第5节. keepalived实现反向代理的高可用
nginx的高可用怎么做,用keepalive做,keepalive的脚本来是新对nginx的HA。
通过脚本,监控Master/Slave的状态,进一步调整各自的优先级,从而抢占VIP,实现HA的故障切换,听着就和VRRP、HSRP差不多了。结果keepalive的配置文件一看全TM是vrrp,哈哈哈~
后面还会学习HA Proxy 反向代理软件。也就是说:
①keepavlie + nginx 实现 nginx的HA
②keepalive + ha proxy 实现ha proxy本身的HA
③其实说白了任何服务之间都可以用keepalive做HA了,不过服务L4和L7里L7大多数用nginx了。
④总之,keepalive经常配合调度器(nginx、haproxy、sql读写分离器也行吧) 一块使用。
⑤其实keepalive通过实验就能知道他就是机器级别的VIP,就是网工知道的VRRP。可以说keepalive做两台机器的IP HA也就是VIP,然后nginx监听在这个VIP上而已。是这么个逻辑
⑥keepalive里不仅仅有vrrp,还有lvs吧,而vrrp有v2和v3的。v2的心跳是秒级 ,v3的心跳是厘秒级的默认是100厘秒也就是1秒
搭建
1、准备两台web服务器也就是realserver


2、搭建master/slave 两台keepalive
yum -y install keepalived
计划虚拟地址--VIP 192.168.126.100
vim /etc/keepalived/keepalived.conf
global_defs 里修改一下
notification_email {
xx@xx.xx 收件箱
}
notification_email_from 发件箱,或者仅仅,就是个发件地址,邮箱其实不存在也可以。。
smtp_server 127.0.0.1 本机的smtp server要启用咯 postfix
router_id xxx 每个服务器起个自己的名字,比如keep1
下面vrrp_instance VI_1 这种就是vrrp的实例,用来实现VIP浮动IP的。
virtual_router_id xx 写个编号比如66,注意两台都写66,虚拟成一个路由器
prioity 不动就用默认的100
authentication {
auth_type PASS
auth_pass xxx 写两台的协商密码;据说密码即使设置了,抓包也是明文的。怀疑~
}
vitual_ipaddress {
a.b.c.d vip和端口也可以直接写成👇
192.168.126.100/24 dev eth0 label eth0:1
}
再往下就是virtual_server a.b.c.d 443 {
这些就是LVS了,L4的调度了,本次实验只是用keepalive做nginx的HA,所以这里不管了后面全删掉
}
将此配置文件复制一份到 另一台 keepalive机器上,并略作修改👇;当然两台需要做防火墙、selinux 禁用、时间同步操作
vim /etc/keepalived/keepalived.conf
修改
router_id ka2
state BACKUP
虚拟路由器id必须一样的
priority 80 优先级和master要不同
其他也都一样
到此就配置完了
systemctl start keepalived 就ok了,ping VIP就通了。
参考:https://blog.51cto.com/sparkgo/6127764
VIP的情况:
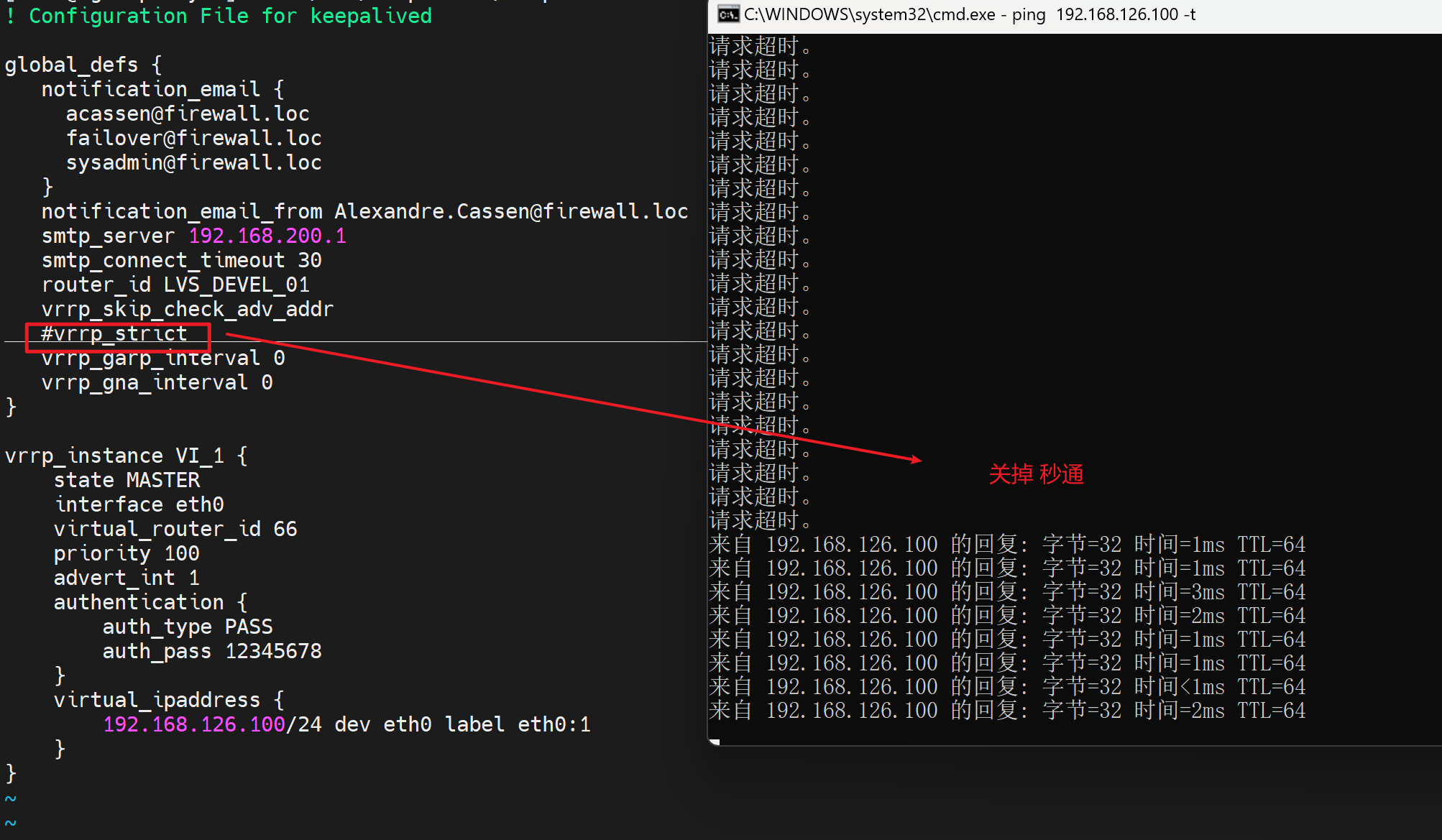
可能存在自动添加iptables的情况看别人的实验是有的,可能是老版本;我的实验就是开启vrrp_strict就ping不通但是没有看到iptables -vnL。
master上只要keepalive服务起来都会一直看到vip的,backup上的vip会被抢回去,说明keepalive默认是开启了抢占的,就是说:
1、master挂了backup拿到vip此时backup上的vip就出现了,
2、master活了又会抢到vip此时backup上的vip就又消失了。
所以keepalive是秒级的HA咯,如何加快收敛呢?交换机里的vrrp也是秒级的?不过有FRR好像可以加速,说错了是BFD。
方法1:修改源代码,编译咯要
https://blog.csdn.net/hitcompass1/article/details/104054934

方法2:使用高版本的vrrp,不是keepalive高版本是否支持厘秒
https://support.huawei.com/enterprise/zh/doc/EDOC1100112421/6e22bde4

方法3:用BFD联动
https://support.huawei.com/enterprise/zh/doc/EDOC1100112421/54b4f71c
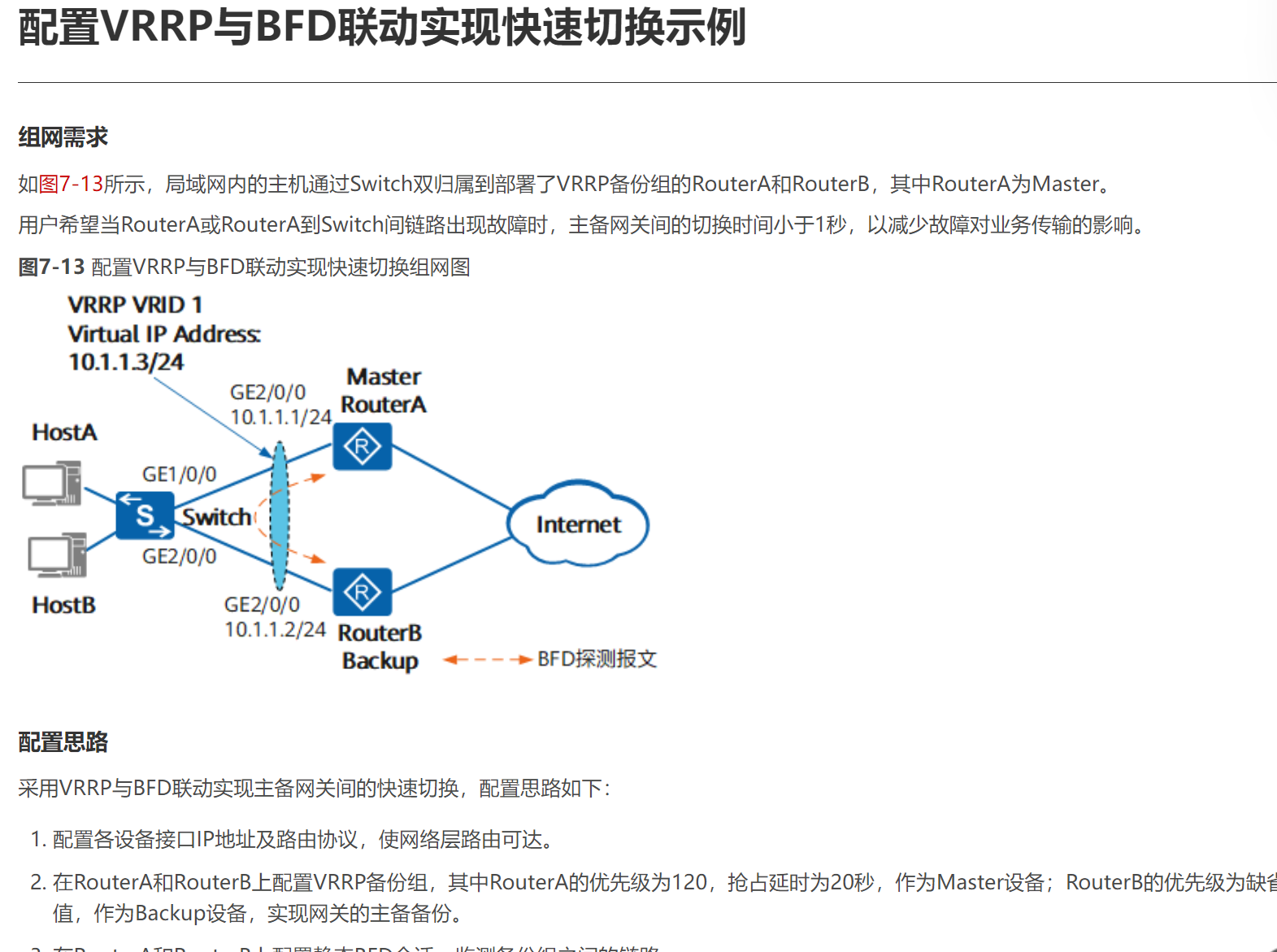
其实方法2 3 都不是keepalive了而是网络设备的vrrp了,所以可以用网络设备来实现加速收敛的vrrp来替代keepalive。这也是个思路,当然前提是你有现成的网络设备而不是另购
方法4:keepalive + BFD
https://zhuanlan.zhihu.com/p/582205167 以下是节选
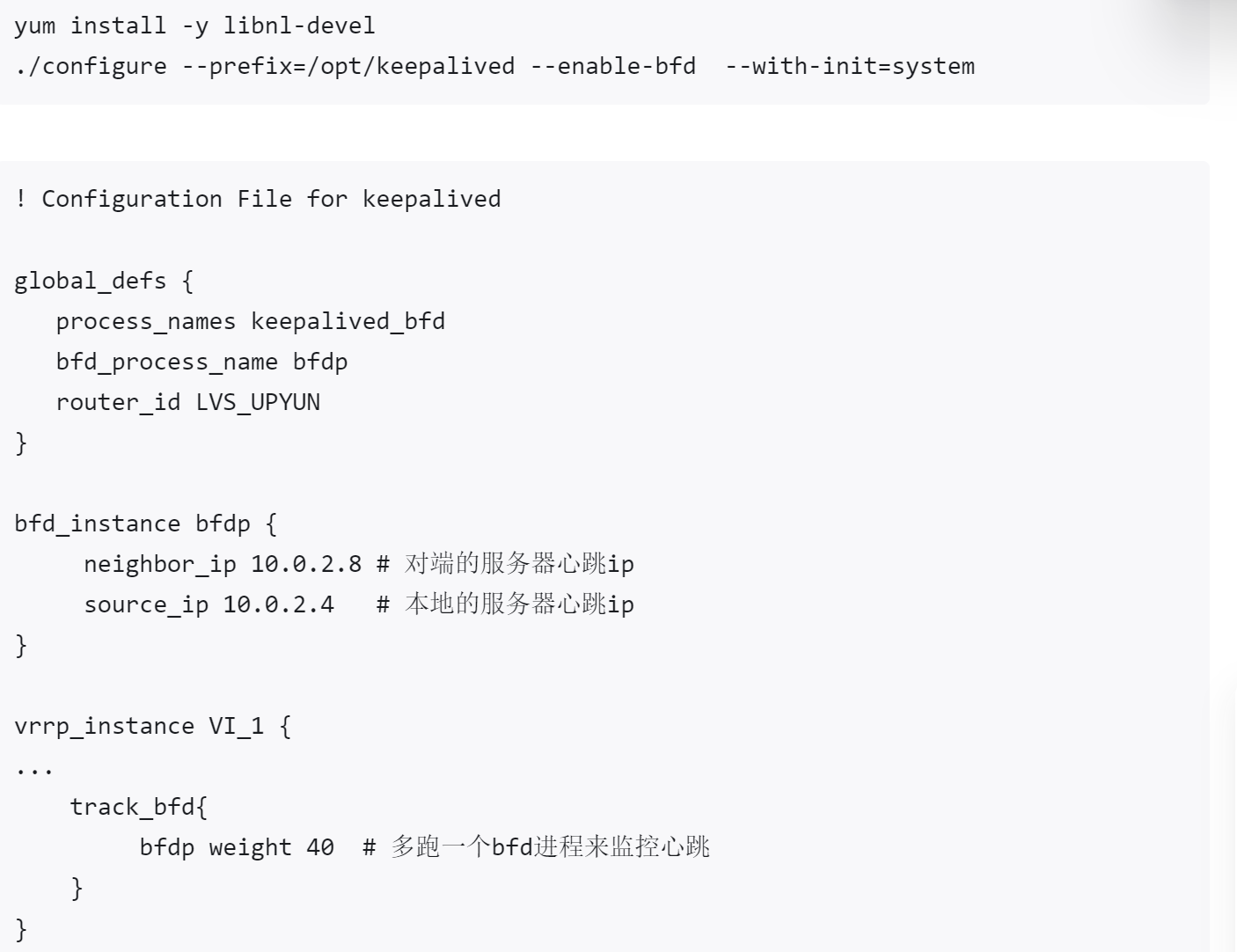
方法5:keepalive + vrrp3
keepalive里的vrrp协议,所以keepalve + vrrp3
https://zhuanlan.zhihu.com/p/582205167 还是这篇,以下是节选防止url失效

