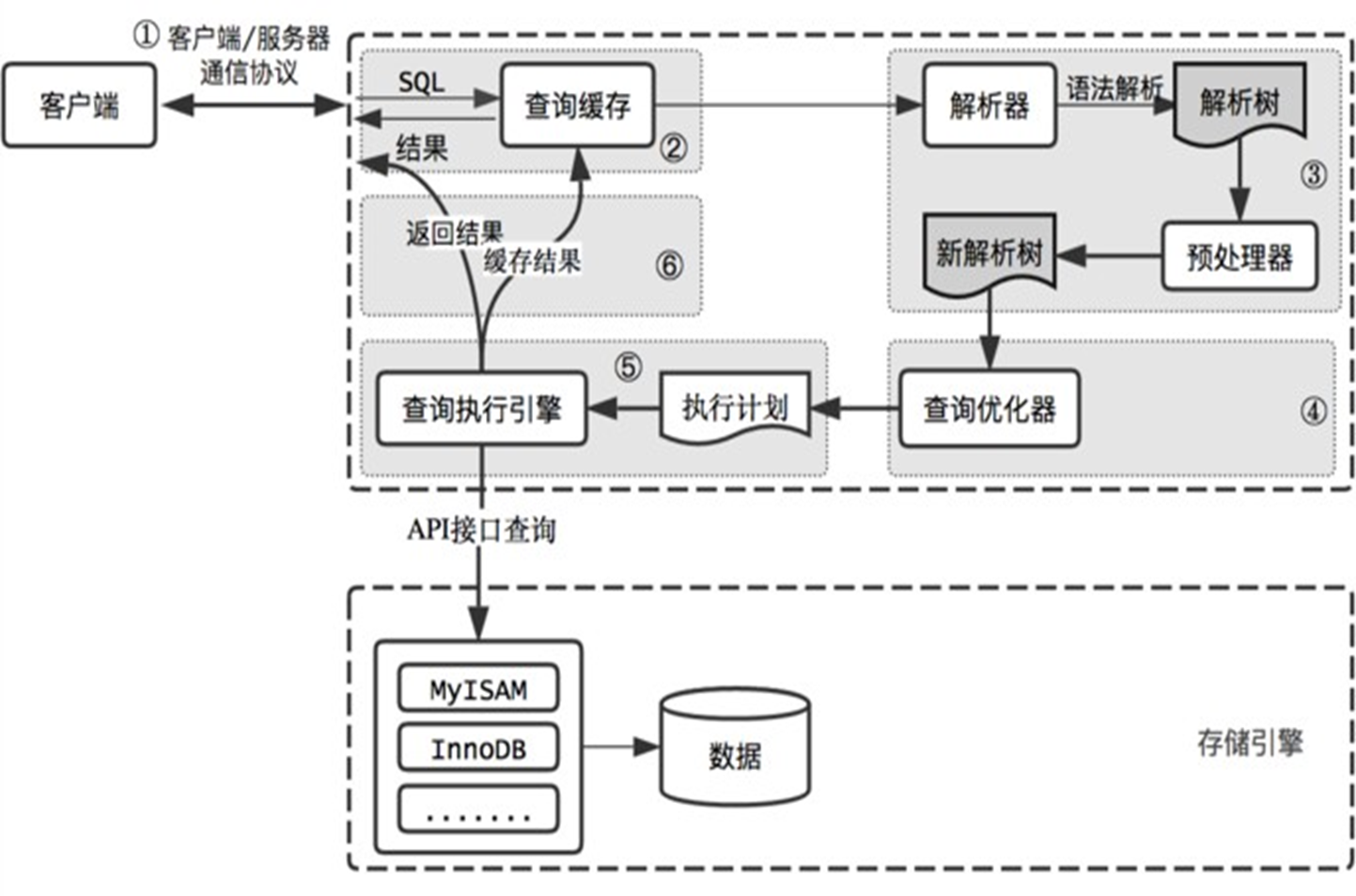
第5节. mysql服务器选项变量和性能优化
区分mysql选项、服务器系统变量、服务器状态变量三个东西
1、服务器选项,是写道配置文件里需要重启服务的一般是,可能mysql -u -p --option也行。

这就叫选项,就是运行时候的option咯;
选项来自于哪儿:在/etc/my.cnf里添加就行。
当然新版本就不是cli option的方式显示了,但是也要知道还是在my.cnf添加的那些就是服务器选项--myslqd 选项。
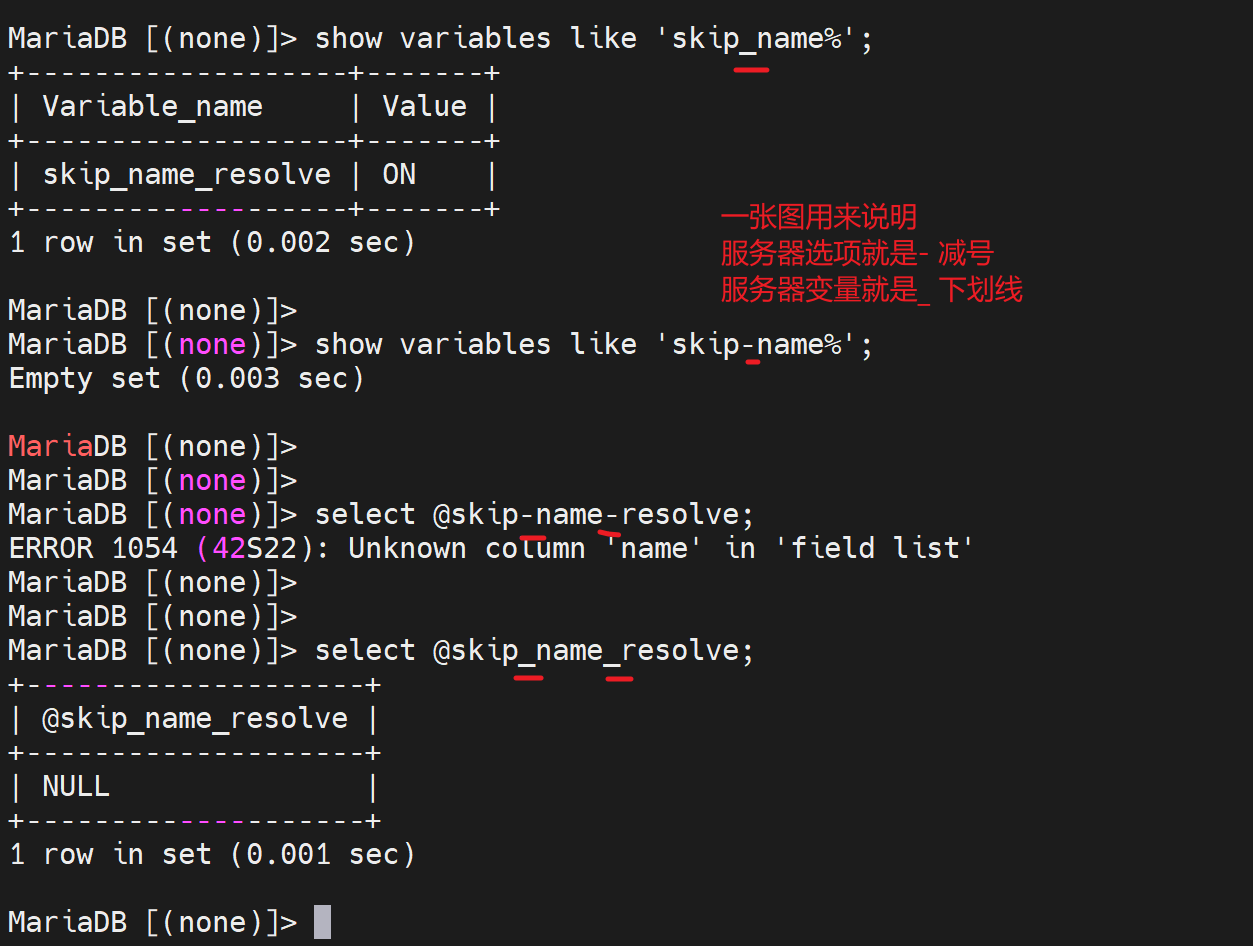
然后选项标准据说是用减号-,下划线只是支持而已,其实也就是不区分-和_的。
2、服务器变量是随时更新的,无需重启服务
然后很多情况下,有些东西,它既是服务器选项 又是 服务器变量。
变量通过show variables;查看
又分类 全局变量 和 会话变量
所谓会话变量,就是mysql -uroot -pxxx 进入的一个交互界面就是一个会话。
比如
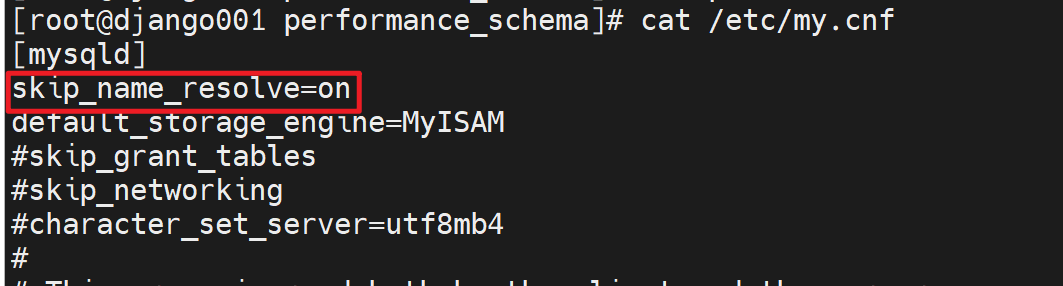
这个选项同时也变量,可以如下方式查看
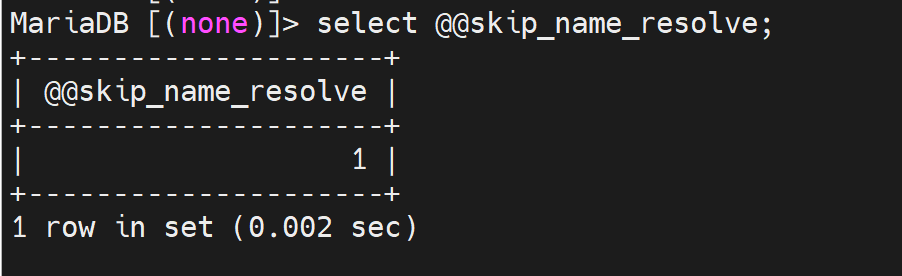
或者这么看
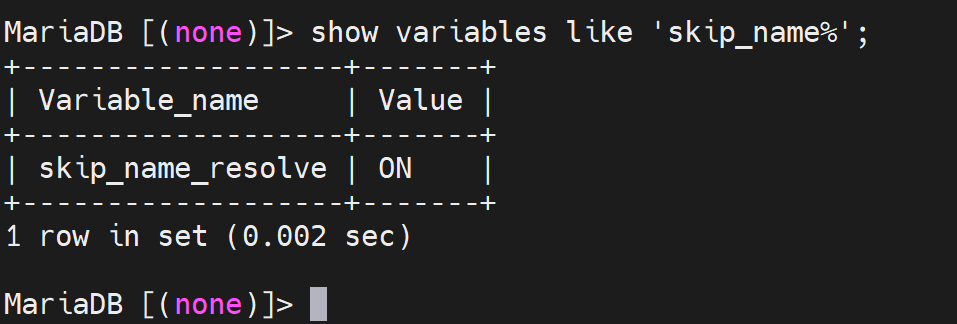
修改变量
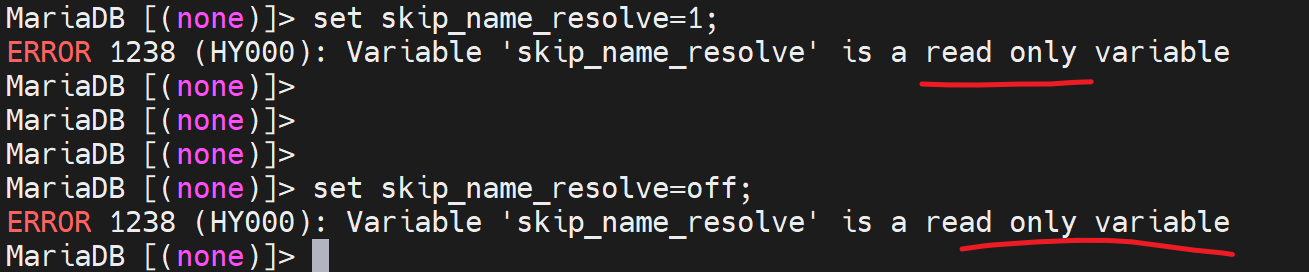
这样直接该就是当前会话里生效,推出后失效。

然后再看一个my.cnf里的服务器选项,这里面写的都是服务器选项,既然写在里面能生效的都是选项,至于这个选项还是不是变量就要看了。
比如:
