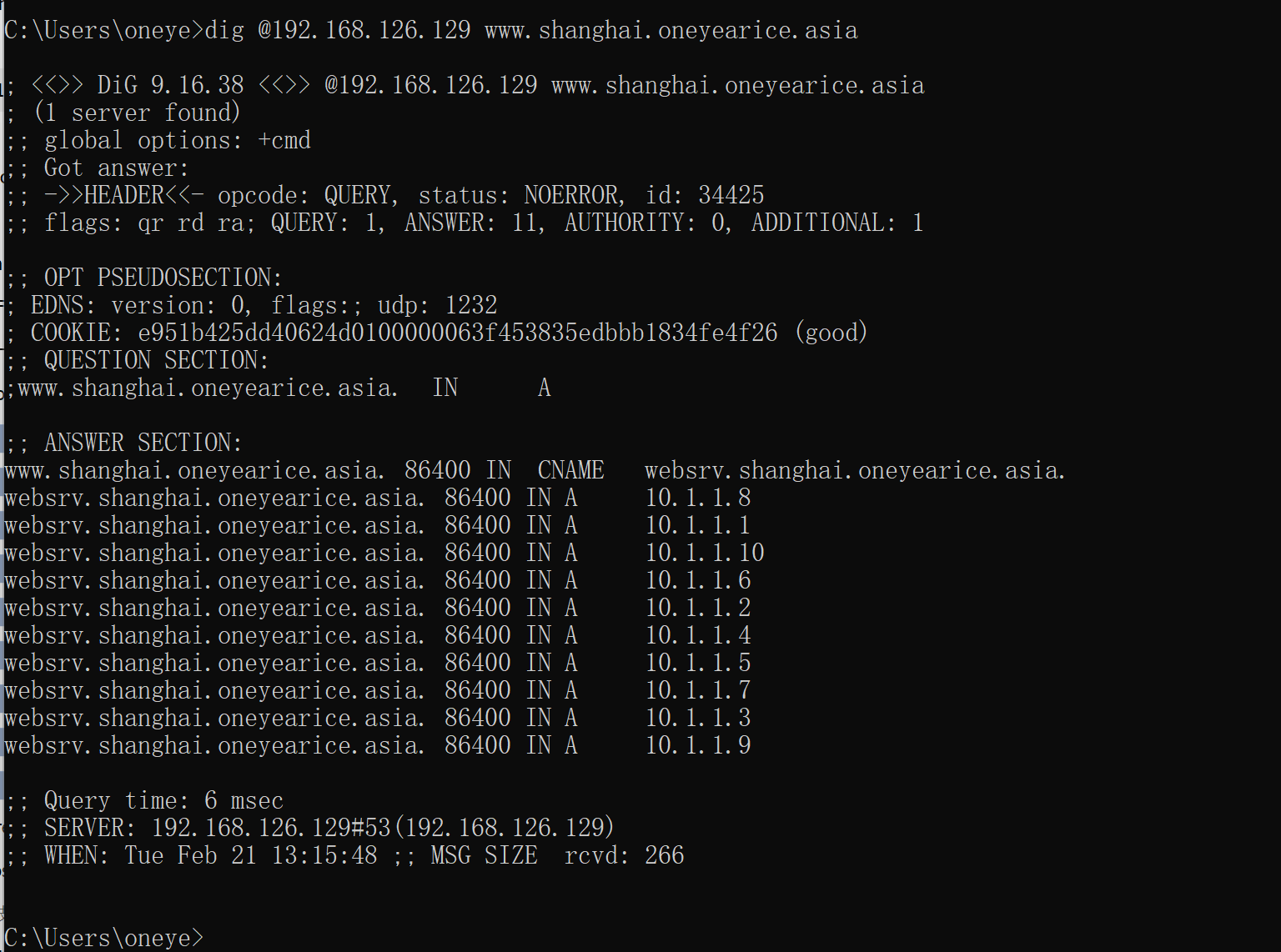
可以了👆
补充:
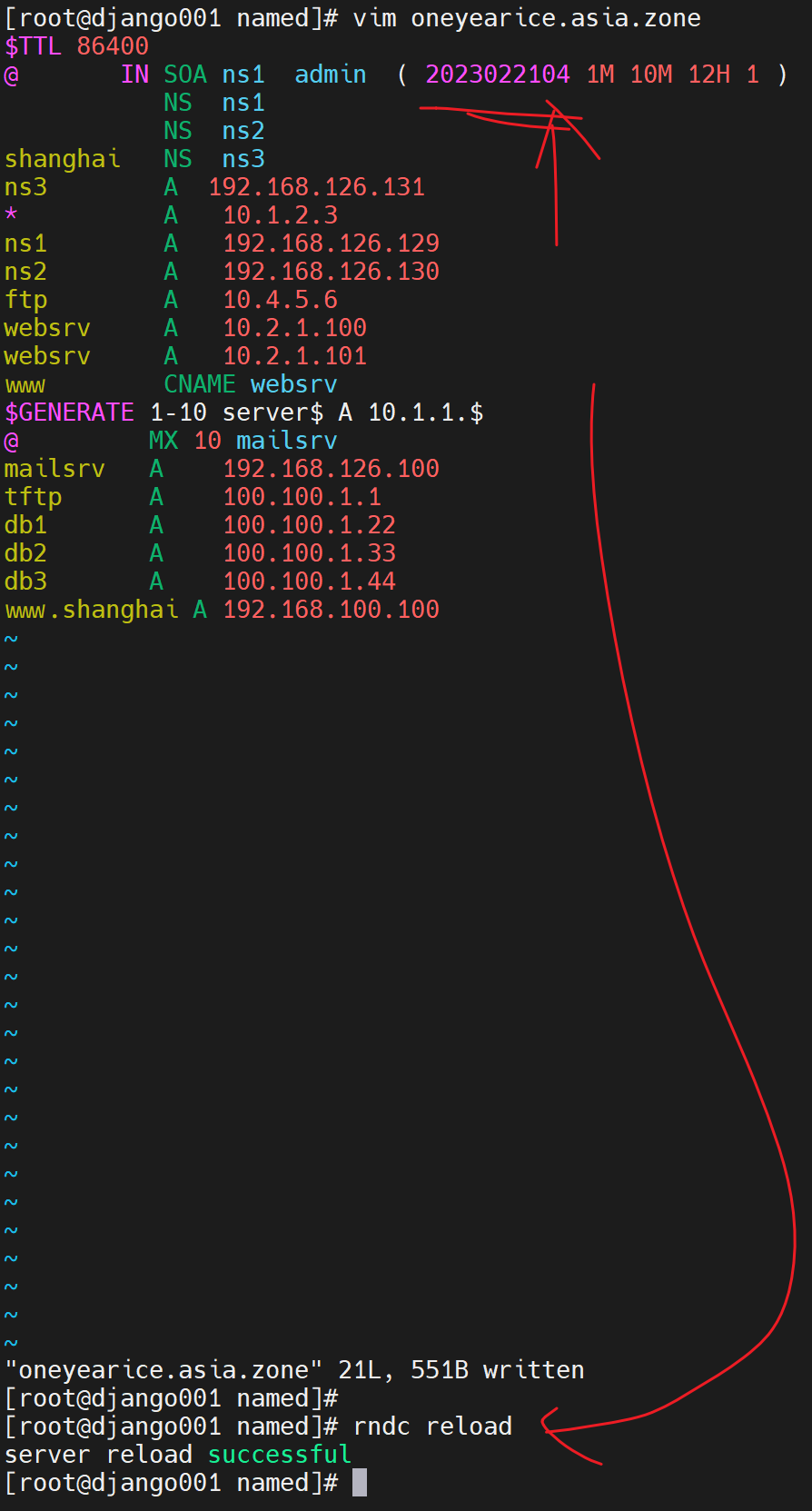
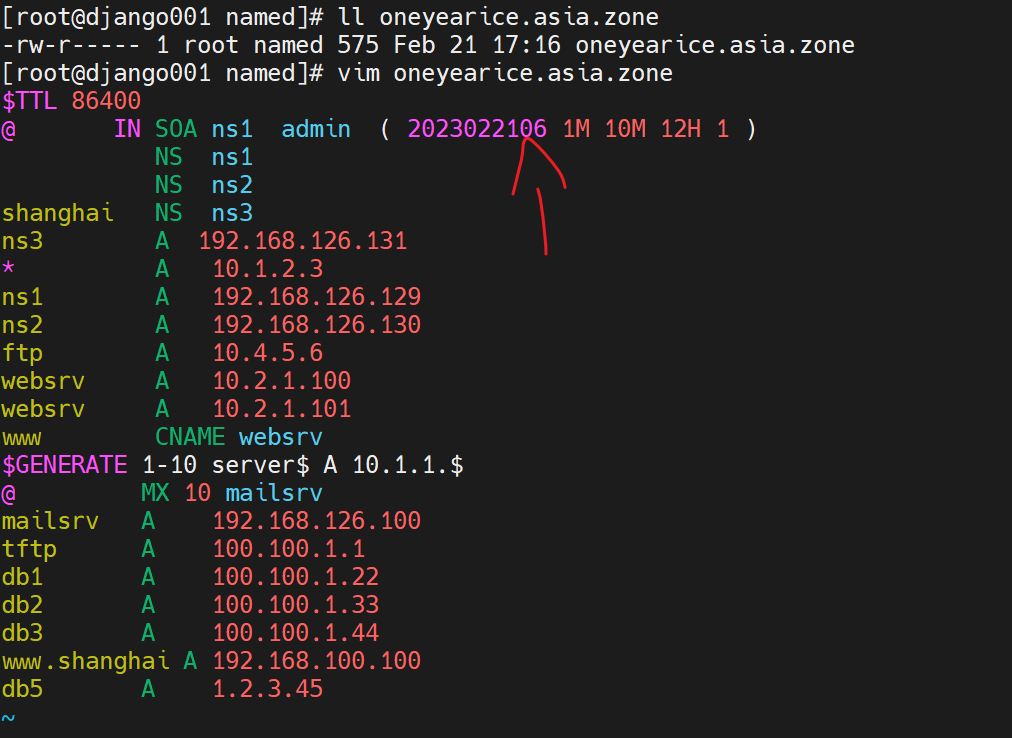
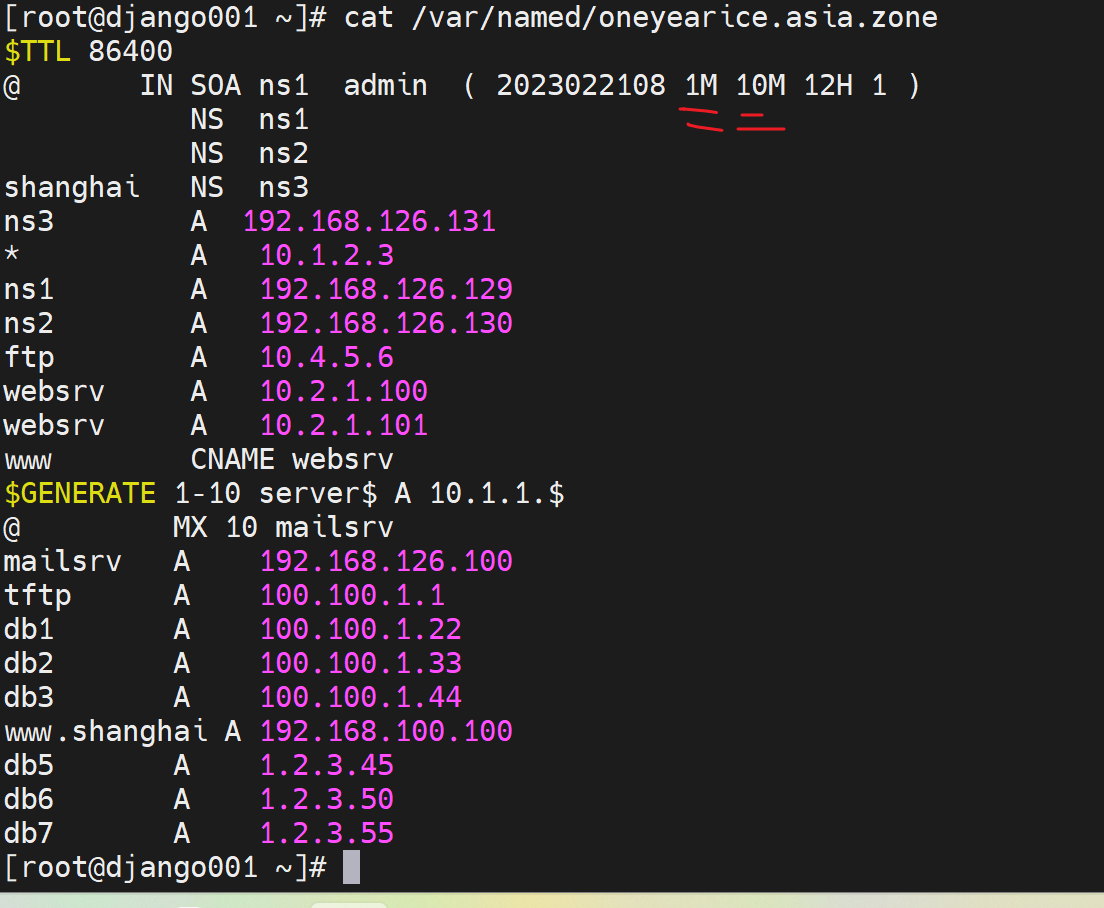
每次修改主DNS的zone记录的时候,一定要记得递增版本号。
NS在很多地方都有看到,这是阿里的关于子域的NS
腾讯上看看
还挺多,功能
不过我记得有oneyearice.asia这种一级域名的NS修改的,现在没找到。。。
还是说必须是www.oneyearice.asia这种,这种倒是直接就能写。
如果是新开一台干净的机器来做子域,
直接上图了,就这么着吧:

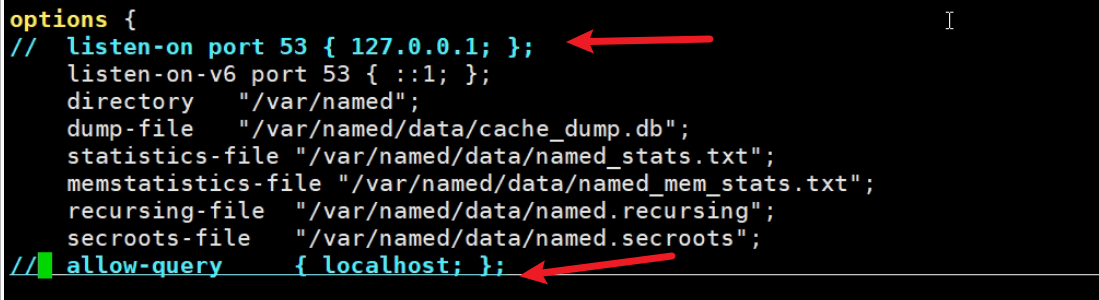



然后人家的报错
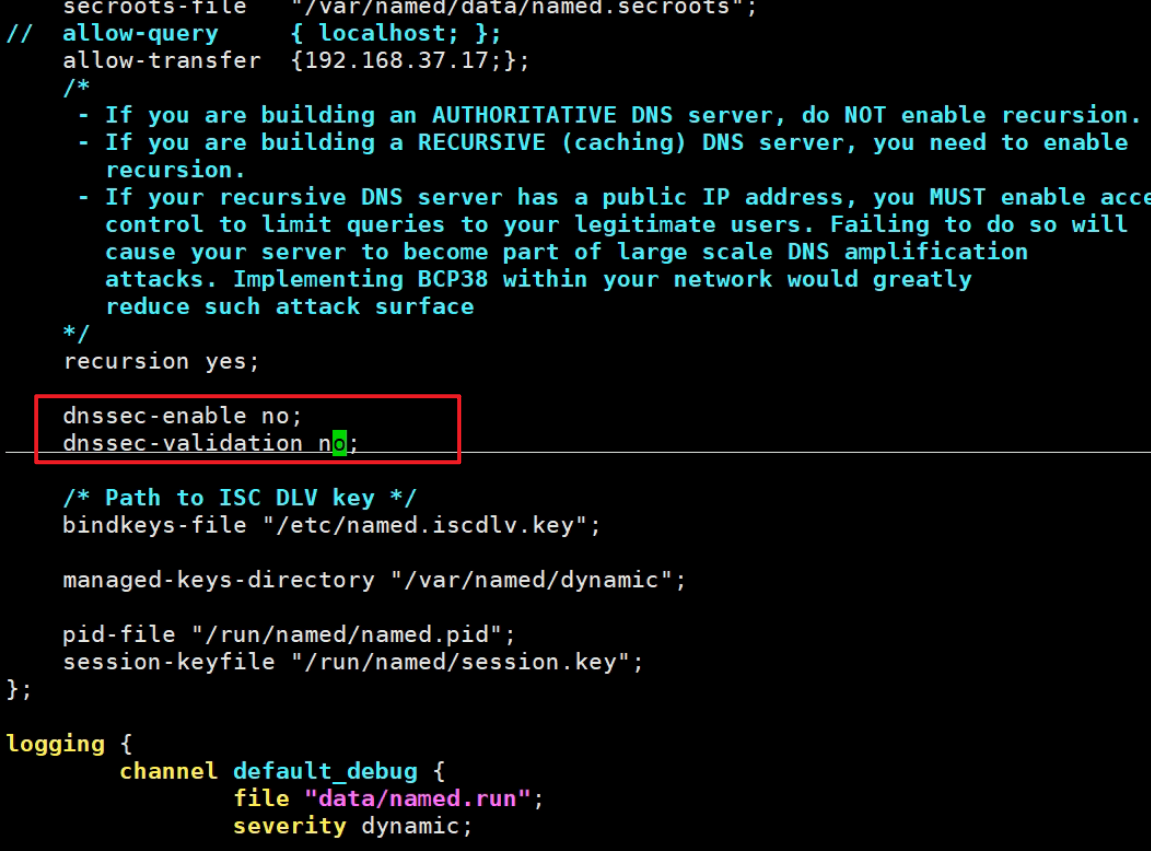
然后他就改了下图两项为no

然后就神奇的好了。反正我没改也成功,不过我的子域委派的那台其实是从啦,和他在这点上不一样。
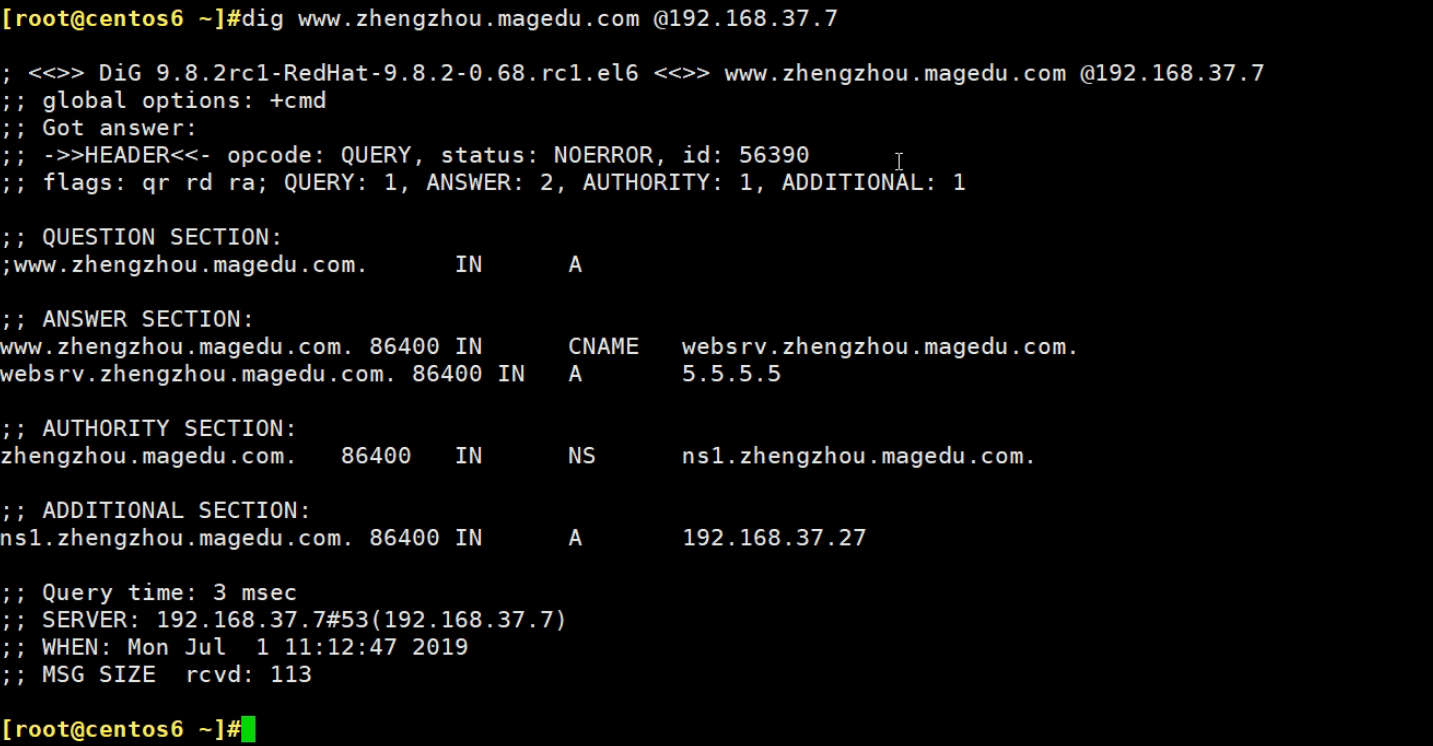
我要新建一台试试了,NND

去到父域上修改ns记录👇
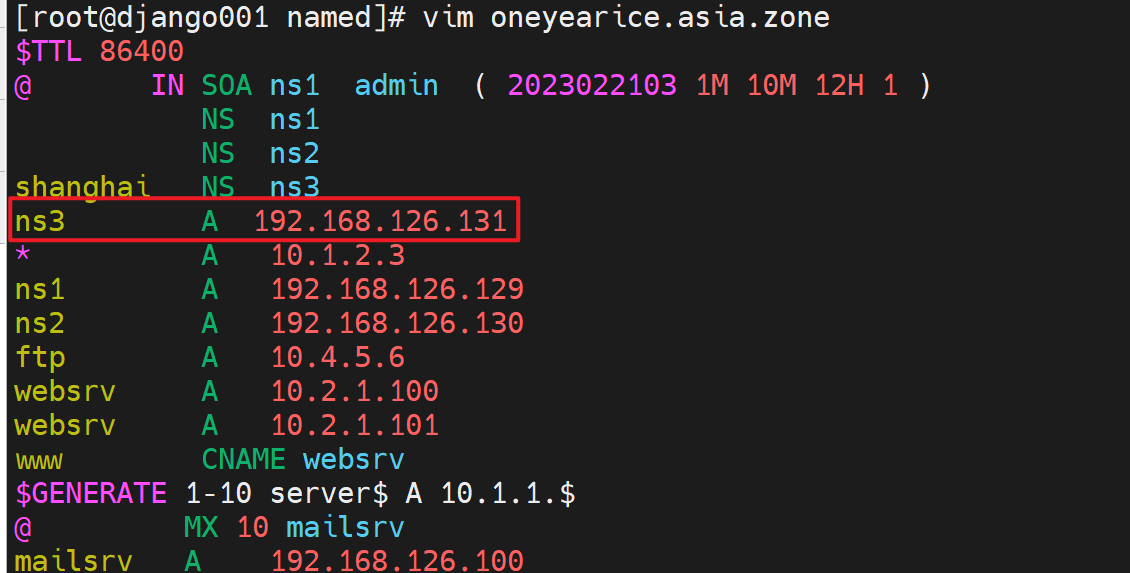

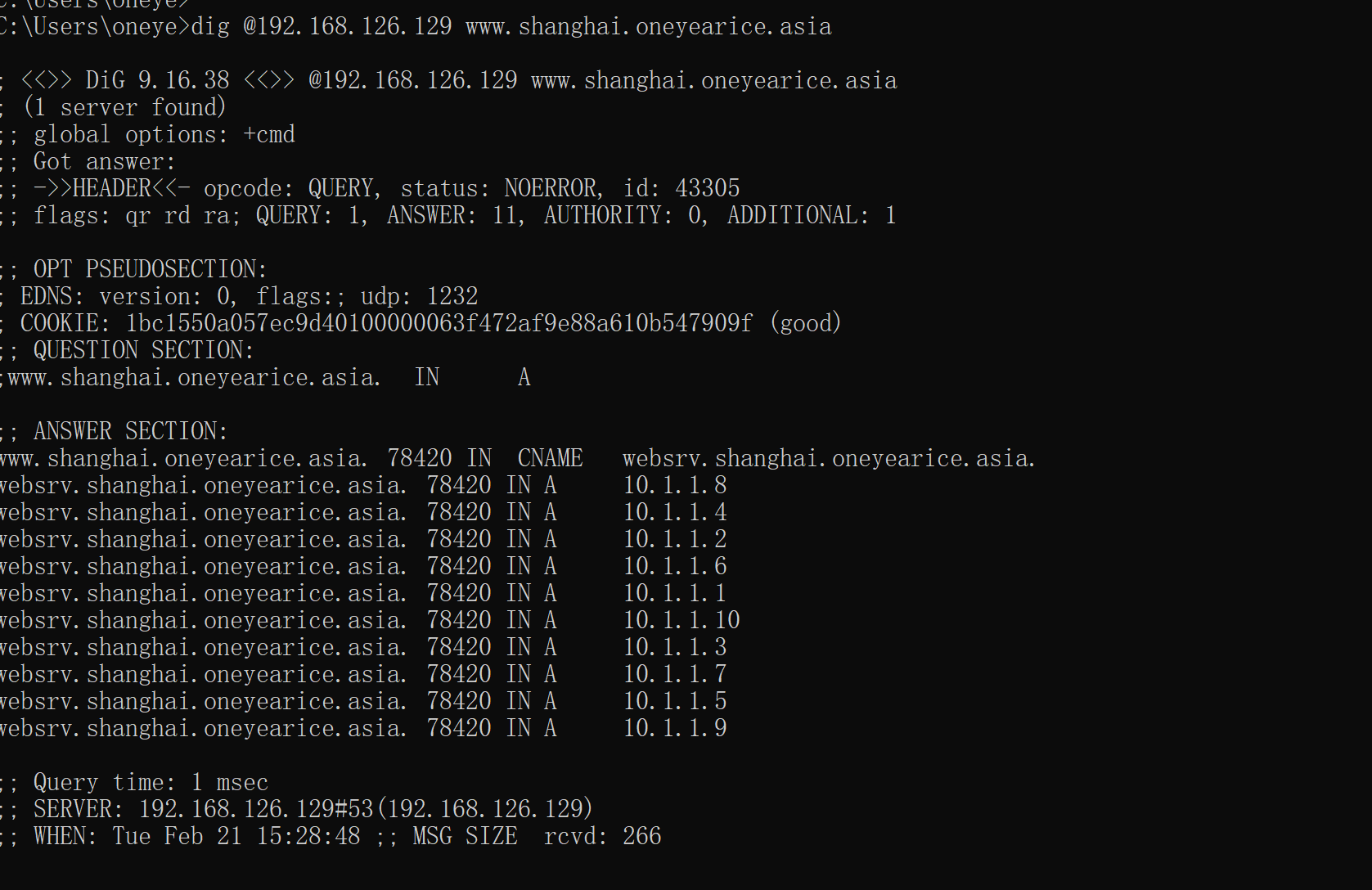
上图说明缓存没清除。
systemctl restart named就行,或者用rndc flush

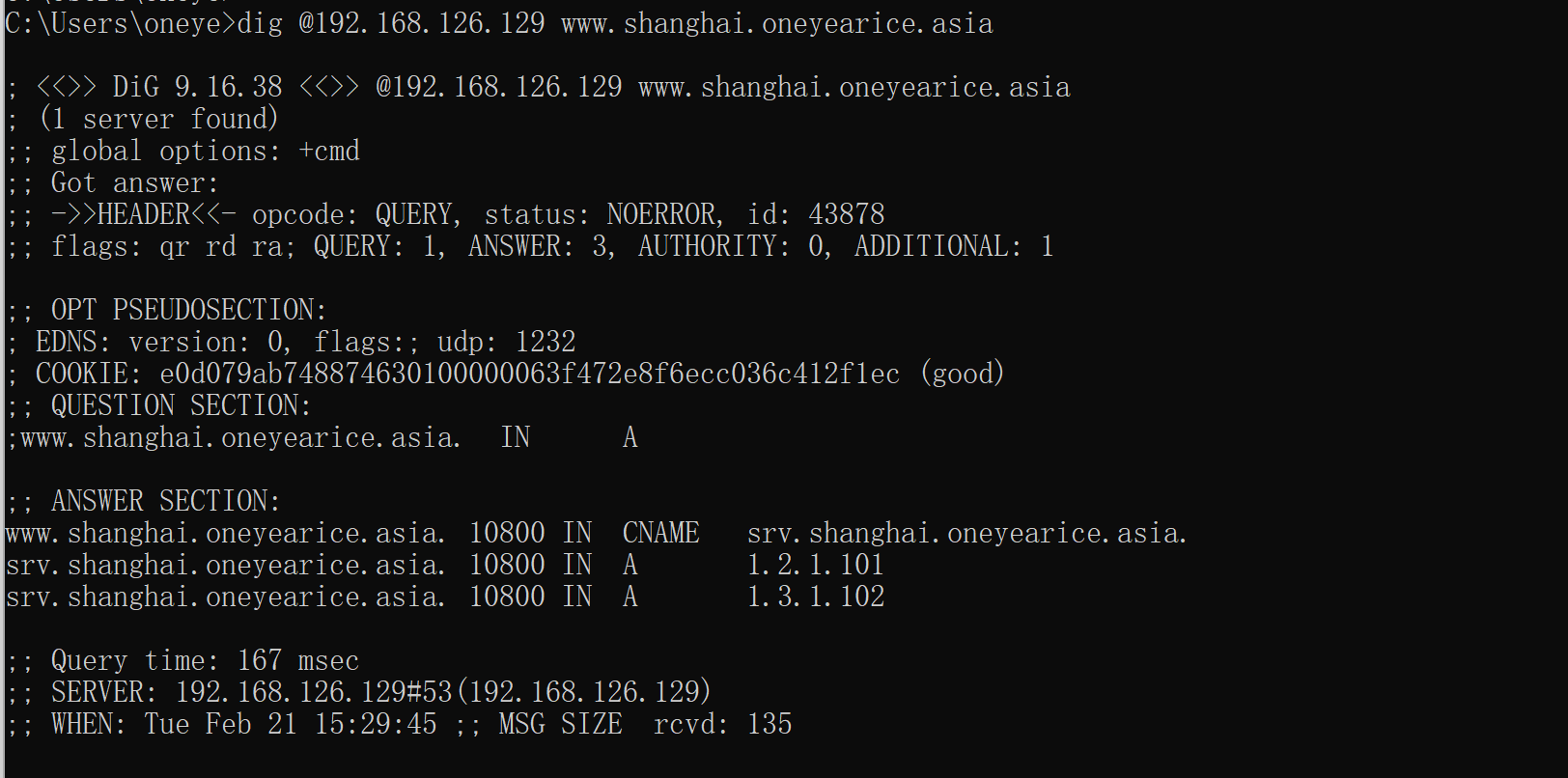
这不好了嘛,也没有修改那两项啊,父域和子域dns服务器上都没有修改啊。

注意缓存一直在,比如你现在修改子域的A记录为,加一条
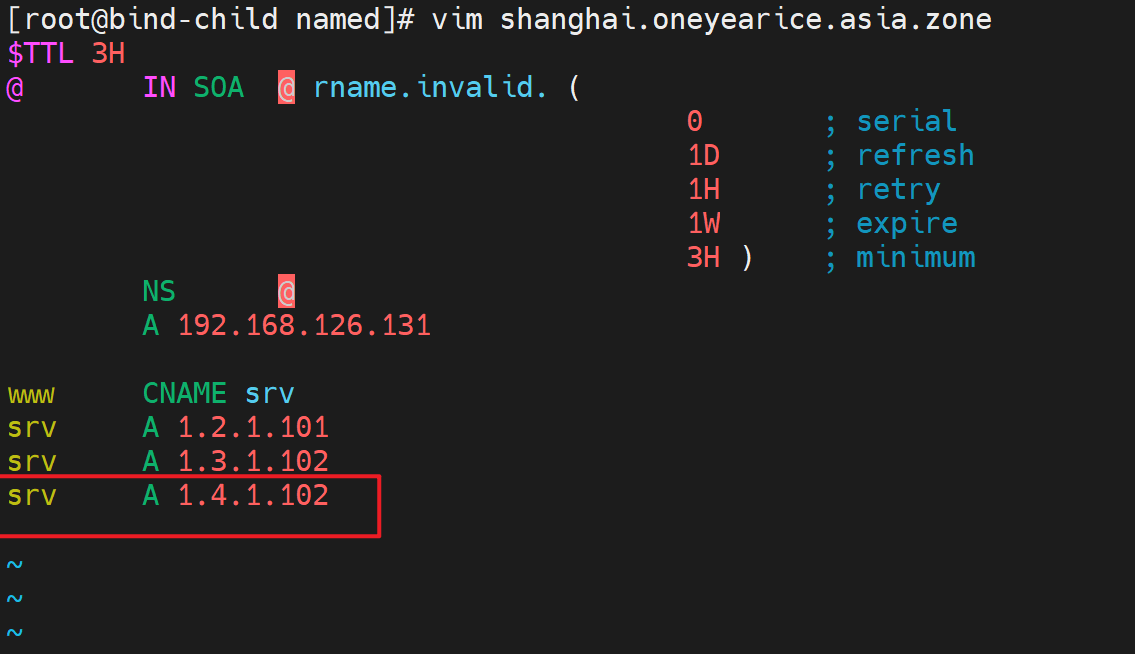
然后子域DNS上reload

此时client dig结果不会变的
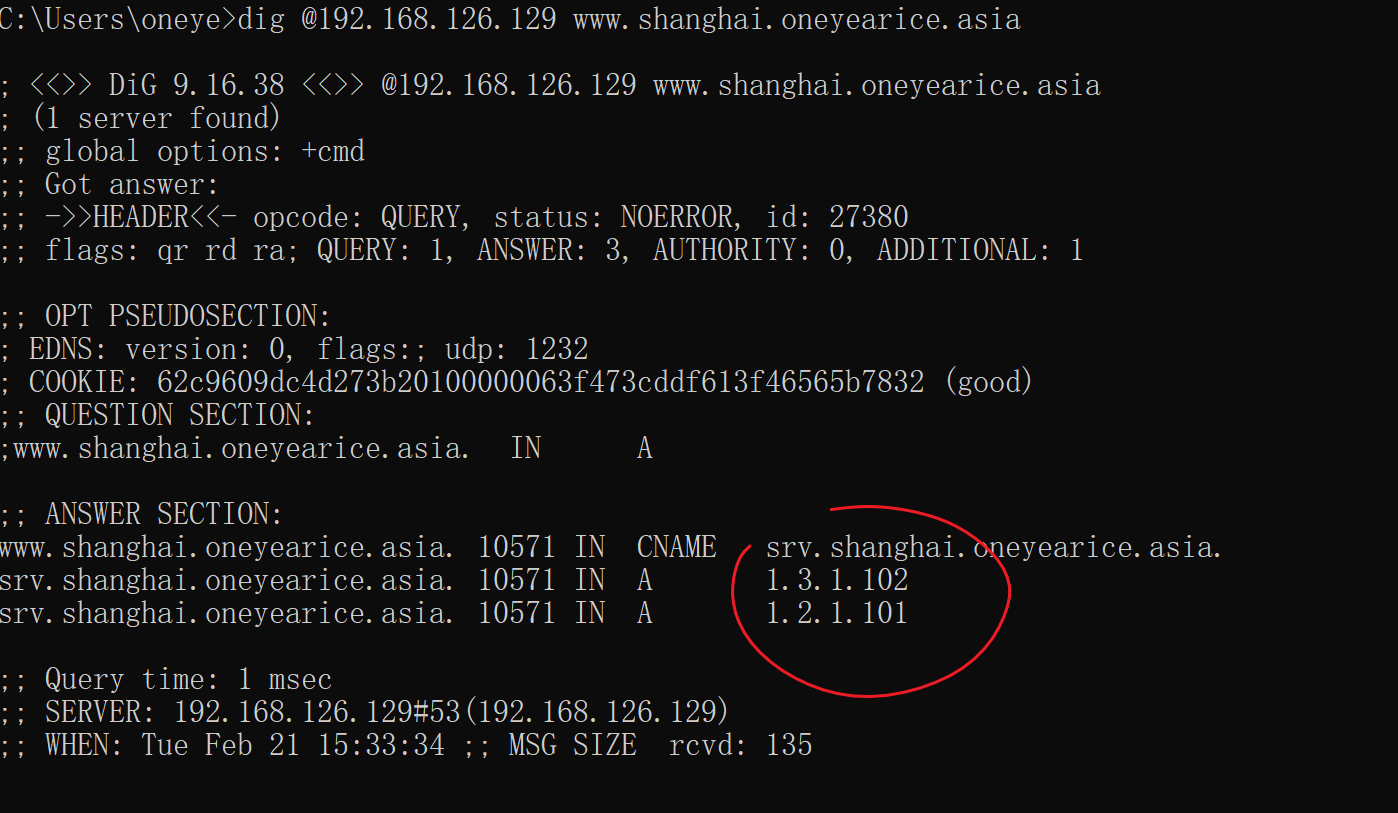
因为你问的还是父域,父域回你还是TTL时间内的缓存给你的,所以要flush一下