! Configuration File for keepalived
global_defs {
router_id SLB-SAD
script_user root
enable_script_security
# 检查vrrp报文中的所有地址比较耗时。默认是跳过检查
vrrp_skip_check_adv_addr
# 重点是启用vrrp3
vrrp_version 3
}
vrrp_script chk_upyun {
# 除了心跳检测外,还可以调用脚本做业务上的健康检测
script "/etc/keepalived/bin/check_vip.sh"
interval 1 # check every 1 seconds # 👈是不是要改小一点才能配得上vrrp v3的厘秒啊,就算这里只支持到秒级,也可以在脚本里写循环做到1s里循环N次来缩短检测进度。 经过下文的脚本实验发现!没用的!脚本里再快,weight -30的动作还是interval 1的秒级,所以主备切换<1>如果是v3的心跳可能确实是厘秒级别的;<2>但是如果是脚本来检测nginx (脚本的整体运行周期以及weight -30) 的主备切换还是1秒的最小值了
fall 1 # require 2 failures for failures
rise 1 # require 1 sucesses for ok
# weight 值为负数时,当脚本检测失败时,Master节点的权值将是“priority“值与“weight”值之差
weight -30
}
vrrp_instance upyun_lb {
strict_mode off
advert_int 0.03
state BACKUP
interface eth3
virtual_router_id 19
priority 100
# 当master和backup角色转换时,触发脚本做业务上的切换
notify "/etc/keepalived/bin/change_state.sh" # 这里就是0.03秒就会nofiy了。配合上秒vrrp_script里的脚本循环可以做到高精度的。
track_script {
chk_upyun
}
virtual_ipaddress {
192.168.147.19 label eth3:9
}
}
# 这一段是可选的,如果和lvs规则就可以调用ipvsadm的转发规则
include /etc/keepalived/virserver.conf
配置中用到了“check_vip.sh”和“change_state.sh”的两个脚本,我们也来简单看下。
check_vip.sh 节选自上面的url 上面配置中只是举例说明,当 ping 丢包严重超过 80% 时,就认为要切换主备关系了。大家也可以根据具体的业务场景做一些逻辑判断,来实现主备切换,以达到高可用的目的。
#!/bin/sh
TMP="/tmp/bad"
GATEWAY=$(ip ro|awk '/default/{print $3}')
LOSS=$(ping -fc10 -s1 $GATEWAY | sed -r -n '/loss/s@.* (.*)%.*@\1@p')
if [ $LOSS -ge 80 ];then
echo "${LOSS}% lost #`date`" >> $TMP
fi
if [ -e $TMP ] ;then
exit 1
fi
change_state.sh 节选自上面的url
当检测到服务器的角色转换时,这个脚本就会调用钉钉报警,并且调整业务上的一些操作。如 sysctl.conf 配置或者 iptables 上的规则,甚至可以配合 LVS 做一些负载均衡的部署。
#!/bin/bash
HOME="/etc/keepalived/"
LIP=`/sbin/ip addr | awk '/192.168./{gsub("/.*","");if($2!=""){print $2}}'|sort -u|head -n1`
VIP=$(awk '/virtual_ipaddress/{getline; print $1}' $HOME/keepalived.conf)
URL="https://oapi.dingtalk.com/robot/send?access_token=07xxxxxxxxxxxxx"
[ -z $LIP ] && LIP=$VIP
############################################################################
dingding(){
curl $URL --connect-timeout 10 -H 'Content-Type: application/json' \
-d '{"msgtype": "markdown",
"markdown": {
"title": "数据中心报警",
"text": "* 报警类别: '"$1"'\n* 报警机器: '"$2"'\n* 报警服务: '"$3"'\n* 报警内容: '"$4"'\n* 报警时间: '"$(date "+%Y-%m-%d %T")"'\n"
}
}'
}
ENDSTATE=$3
NAME=$2
TYPE=$1
dingding Keepalived $LIP Change_state "$ENDSTATE"
case $ENDSTATE in
"BACKUP") # Perform action for transition to BACKUP state
echo "--- I am $ENDSTATE #`date`" >> /tmp/keepalived.log
sed -r -i '/state/s#MASTER#BACKUP#g' $HOME/keepalived.conf
sysctl -w \
net.ipv4.conf.all.arp_accept=1 \
net.ipv4.conf.all.arp_ignore=0 \
net.ipv4.conf.all.arp_announce=0 \
net.ipv4.ip_nonlocal_bind=1
#$HOME/tunl start
exit 0
;;
"FAULT") # Perform action for transition to FAULT state
exit 0
;;
"MASTER") # Perform action for transition to MASTER state
echo "+++ I am $ENDSTATE #`date`" >> /tmp/keepalived.log
sed -r -i '/state/s#BACKUP#MASTER#g' $HOME/keepalived.conf
sysctl -w \
net.ipv4.conf.all.arp_ignore=1 \
net.ipv4.conf.all.arp_accept=1 \
net.ipv4.conf.all.arp_announce=1 \
net.ipv4.ip_nonlocal_bind=1
iptables -L -vn | grep -iqE "vrrp|112"
[ $? = 0 ] || iptables -I INPUT -p vrrp -j ACCEPT
iptables -L -vn | grep -iq "accept .*$VIP"
[ $? = 0 ] || iptables -I INPUT -d $VIP -j ACCEPT
exit 0
;;
*)
echo "Unknown state ${ENDSTATE} for VRRP ${TYPE} ${NAME}"
exit 1
;;
esac
看看GPT怎么回答的,不过我没有测试,参考参考👇
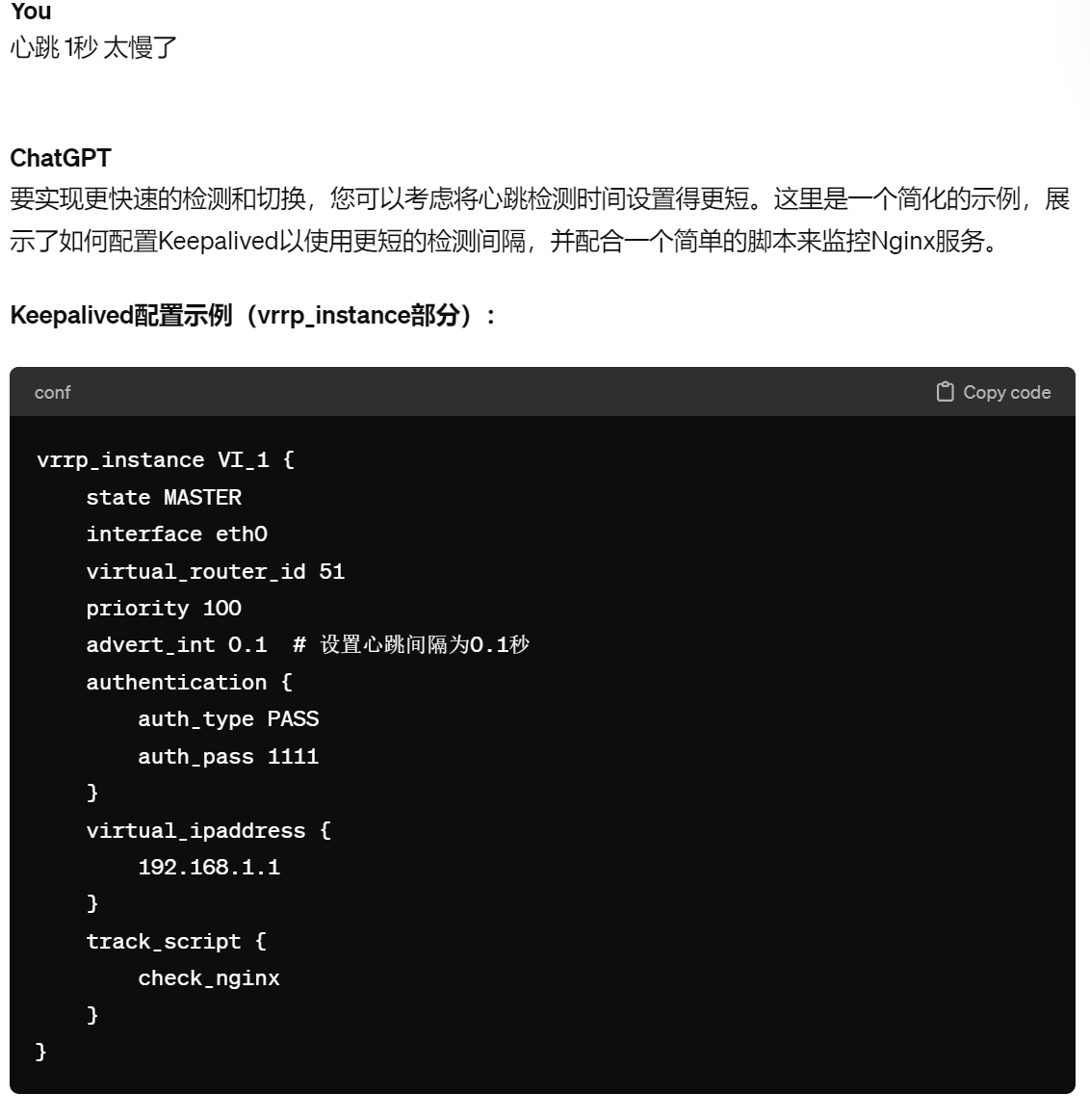
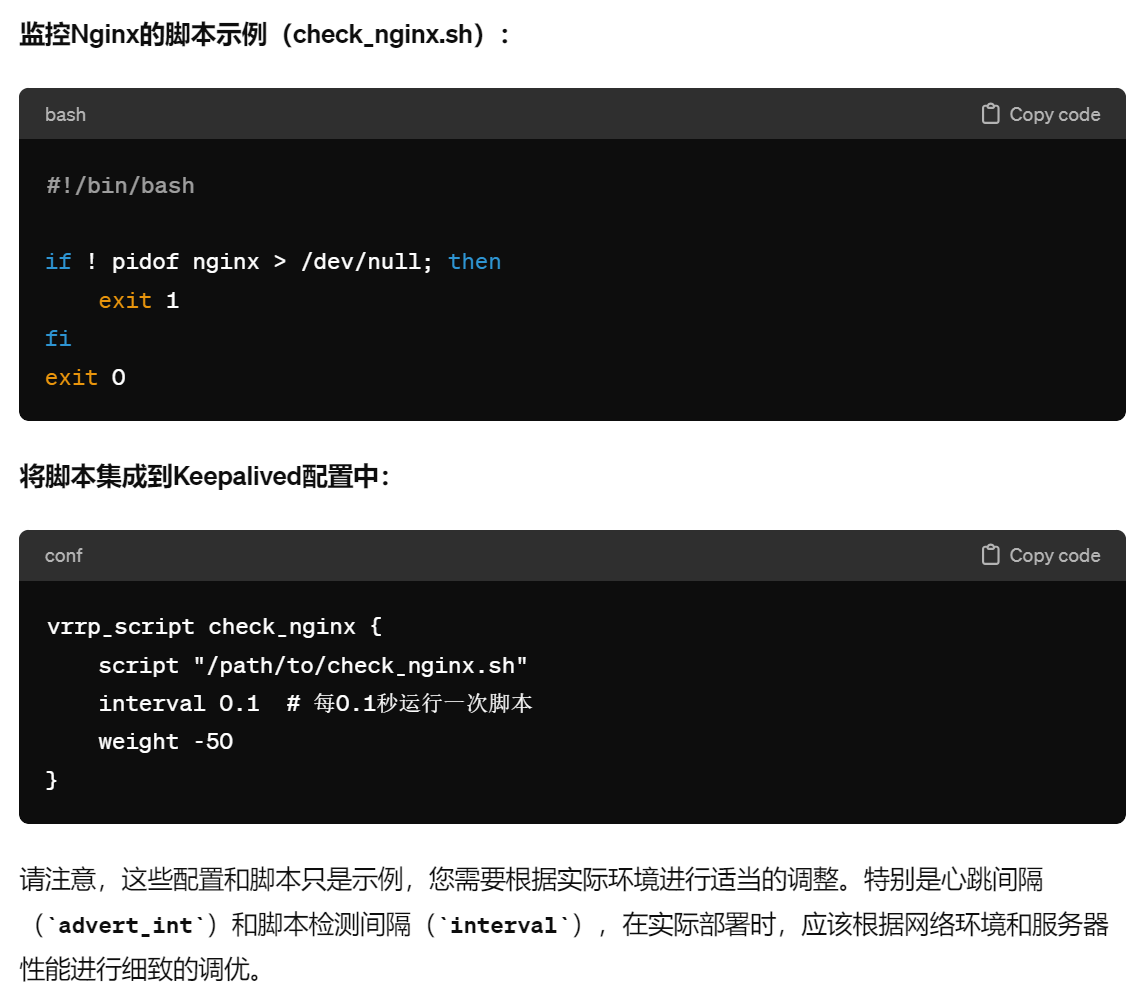
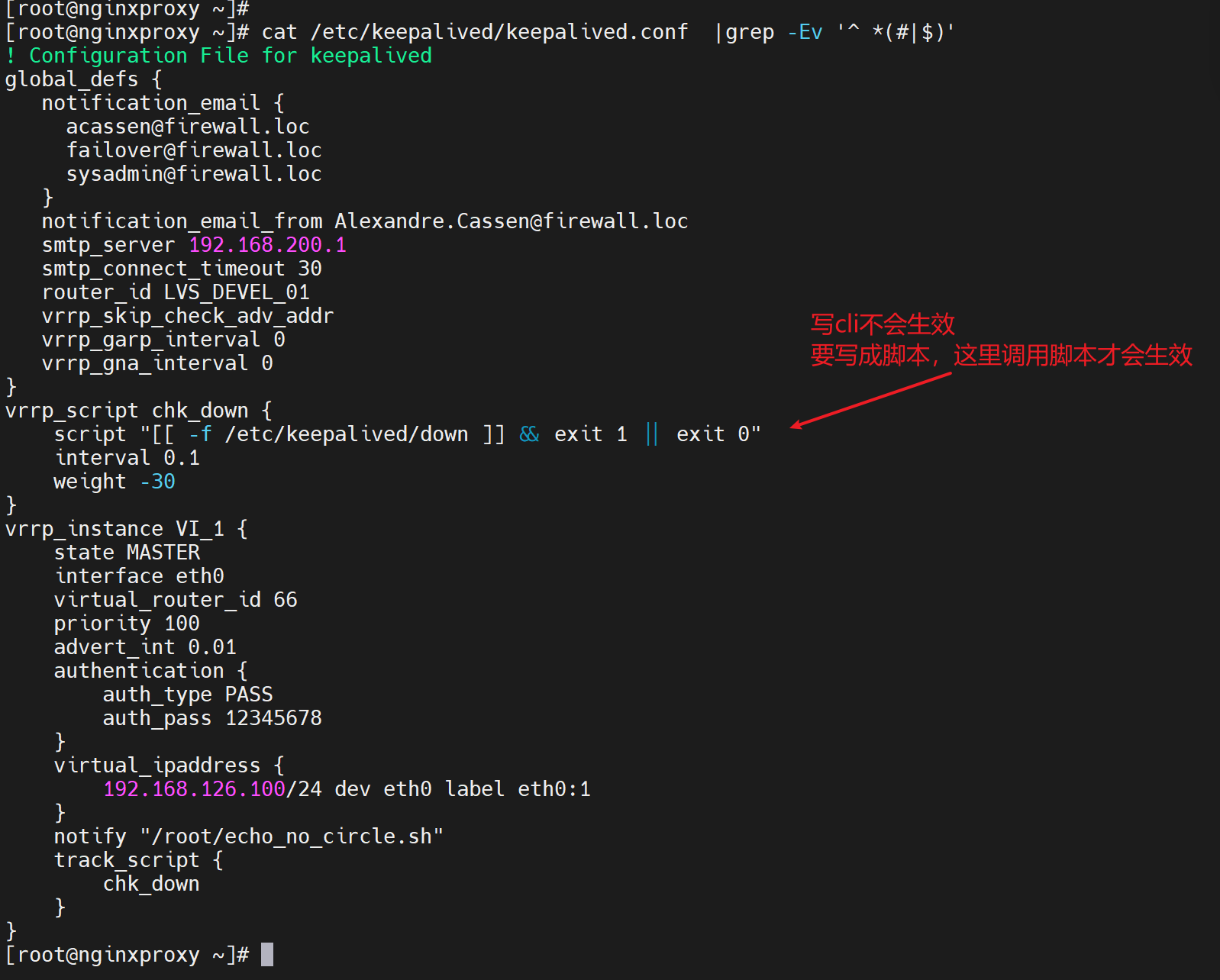
上图的interval 0.1如果没效果,也就是不支持低于秒级的频率,就可以在脚本里写循环来提供检测频率。只要advert_int 0.1 生效就行了。而且advert_int 的频率看起来是可以作用到nofity 后面的脚本的,所以检测和动作一套组合 都可以降低到厘秒级别的。
具体精度实验验证见下文的 vrrp_script脚本章节
3、vip有了就搭建nginx
在两台已经搞定了keepalive的机器上安装nginx
yum -y install nginx
vim /etc/nginx/nginx.conf
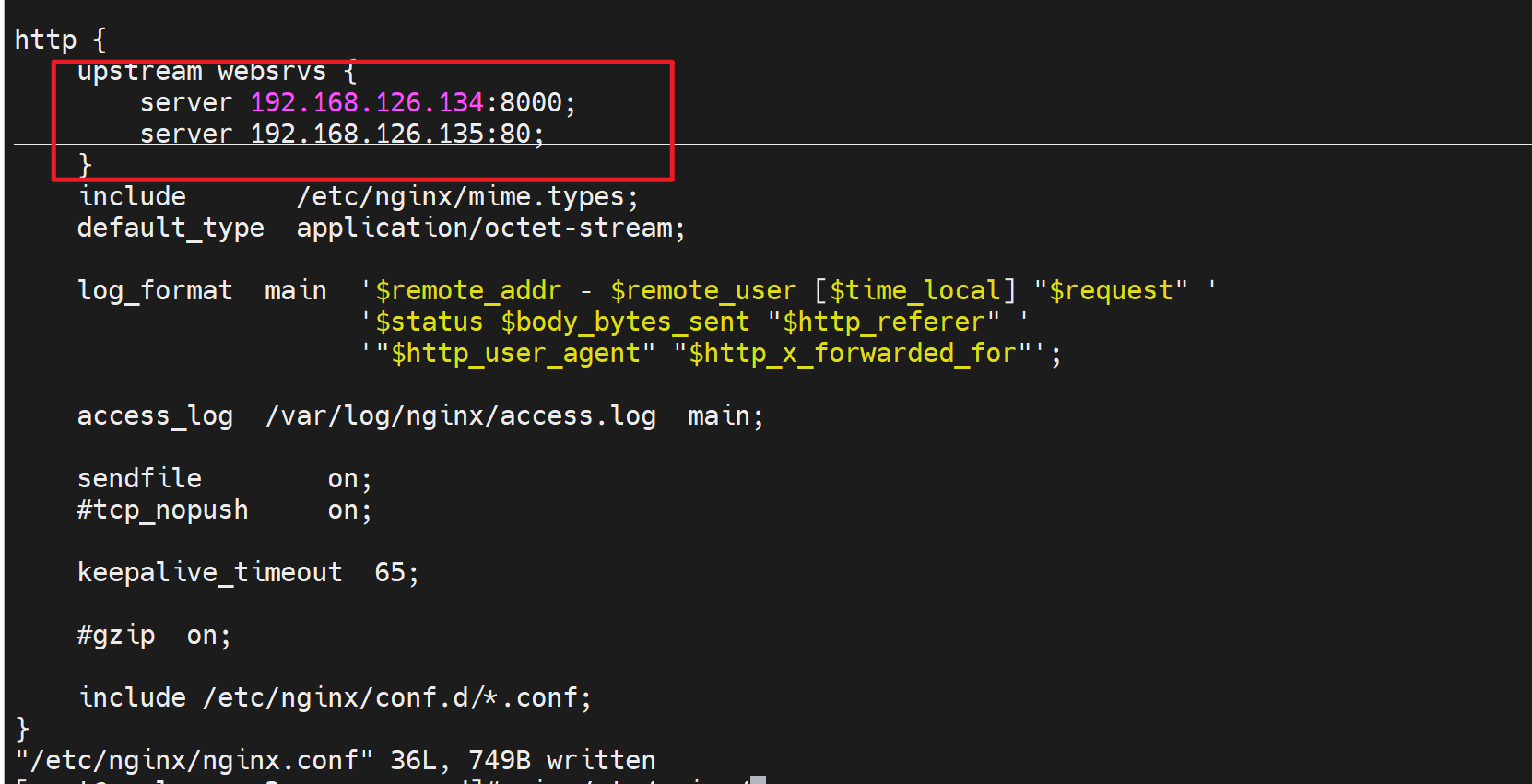
upstream websrvs {
server 192.168.126.134:8000;
server 192.168.126.135:80;
}
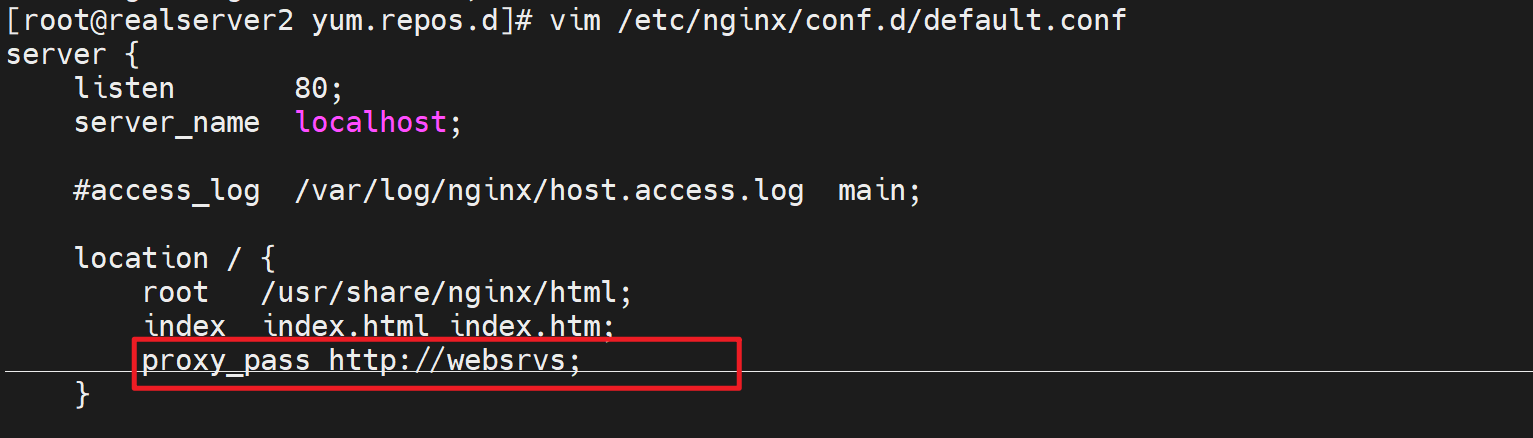
server {
location / {
proxy_pass http://websrvs;
}
}
systemctl restart nginx
然后就👇
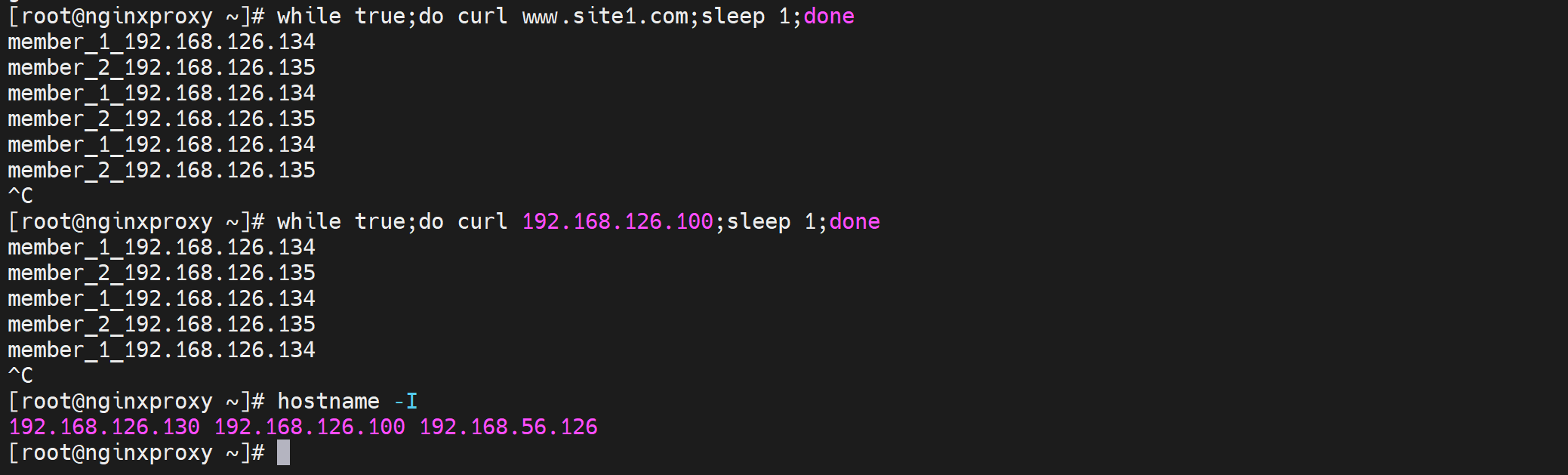
当然我也遇到了问题,就是子配置文件抢了主配置文件的server块,这就涉及优先级了,删掉子配置文件就行了。
反正就这么多配置
第二台发现nginx 同样的rocky 9.0,同样的yum remove yum install结果nginx -v版本不同,研究下,发现
第一台是这么安装的,干脆第二台也这么安装下

yum -y remove nginx
yum -y install nginx就行了
总共就加红框里的这么多就行了

好了 这台nginx也调度ok了

windows cmd curl一下,这个测试不能在两台 keepalive上curl,因为backup上没有VIP生效,所以测试就用正规的client测试就好了
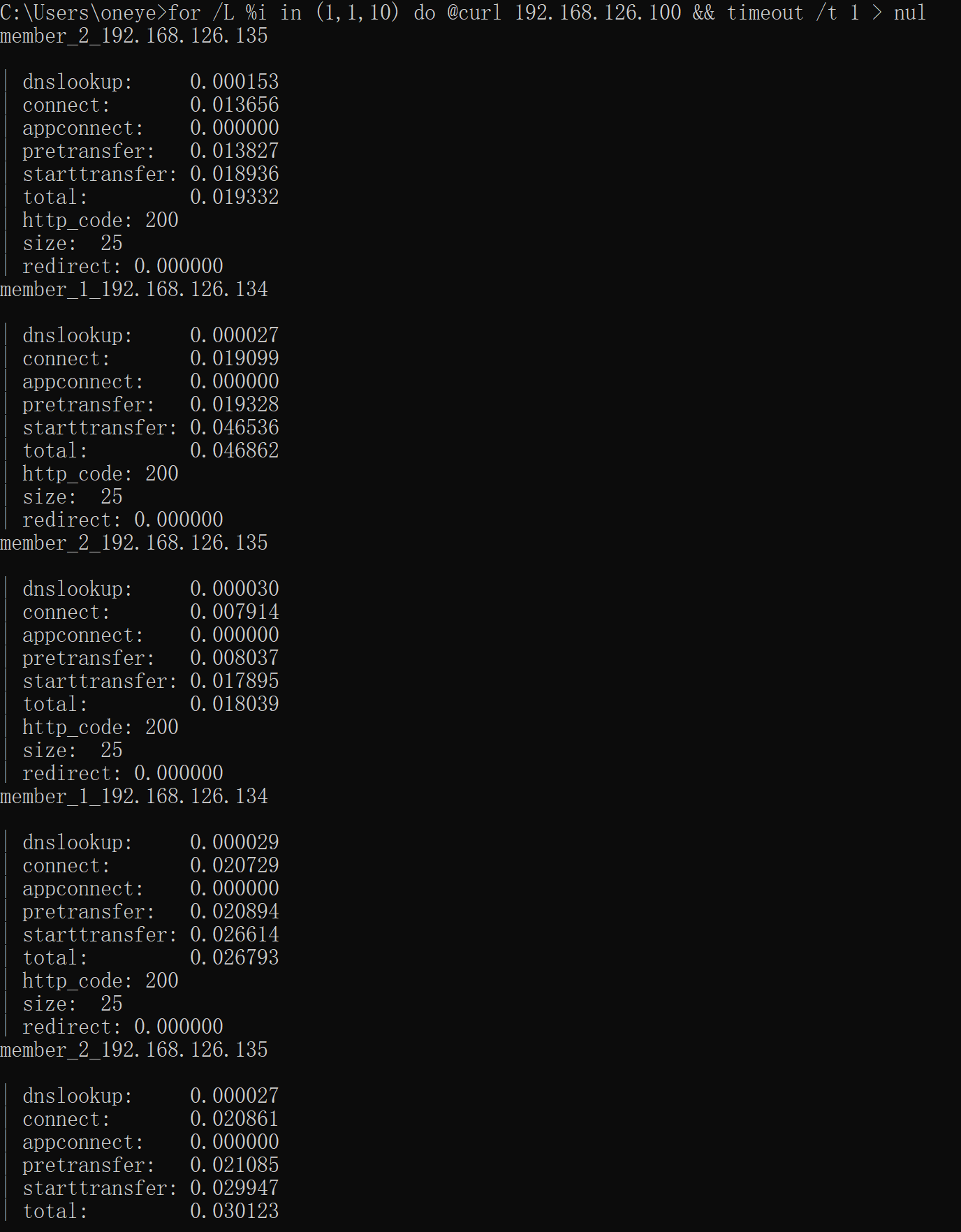
此时就已经实现了简单的nginx的HA了。就是,不是基于nginx服务,而是基于机器系统级别的HA也就是实际的 IP down了就切BACKUP了。
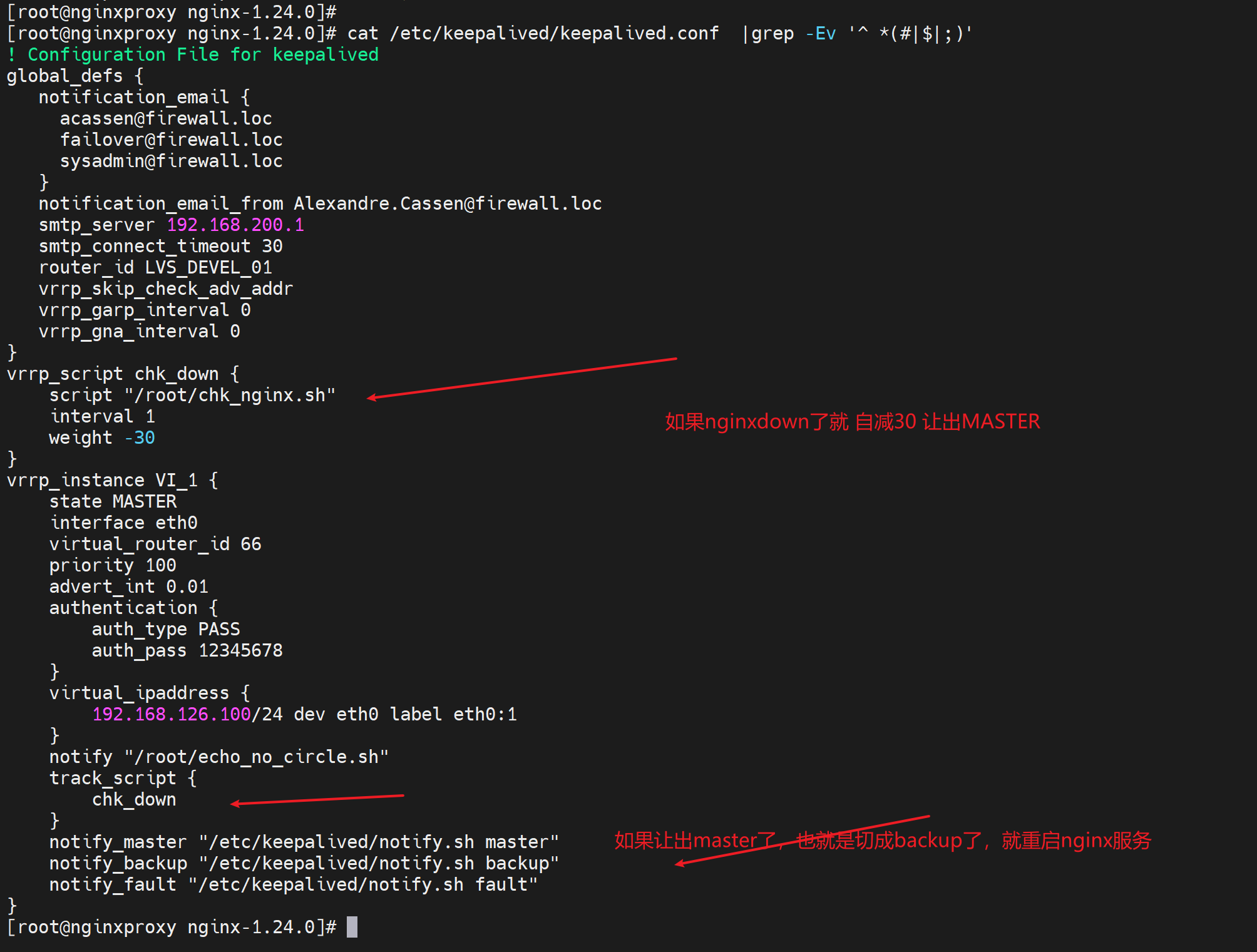
如果要让keepalive监控nginx的服务,可以走脚本。
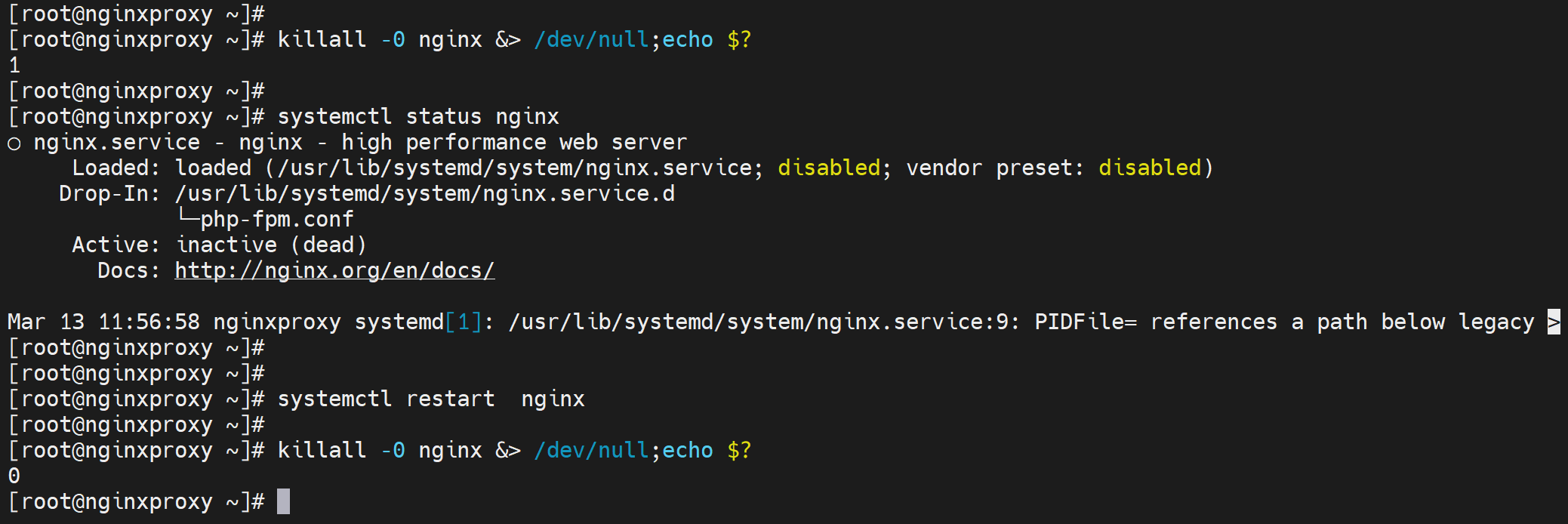
判断进程死没死
killall -0 nginx &> /dev/null;echo $?