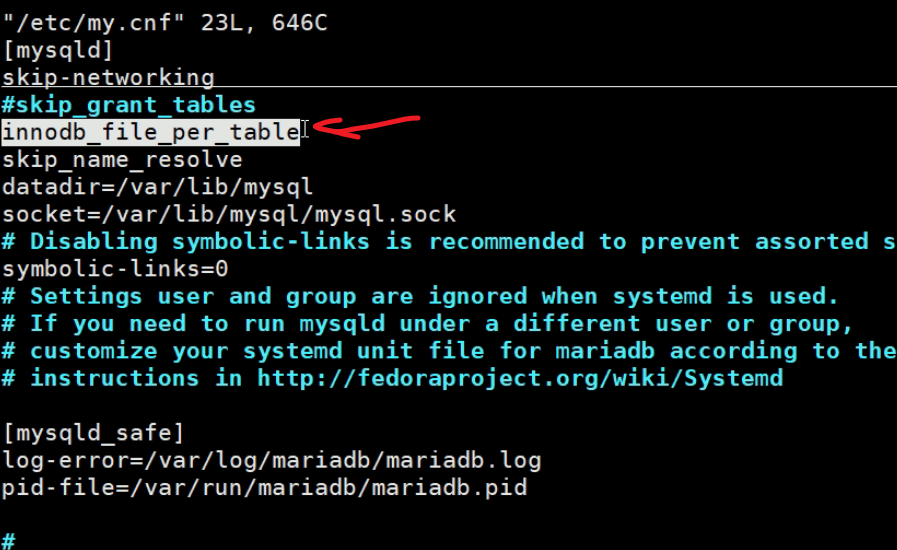
正儿八经上图选项要统一用减号-而不是下划线的,只不过人家不区分而已。然后看看这个innodb_file_per_table是不是同时也是变量,而查看变量的时候就要区分\减号和_下划线了
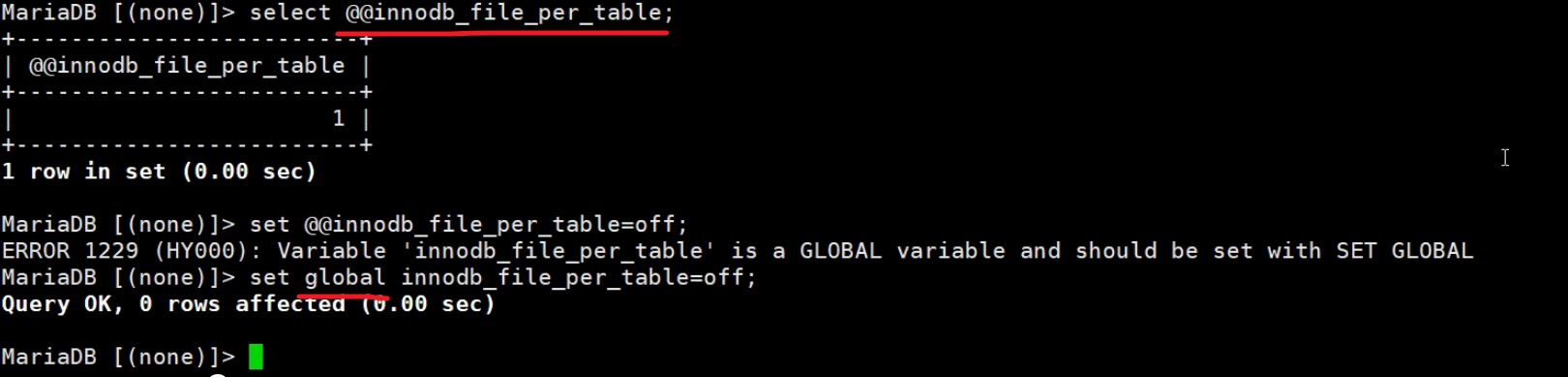
上图说明这个变量不是一个局部性的会话级变量,要改就是基于全局去修改的。
然后看一个仅仅是服务器选项,不是变量的东西
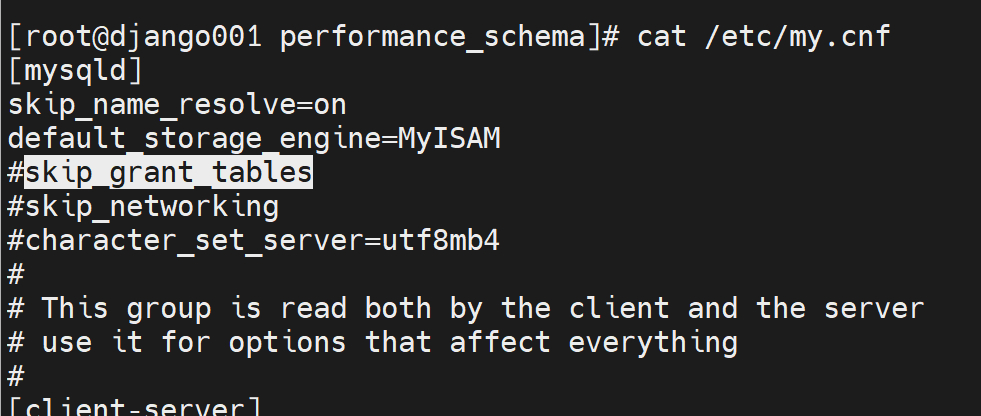
哈哈,新版本也是变量了
老板本就不是变量哈哈,所以这个东西研究没啥具体价值可能
上图就是老版本的情况。
show variables \G; 看所有变量
show variables like 'var_name'; 查看特定变量
show variables like 'var_na%'; 查看特定变量
show variables like '%var_nam%'; 查看特定变量
%就是等价于ls xxx*里的*就是通配符
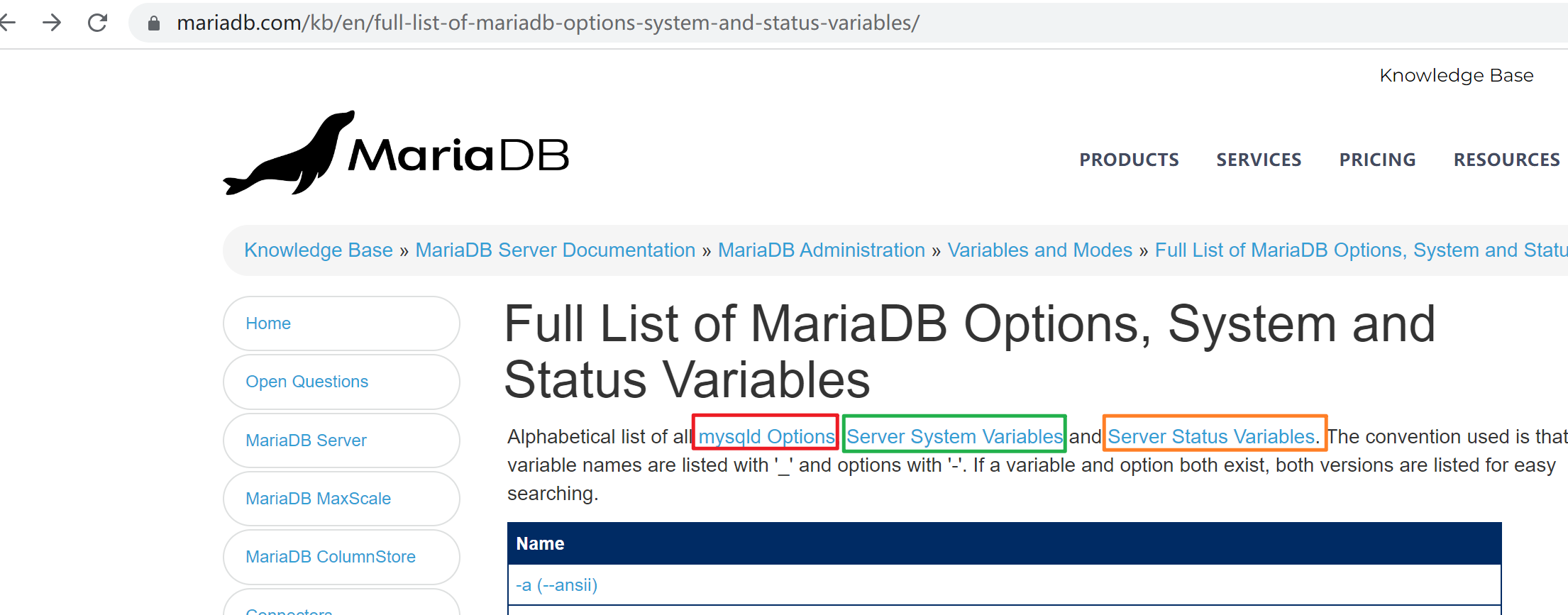
关于服务器选项和服务器变量的官方表格
https://dev.mysql.com/doc/refman/5.7/en/server-option-variable-reference.html
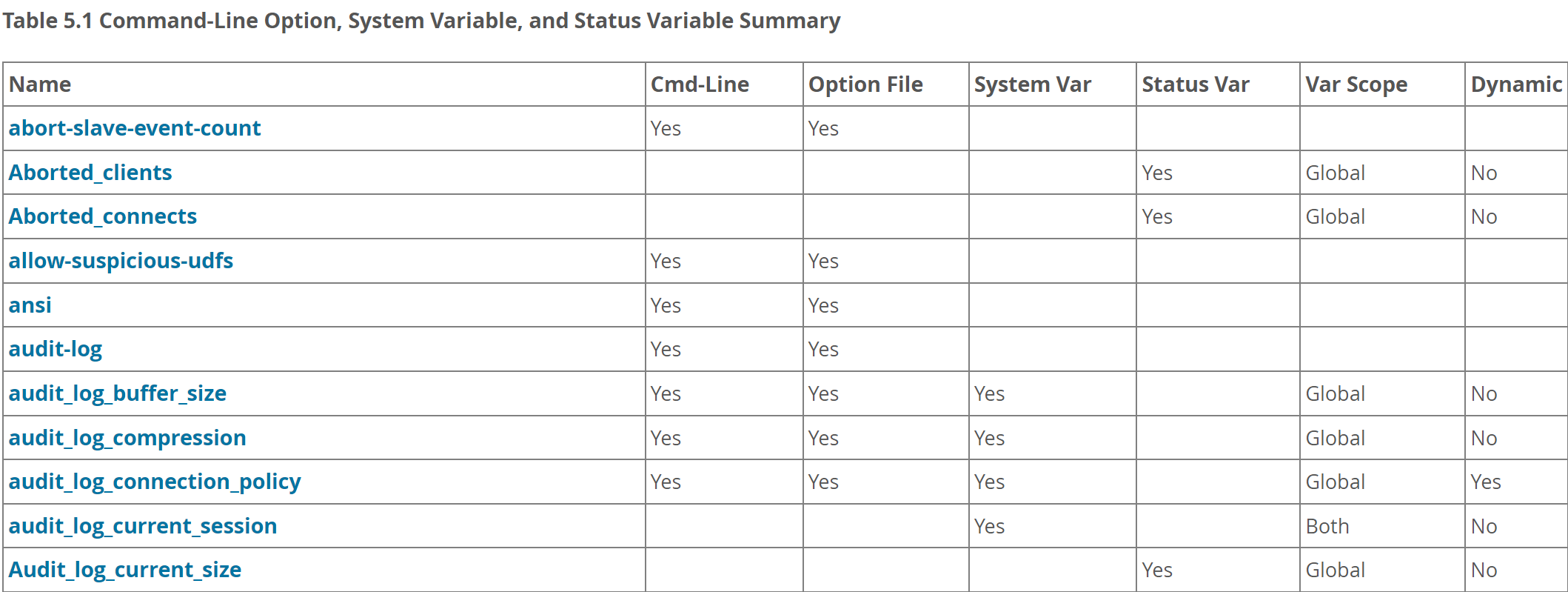
既是命令行cli、又是option选项、还是var变量。
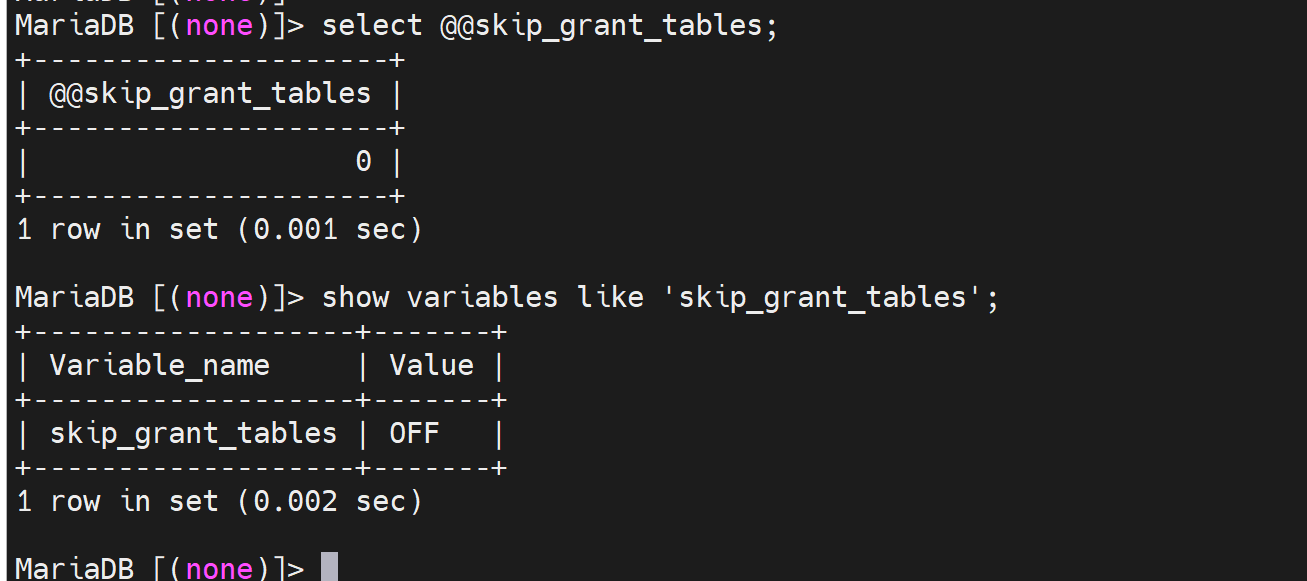
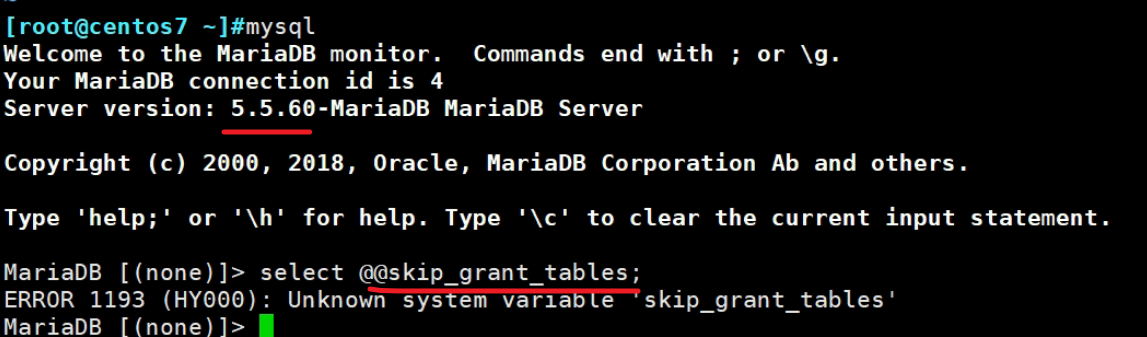
