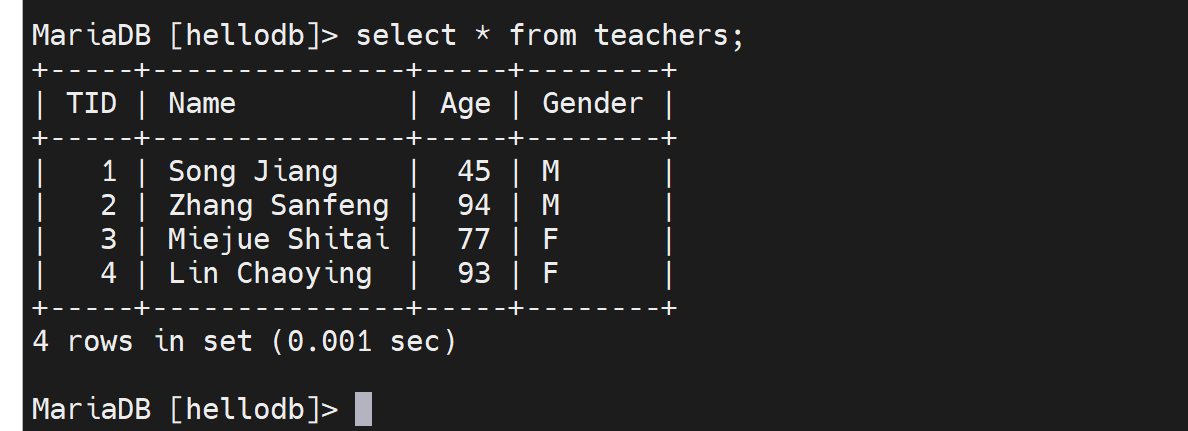
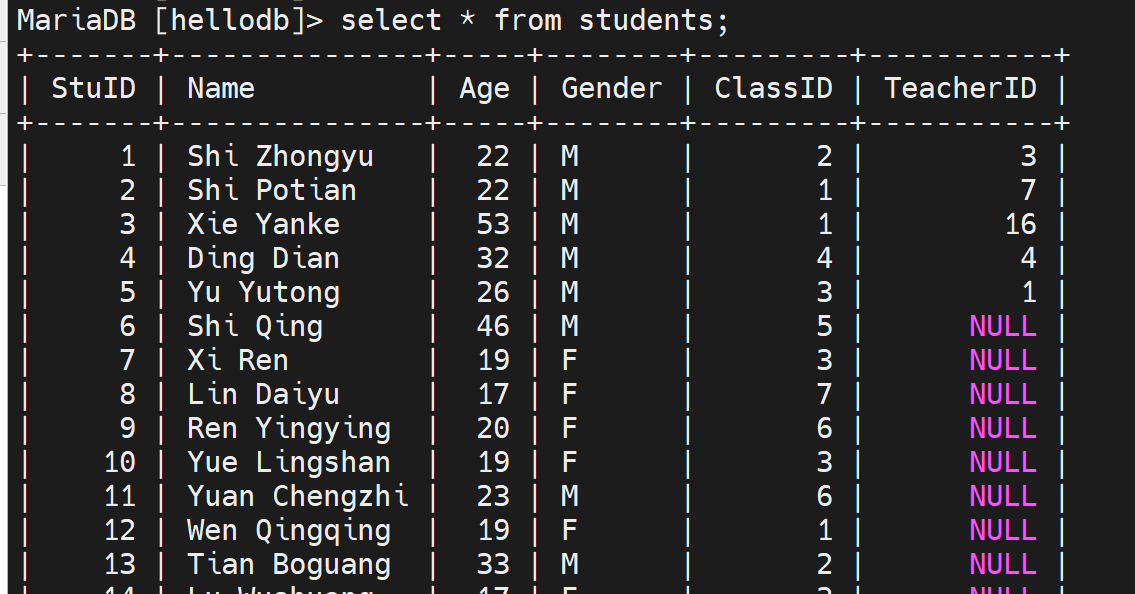
第3节. 事务特性和四种隔离级别
事务的概念
事务Transactions:一组原子性的SQL语句,或一个独立工作单元 事务日志:记录事务信息,实现undo,redo等故障恢复功能 ACID特性: A:atomicity原子性;整个事务中的所有操作要么全部成功执行,要么全部 失败后回滚
C:consistency一致性;数据库总是从一个一致性状态转换为另一个一致性 状态
I:Isolation隔离性;一个事务所做出的操作在提交之前,是不能为其它事务 所见;隔离有多种隔离级别,实现并发。
隔离有隔离级别:一个修改事务过程中,另一个事务能否看到是取决于隔离级别的,比如你你修改1000未1100,别人不一定能看到1100。
一个事务没有结束,中间过程的数据就叫做“脏数据”。
D:durability持久性;一旦事务提交,其所做的修改会永久保存于数据库中
撤销叫做回滚,commit就确定了就永久保存在数据库中了。
事务日志类似于ext3的文件系统日志
1、100变成200,200变成300,然后还没来得及commit就停电了
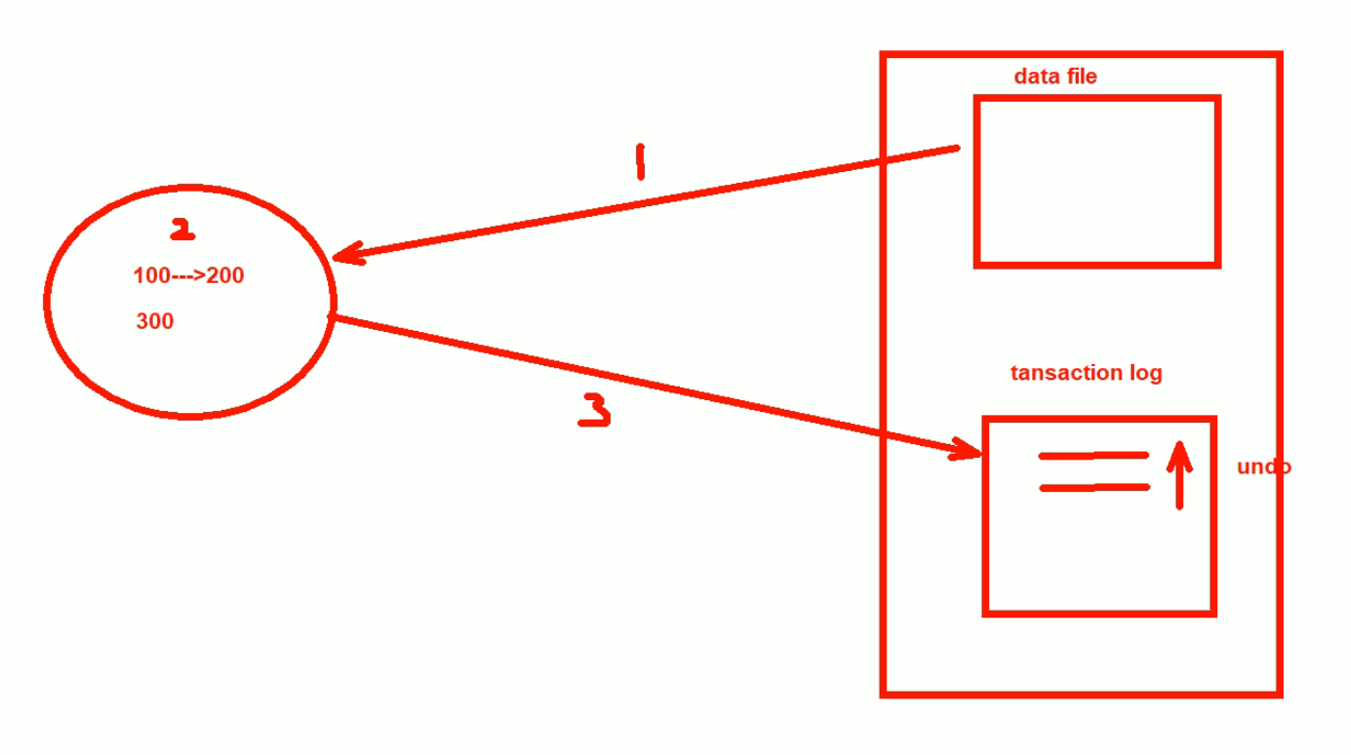
此时后面来电mysql起来后,会对这个100->200,200->300的 事务日志 做undo撤销动作。
1、2、3本来只是完成到事务的日志记录,实际上并未提交
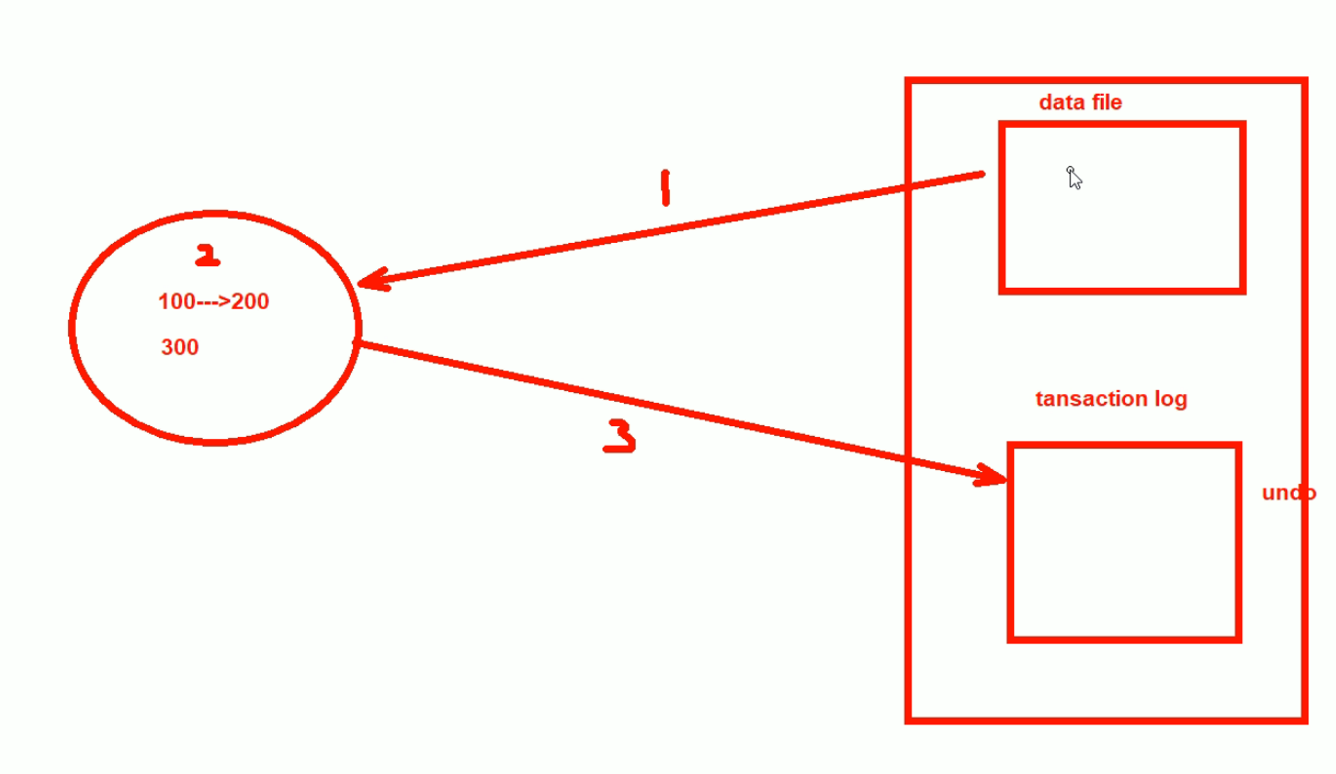
此时就是100大不了没有改成300,就是100不变。
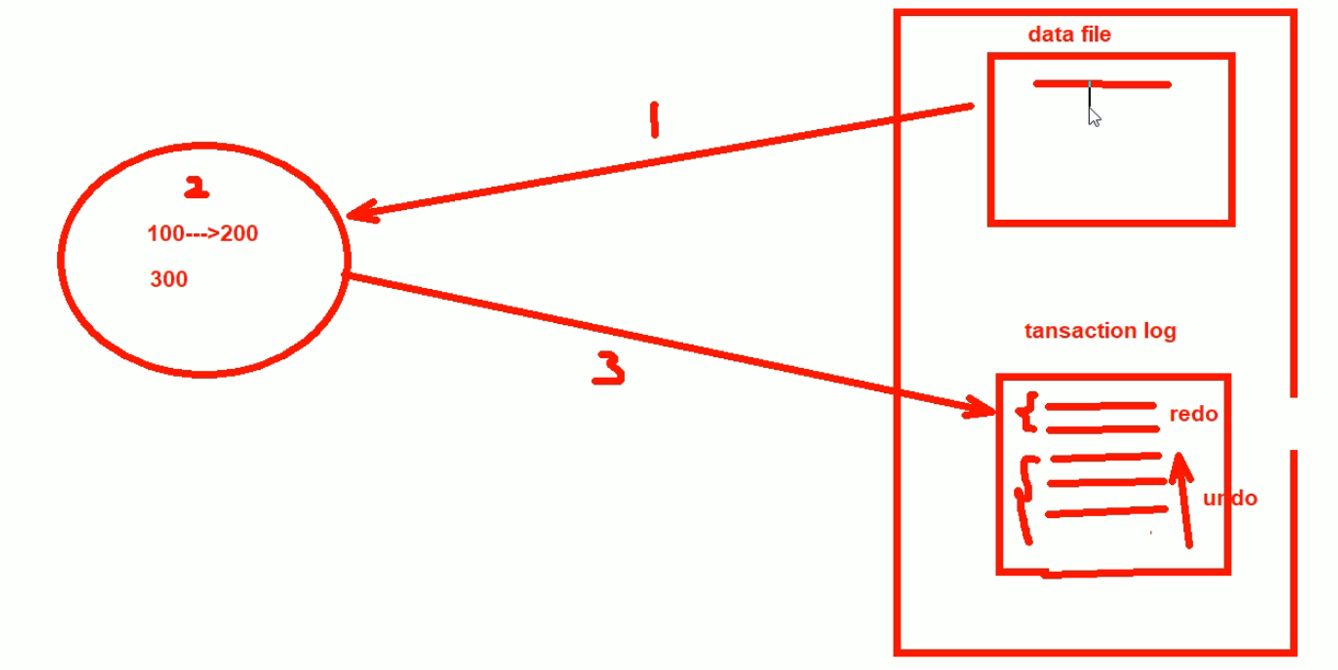
事务日志已经commit提交的是一个完整的事务,就redo--在数据库里重新执行一遍写进数据文件里,没有的undo撤销。
所以事务日志里有redo日志和undo日志。
事务的执行过程
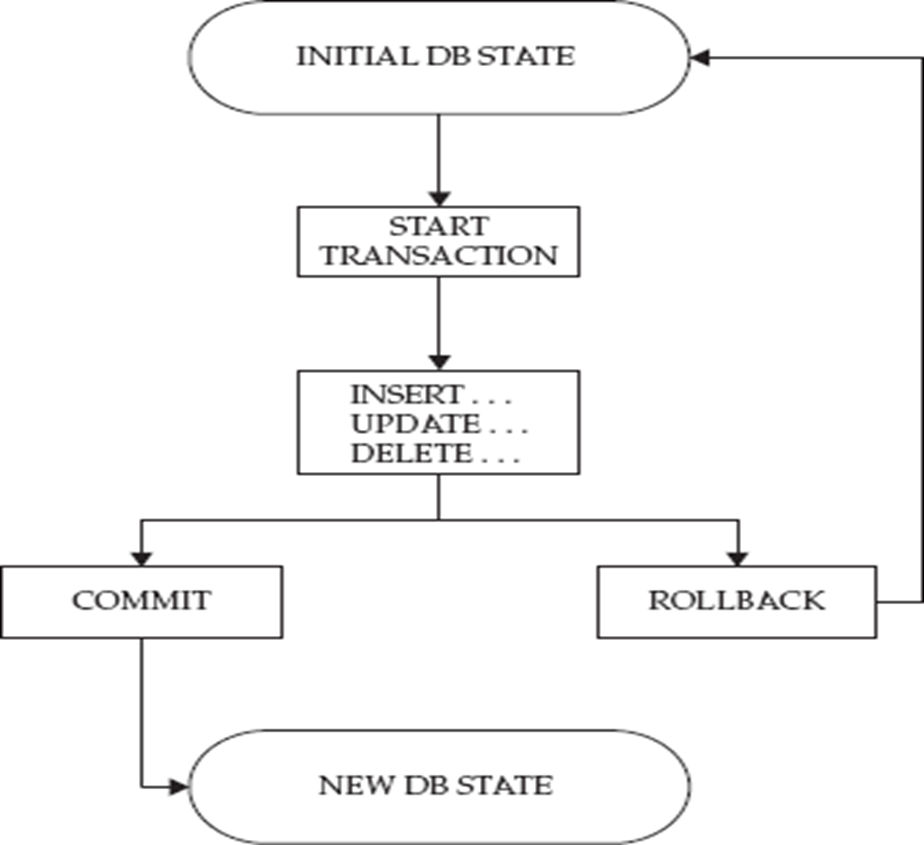
1、刚开始数据库是初始化状态
2、开始一个事务,事务开始的标志是:人工手动,或者 隐式的开始
3、事务中:增、删、改;查应该不算在是事务里了,看来不是说算不算的问题,而是你放不放的问题,你手动制动select就是事务里的,就是啦,隐式估计不放吧。


4、commit,如果事务确定要提交了也就是结束了,就是commit。相当于订单提交,不过也可能是加入购入车哈哈。
一旦提交就进了新的数据状态了。
5、rollback,回到原来状态。
事务的CLI
自动提交:回车就默认commit了
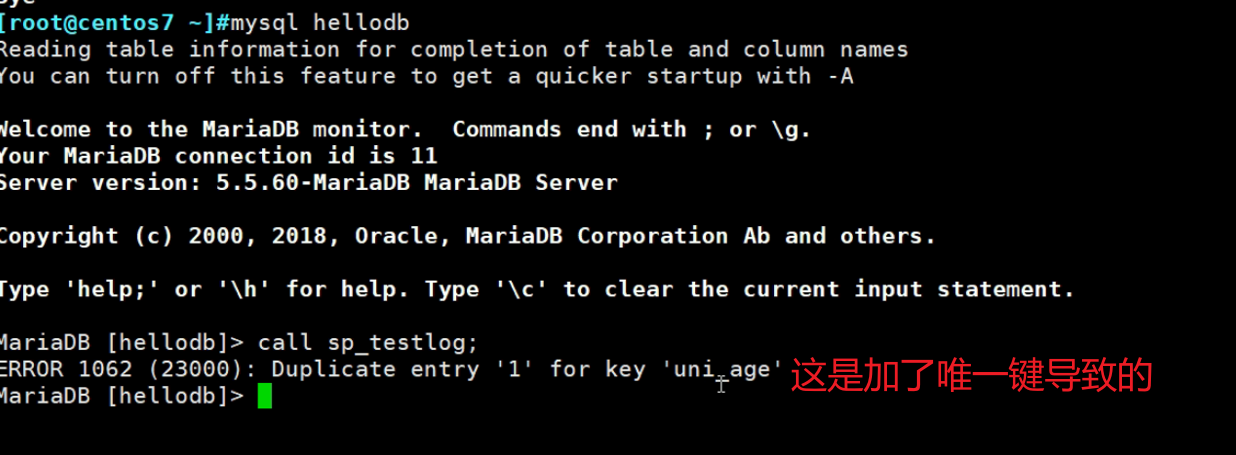
同样我的测试

