1.Haproxy的全局配置和性能优化及日志管理
全局配置
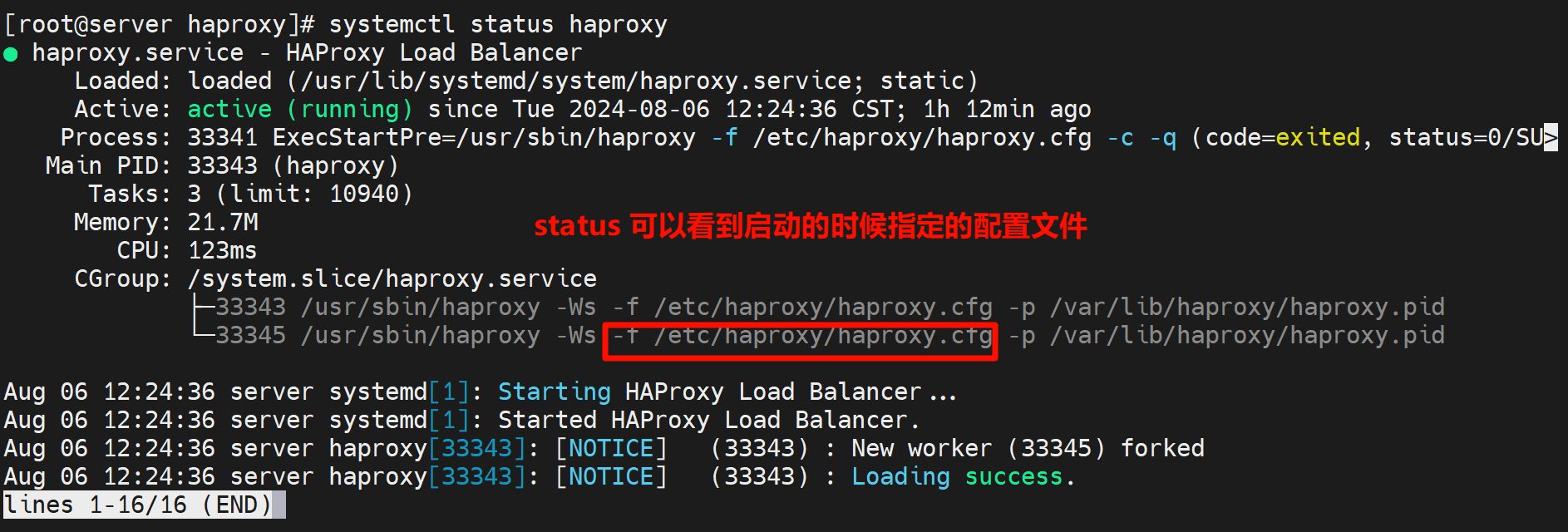
而这个配置文件的指定也是自己写的service文件
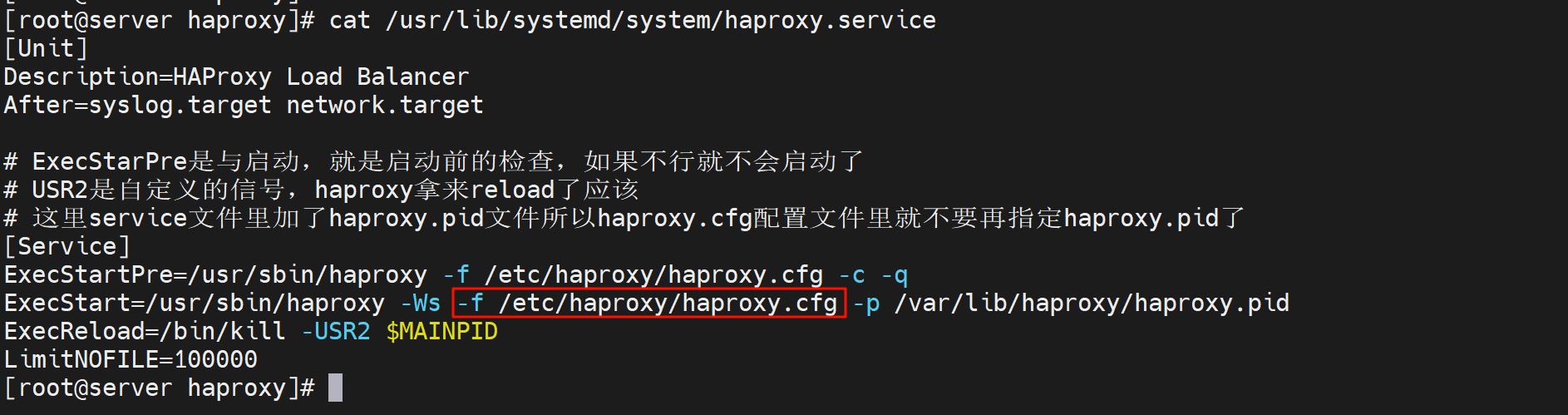
然后配置文件里整体分为两大块:全局和代理
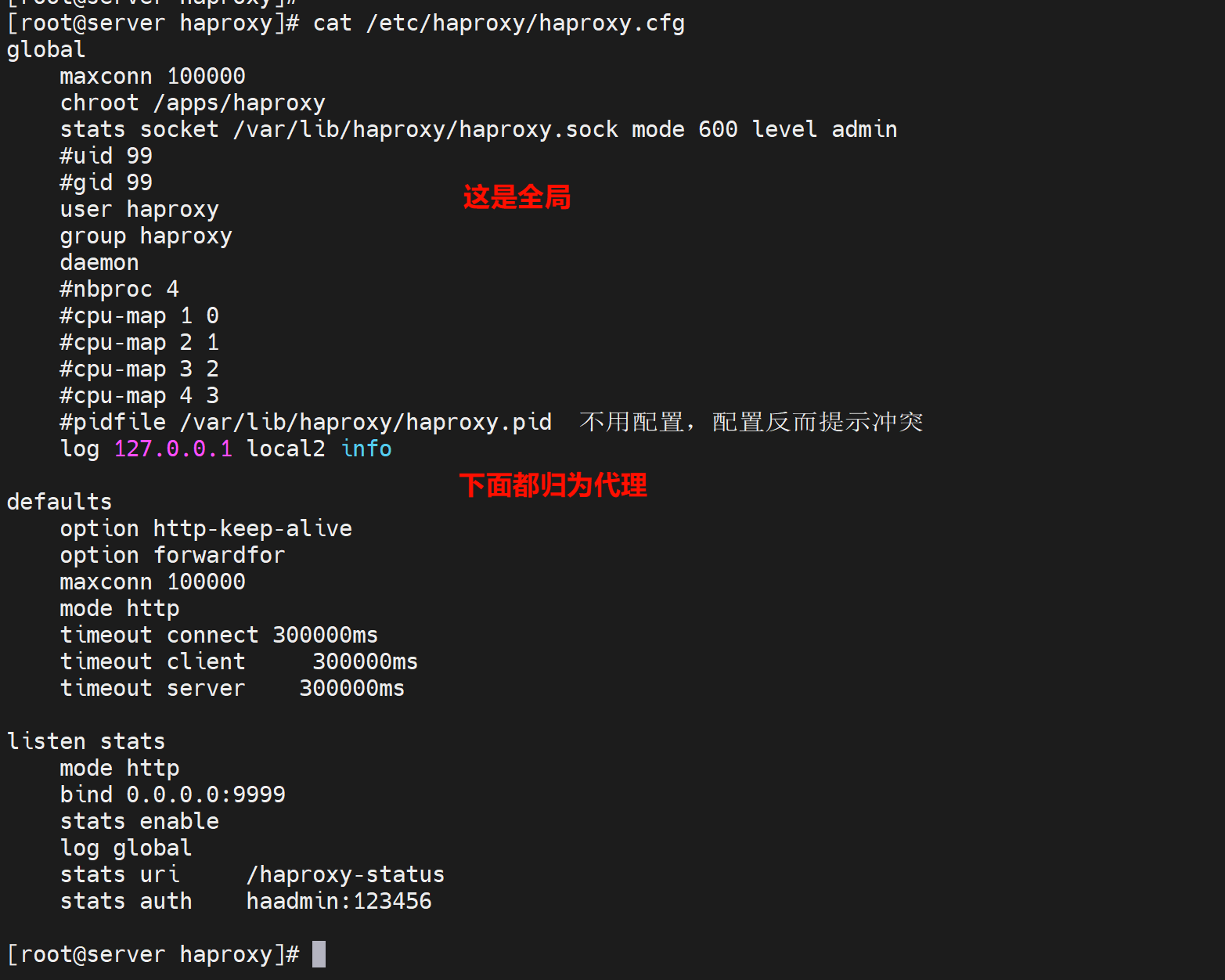

chroot有点类似os.chdir吧,就是修改工作目录的,不过change root就是修改工作目录的根了,ls /实际就是chroot后面的目录了,主要是安全。

deamon 后台运行,如果将来制作为容器,就要拿掉这行,前台运行。
stats socket /var/lib/haproxy/haproxy.sock mode 600 level admin process 1
1、首先mysql也好,docker也罢,都是通过socket和服务进程通信的,socket可以是tcp/ip套接字,也可以是套接字文件。
2、文件就是600权限
3、level admin,是运行通过这个socket文件对其服务进行admin级别的管理
4、process 1就是,只存在和主进程的通信或者主进程下的第一个子进程通信?