然后看下skip_grant_tables的这个跳过密码直接登入的东西

在mysql里就是cli、option、但不是var
在mariadb里既是option也是var 👇,同样这一点上文也说过了。

PS:--xxx就是option选项,不带--的就是var变量。
然后同样再次提醒一个写法规范性
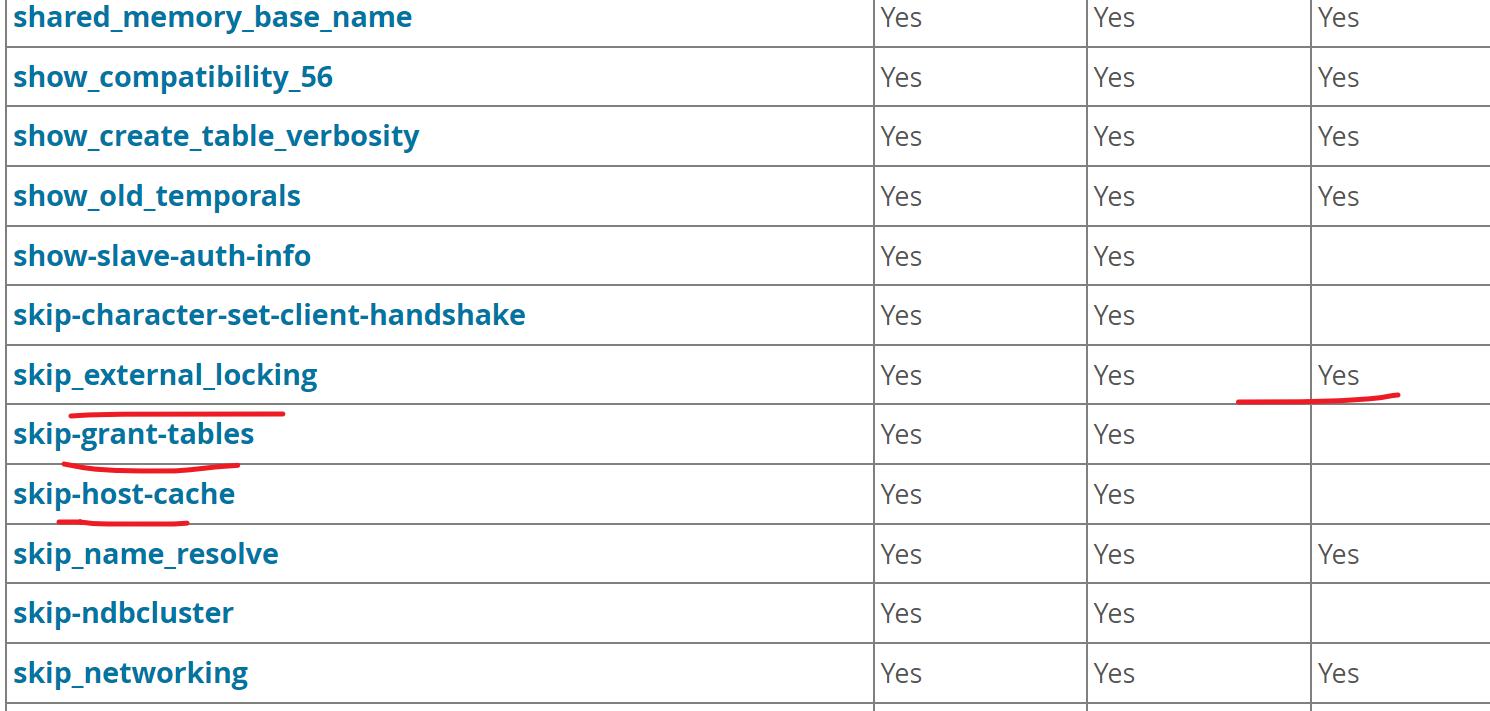
- 减号就是纯选项的写法
_下划线,就是只要是变量就用下划线了,有没有纯变量的
还真有👇

还有一个服务器状态变量
这个一般不用改的,就是用来看服务器的当前状态的
登录了两个 msql -uroot -pxxx,所以是两个thread线程。
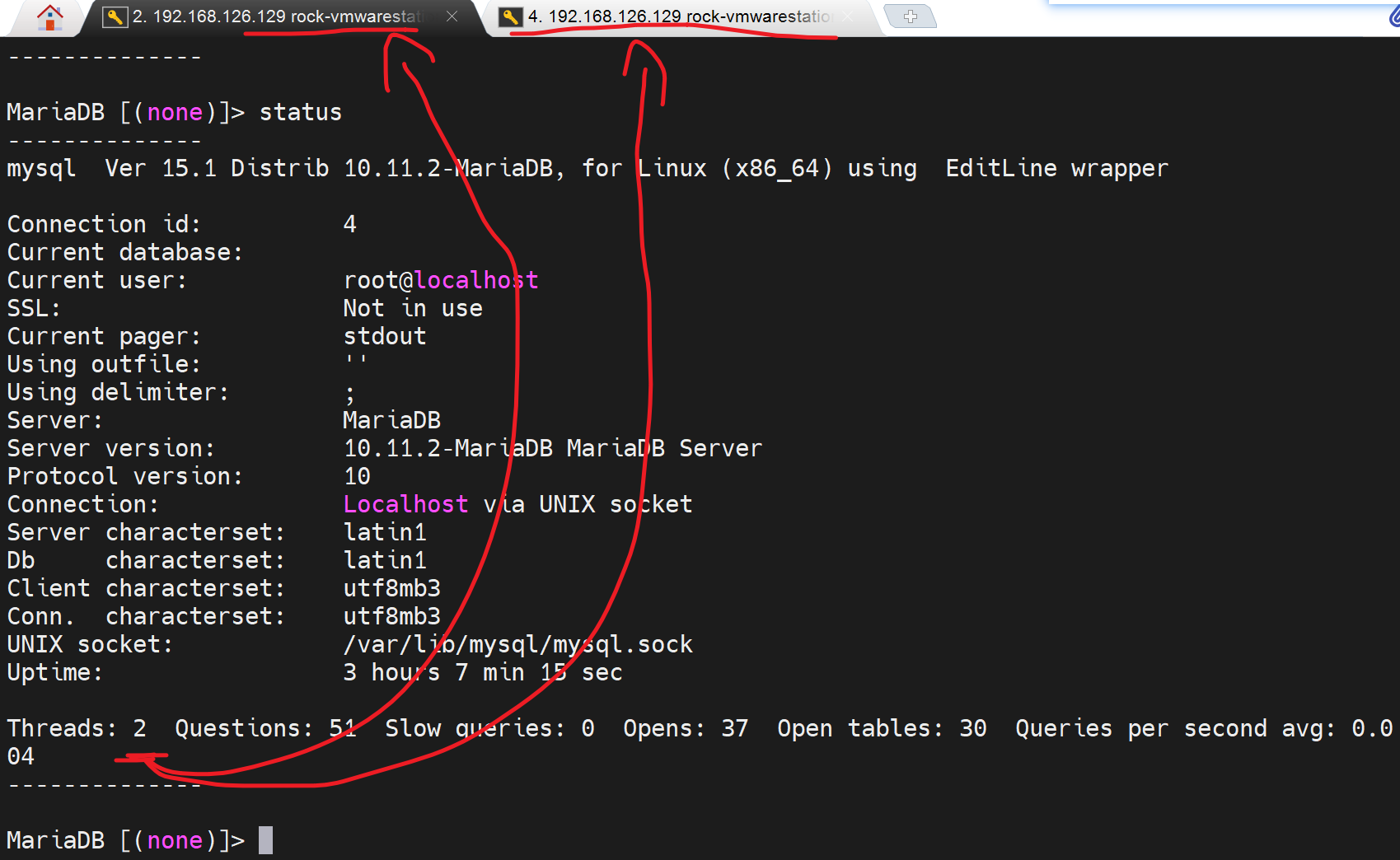
show status;或show status\G; 查看状态变量
show status like '%thread%'; 使用通配符看命中的变量
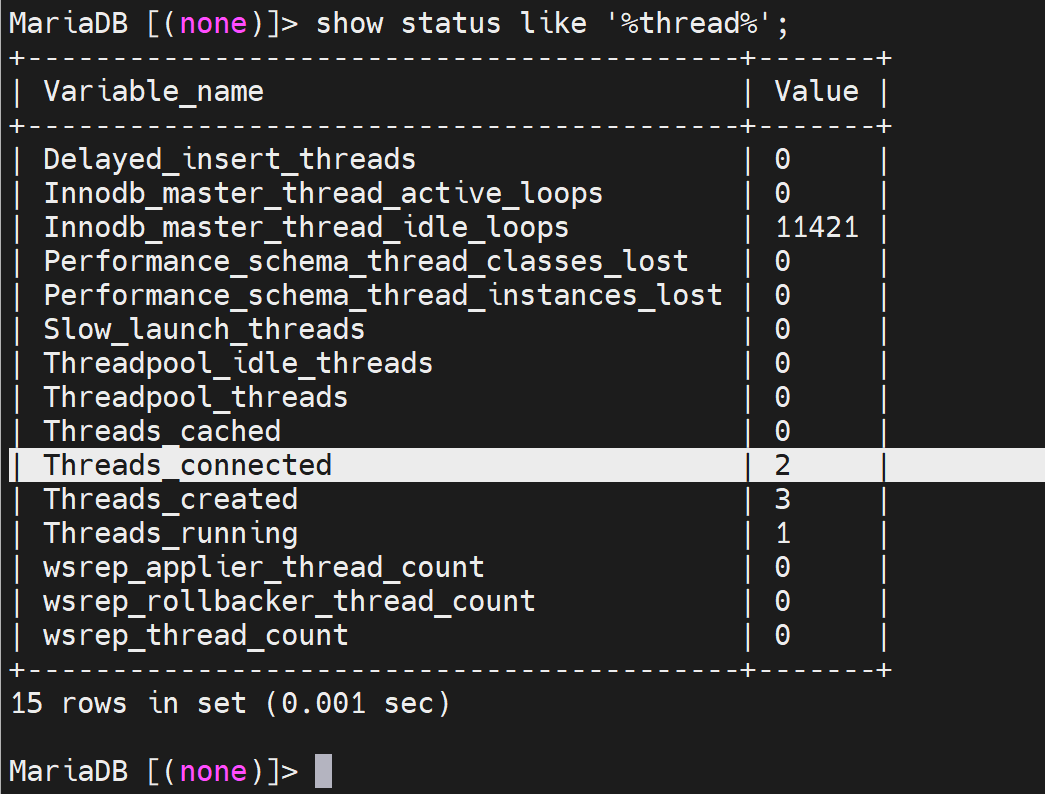
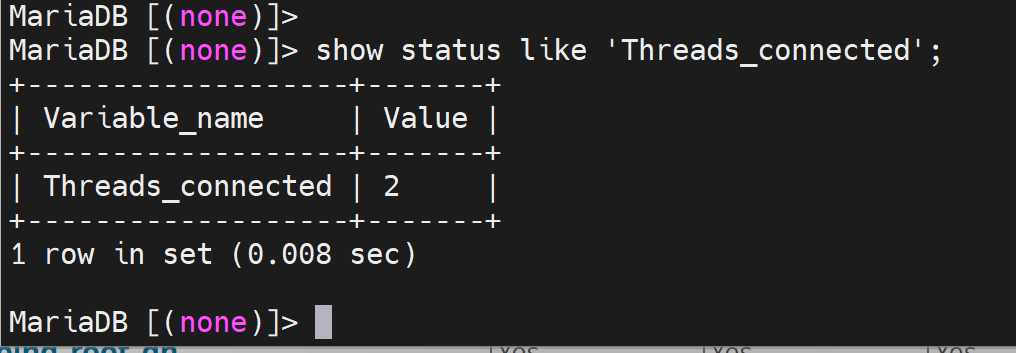
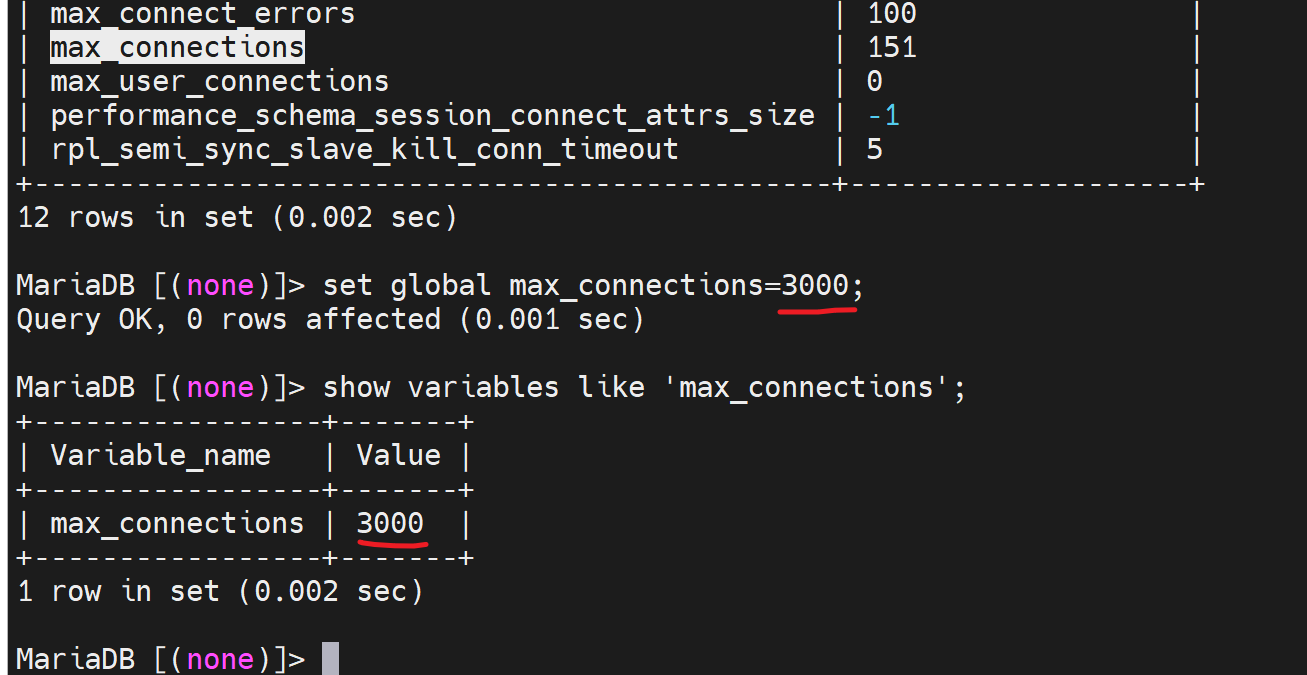
修改最大并发连接数
默认是151
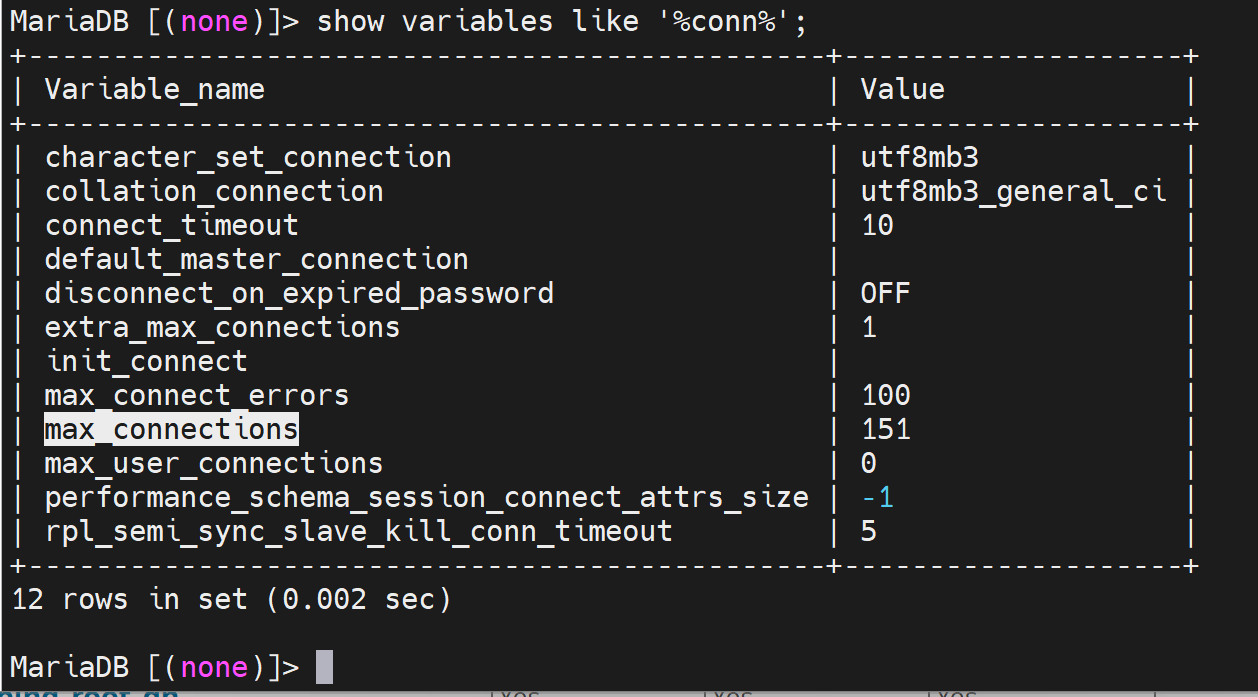
这是个全局变量,需要加上global参数;全局变量就是所有会话生效,意味着退出重进全局变量的值一样保留的住的;重启服务后失效。
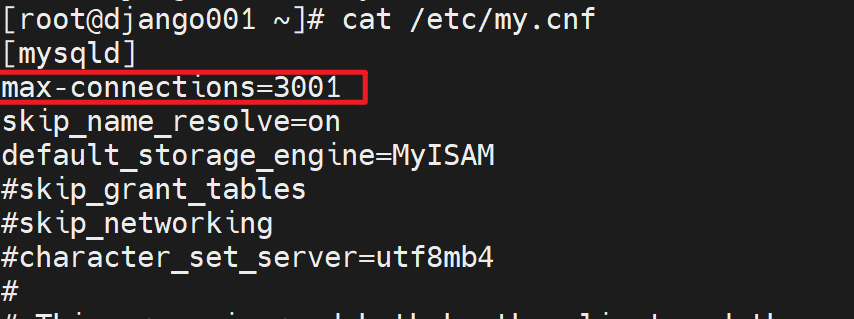
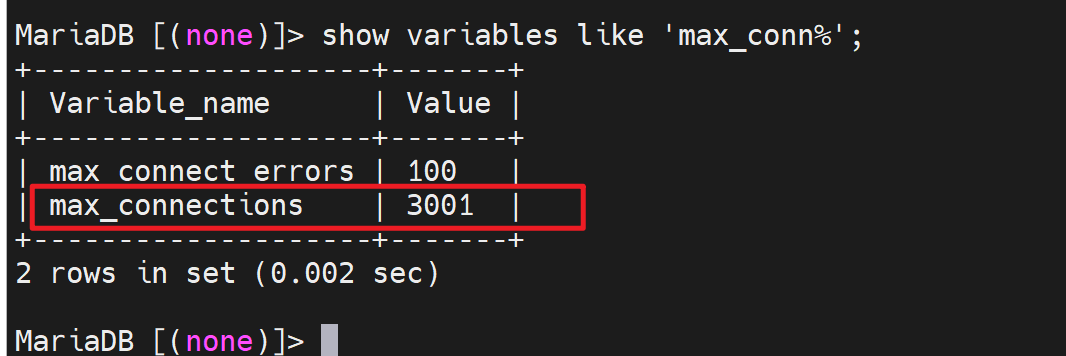
那么这个是不是选项呢,去写到配置文件里,重启服务,如果能重启OK,就是选项咯
