第2节. 文本三剑客1_grep和正则
wc统计

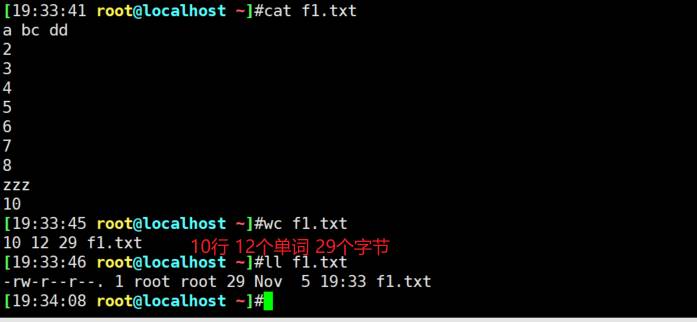

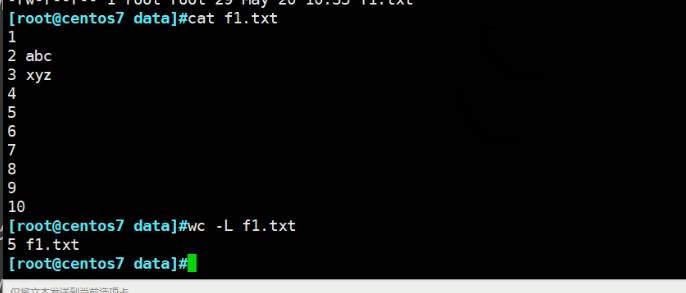
显示最长一行的长度(单位字符?5个字符)