5、还可以通过相关指令 把后端服务器上线、下线。
uid gid 这个应该是创建haproxy这个用户的时候指定的id了,不过我没有指定id,而是指定用户也行的。
,貌似是用来执行worker进程--我理解就是和nginx一样的进程咯:

不指定就是root运行了
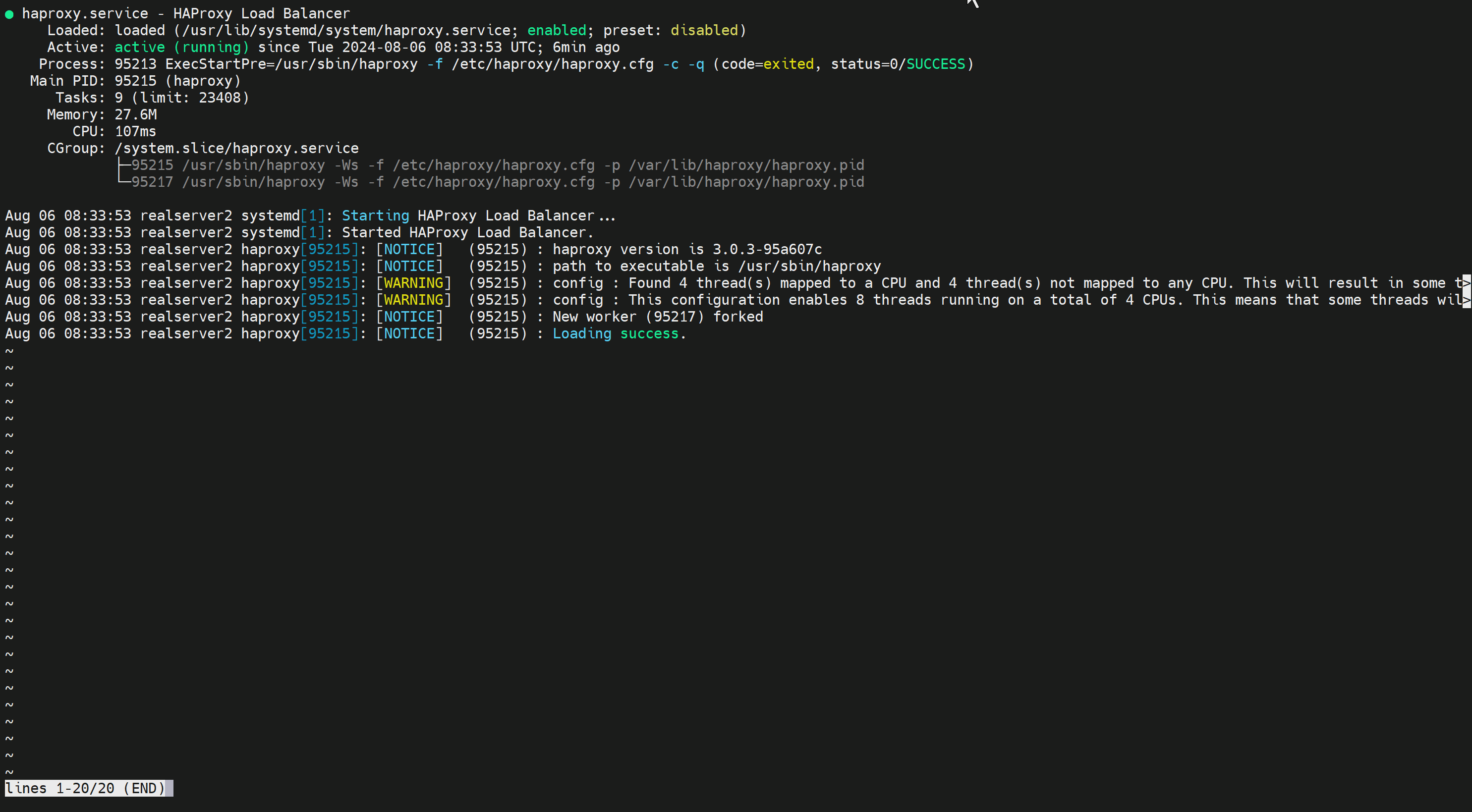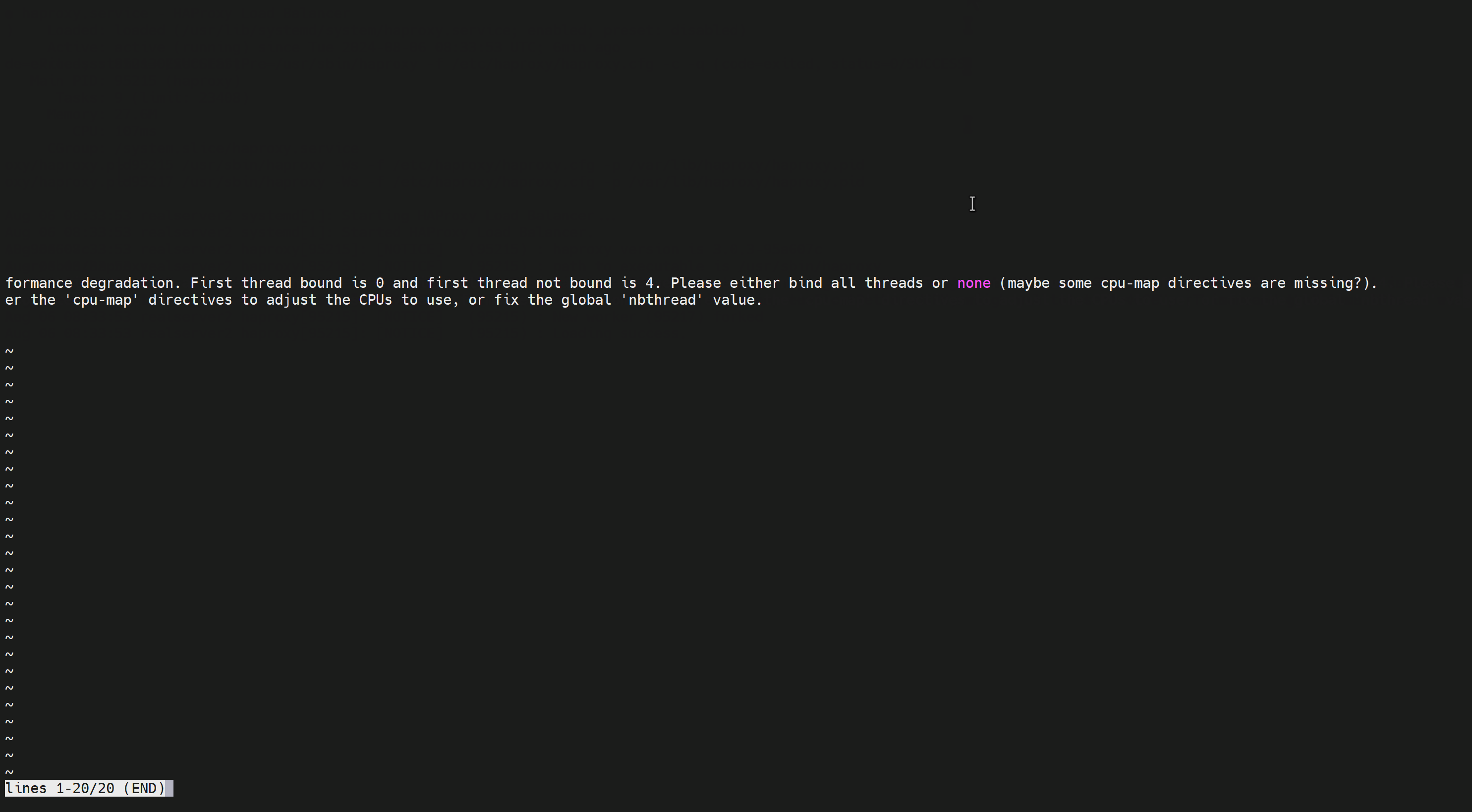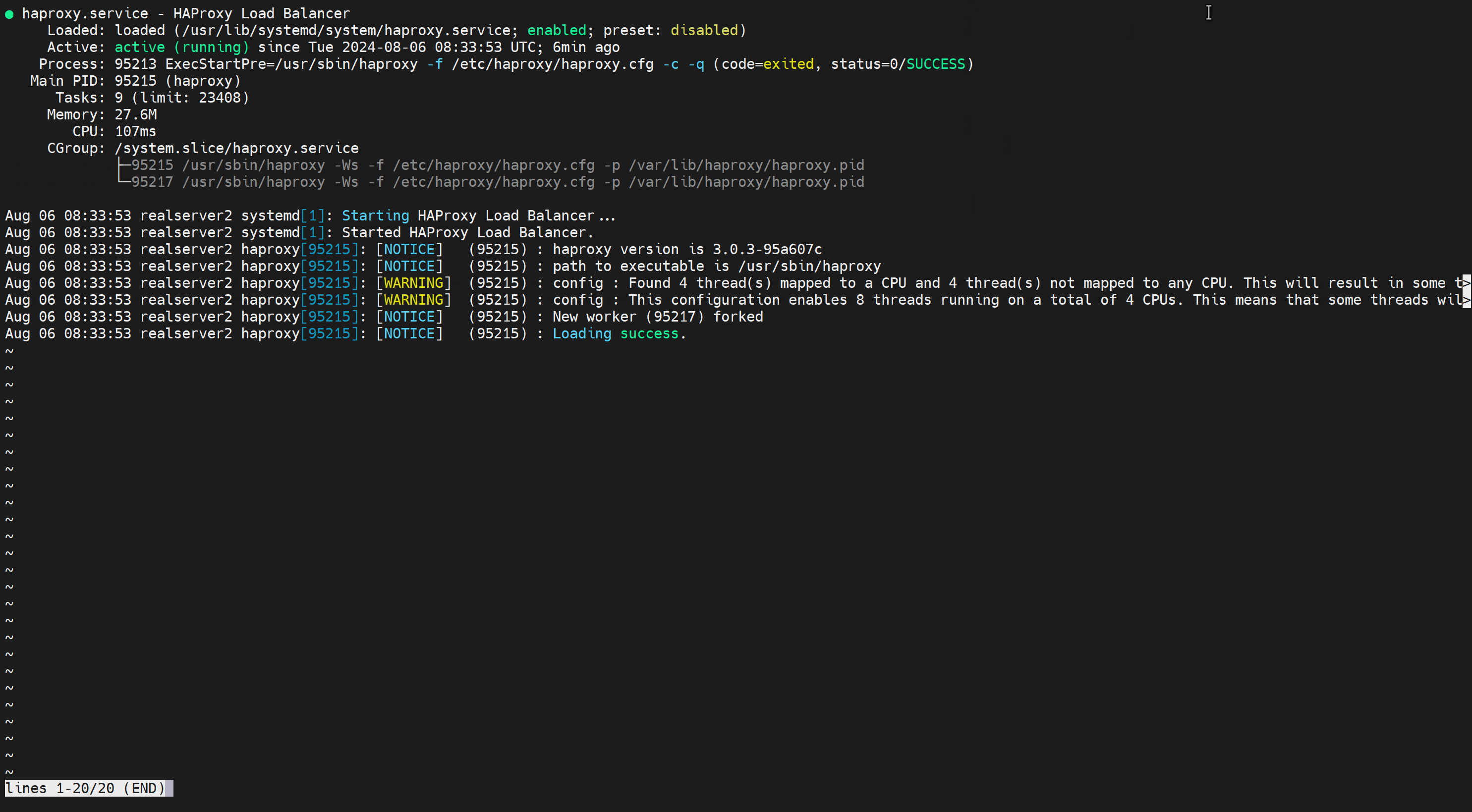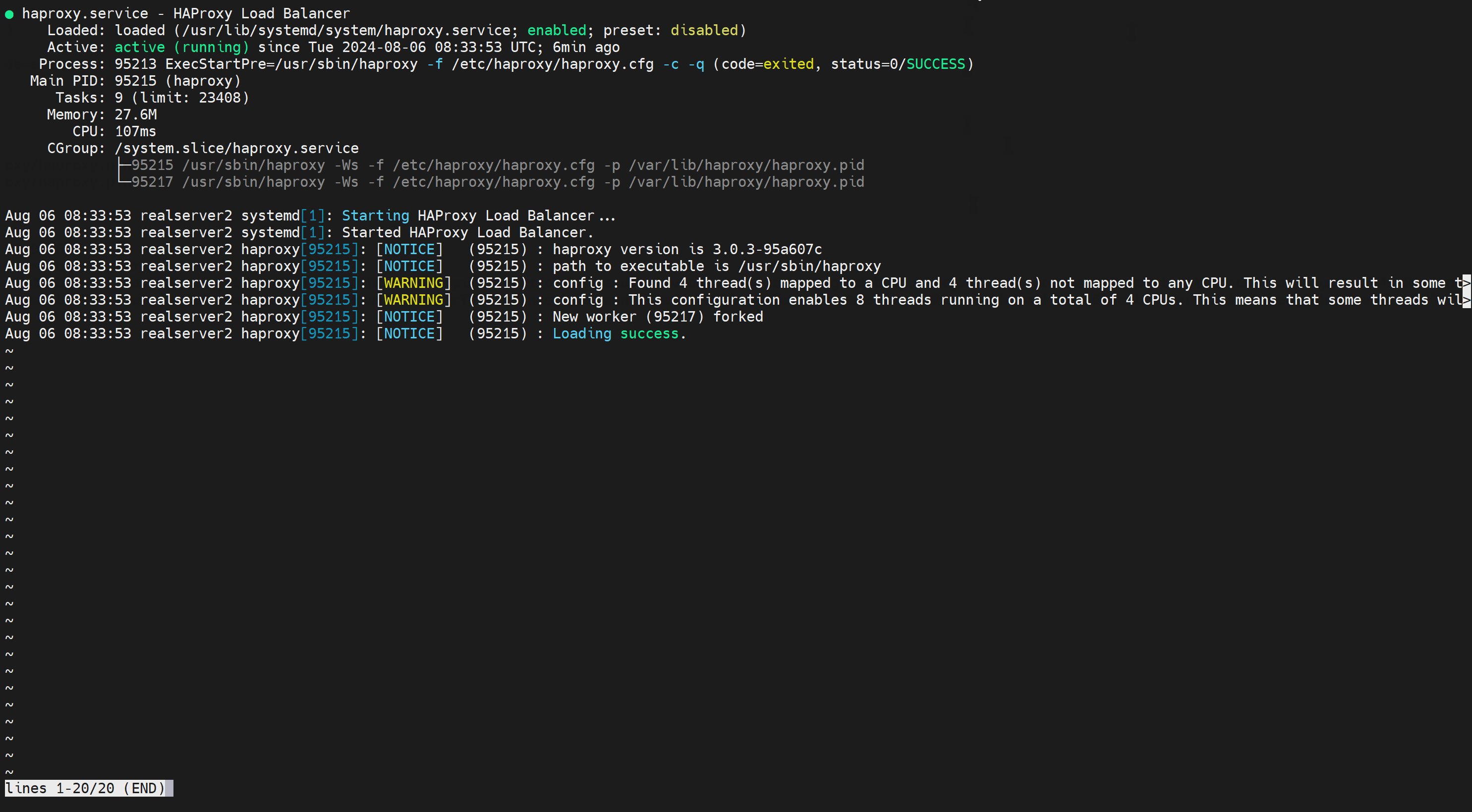
看看多线程和CPU绑定
nbthread vs nbproc
nbproc就是和nginx一样多个子进程了
nbthread就是进程下的多线程了。
2.5之前的haproxy用nbproc开启多个wokers进程,这个worker和nginx一个意思
之后的版本就用nbthread来做多个worker,不过没有看到多个worker,因为多个worker也是跑在一个子进程下(33740 pid)的,所以ps aux只会看到一个root 跑起来的haproxy主进程和一个haproxy用户跑起来的一个子进程
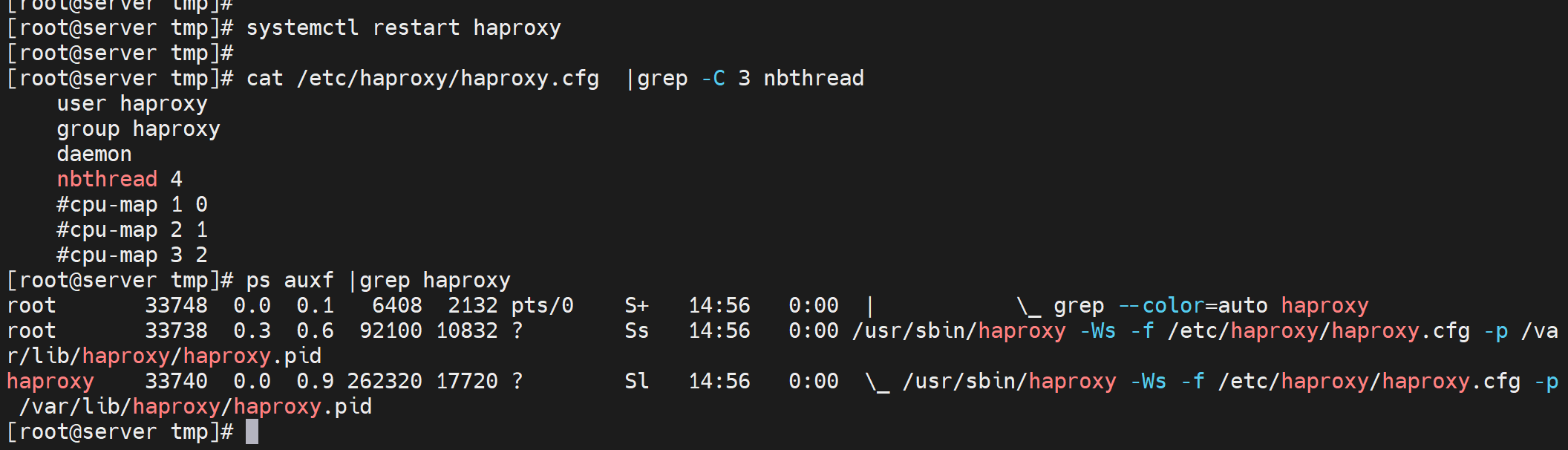
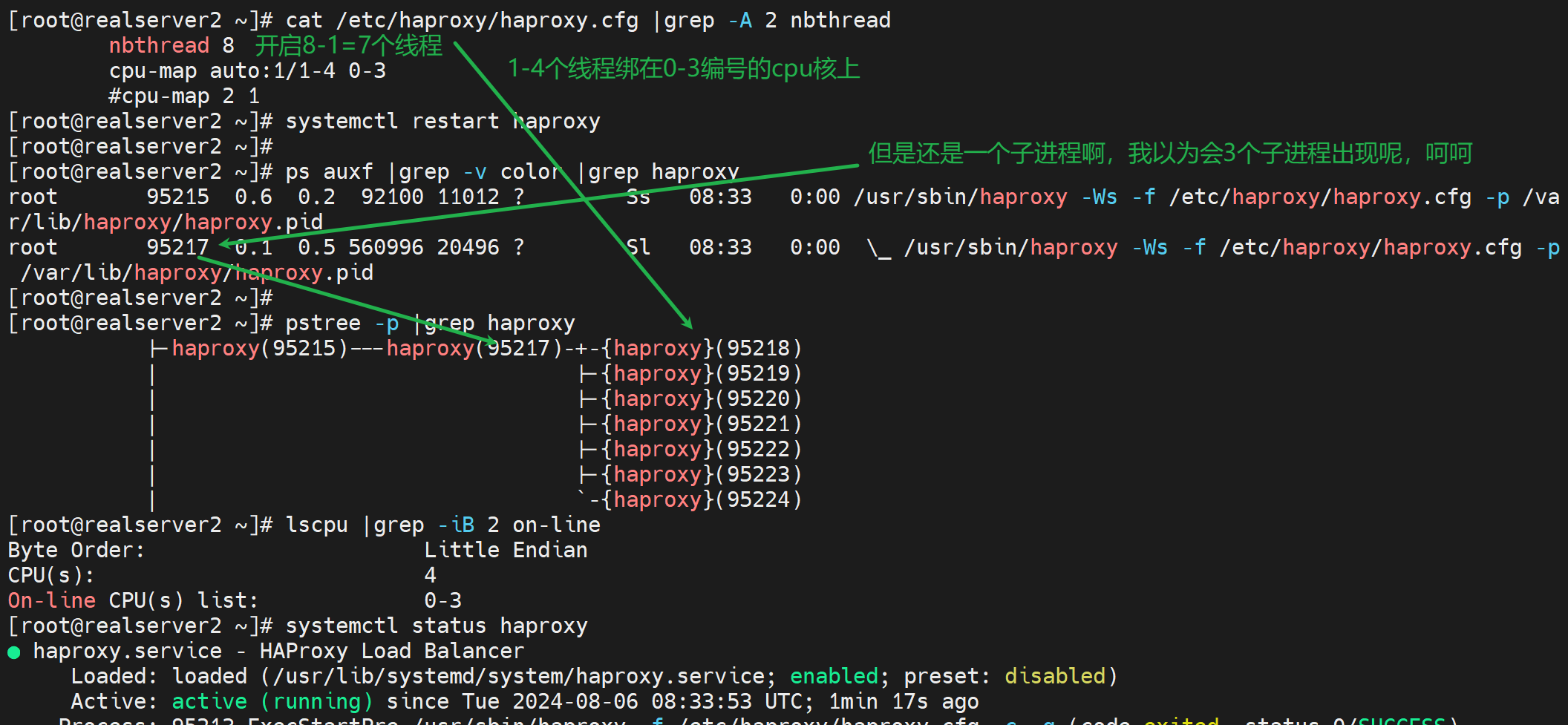