如果做到限制为最多3-5个用户
思路,可以从系统层面做连接数的限制,
如果仅仅从mysql或mariadb本身来做👇
mysql的最大连接数1-100000
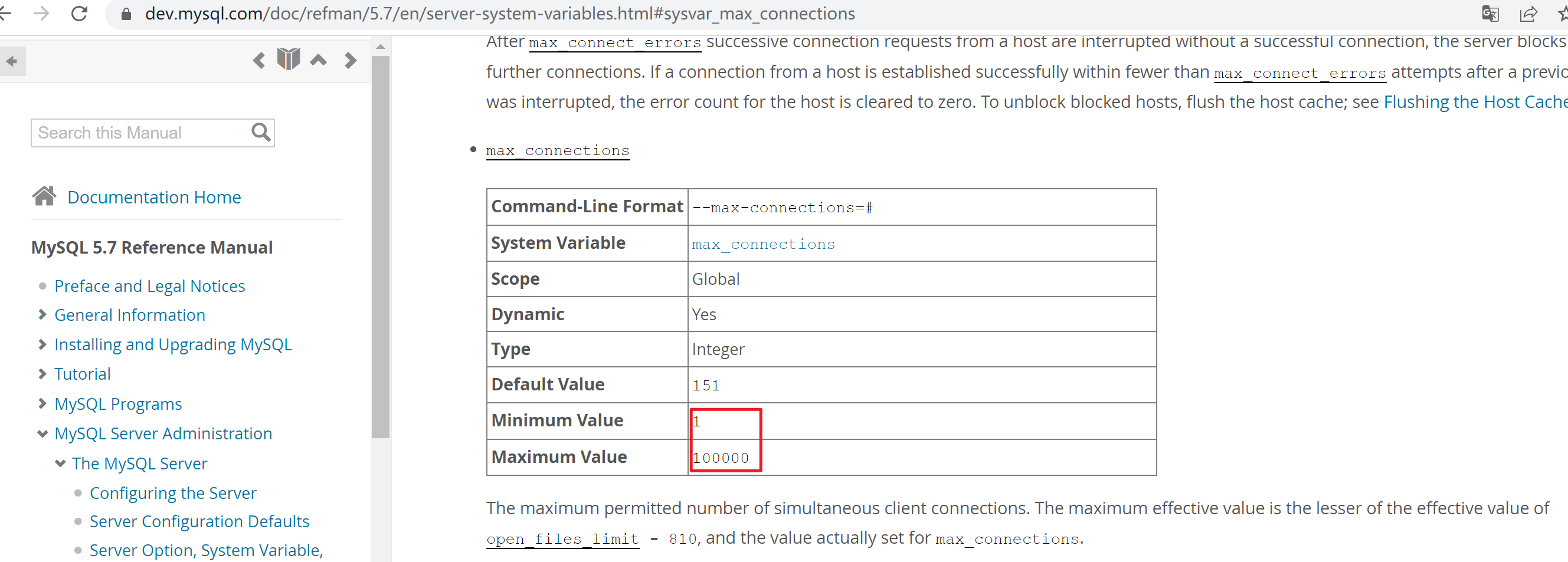
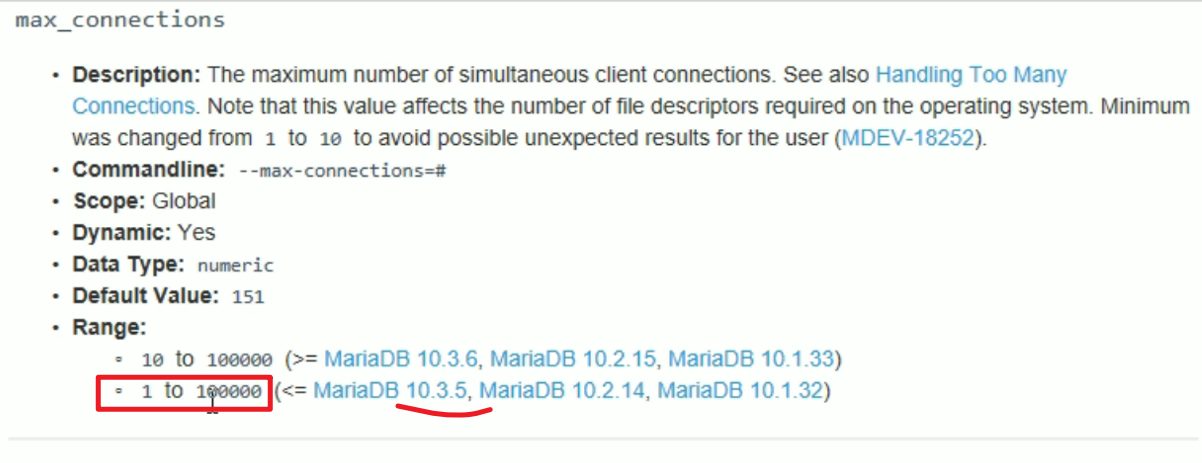
mariadb的最大连接数就有点,最小必须是10起步

然后根据视频上说的,版本小于10.3.5是可以做到1-100000的
关于并发:
数据库的并发一般是1-2k,1w就崩了可能
web的httpd也就是apache可以达到1W
nginx可以达到2W
考虑监控这件事,你要从这半百一千个变量中找到你需要的就行了,这么多肯定能满足你拉。
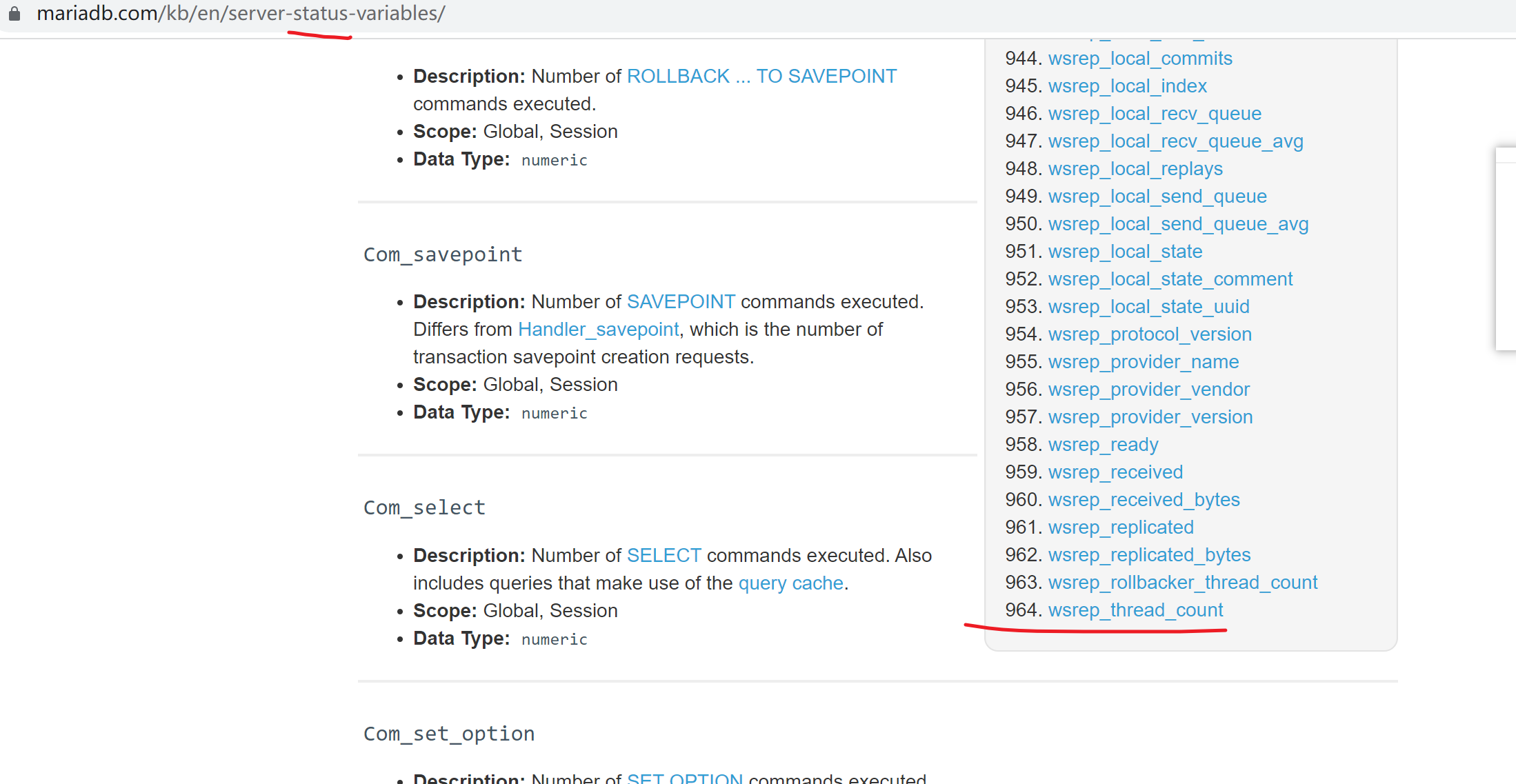
mariadb的状态变量有964个
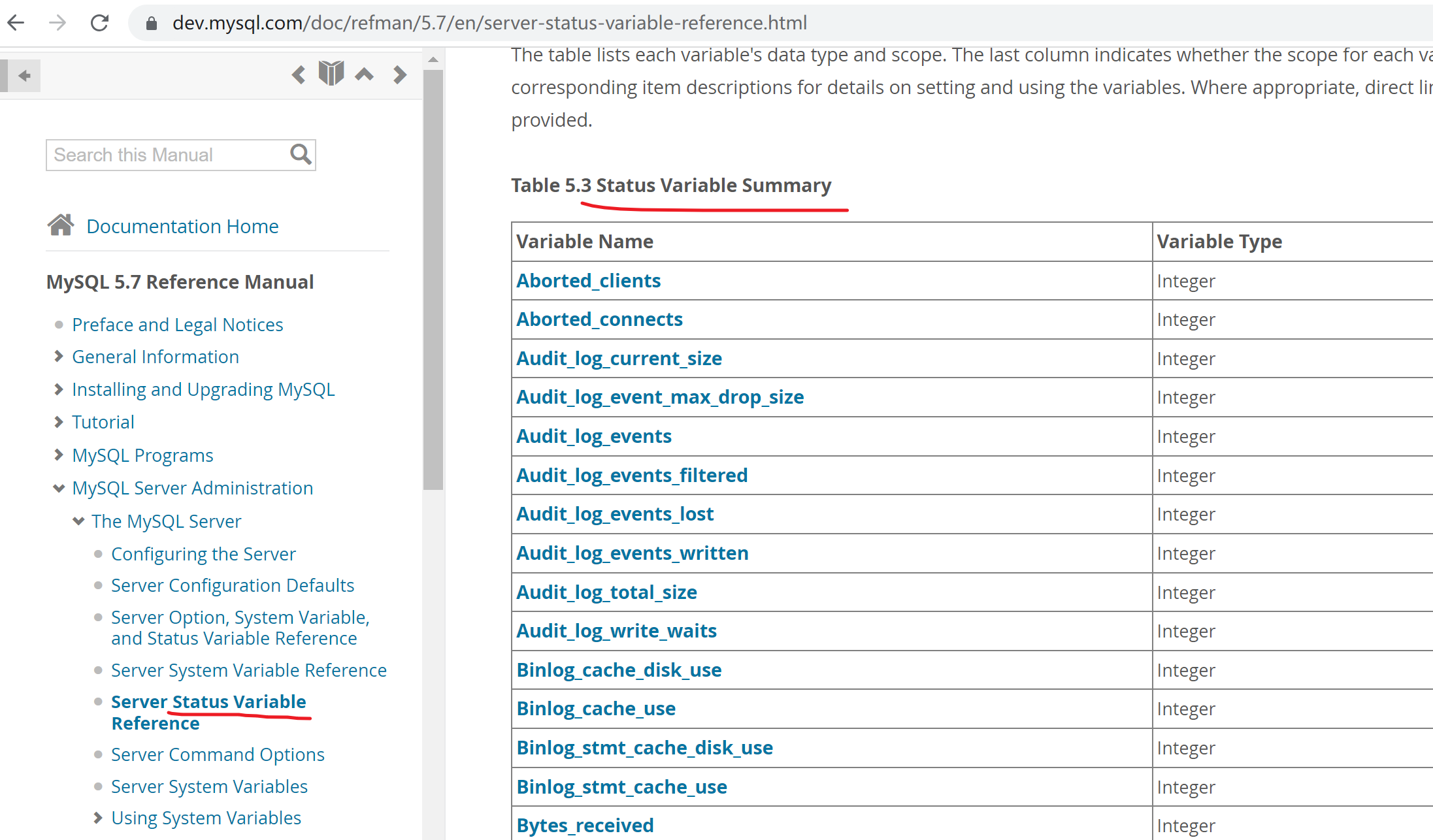
mysql的状态变量有568个
同样考虑一些需求要找数据库是否有自带的功能的时候,就去服务器选项和变量里找
https://mariadb.com/kb/en/full-list-of-mariadb-options-system-and-status-variables/
然后可以通过cli方式看选项的启用情况

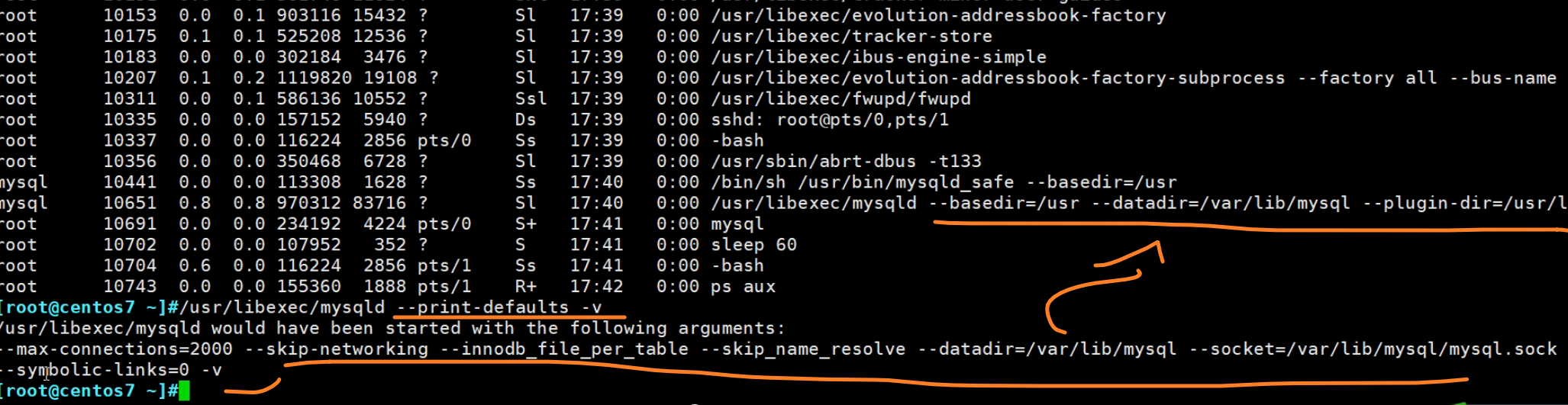
老的版本呢ps aux能看到一些选项,新版本都看不到了,其实看也看不全,要通过cli去看。
sql_mode,综合性变量

NO_AUTO_CREATE_USER:进展用grant命令创建密码为空的用户




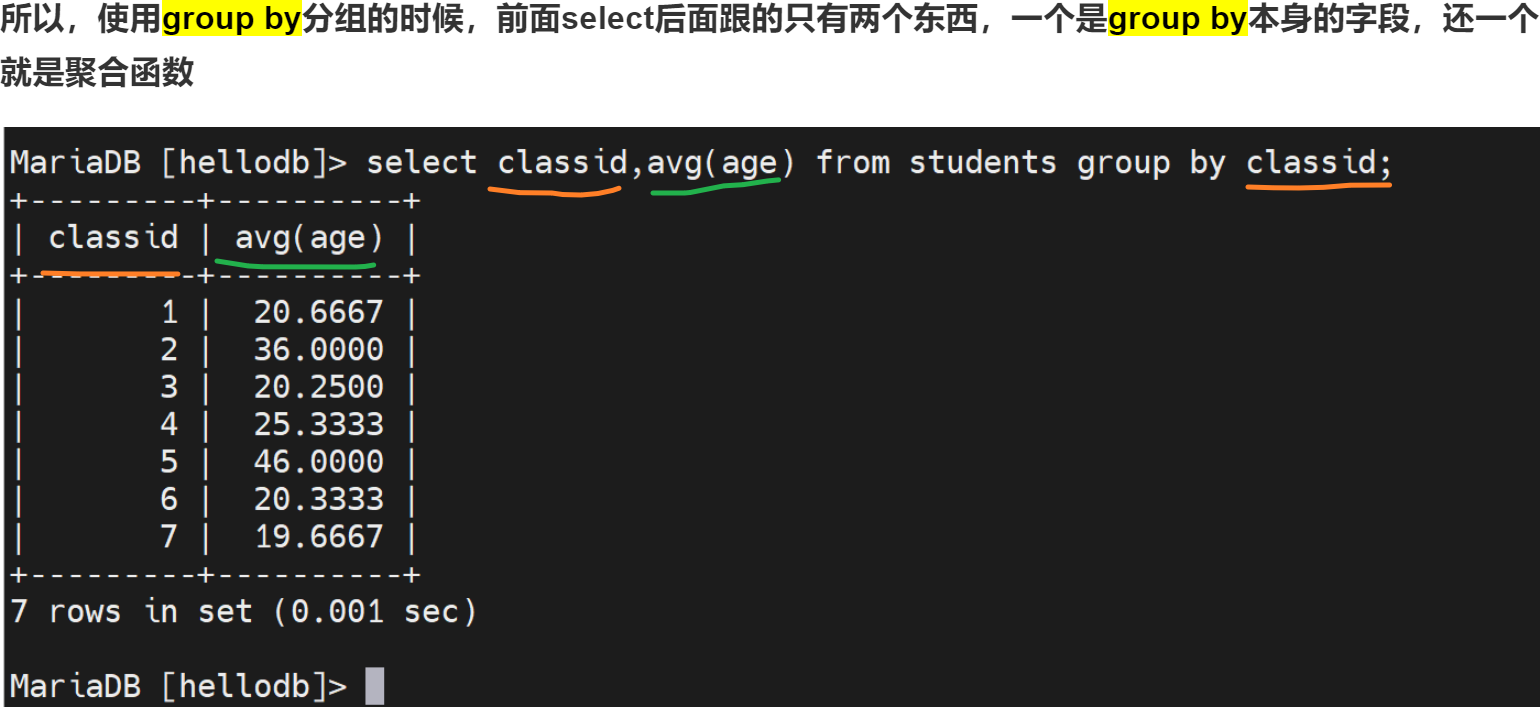
