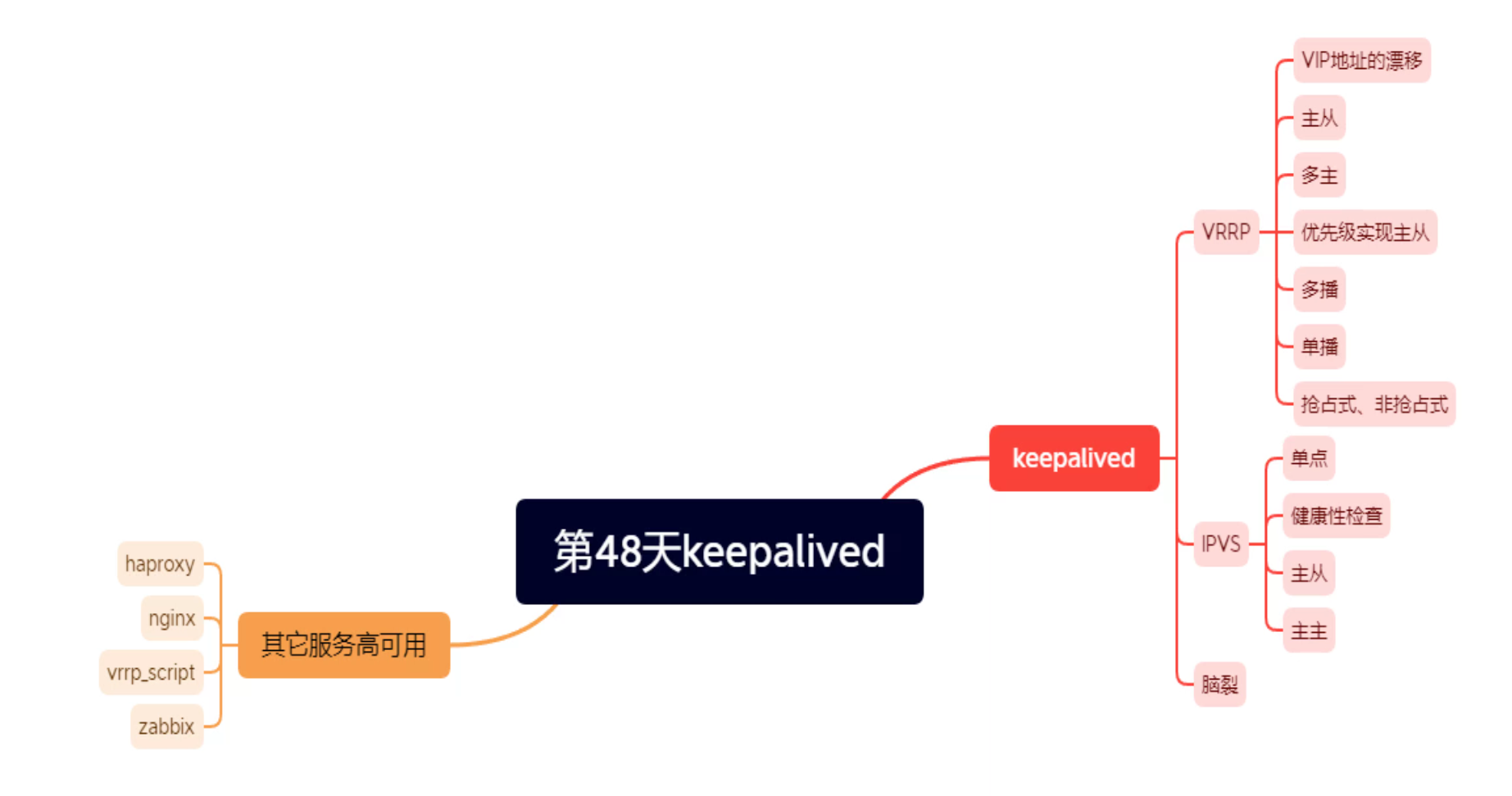
7.Keepalived实现Haproxy和Nginx其它服务的高可用.md
基于VRRP Script 实现其他应用的HA
nginx和haproxy的服务HA
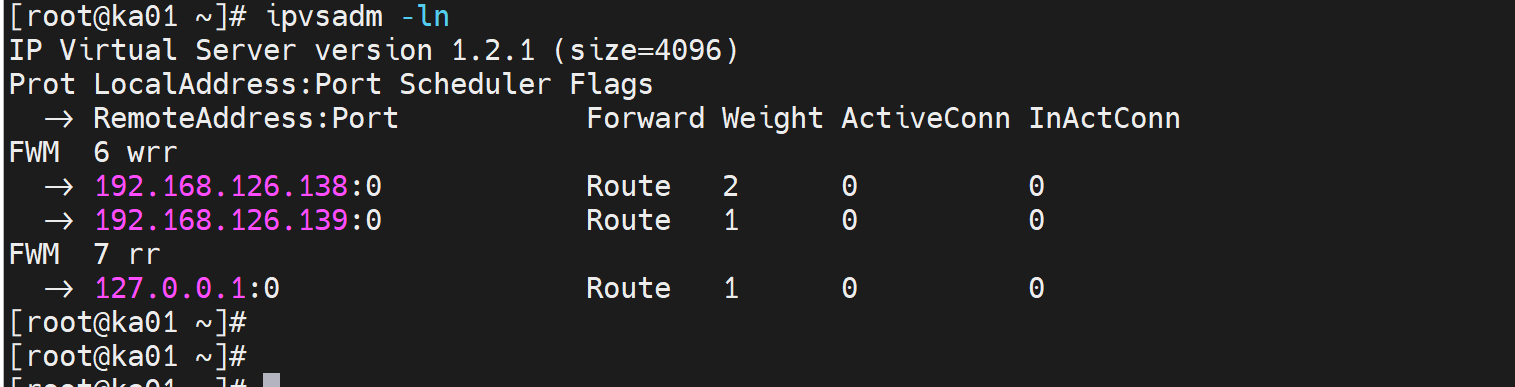
上面讲了virtual_server自带集成的语句块实现了LVS的HA,下面用脚本曲线救国了
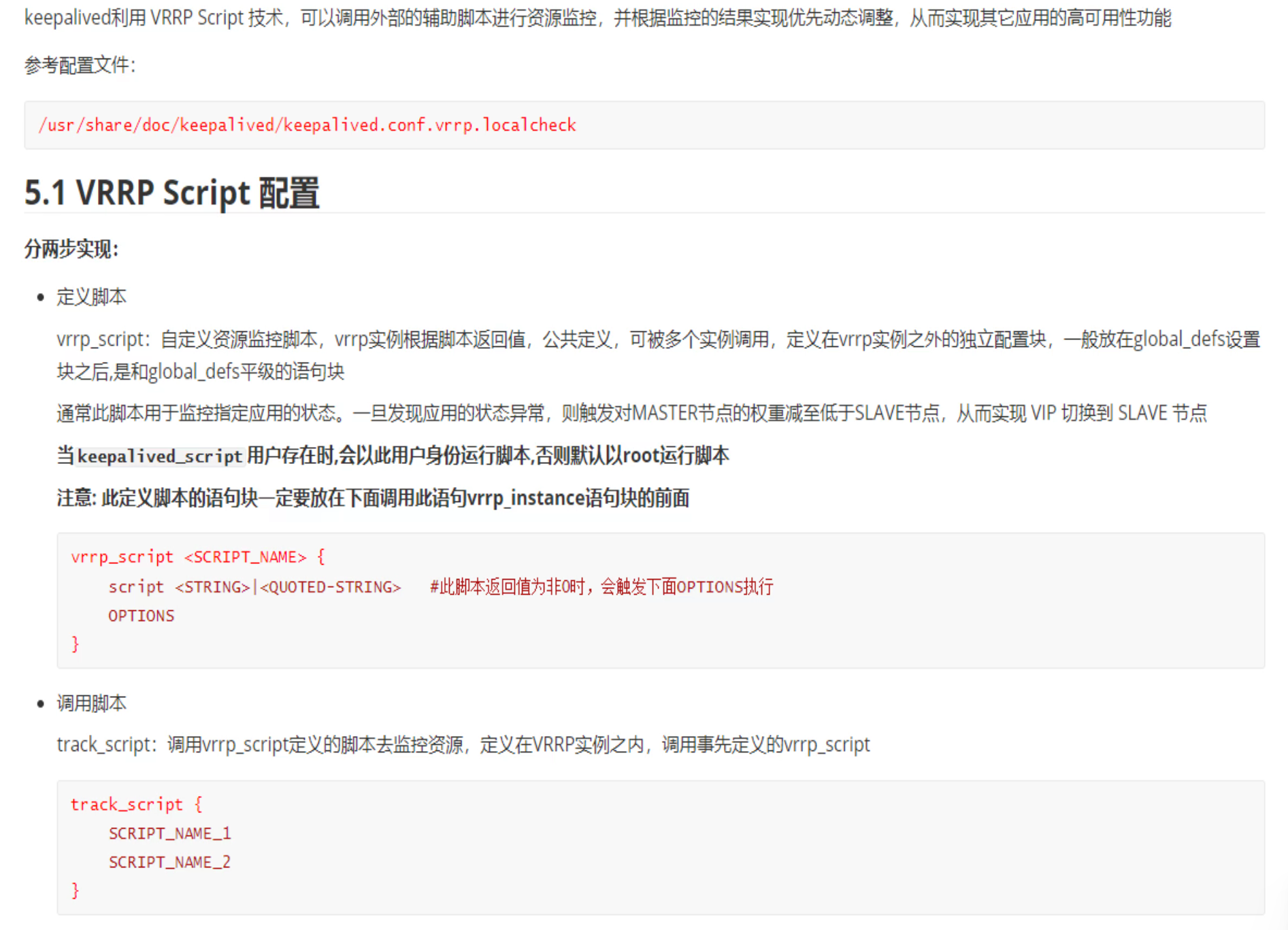
利用kill 0 检查进程是否OK
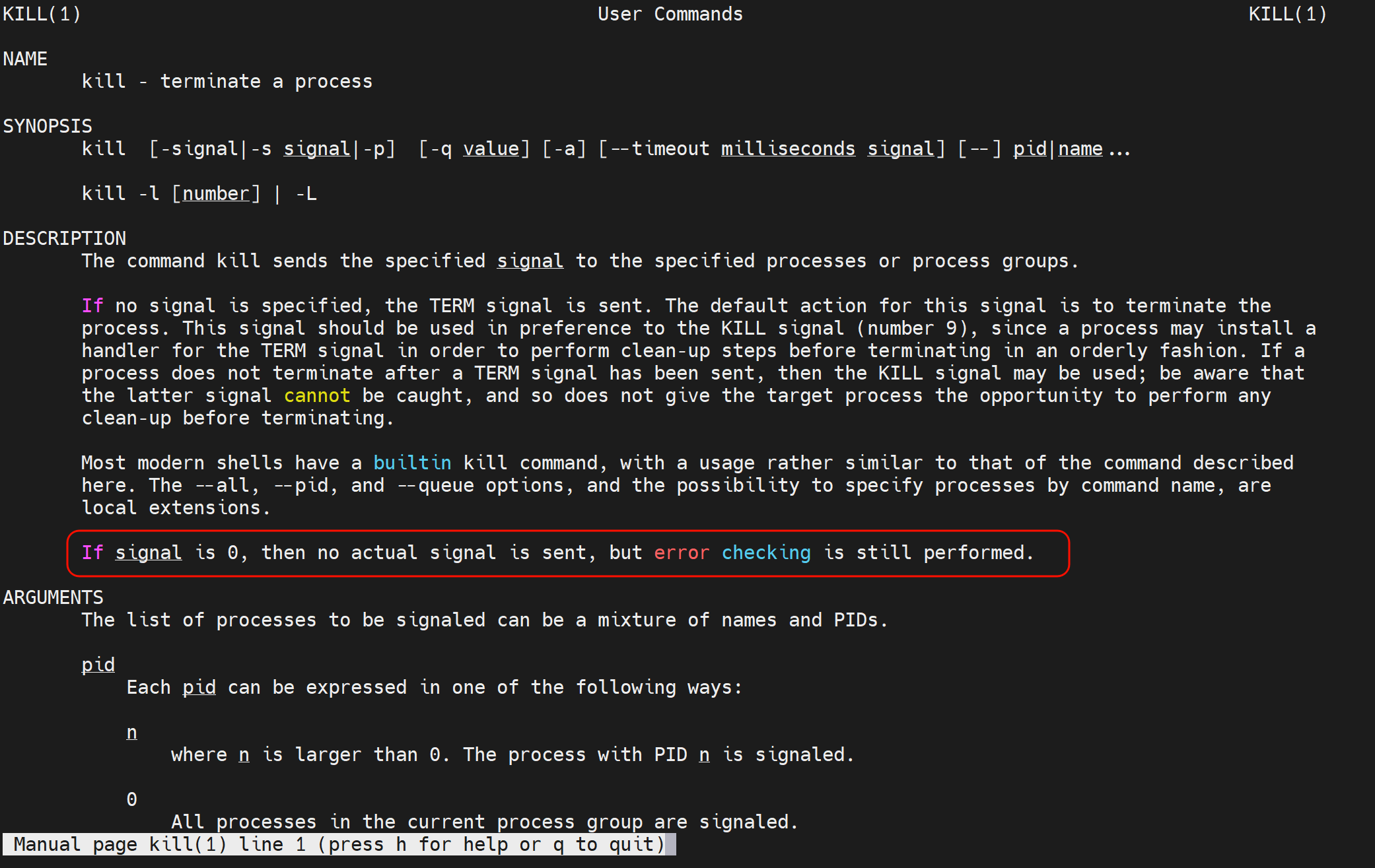
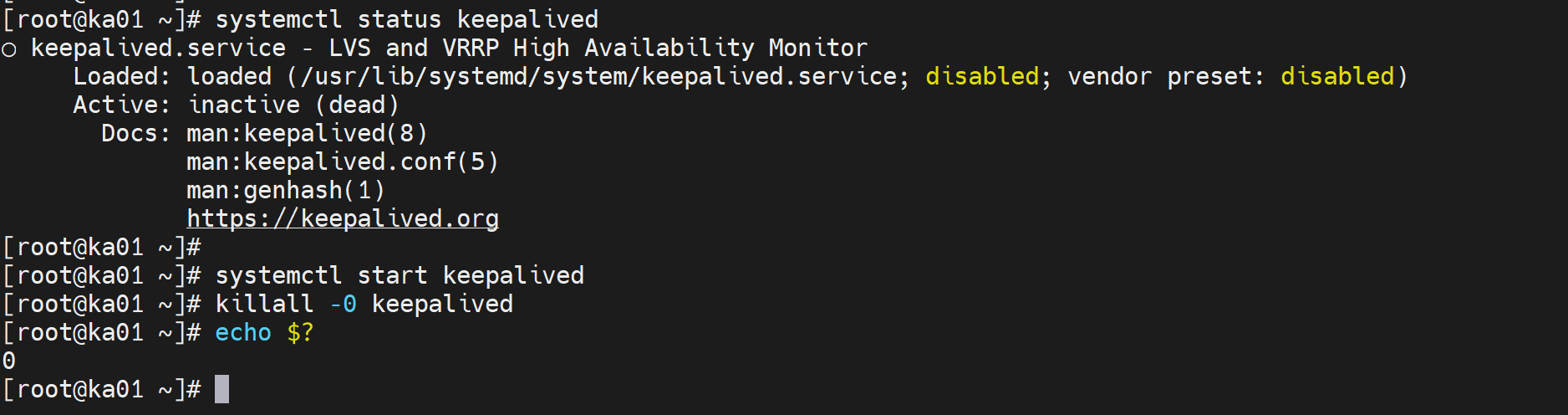
只是检查进程死活,并不代表好坏,curl才是业务的检查
haproxy+keepalived
yum -y install haproxy
vim /etc/haproxy/haproxf.cfg
...