而多个线程可以通过pstree -p去观察到,一般就是N个cpu,就开启N-1个线程来着
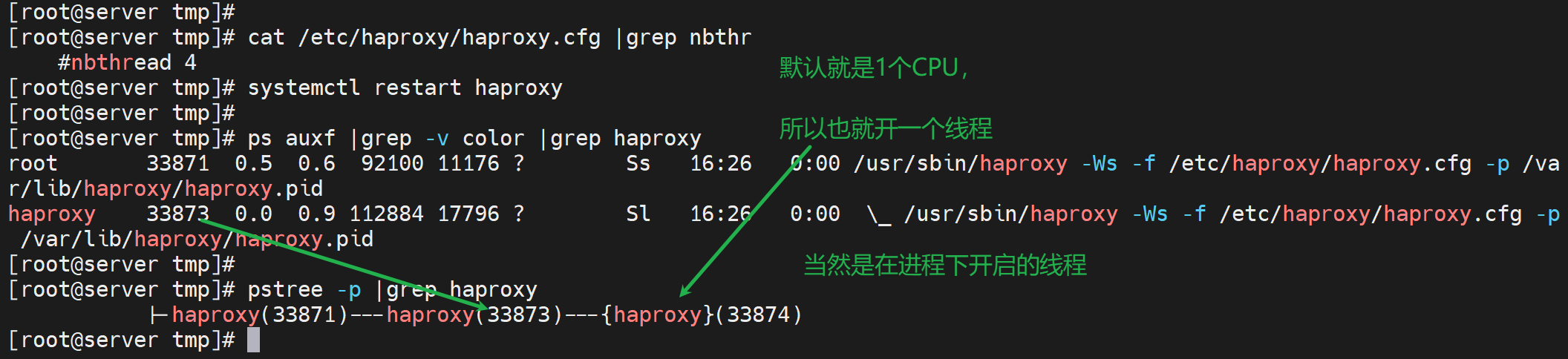
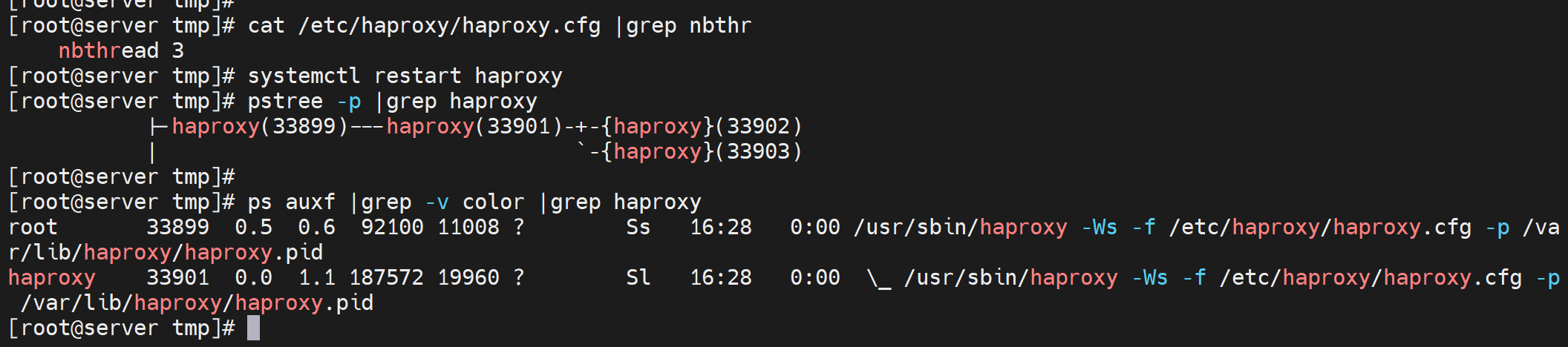
3个线程的配置nbthread 3,就是开启2个线程,同样是一个子进程下开启的
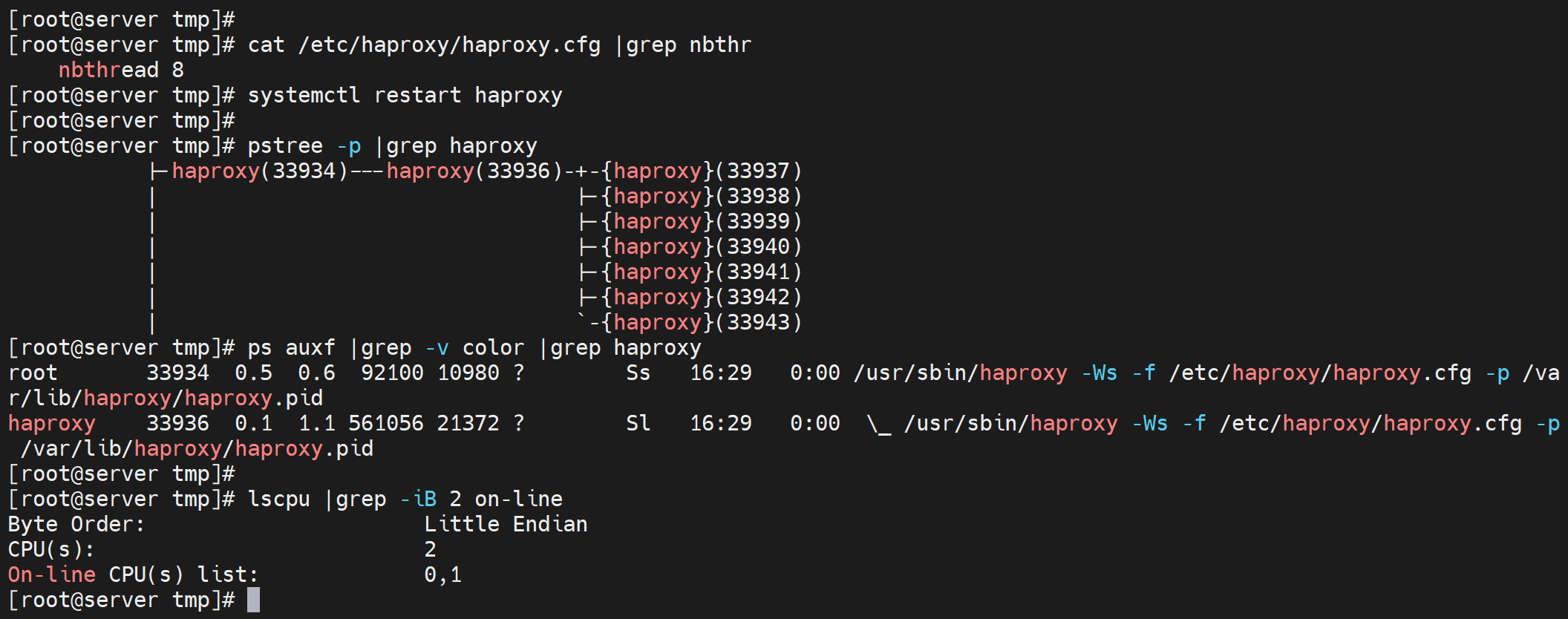
即使CPU实际就2个,同样可以开到8个线程,反正就是绑在一个子进程下的
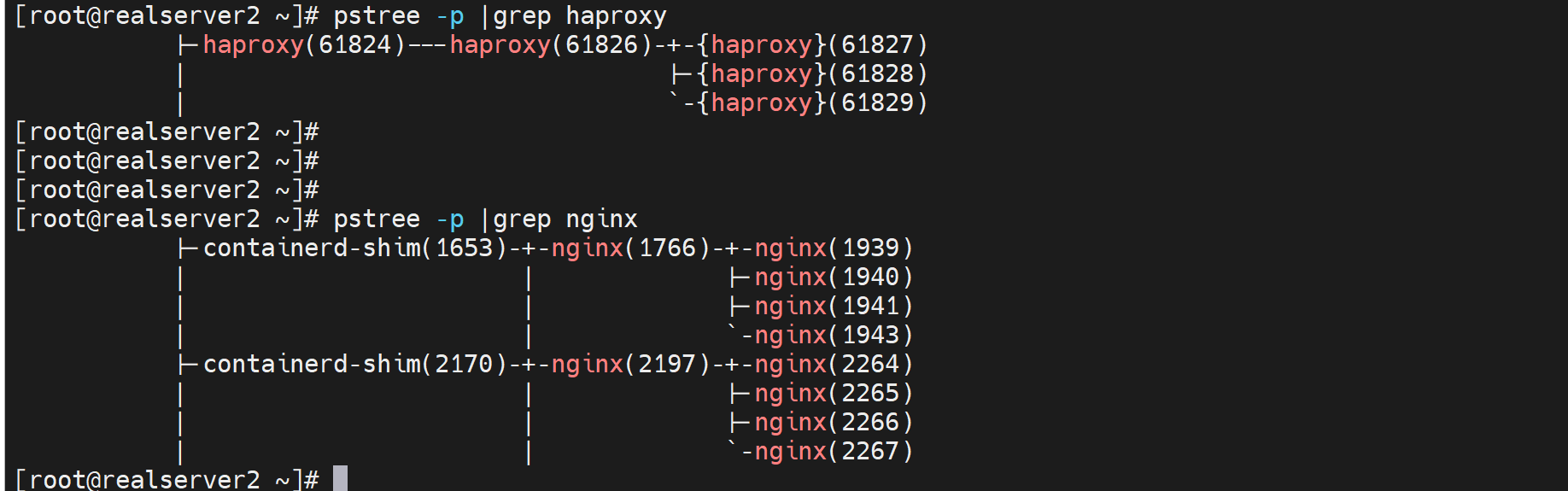
这是nginx的worker进程,不过id应该是发生变化了,导致找不到用户了,这个不用管,此图就是看下nginx也是多个worker来着。 不是找不到用户,是docker运行的
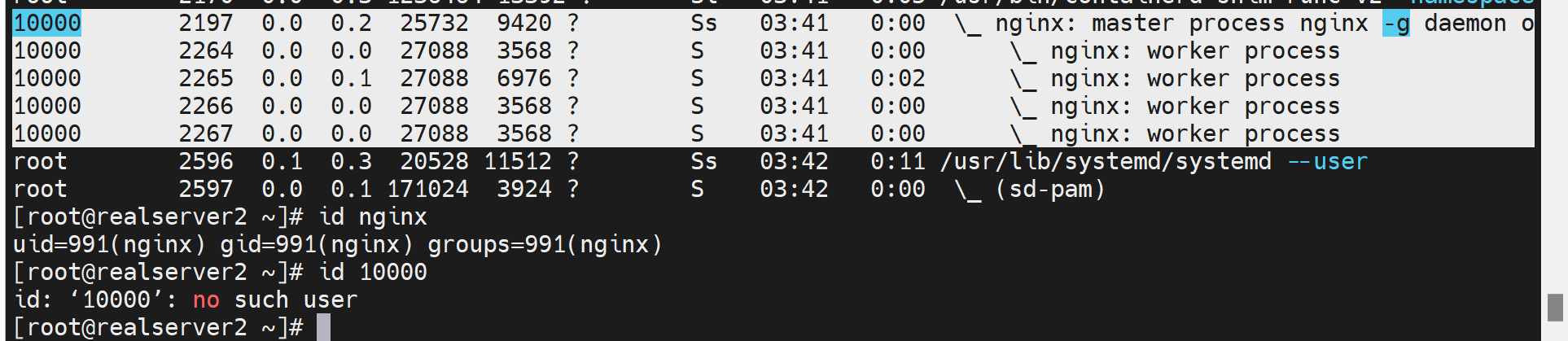
不是找不到用户,是docker运行的就这样
haproxy好像是花括号,也就是说haproxy是 线程在跑的,和主线程享用同样的内存空间。
而nginx是子进程再跑的,不是和父进程一个内存空间。
这还有一个区别
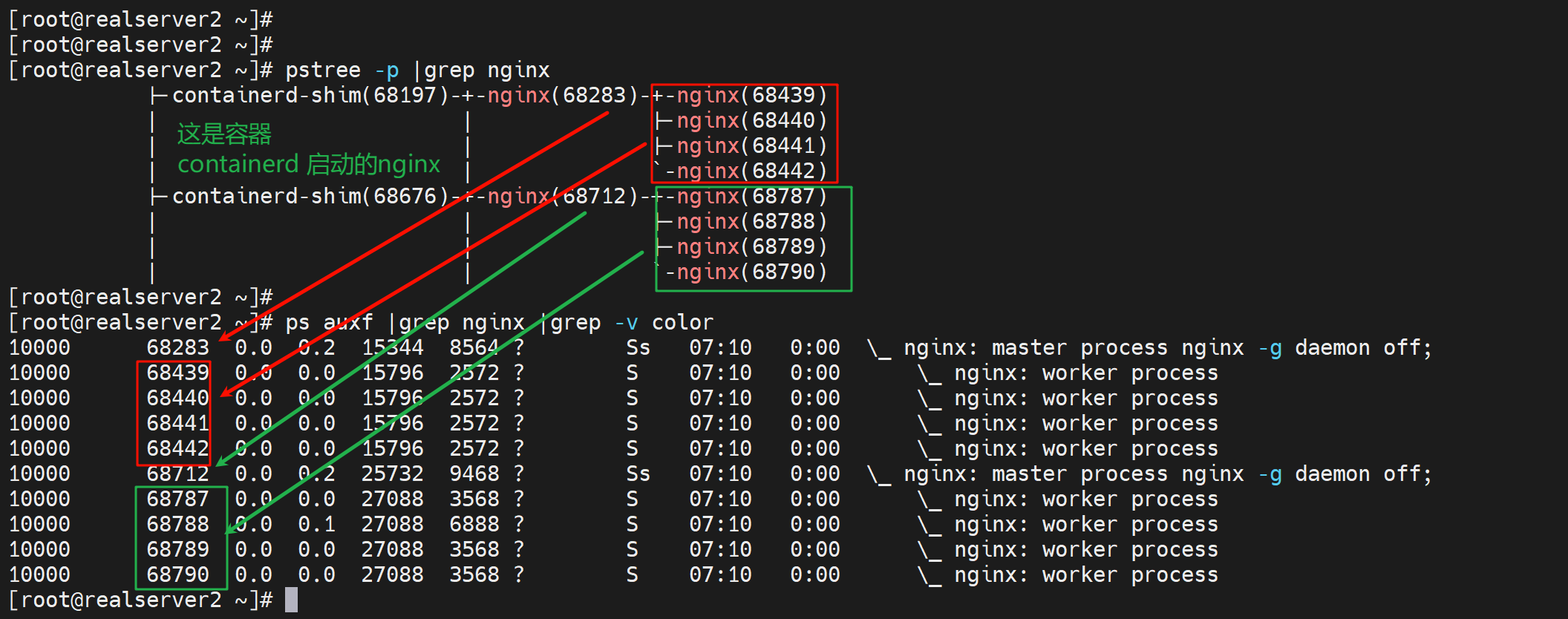
而haproxy因为是用的多线程,所以看到了3个线程开在了一个74172下,而74173和74174和74175看不到,应该是开在74172这个子进程里的内存空间了。是共用的内存空间,所以进程ID不会再次显示出来了。