就是要规范命令:你用什么分组的,就要select里面写出来👆,ONLY_FULL_GROUP_BY就是这个意思,可能select出来的几个列,必须在group by里都出现才行呢。不过group by跟多个列是什么意思啊?可能就是先按名字后按日期进行排序比如👇,不过此时聚合函数就没啥意义了:
来个聚合函数有意义的
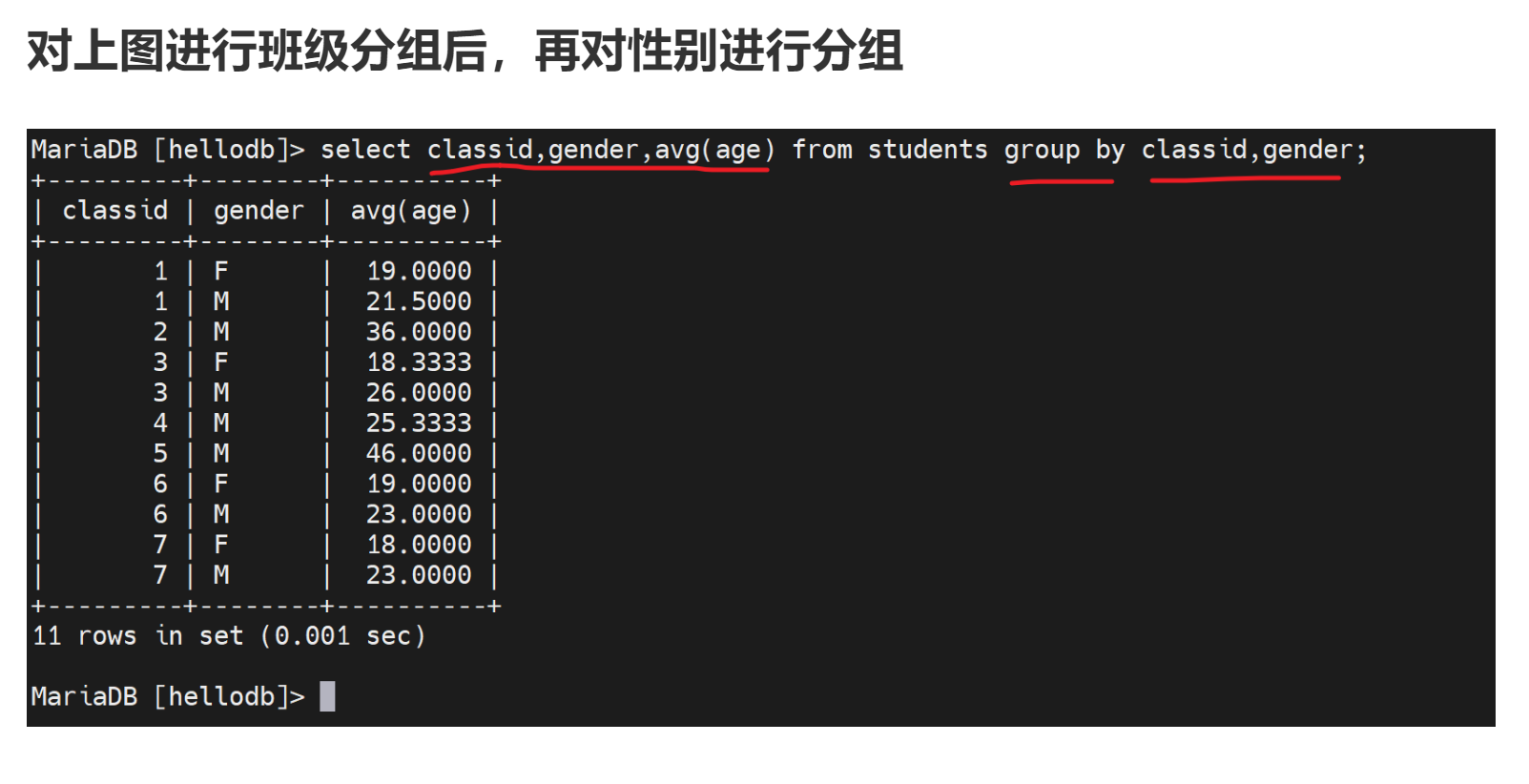
所以说select后面的几个,必须是在group by后面出现是有一定道理的。
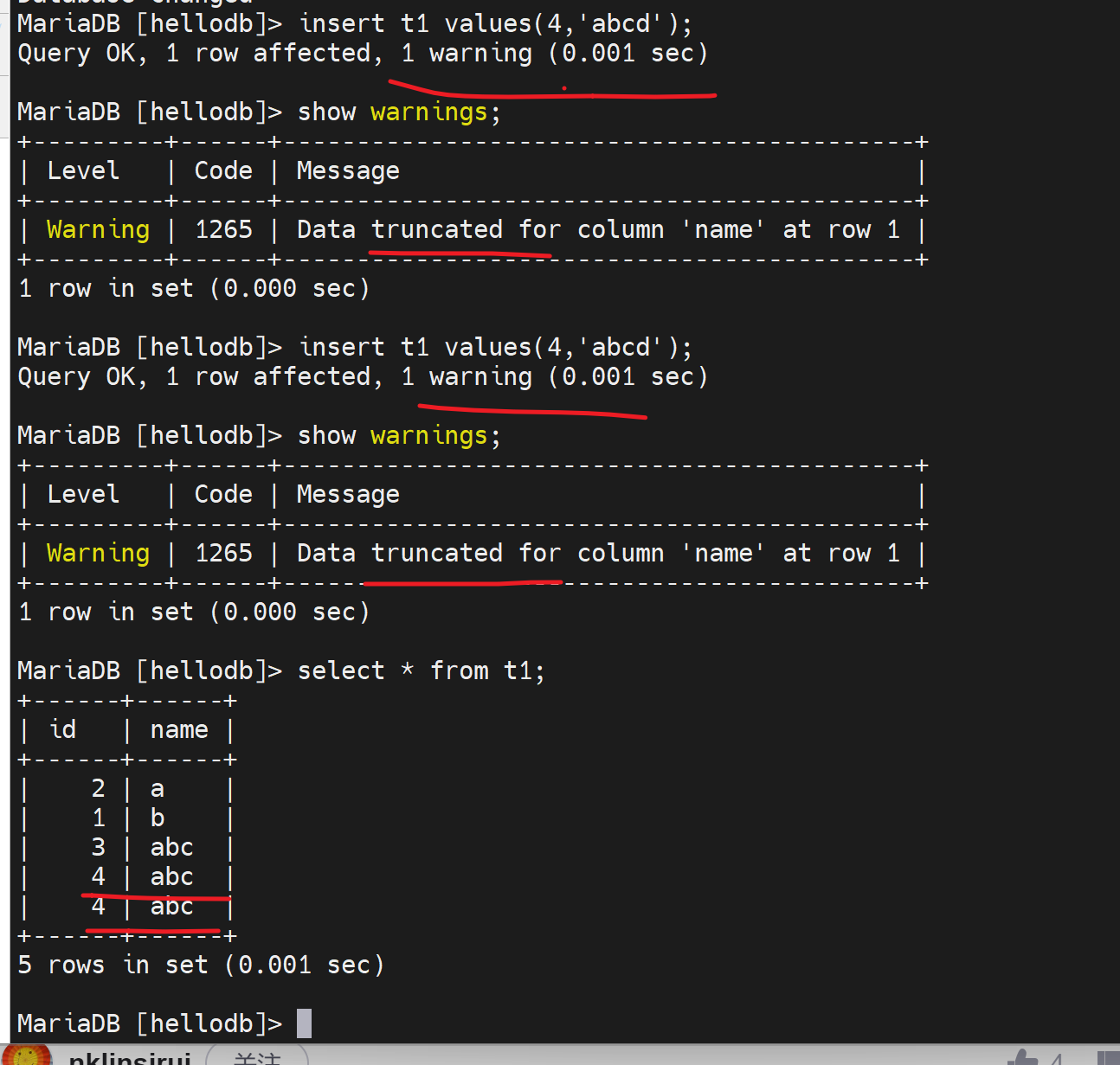
报错error可以在warnings里直接看到
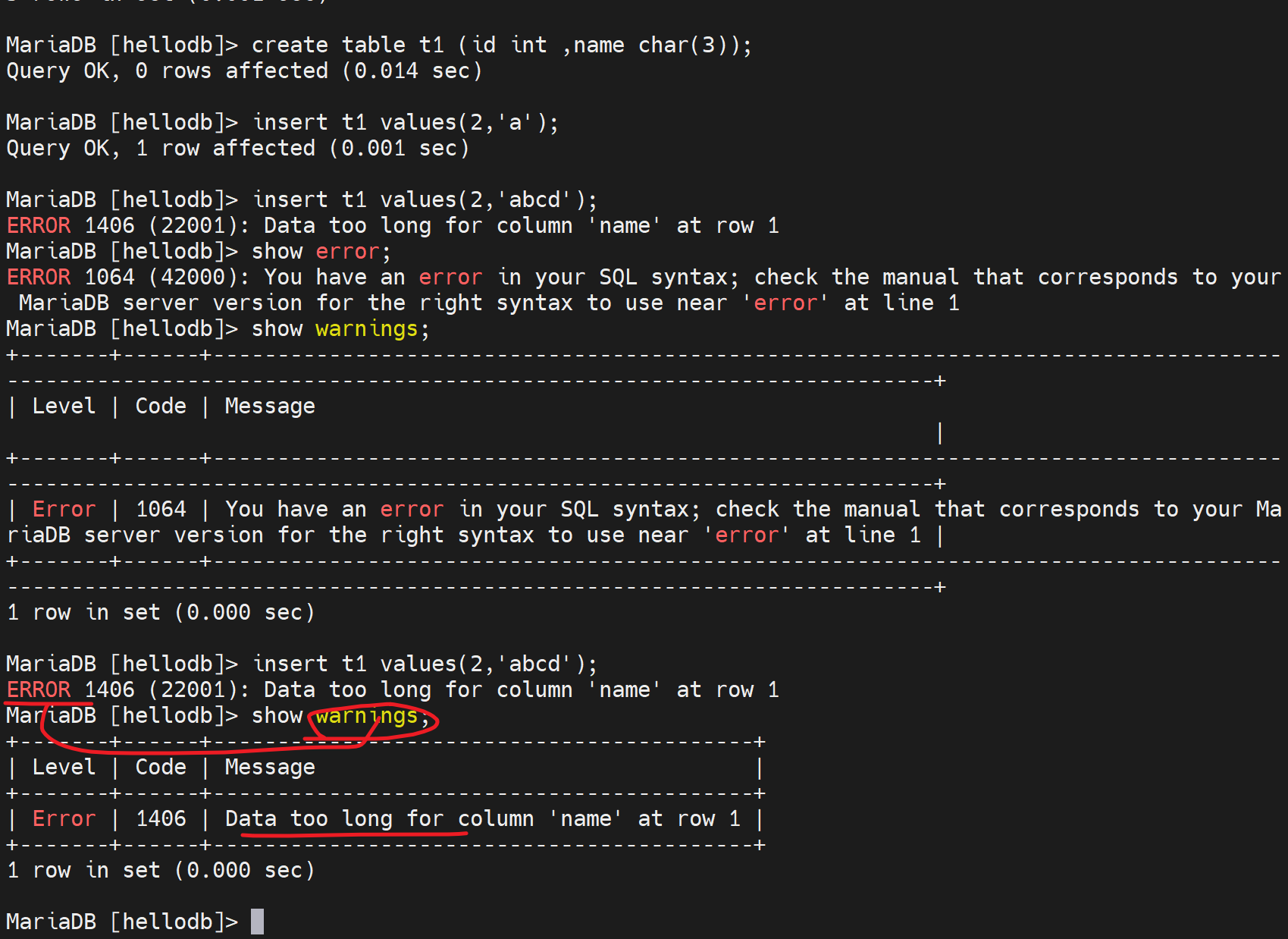
上图是error直接报错,就没写进去,而下图👇
同样有的版本出现warning个数提醒,但是没有详情,也可以这么看
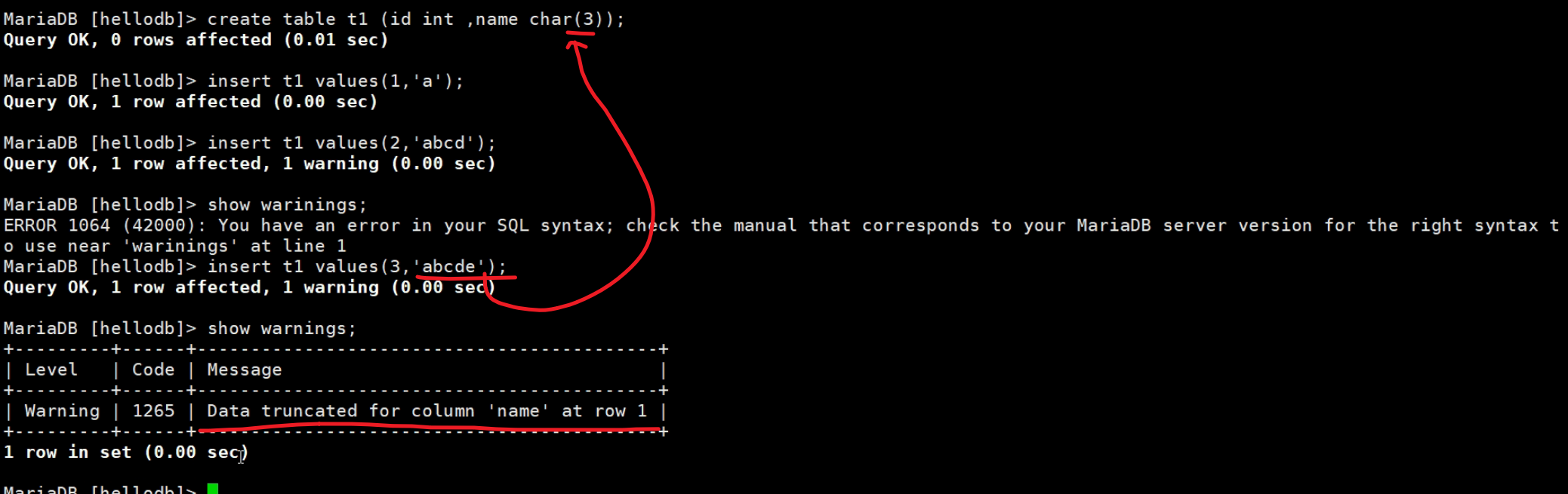
上图是warning,然后截断后写进去了的,
两张图 不同的行为,一个是写不进去,一个是截断后写进去了,其实就是sql_mode的配置区别。

这个就是traditional,其实是一个意思

拿掉就可以做 截断插入了
配置文件就是my.cnf里写
CLI就这样👇
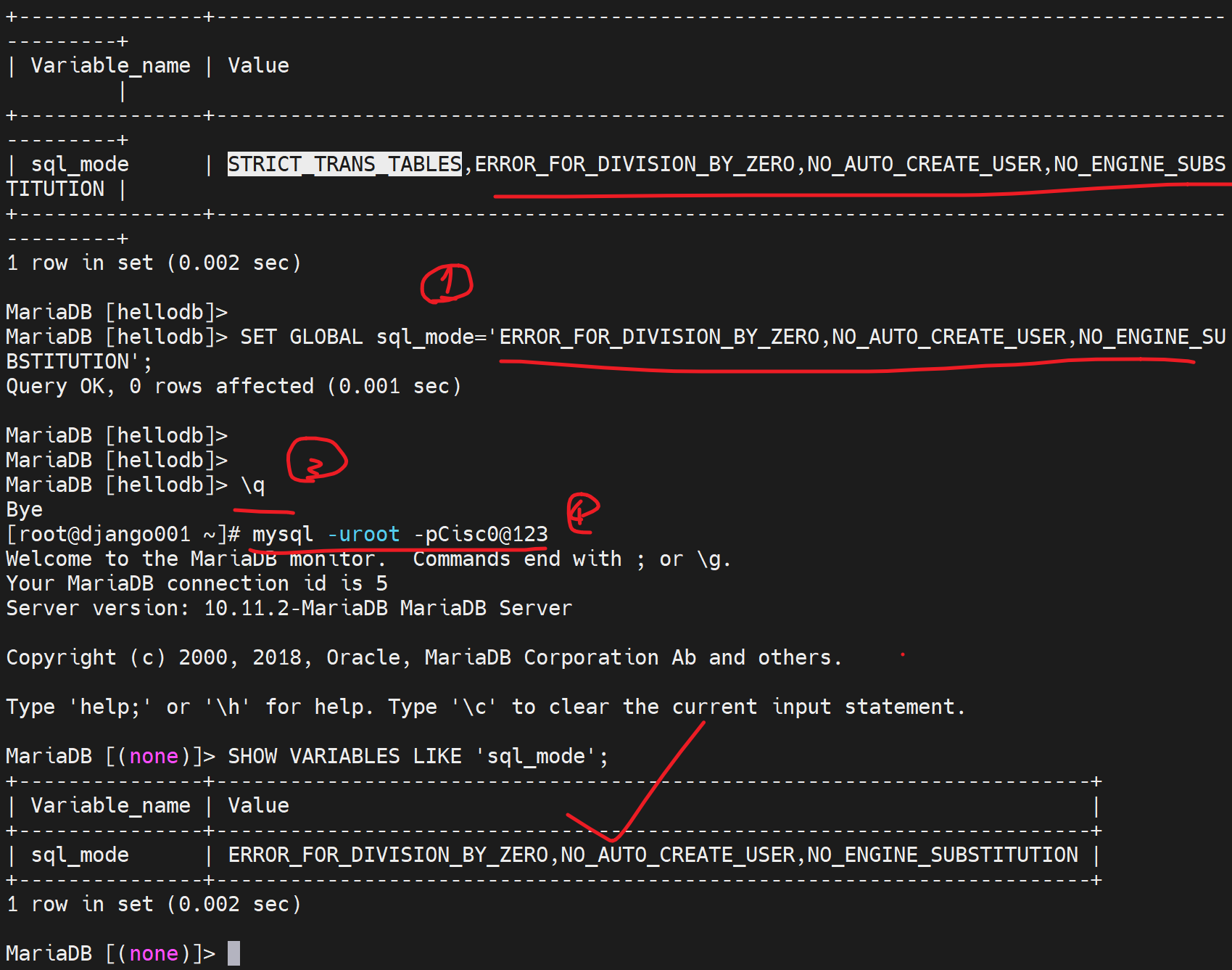
就可以实现截断了
两张图对照理解
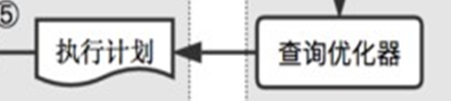 这里就是根据优化的结果,可以选择采用索引或 不采用索引。
这里就是根据优化的结果,可以选择采用索引或 不采用索引。
缓存的利用
必须前后两次的sql语言的哈希值一样才能利用上一次的缓存,也就是说大小写、空格、sql cli必须一摸一样才行。