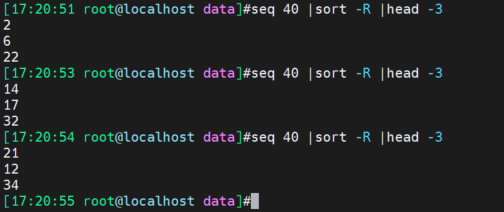
sort排序

排名部分先后,可以用R
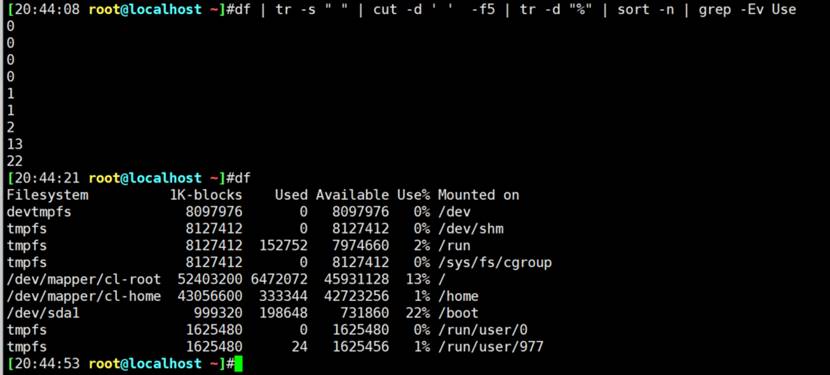
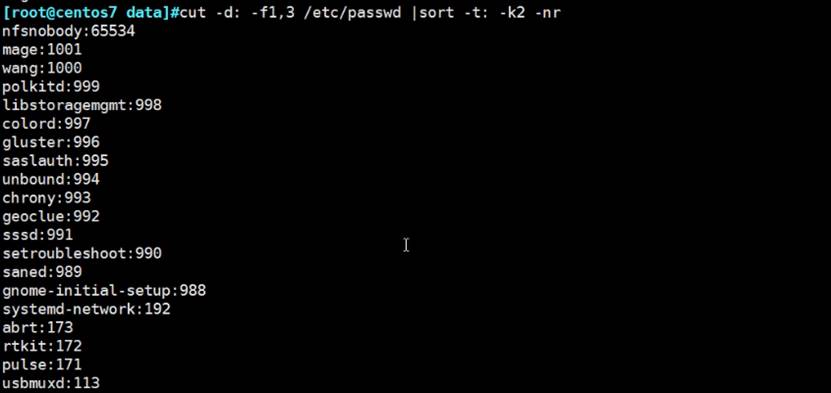
对第3列当作数字进行排序
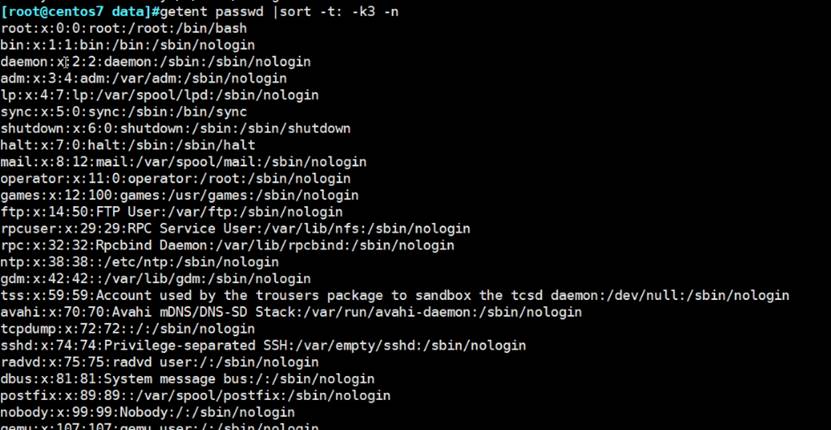
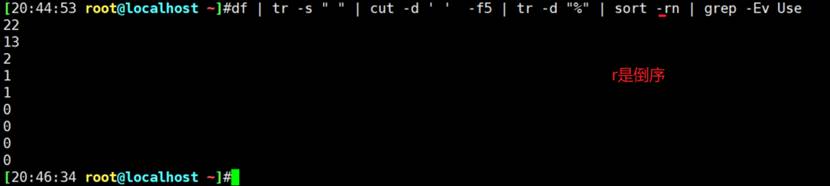
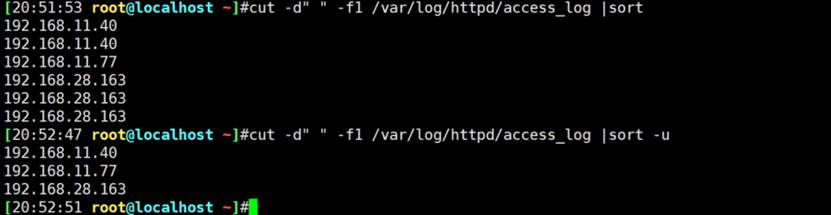
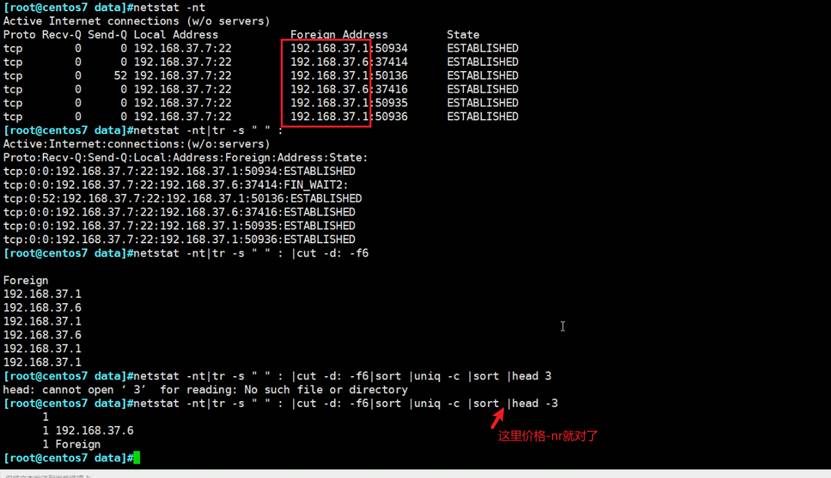
对IP地址排序,
这个还是要用lambda去排的,比如接口和IP这种g1/0/1,192.16.10.1分段去比较的,这里仅仅是整体比一下,看下效果就好。
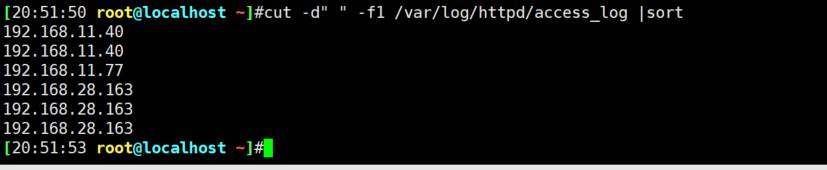
sort -u 去掉重复行
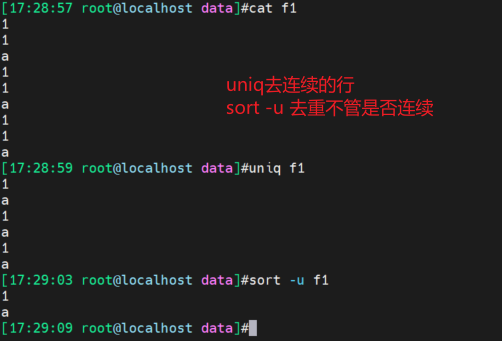
uniq删除上下连续的重复行