haproxy就是一个总入口,硬盘要求不高不存在存数据的关键要求除非你开log?,正常就是CPU内存要给多谢,转发数据代理这块。
然后由于是多线程的,不知道CPU的使用率会不会出现盯着一个CPU干的情况。。。
所以就有了线程绑定cpu的配置
cpu-map auto 原来2.5之前的版本是进程,就用cpu-map 1 0 (# 1 woker 进程 和cpu0进行绑定,多个就写多行 ) 这种方式来绑定进程和cpu;
现在2.5之后的版本只能是线程,所以的用cpu-map auto: 1/1-8 0-7 (# 1-8的worker 线程和0-7的cpu分别绑定 ) 来绑线程和cpu了
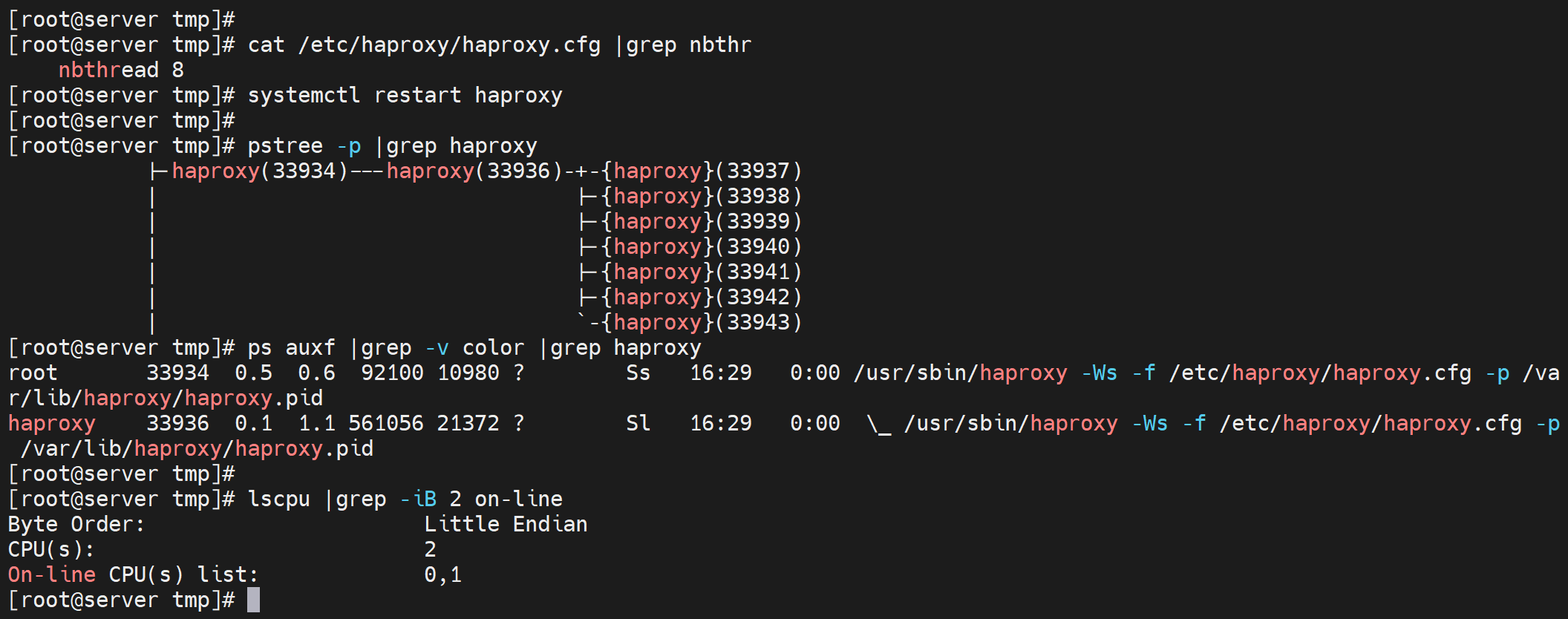
上图是2核,开了8个线程,然后都是在一个子进程下的。尝试绑到cpu上去
通过systemctl status haproxy可见,看不全?键盘左右键可以看咯👇
找了半天没找到找个日志文件,但是除了上图的方法看全,还可以这么导出来看全
👆这是journalctl -u haproxy看的,和systemctl status haproxy一样看不全,
但是可以导出来
journalctl -u haproxy |tail -10 > xxxxx
人家说要么帮帮好,要么不绑,那么问题来了,不绑的话你会自动分担到多个cpu核上吗?