# 结尾加上
listen www.ming.org_80
bind 192.168.126.100:80
server server1 192.168.126.138:80 check
server server2 192.168.126.139:80 check
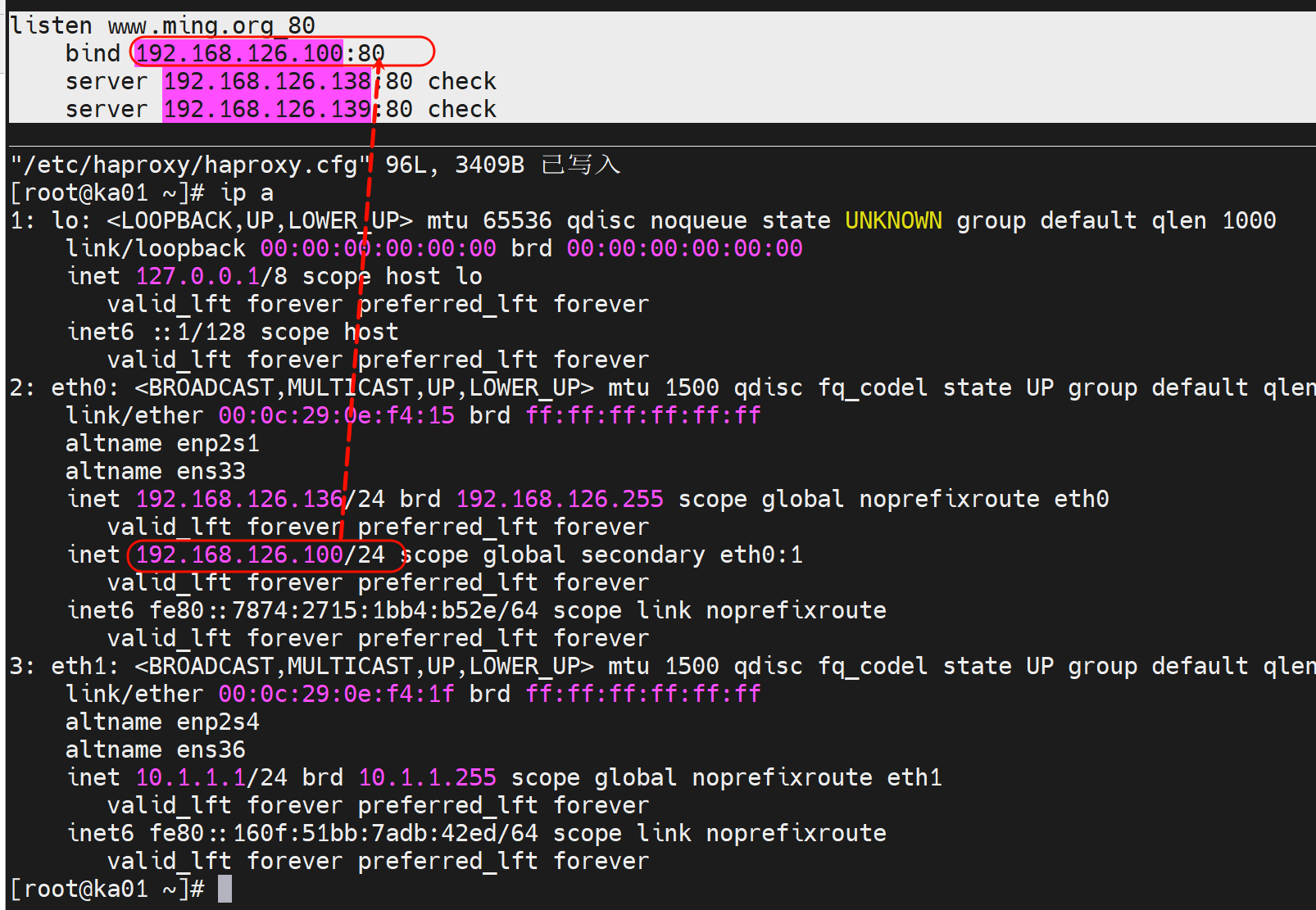
但是haproxy的bind地址要存在的,VIP没有落在的从节点是没有这个IP的,所以haproxy服务起不来

通过journalct -u可见👇
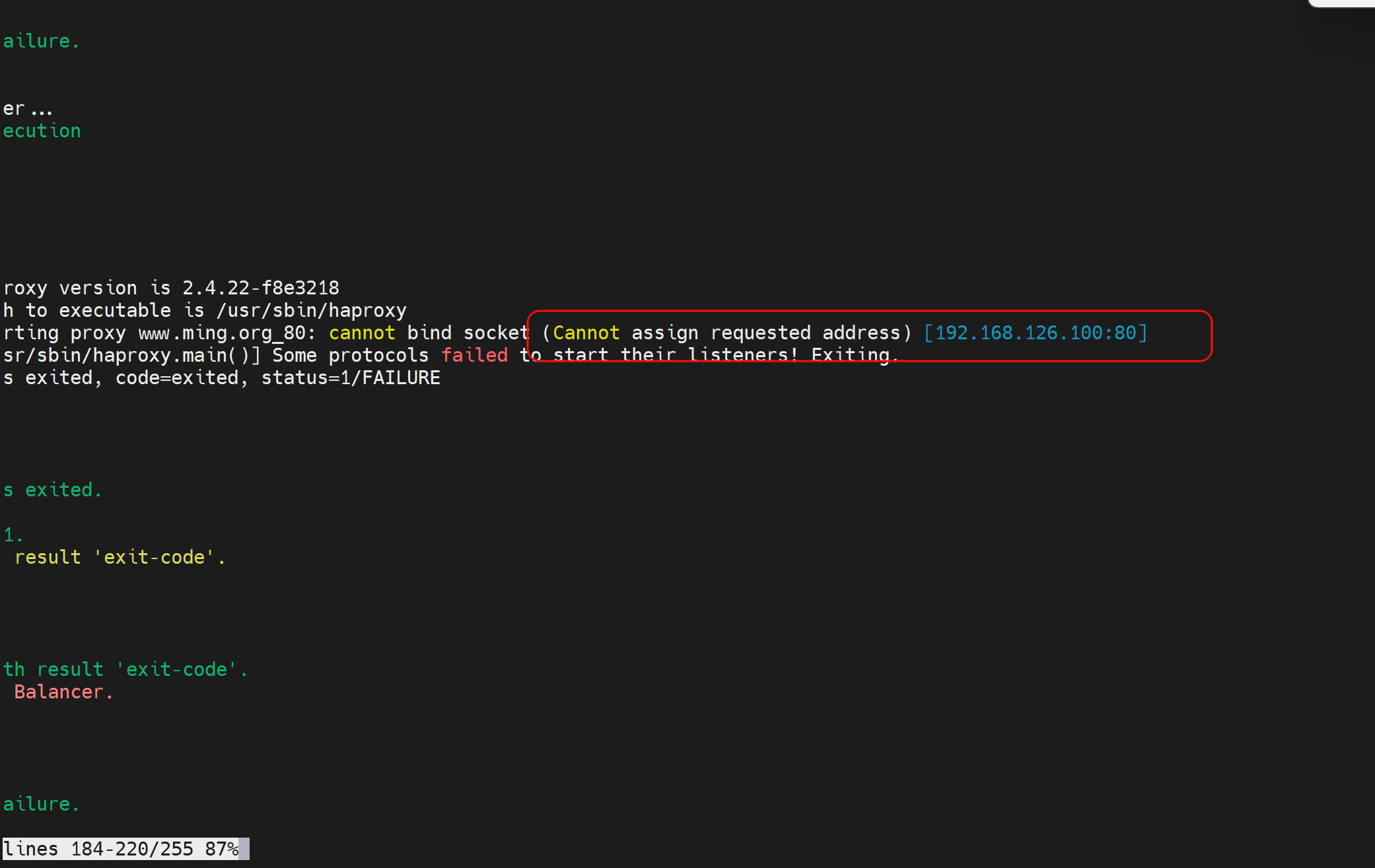
修改内核参数使得haproxy监听在VIP(没落过来-从节点)上

echo "net.ipv4.ip_nonlocal_bind = 1" >> /etc/sysctl.conf
sysctl -p

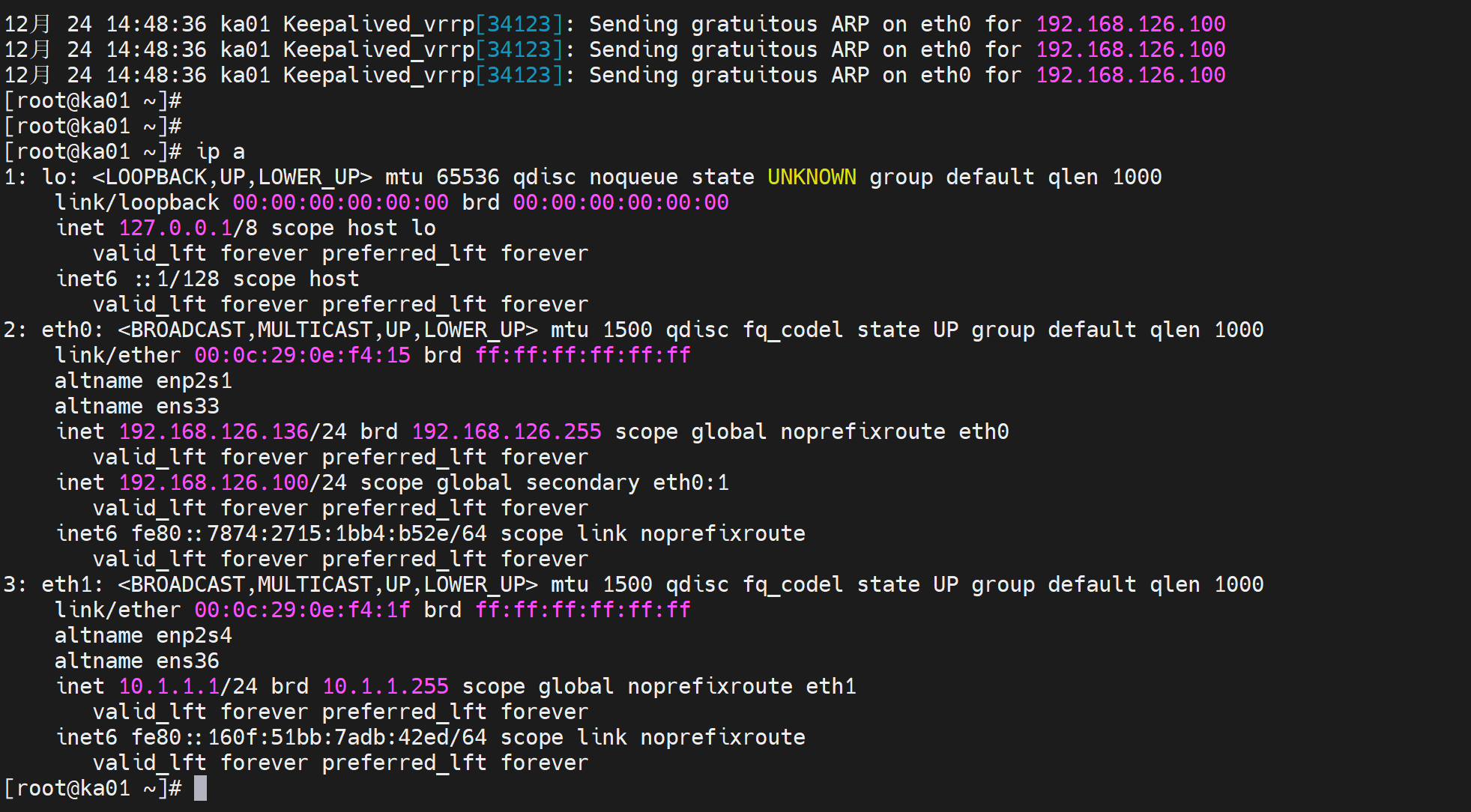
此时就可以了

同样主节点也要配置否则VIP飘走了,haproxy到时候就起不来了

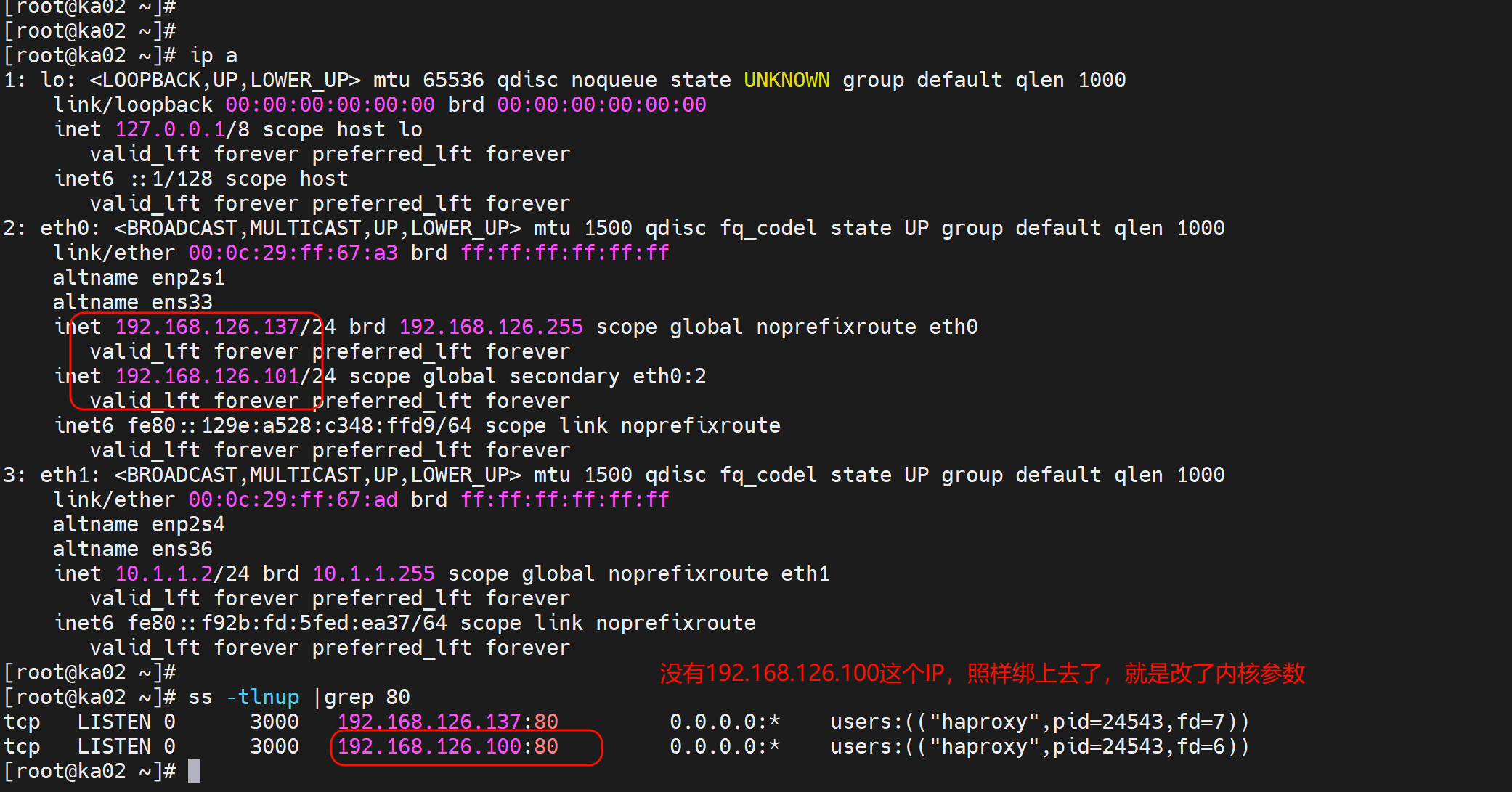
删除之前实验的lvs配置就是vs的语句块,主从都删,这些配置会导致lvs的转发规则👇,清干净就行,和haproxy冲突了
测试OK

实现haproxy的HA
要实现haproxy挂了,keepavlied的VIP也要切走
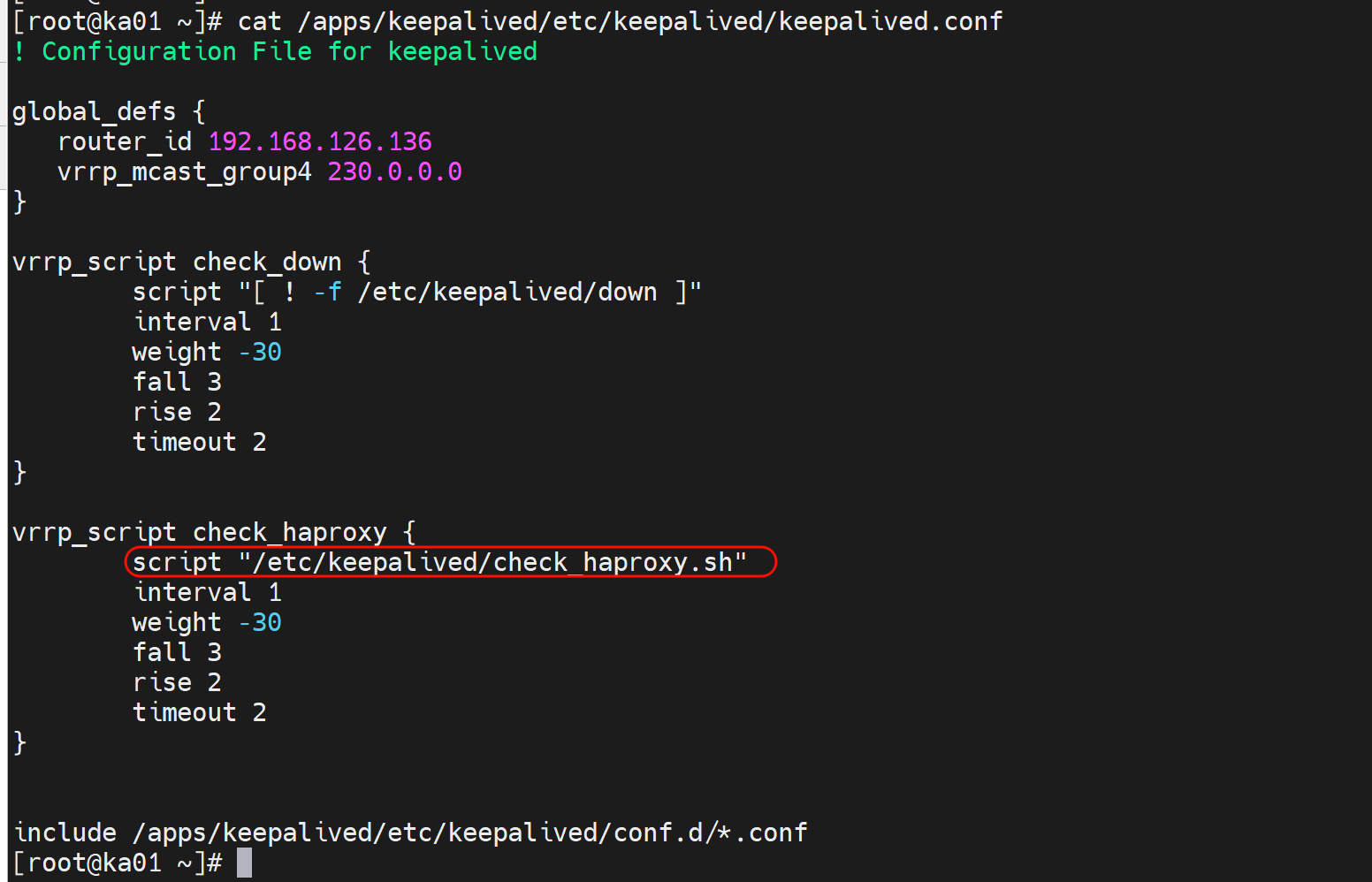
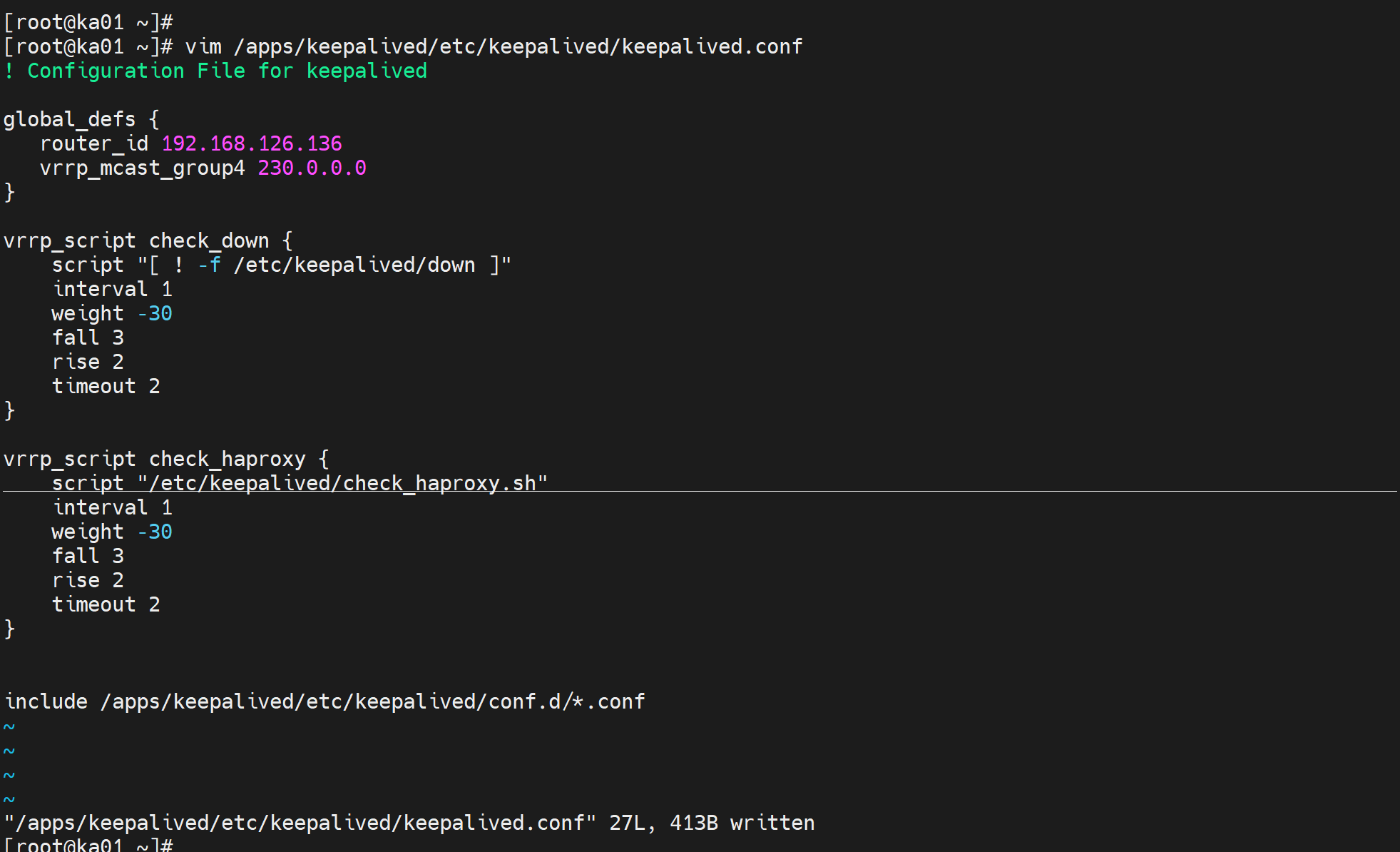
把脚本写到keepalived的主配置文件里,推荐这么做,以便复用
[root@ka01 ~]# cat /apps/keepalived/etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id 192.168.126.136
vrrp_mcast_group4 230.0.0.0
}
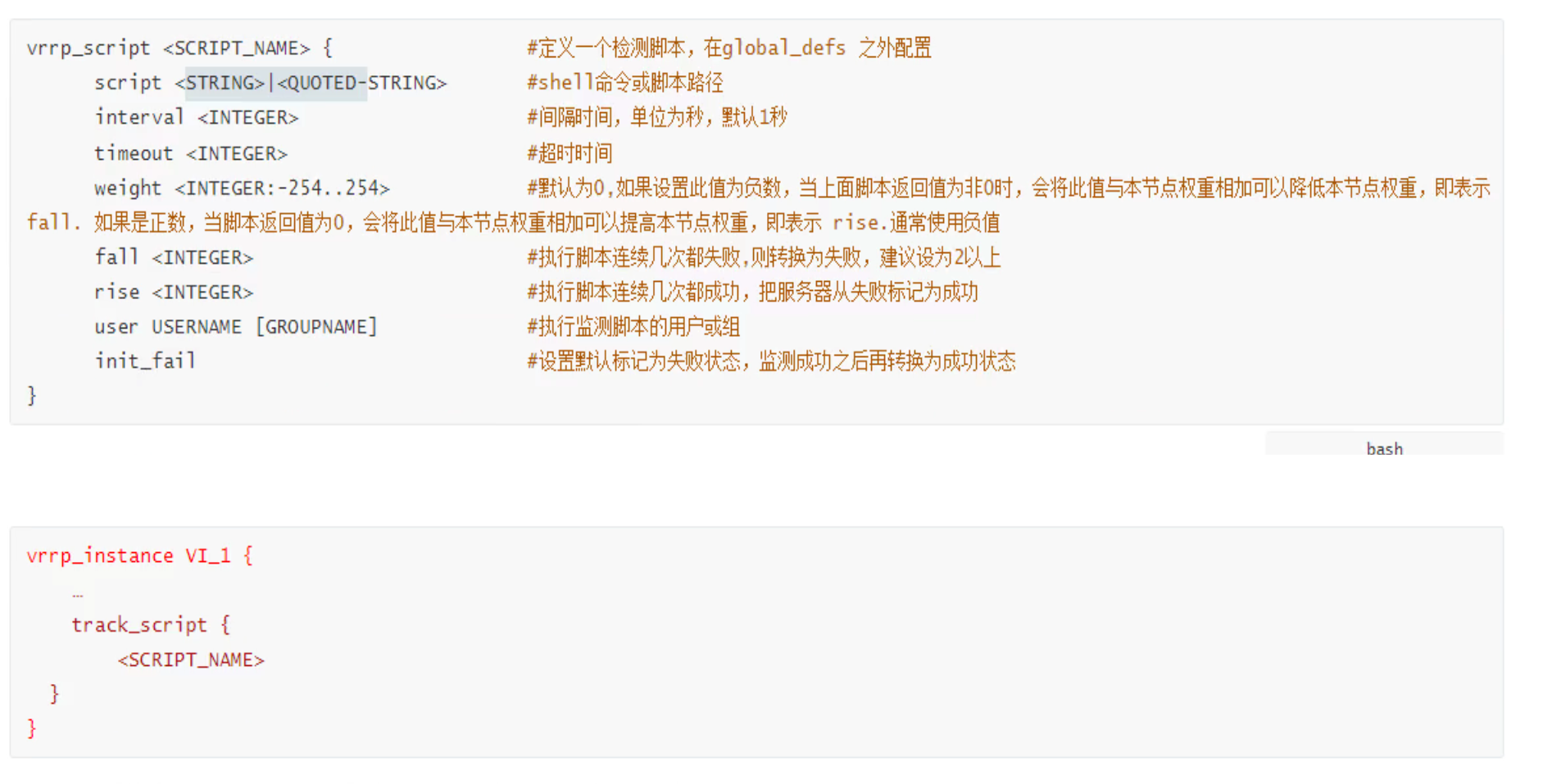
vrrp_script check_down {
# 翻译下👇:如果文件不存在就为True,真就是不执行下面的操作OPTIONS(interval\weight\fall\rise\timeout这些);如果文件存在(文件被创建出来了)就为fasle假-那么就会执行下面的OPTIONS特别时weight权重-30。
script "[ ! -f /etc/keepalived/down ]"
interval 1
# 这个权重就是vrrp的优先级,具体时在子配置文件vrrp语句块里定义的
weight -30
fall 3
rise 2
timeout 2
}
include /apps/keepalived/etc/keepalived/conf.d/*.conf