vrrp_script脚本接口
1、精度 之 脚本运行的频率 interval
结论:interval 1 的1就是最小值了。提高精度就脚本里写while sleep,可达到20ms的精度。
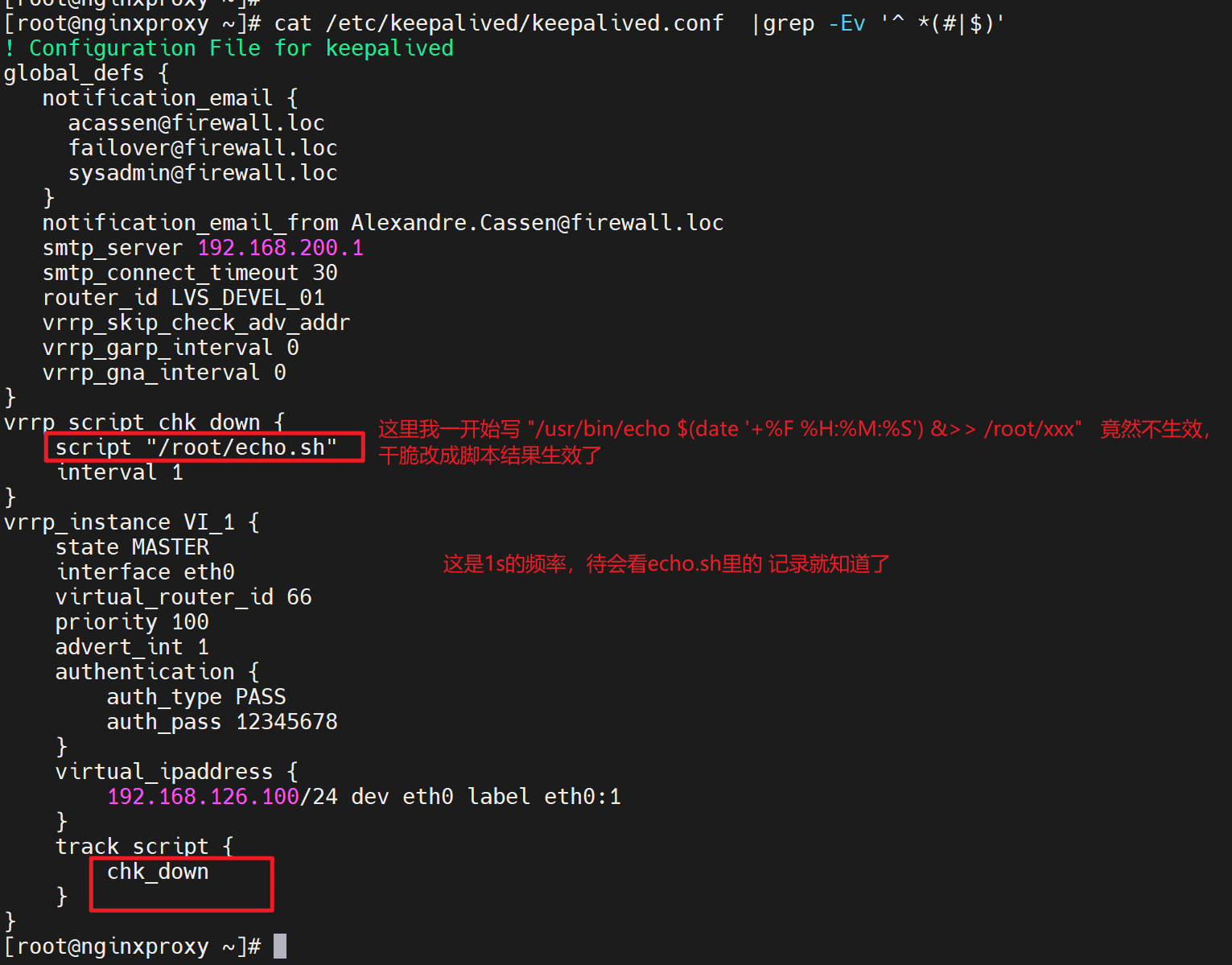

可见是1s一次的精度
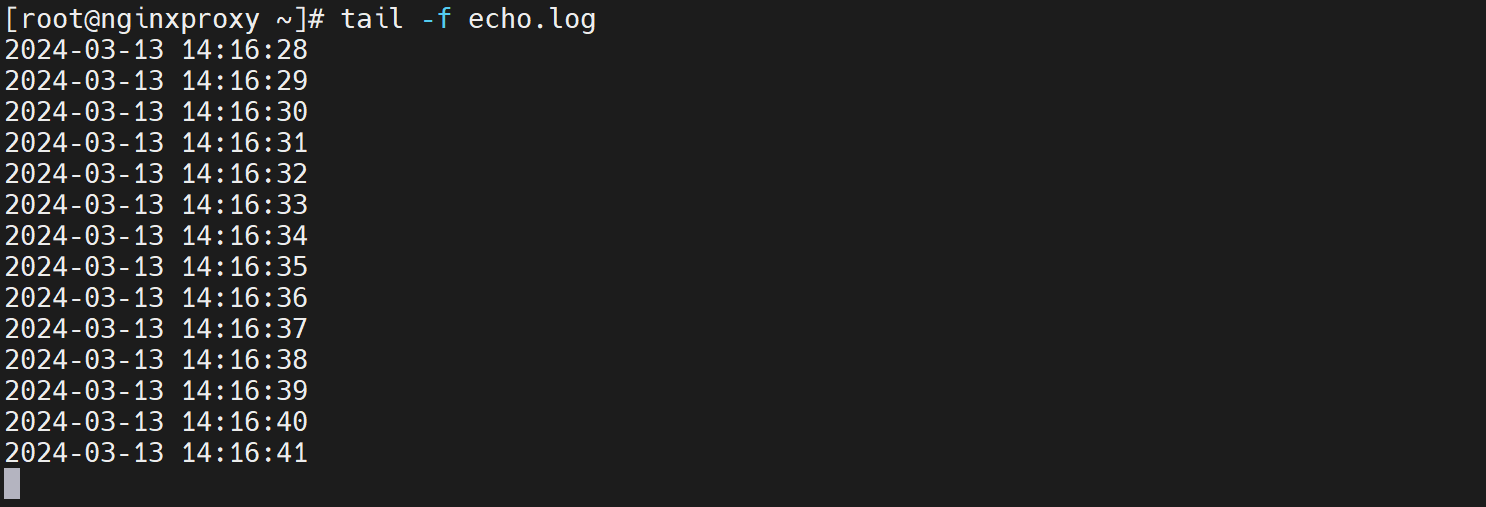
先调整echo.sh脚本的显示时间,%3N就是毫秒了,因为%N是纳秒取前3位(从左到右高3位)就是毫秒。

修改0.1👇,没变化,
修改vrrp v3,还是没变化
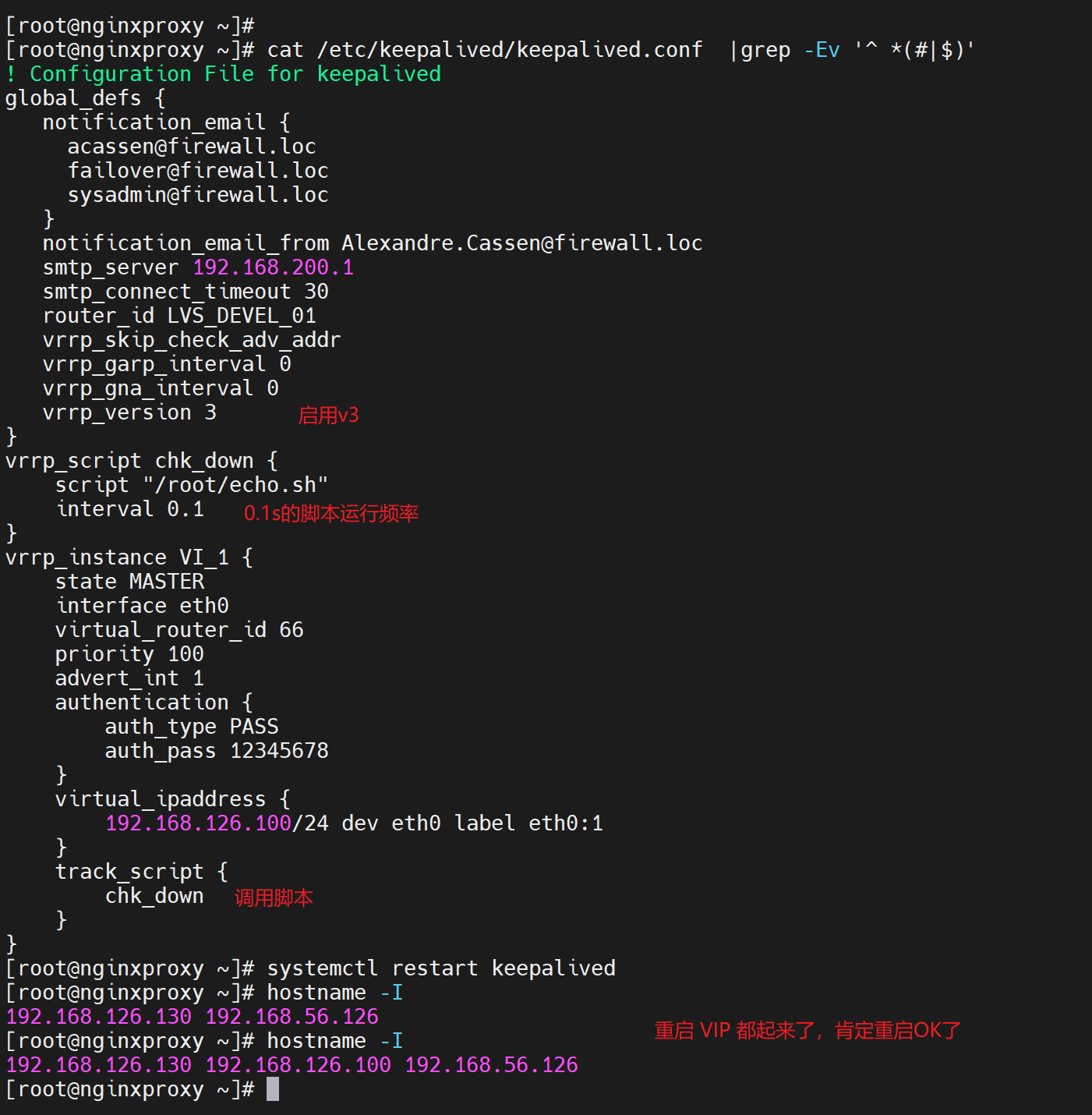
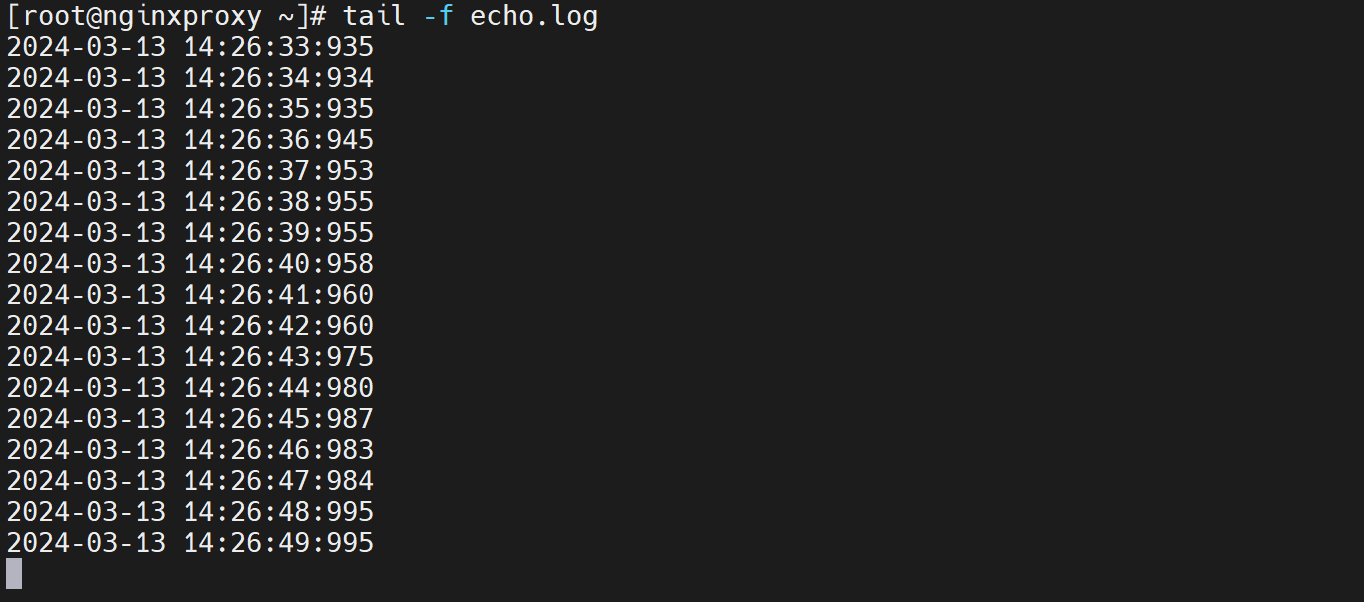
变通修改echo.sh为循环
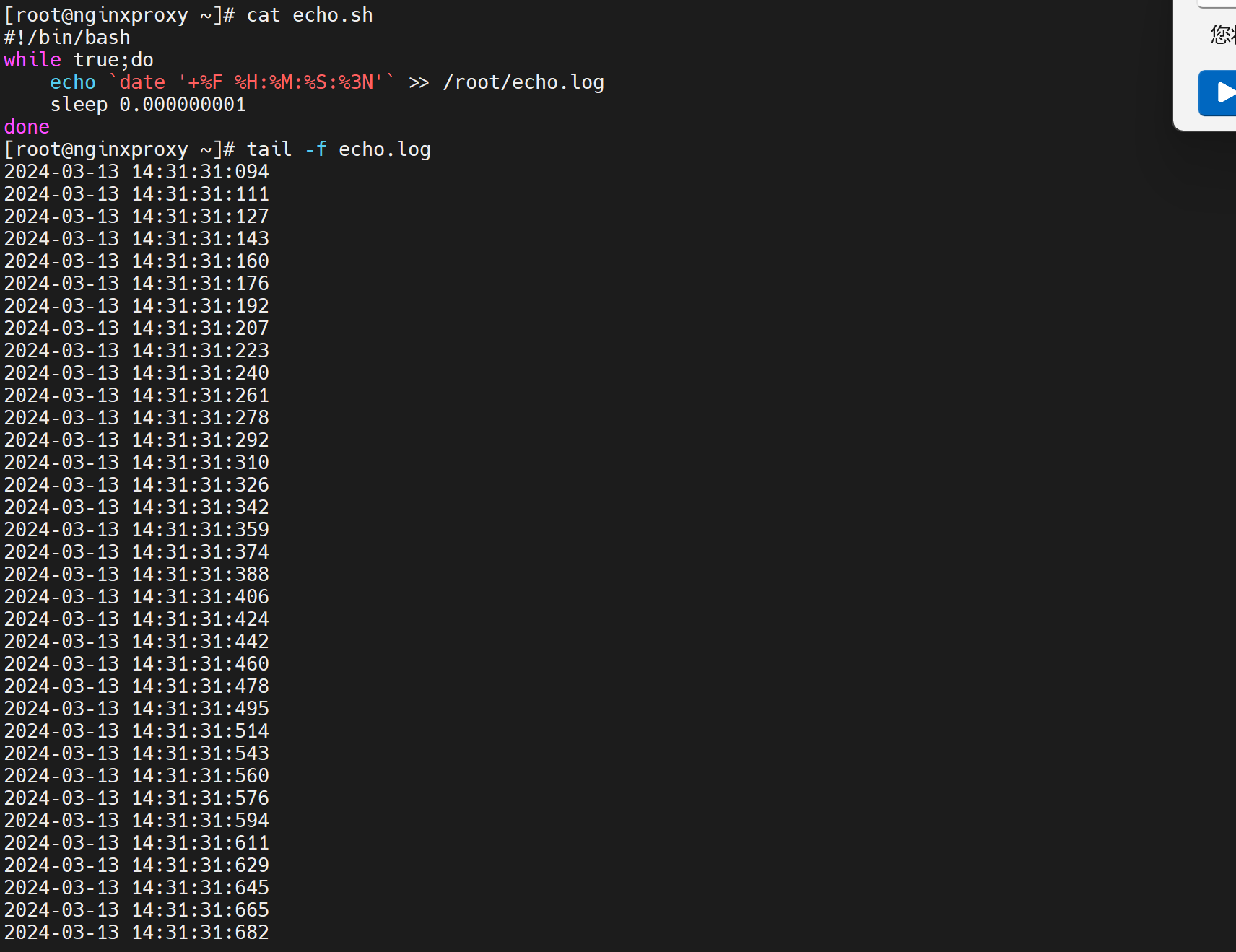
虽然没有达到理论上的1纳秒1个,但是可见1秒钟里已经有很多行了,精度已经不低了。差不多在20ms的精度了,已经八错啦。
但是这是脚本里的精度,vrrp_scrpts里只支持到1s👇也就是说即使脚本检测频率很高,但是我weight -20的自减权重让出优先级的动作还是1s,所以解决方案就卡在这里了。