观察CPU绑定的情况
ps axo pid,cmd,psr 和 ps axo pid,cmd,psr -L
-L Show threads, possibly with LWP and NLWP columns.
-L 用来显示线程信息的
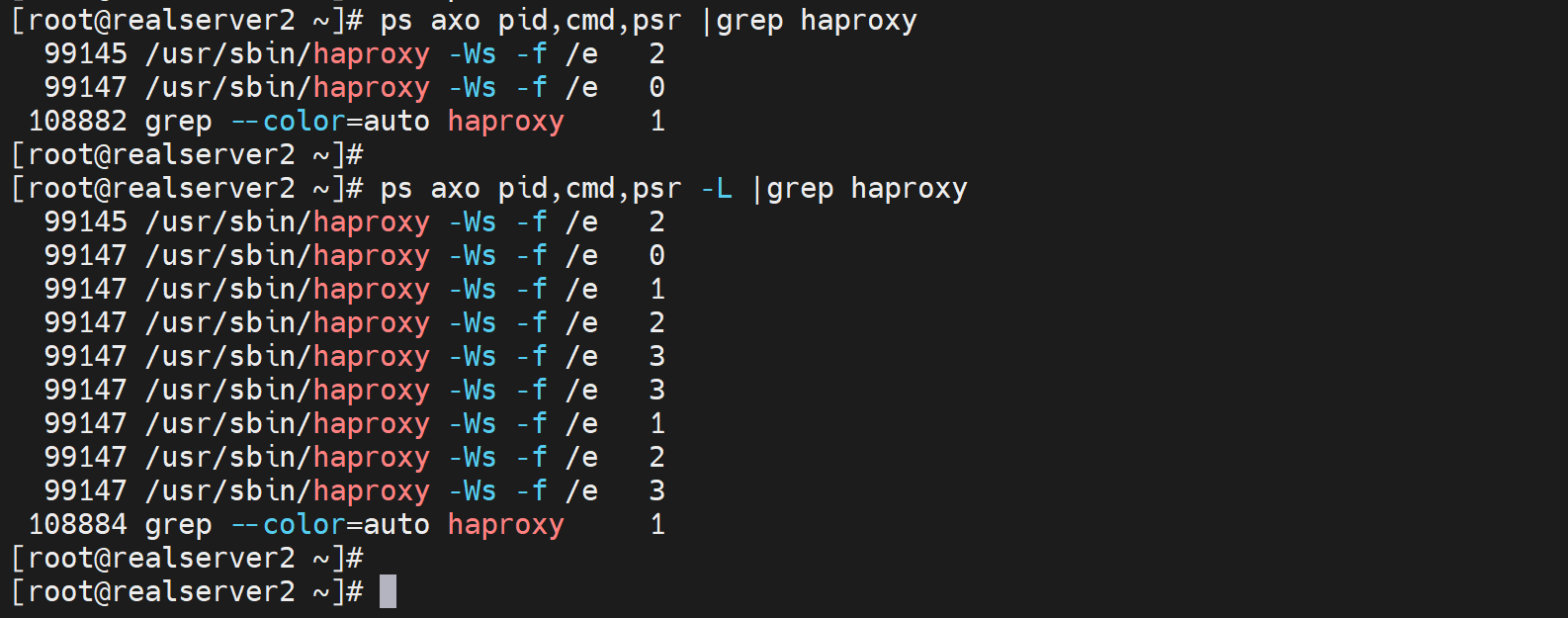
还可以带上user
突然发现子进程没有用haproxy跑啊
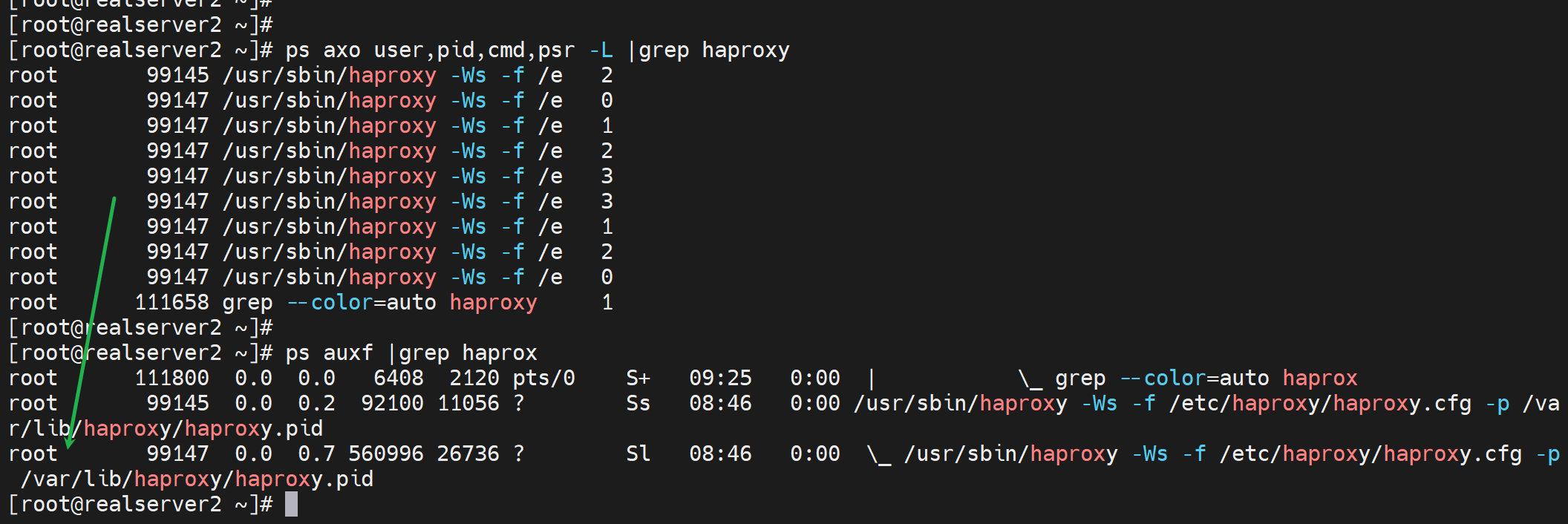
看看配置文件

果然👆
改改

重启服务后就好了👇
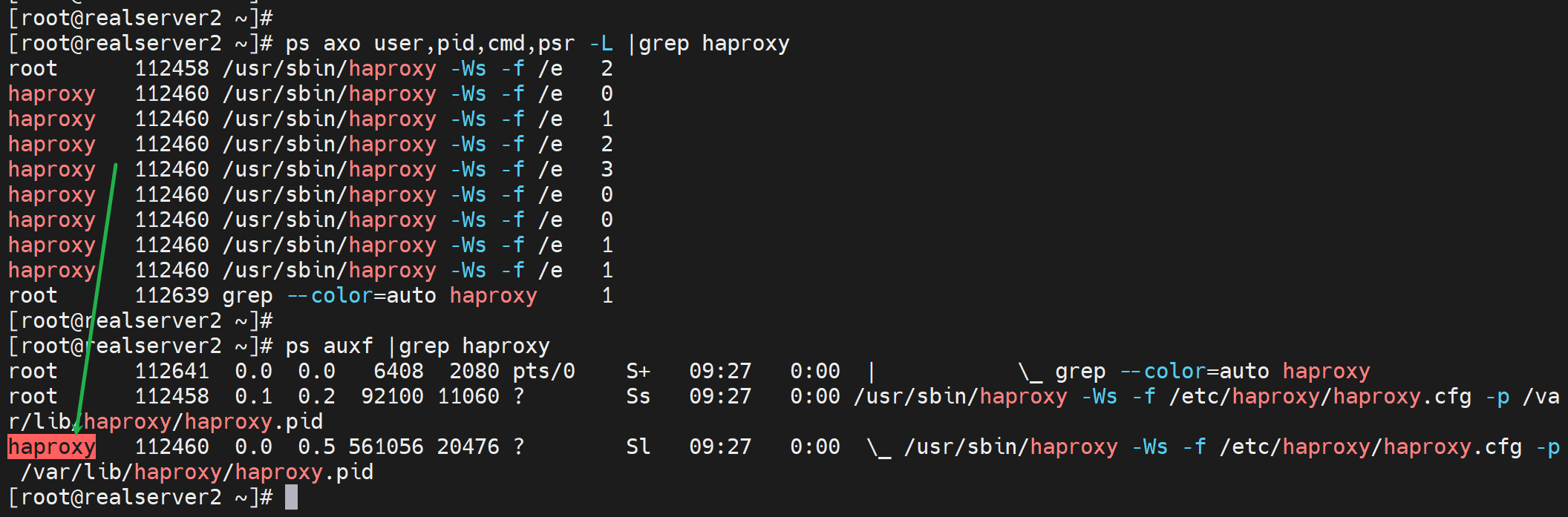
即使不手动绑定CPU,也是会自动分担的
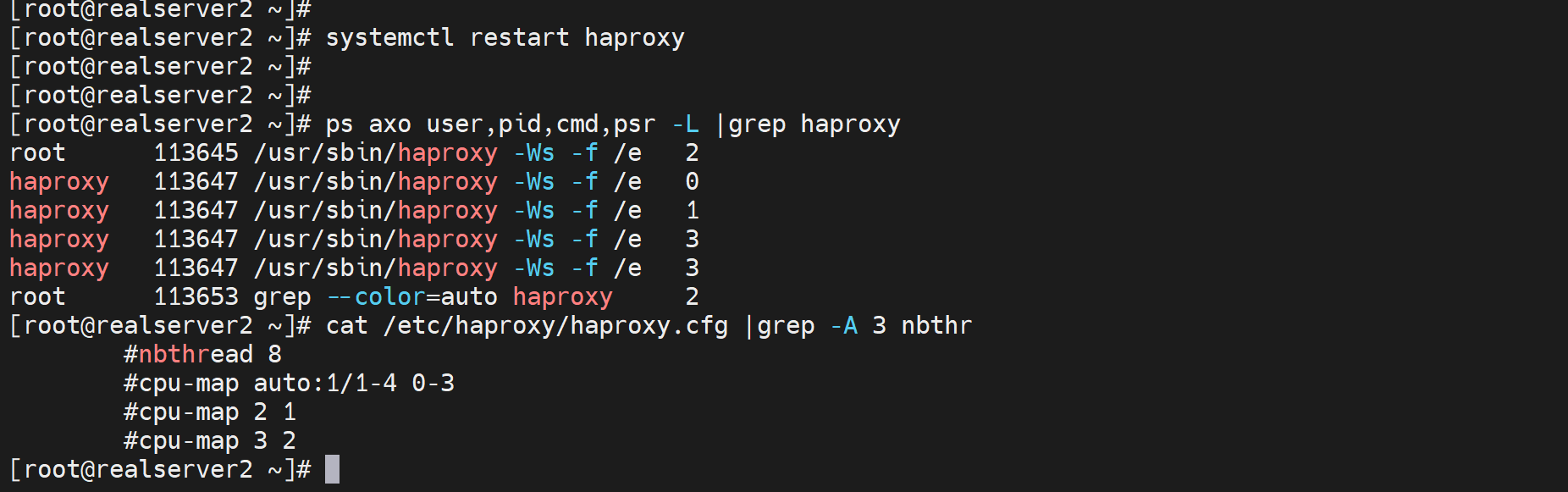
就是效率肯定没有绑过去稳定吧,因为要利用L1和L2 缓存还是要绑的,否则CPU一旦飘走就无法利用之前那个CPU的1级和2级的缓存了。
奇葩👇我只能称之为未知渲染shell
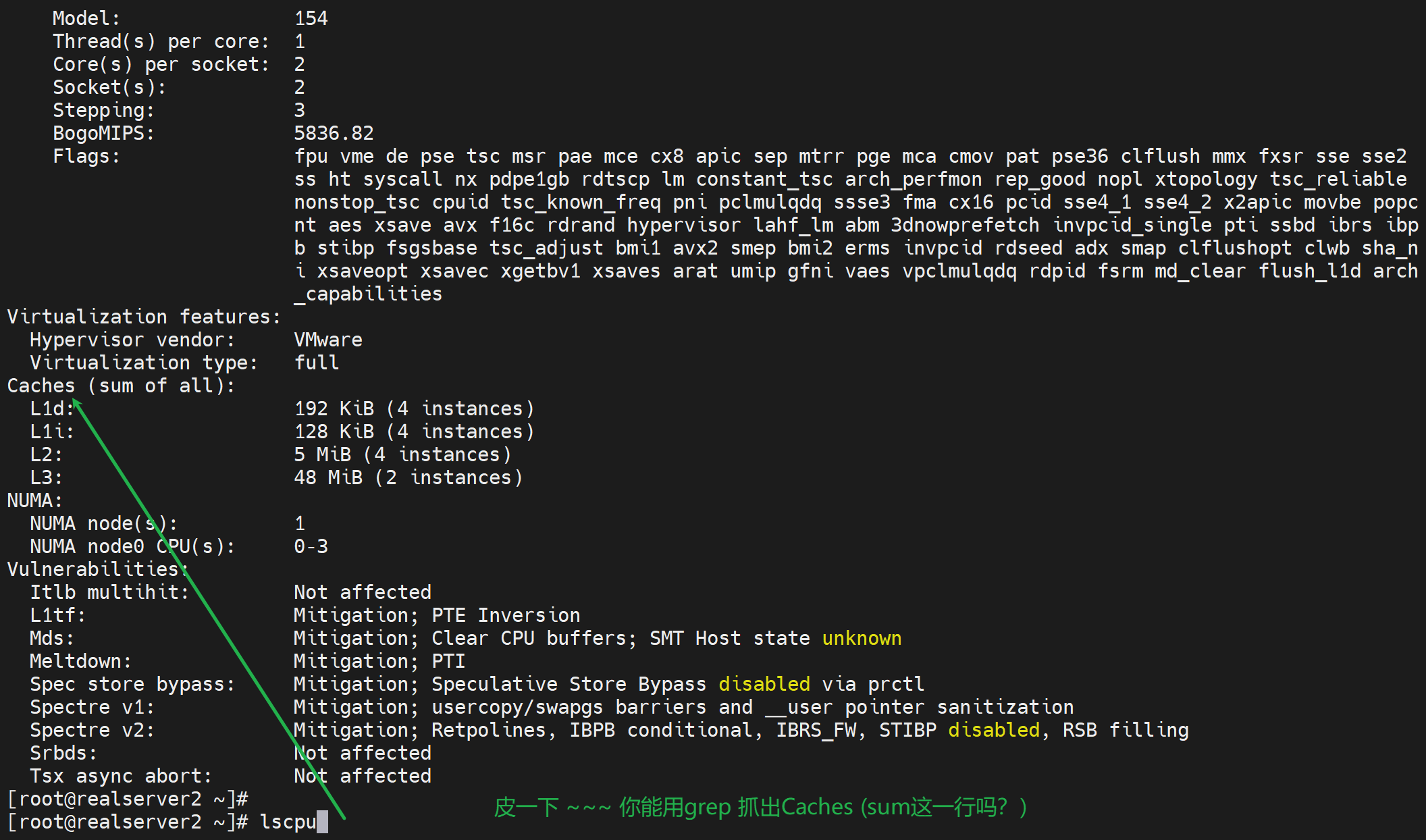
没用的,grep不出来,lscpu |tee >> xxx ,标题内容也会丢掉的。
lscpu |awk '{print $0}'
一样看不到标题,分析....肯定有其他程序参与进来了,lscpu的输出一定是经过了其他处理工序了,
呵呵呵,解释来了,小飞棍来咯~
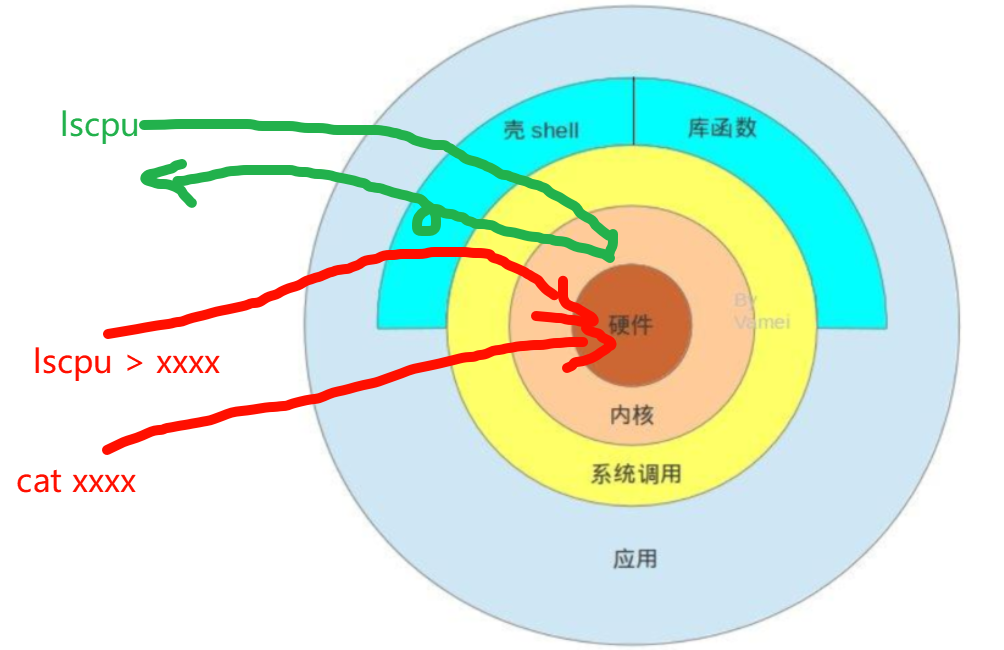
1、在rocky里 敲lscpu看到的东西 为什么 比 lscpu > xxxx ,然后看xxxx的东西多出标题行
2、因为lscpu的本质是,用户通过shell和系统调用交互的,通过系统调用拿到的结果再返给shell后,shell再次 渲染 拿到的东西
3、而lscpu > xxxx ,是用通过shell和系统调用交互其结果直接再系统调用层面重定向到了xxxx里,并没有返回经过shell 渲染,所以结果就不同了
4、画图意思意思:lscpu是有去有回,terminal--->shell--->sys.call--->内核,完了再返回给termnal
lscpu > xxxx,是terminal-->shell-->sys.call-->内核--->硬盘,返回不经过shell,也就没有渲染了
lscpu |tee ,同理返回的路径也不同了,走的tee,没有走lscpu的shell的渲染了。