[root@ka01 ~]#
# 调用上面定义的脚本
[root@ka01 ~]# vim /apps/keepalived/etc/keepalived/conf.d/www.ming.org.conf
vrrp_instance VI_1 {
state BACKUP
interface eth1
virtual_router_id 51
priority 100
advert_int 3
#nopreempt
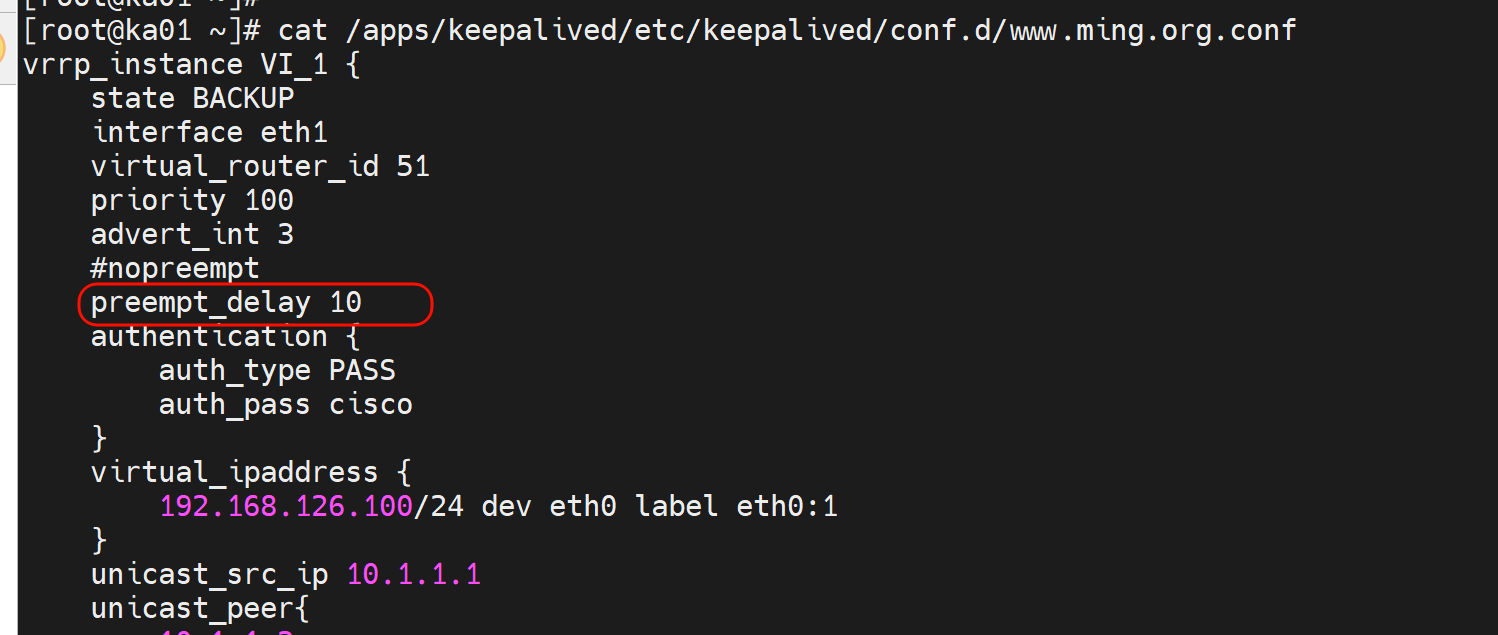
preempt_delay 10
authentication {
auth_type PASS
auth_pass cisco
}
virtual_ipaddress {
192.168.126.100/24 dev eth0 label eth0:1
}
unicast_src_ip 10.1.1.1
unicast_peer{
10.1.1.2
}
#notify_master "/apps/keepalived/bin/notify.sh master"
#notify_backup "/apps/keepalived/bin/notify.sh backup"
#notify_fault "/apps/keepalived/bin/notify.sh fault"
# Allow packets addressed to the VIPs above to be received
accept
track_script {
check_down
}
}
主从keepalived节点都配置下
然后由于此时脚本判断原则是:script "[ ! -f /etc/keepalived/down ]",所以此时该down文件不存在=>取非为真,所以脚本执行为真,就不会启用语句块下面的配置项。也就不会切主,VIP不会飘。
测试,切换,只需要创建该文件就行了
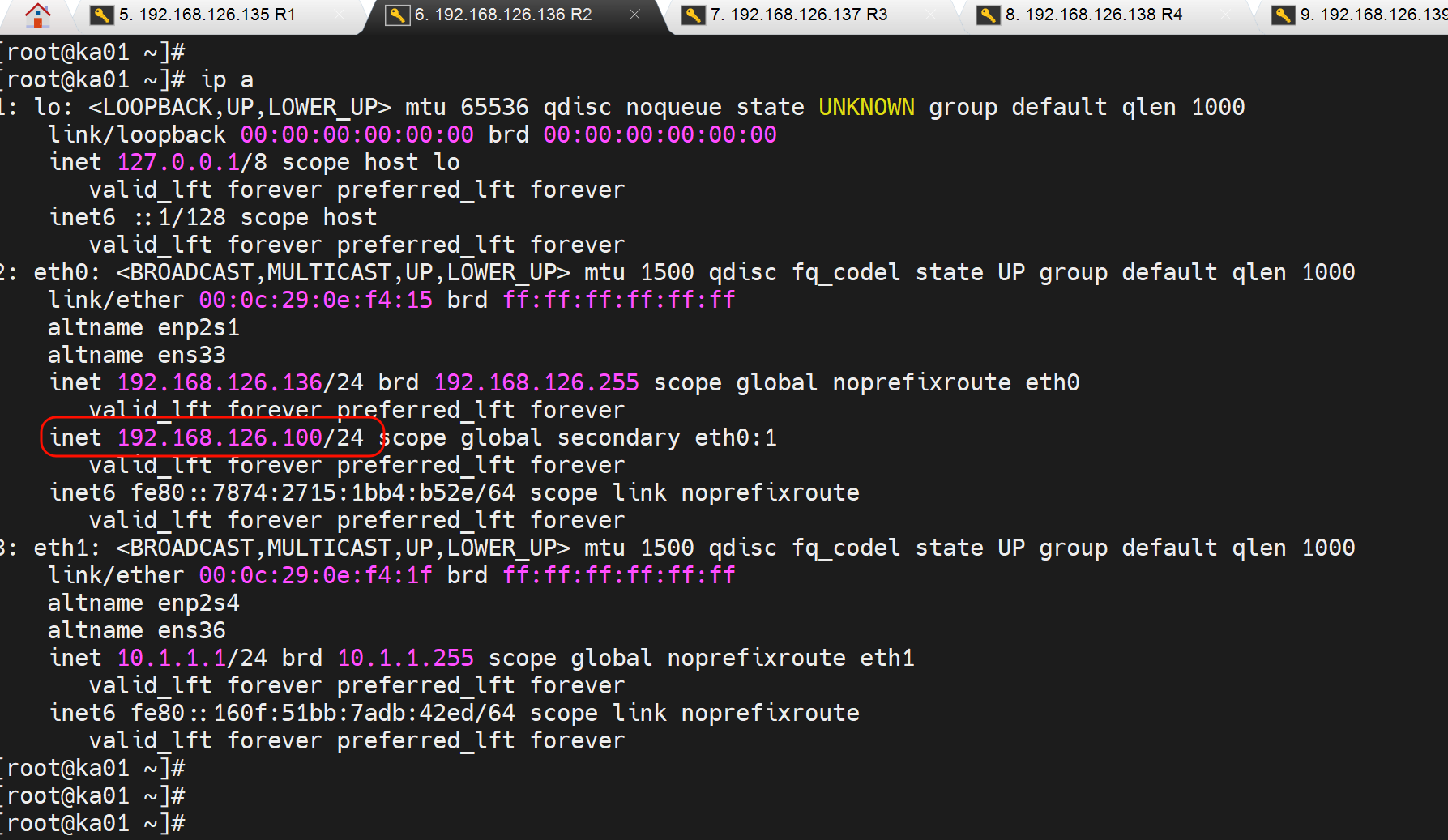
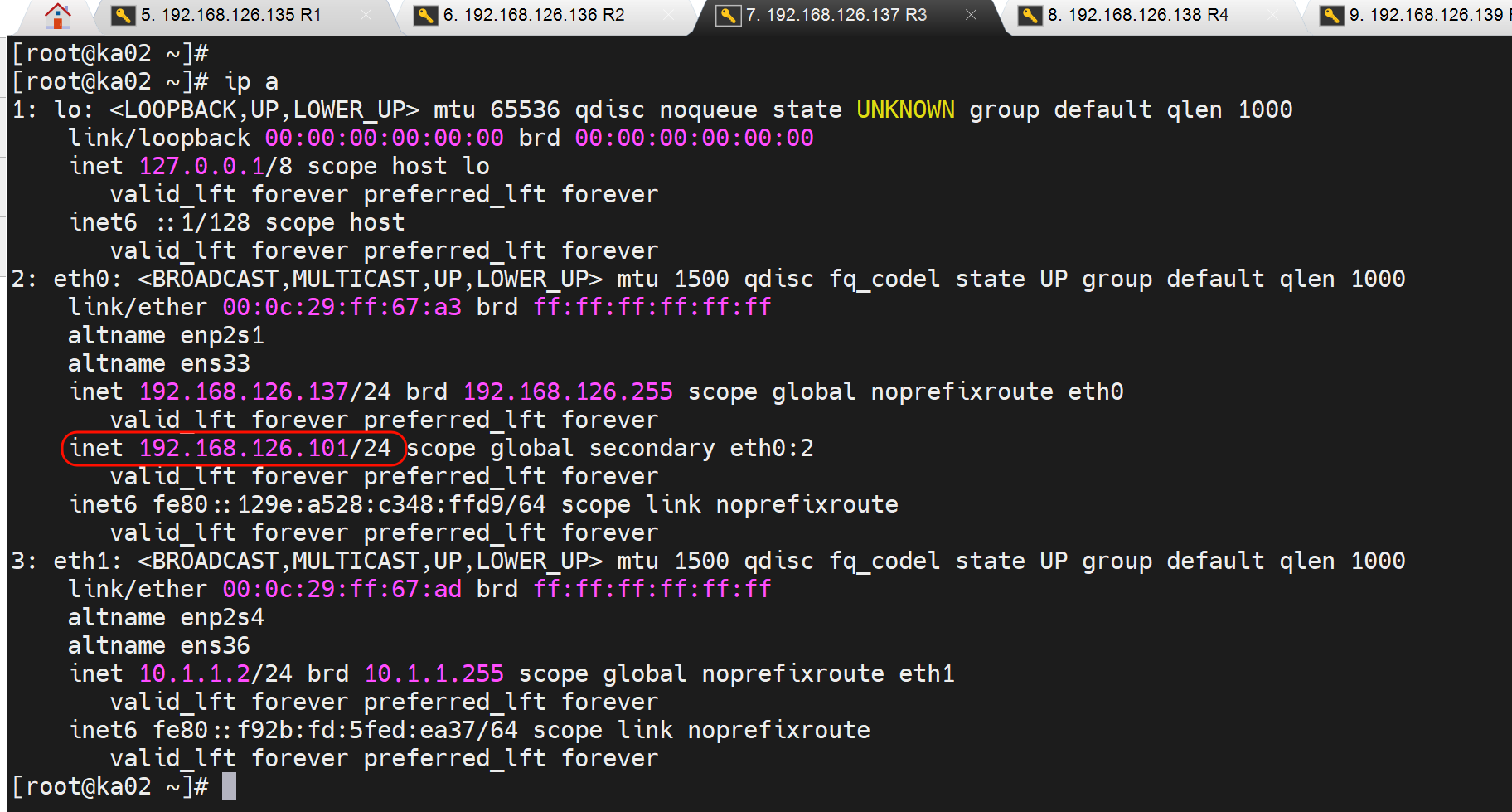
创建文件触发脚本👇,主从切换,VIP漂移了
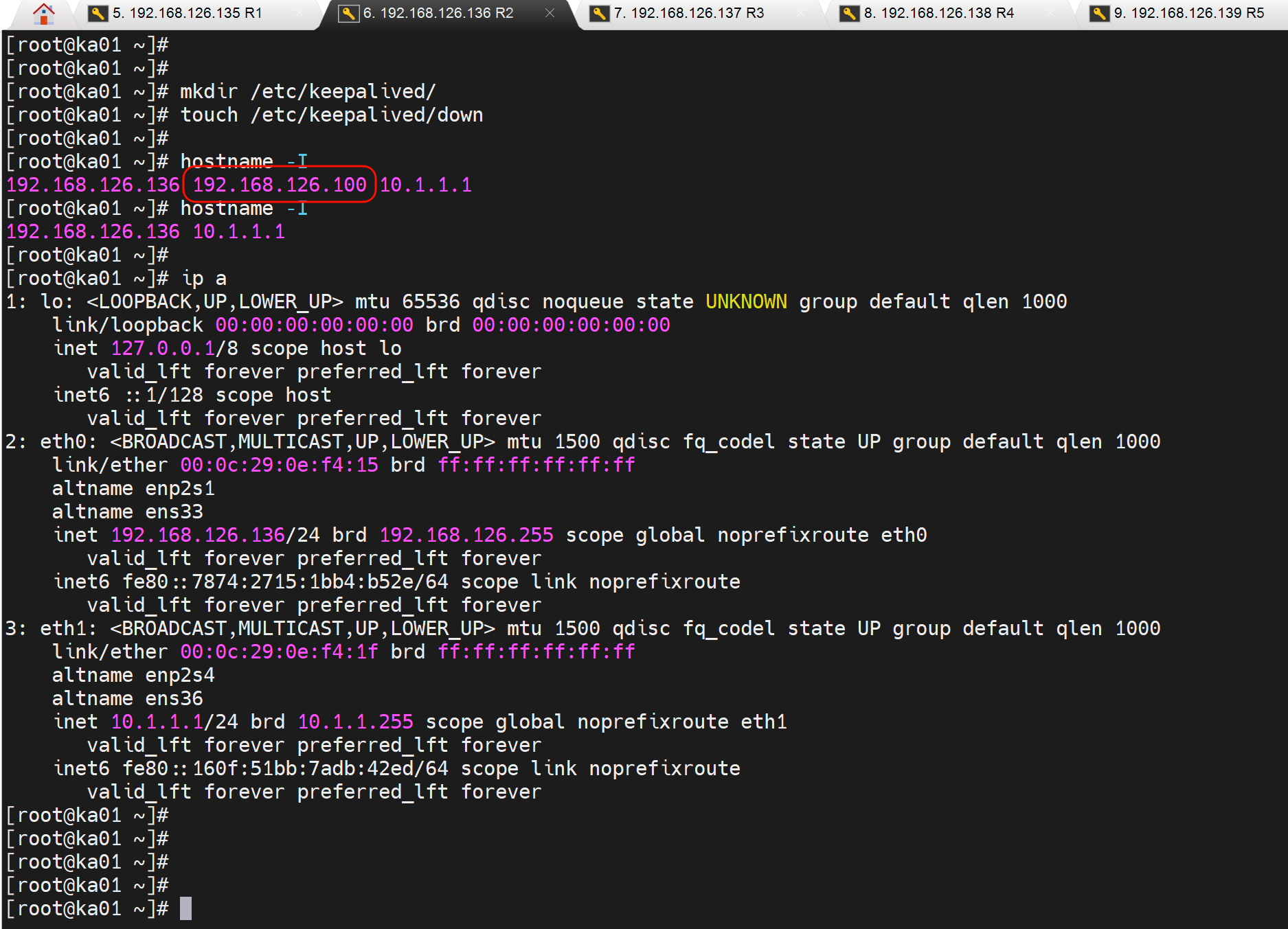
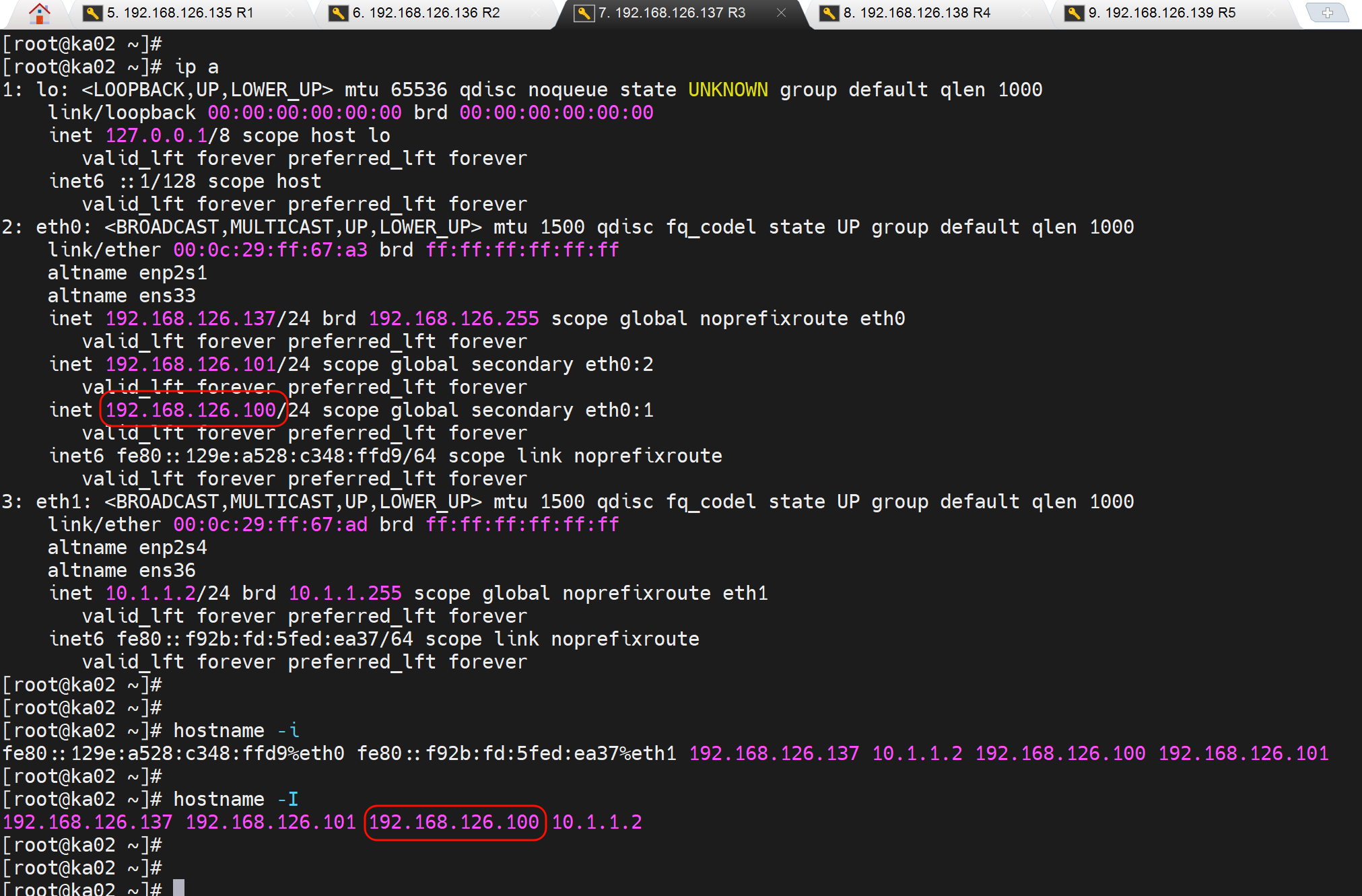
继续在从节点测试,创建down文件,可以看到VIP就让出去了👇
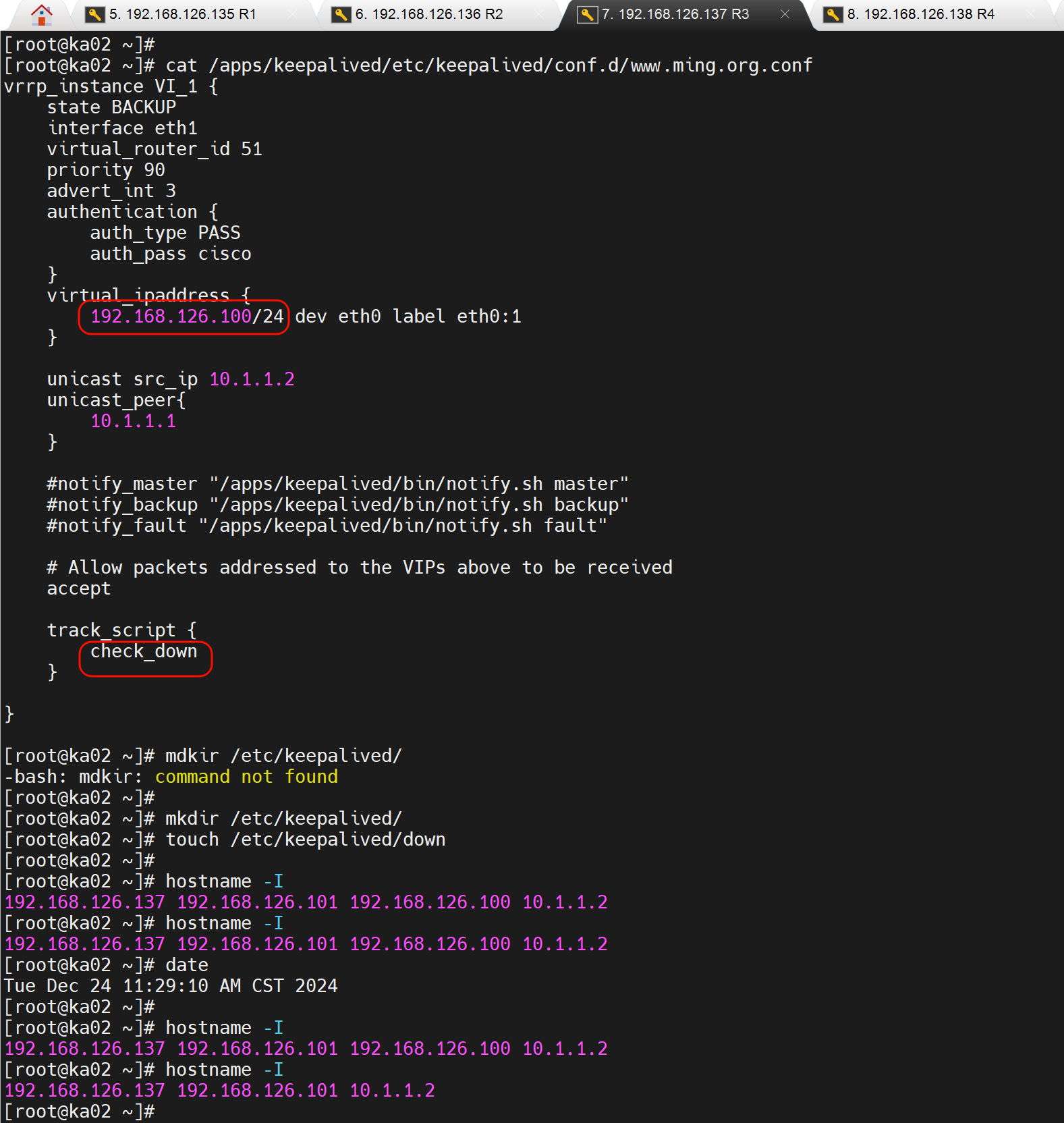
两边都有脚本执行失败的情况,所以还是看各自原始优先级都减去weight后的大小了。
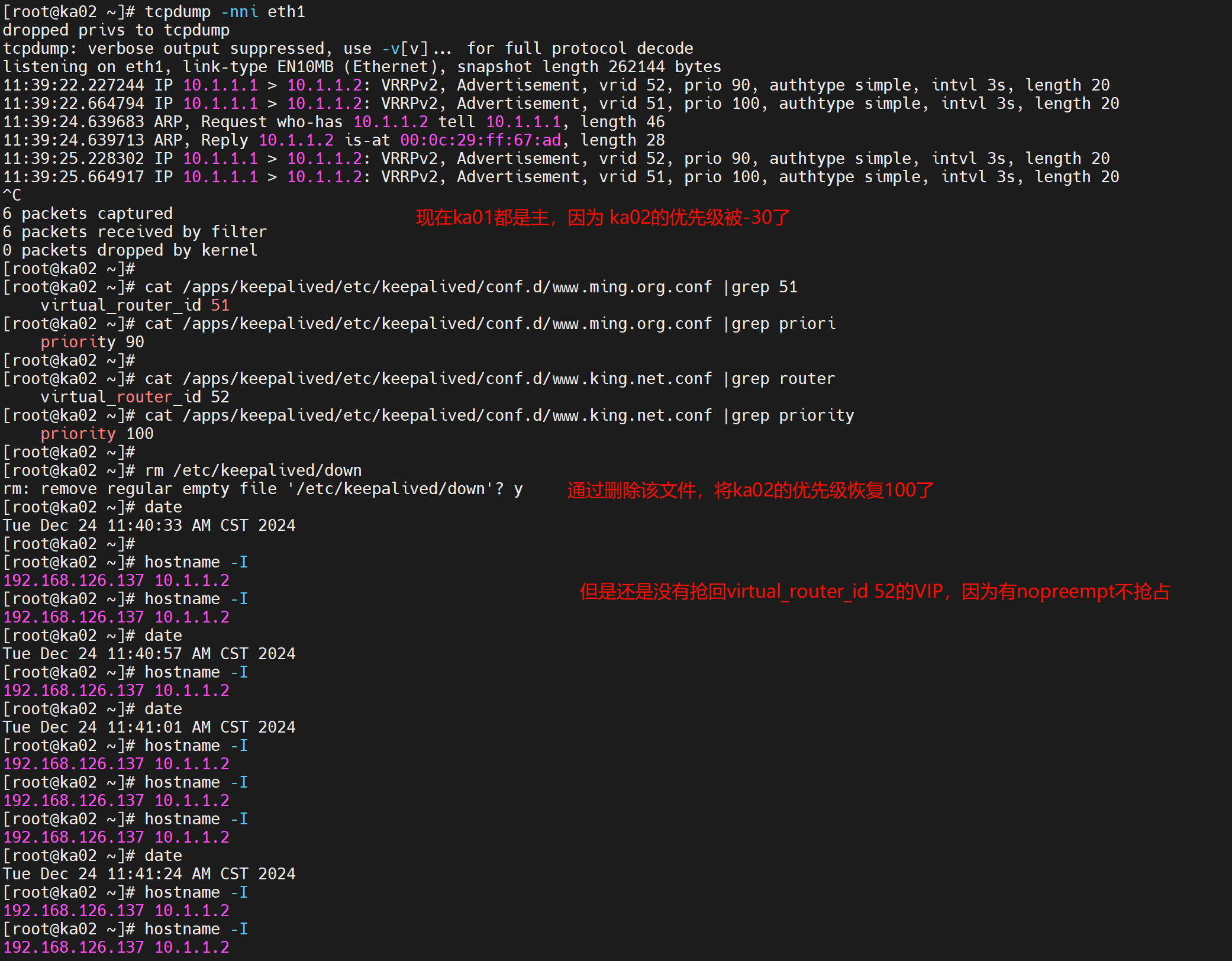
注释掉nopreempt 观察可见
恢复了