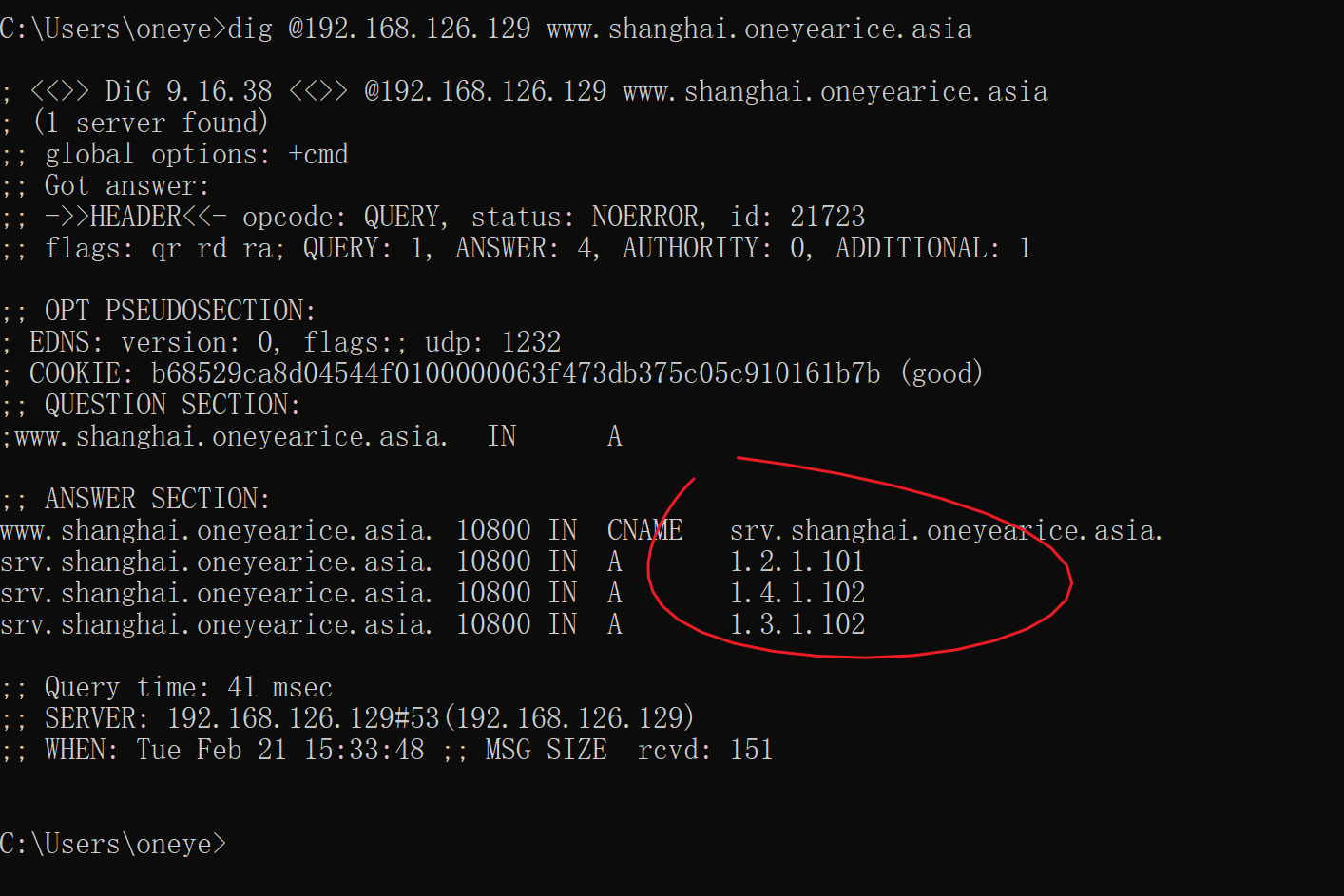
好啦。
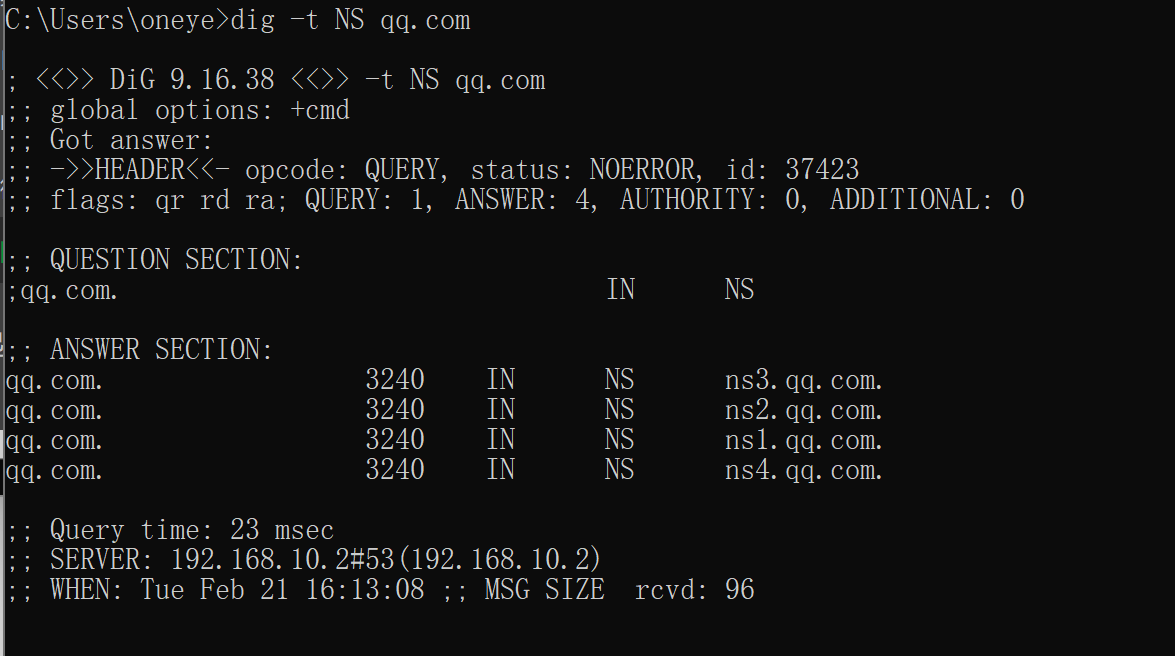
dig -t NS查看NS
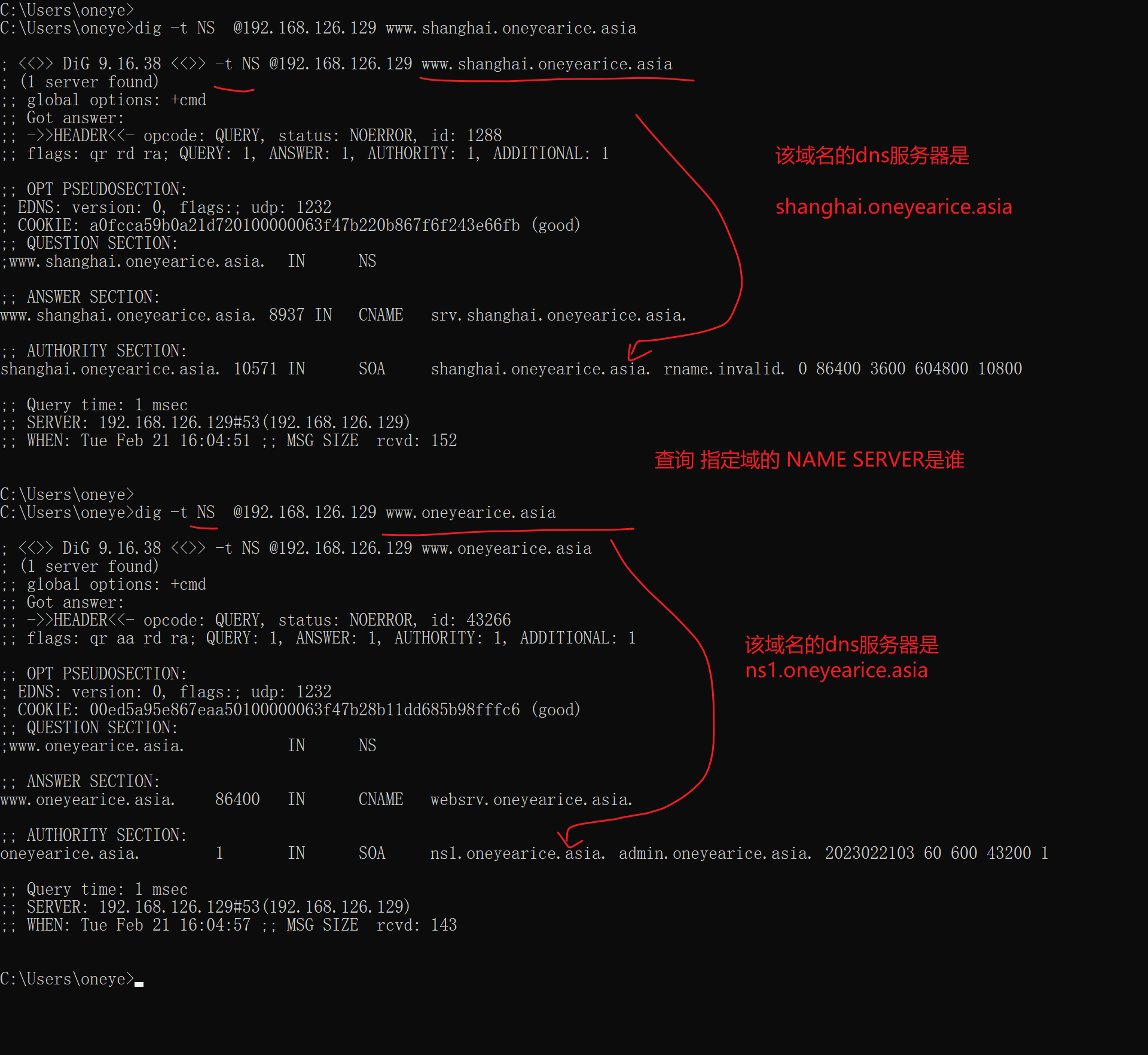
腾讯还不显示,直接自己查
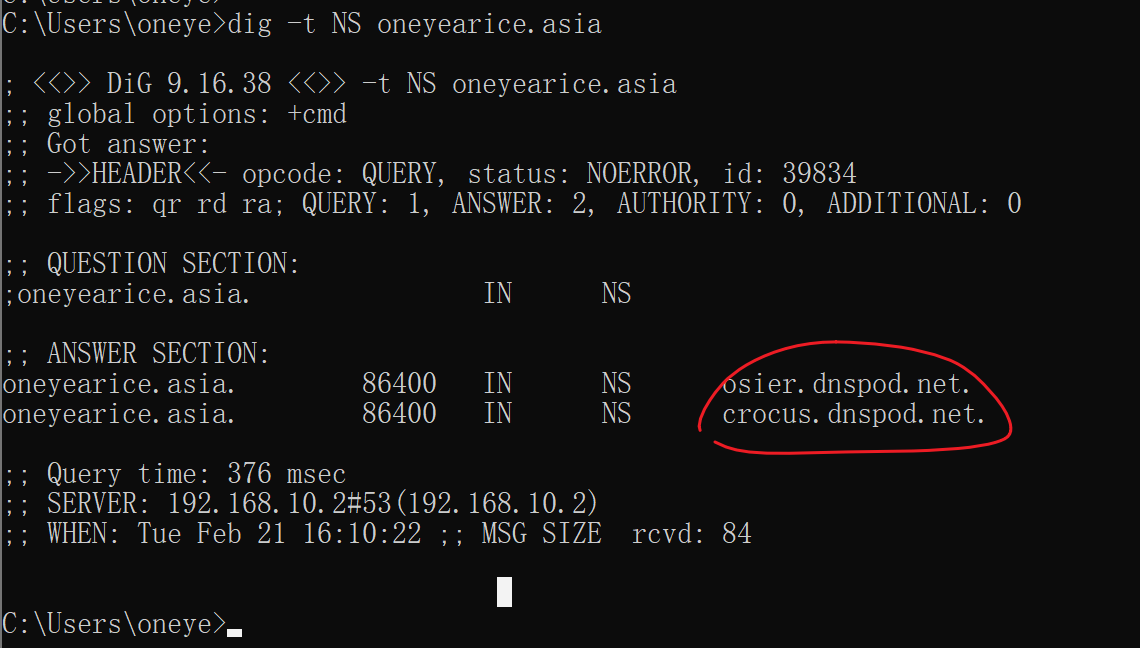
qq的ns
根的
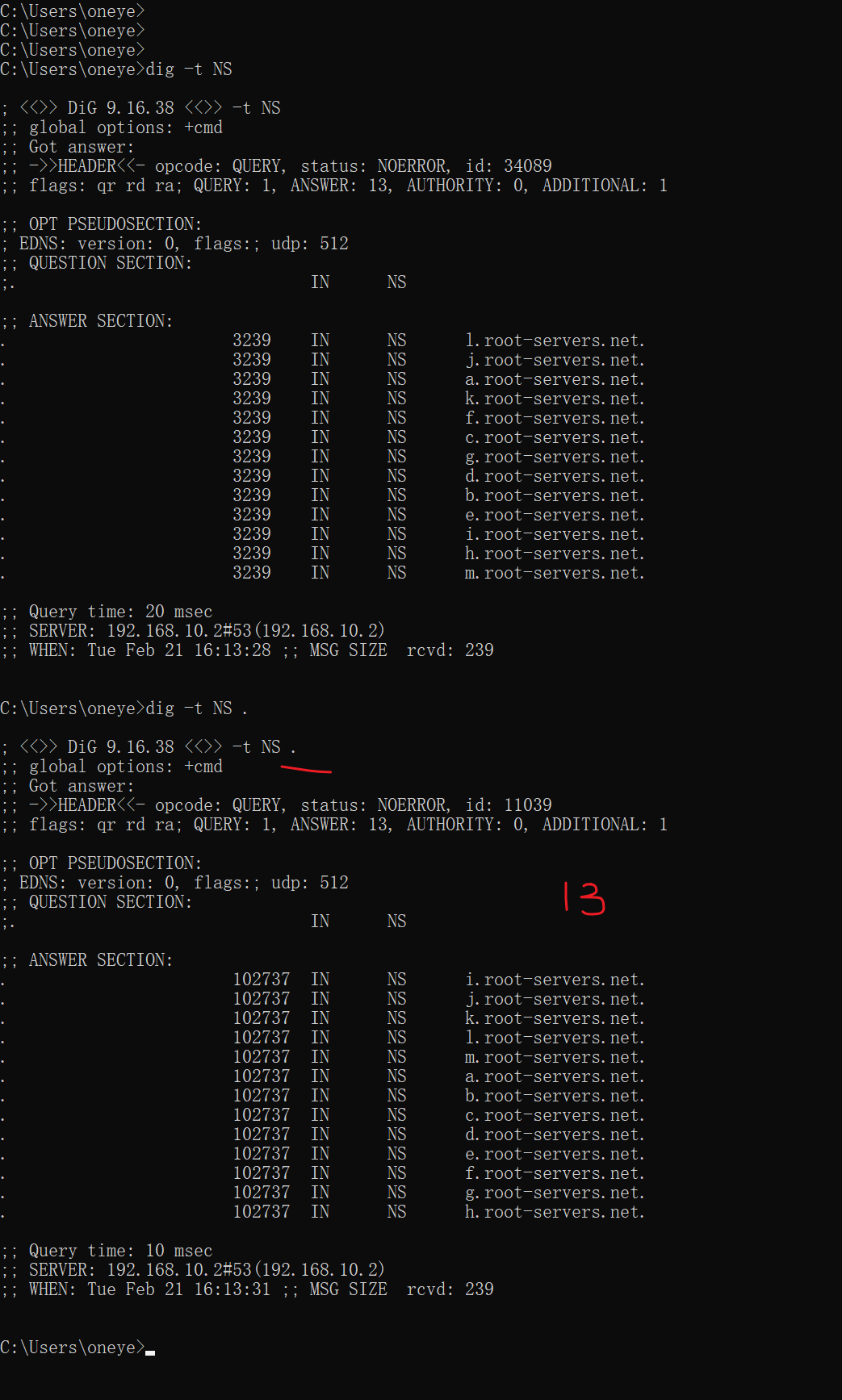
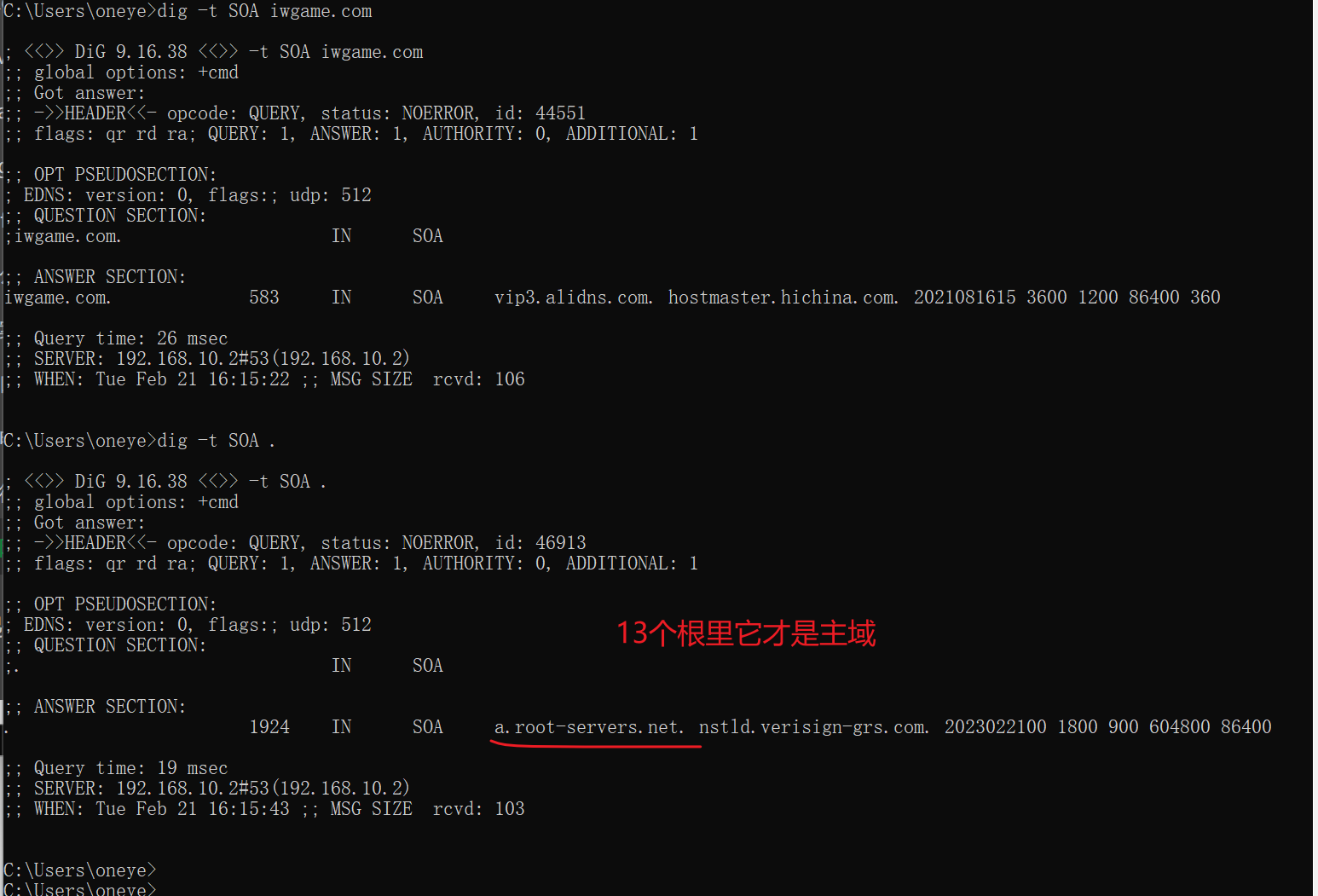
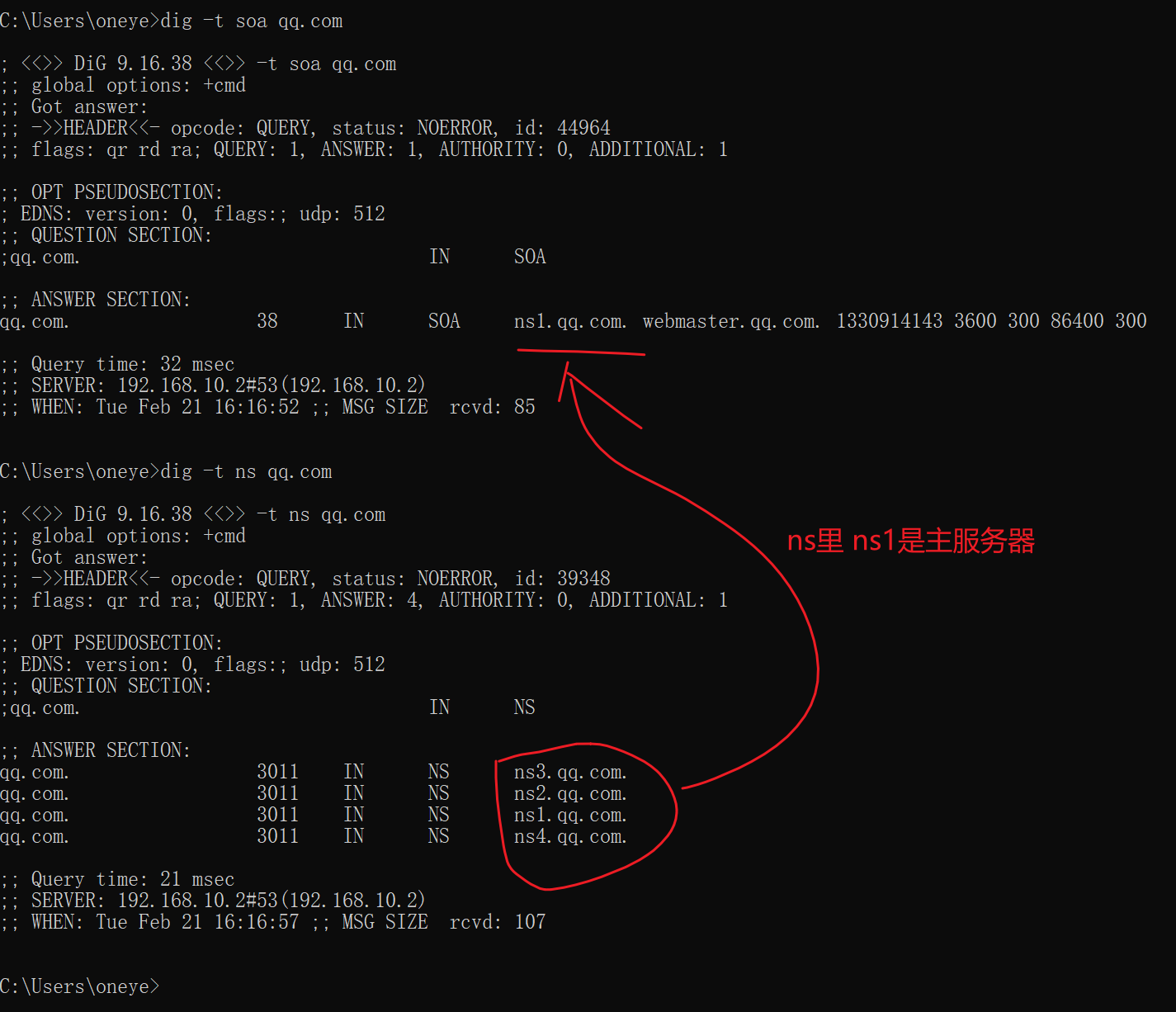
上图ns1是master,其他都是slave;同样可见版本号就很大了,也不是以年月日NO来编写的。
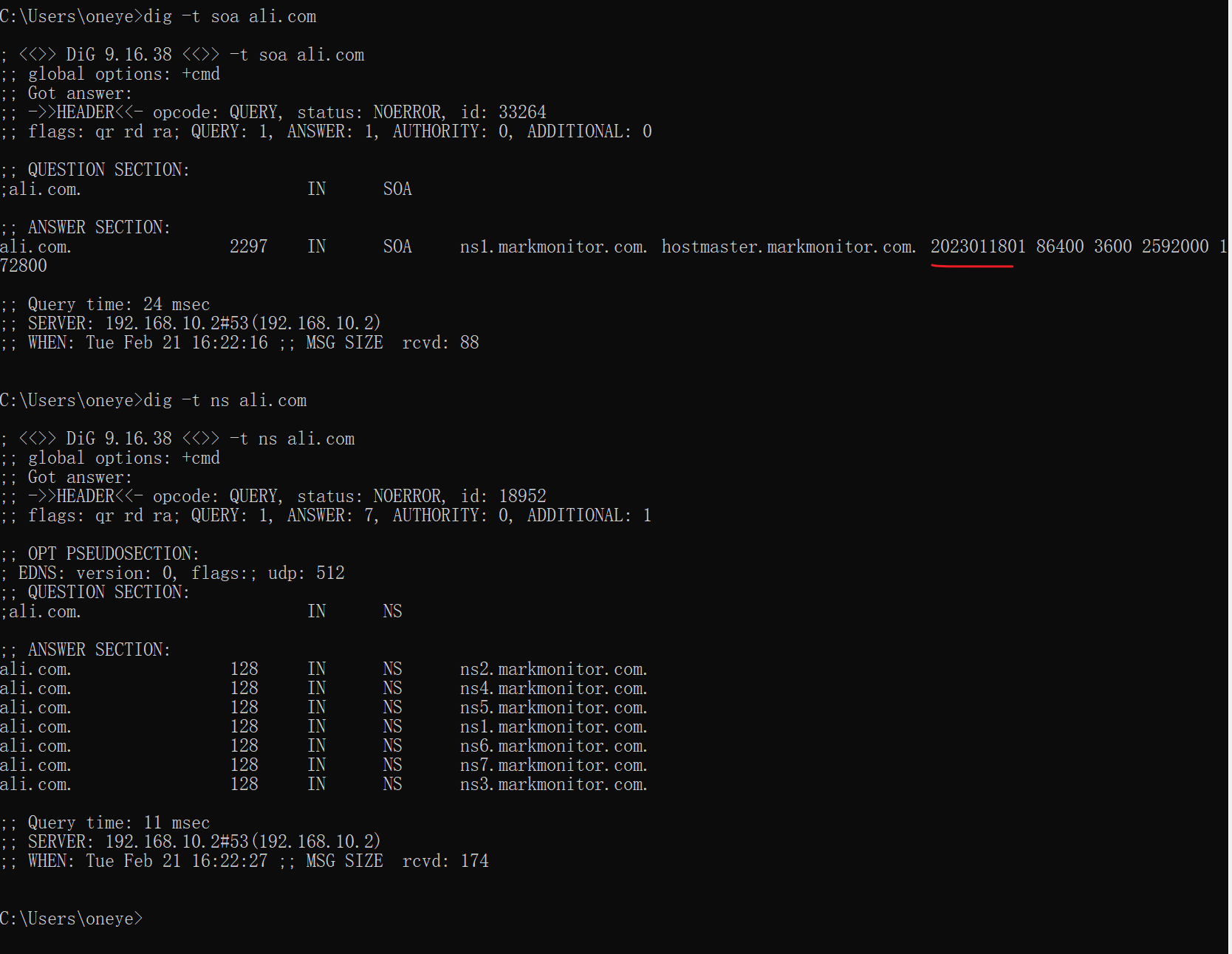
阿里还不错,按官方推荐来编写的版本号
以上就完成了子域创建和委派,
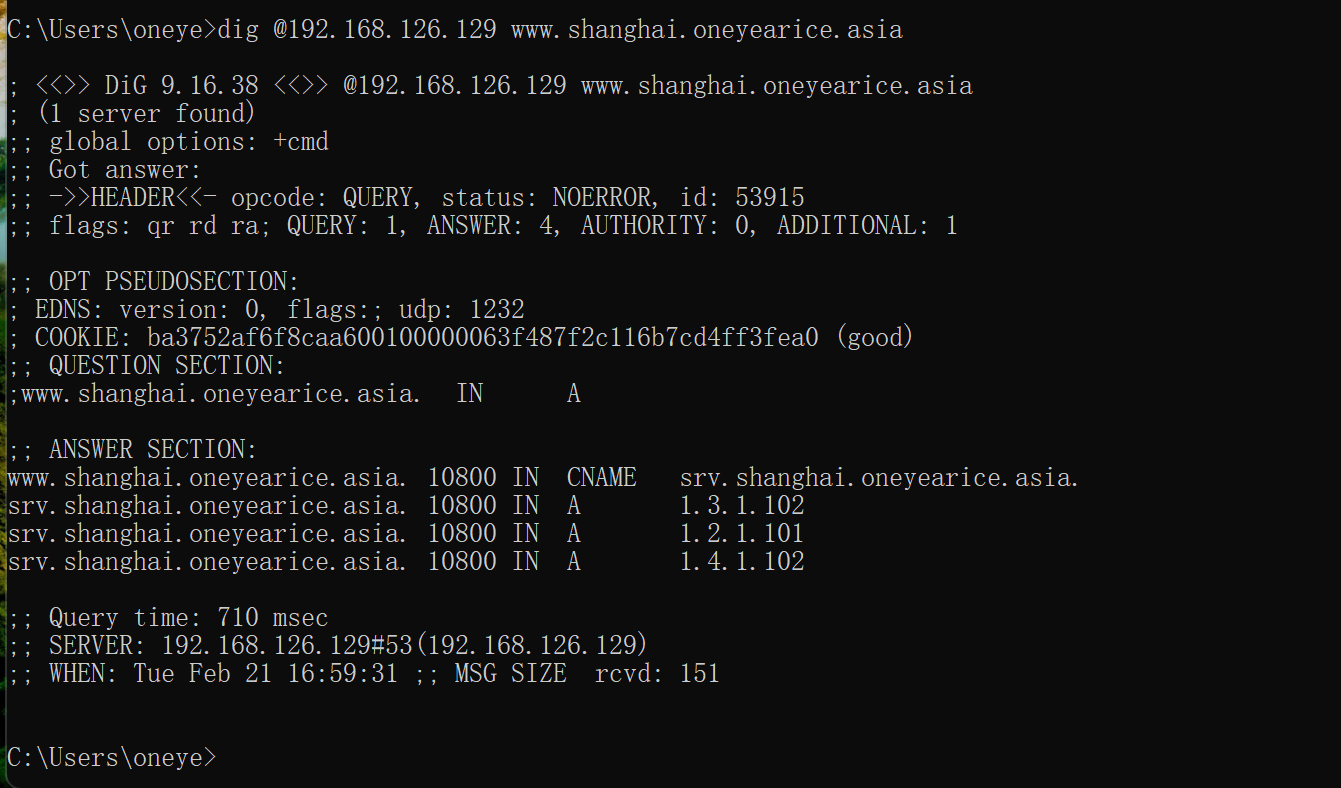
然后研究下53端口的tcp和udp的情况
先上结论,client查询一般就是udp 53,子域委派也就是域间也是只有UDP53;主从复制的时候是TCP53和UDP53都有。
当前client 去问 子域的www.shanghai.oneyearice.asia的解析情况,这样涉及父域和子域的情况,用iptables进行查看
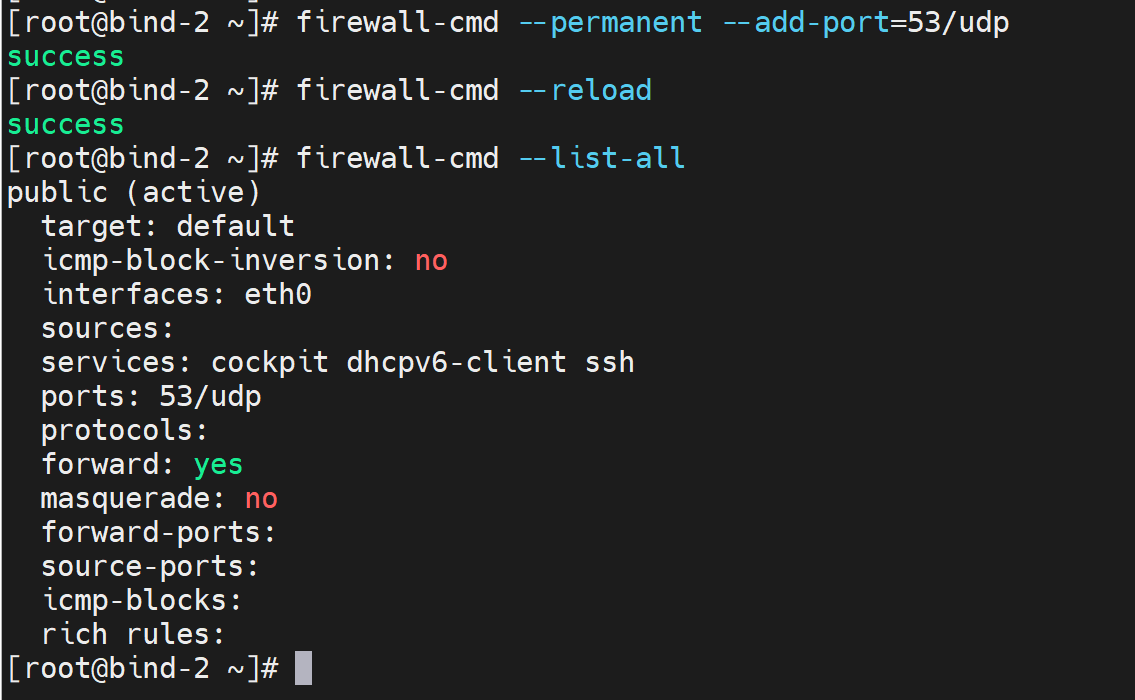
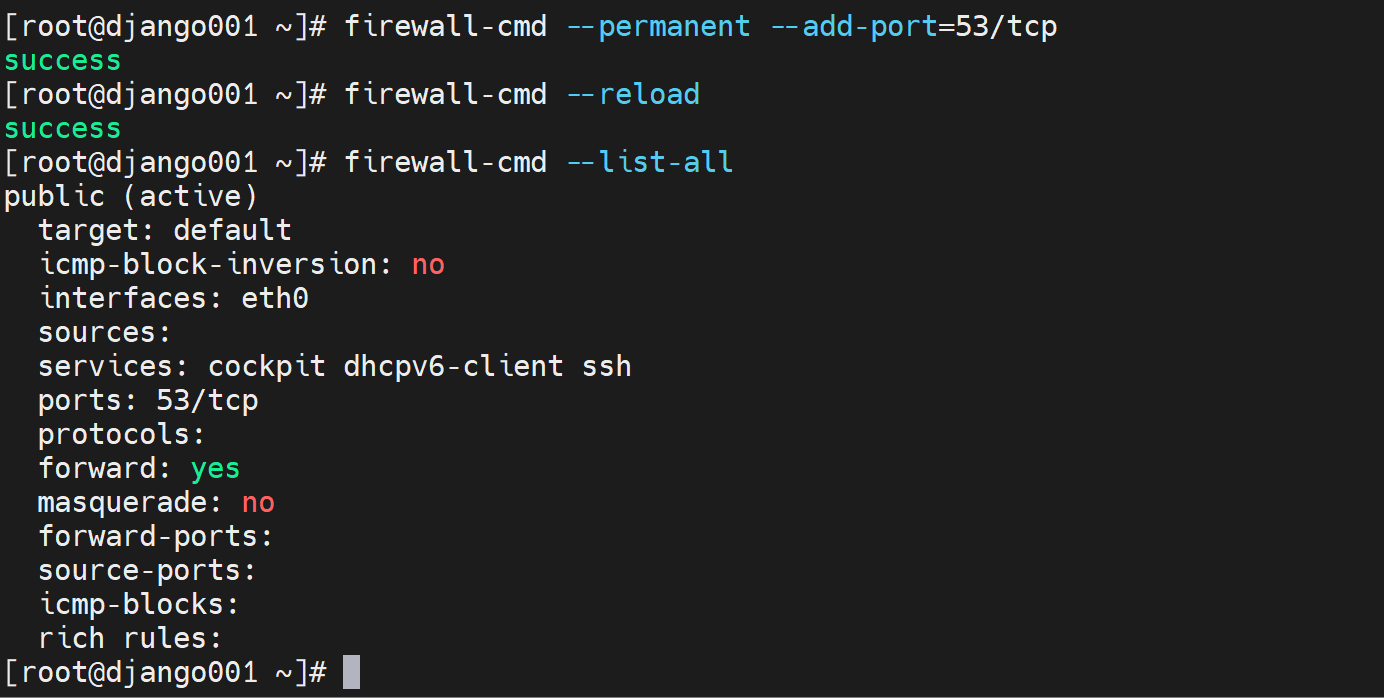
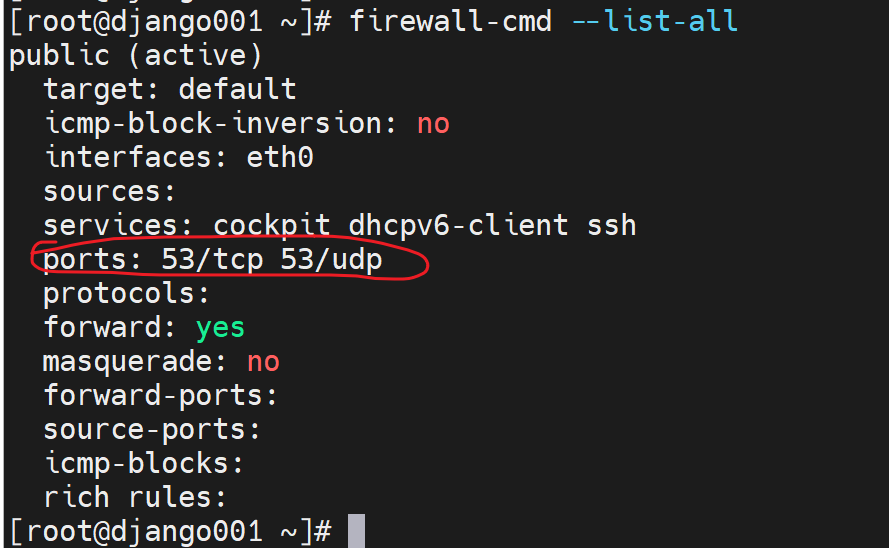
1、打开firewalld

2、放行udp 53
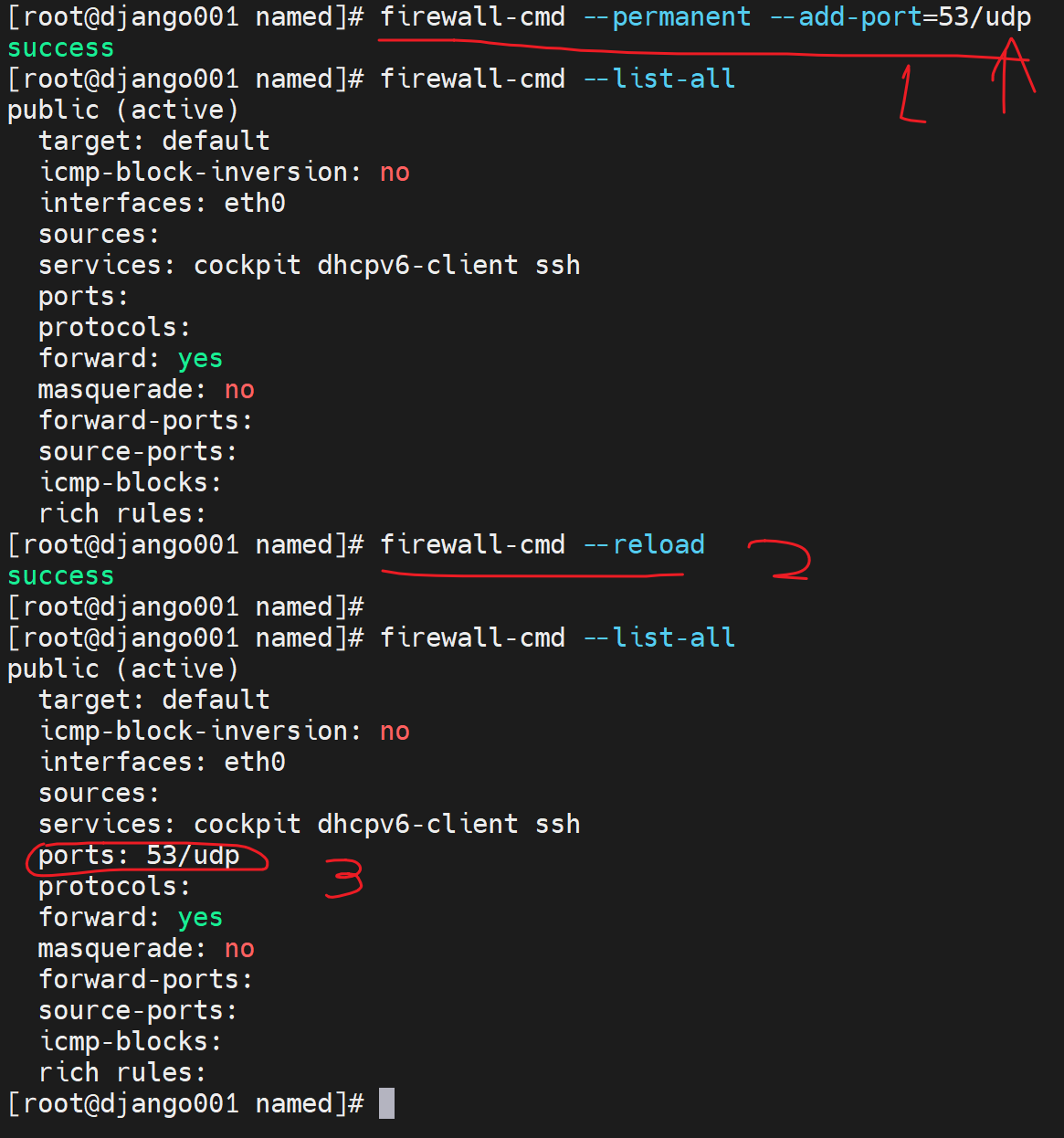
3、OK
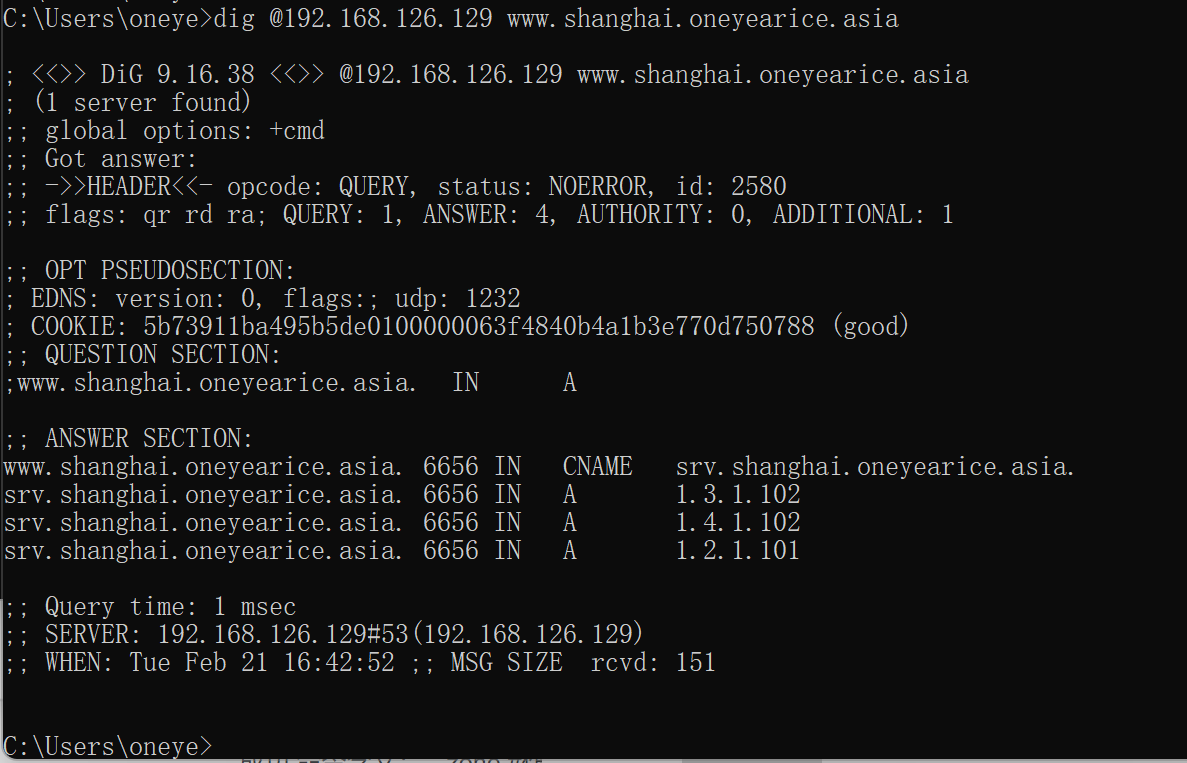
说明client和dns server只需要UDP 53,
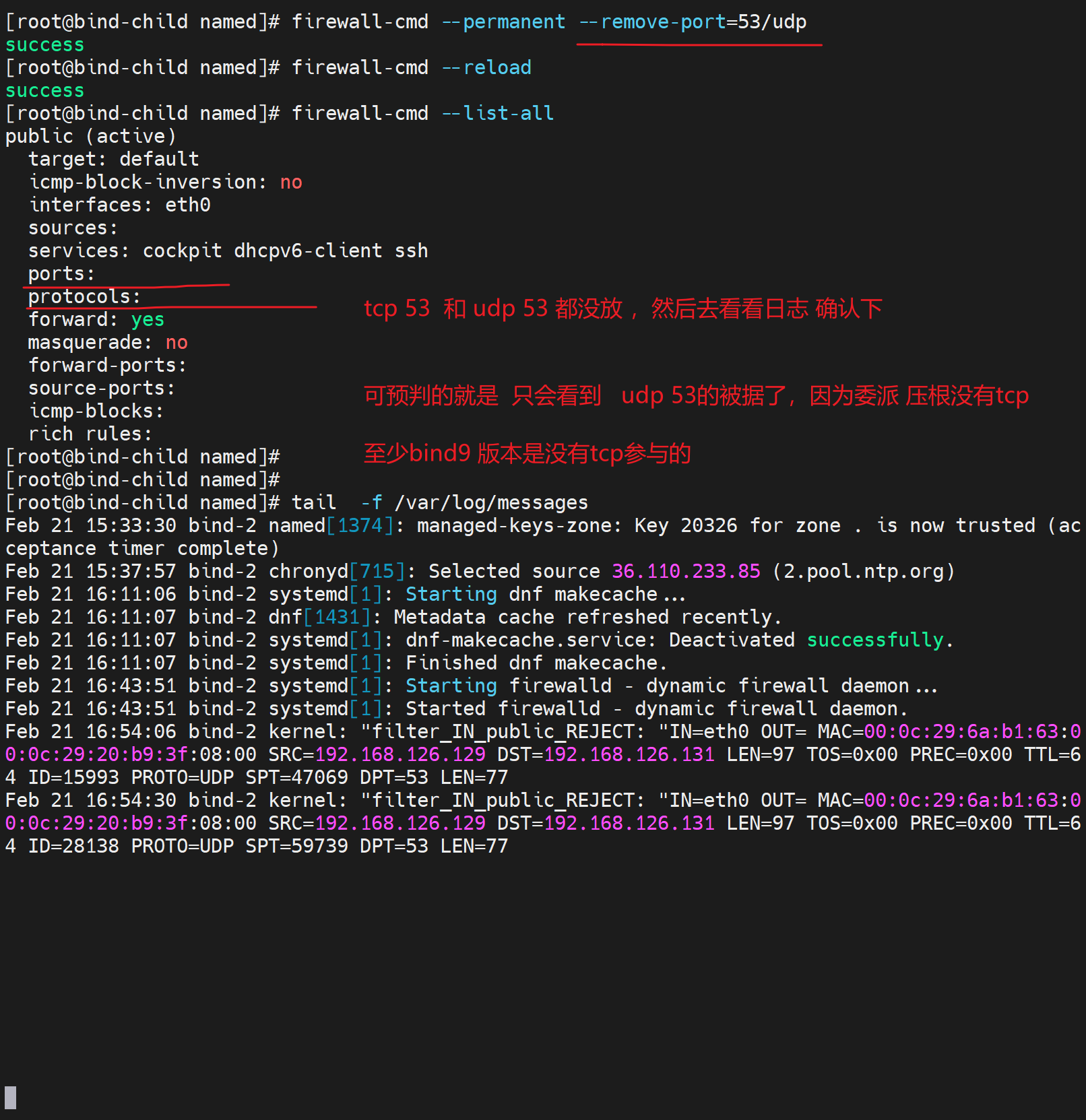
4、进一步研究父域和子域之间的53
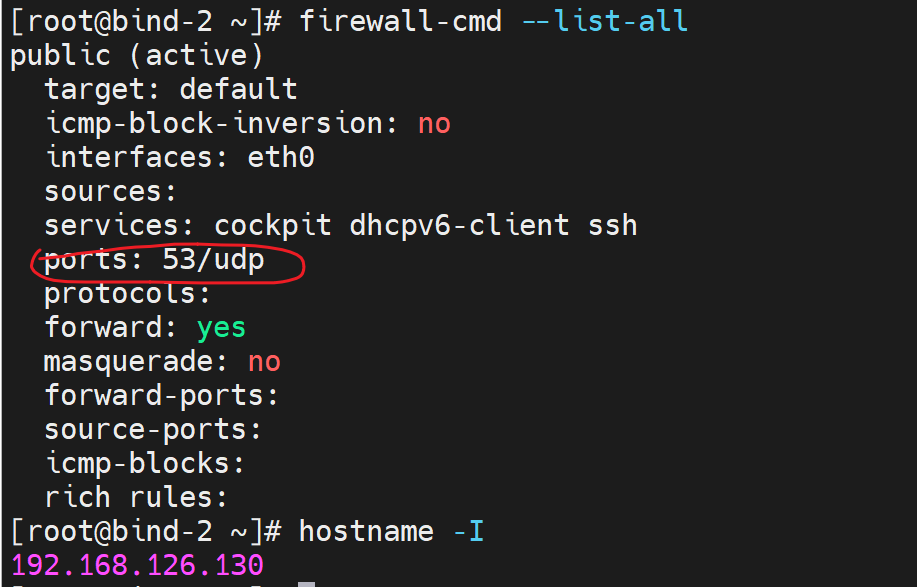
去子域开启firewalld
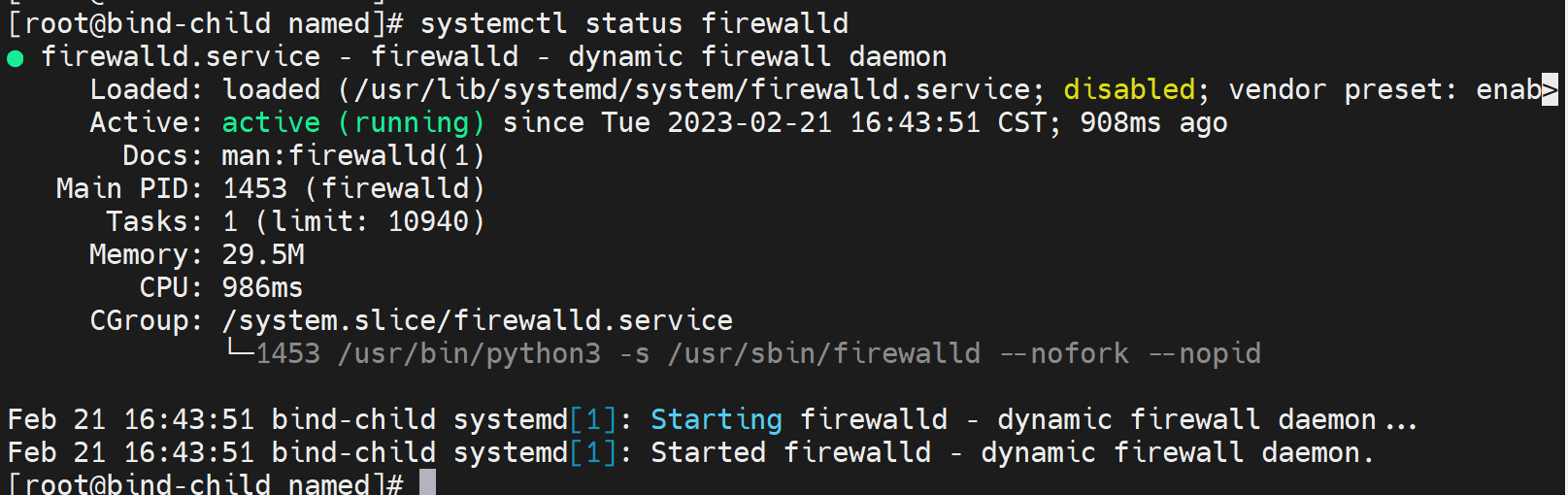
清父域的缓存