也就是shell针对不同的cli肯定有不同的渲染了。
同理 lscpu |awk '{print $0}' 也没有lscpu本身的标题栏,应该也是shell只针对lscpu做了输出渲染。
我就这么分析了 怎么滴,要不你给一个合理的解释,我反正没有资料,也不会查,我就爱用渲染这个词怎么地。fuck
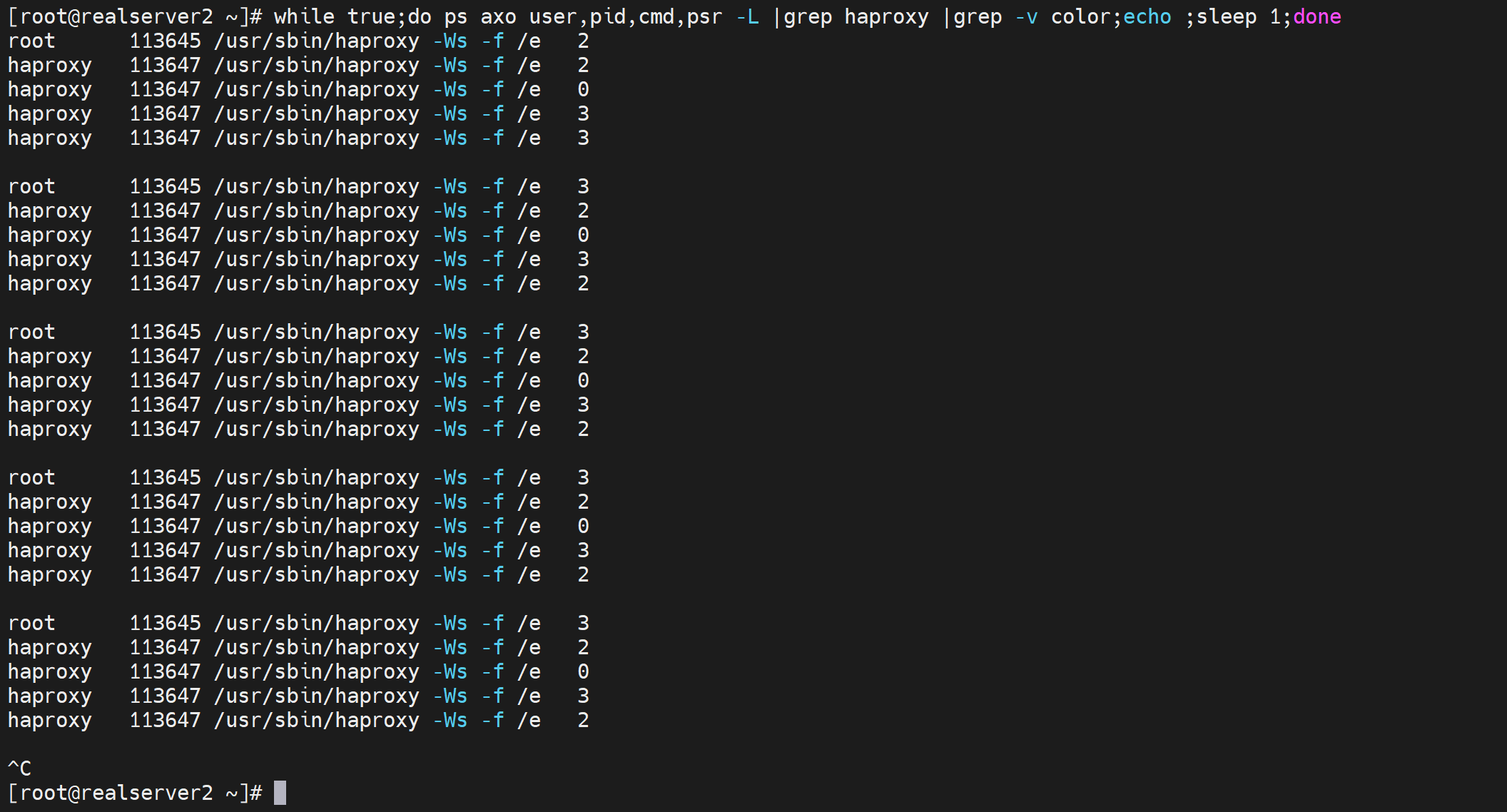
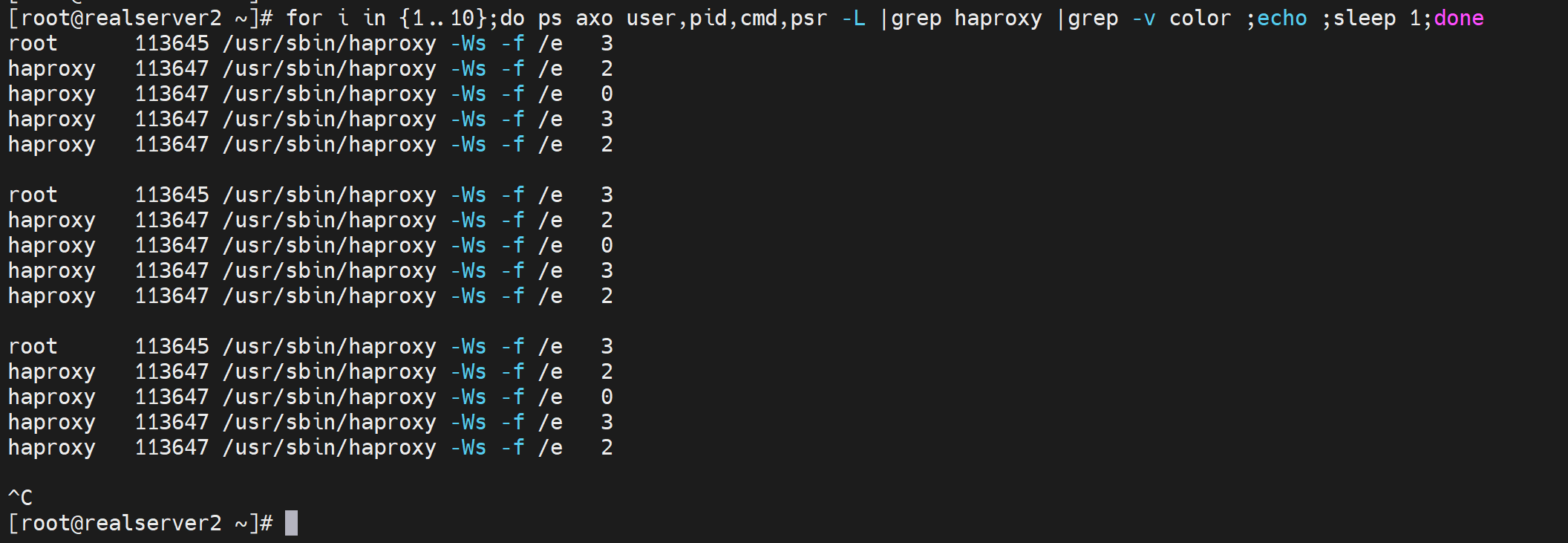
做个压力测试知道pstree少一个线程
while true;do ps axo user,pid,cmd,psr -L |grep haproxy |grep -v color;echo ;sleep 1;done
for i in {1..10};do ps axo user,pid,cmd,psr -L |grep haproxy |grep -v color ;echo ;sleep 1;done
ab 压力测试 如果不绑cpu就会飘的
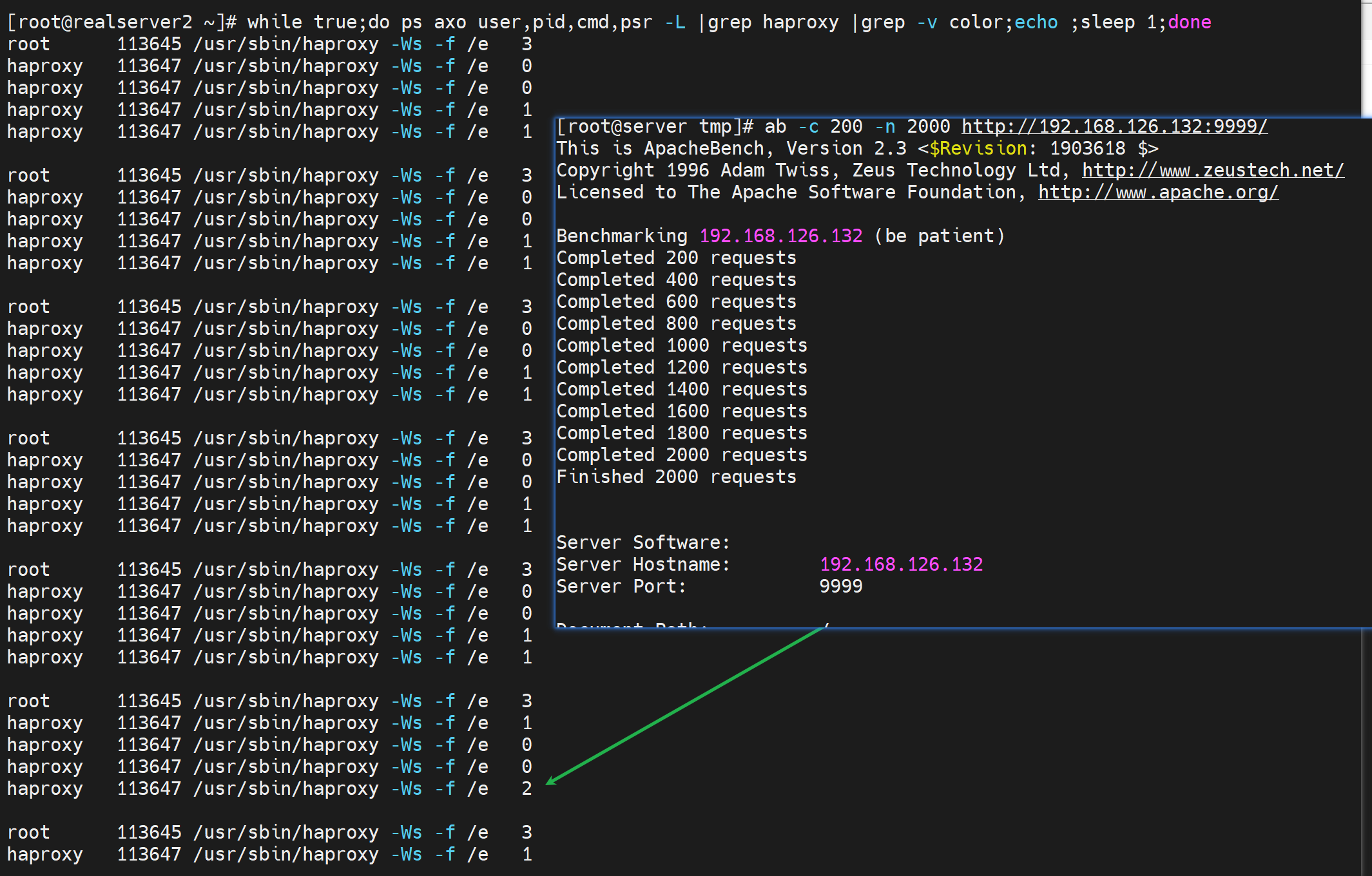
L1 L2缓存利用不上了基本上,绑一下就不会飘了
有个疑问,pstree -p看到线程好像少一个,不对,就是2个,ps axo -L看到的一个主进程,然后一个pid子进程下的三个线程?对不上啊。
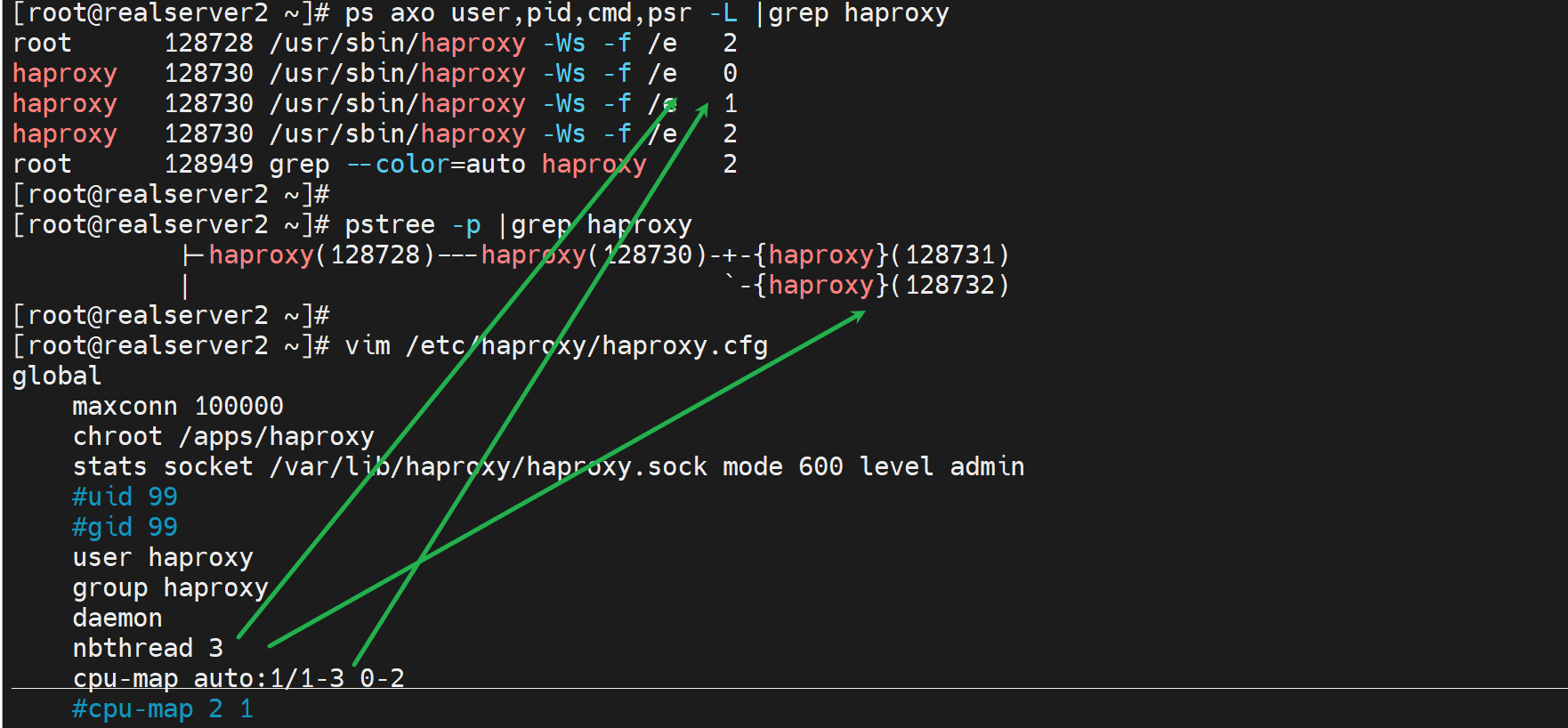
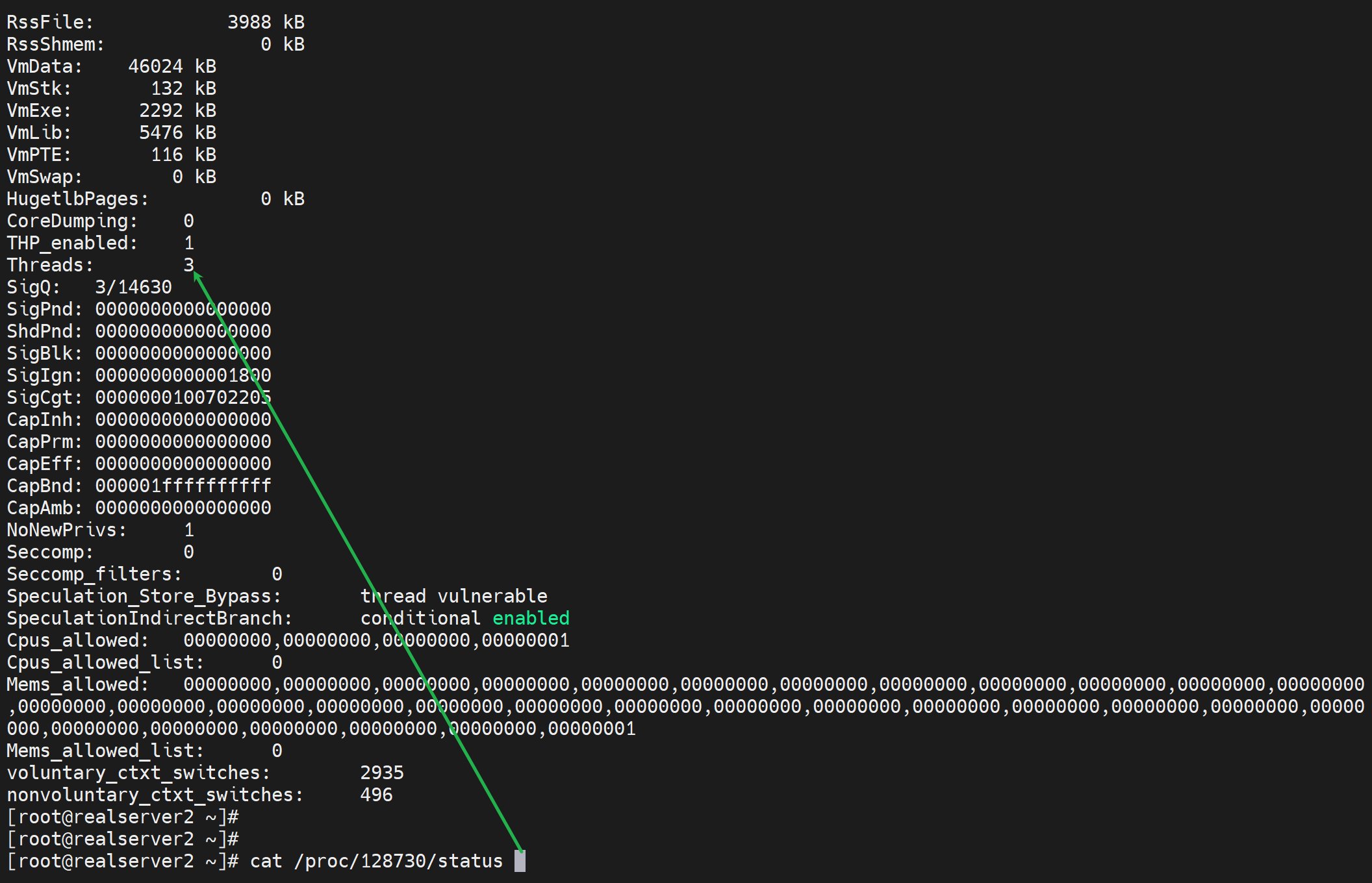
权威点的查看进程ID下的线程👇可见就是3个,pstree -p看的竟然不全啊--不是不全就是少一个,估计算到进程头上去了。
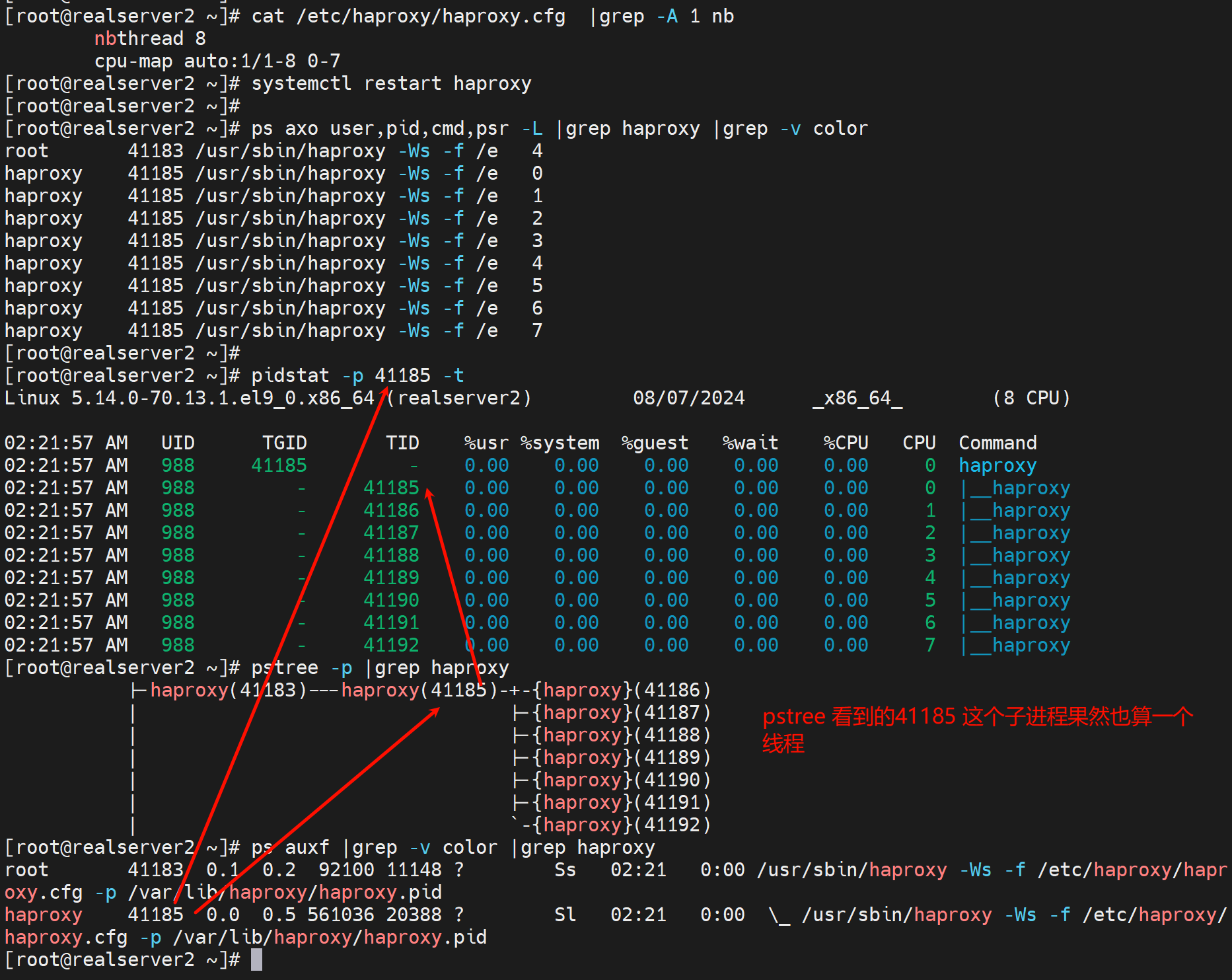
还可以用pidstat命令去查看
yum -y install sysstat
pidstat -p 41185 -t
然后curl 可以带密码的
[root@realserver2 ~]# curl http://haadmin:123456@192.168.126.132:9999/haproxy-status
maxconn 每个haproxy进程的最大并发连接数
maxssiconn 每个haproxy进程ssl最大连接数,用于haproxy配置了证书的场景下
maxconnrate 每个进程每秒创建的最大连接数,这属于新增的速度限制