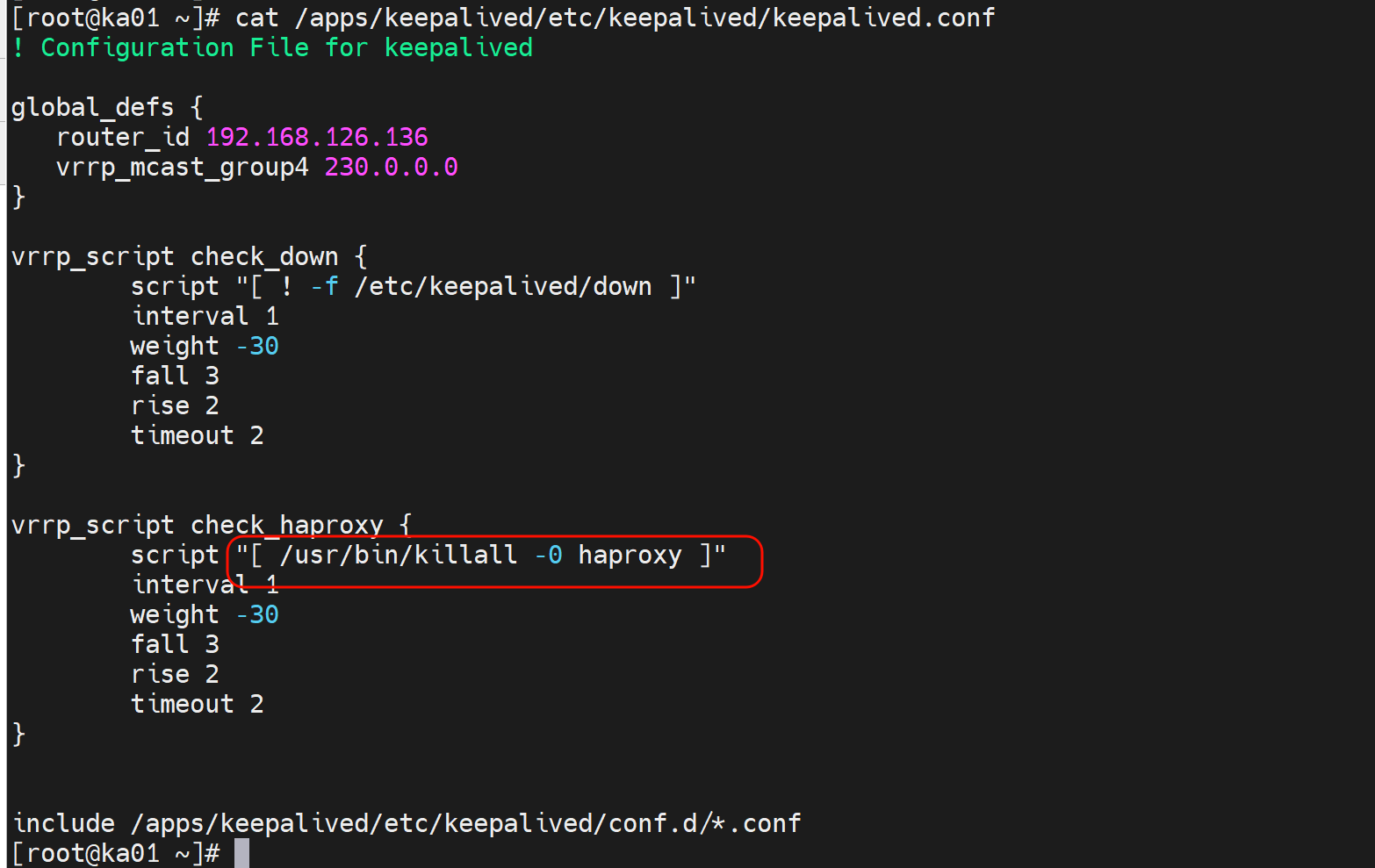
利用killall实现haproxy的检查-不是很严谨
错误写法
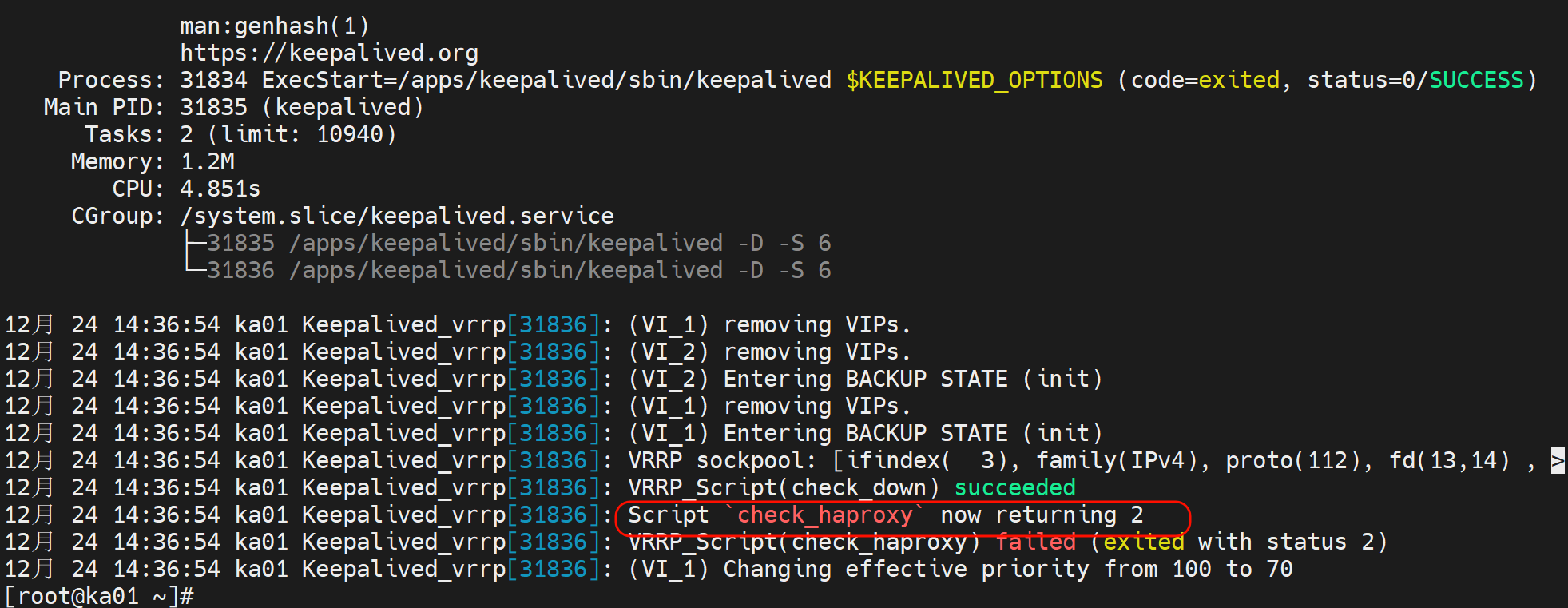
脚本后面 不要总是带[]方括号,这种test判断是否为比较结果为真的语法,👆上图一定会丢失VIP的,主变从的,因为脚本存在错误👇

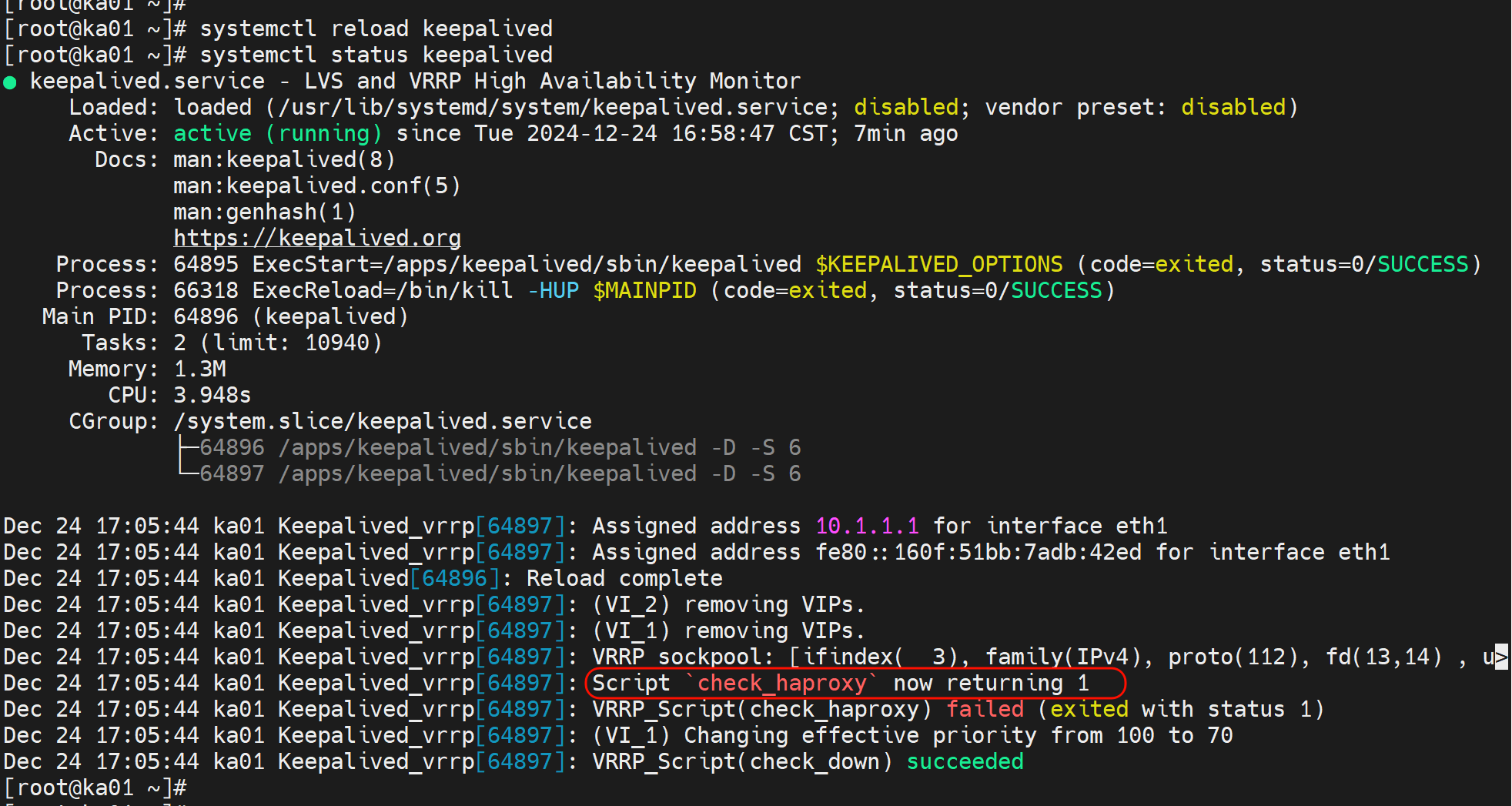
然后reload后看status果然是2👇
去掉方括号就行
[root@ka01 ~]# cat /apps/keepalived/etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id 192.168.126.136
vrrp_mcast_group4 230.0.0.0
}
vrrp_script check_down {
script "[ ! -f /etc/keepalived/down ]"
interval 1
weight -30
fall 3
rise 2
timeout 2
}
vrrp_script check_haproxy {
script "/usr/bin/killall -0 haproxy"
interval 1
weight -30
fall 3
rise 2
timeout 2
}
include /apps/keepalived/etc/keepalived/conf.d/*.conf
[root@ka01 ~]#
[root@ka01 ~]# cat /apps/keepalived/etc/keepalived/conf.d/www.ming.org.conf
vrrp_instance VI_1 {
state BACKUP
interface eth1
virtual_router_id 51
priority 100
advert_int 3
#nopreempt
preempt_delay 10
authentication {
auth_type PASS
auth_pass cisco
}
virtual_ipaddress {
192.168.126.100/24 dev eth0 label eth0:1
}
unicast_src_ip 10.1.1.1
unicast_peer{
10.1.1.2
}
#notify_master "/apps/keepalived/bin/notify.sh master"
#notify_backup "/apps/keepalived/bin/notify.sh backup"
#notify_fault "/apps/keepalived/bin/notify.sh fault"
# Allow packets addressed to the VIPs above to be received
accept