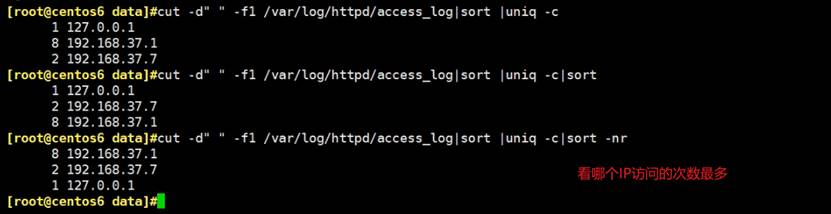
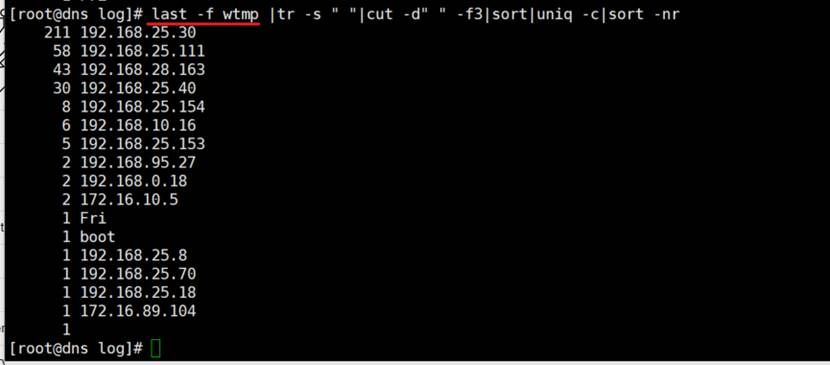
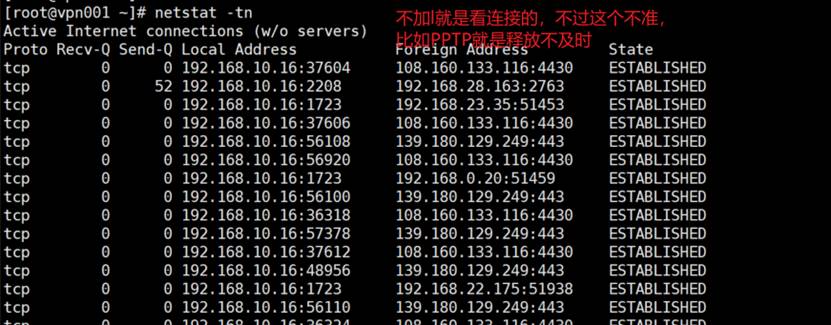
last -f wtmp就是last一个意思
[17:33:36 root@localhost data]#ll /var/log/*tmp
-rw-rw----. 1 root utmp 2688 Jan 17 12:00 /var/log/btmp 👈lastb看的是这个文件,是密码输错了的记录
-rw-rw-r--. 1 root utmp 36480 Jan 29 11:15 /var/log/wtmp 👈last看的就是这个文件,是登入成功的记录
[17:33:41 root@localhost data]#
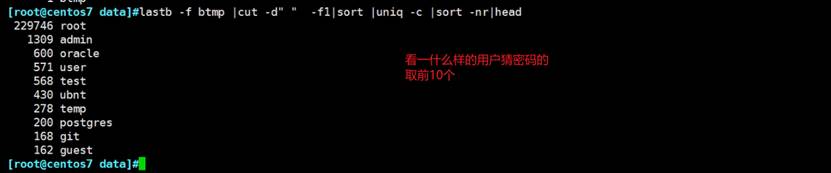
👆以什么样的用户猜密码的,安全加固的方式
uniqd -d 只显示重复的
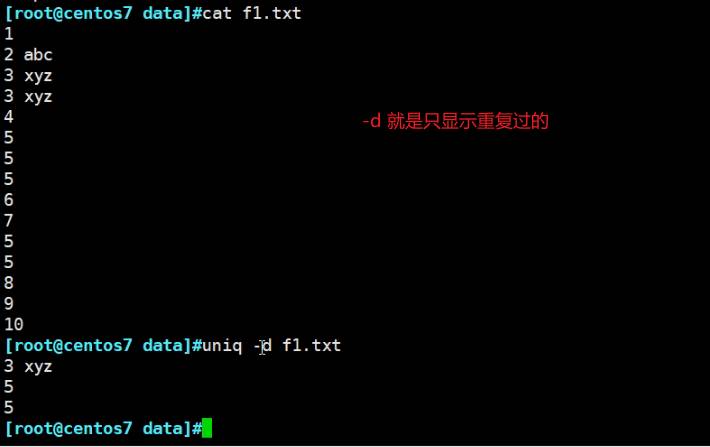
uniq 的话如果不前置一个sort排序的话,就只是抓取连续的情况。

找出两个文件的相同行
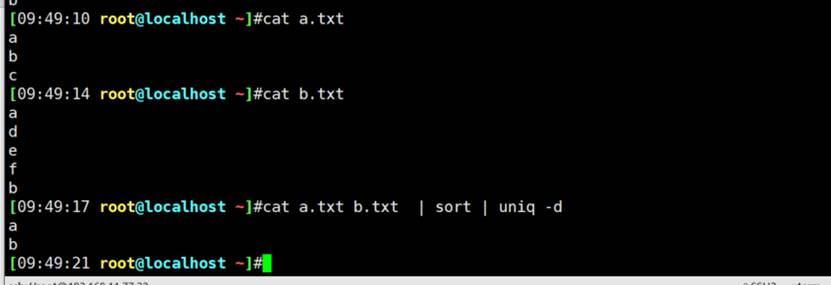
👆上面的题目有BUG啊,如果a.txt里有两行z,那么就会误判咯。
[17:50:07 root@localhost data]#cat f1
z
z
a
b
c
[17:50:10 root@localhost data]#cat f2
b
c
[17:50:11 root@localhost data]#cat f1 f2 | sort |uniq -d
b
c
z
[17:50:23 root@localhost data]#
可以这样优化👇,先各自去重后再cat结合再找出重复的就行了。
[17:51:20 root@localhost data]#cat f1
z
z
a
b
c
[17:51:29 root@localhost data]#cat f2
b
c
[17:51:49 root@localhost data]#uniq f1 |cat - f2
z
a
b
c
b
c
[17:52:22 root@localhost data]#uniq f1 |cat - f2 | sort | uniq -d 👈这才是正解-d就是重复的
b
c
[17:52:29 root@localhost data]#uniq f1 |cat - f2 | sort | uniq -u 👈u就是取uniqu不一样的
a
z
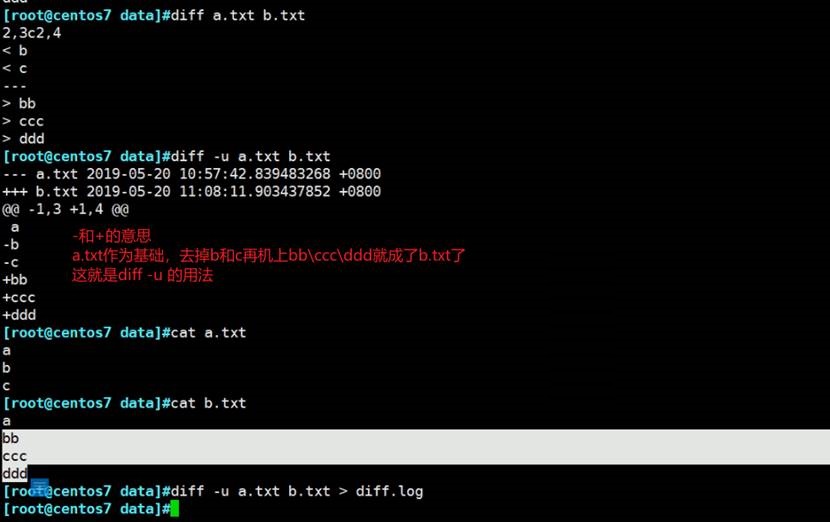
比较文件