spread-checks 后端server状态check随机提前或延迟百分比时间,建议2-5(20%-50%)之间,默认值0
nginx默认的后端server检查叫做被动检查,就是请求来了,转发的当口之前吧,看看后面的server提供的服务是否正常,如果NG,就不转过去了,或者转到其他server上。当然也可以用第三方插件实现主动检查。
而haproxy是主动检查,比如3s一次检查,那么问题来了,如果后端100台机器,那么3s一次,就会100个请求一次性发出去了,流量存在一个高峰现象,所以要随机差值来错开检查动作时间点,不能扎堆~
这个值建议设置成3,就是实际发送检查的时间区域再2.7--3.3之间。考虑一个问题
第一次检查 和 第二次 检查 相隔3秒,然后 有错开时间,可能导致第二次检查往前错开和第一次检查的往后错开重叠,那么3s的 50%最大了就是下图黄线代表50%的随机错开时间。50%已经就会出问题了,所20%是保证错开一点,45%才是最大值了。下图绿线框框代表30%的错开时间

pidfile 指定pid文件路径
log 127.0.0.1 local2 info 定义全局的syslog服务器,日志服务器需要开启UDP协议,最多可以定义两个。 info应该是日志级别对应常识里的debug, info, notice, warn, err, crit, alert emerg这些。
local2是啥? local2是基础设置,rsyslog里也有的;可以参考👇,总体就是什么"设施"--local2的什么日志,发送到127.,然后再用rsyslog接收进一步处理?估计是的,不是估计,就是,haproxy的local2这个自定义设备记入info日志然后,发送127的514端口,然后rsyslog从514接收这个日志,再通过local2.info来取出日志。

====================
不过一般haproxy作为总入口,也不推荐记录日志,减轻压力主要是I/O消耗,然后日志记录,坐在后端服务器上,后端服务器如果是nginx、tomcat这些各自记录日志。
其实实际应用如果压力不大,也可以开启日志,没啥问题。
开启配置方法
# 本机记录日志
log 127.0.0.1 local2 info
# 远端机器也记录日志
log 192.168.11.117 local2 info
#然后在本地的以及远端机器上的rsyslog里配置,打开下面两行