track_script {
check_down
check_haproxy
}
}
[root@ka01 ~]#
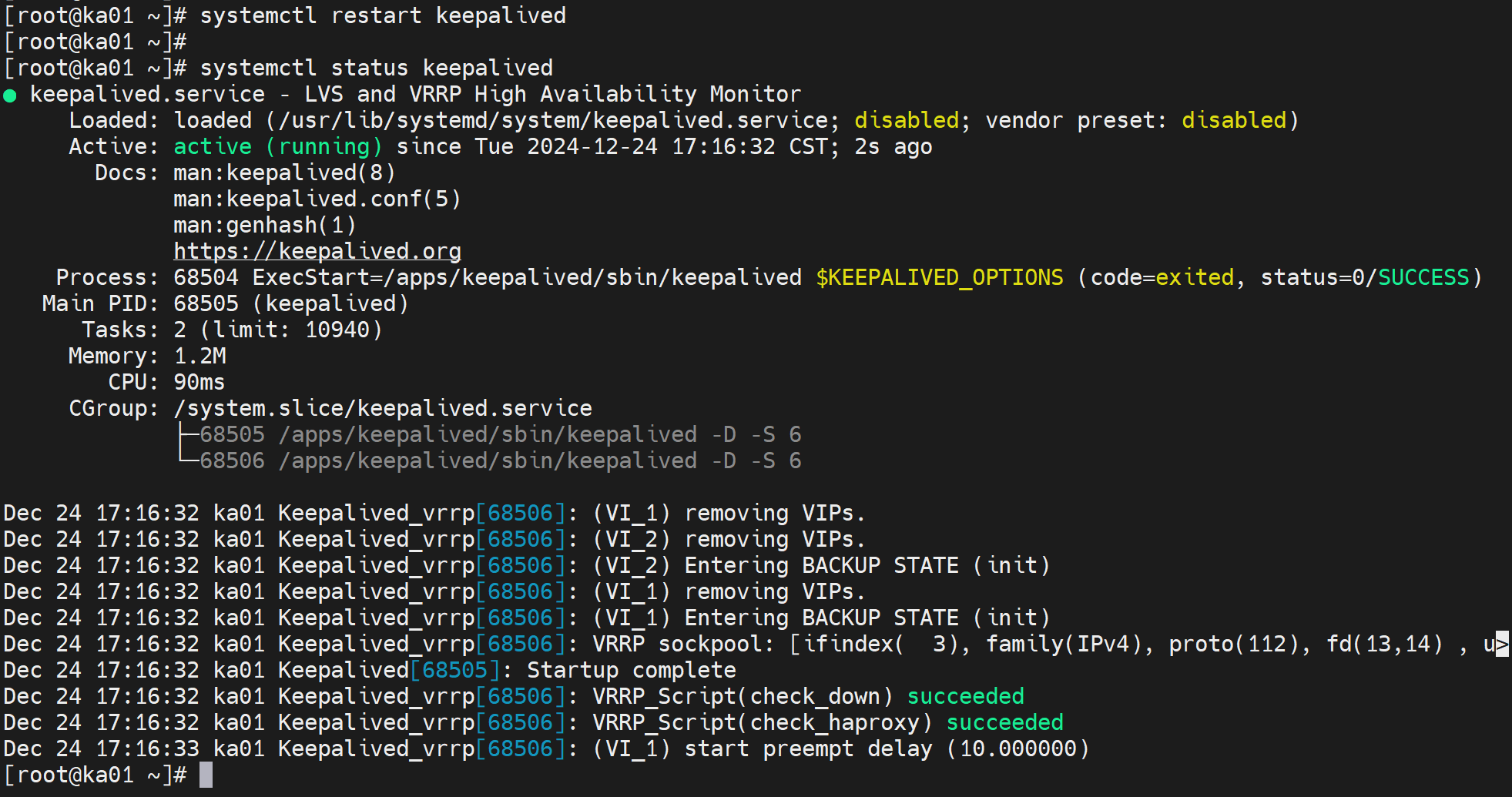
reload即可,不放心restart都没有问题
VIP也在,没问题
停掉haproxy观察是否切换主从
还可以写脚本去调用,这里依旧使用不太严谨的killall
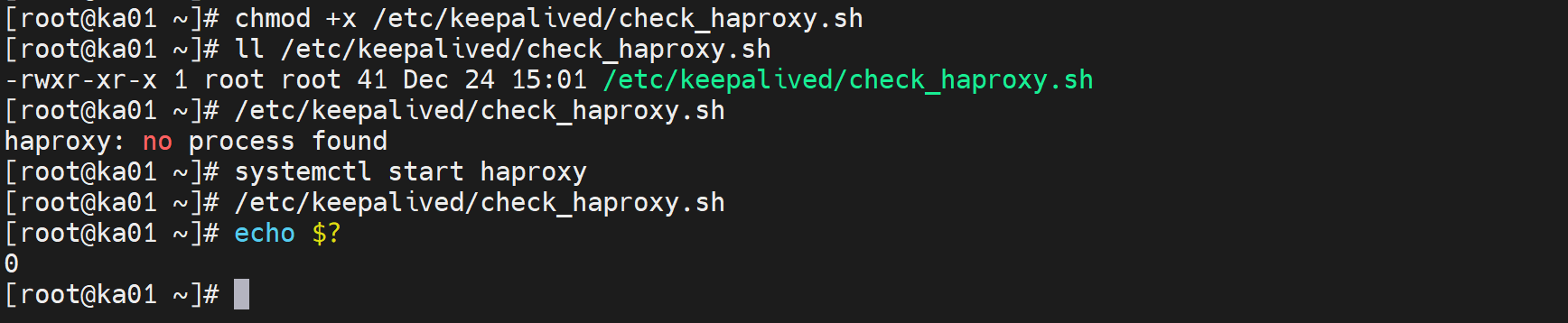
[root@ka01 ~]# cat /etc/keepalived/check_haproxy.sh
#!/bin/bash
/usr/bin/killall -0 haproxy
[root@ka01 ~]#
[root@ka01 ~]# chmod +x /etc/keepalived/check_haproxy.sh
[root@ka01 ~]# ll /etc/keepalived/check_haproxy.sh
-rwxr-xr-x 1 root root 41 Dec 24 15:01 /etc/keepalived/check_haproxy.sh
[root@ka01 ~]#
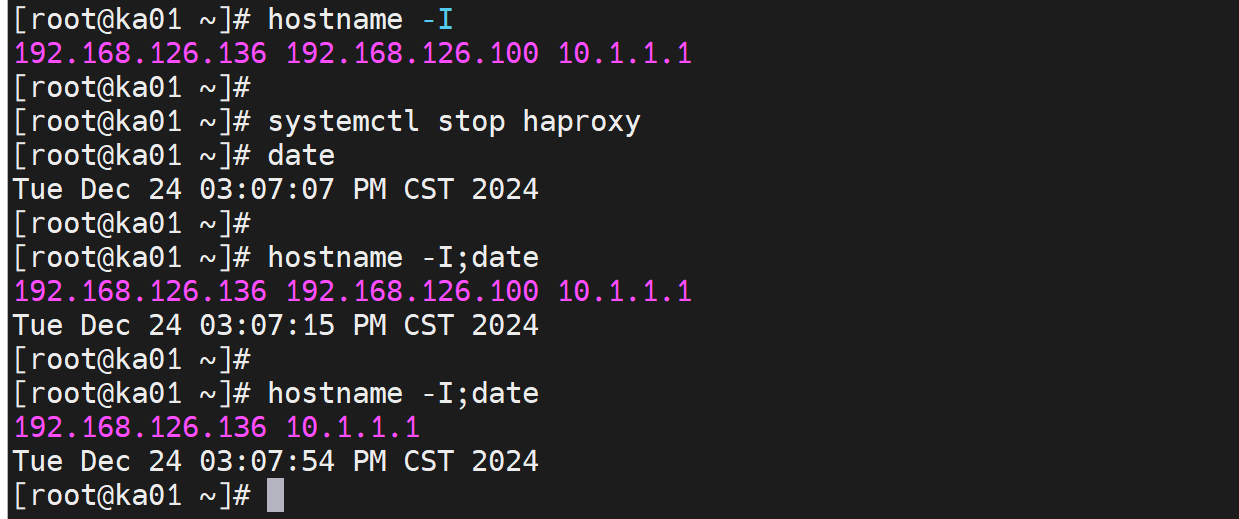
由于是restart,会将VIP让出去的,但是由于开启了preempt_delay 10所以10s后会抢回来的
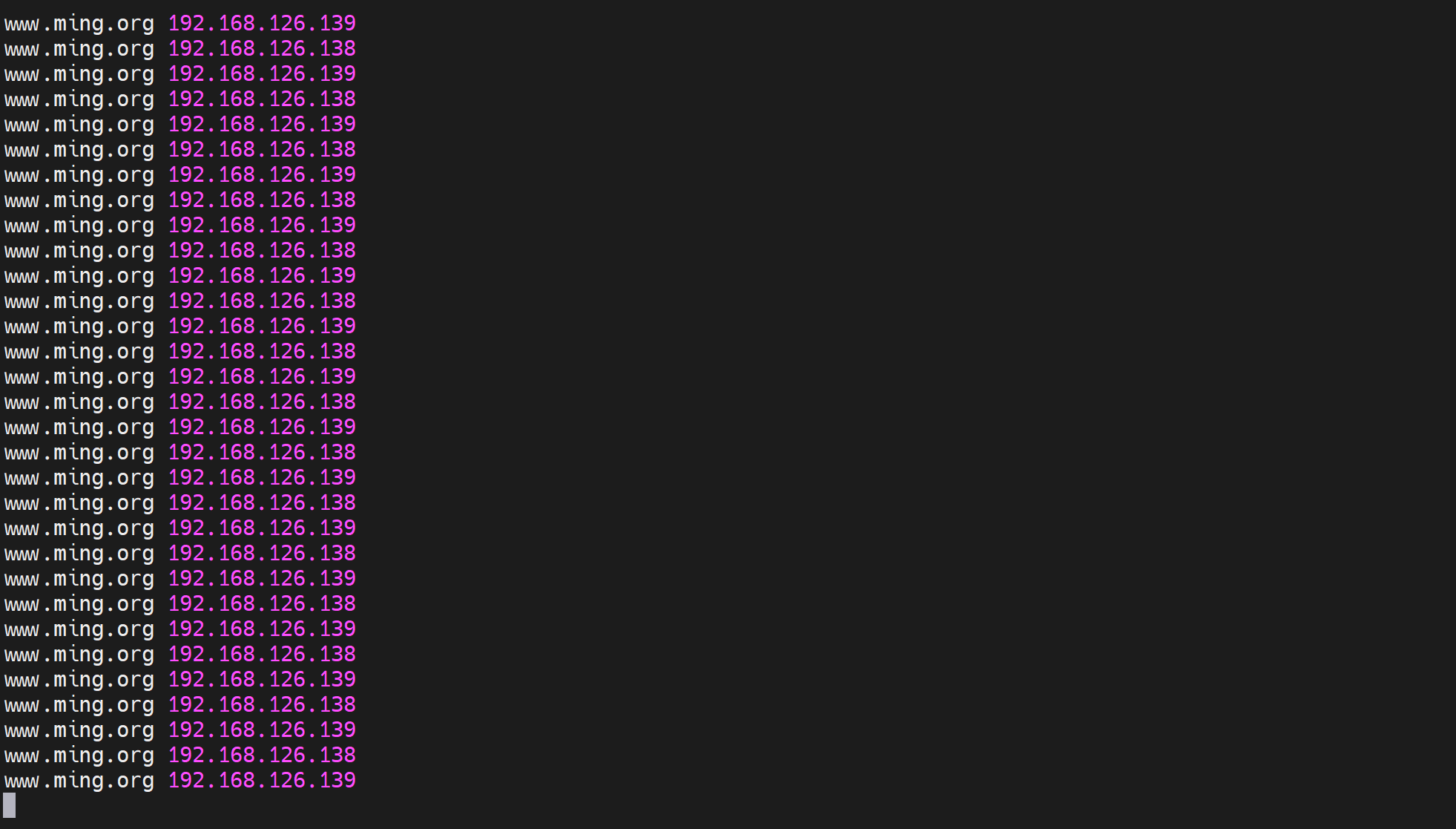
然后停掉haproxy,发现可以实现VIP的切换的👇
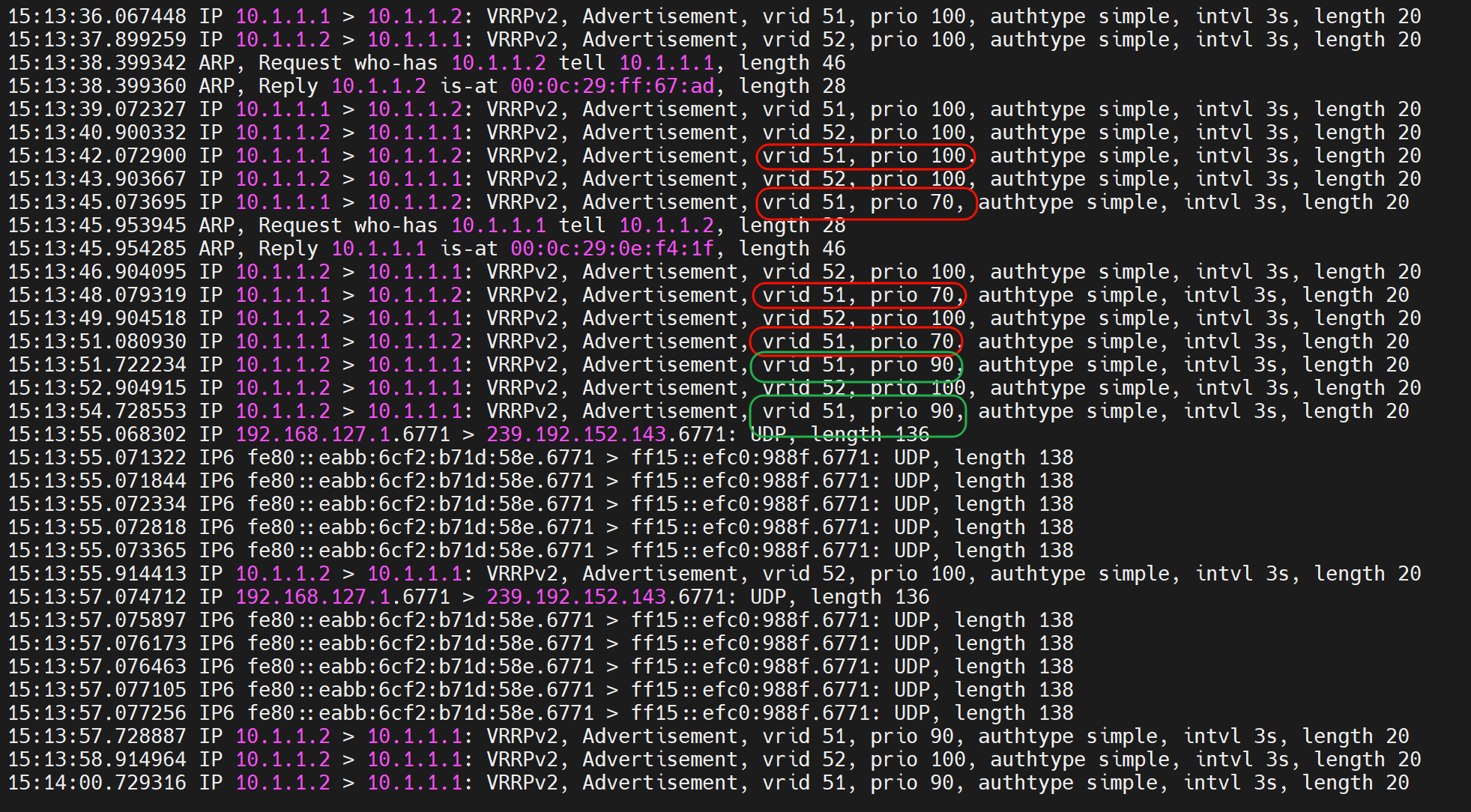
ka001从100 减到了70,然后交出VIP变成从了👆
👇这是ka01上的haproxy又起来了,prority就恢复为100了,然后又开启了抢占,就回来了👇
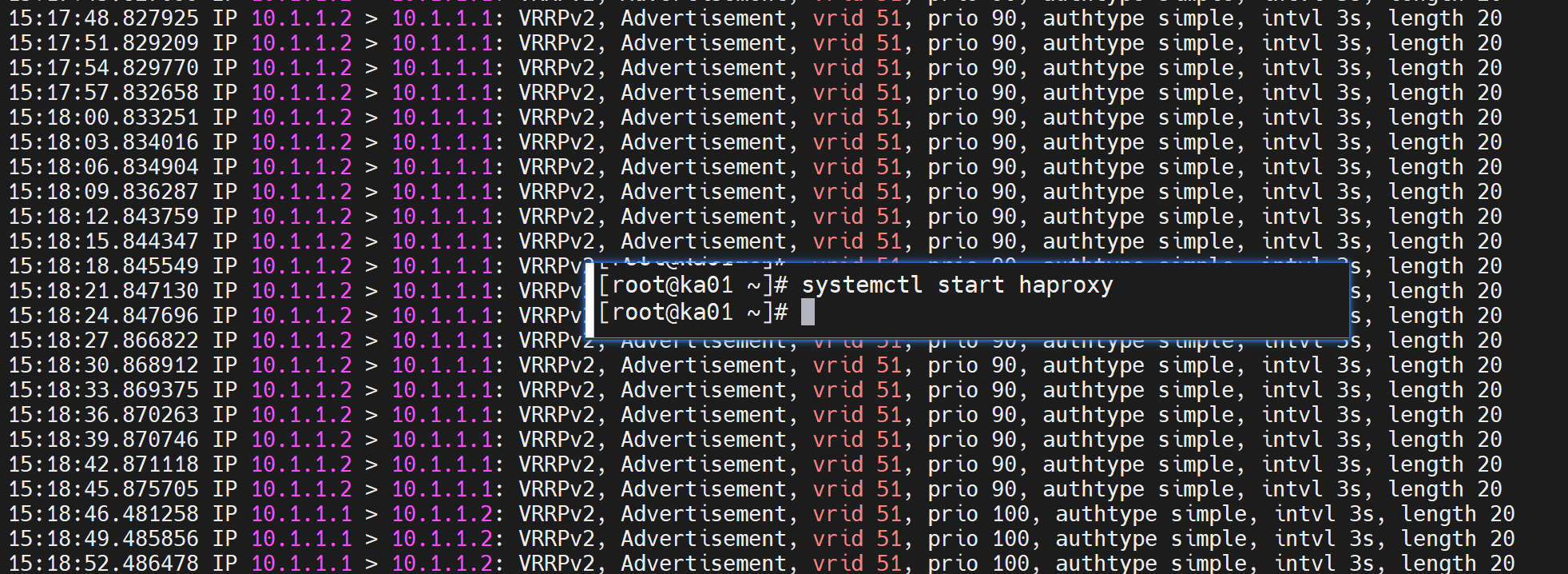
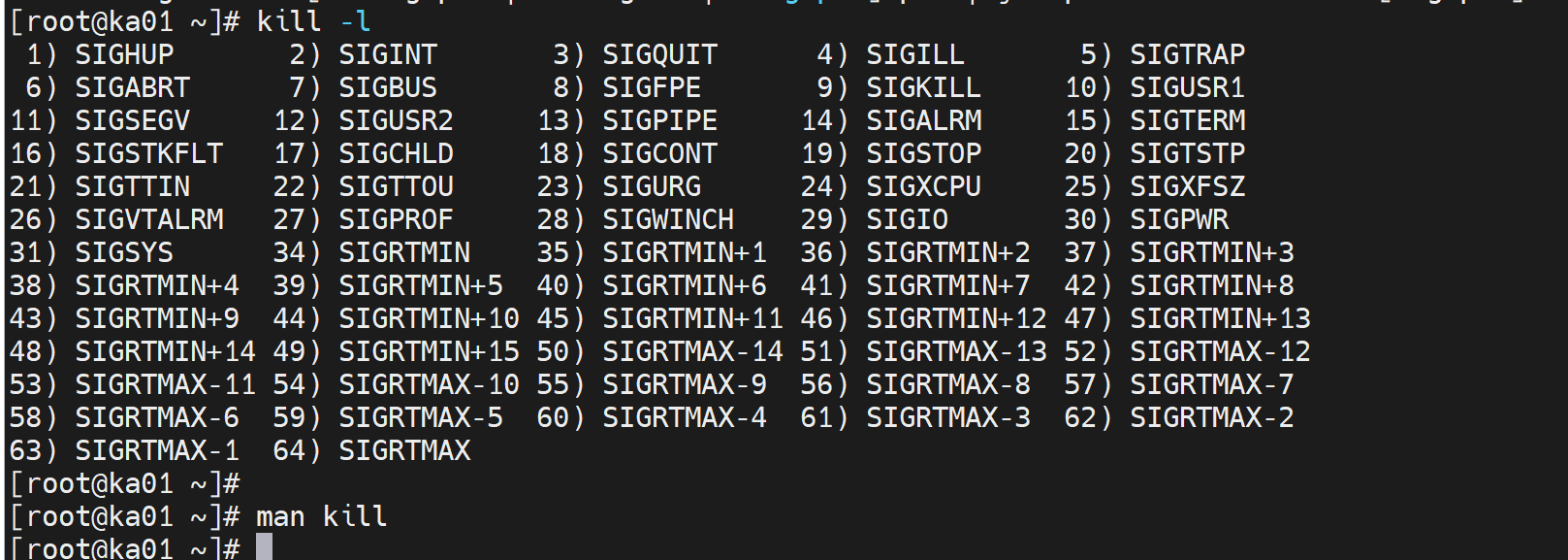
但是killall -0 也有局限性
他只能查看进程在不在,但是进程STOP在那,还是正常运行在那,killall -0是看不出来的👇
killall -19 STOP,killall -19 恢复CONT
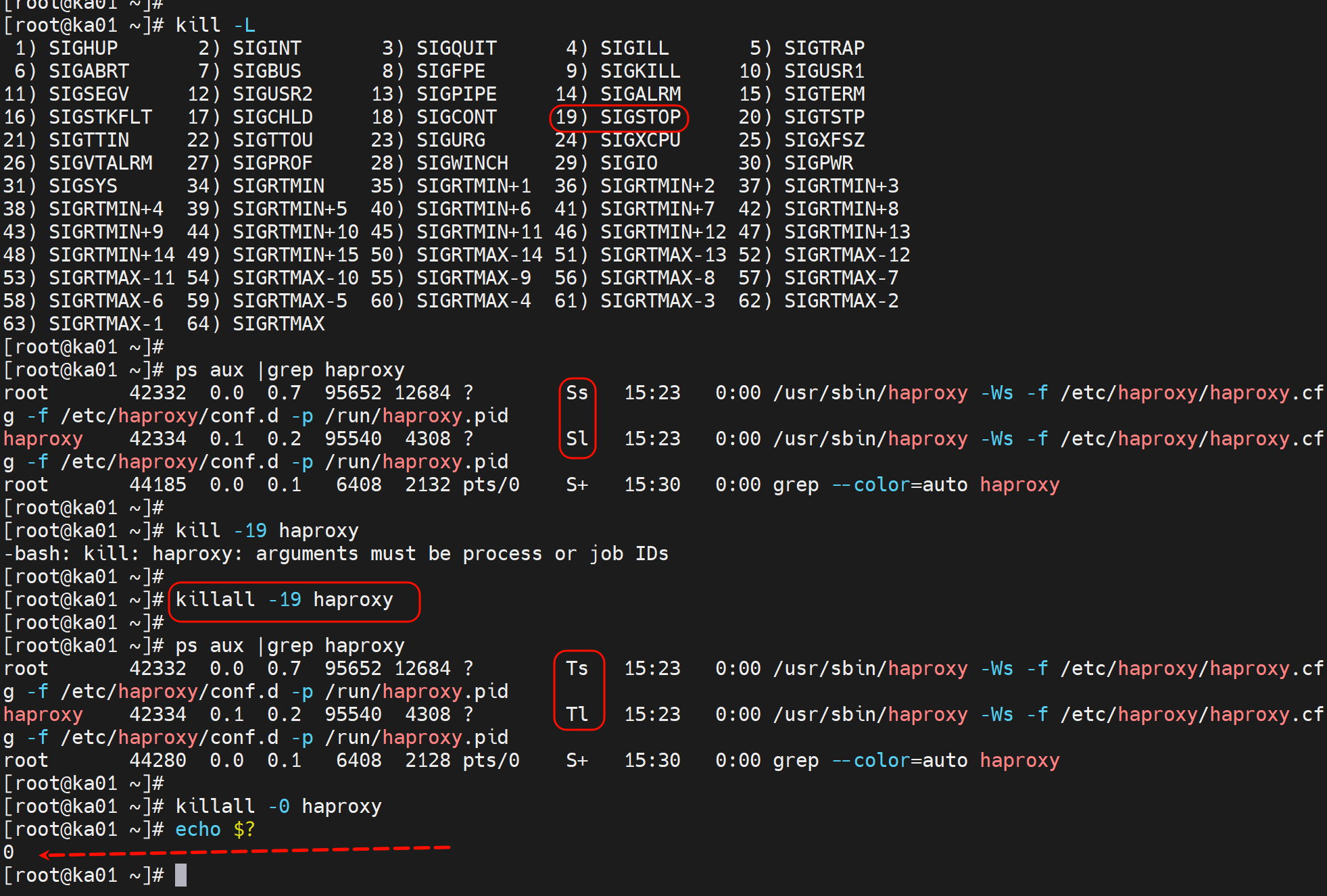
此时VIP应该切走,但是由于判断逻辑导致未切,所以业务挂了

就应该用curl去检查-然后这也是一个错误的思路
[root@ka01 ~]# cat /apps/keepalived/etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id 192.168.126.136
vrrp_mcast_group4 230.0.0.0