-号代表第一个文件,+代表第二个文件,-号去掉+号加上
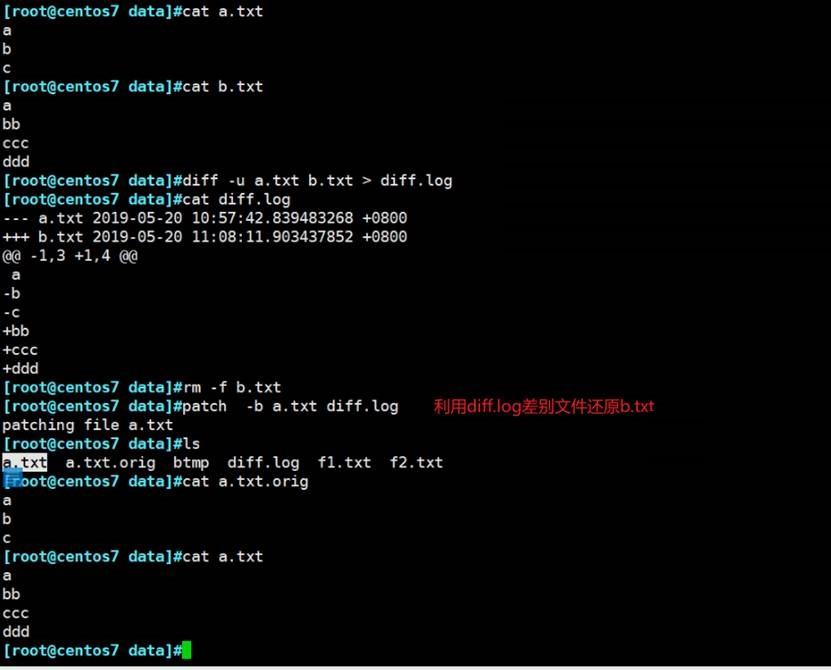
👆注意patch -b 选项是为了恢复之前先备份a.txt,因为patch的还原文件时直接将a.txt原文件覆盖掉的。

grep三剑客之一

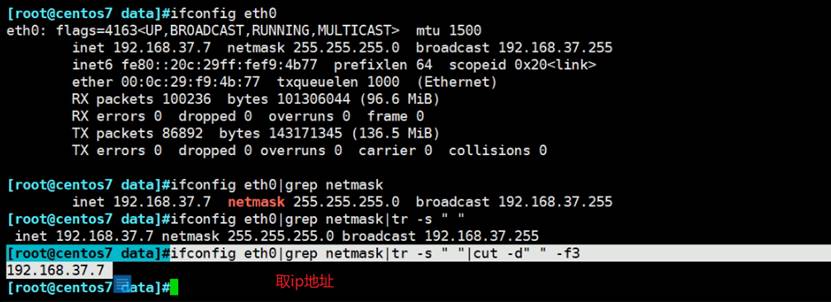

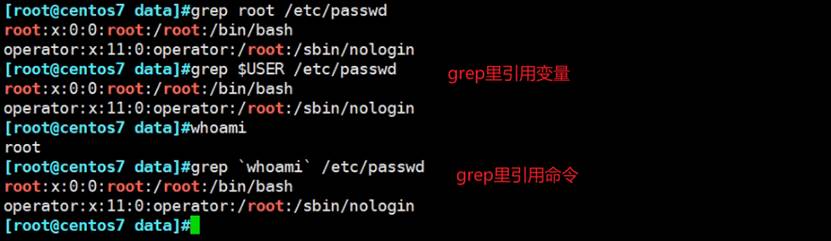
grep不一定都带颜色,因为root的grep系统默认是别名
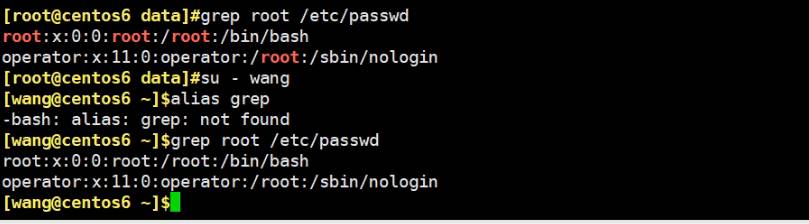
grep选项