主键就是理解成主键索引,同理唯一键也是等价于唯一键索引,比如你创建一个唯一键,其实就是默认创建了唯一键索引
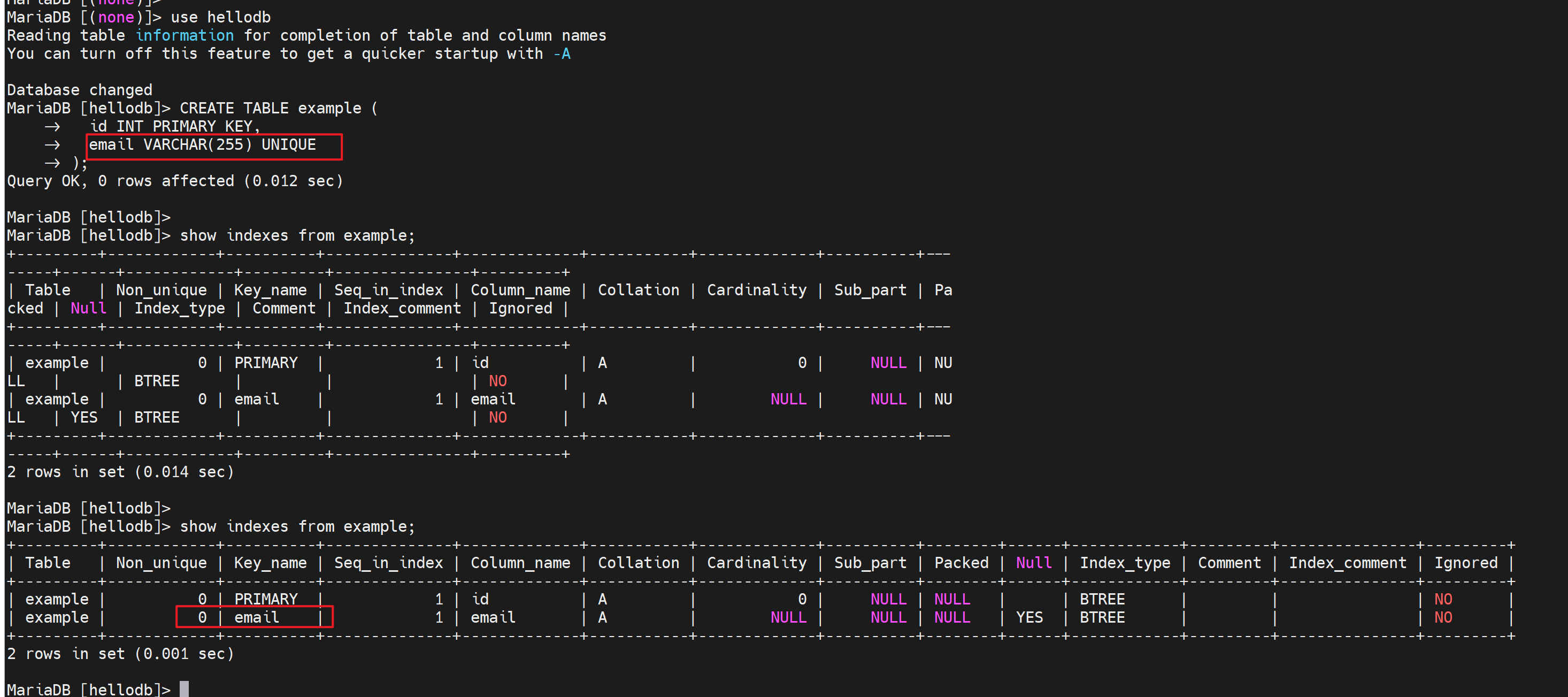
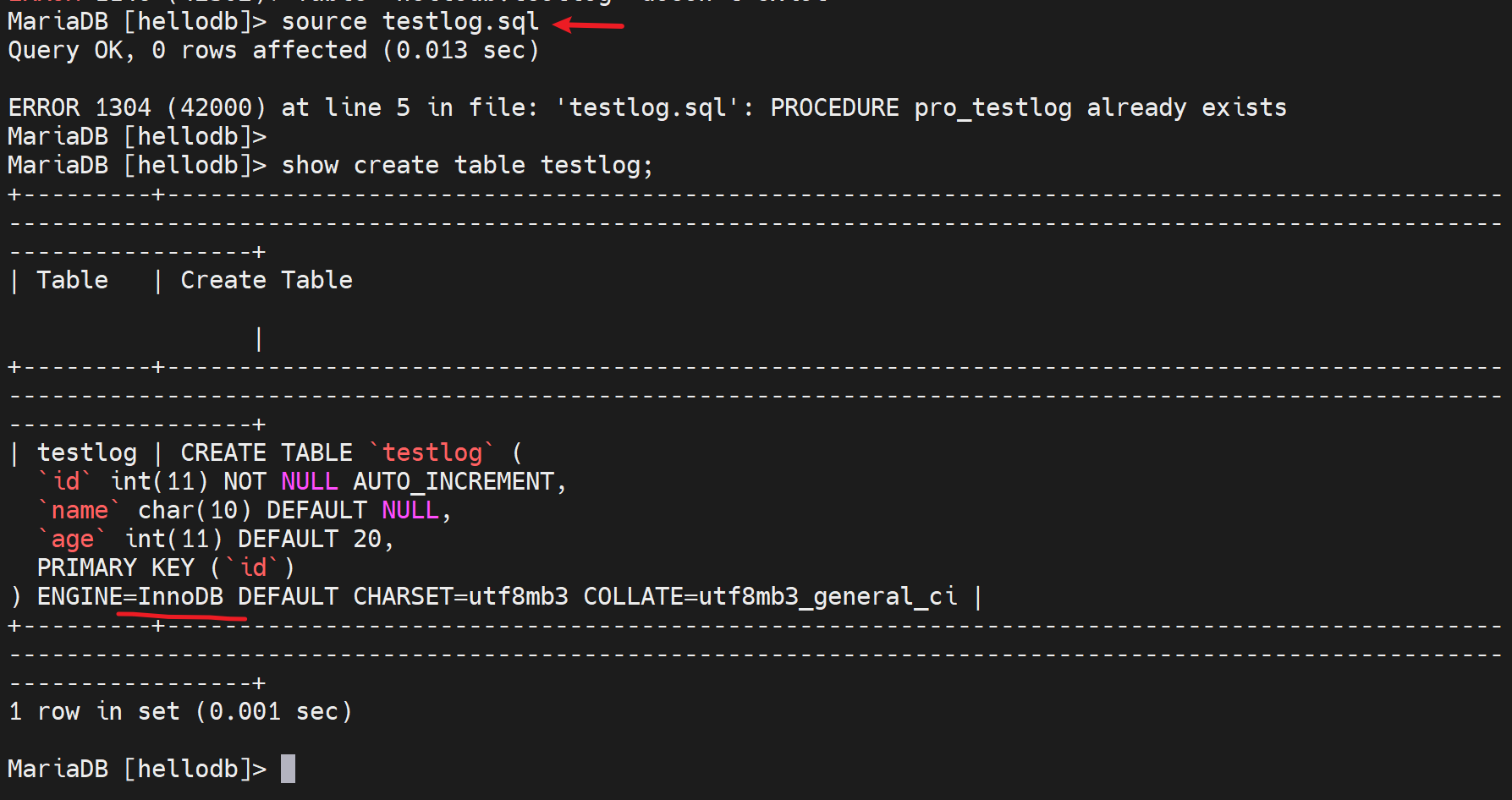
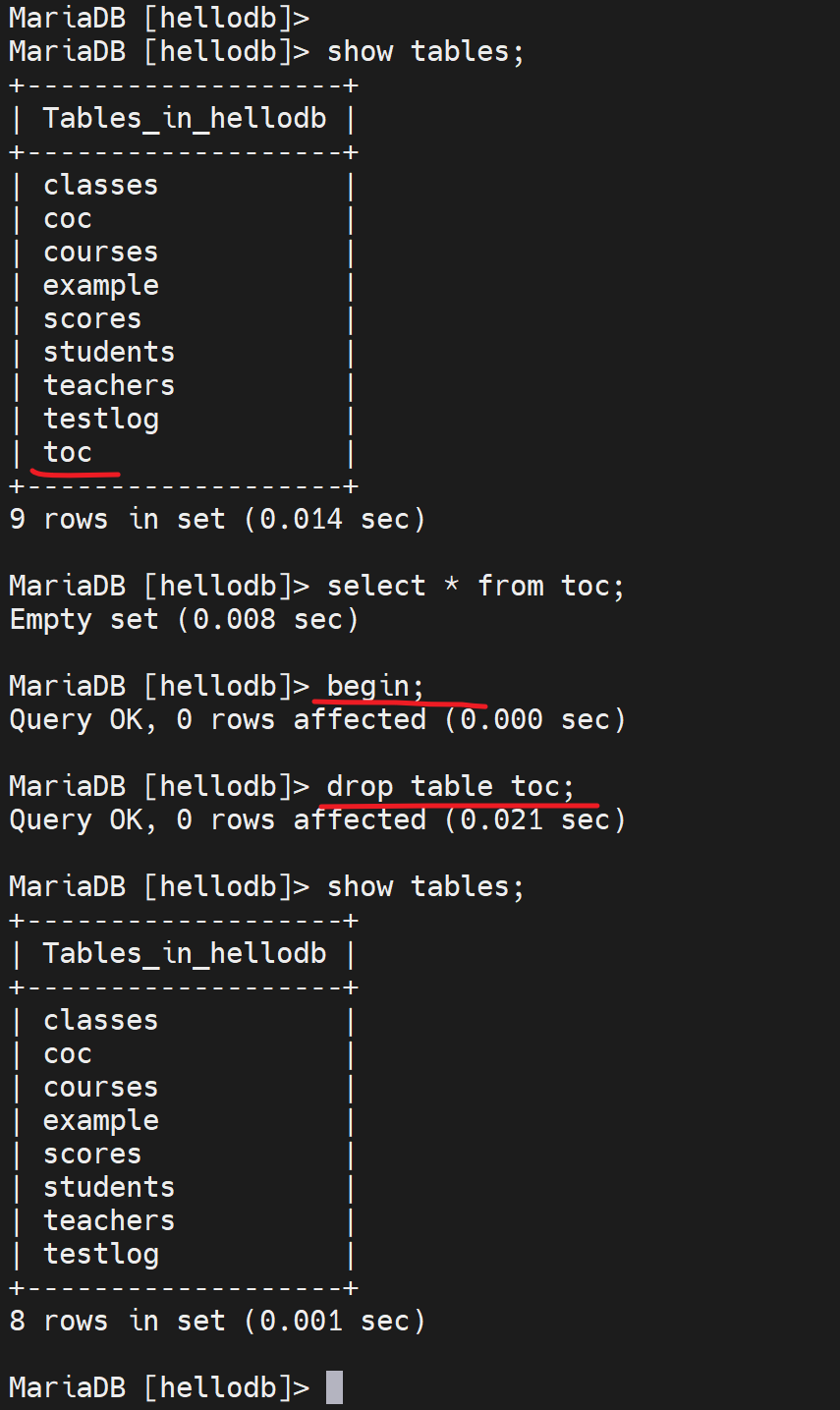
drop index uni_age on testlog;删除唯一键,就可以使用存储过程插入了。
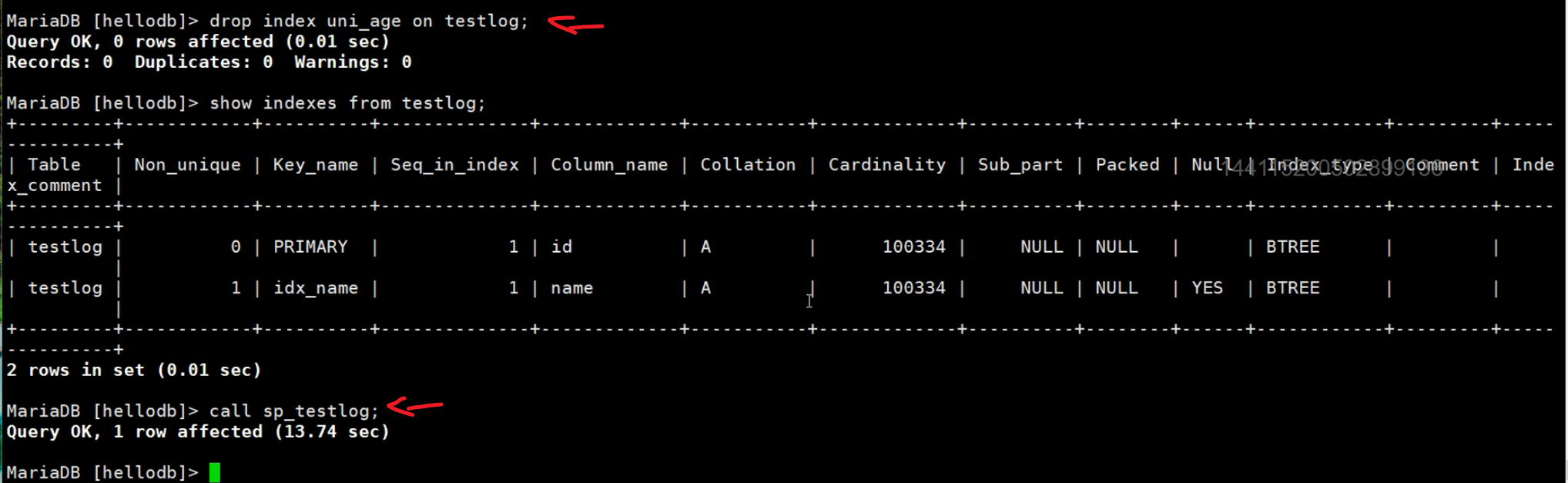
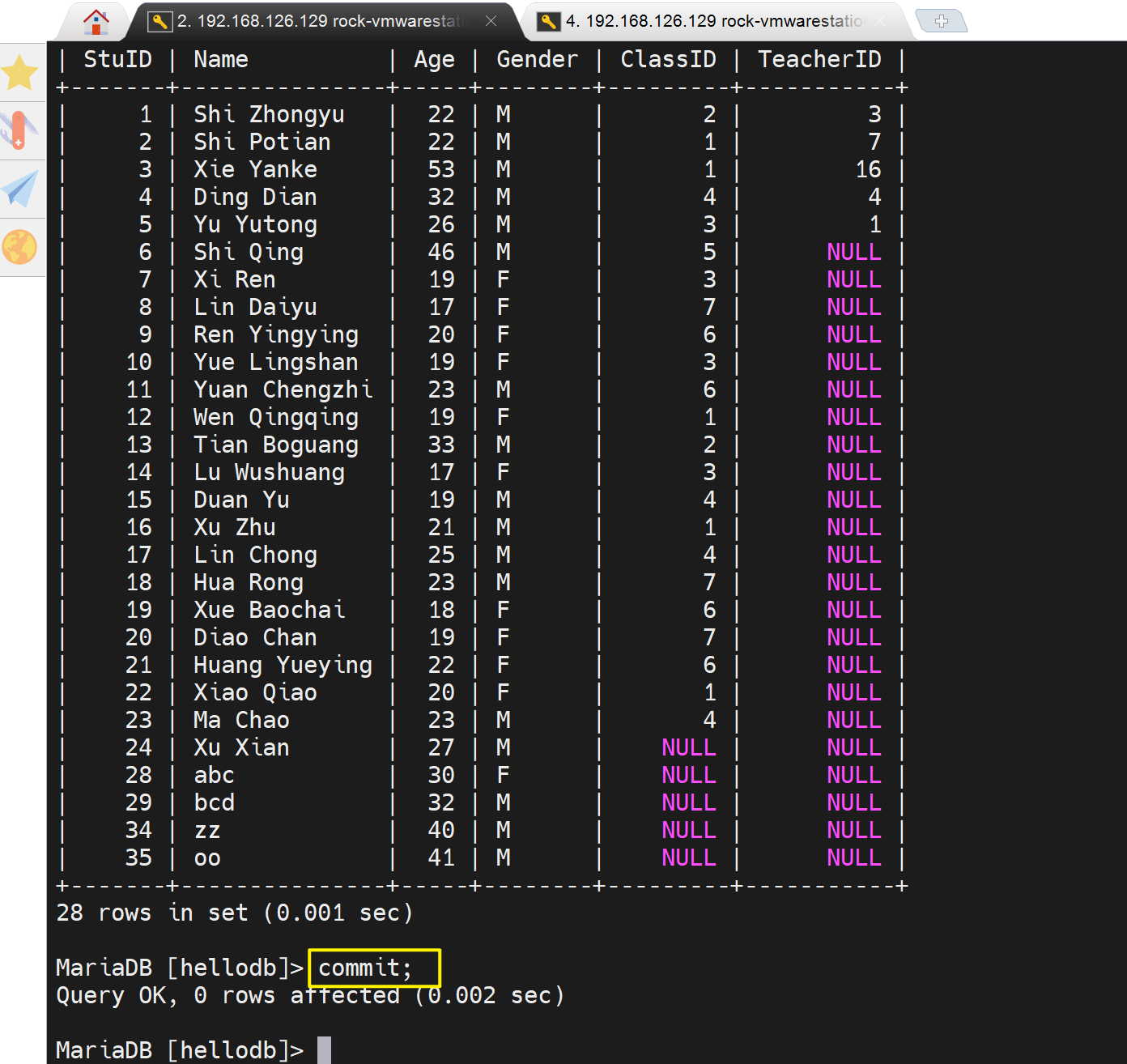
10万条记录,所以耗时13.74
看看我自己的测试
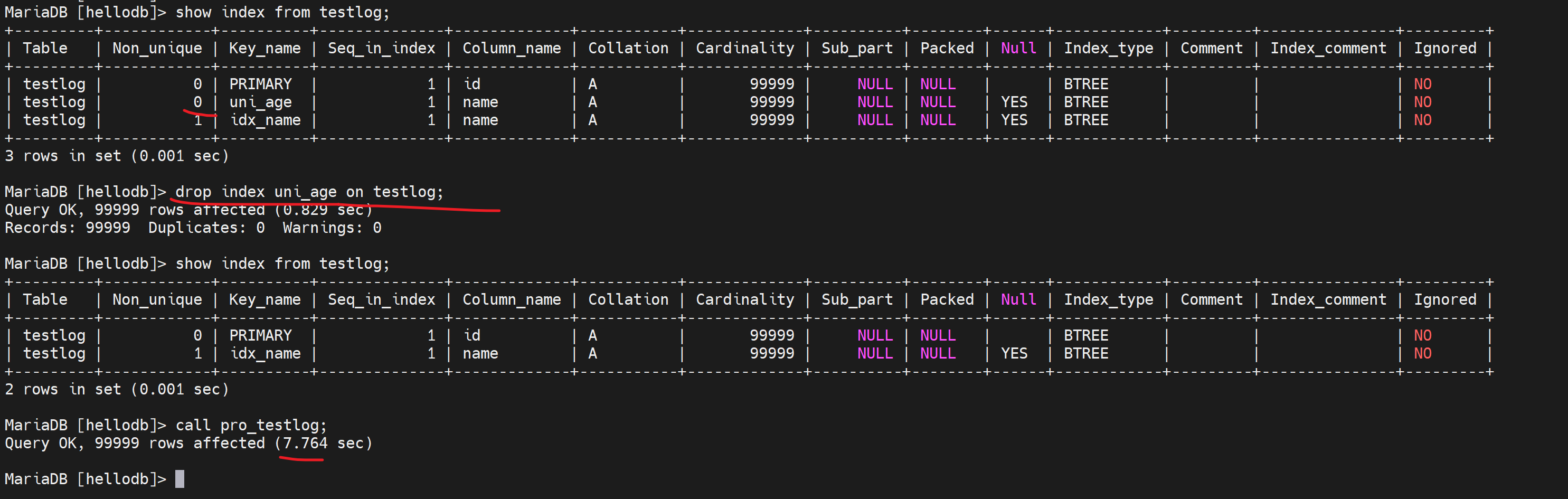
这个call执行完就是自动提交了,而且可能还是一行行的提交的,因为10万行嘛
你也可以改成像orcale一样的方式--默认不自动提交。
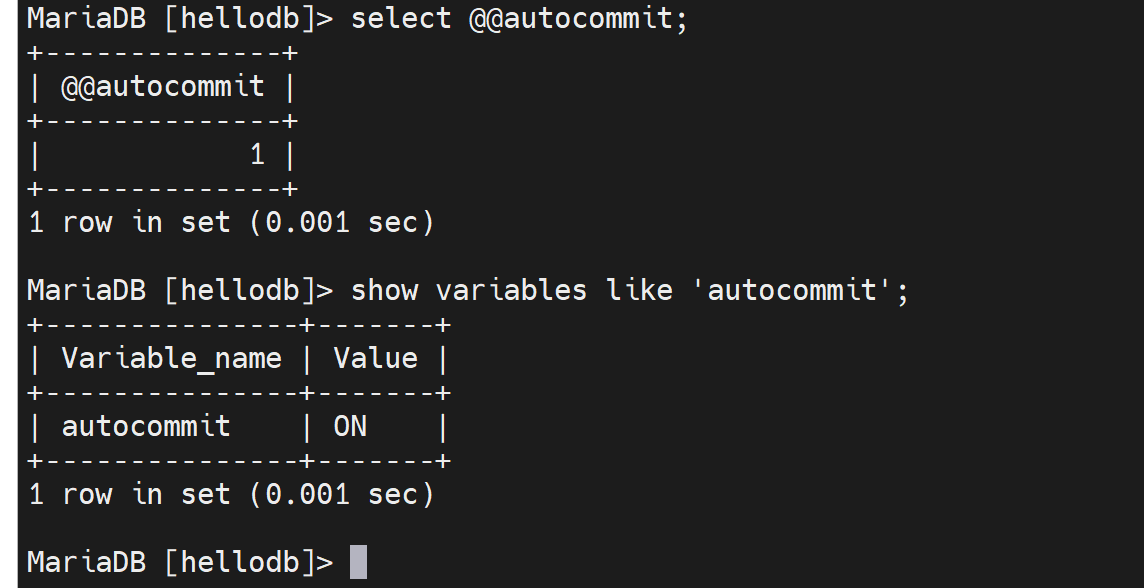
可以修改为不自动提交。
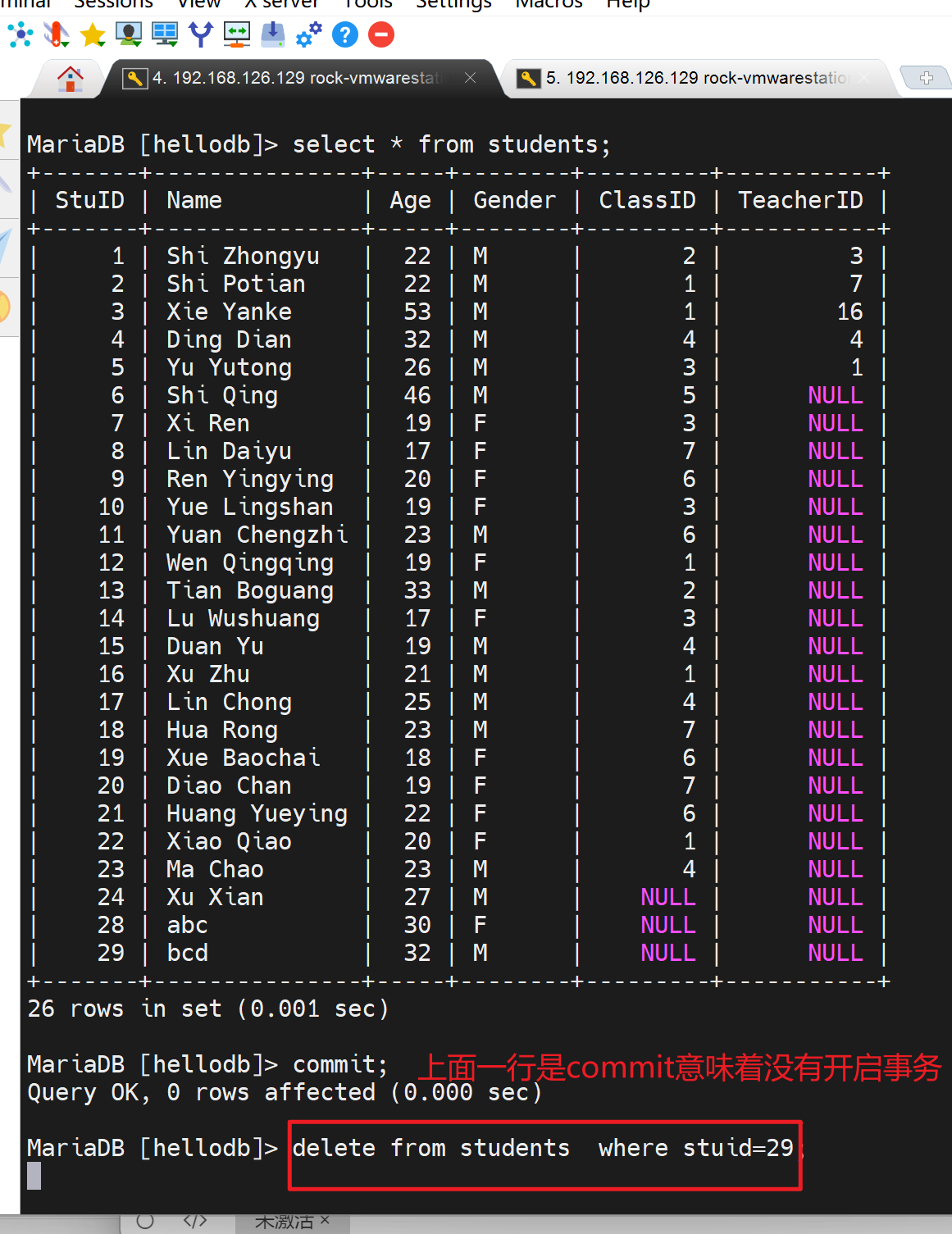
然后删除一行记录看看
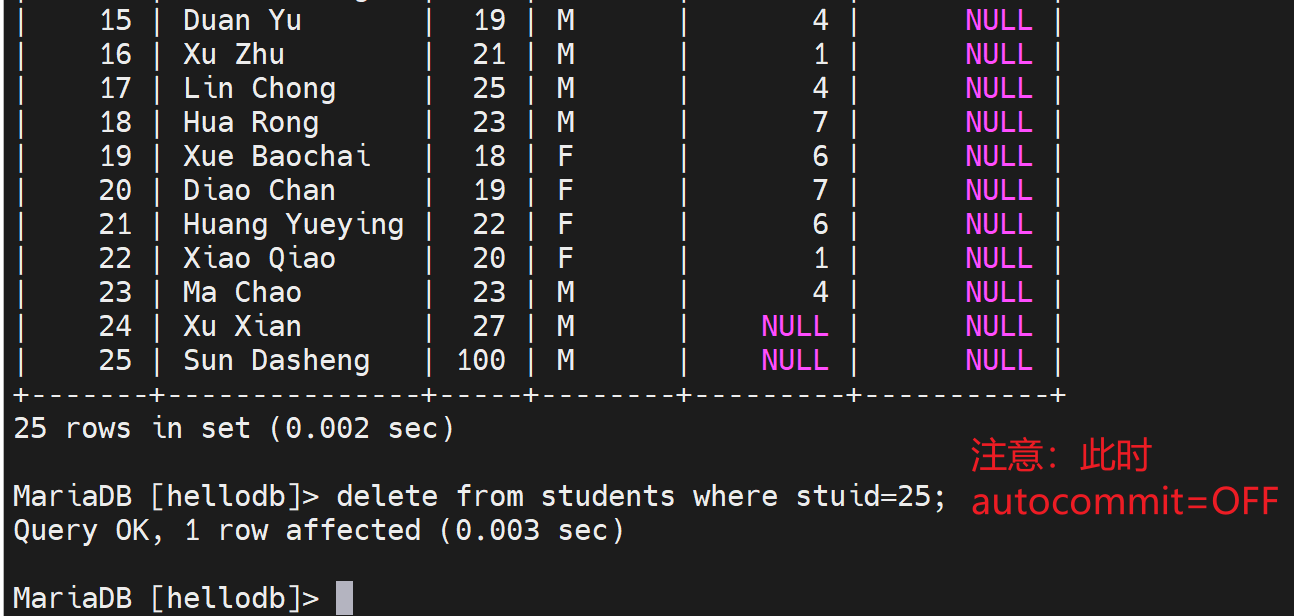
删掉后,自己看确实删掉了
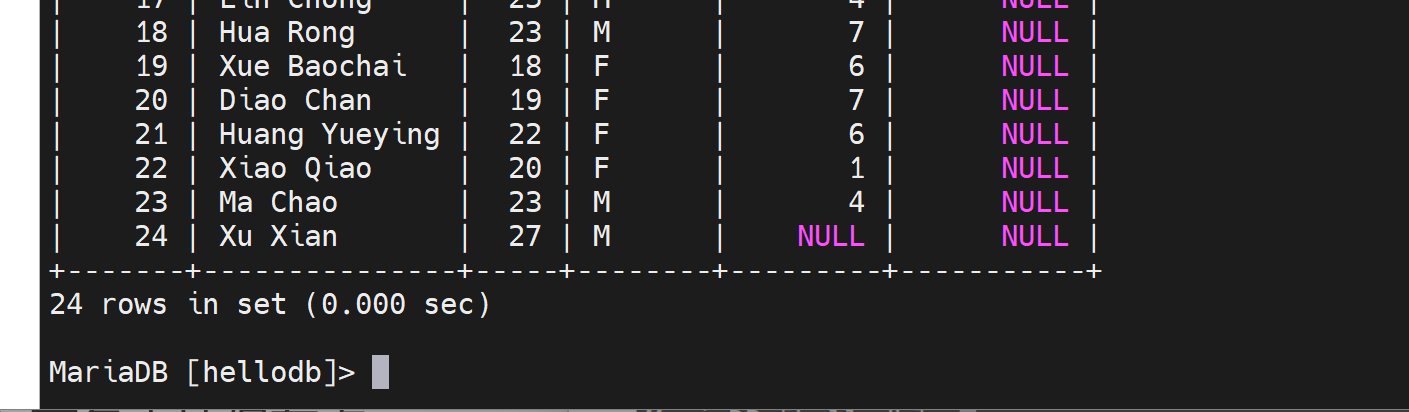
但是别人看--另外开一个终端ssh去看👇还在:

所以
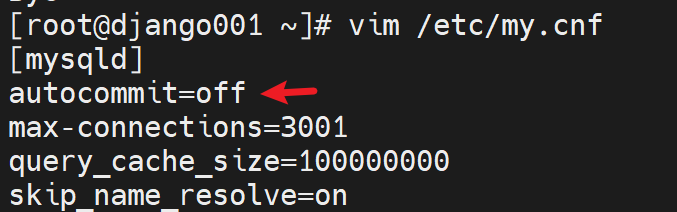
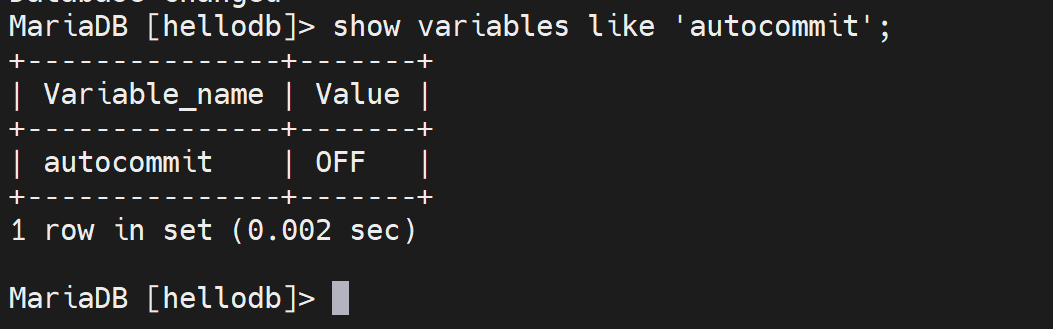
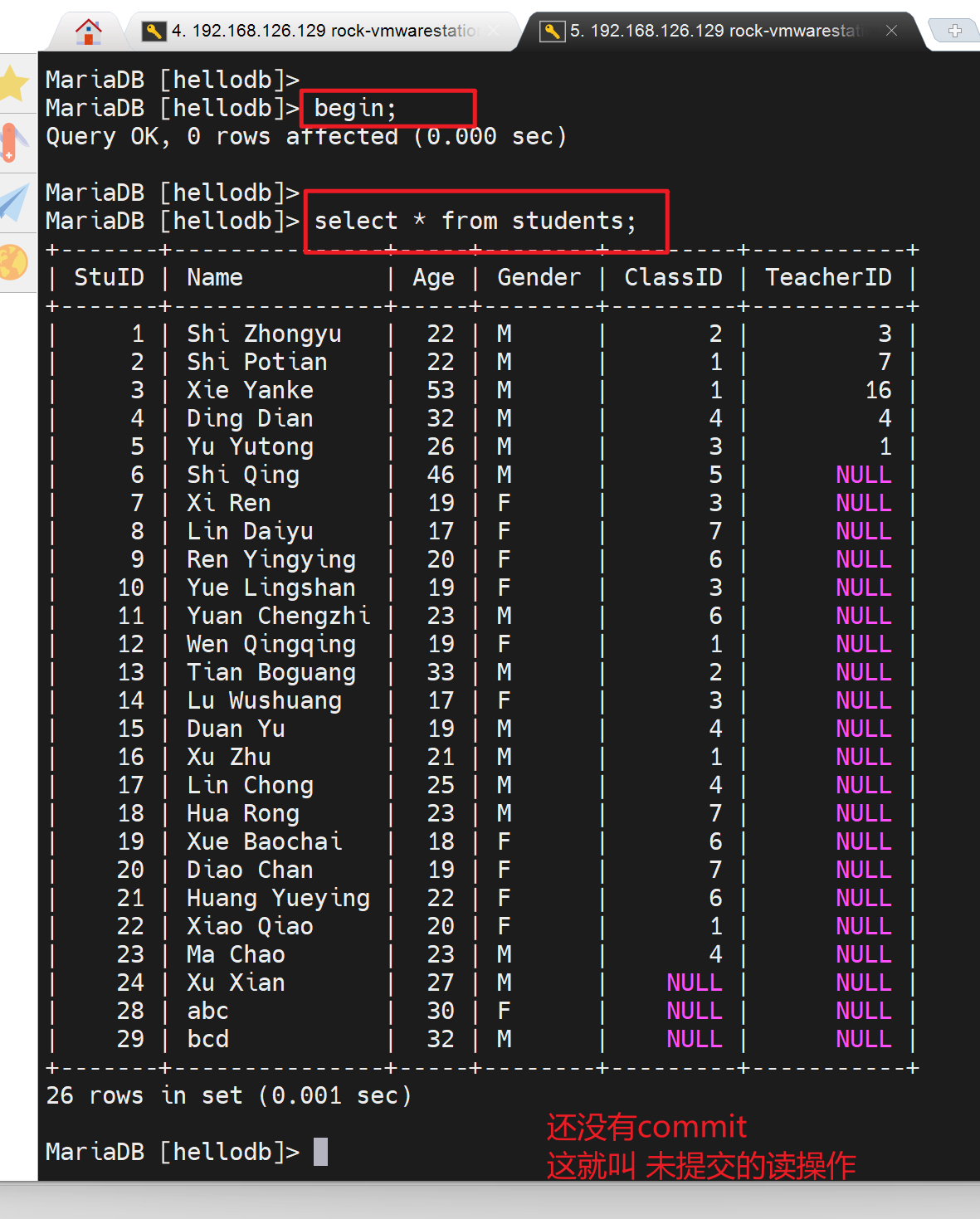
1、修改autocommit自动提交为OFF
2、自己删除一行,自己看得到;但是属于事务中间状态的数据,
3、别人看不到;如果别人看到就是脏数据。
4、能不能看到和隔离级别有关,默认是看不到的。
这就是事务的隔离性,你没commit就不是一个完整的事务。
5、把shell窗口关掉,模拟事务没有提交的异常断开效果,看看undo效果

肯定的啊,这个动作不就等价于别人看嘛,还验证个啥哦。不过这里和别人看不到是两回事,这里涉及一个undo也就是rollback。
6、commit后别人所见不变;这还是 事务的隔离性,事务的隔离性后面讲,一共有4种。

自己删除25行后,提交后,别人还能看到25行
人为的起止事务
启动事务:下面3个cli照抄就行就是事务开始的cli
BEGIN
BEGIN WORK
START TRANSACTION
结束事务:
COMMIT:提交 ROLLBACK: 回滚
注意:只有事务型存储引擎中的DML语句方能支持此类操作
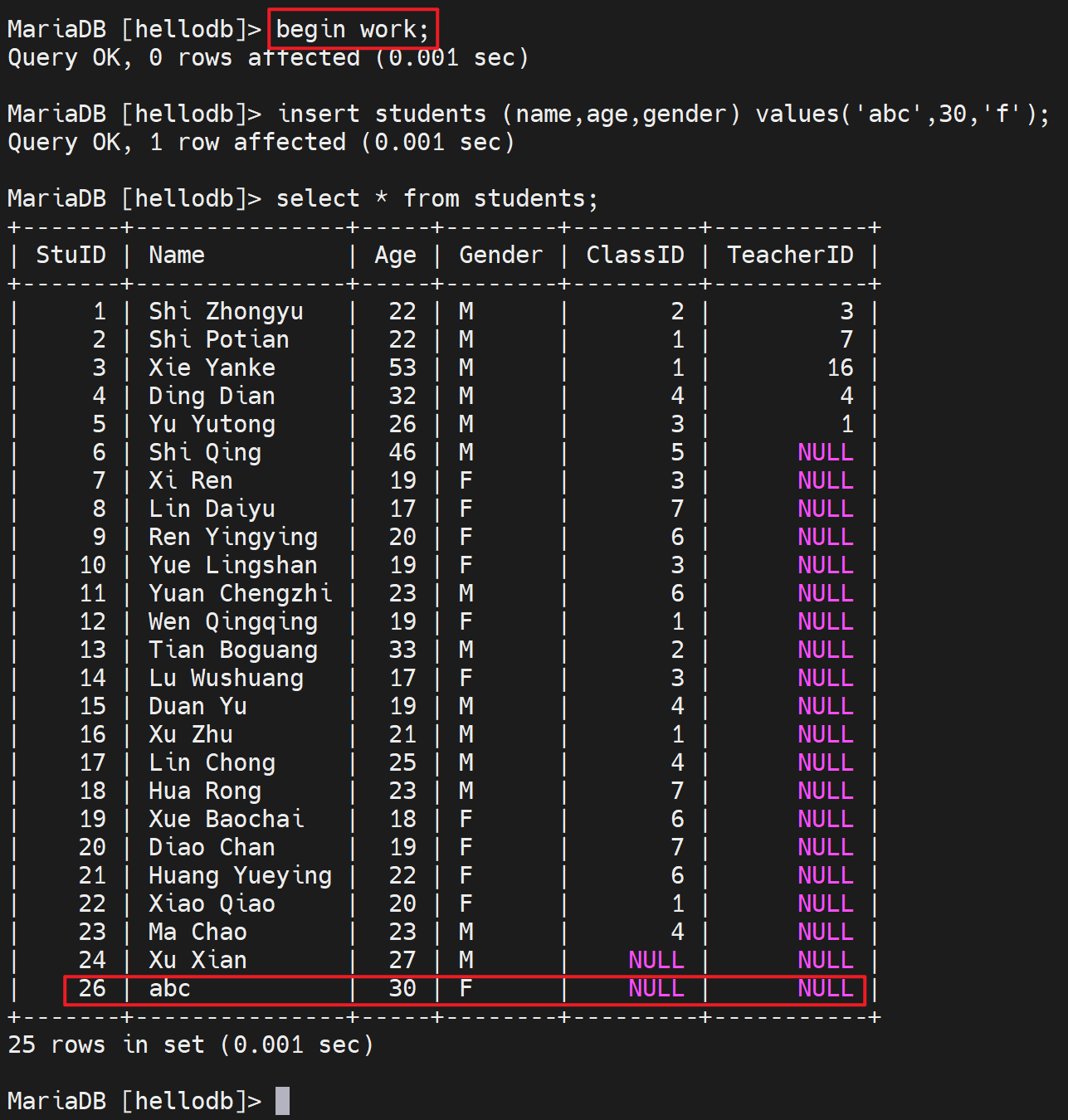
再加一条
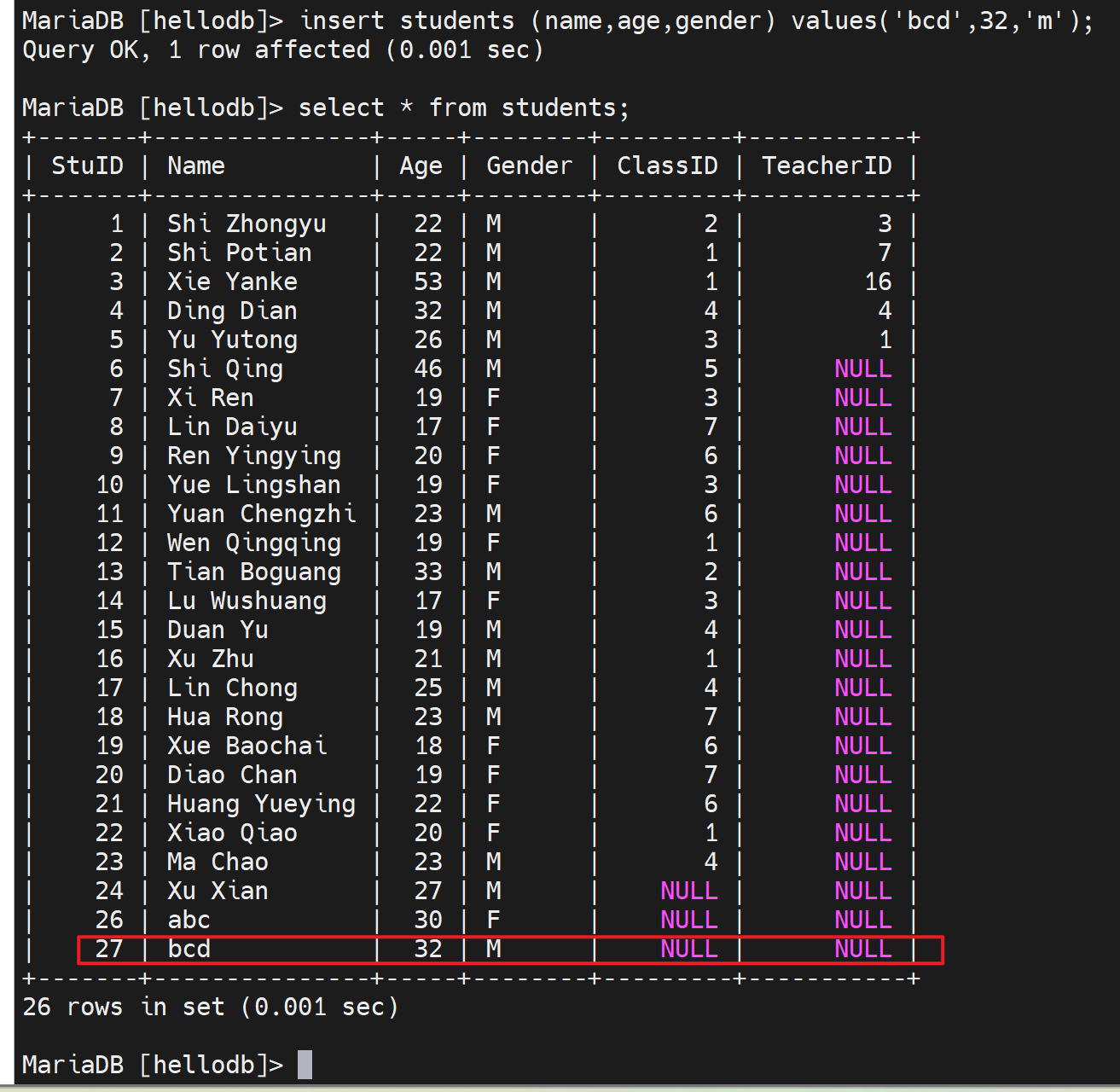
撤销
一旦提交,就真的把数据库文件改了
但是我这边没做出来,奇了怪了,难道是mariadb版本太高了?