}
vrrp_script check_down {
script "[ ! -f /etc/keepalived/down ]"
interval 1
weight -30
fall 3
rise 2
timeout 2
}
vrrp_script check_haproxy {
# 这个检查貌似OK,其实会抖动的业务,因为当curl的结果不是0的时候就是false于是执行下面的优先级权重降低,让出主,VIP飘走,于是curl 就变成了true,于是VIP就抢回来了,所以这是一个错误的案例!!
script "/usr/bin/curl -Im1 192.168.126.100"
interval 1
weight -30
fall 3
rise 2
timeout 2
}
include /apps/keepalived/etc/keepalived/conf.d/*.conf
[root@ka01 ~]#
最终针对haproxy还是改成
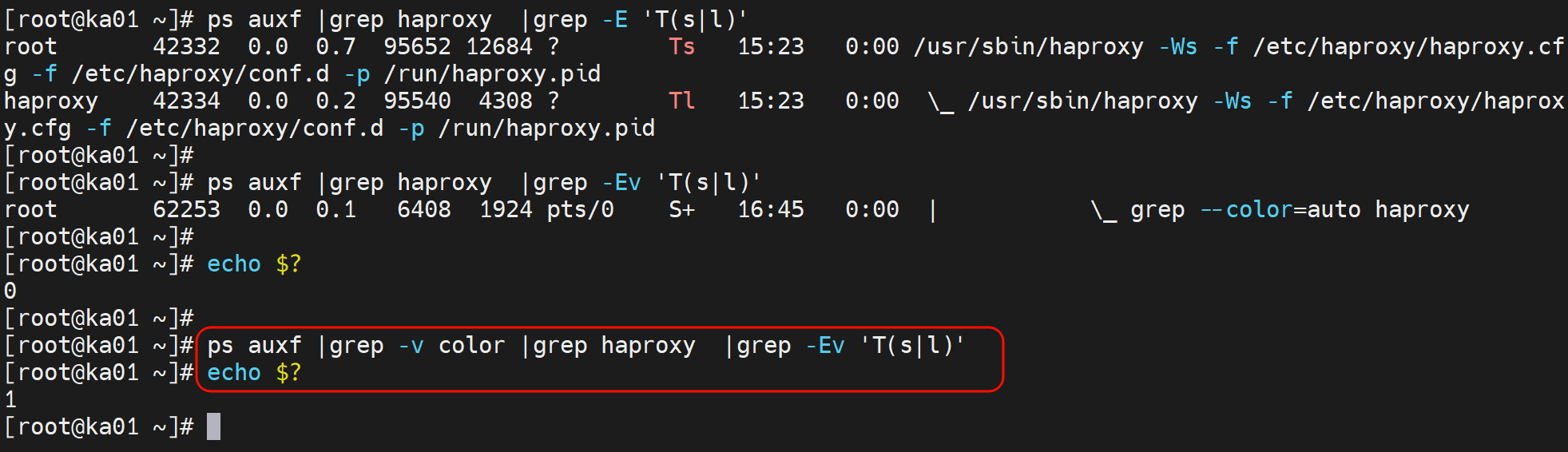
找到进程,且不是STOP的就行啊
[root@ka01 ~]# cat /apps/keepalived/etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id 192.168.126.136
vrrp_mcast_group4 230.0.0.0
}
vrrp_script check_down {
script "[ ! -f /etc/keepalived/down ]"
interval 1
weight -30
fall 3
rise 2
timeout 2
}
vrrp_script check_haproxy {
script "ps auxf |grep -v color |grep haproxy |grep -Ev 'T(s|l)'"
interval 1
weight -30
fall 3
rise 2
timeout 2
}
include /apps/keepalived/etc/keepalived/conf.d/*.conf
[root@ka01 ~]# cat /apps/keepalived/etc/keepalived/conf.d/www.ming.org.conf
vrrp_instance VI_1 {
state BACKUP
interface eth1
virtual_router_id 51
priority 100
advert_int 3
#nopreempt
preempt_delay 10
authentication {
auth_type PASS
auth_pass cisco
}
virtual_ipaddress {
192.168.126.100/24 dev eth0 label eth0:1