报错
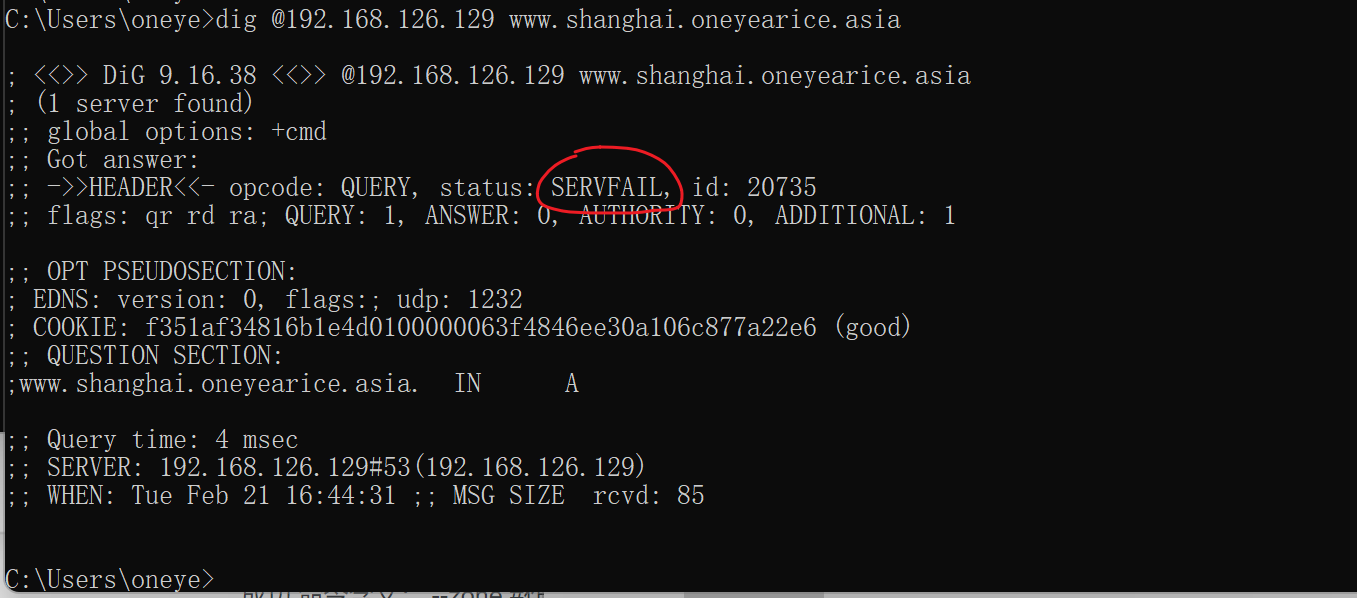
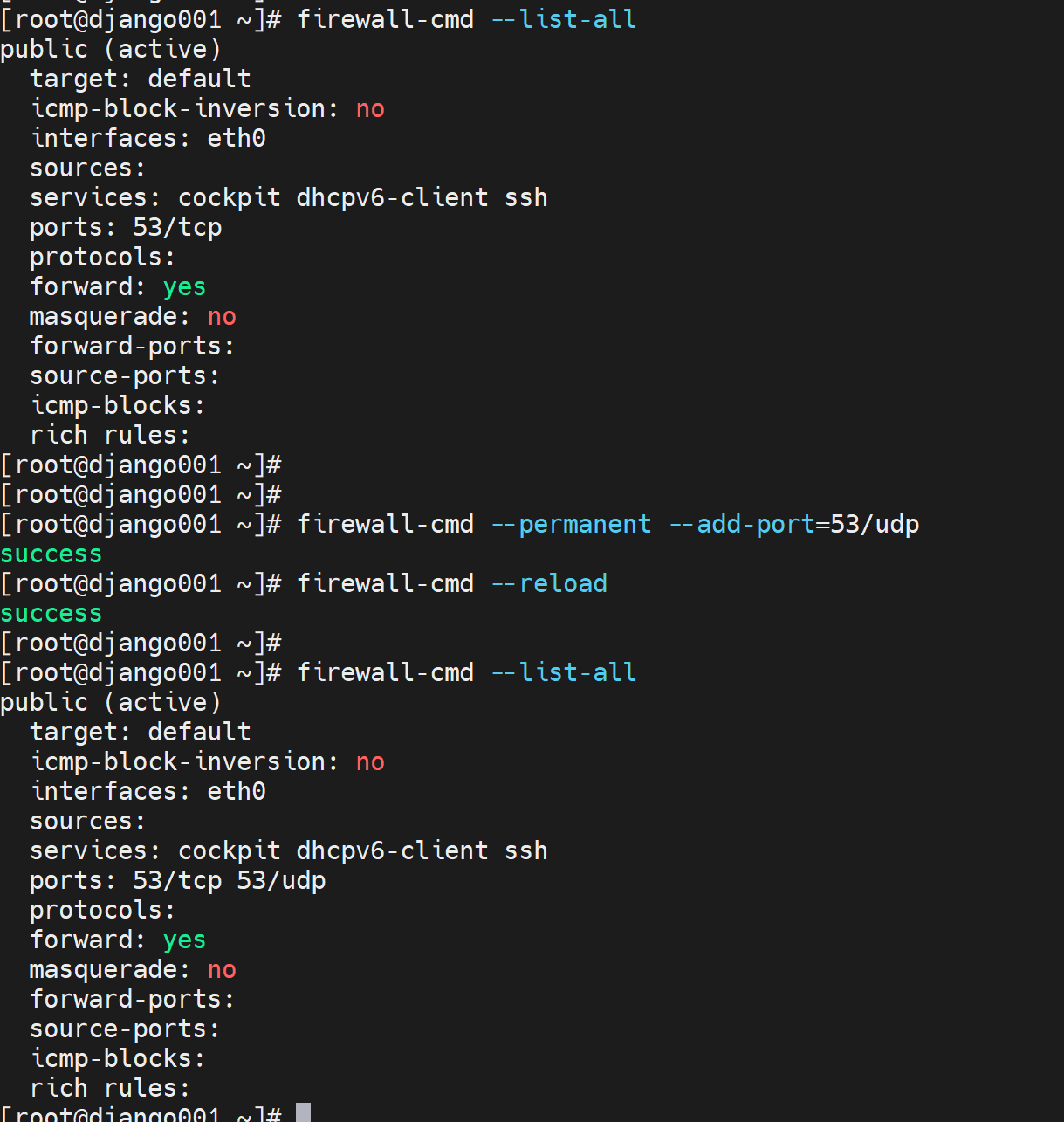
5、打开子域的tcp 53
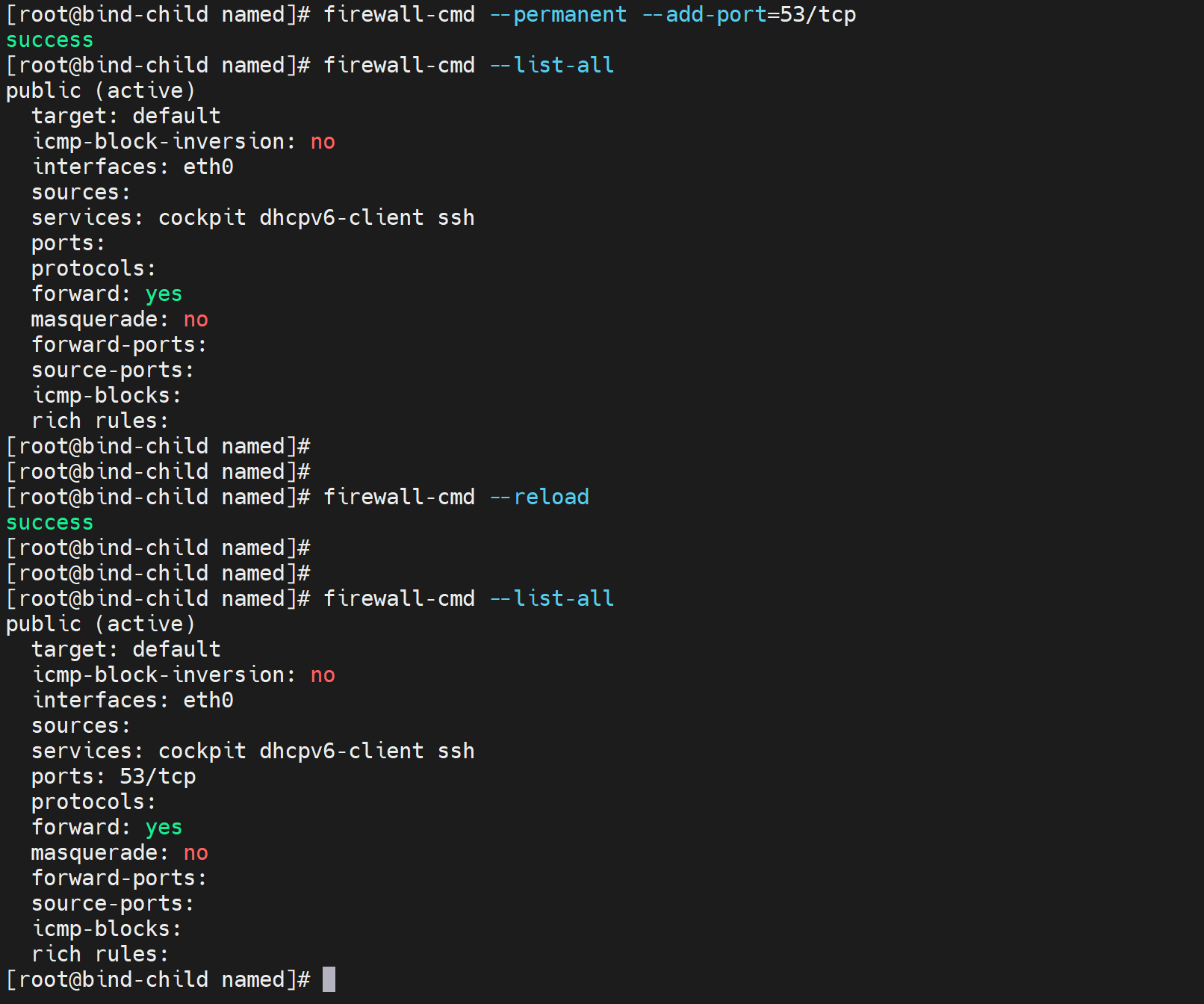
测试 依然不行,
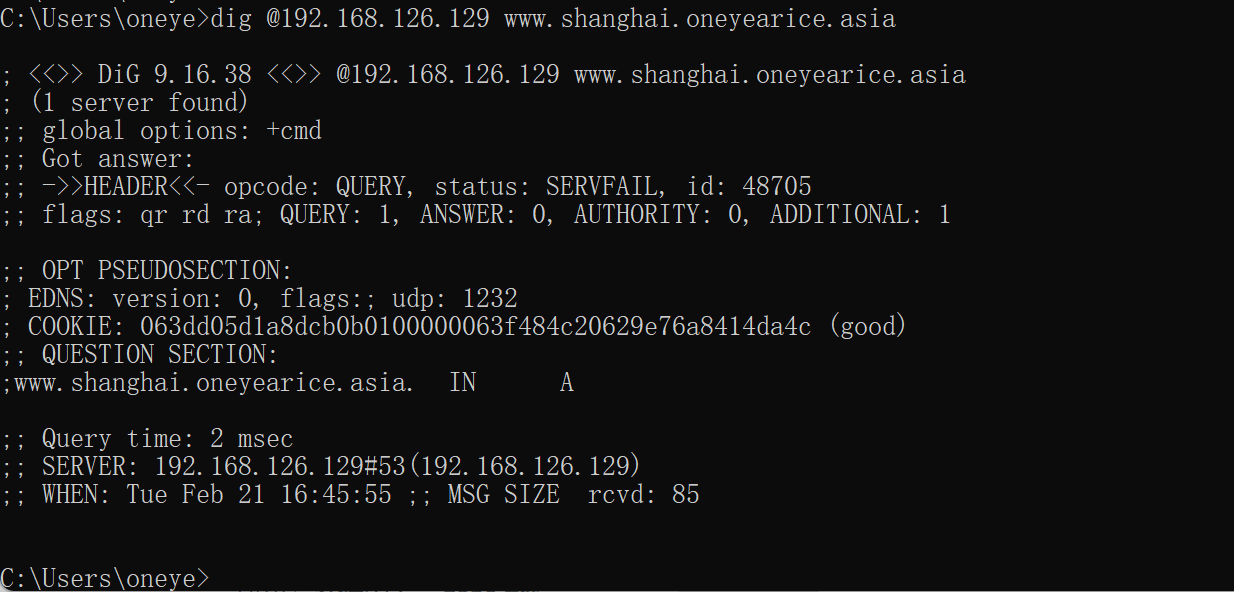
查看firewall的抓包记录看是否命中TCP 53
https://developer.aliyun.com/article/1100649
https://www.onitroad.com/jc/linux/sec/firewall/firewalld-log.html
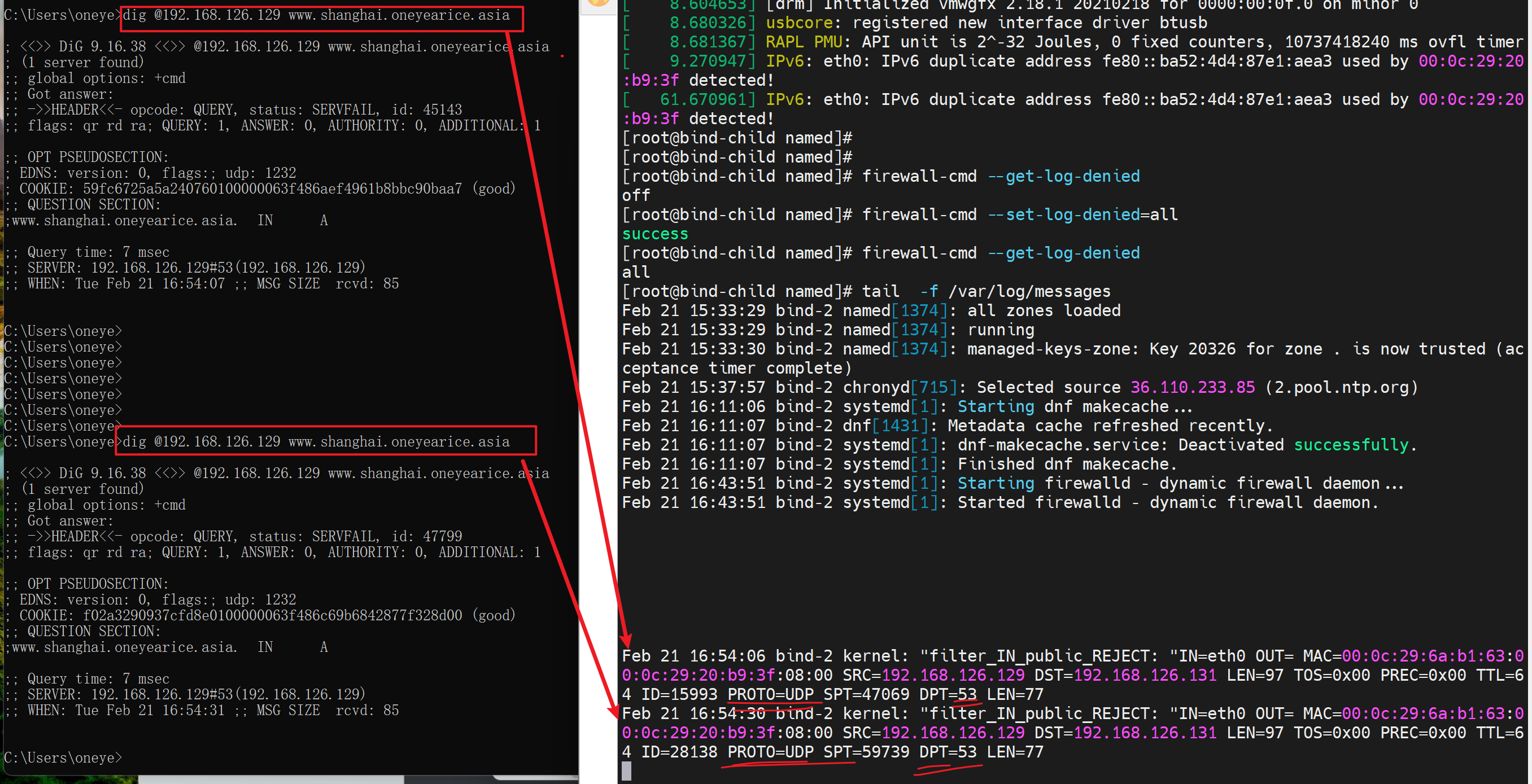
明确可见udp 53被拒了,但是tcp 53 没看到,所以
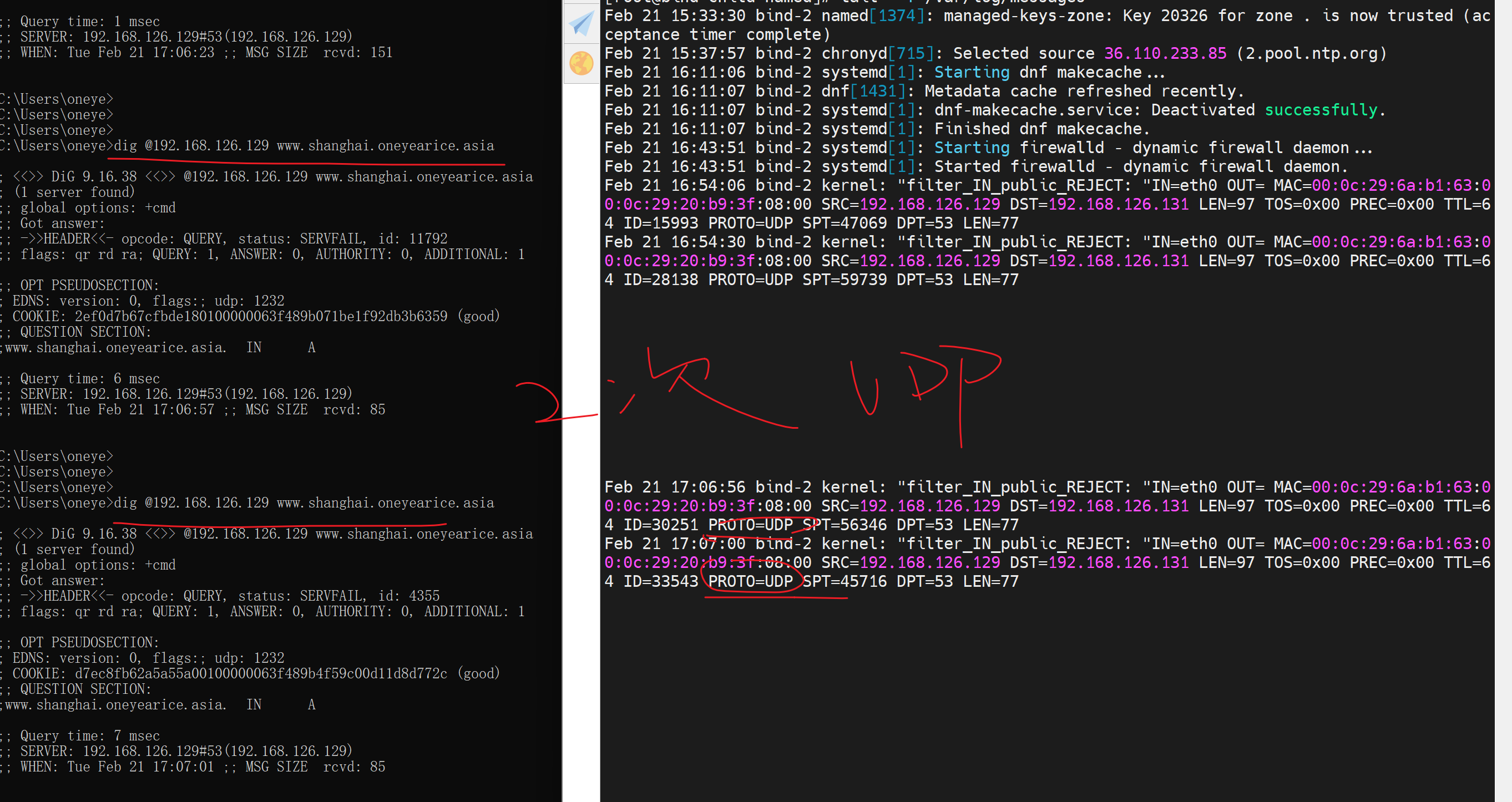
6、子域firewall改放行UDP 53 tcp干掉。
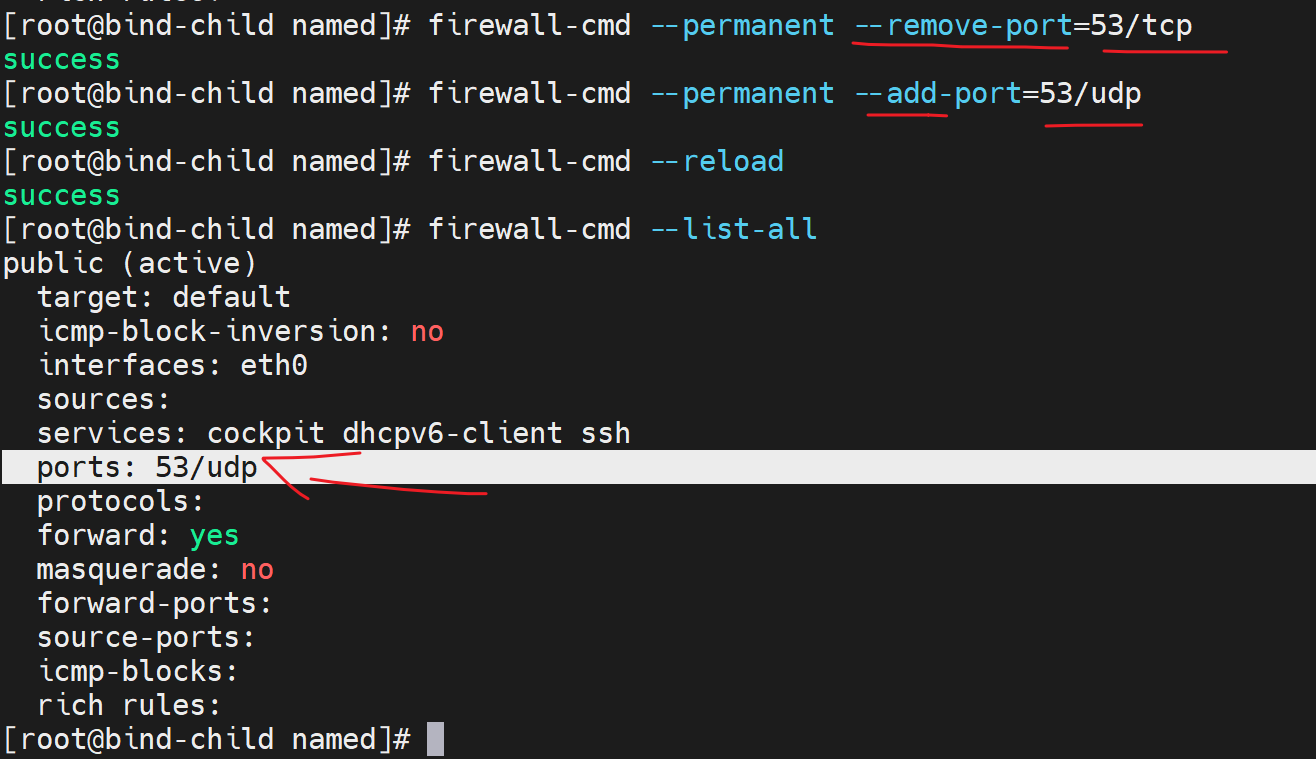
测试,竟然就可以了
只需要UDP53,啊哈哈
记得client 上一次解析成功了,要去父域上flush缓存的

这个firewall不像iptables可以看到命中报文,有点不爽,估计是有其他方法我没找到。
然后考察主从复制的53是哪种L4协议
去从服务器上
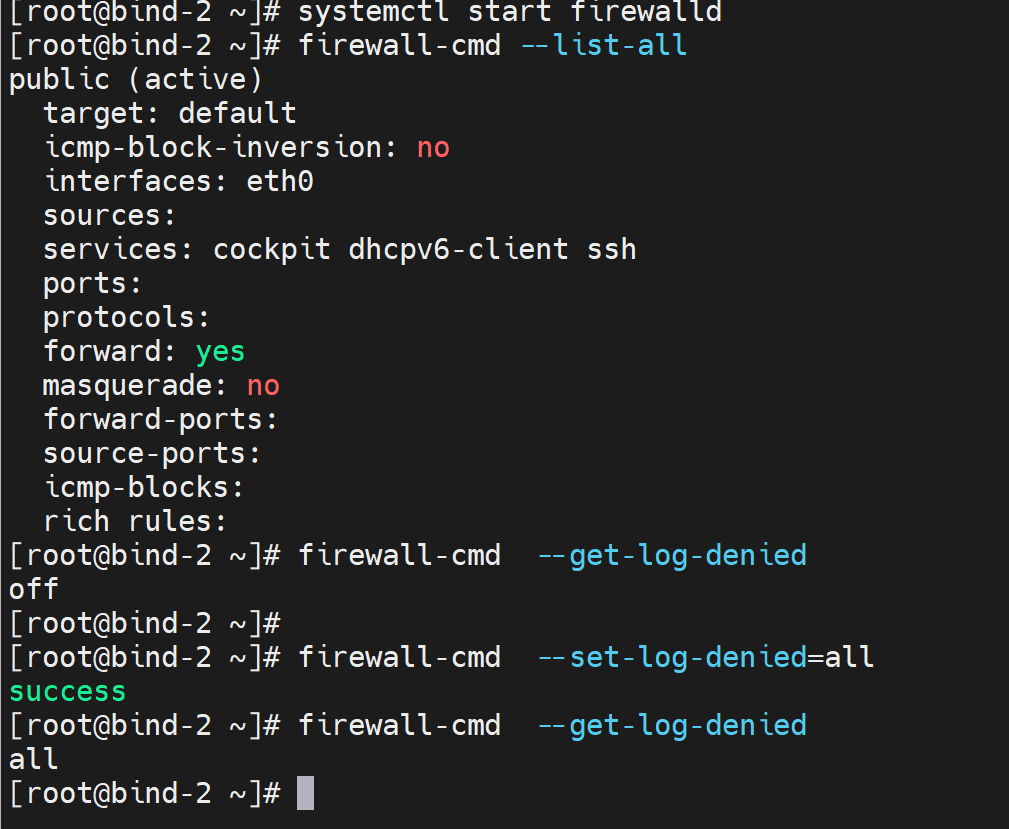
将日志挂在那,然后去主上编辑一下,记得修改版本号
1、只是修改了master的版本号
2、然后看到从服务器有拒绝日志
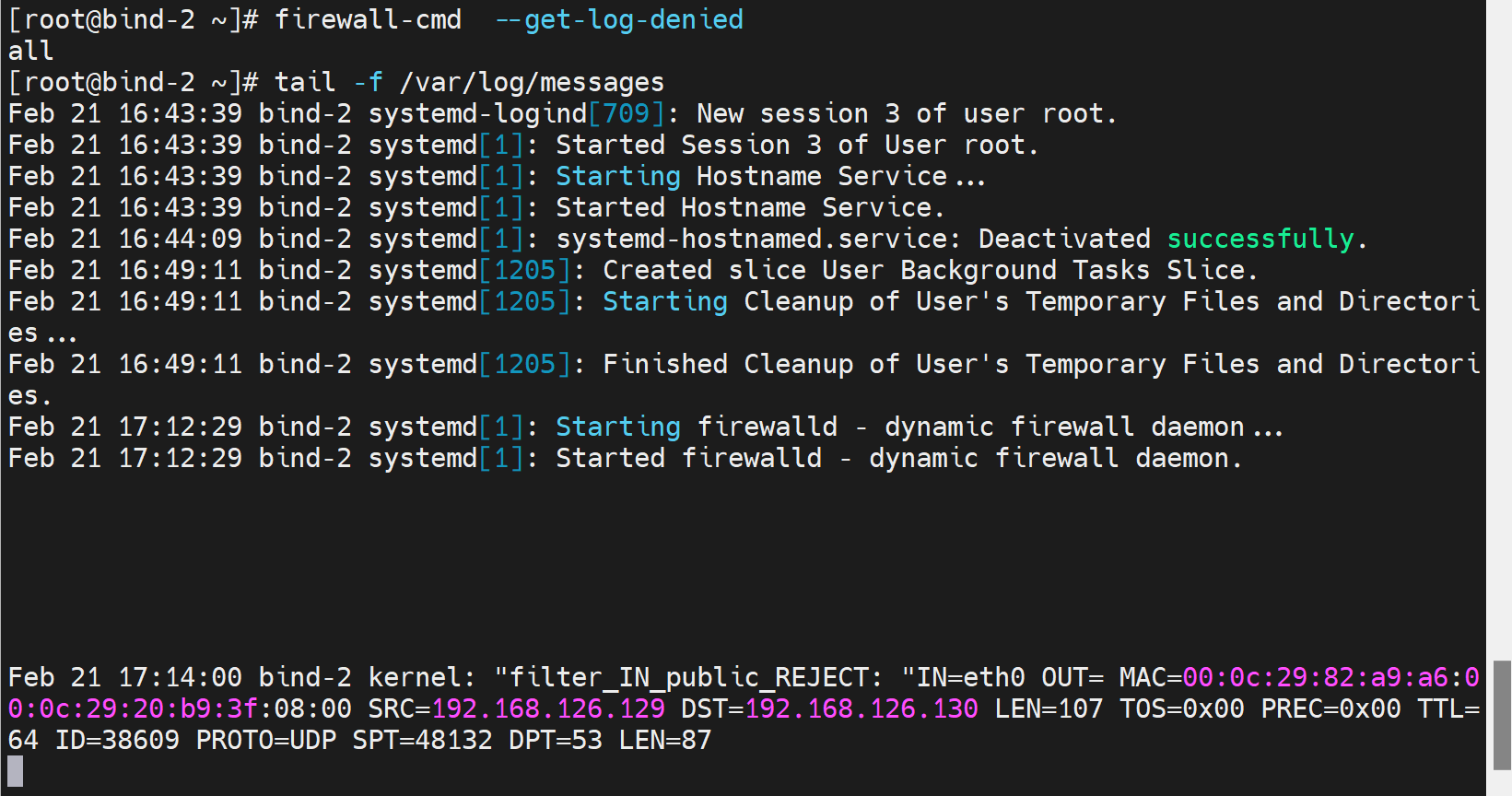
说明UDP53存在
3、继续修改master的记录+调大版本号
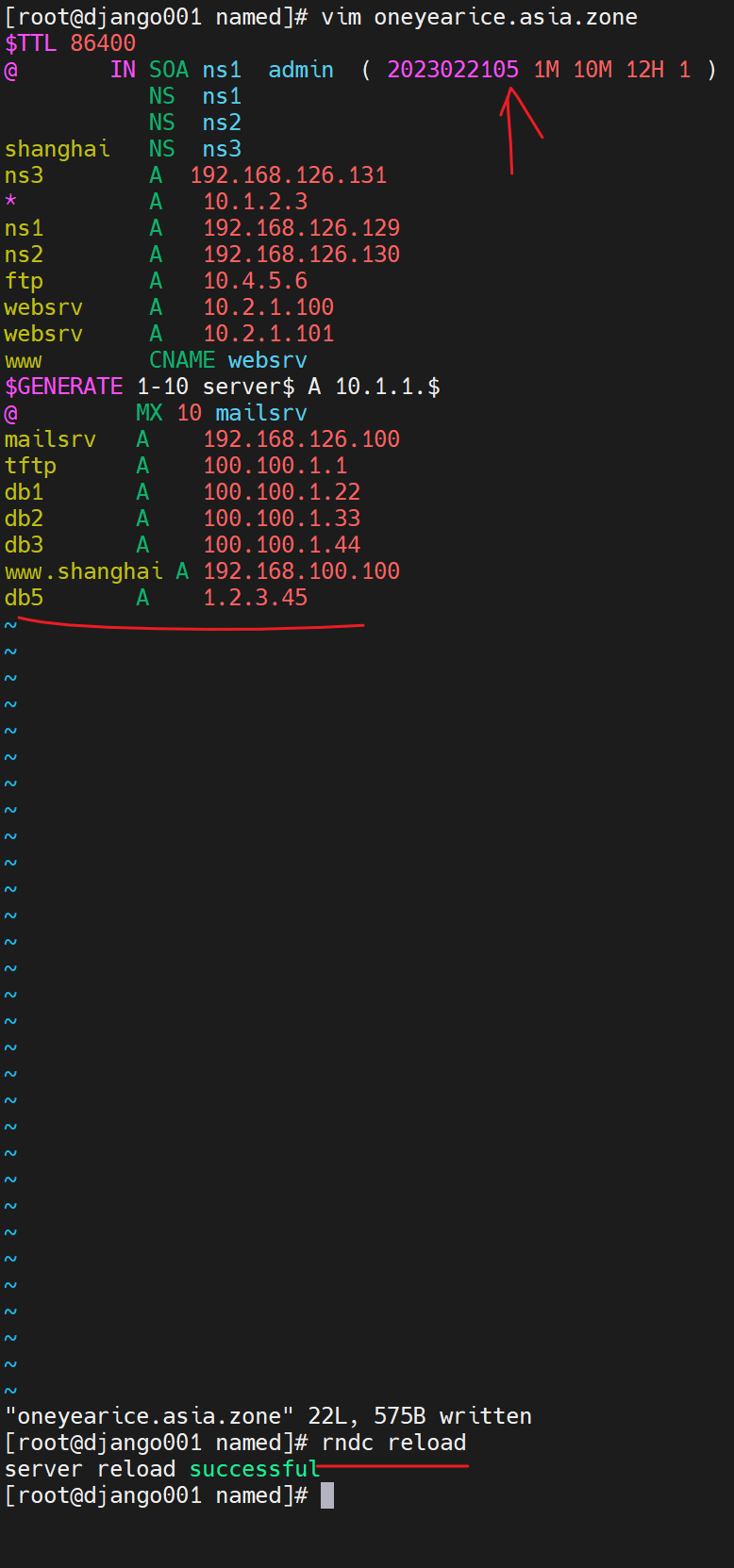
依然只有UDP 53 未见TCP53
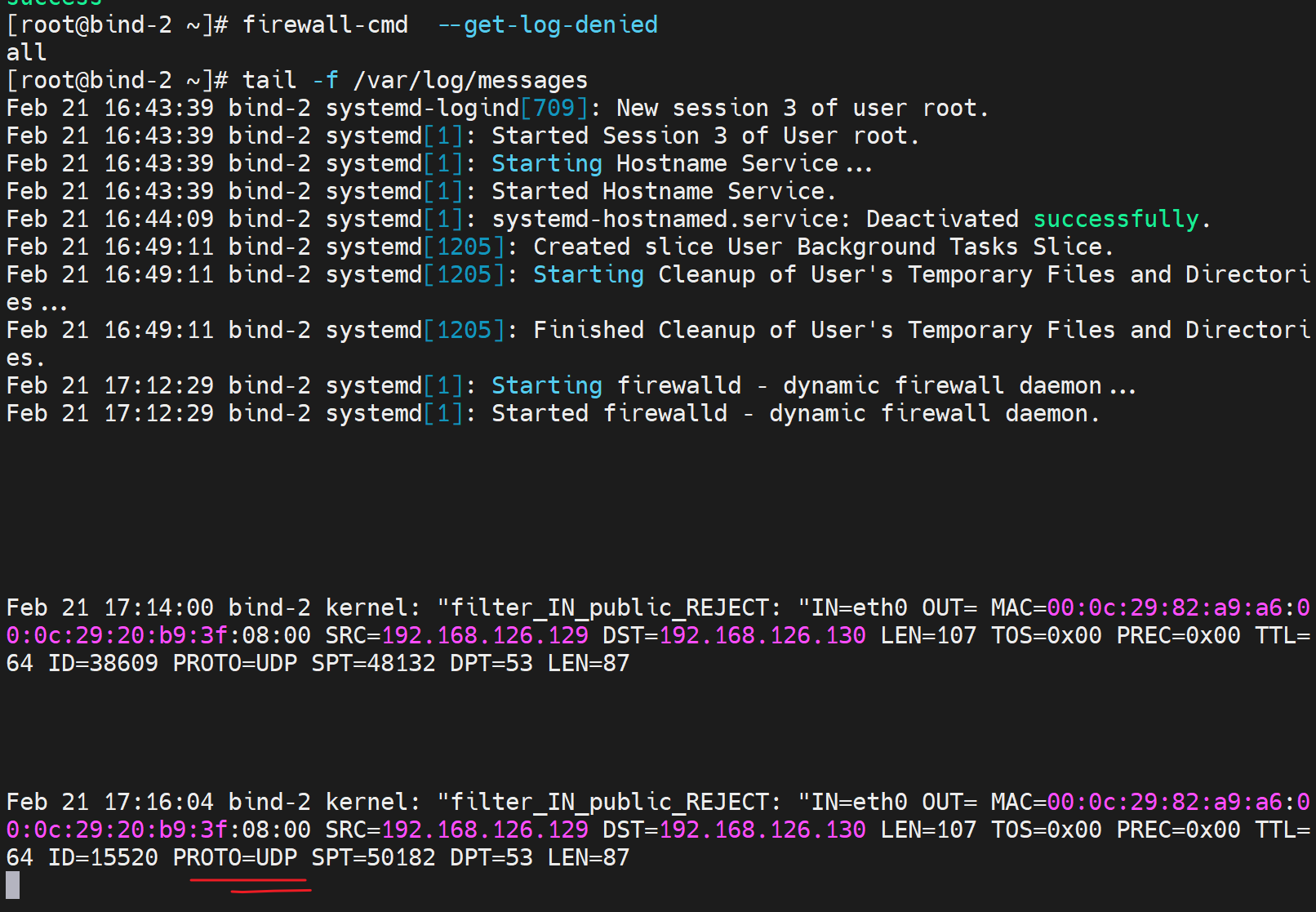
放行防火墙的UDP53,同时用户解析也需要UDP的
client去dig下
发现named没开
开了,也要同步一下

从服务器上还是没有同步

看看日志
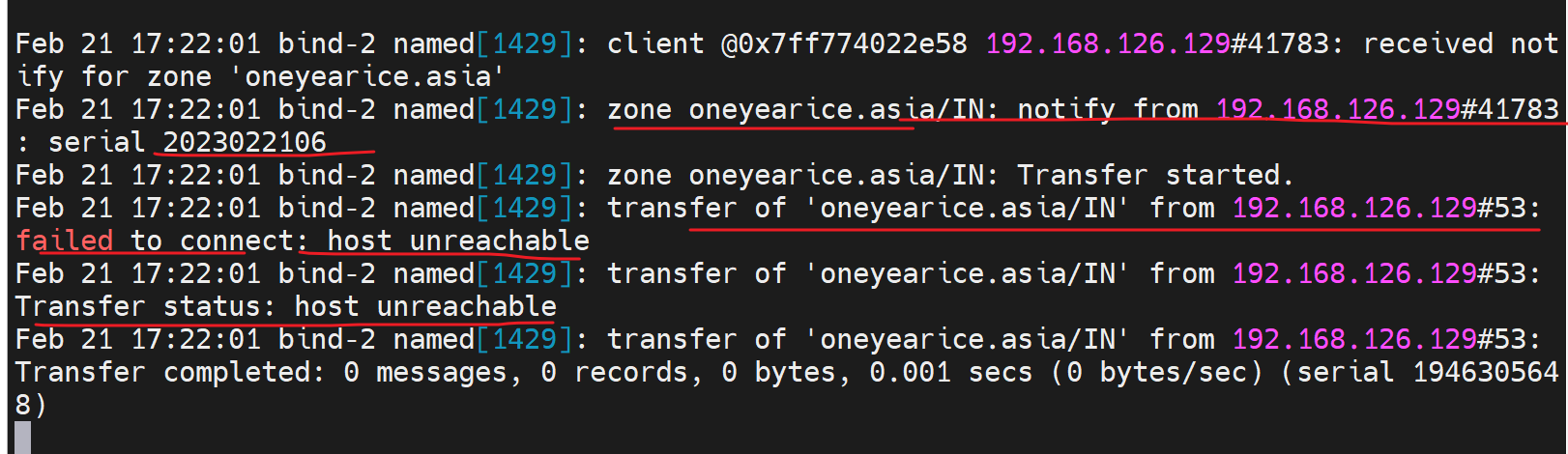
这里就看到日志,但是不清楚是 要主的TCP53还是从的TCP53
1、放行从的TCP 53看看,虽然我觉得是from 129嘛应该是主的TCP,但是,就像小学老师说的,我这个人明知的情况下就爱绕路
然后我就去主上放行了tcp 53 ,啊哈哈哈哈~
等等,看看之前没同步的,能否再retry
坐等10分钟,不管是从服务来啦,还是10M重试,都差不多了,15分钟吧
要是不成功,这个版本号就太讨厌了。
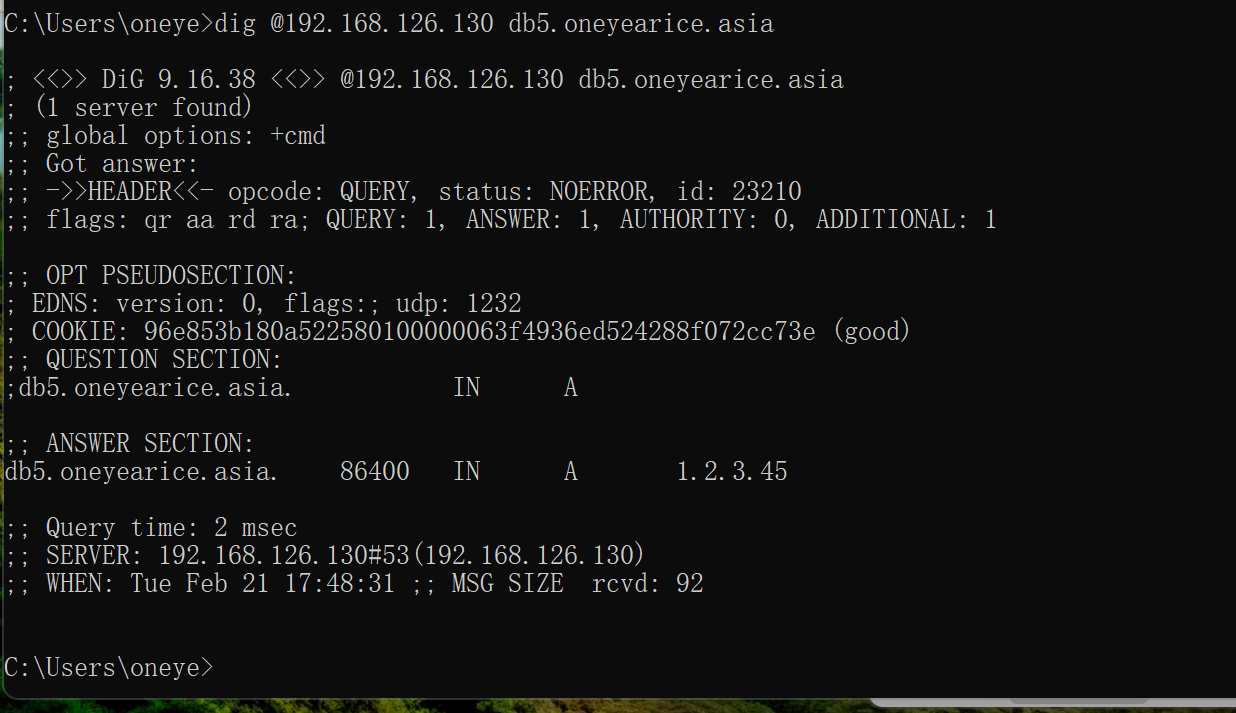
可以了,看来它还是知道这个同步没成功,会拉也好,会重试也好,这个点需要继续验证的,否则业务处理故障会模糊的。
结论:主从:①从服务器需要访问主的tcp53和udp53;②主服务器需要访问从的udp53。
进一步测试
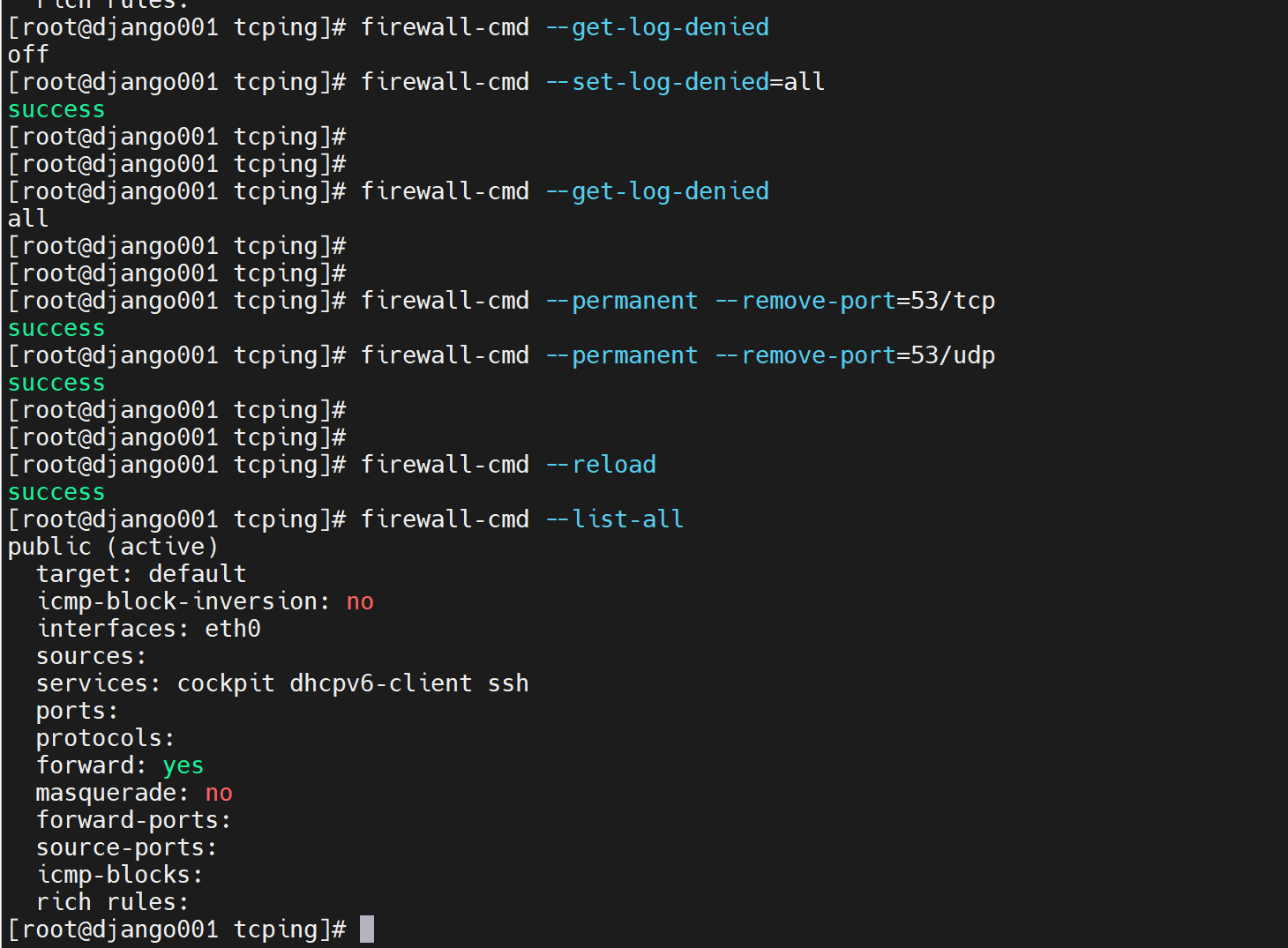