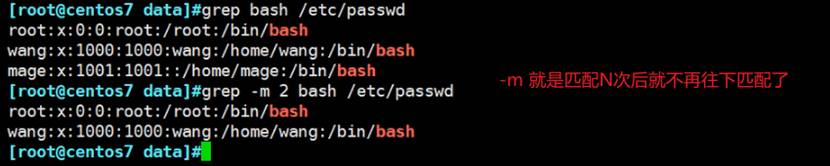
grep -m匹配N次后停止
grep -i忽略大小写

grep -n命中第几行

grep -c匹配的行数
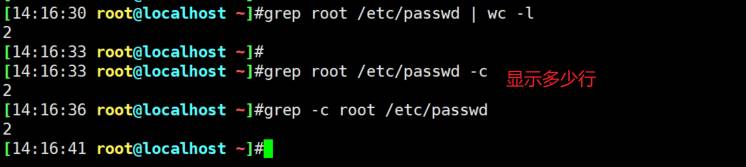
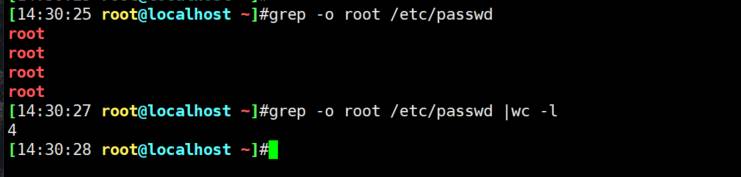
grep -o 命中多少个单行内多次也算
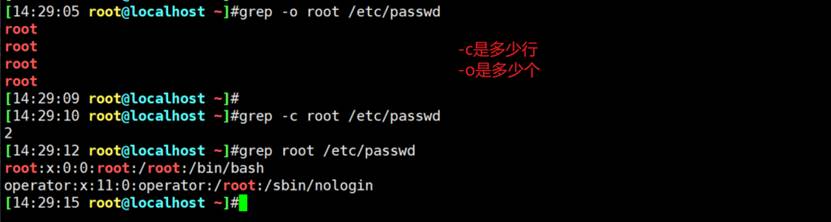
统计文本出现字符的次数-o出现一次单行列出来,再wc -l计算行数
grep -q 静默输出0找到1没找到0是true保持一惯的linux的真假标准