缓存的不利用
有一些即时你启用了缓存,也用不上的情况:比如:动态的时间、日期、特意不使用缓存、还有什么临时表、共享模式的锁?

数据有几个query打头变量
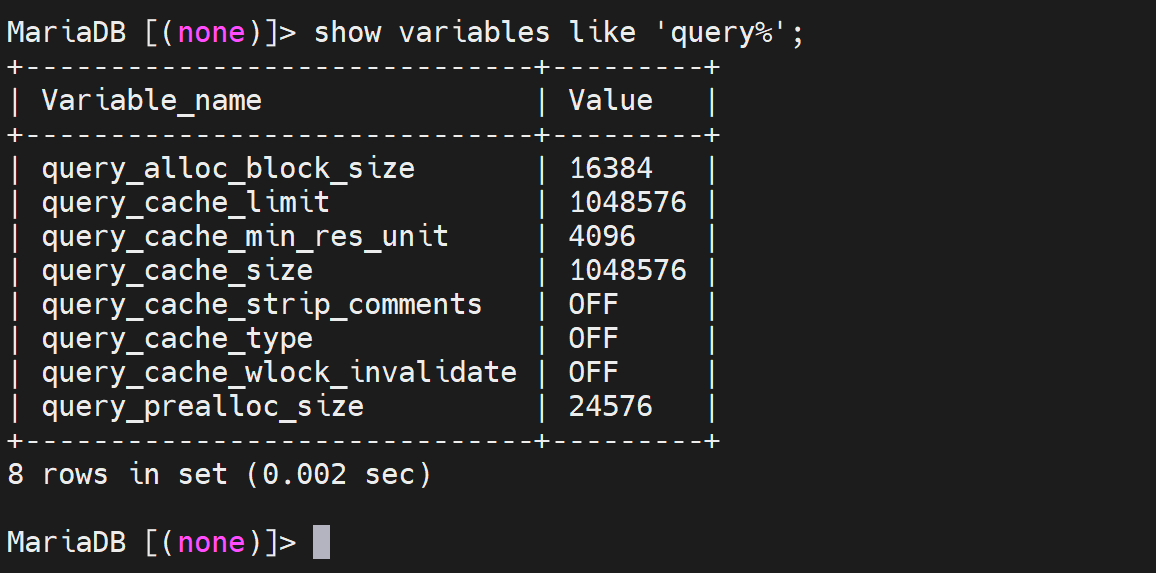
query_cache_type:是否开启缓存功能,取值为ON, OFF, DEMAND
ON就是开启缓存机制,但是要注意开启了以后,还得设置query_cache_size才行,有的版本size默认=0,就是开了也是白开。
query_cache_min_res_unit:查询缓存中内存块的最小分配单位,默认4k,较 小值会减少浪费,但会导致更频繁的内存分配操作,较大值会带来浪费,会导 致碎片过多,内存不足;
缓存4k、4k地分出去地,如果查询地数据量是5K,但是缓存的占用其实就是8K。或者是查1K,浪费3K。
query_cache_limit:单个查询结果能缓存的最大值,默认为1M,对于查询结 果过大而无法缓存的语句,建议使用SQL_NO_CACHE
单个sql cli捞出来的结果超过1M就无法利用缓存了,所以针对这个sql cli就直接使用SQL_NO_CACHE来告诉数据直接就不去尝试使用缓存。
query_cache_size:查询缓存总共可用的内存空间;单位字节,必须是1024 的整数倍,最小值40KB,低于此值有警报
如果这个值=0,就代表当前缓存未启用,而上图是1M和quer_cache_limit单个查询缓存一样了就,肯定 不好啦!常识就是觉的不好。
query_cache_wlock_invalidate:如果某表被其它的会话锁定,是否仍然可以 从查询缓存中返回结果,默认值为OFF,表示可以在表被其它会话锁定的场景 中继续从缓存返回数据;ON则表示不允许