所谓的vrrp v3支持厘秒,只是支持心跳的厘秒级,也就是keepalive本身的 A/S切换而已,不支持通过脚本对nginx或其他应用服务的高精度HA切换。也就是说场景支持仅仅是IP故障,而不是L7的服务故障厘秒级。L7的服务切换仅支持秒级而已。
2、精度 之 心跳的频率同样但不是nofiy通知的频率 advert_int
notfiy同样可以调用脚本
但是要明白notify是 主备 切换 的时候才会触发动作,
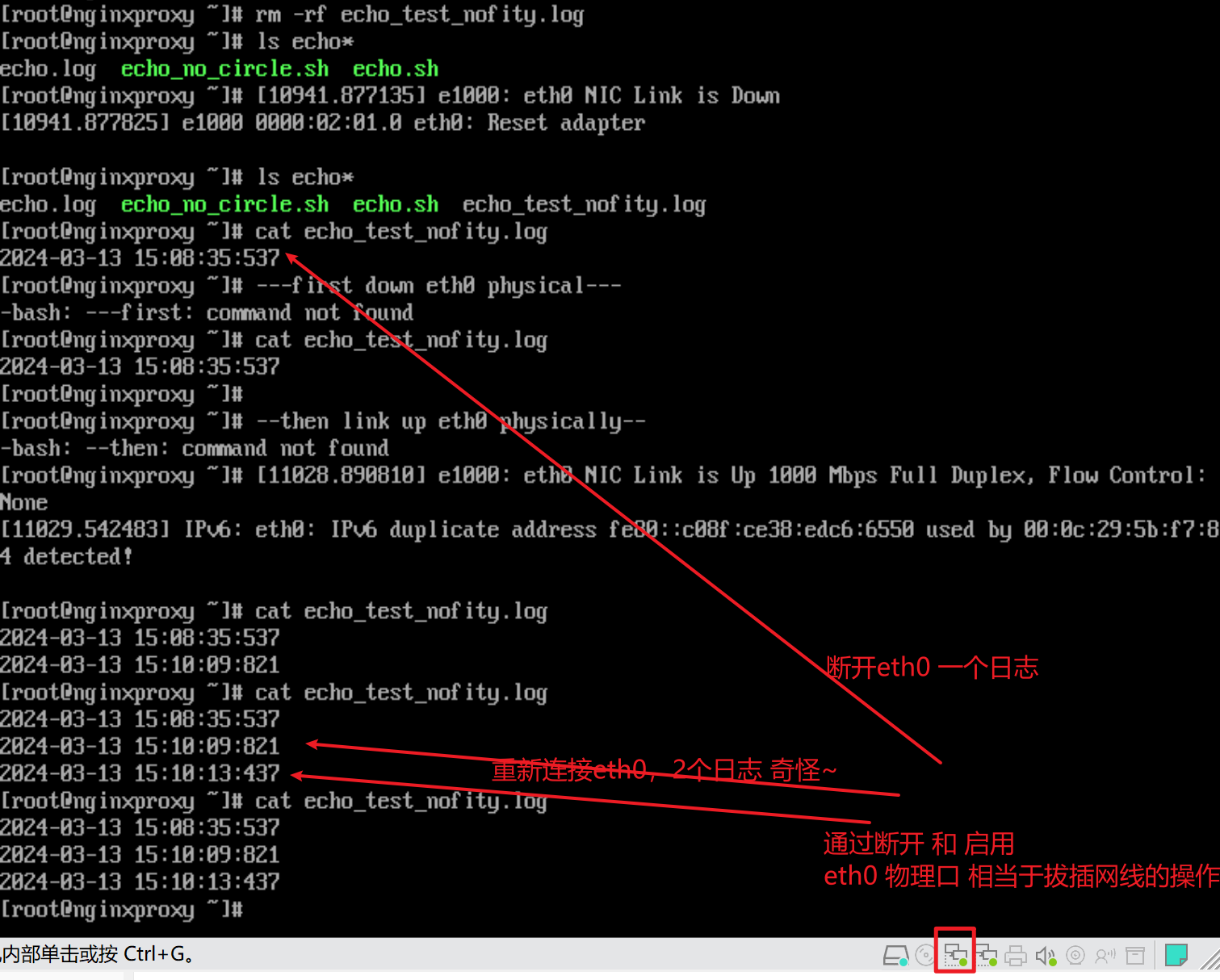
如何证明心跳是支持厘秒的,通过keepalive的心跳--组播报文
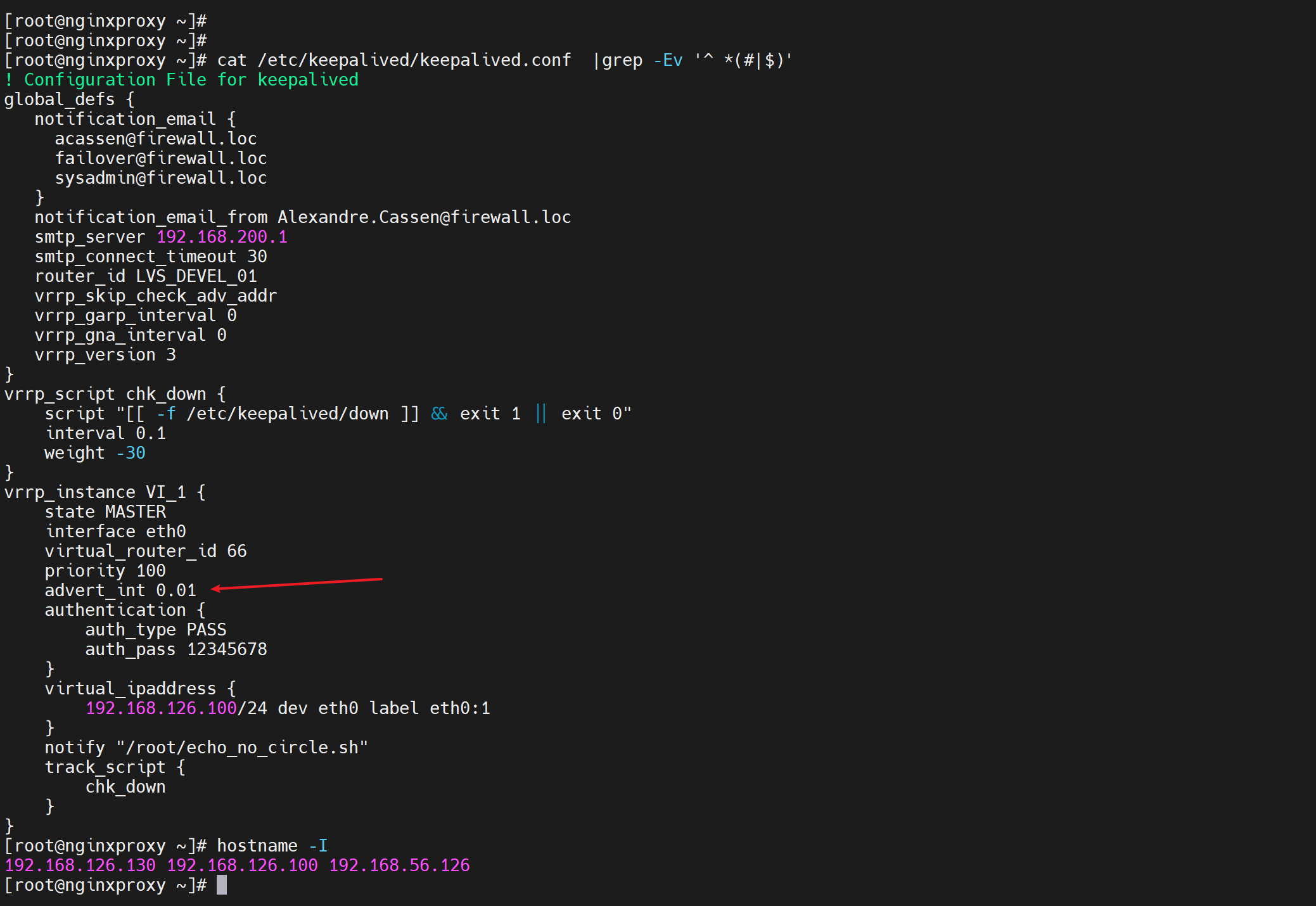
到对方去抓包,抓224.0.0.18组播包就可见
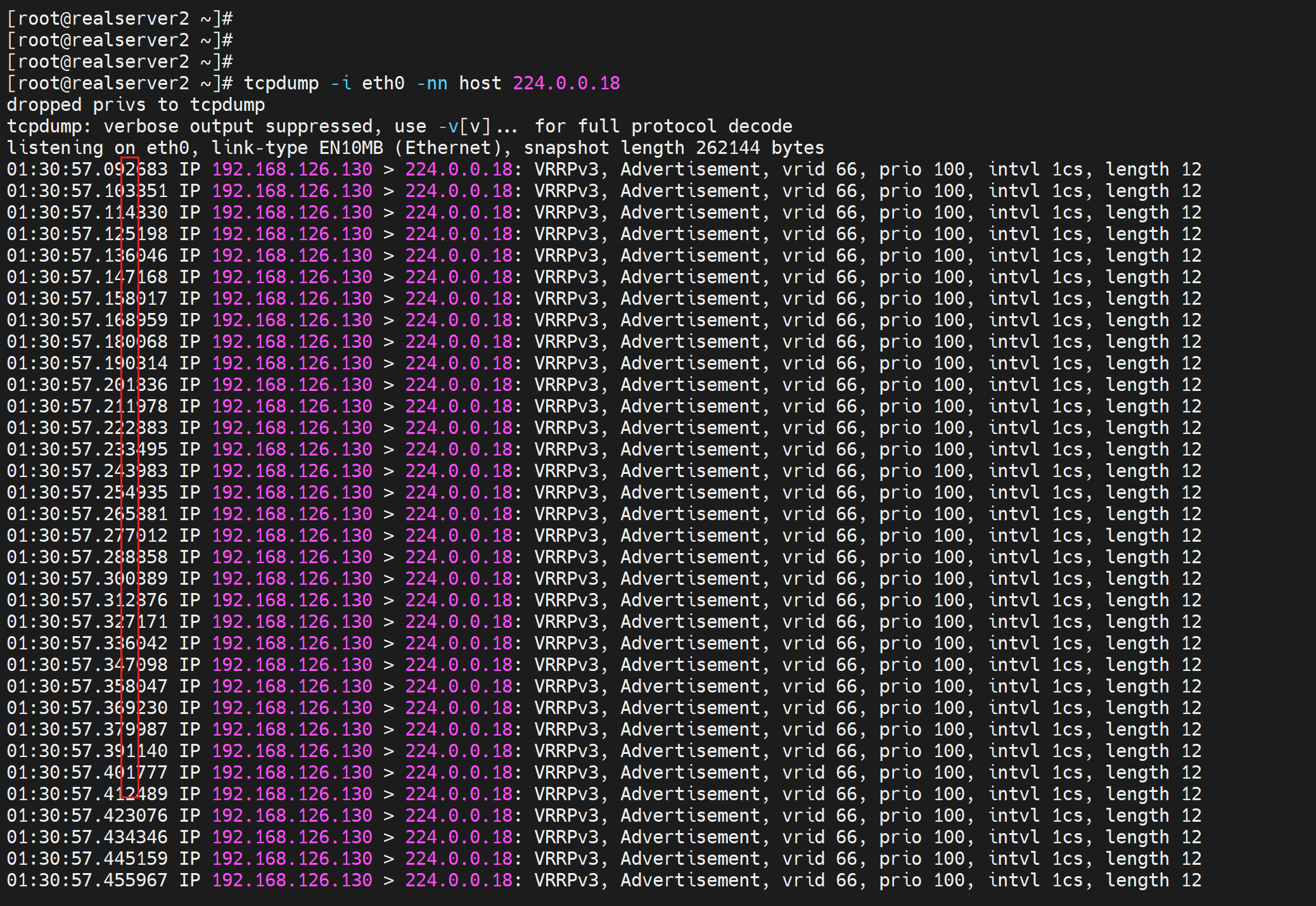
反之master看slave的keepalive应该还是1s一个,要验证下,
两个疑问?
①协商不是应该V3不能和V2协商成功嘛,或者V3向下兼容协商成V2才合理啊?
②组播的hello报文不是MASTER/BACKUP 两台机器都 会发送才对嘛,显然不对,只是当前激活的MASTER才会发送helllo报文。
③实测就是版本不一致可以工作,反正hello报也是单边发送,只是hello包的发送以master为准,但是其他功能就不好说了。当然实际干活不能两边version不一致的。
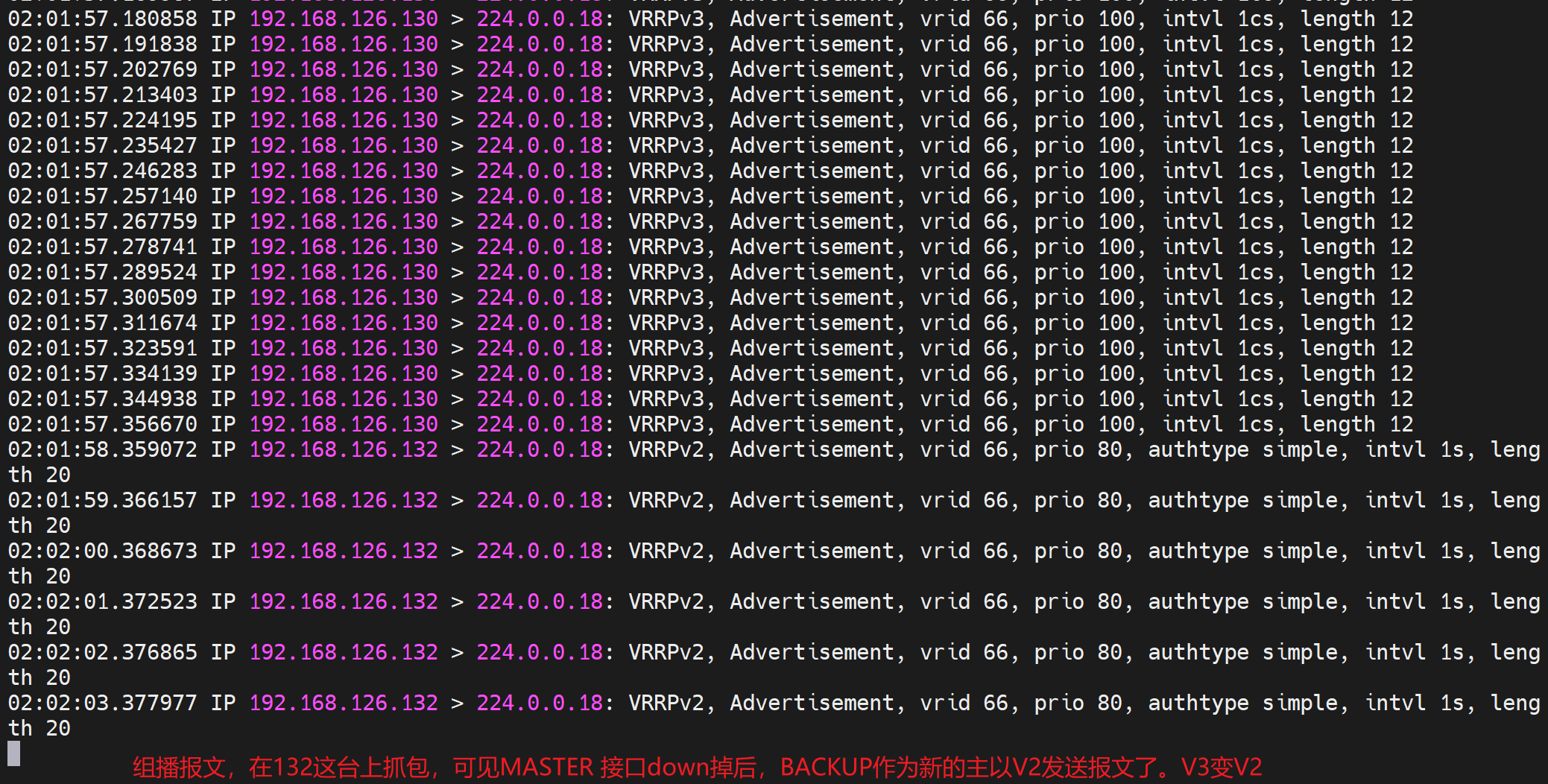
3、常规实验 之 文件是否存在的脚本
修改
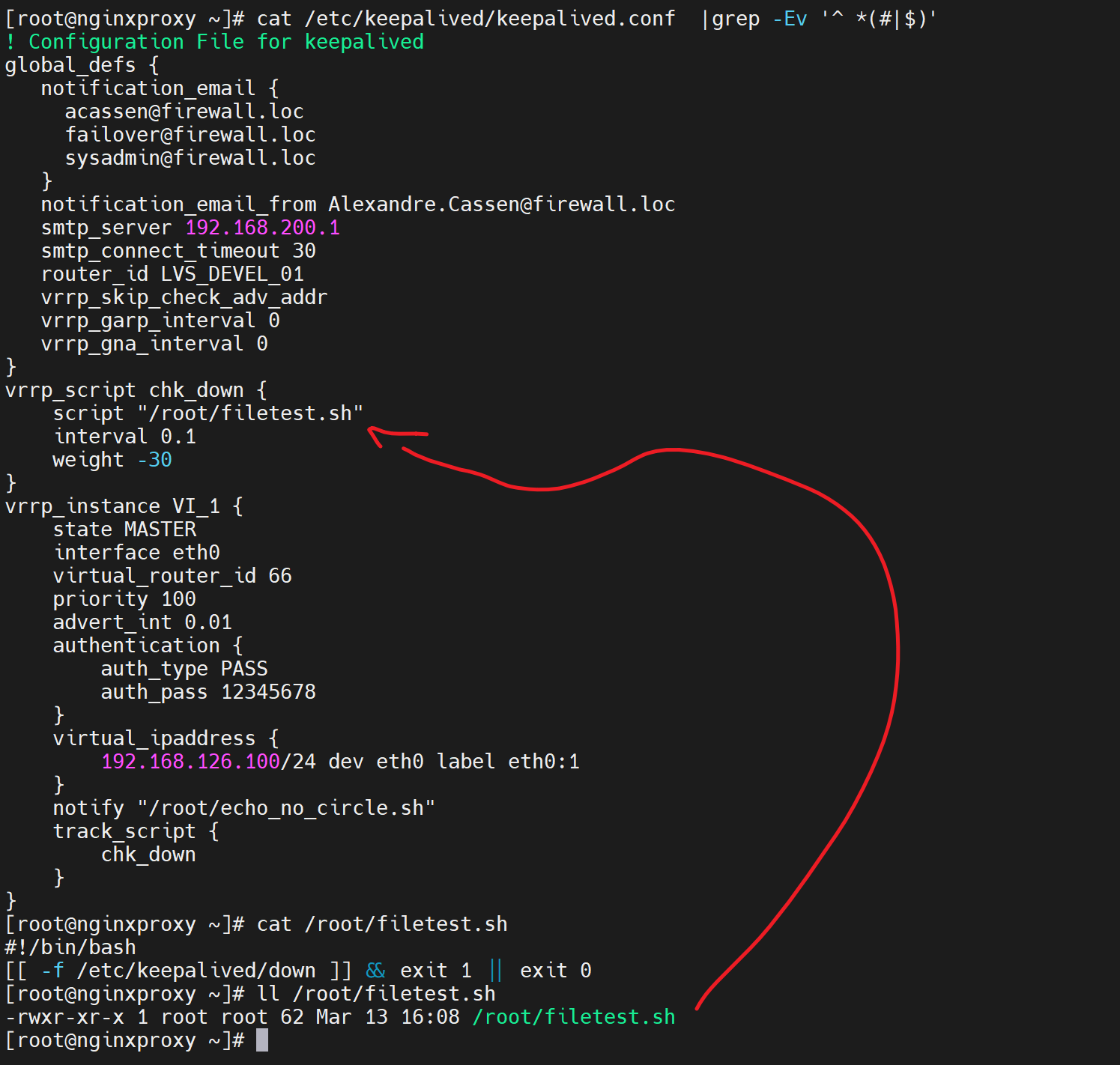
先删掉测试文件,重启服务,是配置文件生效,

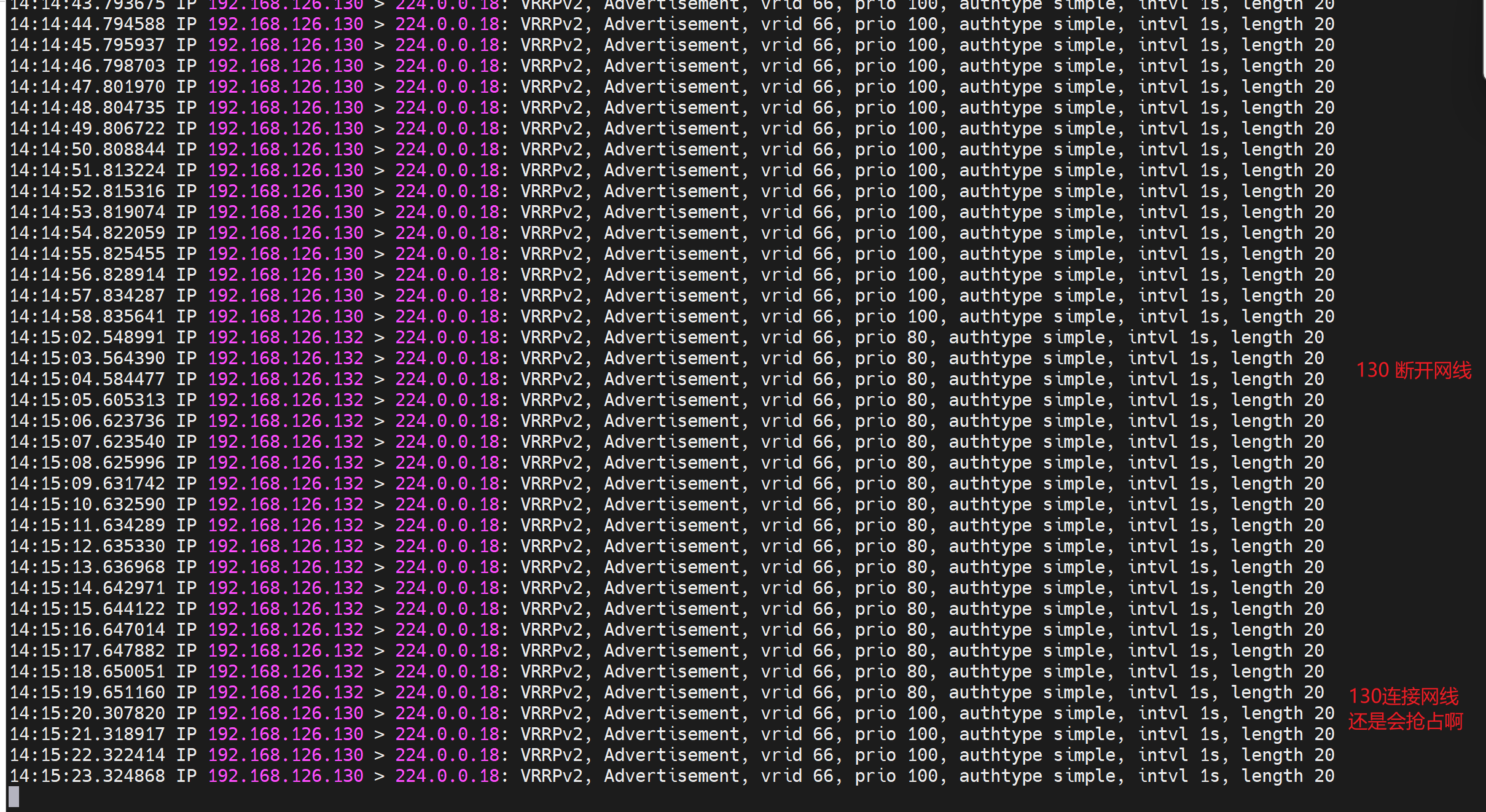
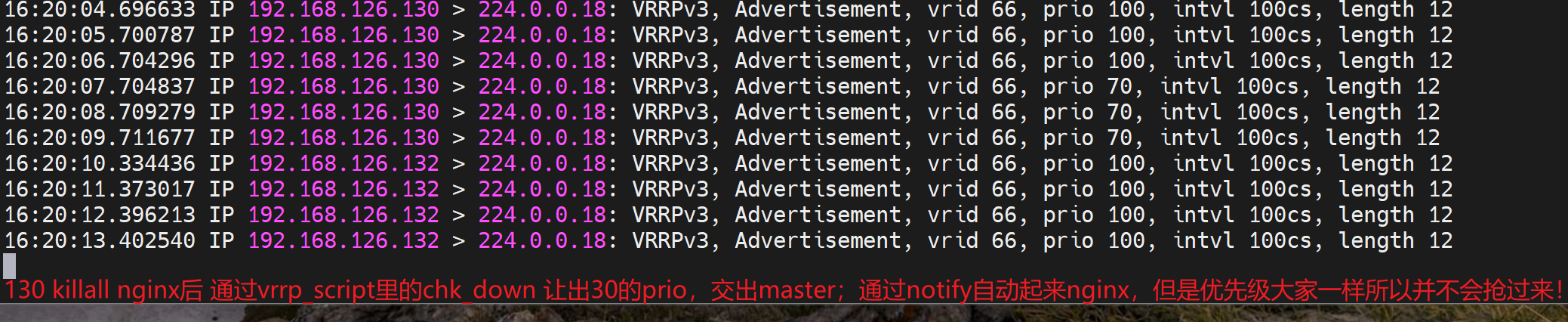
创建文件,满足脚本判断所以exit 1 ,1就是报错,报错就是 触发vrrp_script chk_down里的weight -30
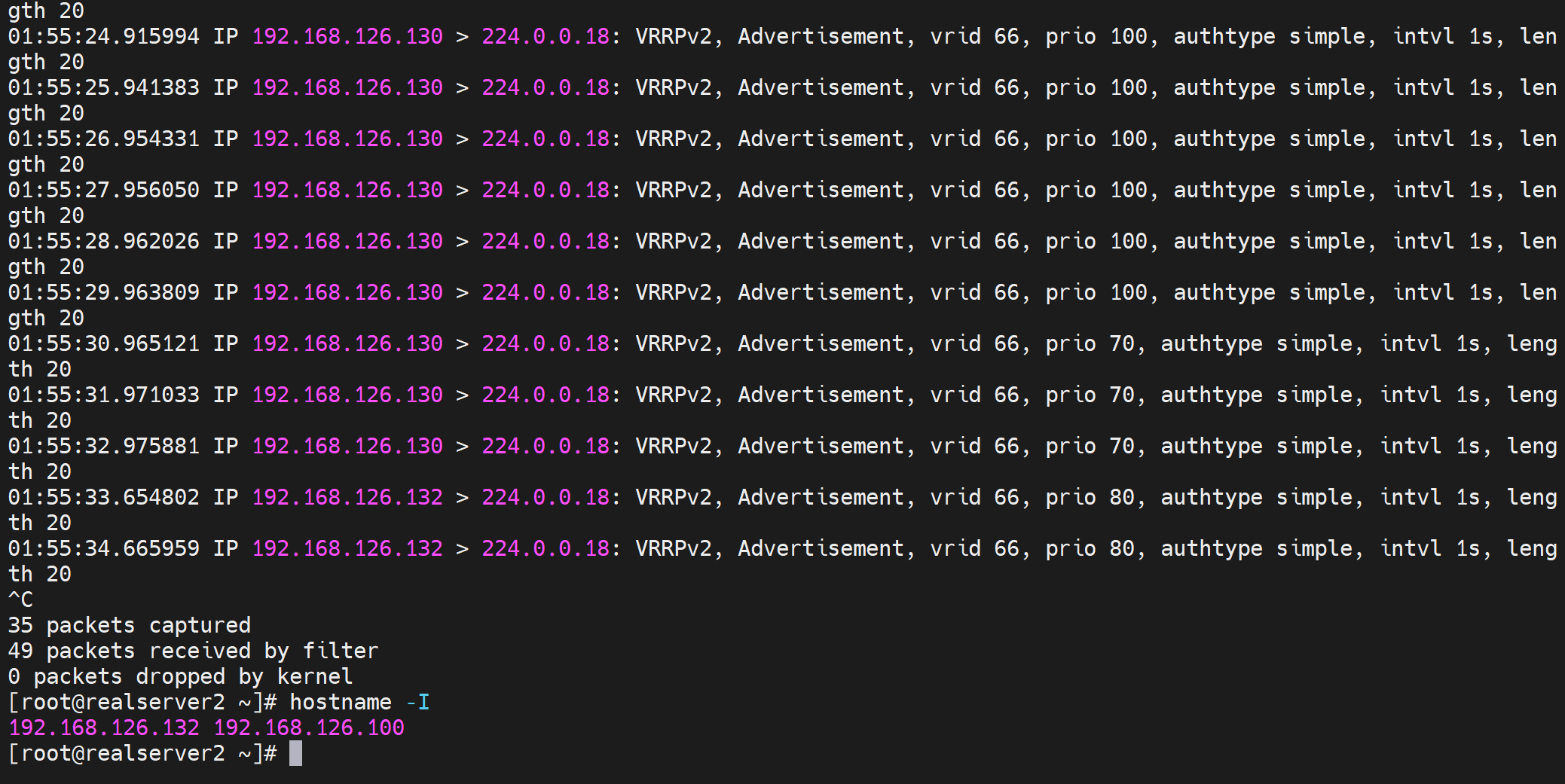
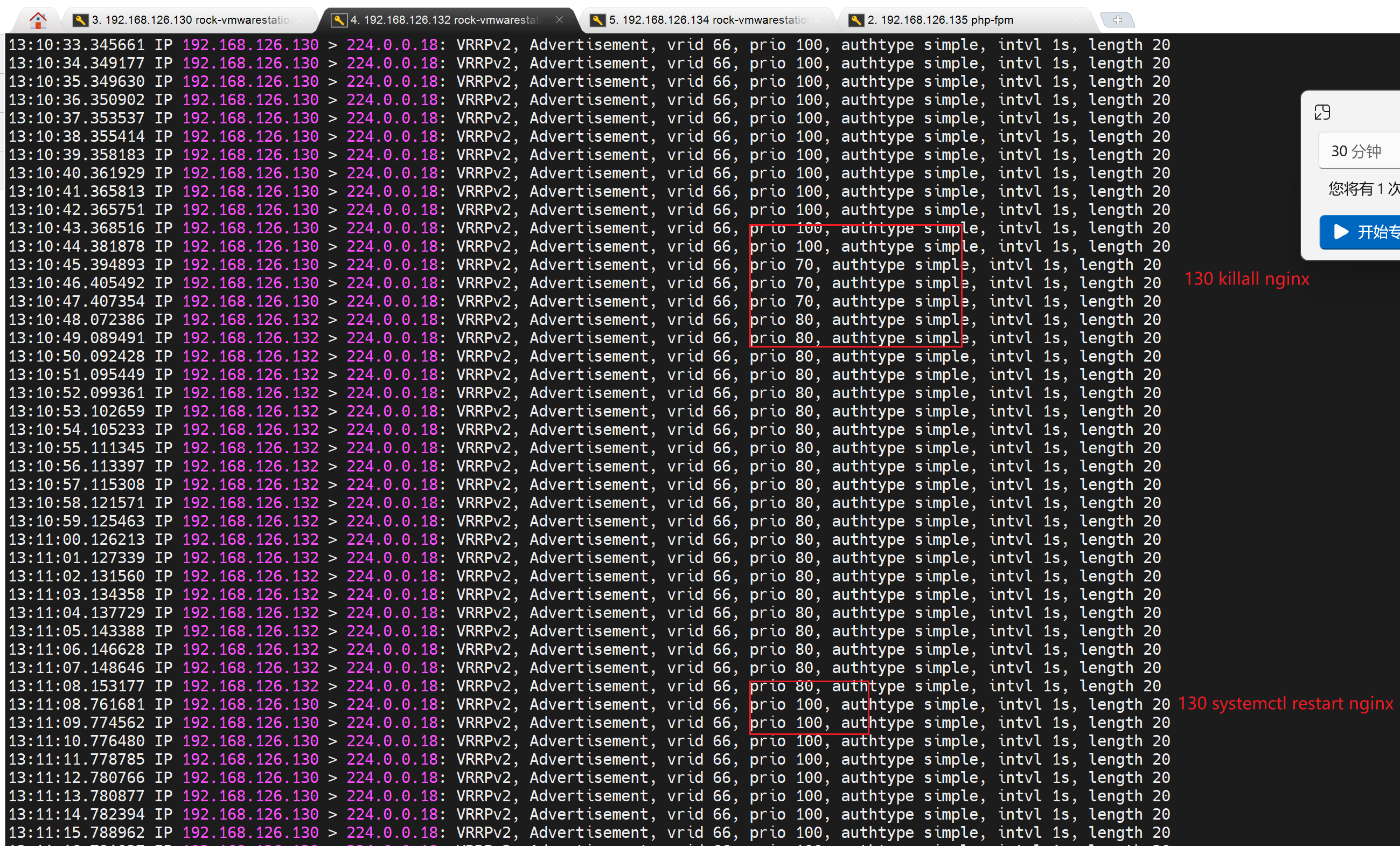
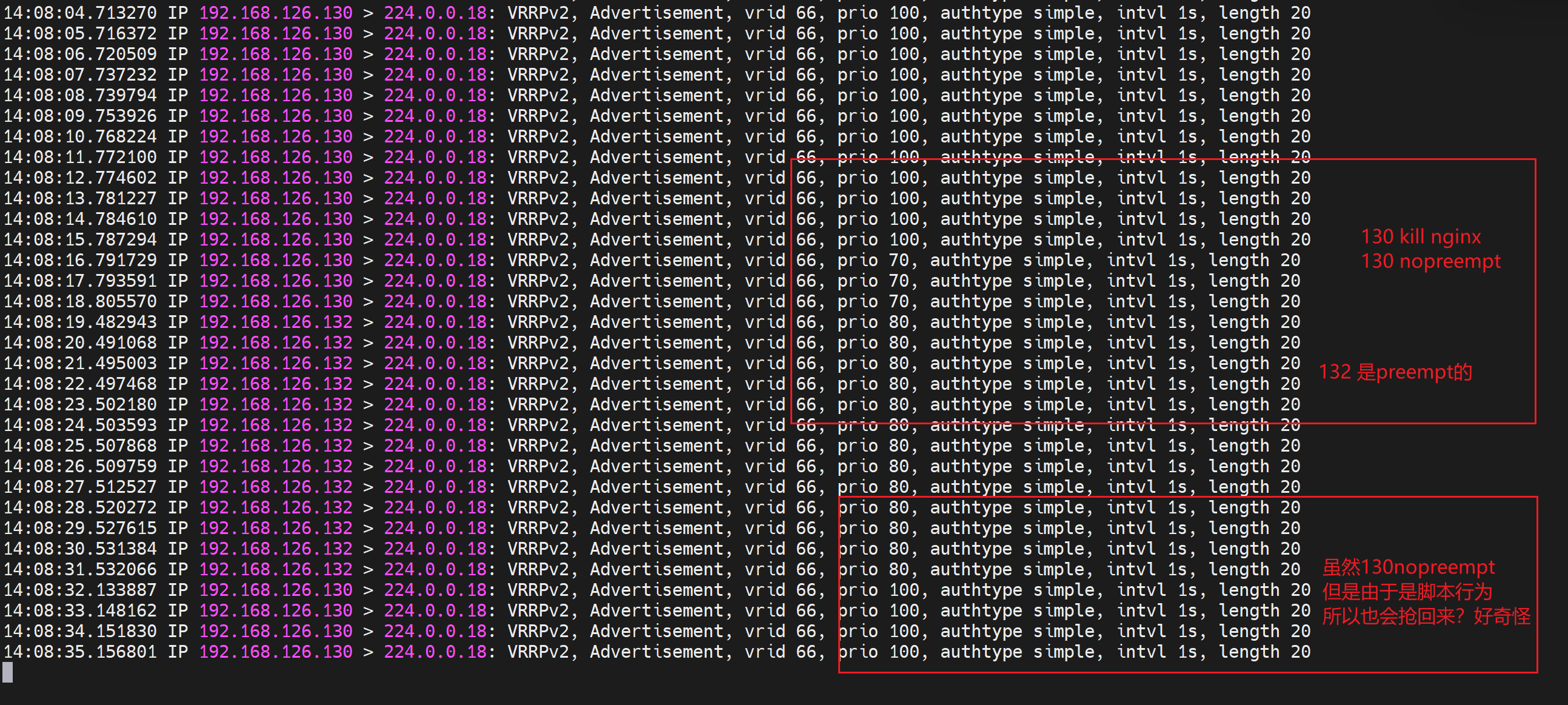
于是,通过tcpdump -i eth0 -nn host 224.0.0.18 可见 原来130这个IP发送的优先级减了30变成了70,从而132这个原来的BACKUP以80的优先级抢了MASTER,于是下图就看到了100->70->80的优先级数字。于此同时132这台BACKUP上变成了MASTER就看到了VIP-126.100了。
4、常规实验 之 nginx服务检测
就是脚本改改就行了