我靠,什么时候改掉了,默认不应该是InnoDB吗
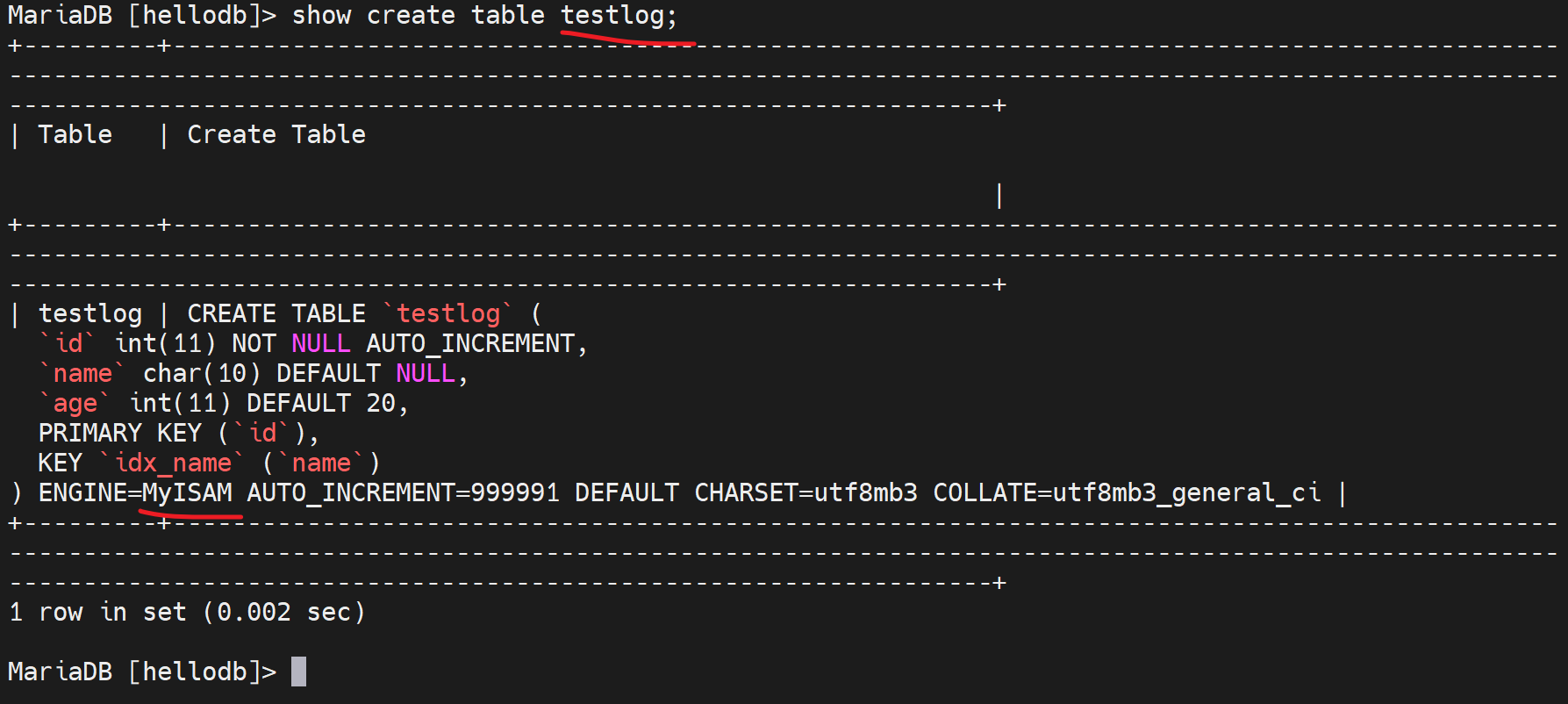
靠,删掉,重来一遍看看效果

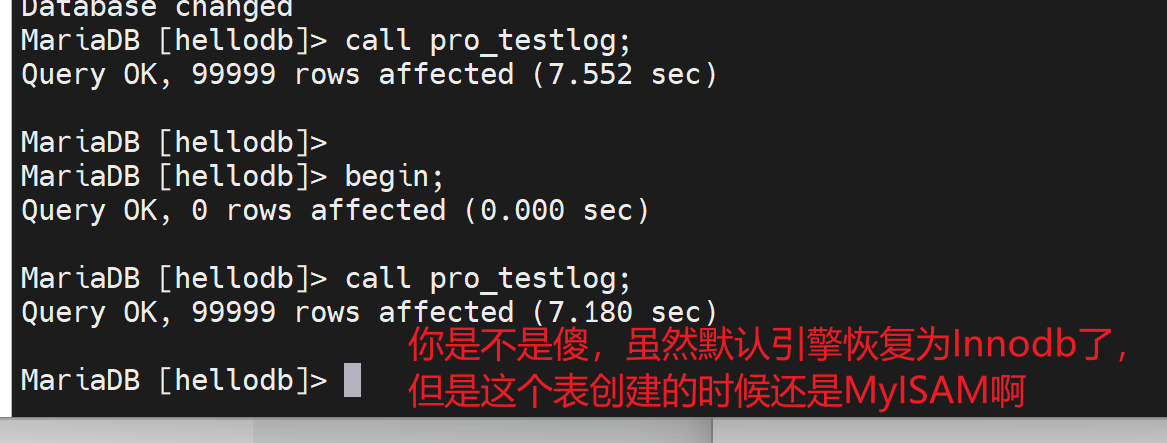
emmm,删表,重建
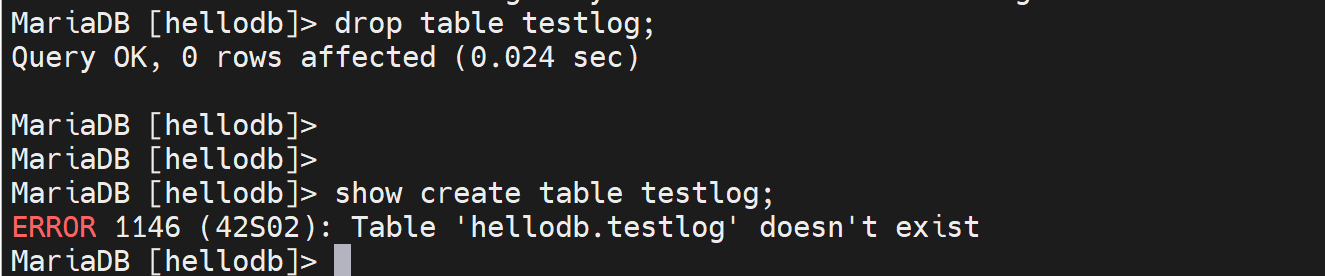
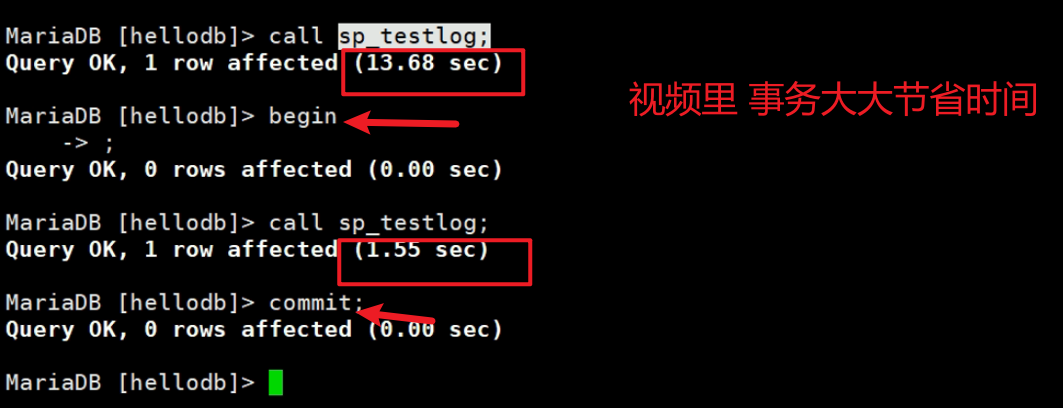
好了,再试试call pro_testlog;的手动begin,整体事务的方式
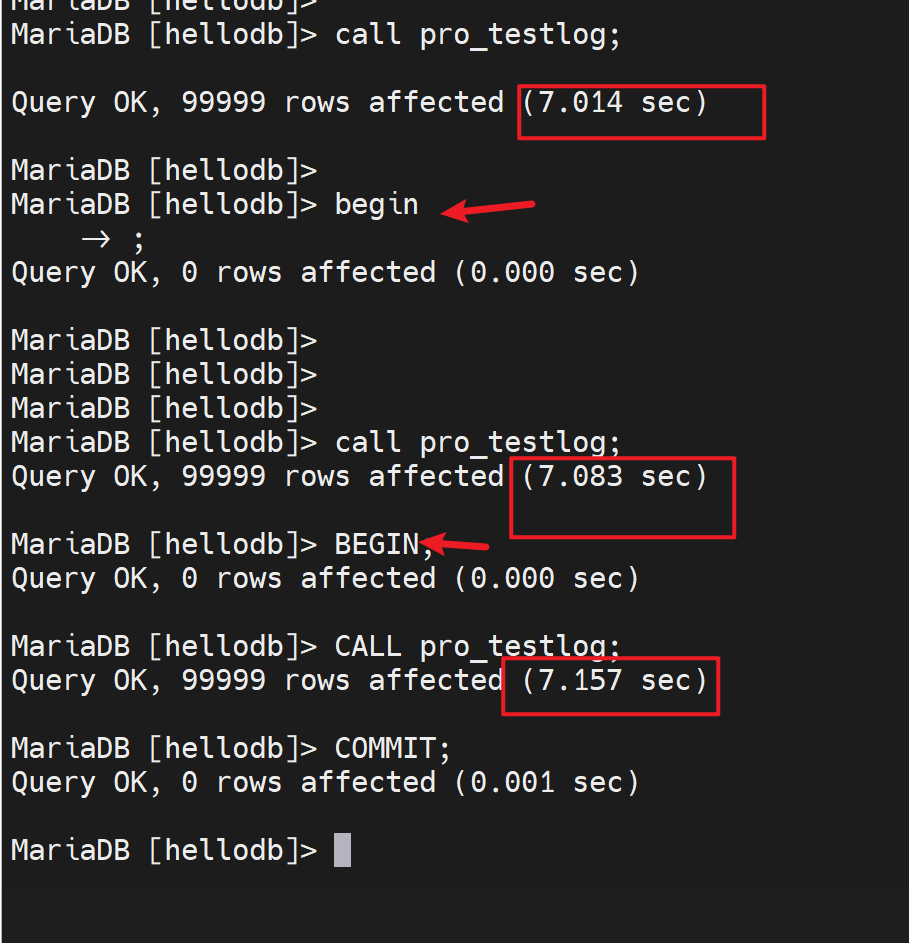
1、直接call就是存储过程里的没一行都会默认自动提交,就会很慢
而且可见innodb的这个调用10w行的存储过程要比MyISAM慢的多的多,可能是MyISAM没有事务,也就没有事务日志,所以快?
感觉下面begin可能时间也是和MyISAM一样,因为整个call xx就是一个事务,感觉相当于MyISAM的没有事务了。
2、其实innodb手动指定事务还是要比没有事务的MyISAM要快一半的时间。
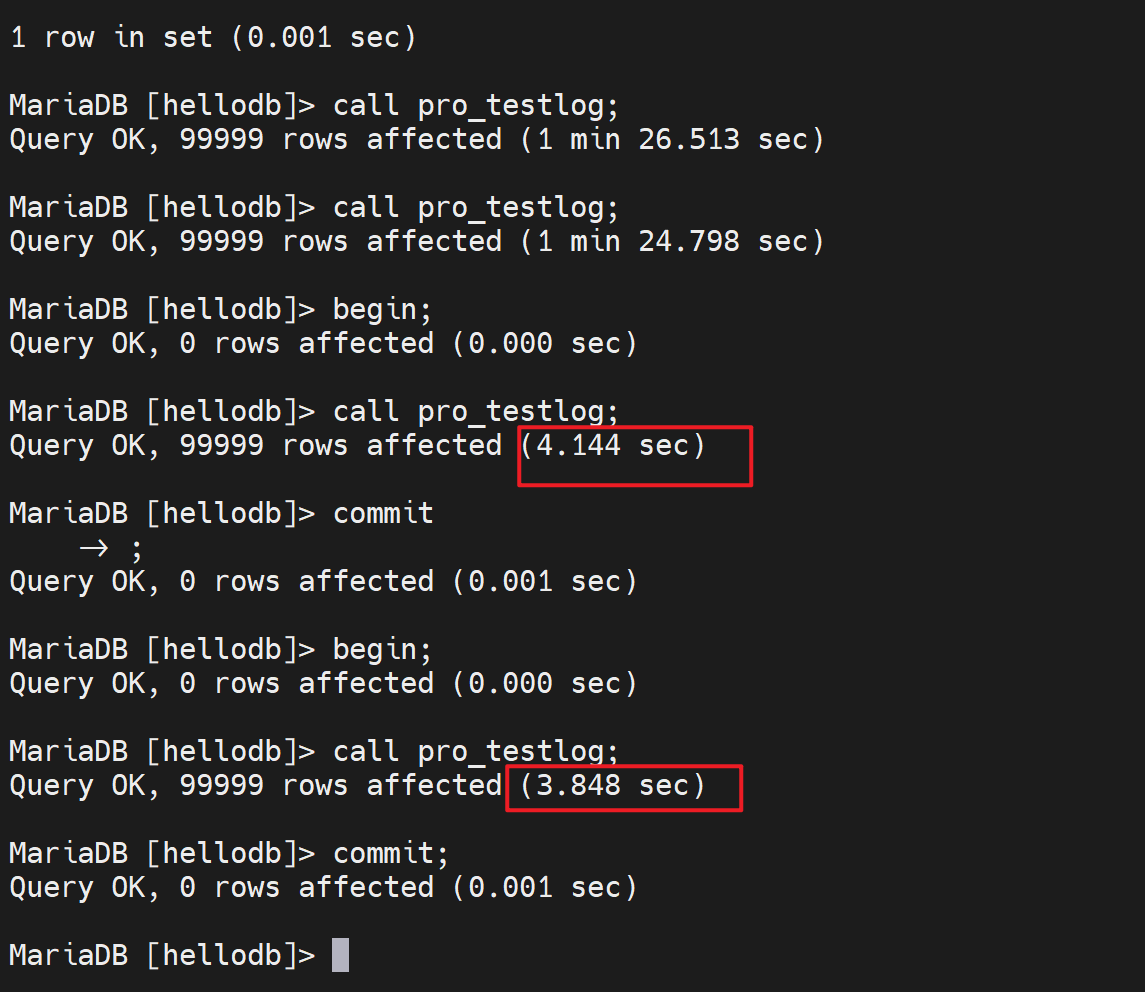
3、结论innodb 调用10万行的存储过程,使用整体一个事务的方式,耗时也是要比MyISAM要快的,我的机器配置是4s的7s。当然老师的就是更快了,看前面的图1.55s。
以上就验证了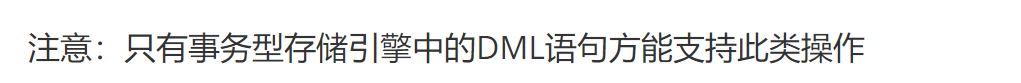
同样drop table这种DDL语言,不是DML语句,也不会支持rollback操作
发现DDL(drop create alter)语句是没法rollback的,这些是和select一样会记录到事务里,但是不是DML(INSERT UDDATE DELETE),不支持rollback,自然也不需要commit。
事务支持保存点:savepoint
SAVEPOINT identifier # 定义保存点
ROLLBACK [WORK] TO [SAVEPOINT] identifier # 回到对应的保存点
RELEASE SAVEPOINT identifier
就是在事务执行的过程种,在某个节点打标签,将来rollback到对应的savepoint。
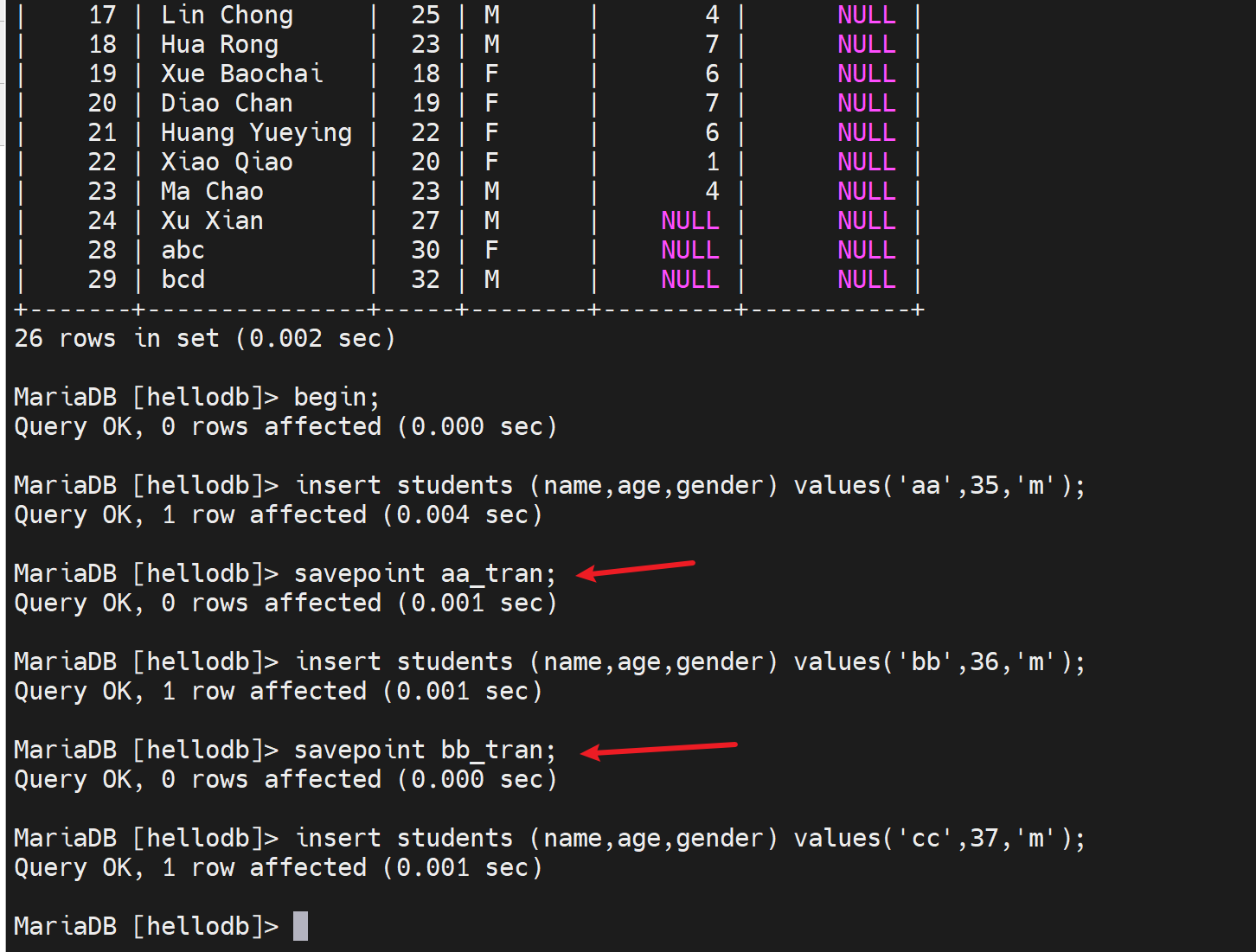
现在表里加了3条记录
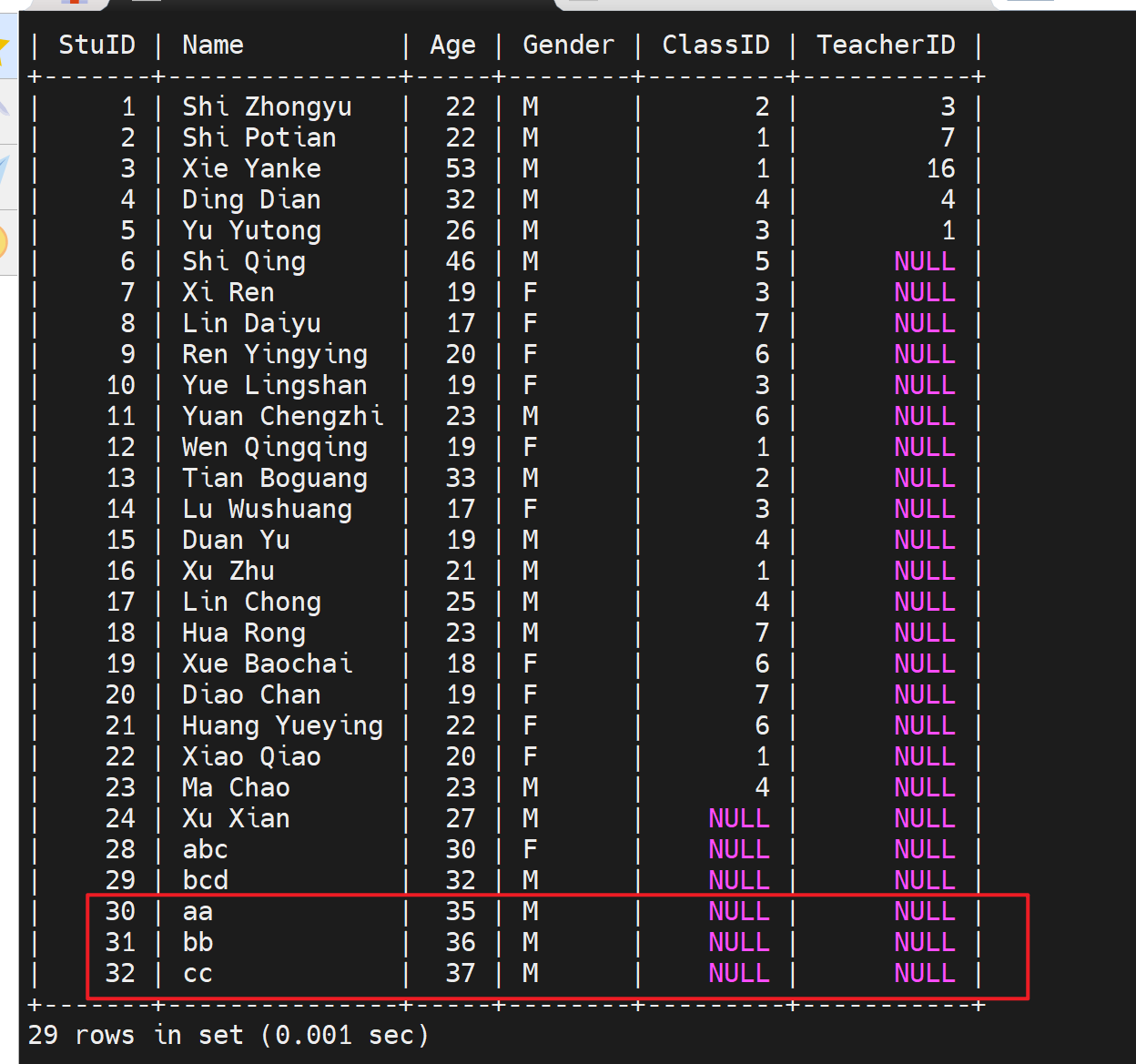
1、直接rollback就全部撤销了
2、rollback to aa_tran
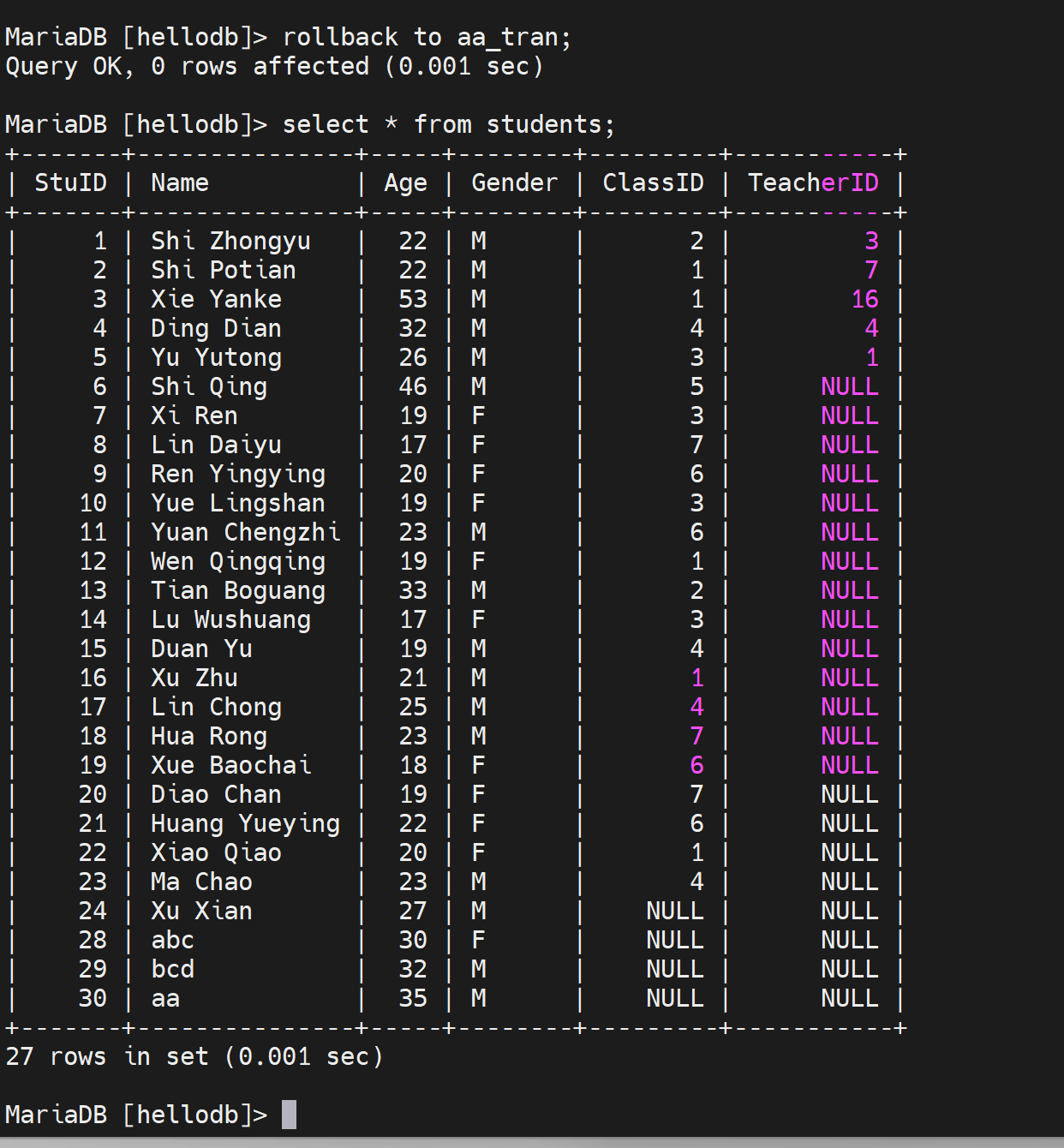
3、撤销过了,一些savepoint没了就没了,bb_tran整个保存点也就没了。

事务的隔离级别
事务隔离级别:从上至下更加严格
READ UNCOMMITTED
可读取到未提交数据,产生脏读。
READ COMMITTED
可读取到提交数据,但未提交数据不可读,产生不可重复读,即可读取到多个提交数据,导致每次读取数据不一致
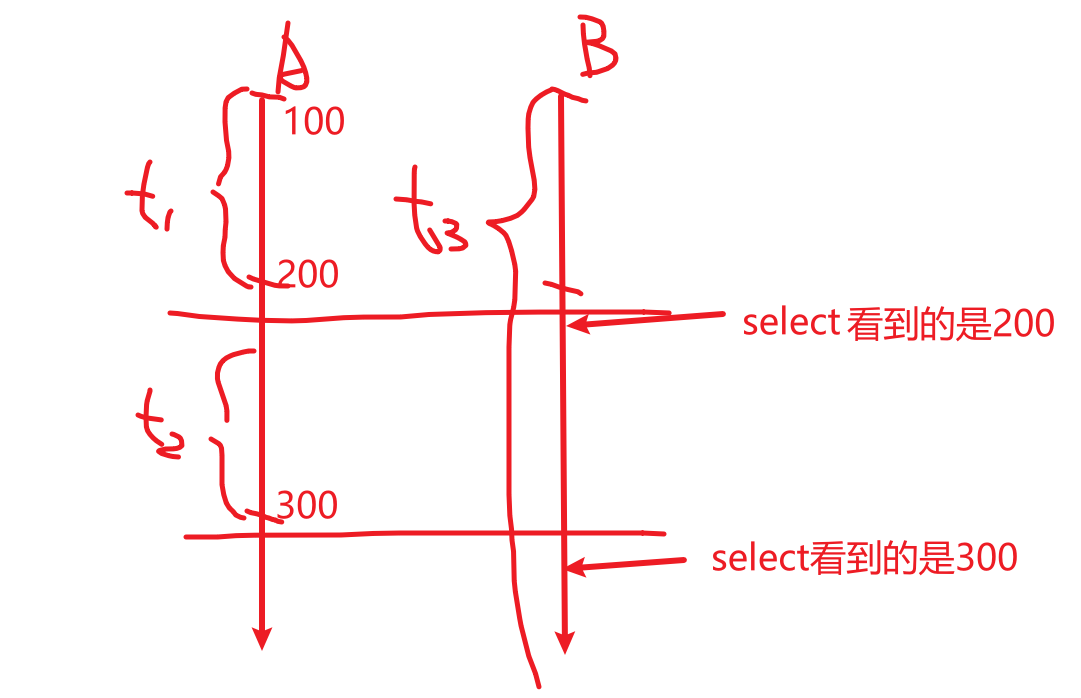
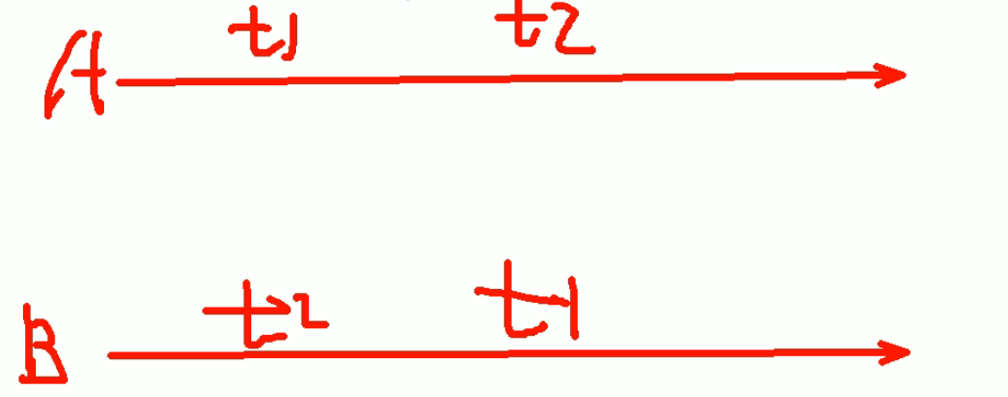
A分别在事务t1修改100为200,又子事务t2修改200为300,
B在一个大的事务t3中,两次时间节点看到的值不同,前面是200,后面又变成了300。
B就在一个事务中读取到了多个不同的值,这就是产生了 不可以重复读的结果,因为重复读数据不同了。
REPEATABLE READ
可重复读,多次读取数据都一致,产生幻读,即 读取过程中,即使有其它提交的事务修改数据,仍只能读取到未修改 前的旧数据。此为MySQL默认设置
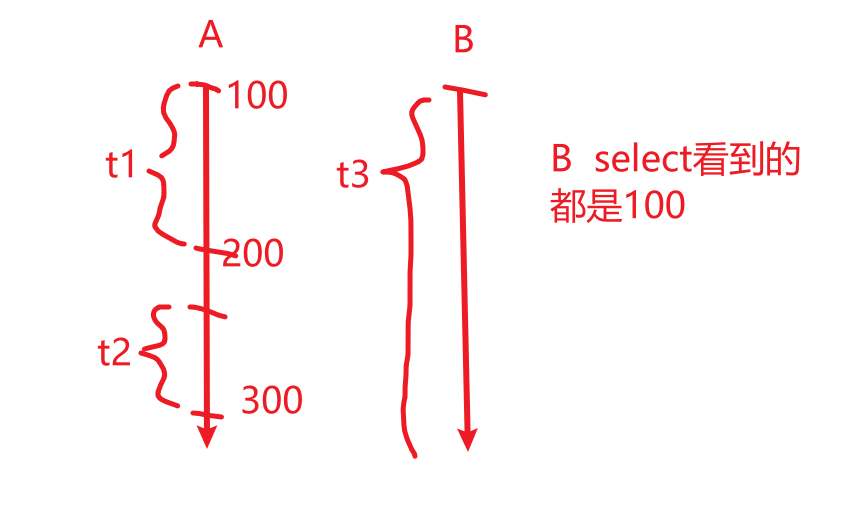
说明repeatable read可重复读,就是B在整个事务t3的执行期间,每次读取的数据都是一样的。从结果上来讲就是可以重复的去读数据,数据是一致的。
但是!数据早就改掉了,甚至删掉了,结果B还是一直认为数据还是原来的样子,这就是幻读。
结论:虽然可能存在幻读,但是恰恰就是保证数据一致性了,所以这个就是mysql的默认机制--mysql默认事务隔离级别为“可重复读”。
举例:备份期间,如果以事务开始,就是备份的前敲一个begin的意思了,无论备份执行多久,数据就是一开始时候的样子,是不变的,哪怕别的用户提交了修改数据,在备份的这个事务期间都是不变的,带来的好处就是:数据的一致性,就是在以事务方式进行的备份中,数据都是一个时间节点的数据。
SERIALIZABILE
可串行化,未提交的读事务阻塞修改事务,或者未 提交的修改事务阻塞读事务。导致并发性能差
就是我读的时候,别人不能改;我改的时候,别人也不能读。
优点:数据很可靠;缺点:无法并行了。
MVCC
多版本并发控制,和事务级别相关
并不是4个隔离级别都能用上这个MVCC
事务隔离级别对比表
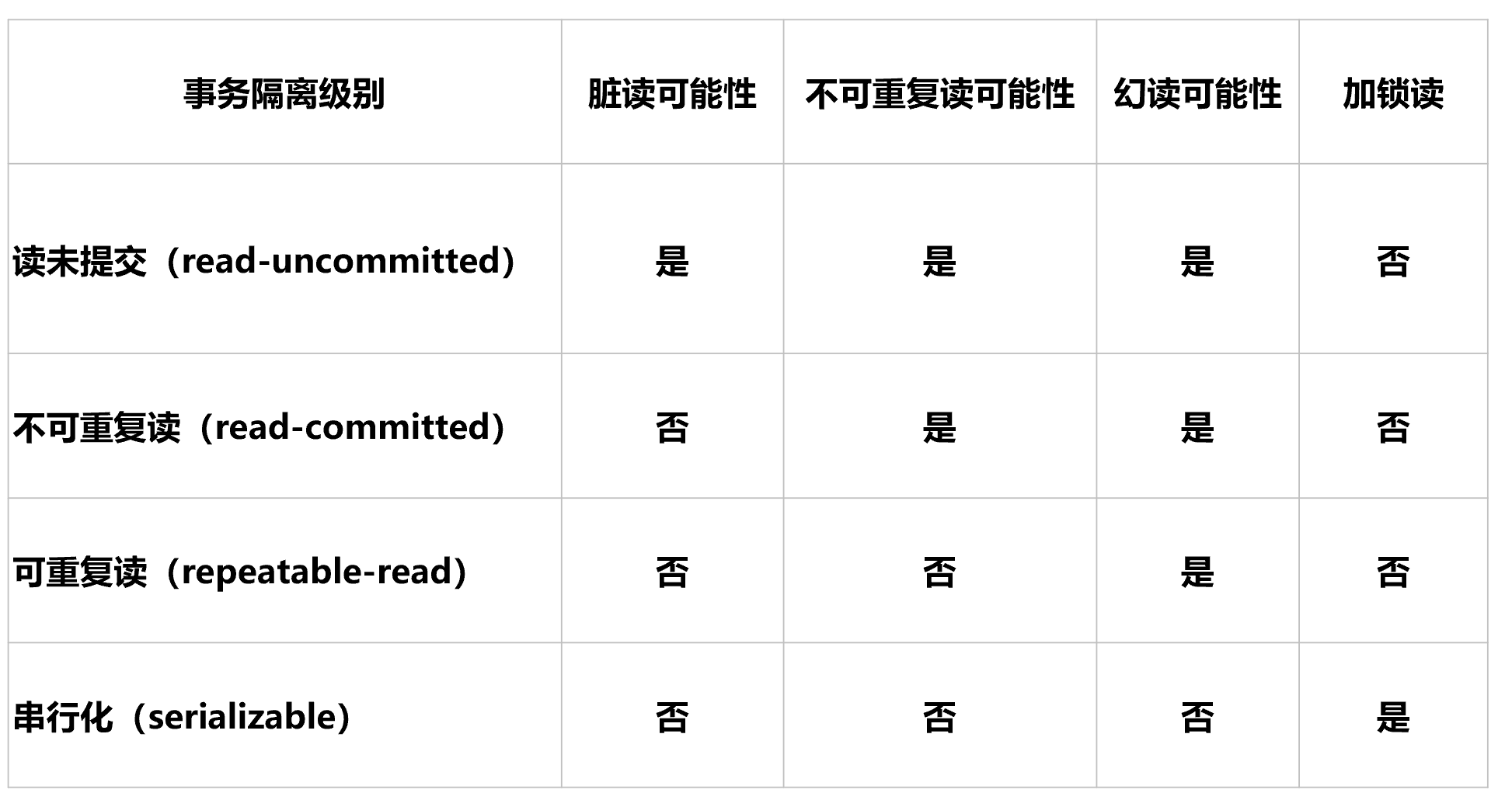
说明: 列上的 "不可重复读可能性",就是读出来数据可能不一致,就不能重复读了,就是这么个意思。 read-uncommitted和read-committed都能读出不一致的情况的。
幻读可能性:

所以:前3个read-uncommitted、read-committed、repeatable-read都能出现幻读。
问:事务和锁的关系:
答:就在上表最后一行啦,串行化事务里就会加读锁。总之锁是锁,事务是事务,锁是并发读写保证数据一致性,事务时讲多个操作看成一个原则来保证数据一致性;前者多个用户I/O数据库的一致性;后者是多个一系列操作的原子性或者叫一致性也行,而且后者事务还提供了隔离级别,这个就是会造成和锁理解冲突或者联系的点。
四种事务级别的设置
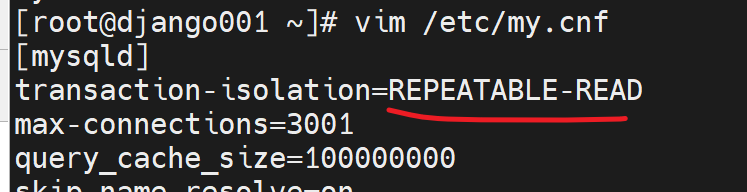
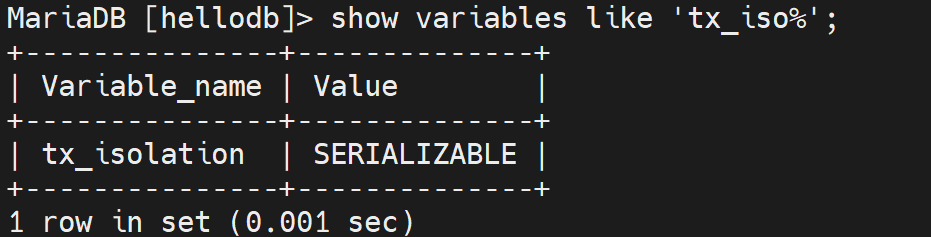
默认级别:
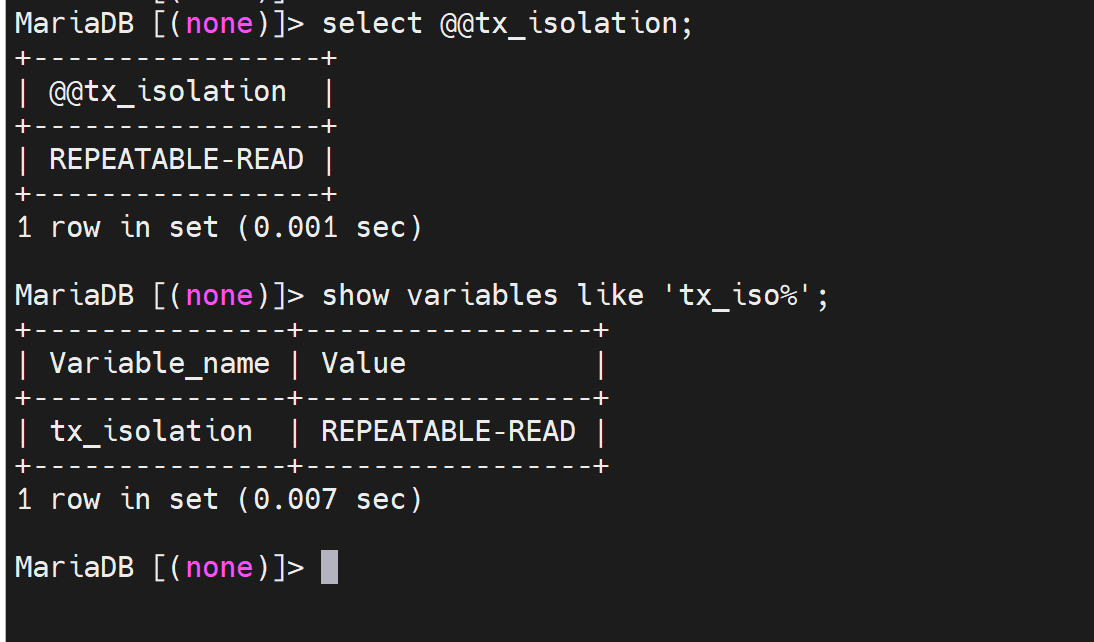
可见这是一个服务器变量,这个是不是一个服务器选项呢。
1、官网查咯:该参数不是服务器选项👇


2、自己试咯:
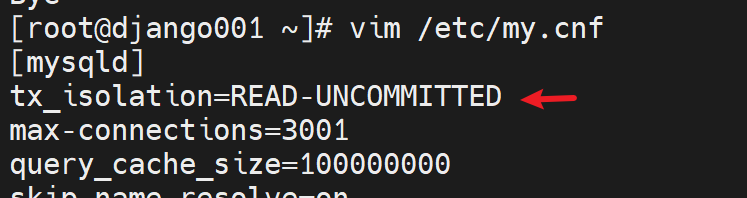

详情倒是没有指明是这一行,不过有unkown variable这个未知变量 该关键字可以联系起来
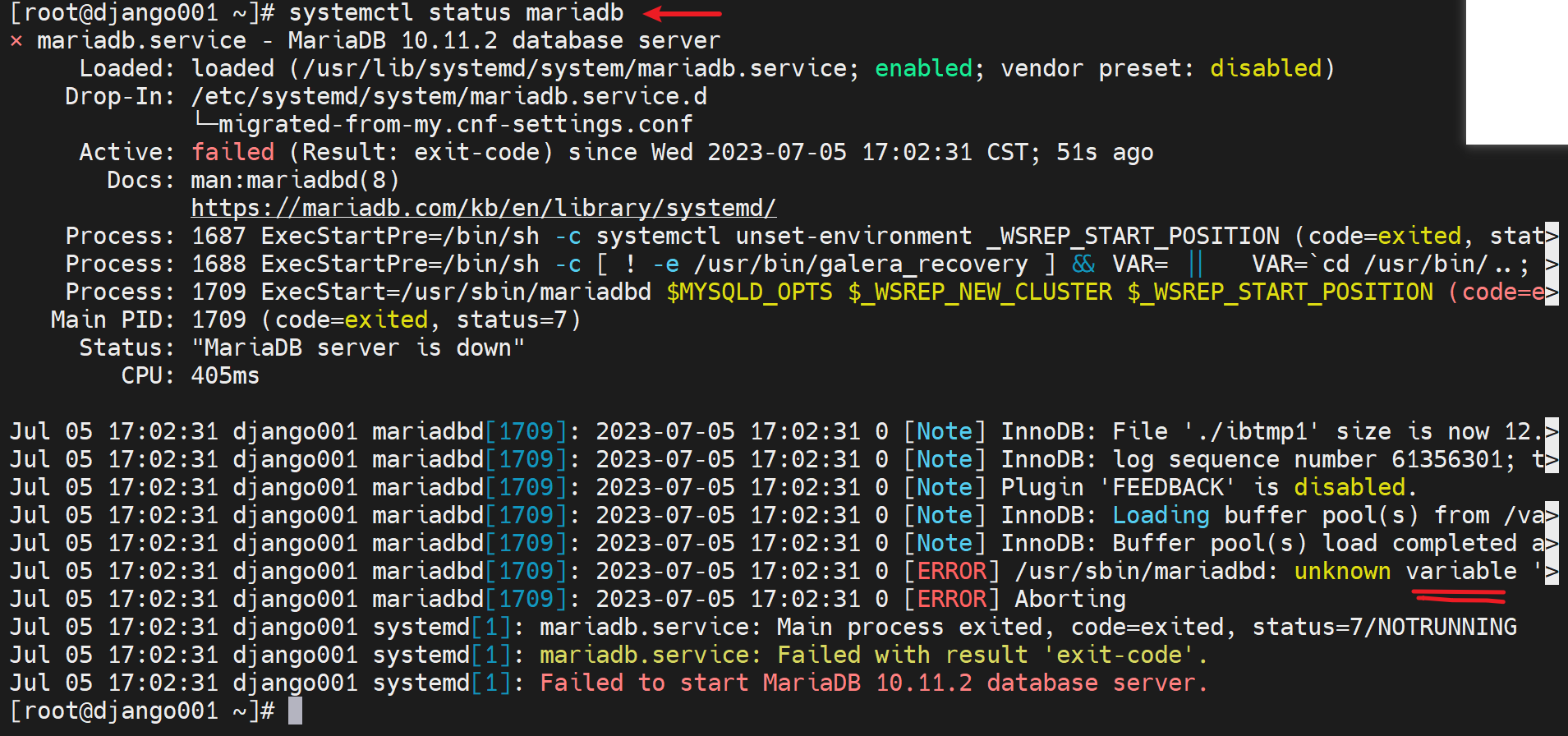
然后注意看

这是mariadb里的
这是mysql里的
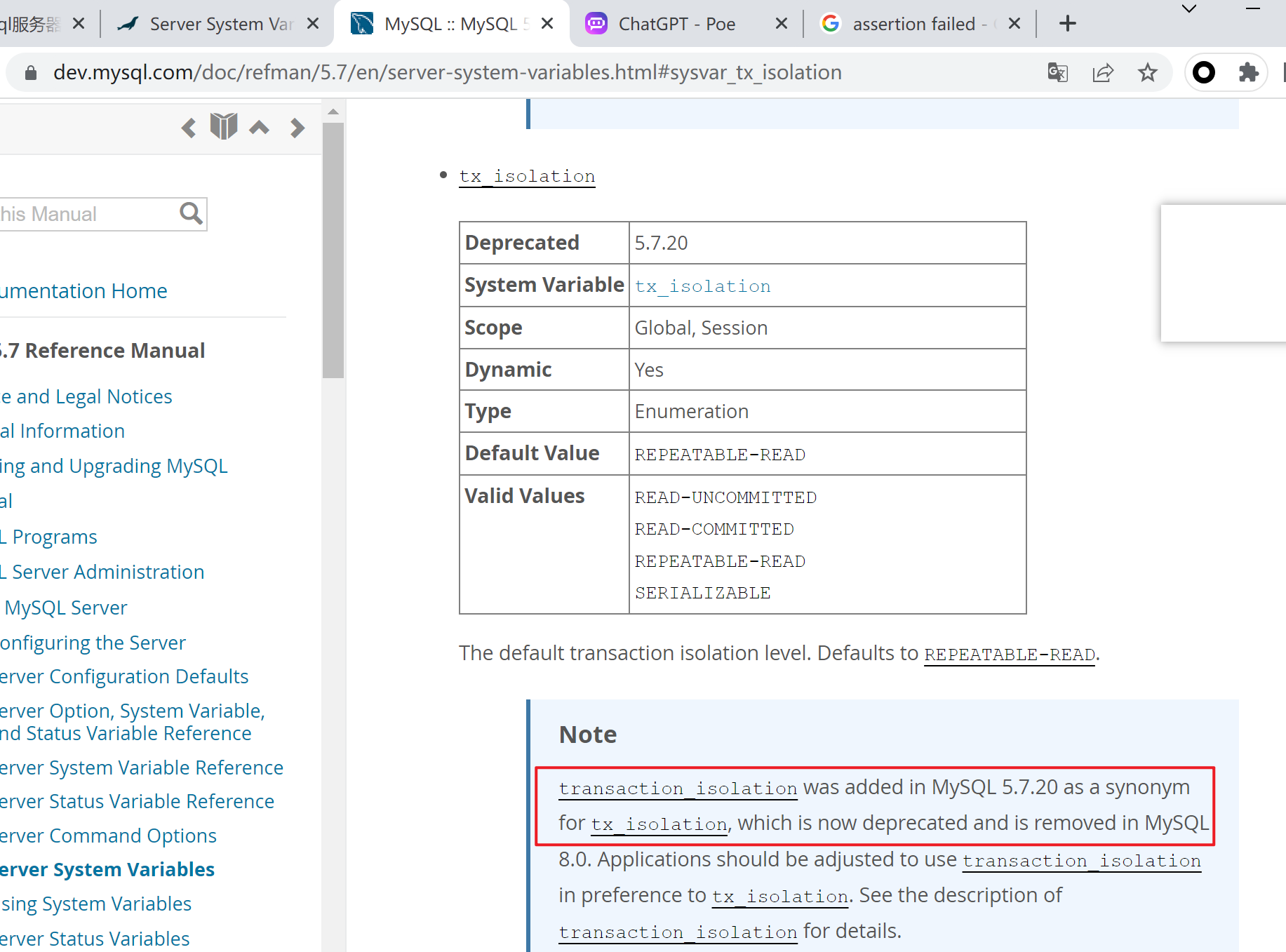
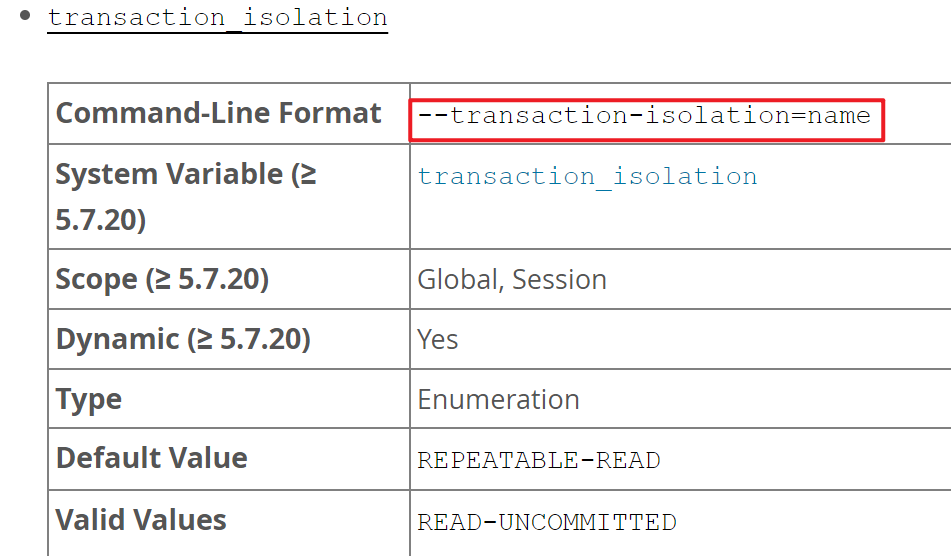

这个transcation_isolation(只是一个选项),用来对应tx_isolation(只是一个变量)
其实眼神好一点,一开始查到的是可以看到了
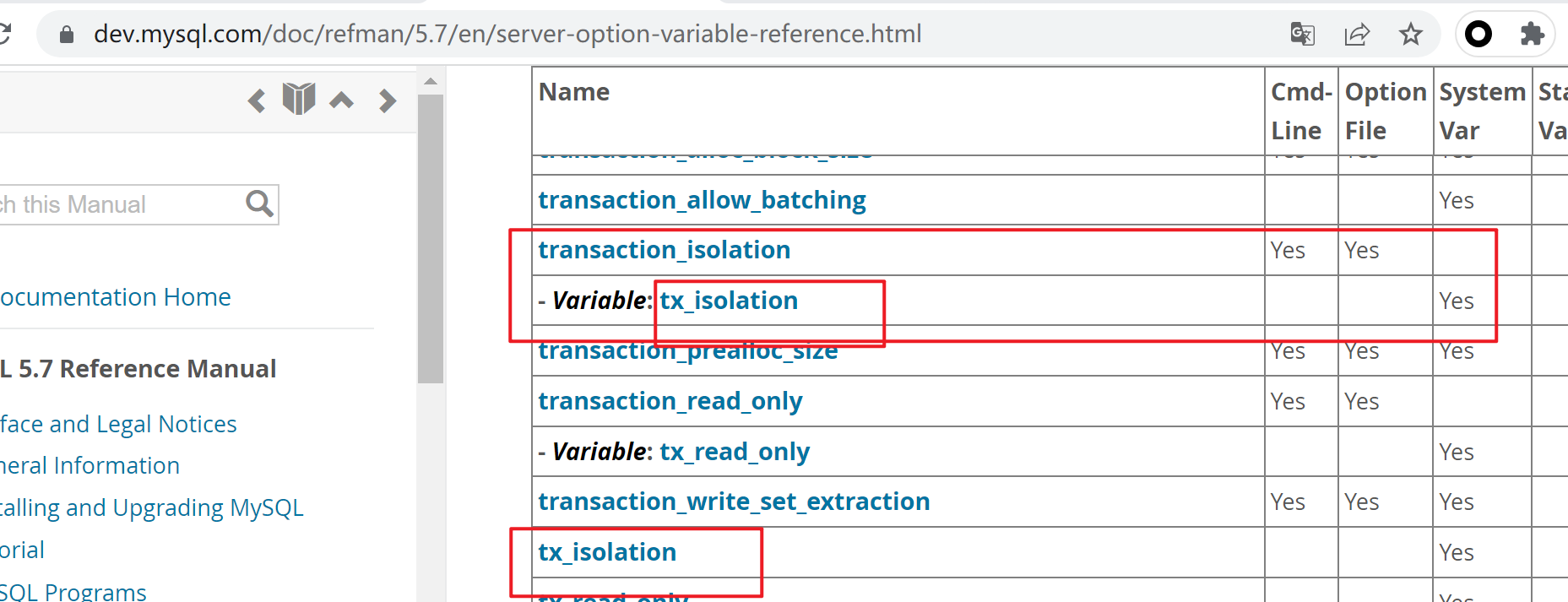
同样mariadb也有
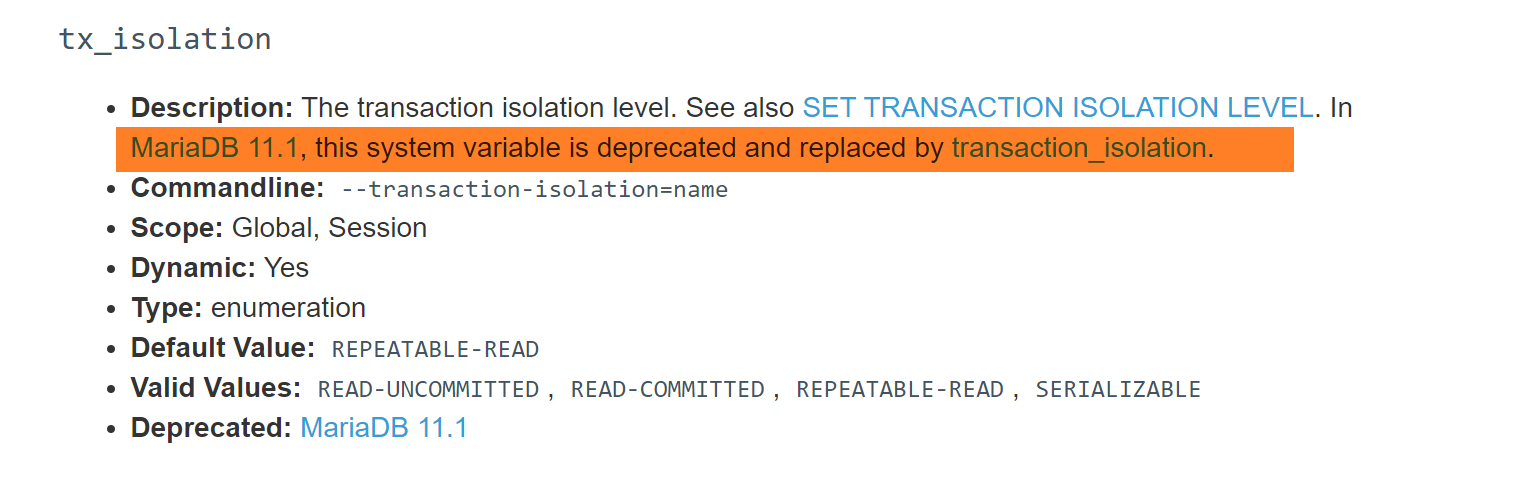
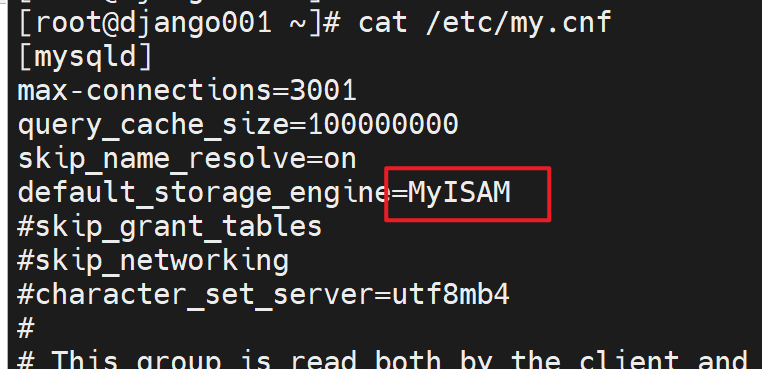
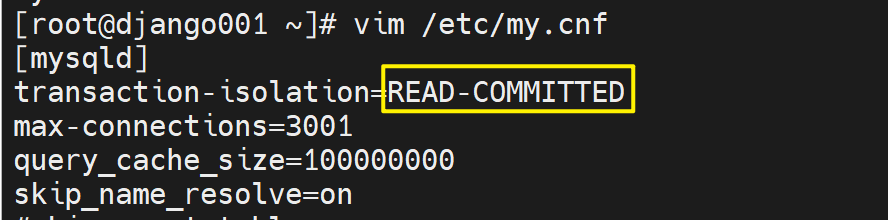
继续修改配置文件