别人正在查看一个数据,该数据被lock,此时其他人去访问就不给访问了,其实也可以让他访问缓存里的数据,实现方式就是将query_cache_wlock_invalidate=OFF就行了。不过此时由于他是访问的缓存,所以数值可能不正确。
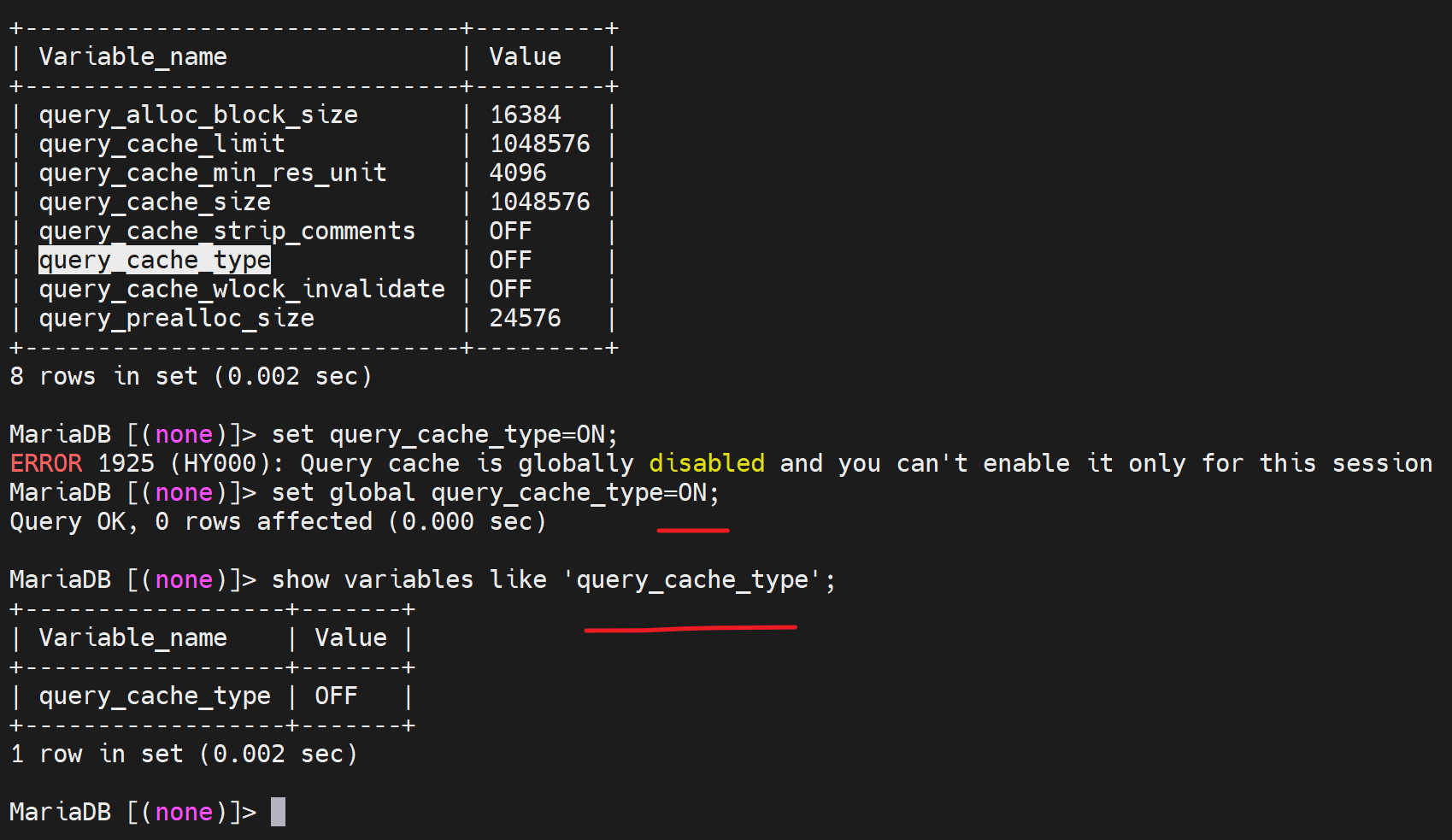
退出重进试试
果然
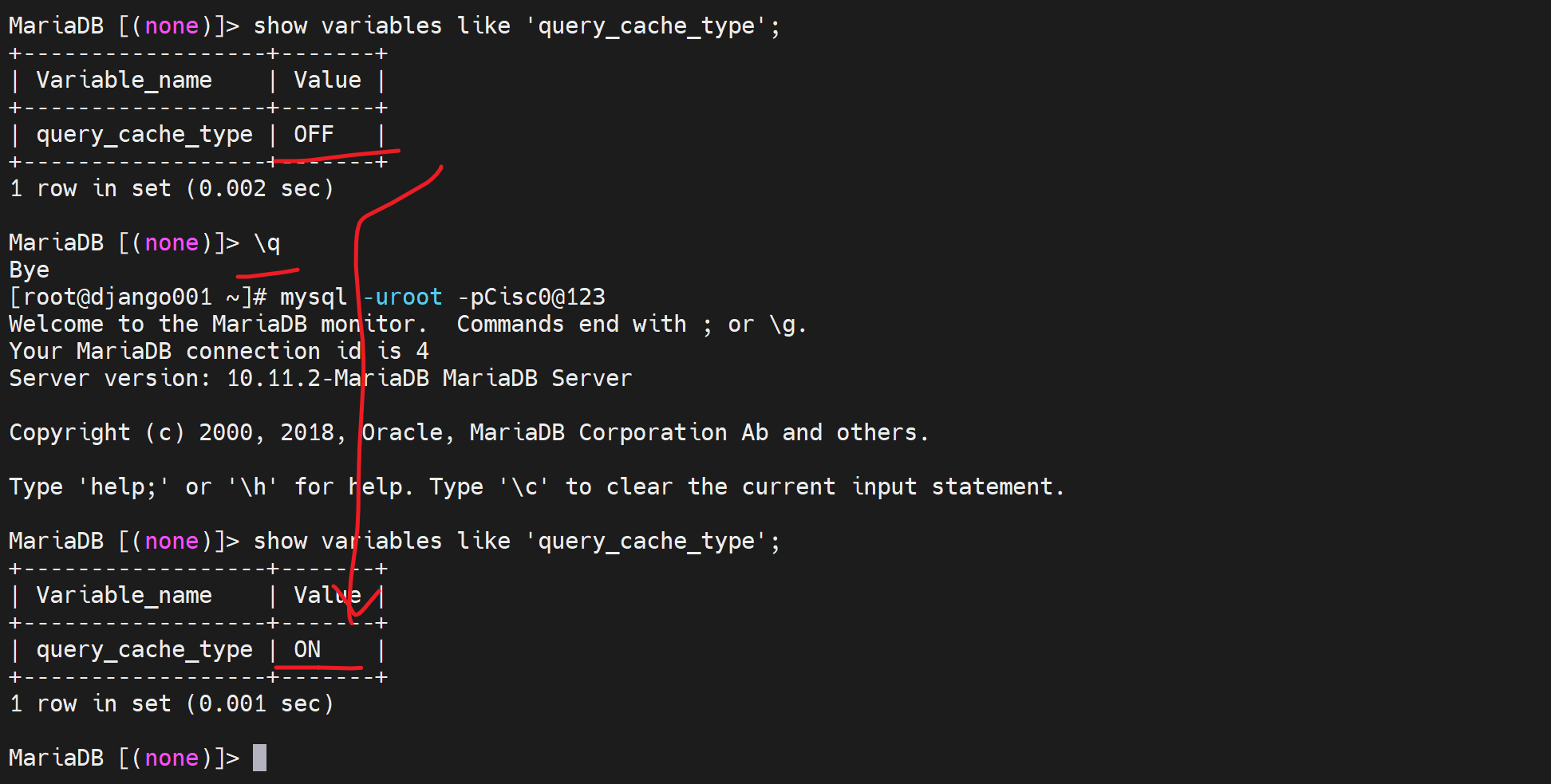
改size
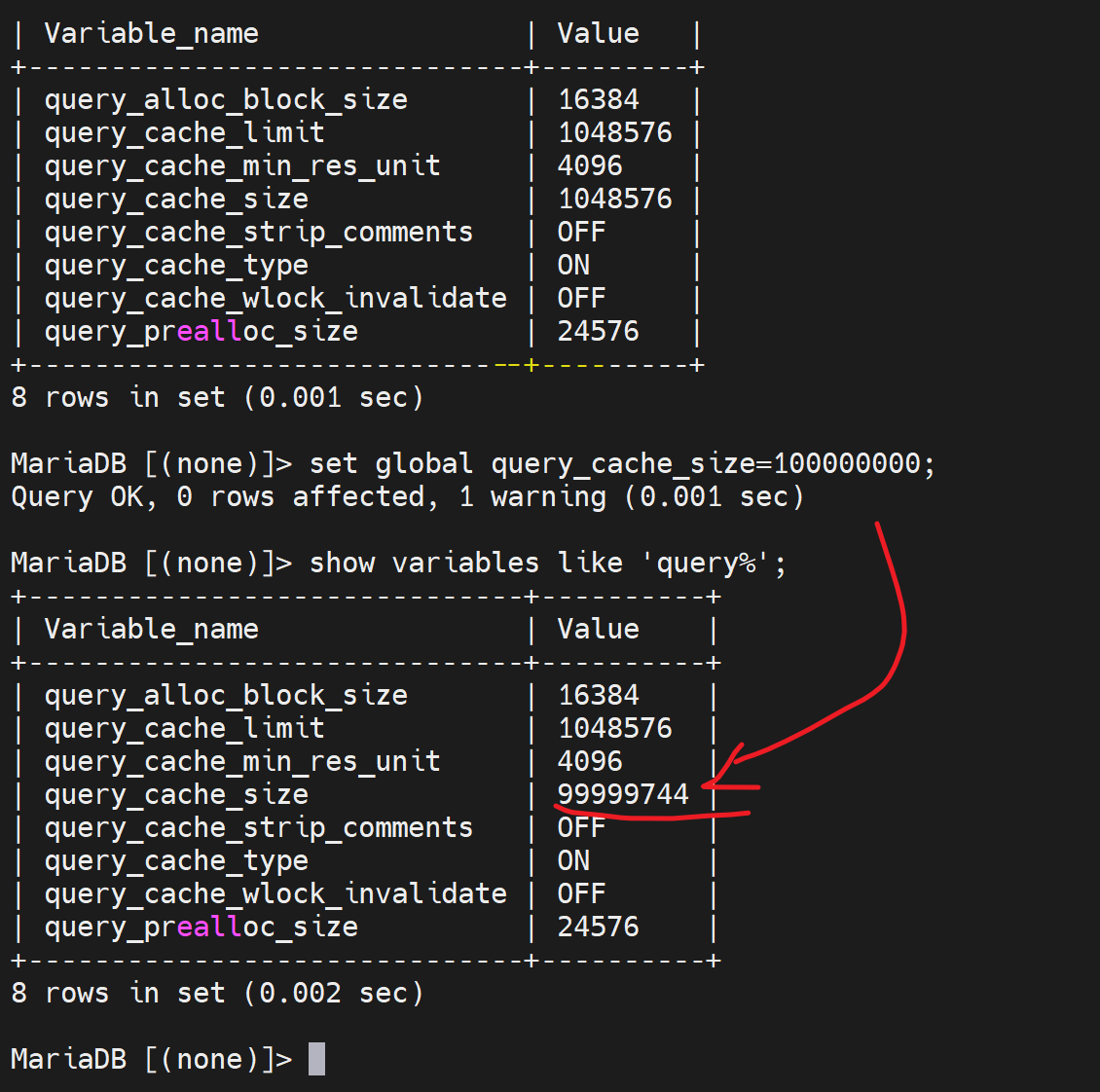
换种改发,写道配置文件里
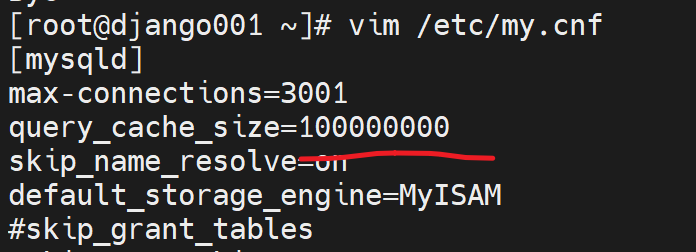
结果一样,还是
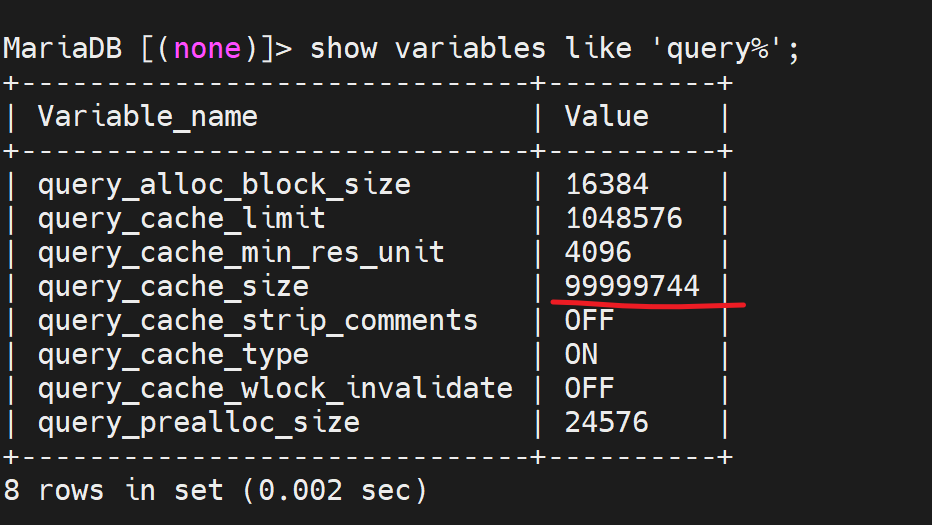
缓存的启用另一种方法-按需启用
就是使用cli里加sql_cache关键字,但是有前置条件的
query_cache_type的值为DEMAND或2时,查询缓存功能按需进行,显式指定SQL_CACHE的SELECT语句才会缓存;其它均不予缓存。
通过状态变量去看下缓存是否启用
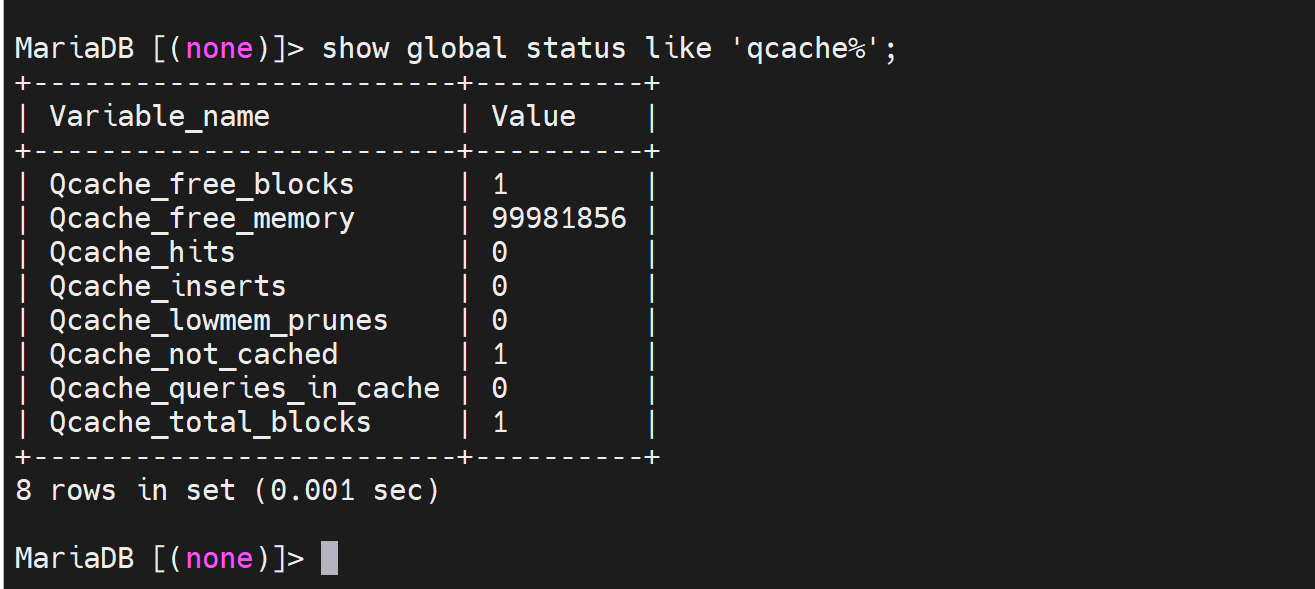
状态变量一般就是看的,不能改的。
Qcache_hits | 0 表示没有一次缓存命中
下图可见cache命中啦👇
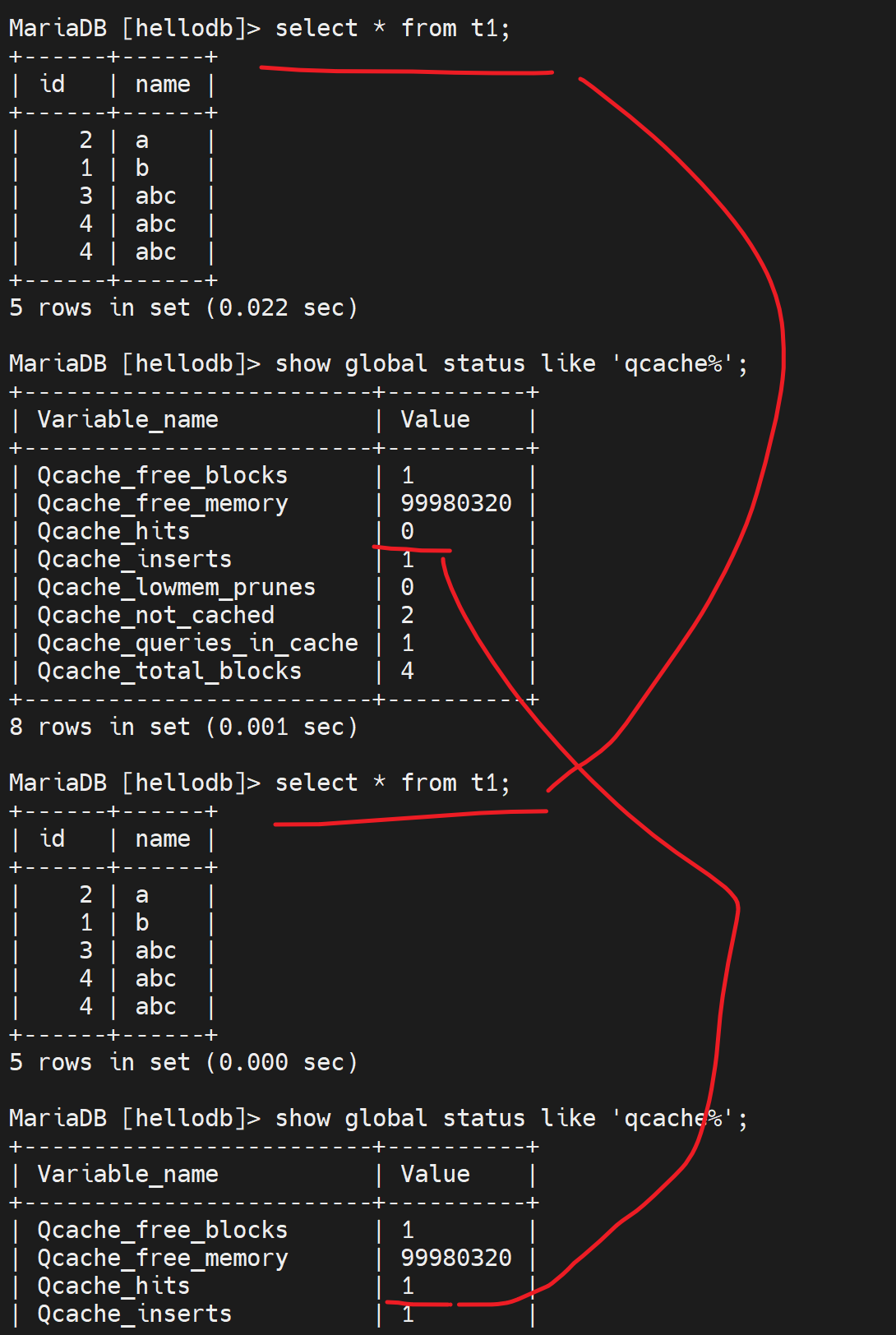
所以通过监控这个Qcache_hits可以知道缓存利用率高不高,命中次数越多缓存利用率越高。

内存free的和blocks块free的👆
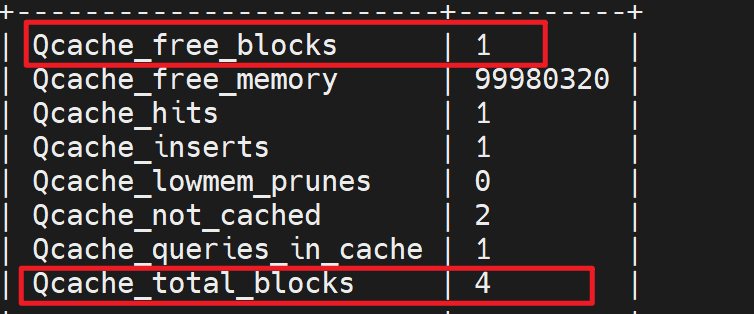
总块数是4块,空闲的就1块?啥意思 系统看情况自动分的?