}
unicast_src_ip 10.1.1.1
unicast_peer{
10.1.1.2
}
#notify_master "/apps/keepalived/bin/notify.sh master"
#notify_backup "/apps/keepalived/bin/notify.sh backup"
#notify_fault "/apps/keepalived/bin/notify.sh fault"
# Allow packets addressed to the VIPs above to be received
accept
track_script {
check_down
check_haproxy
}
}
[root@ka01 ~]#
此时用户访问都OK了
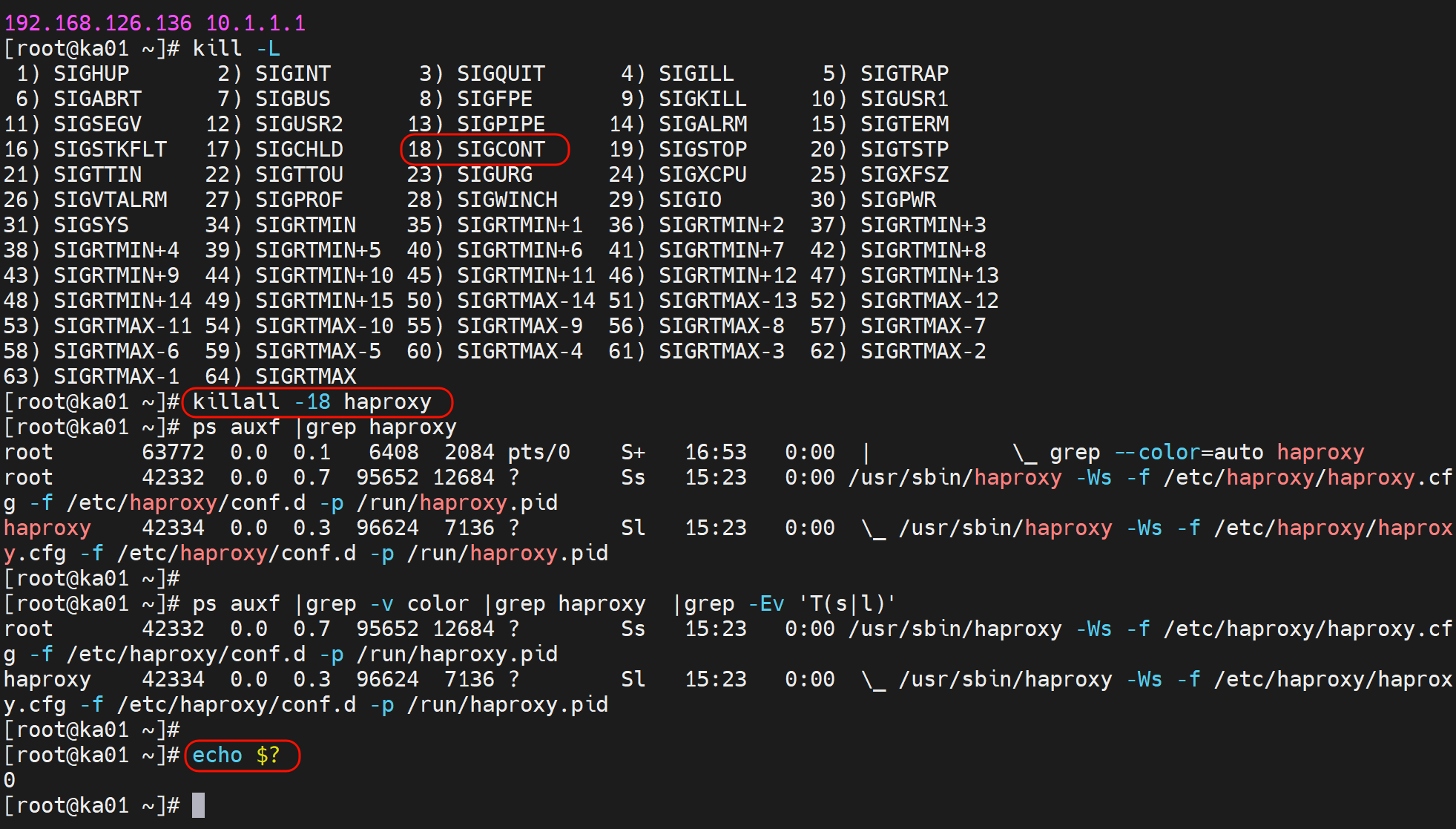
最终改成这样了👇
如果不用脚本,会这样👇报错
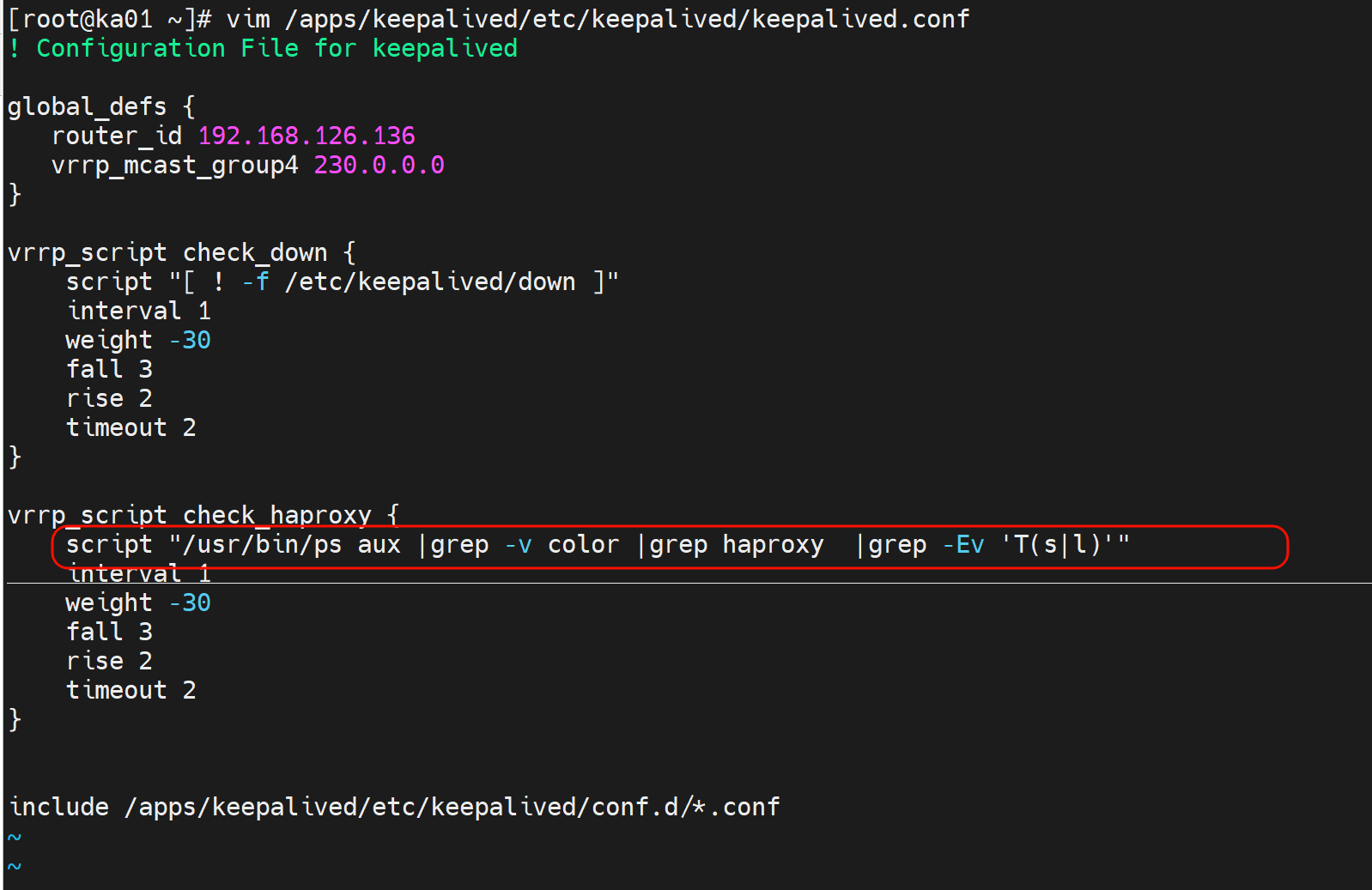
上图👆不写成脚本,执行有问题,明明单敲就是echo $?是0来着,走vrrp里就是1👇,所以还是写成脚本。
nginx的ha也用keepalived来做
观察nginx的配置文件,当然不观察一般也是如此
站点反代也好,页面实实在在的内容也罢,都推荐一个站点写到一个子配置文件(注意以.conf结尾)里,然后,优先抢在下面的server 80上。
[root@ka01 conf.d]# cat /apps/keepalived/etc/keepalived/keepalived.conf
! Configuration File for keepalived
global_defs {
router_id 192.168.126.136
vrrp_mcast_group4 230.0.0.0
}
vrrp_script check_haproxy {
script "/etc/keepalived/check_nginx.sh"
interval 1
weight -30
fall 3
rise 2
timeout 2
}
include /apps/keepalived/etc/keepalived/conf.d/*.conf
[root@ka01 conf.d]#
[root@ka01 conf.d]# cat /apps/keepalived/etc/keepalived/conf.d/www.ming.org.conf
vrrp_instance VI_1 {
state BACKUP
interface eth1
virtual_router_id 51
priority 100
advert_int 3
#nopreempt
preempt_delay 10
authentication {
auth_type PASS