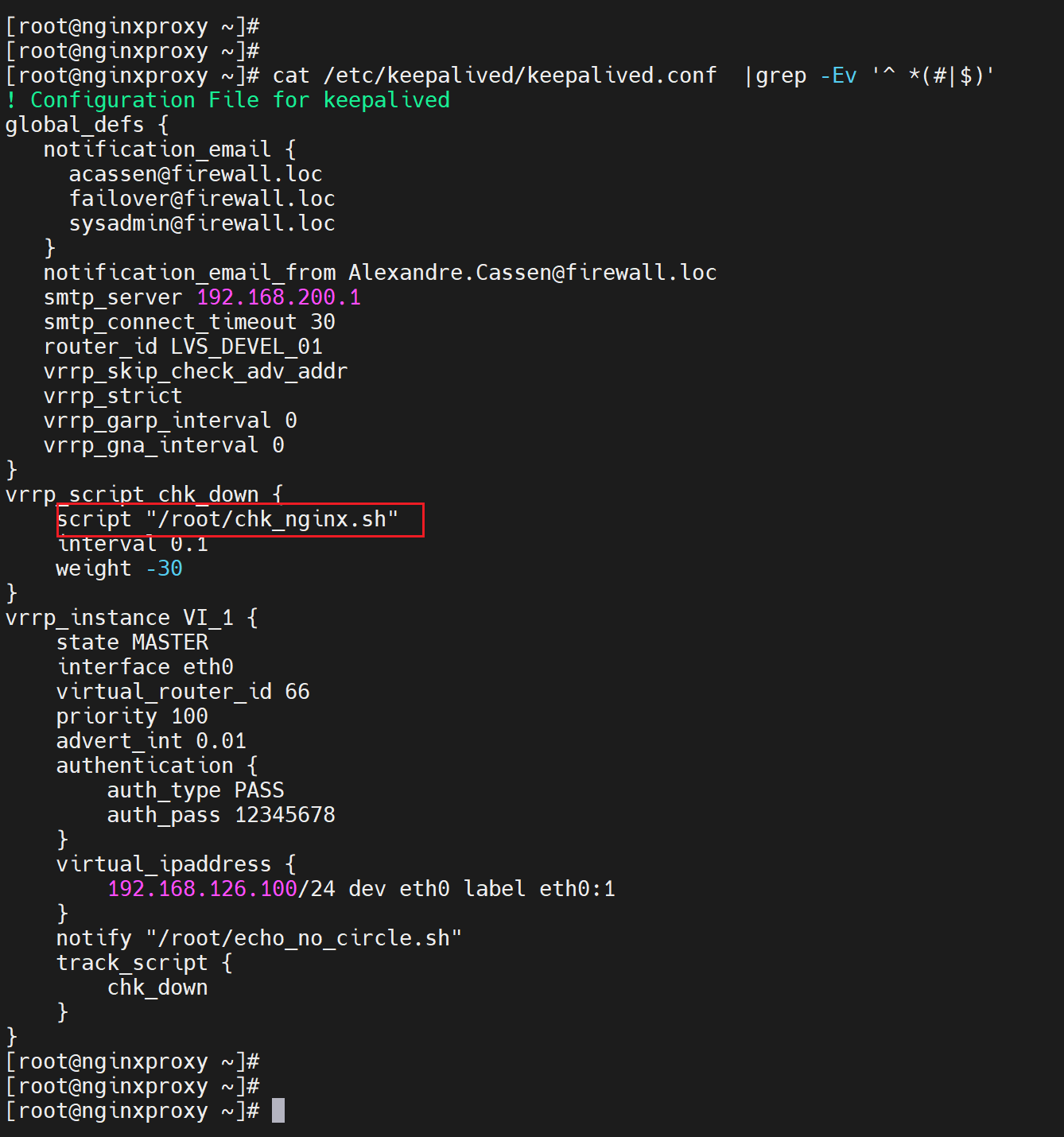
无需关注0.1,vrrp_v3都没开,0.1不生效也不报错的
keepalive的两台机器都需要配置一样的脚本,就是脚本一样,配置文件一样
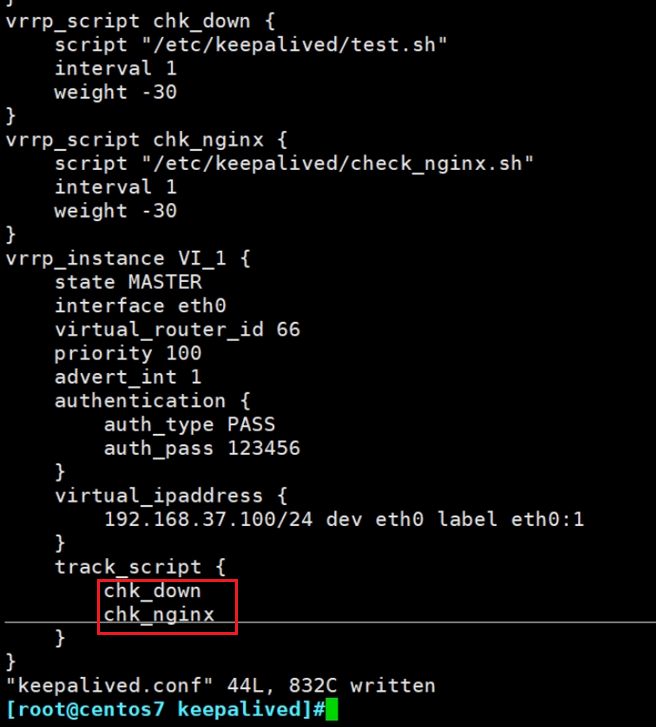
遇到个现象
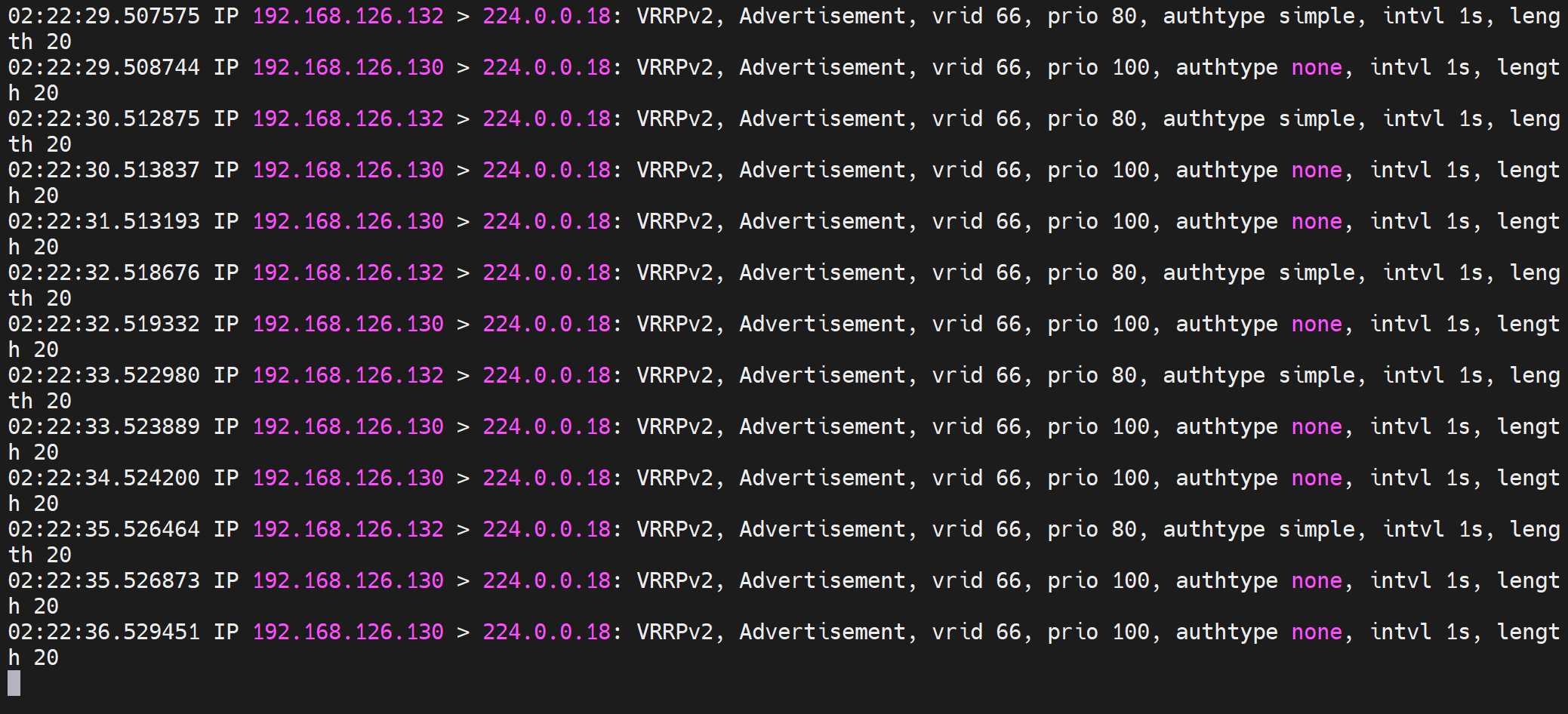
发现是130的vrrp_strict没注释掉。注释掉就行
保证cmd测试效果
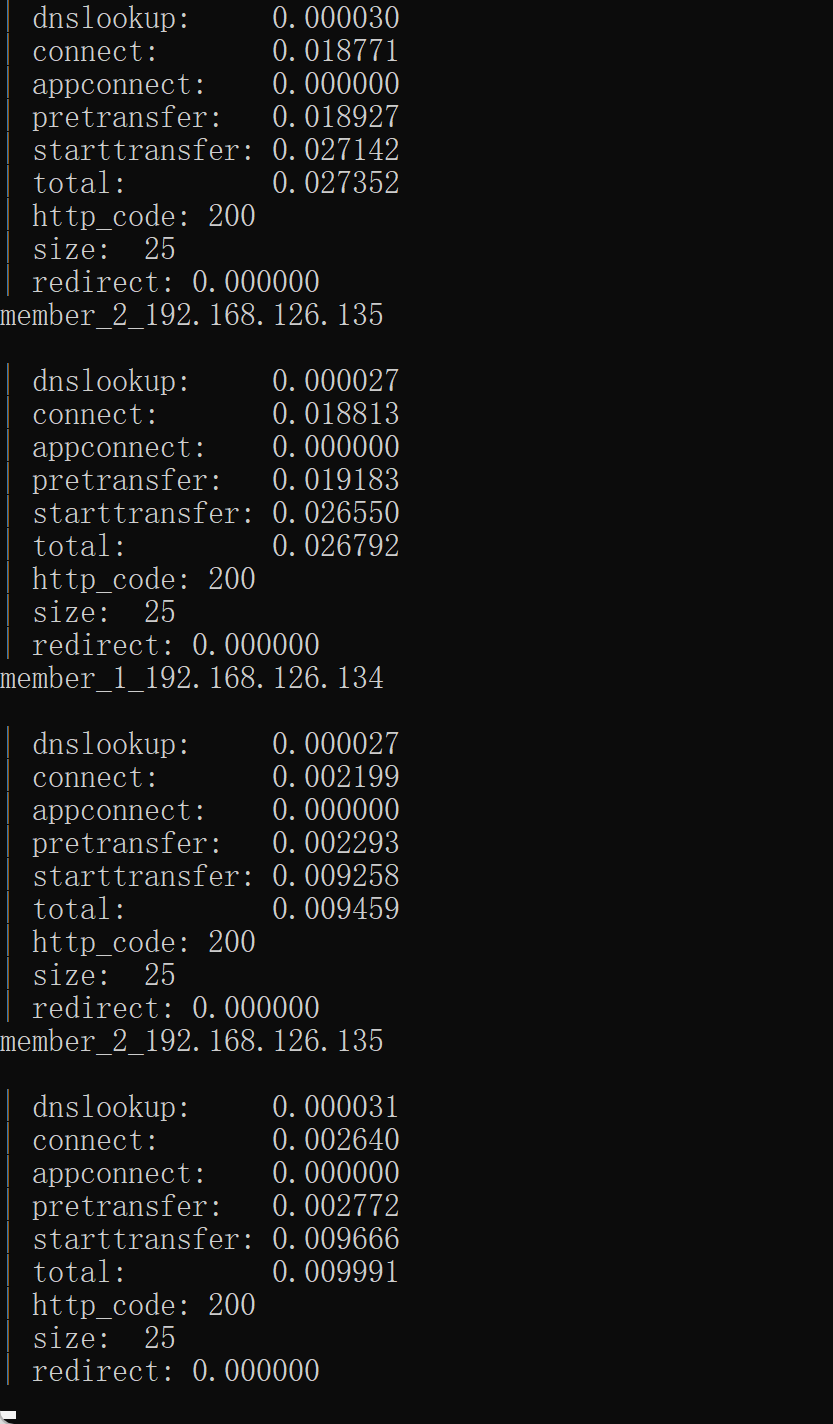
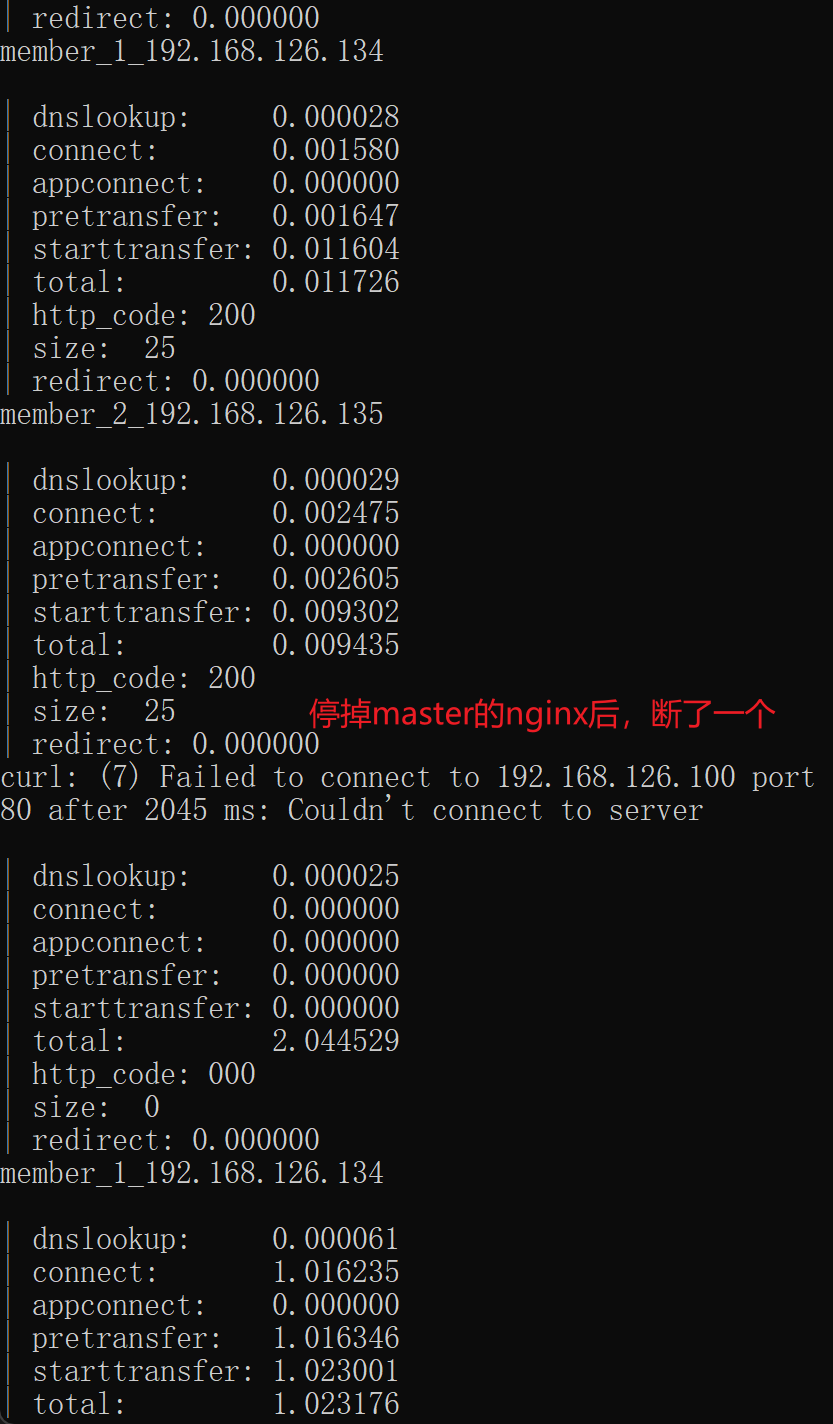
此时停掉一个nginx服务--肯定停掉master的nginx了
在192.168.126.130上stop nginx,如果nginx和keepalive不在同一个机器就需要远程跑脚本了,sshpass之类的也行啊
nofity可以进一步做故障修复
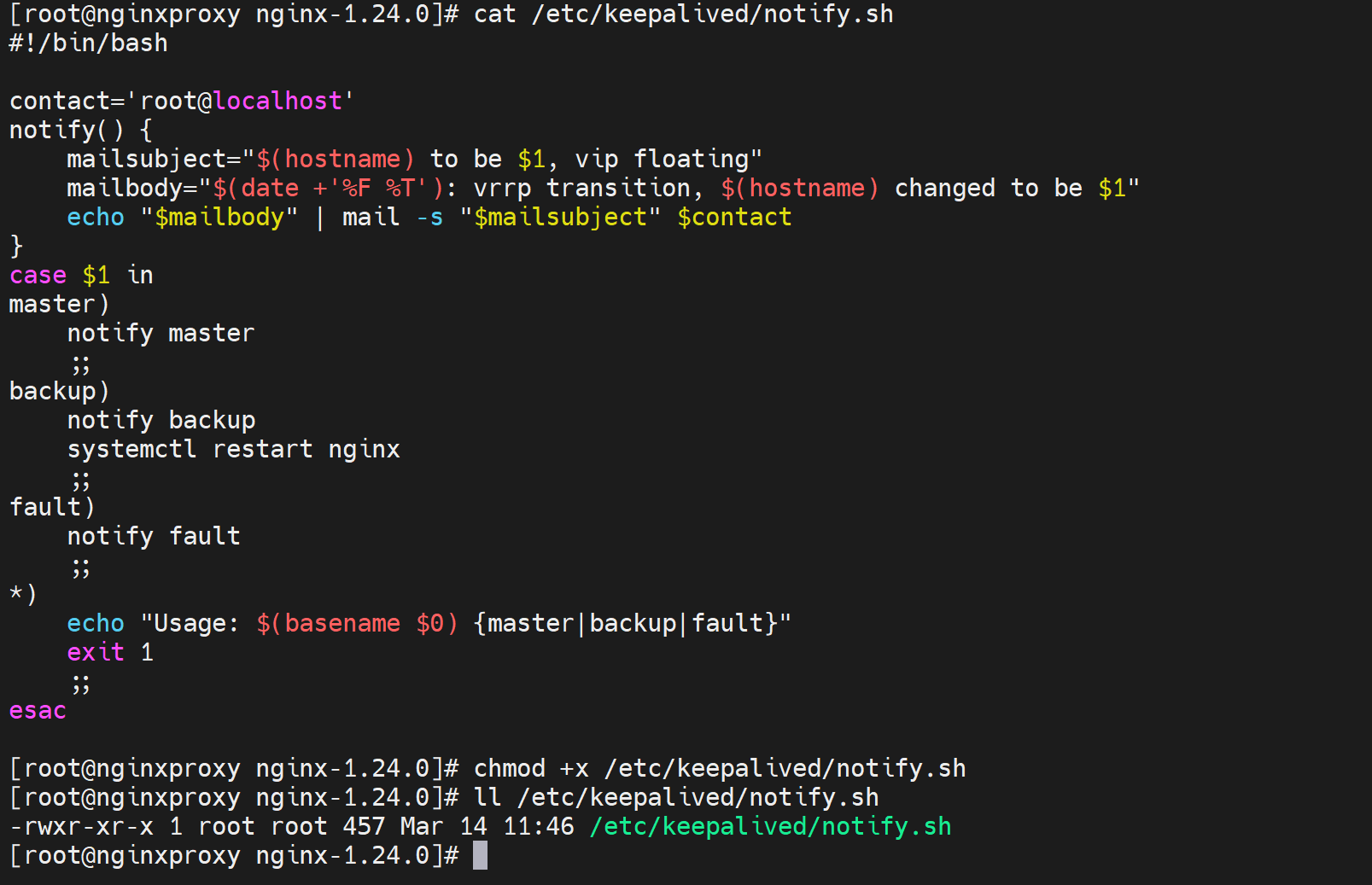
keepalive 通过vrrp_script 检测发现问题,然后切换主备,然后notify 调用修复脚本同时脚本自带信息发送,比如讨厌的dingd