看来从服务器需要访问主的tcp和udp 53,都要访问的
从上的日志倒没有具体的UDP 和TCP的 字眼

放开主的tcp


上图没有提示了--在从服务器上,说明从服务器的消息是TCP的,正所谓TCP才会有一些完善的报错回显,可靠啊,而UDP正应了那句话,丢了就丢了。
坐等同步,因为此时从服务器上的版本号肯定是低的,因为之前没同步过去啊。
1M?还是10M,哈哈,有懵逼了,应该是1M没成功啊,刚才firewall调整的1M的拉肯定失败,不过1M不是周期的嘛,1M也应该重新拉了啊,
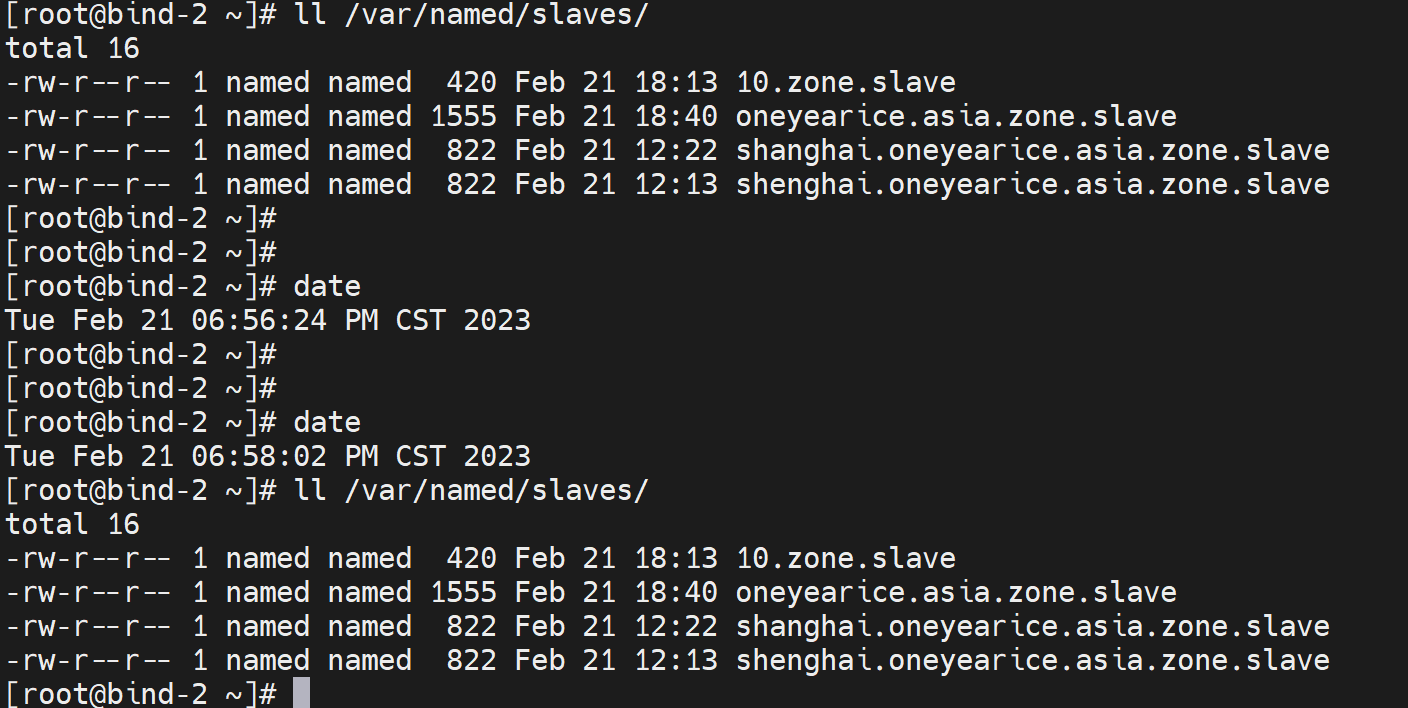
反正之前失败1M周期到了没有拉--从没有拉
然后等10M再看吧,
我就不加版本号。
👇有了大概过了也不到10分钟
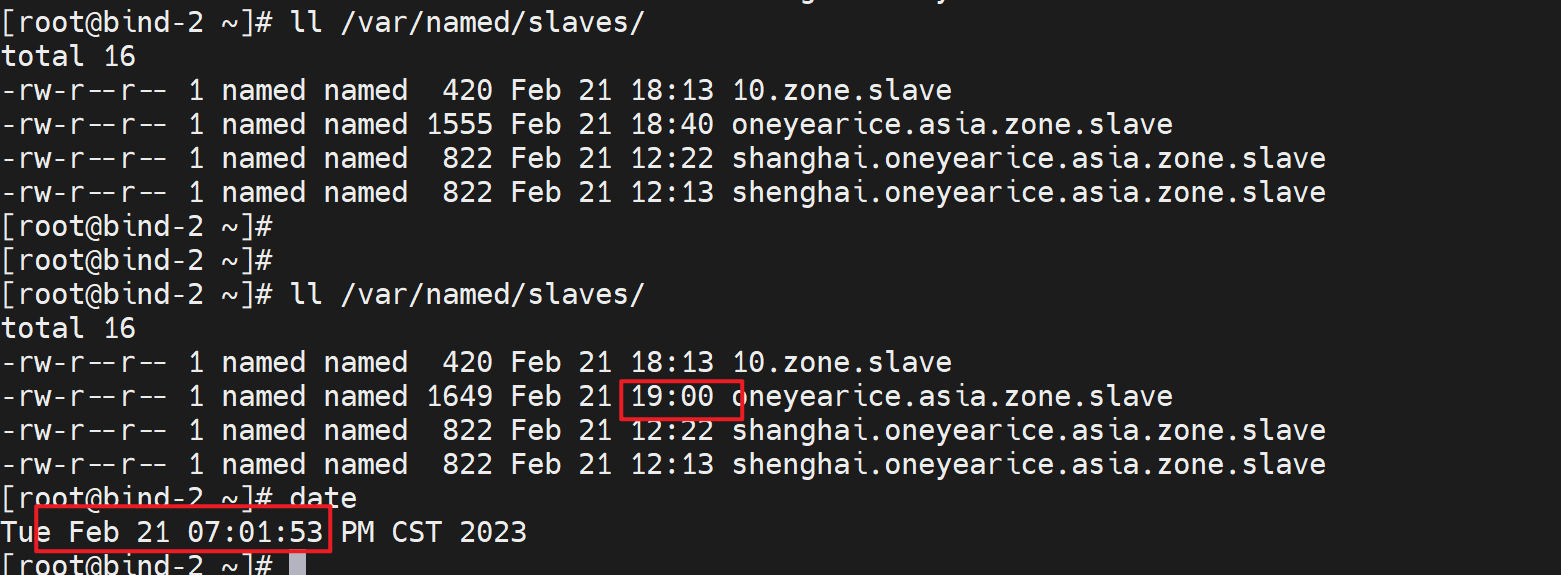
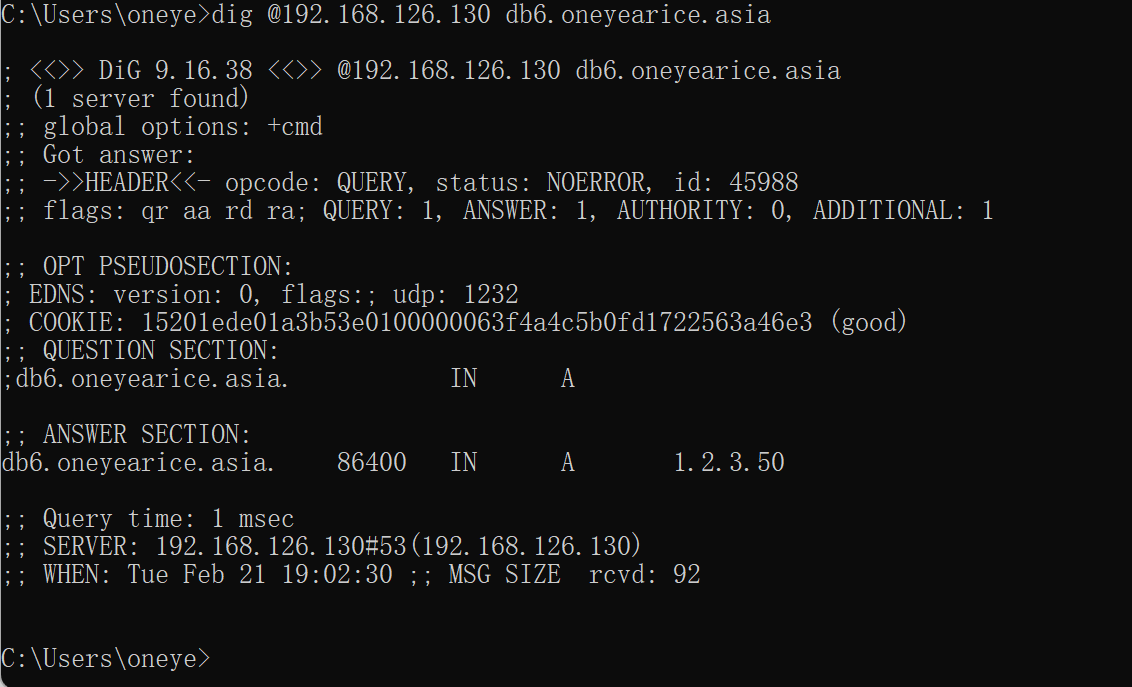
最新的两个A记录都过来了
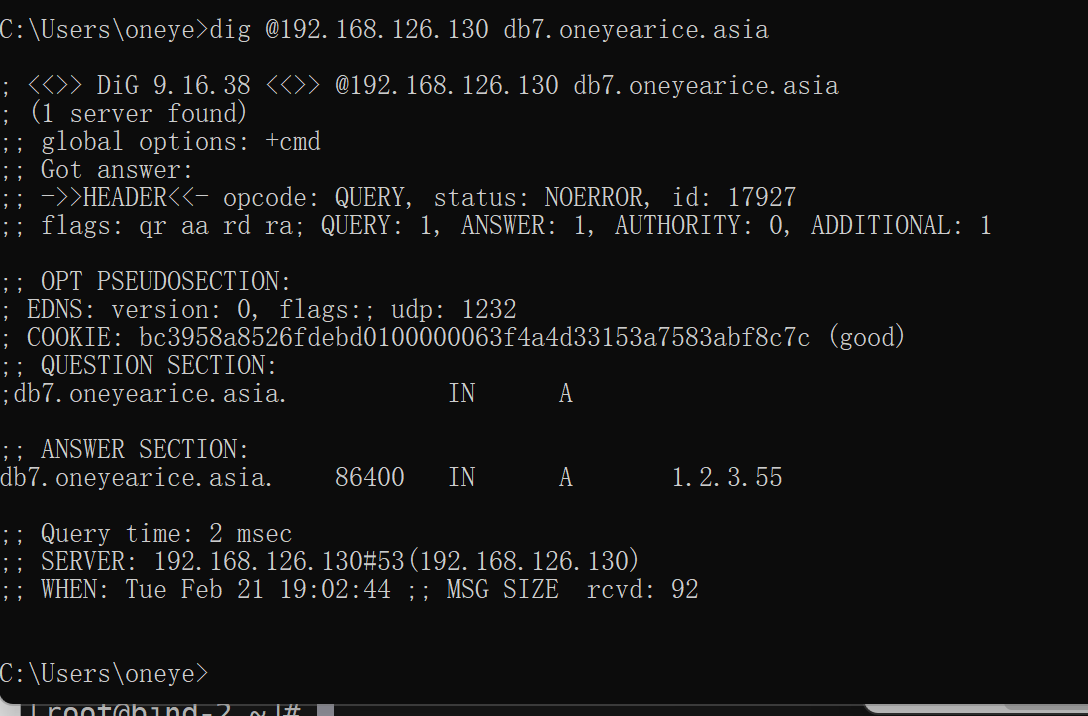
所以验证完毕
主要放开的
从要放开的
UDP要放开的原因,是同步之前需要有查询的动作,而查询就是和client去查询一样了,就是依靠UDP53。
确定了不一样之后,再利用TCP53去同步传递文件。--据说是这样,应该是正确的。
验证
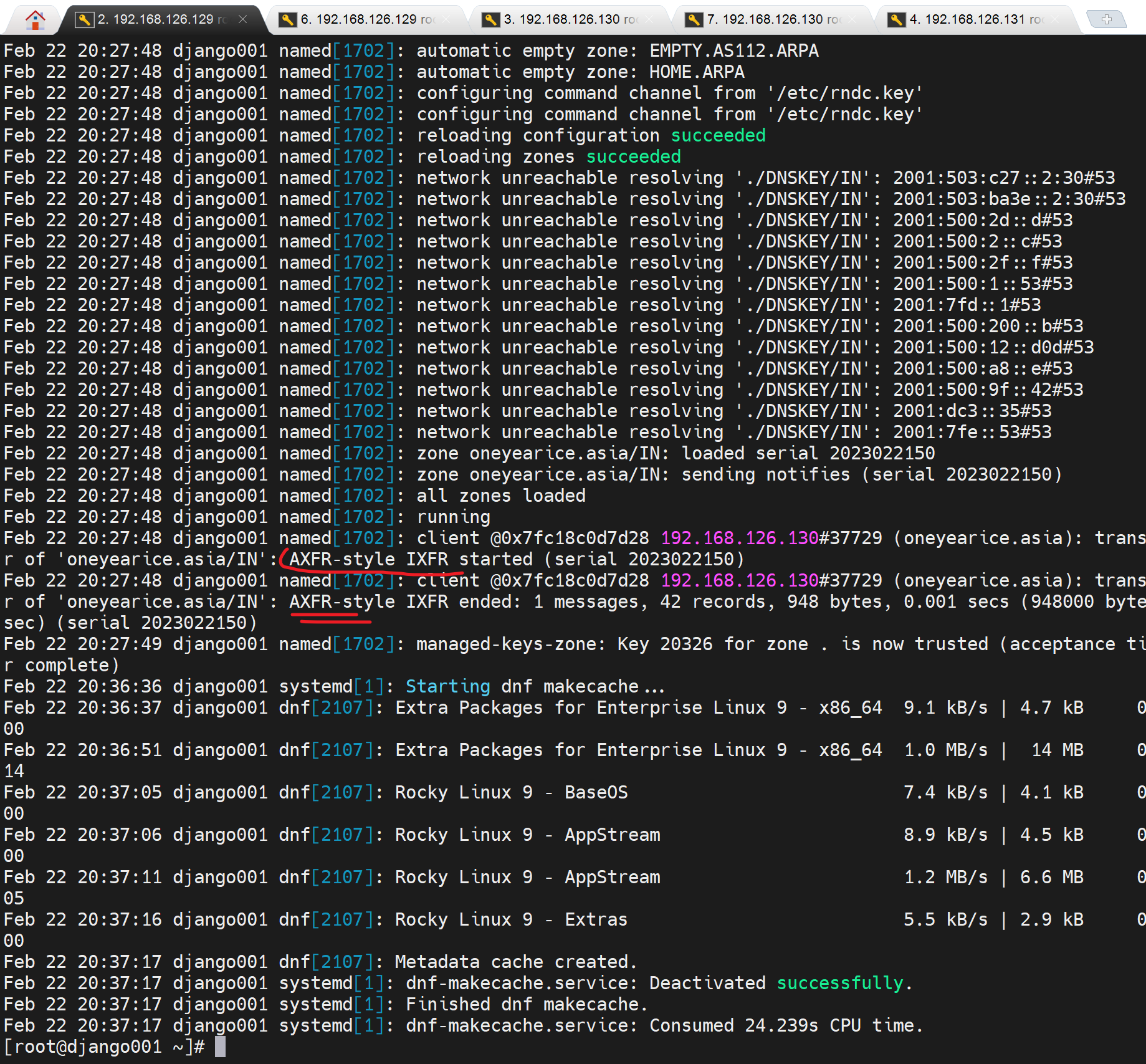
动作1、在master上只修改版本号后rndc reload,也不用加rr,然后看提前挂载那边的tcpdump就能看见
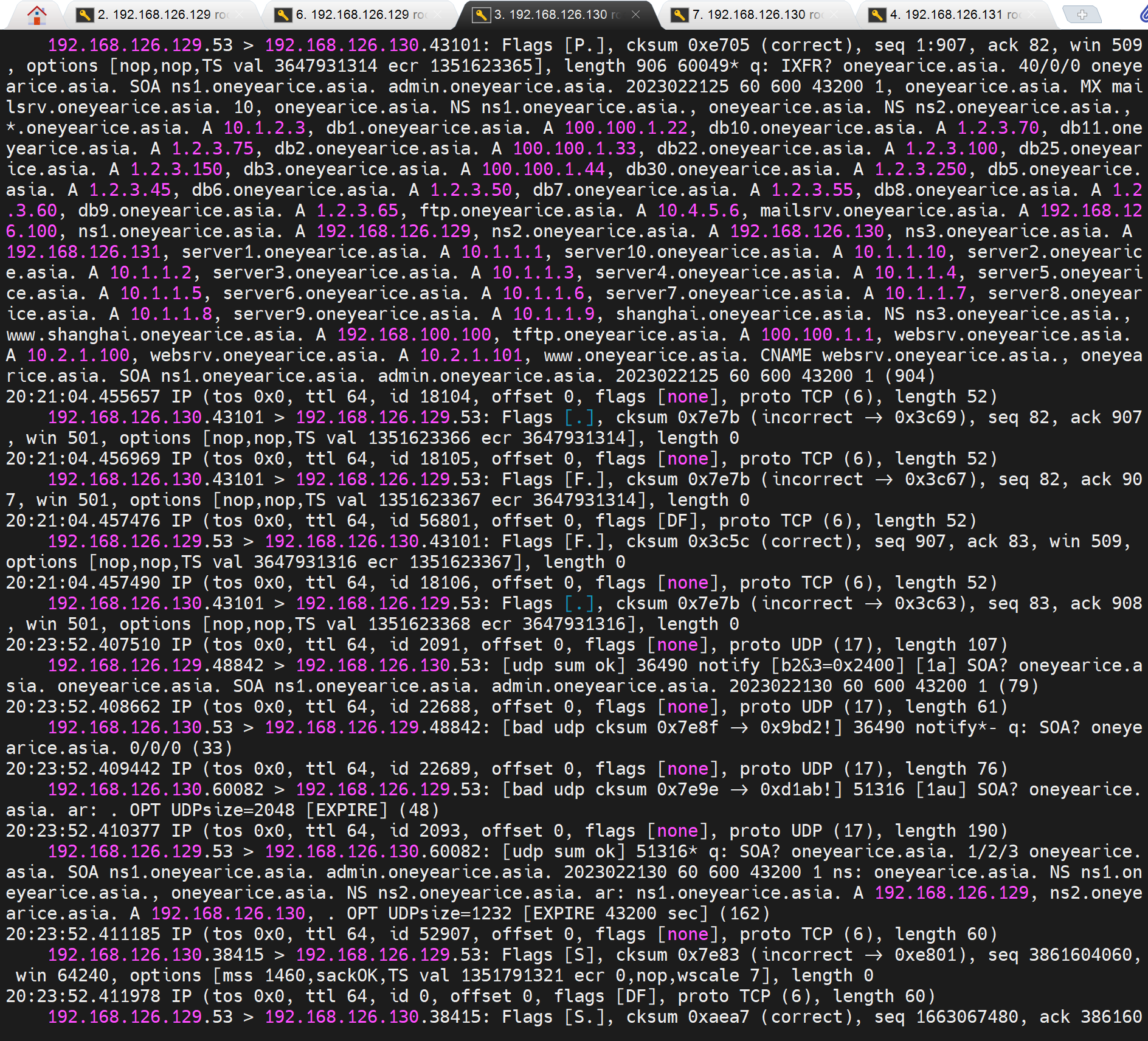
①先是udp,②后是tcp,前四行就是主获取从的全部记录,从获取主的全部记录,类似dig -t axfr
其实在message里有同步日志的:AXFR-style IXFR started AXFR就是ALL完全RR,IXFR就是增量
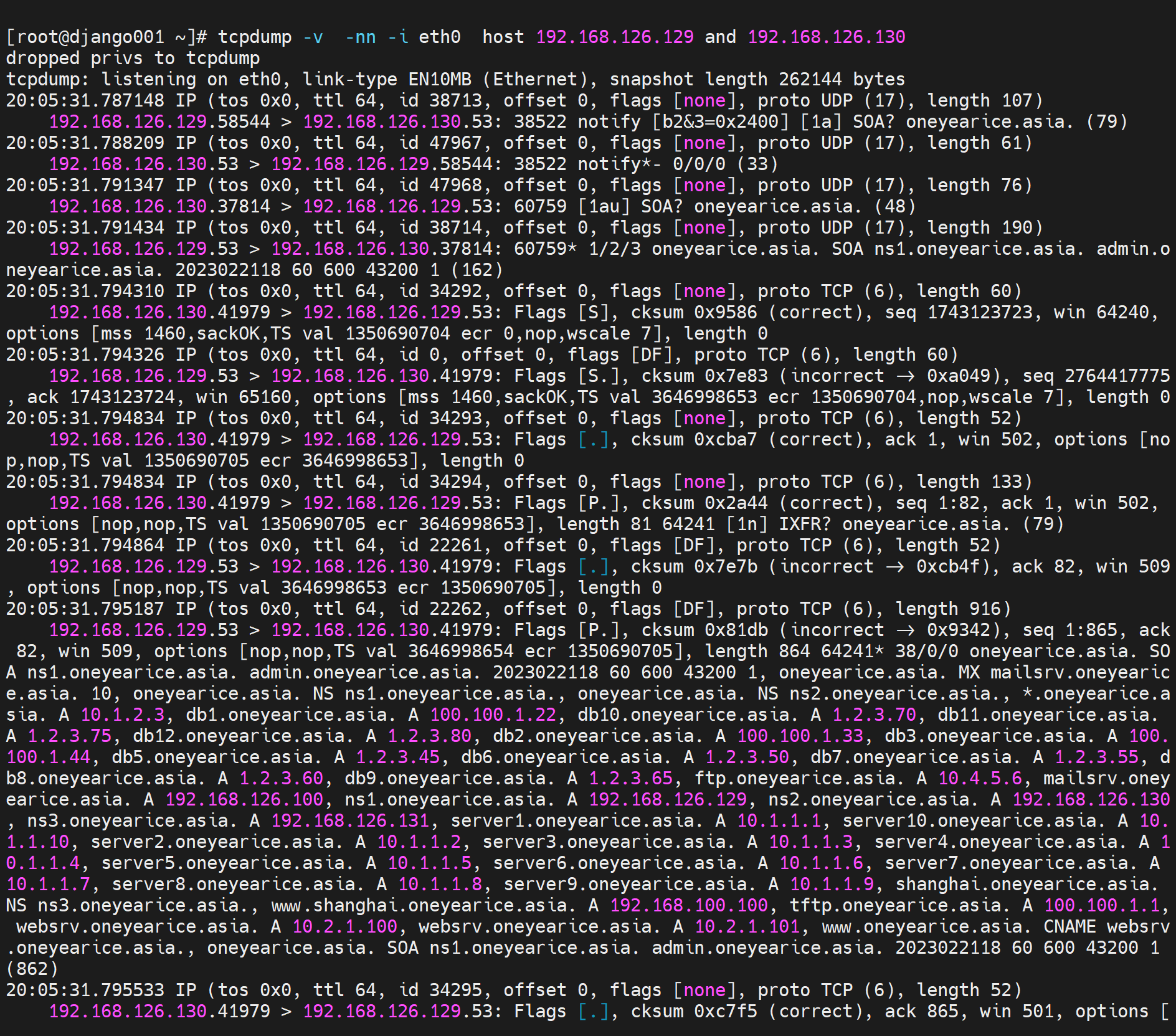
卧槽,还是明文的,我的乖乖,不小心被我发现一个漏洞。
总之 主从两头开抓包,效果杠杠的,记得带上v,vv就算了
tcpdump -v -nn -i eth0 host masterIP and slaveIP |grep -E '.53'
一下是一次完成记录
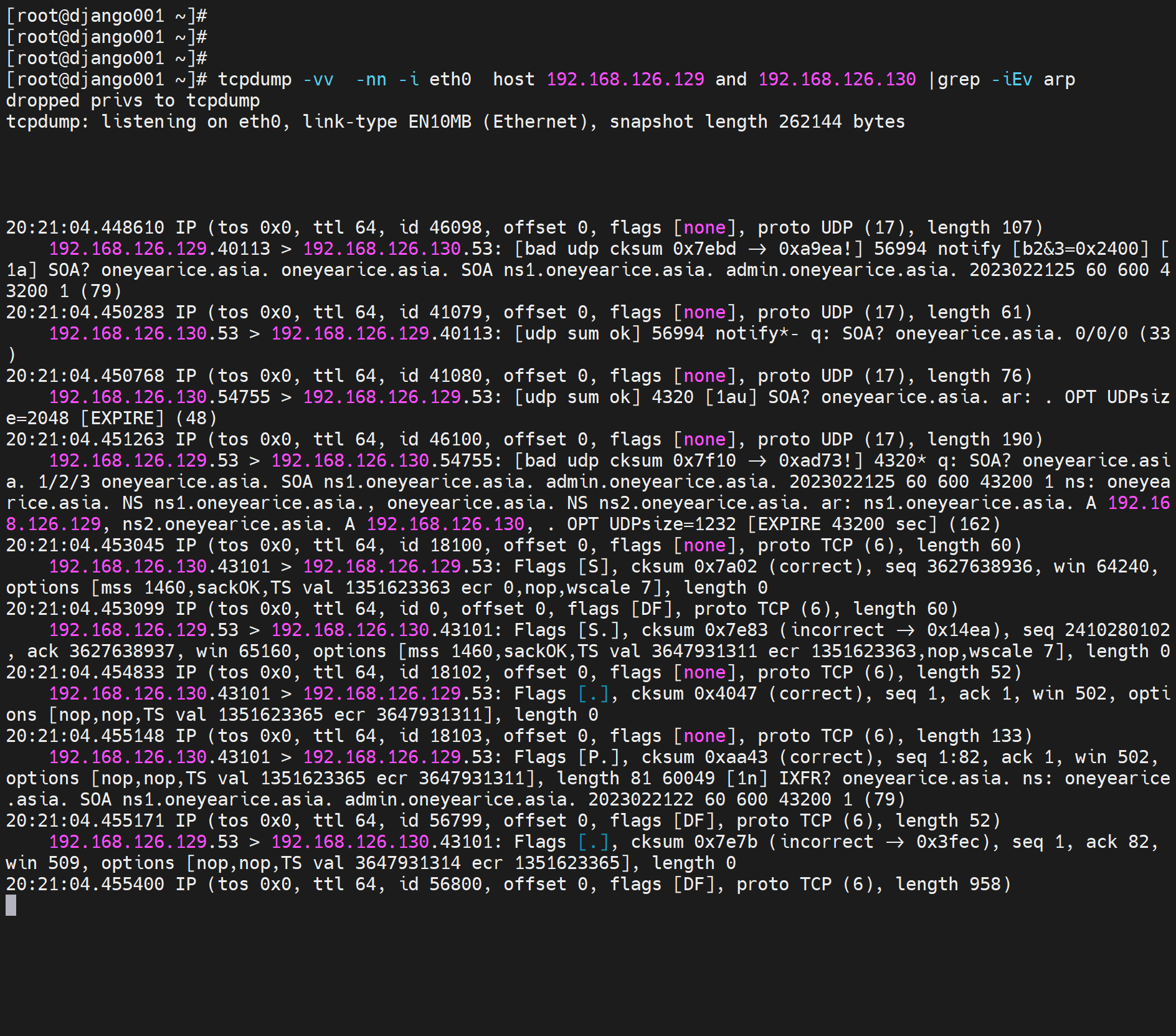
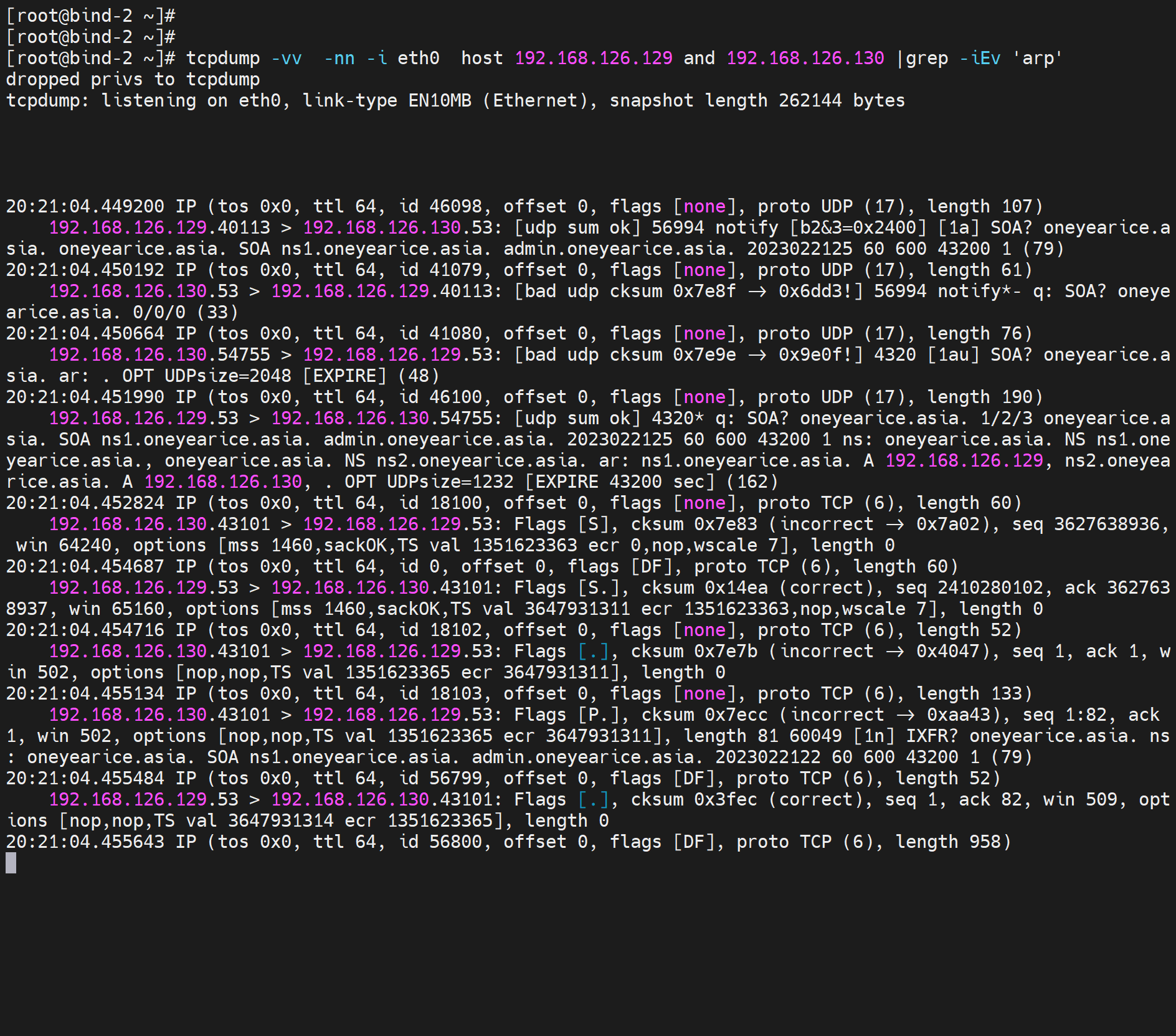
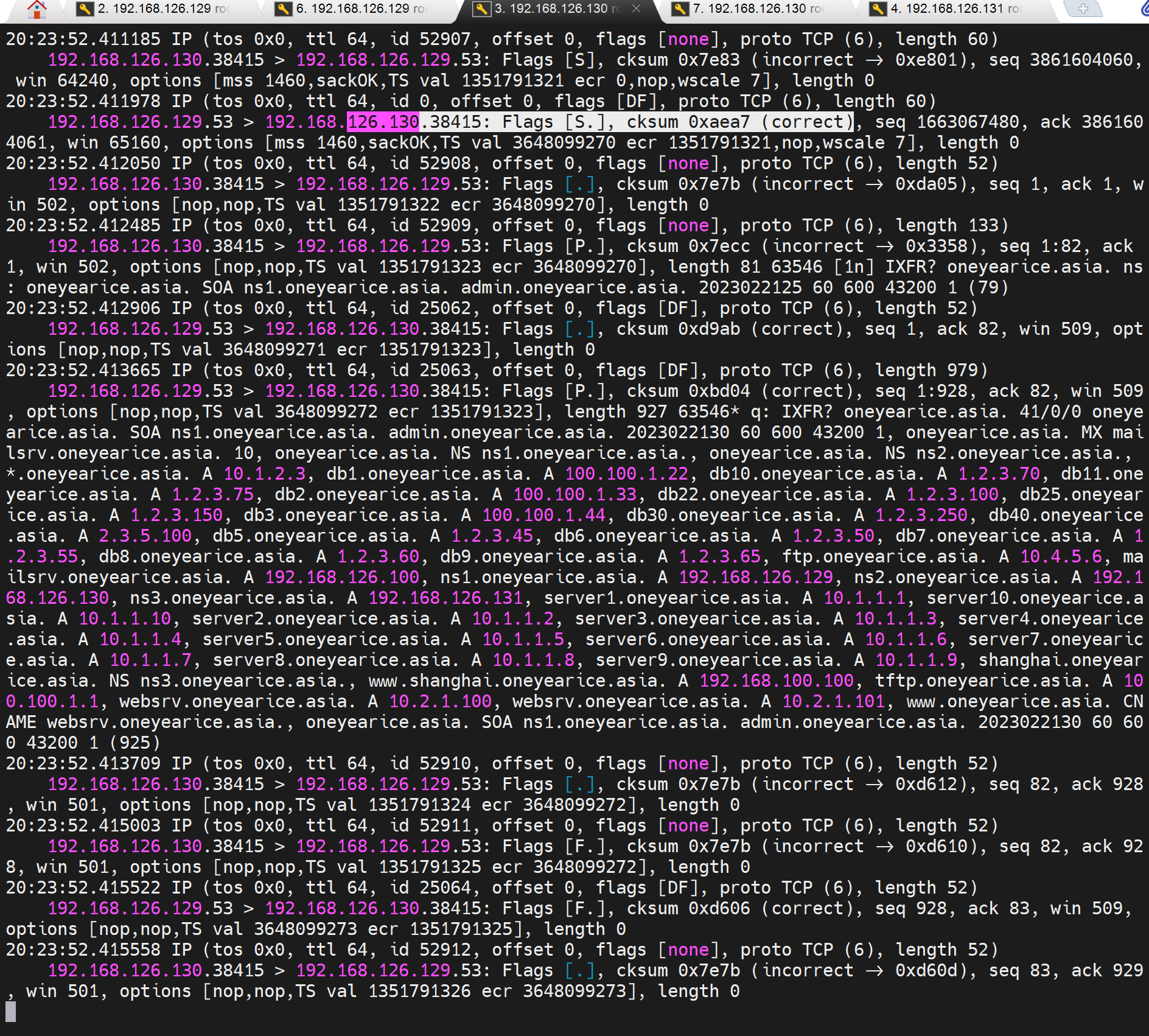
第二次的交互如下,明显比第一次要多,但是不要怀疑,第一次的解析确实同步了--虽然没有看到rr明细的传递,但是我再次测试dig 是确实过去了,而且,两次为一组,第一次抓包条目少,第二次多很多,不细究了。
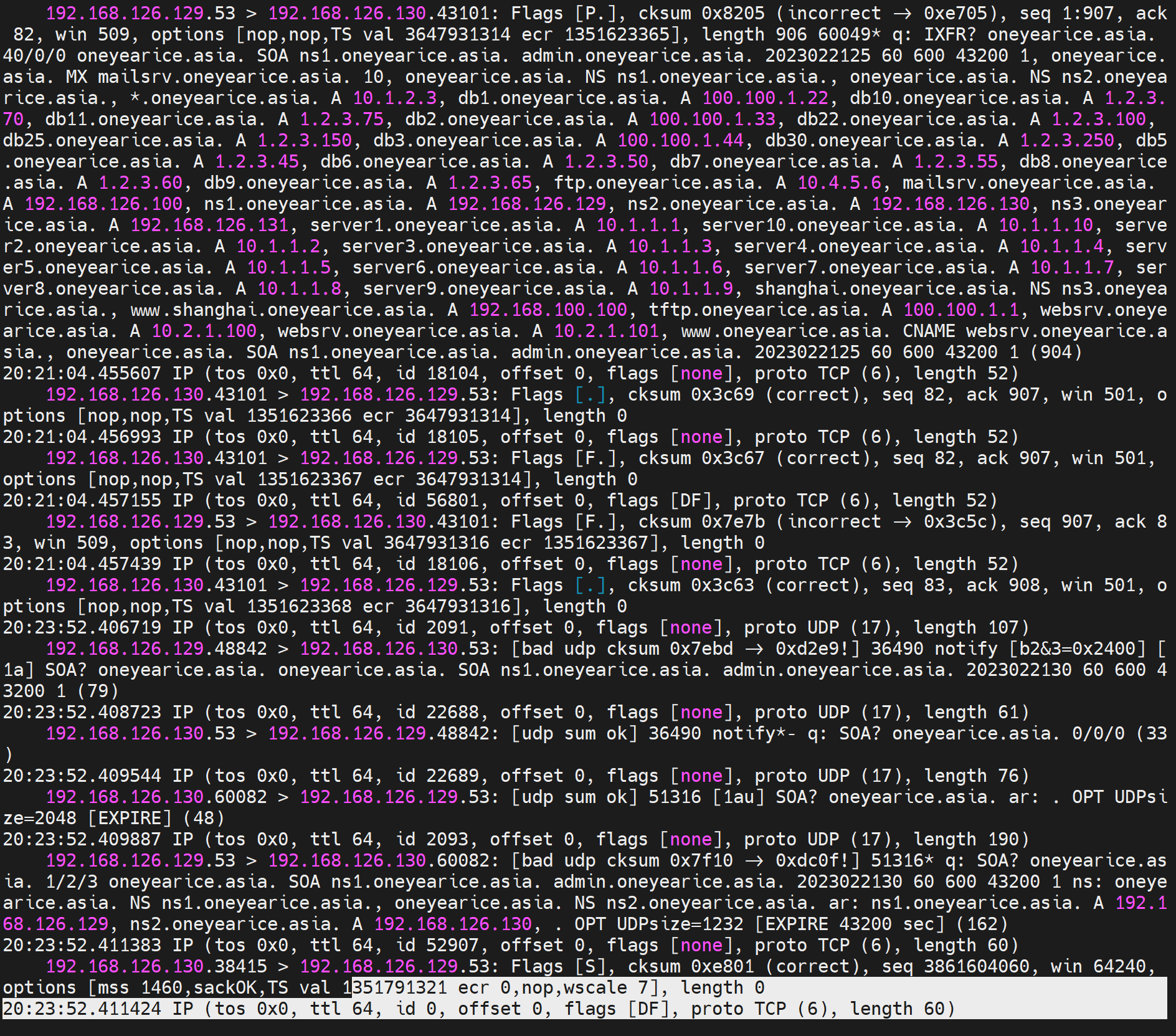
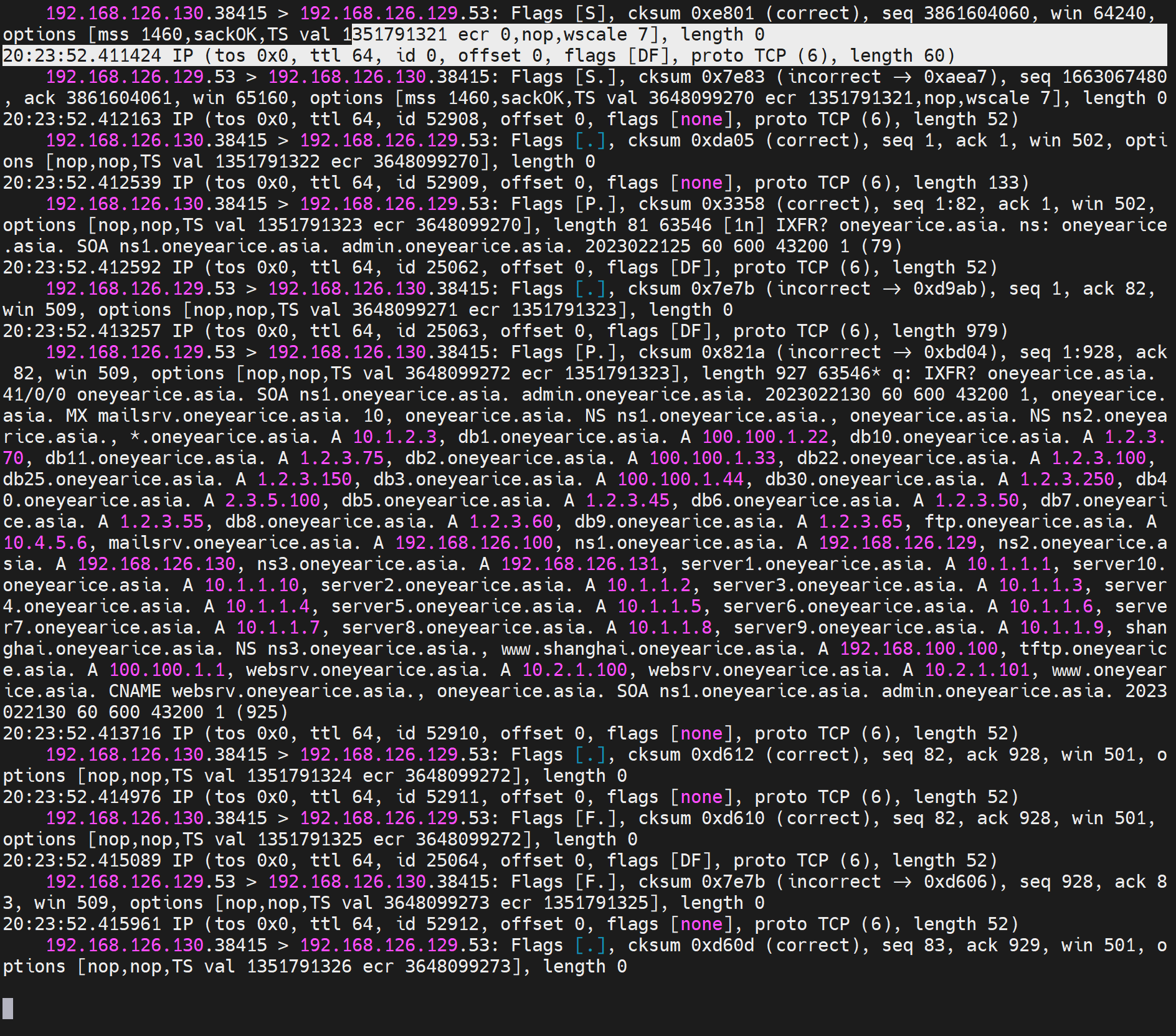
然后是从上面
关于同步的进一步研究
动作1、仅修改zone 数据文件的RR
--->修改zone 数据文件的RR,
但是不改版本号,
也不rndc reload ,
也不重启服务
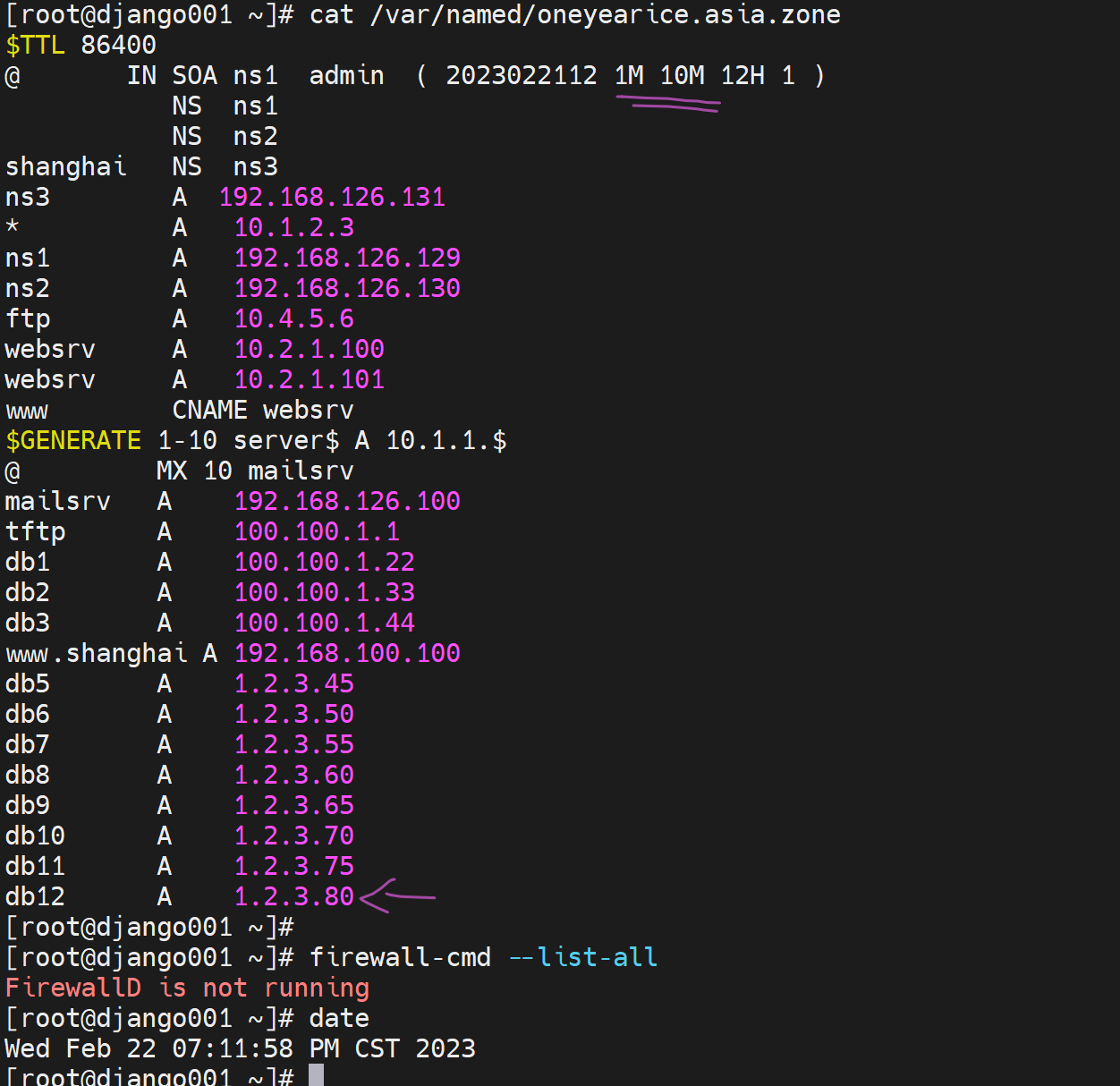
坐等5Mins
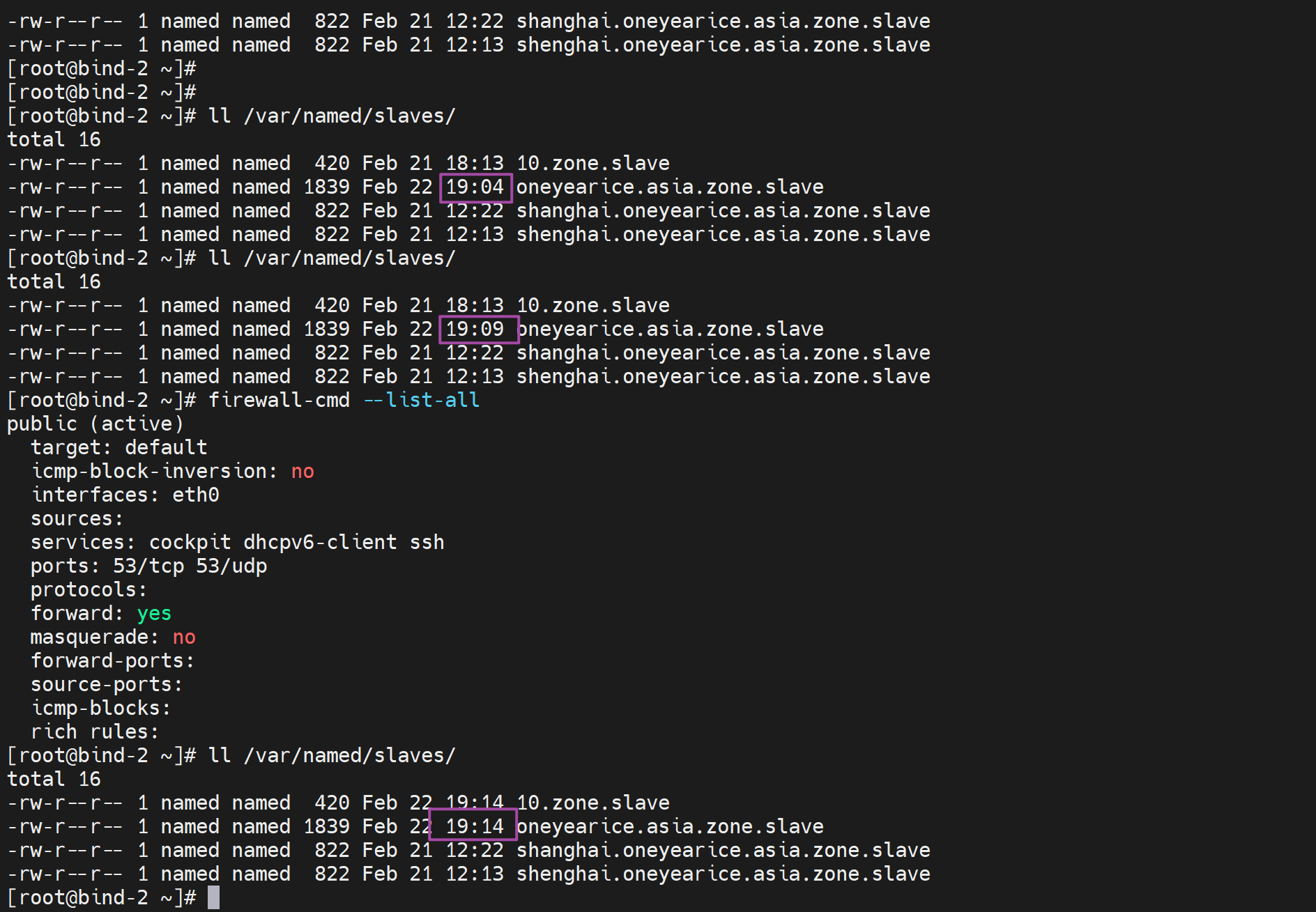
时间还是在变,但是解析就是没过来
当然master上由于没有rncd reload所以也无法正确解析
动作2、master上rndc reload
完整的条件就变成了
=============
--->修改zone 数据文件的RR,
但是不改版本号,
---> rndc reload ,
也不重启服务
==============
master 自然更新了
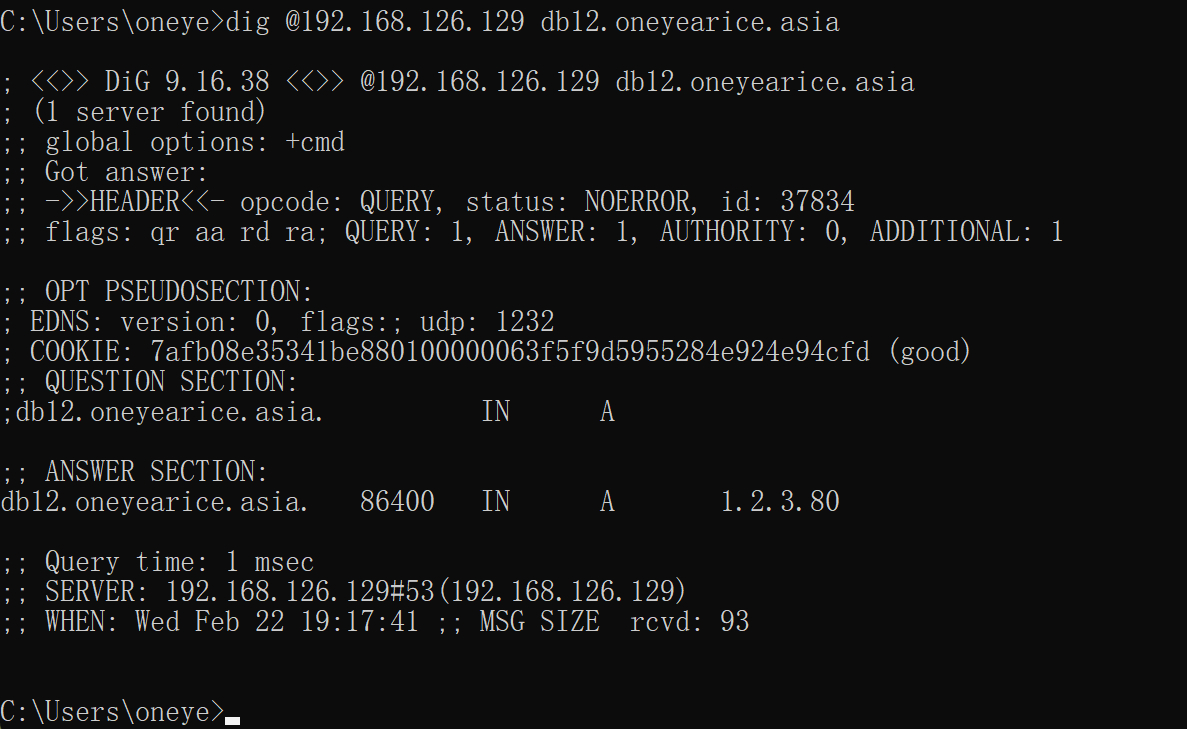
10分钟过去了,还是没有更新,虽然文件的时间在变
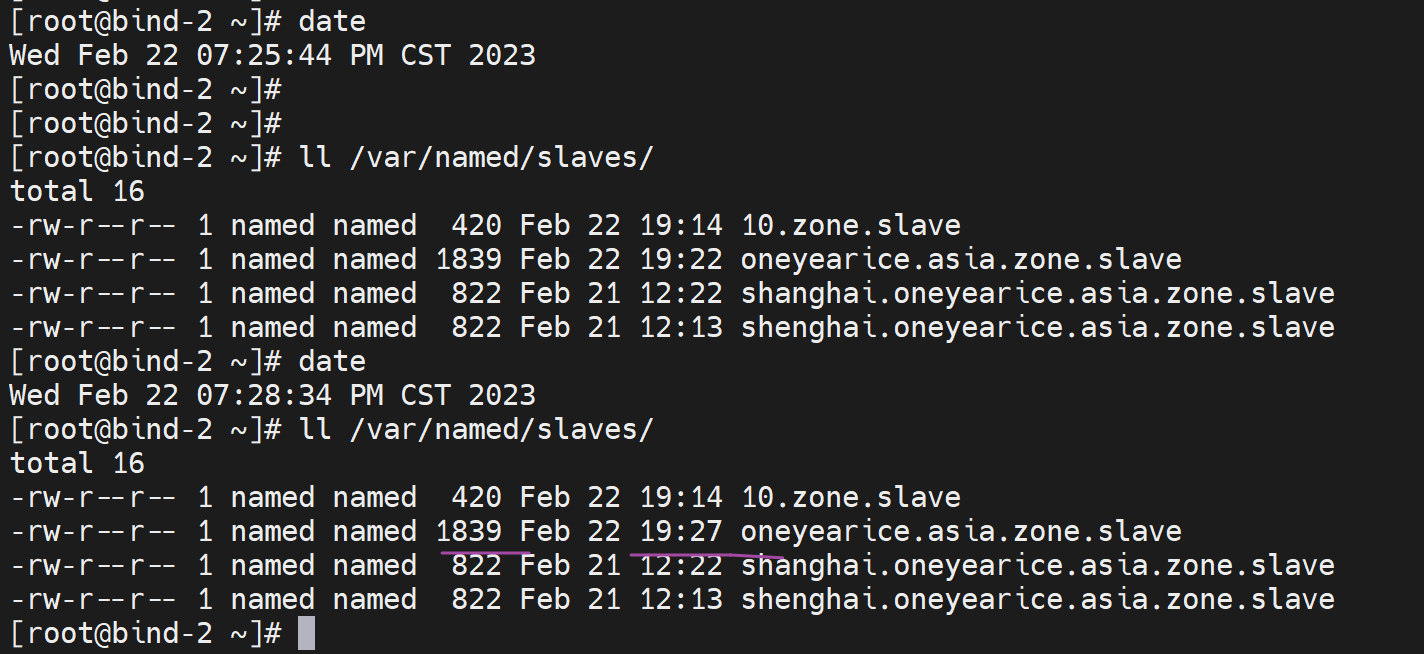
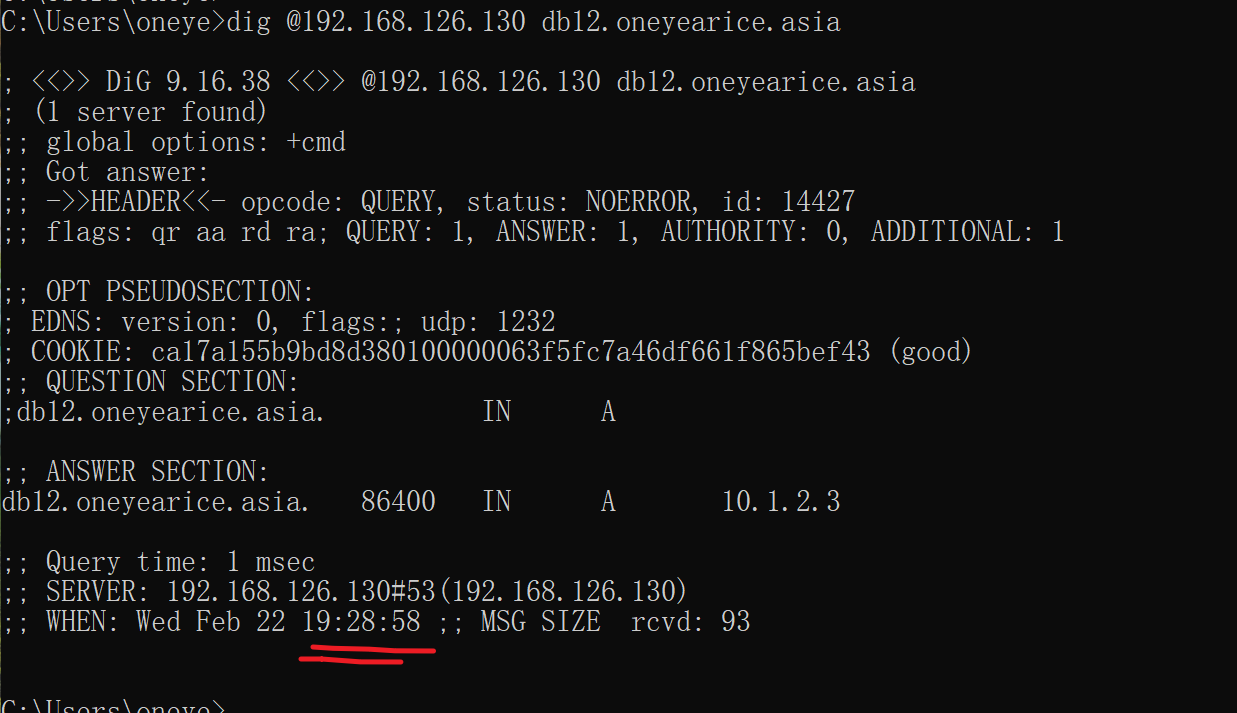
动作3、master上修改版本号
完整的条件就变成了
=============
--->修改zone 数据文件,
--->修改改版本号,
不做rndc reload ,
也不重启服务
==============
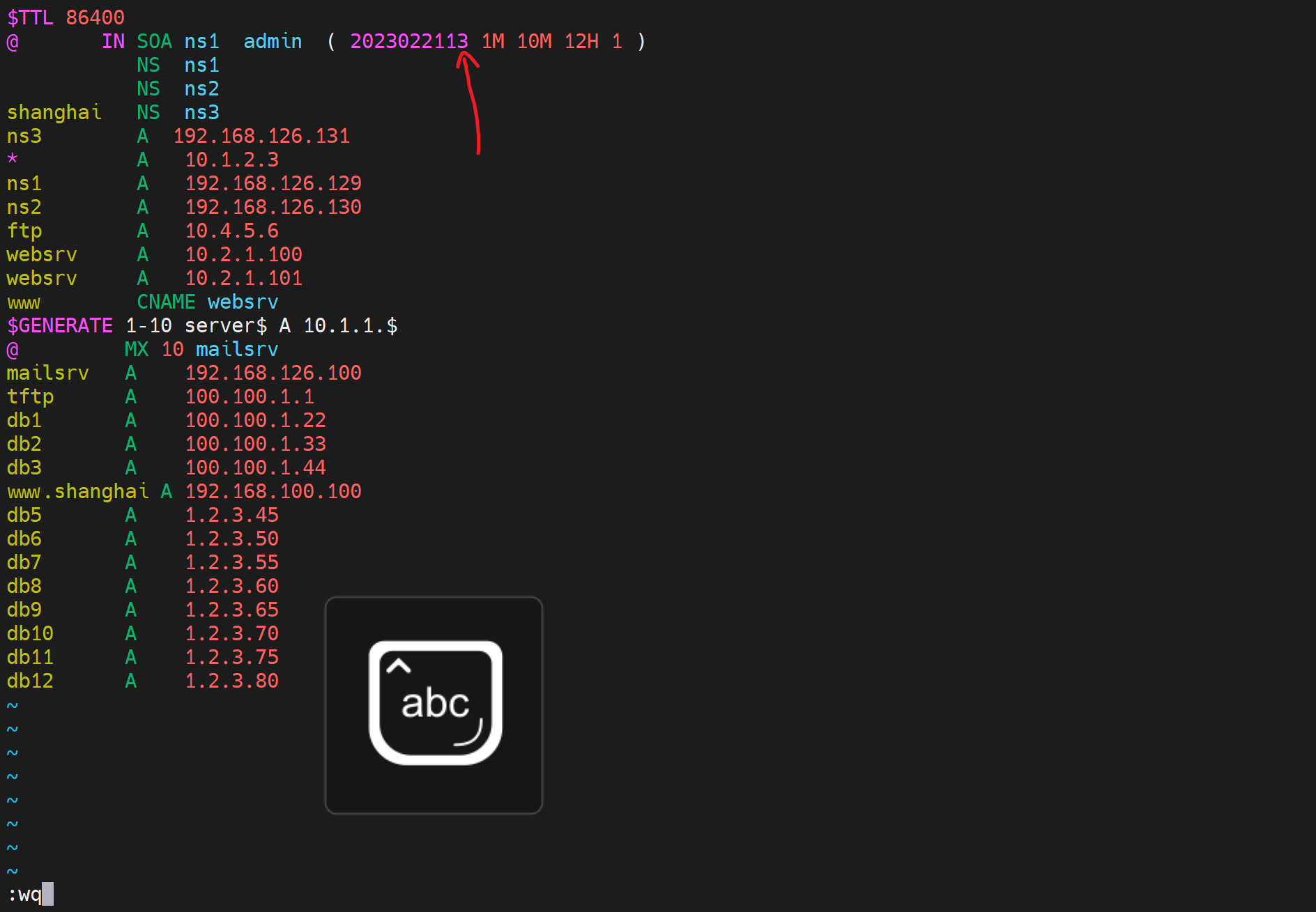
从依然没有更新
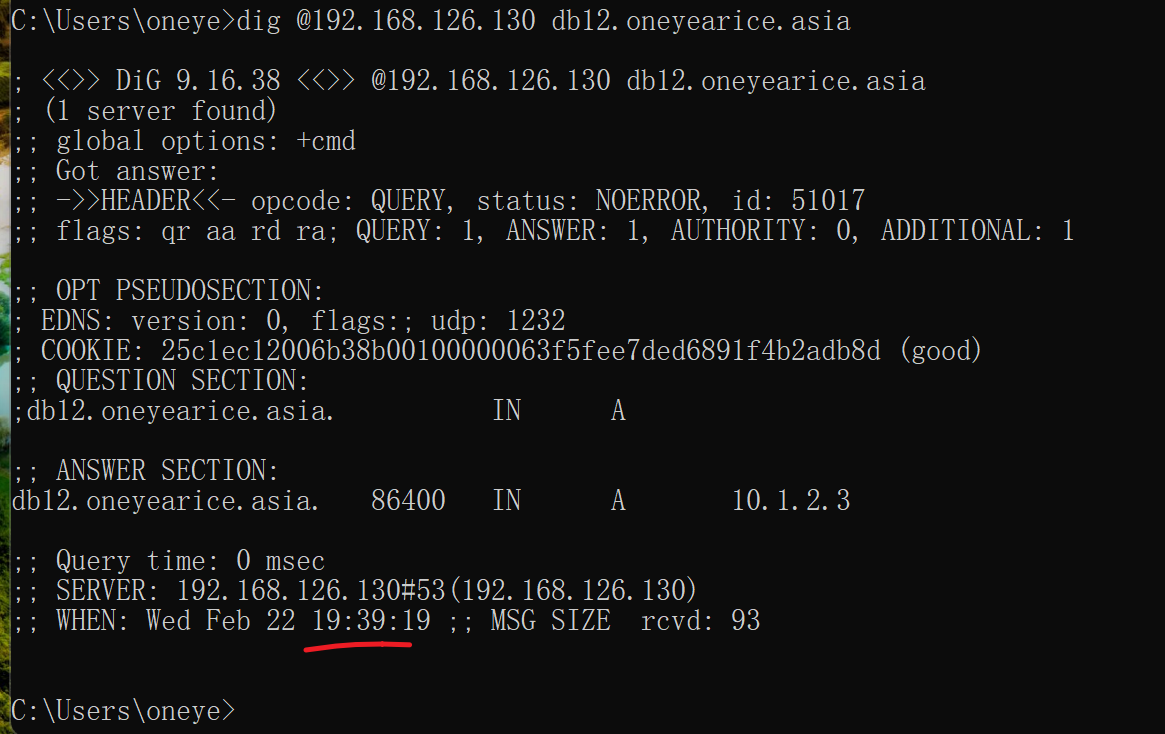
重启从服务的named也没用
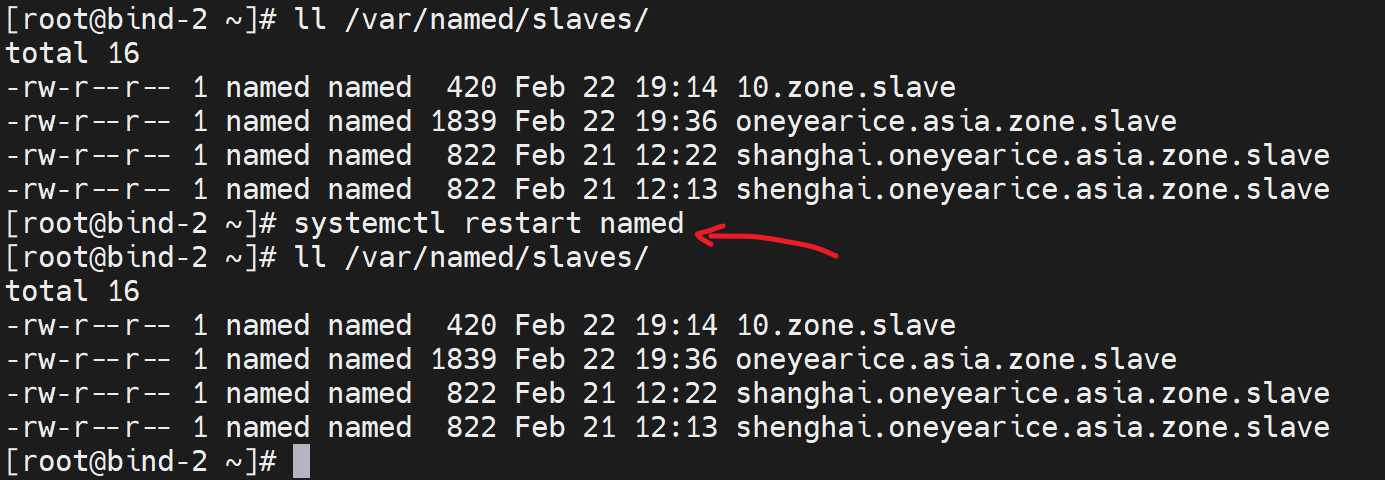
动作4、master上rndc reload
完整的条件就变成了
=============
--->修改zone 数据文件的RR,
--->修改版本号,
--->rndc reload ,
也不重启服务
==============
秒同步
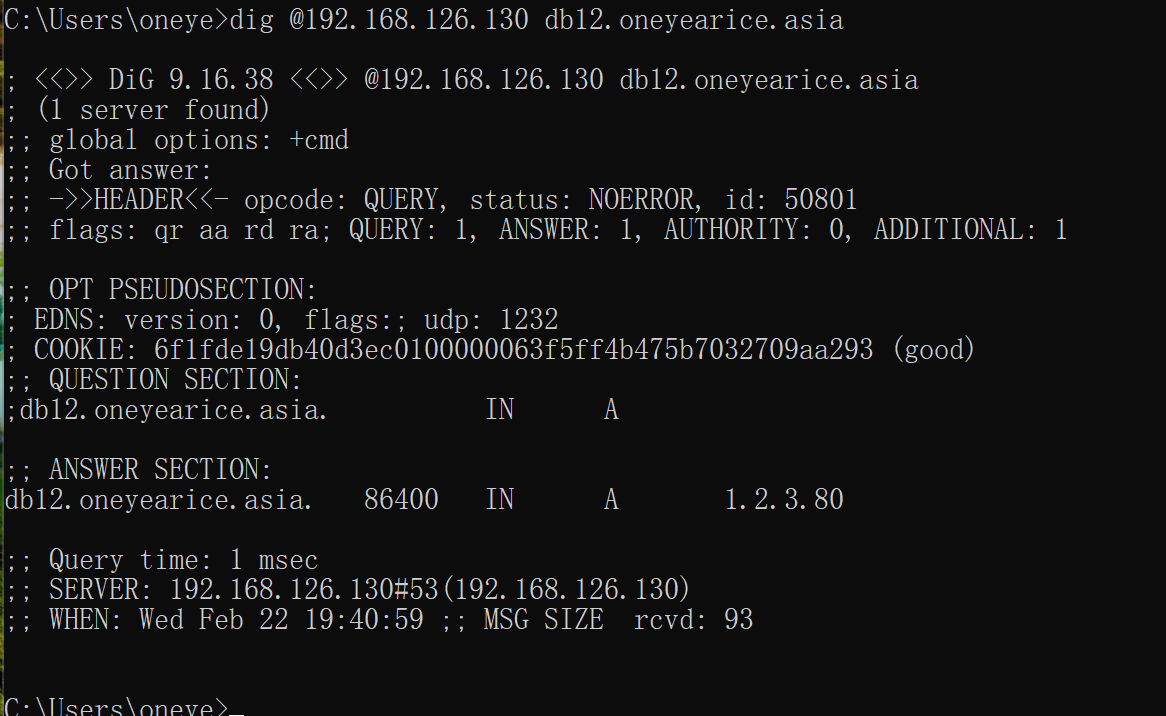
结论:不管是推还是拉,都需要2个动作:
①版本号增加↑②reload(重启服务自然也行咯),至于你改不改RR,哈哈,无所谓反正2个必须要有。不改你也看不出来哈哈。
rndc工具介绍