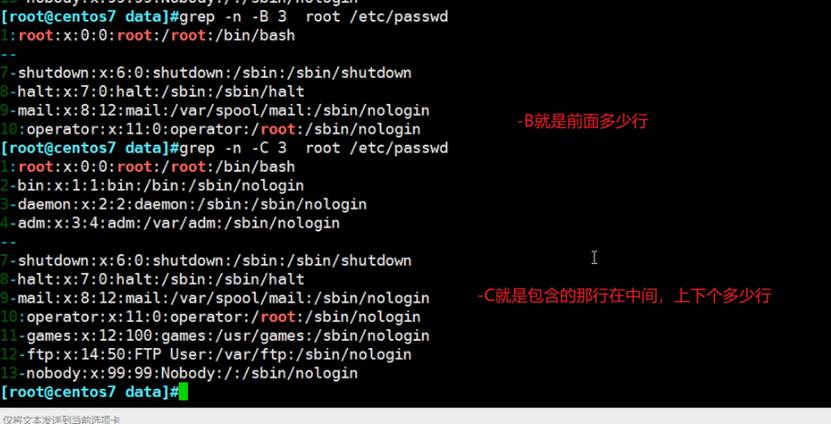
grep -A或-B或-C还是经常用的,但是cisco的show run | section router ospf显然更优化
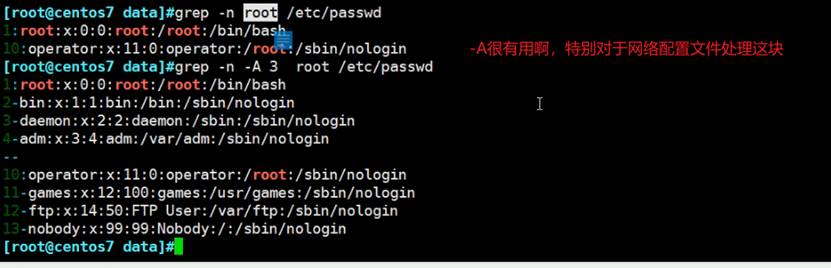
此外还有-B -C
nmap扫描、关于IP探测要总结一下好几种呢ping呢也是有灰常快速的方法的很赞的,当然ping肯定不可靠的。
👉最好是探测该IP上的几个常用端口,然后才能说这个IP是不是UP。他这个sP就是scan ping,聊胜于无,要用-Pn去扫
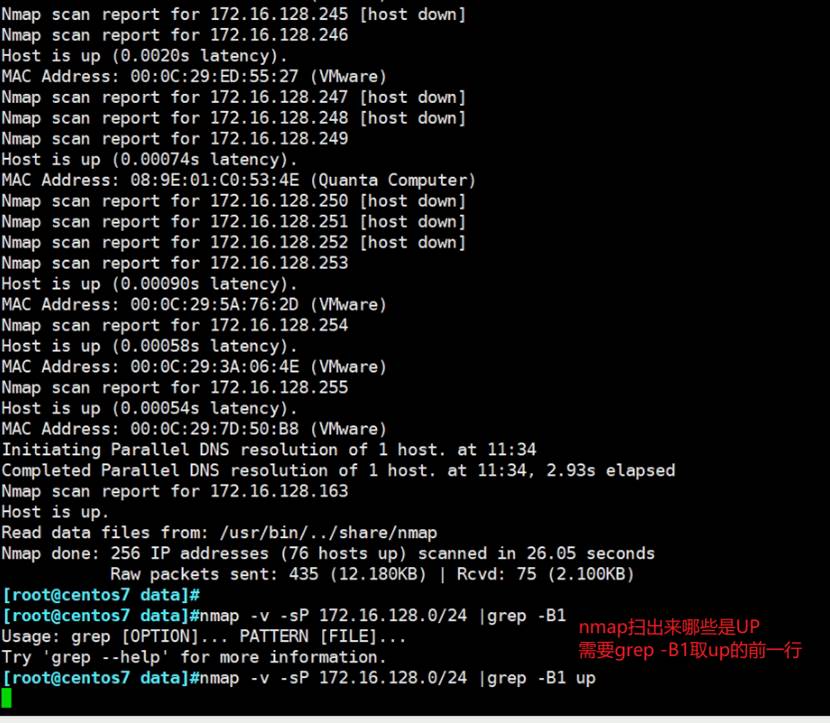
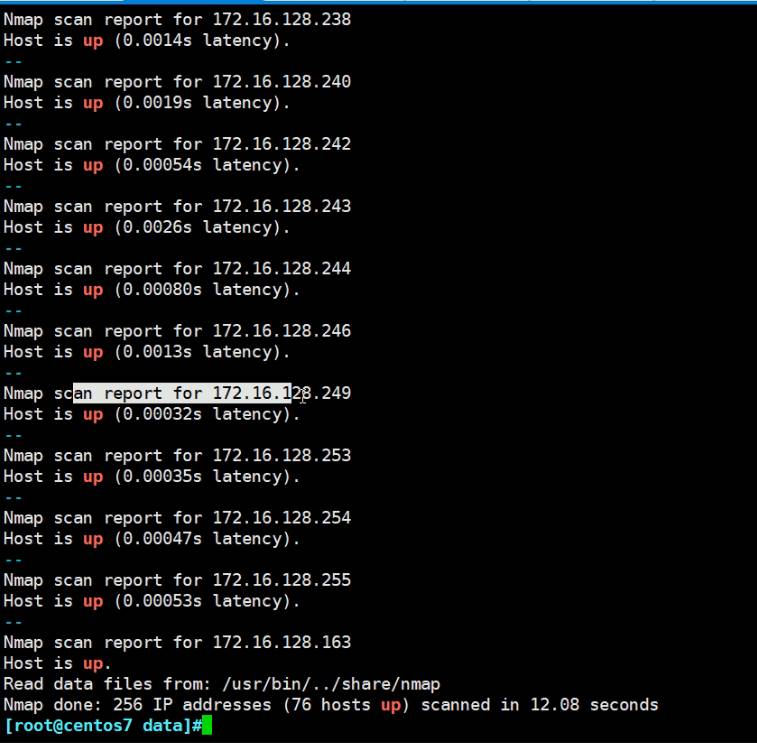