auth_pass cisco
}
virtual_ipaddress {
192.168.126.100/24 dev eth0 label eth0:1
}
unicast_src_ip 10.1.1.1
unicast_peer{
10.1.1.2
}
#notify_master "/apps/keepalived/bin/notify.sh master"
#notify_backup "/apps/keepalived/bin/notify.sh backup"
#notify_fault "/apps/keepalived/bin/notify.sh fault"
# Allow packets addressed to the VIPs above to be received
accept
track_script {
check_down
check_haproxy
}
}
[root@ka01 conf.d]# cat /etc/keepalived/check_nginx.sh
#!/bin/bash
/usr/bin/ps aux |grep -v color |grep nginx |grep -Ev 'T(s|l)'
[root@ka01 conf.d]#
这个nginx检测脚本只需要配置在master上就行了,因为主上发现nginx挂了,然后自降优先级,让出VIP,slave升级成主,告警发出,然后人工或者自动介入修复故障,delay xxx 抢回主。从没必要配置nginx检测脚本,从的nginx检测如果有意义就是从节点此时升级为主节点了,发现nginx挂了,自降prority让出VIP给别的节点,这个别的节点可能是第三个,或者是之前的主,而一般我们就2个节点,所以还是让给之前的主,加入之前的主恢复了自然有抢占和prority优先级恢复结合后会抢回来,不用从去让的动作的。所以从无需配置nginx检测脚本。
mysql的HA-应该不是和keepalived来干吧
有状态的HA可能还是要找应用自身的HA解决方案,而不是用keepalived来弄,keepalived比较适合无状态的服务的HA来着。
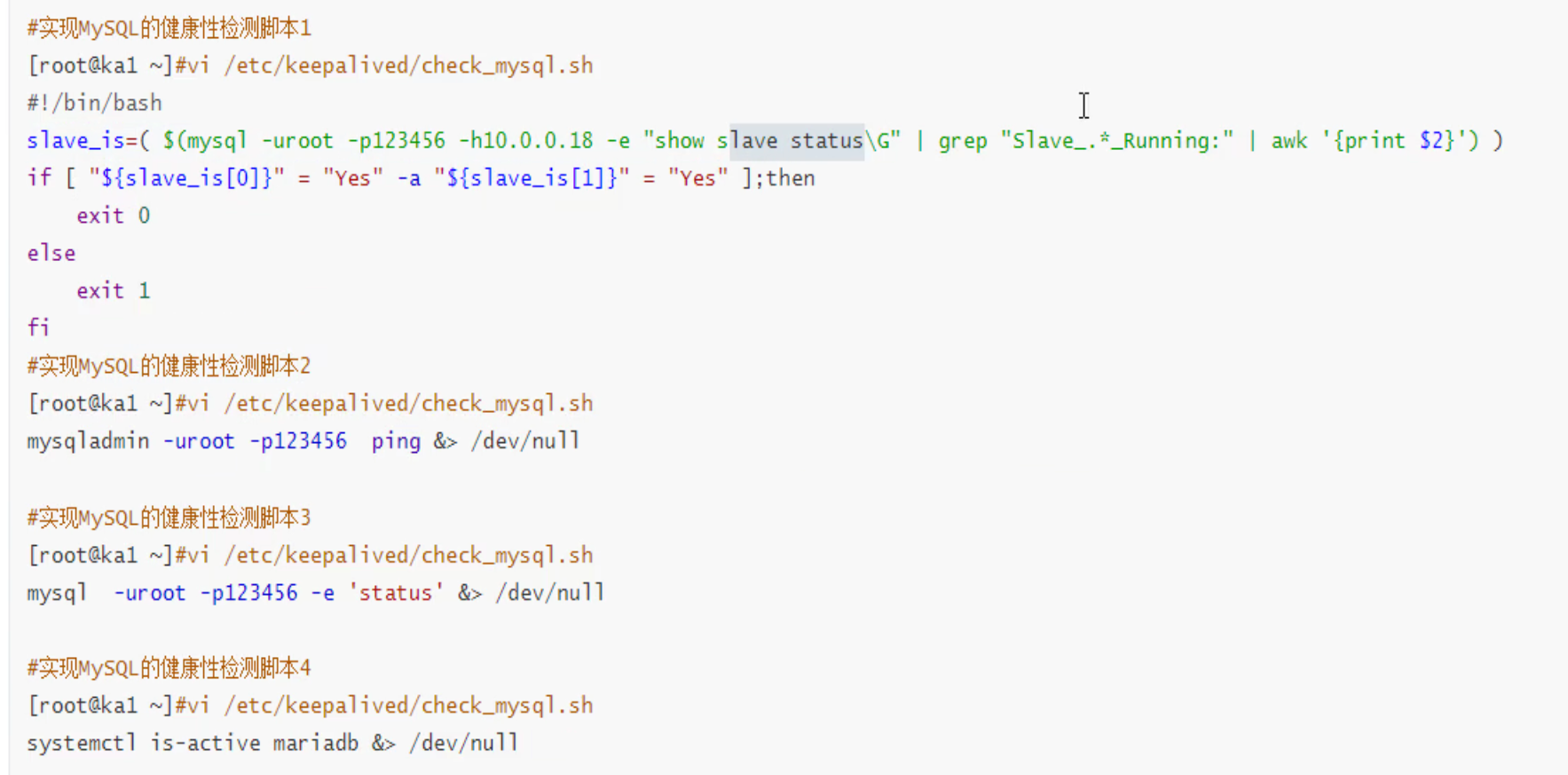


zabbix-server的ha
和msyql一样,zabbix 6.0开始本身自带HA了,还是不要用keepalive来实现zabbix的HA了。
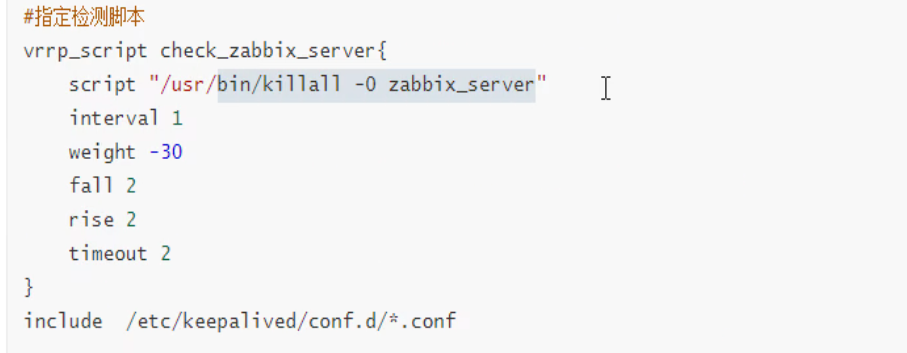
keepalived的脚本执行行为
有一个默认账号,一般是不存在反而比较好的,编译安装好像就是没有该默认用户的,yum搞不好有,就要注意权限可能不够的问题。 不存在最好,就以root运行了,权限没问题~

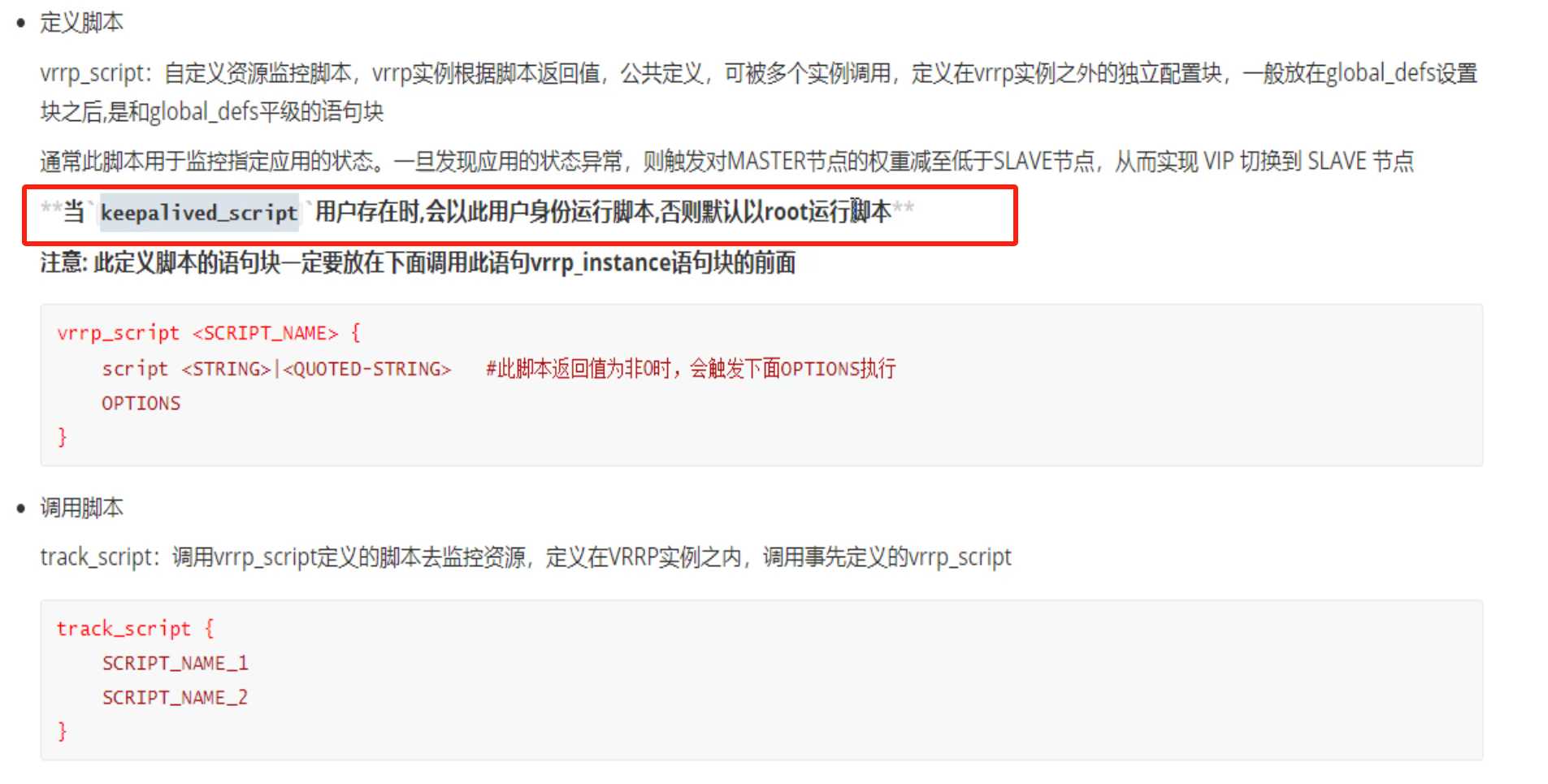
总结