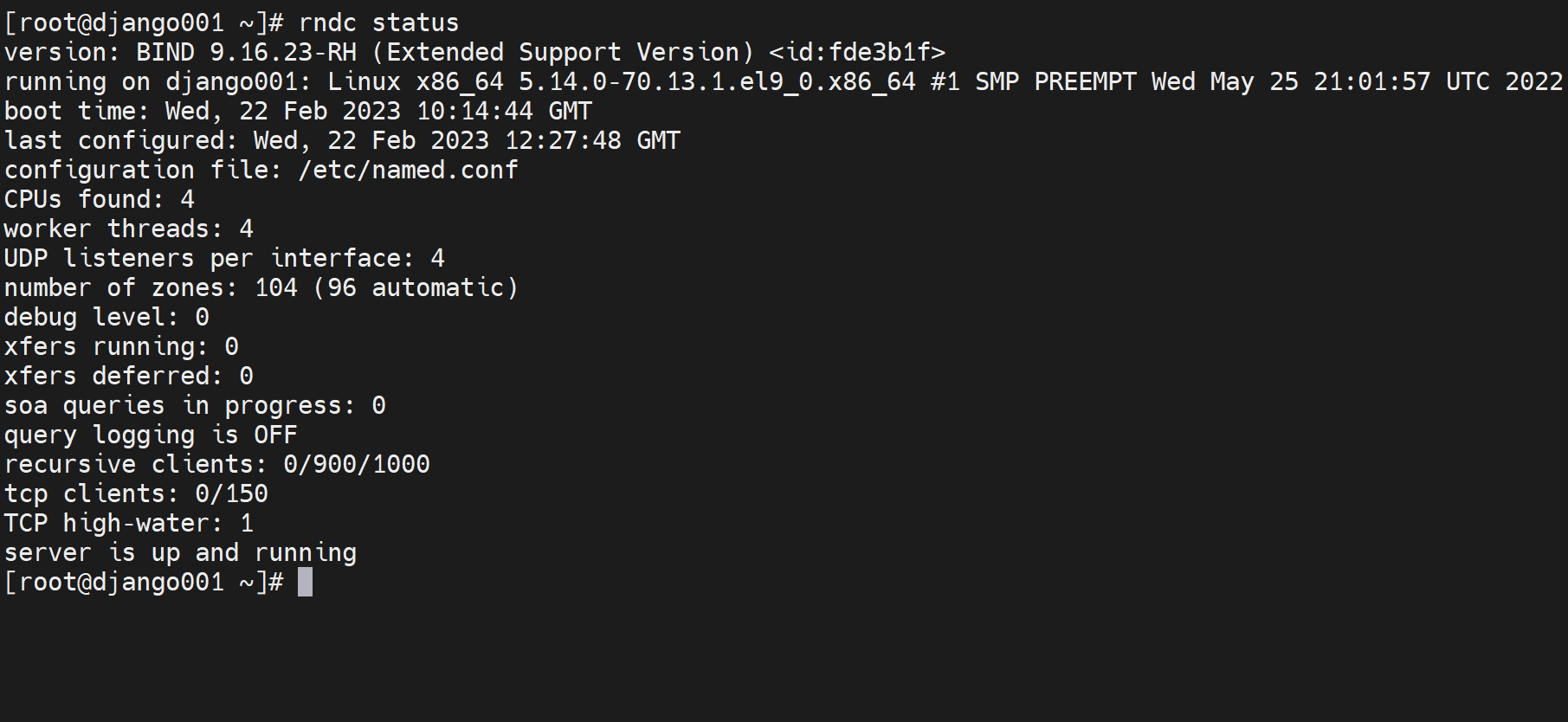
上图可见query loggin is OFF 意味着查询日志没有开启
rndc querylog即可开启
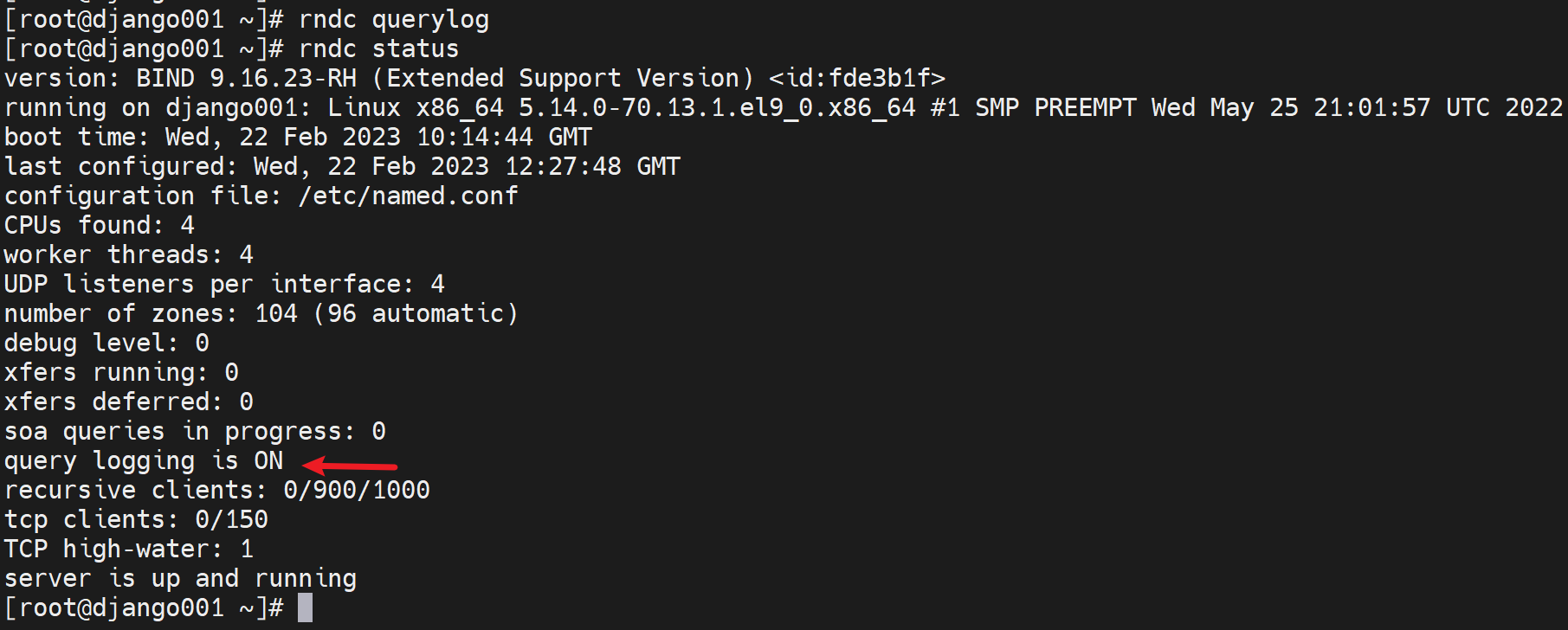
这是临时开启,测试用
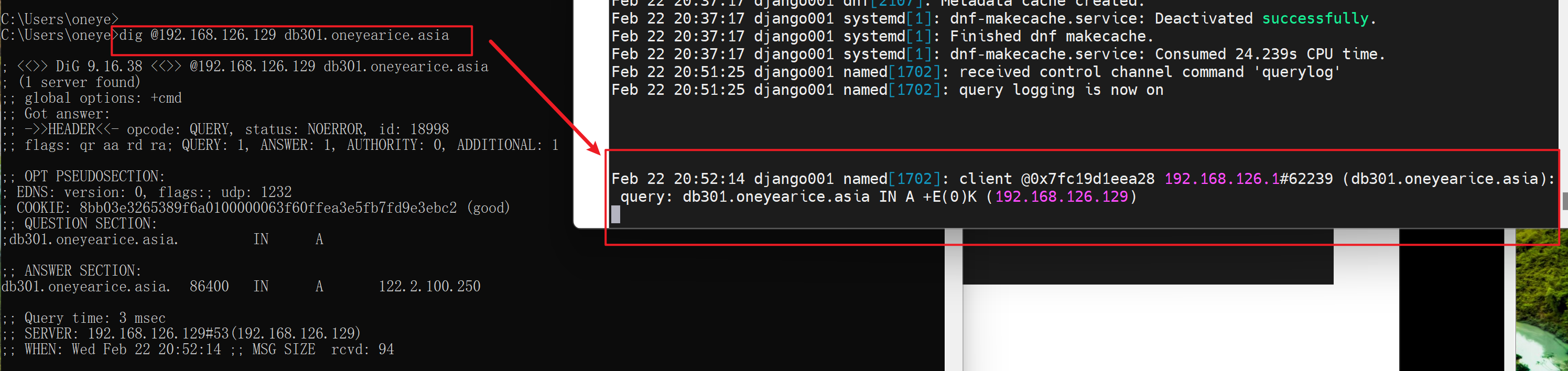
下面开始讲转发,也就是我要学bind的直接目的,不知道能否满足我啊,我可是要奇偶分开转发的哦,不行只能去研究nginx了,都一样,巴不得不行,正好跳到ningx,否则就慢慢腾腾的学了又,哈哈哈
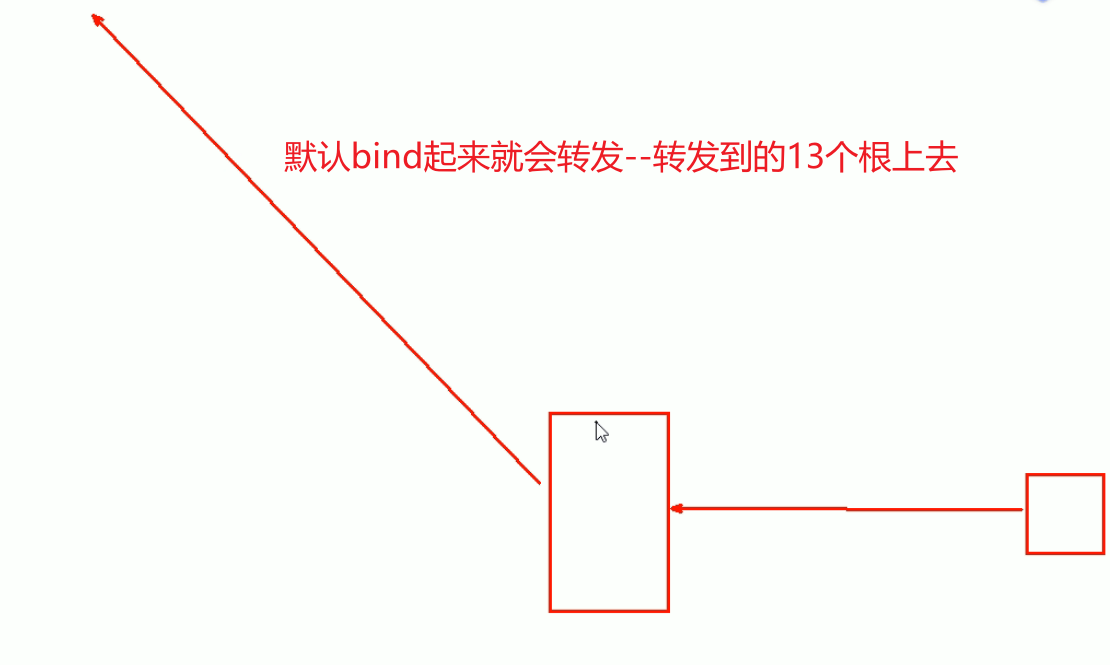
转发听起来有点像NS哦,有点像子域委派,都是请求的转发出去,接着往下看,去看大腿
1、首先不要像也知道,子域委派--指的是 域相关的 请求 转移
2、而转发,必然是针对的请求,去做转移,而不再受限于 本域下的子域去NS,而是针对请求全面的细化的 转移。
1、本地的直接dns服务器,不能访问互联网,所以需要转发
类似案例如下
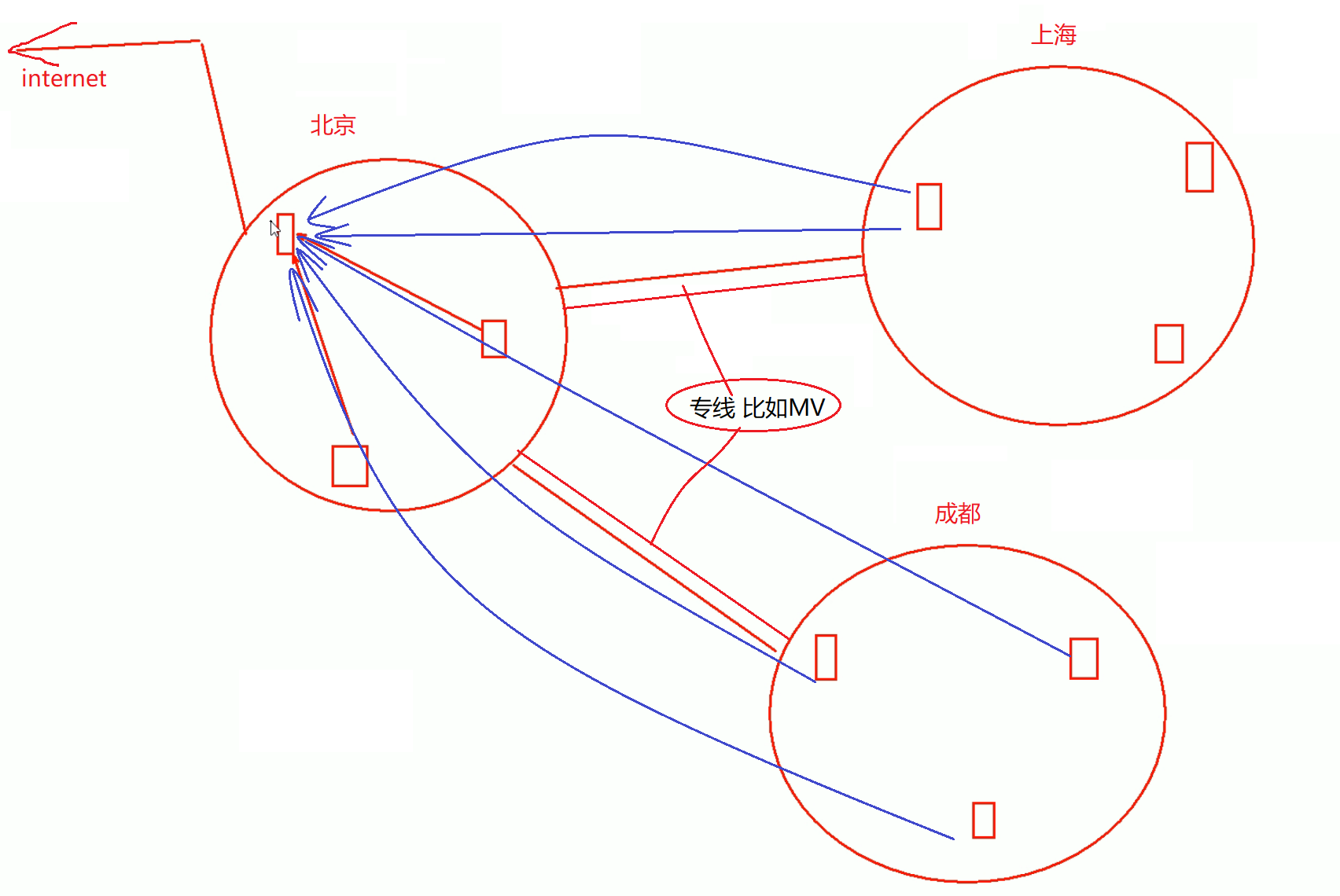
如果上海、成都的分公司机器的dns请求都从专线 去 问北京的DNS server,就很费专线带宽啦。
此时分公司的dns server可以搭建起来,只要请求过后就有缓存了,可以大大节省带宽
1、此处我用了大大,因为我在推销这种架构
2、不要听信我说的,以为缓存过期后,一样会请求出去,这个时候就有一个矛盾,缓存多久比价好,
3、1D还是1H,假设1H的$TTL,那么1小时候就会产生一波DNS 请求高潮,怎么地~语文老师教的好,所以1D的TTL是比较合适的,
以下👇4 、5 两点理解错误,主从,什么是主从,是针对本地的rr进行同步的,现在讨论的架构哪来的主从模式!
都是针对互联网上的域名请求,北京本地没有记录,三地都是缓存,都是只缓存服务器啊,同步个啥哦!
4、其实针对这个架构,我倒是希望北京是master,分公司部署从,这样分公司的请求压根不会到master上去,直接去本地的从就行了,DNS的流量也就是区域间的同步流量啦,
5、此时考虑的问题就变成了同步流量是否很大的问题,而同步 push势必频繁的,改一个就会推一个,pull也是希望能及时处理的,所以此时我想的这个架构就不合适哦,还是希望分公司为转发+缓存的模式
建立主从的概念,前提是你个有本地记录的服务器--区域数据库-区域数据都在互联网上呢,而现在讨论的必然是互联网上的请求,你只是个只缓存服务器。加上北京的说我确实有本地解析,那么4、5的分析就可以i上啦。结论也是 主从可能也不能这么玩。
6、抽象出来一个解决思路--宇宙法则之--专线+缓存才是王道,就是说如何节省专线带宽,主说:缓存。其实SDWAN的2个核心①选路②去重③缓存。
7、其实回过头来,看分公司的dns 缓存,我是这么想的,缓存为1万年,如果rr变了,就重新问一下这个记录,去覆盖老的缓存。这就是老话讲的好--爱你一万年。那怎么才能爱你就1年呢,就是分公司的dns请求AXFR的时候啊,不要请求具体内容,就是请求①整体rr的哈希②每条rr的哈希③哈希要短一点④cisco安全里讲过要给技巧就是将一些值也就是哈希放到报文结构里好像是tcp的seqnumber?
8、分公司的用户访问xx.yy.zz,此时三地的DNS上就都有缓存了
然后我又继续往下看,发现这个转发不是我之前搜到的bind的view,view看这里就挺香的
https://blog.51cto.com/360admin/677254
然后man named.conf可见view有通配符字眼,一开始我搜regex没有心都凉了
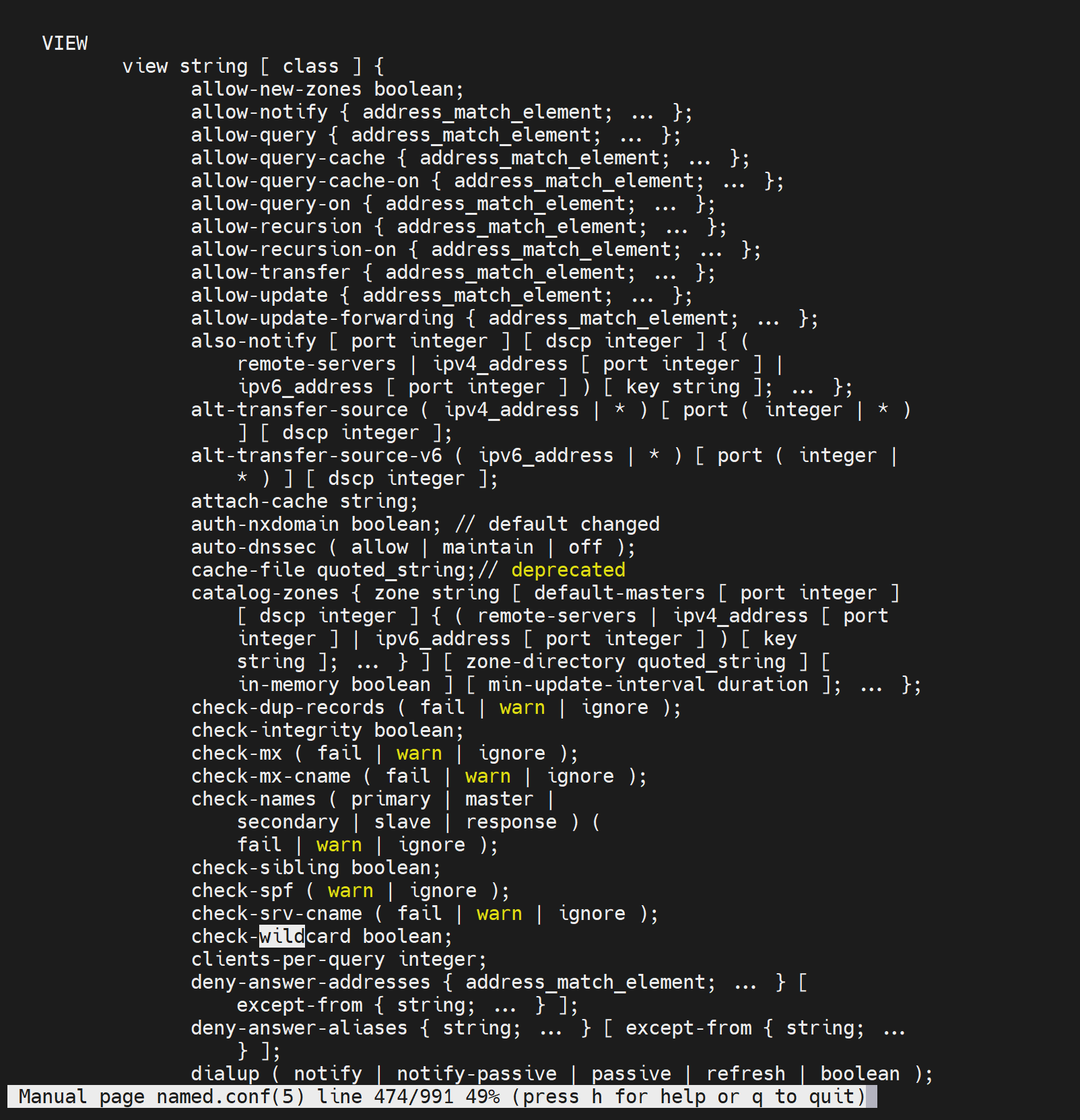
可能是支持通配符的,下午研究研究
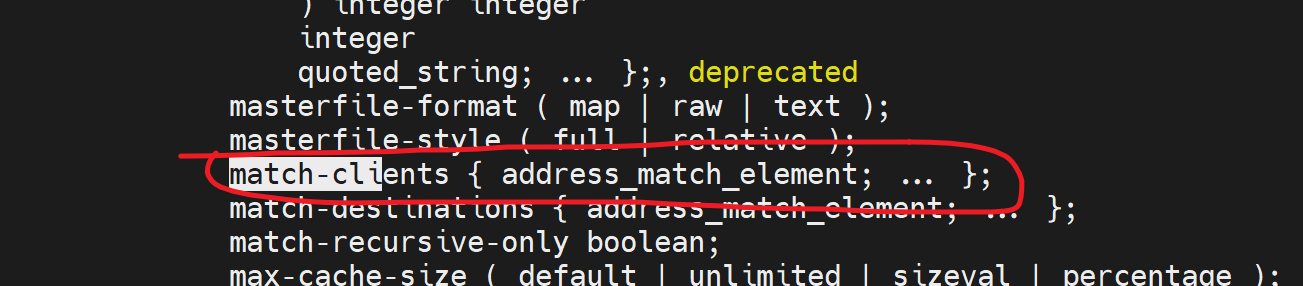
貌似他不支持通配符啊,下午敲一敲。
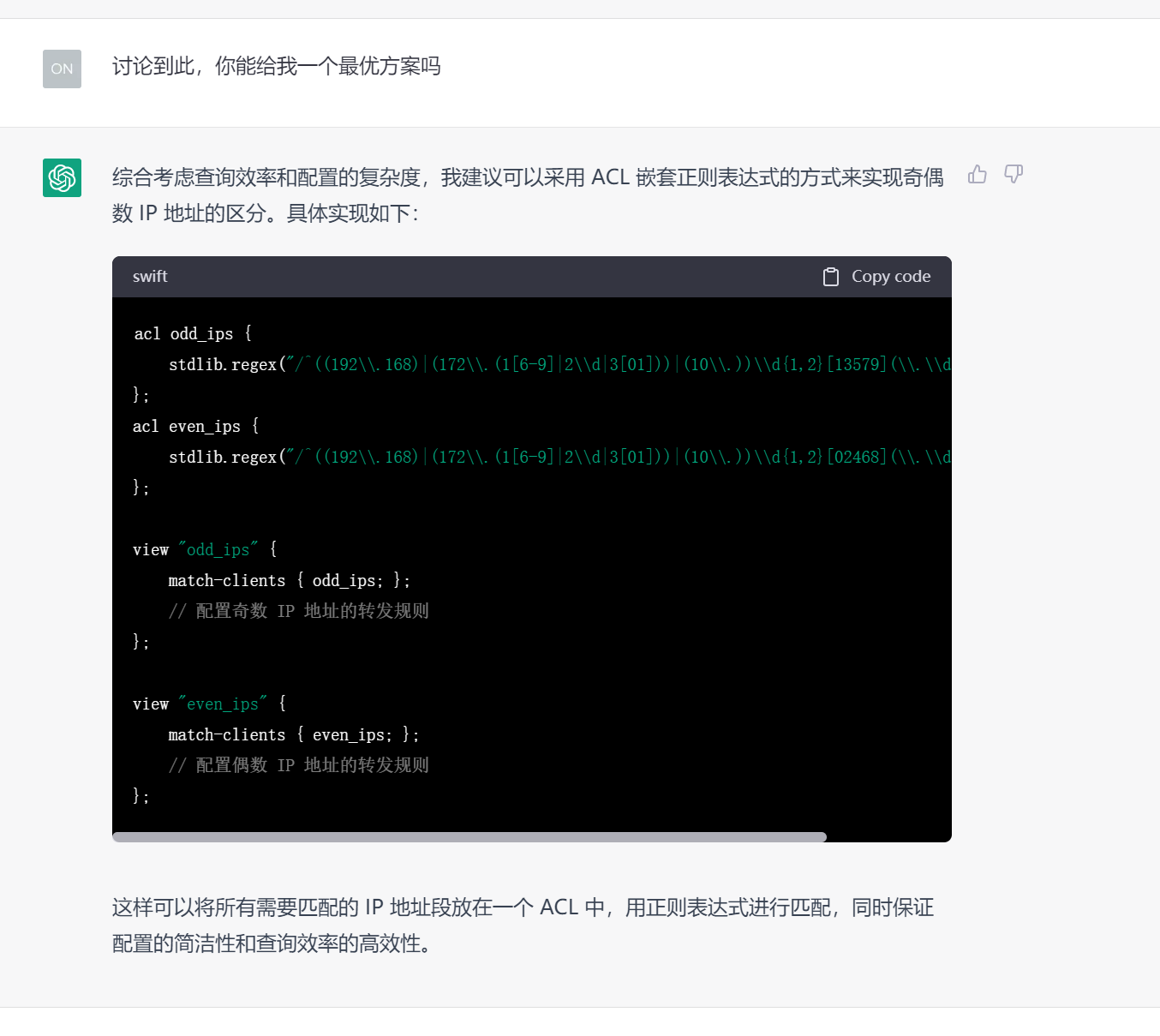
思路如上,正则我要改成这样,这样比对起来也会快很多。