OK啦
此时变量就改过来了
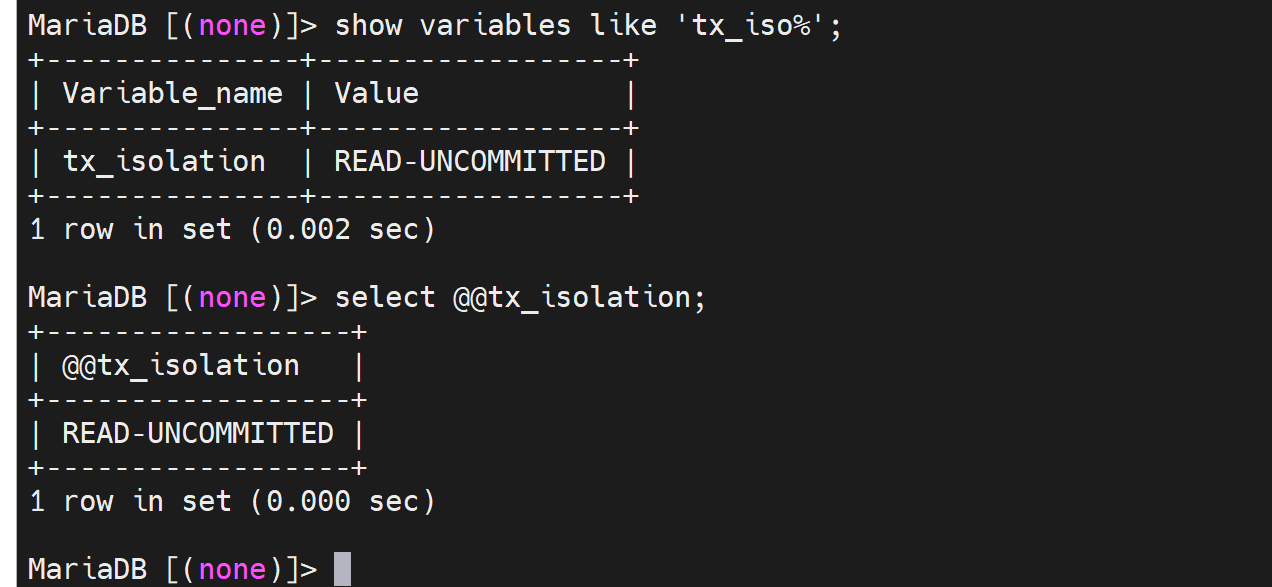
开始体会下事务
1、第一种事务级别read-uncommitted
两个窗口都开启事务
左边的用户insert一条记录,但是没有commit,
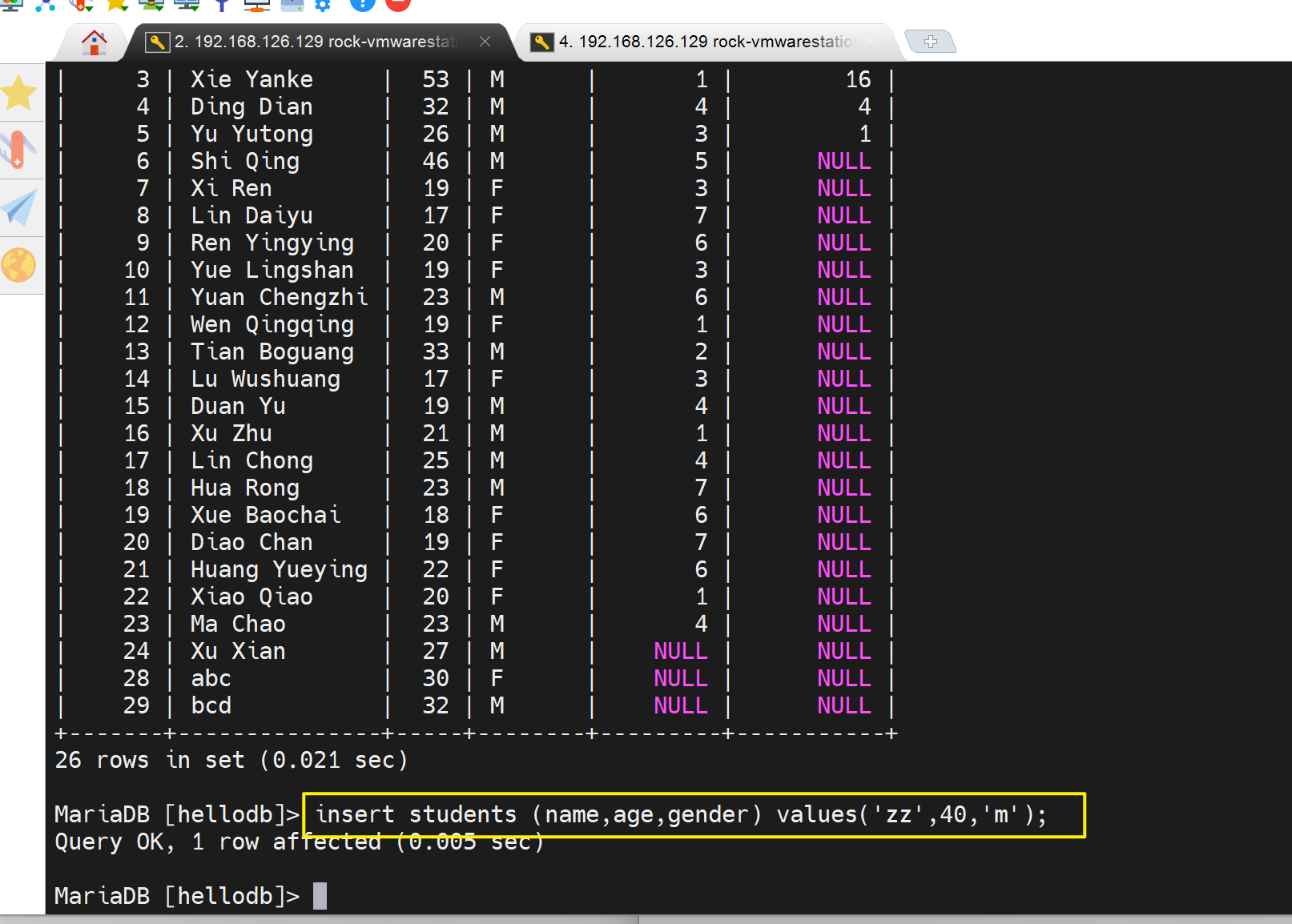
此时由于事务级别是 READ-UNCOMMITTED
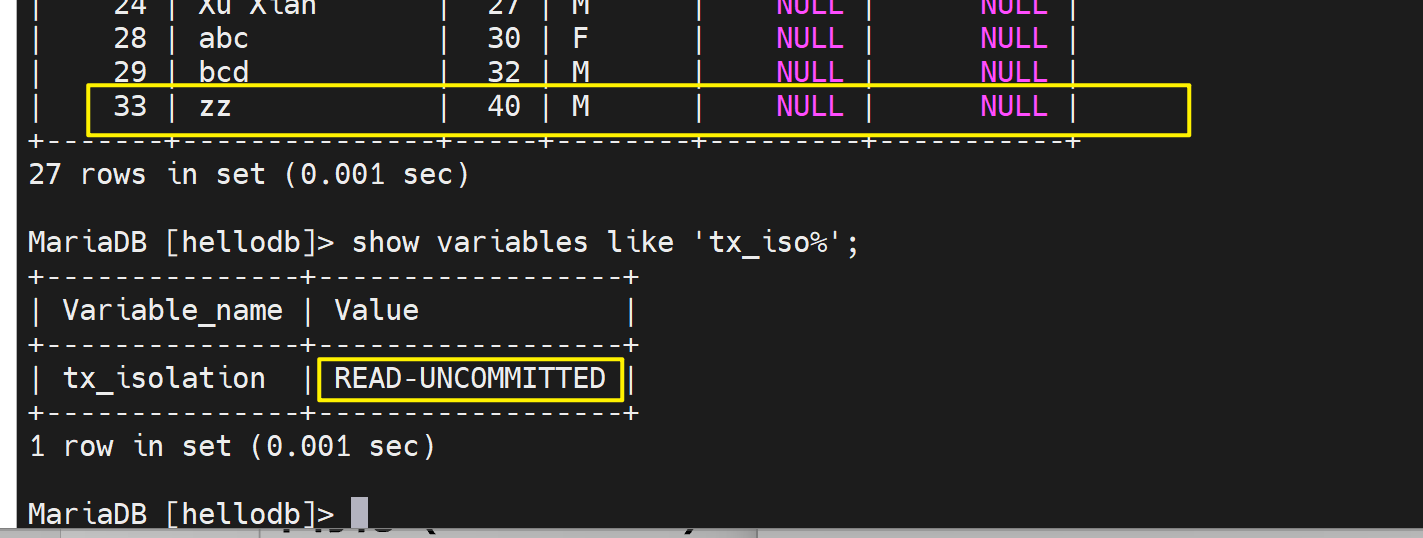
这就是脏数据了
然后左边的用户rollback撤销
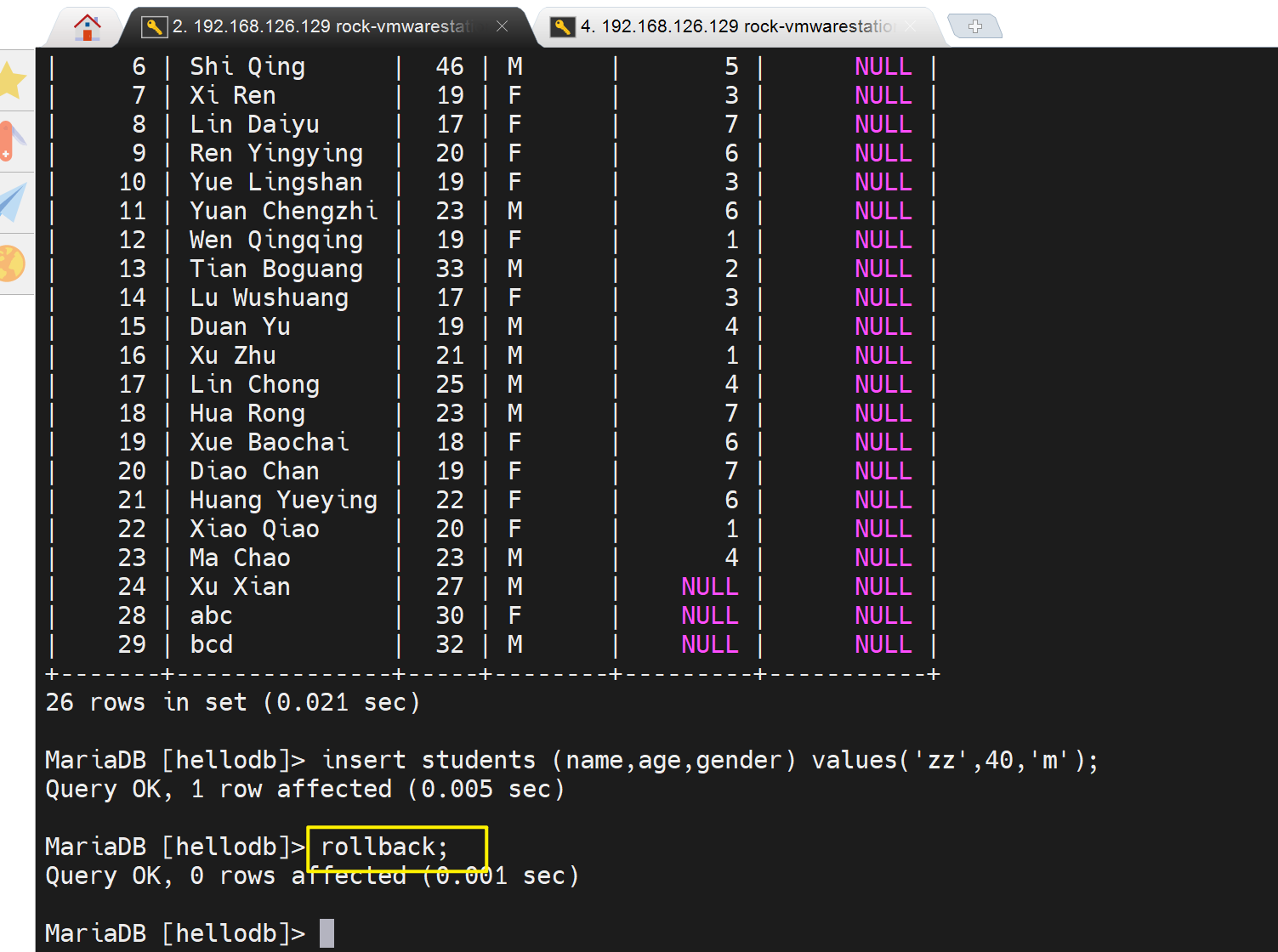
左边用户自己肯定也就没了
右边用户自然也就同步了
这种情况对于右边的用户,看到了事务中间过程的数据--未提交的就是脏数据,然后换个角度来讲,对于右边的用户来讲,这个"33 zz"行 一会出现,一会又消失,就是幻读啦。

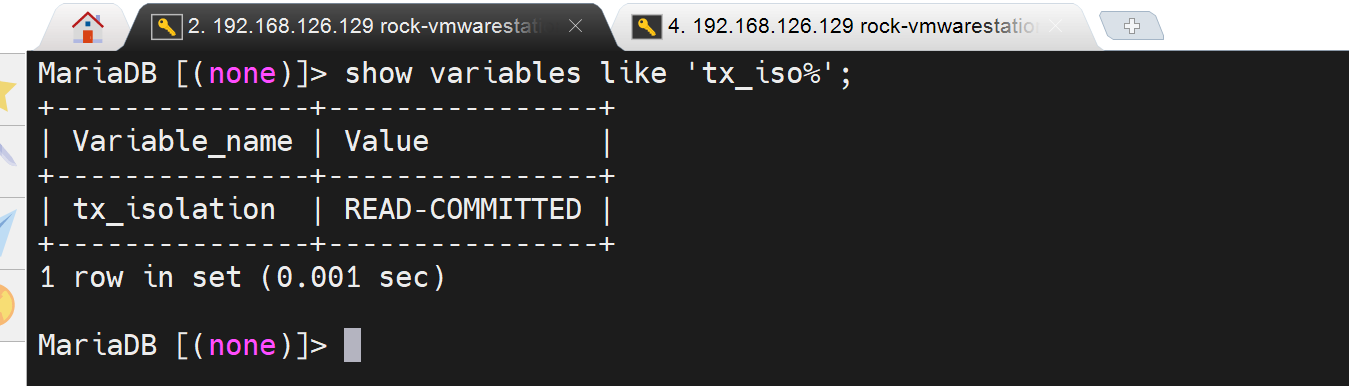
2、再看看地中事务级别-read-committed
重启服务后看下当前两个窗口的事务级别:
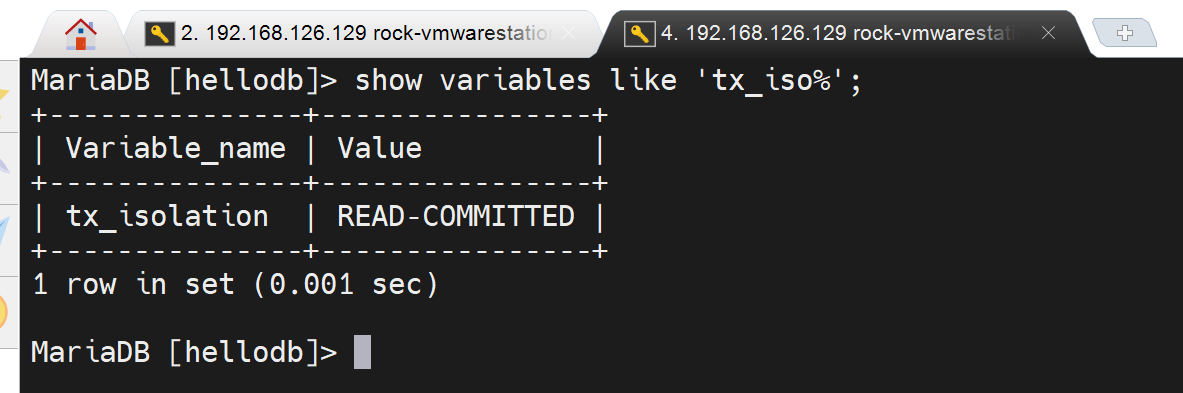
左边的用户插入
左边自己自然可见

未提交的时候,右边用户select是看不到的,因为当前事务级别是read-committed
然后左边用户commit提交一下
此时右边的用户就看到了👇。
虽然上面演示完了,但是存在一个点,就是右边的用户开不开其事务,其实在这个实验中效果是一样的,已测试。
存在第二个点,这个是疑点,就是用户begin;开启事务后,你别的人重启数据库,然后该用户虽然界面看起来没有变化--还是在myslq交互界面里的,但是他继续commit就会报错了,当然commit之前insert的数据其实就丢了。看下面的过程演示:👇
1、用户begin一个,然后insert一行,未提交
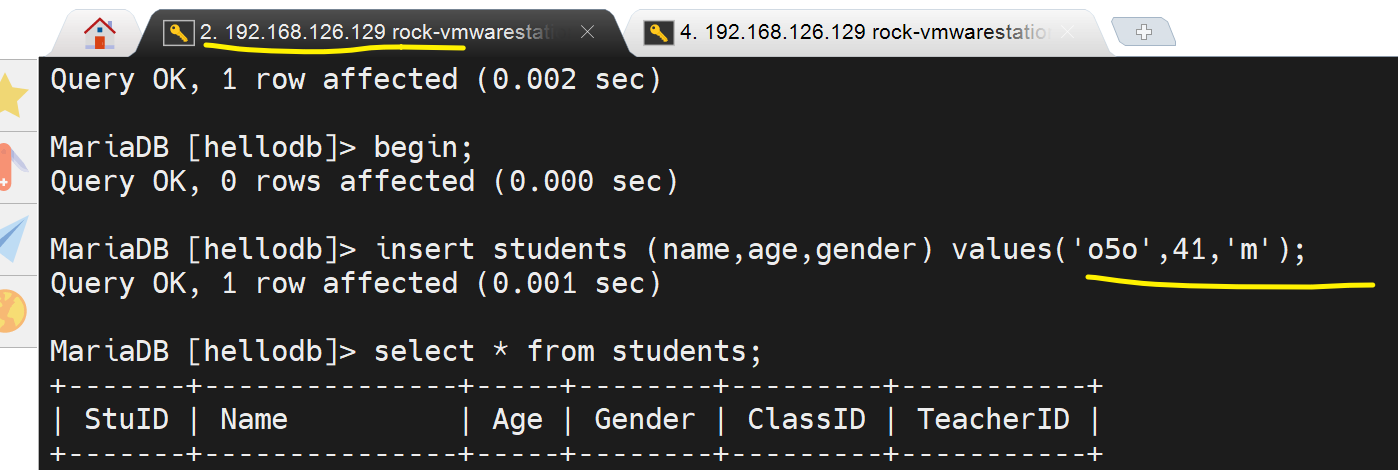
当然自己可见:👇