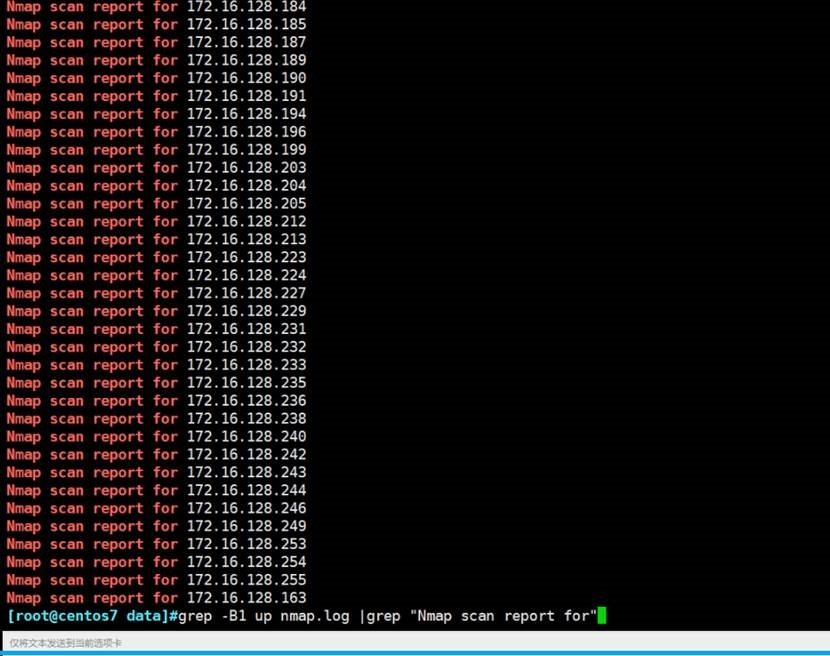
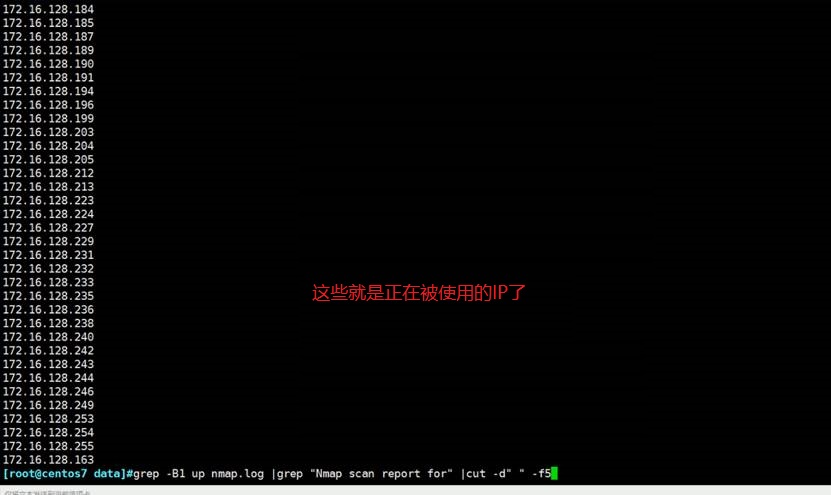
这招可以用来梳理IDC或者内网的HOST网段使用情况,选项不靠谱,仅作参考咯。
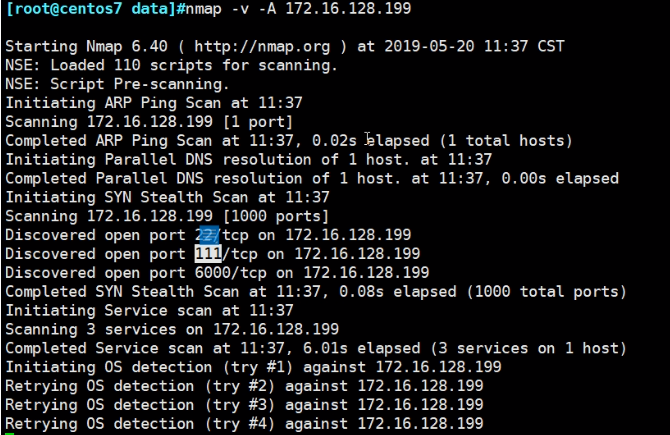

---
grep -E "XX|YY|ZZ"或的关系等价于grep -e xx -e yy -e zz 一样

grep 并且过滤

grep -w单词等价于grep的定界符grep "\
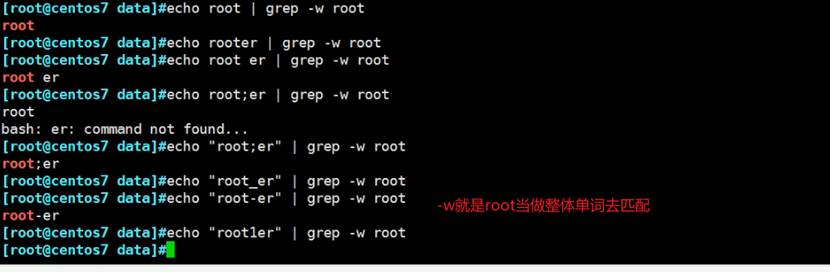
grep -w 或grep "\"的这个单词整体 判断的能力: 👆数字 字母 下划线 是一个单词,- 默认会当作分隔符的 ;同样也算作分隔符了
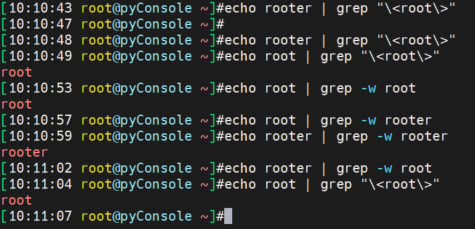

-w就是查找root单词,而root-er是当做root和er两个单词的。-不会被当做一个整体的。
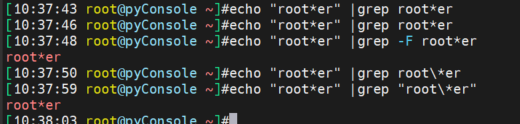
不支持regex,这是什么需求?👇就是比如. *这玩意不做正则的时候,省的转义了 -F 或者fgrep就挺好,挺好~lizheng~tt tx sf sx