算了,咱继续把转发学玩吧~
由于都是中间间隔,的所以难免回不到之前的状态,也记不住,总之遇到问题就去查好了~
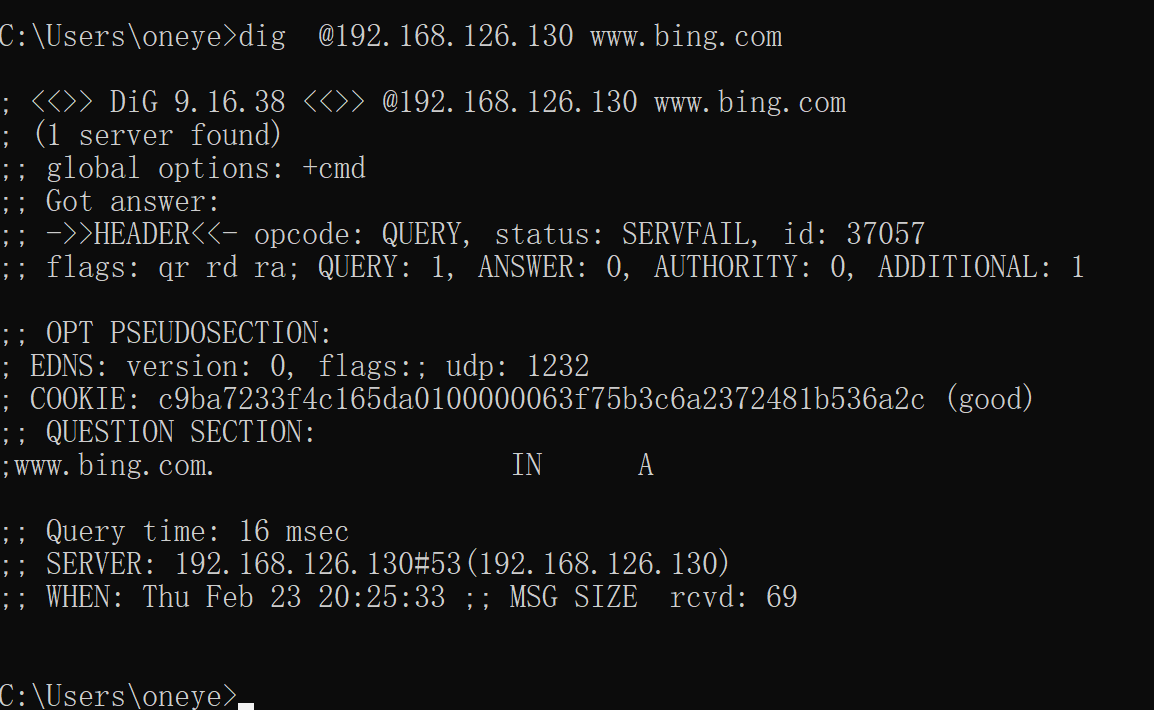
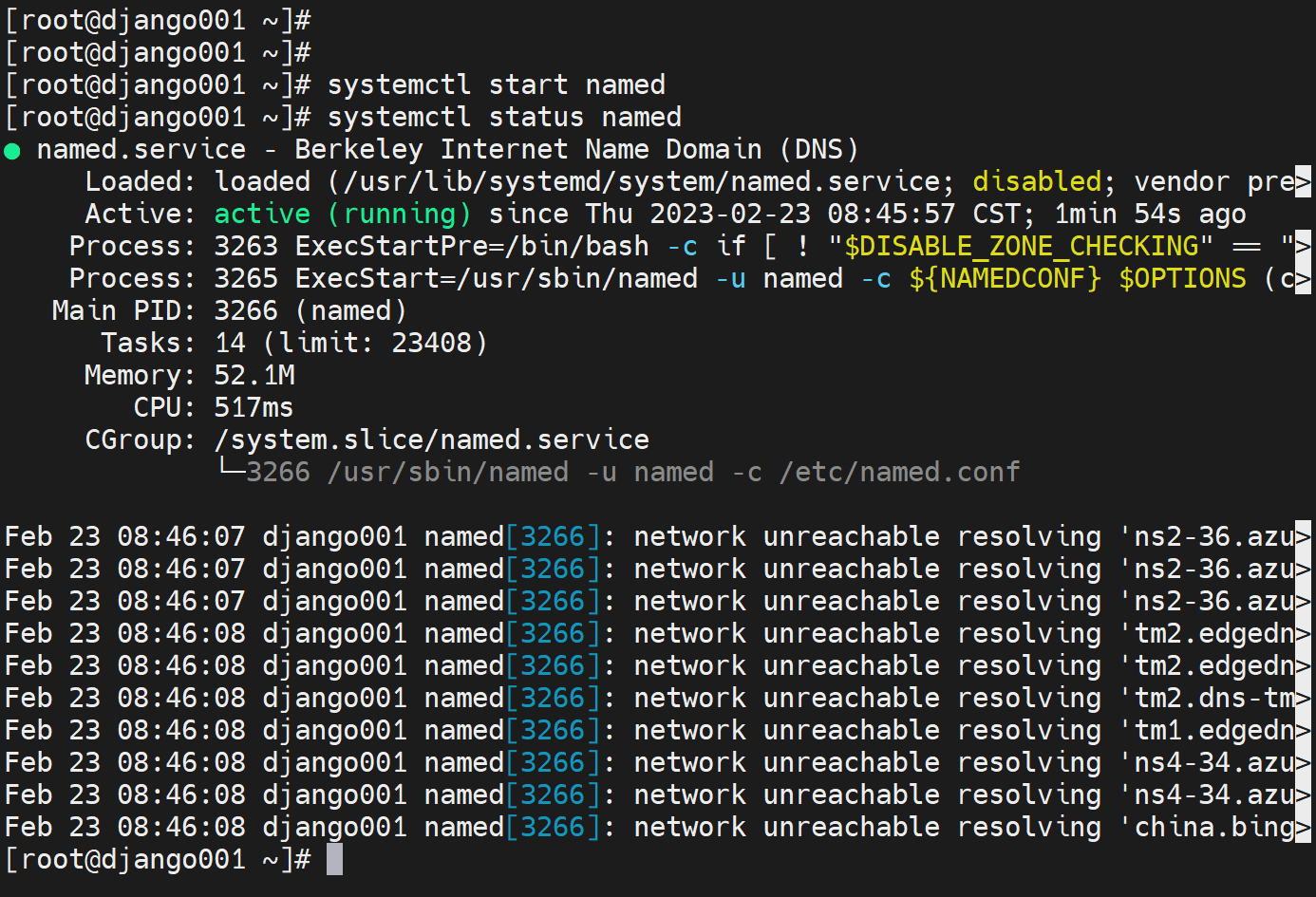
用这台130进行转发,所以删除GW后,重启named,等价于缓存没了应该把,不放行再rndc flush
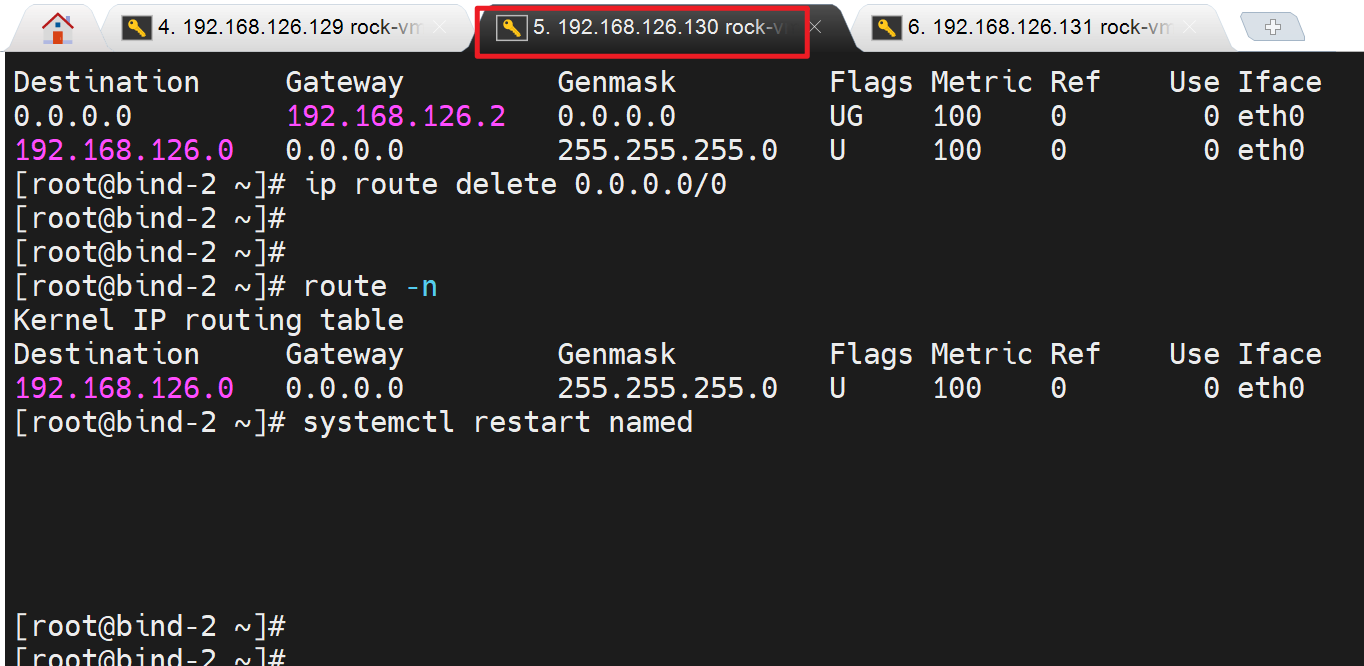
此时解析不成功
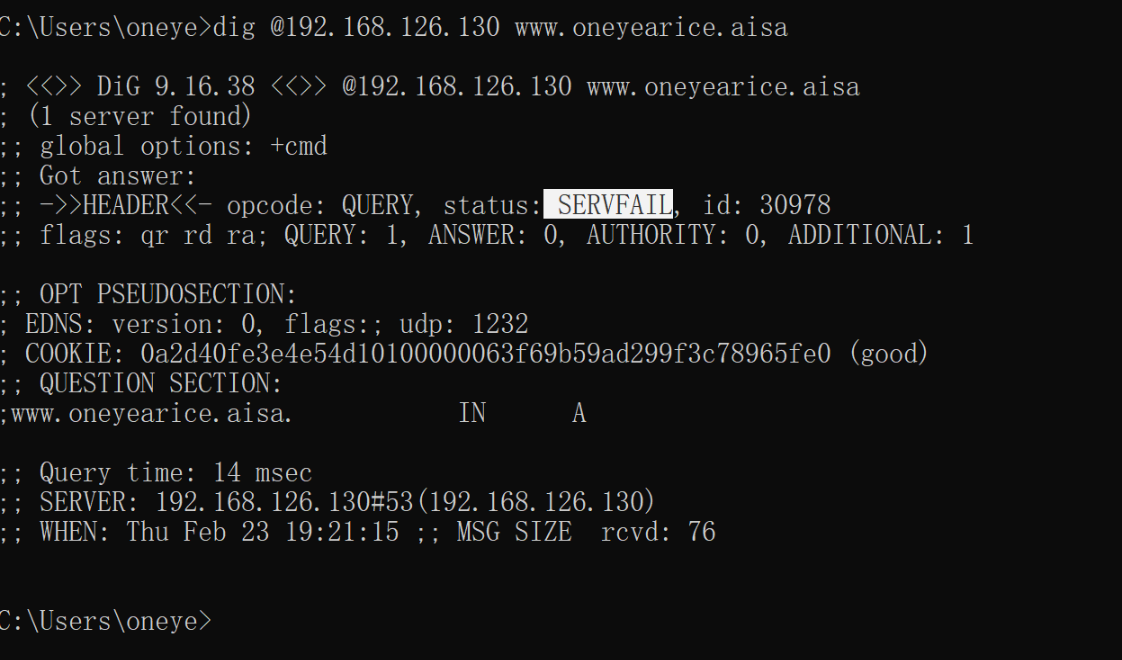
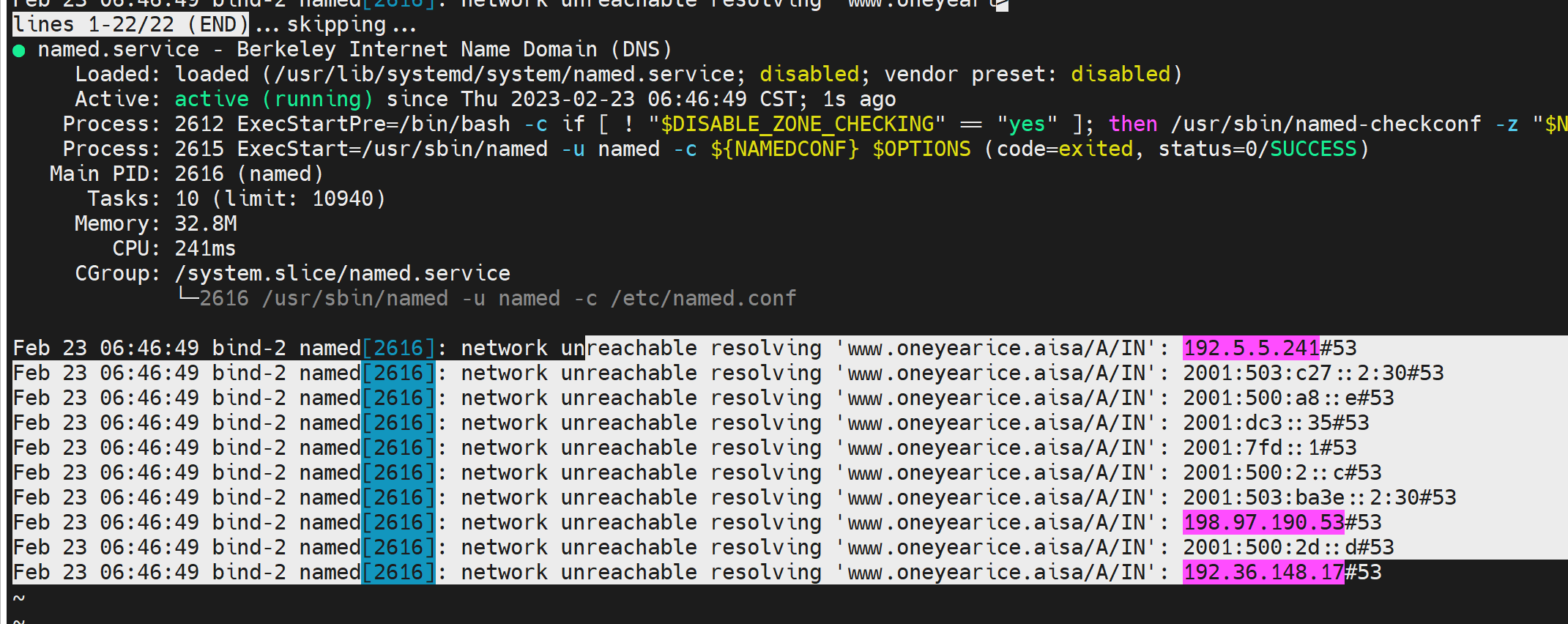
看见他是问根去了,所以看看zone的配置,是否有本地的区域数据
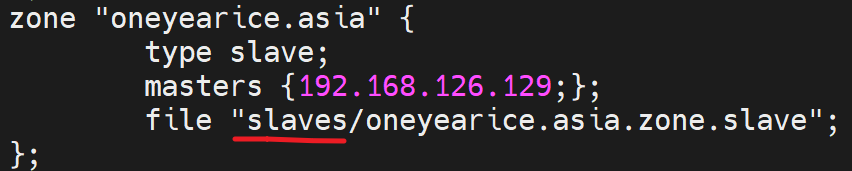
他是slave,那也不影响啊
哦,我知道了slave有一个自行惭愧的机制,
由于看不到data格式的内容,我要看soa信息,看下自行惭愧的时间是多少
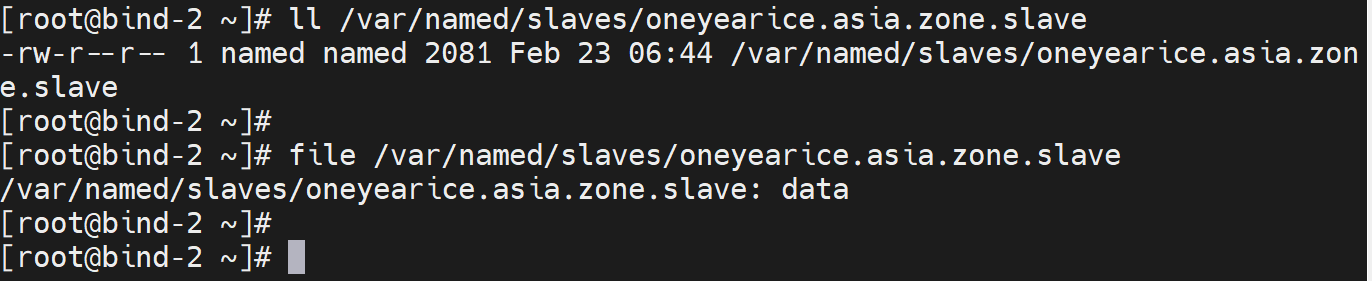
dig 去看就好了
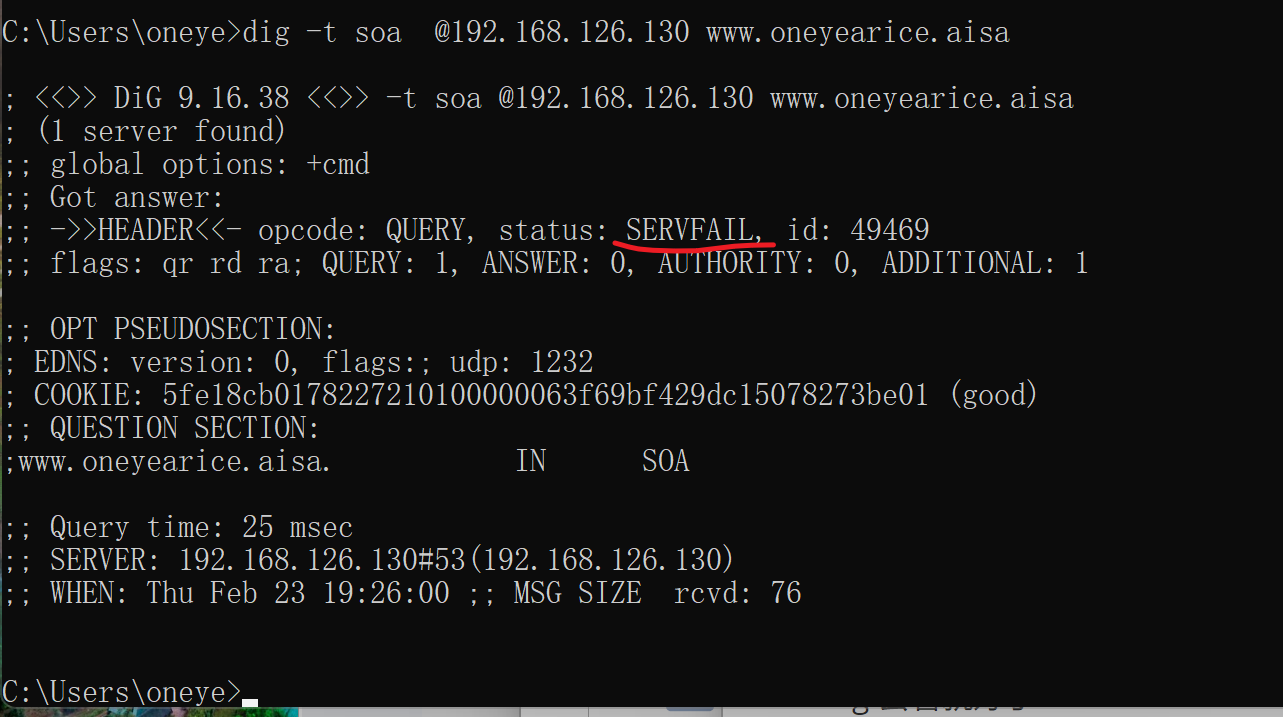
只能去主上面看了
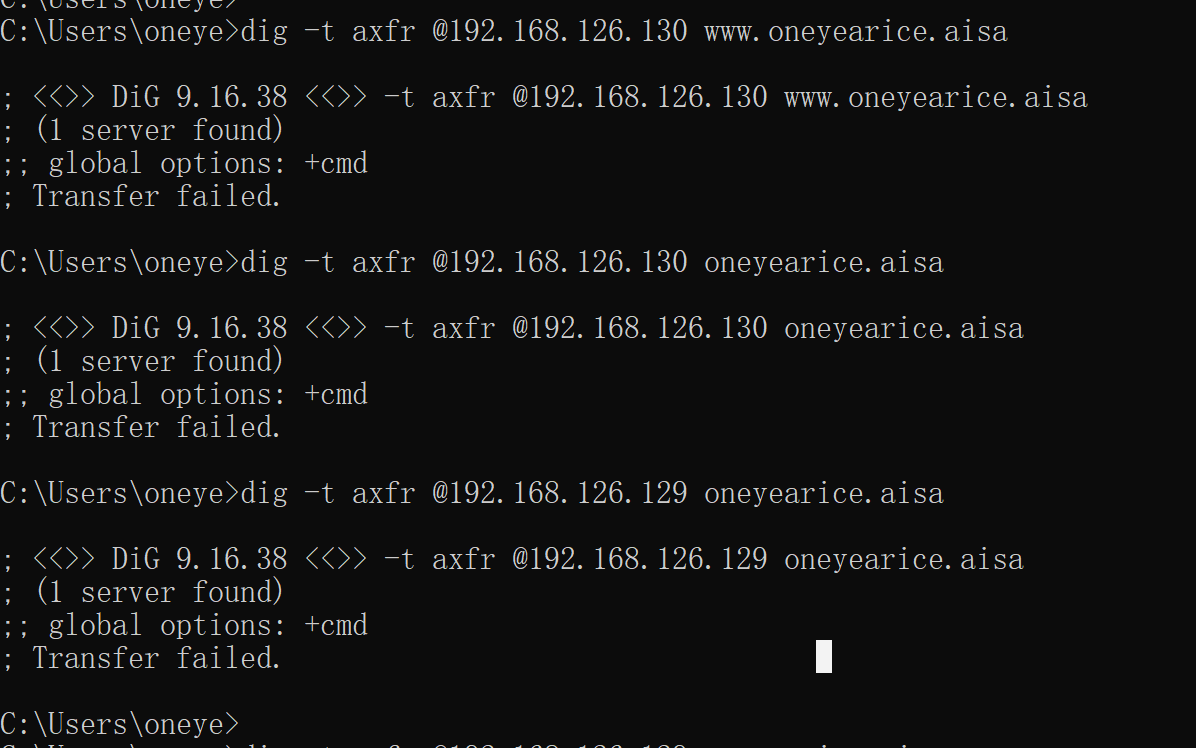
查下这个
主的namde开机就没enable