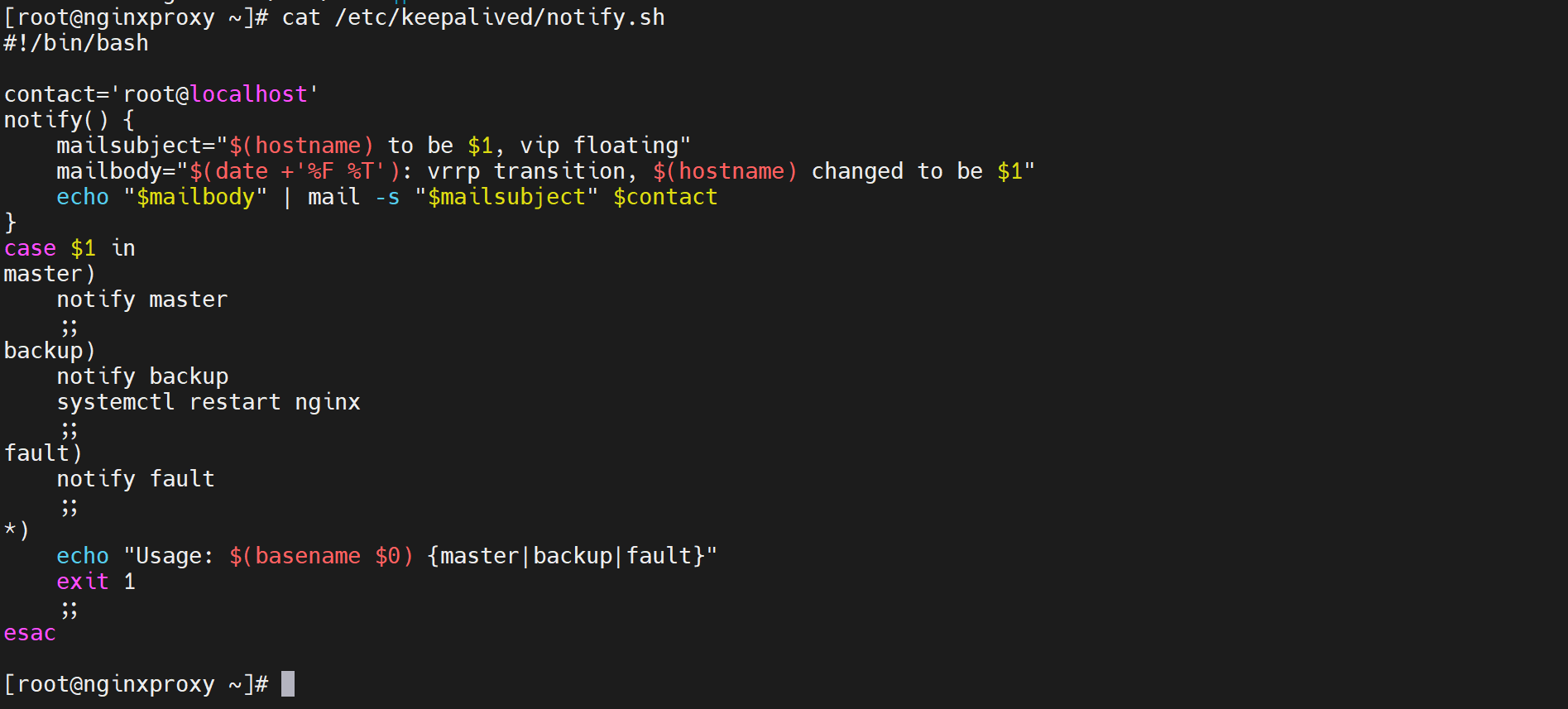
nofiy.sh脚本内容👇 记得chmod +x
#!/bin/bash #
contact='root@localhost'
notify() {
mailsubject="$(hostname) to be $1, vip floating"
mailbody="$(date +'%F %T'): vrrp transition, $(hostname) changed to be $1" echo "$mailbody" | mail -s "$mailsubject" $contact
}
case $1 in master)
notify master
... # 切成主是否需要进一步做动作
;;
backup)
notify backup
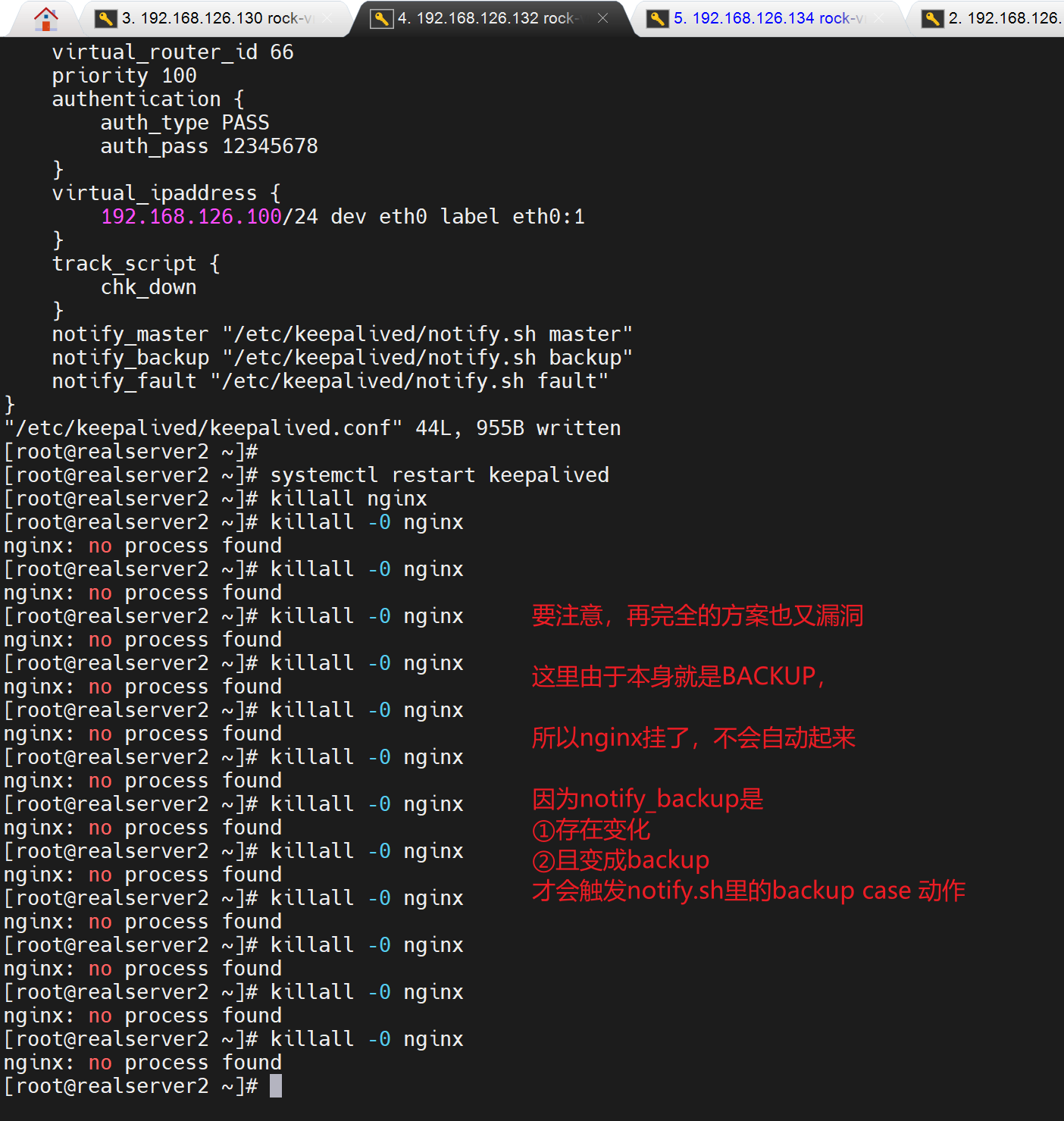
... # 切成备是否需要进一步做动作,既然切成备了,说明vrrp_script语句块里的检测到nginx 挂了,所以这要做systemctl start nginx动作去修复的。
;;
fault)
notify fault
;;
*)
echo "Usage: $(basename $0) {master|backup|fault}" exit 1
;;
esac
vim /etc/keepalived/keepalived
vrrp_instances xxx 块里 最后一行加上
notify_master "上面的notify.sh脚本的路径 master(这是往脚本传递参数$1位置调用)" # 切成master就执行这一行
notify_bakcup "上面的notify.sh脚本的路径 bacup(这是往脚本传递参数$1位置调用)" # 切成master就执行这一行
notify_fault "上面的notify.sh脚本的路径 fault(这是往脚本传递参数$1位置调用)" # 切成master就执行这一行
以下就是2个脚本,和配置文件完整的内容
需要安装mail命令的。centos就 yum -y install mailx,rocky就yum -y install s-nail,mail的cli就有了