Qcache_inserts | 1
这个就是未命中缓存的次数,
解释:本意是缓存插入次数,就是记录缓存的次数,既然是记录缓存,就是第一次查询没有缓存利用,只能从磁盘文件查询,自然就是未命中缓存的次数啦,然后cache inserts记录缓存
查询总次数就是 命中次数+未命中次数
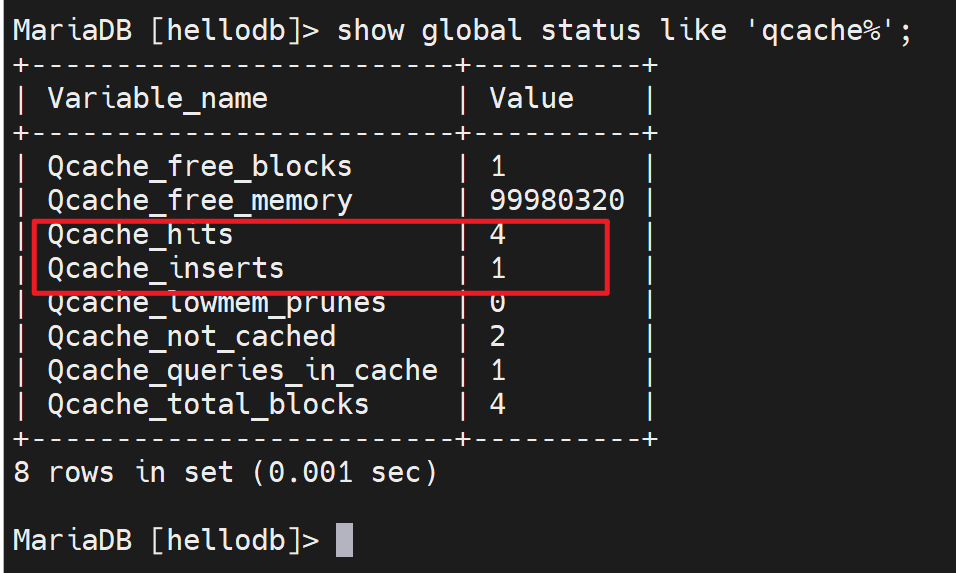
然后命中率就是 hits/(hits+inserts)
通过利用率可以判断你的业务适不适合用缓存,如果太低可能你的业务本身就不适合使用缓存。
注意些sql一定要注意大小写,而且是在web前端开放给用户比如网点查看商品的页面,用户其实是通过web去调db的,所以一定要将sql的cli统一大小写(多一个空格都不行),所以规范就是用SELECT * FROM XXX这种大写去做,才能利用好缓存。
| Qcache_lowmem_prunes | 0 |
Qcache_lowmem_prunes:记录因为内存不足而被移除出查询缓存的查询数
内存不够了分配的小,缓存空间不够了,只能利用LRU算法淘汰缓存中的记录。
如果这个值比较多,可以考虑加点内存
| Qcache_not_cached | 2 |
输入的sql cli 无法被缓存的次数
多敲几次select发现 total_blocks变大了
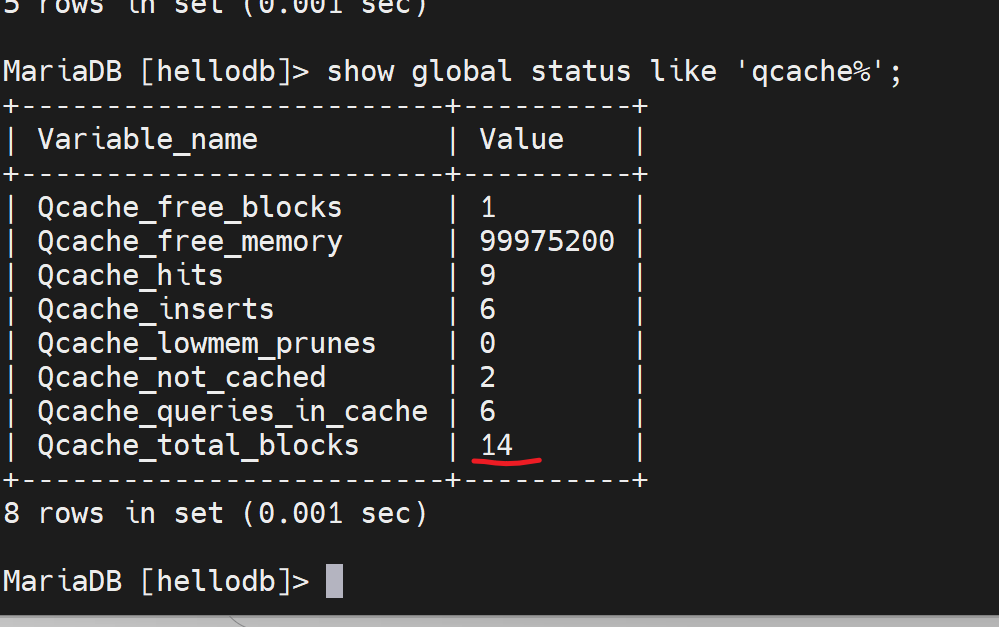
查 询 缓 存 中 内 存 块 的 最 小 分 配 单 位 query_cache_min_res_unit : (query_cache_size - Qcache_free_memory) / Qcache_queries_in_cache
查询缓存命中率 :Qcache_hits / ( Qcache_hits + Qcache_inserts ) * 100%
查询缓存内存使用率:(query_cache_size – qcache_free_memory) / query_cache_size * 100%
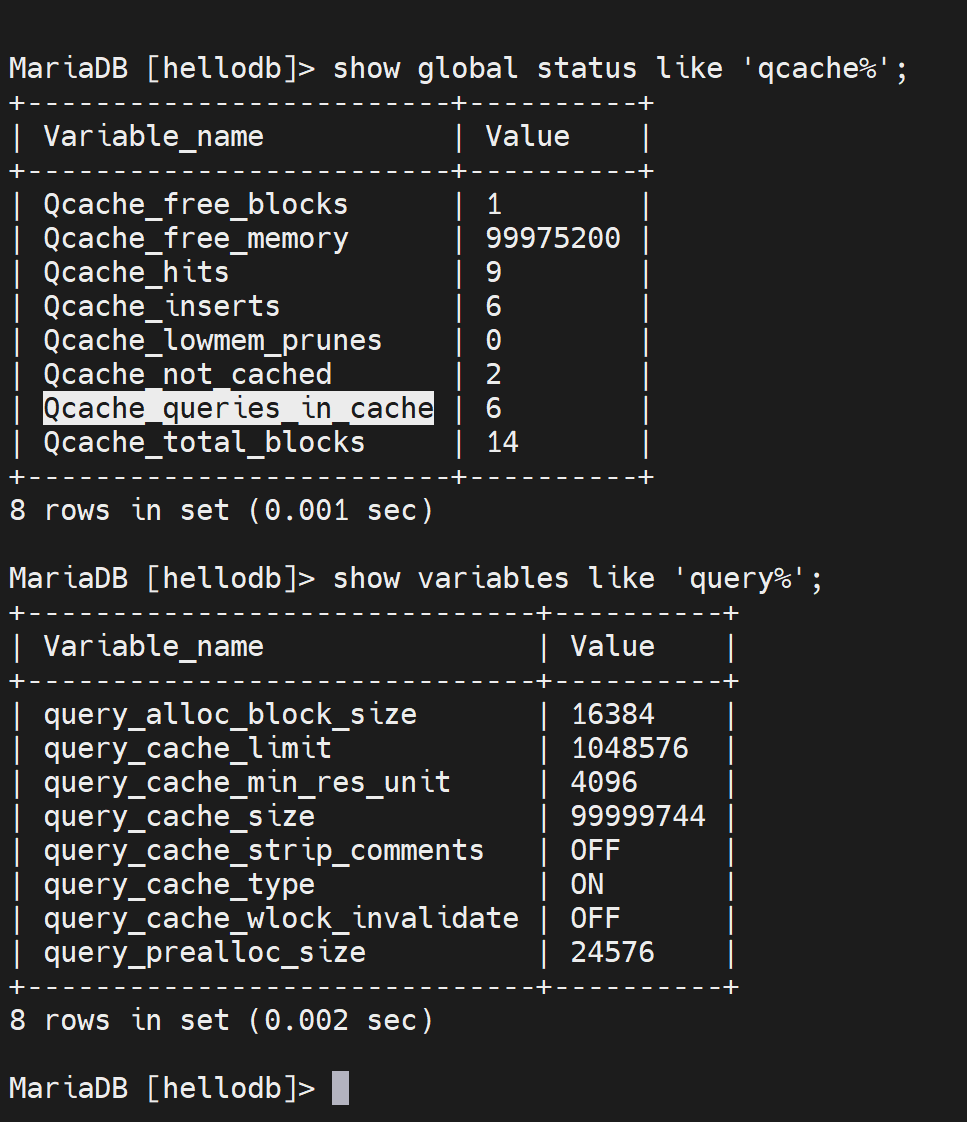
如果缓存利用率很高,可以考虑调大一点。
优化查询缓存
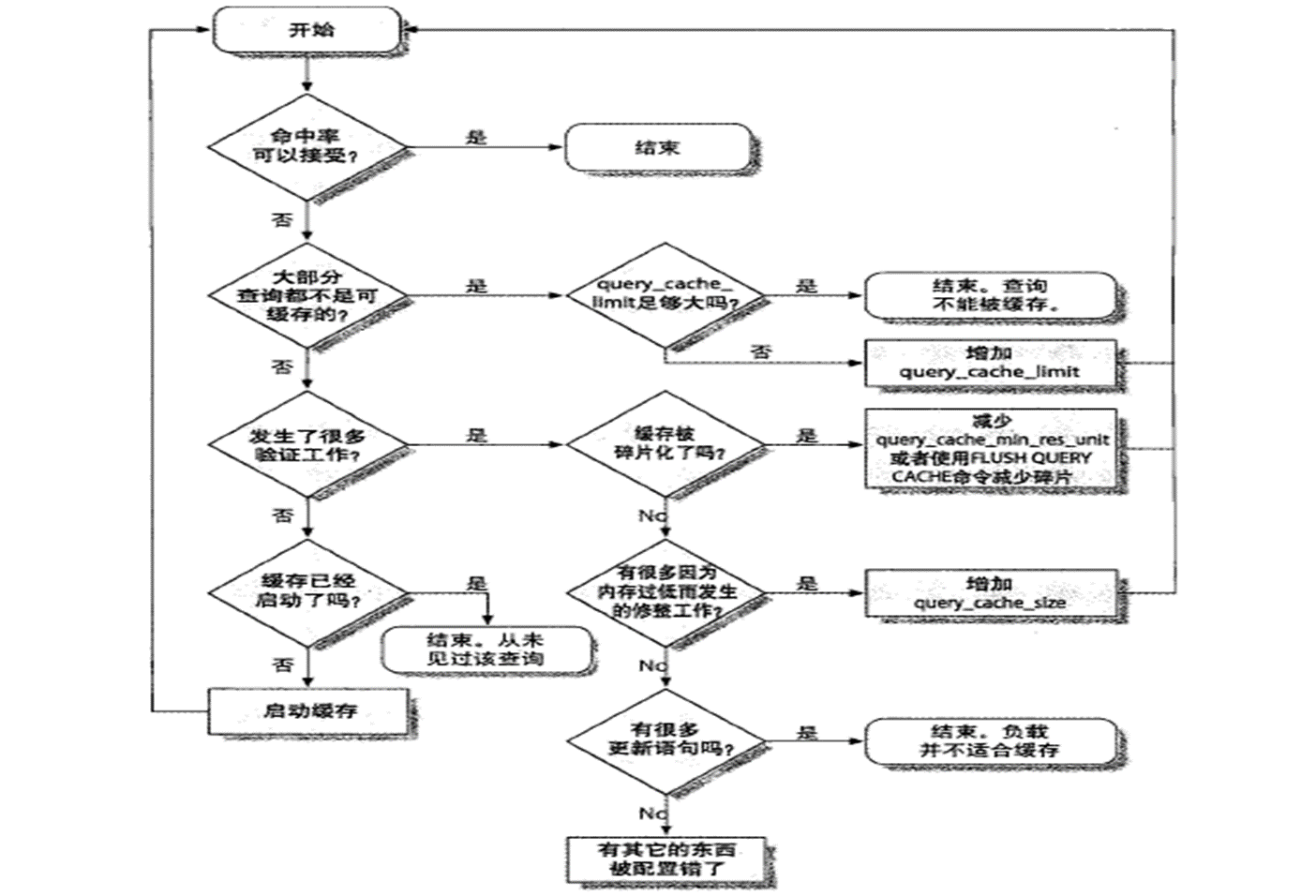
“发生了很多验证工作”:
 验证就是 查询的结果这个,数据频繁的发生了变化,一旦变化,就要验证缓存是否有效,肯定啊,缓存里的结果都不对,肯定要重新查拉。
验证就是 查询的结果这个,数据频繁的发生了变化,一旦变化,就要验证缓存是否有效,肯定啊,缓存里的结果都不对,肯定要重新查拉。
所以缓存生效,①sql cli是否有hash②有hash也不行啊,本身缓存的sql cli捞的结果都频繁变化,db也来不及刷新了吧,我在想。。算了我不想了,按他的来。
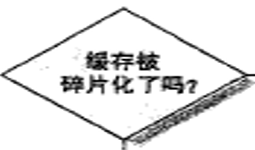 就是设置的单位4k比如,太大了,碎片空间多,就减少。
就是设置的单位4k比如,太大了,碎片空间多,就减少。
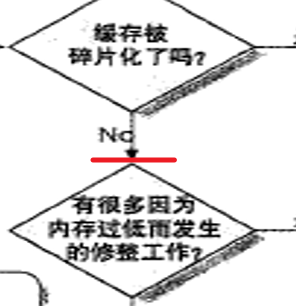 没有碎片化,就看看是不是内存过低导致。
没有碎片化,就看看是不是内存过低导致。