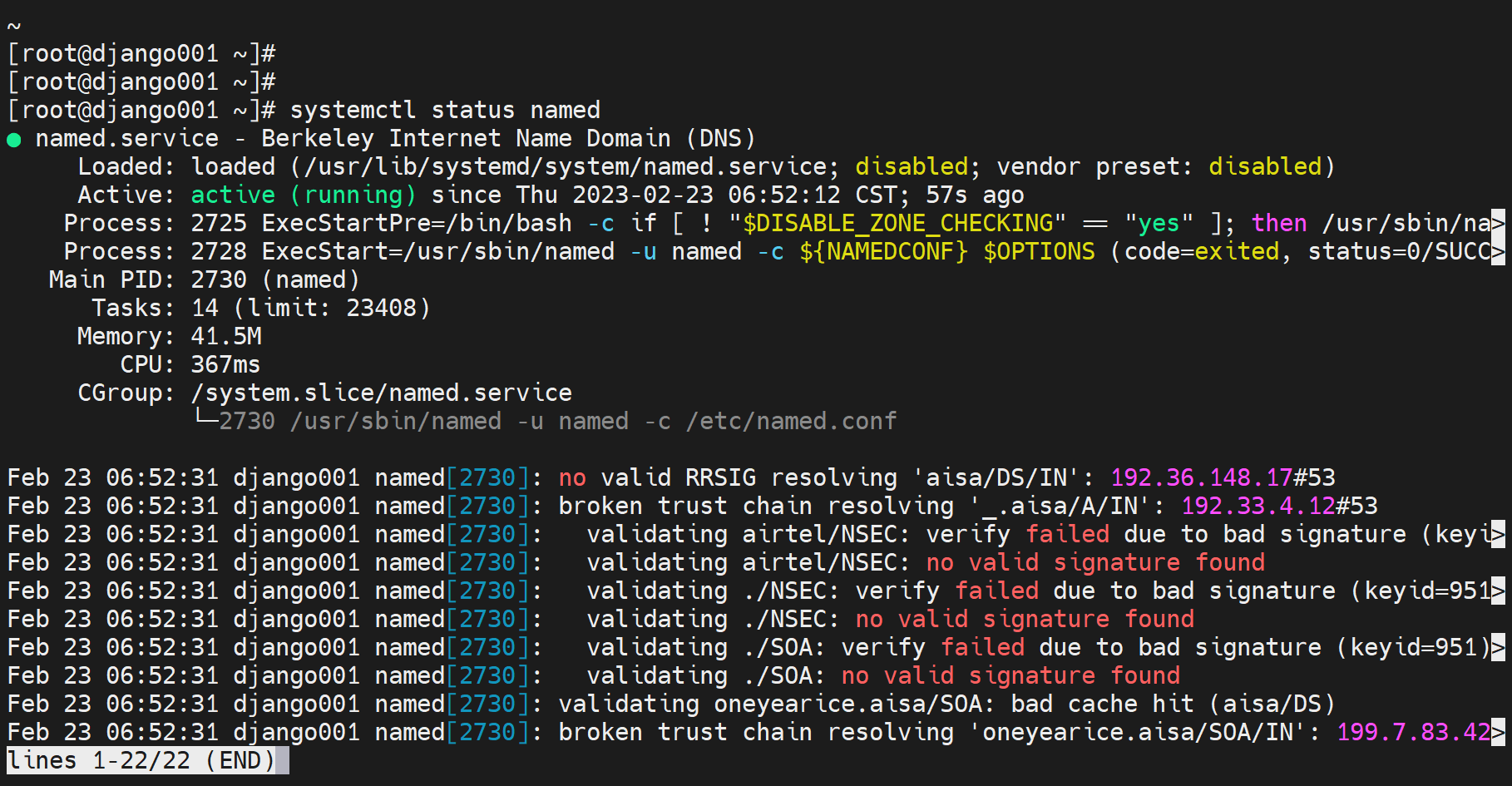
还是报错是根的可达性

确实不通,不通你就不给client dns响应?不应该啊,本地有区域数据库的啊
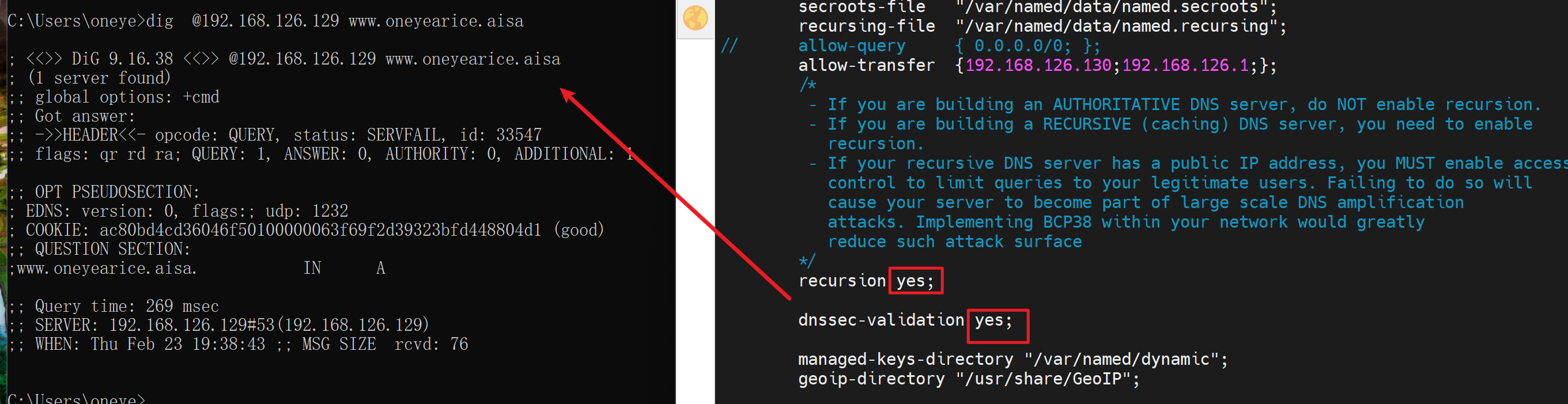
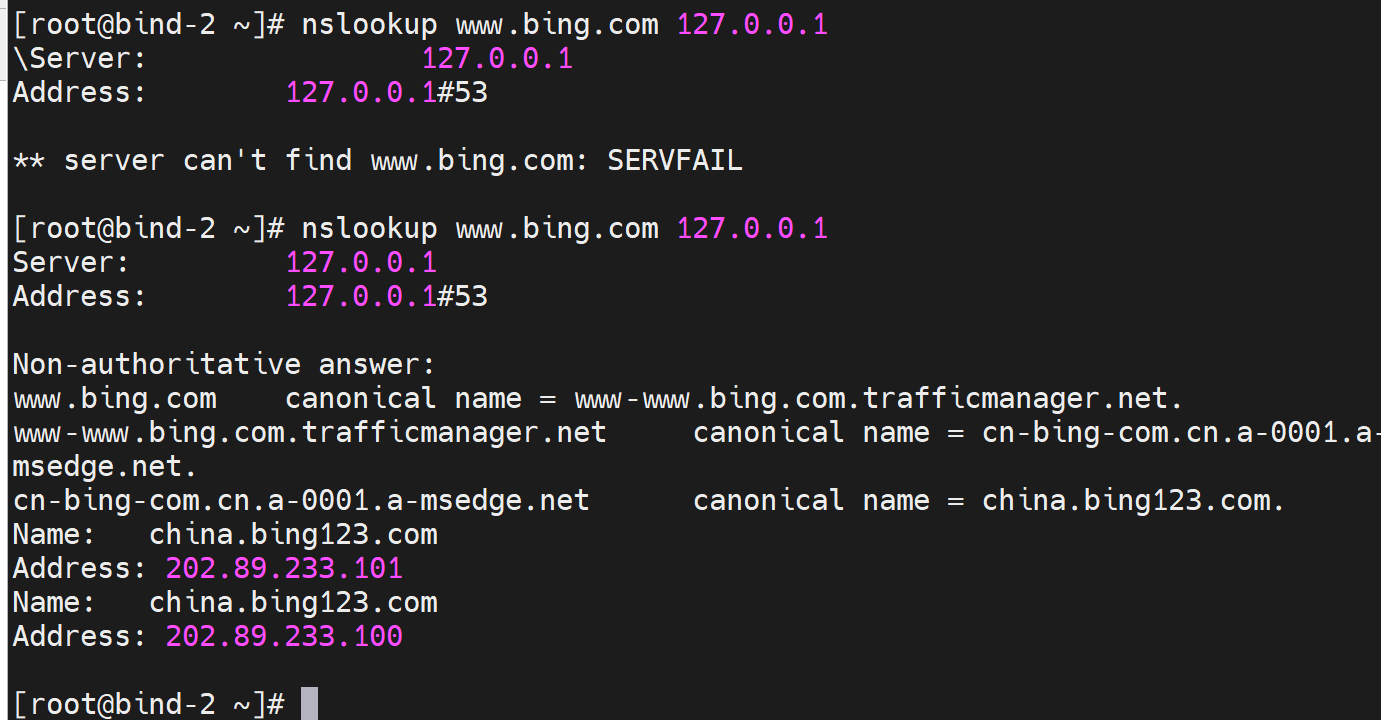
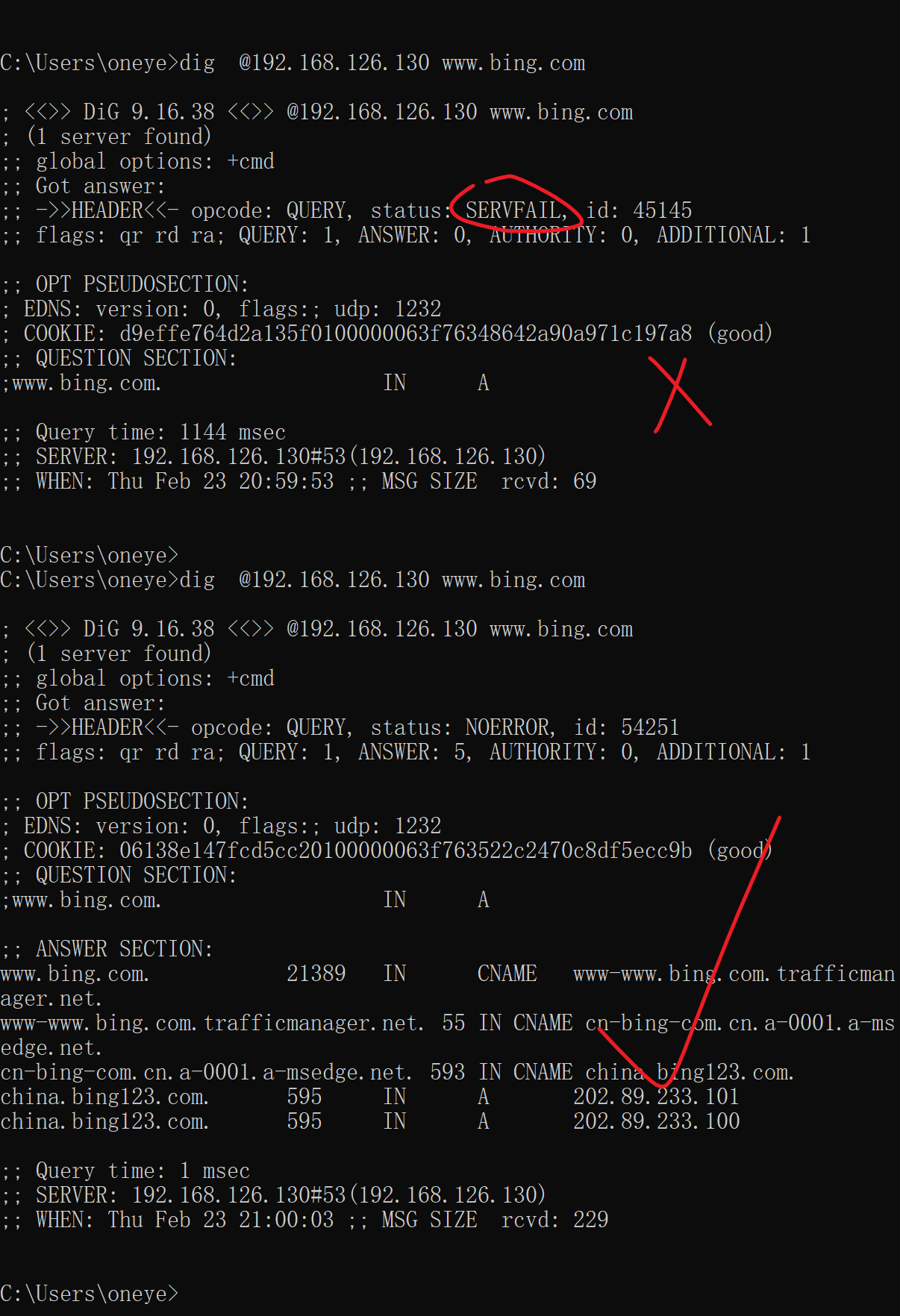
这两个选项开了,dig 发现要等几秒钟才会有结果,然后就是SERVERFAIL。
这两个选项关掉,dig就发现秒出结果,但是是REFUSE,如下图,
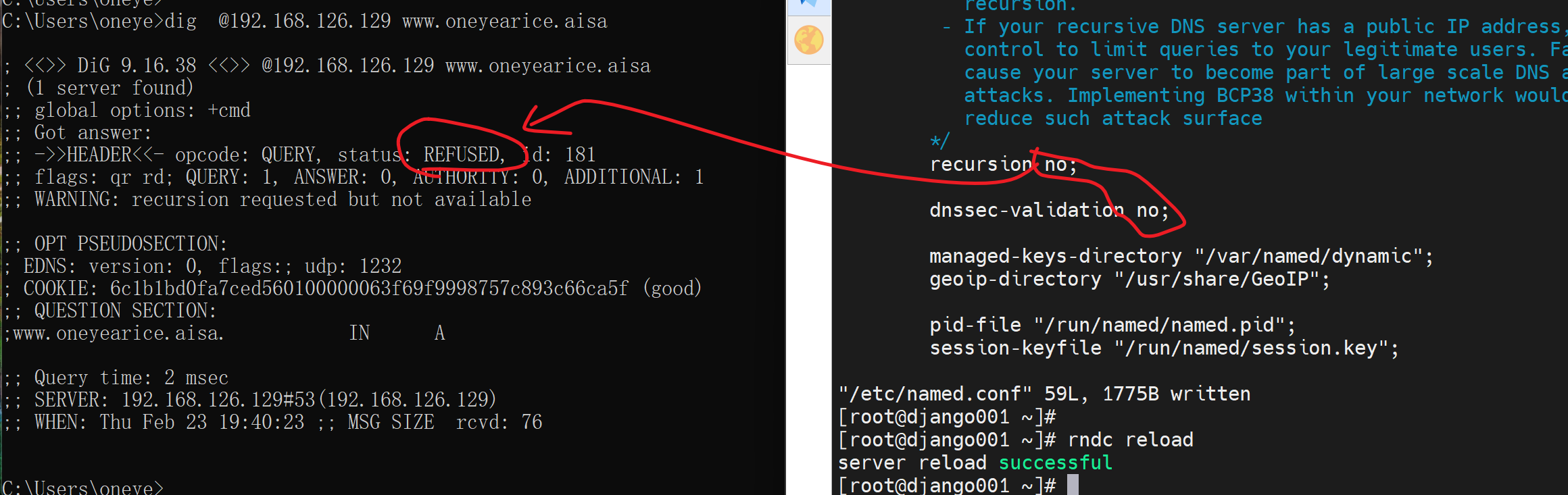
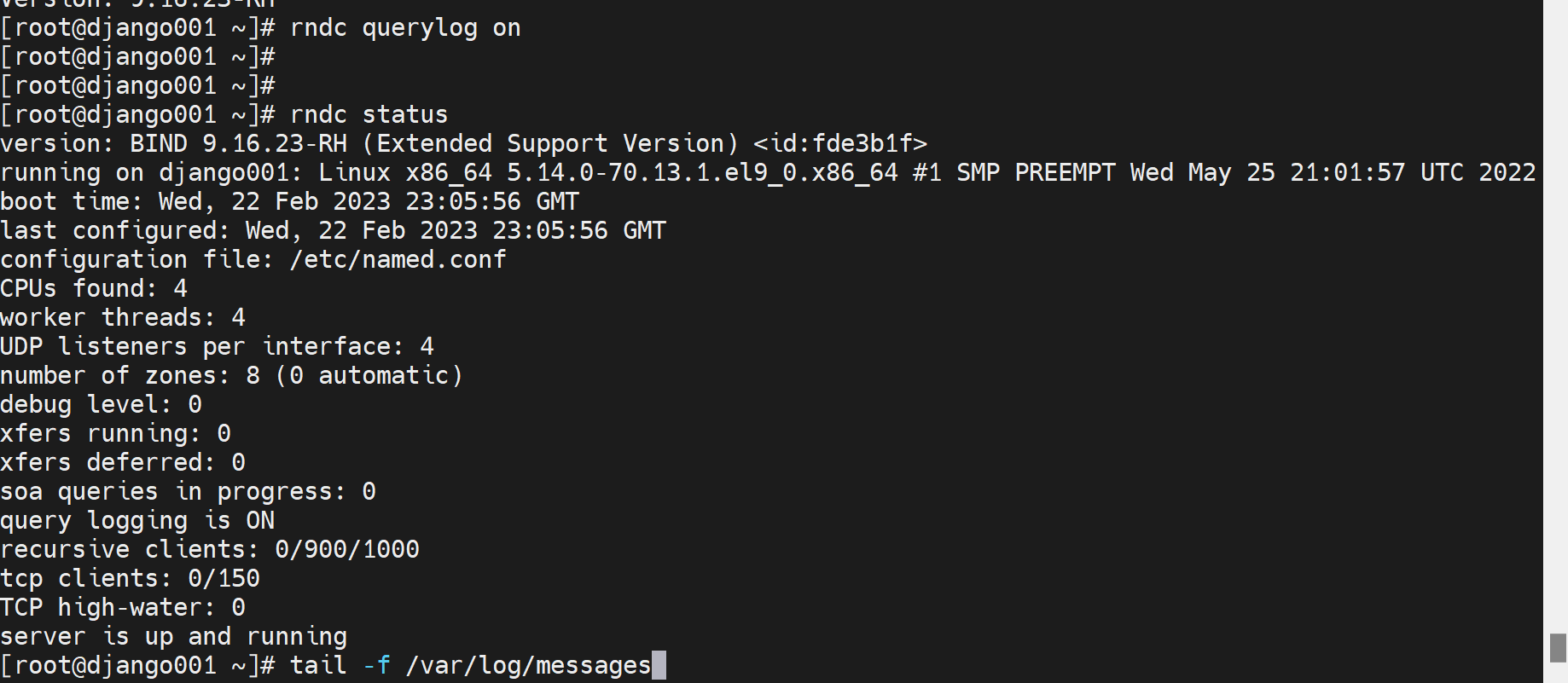
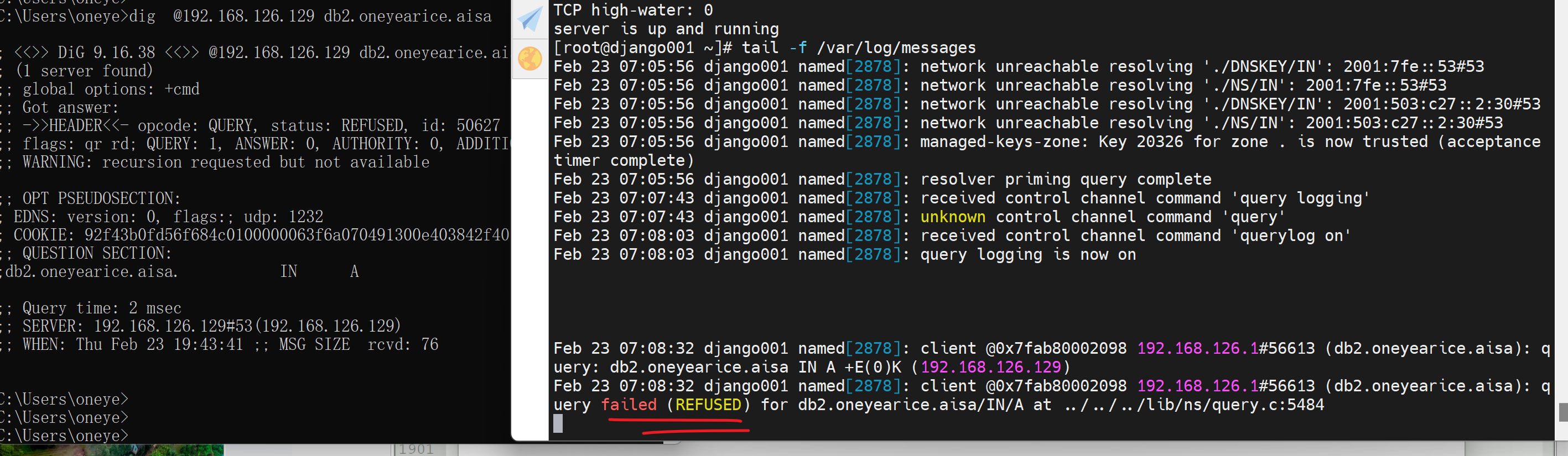
感觉还是根的问题,奇怪了
哦,原来是我打错字了,asia不是aisa,唉,要注意睡眠了
其实都是好的
继续做转发实验
关闭192.168.126.130的网关,
哈哈
重启恢复继续
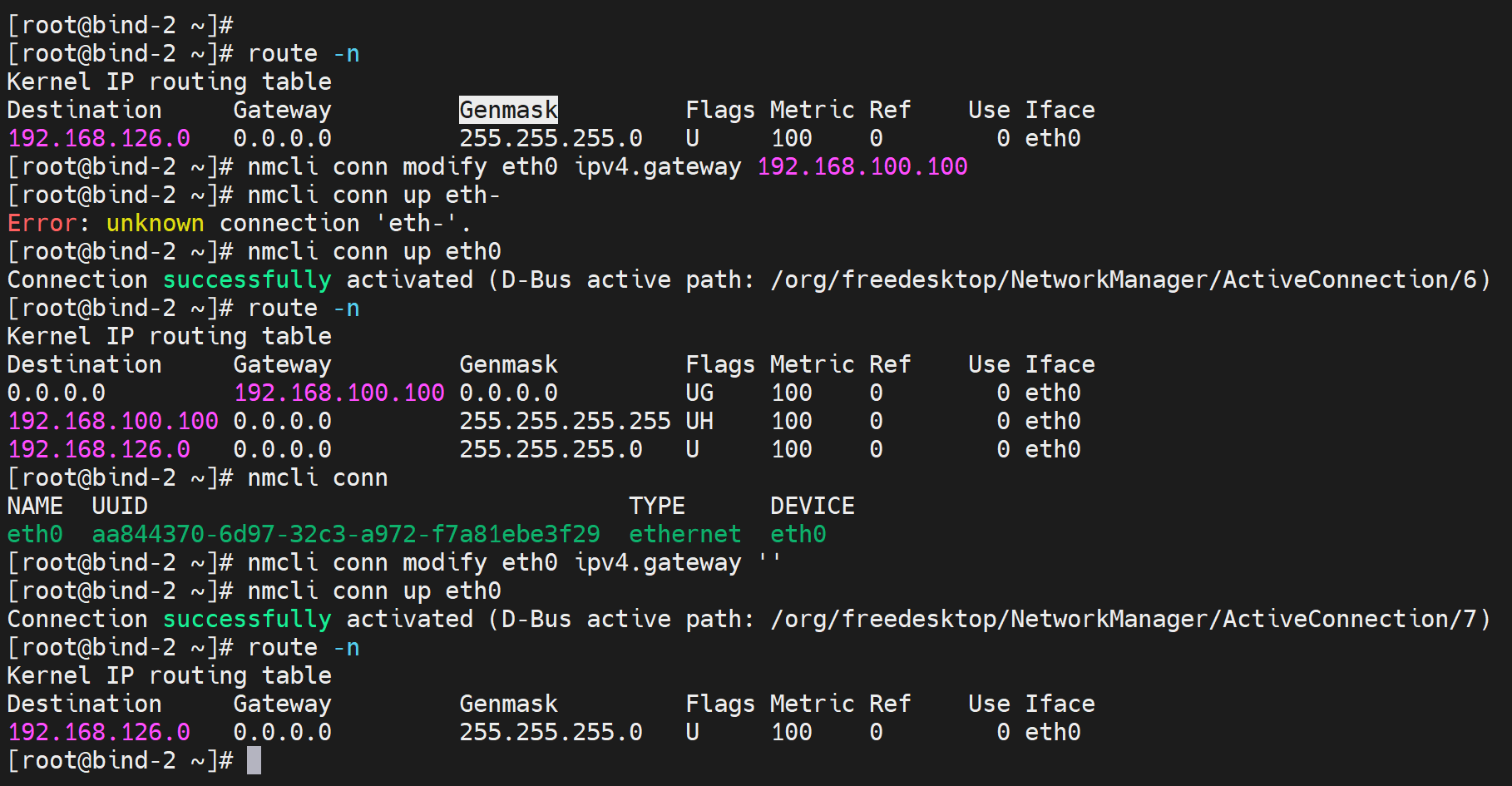
此时130变成 无法访问互联网了,当然可能涉及海外的根需要通的哦,呵呵
删默认之前OK的
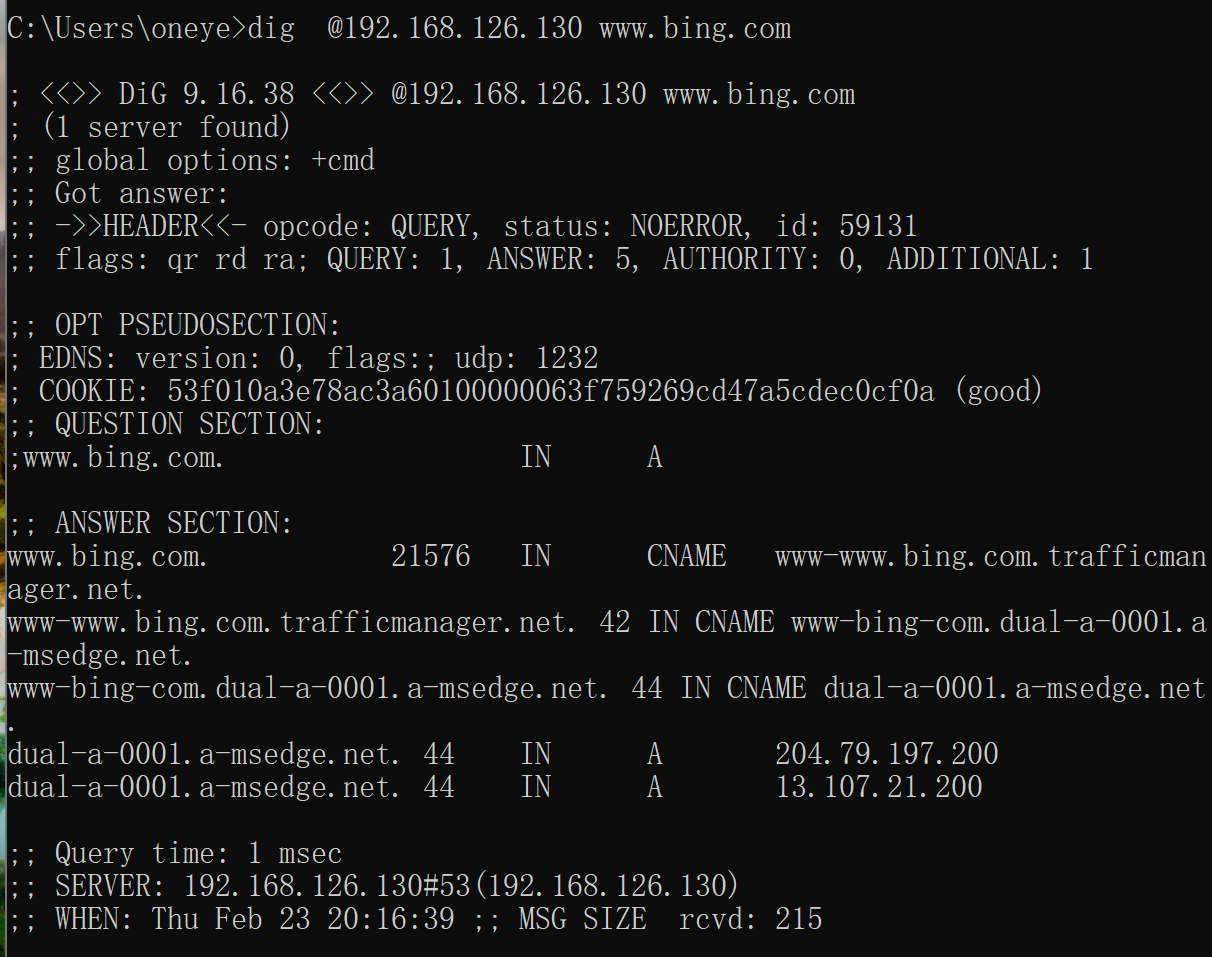
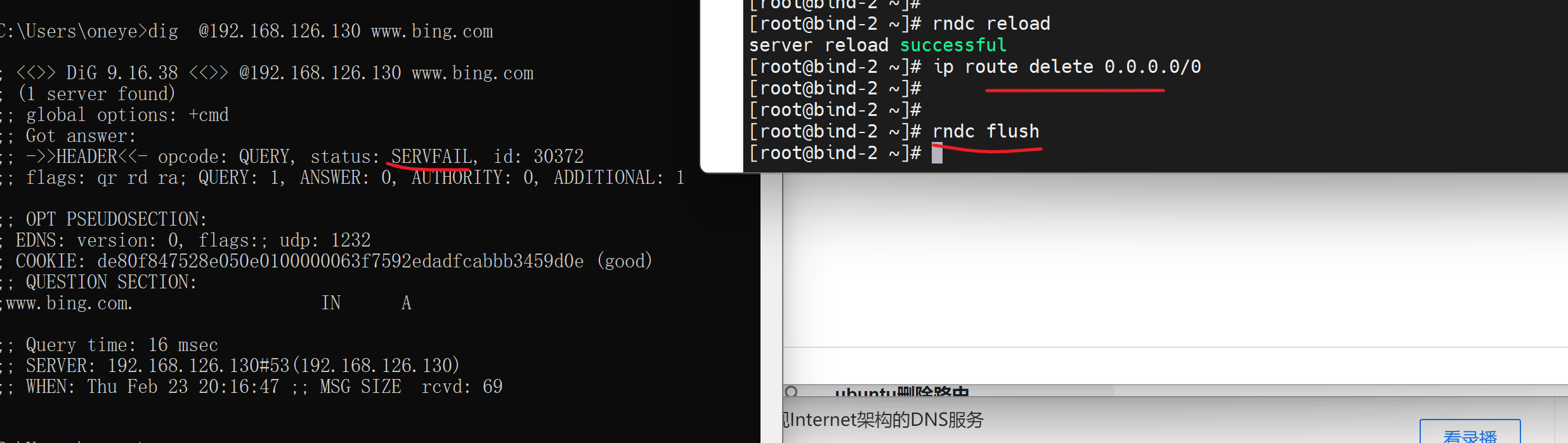
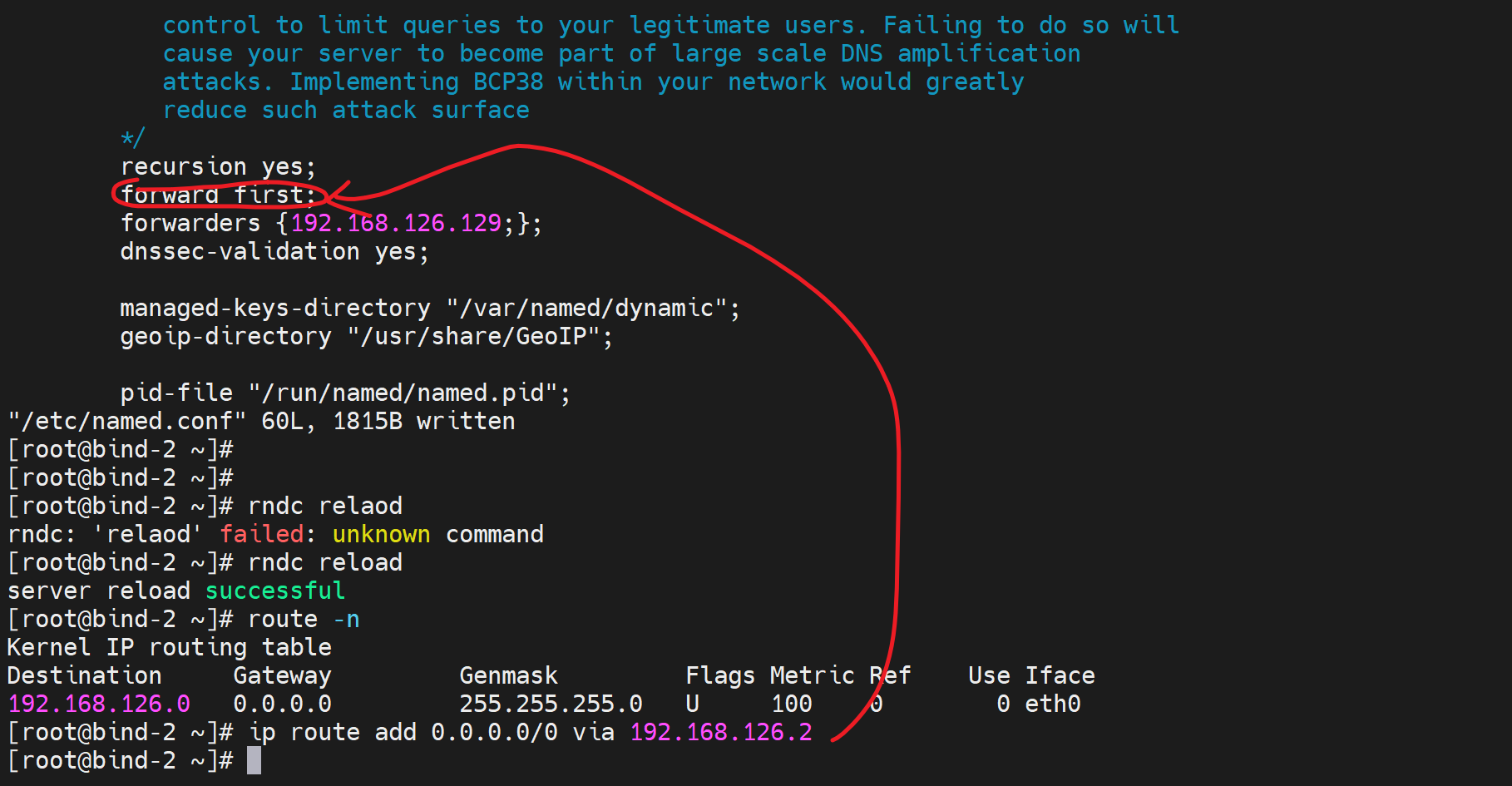
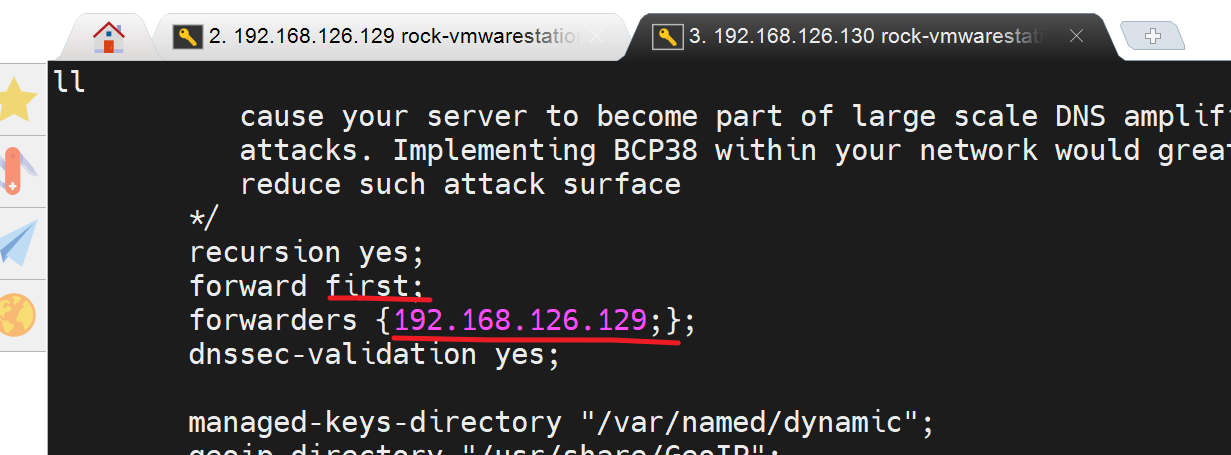
此时130 需要转发请求给129去处理,发现最好还是关掉sec选项
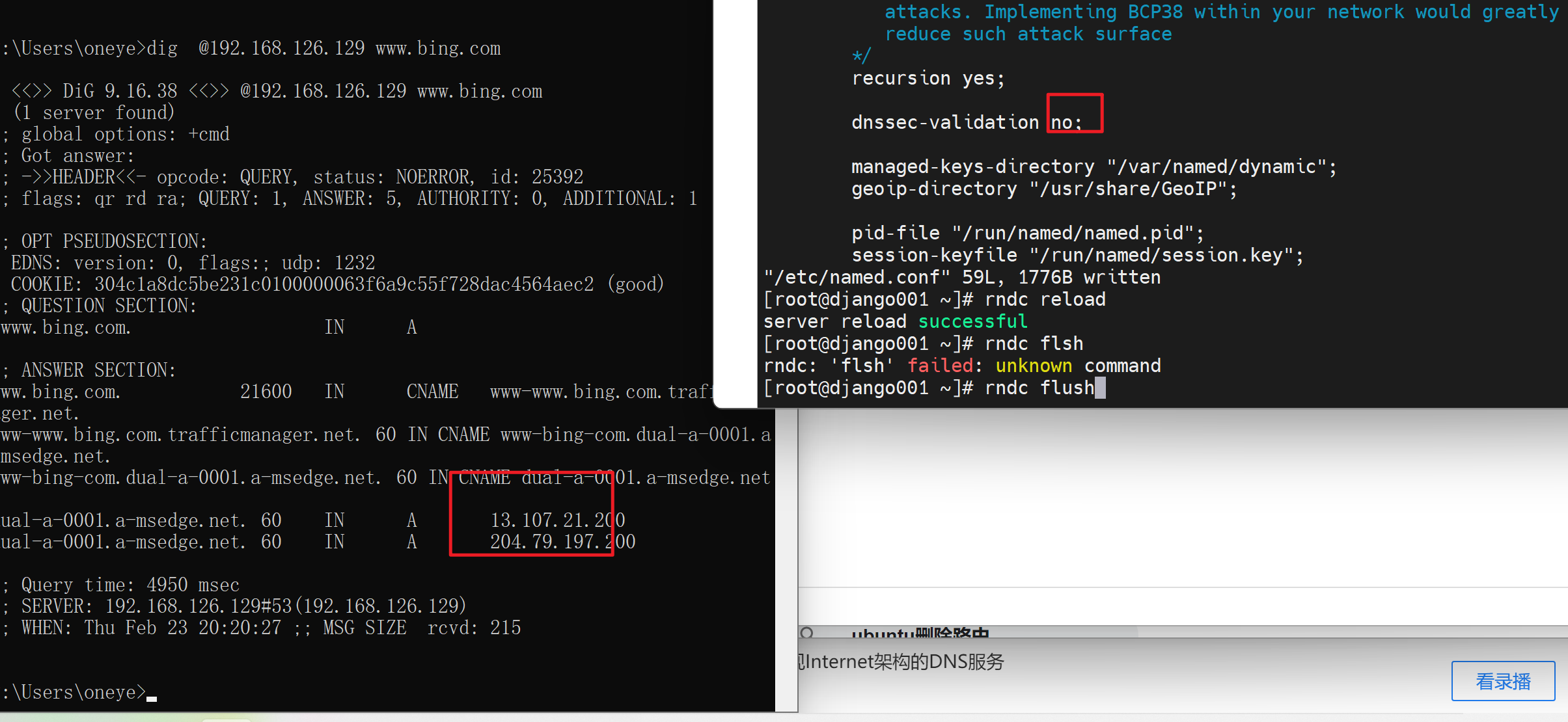
让130转发到129
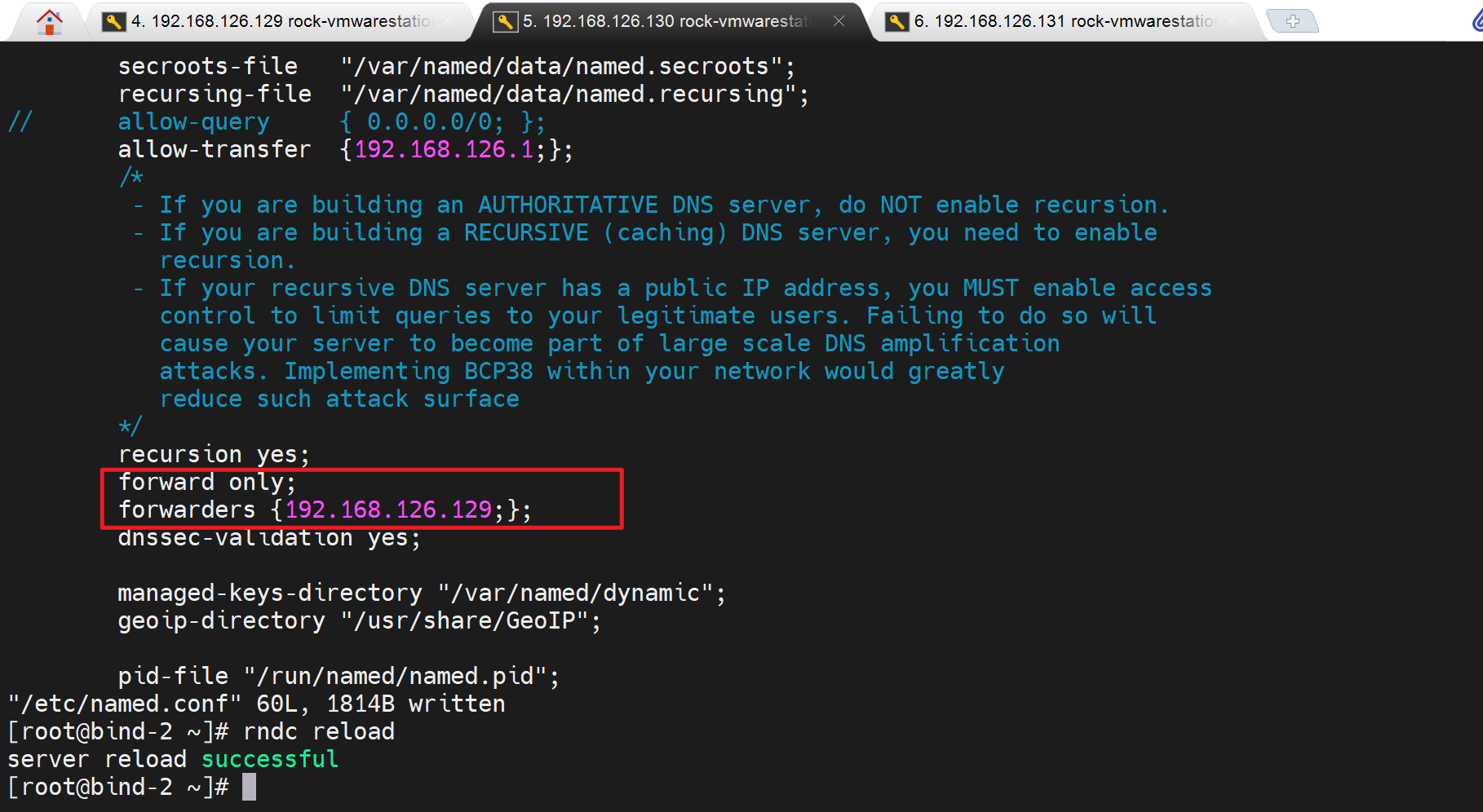
就好啦,与其好,sec也没关
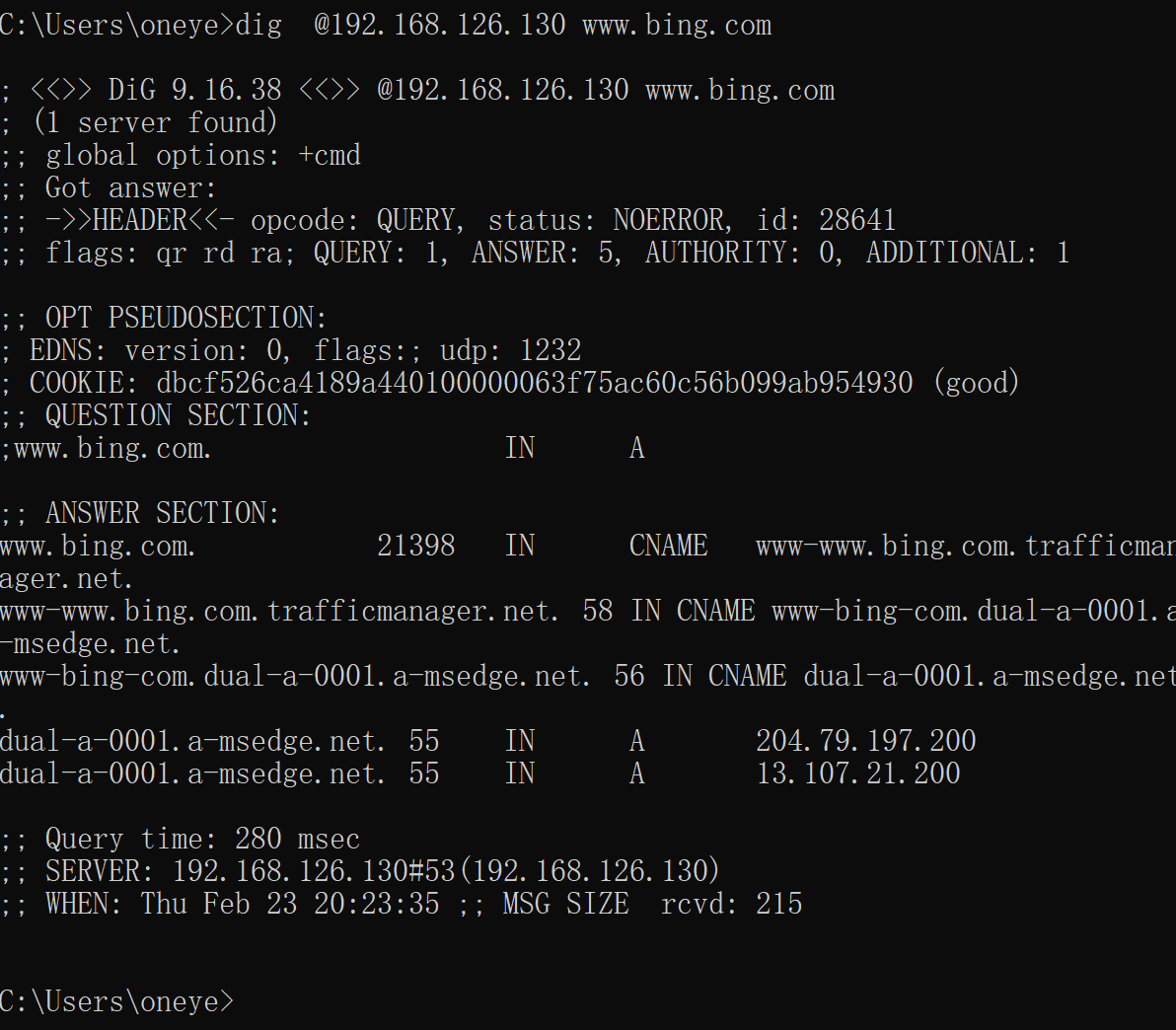
然后
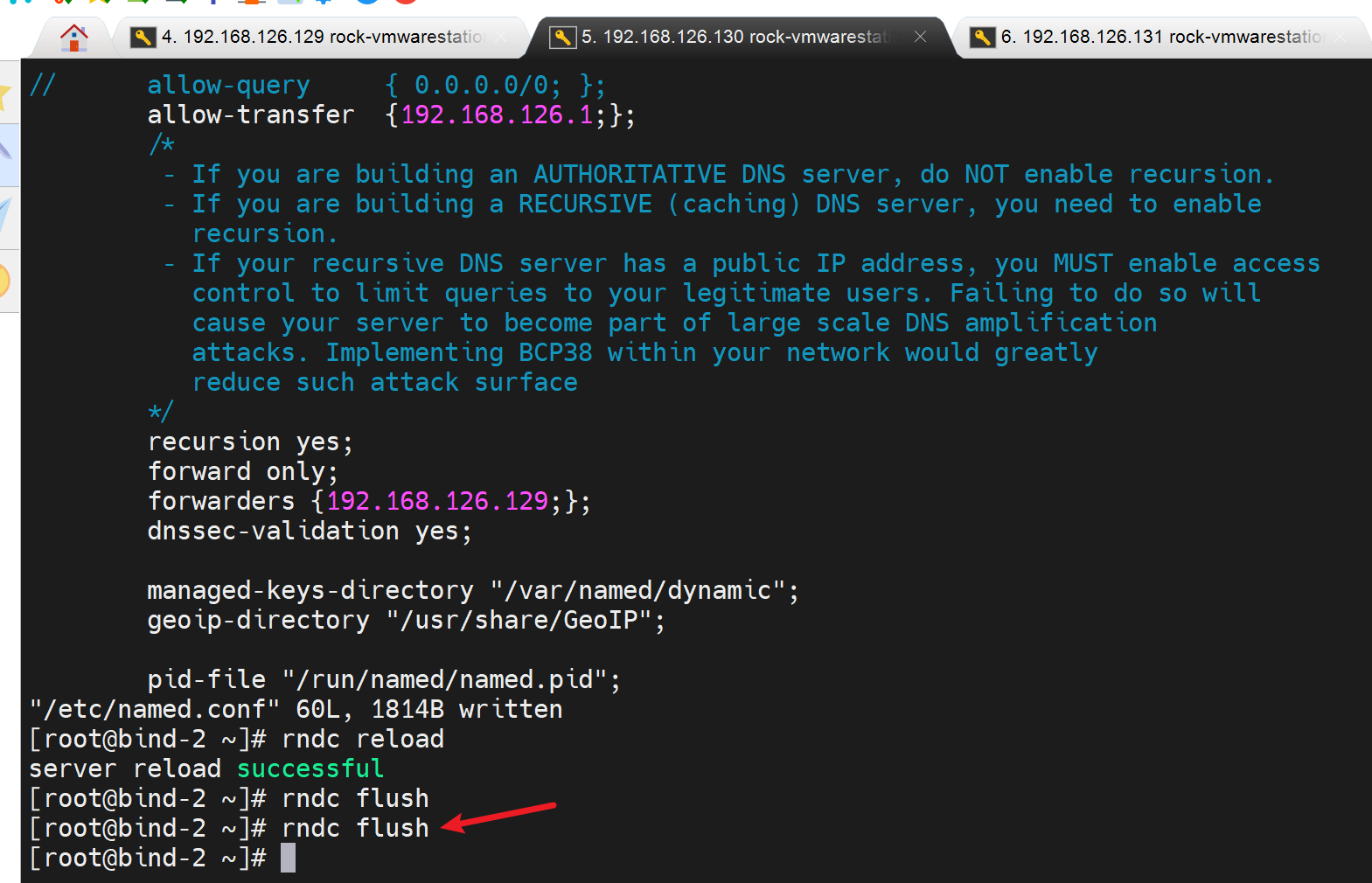
这样两台针对www.bing.com的只缓存dns就都没有缓存了,也无法访问互联网了
此时
然后将only改成first
敲了两次OK了
所以sec应该最好关掉。
配置就这一点点