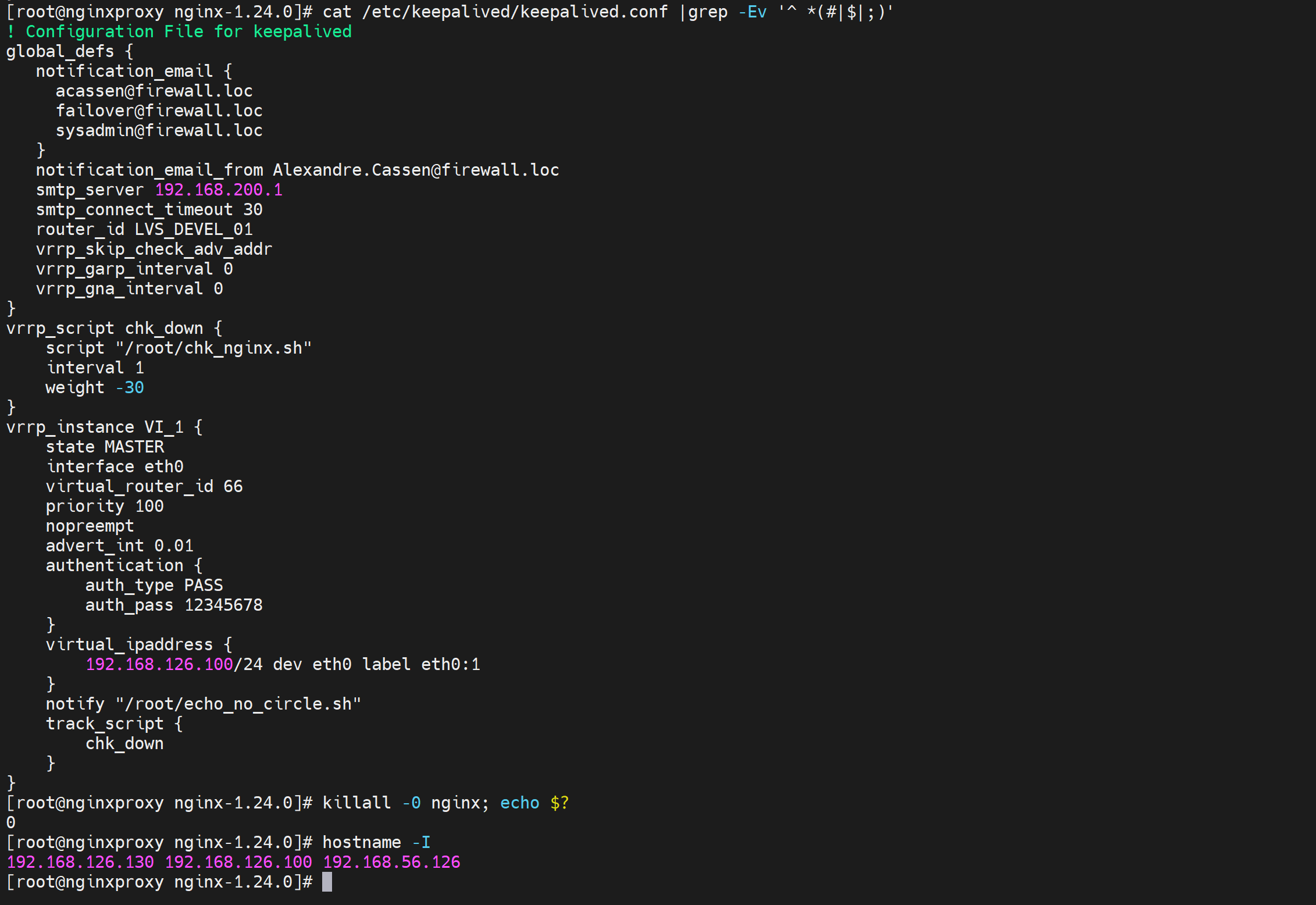
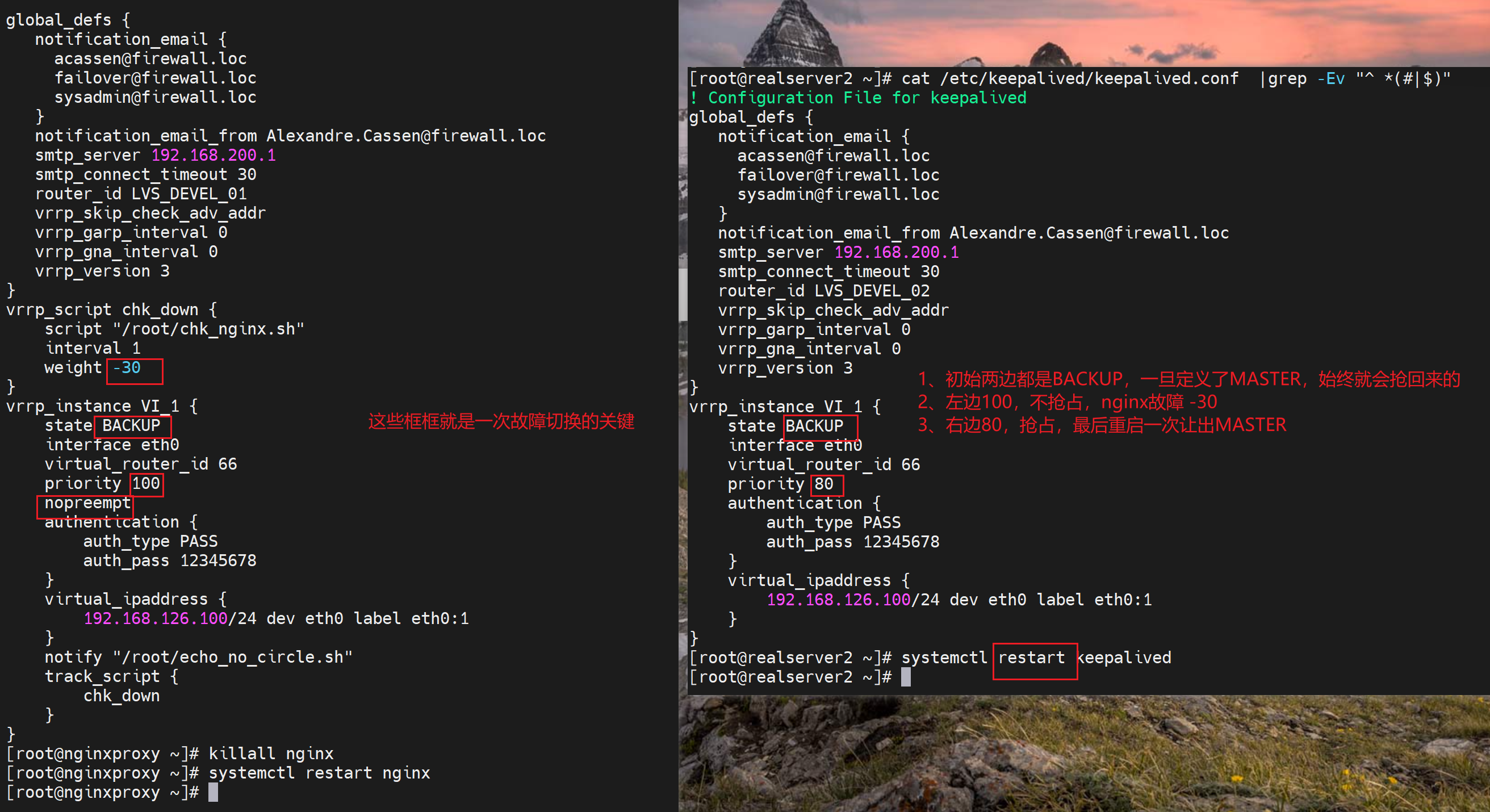
测试下,由于默认是开启preempt抢占的,但是这个抢占是keepalive之间的prioriy高复活了就抢回来,而不涉及脚本的监控(实验过了是涉及脚本监管的,你脚本监控的是nginx down就weight -30,对比,等你nginx起来了,会自动恢复原来的权重的,这个恢复功能是默认就有的。你不需要就使用nopreempt来实现不回切就行了,但是优先级应该是恢复了的),所以实验步骤和现象预判为:
1、130 132 两个IP地址 分别前后为MASTER 和 BACKUP
2、130上执行 killall nginx 杀掉nginx后,130 触发chk_down检测脚本,变为BACKUP
3、130变成BACKUP后,触发notify_backup脚本,重启nginx,但此时不会抢回来(这里是猜测,其实是会抢回来的,会抢回来是因为初始手动指定为Master的,这里下文有总结的)。-- 实验到此结束。
因为没有哪个脚本说是nginx起来会怎么怎么样的,不管是chk_down里还是notify_xxx里都没有配置,更准确来讲是notify是切换状态一次触发一次来着,而且你写的是notify_master 这种就是切成master才会触发,而不是直接notify ""这种是切一次执行一次,不管是什么切成了角色。
*想nginx活了抢回来,就要再写一个chk_up脚本,来检测到nginx up就将weight 值+30,这样weight就恢复成了100;于此同时还需要辅以notify_master的动作嘛?好像没必要,之前变成BACKUP的时候启用了nginx了,然后chk_up有检测过了确实起来了,才会让keepalive +30重新变成100为MASTER啊。所以ok的思路
而且这种脚本的配置也要考虑清楚,正常时两边MASTET和BACKUP一样的。
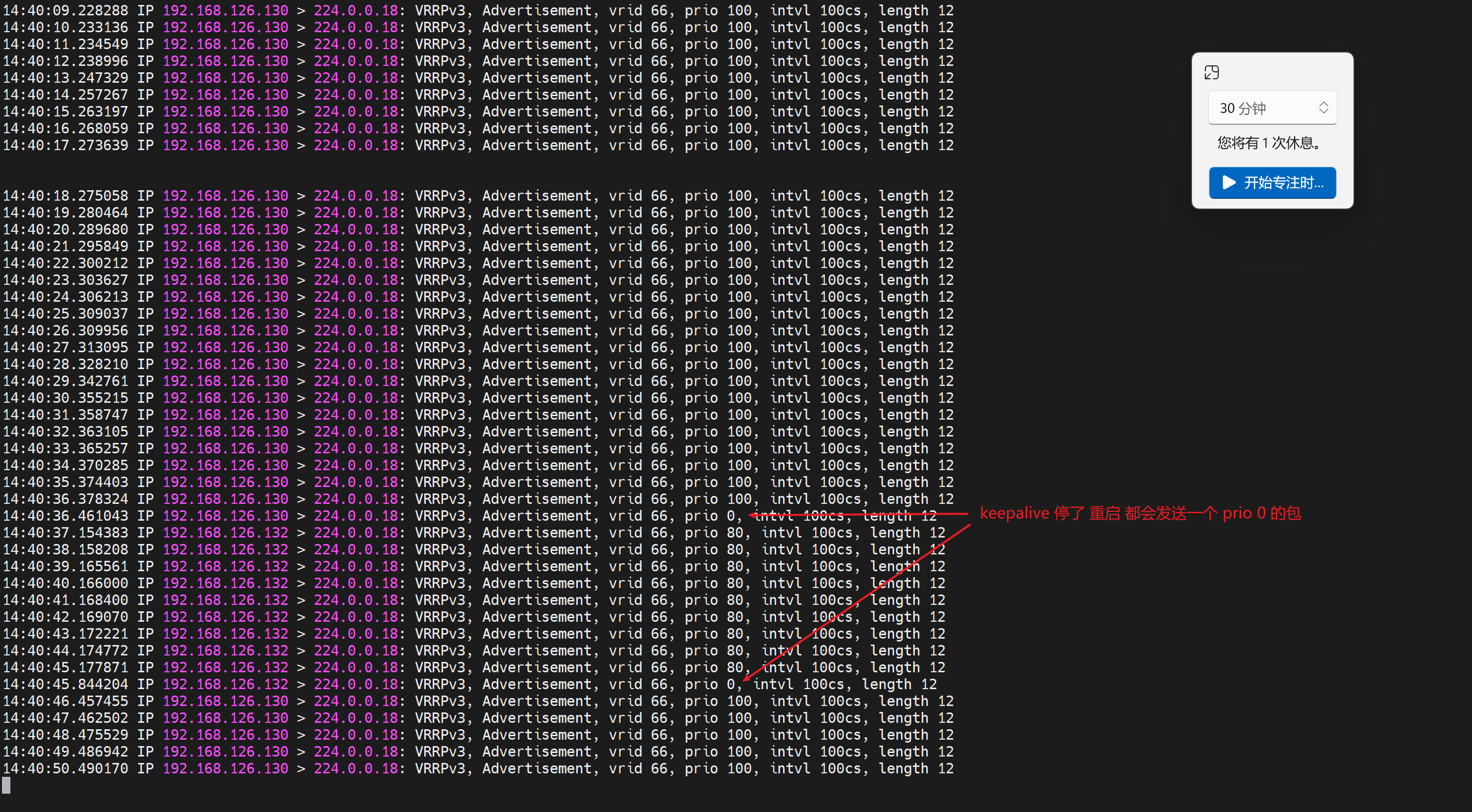
4、关于抢占,重启keepalive服务这种就是会发送prio 0 的报文,通知对方自己下线了,呵呵,这种属于重新协商的层面,和抢占无关,preempt抢占是发生在keepalived服务活着的情况下的优先级的上下浮动的时候的M/S的切换,抢占。
结果发现nginx起来后会抢回来,
通过删除notify配置cli,然后测试,发现keepalive的vrrp确实周到,nginx恢复了,会抢回来的。分析逻辑就是vrrp_scritp脚本 监控 nginx down 权重-30,如果监控发现nginx up会自动恢复权重。
preempt关于抢占
1、keepalive服务重启,意味着vrrp协议重新协商,不涉及preempt于否,keepalive活着 优先级的升降才设计抢占。
2、以下配置,两头都 nopreempt关闭抢占,130 那边脚本检测到nginx down就自降30 prio后,由于那头131不抢占,所以还是130 作为master。当然题外话:此时由于本身nginx 没了自然业务就出问题。
130和132都关闭抢占,
此时130上killall nginx,130 prio -30,但是由于132上未开启抢占,所以对于132来讲就不回抢占,好烦啦老说这个词。
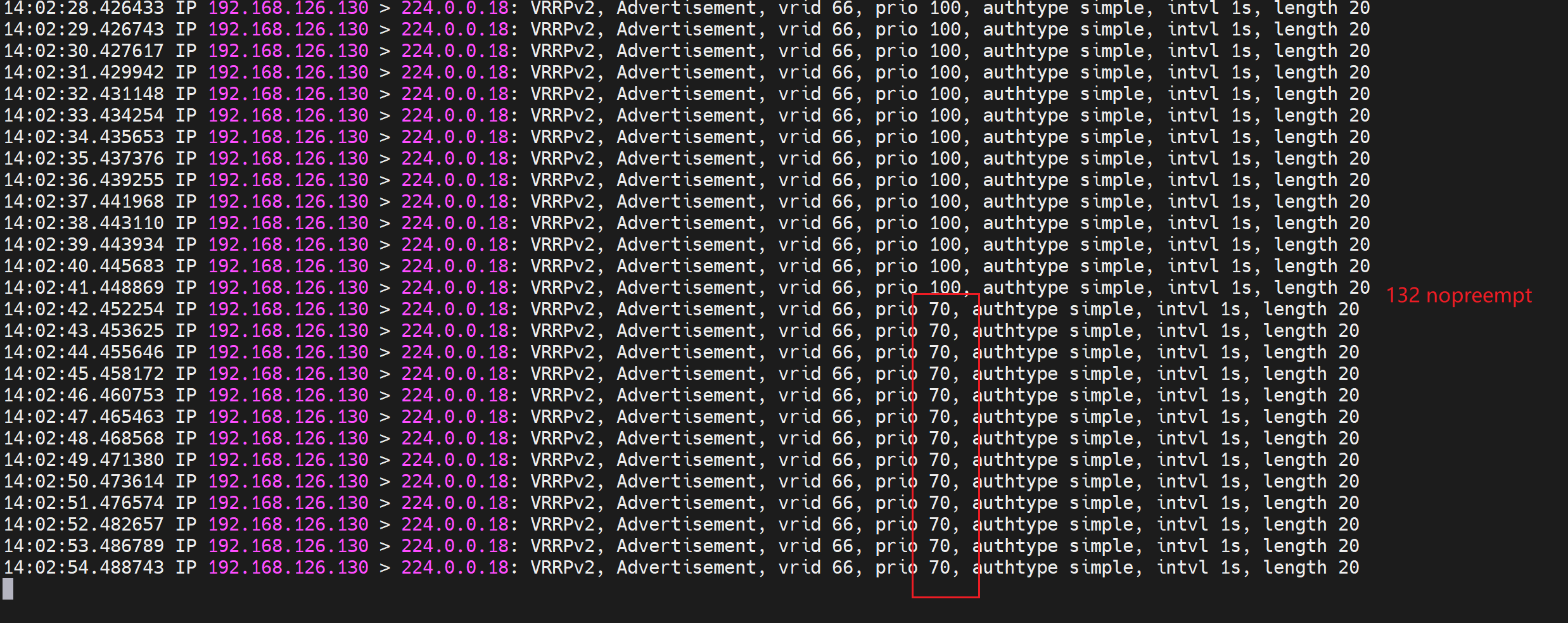
如果此时130恢复nginx,自然也没说什么特别的现象,因为从头到尾130就没有将Master交出去过。
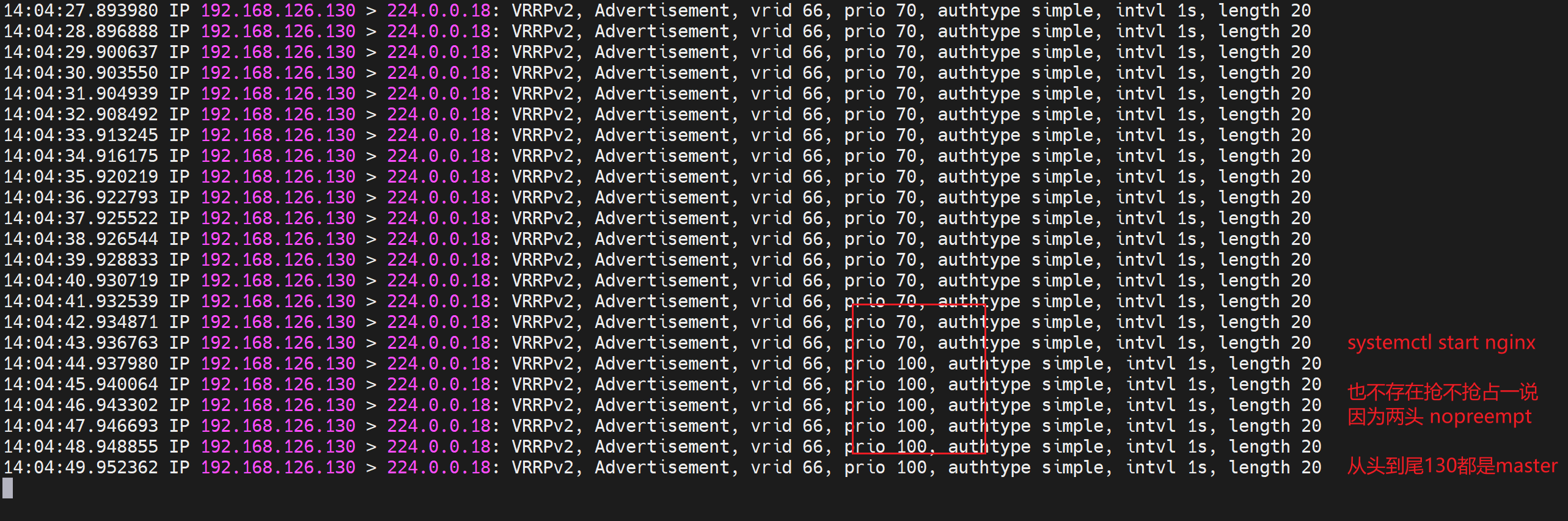
如果此时132开启抢占,才是好玩的地方
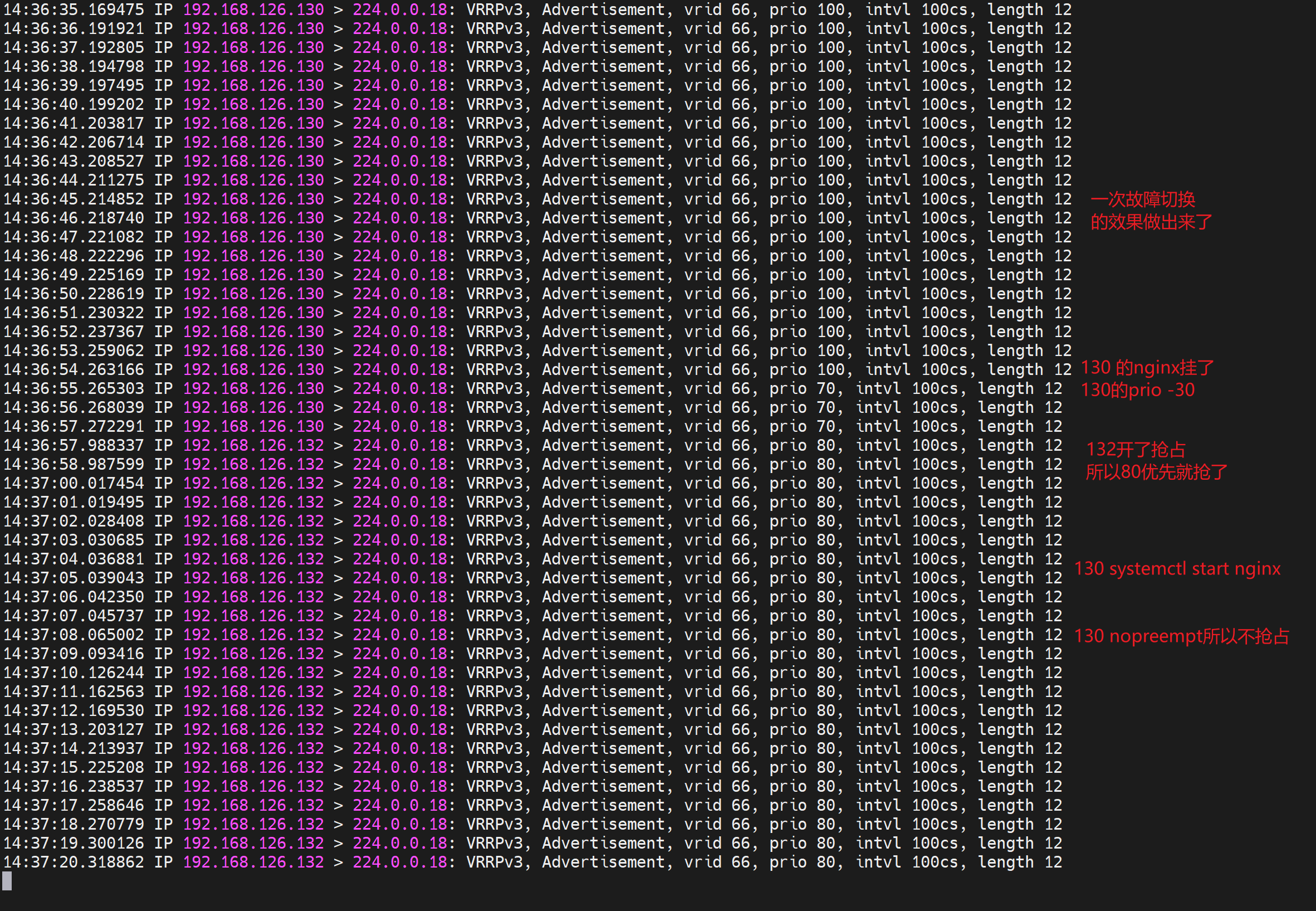
测试如图,说好的130不抢占,但是其实会抢回来。
到底怎么才能看到130故障恢复后的不抢占效果呢,这个很重要啊,要知道 切一次就是一次故障,你不能说原来的MASTER好了,再切一次,造成二次故障吧。
https://blog.csdn.net/MssGuo/article/details/127336013
扫了这篇,我有点想法
preempt完整总结
1、A/S 初始化协商,如果定义了master,那么在hello的 比如说3个周期内会以手动指定的master来顶定的。这个就是叫做初始的master竞选规则,当然这是我猜的,比如DR/BDR的选举,
2、注意:要使nopreempt参数起作用,初始状态不能是MASTER
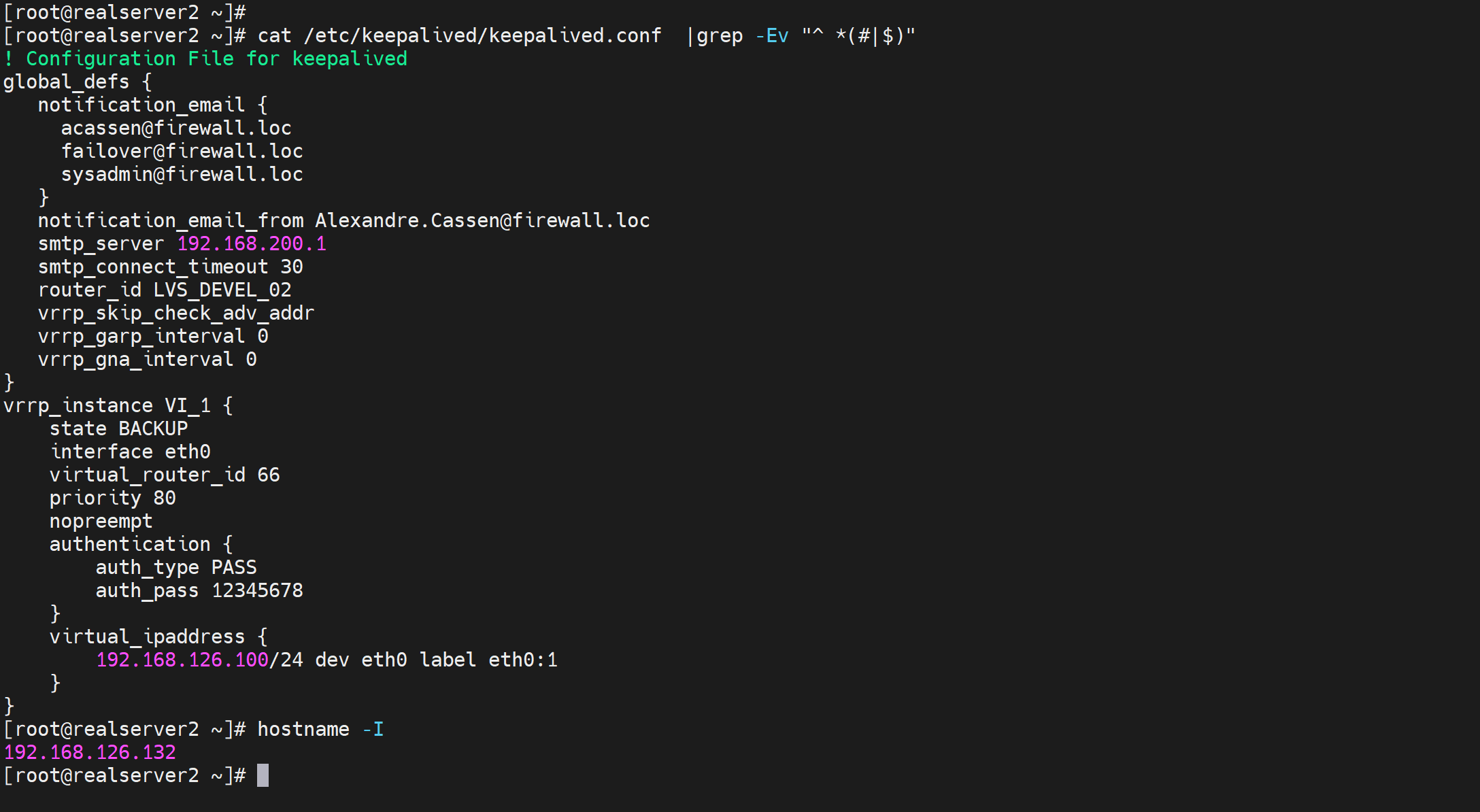
3、两边都为backup,preempt才能 在 prio 高的时候 实行抢占的。
1、两边都配置BACKUP,满足不抢占的初始条件,
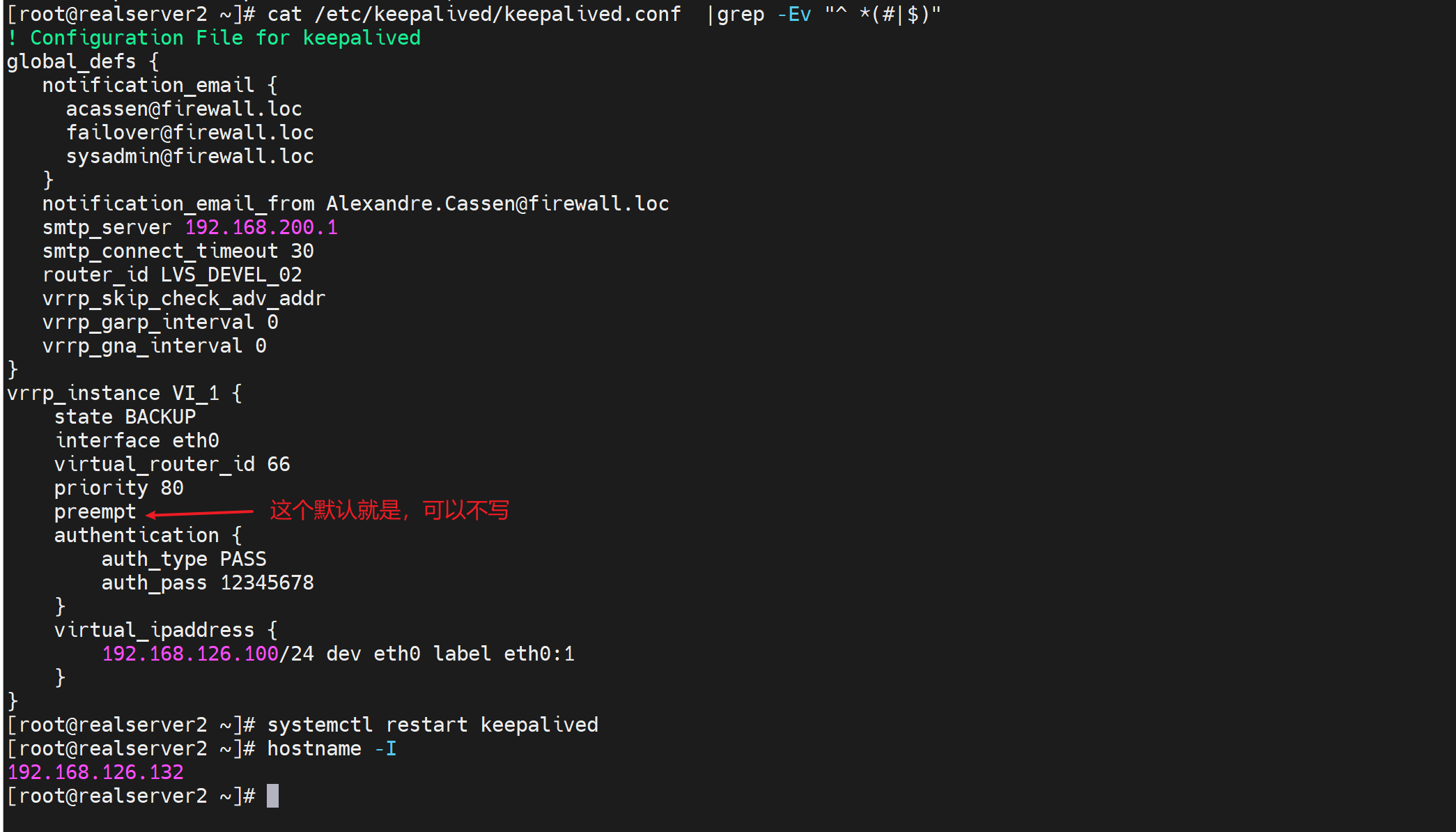
2、然后一边开启抢占,同时它的prio 要低哦。它最后重启以下keepalive就行了,由于prio低,所以即使开启了preempt,也不会抢,也会让出master。
3、重启开启了抢占的那边 让 配置了nopreept 的那边为MASTER。然后就OK了,再配置检测脚本如果nginx 挂了,就自减prio 30,从100变成70,此时由于对边是80切开启抢占,所以对边抢了过去;等原来的nginx恢复了即使prio变为100,由于没有开启抢占所以不会超出二次故障。
4、如果A挂-->B,B再挂-->A哪怕好了也切不回来了,因为你不想自动切带来二次故障,
5、所以一次切换的,后面需要脚本参与,判定是夜里低业务期间,就脚本自动切回主,这样算不算最佳实践了恩?也许吧,折腾~~
这是配置
还有👇
然后再完整地看看notify的自动修复思路
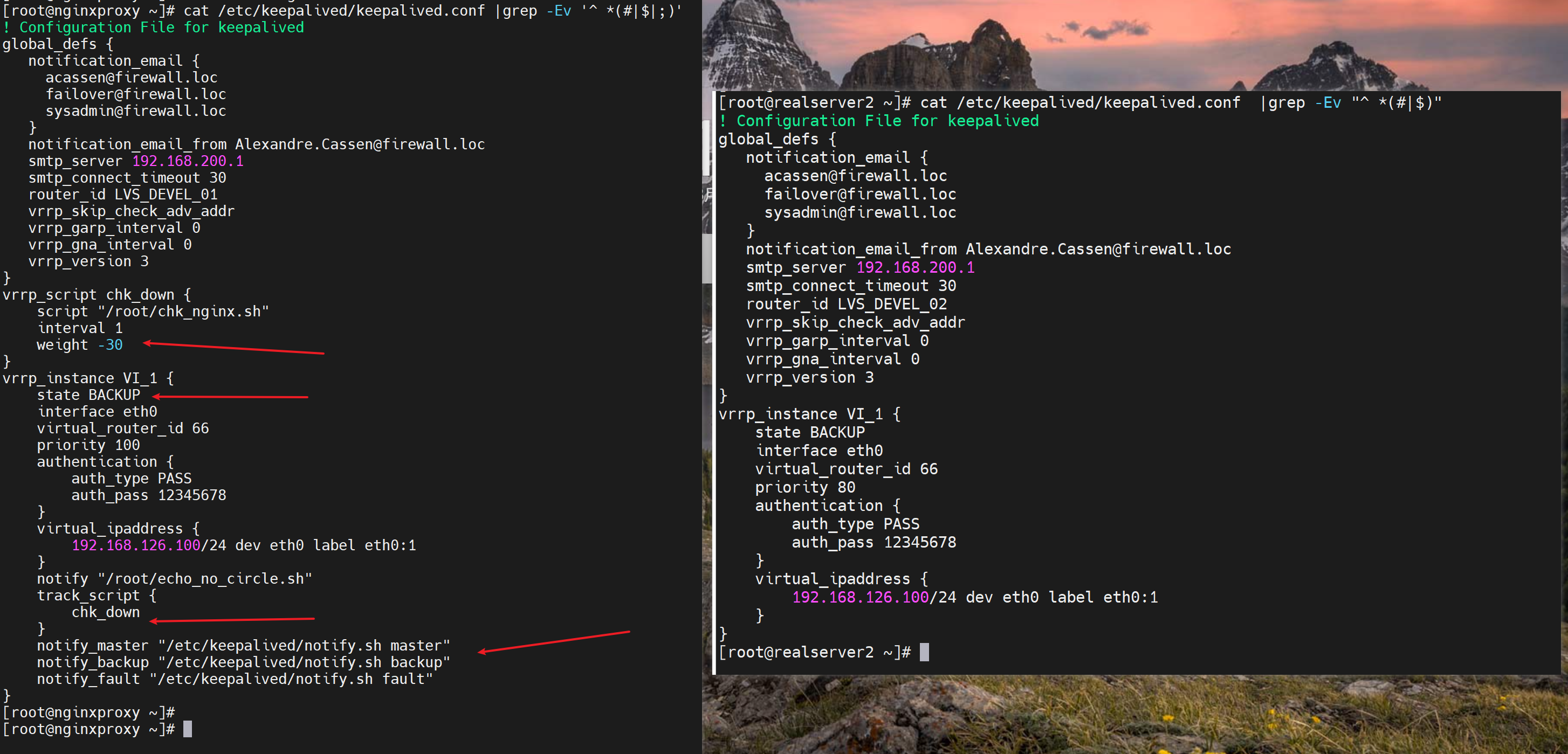