grep -f 文件内容去匹配,这个玩意支持regex吗?支持的

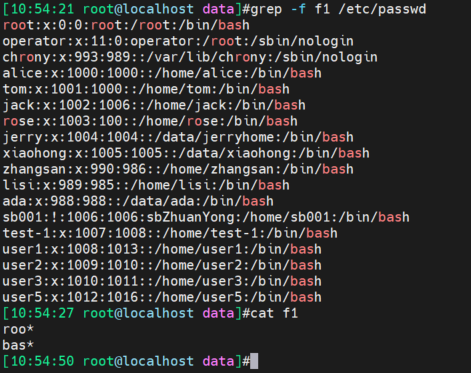
用文件过滤文件,文件里也是可以写正则的


说明:以前学习的通配符是匹配文件名的,而grep里的正则是匹配文本内容的。
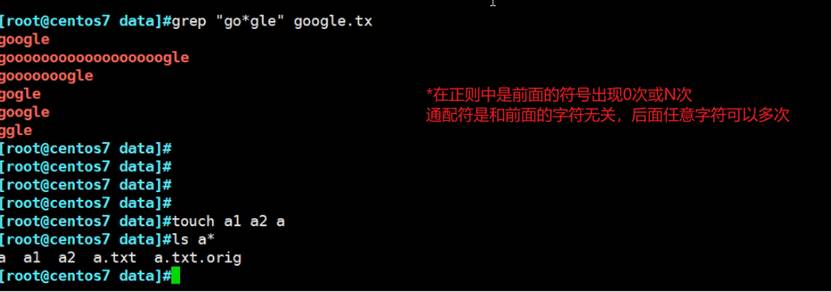
而且通配符的*和regex的\,以及通配符的.和regex的.都不太一样。regex的.\表示所有差点比如换行符?,而且regex的*不能独立存在,然是通配符的*就是自称一体表示所有。
1、regex的 .表示 除了 \n以外任何一个字符,*表示前面的字符不出现或者出现N次。
2、通配符的.就表示. 而通配符的*表示除了.开头的文件名,其他都可以匹配(大概吧哈哈,有的文章说明什么路径中带/的,我就纳闷了通配符是抓文件名的,你文件名中能带/这玩意?呵呵所以这块理解的差不多得了,够了),包括文件名中带.的(只要不是.开头的就好)
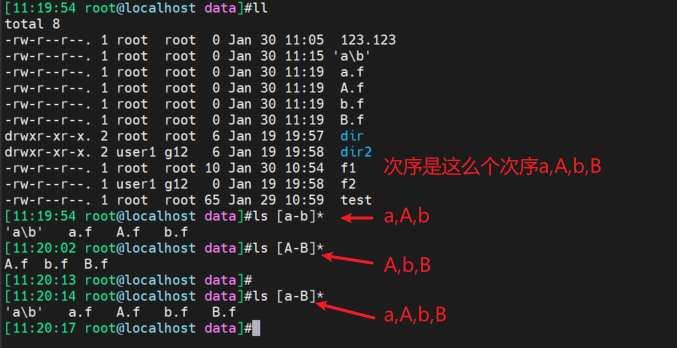
3、还有regex和通配符的其他区别,比如[a-z]在通配符中表示小写的a-z和大写的A-Y不到Z;regex显然没这么奇葩。
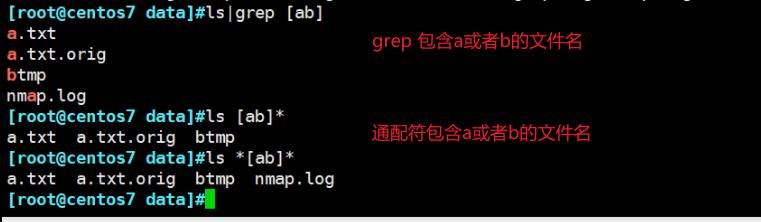


好,下面是工作中遇到的补充👇
-l, --files-with-matches
Suppress normal output; instead print the name of each input file from which output would normally have
been printed. The scanning will stop on the first match.
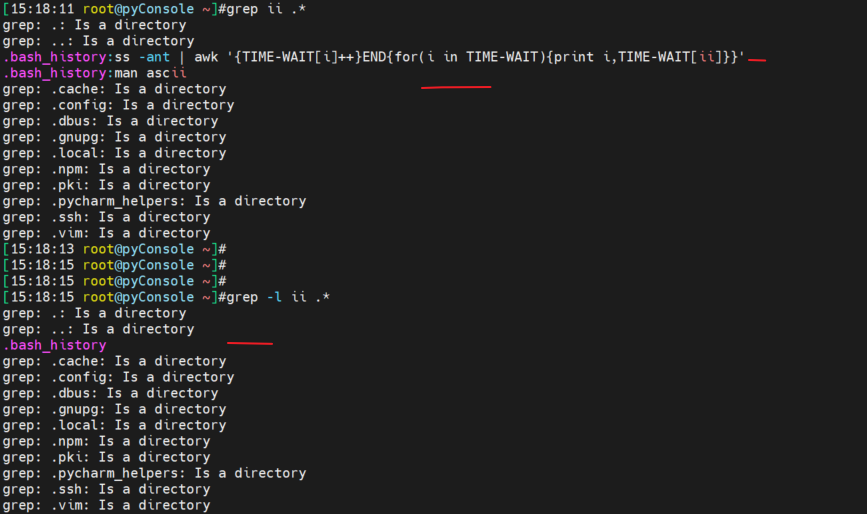
就是去重的效果咯,我只要知道在哪个文件里,不需要知道一个文件里出现了几次,所以加上-l。