ZONE特定区域转发
1、此情况
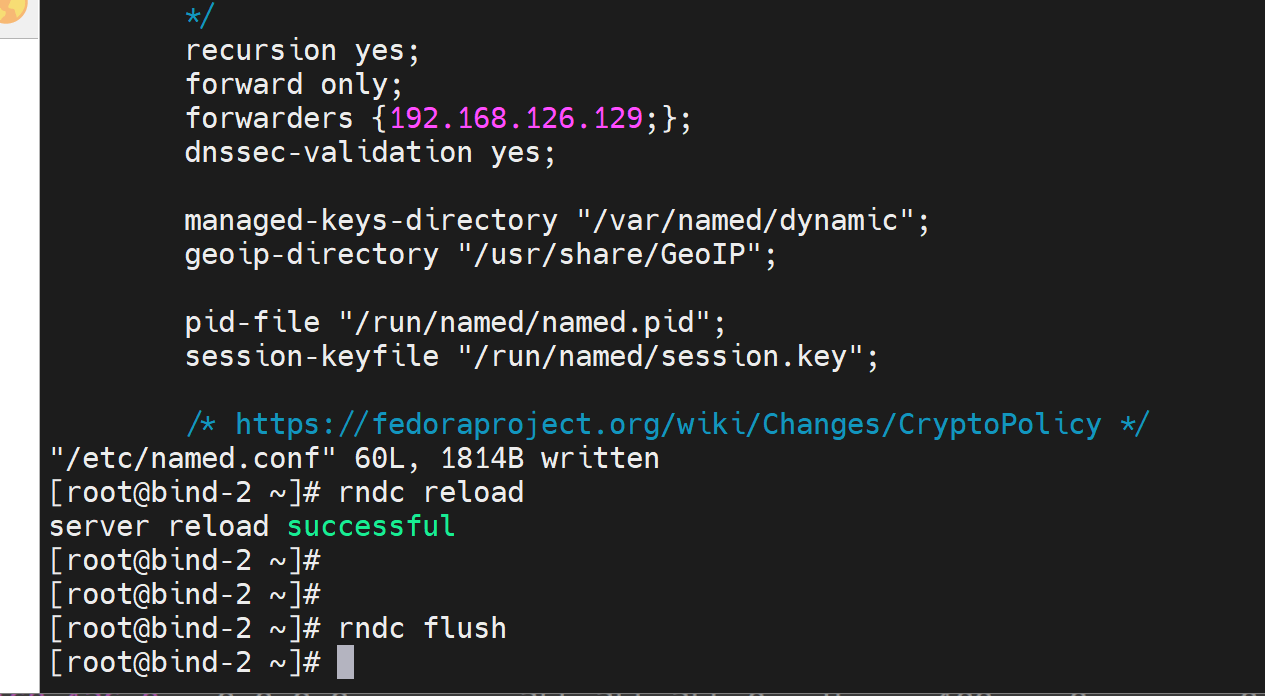
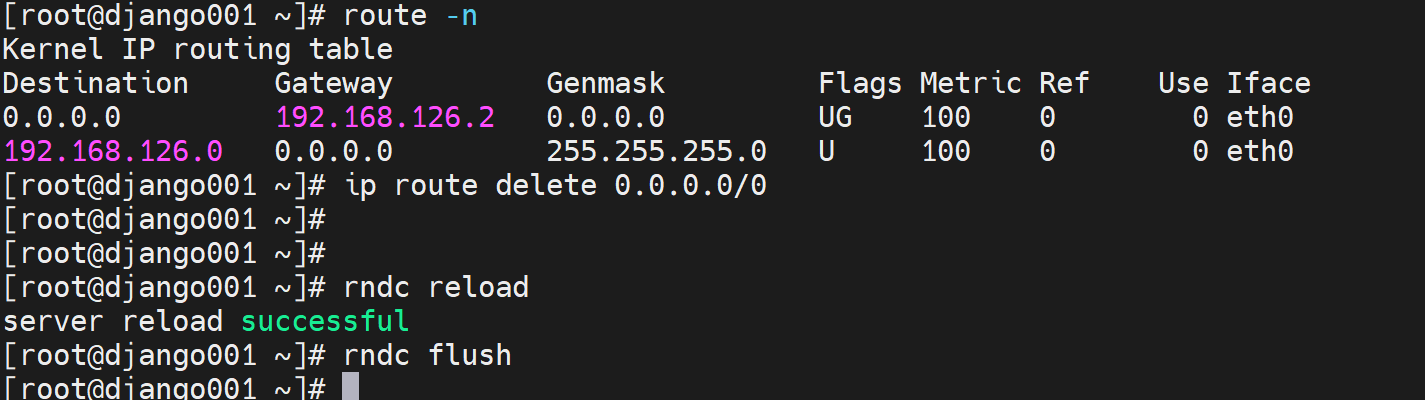
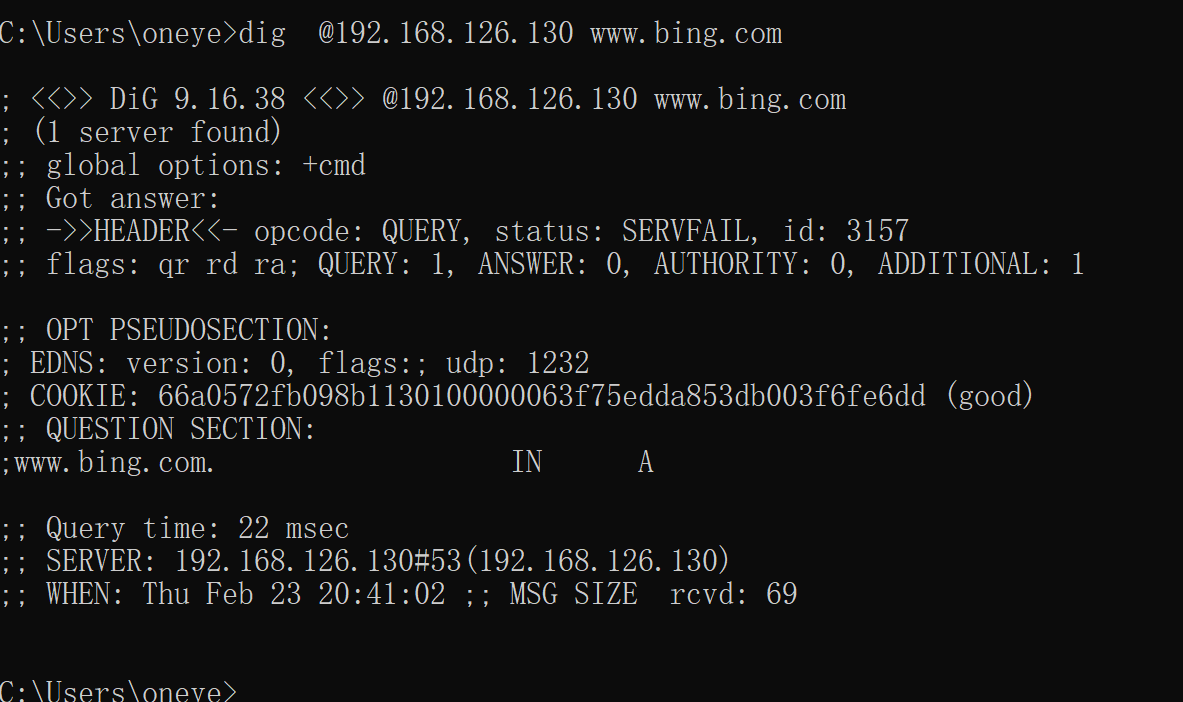
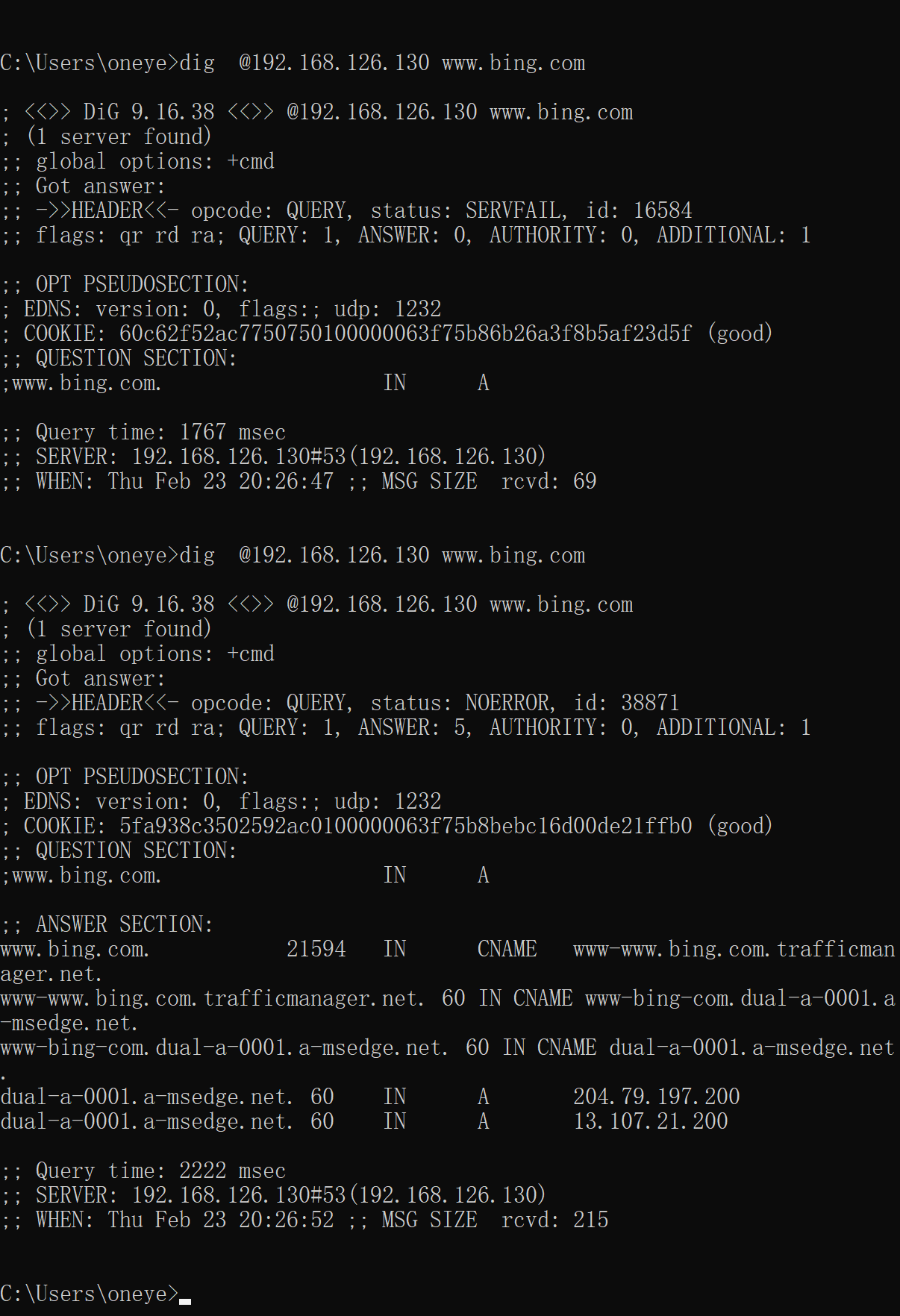
也就是说,130 only 到 129,129没有GW,缓存清空,自然解析不出来了
2、129打开GW
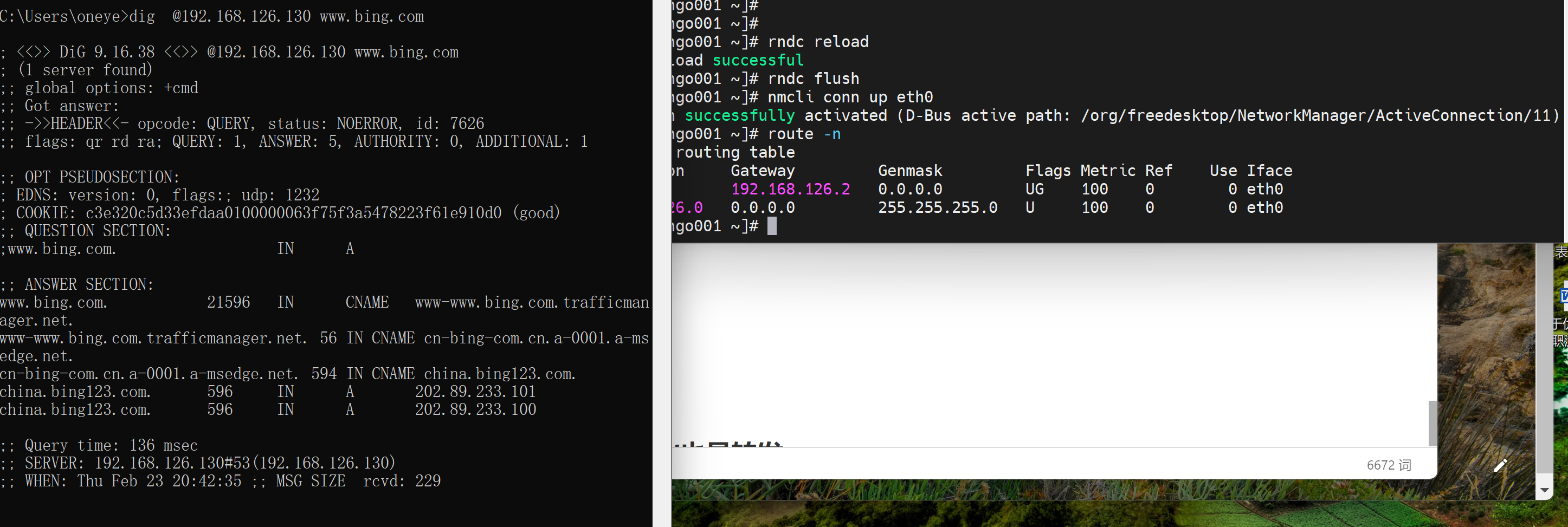
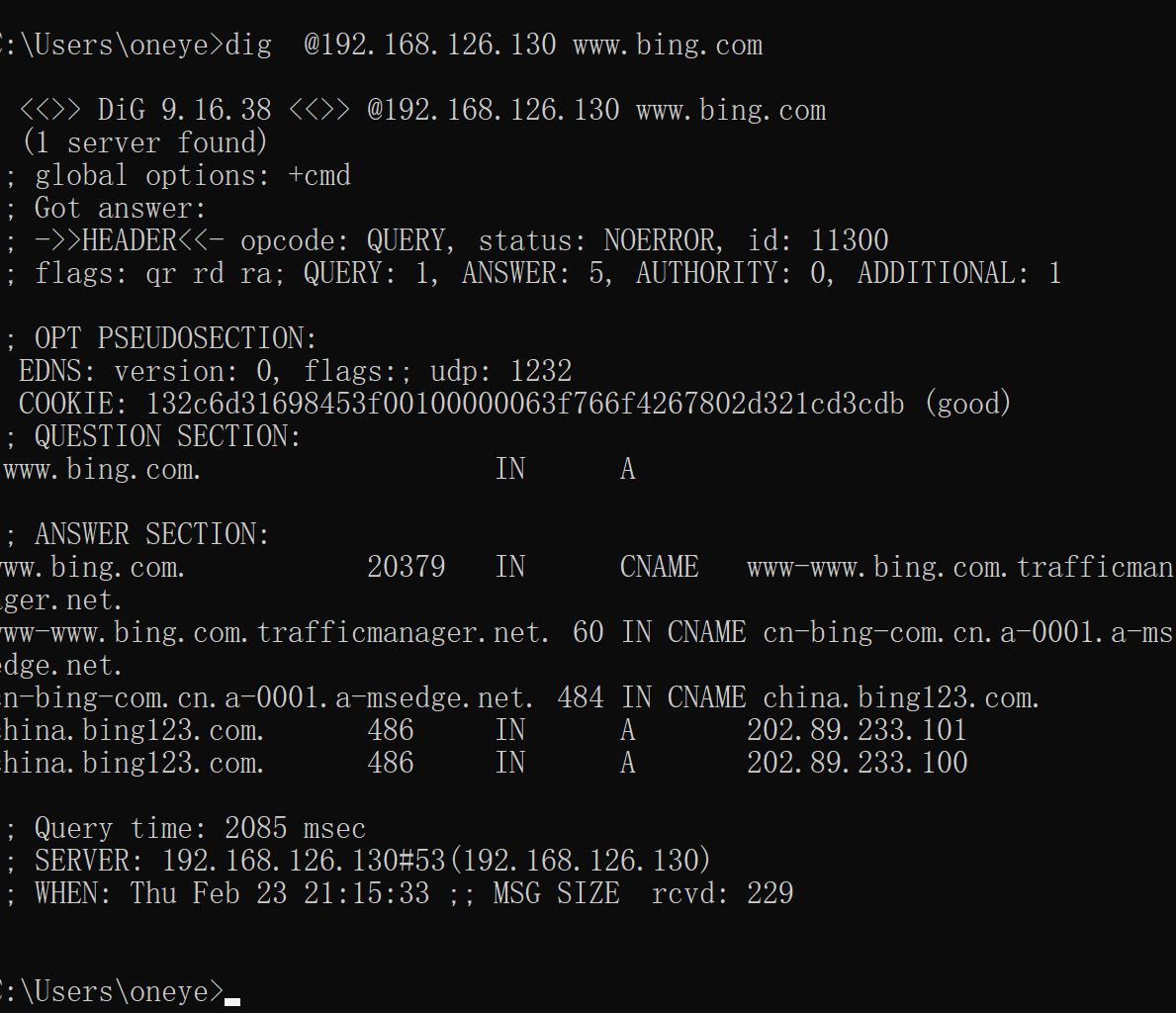
好了
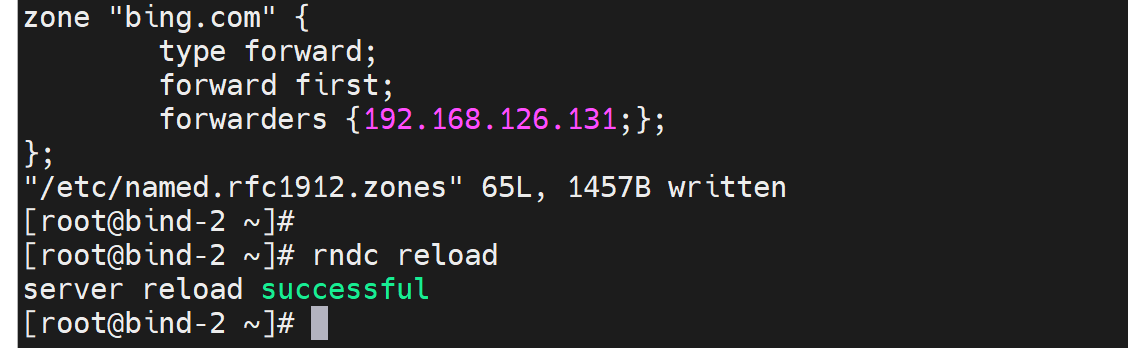
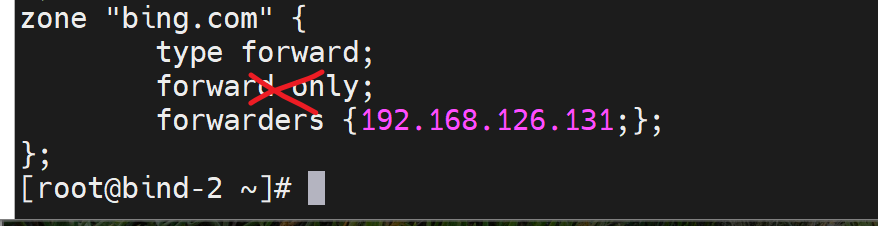
3、将bing.com在zone里去转发
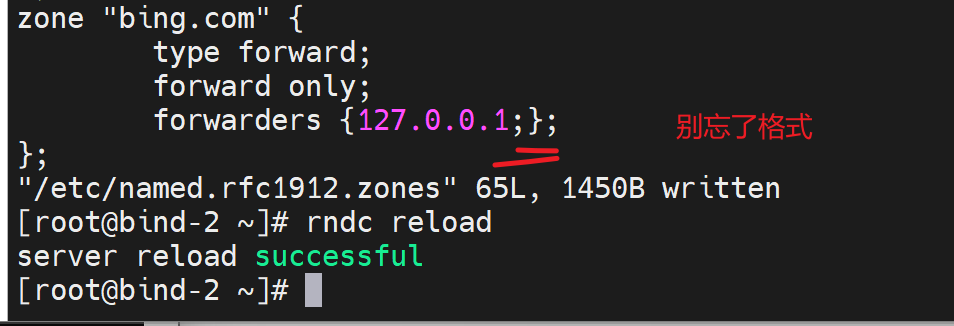

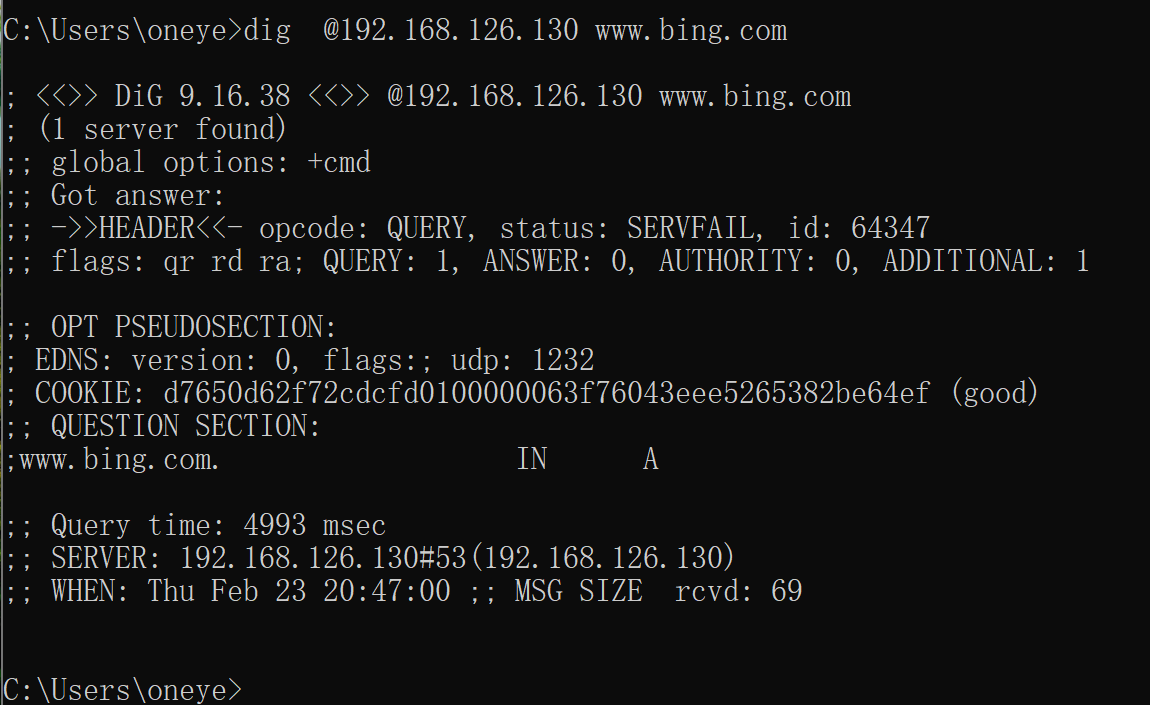
所以zone 指定了域名的转发,抢先了 比option里的先,127.0.0.1不变,本地GW打开

127.0.0.1不行?改成
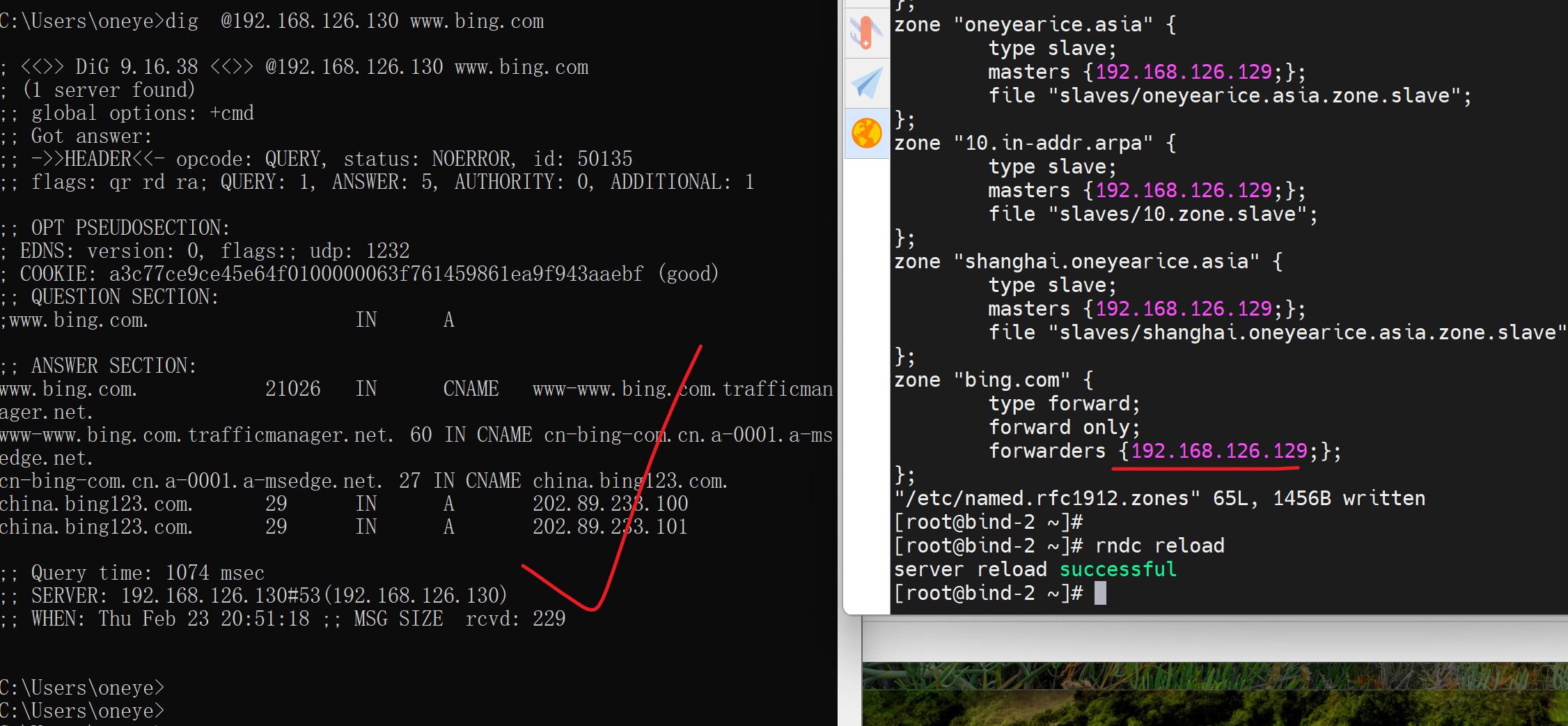
好了
但是
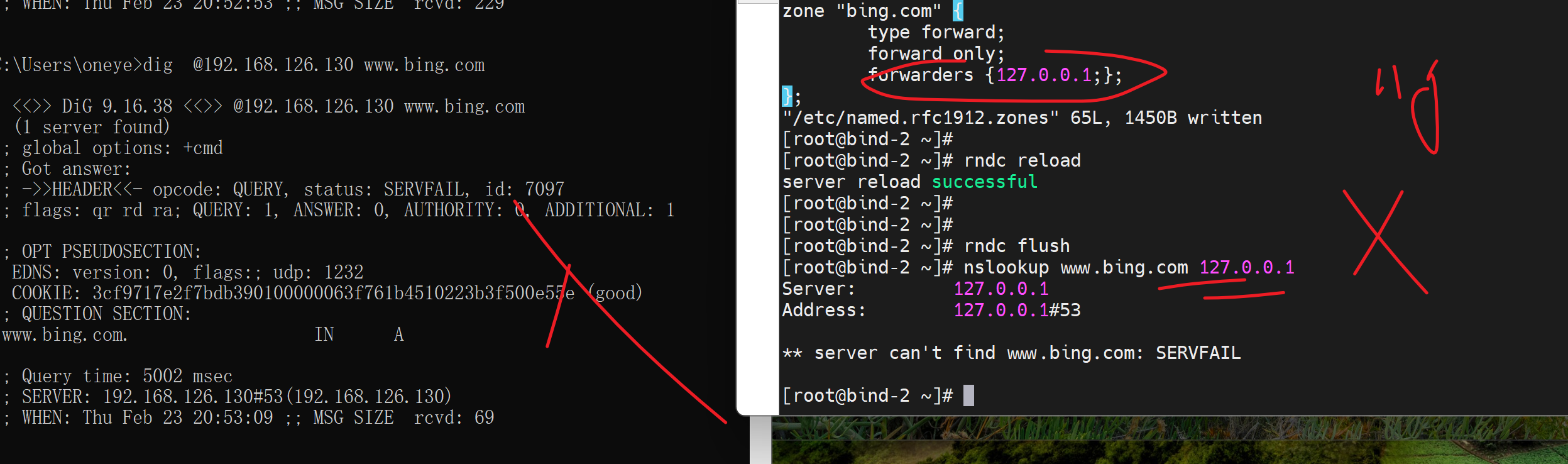
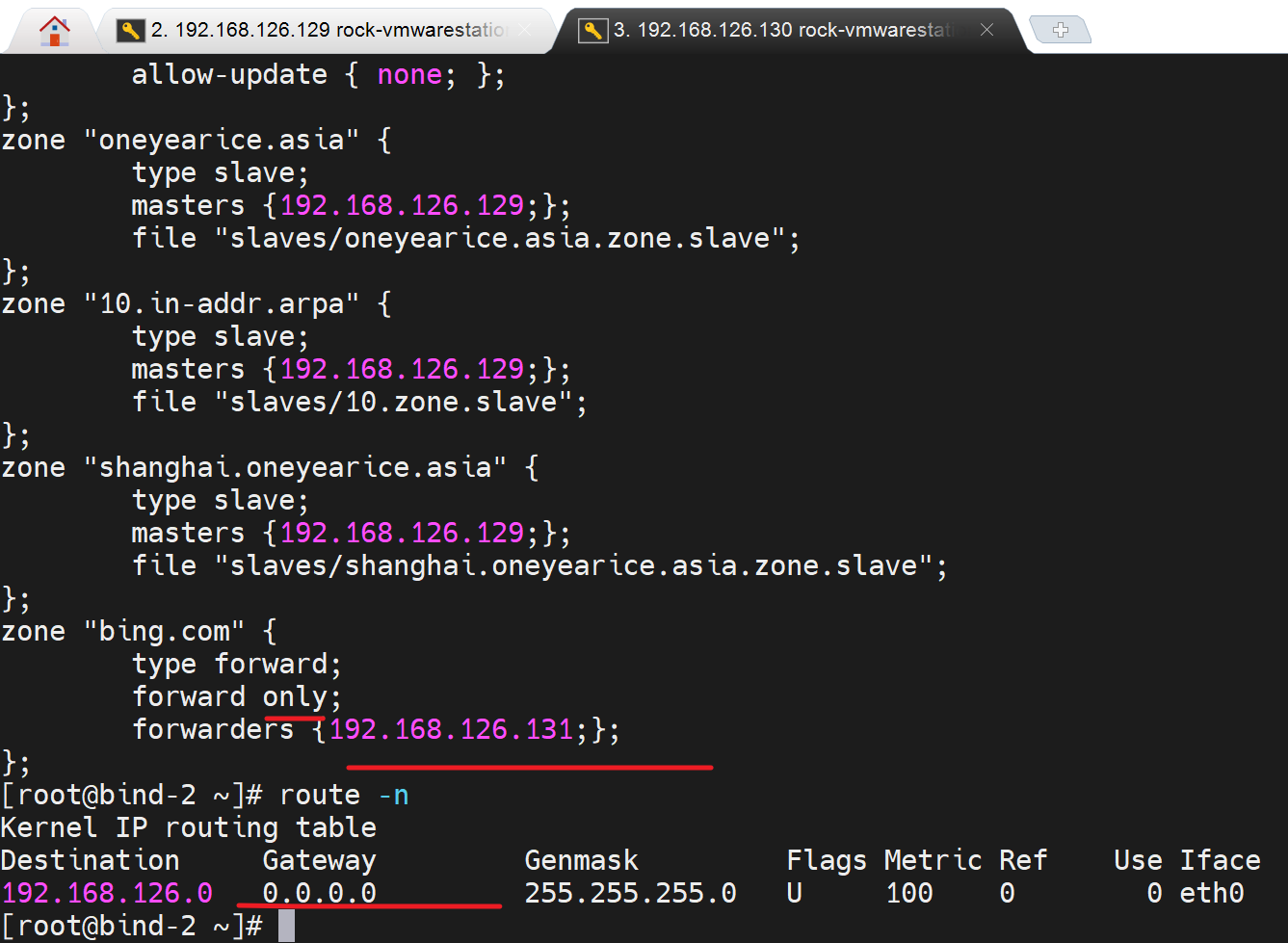
说来也奇怪,nslookup 127.0.0.1也不行--当 zone里转发写成127.0.0.1的时候,转发不写127或者自己IP就没问题
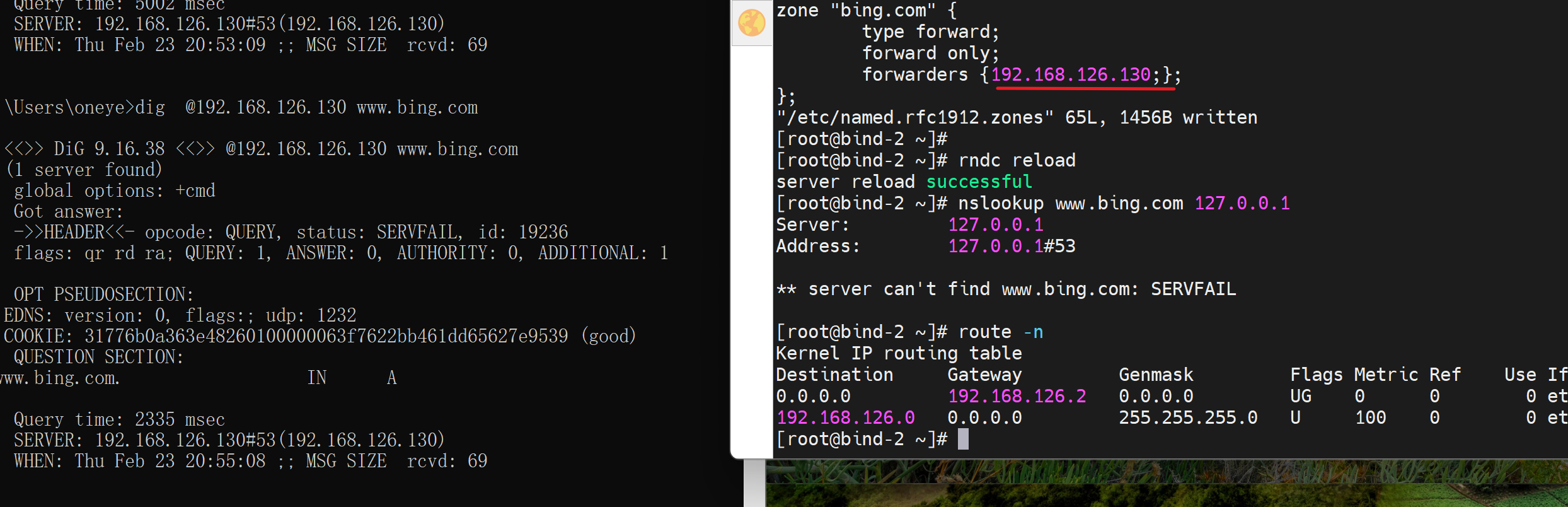
问为什么写成 非自己就可以了?写自己就不行
1、自己问自己,不让这种写法,我初步判断,自己问自己,你就用first 不要用only
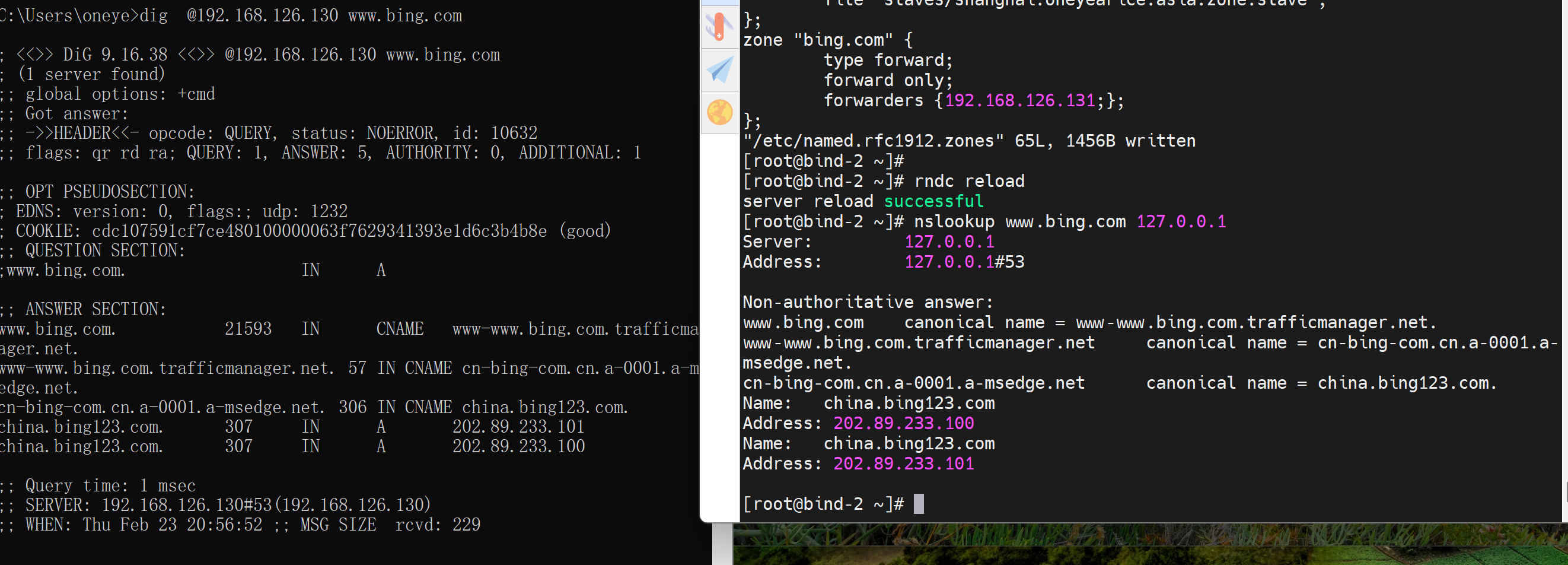
2、写非自己的IP,可以的原因,是比如192.168.126.131不可达,于是用了option里的转发配置到192.168.126.129了,此时你把129的named关掉就没啦。然后再把129的named开启,又可以了。
继续关掉129的named,让他ng,该130的first
不行,必须去改option全局里的转发方式为first才行。
所以我不清楚zone和option里的forward first 是怎么一个逻辑。
我如果设计的话
1、zone里的优先:forwarders的IP比全局里的优先
2、如果zone里的转发ip 失败,是不是就直接用本地出去问呢,不是还有全局的转发,要去问全局的。
3、然后全局里的转发IP失败,再回来看zone里的是不是又first
所以此时改一下测试
然后129
关闭129的named,然后130的flush

解析NG
然后开启130的GW
就好了
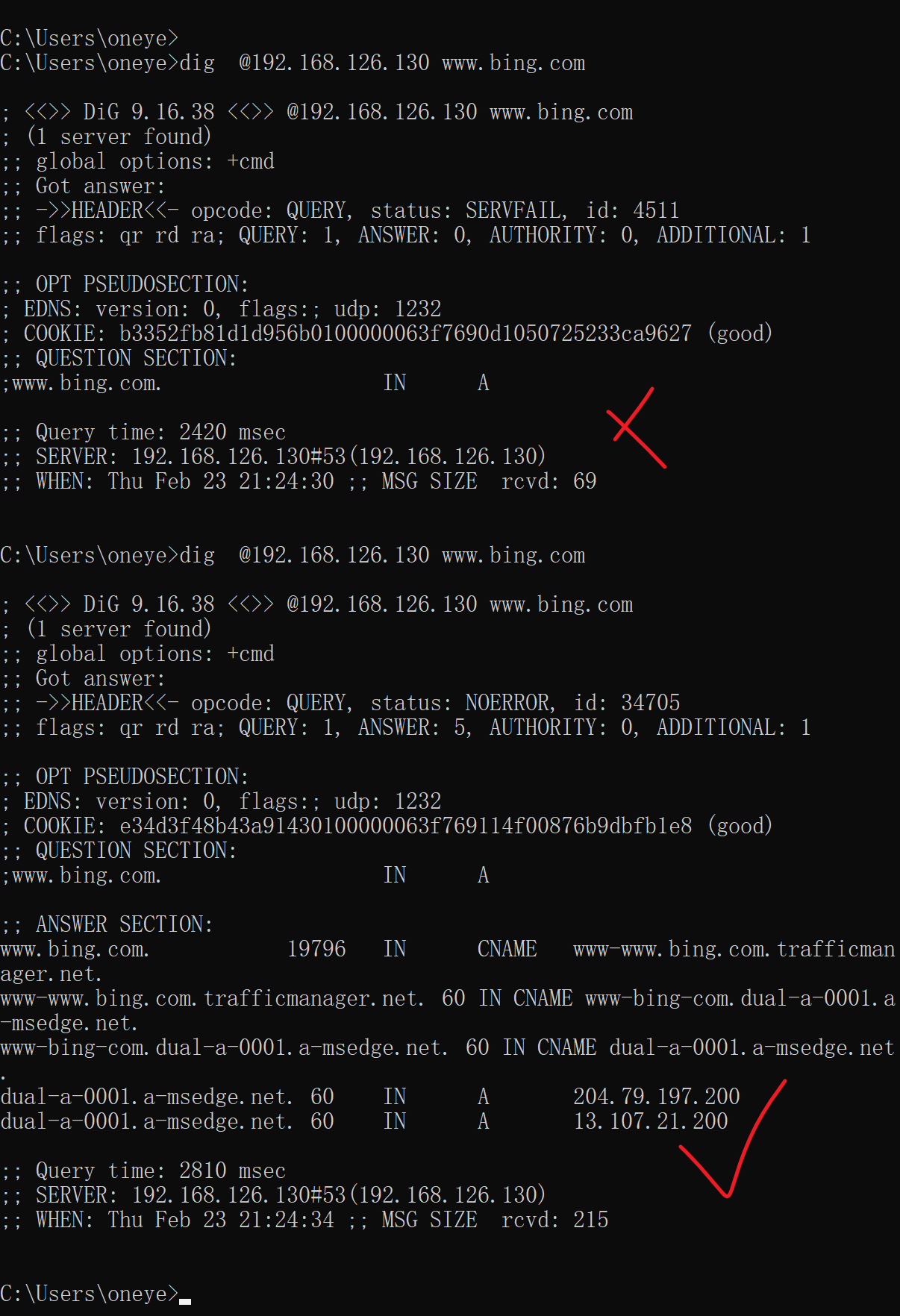
看来zone里的only没生效,我估计zone里的forward first|only 不生效!
BIND9的VIEW也是转发
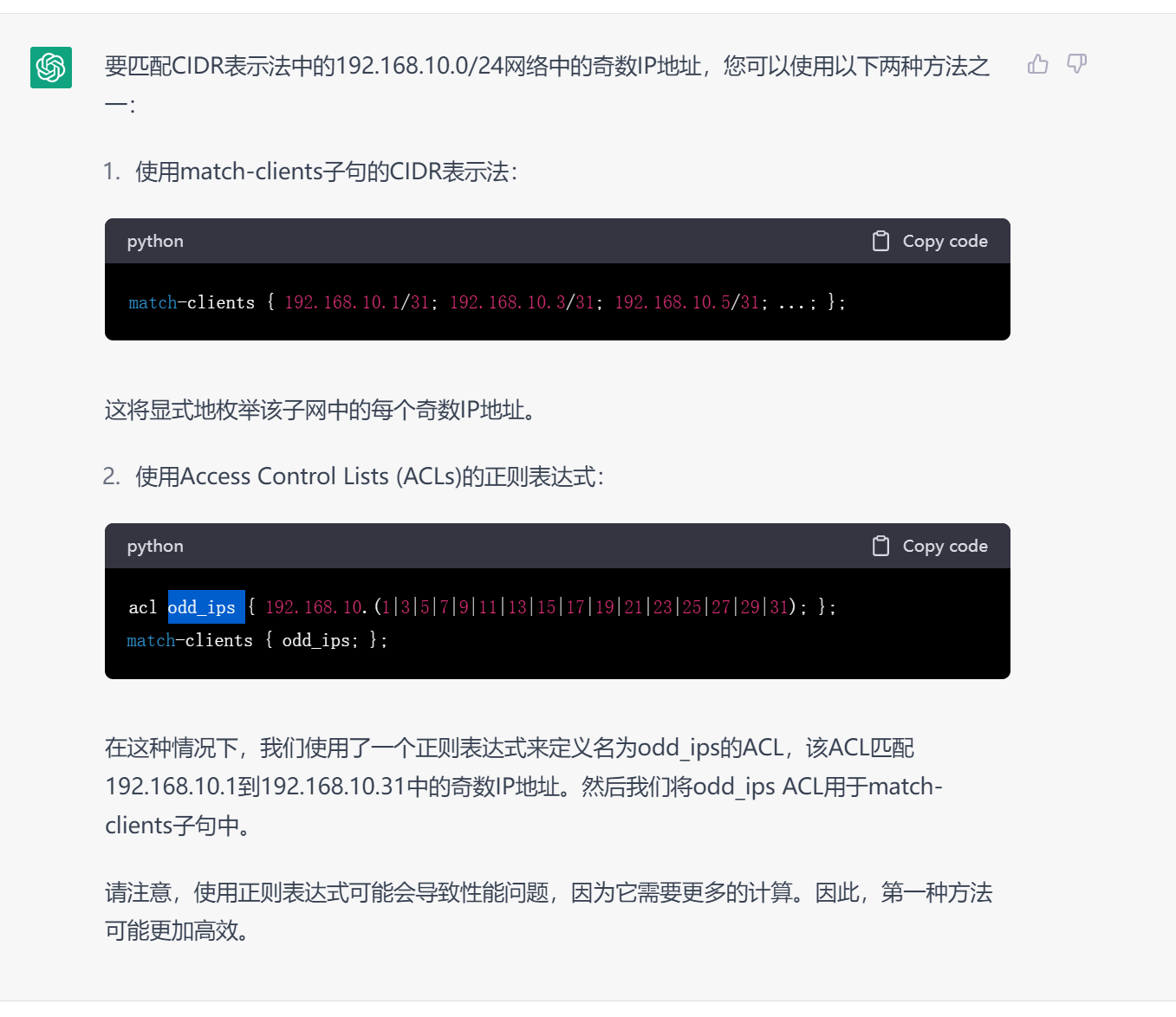
直接上需求,将奇数IP的dns请求转发到10.3,偶数的转发给10.2
开搞,搞不了,BIND view里的acl不支持正则,思路换到智能DNS里吧。看看那篇有什么新的东西,至少常见的基于ISP的归属地的,各种智能DNS不都在商用吗,我不信一个奇偶数还不能做出来了,
当然这里的VIEW也能做,就是把acl add_ips和acl eve_ips里写满所有的私网网段的奇数,和偶数。当然eve_ips可以! add_ips 直接取反。
acl odd_ips {
# 匹配奇数IP地址
!acl even_ips;
};
1、配置主备好
vim /etc/named.conf
------------------------------
acl odd_ips {
stdlib.regex("/(\d{1,3}\.){3}\d{0,2}[13579]/"); # 可惜这种chatGPT的一厢情愿,然而BIND并不支持
};
acl even_ips {
stdlib.regex("/(\d{1,3}\.){3}\d{0,2}[02468]/");
};
view "odd_ips" {
match-clients { odd_ips; };
match-destinations { any; };
recursion yes;
forwarders { 192.168.126.129; }
};
view "even_ips" {
match-clients { even_ips; };
forwarders { 192.168.126.130; }
};
毛啊~更不不支持regex,唯一找到的信息是bind的一条漏洞
https://www.tenable.com/plugins/nessus/65736
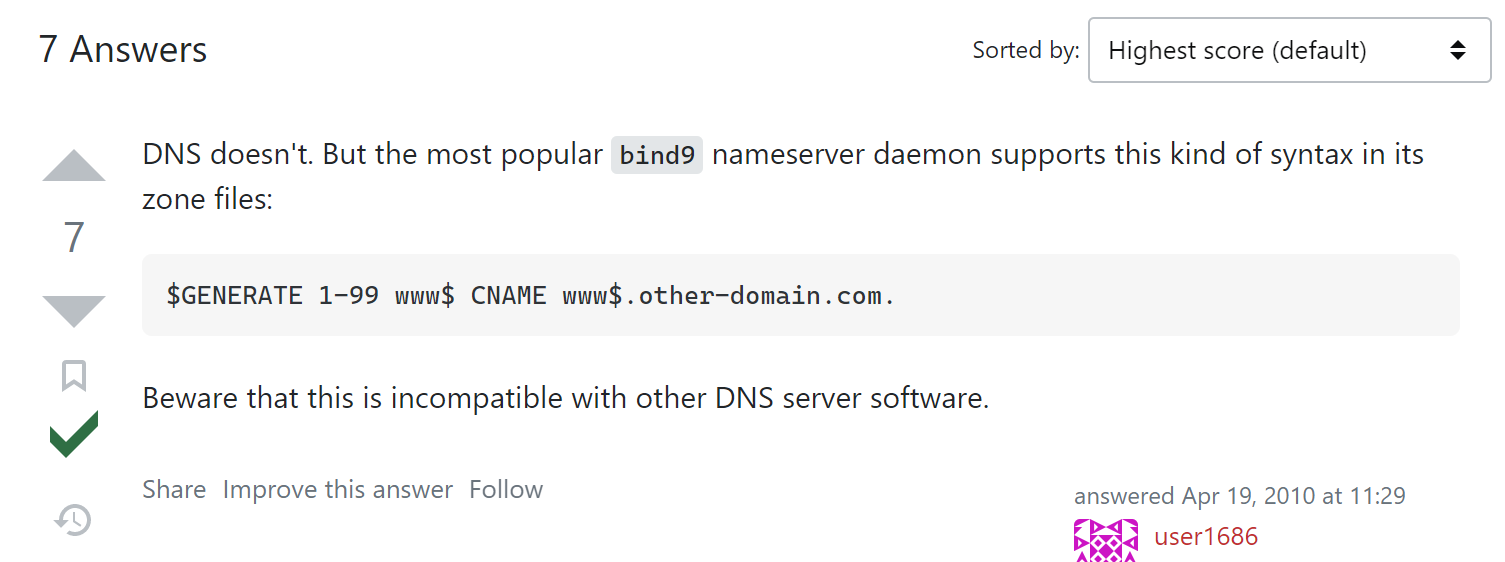
这里支持这种,这是zone数据库里支持的写法
就是不支持regex