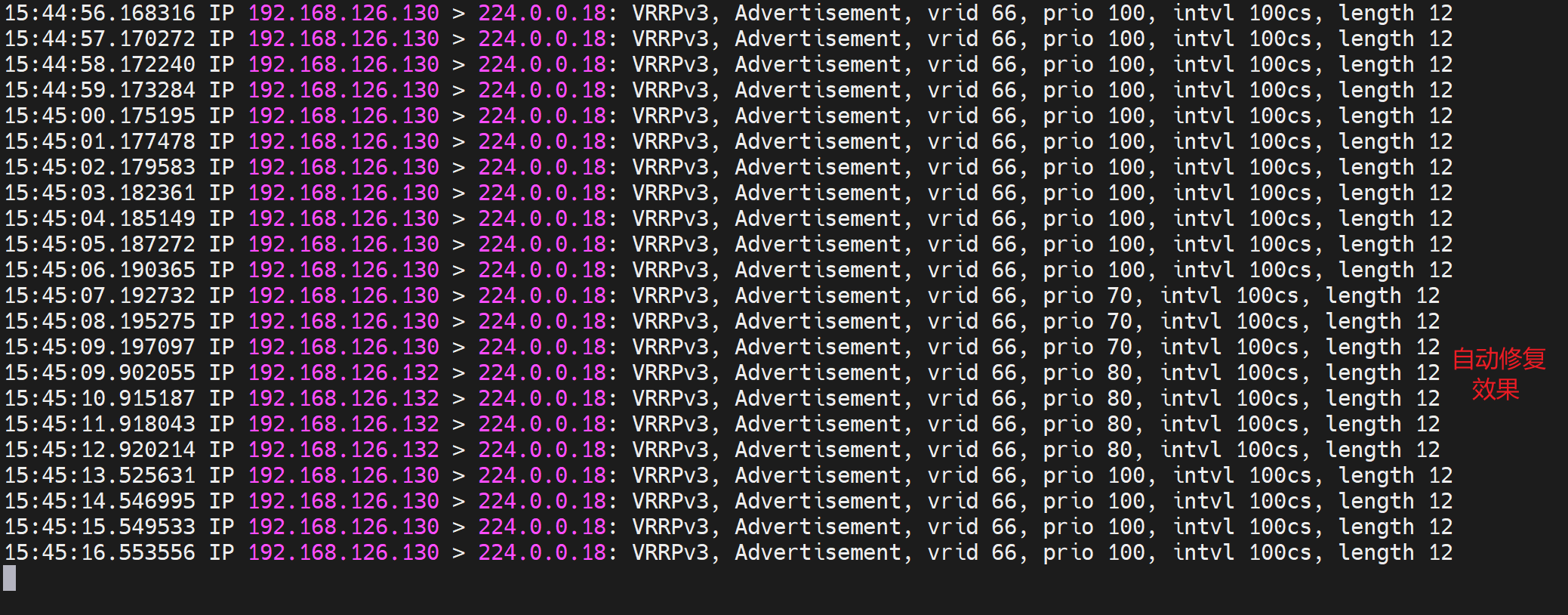
补充:
1、配置和脚本要两边一致
2、二次故障,需要优化为一次故障切换和脚本低峰业务回切
我怎么觉的备机上无需做脚本呢,哈哈,
3、两边都BACKUP,两边都prio 100,这样都是一次切换,抢占也开了的情况下
所以进一步优化最佳实践我认为
1、配置
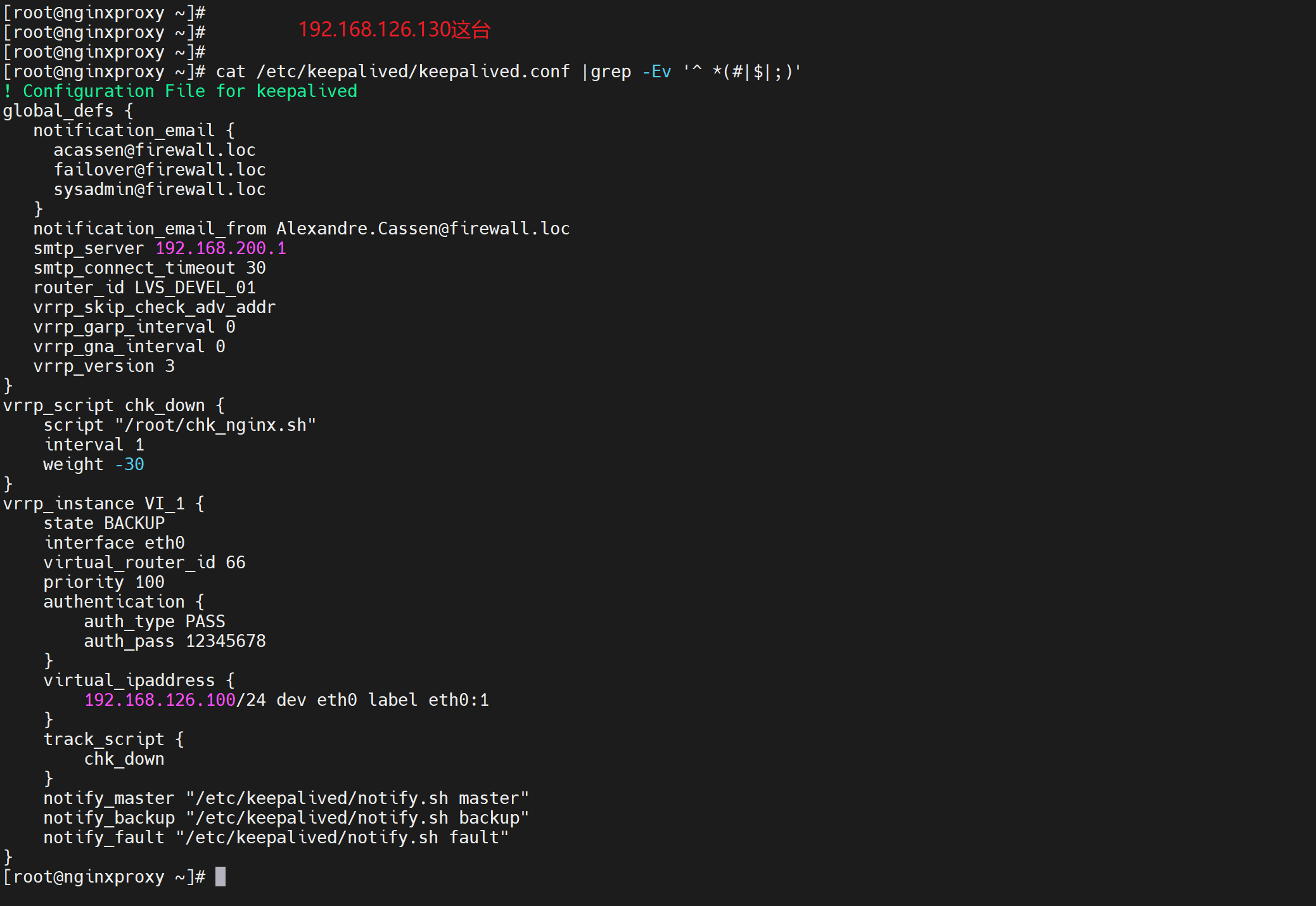
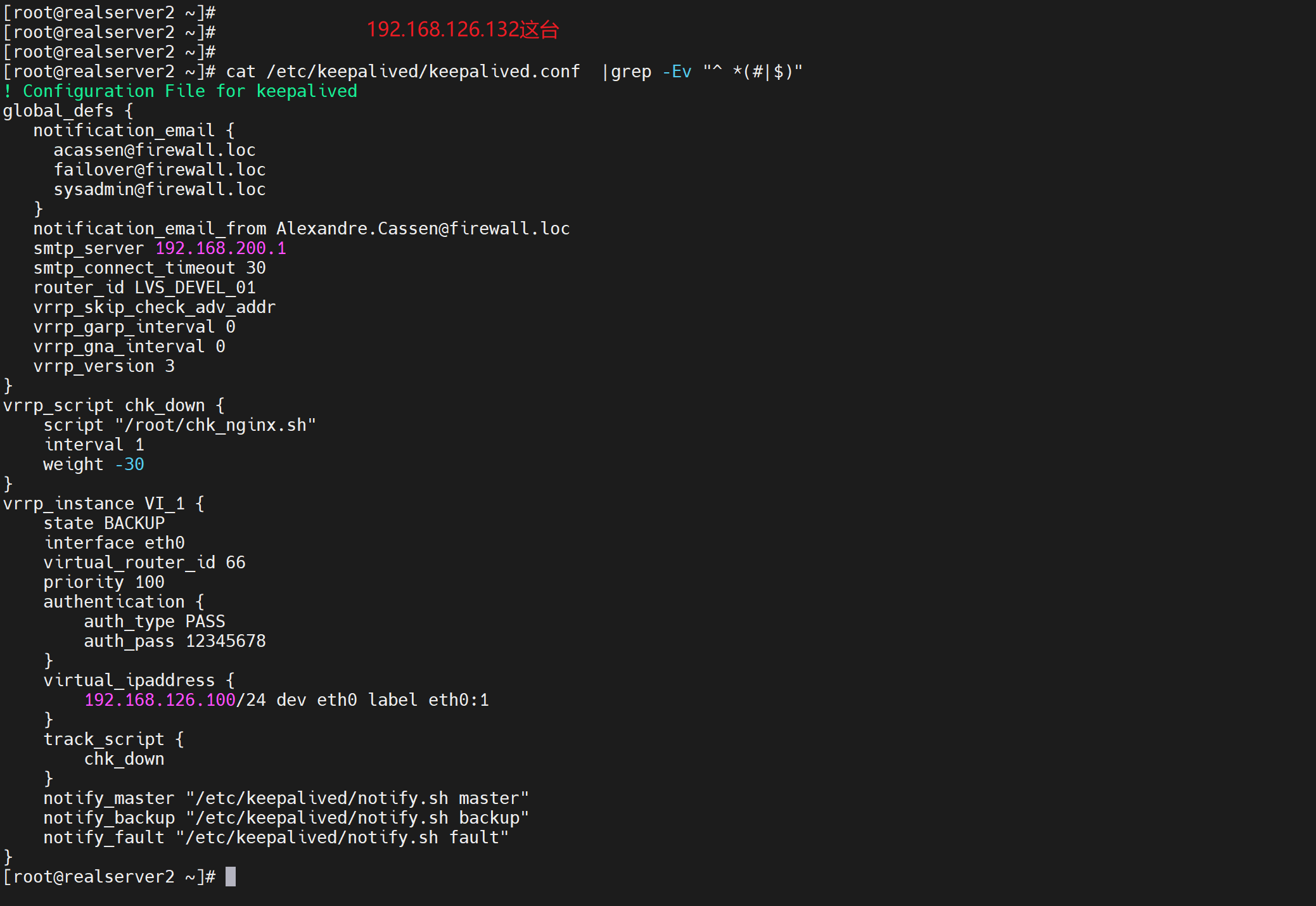
两台一样的配置哦,优先级都一样的哦,都是BACKUP(这里无所谓M/M M/B B/B都行,其实就是通过一样的优先级来实现:M恢复故障后优先级恢复了,但两边一样,所以也是无法回抢的),脚本都一样的哦

都需要有mail 命令哦
2、测试
初始通过132最后重启以下keepalive让130为master

当前130为master发送hello
下面开始模拟nginx故障
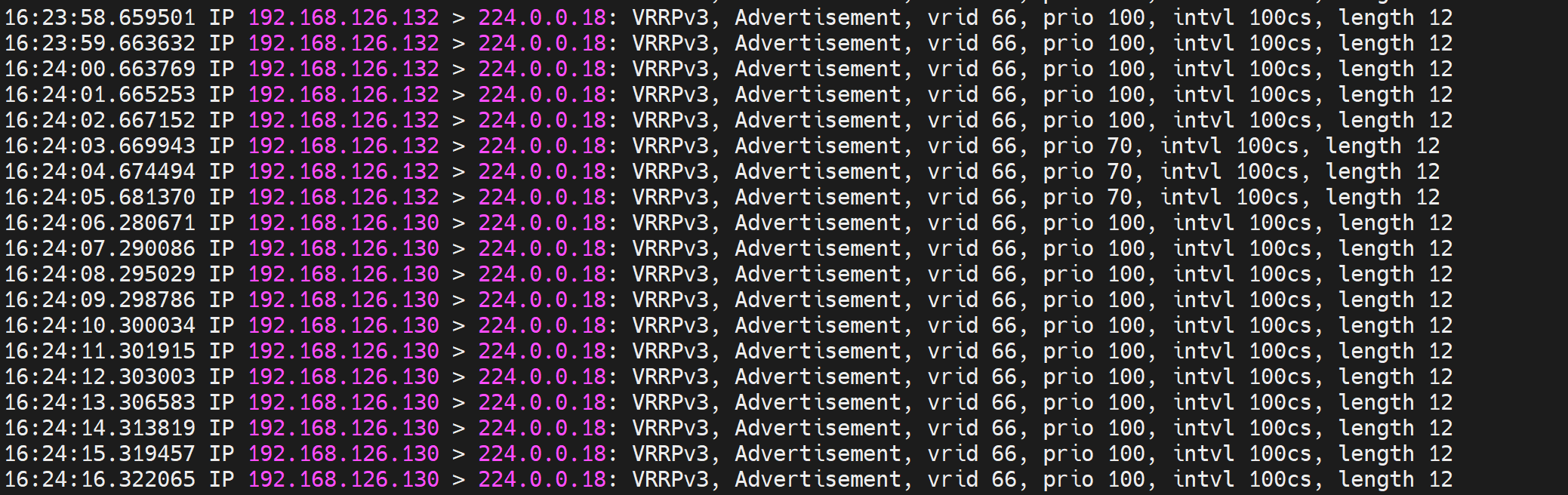
130上killall nginx,prio -30 ,两边都开了preempt的所以对面抢了master,紧接着130又重启nginx了,但是两边prio一样所以不会抢的。
PS:chk_down 导致的-30,后面nginx起来又会自动+回去的,神奇的地方就是这里咯~。
132上killall nginx,prio -30 ,两边都开了preempt的所以对面抢了master,紧接着132又重启nginx了,但是两边prio一样所以不会抢的。 好处就是我出故障我让出master,后紧接着我修复好了,但我不抢了
所以,这tm就实现了一次故障切换,也无需人工什么 低峰业务 去让master抢回原先的也就是130了。因为之前上面那个所谓的最佳实践--就是单边master配置nopreempt---对边preempt+低优先级来实现一次切换,但是如果切过去新的master也出现故障就没法自动回切了--虽然做到了master故障恢复后不抢回来的二次故障--但是万一新的master也出现故障是无法回切的。终于让我找到了最佳方案,就差实践了,实践也一样哈哈哈哈~~~
他这个有意思的地方就是不像sw的BPDU那里是prio+mac总会有一个竞选出来,不会和linux里的keepalive一样prio一样就是一样preempt开启也不会说再去找一个其他参数判定以下优先级。
3、总结
多测试,反复论证,设计好方案仅此而已
到此
1、nginx 的 ha有了,靠keepalive
2、后端server的健康性调度也有了,靠nginx
此外还有一个LVS里的东西,keepalive之前我没梳理,本篇主要是针对nginx的HA的配置研究,回头有时间再返工前面的一些空白页吧空白页在这里


这是将vrrp_两个实例 合成一个组,要切 整个group一起切走,这样的目的是为了应对NET的场景
就是两台机器,对外虚拟两个ip,就是两个VIP,一个作为内网VIP,一个作为外网VIP的发布IP(而这个外网VIP还是个DNAT,差不多整个意思吧),要切一切到同一台机器上,不过上图是示意图吧,哪有vip dip这种cli关键字的。
然后NAT一般用的也少,LVS里不怎么用NAT

排错20240313
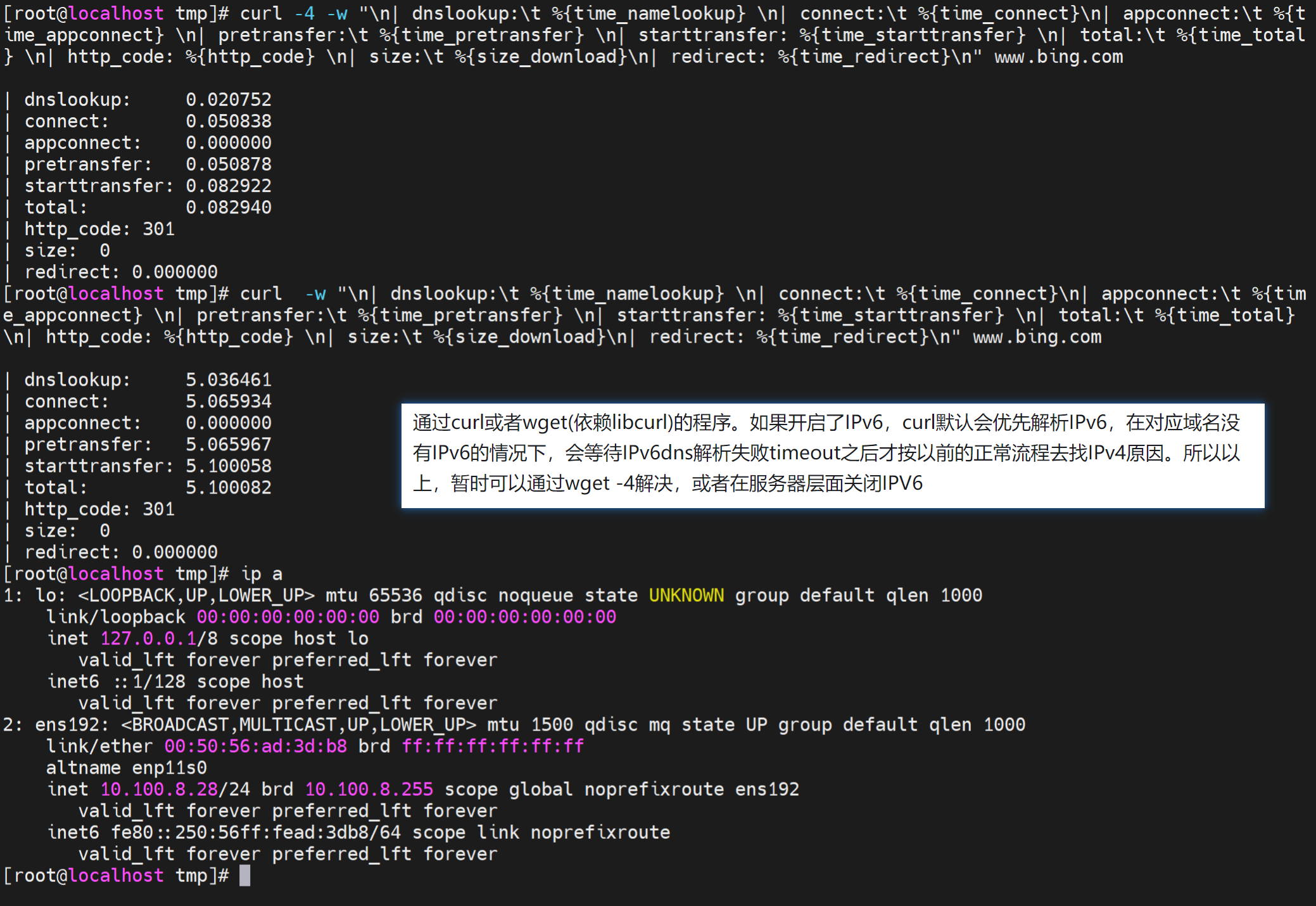
不加-4,就是一致都是5s的dns解析,ping也一样,一旦写了hosts,解析就有了,curl 和 ping就秒出结果一点都不卡,原因如图咯。
处理方式 关闭IPv6好像还是不行唉,但可以肯定是V6导致的
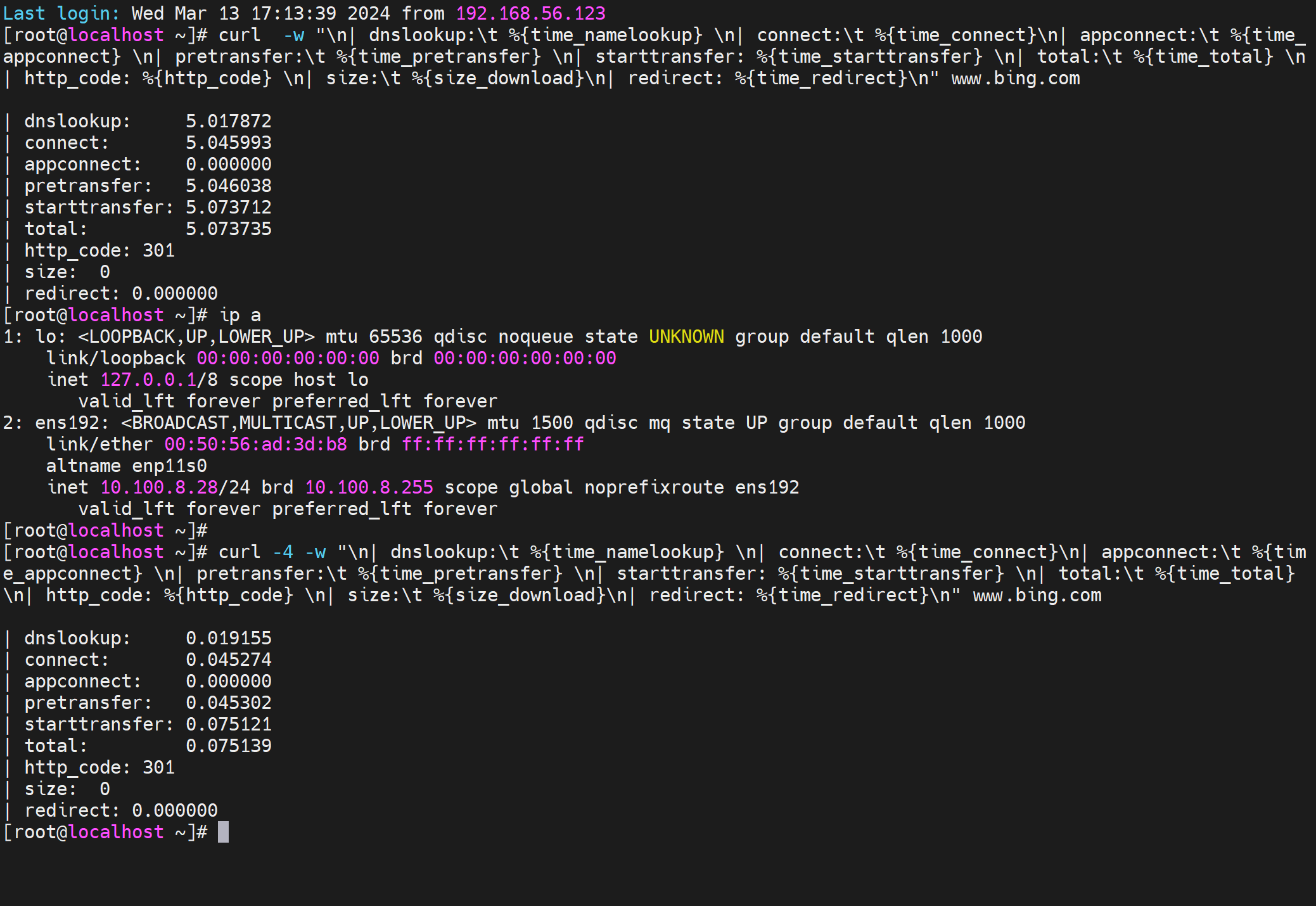
不太好解决,写hosts才稳定解决。