还未commit哦。
2、别的用户重启服务

3、回到左边的用户,myslq还是登入着的
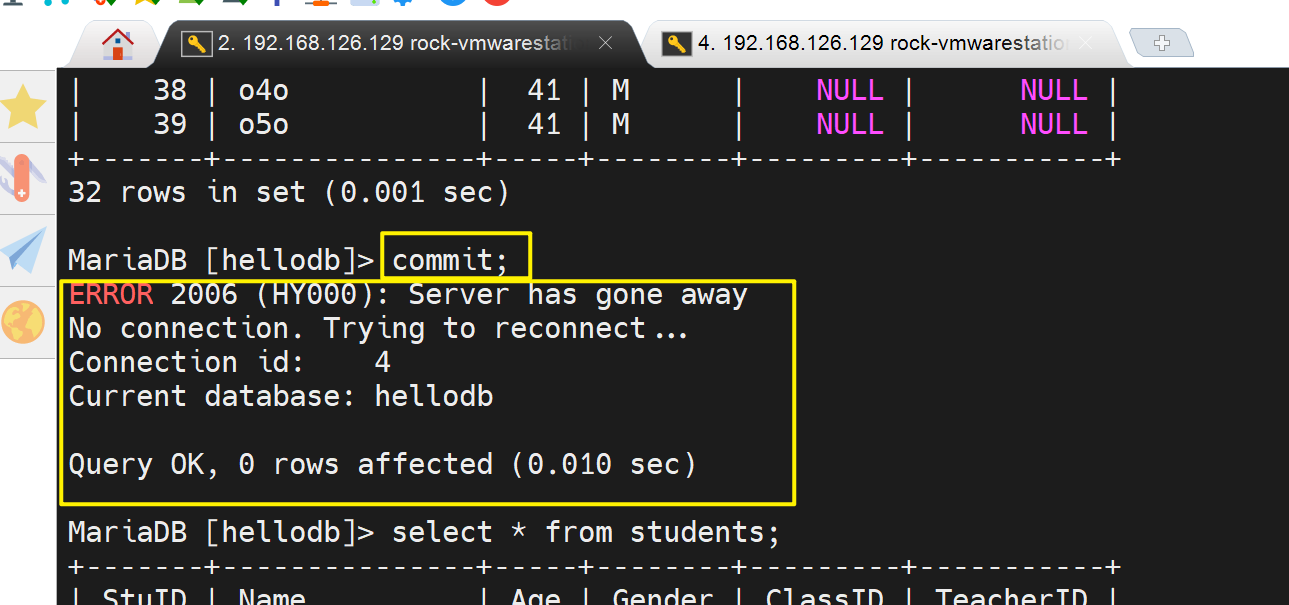
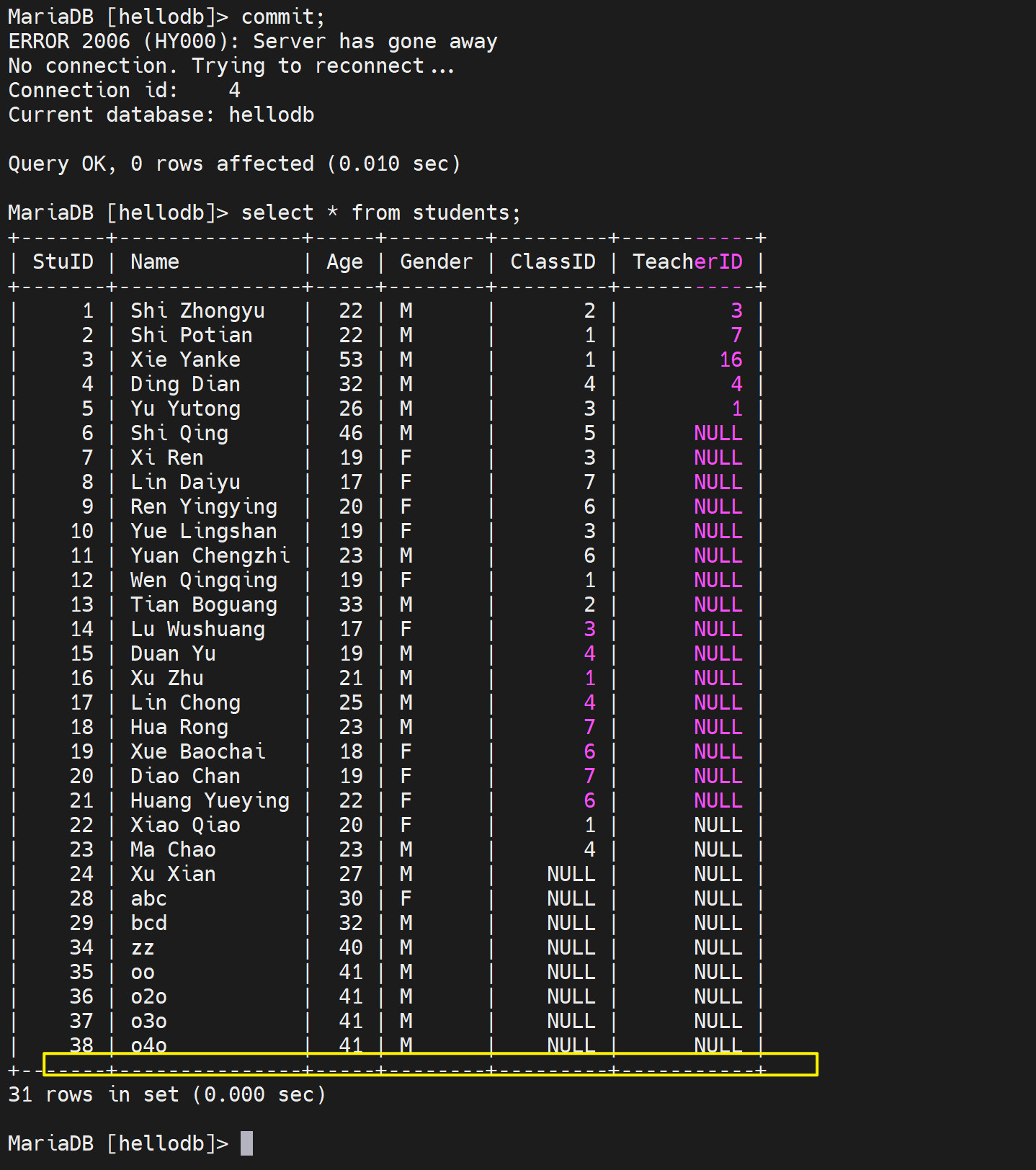
但是像接着之前的事务,进行commit,就发现报错了,server has gone away
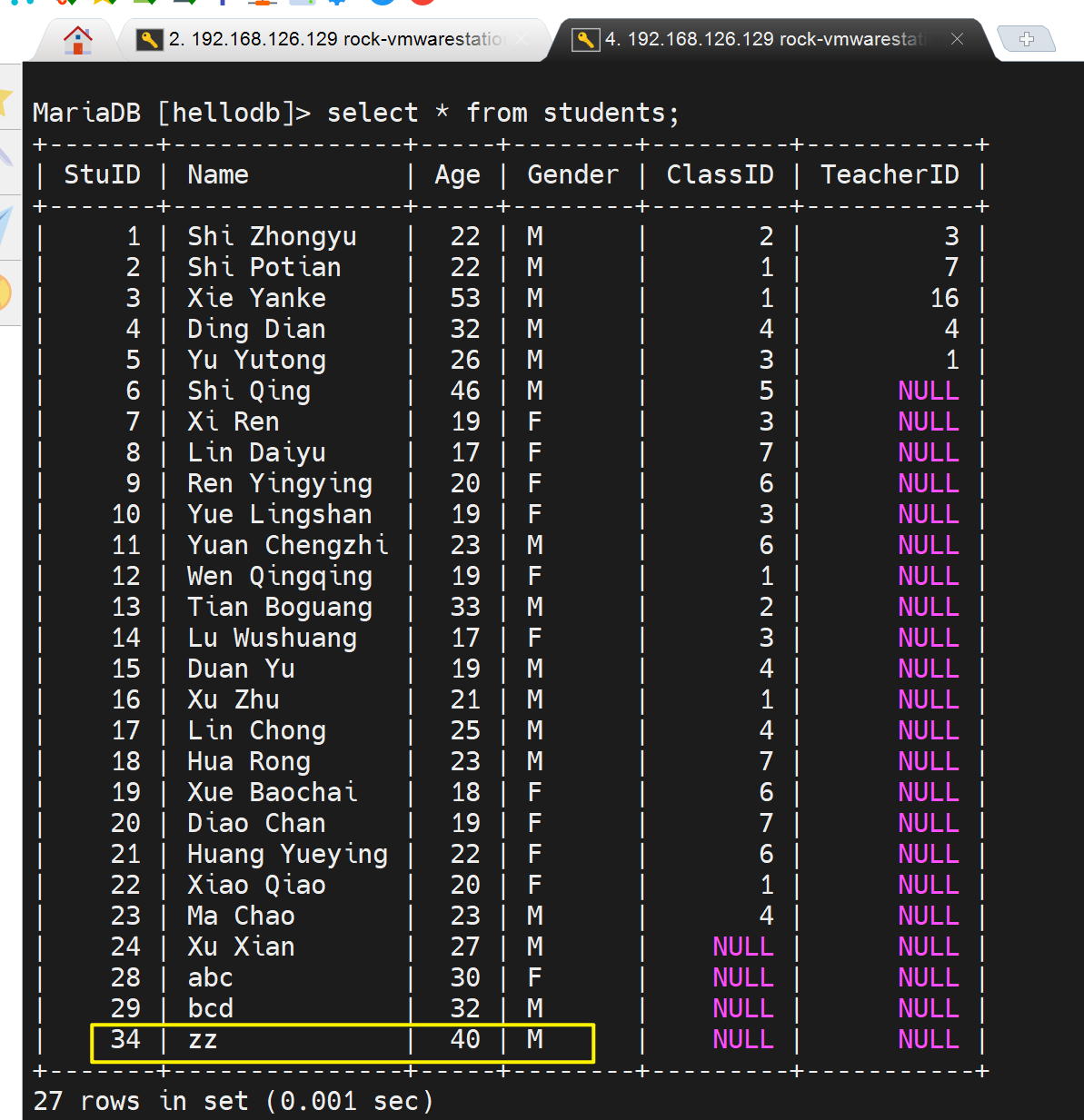
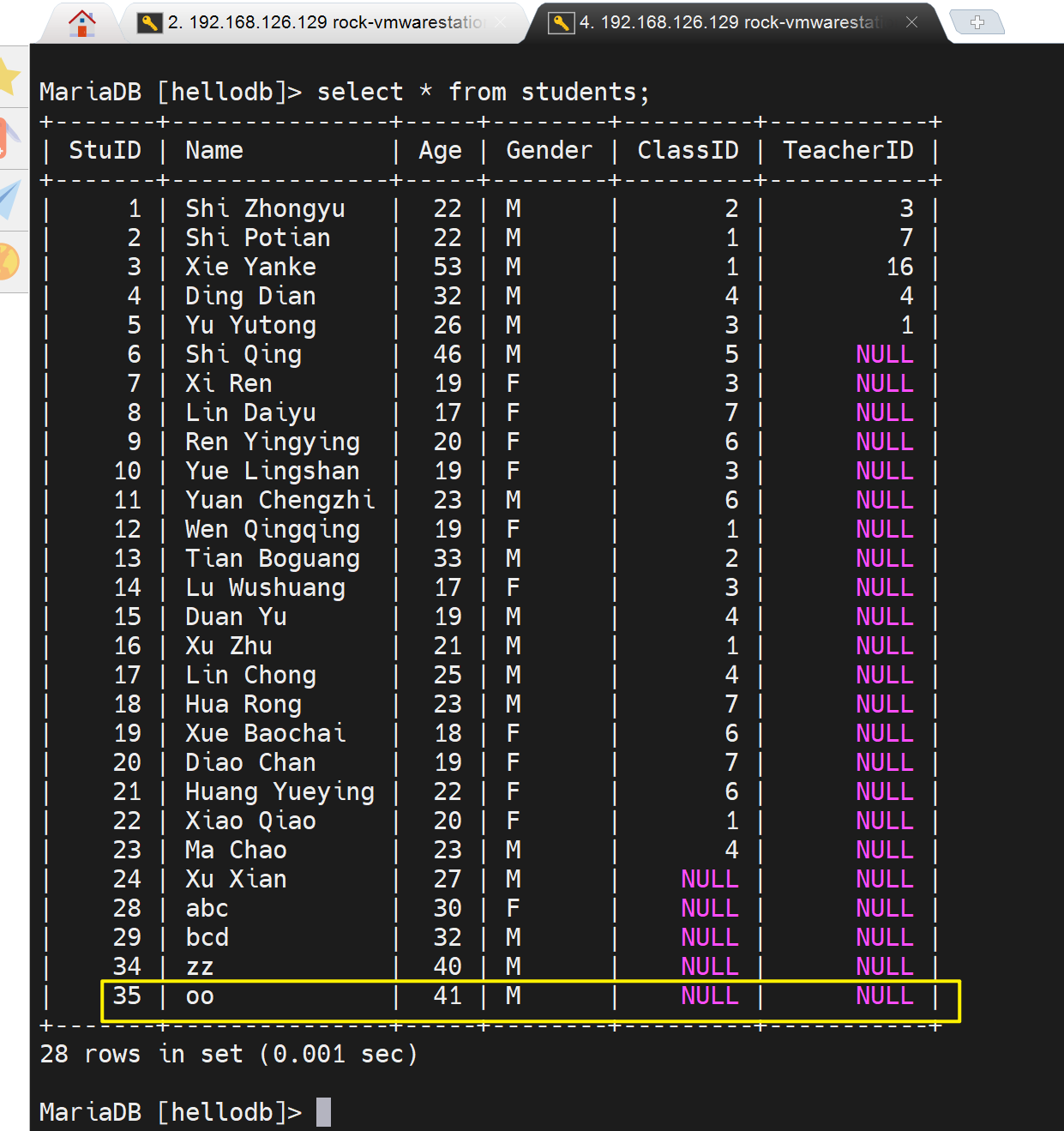
然后实际上,之前的insert 记录就丢了,下图👇39记录o5o就没了。
3、看第三个事务级别repeatable-read
重启服务,哦,对了删掉,这是默认的事务级别,不用特地手动写。
确认事务隔离级别
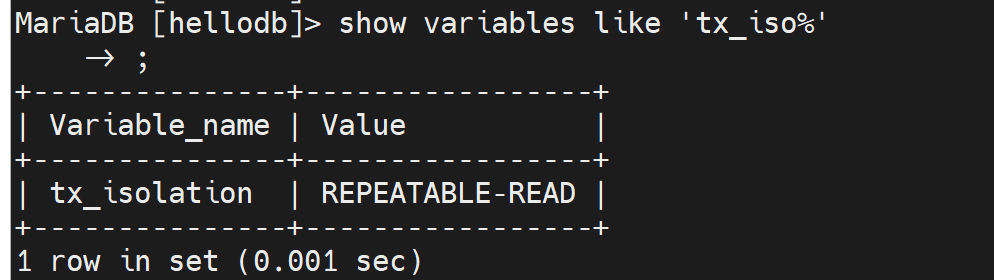
开始实验测试可重复读的效果
可重复读嘛,就是B一开始读了后就不会变,但是要注意右边窗口要开启事务的,左边随便开不开都一样,因为这个级别就是可以重复读机制。
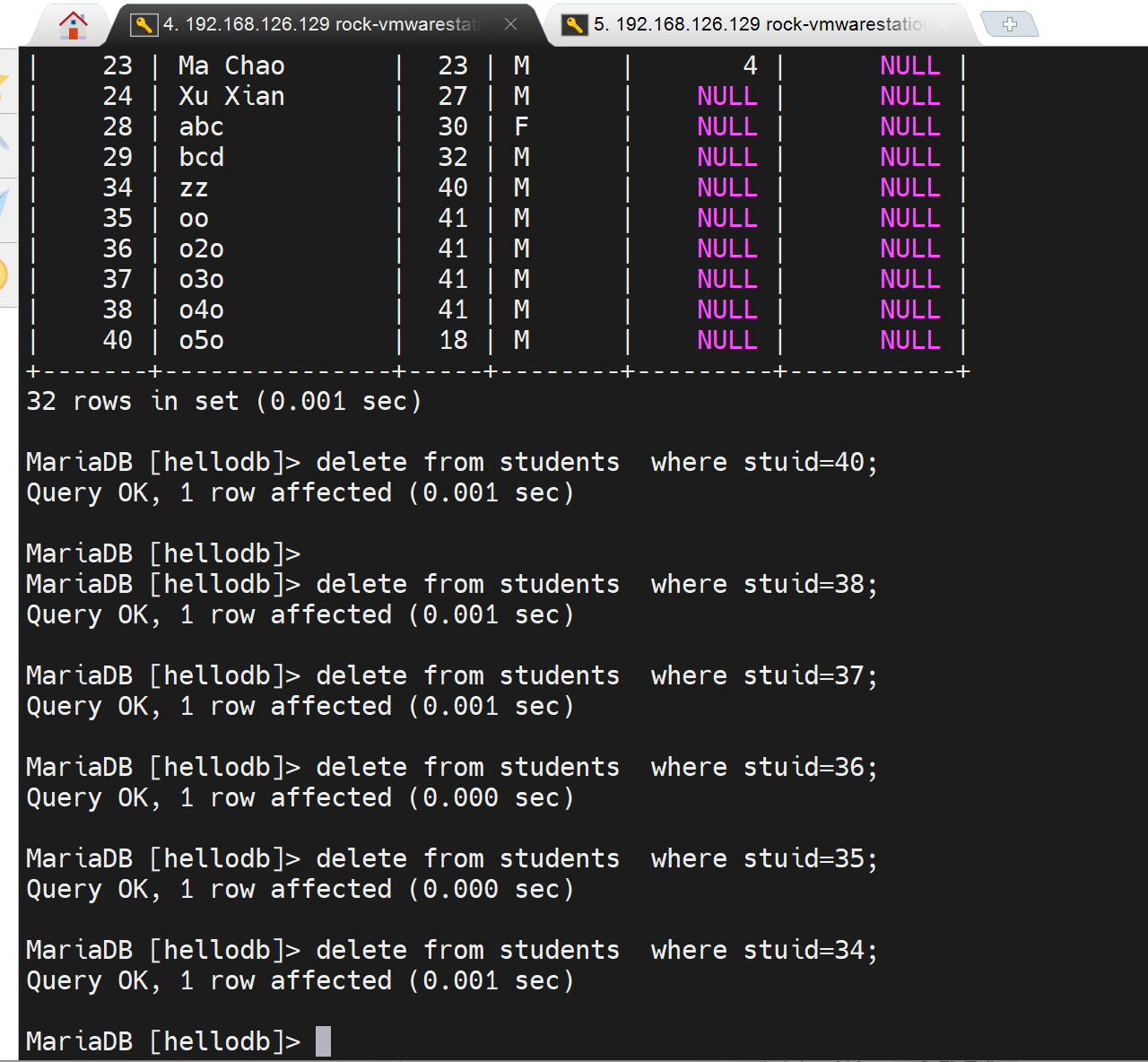
左边删了好多,并自己可见,且commit了
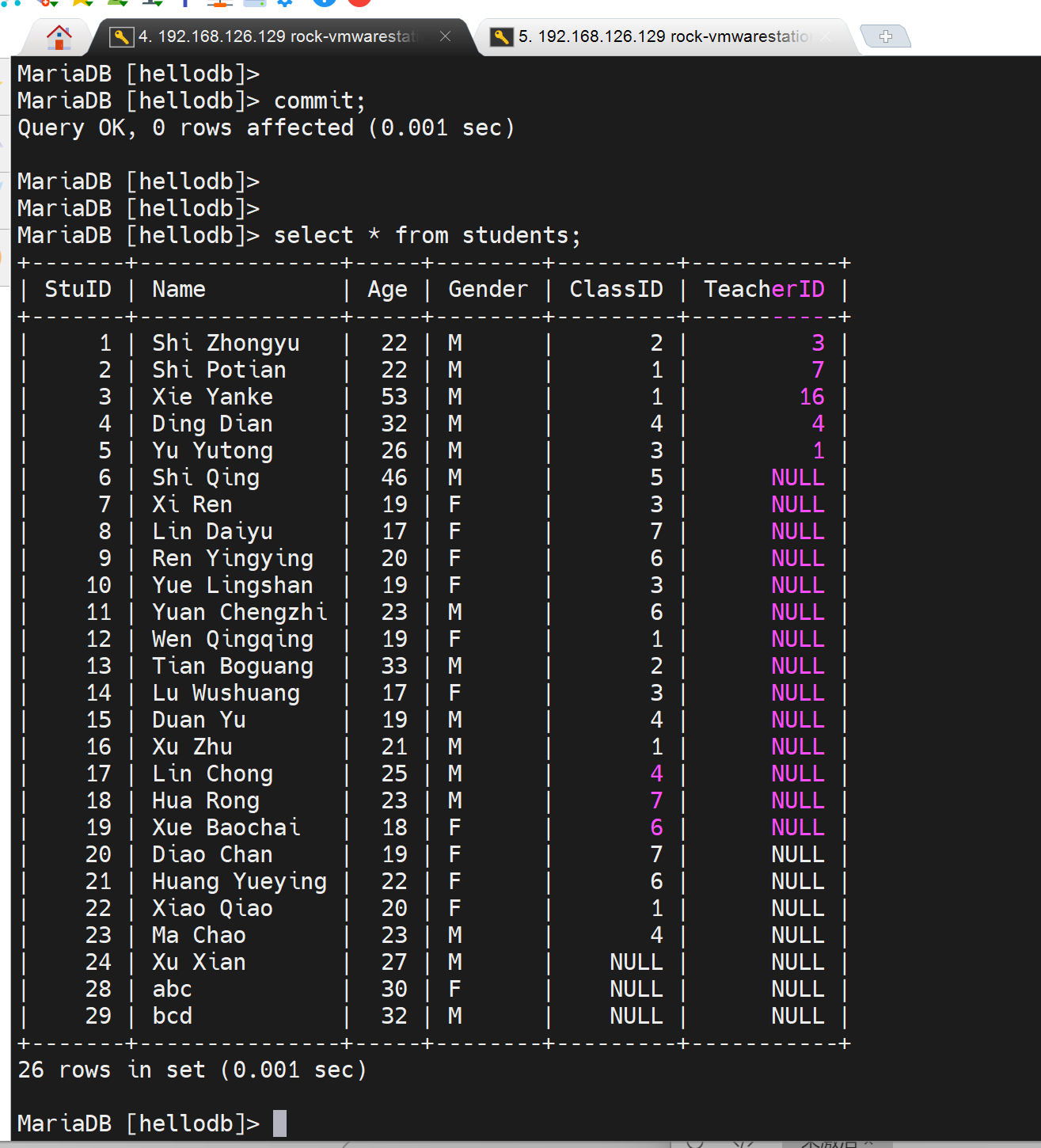
右边还在
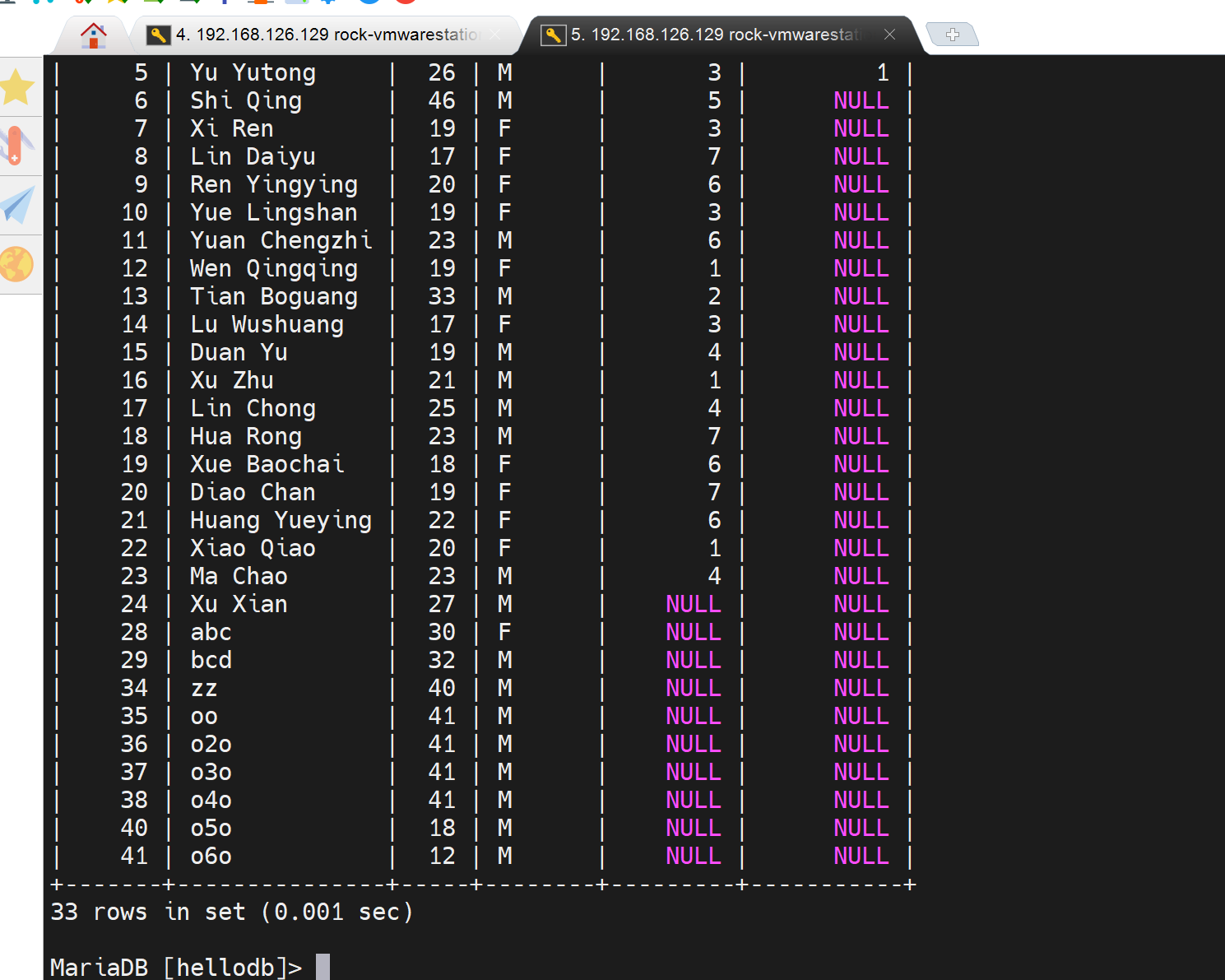
右边用户只要退出自己的事务commit一下,就可以看待最新的数据了。
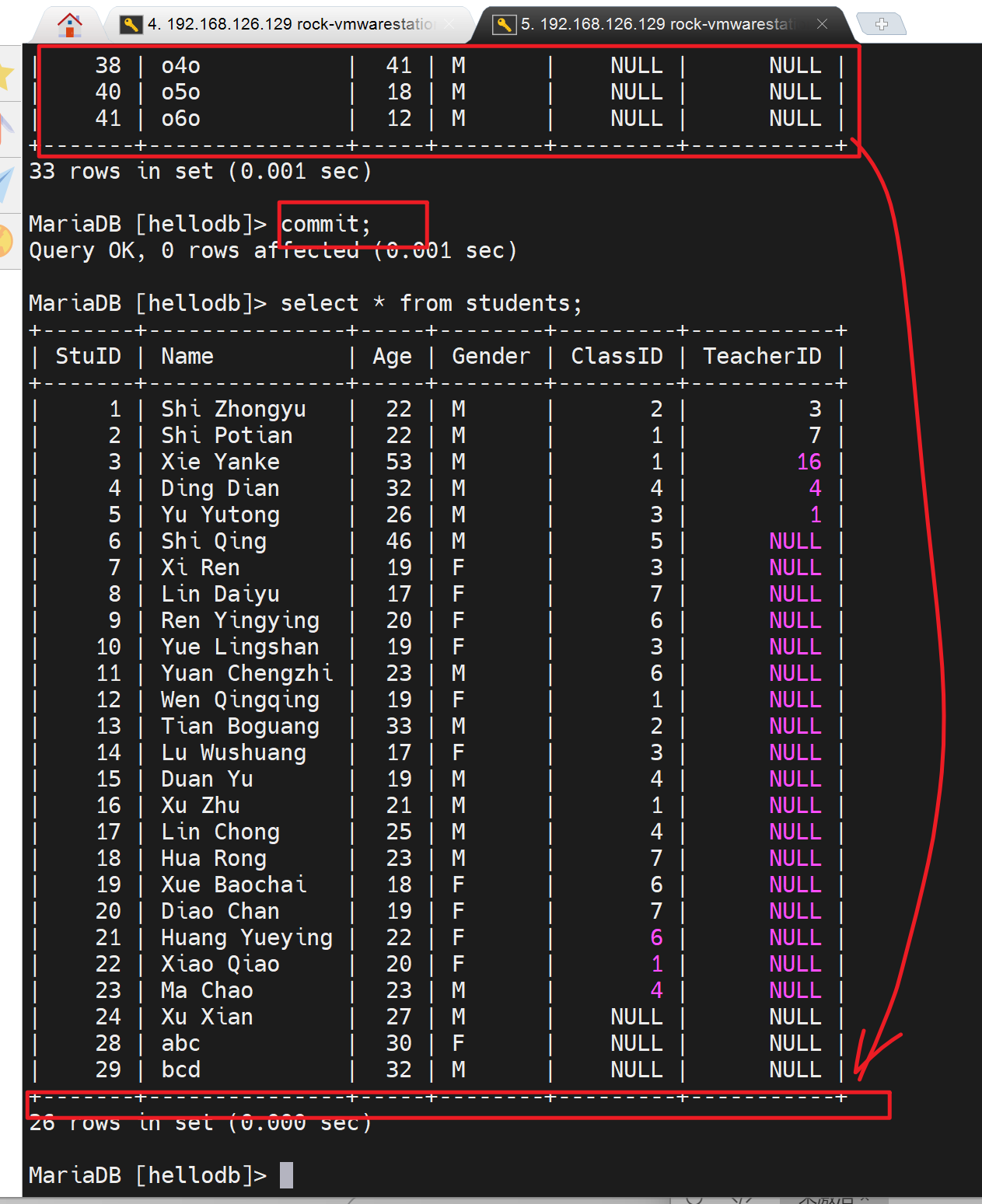
所以这个默认的repeatable-read重复读机制是说的一个用户开启了事务后,重复读的结果一样不变,适用于备份,也就是说备份的时候要开启这个事务日志来备份。
4、第四个也就是最后一个事务级别serializable
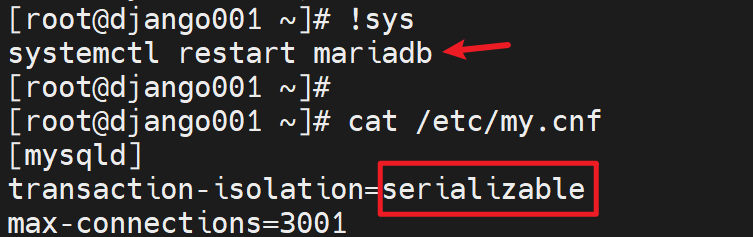
重启服务后确认
这种begin只是开启事务,但是没有读也没有写,所以不叫 "未提交的读事务 "

SERIALIZABILE 可串行化,"未提交的读事务"阻塞修改事务,或者未 提交的修改事务阻塞读事务。导致并发性能差
此时右边有一个 未提交的读事务 ,所以其他人的 修改都不可以了,看下
此时右边窗口随便开不开事务了应该,
开启事务也是一样的效果