module(load="imudp") # needs to be done just once
input(type="imudp" port="514")
# tcp应该不用开了吧
module(load="imtcp") # needs to be done just once
input(type="imtcp" port="514")
....
# 再加一个行
local2.info /var/log/haproxy/haproxy.log
#然后重启haproxy和rsyslog
[root@realserver2 ~]# systemctl restart haproxy rsyslog
#远端一样操作夏
# 最后别忘了chmod 下
mkdir /var/log/haproxy/
chmod a:haproxy:w /var/log/haproxy

然后ubuntu配置是单独放置的

最后效果如下,能看到日志就行了,然后要注意/var/log/message下也是有的,理由就是cfg里他在前面也能接收到。
然后抓以下udp的包,问:tcpdump可以抓udp吗?阔以的
[root@realserver2 ~]# tcpdump -nni lo udp
[root@realserver2 ~]# tcpdump -nni lo udp port 514
# 都行

工作案例
1、办公网络的IP冲突,如何知晓,
首先dhcp日志先弄出来
linux的dhcpd的日志处理
1、配置dhcpd的日志
vi /etc/dhcp/dhcpd.conf
log-facility local6; #为local6自定义设备,local1-xxx都是设备名称
2、配置rsyslog
vi /etc/rsyslog.conf
# Save dhcpd messages also to dhcpd.log
local6.* /var/log/dhcpd.log
# 以下配置是移除操作,local6不再往message文件发送,
# Don't log private authentication messages!
*.info;mail.none;authpriv.none;cron.none;local6.none /var/log/messages
3、重启dhcpd和rsyslog服务
systemctl restart dhcpd
systemctl restart rsyslog