插入一样阻塞在那

这个时候,只要左边的窗口提交commit一下,右边卡住的就可以继续进行下去了。

时间太长也不行,
上图commit也可以缓存rollback一样的效果。
commit是提交+退出了事务,rollback直接是撤回+退出事务

19.254sec的耗时👆,

上图的毛病在于,右边的查看要开启事务的,才会被阻塞;不开启不会被阻塞

①未提交的读事务,可以阻塞别人的修改事务,别人读,开不开都会被阻塞。不影响别人的读;
②未提交的改事务,可以阻塞别的读事务,但是别人需要开启事务,在事务里读才会被阻塞。不影响别人的改。
恢复默认的事务机制后,研究下死锁现象
死锁现象
这里有两张表t1和t2
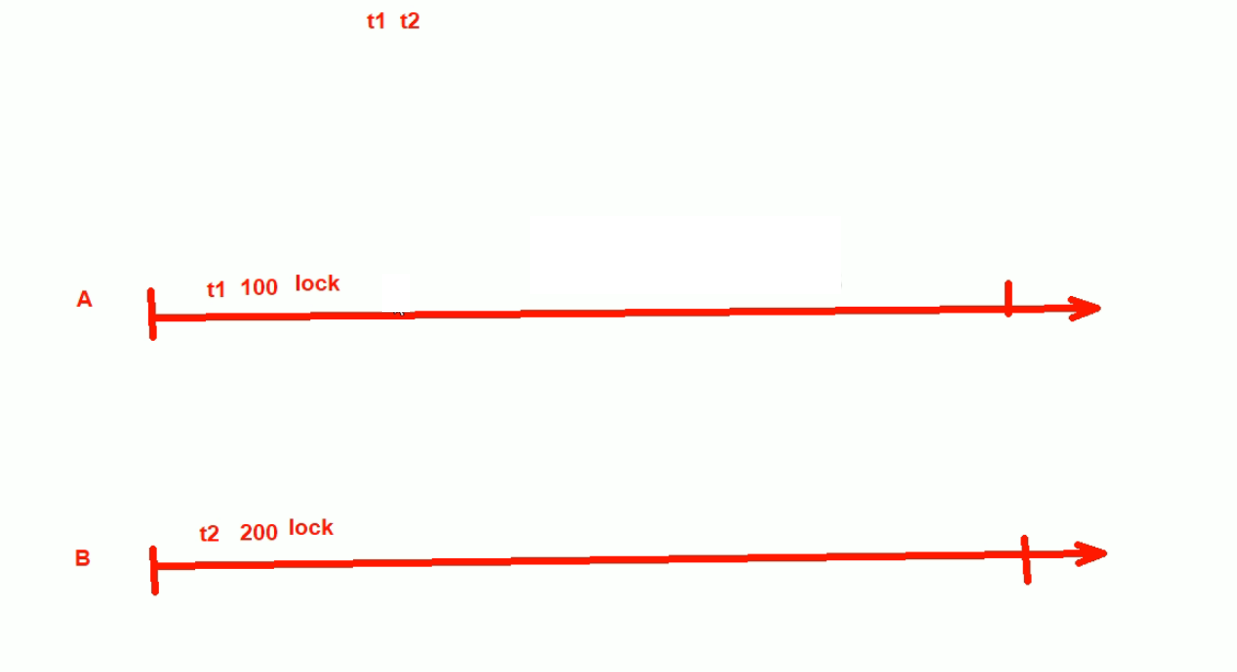
1、A用户去需改t1表,B用户修改t2表。互相没关系咯应该~
2、innodb是行级锁,
现在A 修改t1表的100行 ,那么那个100行就lock了
B修改t2表的200行,200行lock
各改各的,没关系吧
此时,新的动作来了A又尝试访问t2表的200行,B呢又尝试访问t1表的100行。
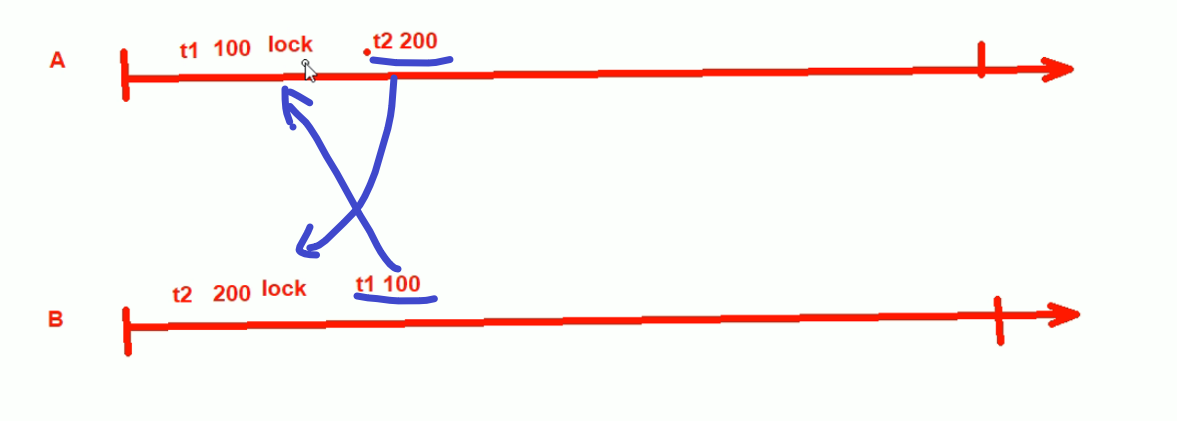

此时就出现了 一跟独木桥,两个人走到中间的情况
这就是死锁了,死锁不用担心,因为数据会自动发现,会自动选择一个事务牺牲掉(rollback撤销掉)。牺牲哪一个呢?哪个下的成本大支持哪一个,放弃另一个,所以基本就是看执行时间哪个久一些,就放弃另一个。实验看下是不是这样的👇
所以接下来看下死锁的实验
1、两边都开启一个事务

2、然后用两张表来模拟一个是students表,一个是teacher表
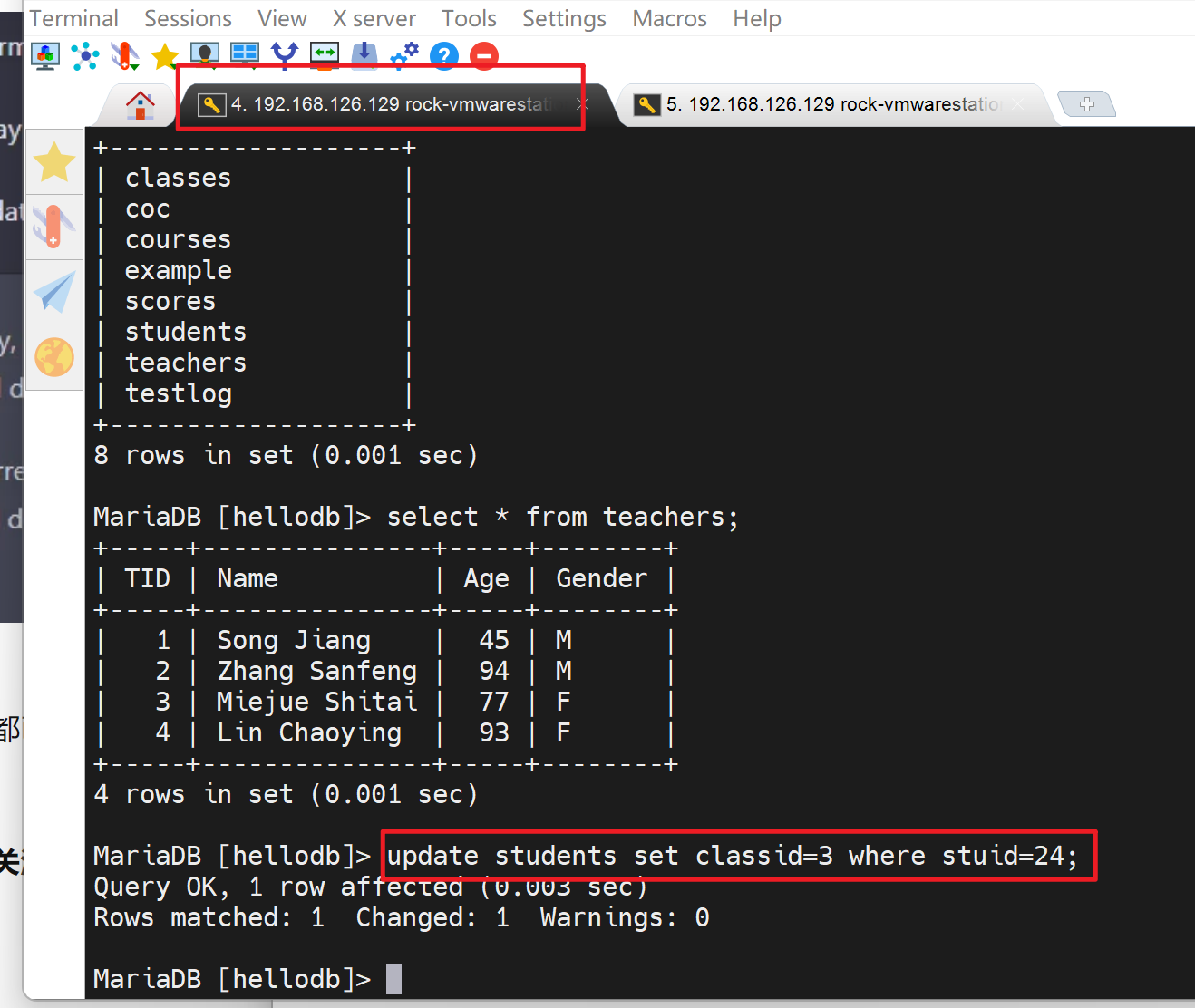
左边用户相当于用户A,update一下,注意哦之前是两个用户都开启了事务的。
左边修改teachers表:相当于这个

右边的窗口就相当于用户B去修改一下teachers表
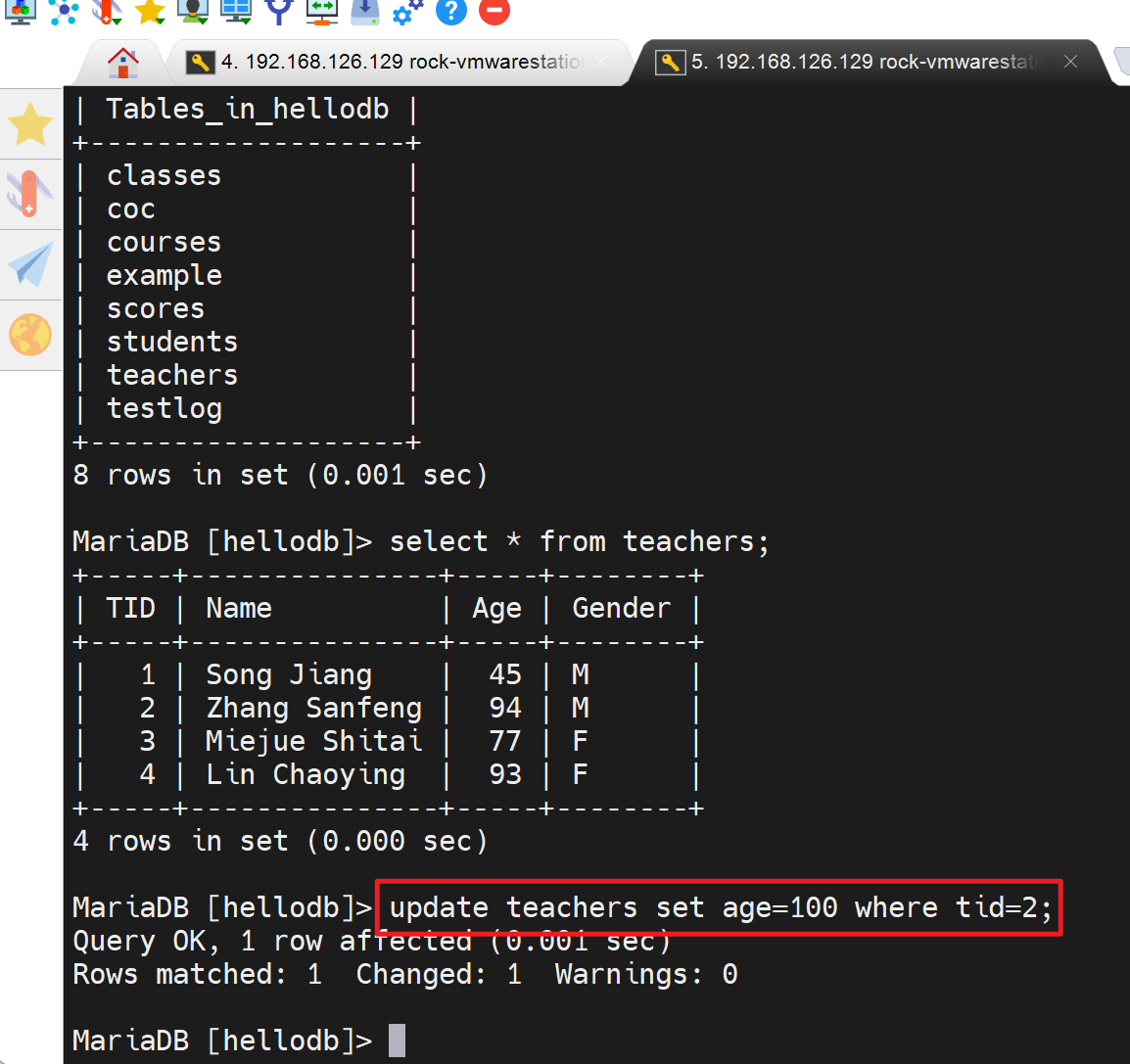
各改各的,目前不相干还。
然后左边A同样改右边B已经改的那一行
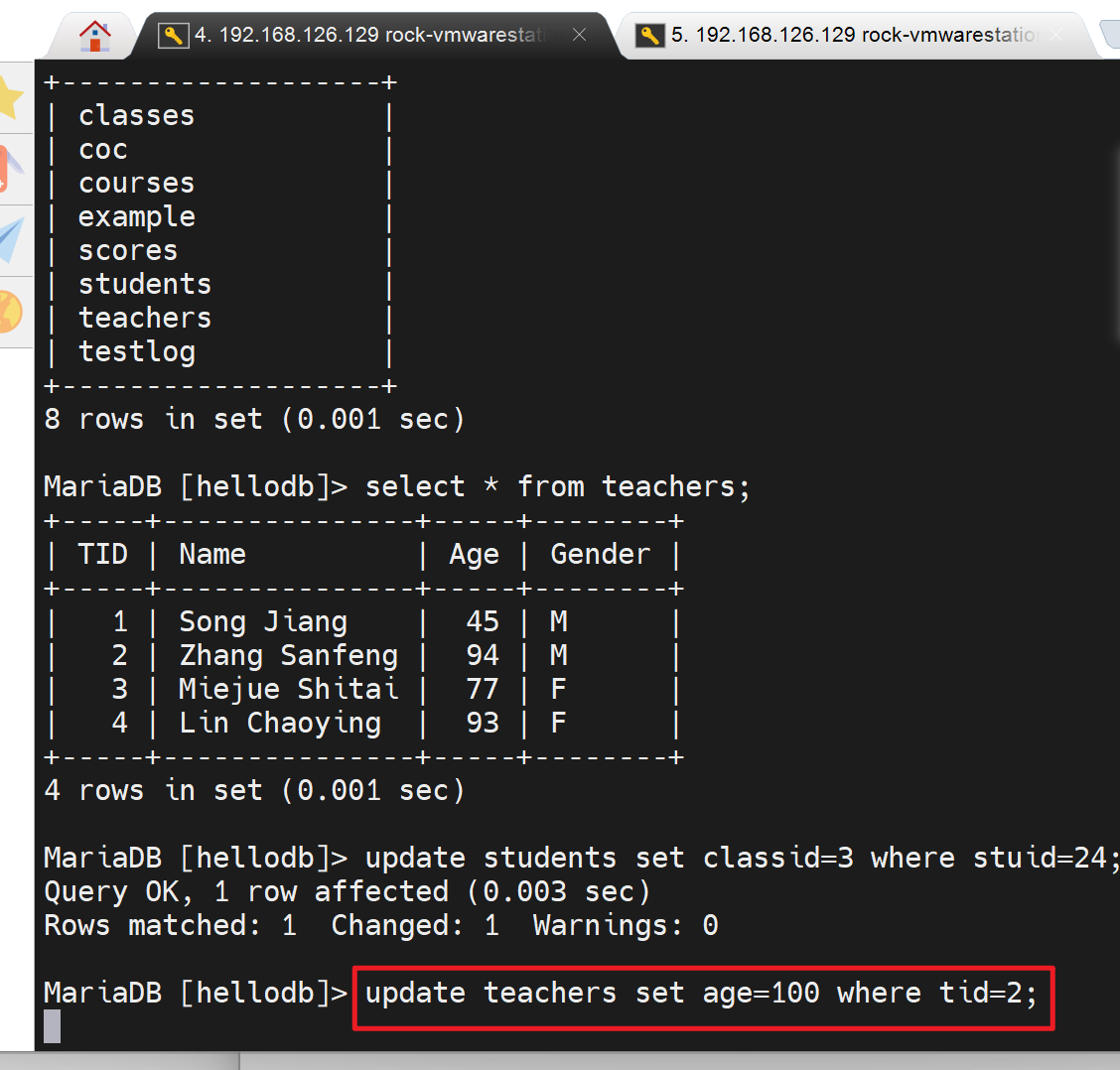
因为B已经加了行锁,注意实验的时候会超时哦,上图会自动断开的,趁着还没断开,去右边的B用户执行一下A已经加锁的哪条命令,
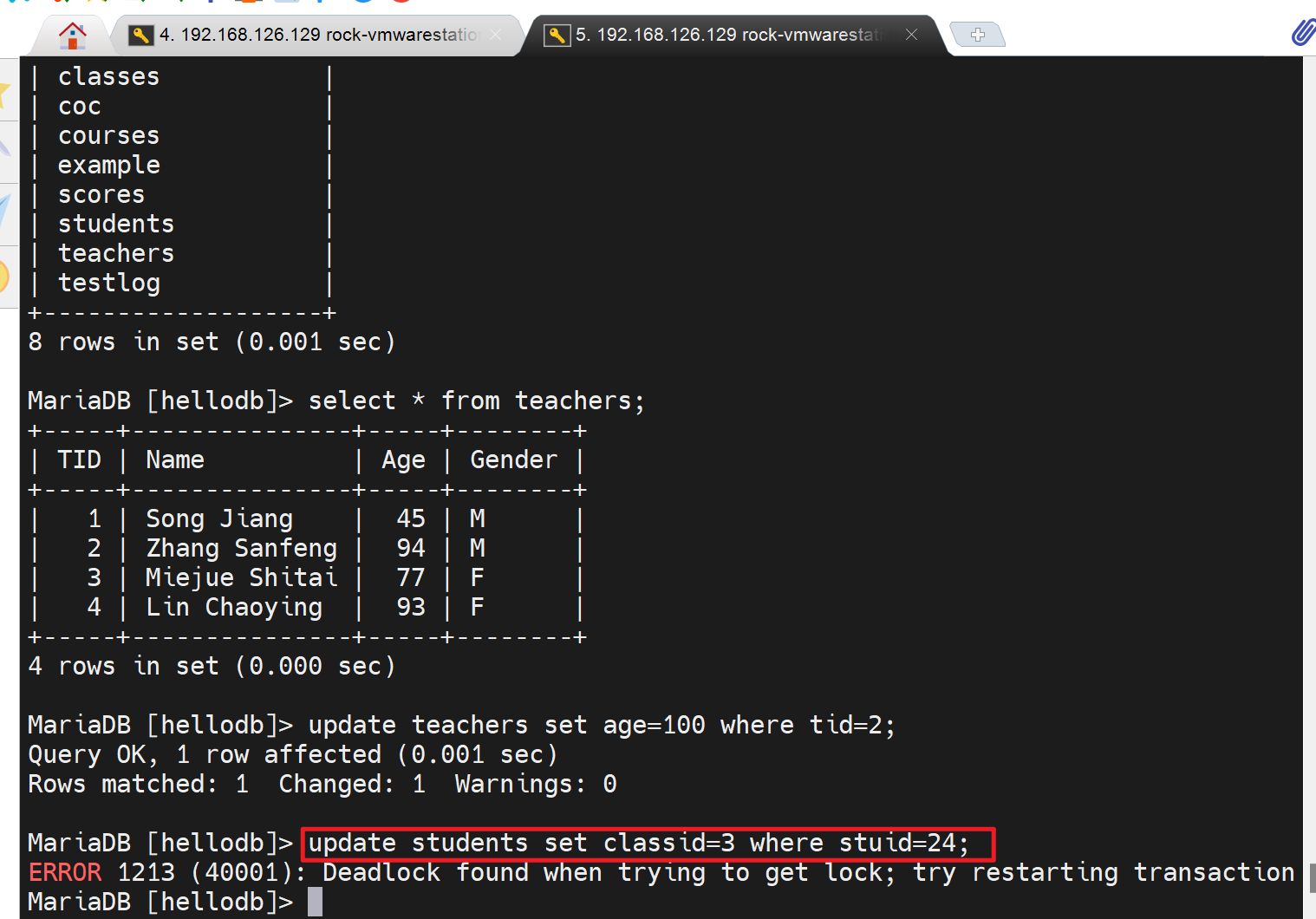
会立马发现两个现象
①B命令敲下去的瞬间,就会报错
②同时A卡在那边的继续进行下去了,就是A人家已经干了那么久,系统就优先保障A了。
一些猜测
左边A
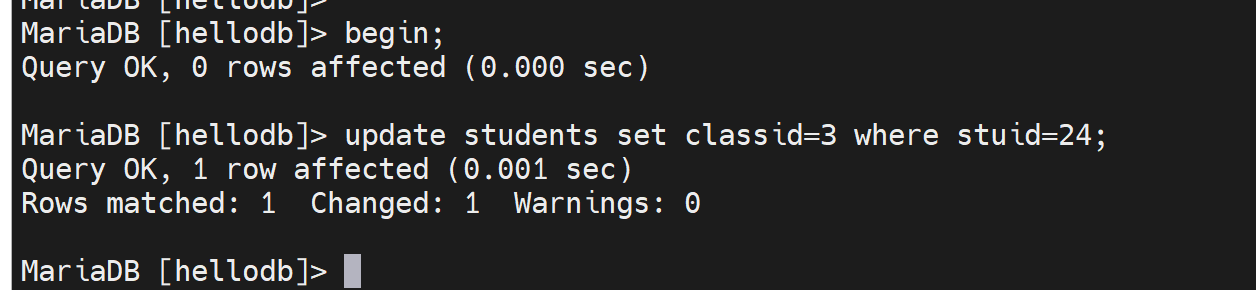
右边B
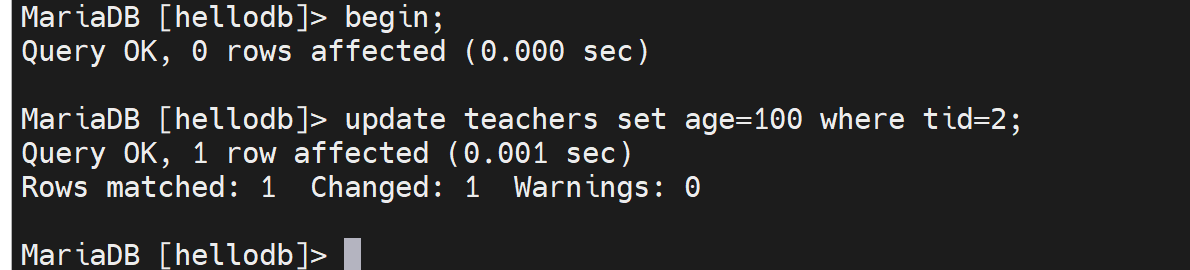
此时
左边A可以读右边B修改的那个表的
同样右边B也课可以读左边A修改的那个表的
不是说写锁是别人不能读的嘛?
如何解决死锁的问题
死锁的原因是👇
避免死锁就要规范用户行为
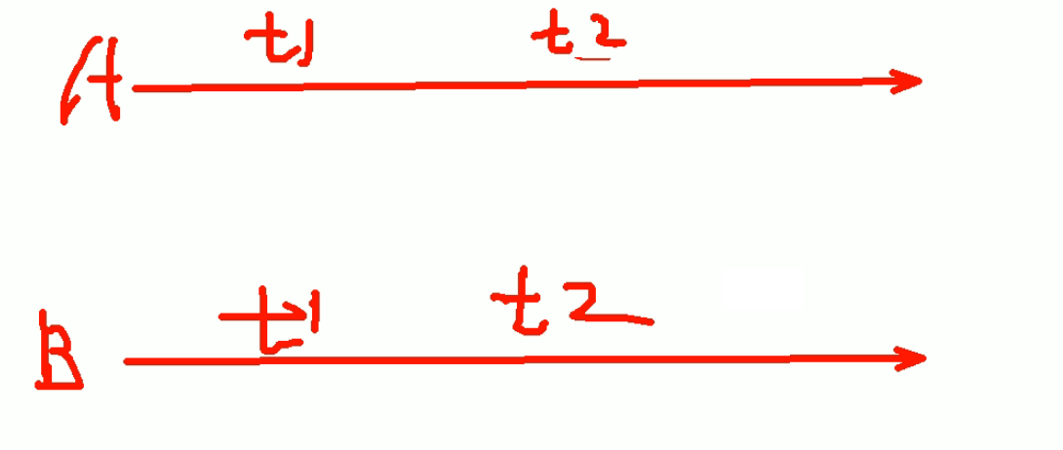
查询的次序是一致的。上图可以避免死锁,不过锁还是在的哦,就是
A改T1表的时候,B去改就阻塞着,等就行了,不过现在又超时机制的,也没事,就是死锁是程序问题,而正常的锁就是阻塞超时就行了